Agrégats de mots sémantiquement cohérents issus d'un grand graphe de terrain( Télécharger le fichier original )par Christian Belbèze Université Toulouse 1 Capitole - Doctorat en informatique 2012 |

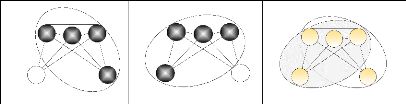
Chapitre 2. Les algorithmes de création de communautés2.3.1 Méthodes de recherche de formes : la percolation de cliquesDès les années 2000, J. Scott [Scott-2000], identifie dans les réseaux sociaux des formes particulières au sein des graphes. Ces formes sont des sortes de motifs récurrents et connus. Le plus célèbre est sans aucun doute la clique. Il va au tout départ travailler sur ces ensembles. Mais il sent très vite que le système de clique s'il est référent quant à sa cohérence, n'est à la fois pas suffisamment défini et trop rigide. Pas suffisamment défini car, dans un réseau dont le degré moyen serait très élevé, cette forme n'est pas forcément suffisamment explicite. Il utilise alors la notion de « composante connexe » pour rechercher des ruptures dans un graphe de grande taille. Puis, pour pallier la rigidité des cliques il propose plusieurs adaptations avec les K-cliques et les n-cliques (qui définissent un chemin maximal entre deux noeuds de n liaisons) et enfin les k-plex dans lesquels les noeuds sont tous connectés deux à deux à l'exception de K noeuds. Nul doute que ces recherches sont les fondamentaux de la méthode la plus connue dans le recherche de communautés avec recouvrement qui est celle définie par G. Palla et al [Palla&al-2005]. Elle est aussi rencontrée ou nommée sous le nom de C-finder, du nom du logiciel libre l'implantant http://cfinder.org/. Palla définit la méthode « C-finder » comme basée sur la localisation de toutes les cliques (sous-graphes complets maximaux) du réseau puis sur l'identification des communautés en effectuant une analyse en composante standard de la matrice de recouvrement entre chaque clique. Pour donner plus de détails, nous pourrions ajouter que la méthode consiste à rechercher des cliques de k sommets nommées K-cliques, où k est un nombre entier supérieur à 3. La communauté est ensuite définie comme l'ensemble des K-cliques qui sont connectées de telle manière qu'un minimum de k-1 sommets de la clique de départ appartiennent à la clique ajoutée. Une image souvent donnée pour expliquer cette méthode est le fait que, si on créait un masque correspondant à une K-clique, toute K-clique sur laquelle on pourrait basculer le masque en gardant k-1 sommets dans le masque serait agrégée pour constituer la communauté. La méthode décrite ici s'applique aux réseaux binaires mais elle peut être étendue à un réseau quelconque en ignorant le sens des liens et en supprimant les liens dotés d'une pondération trop faible.
Figure 2.4 : Système de percolation de K-cliques pour k=4, par rotation de masque et communauté résultante. 2.3. Les différentes méthodes de recherche de communautés avec recouvrement 57 Chapitre 2. Les algorithmes de création de communautés Cette solution permet de créer des zones de recouvrement. En effet, un ensemble de 1 à k-2 noeuds peut être présent dans plusieurs communautés.
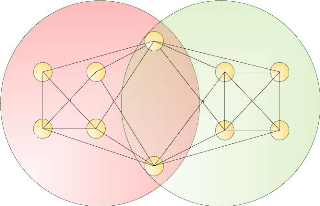
Figure 2.5 : Deux communautés de K-cliques pour k=6 partageant deux sommets. Une autre vision de la méthode donnée par Palla lui-même est la méthode nommée « K-clique template rolling ».
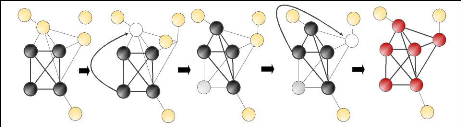
A B E F E F E F E F Etape 0 D C A B Etape 2 Etape 4 D C B A D C B A D C B A E F D C Figure 2.6 - Illustration de la méthode « K-clique template rolling ». Comme on peut le voir dans la figure 2.6, la clique ABCD roule sur son axe AC en étape 1 pour former la clique ADCE en étape 2. Le point E vient ainsi rejoindre la communauté. Une autre rotation autour de l'axe EC en étape 3 permet de rajouter le point F et ainsi de créer la communauté finale ABCDEF en étape 4. Etape 3 Etape 1 En 2007, Gregory Palla, Farkas, Pollner, Derényi et Vicsek ont fait évoluer leur méthode pour la rendre compatible avec des graphes dirigés [Palla&al-2007]. Si cette solution est très performante dans le domaine du vivant, elle possède plusieurs inconvénients. Ainsi, fixer la valeur K du nombre de sommets à prendre en compte est critique et peut se révéler difficile. Car les graphes de terrain présentent par définition des zones de faible densité et d'autres de très forte densité. Choisir un K faible permettra de créer des communautés dans les zones de plus faible densité mais cela, au risque de créer des communautés immenses dans les zones de densité plus importante. Choisir une valeur de K 2.3. Les différentes méthodes de recherche de communautés avec recouvrement 58 Chapitre 2. Les algorithmes de création de communautés plus élevée ne nous permettra plus de créer de communautés dans les zones à faible densité. Cette méthode est très efficace dans le cas de graphe de densité relativement homogène. Cependant elle semble plus difficile à mettre en oeuvre dans le cas de graphes à forte densité ou possédant une distribution très hétérogène des degrés ou encore dans l'étude de graphes pondérés. |
|