Chapitre 2. Les algorithmes de création de
communautés
La validation d'un système de création de
communautés avec recouvrement est plus délicate. Les
méthodes de validation de ces communautés sont dans l'ensemble
des méthodes qui n'ont pour but que de chercher à
démontrer la validité de l'algorithme. On choisit pour cela des
graphes « jouets » de petite taille. Ces graphes que l'on va
retrouver dans la majorité des expérimentations
[Chen&al-2010], [Shang&al-2007],
[Nicosia&al-2009], [Baumes&al-2005-1],
[Zhang&al-2007], [Breve&al-2010] ont
l'avantage de présenter une solution connue.
Il y a ainsi des incontournables (cf. figure 2.15), tels le
fameux « Club de Karaté de Zachary ». Dans ce club, on
connaît les liens d'amitié initiaux entre les membres à
partir desquels on peut construire un graphe de type réseau social. Les
membres sont les noeuds et les relations d'amitié les liens.
Historiquement, le club s'est ensuite scindé en deux clubs distincts
après la dispute de l'entraîneur et du directeur. Chacun des deux
a créé un nouveau club. Pour l'anecdote, cette scission s'est
faite sans aucun recouvrement. Ceci n'empêchera pas Wei Chen, Zhenming
Liu, Xiaorui Sun et Yajun Wang de nous proposer pour valider la méthode
de déplacement de noeuds présentés au chapitre 2.3.3,
jusqu'à six communautés en recouvrement sur ce graphe (cf. figure
2.16) [Chen&al-2010]. La qualité des
communautés est mesurée dans ce cas sur les valeurs des
modularités atteintes.
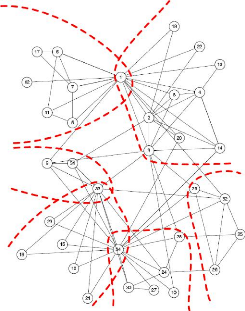
Figure 2.16 : les 6 communautés issues de
l'algorithme de Wei Chen, Zhenming Liu, Xiaorui Sun et Yajun Wang
[Chen&al-2010] sur le graphe représentant le Karaté Club de
Zachary.
On peut d'ailleurs remarquer que la plupart des algorithmes
présentés doivent être paramétrés (ne
serait-ce que par le nombre de communautés à créer).
Connaitre la solution permet de les choisir de façon à retomber
sur le nombre de communautés souhaité.
2.4. Les méthodes de validation des communautés
76
Chapitre 2. Les algorithmes de création de
communautés
D'autres exemples partagés par plusieurs
méthodes (comme les réseaux de collaboration entre scientifiques
[Latouche&al-2010 ou la recherche des régions des
équipes de football aux Etats-Unis en fonction des matchs joués)
présentent aussi la même dérive. Soit le résultat
recherché est connu, soit il n'est pas facilement vérifiable et
donc pas vérifié. À notre connaissance, aucune
expérimentation utilisant les signatures conjointes d'articles n'a
cherché à croiser les résultats avec les sentiments
d'appartenance à des communautés des auteurs.
De plus, ces exemples ne sont pas à proprement parler
des graphes de terrain. En effet, les éléments sont en fait
extraits de graphes de terrain plus complexes. Par exemple, le graphe des
relations sociales des membres du Karaté Club ne représente
qu'une partie microscopique d'un graphe sans aucun doute plus large des
relations sociales incluant les membres du club. Les graphes de co-signatures
sont aussi limités par une thématique et le plus souvent une
université ou un laboratoire. Ces extractions et la petite taille
permettent alors de limiter grandement les problématiques liées
aux graphes de terrain.
Matthieu Latapy dans son HDR [Latapy-2007]
déclare à ce sujet « on se retrouve à
évaluer les résultats par l'intuition qu'on a sur de tout petits
exemples, sur des modèles dont on sait qu'ils capturent pauvrement la
réalité et/ou sur des cas réels sur lesquels on n'a
guère de point de comparaison ».
Ces exemples jouets et de petites tailles ont peu de
ressemblance avec les grands graphes de terrain. Et la principale
différence est sans nul doute l'importante disparité que l'on va
rencontrer dans les grands graphes de terrain sur les valeurs des
degrés. Un autre aspect de la simplification de ces graphes jouets est
la non-pondération des liaisons. En effet, les relations sociales n'ont
pas toutes la même importance. De même, une co-signature dans un
article de vulgarisation n'a pas la même valeur qu'un ensemble de
co-signatures dans un domaine particulièrement pointu ou sur des
articles majeurs de revue.
Ces exemples jouets ne sont pas pour autant à
écarter. Les algorithmes validés à travers eux n'ont pas
pour cela moins de valeur ou d'intérêt. Pratiques et de petite
taille, ils permettent de comparer des résultats. Cependant, ces
exemples ne peuvent être assimilés à de véritables
grands graphes de terrain.
En 2009, dans l'article « Overlapping Community
Search for Social Networks », Arnau Padrol-Sureda, Guillem
Perarnau-Llobet, Victor Muntès et Julian Pfeifle
[Padrol-Sureda&al-2010] utilisaient comme espace de test le graphe
de terrain des articles de Wikipedia. Celui-ci est sans aucun doute, avec plus
de 16 millions de noeuds, un grand graphe de terrain. Pourtant de notre point
de vue, plusieurs aspects essentiels sont occultés. En premier lieu, le
lien hypertexte qui ici est utilisé comme élément de
liaison est par nature dirigé. Un article A cité par un article B
ne signifie pas que l'article B citera le A. Le graphe étudié
n'est pas dirigé. Il devrait aussi être pondéré, une
page pouvant avoir plusieurs liens vers une autre page. Le graphe n'est pas
pondéré dans l'étude. Enfin, les articles ne sont pas
étudiés ici comme faisant partie d'un tout mais comme des
éléments indépendants. En effet, sur chaque article
Wikipédia, on retrouve des liens vers des pages repères comme
l'accueil du site ou l'index ou même la possibilité de rechercher
un article au hasard. On retrouve aussi un
2.4. Les méthodes de validation des communautés
77
Chapitre 2. Les algorithmes de création de
communautés
lien vers les articles du même sujet dans les autres
langues. Ces liens sont issus de la nature d'un Grand Graphe de Terrain. Les
noeuds communiquent pour assurer leurs fonctions de base, mais certains noeuds
ont pour fonction la communication. Dans le graphe de Wikipédia, pour
pouvoir être trouvés plus facilement, beaucoup d'articles sont
cités dans l'index alphabétique. Cette liste possède donc
des liens vers un très grand nombre d'articles. Il existe dans l'autre
sens depuis chaque page un lien vers ce glossaire. En excluant l'index
alphabétique du graphe, on en change la nature. Nous reviendrons sur cet
aspect des grands graphes de terrain dans la partie 3 de notre travail.
Une autre piste est souvent explorée, il s'agit
d'étudier les algorithmes de création de communautés sur
des graphes générés aléatoirement par des
algorithmes spécifiques. Le but de ces algorithmes créateurs de
graphes est de recréer un graphe aux caractéristiques identiques
à celles d'un Grand Graphe de Terrain. Quelles que soient les techniques
de génération [Barabas&ali-2000]
[Watts-1998], leur capacité à imiter des graphes de
terrain ou des petits mondes n'est pas mesurable. De plus, les
communautés ainsi obtenues ne peuvent être comparées
qu'entre diverses méthodes, la nature mathématique du graphe ne
pouvant être modifiée. Pour être concret, il n'est pas
possible de demander à un noeud d'un graphe généré
aléatoirement si effectivement il se sent bien dans cette
communauté comme on pourrait le faire avec des acteurs d'un
réseau social.
Ces difficultés sont particulièrement bien
explicitées dans l'article publié en 2010 par Emmanuel Navarro et
Rémy Cazabet : « Détection de communautés
étude comparative sur graphes réels »
[Navarro&al-2010]. Dans cette étude, les
auteurs comparent plusieurs algorithmes sur plusieurs types de graphes et
notamment sur des graphes de terrain de taille « moyenne », le plus
important comportant moins de 10000 noeuds. Les auteurs concluent en disant :
« ... il en ressort que le problème de détection de
communautés est plus complexe sur des graphes réels que sur les
graphes artificiels habituellement utilisés pour l'évaluation.
L'accord entre les méthodes est faible sur les graphes réels
alors qu'il est généralement important sur les graphes
d'évaluation. Aussi les résultats sont bien moins robustes sur
les graphes réels que sur les graphes d'évaluation. Et enfin les
algorithmes ont tendance à trouver, sur les graphes réels, des
« super-communautés » peu réalistes. ».
Pour faire face à cette difficulté de validation
qualitative des communautés, nous proposons une projection de ce que
Matthieu Latapy suggère pour valider les caractéristiques des
graphes : « la comparaison à l'aléatoire »
[Latapy-2007]. Nous proposons, la comparaison du comportement
et des propriétés des communautés créées par
la comparaison à des communautés créées
aléatoirement. Puis, dans la mesure où cela est possible,
reconduire la comparaison avec des regroupements reconnus comme des
communautés valides. Il est aussi possible de comparer les
communautés créées avec des ensembles de population aux
caractéristiques connues. Cet ensemble de comparaisons permettra
d'obtenir une estimation plus juste de la qualité du système de
regroupement.
2.4. Les méthodes de validation des communautés
78
Chapitre 2. Les algorithmes de création de
communautés
2.4.2 Évaluation de la complexité
Une autre préoccupation des utilisateurs et concepteurs
de méthodes de création de communautés avec ou sans
recouvrements est la complexité des algorithmes. La complexité
d'un algorithme (notée á) est une indication du
coût théorique « temps CPU » que l'on aura à
considérer pour exécuter l'algorithme. Il est globalement
calculé sur le nombre d'opérations à effectuer en fonction
du nombre d'éléments. Pour exemple, le parcours d'une liste de
complexité linéaire de n éléments sera
noté á(n).
Nous n'avons pas, volontairement abordé dans notre
travail, cet aspect et cela pour plusieurs raisons :
? l'expérience montre que, plus que la
complexité des algorithmes, ce sont les technologies qui influencent les
temps de traitement. Ainsi, par exemple, la mise en oeuvre de bases de
données permet, par l'utilisation d'index, de transformer des
complexités linéaires de lecture de liste en complexités
quasi constantes ;
? les algorithmes locaux qui possèdent de très
hauts coefficients de complexité sont facilement parallèlisables
et cet aspect n'apparait pas dans le calcul du coefficient de
complexité. Le parallélisme étant aujourd'hui une
technologie native sur tous les ordinateurs, il semble que le coefficient de
complexité doive évoluer pour le prendre en compte ;
? les temps de traitement ne nous apparaissent pas comme une
des caractéristiques à prendre en compte prioritairement tant que
les communautés n'ont pas été validées
qualitativement. De plus, la validation qualitative d'une méthode
apporte par nature des éléments de modification. Il semble donc
inapproprié de vouloir comparer la complexité relative des
méthodes avant que celles-ci ne soient stabilisées ;
? les coefficients de complexité sont parfois
présentés de manière avantageuse par les créateurs
de méthodes sans que l'on puisse véritablement les
vérifier.
Une fois que les communautés seront
déterminées valides, il sera alors temps de rechercher
l'algorithme le moins coûteux possible et cela en fonction des
technologies présentes.
2.5. Synthèse 79
| 

