Agrégats de mots sémantiquement cohérents issus d'un grand graphe de terrain( Télécharger le fichier original )par Christian Belbèze Université Toulouse 1 Capitole - Doctorat en informatique 2012 |

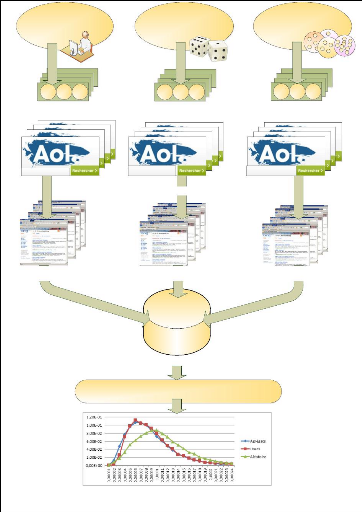
ConclusionNous savons que rajouter des mots dans une requête n'est pas toujours synonyme de meilleure performance et cela même si ces mots sont effectivement liés au contexte recherché. En effet, la recherche s'effectuant sur un grand nombre d'articles, l'ajout de mots peut en quelque sorte « flouter » la requête en ramenant des articles moins spécifiques [Boughamem&al-1997]. 4.3 : Les méthodes de validation sémantique 139 Chapitre 4. Expérimentations, validations sémantiques et résultats de mesure Rajouter des mots en maintenant un même niveau de qualité de requêtes est donc déjà un défi qui nous permet de confirmer que le système d'agrégation est bien porteur d'une cohérence sémantique. 4.3.3 Méthode MCCDR ou « Méthode de Comparaison de Cohérence de Documents Retournés »Principe et hypothèse Cette méthode s'appuie sur la comparaison des trois populations typiques déjà rencontrées : ? trios de mots aléatoires ; ? triades présentes dans au moins une requête d'utilisateur ; ? trios de mots issus d'un même agrégat. Le but est de mesurer la cohérence des documents retournés et de comparer ensuite la distribution de cette cohérence en fonction de la nature des requêtes. Pour cela nous mesurons la distance moyenne entre documents retournés par les trois types de requêtes. L'hypothèse est la suivante : plus les mots d'une requête font référence à un espace sémantique précis, plus les documents retournés par un moteur de recherche dans une requête sont proches les uns des autres. Si cette hypothèse est vérifiée, nous devrions observer une différence entre les documents retournés par des requêtes construites aléatoirement et ceux obtenues avec les requêtes rejouées des utilisateurs. Si les agrégats sont sémantiquement cohérents, on peut espérer une similarité importante et proche des « triades issues des requêtes utilisateurs » dans les documents retournés par les trios de mots issus des agrégats. La distance moyenne entre documents doit être aussi faible que possible à l'intérieur d'un ensemble de documents retournés par les requêtes effectuées à partir des mots d'un agrégat. À contrario, la distance moyenne entre les documents retournés en utilisant deux agrégats comme sources de création de requête devrait être la plus élevée possible. C'est ce que nous tentons de mesurer en comparant deux à deux les documents récupérés par des requêtes issues de deux agrégats différents. Requêtes et moteurs de recherche Les requêtes sont formées de trois mots et issues d'une des trois familles (aléatoires, issues des requêtes utilisateurs et issues des agrégats). Elles sont constituées sur le même ensemble de mots. Le moteur de recherche utilisé est bing.com. La recherche est limitée au contenu de Wikipédia par l'utilisation de la syntaxe « site : wikipedia.org ». Les articles de plus de 15000 mots et de moins de 200 mots sont écartés. Les articles de plus de 15000 mots sont en général 4.3 : Les méthodes de validation sémantique 140 Chapitre 4. Expérimentations, validations sémantiques et résultats de mesure des sites agglomérant des listes d'articles archivés, ils sont sans valeur sémantique globale. Les articles de moins de 200 mots sont le plus souvent des articles en préparation qui ne contiennent pas vraiment d'informations ou simplement un message d'erreur (lien mort, erreur sur le site, ...). Les recherches dans bing.com se font sans aucun filtre (langues, contenu pour adultes, ...) Calcul de la cohérence des documents retournés Pour chaque requête, nous stockerons les dix premiers articles de Wikipédia valides (plus de 200 mots et moins de 15 000 mots) présentés dans la liste. L'ensemble des documents retournés par bing.com pour l'ensemble des requêtes est ensuite filtré pour enlever le code (html, xhtml, java, vbs, ...) puis stocké dans une base de données. 4.3 : Les méthodes de validation sémantique 141 Chapitre 4. Expérimentations, validations sémantiques et résultats de mesure
Récupération du texte des 10 premiers articles valides trouvés pour chaque requête dans Wikipedia Requêtes utilisateurs +U1 +U2 +U3 Triades de mots issus de requêtes utilisateurs U1 U2 U3 Trios de mots utilisés comme requêtes dans un moteur de recherche Comparaison de la distribution des distances moyennes entre documents par type de requête Calcul de la valeur idf de chaque mot Calcul des distances entre les documents 2 à 2 Trios de mots issus d'un tirage aléatoire +S1 +S2 +S3 Base de données Mots combinés aléatoirement S1 S2 S3 Trios de mots issus chacun d'un même agrégat +A1 +A2 +A3 Mots issus des agrégats A1A2A3 Figure 4.8 : Méthode de récupération des articles de Wikipedia et calcul de similarité entre documents retournés par type de requête. 4.3 : Les méthodes de validation sémantique 142 Chapitre 4. Expérimentations, validations sémantiques et résultats de mesure Pondération des mots et tf.idf Afin de comparer les articles de la façon la plus efficace possible, nous utilisons un système de pondération. Ce système connu sous le nom de « tf.idf » a pour but de valoriser les mots rares au sein du corpus et de permettre la comparaison de documents de tailles très différentes [Salton&al-1983]. idf : Chaque mot se voit affecter d'une valeur en fonction de sa présence dans un plus ou moins grand nombre de documents. La pondération est inverse au nombre de documents dans lequel le mot a été trouvé. Ainsi les mots présents dans un grand nombre de documents ne seront pas représentatifs. Au contraire, un mot trouvé uniquement dans quelques documents, présentera un poids particulièrement élevé. La fréquence inverse de présence du mot dans le corpus de documents (inverse document frequency) est notée idf. L'idf est aussi appelé « fonction inverse de la fréquence absolue ». On calcule l'idf par la formule : fdj ti dj} Où représente le nombre de documents du corpus et | fdj ti dj}| le nombre de documents dans lesquels le terme ti apparaît. Le but est d'éliminer au plus tôt les termes de fréquence absolue élevée et de donner plus de poids à des mots discriminants. Si un mot est présent dans 25 documents sur un corpus de 1000 documents son idf sera de idf = log(1000/25) = 1.6 ; Si un autre mot est présent dans 750 documents sur un corpus de 1000 documents son idf sera de log(1000/750) = 0.125 et enfin si un mot est présent dans tous les documents son idf sera nul. L'idf est donc une valeur associée au mot à l'intérieur du corpus. tf : Le tf est le poids relatif du mot dans le document. Il permet de redonner une valeur relative à la taille du document et de pouvoir, ainsi, comparer des documents de tailles différentes. Le tf d'un mot dans un document est calculé par la formule suivante :
Où ni,j est le nombre d'occurrences du terme dans ti dans le document dj. Le dénominateur est la somme de toutes les occurrences de tous les termes du document. Un terme présent 10 fois dans un document de 1500 mots aura donc un tf de 10/1500 soit 0.00666. 4.3 : Les méthodes de validation sémantique 143 Chapitre 4. Expérimentations, validations sémantiques et résultats de mesure Le poids des mots à comparer est donné par :
Calcul de la distance entre deux documents Le calcul de la distance entre deux documents est ici basé sur la transformation des documents en vecteurs de n dimensions où n est le nombre de termes différents dans le document et où chaque dimension représente un terme unique. En calculant (sur l'ensemble des dimensions) le cosinus entre deux vecteurs, nous obtenons une valeur liée à la similarité entre les documents. Plus les documents sont proches et plus le cosinus est élevé. Soient deux documents A et B tels que A={a1, a2, ...ax} et B={a1, a2, ...ay} n est égal au nombre de termes présents dans un document au moins. Le calcul du cosinus ou de la similarité entre le document A et le document B sera alors : ? ai bi J? (ai) J? (bi) S(A,B) = ( ) 4.3 : Les méthodes de validation sémantique 144 Chapitre 4. Expérimentations, validations sémantiques et résultats de mesure Dans cet exemple nous allons mesurer la distance entre trois textes en utilisant la notion de tf.idf.
On calcule pour chaque mots sont idf. Les mots présents dans tous les textes présentent un idf nul.
Sachant que le document A contient 10 mots, la valeur tfA(nuit) =2/10. Le poids du mot « nuit » dans le premier document tf.idfA(nuit) sera donc 2/10*log(3/2)=0.0352. La similarité entre les documents A et B est notée S(A,B).
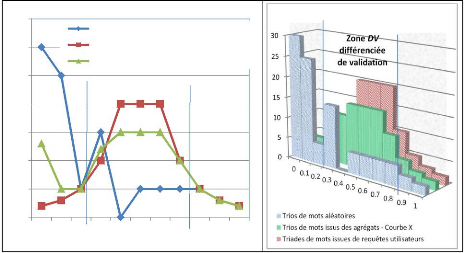
S(A,B ) = 0,802 S(A,C) = v(tf.idfA( )) (tf.idfA( )) (tf.idfA( )) v(tf.idf ( )) (tf.idf ( )) (tf.idf ( )) (tf.idf ( )) S(A,C) = 0 Comme on peut le voir dans cet exemple, bien que les documents A et C partagent plusieurs mots, leur coefficient de similarité est nul. La méthode peut bien sûr être améliorée par des algorithmes capables de retrouver des racines communes comme pour la langue anglaise, le célèbre algorithme de « Porter ». On peut ainsi faire des rapprochements entre des mots qui ne sont pas identiques mais qui possèdent des racines communes. 4.3 : Les méthodes de validation sémantique 145 Chapitre 4. Expérimentations, validations sémantiques et résultats de mesure Mesure de similarité intra-requête La mesure de similarité au sein des articles retournés par une requête est la moyenne des similarités entre chaque article. Les articles sont comparés deux à deux. Mesure de similarité inter-requête La mesure de similarité inter-requête des articles retournés par deux requêtes A et B est la moyenne des similarités entre chaque article retourné par la requête A avec tous ceux de la requête B. Les articles sont comparés deux à deux. Le postulat de départ est que : ? les requêtes utilisateurs retournent des documents plus similaires que les requêtes de mots aléatoires ; ? les documents retournés par deux requêtes utilisateurs sont moins similaires que des documents retournés par deux requêtes aléatoires ; ? les documents retournés par une requête aléatoire déterminent la base de calcul qui représente le niveau 0 de similarité ; ? les documents retournés par une requête utilisateurs déterminent la valeur maximale de notre calcul qui représentent le niveau 1 de similarité. QCSC ou le Quotient de Centralité Sémantique Comparé La comparaison de la similarité des articles retournés par une même requête ou intra-requête entre les trois types de requêtes (aléatoires, agrégats, utilisateurs) ainsi que la comparaison de la similarité des articles retournés par deux requêtes différentes ou inter-requêtes permettra de cerner la validité sémantique des agrégats. Calcul du CCSR IntraQ ou Coefficient de Centralité Sémantique Comparé Intra-Requête Nous recherchons enfin à calculer la valeur de CCSR_IntraQ ou le Coefficient de Centralité Sémantique Comparé Intra-Requête d'une Courbe X qui provient des mesures effectuées à partir des trios de mots issus d'agrégats (cf. figure 4.9). 4.3 : Les méthodes de validation sémantique 146 Chapitre 4. Expérimentations, validations sémantiques et résultats de mesure
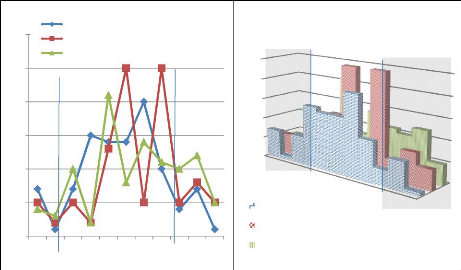
35 30 25 20 15 10 0 5 0 0,1 0,2 0,3 0,4 0,5 0,6 0,7 0,8 0,9 1 Trios de mots aléatoires Triades de mots issues de requêtes utilisateurs Trios de mots issus des agrégats - Courbe X Zone DV Figure 4.9 : CCSR_IntraQ : courbes et aires de distribution des valeurs de similarité retournées en fonction de la nature de la source du trio de mots constituant la requête et incluant en courbe X la courbe des trios de mots issus d'agrégats. Après une détection de la zone DV comme étant la plus « différenciée », nous pouvons calculer CSV-Inter-RC sur cette zone de validation. CCSR_IntraQ est défini comme la moyenne des aires de chaque valeur de chacune des classes incluses dans la zone étudiée : ? Chaque aire de la courbe étudiée est pondérée en fonction de la valeur des aires des deux courbes de référence sur la valeur de la classe en ordonnée de telle manière que plus la similarité de la courbe X se rapproche de celle des requêtes utilisateurs et s'éloigne de celle des trios aléatoires plus la valeur de CCSR_IntraQ augmente ; ? CCSR_IntraQ indique la similarité des documents retournés au sein d'une requête. Une valeur de 1 signifie une similarité comparable à celle des documents retournés par les triades issus de requêtes utilisateurs et 0 une similarité comparable aux trios de mots aléatoires. La mise en valeur absolue des différences entre valeurs d'aires permet de ne pas avoir à tenir compte de l'ordonnancement des courbes dans le calcul relatif, le signe étant alors donné par une valeur K calculée pour chacune des aires selon la valeur de l'aire des requêtes issues d'agrégats par rapport aux aires définies par les courbes de références. De plus, pour chaque mesure nous maximisons la mesure à 1 et la minimisons à 0 en suivant le postulat précédemment défini qui détermine qu'il n'est pas possible d'obtenir des trios de mots plus sémantiquement cohérents que les triades utilisateurs et moins sémantiquement cohérents que les trios de mots aléatoires. 4.3 : Les méthodes de validation sémantique 147 Chapitre 4. Expérimentations, validations sémantiques et résultats de mesure La formule mathématique de CCSR_IntraQ sera donc définie pour une courbe particulière X comme suit : Si ( A(i) < R(i) et X(i) <A(i) ) ou ( A(i) > R(i) et X(i) >A(i) ) alors K(i) = -1 Sinon K(i) = 1 Fin de SI CCSR_IntraQ X = Où R(i) définit l'aire de l'histogramme des triades dont tous les mots sont inclus au moins une fois tous ensemble dans une recherche pour l'ordonnée i. Où A(i) définit l'aire de l'histogramme des trios de mots combinés aléatoirement dans une recherche pour l'ordonnée i. Où X(i) définit l'aire de l'histogramme des trios dont les mots sont issus des agrégats dans une recherche pour l'ordonnée i. CCSR_IntraQ représente le niveau de similarité entre documents pour une requête. La valeur 0 de CCSR_IntraQ représente alors le niveau de qualité le plus faible et 1 le plus élevé. Calcul du CCSR InterQ ou Coefficient de Centralité Sémantique Comparé Inter-Requêtes Nous calculons ensuite sur la zone déclarée comme zone de validation le coefficient CCSR_InterQ. Ce coefficient est calculé exactement selon le même principe que CCSR_IntraQ, si ce n'est que les courbes de références peuvent être amenées à se croiser dans la zone DV ou simplement à être inversées. En effet selon l'emplacement de cette zone, les valeurs du pourcentage de comparaison de documents issus de requêtes différentes peuvent être orientées différemment (cf . figure4.10). 4.3 : Les méthodes de validation sémantique 148 Chapitre 4. Expérimentations, validations sémantiques et résultats de mesure
30 25 20 15 10 0 5 0,1 0,2 0,3 0,4 0,5 0,6 0,7 0,8 0,9 1 Trios de mots aléatoires Triades de mots issues de requêtes utilisateurs Trios de mots issus des agrégats-courbe X Zone DV 25 20 15 10 5 0 Triades de mots issues de requêtes utilisateurs Trios de mots issus des agrégats-courbe X 0 0,1 0,2 0,3 0,4 0,5 0,6 0,7 0,8 0,9 1 os mots de aléatoires Trios de mots aléatoires 0 0,9 1 Zone DV Figure 4.10 : CCSR_InterQ : Courbes et aires de distribution des valeurs de similarité retournées en fonction de la nature de la source du trio de mots constituant la requête. Pour calculer la valeur de CCSR_InterQ ou le Coefficient de Centralité Sémantique Comparé Inter-Requêtes d'une Courbe X (qui provient des mesures effectuées à partir des trios de mots issus d'agrégats) (cf. figure 4.10), les modalités sont les suivantes : ? CCSR_InterQ est défini comme la moyenne des sommes des valeurs d'aires de chacune des classes incluses dans la zone étudiée. ? Chaque aire de la courbe étudiée est pondérée en fonction de la valeur des aires des deux courbes de référence sur la valeur de la classe en ordonnée de telle manière que plus la similarité de la Courbe X se rapproche de celle des requêtes utilisateurs et s'éloigne de celle des trios aléatoires, plus la valeur de CCSR_InterQ baisse. Comme pour la valeur de CCSR_IntraQ, nous utilisons la mise en valeur absolue des différences entre valeurs d'aires de façon à ne pas avoir à gérer l'ordonnancement des courbes. Le signe est alors donné par une valeur K calculée pour chacune des aires selon la valeur de l'aire des requêtes issues d'agrégats par rapport aux aires définies par les courbes de référence. Nous maximisons et minimisons les valeurs de la même manière que pour CCSR_IntraQ. La formule mathématique de CCSR_InterQ est définie pour une courbe particulière Courbe X comme suit : Si ( A(i) < R(i) et X(i) <A(i) ) ou ( A(i) > R(i) et X(i) >A(i) ) alors K(i) = -1 4.3 : Les méthodes de validation sémantique 149 Chapitre 4. Expérimentations, validations sémantiques et résultats de mesure Sinon K(i) = 1 Fin de Si CCSR_InterQ X = Où R(i) définit l'aire de l'histogramme des triades dont tous les mots sont inclus au moins une fois tous ensemble dans une recherche pour l'ordonnée i. Où A(i) définit l'aire de l'histogramme des trios de mots combinés aléatoirement dans une recherche pour l'ordonnée i. Où X(i) définit l'aire de l'histogramme des trios dont les mots sont issus des agrégats dans une recherche pour l'ordonnée i. CCSR_InterQ représente la similarité des documents inter-requête. La valeur 0 de CCSR_InterQ représente alors le niveau de qualité le plus élevé et 1 le plus faible. QCSC ou le Quotient de Centralité Sémantique Comparé Le Quotient de Centralité tient compte des mesures de distance faites en inter-requêtes autant qu'en intra-requêtes. Il est directement proportionnel au premier CCSR_IntraQ et inversement proportionnel au second CCSR_InterQ. Afin de tenir compte des deux coefficients et ensuite de pouvoir comparer le résultat à celui d'autres méthodes, nous définissons le QCSC comme la racine carrée du produit des deux coefficients. Le quotient de centralité sémantique s'exprime comme suit : QCSCX =.ICCSR_IntraQ x ( 1-- CCSR_InterQ) 4.1.1 Conclusion sur les méthodes de validation Nous en arrivons à la conclusion qu'il existe deux démarches pour valider sémantiquement un agrégat de mots :
4.3 : Les méthodes de validation sémantique 150 Chapitre 4. Expérimentations, validations sémantiques et résultats de mesure rechercher une validation par des utilisateurs. L'expérimentation manuelle effectuée par un expert du domaine (si les agrégats sont créés dans un domaine précis) ou des utilisateurs est toujours tentante. En effet, c'est en fait une externalisation du travail et puisque le responsable du jugement est, soit un expert, soit un groupe d'utilisateurs ayant des exigences, nous attendons un jugement certain. Mais qu'en est-il ? Dans le paragraphe suivant, nous étudions en détail les avantages et les inconvénients de chaque méthode de validation. Les différentes techniques de regroupement ont été utilisées en fonction de plusieurs critères et opportunités : ? la présence et la disponibilité d'experts : les validations manuelles sont liées à la disponibilité d'un expert du domaine des agrégats ; ? les résultats obtenus par les différentes méthodes : les méthodes de regroupements et de validation sont confrontées en fonction de leurs résultats respectifs. Il est inutile de tester avec plusieurs méthodes de validation sémantique une solution de regroupement qui ne fonctionne pas. De la même manière, il est peu productif de tester des agrégats créés avec plusieurs méthodes si la méthode de validation sémantique n'a pas démontré son efficacité. Quels réseaux, testés avec quelles méthodes de validation ? Dans le tableau 4.6 le lecteur trouve l'ensemble des méthodes d'agrégation ou d'enrichissement, les méthodes de validation et les réseaux. Le tableau suivant permet de faire le lien entre ces diverses expérimentations.
Tableau 4.6 : les méthodes de regroupement, les méthodes de validation sémantique et les réseaux. Ainsi, par exemple, seule la méthode de Rigidification Régulée qui apparaît comme la plus performante est validée par l'ensemble des méthodes de validation. La méthode de regroupement par cliques, qui a immédiatement montré ses limites, n'est pas suffisamment digne d'intérêt pour justifier d'autres tests. 4.4 : Résultats des regroupements et validation sémantique 151 Chapitre 4. Expérimentations, validations sémantiques et résultats de mesure |
|