Agrégats de mots sémantiquement cohérents issus d'un grand graphe de terrain( Télécharger le fichier original )par Christian Belbèze Université Toulouse 1 Capitole - Doctorat en informatique 2012 |

Chapitre 4. Expérimentations, validations sémantiques et résultats de mesure
Tableau 4.9 : Comparatif des valeurs de CVSC pour les agrégats de moins et de plus de 30 mots-clés sur deux réseaux différents. Nous avons donc traité l'échantillon du 17 mars 2006 avec une méthode HLS-CVSC identique à celle du 17 avril 2006. On observe une grande cohérence entre les courbes issues des logs du 17 avril 2006 et celles issues des logs du 17 mars 2006. Cela confirme les conclusions sur la relation entre la taille des agrégats et les valeurs de CVSC et le fait que cette information semble indépendante du contexte temporel. Comparaison des CSVC entre les triades et les trios de mots au sein des agrégats Un terme n'est pas toujours monosémique. Ainsi, les agrégats incluant des mots polysémiques, sont susceptibles de contenir des combinaisons de mots (trios) de faible coefficient sémantique, en raison de ces multiples sens. Dans cette section, au travers de deux exemples nous illustrons la baisse du coefficient identifiée précédemment. Le premier exemple est purement théorique (cf. figure 4.19), le deuxième est un véritable agrégat créé avec la méthode de Rigidification Simple sur le réseau AOL-17/04/2006. Exemple 1 Le graphe de la figure 4.19 ci-dessous, illustre les concepts de musique et de cuisine, notamment au travers des mots « chef », « piano » et « sol ».
Cuisine Nettoyage Piano Chef sol orcheste Musique Figure 4.19 : Exemple d'agrégat intégrant des mots ayant plusieurs acceptions (musique/cuisine). 4.4 : Résultats des regroupements et validation sémantique 160 Chapitre 4. Expérimentations, validations sémantiques et résultats de mesure Supposons que nous ayons obtenu ce graphe à partir des requêtes utilisateurs suivantes : ? {sol, cuisine, nettoyage} ? {chef, cuisine, piano, nettoyage} ? {musique, chef, piano, orchestre} ? {sol, piano, musique} Supposons que la méthode permette de construire un agrégat AG contenant tous ces mots tel que : AG = {sol, cuisine, nettoyage, chef, piano, orchestre, musique}. Différentes acceptations des mots « piano », « sol » et dans une moindre mesure « chef » interviennent dans cet agrégat. Lors de l'évaluation de la cohérence sémantique de cet agrégat, la combinaison systématique en trios de tous les mots-clés dans l'agrégat génère un certain nombre de trios ayant une faible cohérence sémantique. En voici trois exemples :
Exemple 2 Prenons un autre agrégat de mots issu du réseau AOL-17/04/2006, nommons cet agrégat Agr. Il est défini tel que : Agr = {abiline, arunde, arundl, aubun, avalanche, b2600, car, cars, chevrolet, dealerships, electronic, fj40, fordsale, gaffn, hamptonroad, ignition, lexus, lynchb, maine, microwave, murrieta, outboard, parts, pax, selecti, ulster, uplander, used, usedfront, virgini, waterville}. Cet agrégat a été construit notamment grâce aux requêtes utilisateurs suivantes : la requête utilisateur « +used +car +pax » qui renvoie 284 000 sites : pax est une référence de pneu de marque Michelin et d'autres pièces détachées ; la requête utilisateur « +used +car +abiline » qui renvoie 1 140 sites : abiline est un centre de vente et d'achat de pièces détachées ; la requête utilisateur « +used +car +murietta » qui renvoie 17 100 sites : murrieta est un centre de réparation de véhicules. 4.4 : Résultats des regroupements et validation sémantique 161 Chapitre 4. Expérimentations, validations sémantiques et résultats de mesure Ces trois requêtes utilisateurs ont toutes des résultats situés dans la zone [C]. Cependant, le trio de mots issu de cet agrégat, utilisé comme requête dans la mesure de la cohérence sémantique, « +abiline +murietta +pax » ne retourne qu'un seul site ( search.AOL.com 2010) où « Abiline » devient un prénom, « Murietta » le nom d'une ville et « pax » le mot latin signifiant « paix ». Pour mesurer les pertes de cohérence sémantique liées à cet aspect du problème et pour mieux connaître la valeur statistique de CSVC sur les trios de mots issus d'agrégats par rapport aux triades issues de requête, nous avons testé séparément les trios de mots et les triades. Afin de rester sur des espaces sémantiquement valides, notre test ne comprend que les agrégats de moins de 30 mots.
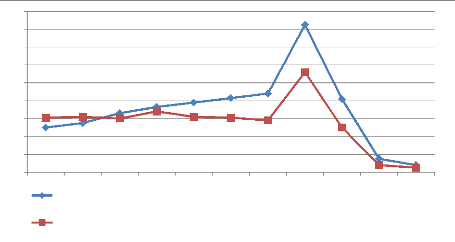
18 16 14 12 10 4 8 0 6 2 2^10 2^11 2^12 2^13 2^14 2^15 2^16 2^17 2^18 2^19 2^20 Triades de mots existantes au moins dans une recherche utilisateur et tirées d'agrégats de moins de 30 mots-clés Trios de mots n'existants pas dans une recherche utilisateurs et tirés d'agrégats de moins de 30 mots-clés Figure 4.20 : Comparaison des valeurs des CVSC des triades et trios issus d'agrégats de 3 à 29 mots-clés.
Tableau 4.10 : Comparaison des valeurs des CVSC des triades et trios issus d'agrégats de 3 à 29 mots-clés. L'agrégat présenté dans l'exemple 2 n'a pas été soumis à ce test puisqu'il possède plus de 29 mots. Les triades incluses dans les agrégats de moins de 30 mots obtiennent très logiquement, le score de 1. Les trios de mots (combinés depuis les agrégats de moins de 30 mots) qui n'ont jamais été utilisés dans une requête utilisateur présentent l'excellent score de 0.7. Si l'agrégation crée bien une baisse du CVSC, celle-ci reste contenue au sein des agrégats de taille inférieure à 30 mots-clés. 4.4 : Résultats des regroupements et validation sémantique 162 Chapitre 4. Expérimentations, validations sémantiques et résultats de mesure Agrégats par la méthode de Rigidification Régulée Matériel et conditions d'évaluation La suppression ou la non-intégration dans les agrégats de mots au sens faible (mots de liaison, déterminants, etc.) pour en maintenir la taille est généralement préférable à la suppression des mots possédant un sens fort. Pour déterminer les valeurs de Val-Min-CFL et de Val-Activ-CFL (cf. paragraphe 3.4), nous étudions et comparons les valeurs des liaisons et plus particulièrement de CFL (Coefficient de Fiabilité de Lien) de deux types de mots-clés :
Tableau 4.11 : Liste de mots déterminés comme monosémiques. Valeur de départ de Val-Min-CFL Pour fixer la valeur de Val-Min-CFL nous allons comparer la nature des liens des deux populations étudiées. Plus précisément nous allons comparer la valeur la plus faible de CFL sur les diades où un des mots de la liaison au moins est monosémique avec la même valeur quand un des mots au moins est dans la liste des mots vides. Le but est de prendre une valeur suffisamment basse pour conserver les mots monosémiques dans les agrégats et une valeur suffisamment haute pour exclure au plus tôt les mots vides. 4.4 : Résultats des regroupements et validation sémantique 163 Chapitre 4. Expérimentations, validations sémantiques et résultats de mesure
35 30 25 20 15 10 0 5 0,01 0,02 0,03 0,04 0,05 0,06 0,07 0,08 0,1 0,11 0,12 13 0,14 0,15 16 0,17 0,18 0,19 0,2 u Au moins moins un un des des mots mots est dans dans la la liste liste des des mots mots monosémiqueinsignifiants Au moins un des mots dans la liste des mots insignifiants u moins un des mots est dans la liste des mots monosém Figure 4.21 : Comparaison de la distribution de la valeur minimale de CFL (Coefficient de Fiabilité de Lien) dans les diades incluant un mot monosémique et celles incluant un mot vide. La valeur la plus basse de CFL pour les diades incluant un mot vide au moins est dans 90% des cas inférieure à 0.1% (cf. figure 4.21). D'un autre côté, choisir cette valeur comme valeur de départ de la boucle principale pour le démarrage du paramètre Val-Min-CFL nous permet de conserver 75% des liens incluant un mot monosémique. Valeur de départ de Val-Activ-CFL Pour déterminer la valeur de départ de Val-Activ-CFL dans la boucle principale nous comparons la valeur maximale des deux valeurs CFL des diades incluant soit un mot monosémique soit un mot vide au moins.
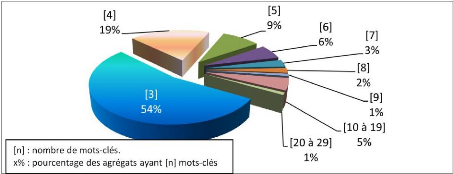
12 10 8 4 0 6 2 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 Au moins un mot vide dans la diade a i i i Au moins un mot monosémique dans la diade Figure 4.22 : Comparaison de la distribution de la valeur maximale de CFL (Coefficient de Fiabilité de Lien) dans les diades incluant un mot monosémique et celles incluant un mot vide. S'il n'y pas de différence notable entre la distribution des diades incluant un mot monosémique et celles incluant un mot vide (cf. image 4.19), on peut affirmer qu'en-dessous de 4% le nombre de liaisons est extrêmement faible et ceci pour les deux familles de diades. Aussi nous utiliserons cette valeur pour valeur de départ de notre expérimentation. 4.4 : Résultats des regroupements et validation sémantique 164 Chapitre 4. Expérimentations, validations sémantiques et résultats de mesure Nombre de « pas » de la boucle principale et de la boucle fine Nous choisissons finalement et arbitrairement 20 « pas » pour la boucle principale et 20 « pas » pour la boucle fine. Au-delà de 50 « pas » l'augmentation du nombre semble avoir un impact très minime dans la construction des agrégats. Cependant, ce nombre de 50 réclame un temps CPU trop important. Le choix du nombre de 20 nous est apparu comme un compromis raisonnable. Moteur de recherche utilisé Le moteur de recherche utilisé dans cette expérimentation est bing.com. Nous modifions le moteur utilisé car AOL.com détecte le fait que la tâche est robotisée et refuse de nous répondre. 4.4.3 Rigidification Régulée sur le réseau « 100 mots dans AOL » avec validation par MCCVSAgrégats créés dans le réseau « 100 mots dans AOL » La méthode de Rigidification Régulée nous a permis de créer, sur le réseau « 100 mots dans AOL » : 2196 agrégats de 3 à 29 éléments. Le nombre moyen de mots par agrégat est de 4.6.
Figure 4.23 : Distribution du nombre de mots-clés par agrégat sur le réseau « 100 mots dans AOL ». Rejet des mots vides La méthode possède une capacité importante à rejeter les mots vides. Si dans certains cas particuliers ces mots vides sont utiles, leur éjection est souvent nécessaire pour éviter la création d'agrégats de trop grande taille. Nous ne retrouvons que 62 mots-clés de la liste http://snowball.tartarus.org/algorithms/english/stop.txt qui en contient 220 sur les 1090 mots-clés utilisés dans les agrégats. 4.4 : Résultats des regroupements et validation sémantique 165 Chapitre 4. Expérimentations, validations sémantiques et résultats de mesure Estimation de la qualité sémantique des agrégats par MCCVS En suivant la méthode MCCVS, nous créons aléatoirement des trios de mots et comparons le nombre de sites retournés par un moteur de recherche avec des triades de mots ayant été utilisées conjointement dans une requête utilisateur au moins. De la nécessité de filtrer les mots avant de les envoyer dans un moteur de recherche Nous travaillons ici sur un réseau représentant le fichier de log d'AOL dans son ensemble. Les mots utilisés une fois ou deux peuvent être considérés, le plus souvent comme des erreurs potentielles. Pourtant, que ce soit dans le choix aléatoire d'un mot pour créer un trio aléatoire ou le test d'un agrégat, ce mot n'est pas utilisé en fonction de son usage par les utilisateurs mais par le simple fait de sa présence. Ainsi, dans la création d'un trio aléatoire, un mot utilisé une fois ou très rarement va avoir autant de chance d'être sélectionné qu'un mot utilisé des centaines de milliers de fois. De même, les mots vides présents dans le réseau peuvent aussi se retrouver combinés. Dans ce cas, le moteur de recherche renvoie un nombre extrêmement élevé de sites trouvés. Par exemple, pour la requête « +the +and +or », big.com retourne 3 860 000 000 sites trouvés ( big.com juillet 2011). Dans le test des agrégats où l'on combine tous les mots en trios, un mot rare « pèse » aussi de manière exagérée. Supposons qu'un mot rare soit présent dans un agrégat de 10 mots, on le trouvera dans 36 des combinaisons testées ; de même, dans un agrégat de 20 mots il sera présent dans 171 combinaisons. Si ce mot est une erreur de frappe, comme c'est le cas pour la plupart de ces mots rares, il conduit le moteur de recherche à retourner très peu de sites voire aucun sur les 171 requêtes. Alors que dans le log d'AOL ce mot n'est présent que dans une seule requête sur plus de 22 millions, il intervient de manière beaucoup trop importante dans la validation des agrégats. Donnons ici pour exemple un agrégat Ag créé par la méthode de Rigidification Régulée sur le réseau « 100 mots dans AOL » (les valeurs entre parenthèses sont le nombre de requêtes utilisant le terme) : Ag = {system (15858), digestive (1378), diapra(25), demonstraion(1)}. Les mots « diapra » et « demonstraion » n'existent pas et nous pouvons imaginer que ce sont des erreurs.
Tableau 4.12 : Exemple de combinaisons de mots incluant des mots à faible usage dans des recherches. 4.4 : Résultats des regroupements et validation sémantique 166 Chapitre 4. Expérimentations, validations sémantiques et résultats de mesure La solution pourrait être de supprimer simplement les mots de faible utilisation et les mots vides du graphe à tester. Mais si nous voulons préserver la capacité à détecter de nouvelles communautés d'utilisateurs par l'usage de nouveaux mots et la capacité à créer des agrégats basés sur l'utilisation conjointe de mots vides, il nous faut conserver ces mots dans le graphe étudié. Ces problèmes ont moins de conséquence dans l'étude des réseaux AOL-17/04/2006 et AOL-17/03/2006. En effet, la part de mots rarement ou très rarement utilisés (et étant des erreurs) ne peut qu'augmenter avec la taille du fichier de log. De plus, dans l'étude de ces réseaux, avec la méthode de Rigidification Simple nous filtrons préalablement les mots vides qui n'étaient donc pas présents ni dans les agrégats ni dans les requêtes de test. La méthode de Rigidification Régulée que nous évaluons ici a permis de les conserver pour les raisons évoquées plus haut. Définition du filtre préalable avant l'évaluation sémantique Afin de créer un ensemble valide et d'éviter des combinaisons surpondérées pour le test d'évaluation sémantique, sont exclus de l'évaluation sémantique les mots très utilisés et les mots très peu utilisés. Les mots très utilisés sont issus de la liste déjà évoquée ; http://snowball.tartarus.org/algorithms/english/stop.txt. Bien que peu nombreux, ils représentent 10.06 % des usages (ensemble des mots multipliés par le nombre de requêtes dans lesquels le mot est présent, ces mots vides étant généralement les plus usités). Les mots de faible utilisation sont écartés en fonction de leur valeur globale d'utilisation (ensemble des mots multipliés par le nombre de requêtes dans lesquelles le mot est présent) jusqu'à obtenir 10% des usages. Nous retirerons donc les mots qui ont été utilisés moins de 94 fois. Ainsi, nous ne conservons ni les mots définis comme vides, ni les termes de faible utilisation (présents dans moins de 94 requêtes) de façon à travailler sur des mots correspondant à 80% des usages. Bien sûr, la démarche est la même dans les trois systèmes de génération de requêtes. Seuls les agrégats ayant au moins trois mots après filtrage sont considérés comme valides pour être évalués. Valeur de CSVC Avec la méthode MCSVS, il s'agit de mesurer et comparer la distribution du nombre de sites retournés sur un échantillon de 100 000 requêtes faites de trios de mots aléatoires avec 100 000 triades issues de requêtes utilisateurs. Les mots sont ici ceux définis dans le paragraphe « Définition du filtre préalable avant l'évaluation sémantique ». 4.4 : Résultats des regroupements et validation sémantique 167 Chapitre 4. Expérimentations, validations sémantiques et résultats de mesure
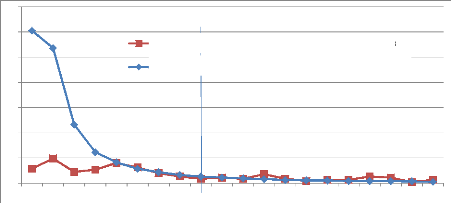
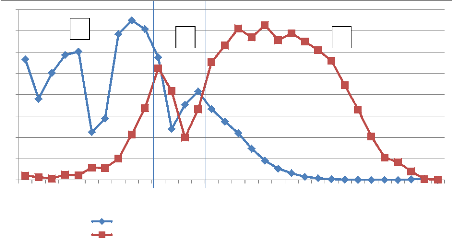
4 8 0 7 6 5 3 2 1 2^0 2^1 2^2 2^3 2^4 2^5 2^6 2^8 2^9 2^10 2^11 2^12 2^13 2^14 2^15 2^16 2^17 2^18 2^19 2^20 2^21 2^22 2^23 2^24 2^25 2^26 2^27 2^28 2^29 2^30 2^31 >2^31 A Trios de mots filtrés, générés aléatoirement Triades de mots filtrés présentes dans une requête utilisateur B C Figure 4.24 : Comparaison des réponses aux requêtes susceptibles d'être les plus éloignées sémantiquement (cf. 4.3.1) et détermination des zones à forte divergence. L'observation des trois courbes nous permet de détecter trois zones : ? la zone « A » très accidentée ; ? la zone « B » où les deux courbes sont proches ; ? la zone « C » où les courbes sont bien différenciées et lisses. Cette dernière caractéristique confirme l'aspect non accidentel des mesures. Nous utilisons donc la zone « C » comme zone de validation sémantique.
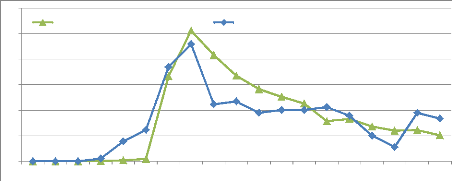
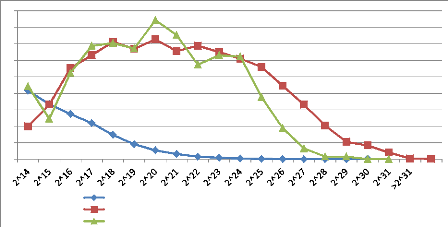
4 9 8 0 7 6 5 3 2 1 Trios de mots filtrés, générés aléatoirement Triades de mots filtrées présentes dans une requête d'utilisateur Trios de mots filtrés issus des agrégats Figure 4.25 : Représentation graphique de la zone « C » de validation sémantique sur les trois courbes représentant les trois sources de requêtes. 4.4 : Résultats des regroupements et validation sémantique 168 Chapitre 4. Expérimentations, validations sémantiques et résultats de mesure Nous calculons le CVSC des requêtes construites à partir des agrégats : CVSCX = (AX - AA) / (AR-AA) où AR définit l'aire de l'histogramme des triades et où les trois mots sont conjointement présents dans une requête utilisateur au moins, où AA définit l'aire de l'histogramme des trios de mots générés aléatoirement, où Ax définit l'aire de l'histogramme des trios de mots issus d'agrégats. On a donc : CVSCX = (73.62 - 16.07) / (80.04 - 16.07) = 0.899 |
|