Table des matières
|
1
I
|
Introduction Générale
Etat de l'Art
|
7
9
|
|
2
|
Notions de base de Système multi agents
|
10
|
|
2.1
|
Introduction
|
10
|
|
2.2
|
Définitions générales
|
10
|
|
|
2.2.1 Agent
|
10
|
|
|
2.2.2 Agent stationnaire
|
11
|
|
|
2.2.3 Mobilité
|
11
|
|
|
2.2.4 Agent mobile
|
12
|
|
2.3
|
Agent stationnaire vs Agent mobile
|
12
|
|
2.4
|
Système multi agent
|
17
|
|
|
2.4.1 Définition
|
17
|
|
|
2.4.2 Caractéristiques principales
|
17
|
|
|
2.4.3 Les domaines d'application
|
18
|
|
|
2.4.4 Problématiques des SMA
|
18
|
|
2.5
|
Les plateformes
|
19
|
|
|
2.5.1 Agent TCl
|
19
|
|
|
2.5.2 Aglets
|
20
|
|
|
2.5.3 Concordia
|
20
|
|
|
2.5.4 Mole
|
20
|
|
|
2.5.5 Telescript
|
20
|
|
|
2.5.6 Odyssey
|
20
|
|
|
2.5.7 Voyager
|
21
|
|
2.6
|
Conclusion
|
21
|
|
3
4
|
Solution de sécurité des agents Mobiles
3.1 Introduction
3.2 La nécessité de la sécurité des
agents mobiles
3.2.1 La confidentialité
3.2.2 L'authentification
3.2.3 L'intégrité
3.2.4 La disponibilité
3.2.5 La non répudiation
3.2.6 Le contrôle d'accès
3.2.7 Le secret du flux
3.2.8 Le confinement
3.3 Les politiques de sécurité
3.3.1 Définition
3.3.2 Les approches de sécurisation des agents mobiles
3.4 Les cas de sécurisation
3.4.1 Sécurité entre deux agents
3.4.2 Sécurité des agents contre les hôtes
3.4.3 Sécurité de l'hôte contre les agents
3.4.4 Sécurité des agents contre intervenant
externe
3.4.5 La sécurité pendant le transfert d'un agent
3.5 Conclusion
La plateforme Aglets
4.1 Introduction
4.2 Aglets
4.2.1 Définitions
4.2.2 Cycle de vie d'un aglet
4.2.3 La création de l'aglet
4.2.4 Le modèle événementiel de l'aglet
4.2.5 Communication des aglets
4.2.6 Les Serveurs d'aglets
4.3 Conclusion
|
22
22
22
23
23
23
23
23
24
24
24
24
24
25
30
31
32
33
33
34
34
36 36 36 36 38
40
41
42
43
44
|
|
II
5
|
Spécification et réalisation Communication inter
Aglets
|
45
46
|
|
5.1
|
Introduction
|
46
|
|
5.2
|
Types de communication
|
46
|
|
|
5.2.1 Communication simple
|
47
|
|
|
5.2.2 Communication synchrone
|
47
|
|
|
5.2.3 Communication asynchrone
|
48
|
|
5.3
|
Protection de la communication
|
49
|
|
|
5.3.1 Approches de protection
|
49
|
|
|
5.3.2 Contrôle d'intégrité
|
55
|
|
5.4
|
Les failles dans Aglets au niveau de la communication entre les
agents
|
56
|
|
|
5.4.1 La confidentialité
|
57
|
|
|
5.4.2 L'authentification et L'intégrité
|
58
|
|
|
5.4.3 La disponibilité
|
59
|
|
5.5
|
Conclusion
|
60
|
|
6
|
Spécification de domaine
|
61
|
|
6.1
|
Introduction
|
61
|
|
6.2
|
Environnement de travail
|
61
|
|
|
6.2.1 Langage de programmation : Java
|
61
|
|
|
6.2.2 Environnement Matériel
|
61
|
|
|
6.2.3 Environnement Logiciel
|
62
|
|
6.3
|
Configuration du serveur Tahiti
|
63
|
|
|
6.3.1 Installation de la plateforme
|
63
|
|
6.4
|
Le diagramme des cas d'utilisation de Tahiti
|
65
|
|
|
6.4.1 Description du système
|
65
|
|
6.5
|
Conclusion
|
66
|
|
7
|
Conception et réalisation
|
67
|
|
7.1
|
Introduction
|
67
|
|
7.2
|
Spécification de la solution
|
67
|
|
|
7.2.1 Etapes de travail
|
67
|
|
|
7.2.2 Description de la solution
|
68
|
|
7.3
|
Conception de la solution
|
70
|
|
|
7.3.1 Diagramme de classes
|
70
|
7.3.2 Diagramme de cas d'utilisation 71
7.3.3 Diagramme de séquence 72
7.4 Implémentation de la solution 73
7.4.1 Cryptage/Décryptage 73
7.4.2 Contrôle d'intégrité 75
7.4.3 Assurer l'authentification 76
7.5 Conclusion 77
8 Conclusion générale 78
A Annexes 82
Table des figures
Scientific WorkPlace 5.0 10
11 INteration ....11
1.2hjytyjuu ....3
1.3Essai 4
1.1 Interaction à travers le réseau 12
1.2 Migration (phase 1) 12
1.3 Migration (phase 2) 13
1.4 Migration (phase 3) 13
1.5 Migration (phase 4) 14
1.6 Migration (phase 5) 14
1.7 Graphique1 : Agents statiques vs. agents mobiles (a = 5000)
15
1.8 Graphique 2 : Agents statiques vs. agents mobiles (a = 25000)
15
2.1 Sécurisation à base de cartes à puces
25
2.2 Génération de variables à noms non
significatifs 26
2.3 sécurité entre deux agents 30
2.3 sécurité entre deux agents 32
2.4 Sécurité des agents contre les hôtes
33
3.1 Relation entre un aglet et son Proxy 36
3. 2 Évolution des Aglets dans un Contexte 37
3.3 Relations entre hôte, moteur et contexte 37
3.4 Modèle du cycle de vie d'un aglet 38
3.5 Transfert d'un aglet 39
3.6 Diagramme de Collaboration pour la création de l'Aglet
40
4.1 L'environnement Aglet 46
4.2 Communications synchrones 47
4.3 Communications Asynchrones 47
4.4 Système de cryptographie symétrique 50
4.5 Système de cryptographie asymétrique 52
4.6 Principe de fonctionnement de l'algorithme RSA 53
4.7 Résultat d'une capture de trafic par le sniffer(1)
55
4.8 Résultat d'une capture de trafic par le sniffer (2)
56
4.9 Faille au niveau de la disponibilité 57
5.1 IRISv4.06.4 59
5.2 Phase d'identification/authentification 61
5.3 Serveur Tahiti 61
5.4 Diagramme des cas d'utilisation du serveur Tahiti 62
6.1 Etapes de travail 65
6.2 Cryptage/Décryptage 66
6.3 Compression/Décompression 66
6.4 Diagramme de la solution 67
6.5 Diagramme de classes 68
6.6 Diagramme de cas d'utilisation 69
6.7 Diagramme de séquence 70
6.8 Processus de l'agent de cryptage A 71
6.9 Processus de l'agent de décryptage B 72
Chapitre 1
Introduction Générale
Suite à l'évolution technologique, l'utilisation
de l'outil informatique s'avère de plus en plus nécessaire dans
tous les domaines. Pour cela, les sociétés publiques cherchent
à améliorer la qualité de leurs services en introduisant
cet outil dans leurs processus de fonctionnement et de traitement de
données. Le domaine de la médecine comme la plupart des domaines,
exploite l'informatique pour le développement des logiciels de
traitement d'informations qui facilitent aux médecins entre autres, le
travail en groupe, mais les échanges des données et la
répartition des tâches d'une application distribuée
nécessites l'interaction entre différentes entités
à travers le réseau.
Pour ces raisons les dirigeants s'orientent vers
l'implémentation des agents mobiles dans les systèmes
informatiques qui donnent à leurs entreprises un avantage face aux
besoins accrus.
Aujourd'hui, la technologie "agent mobile" est de plus en plus
attractive vu les avantages qu'elle offre pour la réalisation des
tâches complexes et répétitives dans des systèmes
ouverts et dynamiques. Cette approche a un grand intérêt pour la
mise en oeuvre d'applications dont les performances varient en fonction de la
disponibilité, de la qualité des services et des ressources et du
volume des données déplacées. Elle permet aux concepteurs
et aux développeurs de systèmes distribués d'utiliser des
approches informatiques autonomes non seulement au niveau de leurs
comportements, mais aussi dans l'espace et dans le temps.
Les particularités des agents mobiles liées
à la mobilité sont, sans être exhaustif :
leur
création (locale ou à distance), leur migration
(forte/faible), leur aptitude à accéder à
des
ressources locales, leurs traces et enfin le plus important le mode de
communication entre eux.
Le modèle à agents mobiles en
particulier la plateforme Aglets, qui représente le
cadre
général de notre projet, étant un domaine
récent de recherche, des travaux y ont été
effectués
dans le but d'avoir un système qui emploie des
agents mobiles coopératifs afin d'améliorer la
qualité
de service. Par la suite, les chercheurs ont trouvé que la communication
inter agents
pose des limitations surtout dans le cas où on cherche
à implémenter les propriétés de
sécurité dans le système. Pour cette raison, ce type
d'applications devient de moins en moins adopté par des domaines qui
nécessitent la confidentialité des données tel que le
domaine médical.
Comment doit-on alors intégrer des protocoles de
sécurité pour la communication inter agents dans la plate-forme
Aglets pour rendre ce type d'applications adaptable en particulier au domaine
médical?
Afin de résoudre les problèmes relatifs à
la sécurité des agents mobiles Aglets, nous avons adopté
une méthodologie de recherche basé sur une études
bibliographique des Systèmes multi agents, dont le résultat est
porté dans le chapitre1, l'étude des solutions existantes de
sécurité des agents Mobiles dans le chapitre 2 et enfin une
étude sur la plateforme Aglets porté dans le 3ieme chapitre.
En second lieu les chapitres 4,5 et 6 Concerneront le cas
pratique où on met en pratique notre solution apportée au
problème de sécurité des agents mobiles.
Première partie
Etat de l'Art
Chapitre 2
Notions de base de Système multi
agents
2.1 Introduction
L'informatique devient de plus en plus diffusée et
distribuée. La décentralisation et la coopération entre
modules logiciels sont donc des besoins pour améliorer la qualité
de service d'un système. De plus, avec la croissance de la taille et de
la complexité des nouvelles applications informatiques, la vision
centralisée et assez statique atteint ses limites. On est ainsi
naturellement conduit à chercher une façon de donner plus
d'autonomie et d'initiative aux différents modules logiciels. Le concept
des systèmes multi agents (SMA) propose un cadre de réponse
à ces enjeux.
A partir de 1995, le monde des agents a été
enrichi d'un nouveau type : l'agent mobile. Un agent mobile est un agent
capable de se déplacer d'un site physique à un autre. Dès
sa naissance, le concept n'a pas arrêté de susciter
l'intérêt des chercheurs et des ingénieurs. Nous pouvons
dire que les agents mobiles jouent déjà un rôle crucial et
le joueront dans l'avenir de l'Internet et de l'informatique en
général.
Dans ce chapitre, nous allons citer quelques
définitions générales qui présentent les notions de
base de ce domaine, une petite étude comparative entre agent
stationnaire et agent mobile ainsi qu'une étude sur les Système
multi Agents et on finit par les différentes plateformes existantes.
2.2 Définitions générales
2.2.1 Agent
Définition 1
Un agent est une entité autonome, réelle ou
abstraite, qui est capable d'agir sur elle-même et sur son environnement,
qui, dans un univers multi agent, peut communiquer avec d'autres agents, et
dont le comportement est la conséquence de ses observations, de ses
connaissances et de ses interactions avec les autres agents.
Définition 2
Un agent est un système informatique, situé dans un
environnement, et qui agit d'une façon autonome et flexible pour
atteindre les objectifs pour lesquels il a été conçu.
- situé : l'agent est capable d'agir sur son environnement
à partir des entrées qu'il reçoit de ce même
environnement (systèmes de contrôle de processus, systèmes
embarqués, etc.);
- autonome : l'agent est capable d'agir sans l'intervention d'un
tiers (humain ou agent) et contrôle ses propres actions ainsi que son
état interne,
- flexible : l'agent dans ce cas est :
· capable de répondre à temps: l'agent doit
être capable de percevoir son environnement et d'élaborer une
réponse dans les temps requis,
· proactif: l'agent doit exhiber un comportement proactif
et opportuniste, tout en étant capable de prendre l'initiative au bon
moment,
· social: l'agent doit être capable d'interagir avec
les autres agents (logiciels et humains) quand la situation l'exige afin
d'accomplir ses tâches.
2.2.2 Agent stationnaire
Un agent stationnaire ou statique est un agent mobile qui
n'exécute en général qu'une seule migration. Cette
migration s'effectue depuis la station de départ vers un noeud bien
défini au lancement. A l'arrivée sur le noeud, l'agent mobile ne
migre plus mais exécute une tâche prédéfinie.
Il peut s'agir d'un calcul de longue durée (par
exemple vérifier périodiquement le nombre de requêtes
exécutées sur une base de données), de la supervision de
l'interface réseau, de la supervision de l'espace disque du
système hôte.
Une autre utilisation d'un agent stationnaire serait de fournir
une ou plusieurs listes d'éléments qui correspondraient à
des itinéraires pour les agents mobiles de la plateforme.
2.2.3 Mobilité
La mobilité se manifeste par la faculté de se
déplacer dans un environnement. On distingue quatre
éléments informatiques différents relatifs à la
mobilité : les données, le code, les objets, et les agents. Dans
un système informatique composé de plusieurs ordinateurs, ces
éléments peuvent être statiques ou mobiles. Donc, nous
pouvons identifier huit types différents. Le tableau
ci dessous montre des exemples de tous ces types.

Eléments informatiques, statiques et mobiles.
Il existe une vaste littérature dédiée
aux éléments du tableau, même aux éléments
mobiles seuls. Mais, dans le cadre de notre mémoire, nous nous
concentrons sur les agents mobiles dont l'exemple est mis en gras dans le
tableau.
2.2.4 Agent mobile
Les agents mobiles sont des entités logicielles
autonomes qui peuvent suspendre leur exécution sur une machine et migrer
avec leur code, variables et état vers une autre machine où ils
reprennent leur exécution.
Caractéristiques des agents mobiles
Les principales caractéristiques d'un agent mobile sont
:
Réduction de la charge Réseau : Il est
généralement plus avantageux, en terme des performances, de faire
voyager du code plutôt que des informations puisque le premier est moins
volumineux et offre la possibilité de poursuivre l'exécution dans
d'autres cites.
- Déplacer le Code vers les données: Les
serveurs contenants des données procurent un ensemble fixe
d'opérations. Un agent peut étendre cet ensemble pour les besoins
particuliers d'un traitement.
- Plus sûr et meilleure tolérance : La vie d'un
programme classique est liée à la machine ou il s'exécute.
Un agent mobile peut se déplacer pour éviter une erreur
matérielle ou logicielle ou tout simplement un arrêt de la
machine.
2.3 Agent stationnaire vs Agent mobile
Notons bien que l'agent stationnaire s'exécute seulement
sur la machine où il est créé. Si jamais il a besoin
d'informations supplémentaires inexistantes localement ou d'interagir
avec
d'autres agents dans différents systèmes, alors
il utilise typiquement le mécanisme RPC (Remote Procedure Calling) qui
est une méthode appliquée dans le modèle client
serveur.
Par contre, Un agent mobile est un processus autonome
contenant du code et des données, capables de se déplacer d'une
machine à une autre afin de réaliser une tâche
précise. Ce code représente l'ensemble des instructions du
programme, et les données sont constituées soit du
véritable contexte d'exécution du programme, soit de variables
émulant ce contexte. Un contexte d'exécution est composé
de la pile de récursivité, du tas et des registres. Ce contexte
évolue au cours de la vie de l'agent.
Le choix d'employer des agents stationnaires ou mobiles dans
un système, dépend non seulement de la nature technique et
conceptuelle de l'agent mais aussi du contexte où il est prévu
d'être employé.
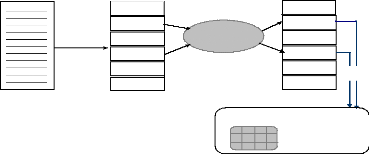
Dans le cas d'un système à agents
stationnaires, on se pose qu'un agent veut accéder à une base de
données distante, dans ce cas l'interaction avec la base se fait
à travers le réseau comme il est indiqué dans la figure
1.1.

Utilisateur A
Site A
Agent A
Site B
BD
Figure 1.1 : Interaction à travers le réseau.
Autrement, dans le cas des agents mobiles, supposons que
l'utilisateur A veuille récupérer des informations sur un certain
sujet. En interagissant avec son agent personnel, la requête est
formellement spécifiée. Ceci est illustré par la
figure1.2.
Site A
Utilisateur A

Agent A
Site B
BD
Figure 1.2 Migration (phase 1).
Puis, comme le montre la figure 1.3, l'agent migre du site A au
site B sur laquelle se trouve une base de données contenant les
informations recherchées.

Site A
Site B
Utilisateur A
Agent A
Agent A
BD
Figure 1.3 Migration (phase 2).
Ensuite, La figure1.4 montre l'agent interagissant avec la base
de données du site distant pour récupérer les
données recherchées.
Figure 1.4 Migration (phase 3).
Utilisateur A
Site A
Agent A
Site B
BD
Puis, une fois l'agent satisfait, il retourne vers le site
d'origine. Ceci est illustré par la figure1.5.

Utilisateur A
Site A
Agent A
Agent A
Site B
BD
Figure 1.5 Migration (phase 4).
Finalement, comme le montre la figure1.6, l'agent rapporte -
d'une manière interactive - les résultats à son
utilisateur.
Site A
Utilisateur A
Agent A
Site B
BD
Figure 1.6 Migration (phase 5).
Dans le plus part des applications, les systèmes
à agents mobiles semblent être plus efficaces que les
systèmes classiques à agents stationnaires, car dans un
système informatique, les interactions intra-site sont moins
coûteuses que les interactions inter-sites, mais ceci n'est pas toujours
vrai, car on peut avoir une négociation entre agents statiques et
même entre agents mobiles dans un système et aussi lorsque il
s'agit du coût de migration, etc.
Prenons un exemple explicatif sur les deux approches à
agents mobiles et à agents statiques.
Dans la première phase de l'approche « agents
mobiles » de cet exemple, l'utilisateur et l'agent établissent la
requête. Supposons qu'elle ait une taille de r octets. Puis l'agent migre
vers le site B. Supposons que la taille de l'agent soit fixe à a octets.
L'agent interagit avec la base de données dont la taille est de b
octets. Finalement, l'agent rentre pour communiquer la solution composée
de s octets. Donc, la quantité totale de données
transférées entre les sites différents est (a + r) + (a +
s) octets. Notons qu'il n'est pas toujours nécessaire qu'un agent
retourne chez son utilisateur et que - souvent - il suffit qu'il envoie le
résultat. Toutefois, en général, on suppose que l'agent
rentre.
Par contre dans l'approche classique de cet exemple,
utilisant un agent statique, la quantité totale de données
transférées peut monter jusqu'à r + b octets. En effet,
dans le pire des cas, on demande le transfert de la base complète et on
la traite localement.
Comparons les deux approches, en supposant que r est
négligeable. Le graphique 1 (Figure 1.7) montre le nombre d'octets
transférés, dans les deux approches, pour b = 100000, a = 5000
et s / b entre 0et 1. Le graphique 2 visualise la même
relation, mais pour a = 25000 (Figure 1.8).
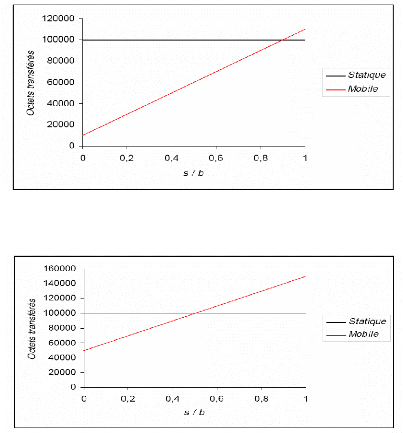
Figure 1.7 Graphique1 : Agents statiques vs. agents mobiles (a =
5000)
Figure 1.8 Graphique 2 : Agents statiques vs. agents mobiles (a =
25000).
Donc, et comme le montrent les deux graphiques, l'application
des agents mobiles n'est pas toujours avantageuse. Surtout lorsque les tailles
des agents et des solutions (relatives à la base de données) sont
grandes, l'approche classique est préférable. Cependant, en
général, la taille des agents et le ratio s / b sont modestes, et
la mobilité prometteuse.
Par contre, ce raisonnement n'est valide que si la
requête ne peut pas être formulée d'une
telle manière qu'elle peut être traitée
directement pas le système de gestion de la base de données. Dans
ce cas, il suffit d'envoyer la requête et de recevoir la solution sans
impliquer des agents. Cette solution est toujours la plus économique car
seulement r + s octets doivent être transférés. Donc, cette
application très étudiée des agents mobiles n'apporte
aucun avantage si les requêtes peuvent être normalisées pour
les bases de données impliquées. Ceci est sans doute une des
raisons principales pour laquelle les agents mobiles ne sont pas encore
utilisés à une échelle importante ainsi que les agents
statiques sont encore employés par les développeurs dans ce
domaine.
Toutefois, dans un monde informatique de plus en plus
sophistiqué et personnalisé, nous pouvons nous attendre à
une croissance importante de requête non standard. De plus, il est
possible que certains utilisateurs préféreront envoyer leurs
agents personnels plutôt que faire confiance au système de gestion
distant, en estimant - par exemple - que leurs agents sont plus fiables.
Pour cette raison, les chercheurs sont dirigés vers le
développement des applications en intervenant des agents
coopératifs stationnaires et mobiles, dont leurs tâches sont
définies après avoir calculé les performances en fonction
des besoins de l'application.
2.4 Système multi agent
2.4.1 Définition
Un système multi agent est un système logiciel
distribué, composé d'un ensemble d'entités (de programmes)
relativement indépendantes des agents dont chacun est dotés de
son propre thread, de buts propres à remplir, et de moyens pour
communiquer et pour négocier avec les autres afin d'accomplir leurs
buts.
Les SMA sont conçus et implantés idéalement
comme un ensemble d'agents interagissant selon les modes de coopération,
de concurrence ou de coexistence
Les SMA peuvent être vus comme la rencontre de divers
domaines :
· L'intelligence artificielle pour les aspects prise de
décision de l'agent,
· L'intelligence artificielle distribuée pour la
distribution de l'exécution,
· Les systèmes distribués pour les
interactions,
· Le génie logiciel pour l'approche agents et
l'évolution vers des composants logiciels de plus en plus autonomes.
2.4.2 Caractéristiques principales
Un SMA est généralement caractérisé
ainsi :
· Chaque agent dispose d'informations ou de
capacités de résolution de problèmes limités
(ainsi, chaque agent a un point de vue partiel),
· Il n'y a aucun contrôle global du système
multi agent,
· Les données sont décentralisées,
· Le calcul est asynchrone.
2.4.3 Les domaines d'application
On distingue généralement trois types
d'utilisation :
· La simulation des phénomènes complexes,
· La résolution de problèmes,
· la conception des programmes.
On utilise les systèmes multi agents pour simuler des
interactions existantes entre agents autonomes. On cherche à
déterminer l'évolution de ce système afin de
prévoir l'organisation qui en résulte.
Notons bien que l'intelligence artificielle distribuée
est née pour résoudre les problèmes de complexité
des gros programmes monolithiques de l'intelligence artificielle :
l'exécution est alors distribuée, mais le contrôle reste
centralisé. Au contraire, dans les SMA, chaque agent possède un
contrôle total sur son comportement. Pour résoudre un
problème complexe, il est en effet parfois plus simple de concevoir des
programmes relativement petits (les agents) en interaction qu'un seul gros
programme monolithique. L'autonomie permet au système de s'adapter
dynamiquement aux changements imprévus qui interviennent dans
l'environnement. En même temps, le génie logiciel a
évolué vers des composants de plus en plus autonomes. Les SMA
peuvent être vus comme la rencontre du génie logiciel et de
l'intelligence artificielle distribuée, avec un apport très
important des systèmes distribués. Par rapport à un objet,
un agent peut prendre des initiatives, peut refuser d'obéir à une
requête, peut se déplacer, etc. Aussi l'autonomie permet au
concepteur de se concentrer sur une partie humainement appréhendable du
logiciel.
2.4.4 Problématiques des SMA
Les développeurs dans ce domaine peuvent relever cinq
problématiques principales lors de la création des
systèmes multi agents (SMA).
· D'abord, la problématique de l'action: comment
un ensemble d'agents peut agir de manière simultanée dans un
environnement partagé, et comment cet environnement interagit en retour
avec les agents? Les questions sous-jacentes sont entre autres celles de la
représentation de l'environnement par les agents, de la collaboration
entre agent et de la planification multi agent.
· Ensuite la problématique de l'agent et de sa
relation avec le système, qui est représentée
par le modèle cognitif dont dispose l'agent. Un agent
dans un SMA doit être capable de mettre en oeuvre les actions qui
répondent au mieux à ses objectifs. Cette capacité
à la décision est liée à l'état et au
comportement de l'agent.
· Les systèmes multi agents passent aussi par
l'étude de la nature des interactions, comme source de
possibilités d'une part et de contraintes d'autre part. La
problématique de l'interaction s'intéresse aux moyens de
l'interaction (quel langage? quel support ?), et à l'analyse et la
conception des formes d'interactions entre agents. Les notions de collaboration
et coopération sont ici centrales.
· On peut évoquer ensuite la problématique de
l'adaptation en terme d'adaptation individuelle ou apprentissage d'une part et
d'adaptation collective ou évolution d'autre part.
· Enfin, il reste la question de la réalisation
effective et de l'implémentation des SMA, en structurant notamment les
langages de programmation en plusieurs types allant du langage de formalisation
et de spécification, au langage d'implémentation effective. Entre
les deux, on retrouve le langage de communication entre agents, de description
des lois de l'environnement et de représentation des connaissances.
2.5 Les plateformes
Plusieurs systèmes, commerciaux et autres, supportant
la mobilité sont actuellement disponibles. Il existe des plateformes
d'agents mobiles basées sur java, pour lesquelles il n'y a pas de
problèmes de portabilité d'un système d'exploitation
à l'autre, et des plateformes d'agent mobile qui ne sont pas
basées sur java et qui peuvent donc poser des problèmes de
portabilité. Dans cette section, nous en présentons
-brièvement- les plates formes les plus répandues et les plus
importantes.
2.5.1 Agent TC1
Un des premiers systèmes supportant les agents mobiles
a été développé par Robert Gray, David Kotz et
d'autres. A l'origine, le système n'avait pas de nom et utilisait
TCP/IP, le courrier électronique et la commande UNIX « rsh »
comme mécanismes de transfert. Plus tard, la même équipe a
introduit « Agent Tcl », un système utilisant Tcl comme
langage principal de programmation des agents.
Toutefois, à la base, le système supporte
plusieurs langages, à savoir Tcl, Java et Scheme, et récemment le
système a été rebaptisé « D'Agents ».
Notons qu'Agent TCL est un des seuls systèmes actuels n'étant pas
basé directement sur Java.
2.5.2 Aglets
Le « Aglet Workbench » d'IBM est sans doute un des
systèmes les plus connus. Danny Lange, un des pionniers de la
communauté, était à la base de son développement au
Japon. Le système est facile à charger du Web et à
installer sur tout système supportant Java. Il est assez fiable, mais la
documentation en ligne n'est pas d'une qualité commerciale.
2.5.3 Concordia
Concordia est également un système basé
sur Java, mais développé par le Horizon Systems Laboratory de
Mitsubishi. C'est un système récent, orienté vers des
applications au niveau des entreprises. Par conséquent, la
sécurité du système est exceptionnellement
soignée.
2.5.4 Mole
Ce système a été développé
dans l'Institute of Parallel and Distributed High-Performance Systems à
l'Université de Stuttgart comme il a été publié sur
le web.
2.5.5 Telescript
Telescript, développé par General Magic, peut
être considéré comme la référence dans le
domaine.Il est parlant que son inventeur, Jim White, tient un brevet sur la
notion même d'agents mobiles. Telescript était un des seuls
systèmes supportant le transfert de l'état d'exécution des
agents.
Toutefois, le système, conçu pour une
application industrielle, exigeait des ressources importantes, était
plutôt cher (5000 USD par moteur), et offrait une fonctionnalité
pas encore demandée par le marché. Par conséquent, le
système n'existe plus et sa valeur est surtout historique.
2.5.6 Odyssey
Le successeur de Telescript, développé
également par General Magic, s'appelle Odyssey. Différent du
premier, ce dernier est basé sur Java. Il est largement inspiré
par Telescript, mais n'à pas exactement la même
fonctionnalité. Par exemple, Odyssey ne supporte pas le transfert de
l'état d'exécution. Le système n'a toujours pas
dépassé la version bêta, et ne joue visiblement pas le
rôle important que jouait Telescript dans la stratégie de General
Magic.
2.5.7 Voyager
Voyager est un produit commercial proposé par
ObjectSpace. Il s'agit d'un système « branché »
incorporant plusieurs normes industrielles populaires à l'heure
actuelle, notamment CORBA, DCOM et Distributed JavaBeans. Différent des
autres systèmes, il ne s'agit pas d'un système
dédié uniquement aux agents mobiles : toute sorte de
développement distribué est supporté. Dans leur
documentation, cependant, le concept d'agent mobile est explicitement
présenté. Puisqu'il s'agit d'un système bien
soigné, d'une nature générale, et compatible avec les
normes existantes, sa popularité est croissante.
Après avoir citer les principales
caractéristiques des différentes plateformes on peut juger que
Aglets intègre les fonctionnalités nécessaires au
développement aisé d'agent mobiles .La plateforme Aglets est
complètement libre, ce qui est intéressant pour avoir
accès au code source et pour utiliser les applications
développées sans contraintes ce qui n'est pas le cas pour
certaines plateformes qui ne sont libres que pour usage non commercial tel que
Odyssey et voyager.
2.6 Conclusion
Le développement d'une application sur un environnement
ouvert distribué comme l'Inter- net nécessite
l'intégration des utilisateurs et de programmes qui travaillent en
coopération, qui sont: le paradigme d'agents et de systèmes multi
agents et en intégrant la technologie d'agents mobiles. Ces derniers
peuvent être implémentés dans plusieurs domaines mais avec
une conception et comportement différents, définis selon la
plateforme utilisée et en fonction des besoins du système.
Parmi les plateformes existantes, Aglets, qui est le cadre de
notre travail, offre une très grande simplicité
d'implémentation ce qui constitue un avantage certain par rapport aux
autres systèmes.
Chapitre 3
Solution de sécurité des agents
Mobiles
3.1 Introduction
Avec l'augmentation de l'utilisation des applications
basées sur le réseau, dans le monde entier, tel que le partage
des ressources et des informations, beaucoup de nouvelles procédures et
systèmes ont été développés pour augmenter
la performance et éviter la surcharge du réseau. Ces
systèmes informatiques qui tendent à être de plus en plus
ouverts et distribués, découvrent par la même occasion
qu'ils sont de plus en plus susceptibles d'être la cible de
dérèglements divers, tels que : les congestions, les accès
malveillants et les attaques. A cet effet, il devient inéluctable de
munir ces systèmes d'outils et de mécanismes capables d'inhiber
ces dérèglements.
Par la suite, l'introduction d'agents dans ces systèmes
a apporté beaucoup d'accomplissements réussis à cause de
leurs caractéristiques spéciales, ainsi que beaucoup de langages
à base d'Agent ont apporté ces caractéristiques dans
l'implémentation. Là, ont été observés peu
d'inconvénients quand les éditions de sécurité
étaient exécutées.
Dans ce chapitre, nous allons parler de la
nécessité de la sécurité des agents mobiles, de
certaines politiques de sécurité ainsi que des différents
cas de sécurisation des agents mobiles.
3.2 La nécessité de la
sécurité des agents mobiles
Les agents mobiles migrent d'un hôte à un autre
et peuvent être exécutés sur chacun d'entre eux. Un
problème de sécurité qui se pose est que ni l'agent ni les
hôtes ne sont nécessairement fidèles; l'agent pourrait
essayer de faire du mal à l'hôte, les machines pourraient essayer
de faire du mal à l'agent ou accéder à ses renseignements
privés et ressources. La machine ou l'agent
peuvent être méchants ou mal programmés.
Pourtant, cette distinction n'est pas le problème principal parce que
l'effet final peut être le même. La sécurité est
peut-être l'édition la plus critique dans un système
d'agents.
La sécurité des agents mobiles tente de maintenir
les caractéristiques principales suivantes :
3.2.1 La confidentialité
Assurer la confidentialité des données, consiste
à faire en sorte que les informations restent secrètes et que
seules les personnes autorisées y aient accès.
3.2.2 L'authentification
Assurer l'authentification dans le système, consiste
à prouver que l'identité des différentes entités
doit pouvoir être vérifiée, et que les informations
reçues sont conformes à celles fournies, il faut ensuite assurer
que les deux entités communicantes sont bien ce qu'elles affirment
être. De plus, le service d'authentification doit montrer que la
connexion ne peut être brouillée par une troisième
entité essayant de se faire passer pour un des deux correspondants.
3.2.3 L'intégrité
L'intégrité permet d'éviter la
corruption, l'altération et la destruction des données dans le
réseau de manière non autorisée, elle reste un domaine
très large couvrant à la fois les modifications, les moyens de
modification mais également la cohérence des données
après la modification.
3.2.4 La disponibilité
Consiste à assurer une disponibilité continue
des informations, des services et des ressources dans le réseau (les
temps de réponse, la tolérance aux fautes, le contrôle de
concurrence, le partage équitable de ressources, etc.). D'une autre
façon, c'est prévenir contre les perturbations et les
interruptions de son fonctionnement et aussi contre toute utilisation abusive
des services et des ressources du système.
3.2.5 La non répudiation
Consiste à assurer que lorsqu'une information est
transmise entre deux entités, l'émetteur ne doit pas pouvoir nier
avoir envoyé l'information, et le destinataire l'avoir reçue.
Chaque partie possède ainsi la preuve de l'existence de la
transaction.
3.2.6 Le contrôle d'accès
L'accès à certaines ressources (informations ou
services) doit être restreint à des entités
autorisées.
Lorsqu'une entité souhaite effectuer une
opération sur un objet, le système transforme l'opération
en une requête qu'il fait passer au moniteur de référence.
Ce dernier est responsable du contrôle d'accès aux ressources. Si
l'entité est autorisée à accéder à l'objet
et à réaliser le type d'opération demandé alors
l'accès à l'objet est accordé et l'opération peut
se dérouler sans aucune ambiguïté. Dans le cas contraire, il
retournera un refus catégorique à l'utilisateur. Les buts du
contrôle d'accès rejoignent ceux de la disponibilité.
3.2.7 Le secret du flux
L'intérêt est d'empêcher tout utilisateur
non autorisé d'avoir la possibilité d'analyser les flux des
données à travers le réseau. Tout accès
illégal, même en lecture, à un flux de données
permet à l'utilisateur de déduire des informations utiles et qui
peuvent, ultérieurement, servir ses intentions malveillantes. La taille
des messages échangés, leurs sources et leurs destinations, ainsi
que la fréquence des communications entre les utilisateurs sont des
exemples de données à préserver pour prévenir le
secret des flux dans le réseau et le rendre plus sûr.
3.2.8 Le confinement
Le principe de confinement est complémentaire à la
confidentialité, s'inscrivant dans le même but du bon usage des
informations.
Le confinement garantit qu'un sujet n'arrive pas à
divulguer volontairement le contenu des objets auxquels il a accès
à quelqu'un qui n'a pas le droit d'y accéder.
3.3 Les politiques de sécurité
3.3.1 Définition
"La politique de sécurité d'un système
est l'ensemble des lois, règles et pratiques qui régissent la
façon dont l'information sensible et les autres ressources sont
gérées, protégées et distribuées à
l'intérieur d'un système spécifique" [Com91].
La politique de sécurité décrit les
objectifs de la sécurité du système et identifie les
menaces auxquelles le système devra faire face.
Il est d'abord utile de faire la distinction entre politique et
mécanisme de sécurité. Les politiques de
sécurité définissent les autorités et les
ressources, spécifient les droits et les règles
d'usage. Les mécanismes de sécurité sont
des moyens pour la mise en oeuvre d'une politique de sécurité.
Donc, le terme "politique de sécurité" est
associé à l'ensemble des propriétés de
sécurité que l'on désire appliquer et déployer dans
un système ainsi que les dispositifs pour les assurer. Les approches de
sécurisation des agents mobiles sont multiples. Ces dernières
peuvent être classées, suivant le moyen de sécurisation, en
sécurité basée sur le matériel et
sécurité basée sur le logiciel.
3.3.2 Les approches de sécurisation des agents
mobiles
Sécurité basée sur le matériel
:
Lorsqu'il s'agit d'une sécurité basée sur
le matériel, il est nécessaire d'avoir un outil matériel.
Ce dernier doit être testé par le système avant et pendant
l'exécution. Certaines applications réseaux, en particulier
Internet, implémentent cette approche pour la sécurisation de
leurs logiciels contre le piratage.
a- Sécurisation à base d'un environnement
d'exécution de confiance: Cette méthode de sécurisation
consiste à utiliser un périphérique (coprocesseur)
assurant l'exécution de l'agent, ce dernier s'exécute
exclusivement à l'intérieur de ce périphérique et
ne dialogue avec le site visité qu'à travers une interface
sécurisée [Wil98]. Cette approche a été
proposée par Wilhelm [Wil98] et elle est basée sur ce qu'il
appelle « environnement d'exécution de confiance TPE »
(Trusted Processing Envirenment). Le périphérique TPE est
fabriqué sous le contrôle d'une autorité de confiance et
dispose d'un certificat et d'une politique de sécurité. Dans
cette approche les agents sont cryptés par la machine de leur
propriétaire et ne seront plus exécutés par le site
visité mais par le périphérique TPE. Ainsi les agents
resteront cryptés tout au long de leurs chemins de migration et sur
chaque site visité. Quand ils arrivent à leurs sites de
destinations ils sont encore cryptés et accèderont au
périphérique TPE où ils seront décryptés
puis exécutés [Wil98].
Une telle approche présente une solution très
puissante pour sécuriser les agents sur site d'exécution ainsi
qu'à travers le réseau. Toutefois, le périphérique
TPE n'est pas facile à fabriquer ce qui explique son coût
élevé. De plus l'environnement d'exécution de confiance
TPE ne présente pas les performances d'un ordinateur, ce qui
réduit l'efficacité d'exécution de l'agent. De plus le
problème d'exécution de plusieurs agents en parallèle
reste posé.
b- Sécurisation à base de cartes à puces :
Cette solution est proposée pour la première fois par Mana
[Man02]
L'idée de Mana consiste à subdiviser le code de
l'agent en sections dont certaines seront cryptées par la clé
publique d'une carte à puces. Ces dernières seront
remplacées par des appels
procéduraux vers la carte. Sur site d'exécution,
on transmet à la carte comme arguments les sections cryptées qui
seront décryptées puis exécutées à
l'intérieur de cette dernière (Figure2. 1). La paire de
clés est générée à l'intérieur de la
carte à puce, la clé publique sera publiée tandis que la
clé secrète résidera exclusivement à
l'intérieur de la carte et ne sera jamais révélée
[ManO2].
Code de l'agent
S1
S2 Crypté
S3
S4 Crypté
S5
S6
Clé publique, clé
secrète
Appel
Subdivision du code
Cryptage
S1
S2
S3
S4
S5
S6
Carte à puces
Figure 2.1 Sécurisation à base de cartes à
puces
De cette façon, on assure la confidentialité du
code et on évite l'exécution de la totalité de l'agent sur
le périphérique de sécurisation.
Sécurisation basée sur le logiciel
Dans ce type d'approches, on cherche à sécuriser
les agents de façon purement logicielle ce qui réduit le
coût de la sécurité et facilite sa maintenance.
Parmi les solutions de sécurisation on cite :
a- Obscurcissement : Cette approche qui est proposée
par Fritz Hohl [Hoh97], consiste à produire à partir d'un agent
A, un autre agent B analogue au premier dans ses fonctionnalités mais
ayant un code difficile à analyser, ce code peut être
assuré par le fait d'introduire un désordre au niveau du code de
l'agent.
Pour cela on peut dire que cette approche présente une
solution de sécurisation de l'agent par son propre code.
Hohl propose la violation totale des règles
nécessaires pour avoir un code non lisible. On peut citer par exemple
les règles suivantes :
- Ecrire un code modulaire.
- Attribuer des noms significatifs aux variables.
- Utiliser des structures de contrôle qui simplifient le
programme.
Ces règles seront respectées au niveau de
l'agent source A et pour passer à l'agent sécurisé B, tout
d'abord on crée à partir des variables originelles de nouvelles
variables ayant des noms non significatifs et un nombre différent. Comme
indiqué dans la figure2.2, chaque nouvelle variable est composée
de fragments de quelques variables originelles.
Variables originelles
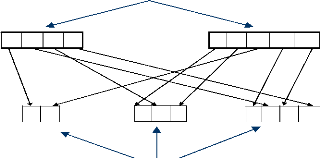
Nouvelles variables ayant des noms non significatifs
Figure 2.2 Génération de variables à noms
non significatifs.
Après l'étape de génération des
variables, on procède à la déstructuration du code. Pour
cela on élimine les variables locales et on les remplace par des
variables globales, on remplace l'appel procédural par le corps des
procédures et on utilise la structure de contrôle "GOTO" pour
remplacer les autres structures [Hoh97]. Enfin, on pourra insérer des
fragments de code mort pour améliorer la protection. Seulement il faut
se méfier des mécanismes de détection de codes morts. Ces
mécanismes assurent la protection de la confidentialité des
agents. Pour assurer l'intégrité de ces derniers, Hohl propose
l'utilisation de la signature électronique de l'agent en totalité
et en association avec sa date de validité après laquelle l'agent
ne sera plus accepté par aucun site et ses actions ne seront plus
valides [Hoh97].
Comme il s'agit d'une sécurisation basée sur le
logiciel, ceci nous a permis de réduire le coût
élevé des solutions matérielles d'où on a pu
retrouver une approche efficace pour sécuriser les agents, mais aussi on
peut lui reprocher le manque de fondement théorique. De plus, la
sécurité de l'agent est temporaire et n'est valide que pour les
agents qui transportent des données à courte durée de
validité. Autrement, l'agent sera enregistré et analysé
lentement afin de déduire les données qu'il transporte.
b- Calcul par fonction cryptographique: Cette idée est
développée par Sander et Tschudin [ST 98], l'objectif de cette
approche est analogue à celui de l'approche d'Obscurcissement. Mais, le
principe est plus développé et dispose d'un fondement
mathématique robuste et la sécurité n'est pas liée
à une durée de vie. Sander et Tschudin proposent l'idée
comme suit :
Soit une fonction f matérialisée par un agent
A, cette fonction sera cryptée en E(f) qui cache les
fonctionnalités et les détails de f. Un programme P(E(f)) sera
écrit pour implémenter E(f), ce qui produit un nouvel agent B.
L'agent B migre sur un site distant où il sera exécuté sur
une donnée x et retourne à son site d'origine qui exécute
l'algorithme de décryptage E1 (P(E(f)))(x)=f(x). Au niveau du site
distant, on exécute P(E(f))(x) qui cache les détails ce qui
assure la sécurité de l'agent. Cette approche définit un
homomorphisme entre l'espace des données claire et celui des
données cryptées tout en se basant sur la fonction PLUS et la
fonction MIXED-MULT. Ces deux fonctions sont valides uniquement sur les
polynômes, ce qui représente la défaillance de l'approche
de Sander sur les données ordinaires. En plus, le travail de l'agent se
limite au calcul d'un résultat sur un site distant puis l'agent retourne
vers son site d'origine, ce qui ne permet ni la négociation sur site ni
la possibilité de signature ou de prise de décision.
c- Traces cryptographiques: Cette approche permet de
vérifier l'intégrité d'exécution des agents
après leur retour; chaque site visité par l'agent
génère une trace d'exécution de l'agent. Cette trace
contient toutes les lignes de code exécutées et toutes les
valeurs externes lues par l'agent. Avant la migration de l'agent vers une
nouvelle destination, en utilisant une fonction de hachage permettant de
caractériser une donnée en faisant subir une suite de traitements
reproductibles à une donnée fournie en entrée et
génère une empreinte servant à identifier la donnée
initiale, le site calcule une représentation condensée de la
trace, la signe et l'accompagne à l'agent mobile lors de sa transmission
vers le site suivant. Afin de réduire la taille de la trace, l'auteur
divise le code de l'agent en segments blancs et segments noirs. Les segments
noirs sont ceux qui résultent des interactions avec la plate-forme
visitée. Et au lieu de la trace d'exécution du code entier, on
génère uniquement la trace d'exécution des segments
noirs.
Après retour de l'agent, son propriétaire aura
une trace de l'exécution de l'agent sur le dernier site et l'adresse du
premier site visité (vers lequel il a envoyé l'agent). Puis si le
propriétaire a un doute envers un site donné, il pourra suivre le
chemin de l'agent et avoir la trace d'exécution sur ce site. Le
propriétaire de l'agent pourra simuler son exécution sur le site
duquel il doute et comparer la simulation avec la trace reçue.
Cette approche permet d'assurer la non répudiation et
la détection de toute manipulation de l'exécution de l'agent
après son retour. Toutefois l'approche reste détective et
n'évite en aucun cas l'utilisation frauduleuse de l'agent.
De plus il faut avoir un doute envers un site particulier pour
lancer le mécanisme de trace, sinon l'utilisation systématique de
ce mécanisme devient assez coûteuse.
d- Agents coopérants : Cette approche de
sécurisation a été proposée par Roth, Schneider et
al. [Sch & al 97].
La protection est assurée en faisant partager
l'information par plusieurs agents analogues dits clones. La tâche
demandée par l'utilisateur est réalisée par plusieurs
agents qui coopèrent plutôt que par un seul agent. L'objectif
principal est que l'information partagée reste protégée
même si plusieurs sites d'exécution collaborent. Dans un exemple
explicatif, Roth [Rot 99] définit deux sous-groupes indépendants
de sites que l'agent visitera, ensuite, deux agents seront créés
et envoyés chacun à l'un de ces sous groupes. Si un agent
retrouve une information pertinente il l'envoie vers son clone qui la
vérifie. Pour avoir plus d'efficacité, l'un des deux agents
s'exécute obligatoirement sur un site de confiance.
L'inconvénient majeur de cette approche, est l'abus
d'utilisation des ressources réseau pour assurer la communication entre
clones. De plus l'approche se base sur l'hypothèse de non- collaboration
entre les différents sites marchands ce qui n'est pas évident.
Enfin, l'approche protège uniquement les données
transportées et non l'agent en totalité.
e- Appréciation d'état : Cette approche permet
de remédier à l'inconvénient majeur de l'approche des
agents coopérants et elle est développée par Farmer et al.
[FGS96a] qui définissent un mécanisme qui permet à un
agent d'évaluer les privilèges dont il dispose sur un site
particulier. Ce qui permet au propriétaire de l'agent de limiter les
actions que l'agent peut effectuer. L'approche repose sur une fonction
protégée qui permet l'évaluation de l'état de
l'agent sur chaque site visité. La fonction sera exécutée
une fois l'agent arrive sur un site donné et permettra de
vérifier la stabilité de son état. L'existence de telle
fonction protège l'agent en détectant les manipulations de son
état. La fonction repose sur un calcul complexe à partir d'un
ensemble de variables d'état.
Une amélioration a été proposée
par Jansen [JanO1] qui consiste à séparer la structure de
données définissant le comportement de l'agent de son propre
code. Cette structure sera définie dans un certificat conforme à
la norme X509 [ISO9594-8]. Dans le certificat, on définit les droits et
les responsabilités d'un agent sur un site donné. On distingue
les certificats d'attributs dans lesquels on définit le comportement de
l'agent et les certificats de politique servant à définir le
comportement du site envers tous les agents qu'il accueille. L'approche
protège l'agent contre une utilisation illicite en fournissant une
preuve des intentions réelles de son propriétaire mais n'offre
aucune protection des données que l'agent transporte.
Une autre approche proposée par Magdy Sayeb [MagO2]
consiste à utiliser un arbre de
diagnostic permettant la détection d'une attaque possible.
Dans cette approche les auteurs associent un symptôme à chaque
attaque et la combinaison de ces symptômes définit un arbre. Parmi
ces symptômes nous citerons :
- La longue durée d'exécution qui informe sur une
analyse du code ou des données au
cours de l'exécution,
- L'enregistrement temporaire de l'agent informe sur une analyse
possible tandis qu'un
comportement anormal de l'agent informe sur la manipulation du
code de l'agent.
L'approche se limite aux attaques dont l'origine ne prend pas
en compte un éventuel mécanisme de détection, sinon il
cherchera à masquer les symptômes et simuler un comportement
normal.
f- Fonction de validation: Les approches à base de
fonctions de validation ont été proposées par Blum [Blu88]
afin de vérifier la fiabilité d'un code. Ces dernières
peuvent être appliquées dans le but de vérifier
l'intégrité d'exécution d'un agent mobile sur un site
distant. L'approche se base sur la propriété de
réductibilité de la fonction qu'implémente l'agent. Une
approche plus récente proposée par Laurero [Lau 01]
définit une fonction de vérification V comme suit :
Soient un programme P qui implémente une fonction f, Y
l'ensemble des résultats possibles de f(xi ), avec xi appartient
à {0,1}n et D(y') le résultat reçu après
exécution à distance. La fonction V satisfait la condition
suivante si (y=D(y')) n'appartient pas à Y alors P(V(y')= accept) < ,
où P représente la probabilité et la probabilité
d'erreur.
Pour conclure, toutes les approches précédemment
vues, qu'elles soient basées sur le matériel ou sur le logiciel,
possèdent des avantages pour la sécurité des agents
mobiles mais aussi elles pressentent certaines limites, comme par exemple : le
coût élevé des solutions matérielles (carte à
puces.) d'une part et la complexité des solutions logicielles et leurs
limites dans des domaines d'applications précis d'une autre part.
3.4 Les cas de sécurisation
Un agent peut être la cible de plusieurs types
d'attaques lors de son déplacement à travers des sites qui
peuvent ne pas être de confiance et à travers un réseau qui
n'est pas toujours sécurisé.
En effet, au cours de son déplacement, l'agent
interagit avec d'autres agents qui peuvent analyser ou altérer son
contenu. Aussi, le site visité et sur lequel l'agent s'exécute a
la possibilité de manipuler l'agent ou même de le détruire.
En effet, ce dernier a un accès total à l'agent et pourra
l'analyser bit par bit et par suite mener tout type d'attaques. On peut classer
alors les aspects de sécurité concernant un agent mobile comme
suit :
- Sécurité entre deux agents,
- Sécurité des agents contre les hôtes,
- Sécurité de l'hôte contre les agents,
- Sécurité des agents contre intervenant externe, -
Sécurité pendant le transfert d'un agent.
3.4.1 Sécurité entre deux agents
Ce problème de protection est semblable à sa
contrepartie dans les systèmes d'exploitation, où
différents domaines de protection sont spécifiés pour
limiter l'accès direct d'un processus à l'état
intérieur d'un autre.
On s'intéresse donc à la sécurité de
l'agent contre les attaques qu'il peut subir de la part d'un autre agent
(Figure2.3)

Agent Y
Agent X
Attaque
Active/Passive
Figure2.3 sécurité entre deux agents
On distingue les attaques passives, qui ne modifient pas le
code de l'agent ainsi que les données qu'il transporte, et les attaques
actives qui consistent à l'altération du code ou des
données de l'agent.
Exemples d'attaques passives
Parmi les attaques passives, on cite :
- Eavesdropping : Le fait d'écouter de manière
indiscrète.
Ce type d'attaque utilise généralement un
moniteur de capture appelé par un programme spécifié. Ce
moniteur peut voir les informations échangées entre les
hôtes en capturant ainsi des agents et les messages qu'ils peuvent
contenir.
- Traffic Analysis : Analyse de La circulation
Ce type d'attaque ne consiste pas seulement en le fait
d'écouter de manière indiscrète et intelligente, mais
aussi de permettre à l'attaquant d'analyser les traces d'agent entre les
systèmes
visités.
Exemples d'attaques actives
L'attaque active peut consister à la modification des
valeurs des variables, à l'insertion de virus ou toute modification du
code.
Comme attaques actives, on cite :
-Mascarade : Bal masqué
Dans ce type d'attaque, une entité fait semblant
d'être une entité différente.
Dans un exemple typique, un agent entre dans un serveur comme
étant une personne fidèle
ou une organisation, s'il réussit à tromper
l'hôte, il peut être capable d'utiliser un service
gratuitement
ou voler des renseignements confidentiels réservés pour
l'entité fidèle. -Alteration : Modification
Dans ce cas, un agent ou un message entre deux systèmes
d'agent sont effacés ou changés pendant qu'ils transitent, par
exemple n'importe quel hôte visité sur l'itinéraire de
l'agent peut enlever des données ajoutées par les hôtes
précédents. N'importe quels renseignements qui sont
modifiés d'une façon inattendue peuvent transformer un agent
solide en méchant où peuvent simplement rendre des
résultats faux.
3.4.2 Sécurité des agents contre les
hôtes
C'est le problème le plus difficile de la
sécurité de système d'agent, puisque pour exécuter
un agent, son hôte doit avoir accès à son code, son
état et ses données.
Un agent qui s'exécute sur un site est alors
exposé aux menaces de sécurité de point de vue
confidentialité (un site peut exploiter ces informations pour modifier
le comportement de ses services) et intégrité (un site peut
rejouer l'exécution d'un agent, fausser les résultats des appels
systèmes faits par l'agent et ainsi duper l'agent) de la part de son
hôte. (Figure 2.4) De plus, l'environnement d'accueil d'un agent peut
terminer brutalement l'exécution de celui-ci et empêcher sa
migration.
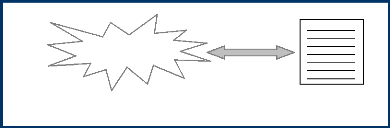
Attaques
Intégrité
Confidentialité
Agent en cours
d'exécution
Hôte
Figure 2.4 Sécurité des agents contre les
hôtes.
Une première solution serait que le propriétaire
d'un agent limite son itinéraire à des sites de confiance. Pour
ce qui est des solutions logicielles, il est possible de chiffrer les
données d'agents afin de les protéger sur un itinéraire.
La technique se base sur un chiffrement à clé publique des
données sensibles.
3.4.3 Sécurité de l'hôte contre les
agents
Un agent qui a un accès libre à un site peut
violer sa confidentialité, par la simple lecture, et violer son
intégrité par l'écriture. Cet agent peut aussi
compromettre la disponibilité de la machine en consommant d'une
manière illimitée et incontrôlée ses ressources, en
se clonant indéfiniment ou en migrant sans fin. (figure 2.4)
Dans ces cas, l'authentification de l'agent avant son
exécution devient le premier recours indispensable. L'environnement
d'exécution, connaissant la provenance de l'agent, est capable de
vérifier le niveau de confiance de l'agent reçu en fonction de
son origine.
Toutefois, l'authentification est une solution
nécessaire mais insuffisante, car le code issu d'un site supposé
de confiance peut contenir des erreurs non intentionnelles qui peuvent nuire
à la sécurité des hôtes.
3.4.4 Sécurité des agents contre intervenant
externe
Cette classe de sécurité regroupe la
sécurisation des agents contre les intervenants externes et contre les
sites d'exécution ainsi que leur sécurisation pendant leur
déplacement à travers le réseau. Au cours de son
déplacement, un agent traverse des canaux de communication et des noeuds
de commutation. Si ces constituants de réseau ne sont pas
protégés, ils peuvent présenter un point de
vulnérabilité de la plate-forme d'agents. (Figure2.5)
Noeud de commutation
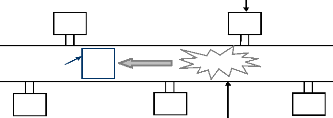
H2
H4
____
____
Agent
Attaque
H1
H5
H3
Canal non sécurisé
de
Commination
Figure 2.5 Protection des agents contre intervenant externe
Au cours de son voyage à travers le réseau, l'agent
est inactif et sa sécurisation revient à un problème
ordinaire de sécurité réseau dont plusieurs solutions
existent, à savoir :
- L'architecture sécurisée pour l'Internet «
IPsec »,
- La version sécurisée du protocole de transfert
d'hypertexte SHTTP,
- Le protocole de canaux sécurisés SSL,
- Le protocole de messagerie sécurisée SMIME.
3.4.5 La sécurité pendant le transfert d'un
agent
Pendant le transfert d'un agent vers sa destination trois types
d'attaques peuvent être présents :
1- Le fait d'écouter de manière indiscrète
(Eavesdropping)
2- Un article de données de communication est
changé, effacé, ou substitué pendant qu'il transit.
(Modification)
3- Une copie capturée d'un agent légitime
auparavant envoyé est retransmise pour des buts illégitimes :
Rejouer (Replay)
En conclusion, ces attaques sont très bien connues et ne
posent plus problème actuellement, car beaucoup d'algorithmes de
cryptage peuvent être utilisés.
3.5 Conclusion
Les agents mobiles semblent être une approche
très utile dans la construction d'un grand ensemble d'applications
réseaux. Pourtant, les problèmes de sécurité qui
peuvent être levés en soutenant des agents, peuvent
prévenir la large utilisation d'applications basées sur des
agents.
Vu la nécessité de la sécurité des
agents mobiles, plusieurs solutions à base de matériel ou
logiciels ont été introduites dans des applications pour
remédier à certaines attaques qui peuvent entraver le travail
d'un agent.
Pour cela, des travaux sont en cours pour introduire les
propriétés principales de sécurité (l'autorisation,
l'authentification, le confidentialité, etc.) en particulier les travaux
de sécurité des agents mobiles Aglets.
Chapitre 4
La plateforme Aglets
4.1 Introduction
Un aglet est la contraction de Agent et Applet. IBM a
confié à une équipe japonaise le soin de développer
une technologie pour les agents mobiles. Aglets est le résultat des
recherches de cette équipe. Il s'agit d'une API java spécifiant
un ensemble de méthodes répondant aux principes fondamentaux des
agents mobiles. Dans ce chapitre nous allons nous intéresser à
bien étudier Aglets en tant qu'une plateforme. Nous allons
définir quelques mots clés tels que hôte, contexte, Proxy,
etc. De plus, on va parler du cycle de vie, mobilité et communication
des aglets.
4.2 Aglets
4.2.1 Définitions
Aglets vs Applets
Les aglets ne sont pas les premiers programmes pouvant
déplacer du code java sur le réseau. Les applets le font depuis
longtemps. Mais contrairement aux applets, quand un aglet migre d'un hôte
à l'autre, il emmène son état avec lui. Une applet est du
code migrant d'un serveur vers un client. Un aglet est un programme java en
cours d'exécution qui peut se déplacer d'un hôte à
l'autre via le réseau.
Les aglets sont similaires aux applets dans la mesure
où ils s'exécutent au sein d'une machine virtuelle java. Un
appletviewer ou un navigateur est nécessaire aux applets. Le navigateur
implémente une politique de sécurité destinée
à interdire au code malveillant d'accéder aux ressources
sensibles du système. De la même manière, un aglet a besoin
d'un hôte d'aglets pour s'exécuter sur une machine. Il s'agira en
principe de Tahiti, mais pas forcément. Cet hôte doit
également proposer une politique de sécurité pour
restreindre les pouvoirs des aglets non dignes
de confiance.
D'une autre manière, on peut dire qu'un aglet est un
objet mobile qui dispose de son propre thread de contrôle, auquel on peut
envoyer des événements et qui a la possibilité de
communiquer par l'intermédiaire de messages.
L'API (Agent Protocol Interface) de communication
utilisée par les aglets est dérivée du standard MASIF
(Mobile Agent System Interoperability Facility) du groupe OMG (Object Managment
Group).
Le modèle d'objet des Aglets définit un ensemble
d'abstractions et de comportements pour le développement d'agents
mobiles sur Internet. Ces abstractions sont les concepts de base de
l'environnement de la plateforme Aglets à savoir : l'Aglet, le Proxy, le
Contexte et l'hôte.
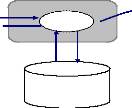
Proxy
Les méthodes des aglets ne sont jamais invoquées
directement. Ces méthodes sont invoquées au travers un objet
AgletProxy (figure 3.1). Cet objet est obtenu en retour lors de la
création d'un aglet ou à l'aide de l'identificateur de
l'aglet.
Monde extérieur
Interactions
Proxy aglet
Figure 3.1 Relation entre un aglet et son Proxy.
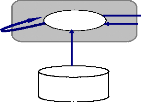
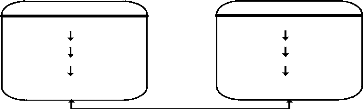
Contexte
Un contexte est un objet statique qui fournit des moyens pour
mettre à jour et contrôler des aglets dans un environnement
uniforme d'exécution où le système hôte est
immunisé contre des aglets malveillants (figure3.2). Un noeud dans un
réseau informatique peut accueillir des contextes multiples.
Aglets
Contexte
Ressources
Figure 3. 2 Évolution des Aglets dans un Contexte.
Hôte
Un hôte est une machine capable d'héberger plusieurs
contextes qui peuvent être gérés par un moteur (figure
3.3). Généralement, l'hôte est un noeud dans un
réseau.
Contexte
Hôte
Contexte
Moteur
Contexte
Figure 3.3 Relations entre hôte, moteur et contexte.
4.2.2 Cycle de vie d'un aglet
Les types de comportement des aglets ont été
implémentés de manière à répondre aux
principaux besoins des agents mobiles.
Libération
Contexte A Contexte B
Clonage
Déportation
aglet aglet
Désactivation Activation
Récupération
Mémoire de
masse
Fichiers.Class
Figure 3.4 Modèle du cycle de vie d'un aglet.
Les principales opérations affectant la vie d'un aglet
sont (figure 4.3) :
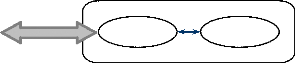
· Création: Se fait dans un Contexte. Un
Identifiant unique est assigné. L'initialisation et l'exécution
de l'aglet commencent immédiatement. Cet identifiant est globalement
immuable durant le cycle de vie de l'aglet.
· Clonage : Création d'un clone dans le même
contexte que l'original. Un Identifiant différent est alors
attribué. A noter que les processus (thread) ne peuvent pas être
clonés.
· Déportation (Dispatching) : Il s'agit ici
d'extraire un aglet de son contexte d'exécution et de l'insérer
dans un contexte destination. Précisément, dispatcher un aglet
entraînera sa suppression de son contexte courant et son insertion dans
son contexte de destination où il va reprendre son exécution;
ceci via la méthode dispatch (URL destination). La destination
spécifiée est de type URL. Elle inclut l'hôte, le nom du
domaine et des informations contenant le protocole utilisé pour
communiquer avec le serveur distant. L'appel de la méthode Dispatch()
mènera immédiatement à une invocation de la méthode
ondispatching() permettant de personnaliser l'envoi de l'aglet. Le protocole
réseau utilisé dans le cas d'envoi d'aglet est ATP (Agent
Transfer Protocol). Ce dernier est invoqué quand un agent demande de
migrer vers un autre serveur agent ou quand une application crée et
lance un agent à son serveur initial. Pour effectuer le transfert d'un
agent, le serveur courant envoie un message ATPRequest à travers la
connexion TCP déjà établie. Ce message contient des
paramètres tels que le temps d'exécution estimé de l'agent
à transférer, son nom, son URN (Uniform Resource Naming). Ces
paramètres d'identification de l'agent qui a demandé à
être transféré vont être utilisés par le
serveur destination pour qu'il décide de l'établissement du
transfert compte tenu de ses critères de sécurité. A titre
d'exemple, une politique de sécurité relative à un serveur
peut interdire l'accès à un ensemble d'agents appartenant
à un propriétaire donné.
· Récupération (Rétractation) :
L'aglet déporté est récupéré (tiré)
dans son contexte
d'origine. Autrement dit, le retrait d'un aglet va le
supprimer de son contexte courant et l'insérer dans le contexte
où l'opération a été invoquée. Le retrait
d'un aglet se fait via l'activation de la méthode retractAglet() qui
mène à une invocation distante de la méthode onReverting.
Ainsi tous les threads de l'aglet distant sont détruits. A
l'arrivée de l'aglet, la méthode onArrival() est invoquée,
suivie de la méthode run().
· Activation et Désactivation: La
désactivation d'un aglet est une interruption temporaire de son
exécution. Elle consiste à le stocker momentanément dans
un espace de stockage secondaire afin de pouvoir le réactiver
ultérieurement.
· Libération ou destruction (dispose) : Cette
dernière opération marque la fin du cycle de vie de l'aglet en le
supprimant de son contexte d'exécution courant.
La figure 5.3 représente le processus de transfert des
données dans le réseau d'un hôte à un autre.
Hote 1 Hote2
Contexte d'Origine
Arrêt de l'exécution
Sérialisation
Codage Expédition ds
te1 données
Contexte de Destination
Reprise de
l'exécution
Désérialisation
Décodage
Réception des données
Réseau
Figure 3.5 Transfert d'un aglet.
4.2.3 La création de l'aglet
La création d'un aglet se fait par l'appel de la
méthode createAglet() du contexte. public abstract AgletProxy
createAglet( URL codeBase, String code, Object init); Cette méthode
retourne le proxy associé à l'aglet nouvellement crée.
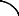
CreateAgletØ
AgletØonCreationØ


Figure 3.6 Diagramme de Collaboration pour la création de
l'Aglet.
L'exemple suivant montre comment un aglet peut créer un
autre aglet : import agl et. *;
public class creationExample extends Aglet{
pubilc void run() {
try{
getAgletContext(). createAglet(getCodeBase(), 'CreationChild",
null); }
Catch (Exception e){ System.out.println(e.getMessage()) ;}
}}
4.2.4 Le modèle événementiel de
l'aglet
La programmation des aglets est basée sur la gestion
des événements. Des notifications alertent l'aglet sur les
actions influant sur son cycle de vie. Le programmeur a la possibilité
d'implémenter des écouteurs (listeners) pour faire réagir
l'aglet. Il existe trois catégories de notifications :
Notifications de clonage
Permettent la capture des événements liés
au clonage de l'aglet. Cette fonctionnalité est obtenue par
implémentation de l'écouteur (interface) CloneListener :
La méthode clone() permet de cloner un aglet. Elle
retourne le proxy associé au clone. L'aglet qui fait l'objet du clonage
reçoit alors les notifications suivantes :
public void CloneAdapter. onCloning(CloneEvent event);
Annonce de clonage de l'aglet. La surcharge de cette
méthode donne la possibilité d'exécuter les actions en
conséquence.
Le clonage est réalisé et nous obtenons deux
aglets : Un original est un clone. L'original reçoit un
événement de type :
public void CloneAdapter. onCloned(CloneEvent event);
Et l'agent cloné reçoit l'événement
:
public void CloneAdapter.onClone(CloneEvent event);
Notifications de mobilité
Il existe deux façons de déplacer un aglet. La
première est l'envoi vers un hôte distant; la seconde consiste
à retirer un aglet d'un hôte distant. Plus
précisément, il s'agit d'ordonner à l'aglet de partir
où de venir.
Envoi: La méthode dispatch (URL destination) permet de
demander à un aglet d'aller s'exécuter sur une autre plateforme.
Dispatch (new URL ("atp ://
unhote.fr"));
Le protocole utilisé est ATP : Aglet Transfer Protocol.
Il est lié à l'API utilisée.
Les événements sont suivis par un
MobilityListener. L'écouteur est ajouté et supprimé
grâce aux méthodes addMobilityListener() et
removeMobilityListener(). Un MobilityListener doit implémenter les
méthodes suivantes :
public void onDispatching () : Cette méthode est
appelée avant l'envoi de l'aglet. public void onArrival () : Cette
méthode est appelée à la réception de l'aglet.
Retrait : Le principe de retrait est similaire au principe de
l'envoi d'aglet. La méthode
retractAglet() permet de retirer un aglet de son contexte
actuel.
AgletContext.retractAglet (URL contextAdress, AgletID id)
AgletID est un identifiant attribué à l'aglet. Il
est obtenu à l'aide de la méthode getAgletID de la classe
Aglet.
4.2.5 Communication des aglets
La communication est basée sur l'échange d'objets
de la classe Message. Ce modèle de communication est indépendant
de la localisation de l'aglet et peut être asynchrone ou synchrone.
Un aglet désirant envoyer un message doit obligatoirement
passer par le proxy du destinataire. En fait, le proxy reste
l'intermédiaire obligatoire pour tout échange.
Chaque aglet possède un gestionnaire de messagerie
MessageManager qui lui permet de les traiter un à un et dans l'ordre de
leurs arrivées respectives. Toutefois, cet ordre peut être
changé par l'aglet en modifiant les priorités des messages dans
la file d'attente. Ceci est possible grâce à la méthode
setPriority().
public void MessageManager. SetPriority (String Kind, int
priority) Les priorités ont des valeurs allant de 1 à 10.
D'autres mécanismes existent pour le traitement
parallèle des messages. Chaque message est caractérisé par
la catégorie (Kind) à laquelle il appartient. La création
d'une instance message nécessite l'affectation d'une valeur à son
paramètre Kind
Message msg =new Message (<î' Mon nom », A): le
deuxième argument représente la valeur affectée au premier
argument (kind).
Messages synchrones
La méthode sendMessage(Message msg) permet l'envoi de
messages synchrones. Elle est donc bloquante car elle retourne la
réponse du récepteur.
Messages asynchrones
La messagerie asynchrone est implémentée
grâce à la notion de futur objet. L'envoi d'un message asynchrone
retourne un lien vers la réponse même si cette dernière
n'existe pas encore. Ce lien permet de tester si la réponse est
arrivée ou pas. Cette technique permet à l'aglet d'envoyer un
message sans être obligé d'interrompre son exécution en
attente de la réponse.
4.2.6 Les Serveurs d'aglets
· Tahiti:
un gestionnaire d'agents visuel. Tahiti utilise une interface
graphique unique pour suivre et contrôler l'exécution des aglets.
Il est possible en utilisant le glisser-déposer de faire communiquer
deux agents ou de les faire migrer vers un site particulier. Tahiti dispose
d'un gestionnaire de sécurité paramétrable qui
détecte toute opération non autorisée et empêche
l'agent de la réaliser.
· Fiji:
un lanceur d'agent sur le Web. Fiji est une applet Java
capable de créer ou de détruire un aglet sur un navigateur Web.
Fiji utilise comme unique paramètre l'URL de l'agent, qui est
intégré directement dans le code HTML d'une page Web.
Comme pour une applet, l'exécution d'un aglet commencera
par le téléchargement du code, puis par son lancement grâce
à Fiji. Si le serveur Web est complété par un
démon
ATP, il devient très facile de répartir des aglets
sur les sites Web.
4.3 Conclusion
Les aglets ajoutent une dimension à la programmation
objet. Ils permettent d'intégrer le réseau dans la conception des
systèmes et ils offrent une très grande simplicité
d'implémentation. Ceci constitue un avantage certain par rapport aux
autres systèmes. Grâce à java, ils sont indépendants
de la plateforme et permettent d'intégrer tout type de machine dans
l'environnement. Il semble néanmoins que cette technologie ne suscite
pas l'engouement attendu. En ce qui concerne spécifiquement les aglets
et l'équipe de développement japonaise d'IBM, les publications
semblent s'être arrêtées en 1998. D'autres plateformes ont
été développées depuis. Elles constituent une base
prometteuse et seront peut être le prochain standard de
développement de systèmes d'informations.
Deuxième partie
Spécification et réalisation
Chapitre 5
Communication inter Aglets
5.1 Introduction
La "communication" est le processus de transmission
d'informations. Ce terme provient du latin « communicare » qui
signifie « mettre en commun ». La communication peut donc être
considérée comme un processus pour la mise en commun
d'informations et de connaissances.
Une propriété importante des aglets est qu'ils
peuvent communiquer entre eux via un environnement dans lequel les aglets qui
ne connaissent pas peuvent échanger des messages. C'est-à- dire,
un aglet doit être capable de coopérer avec des aglets
développés par d'autres développeurs.
Dans cette partie, nous allons décrire les
différentes techniques de communication par messages entre aglets.
Plusieurs moyens de communication inter aglets sont supportés; ainsi
qu'une description des failles da la plateforme Aglets au niveau de la
communication sera donnée.
5.2 Types de communication
Les aglets d'IBM fournissent un modèle d'interface pour
la communication plus flexible, et plus extensible que l'invocation normale de
méthodes.
L'aglet supporte un environnement de communication (Figure4.1)
qui est:
· extensible
· indépendant de la localisation
· synchrone / asynchrone
_
_
_
_
___
___
_
_
Message Object
Agletcontext Communication
AgletAglet
message
Figure 4.1 L'environnement Aglet.
5.2.1 Communication simple
Le principal moyen pour les aglets de communiquer est l'envoi
de messages. La méthode d'appel du service de messagerie dans la classe
Aglet s'appelle handleMessage(). Ce n'est pas une méthode à
utiliser directement pour envoyer un message à un aglet, les
méthodes sendMessage() ou sendAsyncMessage() sont utilisées
à la place. Ces 2 méthodes ont l'avantage d'abstraire
l'emplacement de l'aglet. Ce qui signifie que peu importe où se trouve
l'aglet, l'interface (sendMessage) reste identique.
5.2.2 Communication synchrone
La communication synchrone entre aglet est assurée par
la fonction getReply(). Après avoir envoyé un message, on peut
attendre la réponse du destinataire par cette fonction. Cette
dernière reste bloquante jusqu'à ce que la réponse soit
retournée (Figure 4.2). La méthode sendMessage (Message msg)
permet l'envoi de messages synchrones. Elle est bloquante car elle retourne la
réponse du destinataire. Ensuite le destinataire du message doit
implémenter un gestionnaire des messages reçus. Cette
fonctionnalité est rendue possible par la surcharge de la méthode
: Agl et.handleMessage (Message msg). Puis la méthode
Message.sendReply() permet de retourner une réponse à
l'émétteur. Elle supporte plusieurs constructions (Figure 4.2)
:
public void Message.sendReply ()
public void Message.sendReply (boolean reply)
public void Message.sendReply (Object reply)

handleMessage(Message msg) getReplyØ handleMessage(Message
msg)
sendMessage(Message msg) sendMessage(Message msg)
Figure 4.2 Communications synchrones.
5.2.3 Communication asynchrone
Dans le cas d'une communication asynchrone, après avoir
envoyé le message, l'Aglet doit vérifier
régulièrement s'il y a eu réponse ou non. L'envoi est non
bloquant (Figure 4.3).
handleMessage(Message msg)

sendMessage(Message msg) sendMessage(Message msg)
Figure 4.3 Communications Asynchrones.
Ce type de communication est implémenté
grâce à la notion de future Objet.Un ensemble de méthodes
de la classe FutureReply concernent la recherche de la réponse d'un
message. La transmission non bloquante ou asynchrones des messages permet de
poursuivre l'exécution jusqu'à ce que la réponse soit
arrivée.
public FutureReply AgletProxy. sendFutureMessage (Message msg) La
classe FutureReply offre des méthodes pour la récupération
des messages.
public boolean FutureReply.isAvailable() Vérifie si la
réponse est arrivée ou non.
public void FutureReply. waitForReply(long duration) Attente de
l'arrivée de la réponse pour la durée duration.
public void FutureReply. waitForReply() Blocage en attente de
l'arrivée de la réponse. public Object FutureReply. getReply()
Récupère la réponse.
Un agent peut avoir besoin de communiquer avec son
propriétaire, avec d'autres agents (locaux ou distants), ou avec des
services. La communication avec le propriétaire, identifiée
dans les attributs de l'agent, doit être asynchrone.
Dans le cas de communication avec un agent ou un service distant, le choix
entre la communication distante et la migration sur le site distant est un
problème complexe (compromis entre le coût de communication et le
coût de migration) dont la résolution est laissée au
programmeur dans les systèmes actuels.
5.3 Protection de la communication
Protéger la communication revient à
préserver la confidentialité et l'intégrité des
messages qui passent à travers le réseau ainsi que le secret du
flux. Quand des informations doivent être transmises entre deux
systèmes surtout hétérogènes par leurs
systèmes de sécurité, elles peuvent être
interceptées ou altérées par un intrus.
5.3.1 Approches de protection
On distingue essentiellement trois approches de protection des
messages en cours de communication
Sécurité orientée liaison
C'est la protection des messages qui circulent à
travers un lien de communication individuel entre deux noeuds (qu'il soit des
noeuds intermédiaires ou finaux) indépendamment de la source et
de la destination. Etant donné que l'information est
protégée sur les liaisons et pas au sein des noeuds qu'elles
relient, les noeuds eux-mêmes doivent être protégées
physiquement; d'ailleurs cette approche pose plusieurs problèmes.
Sécurité de bout en bout
Le but de cette approche est de protéger le message
pendant sa transmission entre source et destination de façon à ce
que la subversion de n'importe quel lien de communication ne peut
altérer le du message.
Sécurité orientée association
C'est un raffinement de l'approche de protection de bout en bout
qui offre aux utilisateurs une grande flexibilité dans le choix des
noeuds intermédiaires de communication.
Les méthodes de protection des messages se basent sur
l'idée de brouiller le message de manière à le rendre
incompréhensible et inintelligible pour l'attaquant. Pour ce faire, il
existe deux techniques différentes :
La stéganographie C'est un mot issu du grec
Stéganô, signifiant Je couvre et Graphô, signifiant
J'écris. Il s'agit de se servir d'un grand message pour cacher un autre
beaucoup plus petit. L'exemple le plus courant est de cacher le message dans
une image en utilisant les bits les moins significatifs de chaque pixel comme
bit de message. Ainsi, le message passe en clair dans le réseau, sans
personne en puisse trouver la composition du vrai message, sauf les personnes
concernées.
L'idée est de prendre un message et de le modifier de
manière aussi discrète que possible afin d'y dissimuler
l'information à transmettre. Le message original est le plus souvent une
image. La technique de base dite LSB pour Least Significant Bit consiste
à modifier le bit de poids faible des pixels codant l'image : une image
numérique est une suite de points, que l'on appelle pixel, et dont on
code la couleur à l'aide d'un triplet d'octets par exemple pour une
couleur RGB sur 24 bits. Chaque octet indique l'intensité de la couleur
correspondante rouge, vert ou bleu (Red Green Blue) par un niveau parmi 256.
Passer d'un niveau n au niveau immédiatement supérieur (n+1) ou
inférieur (n-1) ne modifie que peu la teinte du pixel, or c'est ce que
l'on fait en modifiant le bit de poids faible de l'octet, l'annexe 6.1 contient
un exemple explicatif.
Toutefois, la stéganographie s'avère peut
utilisée à cause du surcoût de communication qu'elle
engendre pour cacher le message. A cet effet, on s'intéresse
spécialement à la deuxième technique qui est la
cryptographie.
La cryptographie La cryptographie est l'étude des
méthodes permettant de transmettre des données de manière
confidentielle. Afin de protéger un message, on lui applique une
transformation qui le rend incompréhensible; c'est ce qu'on appelle le
chiffrement, qui, à partir d'un texte en clair, donne un texte
chiffré. Inversement, le déchiffrement est l'action qui permet de
reconstruire le texte en clair à partir du texte chiffré en
utilisant une clé particulière et un algorithme de
déchiffrement.
On distingue deux catégories de systèmes
cryptographiques:
· Systèmes de cryptographie symétrique:
Les algorithmes de chiffrement symétrique se fondent
sur une même clé pour chiffrer et déchiffrer un message
(Figure 4.4). Le problème de cette technique est que la clé, qui
doit rester totalement confidentielle, doit être transmise au
correspondant de façon sûre.
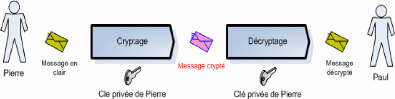
Figure 4.4 Système de cryptographie symétrique.
Le principe de fonctionnement du système
d'authentification à clés symétriques est le suivant :
Soit 'M' un ensemble de messages vérifiant une
propriété particulière (définie à l'avance
par les deux interlocuteurs) et soit 'm', appartenant à 'M', le message
à échanger. L'émetteur chiffre 'm' avec la clé
secrète 's' et envoie le résultat Es(m) au destinataire, ce
dernier déchiffre le message Ds(Es(m))= m et vérifie si le
message déchiffré appartient à 'M', si c'est le cas alors
l'authenticité du message est prouvée, sinon le message est
rejeté.
Parmi les algorithmes de cryptographie symétrique les plus
connus on cite :
a- DES (Data Encryption Standard) : C'est-à-dire
Standard de Chiffrement de Données est un standard mondial depuis plus
de 15 ans. Bien qu'il soit un peu vieux, il résiste toujours très
bien à la cryptanalyse et reste un algorithme très sûr.
Au début des années 70, le développement
des communications entre ordinateurs a nécessité la mise en place
d'un standard de chiffrement de données pour limiter la
prolifération d'algorithmes différents ne pouvant pas communiquer
entre eux. Pour résoudre ce problème, L'Agence Nationale de
Sécurité américaine (N.S.A.) a lancé des appels
d'offres. La société I.B.M. a développé alors un
algorithme nommé Lucifer, relativement complexe et sophistiqué.
Après quelques années de discussions et de modifications, cet
algorithme est devenu alors D.E.S.
Le D.E.S. est un système de chiffrement par blocs,
c'est a dire il ne chiffre pas les données à la volée
quand les caractères arrivent, mais il découpe virtuellement le
texte clair en blocs de 64 bits qu'il code séparément, puis qu'il
concatène. Un bloc de 64 bits du texte clair entre par un coté de
l'algorithme et un bloc de 64 bits de texte chiffré sort de l'autre
coté. L'algorithme est assez simple puisqu'il ne combine en fait que des
permutations et des substitutions. On parle en cryptologie de techniques de
confusion et de diffusion.
C'est un algorithme de cryptage à clef secrète.
La clef sert donc à la fois à crypter et à
décrypter le message. Cette clef a ici une longueur de 64 bits,
c'est-à-dire 8 caractères, mais seulement 56 bits sont
utilisés. On peut donc éventuellement imaginer un programme
testant l'intégrité de la clef en exploitant ces bits
inutilisés comme bits de contrôle de parité.
L'entière sécurité de l'algorithme repose
sur les clefs puisque l'algorithme est parfaitement connu de tous. La clef de
64 bits est utilisée pour générer 16 autres clefs de 48
bits chacune qu'on utilisera lors de chacune des 16 itérations du D.E.S.
Ces clefs sont les mêmes quel que soit le bloc qu'on code dans un
message.
En effet la sécurité du D.E.S. avec ses 16
rondes est grande et résiste à l'heure actuelle à toutes
les attaques linéaires, différentielles ou par clefs
corrélées, effectuées avec des moyens financiers et
temporels raisonnables (i.e. moins de 10 millions de dollars et moins d'un
mois). La grande sécurité repose sur ses tables de substitutions
non linéaires très efficaces pour diluer les informations. De
plus le nombre de clefs est élevé (256=7,2*1016) et peut
être facilement augmenté en changeant le nombre de bits pris en
compte. D'autres avantages plus techniques au niveau cryptanalyse existent. De
plus, cet algorithme est relativement facile à réaliser
matériellement et certaines puces chiffrent jusqu'à 1 Go de
données par seconde ce qui est énorme : c'est plus que ce qu'est
capable de lire un disque dur normal.
b-IDEA (International Data Encryption Algorithm) : Cet
algorithme a été conçu dans les années 90. C'est un
algorithme de chiffrement symétrique par blocs utilisé pour
chiffrer et déchiffrer des données. Il manipule des blocs de
texte en clair de 64 bits. Une clé de chiffrement longue de 128 bits
(qui doit être choisie aléatoirement) est utilisée pour le
chiffrement des données, et on a besoin de la même clé
secrète pour les déchiffrer. Comme tous les algorithmes de
chiffrement par blocs, IDEA utilise à la fois la confusion et la
diffusion. L'algorithme est basé sur le mélange
d'opérations de différents groupes algébriques(voir Annexe
6.1).
· Des systèmes de cryptographie
asymétrique
Ces systèmes ont été proposés par
Whitfield Diffie et Martin Hellman en 1976 marquant ainsi la naissance de la
cryptographie moderne. La cryptographie asymétrique (appelée
aussi
cryptoraphie à clé publique) utilise deux
clés : une clé publique et une clé privée. Les
clés publique et privée sont mathématiquement liées
par l'algorithme de cryptage de telle manière qu'un message
crypté avec une clé publique ne puisse être
décrypté qu'avec la clé privée correspondante. Mais
ces clés ont la propriété que si l'on connaît la
clé publique, il est impossible de trouver par calcul la clé
privée. Dans un système cryptographique à clé
publique, chaque partie communicante possède sa propre paire de
clés publique/privée. Comme son nom l'indique, la clé
publique est mise à la disposition de quiconque désire chiffrer
un message. Ce dernier ne pourra être déchiffré qu'avec la
clé privée, qui doit être confidentielle.
Voici comment un tel système peut assurer la
confidentialité des communications : deux sujets, Paul et Pierre,
désirent échanger des informations qu'il tiennent à garder
secrètes et intègres. Pierre va chiffrer l'information avec la
clé publique de Paul. La confidentialité de l'information est
maintenue, car seul Paul peut la déchiffrer au moyen de sa clé
privée (Figure 4.5).
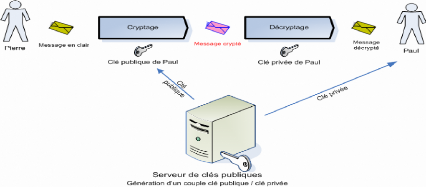
Figure 4.5 Système de cryptographie asymétrique.
Quelques algorithmes de cryptographie asymétrique
très utilisés :
a- RSA (Rivest, Shamir et Adleman) :
Cet algorithme est très largement utilisé, par
exemple dans les navigateurs pour les sites sécurisés et pour
chiffrer les emails. Il est dans le domaine public (Figure 4.5).
L'algorithme est remarquable par sa simplicité. Il est
basé sur les nombres premiers. Pour encrypter un message, on fait : c =
m^e mod n
Pour décrypter : m = c'd mod n
m = message en clair
c = message encrypté
(e,n) constitue la clé publique
(d,n) constitue la clé privée
n est le produit de 2 nombres premiers
^est l'opération de mise à la puissance (a'b : a
puissance b)
mod est l'opération de modulo (reste de la division
entière)
Créer une paire de clés : C'est très simple,
mais il ne faut pas choisir n'importe comment e, d et n. Et le calcul de ces
trois nombres est tout de même délicat (figure 4.6).
e n d n

Texte en clair
Texte codé
Décryptage
Texte en clair
Cryptage
n m
m c = m^e mod n c m = c^d mod
Figure 4.6 Principe de fonctionnement de l'algorithme RSA.
Voici comment procéder :
1. Prendre deux nombres premiers p et q (de taille à peu
près égale). Calculer n = pq.
2. Prendre un nombre e qui n'a aucun facteur en commun avec
(p-1)(q-1).
3. Calculer d tel que ed mod (p-1) (q-1) = 1
Le couple (e,n) constitue la clé publique. (d,n) est la
clé privée.
l'annexe6.2 contient un exemple bien detaillé de cet
algorithme.
b- DSA (Digital Signature Algorithm) :
Plus connu sous le sigle DSA, est un algorithme de signature
numérique standardisé par le NIST aux États-Unis, du temps
où le RSA était encore breveté. Le processus de cet
algorithme se fait en trois étapes :
1. Génération des clés
Leur sécurité repose sur la difficulté du
problème du logarithme discret dans un groupe fini.
· Choisir un nombre premier p de L-bit, avec 512 < L
< 1024, et L est divisible par 64
· Choisir un nombre premier q de 160 bits, de telle
façon que p - 1 = qz, avec z un entier
· Choisir h, avec 1 <h < p - 1 de manière
à ce que g = h^z mod p> 1
· Générer aléatoirement un x, avec 0
<x < q
· Calculer y = g^x mod p
· La clé publique est (p, q, g, y). La clé
privée est x
2. Signature
· Choisir un nombre aléatoire s, 1 <s < q
· Calculer s1 = (g's mod p) mod q
· Calculer s2 = (11(m) + s1xx)s'-1 mod q, où 11(m)
est le résultat d'un hachage cryptographique
· La signature est (s1,s2)
3. Vérification
· Rejeter la signature si 0<s1<q ou 0<s2<q
n'est pas verifié
· Calculer w = (s2) -1 (mod q)
· Calculer u1 = H(m)xw (mod q)
· Calculer u2 = s1 xw (mod q)
· Calculer v = [g^u1xy^u2 mod p] mod q
· La signature est valide si v = s1
5.3.2 Contrôle d'intégrité
Pour le contrôle d'intégrité des
données on peut utiliser la fonctions de hachage.
Une fonction de hachage calcule le résumé d'un
texte, ce résumé est très sensible au texte initial (une
petite modification du texte provoque une grande modification du
résumé). Les 2 algorithmes de hachage les plus utilisés
sont le SHA (Secure Hash Algorithm) qui calcule un résumé de 160
bits, et le MD5 (Message Digest version 5), qui calcule un résumé
de 128 bits. Nous présentons ce dernier algorithme, qui se
déroule en plusieurs étapes (Figure 4.7) .
· Etape 1 : Complétion
Le message est constitué de b bits m1. ..mb. On
complète le message par un 1, et suffisamment de 0 pour que le message
étendu ait une longueur congruente à 448, modulo 512. Puis on
ajoute à ce message la valeur de b, codée en binaire sur 64 bits
(on a donc b qui peut valoir jusque 264... ce qui est énorme). On
obtient donc un message dont la longueur totale est un multiple de 512 bits. On
va travailler itérativement sur chacun des blocs de 512 bits.
· Etape 2 : Initialisation
On définit 4 buffers de 32 bits A, B, C et D,
initialisés ainsi (les chiffres sont hexadécimaux, ie a=10,
b=11...).
A=0 1234567
B=89abcdef
C=fedcba98
D=76543210
On définit aussi 4 fonctions F, G, H et I, qui prennent
des arguments codés sur 32 bits, et renvoie une valeur sur 32 bits, les
opérations se faisant bit à bit.
F(X,Y,Z) = (X AND Y) OR (not(X) AND Z)
G(X,Y,Z) = (X AND Z) OR (Y AND not(Z))
H(X,Y,Z) = X xor Y xor Z
I(X,Y,Z) = Y xor (X OR not(Z))
Ce qu'il y a d'important avec ces 4 fonctions et que si les bits
de leurs arguments X,Y et Z sont indépendants, les bits du
résultat le sont aussi.
· Etape 3 : Calcul itératif
Pour chaque bloc de 512 bits du texte, on fait les
opérations suivantes :
1. on sauvegarde les valeurs des registres dans AA,BB,CC,DD.
2. on calcule de nouvelles valeurs pour A,B,C,D à partir
de leurs anciennes valeurs, à partir des bits du bloc qu'on
étudie, et à partir des 4 fonctions F,G,H,I.
3. on fait A=AA+A, B=BB+B, C=CC+C, D=DD+D.
Le détail des calculs se trouve en annexe 4.4
. Etape 4 : Ecriture du résumé
Le résumé sur 128 bits est obtenu en mettant bout
à bout les 4 buffers A, B , C et D de 32 bits.
Figure 4.7 Description du fonctionnement du MD5
5.4 Les failles dans Aglets au niveau de la
communication entre les agents
Malgré que la plateforme Aglets possède un Package
qui contient des classes assurant la sécurité des aglets
ça ne suffit pas de dire que la communication entre aglets est bien
sécurisée.
Dans cette partie de ce chapitre, nous mettons l'accent sur
les failles existantes dans la plateforme Aglets au niveau de la communication
entre les agents. Nous allons nous baser sur des tests, pour cela nous allons
utiliser un outil d'écoute dans le réseau qui est une sorte de
logiciel qui peut récupérer les données transitant par le
biais d'un réseau local, et il permet une consultation aisée des
données non chiffrées et peut ainsi servir à intercepter
des mots de passe qui transitent en clair ou toute autre information
non-chiffrée, cet outil est appelé « sniffer ».
Le principal moyen pour les aglets de communiquer, est l'envoi
de messages et comme il a été déja énoncé au
début de ce chapitre que la communication peut être asynchrone ou
synchrone et dans les deux cas il y a un manque de sécurité des
données à envoyer.
On va prendre à titre d'exemple deux aglets A et B qui
communiquent entre eux par envoie des messages.
A: connecter sur le port 4434 et sur la machine d' IP :
192.168.10.37
B : connecte sur le port 4435 et sur la machine d' IP :
192.168.10.192
Nous avons classé les failles en fonction de quelques
propriétés de sécurité des agents mobiles.
5.4.1 La confidentialité
On suppose que l'Aglet A va envoyer des données
confidentielles vers B. Dans ce cas les données ne sont pas
secrètes et il se peut que des personnes non autorisées y aient
accès.
Cela peut être expliqué par la figure 4.7, qui
représente l'écran d'une capture faite par le sniffer pendant le
transfert du message de A vers B.
Comme il est indiqué le message est en clair et n'importe
quel hôte dans le réseau peut l'observer.
Figure 4.7 Résultat d'une capture de trafic par le
sniffer(1).
5.4.2 L'authentification et L'intégrité
Par le même exemple, et à partir de la même
figure, on suppose qu'un autre aglet accède au message et modifie ou
efface son contenu pendant sa transmission. Ainsi les informations
reçues par B ne seront pas conformes à celles fournies par A. Le
service d'authentification doit montrer que la connexion ne peut être
brouillée par une troisième entité cela veut dire que
n'importe quel hôte visité sur l'itinéraire de l'agent n'a
pas le droit d'enlever des données ajoutées par les hôtes
précédents car à la suite n'importe quels renseignements
qui sont modifiés d'une façon inattendue peuvent rendre les
résultats faux ou rendre les données incohérentes
après la modification.
Le sniffer détecte les informations des hôtes
connectés dans le réseau, tel que les adresses IP et MAC, ainsi
que le temps précis de passage ou d'envoi des messages, sous la forme
suivante: 13 :56 :17 :421. (Figure 4.8).
Avec ce degré de précision et par le calcul de
temps de transfert d'un message à envoyer de A vers B en savant leurs
adresses on peut détecter l'attaque sur le message.
Prenons l'exemple suivant :
Soit le message MSG1 qui est transmit par A vers B avec un temps
de transfert de 10ms
au pires de cas. Ensuite on suppose qu'il y a un autre hôte
C n'est autorisé que a transmettre le message et n'est pas autoriser ni
a lire ni a modifier son contenu.
Dans ce niveau, et à l'aide de sniffer IRIS on peut
prouver que C occupe le message pendant un temps de 100ms (par exemple) dans
lequel il procède à le modifier ça qui ne convient pas
avec l'authentification et l'intégrité des données dans le
réseau. Et puisque le sniffer détecte les informations des
hôtes, ça nous a permis de bien localiser l'hôte
malveillant.
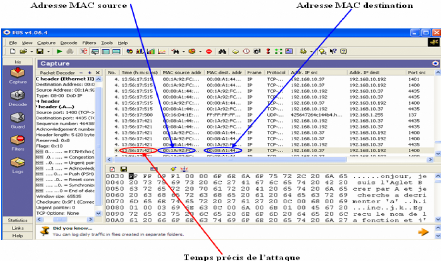
Figure 4.8 Résultat d'une capture de trafic par le sniffer
(2).
5.4.3 La disponibilité
La disponibilité peut être non
vérifiée. Par exemple dans le cas suivant :
Si l'Aglet A transmet un paramètre (donnée,
ressource, etc.) vers B qui l'utilise pour effectuer son travail et
réaliser un service (calcul, test, etc.) et que pendant son transit, ce
paramètre sera capturé par d'autres hôtes, alors que B,
à un temps bien précis, a besoin de ce paramètre qui est
indisponible, donc le temps de travail de B va se prolonger grâce au
retard et parfois son travail peut échouer (Figure 4.9).
Noeud de commutation

A 1-13
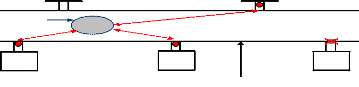
Paramètre
1-1 1
Vers
t B t+1
t+2
1-12 B
Canalde Communication non
sécurisé

Retard
Figure 4.9 Faille au niveau de la disponibilité.
Et par le même outil, nous avons pu découvrir ce
type d'attaque, puisque le sniffer nous donne le temps d'occupation de message
par un hôte avec précision (Figure 4.8).
5.5 Conclusion
Les solutions déployées pour la protection des
ressources et de la communication entre les aglets au sein d'un réseau
s'acharne pour défendre l'armature de la sécurité
informatique formée de quatre buts différents mais
complémentaires et indissociables, qui sont : la confidentialité,
l'intégrité, l'authentification et la disponibilité.
Mais, malgré toutes ces techniques utilisées
pour décliner les menaces et les attaques sur le réseau ainsi que
toutes les approches de protection de la communication inter aglets, sur
lesquelles nous avons mis l'accent dans ce chapitre, un système n'est
jamais totalement sûr. L'implémentation de la cryptographie dans
les systèmes informatiques offre de bons résultats au niveau de
la sécurité des données.
Chapitre 6
Spécification de domaine
6.1 Introduction
Dans ce chapitre, nous allons décrire l'environnement
(matériel et logiciel) dont lequel nous avons travaillé. Ensuite,
nous allons présenter les étapes de la configuration du serveur
Tahiti dans une machine.
6.2 Environnement de travail
6.2.1 Langage de programmation Java
Dans le cadre de notre travail nous avons utilisé le
langage Java qui est favorable au développement des applications
distribuées à base d'agents mobiles ainsi que la plateforme
Aglets d'IBM. Alors il suffit que le JDK1.4 au minimum soit installé sur
nos machines.
6.2.2 Environnement Matériel
Comme matériel, nous avons besoin d'au moins deux
machines qui doivent être dotées d'un serveur d'agents pour
pouvoir tester le bon fonctionnement des agents mobiles « aglets »
sous un système d'exploitation Windows ou Linux.
- Machine1 : Toshiba Intel Pentium, Dual-coreT2O8O 1,73Ghz ,1GO
de RAM - Machine2 : Versus Céléron, 1,73Ghz ,512MO de RAM
- Un réseau Local pour tester l'application.
6.2.3 Environnement Logiciel
NetBeans
Nous allons utiliser ce logiciel pour la programmation et le
développement des classes en Java pour avoir les testes. C'est un outil
de développement puissant, qui se distingue par sa facilité
d'utilisation due à son ergonomie qui utilise toutes les technologies
possibles d'aide au développement. NetBeans est un environnement complet
incluant toutes les fonctionnalités de développement et toutes
les technologies liées à Java permettant un développement
rapide et visuel des applications java.
Serveur Tahiti
Tahiti est le serveur propre aux aglets, il est simple à
configurer et facile à manipuler. Nous l'utiliserons pour faire les
tests de manipulation des Aglets développés sous NetBeans.
Sniffer IRISv4.06.4
Nous avons utiliser ce logiciel dans nos tests, il est simple
a manipulé (figure 5.1). Il permet de récupérer les
données transitant par le biais d'un réseau
local. et il permet une consultation
aisée des données non-chiffrées et peuvent ainsi servir
à intercepter des mots de passe qui transitent en clair ou toute autre
information non-chiffrée, à résoudre des problèmes
réseaux en visualisant ce qui passe à travers l'interface
réseau, ou à effectuer de la rétro-ingénierie
réseau à des buts d'interopérabilité, de
sécurité ou de résolution de problème.
Figure 5.1 IRISv4.06.4
6.3 Configuration du serveur Tahiti
6.3.1 Installation de la plateforme
La version 2.0.2 d'Aglets est considérée comme la
version la plus stable. Pour pouvoir l'installer, il faut d'abord installer
JDK1.4 au minimum comme on a dit.
Les étapes suivantes décrivent la
procédure d'installation de la plateforme Aglets 2.0.2 à partir
du fichier archive aglets-2.0.2.jar que nous avons
téléchargé gratuitement à partir du site de
sourceforge.net : http : //
sourceforge.net/projects/aglets/
1. Décompresser le fichier aglets-2.0.2.jar à
l'aide d'un utilitaire de compression/décompression tels que Winzip et
Winrar ou bien à l'aide de la commande:
Jar xvf aglets-2.0.2.jar
2. Après avoir décompressé ce fichier, les
répertoires suivants apparaîtront à l'emplacement de la
décompression:
o Bin contient des programmes exécutables pour le
lancement et la configuration du serveur Tahiti.
o Cnf contient les fichiers de configuration de la plateforme
Aglets.
o Public contient des exemples d'aglets et sera
considéré comme répertoire racine pour les aglets
créés par la suite.
o Lib contient les classes java nécessaires pour
l'exécution de la plateforme.
3. Pour installer le serveur, il suffit de lancer l'execution
du fichier « ant » se trouvant dans le répertoire bin et qui
est un outil pour la compilation et l'installation des applications JAVA.
4. Exécuter la commande « ant install-home »
qui permet de génèrer deux entée dans le magasin de
clés créé par la plateforme JAVA qui servent pour
l'authentification au lancement du serveur Tahiti.
5. Créer les variables d'environnement.
6. La dernière étape est le démarrage du
serveur Tahiti par la commande agletsd.
Configuration des variables d'environnement
Pour démarrer le serveur Tahiti, nous devons ajouter deux
nouvelles variables d'environnement AGLET _HOME et AGLET_PATH
o Sous Unix ou Linux avec bash
export AGLETS_HOME=/java/aglets-2.0.2
export AGLETS_PATH=$AGLETS_HOME
export PATH=$PATH :$AGLETS_HOME/bin
export CLASSPATH=$CLASSPATH :$AGLET_HOME/lib
o Sous Microsoft Windows
set AGLETS_HOME=c : \java\ aglets-2.0. 2
set AGLETS_PATH=%AGLETS_HOME%
set PATH=%PATH% ;\% AGLETS _HOME %\bin
set CLASSPATH=%CLASSPATH% ;\%AGLET_HOME%\lib
Démarrage du serveur Tahiti
Après avoir configuré la machine, on peut à
ce stage lancer le serveur par la commande agletsd. On obtient une
fenêtre d'authentification (Figure 5.2, Figure5.3)
Figure 5.2 Phase
d'identification/authentification.
Comme nous avons indiqué ci-dessus, le fichier .keystore
contient deux utilisateurs par défaut:
- anonymous avec le mot de passe aglets.
- aglet_key avec le mot de passe aglets.
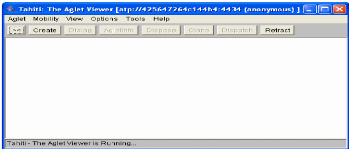
Figure 5.3 Serveur Tahiti.
6.4 Le diagramme des cas d'utilisation de Tahiti
Les diagrammes de cas d'utilisation sont des diagrammes UML
utilisés pour donner une vision globale du comportement fonctionnel d'un
système logiciel. Un cas d'utilisation représente une
unité discrète d'interaction entre un utilisateur (humain ou
machine) et un système. Il est une unité significative de
travail. Dans un diagramme de cas d'utilisation, les utilisateurs sont
appelés acteurs (actors), ils interagissent avec les cas d'utilisation
(use cases).
6.4.1 Description du système
Le serveur Tahiti de la plateforme Aglets permet de manipuler
nos agents. Dans nos test nous avons utilisé un réseau local pour
ce là il est nécessaire d'avoir un serveur distant. Alors on peut
distinguer trois acteurs externes au serveur :
L'utilisateur, Les agents mobiles Aglets et le serveur distant
(avec un port différent de celle de serveur local).
Description des cas d'utilisations
· Configurer
-Manipuler les options de configuration de Tahiti tel que;
general preference, network preference, security preference et server
preference, etc.
-Modifier les fichier .policy et .props du serveur.
· Identifier/authentifier
- Ca ce fait avec la commande agletsd ensuite donner un login
et un mot de passe de compte à ouvrir. (on peut aussi s'authentifier et
identifier à travers le fichier .props qui contient les informations de
compte par défaut par la commande suivante :agletsd --f..
\cnf\aglets.props
· Crée
- Lancer un aglet déjà existant dans la liste
enregistrée.
- Ajouter une classe grâce au nom de son package pour
lancer l'aglet.
· Cloner
- Créer un clone dans le même serveur ou dans un
serveur distant (selon le numéro de port occuper et l'URL de serveur en
question).
· Activate/Deactivate
- Activation ou désactivation des aglets grâce au
bouton activate/desactivate dans le menu de serveur.
· Envoyer/Rétracter
Migration ou retirer un aglet selon son URL et le numéro
de port.
· Echanger des agents
- Envoyer des agents (aglets).
- Retirer des agents (aglets).
· Communication par messages
- Envoyer un message à un agent distant.
- Répondre à un message envoyé par un agent
distant.
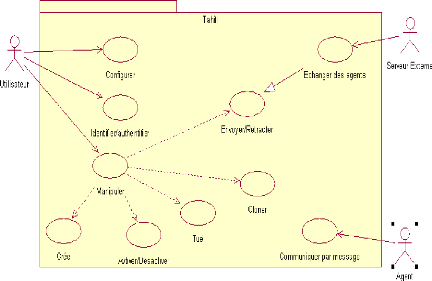
Figure 5.4 Diagramme des cas d'utilisation du serveur Tahiti.
6.5 Conclusion
Dans ce chapitre nous nous sommes intéressées
à étudier notre environnement de travail matériel
(machines, réseau) et logiciel (serveur Tahiti, sniffer.. .) . Cet
environnement demeure très important dans l'élaboration de notre
solution sujet du chapitre suivant.
Chapitre 7
Conception et réalisation
7.1 Introduction
Après avoir fixé les bases théoriques de
notre système, il faut pouvoir intégrer le tout dans une
application réelle afin de bien assimiler le principe de fonctionnement
et de démonter la faisabilité de notre approche.
Pour sécuriser les agents mobiles aglets au cours de
leurs communications, nous avons proposé une solution basée sur
le logiciel qui va être appliquée dans le cadre du domaine
médical. Cette solution est le sujet de ce chapitre. En premier lieu
nous avons spécifié les étapes de notre solution, en
deuxième lieu nous avons élaboré une conception de cette
dernière pour finir par sa implémentation.
7.2 Spécification de la solution
7.2.1 Etapes de travail
Les tests des codes simples des aglets qui communiquent
constituent la première étape dans notre travail, suivie de
l'étude des failles de sécurité existantes dans la
plateforme au niveau de la communication. En suite, nous nous sommes
intéressées à faire la conception de la solution
proposée afin de passer à l'étape de
l'implémentation. (Figure 6.1)
Tahiti

Sniffer

Tests de code (Aglet Simple)
|
Détermination des failles de iti
|
Conception de la solution
Implémentation
NetBeans
UML
Figure 6.1 Etapes de travail.
7.2.2 Description de la solution
La plate-forme Aglets a plusieurs caractéristiques et
vu que l'agent est programmé en Java et que celui ci offre des
possibilités de sécurité, nous avons donc pensé
à intégrer une sorte d'approche de sécurité de cet
agent.
Notre but est alors de sécuriser les aglets pendant
leurs communications dans un système multi agents, pour
transférer ou recevoir des informations médicales par exemple
image d'extension .tiff.
Notre solution consiste à implémenter un
ensemble d'agents coopératifs qui travailleront et manipuleront les
informations en fonction des besoins d'un utilisateur ou du type de
données.
Pour échanger des informations, les agents
coopératifs se comportent comme suite :
Le premier agent, appelé agent utilisateur du fait
qu'il doit être lancé par l'utilisateur, va satisfaire les
désires de l'utilisateur, ce qui lui permettra à son tour de
choisir et de lancer l'exécution d'un autre agent .Dès lors deux
cas se présentent :
1) S'il s'agit d'un fichier qui contient des données
confidentielles (par exemple en teste sur l'existence des codes, des
identifiants, etc.), l'agent utilisateur lancera un autre agent
appelé
agent cryptage qui va crypter les données du fichier
à l'aide d'un algorithme de cryptage asymétriques le RSA (Figure
6.2).

Image.tiff en clair
Cryptage
Décryptage
Image.tiff en clair
Image codée
Figure 6.2 Cryptage/Décryptage.
2) Si l'utilisateur désire contrôler
l'intégrité d'un document, l'agent utilisateur lancera un autre
agent appelé agent hachage. Cet agent va contenir une classe de
vérification développée en java implémentant une
fonction de hachage par l'approche MD5. Dans notre cas nous avons
réalisé nos tests sur un simple message puis sur une image
médicale d'extension .tiff
L'agent hachage va créer un hash (Digest) lors de
l'envoi d'un message et la transmet avec le message afin que le
récepteur puisse recalculer l'hash du message et la comparer à
celui envoyé.
Dans notre solution, l'agent utilisateur est un agent
stationnaire qui s'exécute seulement sur la machine où il est
créé, il permet de lancer d'autres agents mobiles tel que : agent
cryptage, agent hachage qui communiquent entre eux par envoi de messages afin
de réaliser des tâches précises.
Si jamais l'agent utilisateur a besoin d'informations
supplémentaires inexistantes localement, ou d'interagir avec d'autres
agents dans différents systèmes ou encore il arrive que l'on ait
besoin d'exécuter une partie du code de cet agent sur une autre machine
que celle sur laquelle est lancé, alors on aura besoin d'utiliser une
méthode appliquée dans le modèle client serveur qui est le
protocole RPC (Remote Procedure Call).
Chaque agent mobile, lancé par l'agent utilisateur
possède un traitement sur les données (cryptage,
vérification) dans la source. Pour cela il est nécessaire que le
code de chaque agent mobile ait des paramètres et des informations qui
permettront aux agents destination de réaliser le traitement inverse sur
les données pour avoir les données en claire ou pour s'assurer
que les données n'ont pas été altérées.
Nous considérerons les agents mobiles comme étant
des aglets qui contiennent des codes java et qui communiquent entre eux pour
maintenir une sorte de sécurité de leurs données.
L'organigramme suivant explique bien le fonctionnement de notre
solution(Figure 6.3)

|
Données à envoyer
|
____
____
|
Agent utilisateur
|
Agent Cryptage
|
|
|
|
|
Agent hachage
|
|
|
|
Figure 6.3 Diagramme de la solution.
7.3 Conception de la solution
____
Afin d'arriver à la phase de l'implémentation de
notre solution, il est nécessaire d'abord de passer par l'étape
de conception, .Nous allons utiliser la méthode UML (Unified Modeling
Language) pour la modélisation des données et des traitements par
des diagrammes nécessaires.
7.3.1 Diagramme de classes
Le diagramme de classe offre une vue statique du système,
en représentant les classes et les relations entre les classes.
La classe aglet possède beaucoup de méthodes tel
que onArrival(), onCreation(), etc. Et tout autre agent hérite toutes
ces méthodes comme il est indiqué dans la figure 6.4
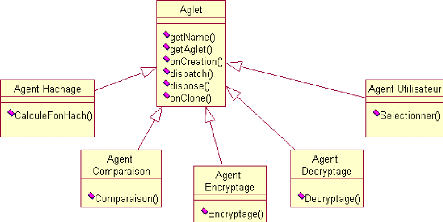
Figure 6.4 Diagramme de classes
7.3.2 Diagramme de cas d'utilisation
Le diagramme de cas d'utilisation donne une vision globale du
comportement fonctionnel de notre solution ce qui est indiqué dans la
figure 6.5.
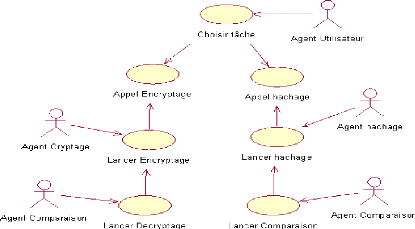
Figure 6.5 Diagramme de cas d'utlisation
Appel Encryptage : le cas d'utilisation Appel Encryptage est
déclenché par l'Agent Utilisateur après avoir choisir la
tâche à réaliser : Cryptage ou bien Hachage.
Appel Hachage : Ce cas d'utilisation est déclenché
par l'Agent Utilisateur si jamais ce dernier a choisit de réaliser la
tâche contrôle de l'intégrité du document.
Lancer Encryptage : déclenché par l'Agent Cryptage
suite à un appel par le cas d'utilisation Appel Cryptage.
Lancer Hachage : déclenché par l'Agent Hachage
après réalisation de la tâche Appel Hachage. Lancer
Décryptage : l'agent Décryptage déclenche le cas
d'utilisation Lancer Décryptage pour décrypter le document.
Lancer Comparaison : ce cas d'utilisation est
déclenché par l'Agent Comparaison, ce dernier compare les deux
hashs générées pour pouvoir déterminer si le
message a été altéré ou non.
7.3.3 Diagramme de séquence
Le diagramme de séquence permet de représenter des
collaborations entre agents selon un point de vue temporel, on y met l'accent
sur la chronologie des envois de messages.
La figure 6.6 pressente le diagramme de séquence de notre
solution :
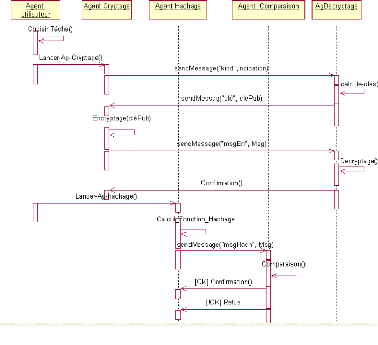
Figure 6.6 Diagramme de séquence
7.4 Implémentation de la solution
7.4.1 Cryptage/Décryptage
A ce stade là, nous avons commencé à
développer des classes java propre à notre solution.
La programmation de deux aglets ;celui du cryptage dans la
source et du décryptage dans un site distant, a été la
première tâche. En premier lieu, Nous avons appliqué le
cryptage sur un simple message et en second lieu sur une image d'extension
.tiff.
Nous avons choisi l'algorithme de cryptage RSA qui fonctionne
par calcule de deux clés public et privé, la première est
utilisée par la source pour crypter, et la deuxième par la
destination pour décrypter.
Considérons deux aglets A et B :
A va envoyer des données confidentielles (message simple
ou image. tif) à B , le processus
se fait comme suit :
1) L'agent A envoi un message d'indication à B pour lui
informer qu'il va commencer le transfert des données.
2) L'agent B reçoit l'indication et procède au
calcule des clés public et privé et n'envoie que la clé
public vers A.
3) Suite à la réception de la clé publique,
l'agent A crypte les données par cette clé et les envoie vers
B.
4) Enfin, B procède au décryptage des
données reçues à l'aide de la clé privé pour
avoir les données d'origine.
NB: Comme nous l'avons déjà indiqué, la
clé privée ne circule pas dans le réseau afin de la
protéger contre les attaques.
Cryptage de message simple
Nous avons testé le bon fonctionnement de notre code
qui crypte le message « AgletsXX » avant son transfert ,la figure 6.7
présente le processus de l'agent de cryptage A lors de son
exécution sur le serveur Tahiti et la figure 6.8 présente celui
de l'agent de décryptage B, d'un serveur distant.
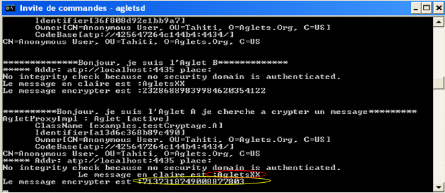
Figure 6.8 Processus de l'agent de cryptage A.
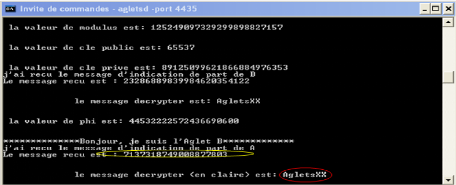
Figure 6.8 Processus de l'agent de décryptage B.
On peut prouver alors que même si les données sont
captées par d'autres sites malveillants ça ne risque pas de nuire
à la confidentialité des données.
Cryptage d'image.tiff
Aprés avoir atteindre notre objectif de cryptage d'un
simple message, nous nous sommes intéressées à ce niveau
à appliquer cette approche à une image médicale
d'extension tiff d'un os, qui doit circuler encryptée d'un aglet source
vers un autre destination.
Comme échantillon d'image, nous avons choisi une image de
résolution 64*64 mais ce choix n'est pas définitif car on peut
crypter n'importe quelle image de n'importe quelle résolution. Pour
crypter l'image, nous avons appliqué le même processus que celui
d'un simple message.
7.4.2 Contrôle d'intégrité
Le processus contrôle d'intégrité comme
nous l'avons indiqué dans la phase de conception, nécessite deux
aglets : le premier va calculer un hash relatif au message puis il le transmet
avec ce dernier afin que le deuxième aglet puisse recalculer ce hash et
le comparer à celui envoyé pour pouvoir s'assurer que le document
qui a circulé dans le réseau n'a pas été
altéré par une station malveillante.
L'approche contrôle d'intégrité
présente une sorte de sécurité sur les données
à envoyer puisque les empreintes MD5 (qui est une fonction d'hachage
cryptographique) permettent de contrôler l'intégrité des
fichiers. En crée une empreinte (ou résumé
électronique) des fichiers et à tous moment on peut
vérifier si les fichiers correspondent toujours à leurs
empreintes.
Si un fichier ne correspond plus à son empreinte cela
signifie soit que ce fichier a été endommagé
accidentellement (support physique, transmission...) soit que ce fichier a
été volontairement infecté. L'empreinte MD5 garantit
sérieusement l'intégrité du document.
Trois cas se présentent :
· Si un fichier ne correspond plus à son empreinte
il a forcement été modifié ou alors c'est l'empreinte qui
a été modifiée.
· Si un fichier correspond à son empreinte, il y
à une très forte probabilité qu'il soit intègre.
· La probabilité que deux fichiers différents
présentent la même empreinte est très faible.
7.4.3 Assurer l'authentification
Pour augmenter le degré de la sécurité de
la communication de nos aglets au niveau de la propriété
authentification, nous avons eu l'idée d'implémenter une approche
qui sert à vérifier l'identité des aglets communicants
avant l'envoi ou la réception des données.
Cela veut dire, protéger la communication des deux
aglets contre une troisième entité malveillante qui essayera
d'apparaître comme l'un des deux en leur volant leurs identité
(numéro de port ou adresse IP),ce qui lui permettra de recevoir et
d'envoyer des messages et même de brouillée la communication.
Notre approche consiste en un simple test qui doit être
exécuté par les aglets communicants avant de commencer
l'échange de leurs données.
Considérons deux aglets A et B qui communiquent par
messages et que A va commencer la transmission.
Prenons par exemple la question : « qui est tu ?»
sa réponse : « Je suis celui qui devrait te
répondre »
La question et sa réponse sont encryptées
(Encquestion et Encréponse) et les deux aglets A et B doivent avoir ces
quatre paramètres : question, réponse, Encquestion et
Encréponse
Le processus d'authentification se fait donc comme suit:
1) L'aglet A envoie à B la question encrypter
«Encquestion»;
2) L'aglet B qui reçoit la question encrypter «
Encquestion» la décrypte puis la compare avec la sienne si c'est la
même il envoie alors à A la réponse encrypter
(Encréponse).
3) Lorsque l'aglet A reçoit la réponse encrypter,
il la décryptera et la comparera avec la sienne :
- Si c'est la même alors il sera sûr que l'aglet B
est bien ce qu'il affirme être, si non il conclura qu'il s'agit d'un
aglet malveillant qui a voler l'identité de l'aglet B.
7.5 Conclusion
Ce chapitre a été consacré pour
développer notre travail, nous avons commencé par la
spécification de notre solution, et nous avons passé par une
phase de conception afin d'arriver à l'implémentation. La
sécurité de la communication inter aglets apportée par
cette solution donne la possibilité à la plateforme Aglets
d'être intégrée dans des applications travaillant sur des
données confidentielles.
Chapitre 8
Conclusion générale
Les aglets ajoutent une dimension à la programmation
objet. Ils permettent d'intégrer le réseau dans la conception de
systèmes. Grâce à java, ils sont indépendants de la
plateforme et permettent d'intégrer tous type de machine dans
l'environnement. Mais L'utilisation de la plateforme Aglets dans n'importe quel
contexte est souvent freinée par des questions de
sécurité.
Ce mémoire présente un état de l'art de
l'environnement dans lequel nous nous sommes intéressées à
bien étudier les concepts d'un système multi agents (SMA) et ceux
des agents mobiles. De plus nous avons réalisé une étude
bien détaillée qui regroupe toutes les approches actuelles pour
le contrôle de la sécurité des agents mobiles.
En outre, nous avons étudié la plateforme des
agents mobiles Aglets. Bien évidemment, nous avons assimilé ses
caractéristiques mais bien sûr ces failles au niveau de la
communication inter aglets qui représente notre principal objectif. De
ce fait, nous avons proposé une approche de sécurité
basée sur le logiciel qui sert à sécuriser les messages
transmis entre aglets.
Finalement, l'intégration des protocoles de
sécurité dans Aglets nous a permis de conclure que cette
plateforme est un concept idéal pour le développement des agents
mobiles sécurisés. Dans le cadre de notre travail nous avons mis
l'accent sur la sécurité au niveau de la communication, nous
avons pu assurer les trois propriétés de sécurité
:la confidentialité par le cryptage en utilisant l'algorithme RSA,
l'intégrité des documents échangés par la fonction
d'hachage MD5 et enfin la propriété d'authentification par
l'approche de vérification des identités des aglets. Mais la
sécurité peut régner tout le processus de cette plateforme
et le meilleur est encore à venir.
Ce travail nous a été la bonne occasion
d'améliorer notre connaissance dans l'Intelligence Artificielle et plus
précisément dans le domaine des SMA, ainsi nous nous avons
approfondi
dans l'étude de la plateforme Aglets et le serveur
Tahiti en plus dans la programmation java ce que nous a permis de programmer
des aglets capables de sécuriser leurs messages en cours de leur
communication.
Bibliographie
[Blu 88] Manuel Blum et Sampath Kanan, "Designing programs to
check their work", Tech-
nical report TR-88-009, International Computer Science
Institute, December 1988.
[Com91] European Comunities. Information technology security
evaluation criteria, Juin
1991
[FGS96a] Farmer, William; Guttmann, Joshua; Swarup, Vipin :
"Security for Mobile
Agents : Issues and Requirements", in : Proceedings of the
National Information Systems Security Conference (NISSC 96), 1996.
[Hoh97] F. Hohl. Time Limited BlackBox Security Protecting Mobile
Agents from Malicious
hosts. Mobile Agents and security, 1998.
[ISO9594-8] ITU-T Recommendation X.509 j ISO/IEC 9594-8 :
Information Technology Open Systems Interconnection -The Directory : Public Key
and Attribute Certificate Frameworks, March 2000.
[Jan01] W.A. Jansen. A privilege management scheme for mobile
agent systems,Janvier
2001.
[Mag02] Magdy Saeb, Meer Hamza, Ashraf Soliman, "Protecting
Mobile Agents against
Malicious Host Attacks Using Treat Diagnostic AND/OR Tree", Arab
Academy for Science,
Technology & Maritime Transport Computer Engineering
Department, Alexandria, Egypt, 2002.
[Man02] Antonio Mafia, Ernesto Pimentel, "An efficient software
protection scheme ", Uni-
versity of Malaga, Spain, 2002.
[Rot99] V. Roth. "Mutual protection of co-operating agents". In
Vitek and Jensen.
[Sch97&al] F. B. Schneider and al., "Towards
fault-tolerant and secure agentry". In Proceedings of 1 1th International
Workshop on Distributed Algorithms, Saarbrflcken, Germany, September 1997.
[ST98] Sander Tomas and Tshudin Christian F. "Protecting Mobile
Agents Against Ma-
licious Hosts", Mobile Agent Security, LNCS Vol.1419,
Springer-Verlag, 44-60, (1988).
[Wil 98] Uwe G. Wilhelm. "Cryptographically Protected Objects".
http ://lsewww.ep.ch/
wilhelm/Papers/CryPO .ps.gz.
Annexe A
Annexes
- Annexe 4.1
La stéganographie
Exemple
Considérons l'image suivante :
|
000
|
000
|
000
|
000
|
000
|
001
|
|
001
|
000
|
001
|
111
|
111
|
111
|
Chaque entrée de ce tableau représente un pixel
couleur, nous avons donc une toute petite image 2*2. Chaque triplet de bits (0
ou 1) code la quantité de l'une des trois couleurs primaires du pixel
(une image couleur aura dans presque tous les cas des groupes de 8 bits,
octets, mais on n'utilise que 3 bits pour clarifier l'exemple). Le bit le plus
à droite de chaque triplet est le fameux bit de poids faible LSB. Si on
souhaite cacher le message 111 111 101 111, l'image est modifiée de la
façon suivante : le bit de poids faible du ie octet est mis à la
valeur du ie bit du message; ici on obtient :
|
001
|
001
|
001
|
001
|
001
|
001
|
|
001
|
000
|
001
|
111
|
111
|
111
|
- Annexe 4.2
IDEA (International Data Encryption Algorithm) :
L'algorithme est basé sur le mélange
d'opérations de différents groupes algébriques. Il y a
trois groupes algébriques dont les opérations sont
mélangées, et toutes ces opérations sont facilement
réalisables à la fois en logiciel et en matériel :
· OU exclusif,
· addition modulo 216,
· multiplication modulo 216+1.
Toutes ces opérations manipulent des sous-blocs de 16
bits. Cet algorithme est ainsi efficace même sur des processeurs 16
bits.
Le bloc de données de 64 bits est divisé en 4
sous-blocs de 16 bits : X1, X2, X3 et X4. Ces quatre sous-blocs deviennent les
entrées de la première ronde de l'algorithme. Il y a huit rondes
au total. À chaque ronde, les 4 sous-blocs sont combinés par OU
exclusif, additionnés, multipliés entre eux et avec 6 sous-blocs
de 16 bits dérivés de la clé. Entre chaque ronde, le
deuxième et le troisième sous-bloc sont échangés.
Enfin, les quatre sous-blocs sont combinés avec les quatre sous-clefs
dans une transformation finale.
A chaque ronde, la séquence d'évènements est
la suivante :
1. multiplier X1 et la première sous-clef;
2. additionner X2 et la deuxième sous-clef;
3. additionner X3 et la troisième sous-clef;
4. multiplier X4 et la quatrième sous-clef;
5. combiner par OU exclusif les résultats des
étapes (1) et (3);
6. combiner par OU exclusif les résultats des
étapes (2) et (4);
7. multiplier le résultat de l'étape (5) avec la
cinquième sous-clef;
8. additionner les résultats des étapes (6) et
(7);
9. multiplier le résultat de l'étape (8) par la
sixième sous-clef;
10. additionner les résultats des étapes (7) et
(9);
11. combiner par OU exclusif les résultats des
étapes (1) et (9);
12. combiner par OU exclusif les résultats des
étapes (3) et (9);
13. combiner par OU exclusif les résultats des
étapes (2) et (10);
14. combiner par OU exclusif les résultats des
étapes (4) et (10);
La sortie de la ronde est constituée des 4 sous-blocs
produits par les étapes (11), (13), (12) et (14). Changez les deux blocs
intérieurs (sauf lors du dernier rond) et cela donne l'entrée de
la ronde suivante.
Après la huitième ronde, il y a une transformation
finale :
1. multiplier X1 et la première sous-clef;
2. multiplier X2 et la deuxième sous-clef;
3. multiplier X3 et la troisième sous-clef;
4. multiplier X4 et la quatrième sous-clef;
Enfin les 4 sous-blocs sont réassemblés pour former
le texte chiffré.
- Annexe 4.3
RSA (Rivest, Shamir et Adleman) Exemple :
Commençons par créer notre paire de clés
:
Prenons 2 nombres premiers au hasard: p = 29, q = 37
On calcule n = pq = 29 * 37 = 1073
On doit choisir e au hasard tel que e n'ai aucun facteur en
commun avec (p-1)(q-1) : (p-1)(q-1) = (29-1)(37-1) = 1008
On prend e = 71
On choisit d tel que 71*d mod 1008 = 1
On trouve d = 1079
On a maintenant nos clés:
· La clé publique est (e,n) = (71,1073) (=clé
d'encryptage)
· La clé privée est (d,n) = (1079,1073)
(=clé de décryptage)
On va encrypter le message 'HELLO'. On va prendre le code ASCII
de chaque caractère et on les met bout à bout :
Ensuite, il faut découper le message en blocs qui
comportent moins de chiffres que n. n comporte 4 chiffres, on va donc
découper notre message en blocs de 3 chiffres :
Ensuite on encrypte chacun de ces blocs :
726^71 mod 1073 = 436 976^71 mod 1073 = 822 767^71 mod 1073 =
825 900^71 mod 1073 = 552 Le message encrypté est 436 822 825 552. On
peut le décrypter avec d :
436^ 1079 mod 1073 = 726 822^ 1079 mod 1073 = 976 825^ 1079
mod 1073 = 767 552^ 1079 mod 1073 = 900 C'est à dire la suite de chiffre
726976767900.
On retrouve notre message en clair 72 69 76 76 79 : 'HELLO'.
- Annexe 4.4
MD5 (Message Digest version 5) Notations :
Les registres sont A,B,C,D. Le bloc de 512 bits est scindé
en 16 mots de 32 bits, et stockés dans M[0],...,M[15].
On définit une table T[i] de 64 éléments,
à partir de la fonction sinus. T[i] vaut la partié entière
de 4294967296 * abs(sin(i)).
X <<< s est la rotation à gauche de X par s
bits.
Une étape de calcul:
Pour j = 0 à 15 faire
Initialiser X[j] à M[j].
Fin pour.
/* Sauvegarde des registres */
AA=A BB=B CC=C DD=D
/* Premier tour. */
/* Soit [abcd k s i] notant l'opération
a = b + ((a + F(b,c,d) + X[k] + T[i]) <<< s). */
/* On fait les 16 opérations. */
[ABCD 0 7 1] [DABC 1 12 2] [CDAB 2 17 3] [BCDA 3 22 4] [ABCD 4 7
5] [DABC 5 12 6] [CDAB 6 17 7] [BCDA 7 22 8] [ABCD 8 7 9] [DABC 9 12 10] [CDAB
10 17 11] [BCDA 11 22 12]
[ABCD 12 7 13] [DABC 13 12 14] [CDAB 14 17 15] [BCDA 15 22 16] /*
Deuxième tour. */
/* Soit [abcd k s i] l'opération
a = b + ((a + G(b,c,d) + X[k] + T[i]) <<< s). */
/* On fait les 16 opérations. */
[ABCD 1 5 17] [DABC 6 9 18] [CDAB 11 14 19] [BCDA 0 20 20]
[ABCD 5 5 21] [DABC 10 9 22] [CDAB 15 14 23] [BCDA 4 20 24] [ABCD 9 5 25] [DABC
14 9 26] [CDAB 3 14 27] [BCDA 8 20 28] [ABCD 13 5 29] [DABC 2 9 30] [CDAB 7 14
31] [BCDA 12 20 32] /* Etape 3. */
/* Soit [abcd k s t] l'opération
a = b + ((a + H(b,c,d) + X[k] + T[i]) <<<s). */
/* On fait les 16 opérations. */
[ABCD 5 4 33] [DABC 8 11 34] [CDAB 11 16 35] [BCDA 14 23 36]
[ABCD 1 4 37] [DABC 4 11 38] [CDAB 7 16 39] [BCDA 10 23 40] [ABCD 13 4 41]
[DABC 0 11 42] [CDAB 3 16 43] [BCDA 6 23 44] [ABCD 9 4 45] [DABC 12 11 46]
[CDAB 15 16 47] [BCDA 2 23 48] /* Etape 4. */
/* Soit [abcd k s t] l'opération
a = b + ((a + I(b,c,d) + X[k] + T[i]) <<<s). */
/* On fait les 16 opérations. */
[ABCD 0 6 49] [DABC 7 10 50] [CDAB 14 15 51] [BCDA 5 21 52]
[ABCD 12 6 53] [DABC 3 10 54] [CDAB 10 15 55] [BCDA 1 21 56] [ABCD 8 6 57]
[DABC 15 10 58] [CDAB 6 15 59] [BCDA 13 21 60] [ABCD 4 6 61] [DABC 11 10 62]
[CDAB 2 15 63] [BCDA 9 21 64] /* On réécrit dans les registres
!*/
A=A+AA
B=B+BB
C=C+CC
D=D+DD
Résumé
Le concept d'agent a été introduit dans le
domaine de l'intelligence Artificielle (IA) depuis la fin des années 70.
Les systèmes muli agents(SMA) sont caractérisés par
l'utilisation d'agents mobiles, une sorte particulière d'agents
logiciels qui peuvent voyager de façon autonome d'un noeud à un
autre dans un réseau. Les Agents Mobiles peuvent être utiles dans
de nombreux domaines d'applications mais ils présentent un
problème de sécurité surtout avec les applications dont
les données sont confidentielles. Le développement d'une
application sur un environnement ouvert distribué -comme l'Internet-
nécessite l'intégration des protocoles de sécurité.
L'implémentation de ces protocoles dans la plateforme Aglets a
été l'objectif de notre mémoire.
Nous avons d'abord donné un aperçu des
caractéristiques, spécifications et implémentations de
Aglets. Puis, nous nous sommes intéressés à la
sécurisation de la communication inter aglets en utilisant le paradigme
d'agents et de systèmes multi agents. Nous avons examiné quelques
manques de propriétés en se basant sur des tests comparant cette
nouvelle approche avec ce qui existe.
Mots clés :
Systèmes multi agents, agent mobile, Aglets, aglet,
communication, sécurité.
Abstract
The concept of Agents dates back to late seventies when it was
used in the field of Artificial intelligence (AI). Multi Agent system is a
software agent that can migrate autonomously from node to node across a
network. They can be used for a variety of application but they pose a
potential security threat no for the applications that need necessitate
confidential transport of data.
The software development on distributed open environment raises
the necessity of security protocols whose implementation on Aglets platform is
the topic of our thesis.
In this thesis, we will start with an overview the
characteristics, realization a specification of the platform Aglets. Then, we
will focus on the security of communication between Aglets systems by using
agents and multi agent paradigms.
We will also investigate some missing properties on the basis of
tests that compare this new approach with others existing approaches
Keywords :
Multi agent System, Mobile Agent, Aglets, aglet, communication,
security.
| 

