III. ANALYSE ECONOMETRIQUE
Nous allons dans cette section estimer les paramètres
de notre modèle et vérifier si les hypothèses qui
sous-tendent la régression linéaire multiple sont
validées.
1.
Modélisation
En introduisant toutes le variables dans le modèle
à l'aide du logiciel SPSS, nous obtenons un modèle globalement
significatif au seuil de 5% avec R2 =0,679 et
R2-ajusté= 0,636. (Voir annexe1 pour plus de
détails).
Tableau 3 :
Estimation des paramètres du premier modèle
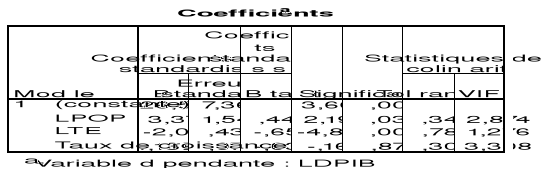
Source : Sortie SPSS
Cependant, le coefficient de la variable Taux de croissance
n'est pas significatif même au seuil de 10 %. Ce qui signifie que cette
variable n'a aucune influence directe sur la variable LDPIB. Compte tenu de ce
constat et de celui fait dans le diagramme de dispersion (Graphique 3), nous
allons éliminer la variable Taux de croissance de notre
modèle.
En introduisant à nouveau les variables dans le
modèle à l'aide du logiciel SPSS exception faite de la variable
Taux de croissance, nous obtenons un modèle globalement significatif au
seuil de 5% avec R2 =0,679 et R2-ajusté= 0,651.
(Voir annexe2 pour plus de détails).
Tableau 4 :
Estimation des paramètres du modèle définitif
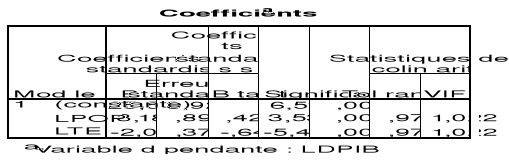
Source : Sortie SPSS
Le modèle peut donc s'écrire : 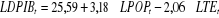
Avant l'interprétation des résultats de ce
modèle, nous allons d'abord vérifier si les hypothèses qui
sous-tendent une régression linéaire multiple sont
vérifiées.
2.
Vérification des hypothèses sous-jacentes du modèle de
régression linéaire multiple
Dans le cadre de ce travail, nous allons vérifier
quatre principales hypothèses à savoir : les
hypothèses de multicolinéarité, de la normalité des
perturbations, de l'autocorrélation des perturbations et de
l'hétéroscedasticité des perturbations.
Test de multicolinearité
Pour qu'il soit possible de calculer les estimateurs du
maximum de vraisemblance, il est nécessaire que les variables
explicatives soient linéairement indépendantes. Pour
détecter la multicolinéarité, nous allons utiliser
l'indice de conditionnement. Si l'indice de conditionnement est
supérieur à 100, il y a un sévère problème
de multicolinearité, sinon, il n'y a pas de problème de
multicolinearité. Les différents indices de conditionnement pour
notre modèle sont récapitulés dans le tableau 5.
Tableau 5 :
Estimation des indices de conditionnement
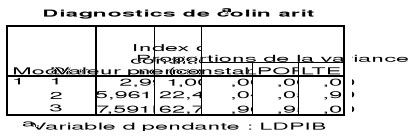
Il ressort du tableau 5 que tous les indices de
conditionnement sont supérieurs à 100. Ainsi, il n'y a aucun
problème de multicolinéarité.
Test de normalité des
perturbations
L'hypothèse de la normalité des perturbations
n'est pas indispensable pour l'estimation des paramètres du
modèle. Cependant, elle devient nécessaire si on veut faire des
tests sur les paramètres estimés ou encore si on veut faire des
prédictions.
Le graphique 4 présente l'histogramme des
résidus comparé à une loi normale.
Graphique
4 : Histogramme de la série des résidus
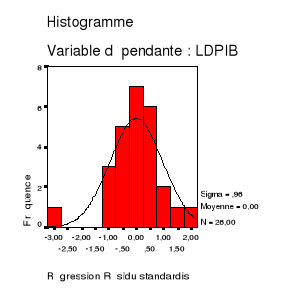
Le graphique 4 nous permet de soupçonner que les
résidus suivent une loi normale. Nous allons confirmer ou infirmer cette
hypothèse avec le test de KOLMOGOROV-SMINOV, qui est un test de
conformité de loi.
Le test de KOLMOGOROV-SMINOV appliqué à la
série des résidus standardisés montre que ces
résidus à 87 % de degré de confiance, suivent une loi
normale centrée réduite (voir annexe3). Ainsi, les résidus
de notre modèle suivent une loi normale centrée
réduite.
Test d'autocorrélation des
perturbations
L'une des hypothèses du modèle linéaire
multiple est l'indépendance des erreurs. Nous allons tester cette
hypothèse à l'aide de la statistique de Durbin Watson qui permet
de tester les autocorrelation d'ordre 1.
Si d2<DW<4-d2 alors, il y a
absence d'autocorrelation.
Dans le cas de notre modèle où nous avons deux
variables explicatives et 26 observations, au risque de 5 %, d1=1,22 et
d2=1,55, ceci d'après la table de Durbin Watson au risque de 5 %. DW=
1,975 (voir annexe 2).
Nous avons alors 1,55<1,975<2,45.
Ainsi, les perturbations de notre modèle ne sont pas
corrélées, elles sont indépendantes.
Test
d'hétéroscédasticité
Il y a hétéroscedasticité des
perturbations lorsque la variance des erreurs n'est pas constante pour toutes
les observations. Nous allons utiliser le test de WHITE. C'est un test
bilatéral avec pour hypothèse nulle
l'hétéroscedasticité des perturbations. Elle se fonde
également sur une régression. Le tableau 6 montre qu'aucun
coefficient de la régression n'est significativement différent de
zéro au seuil de 5%. On rejette donc
l'hétéroscedasticité.
Ainsi, les perturbations sont homoscedastiques.
Tableau 6 :
Résultat Tes de d'hétéroscedasticité (test de
WHITE)
|
White Heteroskedasticity Test:
|
|
F-statistic
|
0.910416
|
Probability
|
0.475997
|
|
Obs*R-squared
|
3.842405
|
Probability
|
0.427754
|
|
|
|
|
|
|
Test Equation:
|
|
Dependent Variable: RESID^2
|
|
Method: Least Squares
|
|
Date: 02/12/05 Time: 08:42
|
|
Sample: 1 26
|
|
Included observations: 26
|
|
Variable
|
Coefficient
|
Std. Error
|
t-Statistic
|
Prob.
|
|
C
|
-423.0206
|
388.6319
|
-1.088487
|
0.2887
|
|
LPOP
|
-190.5433
|
183.0463
|
-1.040957
|
0.3097
|
|
LPOP^2
|
-22.04199
|
21.40641
|
-1.029691
|
0.3149
|
|
LTE
|
5.017313
|
8.688131
|
0.577490
|
0.5697
|
|
LTE^2
|
-0.482284
|
1.094934
|
-0.440468
|
0.6641
|
|
R-squared
|
0.147785
|
Mean dependent var
|
0.504935
|
|
Adjusted R-squared
|
-0.014542
|
S.D. dependent var
|
1.102149
|
|
S.E. of regression
|
1.110133
|
Akaike info criterion
|
3.217879
|
|
Sum squared resid
|
25.88032
|
Schwarz criterion
|
3.459820
|
|
Log likelihood
|
-36.83242
|
F-statistic
|
0.910416
|
|
Durbin-Watson stat
|
1.482684
|
Prob(F-statistic)
|
0.475997
|
Source : Sortie Eviews 3.1
Toutes les hypothèses qui sous-tendent une
régression linéaire multiple sont vérifiées. Ainsi,
nous pouvons interpréter les coefficients de notre modèle.
| 

