|
République Algérienne Démocratique et
Populaire.
Ministère de l'Enseignement Supérieur et de la
Recherche Scientifique.
Université A. Mira de Béjaia. Faculté des
Sciences Exactes
Département Informatique
Mémoire Master recherche
en Informatique
Option:
Réseaux et Systèmes Distribués
Thème
abbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbc
Conception et réalisation d'une base de
données répartie sous
Oracle :
dCas de l'hébergement des
résidences universitaires e
fggggggggggggggggggggggggggggggggggggggggh
Présenté par :
Mr MADI A/Hakim Mr MOKRANI Fares
Encadré par :
Mme TAHAKOURT Zineb
Devant le jury composé de :
Président : ALOUI Abdelouhab Examinateur : BOUTRID
Samia
Résumé
Une base de données répartie est une collection
de données logiquement reliées et physiquement réparties
sur plusieurs machines interconnectées par un réseau de
communication. L'objectif de ce travail est d'essayer de résoudre les
problèmes de localisation des données et d'exécution
distribuée des requêtes posées par la répartition
d'une base de données.
Ce mémoire comprend deux parties; la première
est purement théorique comprenant une présentation des
systèmes répartis et les bases de données
réparties. Elle décrit aussi, les différentes techniques
de conception des bases de données réparties, leurs gestion et
les principes de la réplication.
La seconde partie est consacrée pour la conception et
la mise en oeuvre d'une BD répartie pour la gestion de
l'hébergement des résidences universitaires,
implémentée sous le SGBD ORACLE 10g Version Entreprise
et interfacée par l'environnement de développement Oracle
Forms.
Mots dles : BD répartie, SGBD réparti,
PL/SQL, ORACLE, Forms, Répartition des données, Merise.
Remerciements
Nous tenons tout d'abord à remercier le bon Dieu qui
nous a donné la santé et le
courage d'accomplir ce
travail.
Nous ne pouvons pas oublier de présenter notre
gratitude à nos parents pour leur
patience et les efforts inlassables
qu'ils ne cessent de déployer pour nous.
Nos vifs remerciements vont à Mme
TAHAKOURT Zineb, notre promotrice pour tous
ses conseils très
précieux, ses encouragements, sa patience et ses orientations qui
nous
ont été très bénéfiques tout au long
de ce travail.
Nous remercions également les membres de jury qui
nous font honneur en acceptant
d'examiner et de juger notre travail.
Enfin, que tous ceux qui ont contribués de prés
ou de loin à l'aboutissement de ce travail trouvent ici l'expression de
notre sincère gratitude et nos remerciements les plus
sincères.
Je dédie ce modeste travail :
A mes très chers parents pour m'avoir donnés
le goût aux études et m'avoir apportés un
grand support
moral lors de la rédaction de ce mémoire et tout au long de mes
études,
qu'ils trouvent ici l'expression de mon profond
Amour.
A mes deux soeurs Nora et Nouara, et mes frères
Kamel et Nordine, ainsi qu'à leurs
familles.
Je ne me permettrais surtout pas d'oublier mes très
chers amis(es).
A mon binôme Fares, ainsi qu'à toute sa
famille.
A tous les étudiants Master Informatique de
l'université de Bejaia.
Et à tous ceux que j'aime . .
.
Je dédie ce modeste travail :
A mes chers parents
qui m'ont aidé et soutenu tout au long de cette période.
A mon
cher frère Sofiane qui m'a aidé et apporté ses conseils et
son soutient.
A mes chers grands parents, et à mes chères
tantes et oncle.
A mes chers cousins et cousines Farah, Amine, Yacine, Samy,
Katia, Yanice, Dany,
Mellissa, Badisse, et Aniése.
A tous mes amie(s) et particulièrement à
Samiha, Sofiane, Moulou, Nawel, Amel,
Khaled, Sabrina, Katia, et
Dania.
A mon binôme Hakim, ainsi qu'à toute sa
famille.
A tous les étudiants de la promotion Master 2 et 1
informatique.
Et à tous les gens qui m'ont aidé et soutenu
tout au long de ce projet.
Table des matières
Table des Figures viii
Liste des tableaux ix
Introduction Générale x
|
1 Généralités sur les bases de
données réparties
1.1 Introduction
1.2 Evolution des bases de données réparties
|
1
1
1
|
|
1.2.1
|
Système réparti
|
2
|
|
1.2.2
|
Architecture des systèmes répartis
|
2
|
|
1.2.3
|
Objectifs des systèmes répartis
|
3
|
|
|
1.2.3.1 Indépendance à la localisation
|
3
|
|
|
1.2.3.2 Indépendance à la fragmentation
|
4
|
|
|
1.2.3.3 Indépendance aux SGBDs
|
4
|
|
|
1.2.3.4 Autonomie des sites
|
4
|
|
1.2.4
|
Inconvénients des systèmes répartis
|
4
|
|
1.3
|
Principe des bases de données réparties
|
4
|
|
1.3.1
|
Définition
|
5
|
|
1.3.2
|
Exemple
|
5
|
|
1.3.3
|
Système de gestion des bases de données
réparties
|
6
|
|
1.3.4
|
Concepts de base
|
7
|
|
|
Table des Matières
|
|
1.3.5
1.3.6
1.3.7
|
1.3.4.1 Schéma local
1.3.4.2 Schéma global
Décomposition et optimisation des requêtes
Contrôle de l'intégrité
Exécution répartie
|
7
7
9
10
10
|
|
1.4
|
Utilisation d'une base de données répartie
|
10
|
|
1.4.1
|
Transparence de la localisation
|
10
|
|
1.4.2
|
Transparence de partitionnement
|
10
|
|
1.4.3
|
Transparence de la duplication
|
11
|
|
1.5
|
La répartition des bases de données
|
11
|
|
1.5.1
|
Buts
|
11
|
|
|
1.5.1.1 Plus de disponibilité et de fiabilité
|
11
|
|
|
1.5.1.2 Meilleures performances
|
11
|
|
|
1.5.1.3 Scalability
|
12
|
|
1.5.2
|
Problèmes à surmonter
|
12
|
|
|
1.5.2.1 Coût
|
12
|
|
|
1.5.2.2 Distribution du contrôle
|
12
|
|
|
1.5.2.3 Sécurité
|
12
|
|
|
1.5.2.4 Gestion distribuée des interblocages
|
13
|
|
|
1.5.2.5 Bases de données hétérogènes
|
13
|
|
1.6
|
Architecture des bases de données réparties
|
13
|
|
1.6.1
|
Autonomie
|
13
|
|
1.6.2
|
Relation entre machines
|
13
|
|
|
1.6.2.1 Architecture Client / Serveur
|
14
|
|
|
1.6.2.2 Architecture Peer To Peer
|
15
|
|
1.6.3
|
Hétérogénéité
|
15
|
|
1.7
|
Conclusion
|
16
|
2
|
|
Table des Matières
|
|
Techniques de conception et de gestion des bases de
données réparties
2.1 Introduction
2.2 Conception d'une base de données répartie
2.2.1 Méthodes de conception
2.2.1.1 Conception ascendante
2.2.1.2 Conception descendante
2.2.2 La fragmentation
|
17
17
17
18
18
18
19
|
|
|
2.2.2.1 Définition
|
19
|
|
|
2.2.2.2 Objectif de la fragmentation
|
19
|
|
|
2.2.2.3 Les problèmes de la fragmentation
|
19
|
|
|
2.2.2.4 Types de fragmentation
|
20
|
|
|
2.2.2.5 Les règles de la fragmentation
|
21
|
|
|
2.2.2.6 L'allocation des fragments
|
22
|
|
|
2.2.2.7 Le schéma de répartition
|
22
|
|
2.3
|
Techniques de répartition avancées
|
22
|
|
2.3.1
|
Allocation avec duplication
|
22
|
|
2.3.2
|
Allocation dynamique
|
22
|
|
2.3.3
|
Fragmentation dynamique
|
23
|
|
2.4
|
La réplication
|
23
|
|
2.4.1
|
Principe
|
23
|
|
2.4.2
|
Type de réplication
|
24
|
|
|
2.4.2.1 Réplication asymétrique
|
24
|
|
|
2.4.2.2 Réplication symétrique
|
25
|
|
2.4.3
|
Vue matérialisée
|
26
|
|
|
2.4.3.1 Objectifs
|
26
|
|
|
2.4.3.2 Mise à jour des vues matérialisées
|
26
|
|
2.4.4
|
Les avantages de la réplication
|
27
|
|
2.5
|
Gestion des données réparties
|
27
|
|
2.5.1
|
Mise à jour des données distantes
|
27
|
|
|
2.5.1.1 Requêtes réparties en lecture
|
27
|
|
|
Table des Matières
|
|
2.6
|
2.5.1.2 Requêtes réparties en écriture
2.5.2 Contraintes déclaratives
2.5.2.1 Contraintes locales
2.5.2.2 Contraintes globales
Conclusion
27
|
28
28
28
29
|
|
3
|
Présentation de l'organisme d'accueil
|
30
|
|
3.1
|
Introduction
|
30
|
|
3.2
|
Présentation de l'Office National des Oeuvres
Universitaires
|
30
|
|
3.3
|
Organigramme de la Direction des Oeuvres Universitaires
|
31
|
|
3.4
|
Organigramme du service de l'hébergement
|
33
|
|
3.5
|
Les tâches du service de l'hébergement
|
33
|
|
3.6
|
Description des tâches
|
33
|
|
|
3.6.1 Inscription
|
33
|
|
|
3.6.2 Réadmission
|
34
|
|
|
3.6.3 Transfert
|
34
|
|
|
3.6.4 Abandon
|
34
|
|
|
3.6.5 Statistiques
|
35
|
|
|
3.6.6 Etats d'impression
|
35
|
|
3.7
|
La situation informatique
|
35
|
|
3.8
|
Description du cadre de l'étude
|
35
|
|
|
3.8.1 Présentation du cadre de l'étude
|
35
|
|
|
3.8.2 Présentation du sujet
|
36
|
|
3.9
|
Conclusion
|
36
|
|
4
|
Analyse de l'existant
|
37
|
|
4.1
|
Introduction
|
37
|
|
4.2
|
Etude du système existant
|
37
|
|
|
4.2.1 Etudes des postes de travail
|
37
|
|
|
4.2.1.1 Introduction
|
37
|
|
|
4.2.2 Fiche d'étude du poste service de
l'hébergement - DOU
|
39
|
4.2.3 Fiche d'étude du poste service de
l'hébergement - Résidence . . . . 40
4.3 Etude des documents 41
4.3.1 Introduction 41
4.3.2 Liste des documents utilisés 41
4.4 Diagramme de circulation du flux 41
4.4.1 Schéma de circulation du flux 42
4.4.2 Le formalisme utilisé 42
4.4.3 Tableau de description des flux 43
4.4.4 La codification existante 43
4.5 Niveau organisationnel du système existant 44
4.5.1 Règles d'organisation existantes 44
4.6 Diagnostique de la situation actuelle 44
4.6.1 Introduction 44
4.6.2 Critique de l'existant 44
4.6.3 Proposition d'une solution 45
4.7 Conclusion 46
5 Analyse conceptuelle 47
5.1 Introduction 47
5.2 Modélisation du nouveau système 47
5.2.1 L'étude conceptuelle du nouveau système
47
5.2.1.1 Règles de gestion 47
5.2.1.2 Dictionnaire de données 48
5.2.1.3 Nouvelle codification 50
5.3 Le modèle conceptuel de données 50
5.4 Niveau organisationnel du nouveau système 51
5.4.1 Nouvelles règles d'organisation 51
5.4.2 Le modèle organisationnel de traitements 52
5.4.2.1 Description des procédures 52
5.4.3 Le modèle logique de données 55
5.4.3.1 Les règles de passage du MCD vers MLD 55
5.4.3.2 Le MLD relationnel 55
5.5 Conclusion 56
6 Réalisation 57
6.1 Introduction 57
6.2 Structure générale de la solution
proposée 57
6.2.1 Justification des choix 59
6.3 Les configurations nécessaires 59
6.3.1 Configuration du réseau 59
6.3.2 Configuration ORACLE 61
6.3.2.1 Côté Serveur 61
6.3.2.2 Côté Client 64
6.4 Aspect pratique 66
6.4.1 Création de la base de données
répartie 66
6.4.1.1 Outils utilisés 66
6.4.1.2 Implémentation de la BDR 67
6.4.2 Le développement de l'application 71
6.4.2.1 Outils utilisés 71
6.4.2.2 Interfaces graphiques 71
6.5 Conclusion 77
Conclusion et perspectives xii
Bibliographie xiii
Annexe xv
Glossaire xvii
Table des figures
|
1.1
|
Exemple de base de données répartie
|
5
|
|
1.2
|
Architecture d'un SGBD réparti.
|
7
|
|
1.3
|
Architecture d'une BD répartie
|
8
|
|
1.4
|
Décomposition et optimisation d'une requête.
|
9
|
|
1.5
|
Architecture Client / Serveur.
|
14
|
|
1.6
|
Architecture Peer To Peer
|
15
|
|
2.1
|
Architecture de la conception ascendante.
|
18
|
|
2.2
|
Architecture de la conception descendante
|
19
|
|
2.3
|
Exemple de fragmentation horizontale.
|
20
|
|
2.4
|
Exemple de fragmentation verticale.
|
21
|
|
2.5
|
Réplication asymétrique synchrone
|
24
|
|
2.6
|
Réplication asymétrique asynchrone.
|
24
|
|
2.7
|
Réplication symétrique synchrone.
|
25
|
|
2.8
|
Réplication symétrique asynchrone
|
25
|
|
2.9
|
Protocole de validation à deux phases - 2PC
|
28
|
|
3.1
|
Organigramme de la D.O.U
|
32
|
|
3.2
|
Organigramme du service de l'hébergement.
|
33
|
|
4.1
|
Fiche d'étude du poste service de l'hébergement -
DOU.
|
39
|
|
4.2
|
Fiche d'étude du poste service de l'hébergement -
Résidence
|
40
|
4.3 Diagramme de circulation de flux au niveau de la DOU. 42
4.4 Le formalisme utilisé 42
4.5 La codification existante 43
5.1 La nouvelle codificaion. 50
5.2 Le modèle conceptuel de données 51
6.1 Structure générale de la solution
proposée. 58
6.2 Propriétés de connexion réseau sans fil
60
6.3 Propriétés du réseau sans fil 61
6.4 Le fichier de configuration du Listener Oracle.
62
6.5 Oracle Net Manager. 63
6.6 Le fichier Listener Oracle. 64
6.7 Le fichier de services TNSNAMES.ORA. 65
6.8 Le fichier SQLNET.ORA. 65
6.9 Les étapes de connexion à une BD distante.
66
6.10 Illustration de la réplication de données.
70
6.11 Structure générale de l'application. 72
6.12 Vue de l'authentification 'Base de données'
72
6.13 Vue de l'authentification 'Application' 73
6.14 Menu application DOU. 73
6.15 Vue de la gestion de l'hébergement DOU. 74
6.16 Inscription des nouveaux bacheliers - DOU. 75
6.17 Vue de l'interface Targa Ouzemour 76
6.18 Vue de la carte du résident. 77
Liste des tableaux
3.1 Situation informatique 35
4.1 Liste des documents. 41
4.2 Description des flux. 43
Le monde de l'informatique évolue très
rapidement, alors que son but initial, était d'offrir des services
satisfaisants, du point de vue vitesse d'exécution des tâches et
obtention de statistiques plus précises. Actuellement, de nouveaux
besoins sont apparus, toute organisation automatisée souhaite stocker et
échanger ses informations qui sont géographiquement
éloignées, ce qui rend la tâche de la collecte et de
traitement d'une grande quantité d'informations dispersées
très délicate, de ce fait, l'amélioration des
systèmes d'informations est devenue une priorité pour les
gérants des entreprises.
La solution qui s'impose est de distribuer les données
et les organiser dans des bases de données sur différents sites
de stockage. L'ensemble de ces sites constitue un système de bases de
données réparties offrant la possibilité aux utilisateurs
de manipuler les différentes bases via un réseau de
manière transparente, comme dans une base de données globale.
Notre projet consiste à développer un
système d'information dont les données sont
intégrées dans un environnement réparti. L'objectif de ce
travail est d'essayer de résoudre les problèmes de localisation
des données et d'exécution distribuée des requêtes
posées par la répartition d'une base de données à
travers un réseau d'ordinateurs. Pour cela, nous avons conçu et
mis en oeuvre une base de données répartie sous Oracle
pour la gestion de l'hébergement des résidences
universitaires de l'université de Bejaia.
Notre mémoire est structuré en 6 chapitres comme
suit :
Dans le premier chapitre, nous présentons un
état de l'art sur les systèmes répartis et les bases de
données réparties ainsi que leurs avantages et
inconvénients, et les principes de leurs mises en oeuvre.
Le second chapitre aborde les différentes techniques de
conception et de gestion des bases de données réparties ainsi que
les principes de la réplication.
Le troisième chapitre donne une vue sur la structure de la
direction des oeuvres universitaires, plus précisément la section
de l'hébergement.
Le quatrième chapitre présente l'étude de
l'existant, la problématique posée et les objectifs
visés.
Le cinquième chapitre présente l'analyse
conceptuelle de la solution proposée.
Dans le dernier chapitre, nous détaillons la
réalisation de la solution proposée; il présente la mise
en place du nouveau système à l'aide de différents outils
tels que ORACLE et Oracle Forms Developper.
Nous finirons par une conclusion et quelques perspectives qui
peuvent être envisagées afin d'améliorer notre
système.
Chapitre1
Généralités sur les bases de
données réparties
1.1 Introduction
L'évolution des techniques informatiques depuis les
vingt dernières années a permis d'adapter les outils
informatiques à l'organisation des entreprises. Vu, le grand volume de
données manipulées par ces dernières, la puissance des
micro-ordinateurs, les performances des réseaux et la baisse
considérable des coûts du matériel informatique ont permis
l'apparition d'une nouvelle approche afin de remédier aux
désagréments causés par la centralisation des
données, et ce en répartissant les ressources informatiques tout
en préservant leur cohérence.
Les bases de données réparties sont un moyen
très efficace pour pallier aux problèmes engendrés par
l'approche centralisée, mais n'en demeure pas moins sans failles.
1.2 Evolution des bases de données réparties
Les entreprises modernes, de nos jours se démarquent
des autres grâce à leur capacité à traiter les
informations avec fiabilité et rapidité. Ainsi, la gestion des
informations prend une place prépondérante dans le
développement et l'atteinte des objectifs de l'organisation. Un
système d'information renferme l'ensemble des éléments
participant à la gestion, au traitement, au transport et à la
diffusion de l'information au sein de l'organisation. Très
concrètement, il peut être très différent d'une
organisation à une autre et peut recouvrir selon les cas, tout ou une
partie des éléments suivants : [Kar05]
1. Bases de données de l'entreprise,
2. Progiciel de gestion intégré
(ERP1),
3. Outils de gestion de la relation client (CRM2),
4. Interface réseau,
5. Serveur de données et systèmes de stockage,
6. Serveur d'application,
7. Dispositifs de sécurité.
1.2.1 Système réparti
Un système réparti est un ensemble de processeurs
autonomes, reliés par un réseau de communication, qui
coopèrent pour assurer la gestion des informations. [Kar05]
Le principe est simple : les données et traitements
sont répartis sur différents sites interconnectés par un
réseau de communication. Ainsi, la défaillance d'un site ne peut
entraîner l'indisponibilité totale du système et sa
probabilité peut être négligée grâce à
la tolérance aux fautes, assurée par la redondance des
informations et des traitements. [CPZ93]
L'autonomie des sites est préservée par ce genre
de système, en permettant à un groupe d'utilisateurs de
créer et de gérer leur propre base de données tout en
autorisant les accès aux autres utilisateurs via le réseau.
Un système réparti peut sensiblement
améliorer les performances des traitements. En effet, avec une
localisation des données et une répartition des traitements bien
étudiées, la déperdition induite par les communications
des données inter-sites peut être compensée par le gain
(temps de réponse), issu du parallélisme dans
l'exécution des traitements.
La sécurité dans un système
réparti vise à garantir la confidentialité,
l'intégrité de l'information et le respect des règles
d'accès aux services. Les méthodes utilisées reposent
d'une part sur un matériel ou un logiciel dédié, et
d'autre part, sur des protocoles de sécurité utilisant la
cryptographie.
1.2.2 Architecture des systèmes répartis
Les systèmes répartis recouvrent diverses
architectures depuis les architectures Client / Serveur jusqu'aux architectures
totalement réparties. [CPZ93]
L'architecture Client/Serveur se base sur deux types de
processeurs généralement distincts :
1Enterprise Resources Planning 2Customer
Relationship Management
- Les serveurs qui offrent un service à des clients, par
exemple un serveur base de données ou un serveur imprimante;
- Les clients qui émettent des requêtes aux
serveurs pour les besoins d'une application.
Dans l'architecture Client / Serveur la plus simple, la
quasi-totalité du SGBD3 se trouve sur le serveur,
les processeurs clients ne disposant que des mécanismes de
décodage et de transmission des requêtes vers ce serveur.
[CPZ93]
Une architecture totalement répartie est une
généralisation de l'architecture Client / Serveur : les
processeurs sont autonomes dans le sens oil ils peuvent disposer d'un SGBD et
assurer la pleine gestion d'une base de données locale
(BDL4). En plus, s'ils ne disposent pas des ressources
nécessaires à une application qui leur est soumise, ils
déterminent la localisation des données et des traitements qui
leur sont nécessaires et établissent une coopération avec
les processeurs détenteurs de ces ressources. Cette architecture permet
d'éviter la présence du goulot d'étranglement du serveur
base de données puisque les données sont réparties voir
dupliquées à travers le réseau. [CPZ93]
1.2.3 Objectifs des systèmes répartis
Au niveau des objectifs des systèmes répartis, il
existe quatre points essentiels :
1. Indépendance à la localisation.
2. Indépendance à la fragmentation.
3. Indépendance aux SGBDs.
4. Autonomie des sites. [Mey03]
1.2.3.1 Indépendance à la localisation
Au niveau des SGBDR5, l'objectif principal
est de permettre l'écriture des programmes d'application sans que
l'utilisateur se soucie de la localisation physique des données. Dans ce
but, les noms des données ne doivent pas dépendre de leurs
localisations.
Les requêtes locales sont similaires aux requêtes
exprimées en SQL6. Les avantages de la transparence
sont de faciliter l'écriture des requêtes pour l'utilisateur et
permettre le déplacement des données sans modifier les
requêtes. [Fer04]
3Système de Gestion des Bases de
Données/En Anglais, DBMS : DataBases Management System 4Base
de Données Locale
5Système de Gestion de Bases de Données
Réparties
6Structured Query Language
1.2.3.2 Indépendance à la fragmentation
Dans un système réparti, une relation est
constituée de différents fragments, situés sur des sites
différents. La relation de base ne doit pas dépendre de la
manière dont les données ont été
découpées et doit pouvoir être modifiée sans
altérer les programmes.
1.2.3.3 Indépendance aux SGBDs
Un système réparti ne doit pas être
dépendant en aucun cas des différents SGBDs, la relation globale
doit être exprimée dans un langage normalisé
indépendant des constructeurs.
1.2.3.4 Autonomie des sites
Vise à garder une administration locale
séparée et indépendante pour chaque serveur participant
à la base de données répartie afin d'éviter une
administration centralisée.
Toute manipulation sur un site (reprise après
panne, mises à jour des logiciels) ne doit pas altérer le
fonctionnement des autres sites. Bien que chaque base travaille avec les
autres, la gestion des schémas doit donc rester indépendante d'un
site à l'autre et chaque base doit conserver son dictionnaire local
contenant les schémas locaux. [Fer04]
1.2.4 Inconvénients des systèmes répartis
Malgré tous les avantages que les systèmes
répartis présentent, cela n'exclut pas l'apparition de certains
inconvénients comme la complexité des mécanismes de
décomposition de requêtes, la synchronisation des traitements et
le maintien de la cohérence due à la répartition de la
base de données sur plusieurs sites, ainsi le cout induit par les
transmissions des données sur les réseaux locaux.
1.3 Principe des bases de données réparties
Depuis ces dernières années, les techniques
informatiques évoluent vers le traitement de grande masse d'informations
de nature diverse, intégrées dans un environnement
géographiquement réparti oil doivent cohabiter du matériel
généralement hétérogène.
Dans ce contexte, et vue la souplesse des SGBDs d'une part et
les performances des réseaux d'autre part, les bases de doonées
réparties sont une solution importante pour parvenir à
maîtriser la distribution des données. [CPZ93]
1.3.1 Définition
Une base de données répartie
BDR7 est une collection de bases de données
localisées sur différents sites, généralement
distants, mises en relations les unes avec les autres à travers un
réseau d'ordinateurs, perçues pour l'utilisateur comme une base
de données unique. Elle permet de rassembler des données plus ou
moins hétérogènes, disséminées dans un
réseau sous forme d'une base de données globale, homogène
et intégrée. [Spa98]
1.3.2 Exemple
LA société de vente du matériel
informatique ' APPLE ' représentée par sa direction
générale à New York, possède deux magasins à
Bejaia et à Paris. Voici un schéma de ce que peut être une
BD8 repartie mise en place par cette société :
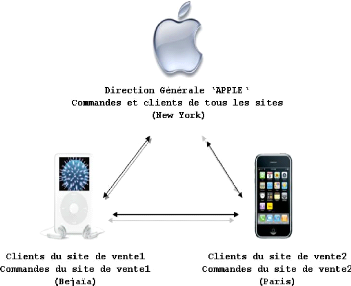
FIG. 1.1 Exemple de base de données répartie.
7Base de Données Répartie
8Base de Données
Dans le cas centralisé, la DG9 gère
tous les comptes clients et les magasins doivent se communiquer avec elle pour
avoir accès aux données. Tandis que dans une BD répartie,
les informations sur les comptes sont distribuées sur les magasins, qui
sont interconnectés via un réseau. La première
conséquence de cette répartition est l'accès rapide aux
données.
1.3.3 Système de gestion des bases de données
réparties
Le SGBDR repose sur un système réparti qui est
constitué d'un ensemble de processeurs autonomes appelés sites
(micro-ordinateurs, stations de travail, ... etc.) reliés par
un réseau de communication qui leur permet d'échanger des
données.
Un SGBDR suppose en plus que les données soient
stockées sur deux sites au moins. Ceux-ci, étant dotés de
leur propre SGBD .
Un SGBDR doit offrir une gestion des priorités, des
verrous et de la concurrence d'accès de la même façon qu'un
SGBD monolithique. Pour cela, il doit disposer de :
- Dictionnaire de données réparties, - Traitement
des requêtes réparties,
- Communication de données inter sites,
- Gestion de la cohérence et de la sécurité.
[Cor99]
Le SGBDR assure la décomposition des requêtes
distribuées en sous requêtes locales envoyées à
chaque site. La décomposition prend en compte la localisation des
données pour atteindre une base de données distante :
Exemple : SELECT * FROM Schema.table@Link_DB ;
Pour les mises à jour, le SGBDR doit assurer la gestion
des transactions10 réparties ainsi vérifier les
règles d'intégrité multi-bases. En cas des bases de
données hétérogènes, le SGBDR doit assurer la
traduction des requêtes.
La figure ci-desous, illustre l'architecture d'un SGBD
réparti :
9Direction Générale
10garantir ACID : Atomicité Cohérence
Isolation et Durabilité
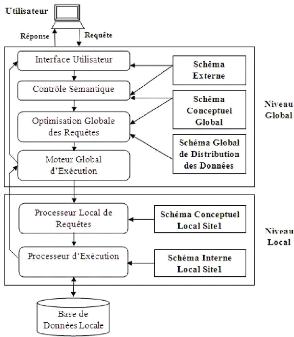
FIG. 1.2 - Architecture d'un SGBD réparti.
1.3.4 Concepts de base
1.3.4.1 Schema local
Une base de données locale comporte un schéma
géré par le SGBD local. Dans une BD répartie, chaque base
locale rend visible toute ou une partie de la base aux sites clients.
1.3.4.2 Schema global
Le schéma global permet de définir l'ensemble
des types de données de la base. Il ignore les concepts
d'implémentation. Il n'est pas forcément
matérialisé, chaque base locale en implémente une partie.
[Mey03]
La figure ci-dessous, résume l'architecture globale d'une
BD répartie avec les deux types de schémas : [BM07]
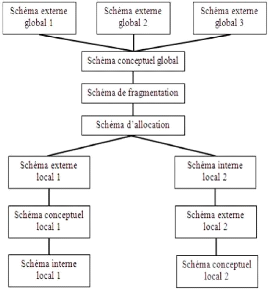
FIG. 1.3 - Architecture d'une BD répartie.
Comme toute BD, une BDR est décrite dans un dictionnaire
de données sous la forme de schémas globaux distincts
conformément à l'architecture ANSI/SPARC : [Gui04]
· Le schéma externe : le niveau externe
décrit les données sous forme de vues, chacune d'elles
étant adaptée à une classe particulière
d'utilisateurs; un schéma externe, élaboré à partir
du schéma conceptuel, peut naturellement mixer des données
stockées dans différentes bases;
· Le schéma conceptuel : où les
données sont représentées sans prendre en compte les
contraintes techniques ou de mise en forme; toutes les données sont
décrites dans ce schéma en utilisant un modèle de
données, indépendamment de leur localisation dans le
système réparti;
· Le schéma interne : le niveau interne global
n'a pas d'existance réelle mais fait place à des schémas
internes locaux, répartis sur différents sites. Ces
schémas correspondent à la description de l'organisation physique
de la base, notamment la spécification de la fragmentation des
données et la localisation de ces fragments;
L'utilisateur accède aux données réparties
à travers ces différents schémas en utilisant le langage
SQL.
1.3.5 Décomposition et optimisation des requêtes
Un traitement réparti fait appel à des
données gérées par des SGBDs distincts. Ce traitement
contient donc des requêtes qui correspondent à un ensemble
d'opérations de recherche et de mises à jour sur des
données de la BDR, formulées à partir d'un schéma
externe global. Le SGBDR contrôle et analyse chaque requête puis la
décompose en opérations locales afin d'être
exécutées par les SGBDs concernés. [CPZ93]
L'optimisation est donc indissociable de la requête car
elle entre en jeu à tous les stades du traitement de la requête.
Au niveau de la décomposition, l'optimisation permet de simplifier la
requête et cela après avoir éliminé les sous
requêtes inutiles ou bien répétées plusieurs
fois.
La figure ci-dessous, illustre le plan d'exécution
répartie d'une requête : [Des00]

FIG. 1.4 Décomposition et optimisation d'une
requête.
1.3.6 Contrôle de l'intégrité
Le contrôle de l'intégrité des
données est un des outils les plus importants d'une base de
données assurant que les données ne soient pas modifiées
ou détruites de façon illicite et limitant les risques d'erreurs
et de malveillance. Selon les contraintes qui ont été
définies sur les relations et les attributs, différentes
anomalies peuvent se déclencher dès qu'un accès aux
données est effectué. L'intégrité des
données se réfère à leurs cohérences par
rapport à ce qui a été défini au départ.
[Des00]
1.3.7 Exécution répartie
Après que les requêtes sont
décomposées en opérations locales par les SGBDR, elles
seront exécutées par les SGBDs concernés.
1.4 Utilisation d'une base de données répartie
Au niveau de la BDR, la transparence est un principe fondamental
qui apparaît dans la localisation, le partitionnement et la duplication :
[Spa98]
1.4.1 Transparence de la localisation
La transparence de la localisation des données
sous-entend que ni les applications ni les utilisateurs n'ont besoin de
connaître la position réelle des tables auxquelles ils
accèdent. Autrement dit, ils ne doivent pas connaître la
localisation physique des données.
Les utilisateurs accèdent à la BD soit
directement par le schéma conceptuel soit indirectement à travers
les vues externes, mais en aucun cas, ils n'ont les moyens pour accéder
aux schémas locaux.
1.4.2 Transparence de partitionnement
Les utilisateurs n'ont pas à connaître les
partitionnements de la base de données. Ils ne doivent pas savoir si
telle information est fractionnée et ne doivent donc pas se
préoccuper de la réunifier. C'est le système qui
gère les partitionnements et les modifie en fonction de ses besoins. Et
c'est donc lui qui doit rechercher toutes les partitions et les intégrer
en une seule information logique présentée à
l'utilisateur.
1.4.3 Transparence de la duplication
Enfin, le principe de transparence de la duplication est que
les utilisateurs n'ont pas à savoir si plusieurs copies d'une même
information sont disponibles. La conséquence directe est que lors de la
modification d'une information, c'est le système qui doit se
préoccuper de mettre à jour toutes les copies.
1.5 La répartition des bases de données
A l'heure actuelle, de nombreuses entreprises ont des annexes
partout dans le monde, et vue la complexité des problèmes
auxquels elles sont confrontées d'une part et l'évolution des
technologies informatiques d'autre part, a mené à penser à
une nouvelle architecture qui s'adapte plus à leurs organisations.
1.5.1 Buts
Les objectifs de la répartition de données sont
multiples :
1.5.1.1 Plus de disponibilité et de fiabilité
Comme les bases de données réparties ont
souvent des données qui sont répliquées, alors la
fiabilité peut être apportée à plusieurs niveaux, la
panne d'un site n'est pas importante pour l'utilisateur. En effet, celui-ci
s'adresse de façon transparente à un autre site qui
possède les données requises. Par ailleurs, la fiabilité
également garantie au niveau des transactions. Elles peuvent être
conduites sur le même site de façon concurrente ou sur plusieurs
sites en même temps.
Le système d'exploitation ou le SGBD doit garantir
qu'une transaction s'accomplira de façon totalement sûre. Une
transaction fait passer la base de données d'un état stable
cohérent à un autre état stable cohérent, quelques
soient les problèmes du réseau rencontrés ou les
accès concurrents aux données. [Des00]
1.5.1.2 Meilleures performances
Réduire le trafic sur le réseau est une
première possibilité d'accroître les performances. Les
gains sont particulièrement appréciables pour deux raisons
principales :
Une grande partie des requêtes s'effectue localement sur
le site possédant les données notamment lorsque les
données sont répliquées partiellement ou totalement. Le
but de la
répartition des données consiste est alors
à les rapprocher au plus près de l'endroit oil elles sont
généralement accédées.
Répartir la base sur différents sites permet de
répartir l'impact sur les processeurs et sur leurs
Entrées/Sorties. L'impact sur le système se trouve grandement
réduit puisque les sites ne traitent qu'une partie de la base de
données globale. [Des00]
1.5.1.3 Scalability
Il est plus facile d'améliorer les performances du
système de gestion de la base de données, en ajoutant des
machines sur le réseau plutôt que de passer d'un grand
système à un autre. Cependant, l'accroissement des performances
n'est pas linéaire. Ajouter des machines sur le réseau
sous-entend augmenter le trafic pour maintenir la cohérence de la base
de données. [Des00]
1.5.2 Problèmes a surmonter
1.5.2.1 Coût
La distribution des données et des traitements
entraîne des coûts supplémentaires en terme de communication
(trafic réseau), et en gestion des communications comme le
hardware et software à installer afin de gérer les communications
et la distribution.
La distribution est également coûteuse en
matière du personnel utilisé car il faut les payer
administrateurs de chaque site. [Des00]
1.5.2.2 Distribution du contrôle
La distribution du contrôle crée des
problèmes de synchronisation et de coordination dans l'accès aux
données. Dans une base de données répartie, on ne se
soucie pas de la consistance et l'intégrité d'une seule base de
données, mais de plusieurs copies de la base de données.
La gestion des copies doit assurer leur cohérence
mutuelle, c'est-à-dire que toutes les copies de données soient
identiques. [Des00]
1.5.2.3 Sécurité
Un des avantages évident des bases de données
centralisées est sans contexte la sécurité apportée
aux données, car elle peut facilement être contrôlée
dans un site unique. Or, les
bases de données réparties impliquent un
réseau dont la sécurité est difficile à maintenir.
La sécurité est donc un problème plus complexe dans le cas
des bases de données réparties que dans le cas des bases de
données centralisées. [Des00]
1.5.2.4 Gestion distribuée des interblocages
Le problème de l'interblocage ' Deadlock '
est le même que celui rencontré dans les systèmes
d'exploitation. La compétition entre les utilisateurs pour
accéder à une donnée peut entraîner des
interblocages. [Des00]
1.5.2.5 Bases de données
hétérogènes
Quand les bases de données sur différents sites
ne sont pas homogènes en terme de modèle de données
(relationnel, objet, XML, . . .), il devient nécessaire de
fournir un mécanisme de translation entre les différentes bases
de données, ce mécanisme de translation exige toujours une forme
canonique pour faciliter la translation des données.
1.6 Architecture des bases de données réparties
1.6.1 Autonomie
L'autonomie se rapporte au degré avec lequel une des
bases locales peut travailler indépendamment des autres. On peut
distinguer trois types d'alternatives dans l'autonomie que peuvent avoir les
bases locales :
- L'intégration totale : une image unique de la base
de données globale est offerte aux différents utilisateurs.
D'où la BD est centralisée, le SGBD contrôle de bout en
bout la requête d'un utilisateur même si elle met en jeu
différentes bases locales et donc différents SGBDs locaux.
L'autonomie n'est donc pas bien importante.
La semi-autonomie : les SGBDs locaux peuvent opérer
indépendamment mais ils participent à une collection de bases qui
coopèrent afin de partager leurs données. L'isolation totale :
une base locale ne connaît ni l'existence des autres bases ni la
façon de se communiquer avec elles. Il ne peut donc pas y avoir du
contrôle global quant à l'exécution d'une requête sur
les différentes bases locales. [Des00]
1.6.2 Relation entre machines
Du point de vue organisationnel, nous distinguons deux types
d'architectures :
1.6.2.1 Architecture Client / Serveur
Dans cette architecture applicative, les programmes sont
répartis en processus clients et serveurs qui communiquent à
travers des requêtes et des réponses. Sur la machine cliente, les
utilisateurs disposent d'une interface.
Sur les serveurs, la gestion des bases de données est
effectuée (analyse, optimisation des requêtes, et
répartition). On peut distinguer deux types de clients : [LFG00]
· Client lourd : l'utilisateur est obligé de se
connecter explicitement à tous les serveurs dont il a besoin pour la
requête qu'il veut formuler. [Des00]
Exemple : dans une application de gestion de la
scolarité universitaire, si la BD est repartie par faculté alors
la recherche d'un étudiant grâce à son matricule et sans
connaître la faculté à laquelle il appartient est
très délicate, car nous sommes obliger à interroger la BD
de chaque faculté une par une jusqu'à trouver un
résultat.
· Client léger : l'utilisateur ne se connecte
qu'à la base de données via un unique serveur. Le SGBDR se charge
alors de gérer les différentes connexions que nécessitera
la requête de l'utilisateur. Donc, il offre plus de transparence.
[Des00]
Exemple : pour reprendre l'exemple précédent
dans le cas d'un client léger, c'est le SGBDR qui se charge de
trouver la faculté de l'étudiant en question, et de retourner un
résultat.
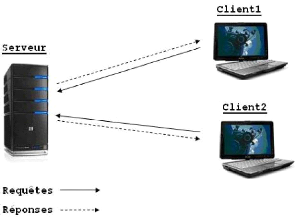
FIG. 1.5 Architecture Client / Serveur.
1.6.2.2 Architecture Peer To Peer
C'est un type de communication pour lequel toutes les
machines ont une importance équivalente. Il n'y a pas de machine qui a
une importance hiérarchique par rapport aux autres. Dite aussi,
l'architecture totalement répartie.
Chacune de ces architectures possède des avantages et
des inconvénients. Le Client / Serveur avec sa structure plus
hiérarchique est très sensible aux problèmes de panne des
serveurs, bloquant ainsi les clients. En revanche, la prise de décision
des serveurs est rapide.
Pour l'architecture Peer-To-Peer, comme les machines sont
strictement équivalentes, la panne d'une machine peut rarement rendre le
système un peu lent. Mais cette architecture engendre
énormément de communication pour toute décision.
[Des00]
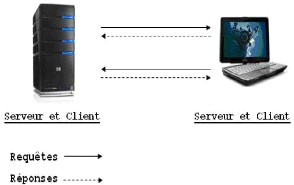
FIG. 1.6 - Architecture Peer To Peer.
1.6.3 Hétérogénéité
L'hétérogénéité peut
apparaître à plusieurs niveaux. En effet, les
incompatibilités matérielles ou logicielles au sein d'une
entreprise, rendent particulièrement délicate la mise en place
d'un SGBD.
L'hétérogénéité peut
exister au niveau de la représentation des données, au niveau du
langage de requête ou au niveau du modèle de données des
différentes bases (BDs relationnelles, BDs objets). [Des00]
1.7 Conclusion
A travers les différents points
développés dans le présent chapitre, nous avons pu
constater l'intérêt particulier porté aux systèmes
répartis et aux différents problèmes auxquels ce type de
solution a pu remédier.
Nous avons pu également, détailler et expliquer
l'intérêt des bases de données réparties et les
différents avantages offerts par ce type d'approche. Ce type de
système est plus difficile à mettre en place et plus
compliqué, et que malgré ses nombreux avantages, néanmoins
des inconvénients existent, et son inconvénient majeur est la
sécurité des données transmises via le réseau de
communication.
Chapitre2
Techniques de conception et de gestion des
bases de données réparties
2.1 Introduction
Avant de concevoir une base de données
répartie, il est nécessaire de bien comprendre les étapes
de conception, car différentes méthodes de conception existent et
chacune d'elles nous offre une approche très différente de
l'autre.
Dans le cas d'une base de données répartie, la
difficulté réside dans le choix des techniques de conception, un
mauvais choix pourrait conduire à la création d'un système
inefficace.
La conception d'une base de données répartie
peut être le résultat de deux approches totalement distinctes,
soit d'une part le regroupement d'une multitude de bases de données
déjà existantes oil d'autre part, que cette dernière soit
construite du zéro.
2.2 Conception d'une base de données répartie
La définition du schéma de répartition
est la partie la plus délicate de la phase de conception d'une BDR, car
il n'existe pas de méthode miracle pour trouver la solution optimale.
L'administrateur doit donc prendre des décisions dont l'objectif est de
minimiser le nombre de transferts entre sites, les temps de transfert, le
volume de données transférées, les temps moyens de
traitement des requêtes, et le nombre de copies de fragments, ... etc.
2.2.1 Méthodes de conception
Deux approches fondamentales sont à l'origine de la
conception des bases de données réparties : la conception
descendante 'Top down design' et la conception ascendante 'Bottom
up design'.
2.2.1.1 Conception ascendante
Cette approche se base sur le fait que la répartition
est déjà faite, mais il faut réussir à
intégrer les différentes BDs existantes en une seule BD globale.
En d'autre terme, les schémas conceptuels locaux
(LCS1) existent et il faut réussir à les
unifier dans un schéma conceptuel global (GCS2).
[Kar05]
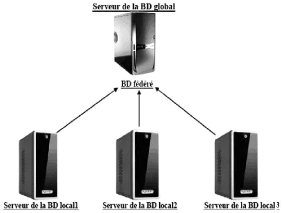
FIG. 2.1 - Architecture de la conception ascendante.
2.2.1.2 Conception descendante
On commence par définir un schéma conceptuel
global de la base de données répartie, puis on le distribue sur
les différents sites en des schémas conceptuels locaux. La
répartition se fait donc en deux étapes, en première
étape la fragmentation et en deuxième étape l'allocation
de ces fragments aux sites. [Des00]
L'approche top down est intéressante quand on part du
néant. Si les BDs existent déjà, la méthode bottom
up est utilisée.
1Local Conceptual Schema 2Global
Conceptual Schema
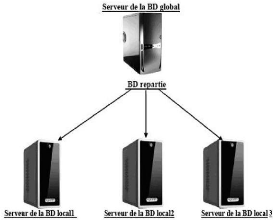
FIG. 2.2 - Architecture de la conception descendante.
2.2.2 La fragmentation
2.2.2.1 Définition
La fragmentation est le processus de décomposition
d'une base de données en un ensemble de sous bases de données.
Cette décomposition doit être sans perte d'information. La
fragmentation peut être coûteuse s'il existe des applications qui
possèdent des besoins opposés. [Gui04]
2.2.2.2 Objectif de la fragmentation
Les applications ne travaillent que sur des sous-ensembles
des relations. Une distribution complète des relations
générerait soit beaucoup de trafic, soit une réplication
des données avec tous les problèmes que cela occasionne :
problèmes de mises à jour, problèmes de stockage. Il est
donc préférable de mieux distribuer ces sous-ensembles.
L'utilisation de petits fragments permet de faire tourner plus
de processus simultanément, ce qui entraîne une meilleure
utilisation des capacités du réseau d'ordinateurs.
2.2.2.3 Les problèmes de la fragmentation
La fragmentation peut être coûteuse s'il existe
des applications qui possèdent des besoins opposés. On est en
quelque sorte dans le cas d'une exclusion mutuelle qui empêche une
fragmentation correcte.
Par ailleurs, la vérification des dépendances sur
différents sites peut être une opération très
longue.
2.2.2.4 Types de fragmentation
· La fragmentation horizontale :
C'est un découpage d'une table en sous tables par
utilisation de prédicats permettant de sélectionner les lignes
appartenant à chaque fragment. L'opération de fragmentation est
obtenue grâce à la sélection des tuples d'une table selon
un ou des critères bien précis et la reconstitution de la
relation initiale se fait grâce a l'union (U) des sous-relations.
[Mou05]
Exemple :
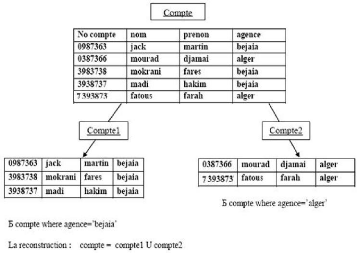
FIG. 2.3 Exemple de fragmentation horizontale.
· La fragmentation verticale :
Elle est le découpage d'une table en sous tables par
projection permettant de sélectionner les colonnes composant chaque
fragment. La relation initiale doit pouvoir être recomposée par la
jointure des fragments. [Gui04]
Exemple :
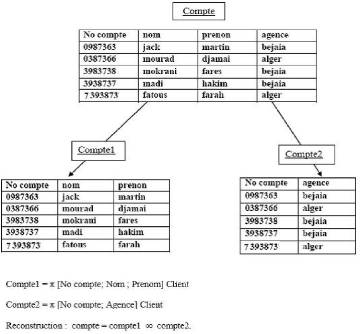
FIG. 2.4 - Exemple de fragmentation verticale.
· La fragmentation mixte :
Elle résulte de l'application successive
d'opérations de fragmentation horizontale et verticale sur une relation
globale.
2.2.2.5 Les règles de la fragmentation
Un problème qui se pose pour la fragmentation est comment
définir un bon degré de fragmentation. Il existe trois
règles pour la fragmentation :
1. Complétude : pour toute donnée d'une relation
globale R, il existe au moins un fragment Ri de la relation R qui
possède cette donnée.
2. Reconstruction : pour toute relation R
décomposée en un ensemble de fragments Ri, il existe une
opération de reconstruction à définir en fonction de la
fragmentation. Pour les fragmentations horizontales, l'opération de
reconstruction est une union. Pour les fragmentations verticales c'est la
jointure.
3. Disjonction : une donnée n'est présente que
dans un seul fragment, sauf dans le cas de la fragmentation verticale pour la
clé primaire qui doit être présente dans l'ensemble des
fragments issus d'une relation. [Des00]
2.2.2.6 L'allocation des fragments
Suite à la fragmentation des données, il est
nécessaire de les placer sur les différentes machines. Un
schéma doit être élaboré afin de déterminer
la localisation de chaque fragment et sa position dans le schéma global,
c'est ce qu'on appelle l'allocation. [Spa98]
2.2.2.7 Le schéma de répartition
Pour fragmenter les requêtes, il est nécessaire
de connaître les règles de localisation des données. Lors
de l'exécution d'une requête, le SGBDR doit décomposer la
requête globale en sous requêtes locales en utilisant le
schéma de répartition.
2.3 Techniques de répartition avancées
2.3.1 Allocation avec duplication
Cette technique consiste à dupliquer des parties de la
base c'est-à-dire les fragments sont dupliqués sur un seul site,
voir plusieurs sites selon les besoins. Cette approche est très
intéressante car elle améliore considérablement les
performances du système, étant donné que les fragments
sont dupliqués un peu partout et que les accès aux données
sont locaux, évitant ainsi la congestion du réseau et
améliorant les temps de réponse. Le principal inconvénient
de cette technique est la difficulté des mises à jour de tous les
fragments dupliqués. [Spa98]
2.3.2 Allocation dynamique
Avec cette technique, l'allocation d'un fragment peut changer
en cours d'utilisation de la BDR, c'est-à-dire qu'un fragment qui se
trouve sur un site A à un instant T, peut être retrouvé sur
un site B à un instant T+1. Cette technique est efficace mais exige le
maintien du schéma d'allocation et des schémas locaux. [Spa98]
2.3.3 Fragmentation dynamique
Cette technique consiste à profiter de l'allocation
dynamique des fragments, c'est-à-dire que dans certains cas, il est
possible que deux fragments complémentaires (verticalement ou
horizontalement) se trouvent sur le même site suite au mouvement
d'un fragment d'un site A vers un site B. Donc, il est alors intéressant
de les fusionner.
A l'inverse, si une partie d'un fragment est appelée
sur un autre site, il peut être intéressant de décomposer
ce fragment et de ne migrer que la partie concernée. Ces modifications
du schéma de fragmentation se répercutent sur le schéma
d'allocation et sur les schémas locaux. [Spa98]
2.4 La replication
La réplication consiste à copier les
informations d'une base de données sur une autre. Elle peut être
accompagnée d'une transformation des données sources, voir
souvent d'une agrégation. Dans tous les cas, il s'agit d'une redondance
d'information.
L'objectif principal de la réplication est de faciliter
l'accès aux données en augmentant la disponibilité. Soit
parce que les données sont copiées sur différents sites
permettant de répartir les requêtes, soit parce qu'un site peut
prendre la relève lorsque le serveur principal s'écroule. Une
autre application tout aussi importante est l'amélioration des
performances des requêtes sur les données locales, et ceci permet
d'éviter les transferts de données et d'accroître la
résistance aux pannes. [Mey05]
2.4.1 Principe
Le principe de la réplication, qui met en jeu au minimum
deux SGBDs, est assez simple et se déroule en trois étapes :
[SL06]
1. La base maître reçoit un ordre de mise à
jour (INSERT, UPDATE ou DELETE).
2. Les modifications faites sur les données sont
détectées et stockées dans un fichier ou une file
d'attente en vue de leur propagation.
3. Le processus de réplication prend en charge la
propagation des modifications à faire sur une seconde base dite esclave.
Il peut bien entendu y avoir plus d'une base esclave.
2.4.2 Type de réplication
2.4.2.1 Réplication asymétrique
La réplication asymétrique distingue un site
maître appelé site primaire, chargé de centraliser les
mises à jour. Il est le seul autorisé à mettre à
jour les données, et chargé de diffuser les mises à jour
aux copies dites secondaires. [Gui04]
Le plus gros problème de la gestion asymétrique
est la panne du site primaire. Dans ce cas, il faut choisir un
remplaçant si l'on veut continuer les mises à jour. On aboutit
alors à une technique asymétrique mobile dans laquelle le site
primaire change dynamiquement. On distingue l'asymétrie synchrone et
l'asymétrie asynchrone :
· Réplication asymétrique synchrone : elle
utilise un site primaire qui pousse les mises à jour en temps
réel vers un ou plusieurs sites secondaires. La table
répliquée est immédiatement mise à jour pour chaque
modification par utilisation de trigger sur la table maître. [Mey05]
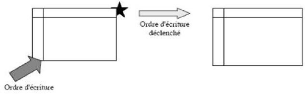
FIG. 2.5 - Réplication asymétrique synchrone.
· Réplication asymétrique asynchrone :
elle pousse les mises à jour en temps différé via une file
persistante. Les mises à jour seront exécutées
ultérieurement, à partir d'un déclencheur externe,
l'horloge par exemple. [Mey05]
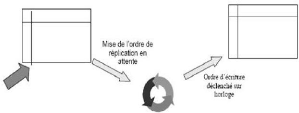
FIG. 2.6 Réplication asymétrique
asynchrone.
24
2.4.2.2 Réplication symétrique
A l'opposé de la réplication
précédente, la réplication symétrique ne
privilégie aucune copie c'est-à-dire chaque copie peut être
mise à jour à tout instant et assure la diffusion des mises
à jour aux autres copies. [Gui04]
Cette technique pose problème de la concurrence
d'accès risquant de faire diverger les copies. Une technique globale de
résolution de conflits doit être mise en oeuvre. On distingue la
symétrie synchrone et la symétrie asynchrone :
· Réplication symétrique synchrone : Lors
de la réplication symétrique synchrone, il n'y a pas de table
maître. L'utilisation de trigger sur chaque table doit
différencier une mise à jour client à répercuter
d'une mise à jour par réplication. Cette technique
nécessite l'utilisation de jeton. [Mey05]
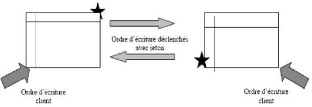
FIG. 2.7 - Réplication symétrique synchrone.
· Réplication symétrique asynchrone : Dans
ce cas, la mise à jour des tables répliquées est
différée. Cette technique risque de provoquer des
incohérences de données.
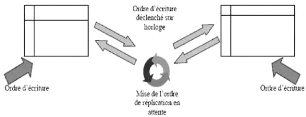
FIG. 2.8 Réplication symétrique asynchrone.
2.4.3 Vue matérialisée
Une vue matérialisée (VM3)
est un moyen simple de créer une vue physique d'une table. Elle
correspond à une photo instantanée des données au moment
de l'exécution de la requête. À la différence d'une
vue standard, le résultat de la requête est physiquement
stocké dans la base de données.
Les vues matérialisées peuvent porter sur des
tables, mais aussi des vues ou des vues matérialisées. [Del08]
Exemple :
CREATE MATERILIZED VIEW mz-relation REFRESH COMPLET
ON DEMAND
AS
SELECT col1, col2 ... FROM ma-table;
2.4.3.1 Objectifs
L'utilisation des vues matérialisées permet
l'amélioration des performances d'accès et la réduction du
trafic sur le réseau, elles sont mises à jour
périodiquement, ce qui les rendent très efficaces. [Del08]
2.4.3.2 Mise à jour des vues
matérialisées
Afin d'assurer une certaine cohérence des
données, il faut mettre à jour les vues
matérialisées et les tables périodiquement. Il existe
trois façons de mises à jour qui sont la
régénération complète, rapide et forcée :
· Rafraîchissement complet :
Il va ré-exécuter la requête basée
sur la table de base et remplace l'ensemble des données de la VM par les
données obtenues et ceci même si la table de base n'a pas
été modifiée, selon le volume de données qui
satisfait la requête, ce rafraîchissement peut être gourmant
en ressource. [Wos05]
· Rafraîchissement incrémental :
Son principe est de propager uniquement les données
modifiées depuis le dernier
rafraîchissement. Ce type de
rafraîchissement dit aussi rapide nécessite que la base
de
données stocke les modifications enregistrées sur les
données des tables de base,
3Vue Matérialisée/En Anglais :
Materialized View
on utilise pour cela un journal (fichier Log). Ces
données sont stockées jusqu'à ce que le
rafraîchissement ait été effectué. [Wos05]
Ce type de rafraîchissement est particulièrement
efficace si les tables de base sont relativement peu modifiées. On
considère que si plus de la moitié des lignes sont
modifiées un rafraîchissement complet sera plus efficace.
[Wos05]
· Rafraîchissement forcé :
Dans ce type de rafraîchissement, lorsqu'une
régénération rapide n'est pas possible, alors une
régénération complète est
exécutée.
2.4.4 Les avantages de la réplication
Les avantages de la réplication sont assez nombreux,
selon le type on trouve :
- Allégement du trafic réseau en
répartissant la charge sur divers sites. Par conséquent,
rapidité des accès aux données.
- Amélioration des performances des requêtes.
- Résistance aux pannes par l'augmentation de la
disponibilité des données.
2.5 Gestion des données réparties
2.5.1 Mise à jour des données distantes
2.5.1.1 Requêtes réparties en lecture
Lors de l'exécution d'une requête en lecture, la
base de données répartie va décomposer la requête
globale en sous requêtes locales à l'aide des méta
données de distribution.
2.5.1.2 Requêtes réparties en écriture
La mise à jour des données sur une base de
données réparties nécessite la validation préalable
de chaque site avant la demande du site coordinateur. Ce protocole se nomme
'Validation à deux phases' 2PC4 et garantit le tout
ou rien dans une base de données répartie. [Mey03]
La première phase réalise la préparation de
l'écriture des résultats des mises à jour dans la base de
données et la centralisation du contrôle.
4Two Phases Commit
Par contre la seconde phase 'phase de validation'
n'est réalisée qu'en cas de succès de la phase 1, elle
intègre les résultats des mises à jour dans la base de
données répartie. Le contrôle du système
réparti est centralisé sous la direction d'un site appelé
coordinateur. Les autres sites sont nommés des participants. [BM07]
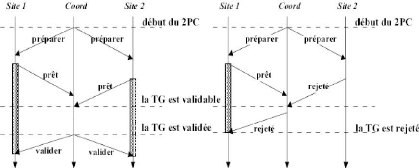
FIG. 2.9 - Protocole de validation à deux phases -
2PC.
2.5.2 Contraintes déclaratives
Il est impératif dans une base de données
répartie de placer des contraintes déclaratives sur les
données qui seront stockées dans le dictionnaire de
données.
Dans une base de données répartie, il est
nécessaire de dissocier deux types de contraintes :
2.5.2.1 Contraintes locales
Les contraintes locales sont des contraintes placées sur
un seul site (schéma local). Ces contraintes sont donc
stockées dans le dictionnaire de chaque site. [Mey03]
2.5.2.2 Contraintes globales
Les contraintes globales doivent être placées
sur la relation globale, il n'est pas possible de les matérialiser. Nous
pouvons dire qu'il est impossible de créer des contraintes sur des vues,
mais il est plus important de comprendre qu'une contrainte globale doit
être placée dans plusieurs dictionnaires. [Mey03]
Le schéma global n'étant pas physiquement
implémenté, il n'est pas possible de mettre en place ces
contraintes de manière déclarative.
2.6 Conclusion
Les bases de données réparties constituent un
domaine important pour la gestion des informations stockées sur
différents sites.
Dans ce chapitre, nous avons présenté les
principes de la répartition des données. Cette répartition
peut se faire selon différents scénarios choisis par le
concepteur, tout en prenant en compte les restrictions et les obligations de
conception.
Nous avons vu également, comment gérer une base de
données répartie avec les principes de réplication
symétrique et asymétrique.
Chapitre3
Présentation de l'organisme d'accueil
3.1 Introduction
Notre projet consiste à réaliser un système
d'information qui se base sur une base de données répartie pour
la gestion de l'hébergement des résidences universitaires.
Pour ce faire, il s'avère nécessaire de
présenter l'organisme d'accueil qui est le service de
l'hébergement au niveau de la Direction des Oeuvres Universitaires
(D.O.U1) de Bejaia afin de comprendre les activités
pricipales qu'il exerce.
3.2 Présentation de l'Office National des Oeuvres
Universitaires
L'Office National des Oeuvres Universitaires
(ONOU2) est un établissement sous la tutelle du
ministère de l'enseignement supérieur et de la recherche
scientifique par le décrit exécutif numéro 95-84 du 22
mars 1995 ainsi que l'ensemble des résidences qui lui sont
rattachées.
Par le biais de l'arrêt interministériel de 22
décembre 2004, plusieurs Directions des Oeuvres Universitaires sont
créées assurant principalement les services suivants :
. Hébergement.
. Restauration.
1Direction des Oeuvres Universitaires
2Office National des Oeuvres Universitaires
· Transport.
· Gestion des bourses.
· Activités culturelles.
· Accueil des étudiants étrangers.
· ... etc.
3.3 Organigramme de la Direction des Oeuvres Universitaires
La D.O.U. de Bejaia est composée de 8 résidences
dotées chacune de plusieurs structures d'accompagnement
représentées par :
· Résidence Targa Ouzamour.
· Résidence Ihaddadene.
· Résidence 1000 lits.
· Résidence 17 Octobre 1961.
· Résidence Aamriw.
· Résidence Ireyahen.
· Résidence nouvelle pépinière.
· Résidence Berchiches.
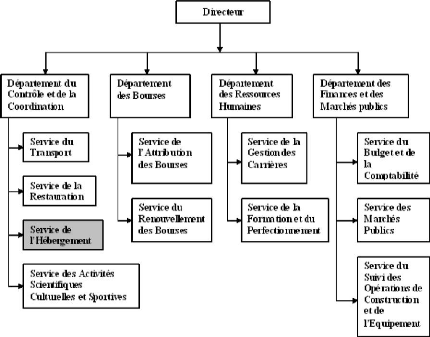
FIG. 3.1 - Organigramme de la D.O.U.
3.4 Organigramme du service de l'hébergement


FIG. 3.2 - Organigramme du service de l'hébergement.
3.5 Les tâches du service de l'hébergement
Les tâches inhérentes au service de
l'hébergement se récapitulent comme suit :
- Effectuer les inscriptions des nouveaux bacheliers
reçus et la réinscription des anciens étudiants se fera au
niveau de chaque résidence.
- Etablissement des listes globales des étudiants et
leurs répartitions par résidence, et par bloc.
- Etablissement des statistiques sur l'état de
l'hébergement des résidences (nombre de places libres, les
abandons, ... etc.).
- Préparation des procès verbaux globaux.
- Contrôle des dossiers.
- ... etc.
3.6 Description des tâches
3.6.1 Inscription
Chaque nouveau bachelier qui se présente pour
l'inscription au sein du service de l'hébergement au niveau de la D.O.U,
doit être muni d'un dossier complet et une décision d'attribution
de chambre lui sera remise. L'étudiant se présente à
nouveau avec cette
décision, auprès du service de
l'hébergement afin de régler les frais du loyer et du transport.
En revanche, il a une affectation de chambre, une prise en charge de couchage
et une carte de résidence lui est délivrée en même
temps.
3.6.2 Réadmission
Elle concerne les anciens résidents, l'étudiant
doit exprimer son voeu de renouveler sa chambre en fin d'année pour
l'année d'après, le renouvellement de chambre se compose de trois
phases :
- Première phase : en fin d'année,
l'étudiant doit fournir une demande de réadmission, visée
par le médecin de la résidence, une photo récente et une
enveloppe timbrée et libellée à l'adresse du
résident.
- Deuxième phase : l'étudiant doit rendre son
couchage, la clé de sa chambre, ainsi la carte de résidence.
- Troisième phase : à l'entrée
universitaire, l'étudiant fournit une copie du certificat de
scolarité de l'année en cours et paie les frais du loyer et
transport. Par contre, il aura une prise en charge de couchage et une nouvelle
carte de résidence lui sera remise.
3.6.3 Transfert
Concernant les transferts d'une résidence à une
autre, le résident doit fournir une demande de transfert suivie de
l'attestation d'inscription oil la carte de résidence de l'année
en cours au sein de sa résidence, le transfert ne s'effectuera que s'il
y a un accord entre la résidence d'origine et la résidence
d'accueil en fonction du nombre de places disponibles.
3.6.4 Abandon
Lorsqu'un étudiant ne se présente pas à
la réadmission oil lorsqu'il retire son dossier d'inscription oil est
déclaré défaillant par le conseil qui se déroule au
niveau de la D.O.U ou de la résidence. A ce moment la, l'étudiant
est déclaré abandon, par la suite s'il désir se reloger,
il doit fournir une justification qui lui permet une réadmission au sein
de la résidence sinon l'étudiant sera en état exclu.
3.6.5 Statistiques
Le service de l'hébergement au niveau de la D.O.U
effectue des statistiques sur le nombre des étudiants inscrits,
abandons, exclus, et les transférés. Ainsi, le nombre de places
libres par résidence.
3.6.6 Etats d'impression
Au niveau de chaque résidence une série
d'attestations et de cartes sont établies par la section de
l'hébergement, à savoir l'attestation d'abandon, d'exclu et les
cartes de résidence. Ainsi que l'établissement des listes
nominatives des étudiants transférés, abandons, ...
etc.
3.7 La situation informatique
La situation informatique est récapitulée en
générale dans le tableau suivant :
Type du matériel
|
Quantité
|
Caractéristiques
|
Micro-ordinateurs
|
03
|
HP, 512 RAM, 80 GO
|
Imprimentes
|
02
|
Canon Laser 1120
|
Onduleurs
|
03
|
Ellipse ASR 1000
|
|
TAB. 3.1 - Situation informatique.
3.8 Description du cadre de l'étude
3.8.1 Présentation du cadre de l'étude
Notre étude s'effectue au sein du service de
l'hébergement au niveau de la D.O.U de Bejaia.
3.8.2 Présentation du sujet
Il s'agit de concevoir et de mettre en oeuvre une base de
données répartie pour la gestion de l'hébergement des
résidences universitaires.
3.9 Conclusion
Ce chapitre nous a permis de présenter la D.O.U et les
différentes tâches accomplies par le service de
l'hébergement comme les inscriptions des nouveaux bacheliers,
l'établissement des statistiques sur l'état de
l'hébergement et d'autres traitements aussi importants.
Etant donné, que ce service souffre de divers
problèmes, liés particulièrement à une mauvaise
gestion de l'hébergement, à savoir principalement, le traitement
manuel et la centralisation des données au niveau de la D.O.U. Ceci,
nous a permis d'avoir une idée générale des
problèmes auxquels nous devrons faire face lors de la conception de
notre système.
Chapitre4
Analyse de l'existant
4.1 Introduction
Avant de concevoir un système informatique, il est
essentiel de faire une analyse du domaine afin d'observer les
différentes lacunes et de proposer une solution aux problèmes
posés.
L'analyse de l'existant constitue l'étape fondamentale
de l'étude préalable de la méthode Merise. Elle consiste
à étudier toutes les procédures existantes au niveau du
service de l'hébergement de la DOU afin d'examiner la situation de
gestion actuelle en vue de l'améliorer par des procédures et des
méthodes bien adaptées. Pour cela, nous nous sommes
intéressés :
Aux postes de travail.
Les documents et fichiers existants.
Les moyens de traitement et de circulation de l'information.
4.2 Etude du système existant
4.2.1 Etudes des postes de travail
4.2.1.1 Introduction
L'étude des postes de travail consiste à les
présenter d'une manière détaillée, ceci en
dégageant les différentes tâches qui constituent ces
derniers, ainsi que l'ensemble des documents circulant et les fiches
manipulées. En effet, nous avons développé deux fiches
d'analyse du poste service de l'hébergement; la
première au niveau de la D.O.U et la deuxième fiche pour une
résidence universitaire donnée, et qui montrent : [Bou04]
- Le code du poste de travail.
- La désignation du poste de travail. - Le service auquel
il est rattaché.
- La dépendance hiérarchique.
- Les tâches accomplies par ce poste.
- Les documents circulant dans ce poste.
4.2.2 Fiche d'étude du poste service de
l'hébergement - DOU
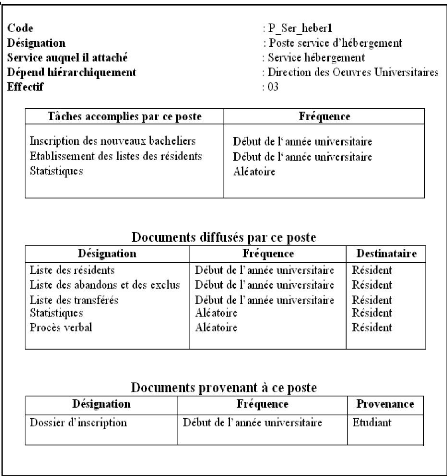
FIG. 4.1 Fiche d'étude du poste service de
l'hébergement - DOU.
4.2.3 Fiche d'étude du poste service de
l'hébergement - Résidence

FIG. 4.2 Fiche d'étude du poste service de
l'hébergement - Résidence.
4.3 Etude des documents
4.3.1 Introduction
Les documents sont des renseignements écrits ou objets
servant de preuve d'information ou de témoignage concernant le domaine
d'étude. Pour cela, nous avons présenté ci-dessous les
documents circulant dans le service de l'hébergement de la D.O.U :
4.3.2 Liste des documents utilisés
Désignation
|
Rôle
|
Nature
|
Origine
|
Destination
|
Nombre
|
Carte du
résident
|
Informations sur
le résident
|
Externe
|
Service de
l'hébergement
|
Résident
|
1
|
Liste des
résidents
|
Regroupe tous
les résidents
|
Externe
|
Service de
l'hébergement
|
Résident
|
1, n
|
Statistiques
|
Progression De
l'hébergement
|
Interne
|
Service de
l'hébergement
|
Service de
l'hébergement
|
1, n
|
Procès verbal
|
Renseignement sur
|
Interne Et
|
Service de
|
Résident et
|
1, n
|
|
l'état du résident
|
Externe
|
l'hébergement
|
Service de
l'hébergement
|
|
|
TAB. 4.1 - Liste des documents.
4.4 Diagramme de circulation du flux
L'échange d'information entre les différents
acteurs (émetteurs, récepteurs) sera représenter
par un diagramme de flux d'informations.
4.4.1 Schéma de circulation du flux
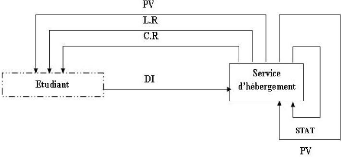
FIG. 4.3 - Diagramme de circulation de flux au niveau de la
DOU.
4.4.2 Le formalisme utilisé

FIG. 4.4 - Le formalisme utilisé.
4.4.3 Tableau de description des flux
Nom flux
|
Désignation
|
Emetteur
|
Récepteur
|
C.R
L.R
P.V
D.I
STAT
|
Carte du résident
Liste des
résidents
Procès verbal
Dossier d'inscription
Statistique
|
Service de l'hébergement
Service de
l'hébergement
Service de l'hébergement
Etudiant
Service de l'hébergement
|
Etudiant
Etudiant
Service de l'hébergement
et résident
Service de l'hébergement
Service de
l'hébergement
|
|
TAB. 4.2 - Description des flux.
4.4.4 La codification existante
La codification est une représentation
abrégée d'une information pour pouvoir la récupérer
sans ambiguïté.
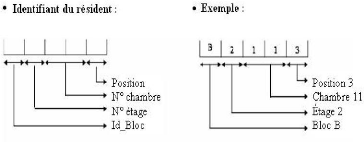
FIG. 4.5 La codification existante.
4.5 Niveau organisationnel du système existant
4.5.1 Règles d'organisation existantes
· A la réception du dossier d'inscription fourni par
l'étudiant, le service de l'hébergement établit des
récépissés de dépôt et effectue un
contrôle du dossier :
Si le dossier est complet, l'étudiant sera affecter
à une résidence. Sinon, le dossier est rejeté ou mis en
instance.
· Une carte du résident lui sera
délivrée.
· Une liste des résidents sera également
établie.
· Un résident ne peut être inscrit qu'à
une seule résidence pour une année donnée.
· Un résident ne peut être qu'un
étudiant.
· L'ajout d'un résident doit obligatoirement
entraîner une association à une résidence et une chambre,
si cette association existe alors il n'y a pas inscription.
· La suppression d'une résidence entraîne une
suppression des blocs associés à cette dernière.
· La suppression d'un bloc entraîne une suppression
des chambres associées à ce dernier.
· La suppression d'une chambre entraîne une
suppression des résidents associés à cette
dernière.
4.6 Diagnostique de la situation actuelle
4.6.1 Introduction
L'objectif de cette étape est d'évaluer la
situation actuelle en faisant ressortir les problèmes et les
insuffisances du système actuel, et de suggérer une
ébauche de solution pour un système futur meilleur.
4.6.2 Critique de l'existant
Après l'exploration du terrain et les interviews que nous
avons réalisées avec le service de l'hébergement de la
D.O.U, nous avons recensé les problèmes suivants :
· La D.O.U dispose d'un réseau informatique
à haut débit mais très mal exploité. En fait, il
n'existe aucune application ou logiciel fonctionnant sous réseau.
· Le transfert de données entre la D.O.U et les
différentes résidences se fait manuellement.
· L'information est centralisée au niveau de la
D.O.U, ce qui entraîne un volume important d'information à
manipuler sur ce site, par conséquent, un risque de goulots
d'étranglement.
· La non disponibilité des informations au bon
moment.
· L'inconsistance et l'incohérence des informations.
4.6.3 Proposition d'une solution
L'objectif principal de notre étude, est de
remédier aux problèmes cités ci-dessus. Pour cela, nous
avons proposé l'implémentation d'une base de données
répartie et le développement d'une application de gestion de
l'hébergement universitaire permettant de :
· Décentraliser l'information par résidence
pour garantir la fiabilité des données et le transfert de
données se fera automatiquement via le réseau existant.
· Automatiser les transferts de données.
· Augmenter la disponibilité de données et
réduire le trafic réseau qui est une première
possibilité d'accroître les performances du réseau en
utilisant la réplication.
· Gagner du temps d'exécution des différents
traitements réalisés. Par conséquent,
satisfaire les
besoins des utilisateurs en matière d'efficacité et de
rapidité d'exécution.
· Proposer une meilleure codification pour le code du
résident, la chambre et de la résidence.
4.7 Conclusion
L'étude de l'existant que nous avons
réalisée au sein du service de l'hébergement, nous a
permis de présenter les différentes situations de
l'hébergement existantes, de bien comprendre les lacunes du
système existant et de proposer une ébauche de solution
conformément aux objectifs soulevés.
Les différentes interviews et investigations
menées auprès des acteurs concernés au sein de cet
organisme, nous ont permis de bien cerner les problèmes auxquels nous
devrons remédier et y compris que l'informatisation d'un tel service est
très délicate car il nous faudra créer un système
qui répondra au mieux à leurs exigences et qui sera très
facile à utiliser.
Chapitre5
Analyse conceptuelle
5.1 Introduction
L'étude détaillée complète les
descriptions réalisées lors de l'étude préalable,
et qui concerne le système existant, elles nous ont permis de comprendre
les problèmes de ce dernier. L'analyse conceptuelle vise à
produire les spécifications de la solution proposée en mettant en
oeuvre d'une manière claire les modèles de données et de
traitements établis.
A l'issu de ce chapitre, le nouveau système devra
pallier aux insuffisances de l'ancien système, nous allons essayer au
mieux de concevoir un système qui répondra aux exigences du
service d'hébergement et qui sera un point de départ pour la
réalisation de l'application.
5.2 Modélisation du nouveau système
5.2.1 L'étude conceptuelle du nouveau système
5.2.1.1 Règles de gestion
Les règles de gestion expriment les règles
auxquelles obéit le futur système d'information. Pour cela, nous
appliquerons l'ensemble des règles de vérification et de
normalisation suivantes :
· Un étudiant peut s'inscrire dans une et une seule
résidence, une seule chambre, pendant une année universitaire
donnée.
· Un résident réside dans une seule
résidence pour une année universitaire donnée.
· Une résidence est résidée par
plusieurs résidents.
· Un résident peut faire le transfert vers une autre
résidence une seule fois pendant une année donnée.
· Une résidence renferme plusieurs blocs.
· Un bloc appartient à une et une seule
résidence.
· Un bloc est constitué de plusieurs chambres.
· Une chambre appartient à un et un seul bloc.
· Une chambre est occupée par un ou plusieurs
résidents (nombre limité).
· Un résident peut être en fin de cycle, exclu
ou transféré vers une autre résidence. 5.2.1.2
Dictionnaire de données
Le dictionnaire de données est un outil
nécessaire pour la construction du modèle conceptuel de
données, il est représenté par un tableau qui regroupe
toutes les données du système d'information.
Code rubrique
|
Désignation
|
Type
|
Longeur
|
Observation
|
ID_resid
|
Identificateur du résident
|
A
|
10
|
|
Nom_resid
|
Nom du résident
|
A
|
20
|
|
Pren_resid
|
Prénom du résident
|
A
|
20
|
|
Sex_resid
|
Sexe du résident
|
A
|
1
|
M OU F
|
Dat_nais_resid
|
Date de naissance du résident
|
D
|
10
|
JJ/MM/AAAA
|
Lieu_nais_resid
|
Lieu de naissance du résident
|
A
|
20
|
|
Adr_resid
|
Adresse du résident
|
A
|
25
|
|
Nat_resid
|
Nationalité du résident
|
A
|
30
|
|
Photo_resid
|
Photo du résident
|
B
|
|
|
Trans_resid
|
Indique un étudiant transféré
|
A
|
1
|
O ou N
|
Fil_resid
|
Filière du résident
|
A
|
30
|
|
Ser_bac_resid
|
Série du bac du résident
|
A
|
30
|
|
ID_res
|
Identificateur de la résidence
|
A
|
10
|
|
Nom_res
|
Nom de la résidence
|
A
|
20
|
|
Adr_res
|
Adresse de la résidence
|
A
|
20
|
|
Nbr_place
|
Nombre places de la résidence
|
N
|
2
|
|
Nom_dir
|
Nom du directeur de la résidence
|
A
|
20
|
|
Pren_dir
|
Prenom du directeur de la résidence
|
A
|
20
|
|
|
Code rubrique
|
Désignation
|
Type
|
Longeur
|
Observation
|
No_chamb
|
Numéro de la chambre
|
A
|
10
|
|
Capacité
|
Capacité de la chambre
|
N
|
2
|
|
Nbr_plac_lib
|
Nombre de places libres
|
N
|
2
|
|
No_bloc
|
Numéro du bloc
|
A
|
10
|
|
Nbr_chambre
|
Nombre de chambre du bloc
|
N
|
2
|
|
Type_bloc
|
Bloc garçon ou fille
|
A
|
1
|
G ou F
|
Année_ins
|
Année d'inscription
|
A
|
9
|
AAAA/AAAA
|
Cycle
|
Cycle du résident
|
A
|
15
|
|
Année_excl
|
Année d'exclusion
|
A
|
9
|
AAAA/AAAA
|
Motif_excl
|
Motif d'exclusion
|
A
|
50
|
|
Année_trans
|
Année de transfert
|
A
|
9
|
AAAA/AAAA
|
De_residence
|
Nom de la résidence d'origine
|
A
|
20
|
|
Vers_residence
|
Nom de la résidence d'accueil
|
A
|
20
|
|
Motif_trans
|
Motif de transfert
|
A
|
50
|
|
Motif_aband
|
Motif d'abandon
|
A
|
50
|
|
|
Légende :
A : Alphabétique.
N : Numérique.
Blob : Type permettant de stocker de grands blocs de
données non structurées.
5.2.1.3 Nouvelle codification
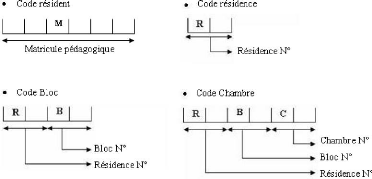
FIG. 5.1 - La nouvelle codificaion.
5.3 Le modèle conceptuel de données
Le modèle conceptuel de données
(MCD1) est une représentation formelle du
système d'information, il décrit la sémantique des
données manipulées par l'entreprise. Il est facilement
compréhensible, permettant de décrire l'aspect statique du
système d'information à l'aide des entités et des
associations.
'Modèle Conceptuel de Données
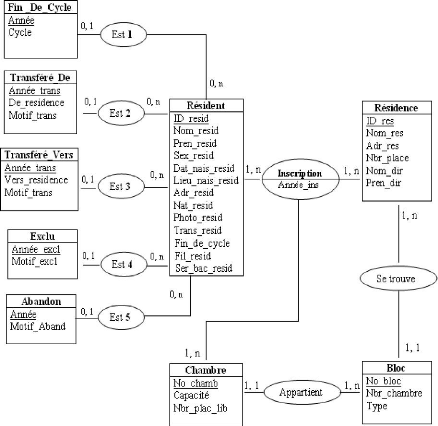
FIG. 5.2 - Le modèle conceptuel de données.
5.4 Niveau organisationnel du nouveau système
5.4.1 Nouvelles règles d'organisation
C'est l'expression de l'organisation mise en terme de poste de
travail, nature des traitements et de chronologie.
· Une fois que l'étudiant est
accepté, une carte de résidence remise à l'étudiant
sera établie automatiquement.
· La liste des étudiants inscrits est
également établie automatiquement.
· Une fois que l'étudiant est affecté et
le dossier de réinscription est complet, le service de
l'hébergement réinscrit l'étudiant et lui délivrera
une carte du résident automatiquement, ainsi que la liste des
résidents sera également établie.
5.4.2 Le modèle organisationnel de traitements
Le modèle organisationnel de traitements
(MOT2) est la modélisation de l'aspect dynamique du
futur système d'information au niveau organisationnel,
c'est-à-dire représenter les choix d'organisation de
l'entreprise.
Il exprime pour chaque traitement, le poste de travail
associé, la nature des tâches décrites en terme de
degré d'automatisation et la chronologie.
5.4.2.1 Description des procédures
2Modèle Organisationnel de Traitements
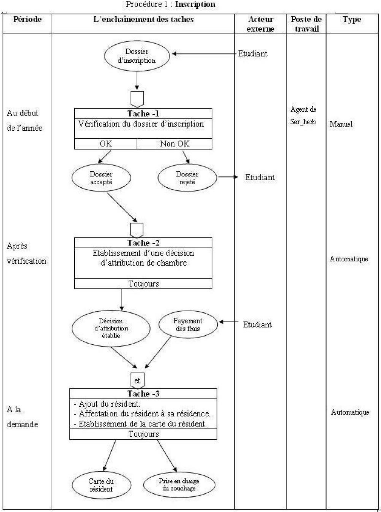
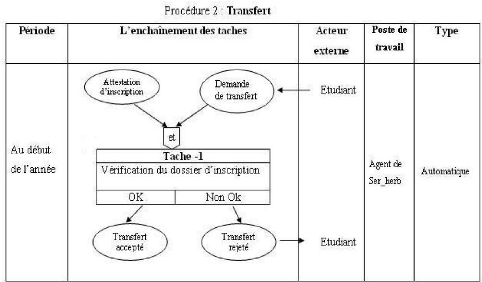
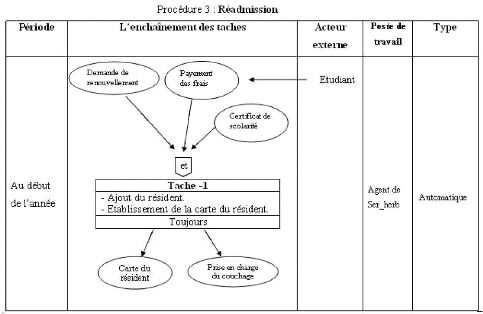
5.4.3 Le modèle logique de données
Le MLD3 est obtenu en traduisant le MCD dans un
formalisme compréhensible par la machine en tenant compte des choix
d'organisation en matière de gestion des données.
A l'issue de cette étape, nous disposerons de
schémas logiques des données qu'il restera à traduire
ensuite dans un langage d'implémentation physique d'une base de
données.
5.4.3.1 Les règles de passage du MCD vers MLD
Règle1 : tout attribut devient un champ et tout
identifiant devient une clé. Règle2 : toute entité devient
une table.
Règle3 : Pour les associations, nous distinguons deux cas
:
- Les associations binaires de type Père / Fils :
l'association disparaît et l'identifiant de l'entité père
migre vers le fils.
- Les associations maillées : toute association devient
une table, sa clé primaire sera la concaténation des identifiants
des entités qu'elle relie.
5.4.3.2 Le MLD relationnel
Après avoir appliqué les règles du passage,
nous avons obtenu le MLD suivant : Résident (ID_resid, Nom_resid,
Pren_resid, Sex_resid, Dat_nais_resid, Lieu_nais_resid, Adr_resid, Nat_resid,
Photo_resid, Trans_resid, Fin_de_cycle, Fil_resid, Ser_bac_resid).
Résidence (ID_res, nom_res, Adr_res, Nbr_place, Nom_dir, Pren_dir).
Bloc (No_bloc, ID_res#, Nbr_chambre, Type).
Chambre (No_chamb, No_bloc# ,Capacité, Nbr_plac_lib).
Inscription (ID_resid#, ID_res#, No_chamb# , Année).
Fin_De_Cycle (ID_resid# , Année, Cycle).
Transféré_De (ID_resid#, Année_trans,
De_residence, Motif_trans).
Transféré_Vers (ID_resid#, Année_trans,
Vers_residence, Motif_trans). Exclu (ID_resid#, Année_excl,
Motif_excl).
Abandon (ID_resid# , Année, Motif_aband).
3Modèle Logique de Données
5.5 Conclusion
Dans ce chapitre, nous avons élaboré et
présenté le futur système, en essayant de répondre
au mieux aux besoins du service de l'hébergement d'une façon
à éviter les anomalies constatées durant notre
étude de l'existant et de proposer une nouvelle codification plus
efficace pour la gestion des identifiants tout en respectant les règles
de gestion adoptées par ce service.
Aussi, nous avons conçu et présenté le
modèle conceptuel de données et le modèle organisationnel
de traitements qui sont traduits en un schéma relationnel du nouveau
système du service de l'hébergement et qui sera mis en oeuvre
dans le prochain chapitre.
Chapitre6
Réalisation
6.1 Introduction
Dans ce chapitre, nous entamons la partie pratique, et cela
après avoir effectué toute l'étude théorique et
préliminaire. Nous essayons au mieux d'utiliser les données, les
informations recueillies et les connaissances acquises tout au long des
chapitres précédents pour implémenter notre solution.
En première partie, nous expliquons la démarche
suivie, et les étapes de création de l'environnement du travail
à savoir un réseau Ad-hoc, ainsi que les
différentes étapes de configuration du serveur et du client
ORACLE.
Dans la seconde partie de ce chapitre, nous allons
présenter la solution proposée, et qui devra répondre aux
exigences de la gestion de l'hébergement des résidences
universitaire en détaillant les étapes qui la composent.
6.2 Structure générale de la solution
proposée
Notre solution consiste à créer sur chaque
résidence universitaire une base de données interfacée
avec notre application de gestion de l'hébergement des résidences
universitaires. Chaque serveur de résidence partage ses données
avec la DOU. Ainsi, ces différentes bases seront consolider au niveau de
la D.O.U pour avoir une base globale qui contiendra toutes les
données.
La figure ci-dessous, illustre la structure
générale de la solution proposée :
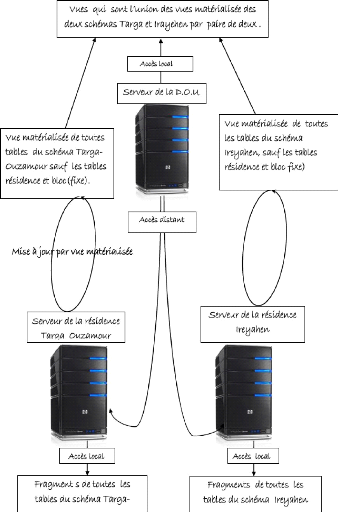
FIG. 6.1 Structure générale de la solution
proposée.
58
6.2.1 Justification des choix
1. La création des vues materialisées
'materialized views' au niveau de la D.O.U, nous permet d'avoir une
localisation physique des données au niveau de cette dernière et
un rafraîchissement complet des données (par exemple, tous les
jours à 10 h du matin). Donc, on favorise les accées locaux qui
ont pour but de réduire le trafic réseau.
2. En cas de panne d'un site ou d'indisponibilité du
réseau, les données seront diponibles, car les accès aux
données sont locaux.
3. Comme la direction a besoin de toutes les données
de tous les sites, la création de vues 'views' au niveau de
cette dernière, nous permet d'avoir accès à toutes les
données en toute transparence.
4. Avec cette solution, une grande disponibilité des
données est assurée.
5. Les vues materialisées de chaque compte utitisateur
au niveau de la D.O.U sont mises à jour quotidiennement à 10h du
matin (cette durée peut étre prolongée après la
période des inscriptions).
6. Les accès distants aux niveau de la D.O.U
permettent à cette dernière d'effectuer la première
inscription des résidents et le suivi du résident
(réadmission, ...) se fera par la residence d'acceuil.
7. La table chambre est fixe normalement mais comme le nombre
de places libres de chaque chambre est mis à jour dynamiquement à
chaque inscription, donc, elle devient dynamique. D'où, la
necéssité de la répliquer vers la D.O.U.
6.3 Les configurations nécessaires
6.3.1 Configuration du réseau
Les ordinateurs dont nous disposons vont être
reliés grâce à un réseau sans fil 'Ad hoc'
afin qu'ils puissent se connecter à distance à la base ORACLE.
Pour cela, il faut définir le même domaine de
travail pour l'ensemble des ordinateurs (MShome ou autre),
désactiver leurs Parfeu et ajouter un nouveau réseau,
repéré par un nom unique SSID1 en cliquant
sur le bouton Ajouter dans la fenêtre
propriétés de connexion réseau sans fll :
'Service Set IDentifier
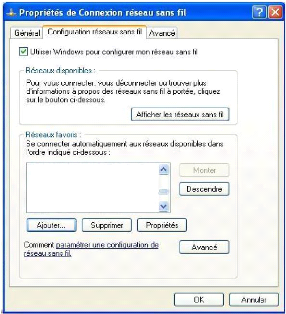
FIG. 6.2 - Propriétés de connexion réseau
sans fll.
Ensuite, une nouvelle boîte de dialogue s'ouvre, il
suffit de saisir sur chacun des ordinateurs le même SSID et de cocher la
case 'Ceci est un réseau d'égal à égal'
dans la fenêtre propriétés du réseau sans
fll. Les autres options servent à renforcer la
sécurité. Dès lors, les machines du réseau Ad
hoc devraient être en mesure de se connecter ensemble.
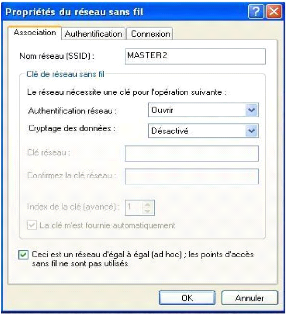
FIG. 6.3 - Propriétés du réseau sans
fll.
Enfln, il nous reste qu'à déflnir une adresse
IP pour chaque poste, en l'occurrence de 192.168.0.1 à
192.168.0.255 et tester la connexion entre les machines.
6.3.2 Configuration ORACLE
Nous installons Oracle 10g Server sur le poste D.O.U
qui contient la base globale et sur chaque serveur des résidences qui
contient une base locale. Tandis que Oracle 10g Client sera installer
uniquement sur chaque poste client.
Ensuite, nous conflgurons la couche réseau grâce au
Net Configuration Assistant pour que les serveurs et les clients
puissent se communiquer.
6.3.2.1 Côté Serveur
Une fois oracle installé, et notre base de données
créée et démarrée, elle est prête à
l'utilisation, mais elle n'est pas encore prête pour être
accessible via le réseau.
I Le processus d'écoute Oracle
Le processus d'écoute Oracle est un service permettant
à des clients d'utiliser le protocole TCP pour accéder
une base de données distante. Son port d'écoute par défaut
est 1521. [Ale03]
Son fichier de paramètre se trouve dans
$ORACLE_HOME/Network/Admin/ et se nomme listener.ora. La configuration
à partir du fichier listener.ora nécessite une bonne connaissance
de la syntaxe de ce dernier (n'est pas recommandée), donc il vaut mieux
utiliser Oracle Net Manager.
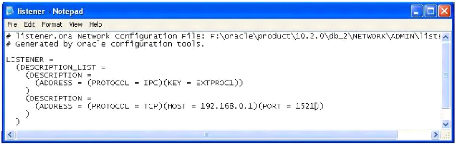
FIG. 6.4 - Le fichier de configuration du Listener
Oracle.
I Création des services de base de données
Le processus d'écoute autorise uniquement les demandes
de connexions des clients pour les noms de services inscrits dans le
listener.ora et chaque nom de service référence une base
de données.
Nous prenons à titre d'exemple la création du
service master2base pour la BD Ireyahen. Pour ce faire, il faut saisir
dans le Oracle Net Manager :
- Le nom du service : master2base ;
- Le protocole connexion réseau :
TCP/IP2 ;
- Le nom de la machine ou l'adresse IP : 192.168.0.2
;
- Saisir le N°du port : 1521 ;
La figure ci-dessous, résume les différents
services de base de données créés, pour lesquels le
processus d'écoute accepte les demandes de connexion :
2Transmission Control Protocol /Internet Protocol
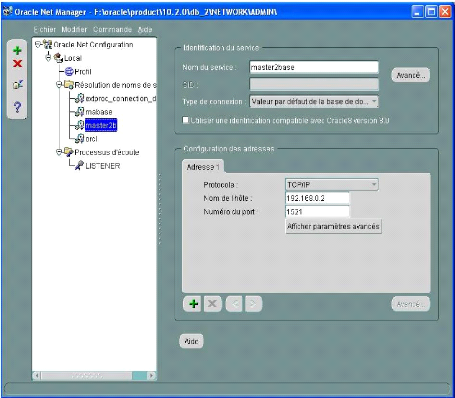
FIG. 6.5 - Oracle Net Manager.
Les définitions des services de base de données
seront stockées automatiquement dans le fichier listener.ora, comme
l'illustre la figure ci-dessous :
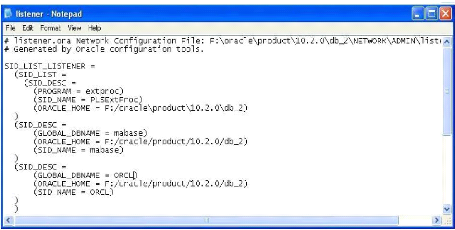
FIG. 6.6 - Le fichier Listener Oracle.
6.3.2.2 Côté Client
Afin de configurer le client, il faut :
- Sélectionner les méthodes de résolution de
noms utilisables par le client; - Configurer les méthodes de
résolution de noms sélectionnées;
Les méthodes de résolution de noms utilisables
par le client sont stockées dans le fichier sqlnet.ora. Si la
méthode de résolution de noms locale est
utilisée, il faut en plus définir un ou plusieurs noms de
services réseau dans le fichier tnsnames.ora.
Voici, à quoi ressemble les fichiers tnsnames.ora
et sqlnet.ora, le plus simple est d'utiliser Oracle Net
Manager pour les configurer :
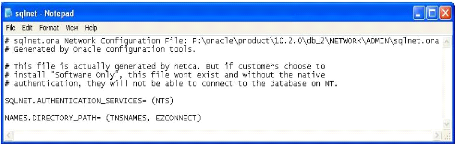
FIG. 6.7 - Le fichier de services TNSNAMES.ORA.
FIG. 6.8 - Le fichier SQLNET.ORA.
65
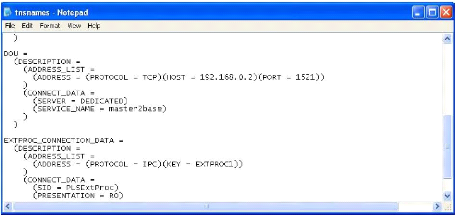
Exemple :
Les différentes étapes de connexion à une
base distante sont récapitulées ci-dessous :
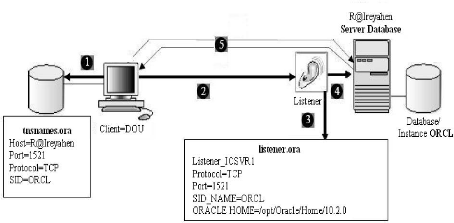
FIG. 6.9 - Les étapes de connexion à une BD
distante.
- (1) : Le client D.O.U récupère les
paramètres de connexion nécessaires pour contacter le listener et
l'instance distante à partir du tnsnames.ora.
- (2) : La demande de connexion est transmise au Listener.
- (3) : Le Listener grâce à son fichier de
configuration lu au démarrage écoute la demande.
- (4) : Il transmet la demande au service de l'instance cible en
créant un processus fils Oracle. A ce stade, le Listener a
terminé son travail pour la connexion de ce Client.
- (5) : Le Client et le Processus Oracle du serveur BD sont
maintenant indépendants par rapport au Listener et sont en mesure de
dialoguer.
6.4 Aspect pratique
6.4.1 Création de la base de données
répartie
6.4.1.1 Outils utilisés
I Serveur ORACLE 10g
Nous avons choisi le SGBD ORACLE 10g. Ce choix est
justifié par sa puissance et son efficacité. Il utilise un
ensemble de processus et de ressources afin d'assurer : [Gil08]
- La définition et la manipulation des données. -
La cohérence des données.
- La confidentialité des données.
- L'intégrité des données.
- La sauvegarde et la restauration des données. - La
gestion des accès concurrents.
. Réseau local
Un environnement réseau, commun entre les
résidences universitaires est indispensable. En d'autre terme, un
réseau LAN3 est mis en place pour partger les
données et relier les serveurs et les clients situés dans chaque
résidence.
. PL/SQL
C'est une extension du langage SQL offerte par le
SGBD Oracle et permettant d'écrire des procédures stockées
(sorte de sous programme). Ce langage est utilisé pour effectuer des
traitements complexes. [Boi06]
6.4.1.2 Implémentation de la BDR
. Au nivau de la résidence TARGA OUZAMOUR
- Création d'un compte utilisateur nommé
targa_ouzamour :
Create user targa_ouzamour identified by targa_ouzamour;
Grant all privileges to targa_ouzamour;
- Création du lien de BD entre la résidence targa
ouzamour et la D.O.U :
Create database link LienBD_DOU connect to DOU identified by
DOU Using 'service DOU';
- Création des tables de la base de données
TARGA OUZAMOUR. . Au niveau de la résidence IREYAHEN
- Création d'un compte utilisateur nommé ireyahen
:
Create user ireyahen identified by ireyahen; Grant all
privileges to ireyahen;
- Création du lien de BD entre la résidence
ireyahen et la direction générale D.O.U :
3Local Area Network
Create database link LienBD_DOU connect to DOU identified by
DOU Using 'service DOU';
- Création des tables de la base de données
IREYAHEN. . Au niveau de la D.O.U
- Création de 3 comptes utilisateurs nommés
respectivements DOU, targa_ouzamour et ireyehen :
Create user DOU identified by DOU; Grant all privileges to
DOU;
Create user targa_ouzamour identified by targa_ouzamour;
Grant all privileges to targa_ouzamour;
Create user ireyahen identified by ireyahen; Grant all
privileges to ireyahen;
- Création des liens de BD entre la D.O.U et les
résidences targa_ouzamour et ireyahen :
Create database link LienBD_targa_ouzamour connect to
targa_ouzamour identified by targa_ouzamour using 'service
targa_ouzamour';
Create database link LienBD_ireyahen connect to ireyahen
identified by ireyahen using 'service ireyahen';
- Création des vues matéralisées dans les
comptes targa_ouzamour et ireyehen respectivement pour chaque residence:
Afin d'illustrer celles-ci, nous allons donner un exemple de
création de deux vues materalisées; une pour la table
résident_targa_ouzamour et l'autre pour résident_ireyahen qui se
trouvent respectivement dans les bases de données des résidences
targa_ouzamour et ireyahen (la procedure de création est la même
pour toutes les tables) :
Create materailized view resident_targa_ouzamour
Refresh start with sysdate
Next ( sysdate+1)/10/24
As select * from
targa_ouzamour@LienBD_targa_ouzamour;
Create materailized view resident_ireyahen Refresh start with
sysdate
Next ( sysdate+1)/10/24
As select * from ireyahen@LienBD_ireyahen;
- Création des vues pour chaque paire de vues
matérialisées dans le compte D.O.U :
Ces vues ont pour but de nous donner une vue globale sur
toutes les résidences en toutes transparence. Pour illustrer celles-ci,
nous allons créer une vue pour tous les résidents en utilisant
les vues matérialisées resident_targa_ouzamour et
résident-ireyahen :
Create view all_residents as
Select * From targa_ouzamour.resident_targa_ouzamour
Union
Select * From ireyahen.resident_ireyahen;
La fugure ci-dessous, illustre la réplication de
données vers la D.O.U basée sur les vues
matérialisées :
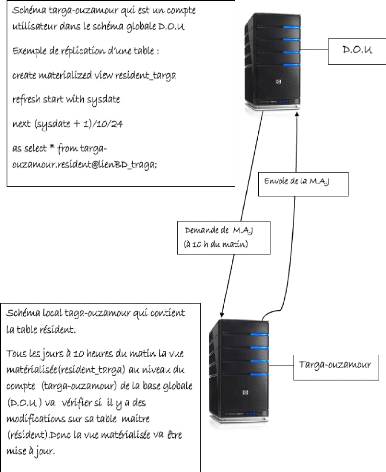
FIG. 6.10 Illustration de la réplication de
données.
6.4.2 Le développement de l'application
Afin de mieux gérer le fonctionnement des
résidences universitaires, ainsi que la D.O.U, nous avons
implémenté une application de gestion de l'hébergement
universitaire manipulant la base de données répartie
créée ci-dessous.
6.4.2.1 Outils utilisés I ORACLE Forms
Oracle Forms est un générateur
d'applications transactionnelles basé sur le language
PL/SQL4. Ce produit fonctionne aujourd'hui exclusivement en
mode WEB. La forme est exécutée sur le serveur d'applications, le
client gérant uniquement l'affichage graphique sous la forme d'une
applet java. [Cha01]
I ORACLE Report
Oracle Report est un module de développement
des états d'impression sous Oracle, il est suffisamment complet en terme
de fonctionnalités pour répondre aux différents besoins
d'édition.
6.4.2.2 Interfaces graphiques
La figure ci-dessous présente la structure graphique de
notre application de gestion de l'hébergement universitaire :
4Procedural Language / Structured Query Language

FIG. 6.11 - Structure générale de
l'application.
Pour éviter tout accès illicite, notre
application est protégée par deux niveaux de
sécurité; le premier s'agit de s'authentifier au niveau de la
base de données concernée et le second au niveau de l'application
de gestion de l'hébergement.
FIG. 6.12 - Vue de l'authentification 'Base de
données' .
FIG. 6.13 - Vue de l'authentification 'Application'
.
I Application D.O.U
L'accès à l'application D.O.U se fait à
partir du menu principal de l'interface suivante :

FIG. 6.14 Menu application DOU.
L'interface ci-dessous permet à la D.O.U d'avoir toutes
les doonées des résidences :
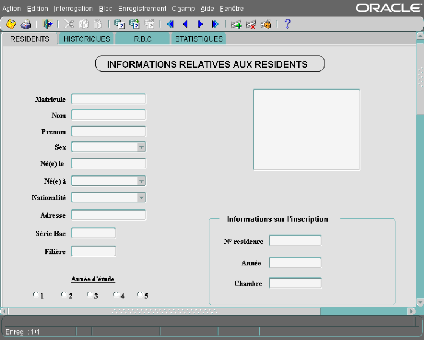
FIG. 6.15 - Vue de la gestion de l'hébergement DOU.
L'inscription d'un nouveau bachelier, s'effectue au niveau de la
DOU, en utilisant la fenêtre illustrée par la figure ci-dessous
:

FIG. 6.16 - Inscription des nouveaux bacheliers - DOU.
I Au niveau des résidences universitaires
Chaque résidence universitaire possède une
interface illustrée par la figure ci-dessous :
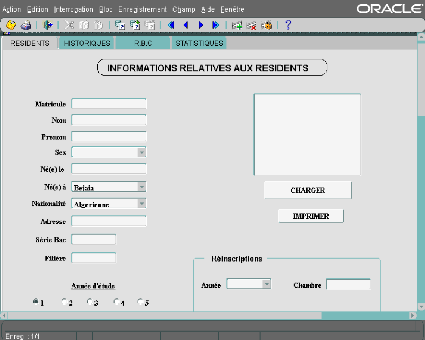
FIG. 6.17 - Vue de l'interface Targa Ouzemour.

FIG. 6.18 - Vue de la carte du résident.
6.5 Conclusion
Dans ce dernier chapitre, nous avons présenté
les aspects pratiques liés à la réalisation de
l'application de gestion de l'hébergement des résidences
universitaires à savoir l'environnement du travail réseau, la
création de la base de données et les différentes
configurations des outils nécessaires au fonctionnement de notre
système.
Conclusion Générale
Une base de données répartie est une collection
de données logiquement unies et physiquement réparties sur
plusieurs machines interconnectées par un réseau de
communication. Elle permet d'intégrer et de partager des données
gérées par des systèmes de gestion des bases de
données réparties.
L'objectif que nous avons visé lors ce projet est la
réalisation d'un système d'information en exploitant le
réseau local existant. Pour cela, nous avons choisi ORACLE 10g
comme SGBD. Ce choix est justifié par sa puissance et son
efficacité, en terme de sécurité, volume de données
traitées, ... etc.
Pour ce faire, nous avons commencé par la
création des bases de données qui modélisent
l'hébergement de chaque résidence, puis consolider ces bases au
niveau la D.O.U et nous avons construit les interfaces graphiques permettant de
réagir avec cette base grâce à ORACLE Forms.
Ce projet nous a permis de se familiariser avec ORACLE,
d'approfondir nos connaissances dans le domaine des bases de données
réparties et d'acquérir des connaissances sur Oracle et
Oracle Forms.
En guise de perspectives futures, notre système peut
être amélioré et complété par :
L'utilisation d'une architecture à trois tiers qui
consiste à séparer logiquement l'architecture du système
en trois couches logicielles.
Magnétiser la carte du résident sur une carte ou
une puce électronique.
Mettre en place des mécanismes de sécurité,
par exemple un protocole d'authentification avancée ou un
crypto-système pour les transferts de données à
distance.
Bibliographie
[Ale03] Alexandre MARIE. Gérer une instance ORACLE,
Août 2003.
[BM07] Cédric BAUDET and Eddy MEYLAN. Bases de
données réparties. Bachelor of science en informatique de
gestion, Haute Ecole de Gestion ARC Neuchâtel Suisse, Octobre 2007.
[Boi06] Pierre BOISSEL. Oracle aujourd'hui, le point de vue de
l'expert, Learning Tree International, 2006.
[Bou04] D. BOUYACOUB. Pratique des systèmes d'information,
Eyrolle, 2004.
[Cha01] Roger CHAPUIS. Les bases de données ORACLE 10g.
Développement, Administration, Optimisation. Dunod, 2001.
[Che01] René J.CHEVANCE. Bases de données
réparties et fédérées. Conservatoire National des
Arts et Métiers, Mars 2001.
[Cor99] Anoine CORNUÈJOLS. Bases de données.
Université Paris Sud, 1999.
[CPZ93] Claude CHRISMENT, Genviève PUJOLLE and Gilles
ZURFLUH. Base de données réparties. Techniques de
l'ingénieur, Décembre 1993.
[Del08] Didier DELEGLISE. Manipulation des vues
matéralisées, Juin 2008.
[Des00] Vincent DESFONTAINsES. Introduction aux bases de
données réparties. Université de Technologie de
Compiègne, Septembre2000.
[Don00] Didier DONSEZ. Répartition, réplication,
nomadisme, hétérogénéité dans les SGBDs.
Université Joseph FOURRIER de Grenoble, 2002.
[Fer04] P.FERRARA. Base de données répartie. HEG
Haute Ecole de Recherche Neuchâtel Suisse, Avril 2004.
[Gil08] Gilles ZURFLUH . Réplication sous Oracle, Juin
2008. [Gui04] Jérôme GUIGNARD. Méthode de conception de
BDR. 2004.
[Kar05] Sacha KARKOWIAK. Introduction aux systèmes et
applications réparties. Université Joseph FOURRIER de Grenoble,
2005.
Bibliographie
[LFG00] Pièrre-Laurent FLEURY and Jérôme
GUIGNARD. Réplication d'une base de données. Ecole Nationale des
Arts et Métiers de Paris, Edition 2000.
[Mey03] Eddy MEYLAN. Base de données distribuées.
Haute Ecole de Gestion ARC Neuchâtel Suisse, Novembre 2003.
[Mey05] Eddy MEYLAN. Réplication de données.
Bachelor of science en informatique de gestion, Haute Ecole de Gestion ARC
Neuchâtel Suisse, Février 2005.
[Mou05] Rim MOUSSA. Système de gestion de bases de
données réparties et mécanisme de répartition sous
ORACLE. Ecole Supérieure de Technologie et d'Informatique à
Carthage, Novembre 2005.
[SL06] Stephan SCHILDKNECHT and Grégoire LEJEUNE.
Introduction à la réplication de bases de données,
Février 2006.
[Spa98] Stefano SPACCAPIETRA. Base de données
réparties. Ecole Polytechnique Fédérale de Lausanne, Mars
1998.
[Wos05] Pascal WOSCICHOWSKI. La réplication sous ORACLE.
Ecole Supérieure d'Informatique, Promotion SUPINFO 2005.
[Yer05] Sheik YERBOUTI. Le guide Oracle Forms 10g, juin 2005.
Annexe
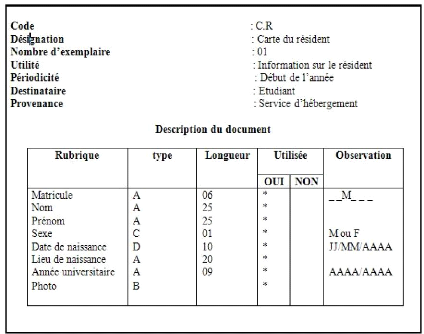
Remarque
La carte du résident doit être signée par le
chef du service de l'hébergement.

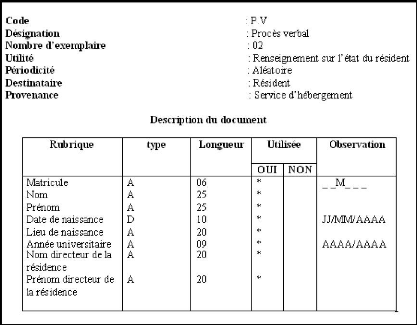
Remarque
Le PV doit être signée par le chef du service de
l'hébergement.
Glossaire
Commit Commande représentant la validation d'une
transaction.
Deadlock C'est l'interblocage, un ensemble de processus est en
interblocage
si et seulement si, tout processus est en attente d'un
événement qui ne peut être réalisé que par un
autre processus de l'ensemble. Goulot Point du système limitant ses
performances.
d'étrangle-
ment
ORACLE 10g Le 'g' signifié 'grid' réseau. Le calcul
réseau est une technologie qui
permet d'accéder continûment et massivement
à un réseau distribué d'ordinateurs homogènes et
hétérogènes. Cette version a apporté plusieurs
propriétés pour améliorer les performances et
l'efficacité d'administration.
Merise Méthode d'analyse et de conception d'un
système d'information
basée sur la séparation entre les données et
les traitements, elle propose deux approches : par étapes ou par
niveaux.
ORACLE Net Ensemble des outils du réseau Oracle, pouvant
être utilisés pour se
connecter à des bases de
données distribuées.
Scalabilité Extensibilité, c'est-à-dire la
facilité d'accroissement.
Schéma Un schéma est un ensemble d'objets tels que
: tables, vues, procé-
dures, et packages associés à un utilisateur
précis. Quand un utilisateur de base de données crée des
objets, son schéma est automatiquement créé.
Tables Elles représentent la structure
élémentaire du SGBD. Elles sont
formées de lignes et de colonnes. Une table est
enregistrée dans un tablespace; souvent, plusieurs tables partagent un
tablespace.
Trigger Signifie un déclencheur, qui provoque
l'exécution d'un algorithme.
Vues Une vue est une fenêtre sur une table ou plus,
n'enregistre pas de
données mais présente les données de la
table. Les vues sont utilisées typiquement pour simplifier
l'accès aux données par les utilisateurs en fournissant des
informations limitées d'une table.
| 

