Chapitre1
Généralités sur les bases de
données réparties
1.1 Introduction
L'évolution des techniques informatiques depuis les
vingt dernières années a permis d'adapter les outils
informatiques à l'organisation des entreprises. Vu, le grand volume de
données manipulées par ces dernières, la puissance des
micro-ordinateurs, les performances des réseaux et la baisse
considérable des coûts du matériel informatique ont permis
l'apparition d'une nouvelle approche afin de remédier aux
désagréments causés par la centralisation des
données, et ce en répartissant les ressources informatiques tout
en préservant leur cohérence.
Les bases de données réparties sont un moyen
très efficace pour pallier aux problèmes engendrés par
l'approche centralisée, mais n'en demeure pas moins sans failles.
1.2 Evolution des bases de données réparties
Les entreprises modernes, de nos jours se démarquent
des autres grâce à leur capacité à traiter les
informations avec fiabilité et rapidité. Ainsi, la gestion des
informations prend une place prépondérante dans le
développement et l'atteinte des objectifs de l'organisation. Un
système d'information renferme l'ensemble des éléments
participant à la gestion, au traitement, au transport et à la
diffusion de l'information au sein de l'organisation. Très
concrètement, il peut être très différent d'une
organisation à une autre et peut recouvrir selon les cas, tout ou une
partie des éléments suivants : [Kar05]
1. Bases de données de l'entreprise,
2. Progiciel de gestion intégré
(ERP1),
3. Outils de gestion de la relation client (CRM2),
4. Interface réseau,
5. Serveur de données et systèmes de stockage,
6. Serveur d'application,
7. Dispositifs de sécurité.
1.2.1 Système réparti
Un système réparti est un ensemble de processeurs
autonomes, reliés par un réseau de communication, qui
coopèrent pour assurer la gestion des informations. [Kar05]
Le principe est simple : les données et traitements
sont répartis sur différents sites interconnectés par un
réseau de communication. Ainsi, la défaillance d'un site ne peut
entraîner l'indisponibilité totale du système et sa
probabilité peut être négligée grâce à
la tolérance aux fautes, assurée par la redondance des
informations et des traitements. [CPZ93]
L'autonomie des sites est préservée par ce genre
de système, en permettant à un groupe d'utilisateurs de
créer et de gérer leur propre base de données tout en
autorisant les accès aux autres utilisateurs via le réseau.
Un système réparti peut sensiblement
améliorer les performances des traitements. En effet, avec une
localisation des données et une répartition des traitements bien
étudiées, la déperdition induite par les communications
des données inter-sites peut être compensée par le gain
(temps de réponse), issu du parallélisme dans
l'exécution des traitements.
La sécurité dans un système
réparti vise à garantir la confidentialité,
l'intégrité de l'information et le respect des règles
d'accès aux services. Les méthodes utilisées reposent
d'une part sur un matériel ou un logiciel dédié, et
d'autre part, sur des protocoles de sécurité utilisant la
cryptographie.
1.2.2 Architecture des systèmes répartis
Les systèmes répartis recouvrent diverses
architectures depuis les architectures Client / Serveur jusqu'aux architectures
totalement réparties. [CPZ93]
L'architecture Client/Serveur se base sur deux types de
processeurs généralement distincts :
1Enterprise Resources Planning 2Customer
Relationship Management
- Les serveurs qui offrent un service à des clients, par
exemple un serveur base de données ou un serveur imprimante;
- Les clients qui émettent des requêtes aux
serveurs pour les besoins d'une application.
Dans l'architecture Client / Serveur la plus simple, la
quasi-totalité du SGBD3 se trouve sur le serveur,
les processeurs clients ne disposant que des mécanismes de
décodage et de transmission des requêtes vers ce serveur.
[CPZ93]
Une architecture totalement répartie est une
généralisation de l'architecture Client / Serveur : les
processeurs sont autonomes dans le sens oil ils peuvent disposer d'un SGBD et
assurer la pleine gestion d'une base de données locale
(BDL4). En plus, s'ils ne disposent pas des ressources
nécessaires à une application qui leur est soumise, ils
déterminent la localisation des données et des traitements qui
leur sont nécessaires et établissent une coopération avec
les processeurs détenteurs de ces ressources. Cette architecture permet
d'éviter la présence du goulot d'étranglement du serveur
base de données puisque les données sont réparties voir
dupliquées à travers le réseau. [CPZ93]
1.2.3 Objectifs des systèmes répartis
Au niveau des objectifs des systèmes répartis, il
existe quatre points essentiels :
1. Indépendance à la localisation.
2. Indépendance à la fragmentation.
3. Indépendance aux SGBDs.
4. Autonomie des sites. [Mey03]
1.2.3.1 Indépendance à la localisation
Au niveau des SGBDR5, l'objectif principal
est de permettre l'écriture des programmes d'application sans que
l'utilisateur se soucie de la localisation physique des données. Dans ce
but, les noms des données ne doivent pas dépendre de leurs
localisations.
Les requêtes locales sont similaires aux requêtes
exprimées en SQL6. Les avantages de la transparence
sont de faciliter l'écriture des requêtes pour l'utilisateur et
permettre le déplacement des données sans modifier les
requêtes. [Fer04]
3Système de Gestion des Bases de
Données/En Anglais, DBMS : DataBases Management System 4Base
de Données Locale
5Système de Gestion de Bases de Données
Réparties
6Structured Query Language
1.2.3.2 Indépendance à la fragmentation
Dans un système réparti, une relation est
constituée de différents fragments, situés sur des sites
différents. La relation de base ne doit pas dépendre de la
manière dont les données ont été
découpées et doit pouvoir être modifiée sans
altérer les programmes.
1.2.3.3 Indépendance aux SGBDs
Un système réparti ne doit pas être
dépendant en aucun cas des différents SGBDs, la relation globale
doit être exprimée dans un langage normalisé
indépendant des constructeurs.
1.2.3.4 Autonomie des sites
Vise à garder une administration locale
séparée et indépendante pour chaque serveur participant
à la base de données répartie afin d'éviter une
administration centralisée.
Toute manipulation sur un site (reprise après
panne, mises à jour des logiciels) ne doit pas altérer le
fonctionnement des autres sites. Bien que chaque base travaille avec les
autres, la gestion des schémas doit donc rester indépendante d'un
site à l'autre et chaque base doit conserver son dictionnaire local
contenant les schémas locaux. [Fer04]
1.2.4 Inconvénients des systèmes répartis
Malgré tous les avantages que les systèmes
répartis présentent, cela n'exclut pas l'apparition de certains
inconvénients comme la complexité des mécanismes de
décomposition de requêtes, la synchronisation des traitements et
le maintien de la cohérence due à la répartition de la
base de données sur plusieurs sites, ainsi le cout induit par les
transmissions des données sur les réseaux locaux.
1.3 Principe des bases de données réparties
Depuis ces dernières années, les techniques
informatiques évoluent vers le traitement de grande masse d'informations
de nature diverse, intégrées dans un environnement
géographiquement réparti oil doivent cohabiter du matériel
généralement hétérogène.
Dans ce contexte, et vue la souplesse des SGBDs d'une part et
les performances des réseaux d'autre part, les bases de doonées
réparties sont une solution importante pour parvenir à
maîtriser la distribution des données. [CPZ93]
1.3.1 Définition
Une base de données répartie
BDR7 est une collection de bases de données
localisées sur différents sites, généralement
distants, mises en relations les unes avec les autres à travers un
réseau d'ordinateurs, perçues pour l'utilisateur comme une base
de données unique. Elle permet de rassembler des données plus ou
moins hétérogènes, disséminées dans un
réseau sous forme d'une base de données globale, homogène
et intégrée. [Spa98]
1.3.2 Exemple
LA société de vente du matériel
informatique ' APPLE ' représentée par sa direction
générale à New York, possède deux magasins à
Bejaia et à Paris. Voici un schéma de ce que peut être une
BD8 repartie mise en place par cette société :
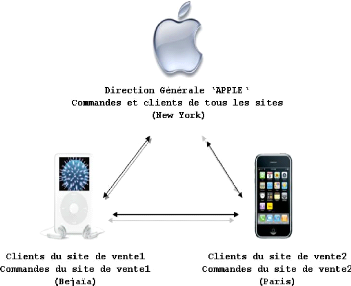
FIG. 1.1 Exemple de base de données répartie.
7Base de Données Répartie
8Base de Données
Dans le cas centralisé, la DG9 gère
tous les comptes clients et les magasins doivent se communiquer avec elle pour
avoir accès aux données. Tandis que dans une BD répartie,
les informations sur les comptes sont distribuées sur les magasins, qui
sont interconnectés via un réseau. La première
conséquence de cette répartition est l'accès rapide aux
données.
1.3.3 Système de gestion des bases de données
réparties
Le SGBDR repose sur un système réparti qui est
constitué d'un ensemble de processeurs autonomes appelés sites
(micro-ordinateurs, stations de travail, ... etc.) reliés par
un réseau de communication qui leur permet d'échanger des
données.
Un SGBDR suppose en plus que les données soient
stockées sur deux sites au moins. Ceux-ci, étant dotés de
leur propre SGBD .
Un SGBDR doit offrir une gestion des priorités, des
verrous et de la concurrence d'accès de la même façon qu'un
SGBD monolithique. Pour cela, il doit disposer de :
- Dictionnaire de données réparties, - Traitement
des requêtes réparties,
- Communication de données inter sites,
- Gestion de la cohérence et de la sécurité.
[Cor99]
Le SGBDR assure la décomposition des requêtes
distribuées en sous requêtes locales envoyées à
chaque site. La décomposition prend en compte la localisation des
données pour atteindre une base de données distante :
Exemple : SELECT * FROM Schema.table@Link_DB ;
Pour les mises à jour, le SGBDR doit assurer la gestion
des transactions10 réparties ainsi vérifier les
règles d'intégrité multi-bases. En cas des bases de
données hétérogènes, le SGBDR doit assurer la
traduction des requêtes.
La figure ci-desous, illustre l'architecture d'un SGBD
réparti :
9Direction Générale
10garantir ACID : Atomicité Cohérence
Isolation et Durabilité
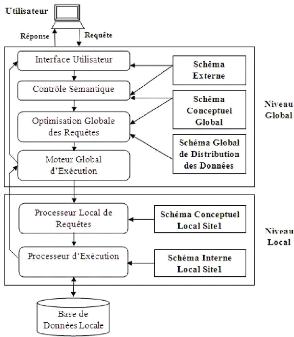
FIG. 1.2 - Architecture d'un SGBD réparti.
1.3.4 Concepts de base
1.3.4.1 Schema local
Une base de données locale comporte un schéma
géré par le SGBD local. Dans une BD répartie, chaque base
locale rend visible toute ou une partie de la base aux sites clients.
1.3.4.2 Schema global
Le schéma global permet de définir l'ensemble
des types de données de la base. Il ignore les concepts
d'implémentation. Il n'est pas forcément
matérialisé, chaque base locale en implémente une partie.
[Mey03]
La figure ci-dessous, résume l'architecture globale d'une
BD répartie avec les deux types de schémas : [BM07]
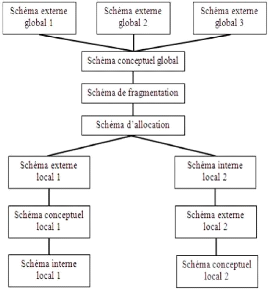
FIG. 1.3 - Architecture d'une BD répartie.
Comme toute BD, une BDR est décrite dans un dictionnaire
de données sous la forme de schémas globaux distincts
conformément à l'architecture ANSI/SPARC : [Gui04]
· Le schéma externe : le niveau externe
décrit les données sous forme de vues, chacune d'elles
étant adaptée à une classe particulière
d'utilisateurs; un schéma externe, élaboré à partir
du schéma conceptuel, peut naturellement mixer des données
stockées dans différentes bases;
· Le schéma conceptuel : où les
données sont représentées sans prendre en compte les
contraintes techniques ou de mise en forme; toutes les données sont
décrites dans ce schéma en utilisant un modèle de
données, indépendamment de leur localisation dans le
système réparti;
· Le schéma interne : le niveau interne global
n'a pas d'existance réelle mais fait place à des schémas
internes locaux, répartis sur différents sites. Ces
schémas correspondent à la description de l'organisation physique
de la base, notamment la spécification de la fragmentation des
données et la localisation de ces fragments;
L'utilisateur accède aux données réparties
à travers ces différents schémas en utilisant le langage
SQL.
1.3.5 Décomposition et optimisation des requêtes
Un traitement réparti fait appel à des
données gérées par des SGBDs distincts. Ce traitement
contient donc des requêtes qui correspondent à un ensemble
d'opérations de recherche et de mises à jour sur des
données de la BDR, formulées à partir d'un schéma
externe global. Le SGBDR contrôle et analyse chaque requête puis la
décompose en opérations locales afin d'être
exécutées par les SGBDs concernés. [CPZ93]
L'optimisation est donc indissociable de la requête car
elle entre en jeu à tous les stades du traitement de la requête.
Au niveau de la décomposition, l'optimisation permet de simplifier la
requête et cela après avoir éliminé les sous
requêtes inutiles ou bien répétées plusieurs
fois.
La figure ci-dessous, illustre le plan d'exécution
répartie d'une requête : [Des00]

FIG. 1.4 Décomposition et optimisation d'une
requête.
1.3.6 Contrôle de l'intégrité
Le contrôle de l'intégrité des
données est un des outils les plus importants d'une base de
données assurant que les données ne soient pas modifiées
ou détruites de façon illicite et limitant les risques d'erreurs
et de malveillance. Selon les contraintes qui ont été
définies sur les relations et les attributs, différentes
anomalies peuvent se déclencher dès qu'un accès aux
données est effectué. L'intégrité des
données se réfère à leurs cohérences par
rapport à ce qui a été défini au départ.
[Des00]
1.3.7 Exécution répartie
Après que les requêtes sont
décomposées en opérations locales par les SGBDR, elles
seront exécutées par les SGBDs concernés.
1.4 Utilisation d'une base de données répartie
Au niveau de la BDR, la transparence est un principe fondamental
qui apparaît dans la localisation, le partitionnement et la duplication :
[Spa98]
1.4.1 Transparence de la localisation
La transparence de la localisation des données
sous-entend que ni les applications ni les utilisateurs n'ont besoin de
connaître la position réelle des tables auxquelles ils
accèdent. Autrement dit, ils ne doivent pas connaître la
localisation physique des données.
Les utilisateurs accèdent à la BD soit
directement par le schéma conceptuel soit indirectement à travers
les vues externes, mais en aucun cas, ils n'ont les moyens pour accéder
aux schémas locaux.
1.4.2 Transparence de partitionnement
Les utilisateurs n'ont pas à connaître les
partitionnements de la base de données. Ils ne doivent pas savoir si
telle information est fractionnée et ne doivent donc pas se
préoccuper de la réunifier. C'est le système qui
gère les partitionnements et les modifie en fonction de ses besoins. Et
c'est donc lui qui doit rechercher toutes les partitions et les intégrer
en une seule information logique présentée à
l'utilisateur.
1.4.3 Transparence de la duplication
Enfin, le principe de transparence de la duplication est que
les utilisateurs n'ont pas à savoir si plusieurs copies d'une même
information sont disponibles. La conséquence directe est que lors de la
modification d'une information, c'est le système qui doit se
préoccuper de mettre à jour toutes les copies.
1.5 La répartition des bases de données
A l'heure actuelle, de nombreuses entreprises ont des annexes
partout dans le monde, et vue la complexité des problèmes
auxquels elles sont confrontées d'une part et l'évolution des
technologies informatiques d'autre part, a mené à penser à
une nouvelle architecture qui s'adapte plus à leurs organisations.
1.5.1 Buts
Les objectifs de la répartition de données sont
multiples :
1.5.1.1 Plus de disponibilité et de fiabilité
Comme les bases de données réparties ont
souvent des données qui sont répliquées, alors la
fiabilité peut être apportée à plusieurs niveaux, la
panne d'un site n'est pas importante pour l'utilisateur. En effet, celui-ci
s'adresse de façon transparente à un autre site qui
possède les données requises. Par ailleurs, la fiabilité
également garantie au niveau des transactions. Elles peuvent être
conduites sur le même site de façon concurrente ou sur plusieurs
sites en même temps.
Le système d'exploitation ou le SGBD doit garantir
qu'une transaction s'accomplira de façon totalement sûre. Une
transaction fait passer la base de données d'un état stable
cohérent à un autre état stable cohérent, quelques
soient les problèmes du réseau rencontrés ou les
accès concurrents aux données. [Des00]
1.5.1.2 Meilleures performances
Réduire le trafic sur le réseau est une
première possibilité d'accroître les performances. Les
gains sont particulièrement appréciables pour deux raisons
principales :
Une grande partie des requêtes s'effectue localement sur
le site possédant les données notamment lorsque les
données sont répliquées partiellement ou totalement. Le
but de la
répartition des données consiste est alors
à les rapprocher au plus près de l'endroit oil elles sont
généralement accédées.
Répartir la base sur différents sites permet de
répartir l'impact sur les processeurs et sur leurs
Entrées/Sorties. L'impact sur le système se trouve grandement
réduit puisque les sites ne traitent qu'une partie de la base de
données globale. [Des00]
1.5.1.3 Scalability
Il est plus facile d'améliorer les performances du
système de gestion de la base de données, en ajoutant des
machines sur le réseau plutôt que de passer d'un grand
système à un autre. Cependant, l'accroissement des performances
n'est pas linéaire. Ajouter des machines sur le réseau
sous-entend augmenter le trafic pour maintenir la cohérence de la base
de données. [Des00]
1.5.2 Problèmes a surmonter
1.5.2.1 Coût
La distribution des données et des traitements
entraîne des coûts supplémentaires en terme de communication
(trafic réseau), et en gestion des communications comme le
hardware et software à installer afin de gérer les communications
et la distribution.
La distribution est également coûteuse en
matière du personnel utilisé car il faut les payer
administrateurs de chaque site. [Des00]
1.5.2.2 Distribution du contrôle
La distribution du contrôle crée des
problèmes de synchronisation et de coordination dans l'accès aux
données. Dans une base de données répartie, on ne se
soucie pas de la consistance et l'intégrité d'une seule base de
données, mais de plusieurs copies de la base de données.
La gestion des copies doit assurer leur cohérence
mutuelle, c'est-à-dire que toutes les copies de données soient
identiques. [Des00]
1.5.2.3 Sécurité
Un des avantages évident des bases de données
centralisées est sans contexte la sécurité apportée
aux données, car elle peut facilement être contrôlée
dans un site unique. Or, les
bases de données réparties impliquent un
réseau dont la sécurité est difficile à maintenir.
La sécurité est donc un problème plus complexe dans le cas
des bases de données réparties que dans le cas des bases de
données centralisées. [Des00]
1.5.2.4 Gestion distribuée des interblocages
Le problème de l'interblocage ' Deadlock '
est le même que celui rencontré dans les systèmes
d'exploitation. La compétition entre les utilisateurs pour
accéder à une donnée peut entraîner des
interblocages. [Des00]
1.5.2.5 Bases de données
hétérogènes
Quand les bases de données sur différents sites
ne sont pas homogènes en terme de modèle de données
(relationnel, objet, XML, . . .), il devient nécessaire de
fournir un mécanisme de translation entre les différentes bases
de données, ce mécanisme de translation exige toujours une forme
canonique pour faciliter la translation des données.
1.6 Architecture des bases de données réparties
1.6.1 Autonomie
L'autonomie se rapporte au degré avec lequel une des
bases locales peut travailler indépendamment des autres. On peut
distinguer trois types d'alternatives dans l'autonomie que peuvent avoir les
bases locales :
- L'intégration totale : une image unique de la base
de données globale est offerte aux différents utilisateurs.
D'où la BD est centralisée, le SGBD contrôle de bout en
bout la requête d'un utilisateur même si elle met en jeu
différentes bases locales et donc différents SGBDs locaux.
L'autonomie n'est donc pas bien importante.
La semi-autonomie : les SGBDs locaux peuvent opérer
indépendamment mais ils participent à une collection de bases qui
coopèrent afin de partager leurs données. L'isolation totale :
une base locale ne connaît ni l'existence des autres bases ni la
façon de se communiquer avec elles. Il ne peut donc pas y avoir du
contrôle global quant à l'exécution d'une requête sur
les différentes bases locales. [Des00]
1.6.2 Relation entre machines
Du point de vue organisationnel, nous distinguons deux types
d'architectures :
1.6.2.1 Architecture Client / Serveur
Dans cette architecture applicative, les programmes sont
répartis en processus clients et serveurs qui communiquent à
travers des requêtes et des réponses. Sur la machine cliente, les
utilisateurs disposent d'une interface.
Sur les serveurs, la gestion des bases de données est
effectuée (analyse, optimisation des requêtes, et
répartition). On peut distinguer deux types de clients : [LFG00]
· Client lourd : l'utilisateur est obligé de se
connecter explicitement à tous les serveurs dont il a besoin pour la
requête qu'il veut formuler. [Des00]
Exemple : dans une application de gestion de la
scolarité universitaire, si la BD est repartie par faculté alors
la recherche d'un étudiant grâce à son matricule et sans
connaître la faculté à laquelle il appartient est
très délicate, car nous sommes obliger à interroger la BD
de chaque faculté une par une jusqu'à trouver un
résultat.
· Client léger : l'utilisateur ne se connecte
qu'à la base de données via un unique serveur. Le SGBDR se charge
alors de gérer les différentes connexions que nécessitera
la requête de l'utilisateur. Donc, il offre plus de transparence.
[Des00]
Exemple : pour reprendre l'exemple précédent
dans le cas d'un client léger, c'est le SGBDR qui se charge de
trouver la faculté de l'étudiant en question, et de retourner un
résultat.
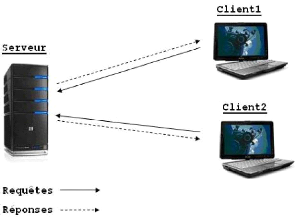
FIG. 1.5 Architecture Client / Serveur.
1.6.2.2 Architecture Peer To Peer
C'est un type de communication pour lequel toutes les
machines ont une importance équivalente. Il n'y a pas de machine qui a
une importance hiérarchique par rapport aux autres. Dite aussi,
l'architecture totalement répartie.
Chacune de ces architectures possède des avantages et
des inconvénients. Le Client / Serveur avec sa structure plus
hiérarchique est très sensible aux problèmes de panne des
serveurs, bloquant ainsi les clients. En revanche, la prise de décision
des serveurs est rapide.
Pour l'architecture Peer-To-Peer, comme les machines sont
strictement équivalentes, la panne d'une machine peut rarement rendre le
système un peu lent. Mais cette architecture engendre
énormément de communication pour toute décision.
[Des00]
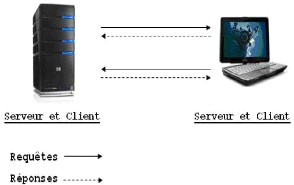
FIG. 1.6 - Architecture Peer To Peer.
1.6.3 Hétérogénéité
L'hétérogénéité peut
apparaître à plusieurs niveaux. En effet, les
incompatibilités matérielles ou logicielles au sein d'une
entreprise, rendent particulièrement délicate la mise en place
d'un SGBD.
L'hétérogénéité peut
exister au niveau de la représentation des données, au niveau du
langage de requête ou au niveau du modèle de données des
différentes bases (BDs relationnelles, BDs objets). [Des00]
1.7 Conclusion
A travers les différents points
développés dans le présent chapitre, nous avons pu
constater l'intérêt particulier porté aux systèmes
répartis et aux différents problèmes auxquels ce type de
solution a pu remédier.
Nous avons pu également, détailler et expliquer
l'intérêt des bases de données réparties et les
différents avantages offerts par ce type d'approche. Ce type de
système est plus difficile à mettre en place et plus
compliqué, et que malgré ses nombreux avantages, néanmoins
des inconvénients existent, et son inconvénient majeur est la
sécurité des données transmises via le réseau de
communication.
| 

