Impact de la performance du secteur agricole sur la performance des autres secteurs et le niveau de vie au Bénin( Télécharger le fichier original )par Codjo Serge ABALLO Université d'Abomey-Calavi (Bénin) - Diplôme d'ingénieur statisticien économiste 2011 |

b- Quelques applications du modèle VARCette application sert à effectuer des chocs sur les innovations d'une variable à une date t donnée et à mesurer l'influence de ce choc sur tout le système. Cependant cette analyse s'effectue en postulant la constante de l'environnement économique9(*) « toutes choses étant égales par ailleurs ». En un premier temps le choc n'affecte que la valeur de la variable ciblée en cas d'orthogonalité des innovations. Puis grâce à la dynamique du système, ce choc est transmis aux valeurs suivantes ou futures de toutes les variables. o La décomposition de la variance Cette application sert à expliquer la variance d'une variable endogène par les variances des autres variables. Cela permet d'apprécier l'impact de la variabilité d'une variable sur une autre. La décomposition de l'erreur de prévision a pour objectif de calculer pour chacune des innovations sa contribution à la variance de l'erreur. Par une technique mathématique, on peut écrire la variance de l'erreur de prévision à un horizon h en fonction de la variance de l'erreur attribuée à chacune des variables, il suffit ensuite de rapporter chacune de ces variances à la variance totale pour obtenir son poids relatif en pourcentage. Contrairement à l'impulsion ou choc, la décomposition de la variance essaye d'expliquer la contribution de l'innovation d'une variable aux fluctuations d'une autre. A ce propos, Hairault (1995) soutient qu'elles (fonction de réponse et de la décomposition) « constituent deux exercices qui permettent de synthétiser l'essentiel de l'information contenue dans la dynamique interne d'un système VAR. Elles mesurent l'influence relative, à différents horizons, des différents chocs dans la dynamique de chaque variable ». Une des questions que l'on peut se poser à partir d'un modèle VAR est de savoir s'il existe une relation de causalité entre les différentes variables du système. Au niveau théorique, la mise en évidence de relations causales entre les variables économiques fournit des éléments de réflexions propices à une meilleure compréhension des phénomènes économiques. D'une manière pratique, « the causal knowledge » est nécessaire à une formulation correcte de la politique économique. En effet, connaître le sens de causalité est aussi important que de mettre en évidence une liaison entre des variables économiques. Il existe plusieurs définitions de la causalité : la causalité au sens de Granger et la causalité au sens de Sims. La causalité au sens de Granger qui est utilisée pour cette étude se définit comme la capacité d'une variable à expliquer par ces valeurs passées et/ou présentes la valeur présente d'une autre variable. Il se base sur le principe simple ci-après. Lorsque nous disposons d'un modèle VAR suivant :
Intuitivement, Il s'agit ici d'utiliser les informations sur les valeurs
passées pour prévoir en partie ou totalement les valeurs
présentes et futures des variables. C'est à juste titre que le
test de causalité se base sur la contribution à la
réduction de la variance de l'erreur sur la prévision de En d'autres termes, On dit que la variable De cette définition découle un corollaire :
On dit que la variable De façon équivalente on dit que la variable y est exogène au sens des séries temporelles. La statistique de test utilisée avec pour hypothèses :
est :
où : - ces valeurs passées ; - passées de Etant donné qu'en cas de non causalité la
première variance est supérieure à la deuxième,
cette quantité reste positive. Elle sera très grande lorsque la
causalité n'est pas valable et nulle dans le cas contraire.
L'interprétation de cette statistique de test est que : * 9 Régis BOURBONNAIS, Econométrie, 3ème édition |
|


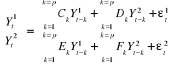
 causerait
causerait  selon Granger lorsque les coefficients des valeurs retardées de
selon Granger lorsque les coefficients des valeurs retardées de
 dans l'estimation de
dans l'estimation de  ne sont pas tous nuls.
ne sont pas tous nuls.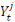 , de la connaissance de
, de la connaissance de 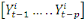 explique connaissant
explique connaissant 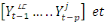
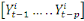
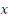 cause au sens de Granger la variable y si et seulement si la
connaissance du passé de
cause au sens de Granger la variable y si et seulement si la
connaissance du passé de  améliore la prévision de y à tout horizon.
améliore la prévision de y à tout horizon.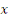 ne cause pas la variable y au sens de Granger, si et seulement
si :
ne cause pas la variable y au sens de Granger, si et seulement
si :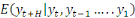 =
= 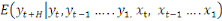
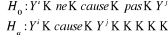
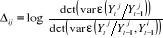
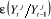 est l'erreur commise en prévoyant
est l'erreur commise en prévoyant 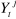 sur la base de la connaissance de
sur la base de la connaissance de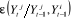 est l'erreur de prévision de
est l'erreur de prévision de 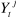 à partir de la connaissance des valeurs
à partir de la connaissance des valeurs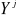 et des valeurs passées de
et des valeurs passées de 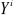 .
.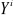 cause
cause 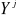 si la connaissance de
si la connaissance de 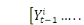 en plus de celle de
en plus de celle de 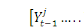 permet de réduire sensiblement les erreurs de prévision
de
permet de réduire sensiblement les erreurs de prévision
de 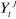 sachant
sachant 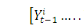 .
.