|

REPUBLIQUE ALGERIENNE DEMOCRATIQUE ET POPULAIRE
MINISTERE DE
L'ENSEIGNEMENT SUPERIEUR ET DE LA RECHERCHE
SCIENTIFIQUE
UNIVERSITE DE JIJEL
FACULTE DES SCIENCES DE
L'INGENIEUR
DEPARTEMENT D'INFORMATIQUE

POUR L'OBTENTION DU DIPLOME D'INGENIEUR D'ETAT
EN GENIE
INFORMATIQUE
OPTION : INTELLIGENCE ARTIFICIELLE


CONCEPTION D'UNE ONTOLOGIE POUR UNE PLATE
FORME
D'ENSEIGNEMENT A DISTANCE
Réalisé par Dirigé
par
Saloua Chettibi & Amina Rouibah Melle. Ouafia
Ghebghoub
Année universitaire
2005/2006
Nous remercions DIEU le tout puissant qui nous a
donné la force, la
volonté et le courage pour accomplir ce
modeste travail.
Nous tenons à remercier notre encadreur, Melle.
Ghebghoub Ouafia,
pour nous avoir donné l'opportunité de
travailler sur ce projet, pour son
grand soutien scientifique et moral, pour
les conseils, les suggestions et
les encouragements qu'elle nous a
apportés durant notre projet.
Nos remerciements aux membres de jury qui ont
accepté de juger notre
travail.
Enfin nous exprimons notre
profonde reconnaissance à toutes les
personnes qui ont
contribué de près ou de loin pour le bon déroulement
de
ce travail.
Dédicaces
A l'esprit de mon père,
A ma très chère mère,
A mes soeurs et frères,
A tous mes amies,
Je dédie ce travail.
Saloua

A celui qui fait de moi que je suis, Mon père
A La chandelle de ma vie, ma chère mère
A mes chères soeurs et frères,
A tous mes
amies,
Je dédie ce
travail.

Résumé
Le web sémantique constitue une nouvelle vision du Web,
dont les ressources sont décrites par des métadonnées, en
utilisant le vocabulaire conceptuel fournis par des ontologies, ce qui permet
aux agents logiciel d'aider plus efficacement différents types
d'utilisateurs dans leurs accès aux ressources sur le Web.
Le e-learning est considéré parmi les domaines
auxquels le Web sémantique peut apporter une véritable
amélioration que ce soit dans la recherche d'information, ou dans la
réutilisation des ressources pédagogiques ou même dans la
personnalisation des parcours d'apprentissage.
Le travail réalisé dans le cadre de ce projet
vise premièrement à concevoir une ontologie afin de fournir un
vocabulaire conceptuel partageable entre la communauté des enseignants
et des étudiants, un vocabulaire qui sera utilisé pour annoter
des documents pédagogiques ; deuxièmement à
développer une application de recherche de documents par leurs
métadonnées tout en se basant sur les technologies offertes par
le Web sémantique.
Mots clés
Ontologie, Web sémantique, OWL, RDF, RDFS,
métadonnés, enseignement à distance, document
pédagogique.
Abstract
The semantic Web constitutes a new vision of the Web, where
resources are described by meta-data, using the conceptual vocabulary provided
by ontologies, that permit software agents to help more effectively various
types of users in their accesses to resources on the Web.
E-learning is considered among the fields to which the
semantic Web can make a real progress that it is in the search for information,
or in the reuse of learning resources or even in the personalization of the
training tracking.
The work realised in this project aims firstly to design an
ontology in order to provide a shareable conceptual vocabulary between the
community of teachers and students, a vocabulary which will be used to annotate
learning documents; secondly to develop an application of document retrieval by
their meta-data all while basing on the technologies offered by the semantic
Web.
Key words
Ontology, semantic Web, OWL, RDF, RDFS, meta-data, e-learning,
learning document.

Introduction générale 1.
I. Introduction 3
II. Insuffisance du Web actuel 3
III. Web sémantique, quoi de nouveau ? 3
IV. Langage du Web sémantique 4
IV. 1. le World Wide Web Consortium (W3C) 4
IV.2. Architecture du Web sémantique 4
IV.3. Langage XML 5
IV.3.1. Document XML 6
IV.3.2. Document XML valide 6
IV.3.3. Espace des noms 8
IV.3.4. Feuilles de style 8
IV.3.5. Parseur XML 8
IV.3.6. Avantage de XML 9
IV.3.7. Limitations du XML 9
IV.4. Langage RDF et RDFS 10
IV.4.1. RDF (1999) 10
IV.4. 1.1. Définition d'URI (Uniform Ressource
Identifier) 10
IV.4.1.2. Syntaxe RDF 10
IV.4.2. RDFS (2000) 11
IV.5. Le langage OWL 12
IV. 5.1. Les ontologies 12
IV.5.2. Présentation du OWL 13
IV.5.3. Document OWL 13
IV.5.4. Structure d'une ontologie en OWL 14
IV.5.4.1. Espace de nommage 14
IV.5.4.2. En-tête d'une ontologie 15
IV.5.4.3. Eléments du langage 15
V. Travaux du Web sémantique et domaines d'application
22
V.1. Recherche d'information 22
V.2. l'adaptation /personnalisation 22
V.3. Intégration des sources de données
hétérogènes 23
VI. Conclusion 23
I. Introduction 24
II. Les ontologies 24
II.1. Historique sur l'ontologie 24
II.2. Notion d'ontologie 25
II.2.1. Différence entre ontologie et base de
connaissance 26
II.2.2. Différence entre ontologie et hiérarchie de
classes 27
II.3. Composantes d'une ontologie 27
II.4. Classification des ontologies 28
II.4.1. Typologie selon l'objet de conceptualisation 28
II.4.2. Typologie selon le niveau de détail de l'ontologie
29
II.4.3. Typologie selon le niveau de complétude 29
II.4.4. Typologie selon le niveau de formalisme 30
II.5. Principes de construction des ontologies 30
II.5.1. Principes 30
II.6. Processus de construction 31
II.7. Méthodologies de construction 32
II.7.1. Méthode de Uschold et King «1995 »
32
II.7.2. Méthode de Uschold et King «1996 »
33
II.7.3. Méthode de Bernaras et al «1996 » 33
II.7.4. Méthode SENSUS de Swartout et al «1997
» 33
II.7.5. Méthode de Assenac-Grilles et al «2000
» 33
II.7.6. Méthode de Bachimont «2000 » 33
II.7.7. Méthode OntoSpec de Kassel «2002 »
34
II.8. Environnements et outils de modélisation 34
II.8.1. ONTOLINGUA 34
II.8.2. ONTOSAURUS 34
II.8.3. ODE 35
II.8.4. PROTÉGÉ 35
III. Les ontologies pour le e-learning 35
III.1. Définitions 35
III.1.1. Objet pédagogique 35
III.1.2. Profil utilisateur 36
III.1.3. Plate forme de formation 36
III.2. Besoin des systèmes e-learning 36
III.2.1. Besoin en archivage et recherche 36
III.2.2. Besoin de partage 38
III.2.3. Besoin en réutilisation des objets
pédagogiques 38
III.2.4. Besoin en personnalisation et adaptation 39
III.3. Exemples de l'utilisation des ontologies 39
III.3.1. IMAT (Integrating Manuals And Training) 40
III.3.2. QBLS (Question Based Learning System) 40
III.3.3. VIUM (Projet de repérage et de visualisation du
modèle de l'apprenant) 40
IV. Conclusion 41
I. Introduction 42
II. Conception de l'ontologie de l'application 42
II.1. Choix d'une méthodologie de construction 42
II.2. Respect des principes de construction 43
II.3. Présentation de l'ontologie conceptuelle 44
II.3.1. Liste des concepts 44
II.3.2. Liste des attributs 48
II.3.3. Liste des relations 50
II.3.4. Représentation hiérarchique des concepts
53
II.3.5. Diagramme UML 54
II.4. Schéma résumant la phase de l'ontologisation
55
II.5. Diagramme des cas d'utilisation 55
III. Conclusion 57
I. Introduction 58
II. Cahier des charges 58
III. les outils et le langage utilisés 58
III.1. Java Server Pages 58
III.2. Tomcat 60
III.3. Protégé 61
III.4. Jena 61
IV. Implémentation 62
IV. 1. Edition de l'ontologie et génération du
code OWL 62
IV. 1.1. Choix d'un langage de spécification 62
IV. 1.2. Normalisation des noms de l'ontologie 63
IV.1.3. Les étapes de l'édition 63
IV. 1.4. Schéma résumant la phase de
l'opérationnalisation 72
IV.2. Exploitation de code OWL dans un programme JAVA 72
IV.2.1. Suivi de session 74
IV.2.2. Architecture de l'application développée
75
V. La démarche suivie pour l'annotation des documents
75
VI. Exécution de l'application 75
VI. 1. Images d'exécution de l'application 77
VI. 1.1 Annotation d'un module 77
VI. 1.2. Annotation d'un enseignant 78
VI.1.3. Annotation d'un document 79
VI. 1.4. Recherche de documents 82
VI.2. Intégration de l'application sur la plate forme
« Plone » 87
VII. Avantage de l'application 89
VIII. Conclusion 90
Conclusion générale 91

Fig I.1 : Exemple de représentation sous forme de graphe
11
Fig II.1 : Processus de construction d'une ontologie 32
FigIII. 1 : Représentation hiérarchique de
l'ontologie 53
Fig.III.2 : Diagramme de classes UML 54
Fig.III.3 : phase d'ontologisation 55
Fig.III.4: Diagramme des cas d'utilisation 56
Fig.IV. 1: Exemple d'un programme JSP 59
Fig.IV.2 : Exécution d'un JSP 60
Fig.IV.3 : La page d'accueil de site http://jena.sourceforge.net/
61
Fig.IV.4 : La documentation associé avec Jena 2-3 62
Fig.IV.5 : Lancement de Protégé 63
Fig.IV.6 : Choix de type de projet 64
Fig.IV.7 : Choix d'un espace des noms 64
Fig.IV.8 : Choix d'un langage 65
Fig.IV.9 : Page d'édition 65
Fig.IV. 10 : Création des classes 66
Fig.IV.11 : Les champs à remplir 66
Fig.IV.12 : Ajout d'une propriété 67
Fig.IV.13 : Spécification des contraintes de
cardinalité 67
Fig.IV.14: Ajout d'une relation 68
fig.IV. 15 : Ajout de la relation inverse 68
Fig.IV.16 : Enregistrement de projet 69
Fig.IV.17 : un fragment de code OWL généré
70
Fig.IV. 18 : Génération de la documentation 71
Fig.IV.19 : Documentation de l'ontologie 71
Fig.IV.20 : Phase de l'opérationnalisation 72
Fig.IV.21 : Installation de JDK 1.4.2 73
Fig.IV.22: Ajout de la librairie Jena 73
Fig.IV.23 : Ajout de JDK 1.4.2 74
Fig.IV.24 : Architecture de l'application 75
Fig.IV.25 : Installation de serveur Tomcat 76
Fig.IV.26 : Emplacement de l'application 76
Fig.IV.27 : Annotation d'un module 78
Fig.IV.28: Annotation d'un enseignant 78
Fig.IV.29 : Affectation d'un module à un enseignant 79
Fig.IV.30 : Saisie de login de l'enseignant 79
Fig. IV.3 1: choix d'un module 80
Fig.IV.32 : Choix de type de document à annoter 80
Fig.IV.33 : préparation à la
génération de formulaire d'acquisition des
métadonnées 81
Fig.IV.34 : Annotation d'un support de cours 81
Fig.IV.35 : écran de recherche de document 82
Fig.IV.36: Recherche d'un support de cours 82
|
Fig.IV.37: Recherche d'un support de cours (suite)
|
83
|
|
Fig.IV.38: Recherche d'un support de cours (suite)
|
.83
|
|
Fig.IV.39 : Recherche d'un support de cours (suite)
|
84
|
|
Fig.IV.40 : Recherche d'un support de cours (suite)
|
84
|
|
Fig. IV.41: Recherche d'un support de cours (suite)
|
85
|
|
Fig.IV.42 : Lancement de la recherche de l'URI
|
85
|
|
Fig.IV.43 : Résultat de la recherche
|
86
|
|
Fig.IV.44 : Espace administrateur
|
87
|
|
Fig.IV.45 : Espace enseignant
|
88
|
|
Fig.IV.46: Espace étudiant
|
89
|

Introduction générale
A sa création par Tim Berners Lee, au début des
années 90, l'objectif du Web était de permettre à tout
internaute d'accéder et de partager un grand volume d'information sur le
net. Le langage HTML a constitué une très bonne solution pour la
mise en forme aisée et rapide de document en ligne, et très
rapidement le Web a atteint ses objectifs.
Jusqu'ici on dispose d'un grand volume d'information, mais
sans aucune maîtrise de contenu, le résultat est que l'utilisateur
du Web gaspille une grande partie du son temps à examiner un grand
nombre de page Web en cherchant ce qui lui convient, car le Web ne fournit pas
un service dans ce sens.
C'est à partir de ce constat que les travaux du World
Wide Web Consortium ont été orientés vers
l'amélioration du Web afin de fournir de l'information pertinente aux
utilisateurs, et de les décharger d'une grande partie de leurs
tâches.
Le Web sémantique est donc la solution, cette nouvelle
vision du Web consiste à rendre les ressources Web non seulement
compréhensibles par les humains mais également par des machines,
pour réaliser cette objectif le W3C commence à se doter de
nouveaux langages et outils plus performants : XML, RDF, OWL ... etc.
Partant de séparation de contenu et de
présentation grâce à XML, à la description des
ressources Web par RDF, à la possibilité de faire des
raisonnements par OWL, le Web sémantique commence à être
une réalité et tout un axe de développement est ouvert.
Rendre le Web sémantique, est aussi munir les agents
logiciel d'une certaine intelligence et donc d'une connaissance pour qu'ils
puissent travailler en coopération avec l'homme.
Le Web sémantique a fait recourt à
l'ingénierie des connaissances, pour disposer d'un outil de
représentation des connaissances adéquat et il paraît que
les ontologies étaient les plus adaptés pour un tel contexte. Une
ontologie est un système conceptuel qui permet le partage de
connaissances entre humains et ordinateurs et entre ordinateurs.
1

Les propriétés clés de l'architecture du
Web Sémantique (sens partagé commun, métadonnées
traitables par les machines), apparaissent suffisamment puissantes pour
résoudre le problème de recherche d'information pertinente, celui
d'adaptation et de personnalisation des contenus, ainsi que le problème
d'intégration des sources de données
hétérogènes.
De ce fait le Web Sémantique est
considéré comme une plateforme adéquate pour
implémenter un système e-learning, du moment qu'il fournit tous
les moyens pour le développement d'ontologies permettant l'annotation du
matériel d'apprentissage.
Cadre du projet
Notre projet se situe à l'intersection du Web
sémantique avec le domaine d'enseignement à distance. Il ne
s'agit pas cependant de développer tout un environnement de formation
à distance, ou de couvrir toutes les utilisations d'ontologies dans ce
domaine.
Le but de notre projet est de concevoir une ontologie pour
annoter et rechercher des documents pédagogiques sur une plate forme
d'enseignement à distance.
Travail à réaliser
Notre projet vise le développement d'une application
qui permet l'annotation et la recherche de documents pédagogiques en
exploitant les métadonnées qui les décrivent, pour
réaliser notre objectif on va se servir des nouvelles technologies du
Web sémantique.
Notre travail va se dérouler en trois grandes
étapes :
1- Concevoir une ontologie d'application qui décrit les
documents pédagogiques utilisés pour l'enseignement
universitaire.
2- Se baser sur le vocabulaire fournis par l'ontologie pour
annoter un ensemble de document de notre choix.
3- Effectuer la recherche des documents, on se basant sur leurs
métadonnées. 2
|
Web sémantique
|
Ontologies & e-learning
|
Conception
|
Implémentation
|
1
Web sémantique
«The Semantic Web is an extension of the current web in
which information is given well-defined meaning, better enabling computers and
people to work in cooperation»
Tim Berners-Lee, James Hendler, Ora Lassila The Semantic
Web, Scientific American, May 2001
Introduction
Le Web Sémantique constitue un environnement dans
lequel les humains et les machines vont communiquer selon une base
sémantique .Une des caractéristiques principales est la
compréhension partagée basée sur un squelette
d'ontologie.
Le Web sémantique, en fait, est une architecture
composée, il se base sur plusieurs technologies, spécifications
et normes (ontologies, XML, RDF, RDFS, OWL).
Dans ce chapitre on va présenter ce qui est le Web
sémantique, ainsi que ses langages et ses applications.
I. Insuffisance du Web actuel
Sur Internet on peut accéder à un grand volume
d'information, ce qu'on considère depuis quelques années,
insuffisant car on s'est rendu compte qu'il n'y a pas un réel partage de
connaissance.
Une recherche d'information sur le Web repose sur
l'utilisation de mots ou de phrases incluses dans des documents, ce qui conduit
à des résultats non pertinents car on ne dispose d'aucune
information de nature sémantique à propos du contenu.
II. Web sémantique, quoi de nouveau ?
Pour rendre le Web sémantique, il faut que toutes les
ressources Web soient décrites par des
|
3
|
|
|
Web sémantique
|
Ontologies & e-learning
|
Conception
|
Implémentation
|
métadonnées, ce qui permet aux machines une
meilleure exploitation de ces ressources.
On peut définir les métadonnées comme
"des données relatives à des données" traitables par une
machine [1], pour le cas des documents pédagogiques, le contenu des
documents sont les données, et les informations relatives aux auteurs,
à leurs champs d'intérêt, à leurs objectifs
pédagogiques sont des métadonnées.
Par ressource on désigne tout ce qu'on peut trouver sur
le Web: par exemple des documents, ou même une composante d'une autre
ressource plus grande; par exemple un paragraphe spécifique d'un
document
IV. Langage du Web sémantique
IV.1. le World Wide Web Consortium (W3C)
Fondé en 1994, pour développer les protocoles
nécessaires à l'évolution du Web, c'est un consortium
international qui regroupe de nombreux professionnels de l'industrie, du
service, de la recherche et de l'enseignement partageant les mêmes
objectifs d'évolution et de stabilisation à long terme des
technologies du Web.
IV.2. Architecture du Web sémantique
L'architecture du Web Sémantique proposée par W3C
s'appuie sur une pyramide de langages :
Au niveau le plus bas se trouvent les données brutes
codées par le standard Unicode, ces données possèdent une
adresse URI (Uniforme Ressource Identifier) qui permet d'attribuer un
identifiant unique à chaque ressource.
Ces données peuvent être structurées
grâce à un langage de balises tels que XML (eXtensible Markup
language). La syntaxe XML peut être considérée comme
un premier niveau de sémantique, elle permet aux utilisateurs de
structurer les données en fonction de leur contenu sans rien dire de la
signification des structures.
Pour attribuer une signification à cette structure et
relier d'une façon pertinente les différents
éléments, Tim Berners-Lee propose le standard RDF (Resource
Description Framework) comme standard de représentation, standard
développée par le W3C.
|
4
|
|
|
Web sémantique
|
Ontologies & e-learning
|
Conception
|
Implémentation
|
Ce langage a pour but de donner une organisation plus
structurée des informations présentes sur le Web à travers
une description sémantique des données fournies par XML [2].
La signification sémantique des données XML
représentées par RDF est largement insuffisante pour assurer une
bonne distinction des différents concepts, il faut qu'on puisse
définir les concepts les uns par rapport aux autre, ce qui est possible
avec RDFS et OWL.
IV.3. Langage XML
Actuellement, Internet est un simple moyen d'accès
à du texte et à des images. Il n'existe pas de normes pour la
recherche intelligente, l'échange de données, la
présentation adaptable. Internet doit être plus qu'un espace
d'accès à des informations et une norme d'affichage. Il doit
définir une norme de gestion de l'information, une manière
commune de représenter les données afin que les logiciels
puissent plus facilement rechercher, déplacer, afficher et manipuler des
informations. Le HTML en est incapable car il s'agit d'un format qui
décrit l'affichage d'une page Web; il ne représente pas les
données [3].
C'est à partir de ce constat que le W3C a mis en place
la norme XML; XML fait Recommandation du W3C depuis le 10 février 1998,
ce langage est un métalangage facilitant l'élaboration de
langages à balises spécialisés.
Au départ, voilà une petite comparaison entre HTML
et XML:
· HTML définit le format de mise en page
(affichage ou impression) d'un document, alors que XML en définit la
structure, le contenu, indépendamment de la mise en page. Les documents
XML ont un DTD (Document Type Definition), les documents HTML n'en ont
pas.
· La grammaire de HTML est fixe, définie par le
standard, avec ses mots réservés et ses structures entre balises
(tags). XML, au contraire, permet de définir n'importe quelle structure
dans la mesure où elle est arborescente, avec notamment les balises que
l'on veut. On peut ainsi définir des structures standard au niveau d'une
profession, des DTD standards ont été définis pour
l'automobile, la chimie, les banques, les mathématiques, etc.
· Les documents HTML ont une structure séquentielle
avec un en-tête (header) et un corps (body). Les documents XML, eux, sont
des hiérarchies [4].
Web sémantique
|
Ontologies & e-learning
|
Conception
|
Implémentation
|
|
IV.3.1. Document XML
Une source de données est un document XML si elle est
« bien formée », c'est à dire si elle correspond
parfaitement à la spécification de XML.
Un document XML est représenté sous la forme d'un
fichier texte structuré en éléments, à l'aide de
balises éventuellement imbriquées.
En en-tête du document doit figurer un « prologue
», une déclaration qui identifie le document comme un document XML.
Ce prologue indique la version de XML employée, le codage de
caractères, et si le document est associé à une DTD ou
s'il est autonome.
Il existe un élément particulier :
l'élément « racine », encore appelé «
élément document ».
Cette racine doit contenir tous les autres
éléments du document et ne peut apparaître qu'une fois dans
un document XML.
A travers un exemple on va essayer de donner un aperçu
général sur la structure d'un document XML, cependant on ne peut
couvrir tout le détail du XML.
<?xml version=' 1.0'
encoding="ISO-8859- 1"?>
<catalogue>
<stage id="XMLpres">
<intitule>XML et les bases de
données</intitule>
<prerequis> connaître les langages
SQL et HTML</prerequis> </stage>
</catalogue>
|
|
IV.3.2. Document XML valide
En XML, des DTD (Document Type Definitions) peuvent accompagner
un document.
Elles définissent essentiellement les règles qui
lui sont propres, telles que les éléments présents et la
relation structurelle existant entre eux.
Web sémantique
|
Ontologies & e-learning
|
Conception
|
Implémentation
|
|
Un document bien formé est dit valide lorsqu'il respecte
une structure type définie dans une DTD.
Une DTD est un composant optionnel du prologue XML, elle peut
être interne ou externe.
Elle est interne lorsque sa définition se trouve dans le
document XML lui même, et si elle se trouve dans un autre fichier elle
est donc externe.
Si on associe une DTD externe à l'exemple
précédent on doit ajouter dans le prologue la balise suivante:
<!DOCTYPE catalogue SYSTEM
"DTDexterne.dtd">
Voici le fichier DTDexterne.dtd:
<!ELEMENT catalogue (stage)*>
<!ELEMENT stage (intitule,prerequis)> <!ELEMENT
intitule(#PCDATA)>
<!ELEMENT prerequis (#PCDATA | xref)*>
<!ELEMENT xref EMPTY>
<ATTLIST stage id ID #REQUIRED>
|
|
· Un catalogue est constitué de 0 jusqu'à N
stages (utilisation de *).
· Le symbole #PCDATA indique que
l'élément intitule peut contenir toute les
données XML.
· Un stage est constitué de deux
éléments qui sont 'intitule' et
'prerequis'
· La balise <ATTLIST stage id ID
#REQUIRED>
Sert à déterminer les attributs de
l'élément stage, ici il y a un seul qui est
"id", on a
spécifié qu'il est de type ID,
cela veut dire que la valeur qu'il peut prendre est un symbole
commençant par une lettre, et contient des lettres ,des chiffres, des
caractères « - » , « _ », «
. »,et « : ».
· Le symbole #REQUIRED indique que la
valeur de l'attribut id doit être spécifié par l'auteur de
document.
· Le symbole EMPTY désigne un
élément vide. NB: Le symbole "| " se lit
"et/ou", et le symbole "," veut dire "et".
Web sémantique
|
Ontologies & e-learning
|
Conception
|
Implémentation
|
|
Cependant, la DTD peut figurer dans le document XML lui
même en incluant dans le prologue l'ensemble des déclarations de
la DTD comme suit:
<?xml version='1
.0'?>
<!DOCTYPE catalogue[
<!ELEMENT catalogue (stage)*>
<!ELEMENT stage (intitule,prerequis)> <!ELEMENT
intitule(#PCDATA)>
<!ELEMENT prerequis (#PCDATA | xref)*>
<!ELEMENT xref EMPTY>
<ATTLIST stage id ID #REQUIRED> ]>
</catalogue>
<catalogue>
<stage id="XMLpres">
<intitule>XML et les bases de
données</intitule>
<prerequis> connaître les langages
SQL et HTML</prerequis> </stage>
|
|
IV.3.3. Espace des noms
Un document peut utiliser plusieurs DTD à la fois ce qui
peut conduire à des ambiguïtés, c'est le cas où deux
éléments appartenants à deux DTD différentes,
portent le même nom.
La solution est de préfixer le nom de
l'élément par l'espace des noms auquel il appartient.
IV.3.4. Feuilles de style
Un document XML peut être transformé en
utilisant des feuilles de style XSLT (eXtensible Stylesheet Language
Transformation) en un nouveau document : fichier XML, évidemment, mais
également tout autre format texte (pages html, fichier PDF, etc.).
IV.3.5. Parseur XML
Un parseur XML vérifie le format et la validité de
document XML, et offre la possibilité à un programme
d'accéder au contenu de document.
Le parseur XML lit le document XML, et déclenche des
événements contenants des informations sur la ligne lue. Par
exemple, lorsqu'il rencontre des balise d'ouverture ou de fermeture.
XML offre deux interfaces de programmation (API) qui
sont SAX (Simple API for XML) et DOM (Document Object
Model).
Web sémantique
|
Ontologies & e-learning
|
Conception
|
Implémentation
|
|
On se basant sur les évènements
déclenchés par le parseur, on peut écrire un programme
dans l'API SAX qui extrait les données qui nous intéresse.
On peut gérer le document XML autrement, grâce
à l'API DOM qui s'articule autour d'une représentation
hiérarchique du document XML.
IV.3.6. Avantage de XML
Le XML présente beaucoup d'avantages, on peut citer:
· Recherche plus significative
Les données peuvent être balisées de
façon très précise en XML. Ainsi un utilisateur peut
spécifier qu'il cherche des livres de `William Chekspir' plutôt
que des livres qui parlent sur `William Chekspir'. En effectuant la même
recherche et si le contenu n'est pas décrit en XML on aura comme
réponse les deux types de livres simultanément.
· Vues multiples sur les données
En XML on décrit les données et non pas la
manière dont elles seront affichés, ainsi les mêmes
données peuvent avoir différentes représentations selon
les préférences des utilisateurs.
· Traitement et manipulation de données en
local
Les données au format XML, une fois transmises au client,
peuvent être analysées, modifiées et manipulées en
local, le traitement étant réalisé par les applications
clientes.
· Interopérabilité
Des données provenant de plusieurs sources peuvent
être intégrées et manipulées par différentes
applications.
IV.3.7. Limitations du XML
C'est vrai qu'on peut définir nos propres balises en XML,
mais ces balises restent compréhensibles par des humains et non plus par
des machines.
Par exemple une machine ignore ce qui est un auteur dans une
balise XML :<auteur>, et ne peut savoir quelle relation peut exister
entre les concepts personne et auteur.
On ne peut exprimer par XML que des hiérarchies simples
de données.
Web sémantique
|
Ontologies & e-learning
|
Conception
|
Implémentation
|
|
IV.4. Langage RDF et RDFS
IV.4.1. RDF (1999)
Norme de description de ressources du Web proposée par
le W3C, comme son nom l'indique, RDF (Ressource Description Framework)
est un métalangage servant à encadrer la description de
ressources, permettant de rendre plus "structurée" l'information
nécessaire aux moteurs de recherche et, plus généralement,
nécessaire à tous outil informatique analysant de façon
automatisée des pages Web.
IV.4.1.1. Définition d'URI (Uniform Ressource
Identifier)
Dans la perspective de rendre le Web sémantique, les
choses doivent être clairement identifiées, sans quoi il n'est pas
possible de partager l'information. La notion de personne fournit un bon
exemple:il existe des dizaines de `François Martin' en France; comment
décrire l'un d'eux sur le web, sans risquer de le confondre avec
d'autres. La solution proposé par le web sémantique est
d'associer un identifiant unique à chaque chose:il s'agit de l'URI.
[5]
On peut créer n'importe quelle métadonnée
sur n'importe quelle ressource du moment où on connaît son URI. On
peut choisir les URL (Uniform Ressource Locator) comme des URI.
IV.4.1.2. Syntaxe RDF
RDF permet de formaliser des connaissances sous forme de
triplets RDF .chaque triplet est constitué d'un sujet
,d'un prédicat et d'un objet, un
ensemble de tels triplets est appelé graphe RDF.
Un objet peut être une ressource, un littéral (Une
ressource référencé par une URI), ou une simple
chaîne ou tout autre type de données primitif défini par
XML.
Sur le graphe on représente les noeuds par des ovales, les
feuilles par des rectangles et Les arrêtes sont étiquetés
par des prédicats.
Ainsi si on prend l'énoncé suivant:
"http ://
www.iutc3.uniacen.fr/serge/présentation-2003-06-19.pdf
" a pour auteur
"
http://www.iutc3.unicaen.fr/serge/",
le nom de l'auteur est "serge Stinckwich ".
Web sémantique
|
Ontologies & e-learning
|
Conception
|
Implémentation
|
|
Dans cet énoncé le sujet est bien"
http://www.iutc3.uniacen.fr/serge/présentation-2003-06-
19.pdf",le prédicat est "a pour auteur",
l'objet est "
http://www.iutc3.unicaen.fr/serge/",
qui représente lui même un sujet dans un deuxième triplet
où le prédicat est "nom" et l'objet
est
" serge Stinckwich ".
Voici la représentation de l'énoncé sous
forme d'un graphe :
http://www.iutc3.uniacen.fr/serge/présentation-2003-06-19.pdf
ref Auteur
http://www.iutc3.unicaen.fr/serge/
Nom
Serge Stinckwich
Fig I.1 : Exemple de représentation sous forme de
graphe RDF repose sur la syntaxe XML, ainsi notre énoncé
sera écrit comme suit :
IV.4.2. RDFS (2000)
L'objectif de RDF est de proposer un cadre formel de
définition de métadonnées, sans préjuger des
vocabulaires et syntaxes utilisés pour écrire ces
métadonnées. Un schéma RDF avec des concepts de bases peut
offrir cette capacité en utilisant des classes de ressources.
Web sémantique
|
Ontologies & e-learning
|
Conception
|
Implémentation
|
|
RDFS (Ressource Description Framework Schema) ajoute
à RDF la possibilité de définir des hiérarchies de
classes et de propriétés dont l'applicabilité et le
domaine de valeurs peuvent être contraints à l'aide des attributs
rdfs:domain et rdfs:range, une classe est
instanciée par l'utilisation de l'attribut rdf:type.
[2]
Voici un exemple qui défini une classe «
herbivore », et qui instancie de cette classe une
ressource "
http://www.ontoknowledge.org/Definedclass
" , et la définie comme sous classe de la classe
"animal":
Voici un autre exemple qui utilise les attributs
rdfs:domain et rdfs:range pour
désigner que la propriété
"frère de" est une fonction qui a pour domaine les
individus de la classe "homme" et pour image les individus de
la classe "humain" :
<rdf:Property
rdf:ID="frère_de" > <rdfs:domain
rdf:resource="#homme"/> <rdfs:range
rdf:resource="#humain"/> </rdf:Property>
|
|
IV.5. Le langage OWL
IV.5.1. Les ontologies
Tout un chapitre sera consacré aux ontologies, mais une
petite définition sera utile pour la compréhension du reste du
chapitre.
Une ontologie est une représentation structurée des
connaissances d'un domaine, sous forme d'un réseau de concepts
reliés entre eux par des liens sémantiques.
Les recherches sur les ontologies sont essentielles pour la
réalisation du Web sémantique. En
effet une fois construite et
acceptée par une communauté particulière, une ontologie
doit traduire
Web sémantique
|
Ontologies & e-learning
|
Conception
|
Implémentation
|
|
un certain consensus explicite et un certain niveau de partage,
qui sont essentiels pour permettre l'exploitation des ressources Web par
différentes applications ou agent logiciels. [6]
Pour représenter les ontologies le W3C propose un
standard qui est le OWL (Ontology Web Language).
IV.5.2. Présentation du OWL
OWL est tout comme RDF un langage XML profitant de
l'universalité syntaxique du XML. OWL offre la possibilité
d'écrire des ontologies Web.
Il ajoute la possibilité de faire la comparaison entre
des propriétés et des classes: identité,
équivalence, contraire, symétrie, cardinalité,
transitivité, disjonction, etc.
OWL permet de définir un vocabulaire extrêmement
riche, ce qui donne aux machines une plus grande capacité de
manipulation du contenu Web.
Le W3C a doté OWL de trois sous langages offrant des
capacités d'expression croissantes et c'est selon les besoins qu'on
choisit le langage qui convient.
· OWL Lite est le sous langage de OWL le
plus simple, il est destiné à représenter des
hiérarchies de concepts simples.
· OWL DL est plus complexe que le
précédent, il est fondé sur la logique descriptive d'ou
son nom (OWL Description Logics) .Il est adapté pour faire des
raisonnements, et il garantit la complétude des raisonnement et leurs
décidabilité.
· OWL Full est la version la plus
complexe du OWL, destiné aux situations ou il est important d'avoir un
haut niveau de capacité de description, quitte à ne pas pouvoir
garantir la complétude et la décidabilité des calculs
liés à l'ontologie. [7]
IV.5.3. Document OWL
Les ontologies OWL se présentent sous forme de
fichiers texte, avec extension <<.owl>>ou
<<.rdf>>. L'intégralité du
vocabulaire de OWL provient de l'espace de nom de OWL,
http://www.w3.org/2002/07/owl#.
OWL repose sur RDF et RDFS, et ajoute notamment des nouvelles
balises.
Web sémantique
|
Ontologies & e-learning
|
Conception
|
Implémentation
|
|
IV.5.4. Structure d'une ontologie en OWL
Cette partie indique les principaux éléments
constituant une ontologie OWL. IV.5.4.1. Espace de nommage
Afin de pouvoir employer des termes dans une ontologie, il
est nécessaire d'indiquer avec précision de quels vocabulaires
ces termes proviennent. C'est la raison pour laquelle, une ontologie commence
par une déclaration d'espace de nom contenue dans une balise
rdf:RDF.
Supposons que nous souhaitons écrire une ontologie sur
une population de personnes ou, d'une manière plus
générale, sur l'humanité. Voici la déclaration
d'espace de nom qui pourrait être employée :
Les deux premières déclarations identifient
l'espace de nommage propre à l'ontologie que nous sommes en train
d'écrire. La première déclaration d'espace de nom indique
à quelle ontologie se rapporter en cas d'utilisation de noms sans
préfixe dans la suite de l'ontologie. La troisième
déclaration identifie l'URI de base de l'ontologie courante.
La quatrième déclaration signifie simplement
que, au cours de la rédaction de l'ontologie humanité, on va
employer des concepts développés dans une ontologie vivant, qui
décrit ce qu'est un être vivant.
Web sémantique
|
Ontologies & e-learning
|
Conception
|
Implémentation
|
|
Les quatre dernières déclarations introduisent le
vocabulaire d'OWL et les objets définis dans l'espace de nommage de RDF,
du schéma RDF et des types de données du Schéma XML.
IV.5.4.2. En-tête d'une ontologie
A la suite de la déclaration d'espaces de nom, un
en-tête décrivant le contenu de l'ontologie courante. C'est la
balise owl:Ontology qui permet d'indiquer ces informations
:
<owl:Ontology rdf:about="">
<rdfs:comment>Ontologie décrivant
l'humanité</rdfs:comment> <owl:imports
rdf:resource="
http://otherdomain.tld/otherpath/vivant"/>
<rdfs:label>Ontologie sur
l'humanité</rdfs:label>
|
|
IV.5.4.3. Eléments du langage
Cette partie ne va pas reprendre toutes les finesses de OWL
Lite, OWL DL et OWL Full, mais uniquement les plus importantes.
> Les classes
Une classe définit un groupe d'individus qui sont
réunis parce qu'ils ont des caractéristiques similaires.
L'ensemble des individus d'une classe est désigné par le terme
« extension de classe », chacun de ces individus étant alors
une « instance » de la classe. Les trois versions d'OWL comportent
les mêmes mécanismes de classe, à ceci près que OWL
FULL est la seule version à permettre qu'une classe soit l'instance
d'une autre classe (d'une méta classe). A l'inverse, OWL Lite et OWL DL
n'autorisent pas qu'une instance de classe soit elle-même une classe.
> Déclaration de classe
La déclaration d'une classe se fait par le biais du
mécanisme de « description de classe », qui
se présente sous diverses formes. Une classe peut ainsi se
déclarer de six manières différentes :
· l'indicateur de classe
La description de la classe se fait, dans ce cas, directement
par le nommage de cette classe. Une classe « humain » se
déclare de la manière suivante :
Web sémantique
|
Ontologies & e-learning
|
Conception
|
Implémentation
|
|
<owl:Class rdf:ID="Humain" />
Il est à noter que ce type de description de classe
est le seul qui permette de nommer une classe. Dans les cinq autres cas, la
description représente une classe dite « anonyme
», crée en plaçant des contraintes sur son extension.
~ l'énumération des individus composant la
classe
Ce type de description se fait en énumérant les
instances de la classe, à l'aide de la propriété
owl:oneOf :
<owl:Class>
<owl:oneOf
rdf:parseType="Collection"> <owl:Thing
rdf:about="#Damien" /> <owl:Thing rdf:
about="#Olivier" /> <owl:Thing rdf:
about="#Philippe" /> <owl:Thing
rdf:about="#Xavier" /> <owl:Thing
rdf:about="#Yves" /> </owl:oneOf>
</owl:Class>
|
|
Si ce mécanisme est utilisable avec OWL DL et OWL FULL,
il ne fait cependant pas partie de OWL Lite.
· La restriction de
propriétés
La description par restriction de propriété permet
de définir une classe anonyme composée de toutes les instances de
owl:Thing qui satisfont une ou plusieurs
propriétés.
Ces contraintes peuvent être de deux types :
contrainte de valeur ou contrainte de
cardinalité.
Une contrainte de valeur s'exerce sur la valeur d'une
certaine propriété de l'individu (par exemple, pour un individu
de la classe Humain, sexe = Homme), tandis qu'une contrainte de
cardinalité porte sur le nombre de valeurs que peut prendre une
propriété (par exemple, pour un individu de la classe Humain,
aPourFrere est une propriété qui peut ne pas avoir de valeur, ou
avoir plusieurs valeurs, suivant le nombre de frères de l'individu. La
contrainte de cardinalité
Web sémantique
|
Ontologies & e-learning
|
Conception
|
Implémentation
|
|
portant sur aPourFrere restreindra donc la classe décrite
aux individus pour lesquels la propriété aPourFrere
apparaît un certain nombre de fois).
Enfin, les descriptions par intersection, union ou
complémentaire permettent de décrire une classe par
l'intersection, l'union ou le complémentaire d'autres classes
déjà définies, ou dont la définition se fait au
sein même de la définition de la classe courante .
Dans l'exemple on définit une nouvelle classe qui est
l'intersection de la classe collection avec la restriction de
la classe etudiantsENST sur les étudiants ayant deux
frères:
<owl:Class>
<owl:intersectionOf
rdf:parseType="Collection">
<owl:Class rdf:
about="#etudiantsENST" />
<owl:Restriction>
<owl:onProperty
rdf:resource="#aPourFrere" />
<owl:cardinality
rdf:datatype="&xsd;nonNegativeInteger"> 2
</owl:cardinality>
</owl:Restriction >
</owl:intersectionOf>
</owl:Class>
|
|
> Héritage
Il existe dans toute ontologie OWL une superclasse,
nommée Thing, dont toutes les autres classes sont des
sous-classes. Ceci nous amène directement au concept d'héritage,
disponible à l'aide de la propriété
subClassOf :
<owl:Class
rdf:ID="Humain">
<rdfs:subClassOf
rdf:resource="&etre;#EtreVivant" />
</owl:Class>
<owl:Class
rdf:ID="Homme">
<rdfs:subClassOf
rdf:resource="#Humain" />
|
|
Web sémantique
|
Ontologies & e-learning
|
Conception
|
Implémentation
|
|
</owl:Class>
<owl:Class
rdf:ID="Femme">
<rdfs:subClassOf
rdf:resource="#Humain" />
</owl:Class>
Enfin, il existe également une classe nommée
noThing, qui est sous-classe de toutes les classes OWL. Cette
classe ne peut avoir aucune instance.
> Les instances de classe
La définition d'un individu consiste à
énoncer un « fait », encore appelé
« axiome d'individu ». On peut distinguer deux types
de faits :
~ les faits concernant l'appartenance à une classe
La plupart des faits concernent généralement la
déclaration de l'appartenance d'un individu à une classe et les
valeurs de propriété de cet individu. Un fait s'exprime de la
manière suivante :
<Humain
rdf:ID="Pierre">
<aPourPere rdf:resource="#Jacques"
/> <aPourFrere rdf:resource="#Paul" />
</Humain>
|
|
Le fait écrit dans cet exemple exprime l'existence d'un
Humain nommé « Pierre » dont
le père s'appelle « Jacques », et qu'il
a un frère nommé « Paul
».
On peut également instancier un individu
anonyme en omettant son identifiant :
<Humain>
<aPourPere rdf:resource="#Jacques"
/> <aPourFrere rdf:resource="#Paul" />
</Humain>
|
|
Ce fait décrit, dans ce cas, l'existence d'un
Humain dont le père se nomme «
Jacques » et qui a un frère nommé
« Paul ».
~ les faits concernant l'identité des individus
Web sémantique
|
Ontologies & e-learning
|
Conception
|
Implémentation
|
|
Une difficulté qui peut éventuellement
apparaître dans le nommage des individus concerne la non-unicité
éventuelle des noms attribués aux individus. Par exemple, un
même individu pourrait être désigné de plusieurs
façons différentes.
C'est la raison pour laquelle OWL propose un mécanisme
permettant de lever cette ambiguïté, à l'aide des
propriétés owl:sameAs,
owl:diffrentFrom et owl:allDifferent.
L'exemple suivant permet de déclarer que les noms «
Louis_XIV » et « Le_Roi_Soleil
» désignent la même personne.
<rdf:Description
rdf:about="#Louis_XIV"> <owl:sameAs
rdf:resource="#Le_Roi_Soleil" />
</rdf:Description>
|
|
> Les propriétés
Maintenant que l'on sait écrire des classes OWL, il ne
manque plus que la capacité à exprimer des faits au sujet de ces
classes et de leurs instances. C'est ce que permettent de faire les
propriétés OWL.
OWL fait la distinction entre deux types de
propriétés :
· les propriétés d'objet
permettent de relier des instances à d'autres instances
· les propriétés de type de
donnée permettent de relier des individus à des valeurs
de données.
Une propriété d'objet est une instance de la
classe owl:ObjectProperty, une propriété de type
de donnée étant une instance de la classe
owl:DatatypeProperty. Ces deux classes sont elles même
sous-classes de la classe RDF rdf:Property.
La définition des caractéristiques d'une
propriété se fait à l'aide d'un axiome de
propriété qui, dans sa forme minimale, ne fait qu'affirmer
l'existence de la propriété
<owl:ObjectProperty
rdf:ID="aPourParent" />
Cependant, il est possible de définir beaucoup d'autres
caractéristiques d'une propriété dans un axiome de
propriété.
|
19
|
|
|
Web sémantique
|
Ontologies & e-learning
|
Conception
|
Implémentation
|
> Définition d'une
propriété
Afin de spécifier une propriété, il
existe différentes manières de restreindre la relation qu'elle
symbolise. Par exemple, si on considère que l'existence d'une
propriété pour un individu donné de l'ontologie constitue
une fonction faisant correspondre à cet individu un autre individu ou
une valeur de donnée, alors on peut préciser le domaine et
l'image de la propriété. Une propriété peut
également être définie comme la spécialisation d'une
autre propriété.
|
<owl:ObjectProperty
rdf:ID="habite"> <rdfs:domain
rdf:resource="#Humain" /> <rdfs:range
rdf:resource="#Pays" />
</owl:ObjectProperty>
|
Dans l'exemple ci-dessus, la propriété
habite a pour domaine la classe
Humain et pour image la classe
Pays : elle relie des instances de la classe Humain à des
instances de la classe Pays. Dans le cas d'une propriété
de type de donnée, l'image de la propriété peut
être un type de donnée, de Schéma XML.
Par exemple, on peut définir la propriété de
type de données anneeDeNaissance :
|
<owl:Class rdf:ID="dateDeNaissance"
/>
<owl:DatatypeProperty
rdf:ID="anneeDeNaissance"> <rdfs:domain
rdf:resource="#dateDeNaissance" /> <rdfs:range
rdf:resource="&xsd;positiveInteger"/>
</owl:DatatypeProperty>
|
Dans ce cas, anneDeNaissance fait
correspondre aux instances de la classe de dateDeNaissance des
entiers positifs .On peut également employer un mécanisme de
hiérarchie entre les propriétés, exactement comme il
existe un mécanisme d'héritage sur les classes :
|
<owl:Class rdf:ID="Humain"
/>
<owl:ObjectProperty
rdf:ID="estDeLaFamilleDe"> <rdfs:domain
rdf:resource="#Humain" />
<rdfs:range rdf:resource="#Humain"
/>
|
|
20
|
|
|
Web sémantique
|
Ontologies & e-learning
|
Conception
|
Implémentation
|
|
</owl:ObjectProperty> <owl:ObjectProperty
rdf:ID="aPourFrere">
<rdfs:subPropertyOf
rdf:resource="#estDeLaFamilleDe" />
<rdfs:range rdf:resource="#Humain"
/>
...
</owl:ObjectProperty>
</owl:Class>
|
La propriété aPourFrere est une
sous propriété de estDeLaFamilleDe, ce qui
signifie que toute entité ayant une propriété
aPourFrere d'une certaine valeur a aussi une
propriété estDeLaFamilleDe de même
valeur.
> Caractéristiques des
propriétés
En plus de ce mécanisme d'héritage et de
restriction du domaine et de l'image d'une propriété, il existe
divers moyens d'attacher des caractéristiques aux
propriétés, ce qui permet d'affiner grandement la qualité
des raisonnements liés à cette propriété.
Parmi les caractéristiques de propriétés
principales, on trouve la transitivité, la symétrie, l'inverse,
etc. L'ajout d'une caractéristique à une propriété
de l'ontologie se fait par l'emploi de la balise type :
|
<owl:ObjectProperty
rdf:ID="aPourPere"> <rdfs:domain
rdf:resource="#Humain" /> <rdfs:range
rdf:resource="#Humain" />
</owl:ObjectProperty>
<owl:ObjectProperty
rdf:ID="aPourFrere">
<rdf:type rdf:resource="&owl; SymmetricProperty"
/>
<rdfs:domain rdf:resource="#Humain"
/> <rdfs:range rdf:resource="#Humain" />
</owl:ObjectProperty>
<Humain
rdf:ID="Pierre">
<aPourFrere rdf:resource="#Paul"
/>
|
|
21
|
|
|
Web sémantique
|
Ontologies & e-learning
|
Conception
|
Implémentation
|
|
<aPourPere rdf:resource="#Jacques"
/> </Humain>
|
L'Humain Pierre a pour frère Paul, de même que
(symétrie) l'Humain Paul a pour frère Pierre.
Par contre, si
Pierre a pour père Jacques, l'inverse n'est pas vrai (aPourPere n'est
pas symétrique).
V. Travaux du Web sémantique et domaines
d'application
V.1. Recherche d'information
Le Web sémantique cherche à atteindre une certaine
maîtrise des contenus, afin de fournir des réponses pertinentes
aux utilisateurs.
A titre d'exemple, un enseignant qui cherche un document de
type « course» aura certainement une réponse pertinente du
moment qu'il peut exprimer qu'il cherche un document de type « course
» , est que tout les document ont une métadonnée « type
de document» qui provient de l'ontologie qui décrit les documents
pédagogique ; ce n'est pas le cas si la requête a
été lancé sur un moteur de recherche classique, qui va
retourné des documents contenant le mot « course » et ceux qui
contiennent le mot « of course».
La recherche d'information fait partie de la plus part des
applications Web, on peut citer : le e-learning, le e-commerce, ... etc.
V.2. l'adaptation /personnalisation
Au travers d'Internet, un nombre potentiellement infini de
services et de documents est accessible à tous les usagers. La plupart
des services et documents fournis actuellement sur Internet proposent une
organisation, un contenu, un mode d'interaction et une présentation
uniques pour tous. Ceci peut être suffisant dans certains cas. Mais tous
les utilisateurs ne sont pas intéressés par les mêmes
informations et n'ont pas les mêmes attentes, connaissances,
compétences, centres d'intérêts, etc. [6]
C'est le cas dans un système e-learning, on cherche
à adapter le contenu d'apprentissage aux préférences des
apprenants, et de donner la possibilité aux enseignants de
réutiliser un contenu, de le combiner avec un autre pour construire un
nouveau document.
|
22
|
|
|
Web sémantique
|
Ontologies & e-learning
|
Conception
|
Implémentation
|
Tout cela peut être possible si le contenu et la
structure des documents utilisés pour la formation, sont décrits
par le biais des ontologies et si on arrive à avoir des standards de
modèles utilisateur/utilisation sous formes d'ontologies.
V.3. Intégration des sources de données
hétérogènes
Le but d'intégration des sources de données
hétérogènes, est d'offrir aux utilisateurs une vision
homogène du système qui les utilise .Le e-commerce
présente un très bon exemple des domaines qui peuvent
bénéficier d'une telle amélioration.
Avant, l'utilisateur était obligé d'interroger
lui même ces source de données, chacune avec son langage de
requête ; des travaux ont été faits dans le cadre de Web
pour construire des systèmes homogènes en se basant sur une des
deux approches:l'approche médiateur et l'approche entrepôts de
données.
Le Web sémantique réutilise l'approche
médiateur, tout en ajoutant une ontologie qui va fournir un vocabulaire
commun, qui sera utilisé pour interroger le système.
Un médiateur va interroger les sources de
données, et répondre à la requête lancée par
l'utilisateur, en utilisant également les termes de l'ontologie.
VI. Conclusion
Dans ce chapitre nous avons présenté la nouvelle
vision du Web sémantique, qui vient pour améliorer l'exploitation
des ressources sur le Web, on ajoutant des métadonnées traitables
par machine.
Nous avons présenté comment la norme XML a
construit un premier niveau sémantique, qui est à la base des
langages RDF, RDFS et OWL qui permettent l'écriture des
métadonnées décrivant les ressources Web.
On a aussi parler de quelques travaux du Web
sémantique, et de comment l'usage des ontologies en particulier, permet
d'améliorer la recherche d'information, l'adaptation, personnalisation
des contenus et encore l'intégration du sources de données
hétérogènes, chose qui va satisfaire les utilisateurs de
la plupart des applications Web dans différents domaines et y compris
le
e-learning.
|
23
|
|
|
Web sémantique
|
Ontologies & e-learning
|
Conception
|
Implémentation
|
2
Ontologies & e-learning
Ontologies are formal and consensual specifications of
conceptualizations that provide a shared
understanding of a domain, an
understanding that can be communicated across people and
application
systems.
(Fensel D., Ontologies: A Silver Bullet for knowledge
Management
and Electronic Commerce ,Springer ,
Berlin-Heidelberg-New York,
2004)
I. Introduction
La démarche du Web sémantique consiste à
ajouter des métadonnées aux ressources Web qui décrivent
leurs contenus et leurs fonctionnalités, ces métadonnées
doivent s'appuyer sur des ontologies afin de pouvoir être partagés
et munies d'interprétations opérationnelles. Les ontologies
constituent l'une des bases les plus importantes de l'approche Web
sémantique pour le e-learning.
Ce chapitre contient une présentation de la notion
d'ontologie, une description des méthodologies et des outils
d'ingénierie ontologique suivie par une exploration de l'apport des
ontologies aux systèmes e-learning.
II. Les ontologies II.1. Historique sur
l'ontologie
L'ingénierie de connaissances (IC) a longtemps
été considérée comme le domaine de
prédilection du développement d'expertise en conception de
système à base de connaissances. Malgré le fait que
l'ingénierie des connaissances ait contribué à
accroître cette expertise en l'organisant dans une perspective
computationnelle, certains membres de la communauté de l'intelligence
ont éprouvé le besoin de passer à une ingénierie
s'appuyant plus solidement sur des fondements théoriques et
méthodologiques, afin d'améliorer la conception des
systèmes intelligents ;historiquement, l'ingénierie ontologique
(IO) a émergé de l'ingénierie des connaissances
l'ingénierie ontologique permet de spécifier la conceptualisation
d'un système,
|
24
|
|
|
Web sémantique
|
Ontologies & e-learning
|
Conception
|
Implémentation
|
c'est à dire, de lui fournir une représentation
formelle des connaissances qu'il doit acquérir, sous la forme de
connaissances déclaratives exploitables par un agent. Ainsi,
l'exploitation par un mécanisme d'inférence, d'une
représentation de type déclarative telle que l'ontologie, tout en
suivant les règles d'inférence définie dans cette
ontologie, est la source de l'intelligence de système.
L'ingénierie de connaissances a ainsi donné
naissance à l'ingénierie ontologique, où l'ontologie est
l'objet clé sur lequel il faut se pencher. La nécessité
d'une ontologie et d'une ingénierie ontologique des systèmes
à base de connaissances commence à être comprise et
accepté. [8]
II.2. Notion d'ontologie
Le mot « Ontologie » vient du grec : ontos
pour être et logos pour univers. C'est un terme
philosophique introduit au XIXème siècle qui
caractérise l'étude des êtres dans notre univers.
En informatique, plusieurs définitions ont
été données à l'ontologie :
En 1993, Gruber propose sa définition : « An
ontology is an explicit specification of a conceptualization »
En 1997, Borst modifia légèrement la
définition de Gruber en énonçant que: « Une
ontologie est définie comme étant une spécification
formelle d'une conceptualisation partagé »
Ces deux définitions ont été
expliquées par Studer et ses collègues comme suit :
Conceptualisation réfère à un modèle
abstrait d'un phénomène dans le monde, en ayant identifiés
les concepts appropriés à ce phénomène.
Explicite signifie que le type de concepts
utilisés et les contraintes liés à leur usage sont
définis explicitement.
Formel réfère au fait qu'une ontologie
doit être traduite en langage interprétable par une machine.
Partagé réfère au fait qu'une
ontologie capture la connaissance consensuelle,c'est-à-dire non
réservée à quelques individus,mais partagée par un
groupe ou une communauté.[8]
Le domaine de l'ontologie attire l'attention parce qu'une
ontologie fournit :
1) une structure conceptuelle de base à partir de
laquelle il est possible de développer des systèmes à base
de connaissances qui soient partageables, et réutilisables.
2) l'interopérabilité entre les sources
d'information et de connaissances.
|
25
|
|
|
Web sémantique
|
Ontologies & e-learning
|
Conception
|
Implémentation
|
Considérons les différences entre deux types
d'ontologies : une ontologie orientée Web sémantique, et une
ontologie orientée concept. Une ontologie orienté concept traite
les concepts fondamentaux du monde cible qui demandent à être
examinés en profondeur tandis qu'une ontologie orienté Web
sémantique est un vocabulaire lisible par ordinateur qui définit
la signification des métadonnées ; elle est utilisée
principalement pour réaliser l'interopérabilité
sémantique entre les ressources informationnelles grâce aux
métadonnées. Ce type d'ontologies peut être
qualifiée d'ontologie de surface, puisqu'elle ne traite pas
nécessairement de la structure conceptuelle profonde du monde cible.
[9]
Pour mieux saisir la notion d'ontologie on présente ici
ce qui est la différence entre une ontologie et une base de connaissance
et entre une ontologie et une hiérarchie de classes dans le paradigme
orienté objet.
II.2.1. Différence entre ontologie et base de
connaissance
Farquhar en 1997 lors d'un forum de discussion sur l'ontologie
propose que plus la réponse aux questions suivantes soit positive, plus
c'est ontologique que base de connaissance:
« Est ce que cela exprime la connaissance
consensuelle d'une communauté de gens ? Est-ce que les gens l'utilisent
comme une référence de termes définis avec
précision ? Est-ce que le langage utilisé est suffisamment
expressif pour que les gens puissent dire ce qu'ils veulent dire ? Est-ce que
cela peut être utilisé pour de multiples cas de résolution
de problèmes ? Est-ce que c'est stable ? Est-ce que cela peut être
utilisé pour résoudre une variété de
différents types de problèmes ? Est-ce que cela peut être
utilisé comme pont de départ pour construire de multiples types
d'applications incluant une base de connaissances, un schéma de base de
données ou un programme orienté objet ? ».
Cela veut dire qu'une différenciation claire entre
« ontologie » et « base de connaissances» devrait se faire
à partir de son rôle, une ontologie fournit un système de
concepts qui sont utilisées pour construire une base de connaissances
par-dessus ; par conséquent, une ontologie peut être une
spécification de la conceptualisation du monde cible que se fait
l'ingénieur qui construit la base de connaissances, donc un méta
système d'une base de connaissances traditionnelle.
|
26
|
|
|
Web sémantique
|
Ontologies & e-learning
|
Conception
|
Implémentation
|
II.2.2. Différence entre ontologie et
hiérarchie de classes
Au niveau supérieur, la méthodologie de
développement d'une ontologie et celle d'une hiérarchie
orientée objet sont similaires. Cependant au niveau inférieur,
l'ontologie se concentre sur les aspects déclaratifs tandis que la
hiérarchie orientée objet se concentre sur les aspects
reliés à la performance. Par conséquent, la
différence essentielle entre les deux est que l'ontologie exploite la
représentation déclarative, tandis que le paradigme
orienté objet est intrinsèquement procédural, la
signification d'une classe, d'une relation entre des classes, ainsi que les
méthodes sont intégrées de façon
procédurale.
Dans le paradigme ontologique les descriptions sont faites de
façon déclarative, ce qui permet au système de modifier
son comportement en modifiant la connaissance qu'il possède. [9]
II.3. Composantes d'une ontologie
Les connaissances décrivant un domaine on utilisant la
notion d'ontologie sont représentés par
les cinq
éléments suivants : Les concepts, les relations, les axiomes, les
fonctions et les instances.
· Concept
Les concepts peuvent être une pensée, un
principe, une notion profonde. Ils sont appelées aussi termes ou classes
de l'ontologie, selon Gomez Pérez ces concepts peuvent être
classifiés selon plusieurs dimensions :
1) niveau d'abstraction (concret ou abstrait).
2) Atomicité (élémentaire ou
composée).
3) Niveau de réalité (réel ou fictif).
· Relation
Les relations d'une ontologie désigne les
différentes interactions et corrélations entre les concepts de
l'ontologie ces relations englobent les associations suivantes :
Sous classe de (spécification ou
généralisation), partis de (agrégation ou composition),
associé a, instance de, est un ... etc.
Web sémantique
|
Ontologies & e-learning
|
Conception
|
Implémentation
|
|
· Axiome
Les axiomes sont utilisés pour décrire les
assertions de l'ontologie qui seront considérés après
comme vrais, cette détermination a pour but de définir les
significations des composants d'ontologie, les contraintes sur les valeurs des
attributs, et les arguments de relations.
· Fonction Elles constituent des cas
particuliers de relation, dans laquelle un élément de la
relation, le nième
est défini en fonction des n-1 éléments
précédents.
· Instance
C'est une définition extensionnelle de l'ontologie, par
exemple les individus « Amina » et « Saloua » sont des
instances du concept «personne». [2]
II.4. Classification des ontologies
Les ontologies peuvent être classifiées selon
plusieurs dimensions. Parmi celles-ci, nous en examinerons quatre :
II.4.1. Typologie selon l'objet de
conceptualisation
Par rapport à l'objet de la conceptualisation de
l'ontologie, quatre catégories au moins peuvent être
identifiées :
· Ontologie d'application
Contrairement a l'ontologie de domaine, l'ontologie d'une
application donnée ne peut pas être réutilisée pour
d'autre application, elle sert a décrire des conceptualisations de
domaine spécifique à l'application en question.
· Ontologie de domaine
Ces ontologies peuvent être réutilisées
pour plusieurs applications qui touchent un domaine, elle concerne la
description et la définition des connaissances d'un domaine à la
qu'elle l'application désirée appartienne.
· Ontologie générique (ontologie de
haut niveau)
Cette ontologie a l'objectif d'exprimer les connaissances
acceptables par différents domaines, elle permet de catégoriser
les choses du monde, par exemple, les relations, les actions, l'espace, le
temps, etc.
Web sémantique
|
Ontologies & e-learning
|
Conception
|
Implémentation
|
|
· Ontologie de représentation des
connaissances (méta ontologie) Elle décrit les concepts
utilisés par les langages de représentation des ontologies.
II.4.2. Typologie selon le niveau de détail de
l'ontologie
par rapport au niveau de détail utilisé lors de
la conceptualisation de l'ontologie en fonction de l'objectif
opérationnel envisagé pour l'ontologie, deux catégories au
moins peuvent être identifiées :
· Granularité fine
On parle sur ce niveau lorsque les ontologies sont
très détaillées, ou possèdent un vocabulaire plus
riche capable d'assurer une description détaillée des concepts
pertinents d'un domaine ou d'une tâche. Ce niveau de granularité
peut s'avérer utile lorsqu'il s'agit d'établir un consensus entre
les agents qui l'utiliseront.
· Granularité large
Correspondant à un vocabulaire moins
détaillé comme par exemple dans les scénarios
d'utilisation spécifiques où les utilisateurs sont
déjà préalablement d'accord à propos d'une
conceptualisation sous -jacente. Les ontologies de haut niveau possèdent
une granularité large, compte tenu que les concepts qu'elles traduisent
sont normalement raffinés subséquemment dans d'autres ontologies
de domaine ou d'application.
II.4.3. Typologie selon le niveau de
complétude
Par rapport au niveau de complétude, trois
catégories au moins peuvent être identifiées :
· Niveau sémantique
Tous les concepts (caractérisés par un
terme/libellé) doivent respecter les quatre principes
différentiels :
> communauté avec l'ancêtre.
> différence (spécification) par rapport
à l'ancêtre.
> communauté avec les concepts frères
(situés au même niveau).
> différence par rapport au concepts frères
(sinon il n'aurait pas lieu de le définir).
Web sémantique
|
Ontologies & e-learning
|
Conception
|
Implémentation
|
|
Ces principes correspondent à l'engagement
sémantique qui assure que chaque concept aura un sens univoque. Deux
concepts sémantiques sont identiques si l'interprétation du terme
à travers les quatre principes différentiels aboutit à un
sens équivalent.
· Niveau référentiel
Outre les caractéristiques énoncées au
niveau précédent, les concepts référentiels (ou
formels) se caractérisent par un terme dont la sémantique est
définie par une extension d'objets. L'engagement ontologique
spécifie les objets du domaine qui peuvent être associés
aux concepts, conformément à sa signification formelle. Deux
concepts formels sont identiques s'ils possèdent la même
extension.
· Niveau opérationnel
Outre les caractéristiques énoncées au
niveau précédent, les concepts du niveau opérationnel ou
computationnel sont caractérisés par les opérations qu'il
est possible de leur appliquer pour générer des inférences
(engagement computationnel).deux concepts opérationnels sont identiques
s'ils possèdent le même potentiel d'inférence.
II.4.4. Typologie selon le niveau de
formalisme
Par rapport au niveau du formalisme de représentation du
langage utilisé pour représenter les ontologies, on distingue des
ontologies:
· informelles :dans un langage naturel
(sémantique ouverte).
· semi informelles : dans un langage
naturel structuré et limité.
· semi formelles :dans un langage
artificiel défini formellement.
· formelles : dans un langage artificiel
contenant une sémantique formelle. [2] II.5. Principes de
construction des ontologies
Le processus de construction d'ontologies, appelé
ingénierie ontologique, peut être décrit selon les
principes qui le gouvernent, et les méthodologies et les outils qui le
soutiennent.
II.5.1. Principes
Il existe un ensemble de critères et de principes qui ont
fait leurs preuves dans le développement des ontologies et qui peuvent
être résumés comme suit :
Web sémantique
|
Ontologies & e-learning
|
Conception
|
Implémentation
|
|
· Clarté et objectivité
(Gruber)
L'ontologie doit fournir la signification des termes
définis en fournissant des définitions objectives ainsi qu'une
documentation en langue naturelle.
· Complétude (Gruber)
Une définition exprimée par des conditions
nécessaires et suffisantes est préférée à
une définition partielle (définie seulement par une condition
nécessaire et suffisante).
· Cohérence (Gruber)
Une ontologie cohérente doit permettre des
inférences conformes à ces définitions.
· Extensibilité ontologique maximale
(Gruber)
De nouveaux termes généraux et
spécialisés devraient être inclus dans l'ontologie d'une
façon qui n'exige pas la révision des définitions
existantes (des définitions sur mesure).
· Principe de distinction ontologique
(Borgo)
Les classes dans une ontologie devraient être
disjointes.
· Distance sémantique minimale
(Arpirez)
Il s'agit de la distance minimale entre les concepts enfants
de mêmes parents. Les concepts similaires sont groupés et
représentés comme les sous classes d'une classe, et devraient
être définis en utilisant les même primitives,
considérant que les concepts qui sont moins similaires sont
représentés plus loin dans la hiérarchie.
· Normalisation des noms (Arpirez)
Ce principe indique qu'il est préférable de normaliser les
noms autant que possible.
Cet ensemble de critères et de processus est
généralement accepté pour guider le processus
d'ingénierie ontologique. [8]
II.6. Processus de construction
Le processus de construction d'une ontologie exploitable au sein
d'un système informatique repose sur deux étapes :
l'ontologisation et l'opérationnalisation.
Web sémantique
|
Ontologies & e-learning
|
Conception
|
Implémentation
|
|
· L'ontologisation consiste à construire une
ontologie conceptuelle. Construire une ontologie signifie qu'on a l'intention
de fournir une description du monde cible qui soit libre ou aussi libre que
possible, face à cette tâche l'ingénieur ontologique
considère les différentes sources de connaissance: des glossaires
de termes, d'autres ontologies, des textes, d'interviews d'experts, etc.
· L'opérationnalisation consiste à coder
l'ontologie conceptuelle obtenue à l'aide d'un langage de
représentation de connaissances opérationnel (doté de
mécanismes d'inférences).
Ontologisation
|
|
Opérationnalisation
|
|
Thesaurus, glossaires, Ontologies, cours, Textes, experts,
etc.
|
|
|
|
|
|
|
Ontologie Opérationnelle
|
|
|
|
Ontologie Conceptuelle
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Fig II.1. Processus de construction d'une
ontologie
Il est à noter que ce processus n'est pas linéaire
et que de nombreux allers-retours sont a priori nécessaires pour
développer une ontologie opérationnelle adaptée aux
besoins.
II.7. Méthodologies de construction
II.7.1. Méthode de Uschold et King «1995
»
Ils ont proposé la première méthode
d'ingénierie "générale", résultat de leurs travaux
de construction d'ontologies dans le domaine de la gestion des entreprises.
Initialement, cette méthode reposait sur quatre étapes :
- Identifier le but et la portée de l'ontologie.
- Construire l'ontologie : capturer les connaissances, coder,
réutiliser et intégrer des ontologies existantes.
- Évaluer l'ontologie.
- Documenter l'ontologie.
Web sémantique
|
Ontologies & e-learning
|
Conception
|
Implémentation
|
|
II.7.2. Méthode de Uschold et King «1996
»
Distinguent trois possibilités pour identifier les
concepts qui seront présents dans l'ontologie :
- On part des concepts les plus génériques que
l'on déclinera en concepts de plus en plus spécifiques. Il s'agit
d'une approche de haut en bas (ou TOP DOWN).
- On part au contraire, de concepts spécifiques que l'on
organise avec des concepts plus génériques. C'est une approche
de bas en haut (ou BOTTOM UP).
- Identifier les concepts les plus importants (pas
forcément spécifiques ou génériques) et partir de
ceux-ci pour trouver les concepts plus génériques et plus
spécifiques dont on aura besoin. Cette approche part du milieu
vers les extrémités (ou MIDDLE OUT).
Dans la pratique, il n'y a pas d'approche purement « TOP
DOWN » ou « BOTTOM UP » surtout lorsqu'une ontologie
déjà existante est réutilisée.
II.7.3. Méthode de Bernaras et al «1996
»
Elle est conditionnée au développement d'une
application. Elle repose sur trois points :
- Spécifier l'application basée sur l'ontologie en
particulier les termes à collecter et les tâches à
effectuer en utilisant cette ontologie.
- Organiser les termes en utilisant les méta
catégories : concepts, relations, attributs, etc.
- Affiner l'ontologie et la structurer selon des principes de
modularisation et d'organisation hiérarchiques.
II.7.4. Méthode SENSUS de Swartout et al
«1997 »
Commence par la réutilisation d'une vaste ontologie
commune dans laquelle les concepts pertinents sont repérés afin
d'extraire le squelette initial de la future ontologie. L'ontologie initiale se
comporte comme une charnière entre les différentes ontologies
développées.
II.7.5. Méthode de Assenac-Grilles et al «
2000 »
La méthodologie de construction d'une ontologie à
partir de texte proposée par Aussenac-Gilles insiste sur l'étape
de conceptualisation.
II.7.6. Méthode de Bachimont « 2000
»
Propose de déterminer le sens d'un concept (noeud) dans
l'arbre ontologique (taxonomie). Cette
Web sémantique
|
Ontologies & e-learning
|
Conception
|
Implémentation
|
|
méthode s'articule sur quatre principes :
- Le principe de communauté avec le père. - Le
principe de différence avec le père.
- Le principe de différence avec les frères.
- Le principe de communauté avec les frères.
II.7.7. Méthode OntoSpec de Kassel « 2002
»
Développée par l'équipe IC de LARIA
d'Amiens repose sur la notion d'axe sémantique groupant les sous
concepts d'un concept selon les caractéristiques impliquées dans
la définition de leur différentiation.
Malgré le nombre important de méthodes et de
démarches proposées, à l'heure actuelle on en compte une
trentaine, aucune n'a pu s'imposer. Ces méthodologies peuvent porter sur
l'ensemble du processus et guider l'ontologiste sur toutes les étapes de
la construction d'ontologies. [2]
II.8. Environnements et outils de
modélisation
Plusieurs environnements d'ingénierie ontologique ont
été développés afin de systématiser
l'ingénierie des ontologies. Les plus connus, selon Gomez-Pérez
(2000), sont :
· ONTOLINGUA.
· ONTOSAURUS.
· ODE.
· PROTÉGÉ .
II.8.1. ONTOLINGUA
Développé à l'Université de
Stanford, le serveur Ontolingua est le plus connu des environnements de
construction d'ontologies , il consiste en un ensemble d'outils et de services
qui supportent la construction en coopération d'ontologies, entre des
groupes séparés géographiquement.
II.8.2. ONTOSAURUS
Développé à l'Information Science
Institut de l'Université de Southern California.
Ontosaurus
consiste en un serveur utilisant LOOM comme langage de
représentation des connaissances, et
en un serveur de navigation
créant dynamiquement des pages HTML qui affichent la
hiérarchie
Web sémantique
|
Ontologies & e-learning
|
Conception
|
Implémentation
|
|
de l' ontologie ; le serveur utilise des formulaires HTML pour
permettre à l'usager d'éditer l'ontologie.
II.8.3. ODE
Développé au laboratoire d'Intelligence
Artificielle de l'Université de Madrid. Les principaux
avantages de ODE (Ontology Design Environment) sont le module de
conceptualisation pour construire des ontologies et le module pour construire
des modèles.
II.8.4. PROTÉGÉ
Développé au département d'Informatique
Médicale de l'Université Stanford ; C'est un outil
qui permet :
- la construction des ontologies ;
- la personnalisation des formulaires d'acquisition des
connaissances ; - la génération automatique de code OWL, RDFS.
III. Les ontologies pour le e-learning
En Juin 2000 la commission européenne définit
le e_learning comme : « l'utilisation des nouvelles technologies
multimédias et de l'Internet, pour améliorer la qualité de
l'apprentissage en facilitant l'accès à des ressources et des
services, ainsi que les échanges et la collaboration à
distance ». Le e-learning et comme tout autre services sur le Web
peut bénéficier de la nouvelle vision du Web sémantique
tout en reposant particulièrement sur le potentiel des ontologies.
Cette partie sera consacrée à illustrer l'apport
des ontologies aux systèmes e-learning, mais au départ on
présentera quelques notions relatives au domaine du e-learning.
III.1. Définitions
III.1.1. Objet pédagogique
Un objet pédagogique, ou Learning Object (LO), peut
être défini comme "toute entité, sur un support
numérique ou non, pouvant être utilisée pour
l'apprentissage, l'enseignement ou la formation".Pour Yolaine Bourda et
Marc Hélier, "les objets pédagogiques peuvent être, par
exemple, des transparents, des notes de cours, des pages Web, des logiciels de
simulation, des programmes d'enseignement, des objectifs pédagogiques,
etc.". [2]
Web sémantique
|
Ontologies & e-learning
|
Conception
|
Implémentation
|
|
Un objet pédagogique peut être
réutilisé pour différentes fins. Par exemple, un exercice
peut bien servir dans une série de TD que dans le cadre d'un examen.
III.1.2. Profil utilisateur
Il s'agit d'un ensemble de données persistantes qui
caractérisent un utilisateur ou un groupe d'utilisateurs particuliers.
Un tel modèle peut contenir des caractéristiques sur les
connaissances, les préférences, les centres
d'intérêts, etc.. d'un utilisateur. [6]
III.1.3. Plate forme de formation
Une plate-forme de formation est un logiciel qui assiste la
conduite des formations à distance. Elle est basée sur des
techniques de travail collaboratif et regroupe les outils nécessaires
aux trois principaux acteurs de la formation : apprenant, tuteur,
administrateur. Une plate forme utilise des moyens de travail et de
communication : visioconférence, e-mail, forums, chats, etc.
L'usage de ces systèmes est relativement standard, le
tuteur crée des parcours de formation, incorpore des ressources
pédagogiques et effectue un suivi des activités des apprenants.
L'apprenant, peut consulter en ligne ou télécharger les contenus
pédagogiques, effectuer des exercices, s'auto-évaluer et
transmettre des travaux à son tuteur pour les corriger. Les apprenant et
les tuteurs communiquent individuellement ou en groupe, et peuvent créer
des thèmes de discussion. L'administrateur, de son côté,
assure l'installation et la maintenance du système. [2]
Aujourd'hui il existe plusieurs choix concernant les plates
formes de formation, on peut citer : Plone, Gannisha, Cartable
électronique... etc.
III.2. Besoin des systèmes e-learning
On aborde ici les différents besoins d'un système
e-learning, ainsi que le rôle des ontologies à satisfaire ces
besoins :
III.2.1. Besoin en archivage et recherche
Une application e-learning est mise en ligne via l'utilisation
du Web. Compte tenu de la diversité
et la croissance exponentielle
des ressources pédagogiques utilisées dans le cadre
d'une
formation de type e-learning, il est de plus en plus difficile de
trouver les documents
Web sémantique
|
Ontologies & e-learning
|
Conception
|
Implémentation
|
|
pédagogiques pertinents. Une application e-Learning
partage donc le même problème de pertinence avec le Web lorsque
les apprenants veulent accéder au savoir mis à leur disposition.
[2]
L'approche basée sur la recherche d'informations dans
la ressource même est limitée d'une part, par l'absence de
certaines informations qui ne sont pas généralement contenues
dans la ressource et d'autre part, par la nature multimédia des
ressources : la plupart des ressources de type image ou son ne contiennent pas
d'information textuelle.
La communauté du e-learning a convenu d'utiliser des
métadonnées. Les métadonnées fournissent un
ensemble commun de balises qui peuvent être appliquées à
n'importe quelle ressource, ce qui permet aux organisations de décrire,
indexer et rechercher leurs ressources.
V' Des métadonnées basées sur les
ontologies
Dans la perspective du Web sémantique, qui est en voie
de devenir une assise pour les environnements de formation à distance,
les ontologies offrent de façon spécifique une
sémantique riche, mieux que toute autre méthode de
représentation des connaissances connue.
Dans une problématique de recherche d'un contenu
pédagogique sur une plate forme d'enseignement, reposer sur le
vocabulaire conceptuel définit dans une ontologie peut aider à
améliorer la précision de cette recherche en évitant des
ambiguïtés au niveau terminologique et en autorisant des
inférences diminuant le bruit et augmentant la pertinence.
Prenons l'exemple simple d'une conversation entre un
étudiant et un enseignant : - « Vous pouvez me conseiller un livre
sur les équations différentielles ? »
- « Il y a le manuel de cours du professeur Carman sur
l'analyse à la bibliothèque. » - « Merci »
Dans une conversation aussi banale, l'étudiant a
généralisé sa requête au concept de « livre
», qui représente la catégorie la plus abstraite recouvrant
toutes les informations de réponses acceptables pour lui. L'enseignant,
sans même y prêter réellement attention, a utilisé sa
taxonomie de concepts pour en déduire qu'un « manuel de cours
» est un « livre », que les équations
différentielles » font partie de « l'analyse » et que par
conséquent sa réponse est pertinente. Le fait que la taxonomie
soit partagée apparaît implicite puisque le professeur suppose que
sa réponse sera comprise et qu'elle est effectivement. [10]
Web sémantique
|
Ontologies & e-learning
|
Conception
|
Implémentation
|
|
De plus la définition et l'utilisation d'une
ontologie, sont une réponse pour résoudre les problèmes de
variabilité linguistique en permettant de contextualiser la
requête, c'est-à-dire en lui associant une sémantique
précise et bien définie. [11]
III.2.2. Besoin de partage
Le problème de compréhension commune dans le
e-learning survient sur plusieurs niveaux orthogonaux qui décrivent les
différents aspects d'usage des documents :
· Lors de la création du contenu
La probabilité que deux auteurs de contenus expriment
différemment le même concept est très élevée.
En d'autres termes, chacun peut fournir le contenu mais en utilisant des
mots-clés différents. Par exemple, le premier peut utiliser le
mot « auteur » alors que le deuxième utilise le terme «
créateur » pour référencer un acteur qui a fournit
une ressource d'apprentissage.
· Lors de l'accès et la recherche du contenu
par un utilisateur
Il existe un problème concernant les mots-clés
à employer pour faire la recherche du matériel d'apprentissage.
[12]
V' Un vocabulaire commun basé sur les
ontologies
La construction d'une ontologie se fait par la voie d'un
consensus, et représente ainsi la compréhension
partagée a priori d'un groupe ou d'une communauté, au lieu, comme
c'est le cas dans la plupart des systèmes, de reposer sur une
signification donnée par quelques individus ou par une autorité,
à laquelle tous doivent s'ajuster. [8]
De ce fait les fournisseurs de contenu d'apprentissage et les
apprenants seront en quelque sorte sur la même longueur d'onde (un
vocabulaire commun) et peuvent ainsi mieux partager le matériel
III.2.3. Besoin en réutilisation des objets
pédagogiques
Devant le volume de plus en plus croissant des documents
pédagogiques disponible sur le net, peu d'objets pédagogiques
sont réutilisables. La recherche et la sélection des fragments de
texte pertinents, des figures, des exercices, à partir d'un document
dans l'objectif de leurs réutilisation dans un nouveau document est
devenu presque impossible, de ce fait il est nécessaire que les
Web sémantique
|
Ontologies & e-learning
|
Conception
|
Implémentation
|
|
concepteurs des documents pédagogiques aient à
leurs disposition un moyen d'accès rapide et flexible aux objets
pédagogiques pertinents.
V' Indexation des documents pédagogiques à
base d'ontologie
Un document pédagogique doit être indexé
selon une ontologie de domaine et une autre pédagogique :
· L'indexation domaine de document pédagogique
vise à indexer par les concepts du domaine les fragments qui y font
référence. Une ontologie de domaine permet de réutiliser
des modélisations déjà faites, construire des cours
cohérents à partir d'un même ensemble de concepts
· L'indexation selon le point de vue pédagogique
permet d'associer à l'objet pédagogique un objectif, un type de
tâche d'apprentissage, une opération d'enseignement... etc. Une
ontologie pédagogique permet de marquer et réutiliser des objets
pédagogiques présentant des propriétés
pédagogiques déjà répertoriées.
III.2.4. Besoin en personnalisation et
adaptation
Un système de e-learning est destiné à
une communauté des utilisateurs qui n'ont pas les mêmes attentes,
connaissances, compétences, centres d'intérêts, etc. Ils ne
sont capables de comprendre ou d'accepter que des documents dont
l'organisation, le contenu et la présentation, soient adaptées
à leurs besoins.
y' Une ontologie qui prit en compte les
caractéristiques des utilisateurs
L'indexation des documents pédagogiques doit prendre en
compte les caractéristiques des utilisateurs, afin de pouvoir fournir
pour chacun le contenu qui correspond à son profil.
Par exemple à partir des connaissances acquises par un
utilisateur dans un domaine particulier et des connaissances nécessaires
à la compréhension d'une ressource, on peut juger de la
pertinence de cette ressource et en informer l'utilisateur. [10]
III.3. Exemples d'utilisation des ontologies
Nous décrivons dans cette section quelques exemples
d'utilisation d'ontologies dans des systèmes de formation e-learning
:
|
39
|
|
|
Web sémantique
|
Ontologies & e-learning
|
Conception
|
Implémentation
|
III.3.1. IMAT (Integrating Manuals And
Training)
IMAT repose sur l'utilisation d'ontologies pour la conception
de manuels de formation à partir de manuels constructeurs dans le
domaine technique de la maintenance. Pour réutiliser les versions
numériques des manuels techniques fournis par les constructeurs, ceux-ci
sont découpés en un ensemble de fragments indexés selon
des ontologies génériques, des ontologies domaines et autres
pédagogiques. Les fragments indexés sont à la disposition
des formateurs pour une recherche rapide et flexible basée sur les
ontologies. [13].
III.3.2. QBLS (Question Based Learning
System)
Pour l'étudiant, QBLS est un outil d'aide à la
résolution de questions de Travaux Dirigés (TD) reliées
aux connaissances clés du cours (les notions, les thèmes, et
le sujet de cours), des accès aux fiches contenant les
connaissances utiles sont conseillées pour répondre aux
questions. QBLS est un moyen d'inciter les étudiants à aller
chercher activement les connaissances. Dans cette optique, QBLS utilise une
ontologie pédagogique selon laquelle le document de cours est vu comme
un réseau de fiches (définition, exemple, formalisation,
précision) et de ressources abstraites (thème, notion, sujet de
cours), où chaque ressource abstraite réfère une ou
plusieurs fiches [2].
III.3.3. VIUM (Projet de repérage et de
visualisation du modèle de l'apprenant)
Dans le cadre de ce projet, un outil de repérage et de
visualisation, VIUM, a été conçu pour permettre
à l'utilisateur de sélectionner un concept central sur
l'écran. Une ontologie est utilisée pour s'assurer que les
concepts les plus proches sémantiquement sont visibles. Cette
sélection de concepts rendus visibles est une partie essentielle de la
visualisation qui assiste les apprenants dans l'exploration de domaines
comprenant des centaines de concepts. La tâche particulière ici,
est de montrer à un utilisateur ce qu'une ontologie computationnelle
permet d'inférer à partir d'informations comme
l'évaluation de l'apprenant sur sa propre connaissance [2].
|
40
|
|
|
Web sémantique
|
Ontologies & e-learning
|
Conception
|
Implémentation
|
IV. Conclusion
Dans ce chapitre nous avons présenté la notion
d'ontologie, ainsi que plusieurs méthodes et outils de
l'ingénierie ontologique, de plus on a montré l'apport des
ontologies aux systèmes elearning, de même on a fait allusion
à quelques projets e-learning, qui ont été
réalisé à base des ontologies.
De notre part, prenant en considération les
caractéristiques et les avantages que présentent les ontologies,
on a réalisé un travail qui s'articule autour d'une ontologie
dans une perspective de construction d'un vocabulaire partageable pour
l'annotation et la recherche de documents pédagogiques.
|
41
|
|
|
Web sémantique
|
Ontologies & e-learning
|
Conception
|
Implémentation
|
3
Conception
I. Introduction
Ce chapitre sera consacré à la
présentation de l'ontologie qu'on a conçue dans le cadre de ce
projet, la conception a été faite en reposant sur une
méthodologie tout en suivant le processus de construction des ontologie,
ce chapitre présente la première phase appelée
ontologisation, la deuxième phase qui est l'opérationnalisation
sera abordé dans le chapitre Implémentation.
II. Conception de l'ontologie de l'application II.1.
Choix d'une méthodologie de construction
Pour construire l'ontologie d'application, la méthode
développée par [Bernaras et al, 1996] a
été utilisée, elle repose sur trois étapes :
· Spécifier l'application basée sur
l'ontologie en particulier les termes à collecter et les tâches
à effectuer en utilisant cette ontologie.
· Organiser les termes en utilisant les méta
catégories : concepts, relations, attributs, etc.
· Affiner l'ontologie et la structurer selon des principes
de modularisation et d'organisation hiérarchiques.
Ce choix peut être justifié par deux raisons :
· Cette méthode est conditionnée au
développement d'une application, en d'autres termes elle est
adaptée à la construction des ontologies d'application
plutôt que des ontologies de domaines.
· Elle s'articule autour d'un ensemble de termes qui
doit être transformé en une ontologie. Dans le cas de notre
projet, on disposait au début d'un ensemble de termes qui sont
couramment utilisés dans le milieu d'enseignement universitaire. A titre
d'exemple on peut citer: enseignant, module, support du cours, série de
TD, série de TP... etc.
Web sémantique
|
Ontologies & e-learning
|
Conception
|
Implémentation
|
|
~ Etape1 : préciser l'application basée
sur l'ontologie
L'ontologie sera construite dans l'esprit de fournir un
vocabulaire conceptuel, qui permet l'annotation des documents
pédagogiques, ensuite une application de recherche de documents par
leurs métadonnées sera développée.
· Etape 2 et 3 : de la collecte des termes à
l'affinement de l'ontologie
On ne peut pratiquement dissocier les étapes de
construction d'une ontologie, car il s'agit d'un processus non linéaire,
plusieurs allers-retours ont été fait lors du
développement de l'ontologie de ce projet, pour les raisons suivantes
:
> Il n'était pas possible de savoir dés le
départ, que les termes collectés sont suffisants pour
répondre à l'objectif pour lequel l'ontologie a été
construite, on a ajouter des nouveaux termes lorsque c'était
nécessaire, tout de même on a retirer des termes qu'on a
jugés inutiles.
> Il n'était pas toujours facile de prédire
qu'un terme va jouer le rôle d'une classe ou
celui d'un attribut, plusieurs modifications ont
été effectuées dans ce sens.
Pour représenter l'ontologie conceptuelle
réalisée, on a construit :
> Une liste de concepts. > Une liste d'attributs. >
Une liste de relations. > Une représentation hiérarchique des
concepts.
> Un diagramme de classe en UML.
II.2. Respect des principes de construction
· Clarté et objectivité [Gruber93]
: pour répondre à ce principe, tous les termes
utilisés dans cette ontologie ont été associés par
des définitions.
· Complétude [Gruber93] : pour
répondre à ce principe les définitions des concepts et des
relations de notre ontologie ont été associés par des
conditions nécessaires, d'autres ont été associés
par des conditions nécessaires et suffisantes, mais bien sure selon la
possibilité de définir ces conditions.
Web sémantique
|
Ontologies & e-learning
|
Conception
|
Implémentation
|
|
· Extensibilité ontologique maximale
[Gruber93] : la définition d'un terme n'explique que le terme
lui-même, sa définition ne peut être la même que celle
d'un terme plus général, ou d'un terme plus
spécialisé.
· Principe de distinction ontologique [borgoA196]
: les concepts dans cette ontologie sont suffisamment disjoints.
· Distance sémantique minimale
[ArpirezA198]: il y a une distance minimale entre les concepts enfants
de même parents.
II.3. Présentation de l'ontologie
conceptuelle
Dans tous les tableaux qui suivent « est un
» désigne une condition nécessaire,
« si et seulement si» désigne une
condition nécessaire et suffisante
II.3.1. Liste des concepts
Dans le tableau qui suit on va présenter les concepts de
l'ontologie ainsi que leurs définitions et leurs sur concepts :
|
Concept
|
Sur concept
|
Définition du concept
|
|
Document pédagogique
|
Concept d'application
|
un document pédagogique est un
concept
d'application, il peut être : un support du cours, une
série de TD ou de TP, un diaporama, un examen, un corrigé d'une
série de TD ou d'un examen.
|
|
Support du cours
|
Document pédagogique
|
un support du cours est un document
|
|
pédagogique il regroupe des connaissances liées
à un module.
un support du cours est composé d'au moins un chapitre.
|
|
Série de TD
|
Document pédagogique
|
une série de TD est un document
pédagogique qui
a pour but l'application des notions
présentées
dans un cours, elle est destinée à
être préparé par
|
|
44
|
|
|
Web sémantique
|
Ontologies & e-learning
|
Conception
|
Implémentation
|
|
|
les étudiants.
une série de TD est composé de un ou plusieurs
exercices.
|
|
Série de TP
|
Document pédagogique
|
une série de TP est un document
pédagogique,
dans lequel l'enseignant demande aux étudiants
de développer une(des) application(s)
informatique(s), ou de réaliser
une(des)
expérience(s)....
une série de TP est composée de deux parties :
partie initiation de TP et partie travail à faire.
|
|
Diaporama
|
Document pédagogique
|
un diaporama est un document
pédagogique, dont le contenu est présenté de
manière moins détaillé, créé à l'aide
d'un logiciel et présenté à partir d'un ordinateur.
un diaporama est composé de un ou plusieurs
diapositifs.
|
|
Examen
|
Document pédagogique
|
un examen est un document pédagogique qui
a pour objectif l'évaluation des étudiants.
un examen est composé de un ou plusieurs exercices.
|
|
Corrigé d'examen
|
Document pédagogique
|
le corrigé d'un examen est un document
pédagogique qui fournit le corrigé type
d'un
examen qui a déjà été
déroulé.
le corrigé d'un examen est composé de un ou
plusieurs exercices corrigés.
|
|
Corrigé de série de TD
|
Document pédagogique
|
le corrigé d'une série de TD est
un document
pédagogique qui fournit le corrigé type d'une
série de TD déjà proposé.
le corrigé contient un ou plusieurs exercices
corrigés.
|
|
45
|
|
|
Web sémantique
|
Ontologies & e-learning
|
Conception
|
Implémentation
|
|
Enseignant
|
Concept d'application
|
un enseignant est un concept d'application,
c'est la personne responsable de la tâche d'enseignement dans un
processus de formation.
|
|
Module
|
Concept d'application
|
un module est un concept d'application, il
regroupe des connaissances liés à une
spécialité et adapté à un certain niveau et un
certain cycle.
|
|
Chapitre
|
Concept d'application
|
un chapitre est un concept d'application, il
est le composant de base d'un support du cours il regroupe un ensemble de
connaissance nécessaires pour la compréhension du module.
un chapitre est composé d'un ou plusieurs
paragraphes.
|
|
Paragraphe
|
Concept d'application
|
un paragraphe est un concept d'application,
il est le composant de base d'un chapitre, d'un diapositif, de la partie
initiation dans une série de TP.
Chaque paragraphe regroupe des connaissances plus
élémentaires, nécessaires pour la compréhension
d'un chapitre, d'un diapositif, de la partie : initiation dans une série
de TP.
Un paragraphe peut contenir une ou plusieurs figures.
|
|
Figure
|
Concept d'application
|
une figure est un concept d'application.
une figure est la représentation graphique de la
connaissance.
Une figure peut apparaître dans un paragraphe, dans un
exercice ou dans un exercice corrigé.
|
|
46
|
|
|
Web sémantique
|
Ontologies & e-learning
|
Conception
|
Implémentation
|
|
Exercice
|
Concept d'application
|
un exercice est un concept d'application.
Un exercice est un problème que l'étudiant doit
résoudre, ou particulièrement un travail pratique qu'il doit
réaliser.
Un exercice est le composant de base d'une série de TD,
d'un examen et de la partie travail à faire dans une série de
TP.
Un exercice peut contenir une ou plusieurs
figures.
|
|
Exercice corrigé
|
Concept d'application
|
un exercice corrigé est un concept
d'application il représente la solution d'un exercice.
Un exercice corrigé est le composant de base d'un
corrigé d'examen ou d'un corrigé de série de TD.
Un exercice corrigé peut contenir une ou plusieurs
figures.
|
|
Diapositif
|
Concept d'application
|
un diapositif est un concept d'application, il
est
le composant de base d'un diaporama.
un diapositif est composé de un ou plusieurs
paragraphes.
|
|
Partie initiation de TP
|
Concept d'application
|
la partie initiation d'un TP est un concept
d'application ; c'est la première partie dans une
série de TP, où l'enseignant doit expliquer le sujet de TP, et
décrire les outils qui seront utilisés pour réaliser le
travail si nécessaire.
la partie initiation est composée de un ou
plusieurs paragraphes.
|
|
Partie travail à faire de TP
|
Concept d'application
|
la partie travail à faire est un
concept
|
|
d'application ; c'est la deuxième partie dans une
série de TP ; c'est la partie où l'enseignant doit
préciser le travail que l'étudiant doit réaliser.
|
|
47
|
|
|
Web sémantique
|
Ontologies & e-learning
|
Conception
|
Implémentation
|
la partie travail à faire est composée de un ou
plusieurs exercices.
II.3.2. Liste des attributs
Dans le tableau qui suit on va présenter pour chaque
concept ses attributs, et s'il a des attributs hérités d'un
concept père.
|
Concept
|
Hérite les attributs
de concept
|
Attributs
|
Commentaires
|
|
Document pédagogique
|
|
URI
|
Par URI on désigne le chemin d'accès au
document(URL).
|
|
Format
|
Par format on désigne, le format numérique du
document (PDF, Word, HTML, PPT)
|
|
Langue
|
|
|
Date de création
|
|
|
Année universitaire
|
|
|
Université
|
|
|
Faculté
|
|
|
Département
|
|
|
Support du
cours
|
Document pédagogique
|
Mots clés
|
|
|
Série de TD
|
Document pédagogique
|
Numéro de série de TD
|
|
|
Série de TP
|
Document pédagogique
|
Numéro de série de TP
|
|
|
Titre de série de TP
|
|
|
48
|
|
|
Web sémantique
|
Ontologies & e-learning
|
Conception
|
Implémentation
|
|
Diaporama
|
Document pédagogique
|
Titre de diaporama
|
|
|
Mots clés de diaporama
|
|
Examen
|
Document pédagogique
|
Numéro d'examen
|
|
|
Date d'examen
|
|
|
Type d'examen
|
Par type d'examen on désigne s'il est un ECD, EMD, un
examen de synthèse, ou de rattrapage.
|
|
Corrigé d'examen
|
Document pédagogique
|
Numéro de corrigé d'examen
|
|
|
Corrigé de
série de TD
|
Document pédagogique
|
Numéro Corrigé de
série de TD
|
|
|
Enseignant
|
|
Nom de l'enseignant
|
|
|
Prénom
|
|
Email
|
|
Module
|
|
Nom de module
|
|
|
Spécialité
|
|
|
Niveau
|
1ere , 2eme , 3eme ,
4eme,5eme année
|
|
Cycle
|
Cycle court ou long.
|
|
Module avec TD
|
Est-ce que c'est un module avec des séances de TD
|
|
Module avec TP
|
Est-ce que c'est un module avec des séances de TP
|
|
49
|
|
|
Web sémantique
|
Ontologies & e-learning
|
Conception
|
Implémentation
|
|
|
Volume horaire
|
Total entre cours, TD et TP
|
|
Chapitre
|
|
Numéro de chapitre
|
|
|
Titre de chapitre
|
|
|
Paragraphe
|
|
Numéro de paragraphe
|
|
|
Titre de paragraphe
|
|
|
Sous titres
|
|
|
Figure
|
|
Numéro de figure
|
|
|
Titre de figure
|
|
|
Type de figure
|
Type de figure : tableau, image, etc.
|
|
Exercice
|
|
Numéro d'exercice
|
|
|
Exercice corrigé
|
|
Numéro d'exercice
corrigé
|
|
|
Diapositif
|
|
Numéro de diapositif
|
|
|
Partie
initiation de
TP
|
|
Numéro de la partie
initiation
|
|
|
Titre de la partie
initiation
|
|
|
Partie travail à faire de TP
|
|
Numéro de la partie
travail à faire
|
|
|
Titre de la partie travail à faire
|
|
II.3.3. Liste des relations
Dans le tableau qui suit on va décrire les relations qui
existent entre les différents concepts de l'ontologie.
|
50
|
|
|
Web sémantique
|
Ontologies & e-learning
|
Conception
|
Implémentation
|
|
Relation
|
Prédécesseur
|
Successeur
|
Définition
|
|
Enseigne
|
Enseignant
|
Module
|
Un enseignant enseigne un module
Pendant une année universitaire, si
et
seulement si il est chargé de cours et
|
|
quand il rédige des documents
pédagogiques concernant ce module
|
|
Est auteur
|
Enseignant
|
Document pédagogique
|
Un enseignant est auteur d'un document
pédagogique,
si et seulement si c'est lui
|
|
qui l'a écrit.
|
|
Concerne
|
Document pédagogique
|
Module
|
Un document pédagogique concerne un
module si
et seulement si il est rédigé (a
|
|
été rédigé) par (qui était)
l'enseignant de ce module, et lorsqu'il l'utilise (l'avait utilisé) pour
enseigner ce module à ses étudiants.
|
|
Est Composé de chapitres
|
Support du cours
|
Chapitre
|
Un support du cours contient au moins un chapitre.
|
|
Est Composé de paragraphes
|
Chapitre
|
Paragraphe
|
Un chapitre contient au moins un
paragraphe
|
|
Contient des
figures
|
Exercice
|
Figure
|
Un exercice peut contenir une Ou plusieurs figures.
|
|
Contient des
figures
|
Exercice corrigé
|
Figure
|
Un exercice corrigé peut contenir une
Ou plusieurs figures.
|
|
Contient des
figures
|
Paragraphe
|
Figure
|
Un paragraphe peut contenir une Ou plusieurs figures.
|
|
51
|
|
|
Web sémantique
|
Ontologies & e-learning
|
Conception
|
Implémentation
|
|
Est composé
d'exercices
|
Série de TD
|
Exercice
|
Une série de TD contient au moins un exercice.
|
|
A pour corrigé
|
Série de TD
|
corrigé de série
de TD
|
Une série de TD a au plus un corrigé.
|
|
Est composé
d'exercice corrigé
|
Corrigé de série de
TD
|
Exercice corrigé
|
Un corrigé de série de TD contient au moins un
exercice corrigé.
|
|
Est composé
d'exercices
|
Examen
|
Exercice
|
Un examen contient au moins un
exercice.
|
|
A pour corrigé
|
Examen
|
Corrigé d'examen
|
Un examen a au plus un corrigé.
|
|
Est composé
d'exercices
corrigés
|
Corrigé d'examen
|
Exercice corrigé
|
Le corrigé d'un examen contient au moins un exercice
corrigé.
|
|
Est composé
d'une partie
initiation
|
Série de TP
|
Partie initiation
de TP
|
Une série de TP contient une et une seule partie
initiation.
|
|
Est composé
d'une partie
travail
|
Série de TP
|
Partie travail à
faire de TP
|
Une série de TP contient une et une seule partie travail
à faire.
|
|
Est composé de
paragraphes
|
Partie initiation de
TP
|
Paragraphe
|
La partie initiation de TP contient au moins un paragraphe
|
|
Est composé
d'exercices
|
Partie travail à faire de TP
|
Exercice
|
La partie travail à faire de TP contient
au moins un exercice
|
|
Est composé de
diapositif
|
Diaporama
|
Diapositif
|
Un diaporama contient au moins un diapositif
|
|
Est composé de
paragraphe
|
Diapositif
|
Paragraphe
|
Un diapositif contient au moins un
paragraphe.
|
|
52
|
|
|
Web sémantique
|
Ontologies & e-learning
|
Conception
|
Implémentation
|
II.3.4. Représentation hiérarchique des
concepts
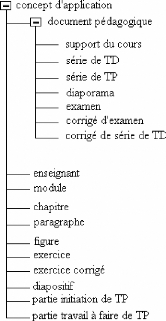
FigIII.1: Représentation hiérarchique de
l'ontologie
|
53
|
|
|
Web sémantique
|
Ontologies & e-learning
|
Conception
|
Implémentation
|
II.3.5. Diagramme UML
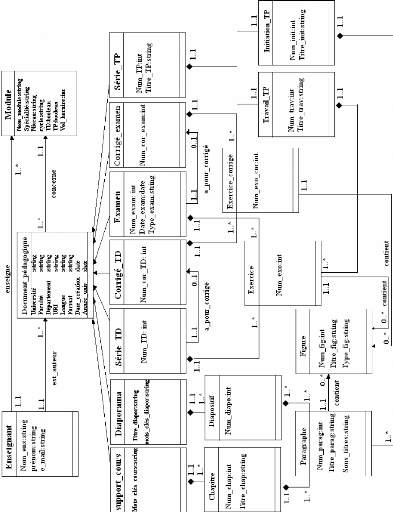
Fig.III.2 : Diagramme de classes UML

54
|
Web sémantique
|
Ontologies & e-learning
|
Conception
|
Implémentation
|
II.4. Schéma résumant la phase de
l'ontologisation de l'ontologie
Le schéma suivant résume la phase de
l'ontologisation, qui est la première phase dans le processus de
construction des ontologies :
Termes condidats
Documents Pédagogiques
Spécification de l'application basée sur
l'ontologie
Révision de l'ontologie
Organisation des termes en concepts, attributs et
relations
Liste des concepts
Liste des attributs Liste des relations
Hiérarchie de
concepts
Ontologie conceptuelle
+
Affinement de
l'ontologie
Diagramme de classes en UML
Fig.III.3 : phase d'ontologisation
II.5. Diagramme des cas d'utilisation
Notre application est orientée vers trois utilisateurs :
l'administrateur, les enseignants et les étudiants.
Les différentes tâches que peut effectuer chaque
type d'utilisateur, sont illustrées sur le diagramme des cas
d'utilisation suivant
|
55
|
|
|
Web sémantique
|
Ontologies & e-learning
|
Conception
|
Implémentation
|
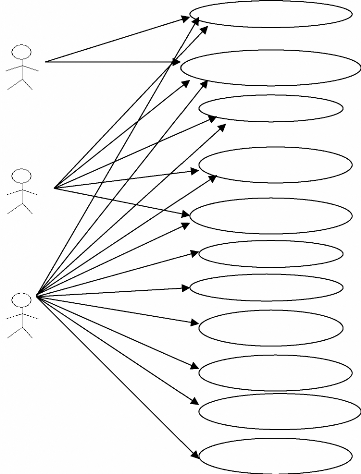
Rechercher des documents
Consulter la documentation de
l'ontologie
Etudiant
Annoter un document
Modifier l'annotation d'un
document
Supprimer l'annotation d'un
document
Enseignant
Annoter un enseignant
Annoter un module
Modifier l'annotation
d'un module
Administrateur
Modifier l'annotation d'un
enseignant
Supprimer l'annotation d'un
module
Supprimer l'annotation
d'un enseignant
Fig.III.4: Diagramme des cas d'utilisation
|
56
|
|
|
Web sémantique
|
Ontologies & e-learning
|
Conception
|
Implémentation
|
III. Conclusion
Dans ce chapitre on a présenté les
différentes phases par lesquelles on a passé pour réaliser
la conception de l'ontologie de ce projet, où on a suivi la
méthode développée par [Bernaras et al, 1996], et
on a présenté le résultat de la conception sous forme
d'une liste de concepts, une liste de relations et une autre des attributs en
plus d'une représentation hiérarchique et une autre sous forme
d'un diagramme UML, et pour présenter les fonctionnalités de
chacun des acteurs de notre application on a utilisé un diagramme de cas
d'utilisation.
La prochaine étape consiste à rendre cette
ontologie opérationnelle c'est-à-dire exploitable par un
ordinateur, c'est ce qu'on va présenter dans le prochain chapitre, en
plus du détail de réalisation de l'application de ce projet.
|
57
|
|
|
Web sémantique
|
Ontologies & e-learning
|
Conception
|
Implémentation
|
4
Implémentation
I. Introduction
Dans ce chapitre nous allons présenter le travail
d'implémentation qu'on a fait, qui consistait premièrement
à l'édition de notre ontologie sous le langage OWL, suivi par son
exploitation dans une application d'annotation et de recherche de documents
pédagogiques qui a été développée en JSP, et
en fin l'intégration de l'application développée dans la
plate forme PLONE.
Avant de s'attarder sur le détail de réalisation
le cahier des charges qui nous a été soumis au début du
projet sera présenté.
II. Cahier des charges
· L'ontologie doit être implémenté avec
les technologies du Web sémantique (OWL, RDF/S, etc.).
· L'ontologie doit être édité avec
l'éditeur d'ontologies « protégé 3.1.1 » et le
programme qui la manipule doit être codé en « JSP ».
· L'application développée doit être
intégrée dans la plate forme PLONE.
· L'application développée doit permettre
principalement l`annotation et la recherche de documents à partir de
leurs descriptions, fournis par l'ontologie développée.
III. les outils et le langage utilisés III.1.
Java Server Pages
Les Java Server pages (JSP) constituent la technologie Java de
pages actives, la technologie JSP est bâtie sur la technologie des
servlets.
Web sémantique
|
Ontologies & e-learning
|
Conception
|
Implémentation
|
|
L'API JSP fait partie de J2EE (Java 2 Entreprise Edition), elle
donne aux développeurs les moyens de développer des applications
Web de façon simple et puissante.
JSP permet de séparer la logique programmatique (le code
java) de la présentation (les balises HTML), voici un exemple :
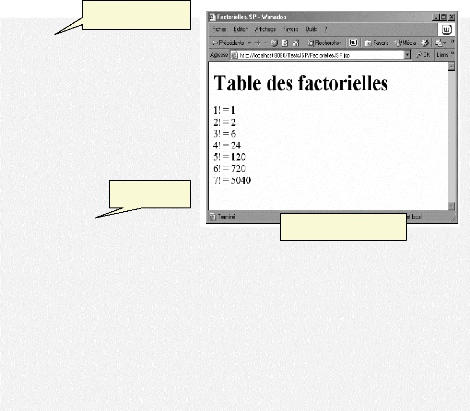
<html> <head>
<title>FactoriellesJSP</title>
</head>
<body>
<h1>Table des
factorielles</h1>
<%
int fact = 1;
{
fact = fact * i;
out.println(i + "! = " + fact);%><br>
<%}%>
</body> </html>
for(int i=1 ;i<=7;i++)
Balises HTML
Code Java
Résultat de l'exécution
Fig.IV.1: Exemple d'un programme JSP >
Exécution d'une page JSP
Une page JSP s'exécute selon l'algorithme suivant :
Web sémantique
|
Ontologies & e-learning
|
Conception
|
Implémentation
|
|
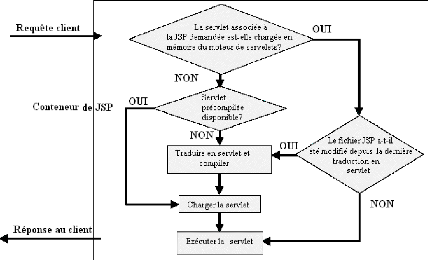
Fig.IV.2 : Exécution d'un JSP
Un conteneur de JSP (JSP container) fournit les services
réseaux par lesquels les requêtes et les réponses sont
émises, il décode également les requêtes et formate
les réponses dans le format approprié. Tous les conteneurs
doivent supporter le protocole HTTP.
III.2. Tomcat
Tomcat est le conteneur web le plus utilisé, il est open
source gratuit et multi plateformes (écrit en Java) et il est
Téléchargeable sur
http://jakarta.apache.org/tomcat.
Tomcat possède deux modes de fonctionnement : >
Autonome (standalone) :
Tomcat est aussi un serveur Web, il est capable de servir des
pages HTML et d'exécuter des Servlets et des JSP.
> Collaboratif (in-process et
out-of-process)
Tomcat peut s'installer comme une extension d'un serveur Web
(Apache, Microsoft IIS ou Netscape NetServer), ce qui permet des meilleures
performances pour le service des pages HTML.
Web sémantique
|
Ontologies & e-learning
|
Conception
|
Implémentation
|
|
III.3. Protégé
Éditeur d'ontologie open source disponible à
l'adresse
http://protege.standford.edu
, développé au département d'Informatique
Médicale de l'Université de Standford.
L'éditeur d'ontologie «
Protégé version 3.1.1 », a
été utilisé pour éditer l'ontologie de ce projet
dans l'objectif de générer automatiquement le code OWL
correspondant, ainsi que pour générer une documentation HTML pour
notre ontologie.
Il est à noter que « Protégé »
offre bien sure beaucoup de fonctionnalités, et on n'en a pas
certainement tous utilisés.
III.4. Jena
Jena est disponible à l'adresse :
http://jena.sourceforge.net/ .
Jena est un ensemble d'outils (une API) open source
développé par HP Labs semantic Web programme ,permettant
de lire et de manipuler des ontologies décrites en RDFS ou en OWL et d'y
appliquer certains mécanismes d'inférences.
Pour notre projet on utilisé la version 2.3 qui
était la version la plus récente de Jena au début de notre
projet.
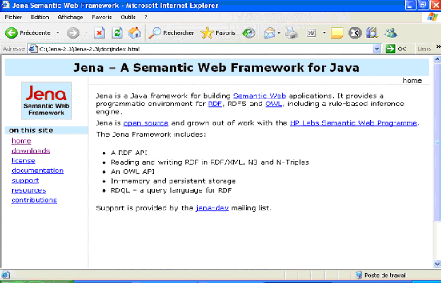
Fig.IV.3 : La page d'accueil de site
http://jena.sourceforge.net/

61
Web sémantique
|
Ontologies & e-learning
|
Conception
|
Implémentation
|
|
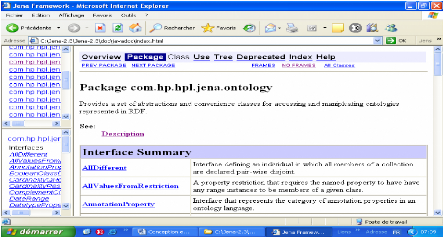
Fig.IV.4 : La documentation associé avec Jena
2-3
IV. Implémentation
IV.1. Edition de l'ontologie et génération
du code OWL
La première étape de l'implémentation
était bien l'édition de l'ontologie avec «
Protégé ». IV.1.1. Choix d'un langage de
spécification
RDFS paraissait insuffisant pour coder l'ontologie de ce
projet, dans la mesure où il ne permet pas d'exprimer des contraintes de
cardinalité, c'est pour cette raison que notre choix a été
orienté vers OWL.
L'ontologie de ce projet a été codée
exactement en « OWL DL », pour les raisons :
> OWL Lite ne permet d'exprimer que des contraintes simples
de cardinalité 0 ou 1, tandis que OWL DL permet d'exprimer des
cardinalités multiples.
> OWL Full offre un plus haut niveau d'expressivité que
demande l'ontologie de ce projet, tandis que OWL DL offre un niveau
d'expressivité assez suffisant.
En plus, le codage d'une ontologie sous format OWL
présente l'avantage de rendre cette ontologie réutilisable,
grâce à l'utilisation des propriétés
d'équivalence, de disjonction entre les concepts et entre les
relations.
Web sémantique
|
Ontologies & e-learning
|
Conception
|
Implémentation
|
|
IV.1.2. Normalisation des noms de
l'ontologie
Les caractéristiques suivantes d'éditeur
d'ontologie affectent le choix de la convention de nomination :
· Le système a-t-il le même espace de
nomination pour les classes, attributs et instances ? C'est à- dire,
permet-il d'avoir une classe et un attribut ayant le même nom
· Le système est-il sensible à la casse ?
· Quels délimiteurs le système autorise-t-il
pour les noms ? C'est-à-dire, les noms peuvent-ils Contenir des espaces,
des virgules, etc. ?
L'éditeur d'ontologie « Protégé
version 3.1.1 » avec lequel l'ontologie de ce projet a été
éditée, maintient un espace de nommage unique pour les classes,
attributs et instances. Il est sensible à la casse, et il ne permet
l'apparition des espaces dans les noms, les délimiteurs autorisés
sont bien « _ » et «-».
C'est pour ces considérations que les noms
déjà présentés dans l'ontologie conceptuelle ont
été légèrement modifiés, lors de leurs
éditions sous « Protégé ».
IV.1.3. Les étapes de l'édition
Dans ce qui suit nous allons présenter comment nous
avons édité l'ontologie de ce projet, à partir de
lancement de « Protégé » jusqu'à la
génération du code OWL et de la documentation HTML
correspondante.
1) lancement de « Protégé 3.1.1» sous
Windows XP :

Fig.IV.5 : Lancement de
Protégé
2) création d'un nouveau projet avec précision
respectivement de type de projet, d'espace des noms, de langage avec lequel
sera édité l'ontologie :
|
63
|
|
|
Web sémantique
|
Ontologies & e-learning
|
Conception
|
Implémentation
|
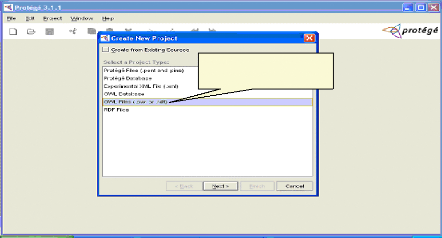
Choisir
OWL files (.owl or .rdf)
Fig.IV.6 : Choix de type de projet
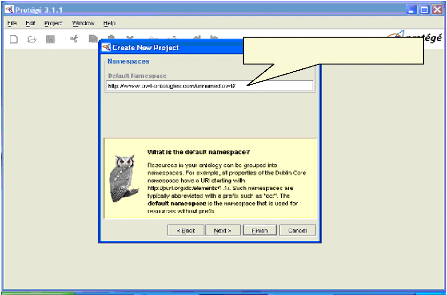
Protégé propose un espace des noms
Fig.IV.7 : Choix d'un espace des noms
|
64
|
|
|
Web sémantique
|
Ontologies & e-learning
|
Conception
|
Implémentation
|
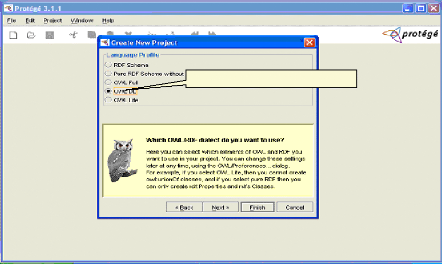
Choisir OWL DL comme langage
Fig.IV.8 : Choix d'un langage
3) Après avoir spécifier les
propriétés de projet la page suivante s'affiche, c'est sur cette
page qu'on édite l'ontologie :
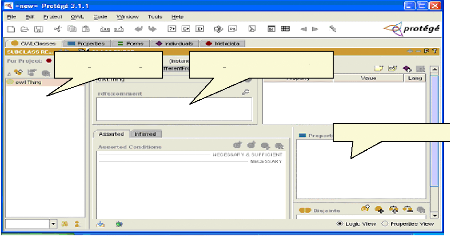
Champ des concepts Champ des commentaires
Champ des propriétés
Fig.IV.9 : Page d'édition
4) Commencer à éditer les classes, les
définitions de classes, les propriétés, les relations et
les relations inverses tout en spécifiant les contraintes de
cardinalités :
|
65
|
|
|
Web sémantique
|
Ontologies & e-learning
|
Conception
|
Implémentation
|
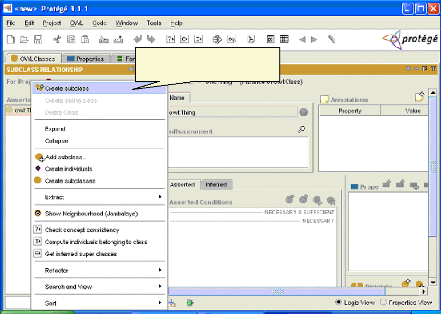
Création d'une Sous classe de `'OWL : Thing»
Fig.IV.10 : Création des classes
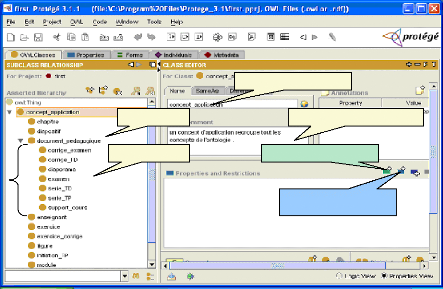
Sous concepts
Sur concept
Nom de concept
Ajouter des propriétés
Ajouter des relations
Définition de concept
Fig.IV.11 : Les champs à remplir
|
66
|
|
|
Web sémantique
|
Ontologies & e-learning
|
Conception
|
Implémentation
|
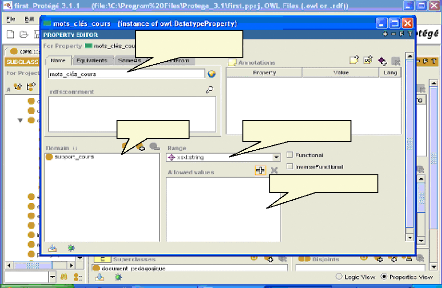
Domaine
Nom de la propriété
Type de propriété
Valeurs permises
Fig.IV.12 : Ajout d'une
propriété
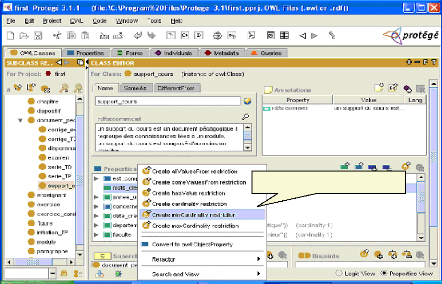
Contraintes de cardinalités
Fig.IV.13 : Spécification des contraintes de
cardinalité
|
67
|
|
|
Web sémantique
|
Ontologies & e-learning
|
Conception
|
Implémentation
|
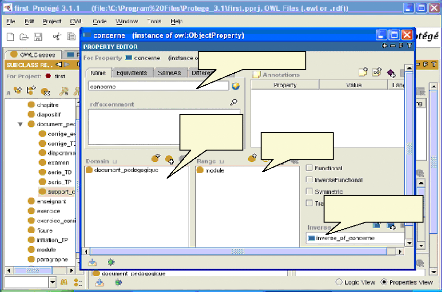
Domaine
Nom de la relation
Image
Relation inverse
Fig.IV.14: Ajout d'une relation

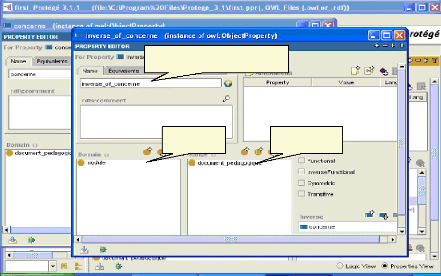
Nom de la relation inverse
Domaine
Image
fig.IV.15 : Ajout de la relation inverse
|
68
|
|
|
Web sémantique
|
Ontologies & e-learning
|
Conception
|
Implémentation
|
5) Après avoir terminer l'édition de l'ontologie,
on sauvegarde le projet :
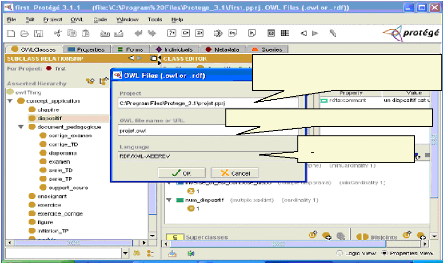
Spécifier un nom pour le fichier OWL
Spécifier un nom pour le projet, et un emplacement
Spécifier un format
<owl:Ontology rdf:about="">
<owl:imports rdf:resource=""/> Concept
Chapitre
</owl:Ontology>
Définition de concept
<owl:Class rdf:ID="chapitre">
<rdfs:comment rdf:datatype="
http://www.w3.org/2001/XMLSchema#string">
un chapitre est un concept d'application, il est le composant de
base d'un support du cours il regroupe un ensemble de connaissance
nécessaires pour la compréhension du module.
un chapitre est composé d'un ou plusieurs paragraphes.
</rdfs :comment>
<rdfs:subClassOf>
<owl:Restriction>
<owl:minCardinality rdf:datatype="
http://www.w3 .org/200 1
/XMLSchema#int"
Relation inverse de Est_composé_chapitre
>1</owl:minCardinality>
69
Fig.IV.16 : Enregistrement de projet Voici un
fragment de code OWL généré :
|
Web sémantique
|
Ontologies & e-learning
|
Conception
|
Implémentation
|
<owl:onProperty>
<owl:ObjectProperty
rdf:ID="inverse_of_est_compose_chapitre"/> </owl:onProperty>
</owl:Restriction>
</rdfs:subClassOf>
<rdfs:subClassOf>
<owl:Restriction> <owl:onProperty>
<owl:DatatypeProperty rdf:ID="num_chapitre"/>
</owl:onProperty>
<owl:cardinality rdf:datatype="
http://www.w3.org/2001/XMLSchema#int"
>1</owl:cardinality>
</owl:Restriction>
</rdfs:subClassOf>
<rdfs:subClassOf>
<owl:Restriction>
<owl:cardinality rdf:datatype="
http://www.w3.org/2001/XMLSchema#int"
>1</owl:cardinality>
<owl:onProperty>

Propriété num_chapitre
Fig.IV.17 : un fragment de code OWL
généré
6) Finalement, on génère la documentation HTML de
l'ontologie :
|
70
|
|
|
Web sémantique
|
Ontologies & e-learning
|
Conception
|
Implémentation
|
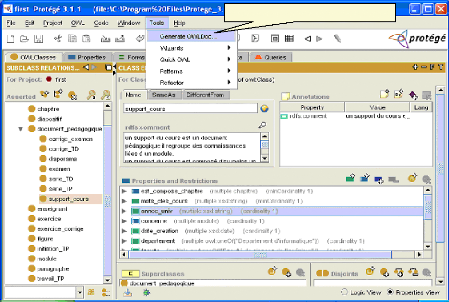
Génération de la documentation
Fig.IV.18 : Génération de la
documentation
La page suivante fait partie de la documentation
généré, elle correspond à la classe « Support
de cours »:
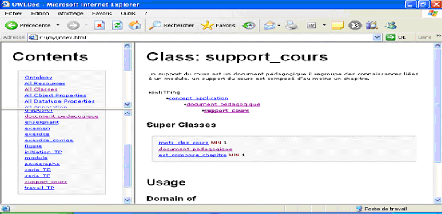
Fig.IV.19 : Documentation de l'ontologie
|
71
|
|
|
Web sémantique
|
Ontologies & e-learning
|
Conception
|
Implémentation
|
IV.1.4. Schéma résumant la phase de
l'opérationnalisation
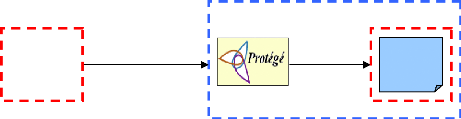
Génération du code OWL
Ontologie Edition de l'ontologie
conceptuelle
Code
OWL
Ontologie opérationnelle
Fig.IV.20 : Phase de
l'opérationnalisation
IV.2. Exploitation de code OWL dans un programme
JAVA
Après avoir générer le code OWL
correspondant à notre ontologie on a été très vite
confronté au problème de son exploitation dans un programme JAVA,
surtout que peu d'articles sont ceux qui parlent de détail
d'implémentation chose qui nous a demandé plus d'effort pour
trouver une solution.
En consultant quelques documents [14] et [15], on s'est rendu
compte qu'il existe une API appelée Jena qui sert de lien entre un code
OWL et un programme JAVA et que Plus de 70% des applications de Web
sémantique sont développées en Jena.
Après avoir répondre à la question «
comment exploiter le code OWL avec Java », il fallait résoudre un
autre problème car tout simplement lorsqu'on a testé Jena sous
JBuilder7 elle n'a pas fonctionné, le problème était dans
la version de JDK (JAVA Development Kit) qui a été la version
« 1.3.1 » et dans la version du serveur Web JSP « Jakarta Tomcat
» qui a été la version « 3.3 » il était
indispensable qu'on passe à des versions plus récentes.
On a testé Jena avec « JDK version 1.4.2 » et
avec « Tomcat version 4.0 » et ça très bien
marché, en ce qui concerne le serveur Tomcat, JBuilder7 est muni de la
version « 4.0 » tandis que pour le « JDK 1.4.2 » il fallait
qu'on le télécharge à partir de site
http://java.sun.com.
|
72
|
|
|
Web sémantique
|
Ontologies & e-learning
|
Conception
|
Implémentation
|
1) Installation de JDK 1.4.2 :
Fig.IV.21 : Installation de JDK 1.4.2
2) Pour la configuration des JDKs et des Librairies avec
JBuilder7, il faut aller au menu Tools/configure librairies et Tools/configure
JDKs
Ajouter Jena
Fig.IV.22: Ajout de la librairie Jena
|
73
|
|
|
Web sémantique
|
Ontologies & e-learning
|
Conception
|
Implémentation
|
Ajouter JDK
1.4.2
Fig.IV.23 : Ajout de JDK 1.4.2
IV.2.1. Suivi de session
Le protocole HTTP est un protocole non connecté (on
parle aussi de protocole sans états) cela signifie que chaque
requête est traitée indépendamment des autres et qu'aucun
historique des différentes requêtes n'est conservé.
Il s'agit donc de maintenir la cohésion entre
l'utilisateur et la requête, c'est-ce qu'on appelle « suivi
de session ».
Il existe 3 méthodes pour garantir le suivi de session
:
1) utilisation des cookies.
2) réécriture d'URL.
3) utilisation des champs de formulaire "hidden".
Pour notre application, on a travaillé avec des champs
"hidden", car c'était pour nous une méthode simple ce qui ne veut
pas dire qu'elle est forcément la meilleure solution.
|
74
|
|
|
Web sémantique
|
Ontologies & e-learning
|
Conception
|
Implémentation
|
IV.2.2. Architecture de l'application
développée
Internet/Intranet
Serveur
Environnement d'exécution
API JENA
SERVEUR
WEB
Tomcat
Réponse

Documents
Code OWL
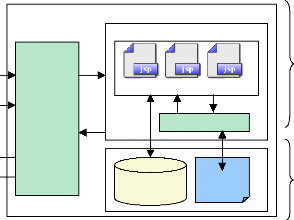

Niveau2 : Applicatif
Niveau3 : Données
Client
Requête (http)

Navigateur Web
Niveau1 :
Présentation
Fig.IV.24 : Architecture de l'application
V. La démarche suivie pour l'annotation des
documents La démarche qu'on a suivi pour annoter les documents
consistait à :
> Ajouter les métadonnées décrivant un
document au fichier OWL qui code l'ontologie d'application.
> Stocker les documents dans un emplacement précis
(dans notre cas le dossier nommé « My ») sur le serveur.
> Gérer l'accès aux documents grâce au
métadonnée « URI ».
VI. Exécution de l'application
La dernière étape de ce projet était de
faire exécuter notre application en dehors de son environnement de
développement « JBuilder7 », de manière qu'elle sera
intégrable sur la plate forme « PLone », pour réaliser
ça on a :
|
75
|
|
|
Web sémantique
|
Ontologies & e-learning
|
Conception
|
Implémentation
|
> Installer le serveur « Tomcat version 4.1» sur
le port « 8086 » au lieu du port «8080 » pour le faire
cohabiter avec le serveur de la plate forme « Plone » qui
réside sur le port « 8080 » :
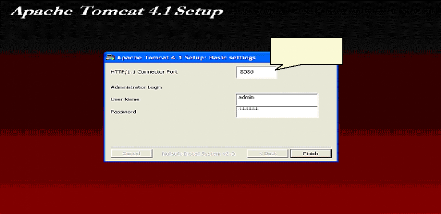
Port 8086
Fig.IV.25 : Installation de serveur Tomcat >
Placer notre application sous le répertoire « Webapps » de
Tomcat :
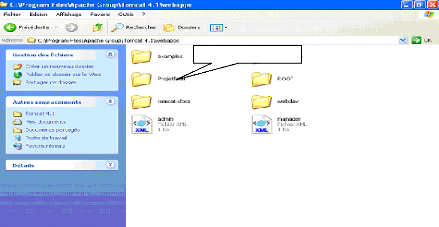
Notre application
Fig.IV.26 : Emplacement de l'application
|
76
|
|
|
Web sémantique
|
Ontologies & e-learning
|
Conception
|
Implémentation
|
> Problème rencontré
Durant l'exécution de notre application, et en particulier
en exécutant les JSP faisant appel à Jena, un problème a
survenu sur le serveur Tomcat.
Après avoir faire quelques recherches sur le net pour
déterminer la cause du problème, et plus exactement en consultant
les FAQ (Frequently Asked Questions) de Jena, on s'est rendu compte qu'il
s'agit d'un problème de version du parseur XML « Xerces» de
Tomcat, qui était une version plus ancienne que celle requise par Jena,
problème qui n'était pas posé sous JBuilder7.
Pour résoudre ce problème il fallait qu'on
change le fichier « xmlParserAPIs.jar», ainsi que le fichier «
xercesImpl.jar » qui se trouvent sous le répertoire « endorsed
» de Tomcat, par ceux associés avec Jena.
VI.1. Images d'exécution de
l'application
Dans ce qui suit nous allons présenter quelques captures
d'écran d'exécution de notre application, mais avant de commencer
en voici quelque remarques :
> La génération des identificateurs des
enseignants des modules, et tous les individus de l'ontologie est automatique
ce qui décharge l'administrateur ainsi que les enseignants de
gérer eux même les identificateurs qui doivent être unique
pour chaque individu.
> La recherche est insensible à la casse.
> Un champ vide dans une requête implique que
l'utilisateur accepte toute valeur possible pour ce champ.
> Pour tester sur le format de certains champs : les champs
numérique, champ de date etc. on a utiliser quelque « Java
Script».
Les images suivantes présentent un scénario complet
de l'utilisation de notre application, afin de mieux expliquer son
fonctionnement:
VI.1.1 Annotation d'un module
L'administrateur effectue l'annotation d'un module, qu'il soit
le module « Logique pour l'IA », qui est un module de 5 ING
informatique, option « Intelligence Artificielle » ayant pour
identificateur « module_1 » :
|
77
|
|
|
Web sémantique
|
Ontologies & e-learning
|
Conception
|
Implémentation
|
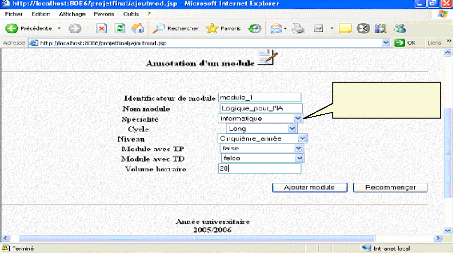
Module Logique pour l'IA
Fig.IV.27 : Annotation d'un module VI.1 .2. Annotation
d'un enseignant
*L'administrateur effectue l'annotation d'une enseignante,
qu'elle soit Melle « Ghebghoub Ouafia » ayant pour identificateur
(login) «enseignant_1 » :
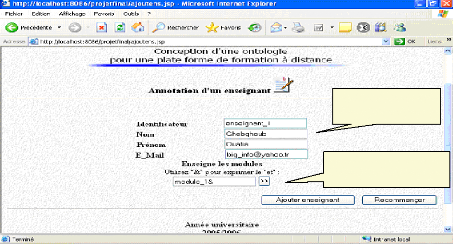
Le choix des modules se fait sur un autre écran
Enseignante
Ghebghoub Ouafia
Fig.IV.28: Annotation d'un enseignant
|
78
|
|
|
Web sémantique
|
Ontologies & e-learning
|
Conception
|
Implémentation
|
* l'administrateur affecte le module « Logique pour l'IA
» à « Melle : Ghebghoub Ouafia » :
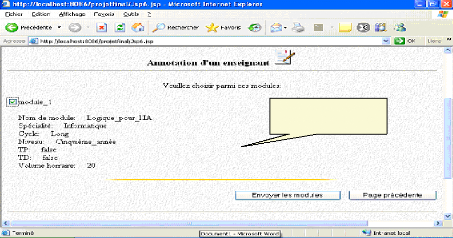
Liste des modules non encore affectés
Fig.IV.29 : Affectation d'un module à un
enseignant
VI.1.3. Annotation d'un document
*Un enseignant commence à annoter un document par saisir
son login :
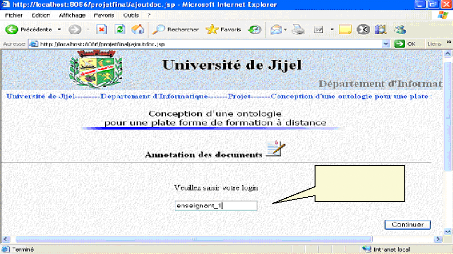
Login de
l'enseignant
Fig.IV.30 : Saisie de login de l'enseignant
|
79
|
|
|
Web sémantique
|
Ontologies & e-learning
|
Conception
|
Implémentation
|
*L'enseignant doit choisir un module parmi ceux qu'il enseigne
:
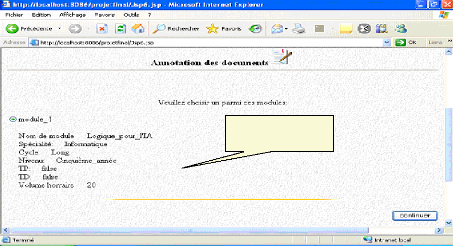
Choix de module Logique pour l'IA
Fig.IV.31: choix d'un module
*L'enseignant doit préciser le type de document qu'il veut
annoter :
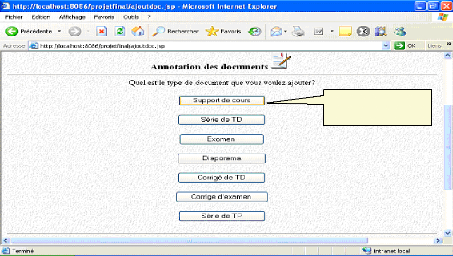
Choix d'un support
de cours
Fig.IV.32 : Choix de type de document à
annoter
|
80
|
|
|
Web sémantique
|
Ontologies & e-learning
|
Conception
|
Implémentation
|
*L'enseignant doit préciser les caractéristiques
de sont support de cours (nombre de chapitre, de paragraphe par chapitre..),
afin qu'on lui génère automatiquement un formulaire d'acquisition
de métadonnées :
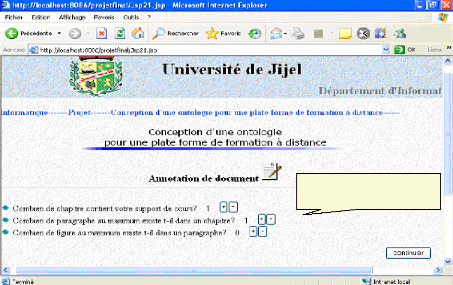
Un cours avec un chapitre, un paragraphe et sans figure.
Fig.IV.33 : préparation à la
génération de formulaire d'acquisition des
métadonnées
*L'enseignant doit maintenant annoter son document :
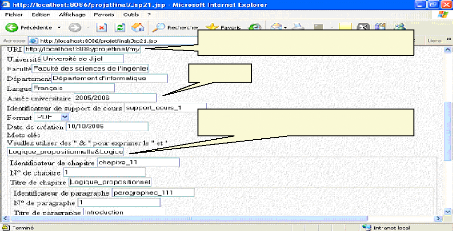
2005/2006
http://localhost:8086/projetfinal/my/cours.pdf
Logique propositionnelle&Logique des prédicats
Fig.IV.34 : Annotation d'un support de
cours
|
81
|
|
|
Web sémantique
|
Ontologies & e-learning
|
Conception
|
Implémentation
|
VI.1.4. Recherche de documents
*Une recherche de document commence à cet écran,
ce dernier permet grâce aux boutons « ? » de passer vers
d'autres écrans pour lancer des requêtes à propos de
document, de l'auteur de document et de module que concerne ce document :
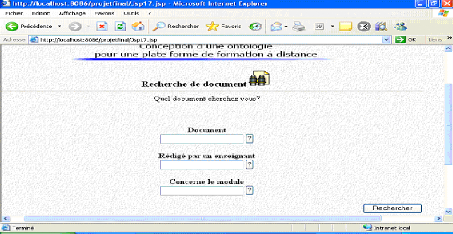
Fig.IV.35 : écran de recherche de
document
*Un utilisateur cherche un document de type support de cours, qui
a été rédigé à l'année universitaire
« 2005/2006 »
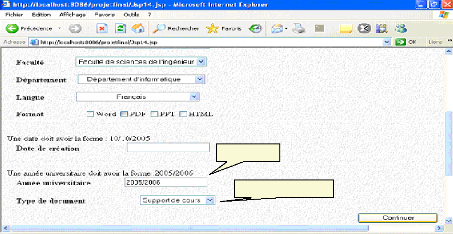
2005/2006
Support de cours
Fig.IV.36: Recherche d'un support de cours
|
82
|
|
|
Web sémantique
|
Ontologies & e-learning
|
Conception
|
Implémentation
|
*Toujours dans la même requête, l'utilisateur passe
vers un autre écran où il spécifie qu'il cherche un
support de cours ayant pour mots-clés « Logique propositionnelle
»:
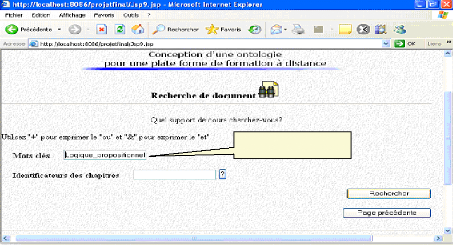
Logique propositionnelle
Fig.IV.37: Recherche d'un support de cours
(suite)
*Le résultat de la requête sera envoyé vers
la page de départ :
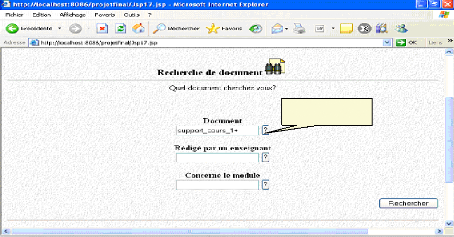
Support_cours_1
Fig.IV.38: Recherche d'un support de cours
(suite)
|
83
|
|
|
Web sémantique
|
Ontologies & e-learning
|
Conception
|
Implémentation
|
* Si encore il veut continuer sa requête en cherchant un
auteur particulier :
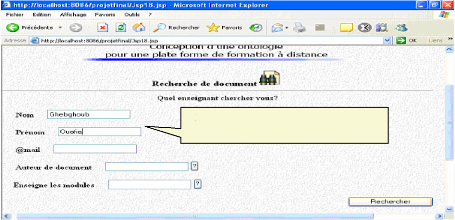
L'utilisateur spécifie le nom et le prénom
de
l'enseignant
Fig.IV.39 : Recherche d'un support de cours
(suite)
* L'identificateur de l'enseignant qui correspond à sa
requête sera envoyé aussi à la page initiale :
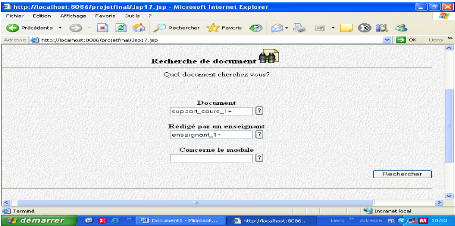
Fig.IV.40 : Recherche d'un support de cours
(suite)
|
84
|
|
|
Web sémantique
|
Ontologies & e-learning
|
Conception
|
Implémentation
|
*de plus il cherche un document concernant un module particulier,
il passe à l'écran suivant :
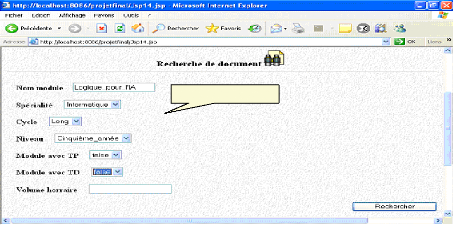
Logique pour l'IA
Fig.IV.41: Recherche d'un support de cours
(suite)
* Une fois terminer, il lance la recherche de l'URI de document
qui correspond à sa requête : Rappelons nous « un support de
cours avec un mot clés «logique propositionnelle »,
rédigé à l'année universitaire « 2005/2006
» par un enseignant ayant pour nom « Ghebghoub » et pour
prénom « Ouafia » et qui concerne un module ayant pour nom
« logique pour l'IA », et pour niveau «cinquième
année » et qui est un module de cycle « long » qui est
sans TD et sans TP.
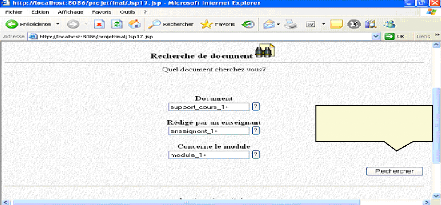
Lancer la recherche de
l'URI
Fig.IV.42 : Lancement de la recherche de
l'URI
|
85
|
|
|
Web sémantique
|
Ontologies & e-learning
|
Conception
|
Implémentation
|
*Le résultat de la recherche est bien le document ayant
pour URI
«
http://localhost :
8086/projetfinal/cours.pdf », par un simple clique sur le lien le document
se visualise :
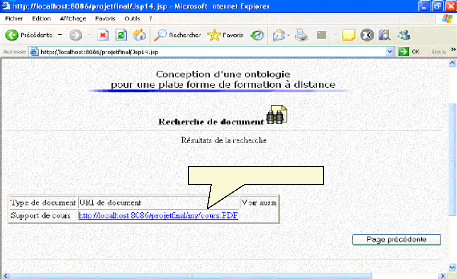
Le résultat de la recherche
Fig.IV.43 : Résultat de la recherche

|
Web sémantique
|
Ontologies & e-learning
|
Conception
|
Implémentation
|
VI.2. Intégration de l'application sur la plate
forme « Plone »
L'intégration de notre application sur la plate forme
Plone, consistait à ajouter des lien dans L'espace de travail
réservé à chacun des acteurs vers les tâche qui lui
sont propres :
> L'administrateur

Fig.IV.44 : Espace administrateur
|
87
|
|
|
Web sémantique
|
Ontologies & e-learning
|
Conception
|
Implémentation
|
> L'enseignant
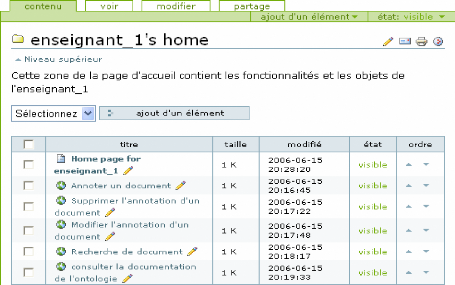
Fig.IV.45 : Espace enseignant
|
88
|
|
|
Web sémantique
|
Ontologies & e-learning
|
Conception
|
Implémentation
|
> Les étudiants


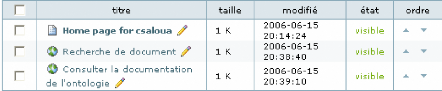
Fig.IV.46: Espace étudiant
VII. Avantage de l'application
Pour terminer on présente ici les avantages de notre
application de recherche qui est basée sur une ontologie, par rapport
à une recherche plein texte:
y' Elle permet de contextualiser les requêtes à
titre d'exemple : Au lieu de lancer la requête « SQL+base de
données », on précise mieux : « SQL concernant le
module base de données ».
y' Elle permet la recherche par des données qui ne font
pas nécessairement partie de document : comme les informations relatives
à l'auteur de document, à la date de création, etc.
y' Elle permet de faire des requêtes plus complexes
à titre d'exemple :
« Quel est le document ayant le format « HTML »
rédigé par l'enseignant qui a rédigé un autre
document « x ». (exploitation des relations définis dans
l'ontologie)
De plus le fait que notre application est basée sur une
ontologie cela présente l'avantage de partage d'un même
vocabulaire entre les différents types d'utilisateurs de l'application
ce qui améliore et facilite la recherche de documents.
|
89
|
|
|
Web sémantique
|
Ontologies & e-learning
|
Conception
|
Implémentation
|
VIII. Conclusion
Dans ce chapitre, nous avons présenté les
détails d'implémentation de l'application de ce projet ; On a
utilisé pour la réalisation de notre application :
-Système d'exploitation : Windows XP
-Outil de développement : Protégé-3.1.1,
JBuilder7
- Machine virtuelle JAVA : J2SDK version 1.4.2.
-Serveur Web JSP: Tomcat 4.x.
- Les bibliothèques : Jena version 2.3 et Servlet/JSP
version 2.3/1.2 (inclus dans Tomcat 4.x).
L'application développée a été
intégrée sur la plate forme « Plone», elle est
destinée pour trois types d'utilisateur : administrateur, enseignants,
étudiants et elle permet l'ajout, la modification et la suppression des
annotations relatives aux enseignants, aux modules et aux documents, et elle
permet principalement la recherche de document à partir de leurs
descriptions (métadonnées) basées sur une ontologie.

Conclusion générale
Tout au long de ce mémoire, nous avons
présenté ce qui est le Web sémantique et sur quoi il
repose en terme de normes et de langages, et nous avons abordé aussi la
notion d'ontologie et l'apport des ontologies dans un contexte Web
sémantique.
Le travail qu'on a réalisé dans le cadre de ce
projet tire part de l'ingénierie ontologique et de domaine de Web
sémantique, il avait pour objectif la conception d'une ontologie pour
fournir un vocabulaire conceptuel permettant l'annotation et la recherche de
documents sur une plate forme d'enseignement à distance.
Et pour implémenter l'application de ce projet on s'est
servit d'un ensemble de technologies proposées par la communauté
du Web sémantique (OWL, protégé, Jena..).
On considère que nous avons réussi à
réaliser une grande part des objectifs de ce projet, et que nous avons
fait les bons choix concernant les outils d'implémentation, de ce fait
notre travail constituera une très bonne piste pour d'autres projets
avenir.
Cependant notre travail n'est pas parfait et il peut être
amélioré sur plusieurs axes, et ce qu'on propose est de :
-Concevoir d'autres ontologies et de les faire combiner avec la
notre afin d'enrichir le vocabulaire utilisé pour l'annotation et la
recherche.
-Tester la possibilité de raisonnement offerte par le
langage OWL.
-Réutiliser cette ontologie dans une plate forme
basée sur les techniques du Web sémantique -Utiliser cette
ontologie dans la réalisation d'un éditeur de documents.
91
OWL : Web Ontology
Langage.
RDF : Ressource Description
Framework, permet de présenter des données et
des méta
données.
RDFS : RDF Schéma, permet de
définir des vocabulaires RDF.
DTD : Document Type
Definition. HTML :
HyperTexte Markup
Language. OWL DL : OWL
Description Logics. XML :
eXtensible Markup
Language. HTTP: HyperText
Transfer Protocol. DOM :
Document Object Model.
SAX : Simple API for
XML.
W3C : World Wide
Web Consortium.
IEEE: Institute of Electrical
and Electronics Engineers.
API : Interface de
Programmation d'Application.
URI : Uniform Ressource
Identifier. URL : Uniform Ressource
Locator.
EAO : Enseignement
Assisté par Ordinateur.
EIAO : Enseignement
Intelligemment Assisté par
Ordinateur.
FOAD : Formation Ouverte et
A Distance. IA : Intelligence
Artificielle.
IC : Ingénierie des
Connaissances.
IMAT: Integrating Manuals
And Training. ODE : Ontology
Design Environment.
TD : Travaux Dirigés.
TP : Travaux Pratiques.
XSLT : Extensible Stylesheet
Language Family Transformations.
JSP : Java Server
Page.
UML : Unified Model
Langage. E-learning : Electronic learning..
E-commerce : Electronic commerce.
FAQ: Frequently Asked
Questions. SQL :Structured
Query Langage. JDK :
JAVA Development Kit.
[1] Les applications de XML à la production d'objets
pédagogiques interactifs.
[2] Benayache Ahcene (2005) Construction d'une mémoire
organisationnelle de formation et évaluation dans un contexte e-learning
: le projet MEMORAe
[3] Pourquoi le XML ?
:www.microsoft.com/france/msdn/xml/whyXml.mspx
[4] Daniel Martin (1999) Stockage et
interopérabilité en XML.
[5] Cours sur le Web Sémantique :
www.greyc.ensicaen.fr/~chris/Cours_ws_cp_2005.htm
[6] Jean Charlet, Philippe Laublet, Chantal Reynaud (2003)
Action spécifique 32 CNRS / STIC: Web sémantique : Rapport
final
[7] Xavier Lacot (2005) Introduction à OWL, un langage
XML d'ontologies Web.
[8]
Sticef.org (2003) Apport de
l'ingénierie ontologique aux environnements de formation à
distance
[9]
Sticef.org (2004) Le rôle de
l'ingénierie ontologique dans le domaine des EIAH.
[10] Ouafia Ghebghoub, M .Djoudi, M,Ibn mouhammed
(Congrès AIPU, Monastir Tunisie du 15 au 18 Mai 2006) Ontologies et web
sémantique en enseignement à distance.
[11] Jean-Yves FORTIER (Octobre 2001) Construction d'une
ontologie pour gérer la documentation d'un centre de recherche
[12] Sabri Boutemedjet (2004) Web Sémantique et
e-Learning.
[13] Cyrille Desmoulins, Monique Grandbastien (2000) .Des
ontologies pour indexer des documents techniques pour la formation
professionnelle
[14] Rahmani Anas, Mallouli Wissam, Iben Said Anis (2004-2005)
Utilisation d'une ontologie distribuée sur des Pockets PC pour la
gestion d'un cabinet médical
[15] Marc Herlin : Introduction à Jena Le framework Java
pour le Web sémantique.
| 

