La réalisation d'une application de contrôle total des processus d'un ordinateur distant( Télécharger le fichier original )par Kitambala OMARI Université pédagogique nationale (UPN) - Licence 2010 |

Processus
Processus Client Serveur Requête Réponse Réseau
Processus I.1.IntroductionCes vingt dernières années ont vu une évolution majeure des systèmes d'information, à savoir le passage d'une architecture centralisée à travers de grosses machines (des mainframes) vers une architecture distribuée basée sur l'utilisation de serveurs et de postes clients grace à l'utilisation des PC et des réseaux. Cette évolution a été possible essentiellement grâce à 2 facteurs qui sont : Ø La baisse des prix de l'informatique personnelle ; > Le développement des réseaux informatiques. I.2. L'architecture Client-serveurI.2.1.DéfinitionL'architecture client-serveur est un modèle de fonctionnement logiciel qui se réalise sur tout type d'architecture matérielle (petites à grosses machines), à partir du moment où ces architectures peuvent être interconnectées. On parle de fonctionnement logiciel dans la mesure où cette architecture est basée sur l'utilisation de deux types de logiciels, à savoir un logiciel serveur et un logiciel client s'exécutant normalement sur 2 machines différentes. L'élément important dans cette architecture est l'utilisation de mécanisme de communication entre les 2 applications. Le dialogue entre les applications peut se résumer par : > Le client demande un service au serveur ; > Le serveur réalise ce service et renvoie le résultat au client. Un des principes fondamental est que le serveur réalise un traitement pour le client. I.2.2. Les principes générauxIl n'y a pas véritablement de définition exhaustive de la notion de client-serveur, néanmoins des principes régissent ce que l'on entend par clientserveur : > Service Le serveur est fournisseur de services. Le client est consommateur de service. > Protocole C'est toujours le client qui déclenche la demande de service. Le serveur attend passivement les requêtes des clients. > Partage des ressources Un serveur traite plusieurs clients en même temps et contrôle leurs accès aux ressources. > localisation Le logiciel client-serveur masque aux clients la localisation du serveur. > Redimensionnement Il est possible d'ajouter et de retirer des stations clientes ; il est possible de faire évoluer les serveurs. > Intégrité. Les données du serveur sont gérées sur le serveur de façon centralisée. Les clients restent individuels et indépendants. > Hétérogénéité. > Souplesse et adaptabilité Ont peut modifier le module serveur sans toucher au module client. La réciproque est vraie. Si, une station est remplacée par un modèle plus récent, on modifie le module client (en améliorant l'interface, par exemple) sans modifier le module serveur. I.2.3. La répartition des tâchesDans l'architecture client-serveur, une application est constituée de trois parties : > L'interface utilisateur ; > Le logiciel des traitements ; > La gestion des données. Le client n'exécute que l'interface utilisateur (souvent une interface graphique) ainsi, que la logique des traitements (formuler la requête), laissant au serveur de bases de données la gestion complète des manipulations de données. La liaison entre le client et le serveur correspond à tout un ensemble complexe des logiciels appelé middleware qui se charge de toutes les communications entre les processus. I.2.4. Générations de client-serveurI.2.4.1. Client-serveur de première générationLa première génération de client-serveur intègre des outils clients autour d'une base donnée relationnelle. L'application est développée sur le client à l'aide d'un langage de 4ème génération (L4G) intégrant une interface graphique et de requetes SQL au serveur. Autour des requetes, les traitements gèrent l'affichage et les saisies. Tout le code est exécuté sur le client, celui-ci envoie des requêtes SQL au serveur via un outil de connexion et récupère les résultats. I.2.4.2. Client-serveur de deuxième générationLe client-serveur de deuxième est plus récent, il est caractérisé pour l'évolution des outils dans trois directions : > Possibilité de développer des traitements sous la forme de procédures stockées sur le serveur. Ces procédures sont soit appelées explicitement par les applications clientes, soit déclenchées par des événements survenant sur les données (triggers) ; > Utilisation intensive de l'approche orientée objet aussi bien pour construire les interfaces que pour modéliser le système d'information ; > Répartition des fonctions en trois niveaux : la présentation incombe au client, la gestion des données à un serveur de données, les traitements à un serveur d'applications. I.2.4.3. Client-serveur universelCette génération de client-serveur s'appuie sur le compte de client léger représenté par un navigateur web. Celui-ci est chargé de la présentation et possède des possibilités d'exécution locale de traitements. Les serveurs sont disséminés, souvent spécialisés (données ou applications) et s'appuie sur un réseau étendu (Internet) ou local (Intranet). I.2.4.4. Tendances et évolutionsLa tendance est très marquée actuellement vers l'adoption du clientserveur universel. Notons aussi que l'évolution des besoins des entreprises pousse à l'intégration d'outils d'aide à la décision. Ces outils s'appuient sur l'exploitation de toutes les données de l'entreprise : base de données de production, fichiers... Ces données sont extraites, agrégées et stockées dans des entrepôts de données (data Ware house) puis exploitées et restituées par des outils spécialisés (datamining). Plus récemment, les « services web » (web service) offrent de nouvelles perspectives dans le domaine du client-serveur universel. Parmi les technologies disponibles, deux options principales dominent le marché : > Java, promu par Sun Microsystems, permet une portabilité sur des systèmes hétérogènes et le déport de l'exécution de traitements vers le client (ce qui autorise une répartition très fine des traitements entre le client et le serveur). La technologie java (J2EE), de par son orientation objets, permet en outre d'imaginer des solutions à base de serveurs d'objet, (EJB) > Microsoft, très actif sur ce marché, propose son architecture.Net qui est une évolution de l'architecture Dcom. I.2.5. Les différentes architecturesI.2.5.1. L'architecture 2 -tiersDans une architecture 2-tiers, encore appelée client-serveur de première génération ou client-serveur de données, le poste client se contente de déléguer la gestion des données à un service spécialisé. Le cas typique de cette architecture est une application de gestion fonctionnant sous Windows ou Linux et exploitant un SGBD centralisé. Ce type d'application permet de tirer de la puissance des ordinateurs déployés en réseau pour fournir à l'utilisateur une interface riche, tout en garantissant la cohérence des données, qui restent gérées de façon centralisée.
La gestion des données est prise en charge par un SGBD centralisé, s'exécutant le plus souvent sur un serveur dédié. Ce dernier est interrogé en utilisent un langage de requête qui, le plus souvent, est SQL. Requête Présentation Traitements Client Retour de la réponse Envoi de la requête Réseau Serveur Données Fig. 2.L'architecture 2-tiers Cet échange de messages transite à travers le réseau reliant les deux machines. Il met en oeuvre des mécanismes relativement complexes qui sont, en général, pris en charge par un middleware. L'expérience a démontré qu'il était coüteux et contraignant de vouloir faire porter l'ensemble des traitements applicatifs par le poste client. On en arrive aujourd'hui à ce que l'on appelle le client lourd, avec un certain nombre d'inconvénients : > On ne peut pas soulager la charge du poste client. Qui supporte la grande majorité des traitements applicatifs, > Le poste client est fortement sollicité, il devient de plus en plus complexe et doit être mis à jour régulièrement pour répondre aux besoins des utilisateurs, > La relation étroite qui existe entre le programme client et l'organisation de la partie serveur complique les évolutions de cette dernière, > Ce type d'architecture est grandement rigidifié par les coüts et la complexité de sa maintenance. Avantage de l'architecture 2-tiers > Elle permet l'utilisation d'une interface utilisateur riche ; > Elle a permis l'appropriation des applications par l'utilisateur ; > Elle a introduit la d'interopérabilité. Pour résoudre les limitations du client-serveur 2-tiers tout en conservant ses avantages, on a cherché une architecture plus évoluée, facilitant les forts déploiements à moindre coût. La réponse est apportée par les architectures distribuées. I.2.5.2. L'architecture 3LIIIELJULes limites de l'architecture 2-tiers proviennent en grande partie de la nature du client utilisé : > Le frontal est complexe et non standard (même s'il s'agit presque toujours d'un PC sous Windows). > Le middleware entre client et serveur n'est pas standard (dépend de la plate-forme, du SGBD,...) La solution résiderait donc dans l'utilisation d'un poste client simple communicant avec le serveur par le biais d'un protocole standard. Dans ce but, l'architecture trois tiers applique les principes suivants : > Les données sont toujours gérées de façon centralisée ; > La présentation est toujours prise en charge par le poste client ; > La logique applicative est prise en charge par un serveur intermédiaire. Cette architecture trois tiers, également appelée client-serveur de deuxième génération ou client-serveur distribué sépare l'application en 3 niveaux de services distincts, conformes au principe précédent : > Premier niveau : l'affichage et les traitements locaux (contrôles de saisie, mise enforme de donnée...) sont pris en charge par le poste client ; > Deuxième niveau : les traitements applicatifs globaux sont pris en charge par le service applicatif ; > Troisième niveau : les services de base de données sont pris en charge par un SGBD.
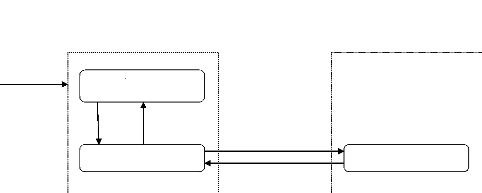
Présentation Traitements locaux Traitements globaux Données Premier niveau Deuxième niveau Troisième niveau Fig. 3.L'architecture 3-tiers Tous ces niveaux étant indépendants, ils peuvent être implantés sur des machines différentes, de ce fait : > Le poste client ne supporte plus l'ensemble des traitements s'il est moins sollicité et peut être moins évolué, donc moins coûteux ; > Les ressources présentes sur le réseau sont mieux exploitées, puisque les traitements applicatifs peuvent être partagés ou regroupés(le serveur d'application peut s'exécuter sur la même machine que le SGBD) ; > La fiabilité et les performances de certains traitements se trouvent améliorées par leur centralisation ; > Il est relativement simple de faire face à une forte montée en charge, en renforçant le service applicatifs. Dans l'architecture 3- tiers, le poste client est communément appelé client léger, par opposition au client lourd des architecture deux tiers, il ne prend en charge que la présentation de l'application avec, éventuellement, une partie de logique applicative permettant une vérification immédiate de la saisie et la mise en forme des donnée. Le serveur de traitement constitue la pierre angulaire de l'architecture et se trouve souvent fortement sollicité. Dans ce type d'architecture, il est difficile de répartir la charge entre client et serveur. On se retrouve confronté aux épineux problèmes de dimensionnement serveur et de gestion de la montée en charge rappelant l'époque des mainframes, de plus, les solutions mises en oeuvre sont relativement complexes à maintenir et la gestion des sessions est compliquée. Les contraintes semblent inversées par rapport à celles rencontrées avec l'architecture deux tiers : le client est soulagé, mais le serveur est fortement sollicité. I.2.5.3. L'architecture n-tieTsL'architecture n-tiers a été pensée pour pallier aux limitations des architectures trois tiers et concevoir des applications puissantes et simples à maintenir. Ce type d'architecture permet de distribuer plus librement la logique applicative, ce qui facilite la répartition de la charge entre tous les niveaux. Cette évolution des architectures trois tiers met en oeuvre une approche objet pour offrir une plus grande souplesse d'implémentation et faciliter la réutilisation des développements. Théoriquement, ce type d'architecture supprime tous les inconvénients des architectures précédentes : > Elle permet l'utilisation d'interfaces utilisateurs riche ; > Elle sépare nettement tous les niveaux de l'application ; > Elle offre de grandes capacités d'extension ; > Elle facilite la gestion des sessions. L'appellation « n-tiers » pourrait faire penser que cette architecture met en oeuvre un nombre indéterminé de niveaux de service, alors que ces derniers sont au maximum trois (les trois niveaux d'une application informatique). En fait, l'architecture n-tiers qualifie la distribution d'application entre de multiples services et non la multiplication des niveaux de service. Cette distribution est facilitée par l'utilisation de composants « métier », spécialisés et indépendants, introduits par les concepts orientés objets (langages de programmation et middleware). Elle permet de tirer pleinement partie de la notion de composants métiers réutilisables. Ces composants rendent un service si possible générique et clairement identifié. Ils sont capables de communiquer entre eux et peuvent donc coopérer en étant implantés sur des machines distinctes. La distribution des services applicatifs facilite aussi l'intégration de traitements existants dans les nouvelles applications. On peut ainsi envisager de connecter un programme de prise de commande existant sur le site central de l'entreprise à une application distribuée en utilisant un middleware adapté. Ces nouveaux concepts sont basés sur la programmation objet ainsi que sur des communications standards entre application. Ainsi est né le concept de middleware objet. I.2.6. Les middlewaresI.2.6.1. PrésentationOn appelle middleware (ou logiciel médiateur en français ou encore intergiciel), littéralement « élément du milieu », l'ensemble des couches réseau et services logiciel, qui permettent le dialogue entre différents composants d'une application répartie. Ce dialogue se base sur un protocole applicatif commun, défini par l'API du middleware. Le Gartner Group définit le middleware comme une interface de communication universelle entre processus. Il représente véritablement la clef de voûte de toute application client-serveur. L'objectif principal du middleware est d'unifier, pour les applications, l'accès et la manipulation de l'ensemble des services disponibles sur le réseau, afin de rendre l'utilisation de ces derniers presque transparente. Adaptateur Protocole de communic Client Serveur
Interface serveur Interface de Interface client Middleware Protocole réseau Protocole réseau Protocole de . Application SGBD Support physique du réseau Fig.4. Présentation des middlewares I.2.6.2. Les services des middlewaresUn middleware est susceptible de rendre les services suivants : > Conversion : service utilisé pour la communication entre machines mettant en oeuvre des formats de données différents. > Adressage : permet d'identifier la machine serveur sur laquelle est localisé le service demandé afin d'en déduire le chemin d'accès. Dans la mesure du possible. > Sécurité : permet de garantir la confidentialité et la sécurité des données à l'aide de mécanismes d'authentification et de cryptage des informations. > Communication : permet la transmission des messages entre les deux systèmes alternation. Ce service doit gérer la connexion au serveur. La préparation de l'exécution des requetes, la récupération des résultats et le dé - connexion de l'utilisateur. I.2.6.3. Exemples de middleware
I.2.6.4. Les middlewares objet
II.1. L'architecture Centralisée Au Client-ServeurII.1.1. Le contexte historique
II.1.2. Définitions du modèle client-serveur
II.2. PrésentationII.2.1. principe
II.2.2. Les mécanismes de la communication
II.2.2.1. Le mode datagramme
II.2.2.2. Le mode connecté (TCP)
II.3. Le navigation et URLII.3.1. Le navigateur
II.3.2. L'URL (Uniform Resource Locator)
II.3.2.1. Structure d'une URL Une URL a la structure suivante
II.3.2.2. Quelques exemples pratiques d'URL
II.4. Les différents modèles de client serveur II.4.1. Le client-serveur de donnéeDans ce cas, le serveur assure des tâches de gestion, de stockage et de traitement de données. C'est le cas le plus connu de client-serveur qui est utilisé par tous les grands SGBD : > La base de données avec tous ses outils (maintenance, sauvegarde...) est installée sur un poste serveur. > Tous les traitements sur les données sont
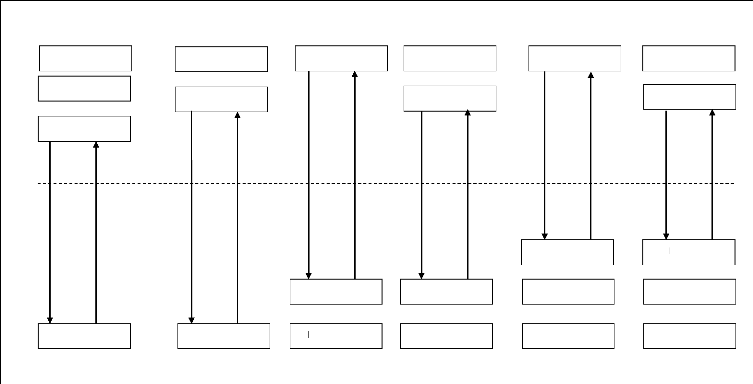
effectués sur le serveur qui renvoie II.4.2.Client-serveur de présentationDans ce cas la présentation des pages affichés par le client est intégralement prise en charge par le serveur. Cette organisation présente l'inconvénient de générer un fort trafic réseau. II.4.3. Le client-serveur de traitementDans ce cas, le serveur effectue des traitements à la demande du client. Il peut s'agir de traitement particulier sur des données, de vérification de formulaires de saisie, du traitement d'alarmes... Ces traitements peuvent être réalisés par des programmes installé sur des serveurs mais également intégrés dans des bases de données (Triggers, Procédures, Stockées), dans se cas, la partie, donnée et traitement sont intégrées. II.4.4. Une synthèse des différents casCette synthèse s'illustre par un schéma de Gartner group qui représente les différents modèles ainsi que la répartition des tâches entre serveur et client.
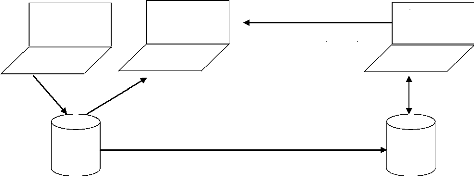
Présentation Présentation Présentation Présentation Présentation Présentation Présentation Traitements Traitements Traitements Traitements Traitements Traitements Données Traitements Traitements Données Serveur Client Reseau Fig.9.Schéma de Gartner group Sur ce schéma, le trait horizontal représente le réseau et les flèches entre client et serveur, le trafic réseau généré par la conversation entre client et serveur. Nous verrons par la suite que la vision du Gartner Group, en ne prenant en compte qu'un découpage en deux niveaux, est quelque peu limitative. Le Gartner Group distingue les types de client-serveur suivants, en fonction du type de service déporté du coeur de l'application. II.4.1. Présentation distribuéeCorrespond à l'habillage « graphique » de l'affichage en mode caractères d'applications fonctionnant sur un site central. Cette solution est aussi appelée revamping. La classification «clientserveur » du revamping est souvent jugée abusive, du fait que l'intégralité des traitements originaux est conservée et que le poste client conserve une position d'esclave par rapport au serveur. II.4.2. Présentation distanteEncore appelée client-serveur de présentation. L'ensemble des traitements est exécuté par serveur, le client ne prend en charge que l'affichage. Ce type d'application présentait jusqu'à présent l'inconvénient de générer un fort trafic réseau et de ne permettre aucune répartition de la charge entre client et serveur. S'il n'était que rarement retenu dans sa forme primitive, il connaît aujourd'hui un très fort regain d'intérêt avec l'exploitation des standards internet. II.4.3. Gestion distante des donnéesCorrespond au client-serveur des données, sans doute le type de client-serveur le plus répandu. L'application fonctionne dans sa totalité sur le client, la gestion des données et le contrôle de leur intégrité sont assurés par un SGBD. Cette architecture, de part sa souplesse, s'adresse très bien aux applications type info centre, interrogeant la base de façon ponctuelle. Il génère toutefois un trafic réseau assez important et ne soulage pas énormément le poste client, qui réalise, encore la grande majorité des traitements. II.4.4. Traitement distribuéCorrespond au client-serveur de traitement. Le découpage de l'application se fait ici au plus près de son noyau et les traitements sont distribués entre le client et le(S) serveur(S). Le client-serveur de traitements s'appuie, soit à un mécanisme d'appel de procédure distante, soit sur la notion de procédure stockée proposée par les principaux SGBD du marché. Cette architecture permet d'optimiser la répartition de la charge de traitement entre machines et limite le trafic réseau. Par contre il n'offre pas la même souplesse que le client-serveur de données puisque les traitements doivent être connus du serveur à l'avance. II.4.5. Bases de données distribuéesIl s'agit d'une variante du client-serveur de données dans laquelle une partie de données est prise en charge par le client. Ce modèle est intéressant si l'application doit gérer de gros volumes de données, si l'on souhaite disposer de temps d'accès très rapides sur certaines données ou pour répondre à de fortes contraintes de confidentialité. Ce modèle est aussi puissant que complexe à mettre en oeuvre. II.4.6. Données et traitements distribuésCe modèle est très puissant et tire partie de la notion de composants réutilisables pour répartir au mieux la charge entre client et serveur. C'est bien entendu, l'architecture la plus complexe à mettre en oeuvre. II.5. Les protocoles de transfert de fichiers le plus utilisésIl existe plusieurs protocoles utilisables pour faire du transfert de fichiers. Chacun d'eux a des spécificités propres décidée à chaque type d'application. II.5.1. HTTP (Hypert Text Transfert Protocol) RF616Ce protocole (qui n'est pas historiquement le premier des protocoles de transfert de fichiers) est l'un des plus simples. Il a été définie pour transférer des documents hypert text (et multimédia) du serveur vers le client (méthode Get) ou du client vers le serveur (méthode post)
Client
4) Réception code d'erreur Serveur Réseau (support du système de communication) Fig.10.HTTP Le client ouvre connexion vers le serveur (généralement c'est sur le port 80 mais un autre port dont le numéro est alors précisé dans l'URL peut être utilisé, le port 8000 par exemple), puis transmet un header de requête qui contient la demande de service, l'URL concerné puis différentes informations supplémentaires optionnelles telles que les cookies, l'authentification, ainsi que d'autres paramètres des clients (ou navigateur). Citons parmi, les serveurs les plus courants : le serveur apache (disponible en open source fonctionnant sous UNIX, linux mais également sous Win 9x) ; le personnal web server (livré avec Win 98 et certain Win 95) ;... II.5.2.TFTP (Trivial File Transfer Protocol) RFC 783Il s'agit d'un protocole de transfert de fichiers sans gestion de droit d'accès ni possibilité d'obtenir la liste des fichiers disponibles. Il est principalement utilisé par des équipements réseau ne disposant pas de Rom ou de FLASH pour conserver leur logiciel de fonctionnement et le téléchargeant donc en Ram à chaque démarrage. Grâce à un client TFTP, on peut charger depuis le serveur ou déposer sur le serveur des fichiers en connaissant leurs noms. Pour pouvoir écrire, il suffit que le système d'exploitation de la machine sur laquelle tourne l'application de serveur autorise l'écriture. En règle générale, l'arborescence géré par le serveur TFTP n'est qu'une portion réduite de la machine sur la quelle il est installé. Le dialogue client-serveur est réalisé par envoie de datagramme, au dessus du protocole UDP. Quand un fichier ne peut tenir dans un datagramme, il est fragmenté et demandé (envoyé) morceau par morceau. II.5.3. File transfert protocol (Protocole de transfert de fichiers)Est un protocole de communication destiner à l'échange informatique de fichiers sur un réseau TCP/IP. Il permet, depuis un ordinateur, de copier des fichiers vers un autre ordinateur du réseau, d'alimenter un site web, ou encore de supprimer ou de modifier des fichiers sur cet ordinateur. FTP obéit à un modèle client-serveur, c'est-à-dire qu'une des deux parties, le client, envoie des requetes auxquelles réagit l'autre, appelé serveur. En pratique, le serveur est un ordinateur sur lequel fonctionne un logiciel lui-même appelé serveur FTP, qui rend public une arborescence de fichiers similaire à un système de fichiers UNIX. Pour accéder à un serveur FTP, on utilise un logiciel client FTP possédant une interface graphique ou en ligne de commande. Le protocole, qui appartient à la couche session du modèle OSI, utilise une connexion TCP. Il peut s'utiliser de deux façons différentes.
Le serveur FTP détermine lui-même le port de connexion à utiliser pour permettre le transfert des données et le communique au client. En cas de présence d'un pare-feu devant le serveur, celui-ci devra être configure pour autoriser la connexion des données. L'avantage de ce mode, est que le serveur FTP n'initialise aucune connexion. Dans les nouvelles implémentations, le client initialise et communique directement par le port 21 du serveur ; cela permet de simplifier les configurations des pare-feu serveur. II.5.4. Protocoles de messagerie électronique et forum de discussionD'une certaine façon il s'agit encore d'un protocole de transfert de fichiers, dans la mesure où le contenu d'un fichier peut être véhiculé dans un message électronique. Mais la messagerie électronique n'est pas prévu à l' origine pour transférer des fichiers et ne sera surtout pas adapte des que la taille du dit fichier sera importante II.5.4.1. SMTP (Simple Mail Transfert Protocol) RFC 821Il s'agit du protocole utilisé pour transférer le courrier électronique d'un serveur vers un autre. Le poste source peut émettre un mail sans avoir de serveur de mail. Il suffit qu'il contact en utilisant le Protocol SMTP le serveur de mail-local (souvent appelé mail host ou smtp host) de son domaine ce premier serveur de messagerie électronique deviendra client d'un serveur « Relay » « ou directement du serveur destination) qui à son tour transmettra. Les serveurs dit « Relay » sont des serveurs intermédiaires utilisés quand le serveur destination n'est pas directement joignable par le serveur local de l'émetteur. Le dialogue entre le client SMTP (c'est-à-dire un client de messagerie ou bien un serveur intermédiaire) et un serveur SMTP suit ce modèle. Ici tout (ordres de transfert et messagerie électroniques) va passer par le même canal. Le modèle de SMTP est basé suivant de communication : suite à une requete de l'utilisateur du courrier user, l'émetteur SMTP établit une communication bidirectionnelle vers un récepteur-SMTP. Celui-ci peut être soit la destination finale, soit seulement un intermédiaire. Les commandes SMTP sont générées par l'émetteur SMTP et sont émises vers le récepteur SMTP. Les réponses SMTP sont envoyées par le récepteur-SMTP à l'émetteur-SMTP en réponse aux commandes. Une fois le canal de transmission établi, l'émetteur SMTP envoie une commande MAIL mentionnant l'émetteur d'un courrier user. Si le récepteur SMTP peut accepter le courrier, il répondra par un message OK. L'émetteur-SMTP envoie alors une commande RCPT identifiant un récipiendaire pour ce courrier. Si le récepteur-SMTP peut accepter un courrier pour ce récipiendaire, alors il répondra par un message OK ; sinon, il répond par un message refusant le courrier pour ce récipiendaire (mais n'annulant totalement pas la transaction de courrier).L'émetteur SMTP et le récepteur SMTP pourrons négocier plusieurs récipiendaires. Une fois cette négociation effectuée, l'émetteur SMTP envoie le contenu du courrier, en le terminant par une séquence spéciale. Si le récepteur SMTP traite avec succès la réception du contenu du courrier, il répondra par un message OK. Le dialogue est volontairement un dialogue pas à pas, à étapes verrouillées.
Emetteur-SMTP Récepteur-SMTP Fig.11.SMTP. SMTP procure un mécanisme de transmission des courriers, directement à partir de l'hôte de l'émetteur du message jusqu'à l'hôte du récipiendaire pour autant que les deux hôtes soient raccordée au même service de transport, ou à travers une chaîne de relais SMTP (serveurs) lorsque les hôtes source et destination ne sont pas raccordés au même service de transport. II.5.4.2. POP3 (Post Office Protocol, Version3) RFC 1225
Serveur SMPT Serveur POP3 Rapatriement des mails Client POP3 Transfert des mails via POP3 Requête POP3 et Mail box de l'utilisateur sur le serveur Mail box de l'utilisateur sur sa machine Si l'utilisateur destinateur de mail travail sur un autre poste que le serveur de mail, il faudra utiliser un autre protocole pour rapatrier les mails vers son post client. Le protocole POP3 est prévu pour cela. Mais il existe également le protocole IMAP qui assure le même type de service. L'utilisateur commence par indiquer au serveur son compte et son mot de passe, puis le serveur transfert (après vérification de l'identité) et supprime les mails du mail box du serveur. Le client récupère alors les mails et les stocke sur le disque de l'utilisateur sous un format qui lui est propre. Parmi, les clients citons entre autre «Net scape communicator» » (Unix et Windows), « outlook express » (Windows), « outlook » (Windows), « Eudora pro » (Windows). II.5.4.3. NNTP (News Net Work Transfert Protocol) RFC977Ce protocole est utilisé pour le service des news groups pour les transferts d'articles entre les clients et les serveurs lors de la soumission ou mail si ce n'est que l'on n'envoie pas l'article dans la boîte aux lettres d'un utilisateur mais dans la boîte aux lettres d'un sujet (le news group) et que toutes les personnes intéressées par le sujet pourront le consulter quand ils le désireront. (Par rapport au principe d'envoie de mail à une liste de diffusion cela présente l'avantage de ne pas devoir dupliquer l'article pour chaque utilisateur) les articles sont conservées, un certain temps (entre 8 jours et 1 mois en moyenne selon la quantité d'articles produits) sur les différents serveurs de Usenet (dénomination de la toile formée par l'ensemble des serveurs de News de l'internet) puis sont détruits. II.6. Partage de disques dur et d'imprimanteII.6.1. Intégration dans le système d'exploitation (S.E)Dans le cas du partage de disques durs et d'imprimantes, le client et le serveur font partie du S.E des 2 machines concernées. Comme vous le savez le système d'exploitation est structuré en 7 couches allant de la couche matériel qui représente la machine et ces différents périphériques à la couche application qui contient les différents programmes que la machine est entrain d'exécuter.
Fig.13.Intégration dans le système d'exploitation C'est donc la couche correspondante à la gestion de service qui sera client dès que cette demande de service doit être transmise sur le réseau. C'est donc la couche « files system » qui sera client ou serveur dans le partage de disques durs et la couche qui gère les « entrées/sorties » qui sera client ou serveur dans le partage d'imprimantes. Quand une application de la machine cliente veut accéder à un fichier d'un disque partagé, elle fait la demande d'accès à son système d'exploitation qui transmet la demande via le réseau au S.E du serveur puis reçoit la réponse et la transmet à l'application. La gestion des droits d'accès au fichier étant gérée par le S.E. Le mécanisme de partage de disque devra éventuellement adapter la gestion des droits si les S.E ne sont pas totalement compatibles. (Exemple : win 9x et Linux) II.6.2. Exemple de protocoleII.6.2.1. NFSC'est le protocole de partage de file système crée par SUN pour Unix. (NFS= Network File System) le serveur transmet les informations relatives aux droits des fichiers. Pour les fichiers utilisateurs (qui n'appartiennent pas à root) les serveurs faits confiance au client dans la gestion des droits. (Cette confiance peut également être étendue aux fichiers de root pour certaines machines.) Dans la configuration du serveur, on indique dans le fichier « /etc/ exports » la liste des répertoires partagés et la liste des machines pouvant être clients. /user1 *. domain.fr (rw) admin.domain.fr (rw, no - root - squash) /cd rom *. domain.fr (ro) Dans l'exemple ci - dessus, toutes les machines de « domaine. fr » peuvent accéder en écriture au répertoire« /user 1» et en lecture seule au répertoire »/cd rom ».la machine« admin. domain. fr » peut accéder en écriture et modifier les fichiers appartenant à root. II.6.2.2. SMBC'est le protocole, de partage de disque dur et d'imprimante, utilisé sous win 9x et win NT. Quand, le serveur est une machine win 9x, il peut être configuré de deux façon différentes : soit en mode « share »soit en made « user ». on choisira le mode de partage en allant dans les propriétés du réseau sur l'onglet « contrôle d'accès ». Si on coche « contrôle d'accès au niveau ressource », on sera en mode « share » et il faudra fournir un mot de passe propre à la ressource qui nous donnera ou bien le droit en lecture sur le contenue du partage soit le droit en lecteur /écriture. Si on coche « contrôle d'accès au niveau utilisateur », on sera en mode « user » et on définira la liste des utilisateurs qui pourront lire et la liste des utilisateurs pouvant à la fois lire et écrire. Pour pouvoir utiliser le mode « user », il faut préciser un serveur de Domain NT qui permettra d'obtenir la liste des utilisateurs et d'effectuer la vérification des mots de passes. II.6.2.3. LPRC'est le protocole d'impression réseau utilisé sous « Unix » la commande « LPR » ou « LP » est le client selon la version d'Unix et le daemon « LPD ». il existe des clients LPR pour win 9x téléchargeable sur internet et le client pour win NT est déjà intégré. La grande majorité des imprimantes équipées de cartes réseau intégré un serveur d'impression connaissant ce protocole. II.7. Autres types d'applications client-serveurII.7.1. Les serveurs d'authentificationCe sont des protocoles de partage des bases de données des utilisateurs. Cela permet à un utilisateur de se connecter avec un même login et un même mot de passe sur l'ensemble des machines d'un parc informatique. II.7.1.1.NISC'est un protocole qui permet d'obtenir des informations provenant de certain fichier Unix tel que la base des utilisateurs et des mots de passe. Le système d'exploitation Unix est client de ce service et obtient ainsi par réseau une liste complémentaire de ces utilisateurs. II.7.1.2. NIS+Le problème avec le protocole NIS, c'est que n'import qui, dès lors qu'il connaît le nom du Domain NIS, peut obtenir la liste des utilisateurs et la version cryptée de leur mot de passe il est alors possible de crypter tour à tour tous les mots d'un dictionnaire pour vérifier s'il correspond au mot de passe d'un utilisateur NIS+ ajoute au protocole NIS, une gestion des droits d'accès aux informations il faut indiquer sur le serveur chaque machine qui a le droit d'accéder à la base NIS+. Chaque machine cliente devra donner son mot de passe d'identification pour avoir le droit de communiquer avec le serveur. Enfin les logiciels clients NIS+ n'affichent pas les chaînes cryptées des mots de passe aux utilisateurs autorisés. II.7.1.3. Quelques autresRADIUS est un protocole de vérification centralisé de mot de passe utilisateurs avec transfert sécurisé entre les clients et le serveur. Il est assez souvent utilisé sur les pare-feu (fire wall) qui demandent la vérification de l'utilisateur pour autoriser ou interdire l'accès à un service réseau.
LDAP est un protocole plus générale d'annuaire, mais pourront également contenir des renseignements sur les utilisateurs que le serveur portagera en réseau avec ses clients. C'est un moyen utilisé par certains outils de messagerie électronique tel que « out look express » pour partager en réseau un carnet d'adresse e-mail. II.7.2. Les serveurs d'applications et serveurs graphique :> Le serveur d'application (appelé également serveur CPU) est de fournir un service d'exécution de programme à distance. > Le serveur graphique est de fournir un service d'affichage pour des applications réseaux s'exécutant sur une autre CPU (c'est-à-dire un autre ordinateur). Dans le cas où l'utilisateur veut exécuter des applications à distance, l'utilisation de ces deux services est liée. II.7.2.1. Terminal (port 23)CPU Fig.14.Terminal.
Sous Unix, système multi - tâches et multi - utilisateurs, il est possible d'utiliser a plusieurs la même machine en y connectant plusieurs terminaux (ensemble de clavier écran). Cette possibilité d'obtenir un prompt de login et de pouvoir ensuite lancé des applications est également disponible via le réseau grâce au daemon (le serveur du protocole « Telnet ») et via l'application cliente « Telnet ». Via le canal de communication ouvert entre le client et le serveur, on simule la connexion directe à la machine d'un terminal alpha numérique. Il existe d'autres protocoles permettant d'assurer un service semblable. Citons l'application standard d'Unix « ssh ». Leurs différences se situent essentiellement au niveau du protocole d'établissement des session qui n'est pas assuré de la même manière et offre des méthodes d'authentifications plus ou moins robuste et plus ou moins évoluées. A chacune des applications clients, on trouvera une application serveur aves son port associé. II.7.2.2. Serveur x11 et serveur XDMLe serveur x 11, développé par le MIT, permet l'affichage graphique pour des applications déportées. On fait tourner le serveur, sur le poste d'affichage et le programme demandant les affichages est Le client x11. Ce que l'on appel des terminaux x sont des postes disposant d'un CPU sur les quelles s'exécute uniquement l'application serveur x11. Les 2 seules autres applications pourront s'exécuter sur la CPU du terminal sont : Le client XDM du terminal, le client telnet du terminal et un Windows manager parfois également disponible. Toutes ces applications font partis de l'équivalent du bios du terminal. Toutes les autres applications provoquent un affichage s'exécuteront sur un autre ordinateur. Le post d'appel du serveur est le 6000 pour le serveur « terminal - name : 1 », « terminal - name : 2 », ... avec pour post d'appel : 6001, 6002,... Une connexion sera crée avec le serveur pour chaque fenêtre demandée par l'application cliente. On appel »Windows manager », un client qui gère le fond d'écran, les menus s'y rattachant ainsi que le « look and feed » des fenêtres crée par les applications. Les ordres de créations, de modifications et de destructions des fenêtres reçus par le serveur x seront retransmis au « Windows manager ». (on ne peut avoir à la fois qu'un «Windows manager » par serveur x.).
III.1. IntroductionIl ne fait désormais plus aucun doute que l'informatique représente la révolution la plus importante et la plus innovante qui a marqué la vie de l'humanité en ce siècle passé. En effet, loin d'être éphémère phénomène de mode, ou une tendance passagère, l'informatique vient nous apporter de multiples conforts à notre mode de vie. Aucun domaine n'est reste étranger à cette stratégie qui offre tant de service de services aussi bien pour l'entreprise ou l'administration que pour le personnel. Mais, au-delà de l'utilisation individuelle de l'informatique, c'est surtout la mise en communication des ordinateurs, le contrôle total des processus d'un ordinateur distant, le gestion du temps d'exécution, qui ont permis de révolutionner les méthodes de travail. Ainsi, on a assisté à l'émergence des réseaux. Ce nouveau progrès offre aux utilisateurs de nouveaux outils de travail et leur permet d'améliorer leur rentabilité et leur productivité. C'est dans ce cadre d'idées que s'inscrit notre réalisation. III.2. Analyse conceptuelleL'analyse conceptuelle débouche bien en entendu sur la mise en oeuvre technique, accompagnée de la réalisation de supports visuels. III.2.1. L'analyse de l'existantNous savons qu'il existe plusieurs logiciels du contrôle total des processus d'un ordinateur distant tel que : > Windows management instrumentation (WMI) ; c'est l'implémentation de Microsoft du web Based Entreprise Management (WBEM), c'est un système de gestion interne de Windows qui prend en charge la surveillance et le contrôle de ressource système via un ensemble d'interfaces. Il fournit un modèle cohérent et organisé logiquement des états de Windows. > Remote Administrator (Radmin) : est un programme de contrôle à distance multifonctions récompensé. Radmin permet de surveiller ou travailler à distance sur un ou plusieurs ordinateurs du réseau, depuis un poste de travail. > Anyplace control : est un logiciel qui permet de contrôler différents ordinateurs a distance, depuis n'importe quel endroit du monde. Le programme affiche le bureau de l'ordinateur distant (via internet ou le réseau local) sur votre propre écran et l'on peut utiliser la souris et le clavier pour piloter l'ordinateur distant. En d'autres termes, on peut travailler sur l'ordinateur distant, comme si l'on était assis devant, tout en étant ailleurs. > Virtual Network Computing (VNC) ; c'est un logiciel ouvert pour se connecter à un ordinateur distant. Il permet de transmettre les saisies au clavier ainsi que les clics de souris d'un ordinateur à l'autre, à travers un réseau informatique. VNC est indépendant de la plate forme : un client VNC installé sur n'importe quel système d'exploitation peut se connecter à un serveur VNC installé sur un autre système d'exploitation. Plusieurs clients peuvent se connecter en même temps sur un même serveur VNC. Une utilisation de ce protocole est le support technique à distance, ainsi que la visualisation de fichiers sur un ordinateur de travail à partir d'un ordinateur personnel. III.2 .2. Cahier des chargesUn cahier des charges est un document contractuel décrivant ce qui est attendu du maître d'oeuvre par le maître d'ouvrage. il s'agit donc d'un document décrivant de la façon la plus précise possible avec un vocabulaire simple, les besoins aux quels le maître d'oeuvre doit répondre dans la mesure où seul le maître d'oeuvre est réellement compétent pour proposer une solution technique appropriée, le cahier des charges doit préférentiellement faire apparaître le besoin de manière fonctionnelle, indépendamment de toute solution technique, sauf à préciser l'environnement technique dans le quel la solution demandée doit s'insérer. III.2.2.1. Cahier des charges fonctionnelLe cahier des charges fonctionnel est un document par lequel une entité à l'origine de la demande ou un utilisateur exprime son besoin en termes de fonctions de services et des contraintes voilà une source qui permet de contrôler complètement les processus d'un ordinateur distant : Nous savons qu'il existe WMI pour gérer les processus à distance, mais WMI n'est pas franchement convaincant car : > Il nécessite d'être installé sur les deux machines ; > Il n'est pas très rapide (en tout cas pour l'utilisation spécifique que l'on en fait en listant les processus) > Très très limité (impossible de faire autre chose que la liste des processus/modules, tuer/créer) Bref voici une solution qui permet de contrôler entièrement les processus d'un ordinateur distant : kill, suspend, priorité, affiné, liste des threads / handles, changement des privilèges, déchargement de module| handle, le tout à distance 1. Processus : un processus est l'instance d'un programme un cours d'exécution, une instance de programme est un espace mémoire composée d'une partie ou de la totalité de l'exécutable chargé en mémoire, de l'espace mémoire et des ressources allouées par le système à la demande du processus ainsi que de toutes les librairies chargées .Il peut exister plusieurs instances d'un même programme simultanément en cours d'exécution sur un ordinateur l'espace mémoire d'un processus est protégé, c'est-à-dire que c'est le seul espace auquel il peut accéder, les autres processus ne pourront y accéder. a. Gestion du temps d'exécution Les systèmes d'exploitation permettent une exécution quasi simultanée en allouant un court temps d'exécution à chaque thread de chaque processus à tour de rôle, selon leur priorité, cela donne l'impression que chaque programme s'exécute en même temps. L'exécution d'un processus dure un certain temps, avec un début et (parfois) une fin. Un processus peut être démarré par un utilisateur par l'intermédiaire d'un périphérique ou bien par un autre processus. b. Etats d'un processus. Initialisation Terminé
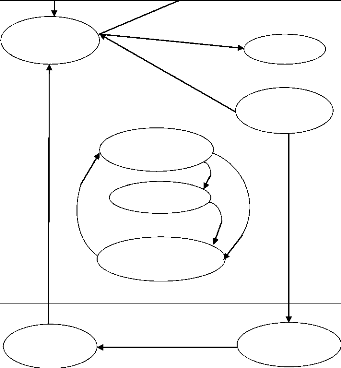
Mémoire vive Prêt (en attente) Zombie Prêt Exécution en Mémoire virtuelle Exécution en Préempté Endormi Endormi Diagramme d'état. Fig.15. Etats d'un processus Cet état existe dans la plupart des S.E : > Initialisation : c'est le premier état d'un processus. Il y attend que l'ordonnanceur le place dans l'état prêt, ce qui prendre plus ou moins longtemps. Généralement, dans les ordinateur du bureau, cela est automatique, dans un système d'exploitation temps réel, cette admission peutêtre reportée. En effet, dans de tels systèmes, trop de processus en attente peuvent amenés à une saturation, notamment des bus, entraînant l'incapacité du système à tenir les délais. > Prêt ou en attente : dans cet état le processus a été chargé en mémoire centrale et attente son exécution sur le processeur, il peut y avoir beaucoup de processus en attente car, sur un ordinateur équipé d'un seul processus, les processus doivent passer un par un. Les processus disponibles sont rangés dans une file ; les autres, ceux qui attendent quelques choses (données provenant du disque dur, une connexion internet, etc.) ne sont pas pris en compte. Cette file d'attente est gérée par l'ordonnanceur. > Exécution : le processus est en cours d'exécution par le processeur. > Endormi ou bloqué : le processus a été interrompu ou attend un événement (la fin d'une opération d'entrée| sortie, un signal,..) > Terminé : le processus est terminé, c'est-à-dire soit le résultat est connu, soit le programme a été forcé de s'arrêter. > Zombie : si un processus terminé ne peut pas être déchargé de la mémoire, par exemple, si un de ces fils n'est pas terminé, il passe dans un état appelé zombie. > Préempté : l'ordonnanceur a décidé de suspendre l'activité d'un processus. Par exemple, un processus qui consomme trop de temps CPU finira par être préempté. Un ordonnanceur préemptif utiliser aussi l'indice de priorité pour décider le processus qui sera préempté. > Exécution en espace utilisateur : l'exécution a lieu dans un espace limité : sel certaines instructions sont disponibles. > Exécution en espace noyau : par opposition au mode utilisateur, l'exécution du processus n'est pas limitée. Par exemple, un processus dans cet état peut aller lire dans la mémoire d'un autre. 2. kill : c'est une commande de certains systèmes d'exploitation (particulièrement Unix et ses dérivés) utilisée pour demander l'arrêt d'un processus en cours d'exécution. Par défaut, le message est un signal d'arrêt, demandant la fin du processus la commande kill encapsule l'appel système kill, lequel envoie des signaux aux processus ou groupes de processus, références par leur identifiant (PID ou PGID). Kill est toujours fournie sous la forme d'un utilitaire à part entière, mais la plupart des Shells possèdent également leur commande kill dont l'implémentation peut être légèrement différente. 3. Priorité : C'est une caractéristique d'une tâche informatique permettant de déterminer son accès à une ressource. Une tâche correspond à un traitement à réaliser. Une ressource est un moyen permettant de réaliser la tâche. Sous Windows, il existe six niveaux de priorité associé au thread du processus et au processus lui-même : > Inactif : l'exécution ne se fait que lorsque le système est en mode inactif lorsque tous les threads dont le niveau est plus élevé que inactif ne sont pas en état d'exécution. > En dessous de la normal : un niveau intermédiaire entre inactif et normal qui sera tendance à s'exécuter moins souvent et avoir un temps d'exécution moindre que les threads avec une priorité normal. > Normal : un niveau spécifiant que les threads n'ont pas de besoin particulier. Ce niveau convient pour les applications utilisateurs les plus courants. > En dessus de la normal : un niveau intermédiaire entre normal et haute priorité qui aura tendance à s'exécuter plus souvent et ou à avoir un temps d'exécution plus important que les threads avec une priorité normal. > Haute priorité : ce niveau convient pour les threads exécutant une tâche critique qui nécessite une exécution immédiate. Il est important de ne pas attribuer ce niveau à un processus qui n'effectue pas de tâche critique afin de ne pas empêcher inutilement une exécution système importante. > Temps réel : le niveau le plus élevé dans le système. Les threads du processus seront priorités sur tous les threads de priorité moins élevé, y compris les processus système. Ce niveau ne doit être attribué qu'à des tâches extrêmement courtes et espacées dans le temps.
Le système d'exploitation a besoin d'un moyen pour s'assurer que tous les processus nécessaires existent dans les systèmes très simples, ou dans des systèmes conçus pour faire fonctionner une seule application, il peut être possible d'avoir tous les processus qui ne sera jamais nécessaire, être présents lorsque le système est en place. Dans les systèmes à des fins générales, cependant, une certaine façon est nécessaire pour créer et mettre fin à des processus au besoin pendant le fonctionnement. Il existe quatre principaux événements qui provoquent des processus d'être crées, ils sont : - l'initialisation du système, - l'exécution d'un appel système processus de création par un processus en cours, - une demande d'utilisateur de créer un nouveau processus, - l'initiation d'un traitement par lots. Quand un système d'exploitation est démarré, le plus souvent plusieurs processus sont crées. des processus d'arrière - plan, qui ne sont pas associés à des utilisateurs particuliers, mais ont une fonction spécifique. Un processus de fond peut être conçu pour accepter les e-mails entrants, dormant la plupart de la journée, mais tout d'un coup en sautant sur la vie quand l'e-mail arrive. Un autre processus d'arrière - plan peut être conçu pour recevoir les demandes entrantes pour les pages web hébergé sur cette machine, en se réveillant, lorsqu'une requete arrive pour traiter la demande. Processus qui restent en arrière - plan pour gérer une activité comme le courrier électronique, page web, des nouvelles, l'impression, et ainsi de suite sont appelés démons. Systèmes à grande échelle ont généralement des dizaines d'entre eux. En Unix, le programme ps peut être utilisé pour dresser la liste des processus en cours. Dans gestionnaire des tâches Windows est utilisé. III.2.2.2. Cahier des charges opérationnelLe cahier des charges opérationnel est un document qui prend naissance à partir d'une expression de besoin c'est-à-dire à partir du cahier des charges fonctionnel. Donc, de présenter les travaux à réaliser, d'estimer les coüts de charges et de planifier. 1. Faisabilité Le but de ce projet est de réaliser une application client-serveur de control total des processus d'un ordinateur distant en temps réel. Notre public concerné étant les administrateurs réseaux, ils trouveront leur satisfaction en utilisant cette application. Pour y arriver, nous aurons : > Fait tourner un serveur sur la machine distante ; > Fait tourner un client sur la machine qui contrôle les processus de la machine distante ; > Relie tout ça par socket > Fait que le client envoie des requêtes au serveur, et le serveur procède aux actions en fonction de la requêtes ( kill, priorité, affiné, création de processus...) ou bien renvoie des informations (liste de processus, modules, threads...) au client . Bref c'est très très simple mais ça permet de faire ce que l'on veut sur la machine distante. Bien sur il est nécessaire de lancer le serveur sur la machine distante, chose qui était inutile avec WMI. Une planification est nécessaire pour aboutir dans un délai bien fini la réalisation de ce projet. 2. Organisation 2.1. Planning indicatif
Tableau n°1 : Planning indicatif 2.2. Répartition des heures.
Tableau n° 2 : Répartition des heures Le projet sera étalé sur une période allant du 22 janvier 2010 au 5 septembre 2010 soit 182 jours avec un délai de 610 heures de charges. Pour la réalisation du dit projet, nous devons en principe réunir une équipe de réalisation en affectant à chacun ses rôles et ses responsabilités. Dans le contexte de ce travail nous jouerons les rôles suivants : > Responsable du projet : nous allons coordonner le projet et assumer la responsabilité de la réalisation du projet dans les délais attribués avec la qualité requise et le budget alloué ; > Chef de projet opérationnel : nous aurons en charge la maitrise d'oeuvre technique et responsable de tous les livrables techniques ; > Concepteur| designer : nous serons nous même concepteur de l'architecture interactionnelle en respectant les indicateurs graphiques, ergonomique et structurelle ; > Ergonomique : nous nous chargerons aussi de récolter toutes les informations sur le comportement possible sur la future utilisation en travaillant avec le designer ; > Directeur artistique : nous jouerons le rôle du garant de la conception de la charte graphique avec le designer ; > Ingénieur/ développeur : en fonction de besoin déjà identifier, nous allons jouer le rôle de l'équipe de développement (découpage et intégration) ; > Administrateur réseau : nous aurons à administrer le réseau sur le quel notre application tournera ; > Chargé d'étude : nous attribuons cette tâche à nos encadreurs (directeur) et co-directeur de ce travail) car ils nous aiderons à la conception et à l'évolution de l'application. 2.3. Estimation budgétaire. Exemple l'estimation budgétaire par poste de travail, l'estimation budgétaire des charges par travaux et activités. Vu l'ampleur, la valeur de notre projet, nous allons présenter seulement une estimation budgétaire des charges par travaux et activités que nous avons à effectuer.
Tableau n° 3 : Estimation budgétaire III.3. DÉVELOPPEMENTIII.3.1. Environnement de développementNous avons choisi de développer notre application dans l'environnement de développement intégré Visual Studio 2008, sous le langage Visual Basic 2008. Ce langage offre des fonctionnalités de développement réseau très élaborées et faciles d'utilisation à travers l'espace de nom System.Net. Pour le développement, nous avons utilisé une machine à base de processeur Centrino Duo 2Ghz avec 1Go de mémoire centrale et Windows XP SP3 comme système d'exploitation. III.3.2. Structure et déroulement de l'applicationL'application est composée d'un module serveur et d'un module client. Le processus serveur tourne sur la machine que l'on désire contrôler.
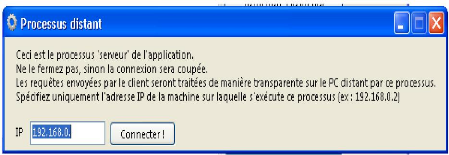
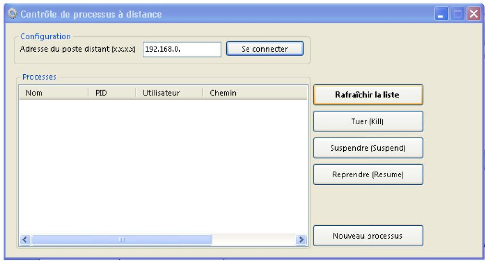
Figure 16 : Interface du processus serveur Le processus client tourne sur la machine que l'administrateur réseau compte utiliser pour contrôler la machine distante.
Figure 17 : Interface utilisateur du processus client. Le processus serveur récupère tous les processus qui s'exécutent sur la machine sur laquelle il est installé puis envoie cette liste au processus client. Le processus client reçoit du processus serveur la liste des processus distants à contrôler et les affiche. L'administrateur réseau peut alors cliquer sur les boutons de commandes appropriés pour contrôler les processus distants sélectionnés. III.3.4. Code sourceCode du processus Serveur Option Strict On Imports System.Net Imports System.Net.Sockets Public Class frmServeur Private WithEvents sock As New cAsyncSocketServer(Me) Private Const PORT As Integer = 8081 Private _readyToLeave As Boolean = True Private Sub frmServeur_FormClosing(ByVal sender As Object, ByVal e As System.Windows.Forms.FormClosingEventArgs) Handles Me.FormClosing Try sock.Disconnect() Catch ex As Exception ' End Try End Sub Private Sub sock_ConnexionAccepted() '_ readyToLeave = False Me.Text = "Connected" End Sub Private Sub sock_Disconnected() '_ readyToLeave = True End Sub Private Sub sock_ReceivedData(ByRef data() As Byte, ByVal length As Integer) Try ' Recréer la classe de données Dim cData As cSocketData = cSerialization.DeserializeObject(data) ' Extraire le type d'informations que nous devons envoyer If cData.Type = cSocketData.DataType.Order Then Select Case cData.Order Case cSocketData.OrderType.CreateNew Shell("explorer.exe") Case cSocketData.OrderType.Kill CoreFunc.cLocalProcess.Kill(cData.Param1) Case cSocketData.OrderType.RequestProcessList Call sendProcList() Case cSocketData.OrderType.Resume Dim p As New CoreFunc.cLocalProcess(cData.Param1) p.ResumeProcess() Case cSocketData.OrderType.Suspend Dim p As New CoreFunc.cLocalProcess(cData.Param1) p.SuspendProcess() End Select End If Catch ex As Exception MsgBox(ex.Message) End Try End Sub ' Envoyer la liste des processus Private Sub sendProcList() ' Constitution de la liste Dim key() As String = Nothing ' Inutilisé Dim _dico As New Dictionary(Of String, CoreFunc.cProcess.LightProcess) CoreFunc.cLocalProcess.Enumerate(key, _dico) Dim _theDico() As cSocketData.LightProcess ReDim _theDico(_dico.Count - 1) Dim x As Integer = 0 For Each proc As CoreFunc.cProcess.LightProcess In _dico.Values _theDico(x) = New cSocketData.LightProcess(proc.name, proc.pid, "OK no need", "OK no need") x += 1 Next ' Envoyer les données au client Try Dim cDat As New cSocketData(cSocketData.DataType.DataDictionnaryOfStringObject) cDat.SetProcessList(_theDico) Dim buff() As Byte = cSerialization.GetSerializedObject(cDat) sock.Send(buff, buff.Length) Catch ex As Exception MsgBox(ex.Message) End Try Private Sub Button1_Click(ByVal sender As System.Object, ByVal e As System.EventArgs) Handles Button1.Click ' Connecter le socket (serveur) Try sock.Connect(Net.IPAddress.Parse(TextBox1.Text), PORT) Catch ex As Exception MsgBox(ex.Message) End Try End Sub Private Sub sock_SentData() Dim oo As Integer = 0 End Sub Private Sub frmServeur_Load(ByVal sender As System.Object, ByVal e As System.EventArgs) Handles MyBase.Load sock.ConnexionAccepted = New cAsyncSocketServer.ConnexionAcceptedEventHandle(AddressOf sock_ConnexionAccepted) sock.Disconnected = New cAsyncSocketServer.DisconnectedEventHandler(AddressOf sock_Disconnected) sock.ReceivedData = New cAsyncSocketServer.ReceivedDataEventHandler(AddressOf sock_ReceivedData) sock.SentData = New cAsyncSocketServer.SentDataEventHandler(AddressOf sock_SentData) End Sub End Class Code du processus client Option Strict On Imports System.Net Imports System.Net.Sockets Public Class frmClient Private WithEvents sock As New cAsyncSocket(Me) Private ipAdd As String = "" Private Const PORT As Integer = 8081 Private Sub sock_ReceivedData(ByRef data() As Byte, ByVal length As Integer) ' Normalement dans l'exemple on reçoit forcément un data class avec ' une liste de process. ' Donc pas de vérification :-) ' Mais évidemment en vrai faudra procéder en fonction du type de donnée de data()... Dim dico() As cSocketData.LightProcess Try Dim cDat As cSocketData = cSerialization.DeserializeObject(data) dico = cDat.GetDico Catch ex As Exception MsgBox(ex.Message) Exit Sub End Try ' Rafraîchir lv For Each proc As cSocketData.LightProcess In dico Dim it As New ListViewItem(proc.name) it.SubItems.Add(proc.ID.ToString) it.SubItems.Add(proc.user) it.SubItems.Add(proc.processPath) lv.Items.Add(it) Next End Sub Private Sub Button1_Click(ByVal sender As System.Object, ByVal e As System.EventArgs) Handles Button1.Click Try sock.Connect(Net.IPAddress.Parse(ipAdd), 8081) Catch ex As Exception MsgBox(ex.Message) End Try Private Sub Button2_Click(ByVal sender As System.Object, ByVal e As System.EventArgs) Handles Button2.Click ' KILL Dim pid As Integer = -1 Try pid = Integer.Parse(Me.lv.SelectedItems(0).SubItems(1).Text) Catch ex As Exception pid = -1 End Try If pid > 0 Then Dim cData As New cSocketData(cSocketData.DataType.Order,
_ pid) Try Dim buff() As Byte = cSerialization.GetSerializedObject(cData) sock.Send(buff, buff.Length) Catch ex As Exception MsgBox(ex.Message) End Try End If End Sub Private Sub Button3_Click(ByVal sender As System.Object, ByVal e As System.EventArgs) Handles Button3.Click ' Suspendre le processu Dim pid As Integer = -1 Try pid = Integer.Parse(Me.lv.SelectedItems(0).SubItems(1).Text) Catch ex As Exception pid = -1 End Try If pid > 0 Then Dim cData As New cSocketData(cSocketData.DataType.Order, _ cSocketData.OrderType.Suspend, _ pid) Try Dim buff() As Byte = cSerialization.GetSerializedObject(cData) sock.Send(buff, buff.Length) Catch ex As Exception MsgBox(ex.Message) End Try End If End Sub Private Sub Button4_Click(ByVal sender As System.Object, ByVal e As System.EventArgs) Handles Button4.Click ' Reprendre le processus Dim pid As Integer = -1 Try pid = Integer.Parse(Me.lv.SelectedItems(0).SubItems(1).Text) Catch ex As Exception pid = -1 End Try If pid > 0 Then Dim cData As New cSocketData(cSocketData.DataType.Order, _ cSocketData.OrderType.Resume, _ pid) Try Dim buff() As Byte = cSerialization.GetSerializedObject(cData) sock.Send(buff, buff.Length) Catch ex As Exception MsgBox(ex.Message) End Try End If End Sub Private Sub Button5_Click(ByVal sender As System.Object, ByVal e As System.EventArgs) Handles Button5.Click ' NEW PROCESS Dim cData As New cSocketData(cSocketData.DataType.Order, _ cSocketData.OrderType.CreateNew) Try Dim buff() As Byte = cSerialization.GetSerializedObject(cData) sock.Send(buff, buff.Length) Catch ex As Exception MsgBox(ex.Message) End Try End Sub Private Sub Button6_Click(ByVal sender As System.Object, ByVal e As System.EventArgs) Handles Button6.Click ' REQUETE DE LA LISTE PAR LE CLIENT Me.lv.Items.Clear() Dim cData As New cSocketData(cSocketData.DataType.Order, _ cSocketData.OrderType.RequestProcessList) Try Dim buff() As Byte = cSerialization.GetSerializedObject(cData) sock.Send(buff, buff.Length) Catch ex As Exception MsgBox(ex.Message) End Try End Sub Private Sub txtAddress_TextChanged(ByVal sender As System.Object, ByVal e As System.EventArgs) Handles txtAddress.TextChanged ipAdd = txtAddress.Text End Sub Private Sub sock_SentData() End Sub Private Sub frmClient_Load(ByVal sender As Object, ByVal e As System.EventArgs) Handles Me.Load 'sock.Connected = New cAsyncSocket.ConnectedEventHandler(AddressOf sock_ConnexionAccepted) 'sock.Disconnected = New cAsyncSocket.DisconnectedEventHandler(AddressOf sock_Disconnected) sock.ReceivedData = New cAsyncSocket.ReceivedDataEventHandler(AddressOf sock_ReceivedData) sock.SentData = New cAsyncSocket.SentDataEventHandler(AddressOf sock_SentData) End Sub End Class Code de la dll Remote YAPM Notre application utilise des fonctions développées par des tiers. Ces fonctions sont réparties dans quatre classes de la dll Remote YAPM dont nous donnons ci-dessous le code (l'auteur donne l'autorisation d'utiliser et diffuser librement ce code). Classe cAsyncSocket.vb ' ' Yet Another Process Monitor (YAPM) ' Copyright (c) 2008-2009 Alain Descotes (violent_ken) ' https://sourceforge.net/projects/yaprocmon/ ' ' YAPM is free software; you can redistribute it and/or modify ' it under the terms of the GNU General Public License as published by ' the Free Software Foundation; either version 3 of the License, or ' (at your option) any later version. ' ' YAPM is distributed in the hope that it will be useful, ' but WITHOUT ANY WARRANTY; without even the implied warranty of ' MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the ' GNU General Public License for more details. ' ' You should have received a copy of the GNU General Public License ' along with YAPM; if not, see http://www.gnu.org/licenses/. Imports System.Net Imports System.Net.Sockets Imports System.Runtime.InteropServices Public Class cAsyncSocket Public Delegate Sub ReceivedDataEventHandler(ByRef data As Byte(), ByVal length As Integer) Public Delegate Sub SentDataEventHandler() Public Delegate Sub DisconnectedEventHandler() Public Delegate Sub ConnectedEventHandler() Public ReceivedData As ReceivedDataEventHandler Public SentData As SentDataEventHandler Public Disconnected As DisconnectedEventHandler Public Connected As ConnectedEventHandler Private sock As Socket Private buffLength As Integer Private bytes() As Byte Private frm As Form ' Constructor Public Sub New(ByVal [Form] As Form) buffLength = 65536 _frm = [Form] ReDim bytes(buffLength - 1) End Sub Public Sub New(ByVal [BufferSize] As Integer, ByVal [Form] As Form) buffLength = [BufferSize] _frm = [Form] ReDim bytes([BufferSize] - 1) End Sub ' Connect Public Sub Connect(ByVal [IpAddress] As IPAddress, ByVal [Port] As Integer) ' New socket Trace.WriteLine("Client Creating socket...") sock = New Socket(AddressFamily.InterNetwork, SocketType.Stream, ProtocolType.Tcp) ' OK, connect Trace.WriteLine("Client connecting...") sock.BeginConnect(New System.Net.IPEndPoint([IpAddress], [Port]), AddressOf connectCallback, Nothing) End Sub ' Disconnect Public Sub Disconnect() ' Do not accept anymore send/receive Trace.WriteLine("Client Shudown connection...") sock.Shutdown(SocketShutdown.Both) ' Disconnect Trace.WriteLine("Client BeginDisconnect...") sock.BeginDisconnect(False, AddressOf disconnectCallback, Nothing) End Sub ' Send something Public Sub Send(ByRef [Bytes]() As Byte, ByVal [Size] As Integer) ' OK let's begin to send Trace.WriteLine("Client Sending...") sock.BeginSend([Bytes], 0, [Size], SocketFlags.None, AddressOf sendCallback, Nothing) End Sub ' Callback for send Private Sub sendCallback(ByVal asyncResult As IAsyncResult) ' OK validate send Trace.WriteLine("Client EndSend...") Dim result As Integer = sock.EndSend(asyncResult) Trace.WriteLine("Client sent data...") _frm.Invoke(SentData) End Sub ' Callback for disconnect Private Sub disconnectCallback(ByVal asyncResult As IAsyncResult) ' OK we are now disconnected Trace.WriteLine("Client disconnected...") _frm.Invoke(Disconnected) End Sub ' Callback for connexion accept Private Sub connectCallback(ByVal asyncResult As IAsyncResult) ' OK, accept Trace.WriteLine("Client EndConnect...") Call sock.EndConnect(asyncResult) Trace.WriteLine("Client connected...") ' Ready to receive ReDim bytes(buffLength - 1) Trace.WriteLine("Client BeginReceive...") sock.BeginReceive(bytes, 0, bytes.Length, SocketFlags.None, AddressOf receiveCallback, Nothing) _frm.Invoke(Connected) End Sub ' Callback for receive Private Sub receiveCallback(ByVal asyncResult As IAsyncResult) ' OK validate reception Trace.WriteLine("Client EndReceive...") Dim result As Integer = sock.EndReceive(asyncResult) Trace.WriteLine("Client received data...") If result > 0 Then sock.BeginReceive(bytes, 0, bytes.Length, SocketFlags.None, AddressOf receiveCallback, Nothing) End If _frm.Invoke(ReceivedData, bytes, result) End Sub ' Set KeepAlive option Const bytesperlong As Int32 = 4 ' // 32 / 8 Const bitsperbyte As Int32 = 8 Private Function SetKeepAlive(ByVal sock As Socket, ByVal time As ULong, ByVal interval As ULong) As Boolean Try ' resulting structure Dim SIO_KEEPALIVE_VALS((3 * bytesperlong) - 1) As Byte ' array to hold input values Dim input(2) As ULong ' put input arguments in input array If (time = 0 Or interval = 0) Then ' enable disable keep-alive input(0) = CType(0, ULong) ' off Else input(0) = CType(1, ULong) ' on End If input(1) = (time) ' time millis input(2) = (interval) ' interval millis ' pack input into byte struct For i As Int32 = 0 To input.Length - 1 SIO_KEEPALIVE_VALS(i * bytesperlong + 3) = CByte((CLng(input(i) >> ((bytesperlong - 1) * bitsperbyte)) And &HFF)) SIO_ KEEPALIVE_VALS(i * bytesperlong + 2) = CByte((CLng(input(i) >> ((bytesperlong - 2) * bitsperbyte)) And &HFF)) SIO_ KEEPALIVE_VALS(i * bytesperlong + 1) = CByte((CLng(input(i) >> ((bytesperlong - 3) * bitsperbyte)) And &HFF)) SIO_ KEEPALIVE_VALS(i * bytesperlong + 0) = CByte((CLng(input(i) >> ((bytesperlong - 4) * bitsperbyte)) And &HFF)) Next ' create bytestruct for result (bytes pending on server socket) Dim result() As Byte = BitConverter.GetBytes(0) ' write SIO VALS to Socket IOControl sock.IOControl(IOControlCode.KeepAliveValues, SIO_KEEPALIVE_VALS, result) ' Catch es As Exception Return False End Try Return True End Function End Class Classe cAsyncSocketServer.vb ' ' Yet Another Process Monitor (YAPM) ' Copyright (c) 2008-2009 Alain Descotes (violent_ken) ' https://sourceforge.net/projects/yaprocmon/ ' ' YAPM is free software; you can redistribute it and/or modify ' it under the terms of the GNU General Public License as published by ' the Free Software Foundation; either version 3 of the License, or ' (at your option) any later version. ' ' YAPM is distributed in the hope that it will be useful, ' but WITHOUT ANY WARRANTY; without even the implied warranty of ' MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the ' GNU General Public License for more details. ' ' You should have received a copy of the GNU General Public License ' along with YAPM; if not, see http://www.gnu.org/licenses/. Option Strict On Imports System Imports System.Net Imports System.Net.Sockets Imports System.Runtime.InteropServices Public Class cAsyncSocketServer ' Public events Public Delegate Sub ReceivedDataEventHandler(ByRef data As Byte(), ByVal length As Integer) Public Delegate Sub SentDataEventHandler() Public Delegate Sub DisconnectedEventHandler() Public Delegate Sub ConnexionAcceptedEventHandle() Public ReceivedData As ReceivedDataEventHandler Public SentData As SentDataEventHandler Public Disconnected As DisconnectedEventHandler Public ConnexionAccepted As ConnexionAcceptedEventHandle ' Private attributes Private sock As Socket Private buffLength As Integer Private bytes() As Byte Private frm As Form ' Constructor Public Sub New(ByVal [Form] As Form) buffLength = 65536 _frm = [Form] ReDim bytes(buffLength - 1) End Sub Public Sub New(ByVal [BufferSize] As Integer, ByVal [Form] As Form) buffLength = [BufferSize] _frm = [Form] ReDim bytes([BufferSize] - 1) End Sub ' Connect Public Sub Connect(ByVal [IpAddress] As IPAddress, ByVal [Port] As Integer) ' New socket Trace.WriteLine("Server Creating socket...") sock = New Socket(AddressFamily.InterNetwork, SocketType.Stream, ProtocolType.Tcp) ' Bind Trace.WriteLine("Server Binding...") sock.Bind(New System.Net.IPEndPoint([IpAddress], [Port])) ' Accept only one connexion Trace.WriteLine("Server Listening...") sock.Listen(1) ' OK, set accept callback method Trace.WriteLine("Server BeginAccept...") sock.BeginAccept(AddressOf acceptCallback, Nothing) End Sub ' Disconnect Public Sub Disconnect() ' Do not accept anymore send/receive Trace.WriteLine("Server Shudown connection...") sock.Shutdown(SocketShutdown.Both) ' Disconnect Trace.WriteLine("Server BeginDisconnect...") sock.BeginDisconnect(False, AddressOf disconnectCallback, Nothing) End Sub ' Send something Public Sub Send(ByRef [Bytes]() As Byte, ByVal [Size] As Integer) ' OK let's begin to send Trace.WriteLine("Server Sending...") sock.BeginSend([Bytes], 0, [Size], SocketFlags.None, AddressOf sendCallback, Nothing) End Sub ' Callback for send Private Sub sendCallback(ByVal asyncResult As IAsyncResult) ' OK validate send Trace.WriteLine("Server EndSend...") Dim result As Integer = sock.EndSend(asyncResult) Trace.WriteLine("Server sent data...") _frm.Invoke(SentData) End Sub ' Callback for disconnect Private Sub disconnectCallback(ByVal asyncResult As IAsyncResult) ' OK we are now disconnected Trace.WriteLine("Server disconnected...") _frm.Invoke(Disconnected) End Sub ' Callback for connexion accept Private Sub acceptCallback(ByVal asyncResult As IAsyncResult) ' OK, accept Trace.WriteLine("Server EndAccept...") sock = sock.EndAccept(asyncResult) ' Ready to receive ReDim bytes(buffLength - 1) Trace.WriteLine("Server receiving...") sock.BeginReceive(bytes, 0, bytes.Length, SocketFlags.None, AddressOf receiveCallback, Nothing) _frm.Invoke(ConnexionAccepted) End Sub ' Callback for receive Private Sub receiveCallback(ByVal asyncResult As IAsyncResult) ' OK validate reception Trace.WriteLine("Server EndReceive...") Dim result As Integer = sock.EndReceive(asyncResult) Trace.WriteLine("Server received data...") If result > 0 Then sock.BeginReceive(bytes, 0, bytes.Length, SocketFlags.None, AddressOf receiveCallback, Nothing) End If _frm.Invoke(ReceivedData, bytes, result) End Sub ' Set KeepAlive option 'Private Sub SetTcpKeepAlive(ByVal keepaliveTime As UInteger, ByVal keepaliveInterval As UInteger) ' ' the native structure ' ' struct tcp_keepalive { ' ' ULONG onoff; ' ' ULONG keepalivetime; ' ' ULONG keepaliveinterval; ' ' }; ' ' marshal the equivalent of the native structure into a byte array ' Dim dummy As UInteger = 0 ' Dim inOptionValues As Byte() = New Byte(Marshal.SizeOf(dummy) * 3 - 1) {} ' BitConverter.GetBytes(CUInt((keepaliveTime))).CopyTo(inOptionValues, 0) ' BitConverter.GetBytes(CUInt(keepaliveTime)).CopyTo(inOptionValues, Marshal.SizeOf(dummy)) ' BitConverter.GetBytes(CUInt(keepaliveInterval)).CopyTo(inOptionValues, Marshal.SizeOf(dummy) * 2) ' ' write SIO_VALS to Socket IOControl ' sock.IOControl(IOControlCode.KeepAliveValues, inOptionValues, Nothing) 'End Sub Const bytesperlong As Int32 = 4 ' // 32 / 8 Const bitsperbyte As Int32 = 8 Private Function SetKeepAlive(ByVal sock As Socket, ByVal time As ULong, ByVal interval As ULong) As Boolean Try ' resulting structure Dim SIO_KEEPALIVE_VALS((3 * bytesperlong) - 1) As By ' array to hold input values Dim input(2) As ULong ' put input arguments in input array If (time = 0 Or interval = 0) Then ' enable disable keep-alive input(0) = CType(0, ULong) ' off Else input(0) = CType(1, ULong) ' on End If input(1) = (time) ' time millis input(2) = (interval) ' interval millis ' pack input into byte struct For i As Int32 = 0 To input.Length - 1 SIO_ KEEPALIVE_VALS(i * bytesperlong + 3) = CByte((CLng(input(i) >> ((bytesperlong - 1) * bitsperbyte)) And &HFF)) SIO_ KEEPALIVE_VALS(i * bytesperlong + 2) = CByte((CLng(input(i) >> ((bytesperlong - 2) * bitsperbyte)) And &HFF)) SIO_ KEEPALIVE_VALS(i * bytesperlong + 1) = CByte((CLng(input(i) >> ((bytesperlong - 3) * bitsperbyte)) And &HFF)) SIO_ KEEPALIVE_VALS(i * bytesperlong + 0) = CByte((CLng(input(i) >> ((bytesperlong - 4) * bitsperbyte)) And &HFF)) Next ' create bytestruct for result (bytes pending on server socket) Dim result() As Byte = BitConverter.GetBytes(0) ' write SIO_VALS to Socket IOControl sock.IOControl(IOControlCode.KeepAliveValues, SIO_KEEPALIVE_VALS, result) ' Catch es As Exception Return False End Try Return True End Function End Class
' Yet Another Process Monitor (YAPM) ' Copyright (c) 2008-2009 Alain Descotes (violent_ken) ' https://sourceforge.net/projects/yaprocmon/ ' ===================================================== ' YAPM is free software; you can redistribute it and/or modify ' it under the terms of the GNU General Public License as published by ' the Free Software Foundation; either version 3 of the License, or ' (at your option) any later version. ' ' YAPM is distributed in the hope that it will be useful, ' but WITHOUT ANY WARRANTY; without even the implied warranty of ' MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the ' GNU General Public License for more details. ' ' You should have received a copy of the GNU General Public License ' along with YAPM; if not, see http://www.gnu.org/licenses/. Option Strict On Imports System.IO Imports System.Runtime.Serialization.Formatters.Binary Public Class cSerialization ' Return byte array from data class Public Shared Function GetSerializedObject(ByVal obj As cSocketData) As Byte() Dim formatter As System.Runtime.Serialization.IFormatter = New System.Runtime.Serialization.Formatters.Binary.BinaryFormatter() Using ms As New MemoryStream() formatter.Serialize(ms, obj) Return ms.ToArray() End Using End Function ' Return data class from byte array Public Shared Function DeserializeObject(ByVal dataBytes As Byte()) As cSocketData Dim formatter As System.Runtime.Serialization.IFormatter = New System.Runtime.Serialization.Formatters.Binary.BinaryFormatter() Using ms As New MemoryStream(dataBytes) Return DirectCast(formatter.Deserialize(ms), cSocketData) End Using End Function End Class Classe cSocketData.vb ' ' Yet Another Process Monitor (YAPM) ' Copyright (c) 2008-2009 Alain Descotes (violent_ken) ' https://sourceforge.net/projects/yaprocmon/ ' ' YAPM is free software; you can redistribute it and/or modify ' it under the terms of the GNU General Public License as published by ' the Free Software Foundation; either version 3 of the License, or ' (at your option) any later version. ' ' YAPM is distributed in the hope that it will be useful, ' but WITHOUT ANY WARRANTY; without even the implied warranty of ' MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the ' GNU General Public License for more details. ' ' You should have received a copy of the GNU General Public License ' along with YAPM; if not, see http://www.gnu.org/licenses/. Option Strict On <Serializable()> Public Class cSocketData ' Type of data to send Public Enum DataType As Byte [Order] = 1 ' An order (nothing expected
after) End Enum ' Type of orders Public Enum OrderType As Byte [Kill] [Resume] [Suspend] [CreateNew] [DoNothing] [RequestProcessList] End Enum ' Structure defining a process <Serializable()> Public Structure LightProcess Dim name As String Dim ID As Integer Dim user As String Dim processPath As String Public Sub New(ByVal [ProcessName] As String, ByVal [PID] As Integer, ByVal [UserName] As String, ByVal [Path] As String) name = [ProcessName] ID = [PID] user = [UserName] processPath = [Path] End Sub End Structure ' Attributes Private _datatType As DataType Private _orderType As OrderType Private _param1 As Integer '<NonSerialized()> Private _dico As New Dictionary(Of String, LightProcess) Private _dico() As LightProcess ' Properties Public ReadOnly Property GetDico() As LightProcess() ' Dictionary(Of String, LightProcess) Get Return _dico End Get End Property Public ReadOnly Property Type() As DataType Get Return _datatType End Get End Property Public ReadOnly Property Order() As OrderType Get Return _orderType End Get End Property Public ReadOnly Property Param1() As Integer Get Return _param1 End Get End Property ' Create a SocketData Public Sub New(ByVal dataT As DataType, Optional ByVal orderT As OrderType = _ OrderType.DoNothing, Optional ByVal param As Integer = -1) _datatType = dataT _orderType = orderT _param1 = param End Sub ' Set process list Public Sub SetProcessList(ByVal dico() As LightProcess) ' Dictionary(Of String, LightProcess)) _dico = dico End Sub End Class 79 ConclusionNous voici au terme de notre travail de fin d'études intitulé « La réalisation d'une application de contrôle total des processus d'un ordinateur distant ». Après investigation sur terrain, nous avons constaté que l'informatique représente aujourd'hui la révolution la plus importante qui ait marqué la vie de l'humanité en ce siècle. La mise en communication des ordinateurs, le contrôle total des processus d'un ordinateur distant, et la gestion du temps d'exécution ont permis de révolutionner les méthodes de travail. Le champ d'action de notre sujet, étant très vaste, nous n'avons pas la prétention de l'avoir totalement épuisé, mais nous espérons avoir répondu aux questions que nous étions en train de nous poser, dans le temps et dans l'espace, laissant l'occasion à d'autres personnes pouvant traiter les autres aspects de la question. 80 Bibliographie
VII 8 SommaireÉpigraphe i Dédicace ii Remerciements iii Liste des abréviations iv Liste des figures v Liste des tableaux vi Sommaire vii I. Introduction 1
Chapitre I : LES NOTIONS DE CLIENT SERVEUR 6 I.1.Introduction 7 I.2. L'architecture Client-serveur 7 I.2.1.Définition 7 I.2.2. Les principes généraux 8 I.2.3. La répartition des tâches 9 I.2.4. Générations de client-serveur 9 I.2.5. Les différentes architectures 11 I.2.6. Les middlewares 16 Chapitre II : LE MODELE CLIENT SERVEUR 19 II.1. L'architecture Centralisée Au Client-Serveur 20 II.1.1. Le contexte historique 20 II.1.2. Définitions du modèle client-serveur 21 II.2.2. Les mécanismes de la communication 23
II.7.1. Les serveurs d'authentification 38 II.7.2. Les serveurs d'applications et serveurs graphique : 39 Chapitre III : LA REALISATION D'UNE APPLICATION DECONTROLE TOTAL DES PROCESSUS D'UN ORDINATEUR DISTANT 41 III.1. Introduction 42 III.2. Analyse conceptuelle 42 III.2.1. L'analyse de l'existant 42 III.2 .2. Cahier des charges 43 III.3. DÉVELOPPEMENT 54 III.3.1. Environnement de développement 54 III.3.2. Structure et déroulement de l'application 54 III.3.4. Code source 55 Conclusion 79 Bibliographie 80
| 
Changeons ce systeme injuste, Soyez votre propre syndic 
"Je ne pense pas qu'un écrivain puisse avoir de profondes assises s'il n'a pas ressenti avec amertume les injustices de la société ou il vit" | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||