V.8
Ecosystème Hadoop
Pour certains, l'avenir appartiendra à ceux qui seront
capable d'analyser les vastes volumes de données qu'ils ont
collectés.
En écologie, un écosystème est l'ensemble
formé par une association ou communauté d'êtres vivants et
son environnement biologique, géologique, édaphique,
hydrologique, climatique, etc. l'écosystème Hadoop est l'ensemble
des projets Apache ou non, liés à Hadoop et qui sont
appelés à se cohabiter.
Hadoop désigne un framework Java libre ou un
environnement d'exécution distribuée, performant et scalable,
dont la vocation est de traiter des volumes des données
considérables. Il est le socle d'un vaste écosystème
constitué d'autres projets spécialisés dans un domaine
particulier parmi lesquels on compte les entrepôts de données, le
suivi applicatif (monitorring) ou la persistance de données.
Le schéma ci-après présente les
différents éléments de l'écosystème Hadoop
en fonction du type d'opération.
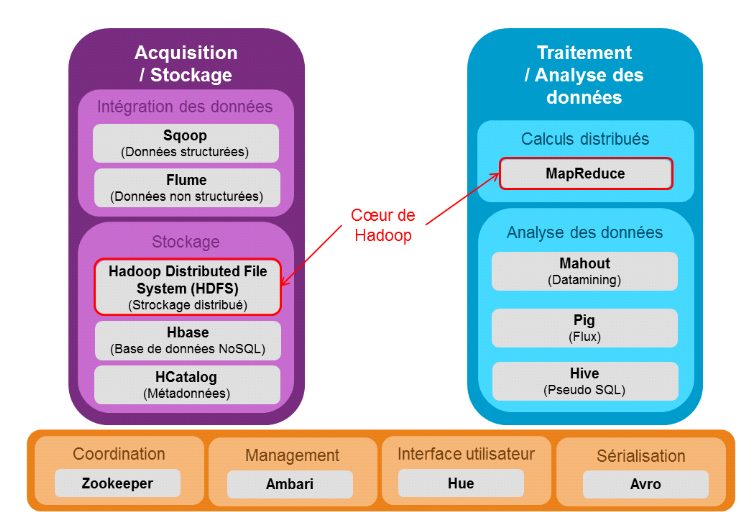
Figure 4 : Ecosystème Hadoop
V.8.1 Hadoop kernel
Hadoop Kernel est le coeur de l'écosystème
Hadoop. Ce framework est actuellement le plus utilisé pour faire du Big
Data. Hadoop est écrit en Java et a été crée par
Doug Cuttting et Michael Cafarella en 2005, (Le framework Apache
Hadoop). Le noyau est composé de 2 composants. Hadoop
présente l'avantage d'être issu de la communauté open
source, de ce fait un porte un message exprimant une opportunité
économique. En revanche, il affiche une complexité qui est loin
de rendre accessible au commun des DSI.
Nous continuerons par une présentation de quelques
grands concepts d'Hadoop.
V.8.1.1
Architecture Hadoop
Le schéma ci-dessous présente l'architecture
distribué dans le contexte Hadoop.
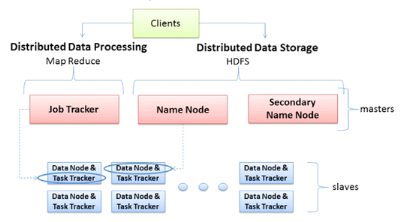
Figure 5 : Architecture Hadoop avec les
principaux rôles des machines, (Le framework Apache Hadoop)
Il est primordial de savoir qu'une architecture Hadoop est
basée sur le principe maître/esclave, représentant les deux
principaux rôles des machines. Les sous rôles relatifs au
système de fichiers et à l'exécution des tâches
distribuées sont associés à chaque machine de
l'architecture.
Les machines maîtres ont trois principaux rôles
qui leur sont associées :
§ JobTracker : c'est le rôle
qui permet à la machine maître de lancer des tâches
distribuées, en coordonnant les esclaves. Il planifie les
exécutions, gère l'état des machines esclaves et
agrège les résultats des calculs.
§ NameNode : ce rôle assure
la répartition des données sur les machines esclaves et la
gestion de l'espace de nom du cluster. La machine qui joue ce rôle
contient des métadonnées qui lui permettent de savoir sur quelle
machine chaque fichier est hébergé.
§ SecondaryNameNode : ce rôle
intervient pour la redondance du NameNode. Normalement, il doit être
assuré par une autre machine physique autre que le NameNode car il
permet en cas de panne de ce dernier, d'assurer la continuité de
fonctionnement du cluster.
Deux rôles sont associés aux machines
esclaves :
§ TaskTracker : ce rôle permet à un
esclave d'exécuter une tâche MapReduce sur les données
qu'elle héberge. Le TaskTracker est piloté par JobTracker d'une
machine maître qui lui envoie la tâche à exécuter.
§ DataNode : dans le cluster, c'est une machine qui
héberge une partie des données. Les noeuds de données sont
généralement répliqués dans le cadre d'une
architecture Hadoop dans l'optique d'assurer la haute disponibilité des
données.
Lorsqu'un client veut accéder aux données ou
exécuter une tâche distribuée, il fait appel à la
machine maître qui joue le rôle de JobTracker et de Namenode.
Maintenant que nous avons vu globalement l'articulation d'une
architecture Hadoop, nous allons voir deux principaux concepts inhérents
aux différents rôles que nous avons présentes.
| 

