Conclusion
Dans ce chapitre, nous avons cerné les objectifs du
système cible. Ces objectifs doivent tenir compte des problèmes
de la solution existante. Cette phase va nous utile pour bien élaborer
le modèle de conception de l'application. Dans le prochain chapitre nous
aborderons la partie conception décrivant la modélisation des
besoins exprimés dans cette section.
6. Crontab est le nom du programme sous Unix (ou Linux) qui
permet d'éditer des tables de configuration du programme cron. Par
extension, on appelle souvent cron (ou cron job en anglais) toute application
lancée à horaire fixe.
Introduction
Après avoir achevé la phase d'analyse et
spécifications, nous entamons maintenant la phase de conception. Cette
étape s'avère primordiale pour le déroulement du projet et
à pour but de détailler les tâches à entreprendre
ainsi que de préparer le terrain pour l'étape de
réalisation.
Pour ce faire, nous présentons une conception
générale de l'application suivie d'une conception plus
détaillée présentant le schéma de la base de
données utilisée. Ensuite nous détaillons les
différents modules de l'application aussi bien que les relations entre
ces modules moyennant un diagramme de paquetage et un diagramme de classe.
Enfin, nous exposons la cinétique de l'application.
4.1 Conception architecturale
Tout système d'informations nécessite la
réalisation de trois groupes de fonctions : le stockage des
données, la logique applicative et la présentation. Ces trois
parties sont indépendantes l'une de l'autre : nous pouvons ainsi
modifier la présentation sans modifier la logique applicative.
La conception de chaque partie doit également être
indépendante. Toutefois la conception de la couche la plus basse est
utilisée dans la couche supérieure.
Ainsi, la conception de la logique applicative se base sur le
modèle de données, alors que la conception de la
présentation dépend de la logique applicative.
4.1.1 Architecture trois-tiers
Le principe d'une architecture trois-tiers consiste à
séparer la réalisation des trois parties vues
précédemment (stockage des données, logique applicative et
présentation)[N5].
permettant la réalisation classique d'un système
en architecture trois tiers sont les suivants :
· Système de base de données relationnel
(SGBDR) pour le stockage des données.
· Serveur applicatif pour la logique applicative.
· Navigateur web pour la présentation.
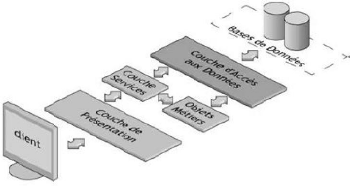
Figure 4.1 -- Les couches d une architecture trois
tiers
4.1.1.1 Couche de présentation
La présentation est la partie la plus
immédiatement visible par l'utilisateur. Au niveau de cette couche se
fait l'enregistrement, la récupération et la gestion des
données persistantes dans une base de données.
4.1.1.2 Couche Services
Cette couche réunit les traitements techniques, non
fonctionnels qui sont pris en charge par le Framework de
développement.
4.1.1.3 Objets métiers
Ces objets font le travail essentiel lié au domaine de
l'application. Ils nécessitent les traitements techniques, non
fonctionnels de la couche service pour gérer la sécurité,
le transactionnel, la concurrence.
4.1.1.4 La couche de persistance
Elle est composée de la base de données. Le
plus souvent on y ajoute une couche qui effectue la correspondance entre les
objets et la base de données. Souvent cette couche sert aussi de cache
pour les objets récupérés dans la base de données
et améliore donc les performances.
4.1.1.5 Avantages de l'architecture trois tiers
L'application trois tiers présente divers avantages à
savoir :
· La logique applicative est déplacée au
niveau du serveur d'application mais reste
programmée à l'aide
des mêmes technologies liées aux bases de données
relationnelles.
· L'application trois tiers présente divers
avantages à savoir : La logique applicative est déplacée
au niveau du serveur d'application mais reste programmée à l'aide
des mêmes technologies liées aux bases de données
relationnelles.
· La facilité de déploiement.
L'application en elle même n'est déployée que sur la partie
serveur (serveur applicatif et serveur de base de données). Le client ne
nécessite qu'une installation et une configuration minime. En effet, il
sufit d'installer un navigateur web compatible avec l'application pour que le
client puisse accéder à l'application. Cette facilité de
déploiement aura pour conséquence non seulement de réduire
le coût de déploiement mais aussi de permettre une
évolution régulière du système. Cette
évolution ne nécessitera que la mise à jour de
l'application sur le serveur applicatif.
· L'amélioration de la sécurité.
Avec une architecture trois-tiers l'accès à la base n'est
effectué que par le serveur applicatif. Ce serveur est le seul à
connaitre la façon de se connecter à cette base. Il ne partage
aucune des informations permettant l'accès aux données, en
particulier le login et le password de la base. Il est alors possible de
gérer la sécurité au niveau de ce serveur applicatif, par
exemple en maintenant la liste des utilisateurs avec leurs mots de passe ainsi
que leurs droits d'accès aux fonctions du système. On peut
même améliorer encore la sécurité par la mise en
place d'une architecture réseau interdisant totalement l'accès au
serveur de base de données pour les utilisateurs finaux[N6].
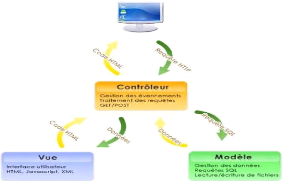
4.1.2 Architecture MVC
Le modèle MVC (Model/View/Controller) est un
schéma de programmation qui prend en compte toute l'architecture d'un
programme et classe les différents types d'objets qui composent
l'application dans 3 catégories:
4.1.2.1 La vue
ne doit être effectué dans cette partie. Mais, en
contre partie ils affichent les résultats provenant des objets "model"
et s'assurent que ces données sont correctement
affichées.[N7]
4.1.2.2 Le modèle
Les modèles représentent les données de
l'application (les bases de données en faisant par-tie) et
définissent la logique de manipulation de ces données. C'est dans
cette partie que vont s'effectuer les traitements, on ne s'occupe absolument
pas de la mise en forme mais bien des données seules. Dans une
application respectant les règles du modèle MVC, les
données les plus importantes seront encapsulées dans les objets
modèles.[N7]
4.1.2.3 Le contrôleur
Le contrôleur gère l'interaction avec
l'utilisateur. Ainsi c'est dans cette partie que va se réaliser
l'interaction entre la vue et le modèle. En effet, les objets
contrôleur reçoivent les requêtes utilisateur puis
détermine quelles parties des objets vues et modèles sont
requises. Ils constituent donc l'intermédiaire entre les deux autres
types d'objets.[N7]
4.1.2.4 Avantages du modèle MVC
Le modèle MVC impose donc une séparation totale
entre le traitement, l'interface et la communication entre ces deux parties.
Cela permet d'avoir non seulement des objets réutilisables pour d'autres
applications, mais aussi de pouvoir faire évoluer aisément son
programme. Ainsi, si l'on souhaite modifier sa base de données il suffit
de revoir son "model" et cela est valable pour le cas ou l'on souhaite changer
d'interface. Les 3 parties du model MVC sont réellement autonomes.
Aucunes d'elles ne s'occupent du fonctionnement de l'autre.[N8]
4.2 La correspondance entre le modèle MVC et
l'application
Grâce à la séparation en couches, la
souplesse, la maintenance et le développement de l'application se
trouveront grandement améliorés. Dans ce cadre, la figure 4.3 met
en évidence la conformité de notre application vis-à-vis
du modèle MVC. Le serveur SMTP/POP (couche métier) qu'on a
implémenté à l'aide des sockets 1, qui sont des
points de connexion pour la communication client-serveur, reçoit deux
types de requêtes.
· Le premier type consiste à la gestion des
messages à l'aide de PHPMAILER 2. Le Serveur
stocke les messages dans le disque dur qui est l'un des parties de la couche de
persistance.
· Le deuxième type consiste en des requêtes
SQL afin de garantir les différentes fonctionnalités
d'administration. Le serveur traite ces requêtes à l'aide de l'API
(Application Programmable Interface) Pear.MDB2 » 3 et
réalise les modifications dans la base de données.
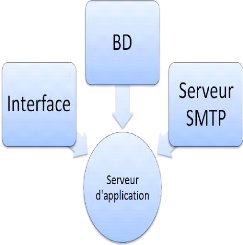
Figure 4.3 -- L'application en MVC
1. Il s'agit d'un modèle permettant la communication
inter processus (IPC - Inter Process Communication) afin de permettre à
divers processus de communiquer aussi bien sur une même machine
qu'à travers un réseau TCP/IP.
2. La librairie PHPMailer permet d'envoyer des courriers
électroniques depuis une application PHP. Lorsqu'elle est
configurée pour utiliser la commande sendmail, une
vulnérabilité au niveau de la validation des champs saisis permet
l'exécution de code arbitraire à distance.
3. L'extension PEAR DB fournit une gamme de fonctions de
gestion de base de données permettant d'utiliser le même code quel
que soit la base de données. Cela permet, si vous décidez de
changer de BDD de ne pas être obligé de modifier de nouveau tous
vos scripts. Un simple changement de variable vous permettra de passer de MySQL
à Oracle par exemple.
4.3 Conception détaillée
Dans cette partie nous commençons par définir en
détail la base de données. Nous présentons par la suite
les différents modules du système avant d'exposer les diagrammes
des classes. Nous finissons par introduire la cinétique de
l'application.
4.3.1 Conception de la base de données
Le schéma 4.4 explique la conception de la base en
illustrant les relations entre les tables. L'entité USER
décrite par un id et un e-mail, le nom et le prénom de
l'internaute ainsi qu'un mot de passe pour l'authentification contient
également d'autres informations supplémentaires.
L'internaute peut consulter sa boite aux lettres (via la table
Mail), son calendrier (via la table
Calendrier) ainsi que le carnet d'adresse (via la table
Carnet-adresse).
Il peut également configurer des paramètres tels
que le langage et les couleurs du fond (par le biais de la table
Configuration), ou bien consulter l'historique des
commentaires. En outre, il peut créer ou joindre des groupes (via la
table Associa-groupe-client).
L'administrateur à son tour peut consulter certaines
tables à travers des interfaces web pour contrôler et gérer
l'application.
Présentation des tables:
· Table Mailbox : regroupe la liste des
boites de réception des clients.
· Table Mail: sauvegarde les emails
échangés par les internautes.
· Table Joindre : contient la liste des
jointures des fichiers de chaque utilisateur.
· ]Table Fichier : regroupe les fichiers
échangés entre les différents utilisateurs.
· ]Table Commentaire : enregistre les
commentaires et les statuts de chaque utilisateur.
· Table Calendrier : contient les
événements créés par les utilisateurs.
· Table Carnet-adresse : regroupe les
listes des contacte de chaque internaute.
· Table Configuration: sauvegarde les
paramètres de l'application choisis par l'utilisateur.
· Table Associa-groupe-client :
Représente l'association groupe client.
· Table Groupe : Contient la liste des
groupes utilisateur.
· Table Session: Sauvegarde la session
utilisateur.
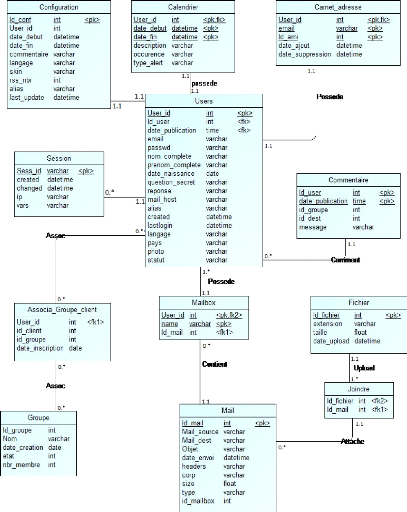
Figure 4.4 -- Modèle Entité
Association
4.3.2 Décomposition en paquetage
Pour passer à la conception, nous nous fondons sur les
principes de l'approche orientée objet. À cet effet, nous passons
d'une structuration fonctionnelle via les cas d'utilisation, à une
structuration objet via les classes et les paquetages.
Vu le nombre de classes candidates défini dans notre
application, il s'avère important de les découper en paquetages
pour mieux comprendre le rôle global de chaque partie et faciliter la
maintenance du code. Pour identifier les paquetages, nous nous sommes
basés sur deux critères : cohérence et
indépendance.
Concernant le premier critère, nous avons
essayé de regrouper les classes qui ont une forte corrélation
entre elles et qui appartiennent au même domaine fonctionnel. Elles
doivent rendre des services de même nature aux utilisateurs. Tandis que
pour le deuxième critère, nous avons essayé de minimiser
les dépendances entre les paquetages en minimisant au maximum le nombre
de relations qui les traversent. Le diagramme de paquetage de notre application
est représenté dans la figure 4.5.
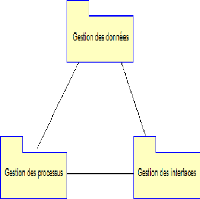
Figure 4.5 -- Diagramme de paquetage
· Package gestion des sources de données : il
comprend les interfaces de connexion, d'ajout et de suppression des sources de
données.
· Package gestion des processus : représente le
noyau de l'application, il regroupe les classes qui gèrent les actions
exécuté par l'utilisateur tel que l'envoie des e-mails.
· Package gestion des interfaces : C'est le module qui
contient tout ce qui est nécessaire pour la gestion des interfaces web
et la génération des templates.
4.3.3 Diagrammes des classes
La modélisation statique permet d'identifier,
d'affiner et de compléter les différentes classes relatives aux
paquetages de la section précédente. Elle consiste à
rechercher les relations entre les classes et les compléter par leurs
attributs spécifiques. Le diagramme de classes est le point central dans
un développement orienté objet. Dans ce paragraphe, on va
présenter les diagrammes de classes par composant.
4.3.3.1 Package gestion des interfaces
Ce diagramme de classe, présenté par la figure
4.6, illustre la couche présentation (View) de notre
application, dont le but est de simplifier la création et la
modification des interfaces. Ce motif répond à la
problématique de génération des Template. Par
conséquence, notre client peut par un simple clique de modifier et de
personnaliser son propre interface.
Nous notons aussi que l'un des avantages les plus important
de la séparation de cette couche c'est que le processus de
génération des interfaces devient plus optimisé est non
redondant ce qui réduit le temps de réponse.
Voici une description de quelques classes de ce diagramme :
· La classe Html-composant : C'est la
classe mère des différents composants graphiques tels que
Html-select, Html-table et Html-textarea.
· La classe Face-html : C'est la classe
qui modélise les différentes interfaces de notre application, il
est composé par des instances de la classe
.Html-composant».
· La classe Template : Cette classe
regroupe tous les vues de l'application.
· La classe Navigateur : Puisque les
applications web2.0 souffrent des problèmes de compatibilités
avec les différents types de navigateur (Internet explorer, FireFox et
googleChrome) donc cette classe teste la compatibilité par la
méthode .test-compatibilité».
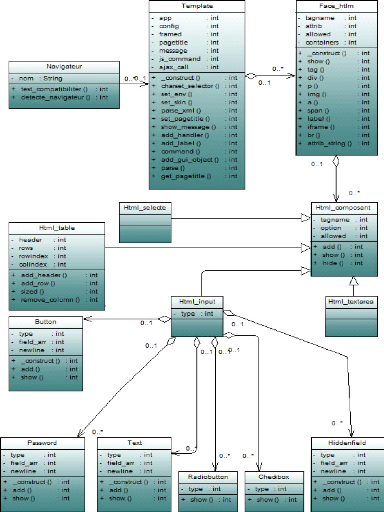
Figure 4.6 -- Diagramme de classe : Gestion des
interfaces
4.3.3.2 Package Gestion des données
Ce package présente la couche persistances des
données, elle modélise la façon de traitements des
ressources et l'interaction avec la base de données.
Le but de cette couche est d'assurer la gestion souple et
facile des données, garantit leur intégrité et d'adapter
l'application sur n'importe quelle source des données. Elle offre des
méthodes pour mettre à jour ces données (insertion,
suppression, changement de valeur). Elle offre aussi des méthodes pour
récupérer ces données.
Voici une description de quelques classes de ce diagramme :
· La classe Mdata-base : c'est la
classe principale qui gère la connexion à n'importe quel type de
base de données (Mysql, PostegerSQL, Oracle, etc), également elle
possède des méthode de gestion des enregistrements.
· La classe Output: Dans le cas ou les
sources de données sont des fichiers structuré tels que des
fichiers xml ou des fichiers json, cette classe a pour mission de fournir une
lecture et écriture simple de données.
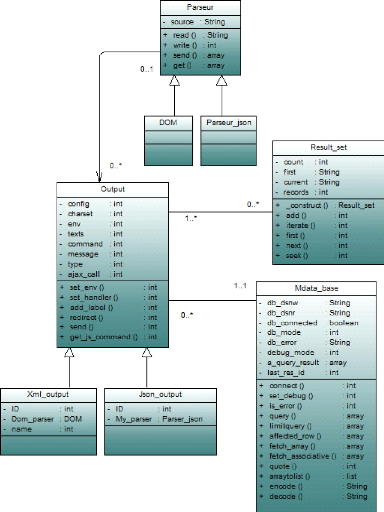
Figure 4.7 -- Diagramme de classe : Gestion des
données
4.3.3.3 Package gestion des processus
Cette couche prend en charge la gestion des
événements d'interaction entre les packages « gestion des
données » et «gestion des interfaces ». Elle
reçoit tous les requêtes de l'utilisateur et exécute les
actions convenables.
Par exemple, si une action d'envoie d'un e-mail est
déclenché, la classe « mailler » reçoit
cette requête, ill'analyse sa structure, puis la classe « SMTP
» prendre la charge d'envoie grâce à la méthode
« send-mail ».
Ce module regroupe les classes suivantes :
· La classe Mailler : C'est la classe
singletons, nous avons besoin d'exactement une unique instance pour coordonner
les opérations dans notre système. Nous avons
implémenté ce singleton en écrivant une méthode qui
crée une instance uniquement s'il n'en existe pas encore. Sinon elle
renvoie une référence vers l'objet qui existe déjà.
Le constructeur de cette classe doit être privé.
· Les classes << IMAP
>> et << SMTP >> :
Ces deux classes présentent les deux protocoles d'envoi et de
réception. Elle contient des appels aux différentes commandes
déjà implémenté dans ces deux derniers.
· La classe
<<LDAP>> : Présente les
méthodes d'authentification des utilisateurs selon le protocole LDAP
(voire annexe).
· La classe <<
Mail>> : Cette classe permet de traiter les e-mails
entrants et sortants.
· La classe << Calender
>> : Cette classe permet de gérer les calendriers des
clients.
· La classe << Meteo
>> : C'est la classe responsable à la consultation de
webservice du météo et l'affichage des résultats.
· La classe << Feed-Rss
>> : En communiquant avec les différents serveurs des
flux RSS (Voir Annexe), cette classe ramène les informations et les
news, pour les afficher sur la page d'accueil de l'internaute.
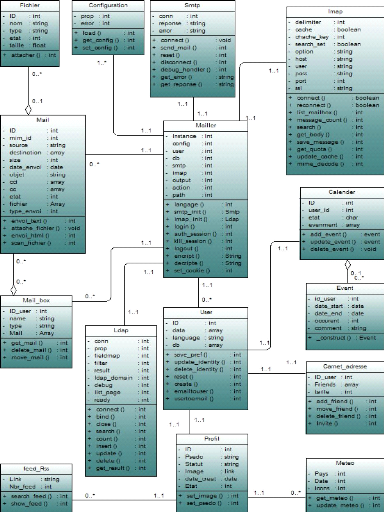
Figure 4.8 -- Diagramme de classe : gestion des
processus
4.3.4 Cinétique de l'application
Nous présentons la cinétique de l'application par
le baise d'un diagramme de transition.
4.3.4.1 Diagramme de transition de la partie
client
Lors du lancement de l'application, l'utilisateur est
redirigé vers la page d'authentification pour accéder à
profil. S'il n'est pas déjà inscrit il sera appelé
à s'inscrire via la page d'inscription rapide ou la page d'inscription
complète. Étant authentifier, et depuis la page d'accueil, le
client peut accéder aux différentes fonctionnalités du
système. Il aura la possibilité de consulter sa boite de
réception en temps réel, d'envoyer un e-mail à destination
unique ou multiple. Il peut également gérer son calendrier,
convertir des e-mails en rendez-vous, partager des événements
avec des amis et être notifié d'une tache planifié. Comme
il possède un carnet d'adresse pour collecter les informations et les
cordonnées de ses contacts, l'ajout des amis et la suppression des
informations redondons sera automatique.
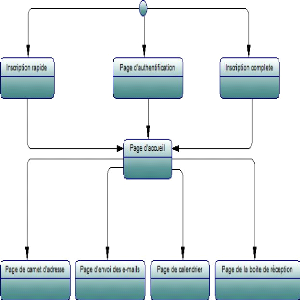
Figure 4.9 -- Diagramme de transition de la partie
client
4.3.4.2 Diagramme de transition de la partie
administrative
d'envoi, te configurer le robot. Il peut configurer les
serveurs ou restaurer d'anciennes configurations. S'il opte pour le
paramétrage, il a le choix entre la gestion des privilèges
utilisateur ou le paramétrage du compte Admin.
Depuis l'interface dédiée à la gestion des
clients, il peut les gérer individuellement ou au sein des groupes
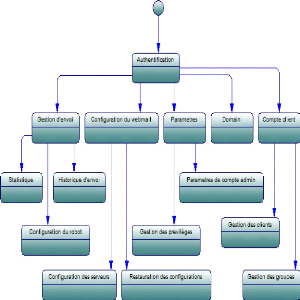
Figure 4.10 -- Diagramme de transition de la partie
administrative
| 

