2.4.2.2.3-
Spécification du Modèle
2.4.2.2.3.1- Ordre optimal et
estimation du var
Le modèle restreint est spécifié de la
manière suivante :
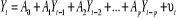
Avec 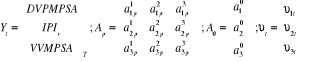
2.4.2.2.4- Validation du
modèle
La validation du modèle se fera par la
réalisation du test de diagnostic sur les résidus. On distinguera
essentiellement trois tests : le test d'autocorrélation des erreurs
de Breush-Godfrey, le test d'homoscédasticité de White et le test
de normalité de Jarque-Bera.
2.4.2.2.4.1- Test d'auto
corrélation des erreurs
Il s'agit de tester si l'erreur à un instant (t) a
d'influence sur l'erreur des autres instants ou encore si l'erreur est
indépendante d'une période à une autre.
Le test de Breusch-Godfrey est réalisé dans le
cas d'espèce. La statistique de Breusch-Godfrey donnée par BG
=n*R2 suit une loi de Khi-deux à p degrés de
liberté avec :
P : nombre de retards des
résidus ;
N : nombre d'observations ;
R2 : le coefficient de
détermination.
L'hypothèse de non corrélation des erreurs est
acceptée si la probabilité est supérieure au seuil
critique de 5% ou si n*R2 <Khi-deux lu.
2.4.2.2.4.2- Test
d'hétéroscédasticité des erreurs
Il est utilisé pour tester la constance de la variance
de l'erreur dans le temps. Ce test permet de mesurer le risque de l'amplitude
de l'erreur quelle que soit la période. Les erreurs sont
hétéroscédastiques si la probabilité est
inférieure au seuil critique de 5%. Rappelons que le test utilisé
est celui de White.
2.4.2.2.2.3- Test de
normalité des erreurs
A cet effet on a recours au test de Jarque-Bera (J-B).
Hypothèses du test :
H0 : X suit une loi normale N (m, ó)
H1 : X ne suit pas une loi normale N (m, ó)
La statistique de J-B est définit par : J-B = n
[s2/6 + (k-3)2/24], où s représente le
coefficient de dissymétrie (Skewness) et k le coefficient
d'aplatissement (Kurtosis).
J-B suit sous l'hypothèse de normalité une loi
de Khi-deux à 2 degrés de liberté. On accepte au seuil de
5% l'hypothèse de normalité si J-B< 5,99 ou si Probability
> 0,05.
2.4.2.2.5- Analyse des chocs
Lorsque le modèle VAR est estimé, il est
important d'étudier les chocs afin de mesurer l'impact de la variation
d'une innovation (résidus) sur les variables. Ces innovations sont
recueillies après estimation du modèle VAR. Juste après,
on estime les fonctions de réponses impulsionnelles et on analyse la
qualité des effets (positif ou négatif) sur l'IPI suite à
un choc positif ou négatif sur une des autres variables. Après
cette analyse des impulsions il est aussi utile de faire une
décomposition de la variance de l'erreur de prévision de l'IPI
pour étudier la sensibilité des autres variables par rapport
à l'IPI.
2.4.3-Traitement des
données
2.4.3.1- Résultats
de l'Analyse en Composantes Principales (ACP)
L'Analyse en Composantes Principales (ACP) est une
méthode d'analyse des tableaux de données du type individus X
variables dans le cas où toutes les variables sont numériques et
très hétérogènes. Cette technique consiste à
réduire en un petit nombre de variables appelées composantes
principales, non corrélées entre elles et résumant aussi
bien que possible les données initiales. L'ACP utilisée dans le
cadre de cette étude, a permis de réduire les variables
superflues tout en détectant les meilleures corrélations entre
l'IPI et celles-ci.
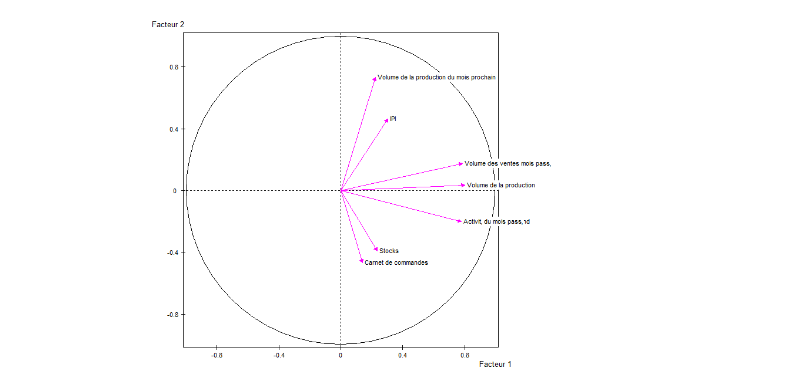
La représentation du cercle de corrélation se
présente comme suit :
Graphique1: Cercle de Corrélation
Source : Nos estimations sur la base de la
BCEAO
Le cercle de corrélation montre que les soldes
d'opinion relatifs au volume de la production du mois prochain et au volume des
ventes du mois passé sont ceux qui se rapprochent le plus de l'Indice de
Production Industrielle dans le plan factoriel. Par ailleurs, la matrice de
corrélation entre les variables (annexe1) permet de constater que ces
variables, en plus du volume de la production courante présentent les
meilleurs liens de corrélation avec l'IPI. Nous retiendrons donc
essentiellement dans le cadre de l'étude économétrique les
trois variables ci-après : le volume de production du mois prochain
(VPMP) que nous pourrons également appelé perspectives
personnelles de production, l'Indice de Production Industrielle (IPI) et le
Volume de ventes du mois passé (VVMP). Notre première
hypothèse est donc par ailleurs validée.
| 

