5.1 Le serveur Oracle
IL s'agit du système installé sur
une machine qui va permettre la gestion de toutes les
bases de données disponibles sur la machine. Le serveur
oracle est basé sur une
Architecture MultiServeurs. Le serveur est responsable de
traitement de toutes les activités
de la base de données tel que l'exécution des
instructions SQL, gestion des ressources et utilisateur, et gestion du
stockage,
Pour consulter les données, l'utilisateur doit tout
d'abord se connecte à un Serveur
Oracle. Il existe trois types de connexions grâce
auxquelles un utilisateur peut accéder à un Serveur Oracle :
1. Connexion locale.
2. Connexion Deux Tiers.
3. Connexion Multi Tiers.
Un serveur Oracle = une base de données sur disque
+ des données chargées en mémoire ou SGA+ Des processus
d'arrière plan.
Lorsque un utilisateur est connecté à une machine
sur laquelle réside un Serveur Oracle, deux
processus supplémentaire sont invoqués : Le
processus utilisateur et le processus serveur. Une connexion spécifique
entre un utilisateur et un serveur Oracle est appelé une
Session.
La session démarre lorsque la connexion de l'utilisateur
est validée par le serveur Oracle et se
termine lorsqu'il se déconnecte ou lorsqu'une fin de
connexion prématurée se produit.
De nombreuses sessions concurrentes d'un même utilisateur
ou de plusieurs peuvent s'exécuter sur le serveur Oracle.
La figure suivante illustre l'architecture du serveur Oracle qui
consiste en les structures du stockage, les processus, et les fichiers.
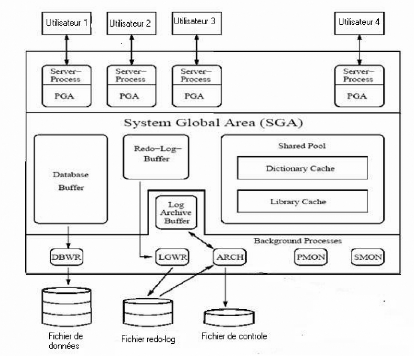
Figure 05 : l'architecture du système
oracle.
5.2. L'instance Oracle
Lors du démarrage d'une base, une partie de la
mémoire principal de l'ordinateur est allouée appelée SGA
; En outre, plusieurs processus d'arrière plan sont lancés, La
combinaison de SGA et les processus d'arrière plan constituent ce que
l'on appelle une instance.
Une fois qu'une instance est démarrée, la base peut
être montée et les utilisateurs peuvent avoir accès aux
informations présentes dans la base.
L'instance est en fait la composition de 2 sous ensembles :
· Une zone mémoire SGA
:assurant le partage des données des différents
utilisateurs, c'est- à-dire qu'il s'agit de la zone contenant les
structures de données accessibles par tous les processus ; Elle va
servir à stocker les données issues des fichiers de
données sur le disque dur. Afin de pouvoir les partager entre les
différents processus.
· Des processus d'arrière plan :
Ils vont servir à gérer les transferts de données entre la
mémoire et le disque dur, plus d'autres actions nécessaires au
bon fonctionnement de la base de données.

Le SGA ou System global Area
Le SGA sert comme la partie de la mémoire où
toutes les opérations de la base de données ont se produire. Par
exemple si plusieurs utilisateurs se connectent en même temps, ils
partagent tous le SGA.
Le dimensionnement de cette zone peut être important
pour les performances de la base. Augmenter la taille de
certaines zones du SGA permet de diminuer les entrées sorties disque,
par exemple.
Le SGA se compose de plusieurs structures de groupe de
mémoire, les trois principales étant :
|
La zone mémoire Shared Pool
|
|
Shared Pool est la partie du SGA qui est utilisé par
tous les utilisateurs. Il Contient les requêtes SQL les
plus récemment exécutées et l'information du dictionnaire
de données la plus récemment utilisée. Elle est
utilisée pour partager les informations sur les objets de la base de
données ainsi que sur les droits et privilèges accordés
aux utilisateurs.
Cette zone mémoire se découpe en 2 blocs :
· Le Library Cache.
· Le Dictionnary Cache.
La zone mémoire Database Buffer Cache
Cette zone mémoire sert à stocker les blocs de
données utilisés récemment. Ce qui signifie que lorsque
vous allez lancer une première fois la requête Oracle, cette
dernière va se charger de rapatrier les données à partir
du disque dur. Mais lors des exécutions suivantes les blocs de
données seront récupérés à
partir de cette zone mémoire, entraînant ainsi un gain de temps.
La zone mémoire Redo Log Buffer
Ce buffer conserve les traces des transactions. Il permet de
stocker les enregistrements redo log. Cette zone mémoire sert
exclusivement à enregistrer toutes les modifications apportées
sur les données de la base. C'est une zone mémoire de type
circulaire et séquentielle.
Le fait que cette zone mémoire soit de type
séquentielle, signifie que les modifications effectuées par une
transaction peuvent être imbriquées avec celles d'autres
transactions.
Le fait que ce buffer soit circulaire signifie que Oracle ne
pourra écraser les données contenues dans ce buffer que si elles
ont été écrites dans les fichiers REDOLOG FILE.

La zone mémoire Program Global Area
(PGA)
Similairement au SGA, il existe La zone mémoire PGA,
cette mémoire est associé à un processus (et inversement).
Ce PGA sert à temporiser les données que manipule le processus,
toujours dans un souci d'optimisation.
Contrairement aux autres zones mémoire celle-ci n'est
pas partagée. Elle est seulement utilisée par des processus
serveur ou d'arrière plan. Elle est allouée lors du
démarrage du processus et libérée lors de l'arrêt du
processus.
|
Les processus d'une instance
|
Le fonctionnement de la base Oracle est régi par un
certain nombre de processus chargés en mémoire permettant
d'assurer la gestion de la base de données. On distingue
généralement deux types de processus :
Les processus utilisateurs (appelés aussi user
process ou noyau oracle)
Ces processus assurent la liaison entre les programmes
utilisateurs, les processus de la base de données, la zone SGA et les
fichiers qui composent la base. Le processus utilisateur affiche aussi
l'information demandée par l'utilisateur
Un processus utilisateur est créé pour chaque
programme exécuté par un utilisateur (par exemple Oracle Forms)
afin de fournir l'environnement nécessaire à l'exécution
de celui-ci.
1. Les processus serveurs (process server)
Les processus serveur, aussi connu comme Shadow
Processes, il communiquent avec l'utilisateur et réagissent
réciproquement avec Oracle pour exécuté les demandes de
l'utilisateur. Par exemple, si le processus utilisateur demande des
données qui ne sont pas dans le SGA, le processus serveur est
responsable pour lire les blocs de données correspondants du datafiles
dans le SGA.
Il existe deux types de processus serveurs
1. Les processus dédiés : une
relation un à un (one to one) est fait entre processus utilisateur et
processus de serveur. Donc un processus s'occupe d'un client unique (comme dans
une configuration dedicated server).
2 .Les processus multi-thread : Un processus
s'occupe de plusieurs clients (comme dans une configuration serveur du
multi-thread), faire donc réduit l'utilisation de ressources de
système.
Le lien entre le processus utilisateur et le processus serveur
est appelé une connexion.

Si l'utilisateur se connecte localement sur le serveur, le chemin
de communication est établi via un mécanisme de communication
inter processus.
Si l'utilisateur se connecte via une machine cliente, un
logiciel réseau est utilisé.
2. Les processus d'arrière-plan (background
process)
Ils sont utilisés pour exécuter plusieurs
tâches dans le système RDBMS, Ces tâches varient entre la
communication avec autre instance Oracle et d'assurer le fonctionnement interne
du SGBD Oracle (gestion de la mémoire, écriture dans les
fichiers, ...).
Oracle 9i comprend cinq processus d'arrière plan
obligatoires pour une instance : 1. Le processus
DataBase WRiter (DBWR)
Ce processus chargé du transfert des blocks de
données modifiés du buffer mémoire du SGA dans les
fichiers disque de la base de données. Ce processus est aussi là
pour vérifier en permanence le nombre de blocks libres dans le Database
Buffer Cache afin de laisser assez de place disponible pour l'écriture
des données dans le buffer.
2. Le processus System MONitor (SMON)
Ce processus, père de tous les processus de l'instance,
s'occupe de plusieurs tâches. Il permet de surveiller la base de son
démarrage puis au cours de son fonctionnement, Il se charge notamment
d'optimiser l'utilisation de la mémoire dans le système. Il se
charge aussi d'assurer la reprise du système lors de tout
démarrage d'une instance.
3. Le processus Process MONitor (PMON)
Ce processus se charge notamment de libérer toutes les
ressources acquises par un processus client, lorsque celui-ci se termine. Il se
charge du nettoyage de la zone mémoire SGA, Il est aussi chargé
de surveiller les processus serveurs et les processus dispatchers : si l'un
d'eux s'arrêtait anormalement, le PMON se chargerait de libérer
les ressources de ce processus et de le relancer.
4. Le processus LGWR (Log Writer)
Le processus LGWR est responsable d'écrire le contenu
des buffers dans des fichiers journaux appelés fichiers Redo Log.
Ce processus garanti la sécurité de la base de
donnés,en fait dés qu'une transaction est validée,oracle
écrit les données modifiées à deux emplacement
différents, de façon a pouvoir repartir si un
problème matériel survient. La première copie est
assurée par le processus DBWR dans les fichiers contenant les
données, cette copie n'est pas forcement immédiate: pour
augmenter les performances et éviter des goulots d'étranglement,
un délai d'écriture peut exister. Pour conserver
l'intégralité des données présentes en
mémoire mais en attente d'écriture sur disque, une seconde copie
immédiate est assurée par le processus LGWR dans les fichiers
Redo Log.
5. Check point (CKPT)
Le processus de point de reprise CKPT enregistre les
données dans le fichiers de contrôle a intervalle
réguliers. Pour identifier l'emplacement de départ de la
récupération. Cette opération appelée point de
reprise.
Il existe également d'autres processus d'importance
secondaire : Recoverer (RECO)
Archiver (ARCn)
Lock (LCKn)
Dispatcher (Dnnn)
Shared Server (Snnn)
Parallel Query Slaves (Pnnn)
| 

