|
UNIVERSITE CHEIKH ANTA DIOP
FACULTE DES SCIENCES ECONOMIQUES ET DE GESTION
CENTRE DE RECHERCHE ET DE FORMATION POUR LE DEVELOPPEMENT
ECONOMIQUE ET SOCIAL (CREFDES)
Année Universitaire 2006-2007

Mémoire de fin d'études pour l'obtention du
diplôme de :
MASTER II Professionnel de
METHODES STATISTIQUES & ECONOMETRIQUES
Scoring du risque de crédit des PME par la
modélisation
statistique et l'intelligence artificielle chez
l'UMECUDEFS :
Une application comparative de la Régression Logistique
et des Réseaux de Neurones
Présenté par :
Fred NTOUTOUME OBIANG-NDONG
Encadré par :
Octave JOKUNG NGUENA,
Ph. D. en Finance
HDR, 3e cycle en Mathématiques
Professeur à l'Université de Lille, et à
l'EDHEC Business School
Fodiyé Bakary DOUCOURE
Ph. D. en Statistiques
Maître en Econométrie
Maître Assistant à l'Université Cheikh Anta
Diop de Dakar
REMERCIEMENTS
Mes remerciements vont à l'endroit des personnes
suivantes, qui ont de près ou de loin contribué à
l'aboutissement de ce travail de recherche :
· DIEU le Tout Puissant ;
· Monsieur et Mme OBIANG-NDONG mes chers parents;
· Monsieur Octave JOKUNG NGUENA, mon Directeur
Général ;
· Monsieur Wade, Directeur Général de
l'UMECUDEF, associé de Babacar Mbaye ;
· Messieurs Bouna NIANG, Fodiyé Bacary DOUCOURE et
Pape NGOME de l'université Cheikh Anta Diop (UCAD) de Dakar ;
· Mes frères et amis parmi lesquels Francis Mba
Zue ;
· Mlle Ingrid Liliane Mengue Me Doumbeneny.
TABLE DES MATIERES
REMERCIEMENTS II
TABLE DES MATIERES III
LISTE DES TABLEAUX VI
LISTE DES FIGURES & GRAPHIQUES VIII
RESUME ANALYTIQUE IX
INTRODUCTION 1
PREMIERE PARTIE : CADRE DE
REFERENCE 3
CHAPITRE IER : REVUE DE LA LITTÉRATURE 4
I/ Généralités sur le Scoring
4
1.1. Définition, Fondements historiques et
théoriques 4
1.2. Les principales techniques de crédit
scoring 6
1.3. L'utilisation des scores de risque 9
II/ Généralités sur la
régression logistique 10
2.1. Définition de la régression logistique
binaire 10
2.2. Principes et propriétés
mathématiques de la régression logistique binaire 10
III/ Généralités sur les
réseaux de neurone 12
3.1. Définition et historique des réseaux de
neurone 12
3.2. Principes et propriétés
mathématiques des réseaux de neurones 12
3.3. Mode et règles d'apprentissage des réseaux
de neurones 14
3.4. Les principaux réseaux de neurone 15
IV / Enseignements de la revue de littérature
16
4.1- Les limites du Scoring 16
4.2- Les limites de la régression logistique 16
4.3- Les limites des réseaux neuronaux 17
CHAPITRE II : PROBLÉMATIQUE GÉNÉRALE
18
I/ Problématique 18
1.1. Contexte et justification de l'étude 18
1.1.1) Le contexte socio-économique, institutionnel,
sectoriel et technologique 18
1.1.2) La justification pour les managers, les
décideurs politiques
et les chercheurs 20
1.2. Problème de recherche et résultats attendus
21
II/ Cadre Conceptuel 23
2.1. Définition des concepts 23
2.2. Objectifs de recherche 26
2.3. Hypothèses et indicateurs 26
2.3.1) Hypothèses de recherche et cadre
opératoire 26
2.3.2) Outils de collecte, sources d'information et
difficultés rencontrées 28
III/ Cadre de l'étude :
présentation de l'UMECUDEFS 29
3.1. Historique et Activités 29
3.2. Structure organisationnelle 29
3.3. Caractéristiques de l'activité 30
DEUXIEME PARTIE : METHODOLOGIE ET ANALYSE
DES RESULTATS 31
CHAPITRE III : MÉTHODOLOGIE 32
I/ Les préalables au Scoring: Collecte et
préparation des données 32
1.1. L'échantillon 32
1.2. Les paramètres analysés 32
1.3. Le traitement des données 32
II/ Le protocole de recherche 33
2.1. Le protocole général 33
2.2. Le protocole de la réduction des variables par
l'analyse factorielle 34
2.3. Le protocole d'expérimentation par les
réseaux de neurone 35
2.3.1) Le réseau utilisé: Perceptron
multicouches (PMC) 35
2.3.2) Les paramètres 35
2.3.3) Apprentissage et généralisation
35
2.4. Le protocole d'expérimentation par la
régression logistique 36
2.4.1) Génération des modalités
discriminantes 36
2.4.2) Estimation du modèle par le maximum de
vraisemblance 36
2.4.3) Test de significativité globale
(Evaluation de la calibration du modèle :
le test de Hosmer et Lemeshow) 36
2.4.4) Evaluation du pouvoir discriminant du modèle :
sensibilité, spécificité 37
CHAPITRE IV : PRÉSENTATION & ANALYSE DES
RESULTATS DES
CLASSEMENTS PREDICTIFS 38
I/ Résultats de l'Analyse Factorielle des
Correspondances Principales 38
1.1. Dimensions de la solution et valeurs propres (inerties)
38
1.2. Qualité de représentation (Fator Analisys
Communalities) 41
1.3. Les variables explicatives retenues 42
II/ Résultats économétriques de
la modélisation par régression logistique 43
2.1. Génération des modalités
« Bon payeur » et « mauvais payeur »
43
2.2. Spécification du modèle logit et
estimation des paramètres prédictifs 44
2.3. Qualité du modèle (Test de
Significativité globale) 47
2.4. Test de Hosmer-Lemeshow (test d'ajustement du
modèle) 48
2.5. Qualité de prédiction du
modèle (performance de classification) 49
2.6. Discussions sur les déterminants du
risque de crédit du modèle Logistique 50
2.6.1) Probabilité de non-remboursement et âge
du dirigeant de la PME 50
2.6.2) Probabilité de non-remboursement et Niveau de
Revenu
du dirigeant de la PME 51
2.6.3) Probabilité de non-remboursement et
Durée d'existence de la PME 52
2.6.4) Probabilité de non-remboursement et Valeur
de la garantie proposée 52
2.6.5) Probabilité de non-remboursement et Montant du
crédit Octroyé 53
2.6.6) Probabilité de non-remboursement et
sélection adverse 53
2.6.7) Probabilité de non-remboursement et Respect des
échéances 54
2.7. Simulations sur le modèle logistique
55
III/ Résultats de la modélisation par
réseaux de neurones 57
3.1. Identification des données en entrée et en
sortie. 57
3.2. La fixation des paramètres du réseau &
apprentissage 59
3.3. Les résultats de la modélisation par
réseaux de neurones 61
3.4. Le réajustement de la structure du réseau
de neurones et les résultats 62
IV/Comparaison des modèles logistique et
neuronal 62
4.1. Comparaison des matrices de confusion (pourcentage de
classement prédictif) 62
4.2. Choix du modèle de scoring final 63
TROISIEME PARTIE : RECOMMANDATIONS
64
CHAPITRE V : RECOMMANDATIONS 65
I/ Recommandations pour une utilisation du
modèle de score 65
1.1. Implémentation informatique 65
1.2. Formation des utilisateurs du modèle de score
65
1.3. Suivi ponctuel par évaluation des utilisateurs
65
1.4. Suivi en continue par tableau de bord 66
II/ Recommandation sur les aspects organisationnels de
l'UMECUDEFS 67
CONCLUSION 68
BIBLIOGRAPHIE XI
Pour l'analyse des données XI
Pour le scoring XII
Pour la régression logistique et les
réseaux de neurones XII
Webographie XIII
ANNEXES XIV
LISTE DES TABLEAUX
Tableau 1 : L'histoire du scoring crédit en 10
dates 5
Tableau 2 : Comparatif des principaux modèles de
Scoring 7
Tableau 3 : Objectifs opérationnels de notre
étude 26
Tableau 4 : Présentation du cadre
opératoire 28
Tableau 5 : Les 212 entreprises de l'échantillon
32
Tableau 6 : Descriptif des
variables initiales 33
Tableau 7 : Fichier de syntaxe de l'analyse factorielle
sous SPSS 39
Tableau 8 : Variance expliquée totale
(Eigenvalues) 40
Tableau 9 : Qualité de représentation des
variables 41
Tableau 10 : Matrice des composantes 42
Tableau 1 1 : Les variables explicatives retenues
apres l'AFC 43
Tableau 12 : Codage de la varible dépendante (Y)
43
Tableau 13 : Récapitulatif du traitement des
observation 45
Tableau 14 : Estimation des paramètres du
modèle logistique 46
Tableau 15 : Récapitulatif des étapes de la
régression logistique 47
Tableau 16 : Test de Log vraisemblance 48
Tableau 17 : Test de Hosmer-Lemeshow 48
Tableau 18 : Performances de classification du
modèle logit 49
Tableau 19 : Signe des coefficients et
significativité 50
Tableau 20 : Test du Khi Carré
REM3MOIS & AGE 51
Tableau 21 : Test du Khi Carré
REM3MOIS & NIVREV 51
Tableau 22 : Test du Khi Carré
REM3MOIS & DUREEXIX
52
Tableau 23 : Test du Khi Carré
REM3MOIS & VALGAR 53
Tableau 24 : Test du Khi Carré
REM3MOIS & MONTANT
53
Tableau 25 : Test du Khi Carré
REM3MOIS & DEMOCT 54
Tableau 26 : Test du Khi Carré
REM3MOIS & DIFDEMRE
55
Tableau 27: Caractéristiques du réseau neuronal
PMC utilisé 58
Tableau 28: Matrice de confusion avec marge
(avec 2 neurones dans la 2e couche cachée)
61
Tableau 29: Performances de classement du réseau de
neurones
(avec 2 neurones dans la 2e couche cachée)
Tableau 30: Résultats de la modélisation
neuronale
(avec 1 neurone dans la 2e couche cachée)
62
Tableau 31: Comparaison des pouvoirs discriminants 63
Tableau 32 : Tableau de Bord de suivi du fonctionnement
du score 66
Tableau 33 : Tableau de Bord de suivi de l'utilisation du
score 67
LISTE DES FIGURES
& GRAPHIQUES
Figure 1: Les propriétés de la régression
logistique 11
Figure 2: Schéma d'un neurone formel 13
Figure 3: Les principaux modèles de réseaux de
neurones 15
Figure 4: Organigramme de l'UMECUDEFS 30
Figure 5 : Schéma du protocole général
de recherche 33
Figure 6: Graphique des valeurs propres 40
Figure 7: Procédure d'estimation du modèle
logistique sous SPSS 44
Figure 8: Choix de la méthode logistique
« Descendante par rapport de vraisemblance »
45
Figure 9 : Simulation sur modèle de scoring
logistique 56
Figure 10: Structure générale du réseau
neuronal PMC utilisé 58
Figure 11: procédure de définition du
modèle neuronal sous SPAD 59
Figures 12: Procédure de fixation des
paramètres du modèle neuronal sous SPAD 60
RESUME ANALYTIQUE
Notre étude avait pour but de proposer à
l'UMECUDEFS, qui est une Institution de Microfinance sénégalaise,
un modèle de scoring-crédit afin d'améliorer la
qualité de son portefeuille client, et plus généralement
sa gestion opérationnelle. Pour ce faire nous nous sommes basés
sur l'hypothèse centrale selon laquelle en dehors même des
indicateurs et ratios purement comptables et financiers, d'autres variables
d'ordres démographique, socioculturel, ou liées aux conditions
d'octroi du crédit lui-même, peuvent expliquer le risque de
contrepartie des PME sénégalaises opérant dans l'informel.
Ce d'autant plus que pour cette frange de clients qui représente 80% du
tissu industriel au Sénégal, les données comptables et
financières rendant compte de leur volume d'activité demeurent
rarement fiables, sinon inexistantes.
Partant de cela, notre stratégie de recherche s'est
basée sur la mise en compétition de deux méthodes de
discrimination prédictive, très robustes, l'une appartenant
à la famille de la modélisation statistique (régression
logistqiue) et l'autre à la famille de l'intelligence artificielle
(réseaux de neurones). L'idée étant, en dehors de
l'intérêt pratique de cette étude pour les dirigeants de
l'UMECUDEF, de participer au débat actuel chez les chercheurs qui tente
de trancher entre deux paradigmes: le constructivisme qui
présuppose l'existence d'un modèle par lequel la solution est
estimée, et le connexionnisme qui privilégie les
résultats par apprentissage. A l'issue de notre démarche
comparative, il s'agissait de sélectionner le modèle ayant les
meilleures performances prédictives, afin de constituer l'hyperplan ou
l'équation de la grille de score.
Les résultats de notre data mining se sont
appuyés sur une base de données reconstituée par les
agents de crédit de l'UMECUDEFS. Cette base portait sur 212 PME ayant
sollicité et obtenu un crédit en 2005, 2006 et 2007. Une analyse
factorielle (analyse en composantes principales sur données
recodées) nous ayant permis de réduire la dimension des
données de départ, nous avons poursuivi l'étude par une
estimation de la probabilité de non remboursement des PME via la
méthode du maximum de vraisemblance (maximum likelihood).
L'équation de régression qui en a résulté nous a
permis de retenir 7 variables comme étant réellement
significatives dans la probabilité de non remboursement. En
l'occurrence, ces variables sont l'age du dirigeant de la PME, son niveau de
revenus, la durée d'existence de l'entreprise, la valeur de la garantie
proposée, le montant du crédit octroyé, la
sélection adverse des micropreteurs et le non respect des
échéances qui met le doigt sur le suivi des dossiers.
Après les tests statistiques nécessaires et les simulations de
validation, nous avons enregistré un taux de prédiction de plus
de 93% pour le modèle logistique.
A contrario, le modèle de prédiction neuronale,
basé sur un réseau de type perceptron multicouches et sur un
fonctionnement par rétroprogation du gradient de l'erreur, nous a fourni
un taux de prédiction de 91%. Pourtant la structure du réseau a
du être réajusté après un premier essai peu
concluant, par soustraction d'un des neurones de la deuxième couche
cachée. Les résultats prédictifs issus de la
méthode par apprentissage sont restés malgré tout moins
robustes (échantillon trop faible ?), que ceux issus de la
méthode par estimation. Nous avons donc conclu à la
supériorité du modèle logistique, que nous avons in
fine gardé comme celui devant faire fonctionner notre grille de
score.
Enfin, notre étude s'est achevée en recommandant
le lancement du scoring-crédit à l'UMECUDEFS pour un premier test
de 3 mois, et sous interface EXCEL dans l'immédiat, en attendant une
implémentation informatique plus poussée. Ce lancement
expérimental serait accompagné par un suivi ponctuel et continue
des performances du score par tableau de bord.
Introduction
Depuis qu'elles existent les banques tentent de lutter contre
le risque de contrepartie. Dans leur rôle d'intermédiation entre
les agents en excédent de liquidité et les agents en besoin de
liquidité, les banquiers ont presque toujours été
préoccupés par les risques d'asymétrie de l'information
des demandeurs de crédit. Le véritable enjeu étant de
prévoir, pour une durée déterminée, la
probabilité de remboursement d'un prêt. Ainsi au fil du temps, et
conscients des risques encourus, les banquiers ont développé un
certain nombre de techniques dont le but consistait à minimiser
l'incertitude liée au niveau de défaillance de chaque demandeur
de crédit. C'est dans ce contexte que le scoring ou
précisément crédit-scoring est né aux USA au
début du XXe siècle, comme instrument d'aide à la
décision de crédit par la gestion et l'analyse systémique
de l'information.
En effet, au coeur du risque de défaillance de
crédit se situe la question épineuse et toujours contemporaine de
l'information, de plus en plus massive, d'origines de plus en plus nombreuses,
et de son interprétation. Ces incertitudes sont plus profondes dans le
contexte des pays africains, où l'information aussi qualitative que
quantitative sur les emprunteurs fait souvent défaut. Le
« tout numérique » constaté dans les pays
développés avec notamment au plan bancaire l'utilisation
généralisée de la carte à puce, permet aux
établissements de crédit du Nord d'accéder à une
qualité et à une quantité d'informations absolument
inédites. De plus la circulation et l'analyse de ces données
reste exacerbée par le world wide web ou la toile mondiale
communément appelée internet. Ceci alors qu'au contraire en
Afrique, l'accroissement de la fracture numérique, de même que
l'inaccessibilité du plus grand nombre au système bancaire ne
permettent de rendre suffisamment compte ni des flux physiques et financiers,
ni des informations y relatives entre acteurs économiques de
façon à servir de base aux banquiers. Ce d'autant plus qu'une
très grande part de l'économie africaine évolue dans
l'informel. Les risques d'aléa moral résultant de ces
incertitudes sont à l'origine d'un certain rationnement du
crédit.
L'une des conséquences de ce rationnement du
crédit, toujours d'actualité en Afrique, a d'ailleurs
été de favoriser l'émergence d'un nouveau type de
structures d'intermédiations financières. Celles-ci sont plus
souples et moins exigeantes que les banques classiques, en plus d'être
organisées sur la base d'une « solidarité
mutualiste » : les Institutions de Microfinance (IMF), encore
appelées Systèmes Financiers Décentralisés (SFD) du
fait de leur proximité avec les populations défavorisées.
Leur objet principal est donc de permettre aux couches de citoyens (ou
d'entreprises) n'ayant pas accès aux services et produits du
système bancaire classique d'avoir tout de même accès aux
services financiers de base que sont l'épargne et le crédit.
Au Sénégal, les SFD connaissent un important
développement depuis la fin des années 80, suite à la
crise du système bancaire classique intervenue quelques années
plus tôt. Aujourd'hui, on compte près de 800 structures
financières décentralisées reconnues (mutuelles de base,
groupements d'épargne et de crédit et structures signataires de
convention). Ces structures offrent des services et produits financiers
à des populations actives à divers niveaux et secteurs de
l'économie nationale, contribuant ainsi à la croissance
économique et à la lutte contre la pauvreté. Mais
malgré leur développement, les IMF sénégalaises
n'échappent pour autant pas à l'une des contraintes majeures
auxquelles continuent d'être confrontées les banques dites
classiques : le risque de contrepartie, encore appelé le
risque de crédit. Pour le cas spécifique de la
microfinance en effet, le dilemme vient du fait que les SFD souffrent de leur
propre objet, qui consiste à faciliter l'accès des produits
financiers aux plus pauvres (ou aux plus modestes des PME). Or cette cible est
justement celle qui présente le moins de garanties quant au
remboursement d'un crédit. La mauvaise qualité du portefeuille de
crédit est de ce fait l'un des premiers écueils au
développement des IMF sénégalaises.
Ainsi, l'intérêt d'étudier les facteurs
qui déterminent le remboursement ou non d'un crédit à
court terme, chez les PME, est de pouvoir développer un système
de SCORING, ou d'évaluation du risque avant l'accord du crédit.
En réponse aux problématiques réglementaires et
opérationnelles de gestion du risque, les entreprises de banque dont
les IMF, ont l'obligation de mettre en place une politique de cotation sur
l'ensemble de leur portefeuille client afin d'obtenir une évaluation en
tant réel. Cette évaluation est stratégique car elle
permet à l'institution financière d'immobiliser les ressources en
fond propre au plus juste pour disposer par ailleurs d'un maximum de
liquidité.
Le principe du scoring est basé sur une espèce
de caractérisation binaire entre mauvais payeur et bon payeur, principe
qui d'ailleurs n'est pas nouveau en soi puisque utilisé (plus ou moins
consciemment) par les banquiers depuis toujours. L'innovation du scoring tient
plutôt à l'utilisation d'une méthode ordonnée et
logique, fondée sur l'octroi d'une note fournie par un ordinateur mais
dont le calcul résulte d'un modèle mathématique ou
algorithme. Le scoring est donc issu d'une réflexion rigoureuse et
empirique, par opposition à la « méthode
d'expert » qui se base sur des appréciations subjectives,
parfois émotionnelles et pas toujours reproductibles. Aussi et surtout,
les modèles de scoring ne sont en fait ni plus ni moins que la
régression d'un comportement type effectuée au moyen de
données historisées. En ce sens établir un modèle
de score nécessite une base de données.
Notre étude, en s'appuyant sur une méthodologie
à la fois quantitative (modélisation statistique) et qualitative
(prise en compte de déterminants sociaux comme le nombre d'enfants, le
niveau d'étude du chef d'entreprise sollicitant le crédit, etc.),
se propose de fournir un modèle de prédiction des risques de
crédit chez les clients PME à court-terme d'une IMF
sénégalaise. Ce modèle sera développé
à partir de l'intelligence artificielle (réseaux de neurones) et
de la modélisation mathématique (régression logistique). A
terme, le système d'estimation attendu permettra aux gestionnaires et
aux analystes crédit de prévoir, avec un très bon seuil de
confiance, le niveau de risque lié à chaque nouveau demandeur de
crédit.
Pour ce faire, trois phases seront proposées dans le
présent mémoire. La première servira à poser les
fondements des théories de scoring et de data mining, en cernant le
sujet grâce à un cadre de référence. Ce sera
l'occasion d'une brève revue de littérature sur la
régression logistique et sur les réseaux de neurone, et d'une
précision sur la problématique qui soutend l'étude. Dans
une deuxième phase, la méthodologie de scoring par le data mining
utilisée sera exposée, ainsi que les résultats qui auront
été obtenus par nos deux modèles (logistique et neuronal).
Après avoir procédé à l'analyse desdits
résultats à l'aide des tests statistiques nécessaires,
nous comparerons la robustesse des modélisations obtenues, avant de
recommander une grille de score. La troisième phase nous permettra de
poursuivre par des recommandations liées à une probable
implémentation du modèle choisi, et à quelques autres
recommandations liées aux aspects organisationnels propres à
l'UMECUDEFS.
PREMIERE PARTIE
CADRE DE REFERENCE
CHAPITRE Ier : Revue de la littérature
[The use of credit scoring technologies] has expanded well
beyond their original purpose of assessing credit risk. Today they are used for
assessing the risk-adjusted profitability of account relationship, for
establishing the initial and ongoing credit limits available to borrowers, and
for assisting in a range of activities in loan servicing, including fraud
detection, delinquency intervention, and loss mitigation [...]
Alan GREENSPAN, U.S. Federal Reserve
Chairman, in October 2002
Speech to the American Bankers Association1(*)
Un des problèmes principaux auxquels font face les
banques en prêtant de l'argent c'est leur incapacité à
déterminer avec certitude si le client va honorer ses engagements et
rembourser l'emprunt en totalité, ou s'il va simplement faire
défaut. Le scoring a été développé dans
cette optique, avec des outils de plus en plus pointus.
Cette sous-partie présente quelques
généralités fondamentales sur le scoring, nous permettant
d'en préciser les principaux développements théoriques, de
différencier les différents types de score retrouvés dans
la littérature bancaire, et de brosser quelques avantages à
l'utilisation du score de risque, objet de notre étude. Par la suite,
les fondements des techniques de modélisation statistique
(Régression logistique) et d'intelligence artificielle
(Régression neuronale) que nous avons choisi d'éprouver seront
exposés, afin d'en retenir les caractéristiques et
propriétés principales.
I/ Généralités sur le
« credit scoring ».
1.1. Définition, Fondements historiques et
théoriques
Qu'est ce que le crédit
scoring ?
Les risques auxquels font face les banques sont de nombreux
ordres. G. Fong & A. O. Vasicek (1997)2(*) ont listé 11 risques dont
les risques de marché, d'option, de liquidité, de paiement
anticipé, de gestion et d'exploitation, de gestion, les
spécifiques, ceux liés à l'étranger et le risque de
crédit. Seul ce dernier encore appelé risque de contrepartie
retiendra notre attention.
Dans la gestion du risque lié au crédit
bancaire, le crédit scoring, ou scoring crédit, est compris selon
R. Anderson (2007) comme étant le recours aux
modèles statistiques en vue de transformer des données
(qualitatives, quantitatives) en indicateurs numériques mesurables
à des fins d'aide à la décision d'octroi ou de rejet de
crédit. 3(*)
L'objectif du crédit scoring est dans ce sens de pouvoir établir
une différenciation entre des individus d'un même ensemble, pour
l'identification des probabilités de défaillances associable
à chacun d'eux en fonction de certains facteurs. La plus simple
différenciation à l'origine est une catégorisation binaire
entre « bons payeurs » d'un coté, et
« mauvais payeurs » de l'autre. Stéphane
Tufféry (2005) définit d'ailleurs cette
catégorisation comme le score de risque, ou la probabilité
pour un client [nouveau ou ancien] de rencontrer un incident de paiement ou de
remboursement4(*).
Le scoring peut cependant revêtir plusieurs
définitions en fonction du but pour lequel il lui est fait recours.
Notamment, le scoring est très utilisé en marketing, dans le
Customer Relationship Management (CRM). On note aussi les scores
d'appétence, de recouvrement, etc. Toutefois, d'autres
théoriciens du scoring pensent qu'il n'y a pas seulement scoring que sur
la base de méthodes statistiques et de probabilités. M.
Schreiner (2002) fait par exemple remarquer utilement que les
démarches de scoring peuvent être menées sur une base
empirique (subjective), c'est-à-dire évaluer plus ou moins
intuitivement les liens entre le passé et le futur sur la base d'une
simple lecture pratique de l'expérience.5(*)
Au plan historique, bien que le crédit
scoring ait été pour la première fois utilisé dans
les années 1960 aux USA, ses origines remontent en fait au début
du XXe siècle, lorsque John MOODY publia la
première grille de notation pour ses trade bonds (obligations
commerciales). Brièvement, nous présentons les 10 dates
clés du scoring crédit dans le tableau ci-dessous.
Tableau 1: L'histoire du scoring crédit en 10 dates
|
Dates
|
Evènements
|
|
2000
av. JC
|
1ere utilisation du crédit en Assyrie, à
Babylone et en Egypte
|
|
1851
|
1ere utilisation de la notation (classement) crédit par
John Bradstreet, pour ses commerçants demandeurs de crédit,
USA
|
|
1909
|
John M. Moody publie la 1ere grille de notation pour les
obligations commerciales négociées sur le marché
marché, USA
|
|
1927
|
1er « crédit bureau »
crée en Allemagne
|
|
1941
|
David Durand professeur de Gestion au MIT écrit un
rapport, et suggère le recours aux statistique pour assister la
décision de crédit, USA.
|
|
1958
|
1ere application du scoring par American
Investments
|
|
1967-70
|
Altman crée le « Z-score » à
partir de l'analyse discriminante mutivariée.
Réglementation des « crédits
bureaux » par le credit reporting act, USA
|
|
1995
|
L'assureur d'hypothèques Freddy Mac & Fannie Mae
adopte le crédit-scoring, USA
|
|
2000
|
Moody's KMV introduit le RiskCalc pour le scoring des
ratios financiers (financial ratio scoring - FRS)
|
|
2004
|
Bâle II recommande l'utilisation des méthodes
statistiques de prévision du risque de crédit
|
Source : tableau inspiré de Rayon Anderson,
« The crédit scoring Toolkit »,
Oxford University Press, 2007, P. 28
Il faut cependant noter que le crédit scoring ne
constitue pas la seule voie à ce jour de gestion du risque de
crédit. Depuis quelques années, l'émergence de produits
financiers dérivés permettant une protection contre le risque de
défaut, ou encore, une protection contre une augmentation des
probabilités de défaut pouvant être mesurées par
l'écart de crédit. Il s'agit notamment des options (options sur
écart de crédit, option sur le défaut), des contrats
à terme sur l'écart de crédit et des credit default
swaps.
1.2. Les principales techniques de crédit
scoring
Les techniques ou méthodologies utilisées dans
la littérature pour mettre en place des modèles de scoring sont
assez nombreuses, à cause des systèmes de crédit scoring
qui sont eux-mêmes inspirés par de multiples besoins.
Selon A. Saunders & L. Allen
(2002)6(*) les
systèmes de crédit scoring peuvent être retrouvés
dans plusieurs types d'analyse de crédit, depuis le crédit de
consommation jusqu'aux prêts commerciaux. L'idée centrale en effet
ne varie point, puisqu'il s'agit d'identifier dans un premier temps les
facteurs qui déterminent la probabilité de défaut, et dans
un second temps de pondérer leurs « poids » dans un
score quantitatif. Ces systèmes sont mis en place, selon la même
source, à partir de quatre principales formes de modélisation
multivariée :
· le scoring par le modèle linéaire
· le scoring par le modèle logit
· le scoring par le modèle probit
· le scoring par le modèle d'analyse
discriminante
M. Schreiner (2002)7(*) utilise principalement, dans une
étude récente sur les IMF, des techniques de
classement et de prédiction par « arbre de
décision ». Ces techniques permettent de détecter des
critères à même de répartir les individus d'une
population en n classes (souvent n=2) prédéfinies. M.
Schreiner distingue de ce fait :
· le scoring de l'arbre à 4 branches, qui
corrèle le taux de remboursement et le croisement de deux facteurs
d'analyse : le sexe de l'emprunteur et le fait que le prêt soit un
premier prêt ou un renouvellement ;
· le scoring de l'arbre à 19 branches, qui prend
en considération un beaucoup plus grand nombre de
caractéristiques de la candidature du client de l'IMF ( le type de
prêt ou le sexe du client, mais aussi l'âge du client, les
éventuels retards antérieurs, le type de garanties ou même
le nombre de lignes téléphoniques ).
Aux techniques présentées ci-dessus, S.
Tuffery (2007)8(*)
ajoute, en considérant les techniques de classement et de
prédiction dans leur ensemble comme potentiel outil de scoring :
· le scoring par réseaux de neurones
· le scoring par »support vector
machine » (SVM)
· le scoring par algorithmes génétiques
· le scoring par système d'experts
Une analyse approfondie de ces approches est disponible dans
Caouette, Altman & Narayanan (1998),
Sanders (1997), ainsi que dans S. Tuffery
(2007). Toutefois, nous accorderons une attention particulière à
trois modèles cités supra : le modèle logit, les
réseaux de neurones, et l'analyse discriminante. Les deux premiers nous
intéresseront plus bas car faisant l'objet du présent
mémoire, tandis que le modèle d'analyse discriminante, le plus
utilisé dans la littérature, mérite d'être
exploré à travers ses principales applications en score.
L'analyse discriminante multivariée
(ADM) est une technique statistique qui permet de classer des observations dans
des sous-groupes homogènes fixés à priori. L'ADM consiste
à réduire la dimension du plan dans lequel on travaille en
faisant une projection d'un point représenté dans un espace de
dimension N, dans un plan de dimension 1 par exemple. Elle traite les variables
explicatives qualitatives binaires: pauvre/riche, bon client/mauvais client. La
plupart des modèles de crédit-score ont été mis au
point à partir de l'ADM. (cf tableau) :
Tableau 2 : Comparatif des principaux modèles de
Scoring
|
« Z Score »
de Altman (1969)
|
Score de Conan Holder (1979)
|
Score Banque de France (BDFI 1995)
|
Score calculé dans le présent
mémoire (par Fred Ntoutoume)
|
|
Méthode de prévision
utilisée
|
Analyse discriminante
(méthodes paramétriques)
|
Analyse discriminante
(méthodes paramétriques)
|
Analyse discriminante
(méthodes paramétriques)
|
-Régression logistique
(méthodes paramétriques)
-Réseaux de neurones
(méthodes non-paramétriques)
|
|
Principe de la méthode
|
Classification des variables dans des groupes définis
à l'avance
|
Classification des variables dans des groupes définis
à l'avance
|
Classification des variables dans des groupes définis
à l'avance
|
Double modélisation, comparaison des résultats
issus des deux modèle l'un de classification l'autre de classement
|
|
Nombre de Variables mesurée dans
l'élaboration du score
|
05 Variables
§ X1= fonds de roulement / actif total
§ X2 = bénéfices non
répartis / actif total
§ X3 = BAII / actif total
§ X4 = valeur marché des fonds propres /
valeur comptable de la dette
§ X5 = ventes / actif total
|
05 variables
§ R1 = Excédent brut d'exploitation / Total des
dettes
§ R2 = Capitaux permanents / Total de l'actif
§ R3 = Réalisable et disponible / Total de l'actif
§ R4 = Frais financiers / CA HT
§ R4 = Frais financiers / CA HT
§ R5 = Frais de personnel /valeur ajoutée
|
08 variables
§ X1=Frais Financiers/ EBE
§ X2= Ressources Stables/Actif Economique
§ X3= CA/Endettement
§ X4= EBE/ CA HT
§ X5= Dettes Commerciales/ Achats TTC
§ X6= Taux de variation de la Valeur Ajoutée
§ X7= (Stocks + Clients - Avances Clients)/ Production
TTC
§ X8= Investissements Physiques/ Valeur Ajoutée
|
20 variables* réparties en 6 axes
prédicteurs :
1-données démographiques du dirigeant
2-expérience passée du dirigeant en
matière de crédit
3-forme et activité de l'entreprise
4- garanties
5-indicateurs temporels
6-montant de la demande de crédit
(*)le détail des 20 variables est fourni en annexe.
|
|
Types de variables
|
Quantitatives
|
Quantitatives
|
Quantitatives
|
Quantitatives
Qualitatives
|
Source : Recherche de Fred Ntoutoume, Crefdes, 2007
S'il fallait ainsi faire la revue des principaux scores qui
ont vu le jour depuis une quarantaine d'années, nous commencerons par
évoquer le « Z-score » d'Altman mis
au point en 1967. Sur un échantillon de 66 entreprises, 33 ayant connu
la faillite et 33 ayant survécu, Altman utilise l'analyse discriminante
multivariée comme technique statistique. La fonction discriminante de
Altman transforme grâce à l'ADM la valeur des variables
individuelles (qui sont les ratios) en un score discriminant appelé
"Z-score" qui permettra de classer un client
dans le groupe faillite, ou non faillite. Sa fonction discriminante
finale est:
· Z score = 1,2xX1 + 1,4xX2 + 3,3xX3 + 0,6xX4 +
0,9xX5
Les coefficients du score étant déterminés,
il ne reste plus qu'à remplacer les variables (X1, X2, X3, X4 et X5...)
par leur valeur pour chaque entreprise à évaluer. Plus le score Z
est faible, plus le risque de défaut augmente. D'après
l'étude de base de Altman, si >Z2,99 le client ne
risque pas de faire défaut et si Z=1, 81 le client risque de faire
défaut.
Après Altman, le score de
CONAN et HOLDER (1979) est venu dix ans plus tard enrichir
les modèles de scoring développés auparavant. Comme le
« z score » le score calculé par Conan et Holder est
une régression par analyse discriminante. Par référence au
bilan financier, les deux chercheurs ont étudié les valeurs de 31
ratios applicables à 190 PME et ont obtenu la fonction-score suivante :
· Z = 0,24 R1 + 0,22 R2 + 0,16 R3 - 0,87 R4 - 0,10
R5
Plus la valeur du score Z est élevée, plus le
risque de défaillance est faible.
Le score sectoriel AFDCC10(*) (2008) est un autre
outil d'aide à la décision, qui probabilise le risque de
défaillance d'une entreprise à partir de données
comptables issues des liasses fiscales. Il débouche sur une note
comprise entre 1 et 20. AFDCC 2008 accorde une place plus importante aux
liquidités et aux cash flows que les précédent scores
élaborés en 1997 et 1999.
Le score de la Banque de France (BDFI 1995)
est aussi une méthodologie célèbre de
prévision des risques de défaillances par l'analyse et la
prévision statistique. Les scores opérationnels
(utilisables par les banques et les entreprises) de première
génération ont été mis au point par la Banque de
France en 1982. Le score BDFI 1995, s'intéresse plus
particulièrement à l'endettement financier (importance, structure
et coût de l'endettement). La formule de ce score se présente
comme suit :
· 100Z = - 1,255 X1 + 2,003 X2 - 0,824 X3 + 5,221
X4 - 0,689 X5 - 1,164 X6 + 0,706 X7 + 1,408 X8 - 85,544
Après tout ce qui précède, on ne recense
que de très rares études de scores totalement conçus pour
l'Afrique. L'un des tout premiers est dû à Viganô
(1993) qui a construit un modèle de crédit scoring pour
la Caisse Nationale du Crédit Agricole (CNCA), au Burkina Faso. Une
étude plus récente a toutefois été effectuée
par Diallo (2006)11(*), pour le compte d'une Mutuelle malienne, et a abouti
à la construction d'un score via l'analyse discriminante et la
régression logistique.
Ce pendant toutes ces études se sont faites sur la base
d'hypothèses sur les déterminants du non remboursement.
Or les entreprises africaines, à n'en point douter, ont
des facteurs de risques sensiblement différents de ceux de leurs
consoeurs occidentales. Par exemple, les pesanteurs culturelles, les
données socio-économiques, les charges familiales sont des
éléments qui peuvent influer de façon significative dans
l'érosion des capacités de remboursement pour les dirigeants
d'une PME. Malheureusement, ces facteurs "qualitatifs" sont
dans la plupart des cas mis en rade dans les scores jusqu'à
présent conçus. Le score que nous proposons s'inscrit dans cette
rupture.
1.3. L'utilisation des scores de risque
La littérature de ces dernières années
s'accorde à dire qu'il existe en général 5 types de scores
(S. Tuffery, 2007, pp. 401-402) :
· Le score d'appétence peut
être définit comme la probabilité pour un client
d'être intéressé par un produit ou un service donné.
· Le score de risque est la
probabilité d'un client avec un compte courant, une carte bancaire, une
autorisation de découvert ou un crédit, de rencontrer un incident
de paiement ou de remboursement.
· Le score d'octroi (ou score
d'acceptation) est un score de risque calculé pour un
client qui est nouveau ou qui à une faible activité avec la
banque. Notons qu'on peut aussi calculer un score d'octroi pour un client
déjà connu, si l'on veut intégrer au calcul des
éléments propres à la demande.
· Le score de recouvrement évalue
le montant susceptible d'être récupéré sur un compte
ou un crédit au contentieux, et peux suggérer les actions de
recouvrement les plus efficaces, en évitant des actions
disproportionnées pour des clients fidèles, rentables et sans
véritable risque.
· Le score d'attrition est la
probabilité pour un client de quitter la banque.
L'utilisation du score de risque, celui qui
nous intéresse particulièrement, dans le domaine du
crédit, permet d'améliorer : (i) la productivité des
analyses de demande de crédit, en traitant assez rapidement les
dossiers ; (ii) les possibilités de délégation en
impliquant les jeunes analystes crédit ; (iii) le sentiment de
sécurité des analystes crédit et des gestionnaires ;
(iv) la satisfaction des clients qui voient leur demande traiter avec le
maximum de diligence ; (v) l'homogénéité des
décisions issues des différentes agences ; (vi)
l'homogénéité des décisions issues d'un même
analyste de crédit ou gestionnaire ; (vii) l'adaptation de la
tarification du crédit au risque effectivement encouru, ou
« pricing » ; (viii) une meilleure
sécurité dans l'allocation des fonds propres, conformément
aux préconisations du comité de Bâle dans la perspective du
ratio Cooke, qui a fait place au ratio McDonough depuis le 1er
Janvier 2008.
Par ailleurs, dans le contexte d'une amélioration de
l'accès au crédit des PME, l'utilisation du score de risque
permet aussi à la banque de limiter son risque de surendettement
grâce à une réduction des impayés, tout en
conquérant une frange de clientèle légèrement
risquée pour laquelle le score permet d'adapter
précisément le montant et le coût (taux
d'intérêt, frais de gestion) du crédit, voire des garanties
demandées, en fonction du risque encouru.
II/ Généralités sur la
régression logistique
2.1. Définition de la régression logistique
binaire
La régression logistique se définit selon
Desjardins (2005)12(*) comme une technique permettant d'ajuster une surface
de régression à des données lorsque la variable
dépendante est dichotomique. Cette technique est utilisée pour
des études ayant pour but de vérifier si des variables
indépendantes peuvent prédire une variable dépendante
dichotomique. Selon Wikipédia en outre, la régression logistique
peut correspondre à une technique statistique dont l'objet est,
à partir d'un fichier d'observations, de produire un modèle
permettant de prédire les valeurs prises par une variable
catégorielle, le plus souvent binaire, en se basant sur une série
de variables explicatives continues et/ou binaires13(*). Contrairement
à la régression multiple et l'analyse
discriminante, la régression logistique n'exige pas une distribution
normale des prédicteurs ni l'homogéneité des variances.
Par ses nombreuses qualités donc, cette technique est de plus en plus
préférée à l'analyse discriminante par les
statisticiens et les spécialistes du scoring.
Ainsi dans le cadre du modèle linéaire
généralisé, des perfectionnements ne cessent d'être
apportés à la régression logistique (McFadden, prix Nobel
d'économie en 2000 fut récompensé pour ses travaux
à ce sujet), la confirmant comme l'une des méthodes de
modélisation les plus fiables, et dont plusieurs indicateurs
statistiques permettent d'en contrôler facilement la robustesse (LR
ratio, R carré de McFadden, Test de Hosmer-Lemeshow).
La régression logistique est enfin largement
répandue dans des domaines nombreux et divers. D'abord utilisée
dans la médecine (caractérisation des sujets malades par rapport
aux sujets sains par exemple), cette technique de classement et de
prédiction s'est rependue dans la banque assurance (détection des
groupes à risque), la science politique (explication des intentions
de vote), le marketing (fidélisation des clients)..
2.2. Principes et propriétés
mathématiques de la régression logistique binaire
Lorsque nous voulons modéliser une variable à
réponse binaire, la forme de la relation est souvent non
linéaire. On recourt alors à une fonction non-linéaire, de
type logistique par exemple, en pareils cas. Le principe de la
régression logistique binaire est de considérer une variable
à prévoir binaire (variable cible admettant uniquement deux
modalités possibles) Y = {0,1} d'une part, et p variables
explicatives notées X = (X1, X2, ..., Xj), continues, binaires ou
qualitatives. L'objectif de la régression logistique est de
modéliser l'espérance conditionnelle E(Y/X=x), par l'estimation
d'une valeur moyenne de Y pour toute valeur de X. Pour une valeur Y valant 0 ou
1 (loi de Bernouilli), cette valeur moyenne est la probabilité que Y=1.
On a donc :
E (Y/X=x) = Prob (Y=1/X=x)
Les propriétés principales de la
régression logistique peuvent être exposées à
travers l'exemple des deux graphiques ci-dessous (Cf. graphiques). On constate
dans les deux cas de figure que la fonction logistique est monotone croissante
ou décroissante, selon le signe de 1 d'une part, et que
la fonction logistique est presque linéaire lorsque E(Y) est entre 0,2
et 0,8 et s'approche graduellement de 0 et 1 aux deux extrémités
du support de X. Aussi, la distribution logistique est symétrique E (-Y)
= 1 - E (Y), et de moyenne nulle ð2 / 6. (F. B.
Doucouré, 2007).
Figures 1: Les propriétés de la régression
logistique
Une autre propriété de la régression
logistique est qu'elle n'exige pas que les prédicteurs (variables
indépendantes) suivent une loi normale, ou soient distribués de
façon linéaire, ou encore qu'ils possèdent une variance
égale entre chaque groupe. La forme de courbe (en
« s ») que nous remarquons par ailleurs sur les deux
graphiques est appelé sigmoïde, ou courbe logistique. Si l'on suit
l'expression de cette courbe, on peut écrire la fonction logistique
E(Y) = pi = prob (Y=1/X=x) sous la forme:
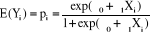
La probabilité d'occurrence selon la formule logistique
s'écrit :
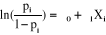
Equation équivalente par transformation à :
En fait, en cherchant à expliquer la probabilité de
réalisation de l'évènement Prob(Y=1/X=x),
il nous faudrait une transformation de E(Y) qui étende
l'intervalle de définition [0,1]. C'est le calcul des
ratios de chance « odds ratio » qui permet d'envisager
cette transformation. Ainsi le quotient pi /(1-pi) est
appelé « odds », et la fonction f(p)=ln
(pi/1-pi) est appelée « logit ».
Le fonctionnement consiste à calculer des coefficients
de régression de façon itérative. En d'autres termes le
programme informatique, à partir de certaines valeurs de départ
pour Y0 et Y1, vérifiera si les log chances (odd ratios) estimés
sont bien ajustés aux données, corrigera les coefficients,
réexaminera le bon ajustement des valeurs estimées,
jusqu'à ce qu'aucune correction ne puisse atteindre un meilleur
résultat (Howell, 1998).
Sous ce rapport, le modèle logistique défini
précédemment peut être utilisé pour :
· décrire la nature de la relation entre la
probabilité espérée d'un succès pour la variable
réponse (ex: probabilité d'acheter, probabilité de
s'abonner) et une variable explicative X;
· prédire la probabilité
espérée d'un succès étant donné la valeur de
la variable X (ex: probabilité de rembourser un crédit
étant donné les caractéristiques sociales,
géo-marketing, etc de l'emprunteur, tel qu'est l'objet de notre
présent mémoire).
Mais au cours de la dernière décennie d'autres
techniques de modélisation, regroupées sous le vocable
« algorithmes d'apprentissage » et initialement
utilisées en bio-physiologie, ont peu à peu émergé
dans les milieux académiques et professionnels pour leurs
capacités de prédiction. Nous porterons notre attention sur l'une
de ces techniques venue de la neurophysiologie, et de plus en plus
utilisée dans le domaine du scoring : les réseaux de
neurones artificiels (RNA).
III/ Généralités sur les
réseaux de neurones
3.1. Définition et historique des réseaux de
neurone
Pour appréhender la définition d'un
réseau de neurones, nous commencerons par définir le neurone
« formel ».
Le neurone formel est une modélisation
mathématique visant à reprendre le fonctionnement d'un neurone
biologique. Le fonctionnement de ce neurone formel est basé sur une
règle de calcul assez simple : on cherche à évaluer
la valeur d'une sortie y, à partir de plusieurs entrées
x, qui elles mêmes sont pondérées par des
coefficients appelés synapses ou poids synaptiques w. Selon
cette description, chaque neurone est relié à d'autres par des
connexions.
L'activation du neurone se produit lorsque celui-ci atteint un
certain seuil (degré) d'activation. Cette activation est
générée par les connexions qui ont pour
propriété d'être excitatrices ou inhibitrices. La sommation
des données reçues à l'entrée du neurone est
transformée par une fonction d'activation ou fonction de sortie ö
non linéaire. Ainsi, selon une définition proposée par
A. Nigrin (1993)14(*), un réseau de neurones est un
circuit composé d'un nombre très important d'unités de
calcul simples basées sur des neurones.
Pour faire un bref historique, les réseaux de neurone
ont connu leurs débuts dans les années 1943 avec les travaux de
Warren Mc Culloch & Walter Pitt sur le « neurone
formel ». En 1949, D. Hebb présente dans son
ouvrage « The Organization of Behavior » une règle
d'apprentissage. De nombreux modèles de réseaux aujourd'hui
s'inspirent encore de la règle de Hebb En 1958 les travaux de
Franck Rosenblatt sur « le
perceptron »15(*) proposent au Cornell Aeronautical Laboratory le
premier algorithme d'apprentissage permettant d'ajuster les paramètres
d'un neurone. Il est à présent communément admis que le
perceptron, comme classifieur linéaire, est le réseau de neurones
le plus simple.
En 1969, Minsky et Papert publient le livre
Perceptrons dans lequel ils utilisent une solide argumentation
mathématique pour démontrer les limitations des réseaux de
neurones à une seule couche. Ce livre aura une influence telle que la
plupart des chercheurs quitteront le champ de recherche sur les réseaux
de neurones. En 1982, Hopfield propose des réseaux de
neurones associatifs et l'intérêt pour les réseaux de
neurones renaît chez les scientifiques. En 1986, Rumelhart,
Hinton et Williams publient l'algorithme de la rétropropagation
de l'erreur, qui permet d'optimiser les paramètres d'un réseau de
neurones à plusieurs couches. À partir de ce moment, la recherche
sur les réseaux de neurones connaît un essor fulgurant et les
applications commerciales de ce succès académique suivent au
cours des années 90.
3.2. Principes et propriétés
mathématiques des réseaux de neurones
Au plan mathématique, le calcul de la valeur
prédite par un réseau de neurones se compose en deux principales
étapes :
m
Ó wj xj
1ere étape : le calcul d'une
série de combinaisons linéaires des variables explicatives, que
F. Robert (1995) appelle l'entrée totale
E, ou « total input » :
j=1
E = w1
x1 + w2 x2 + ... + wm
xm = ( 1 )
m
Ó wj xj
Le seuil d'entrée w 0 est ensuite
ajouté à la grandeur E, ce qui permet de noter :
j=1
E =
w0 +
( 2 )
2e étape : Le calcul
d'une sortie (le seuillage) par transformation16(*) non linéaire : un seuil w0
étant donné, la fonction à seuil ou fonction d'activation
s'écrit :
f (x) = 1 si E > w 0
= 0 sinon
m
Ó wj xj - w0
Donc la sortie du neurone formel à prédire y = f
(x) = f (x1, x2, ..., xm )
s'écrit :
j=1
y = f (x) = ö (
) ( 3)
Où ö est la fonction d'activation non
linéaire
y est la sortie du neurone (la valeur à
prédire)
xj représente les valeurs
d'entrée
m
Ó wj xj - w 0
wj représente les poids synaptiques
(ou coeficients)
j=1
si > w0, alors y
=1
m
Ó wj xj - w 0
j=1
si < w0, alors y =
0
Le neurone formel applique par conséquent {0, 1}m
dans {0, 1}. D'où son nom de classifieur avec seuil
d'entrées xj, coefficients synaptiques wj, et
seuil w0.
Figure 2: Schéma d'un neurone formel
Variables explicatives
(Couches d'entrée)
Fonction de sortie (couche de sortie)
Fonction de sommation (couche cachée)
Poids synaptiques
x1
w1
m
Ó wj xj - w0
m
Ó wj xj
y = ö ( )
x2
w2
j=1
j=1
xm
wm
Source : Recherche de Fred Ntoutoume, Crefdes, 2007
Les réseaux de neurones présentent les
propriétés suivantes :
· ils sont universels (capables de résoudre des
problèmes simples ou complexes) ;
· ils se comportent plus d'une façon adaptative
que programmée ;
· Ils sont capables de fonctionner même en
présence d'une information partielle ou d'une information
brouillée ;
· Ils fonctionnent comme une machine de classification
qui extrait les traits caractéristiques des objets
présentés lors de l'apprentissage, pour réorganiser sa
connaissance en conséquence.
3.3. Modes et règles d'apprentissage du
réseau de neurones (R. Ladjadj, 2002)17(*)
Nous l'avons dit, les RNA sont des algorithmes, ou un ensemble
d'équations mathématiques, dont le principe de fonctionnement est
schématiquement inspiré du neurone humain. Ce principe est
l'apprentissage par l'expérience. Pour qu'un réseau fonctionne,
on lui fournit des données en entrée qu'il doit
« apprendre » à reconnaître, soit pour les
classer en sous groupes homogènes (apprentissage non supervisé
à des fins descriptives), soit pour les associer à une variable
indicatrice de sortie (apprentissage supervisé à des fins
prédictives, conformément aux objectifs du présent
mémoire).
a) Modes d'apprentissage
· Le mode supervisé et le renforcement:
Dans ce type d'apprentissage, le réseau s'adapte par
comparaison entre le résultat qu'il a calculé, en fonction des
entrées fournies, et la réponse attendue en sortie. Ainsi, le
réseau va se modifier jusqu'a ce qu'il trouve la bonne sortie,
c'est-à-dire celle attendue, correspondant à une entrée
donnée.
Le renforcement est en fait une sorte d'apprentissage
supervisé et certains auteurs le classe d'ailleurs, dans la
catégorie des modes supervisés. Dans cette approche le
réseau doit apprendre la corrélation entrée/sortie via une
estimation de son erreur, c'est-à-dire du rapport
échec/succès. Le réseau va donc tendre à maximiser
un index de performance qui lui est fourni, appelé signal de
renforcement. Le système étant capable ici, de savoir si la
réponse qu'il fournit est correcte ou non, mais il ne connait pas la
bonne réponse.
· Le mode non-supervisé (ou auto-organisationnel)
:
Dans ce cas, l'apprentissage est basé sur des
probabilités. Le réseau va se modifier en fonction des
régularités statistiques de l'entrée et établir des
catégories, en attribuant et en optimisant une valeur de qualité,
aux catégories reconnues.
b) Règles d'apprentissage
· Règle de correction d'erreurs :
Cette règle s'inscrit dans le paradigme de la
retropropagation du radient. Si on considère y comme étant la
sortie calculée par le réseau, et d la sortie
désirée, le principe de cette règle est d'utiliser
l'erreur (d-y), afin de modifier les connexions et de diminuer ainsi
l'erreur globale du système. Le réseau ajuste ensuite les poids
des différents noeuds. Il s'agit, comme dans une régression
classique, de résoudre un problème de moindres carrés.
· Règles de Hebb
Selon Hebb « si des neurones, de part et d'autre
d'une synapse, sont activés de manière synchrone et
répétée, la force de la connexion synaptique va aller
croissant ». Il est à noter ici que l'apprentissage est
localisé, c'est-à-dire que la modification d'un poids synaptique
wij ne dépend que de l'activation d'un neurone i et
d'un autre neurone j.
· Règle d'apprentissage par compétitions :
La particularité de cette règle, c'est qu'ici
l'apprentissage ne concerne qu'un seul neurone. Le principe de cet
apprentissage est de regrouper les données en catégories.
3.4. Les principaux réseaux de neurone
Selon une classification en deux grands groupes
(modèles à apprentissage supervisé et non
supervisé), on peut généralement retenir 6 principaux
réseaux de neurones.
Dans le groupe des RNA à apprentissage supervisé,
encore dits non bouclés on distingue :
· Le perceptron monocouche
· Le perceptron multicouches (PMC)
· Les réseaux à fonction radiale de base
(Radial basis fonction RBF)
Dans le groupe des RNA à apprentissage non
supervisé, encore dits récurrents ou bouclés, on
distingue
· Le réseau de Kohonen (ou réseau à
compétition, SOM,..)
· Le réseau de Hopfield
· Les réseaux ART (Adaptative Resonance Theory)
Une description schématique de la représentation
des différents réseaux de neurone est proposée
ci-dessous.
Figure 3: Les principaux modèles de réseaux
de neurones
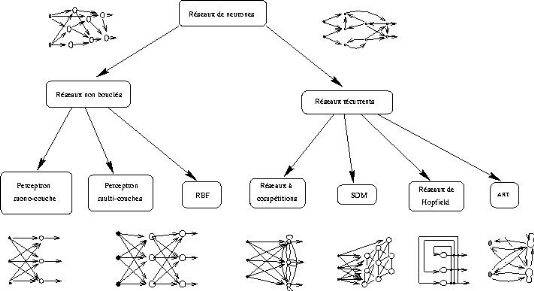
Source :
http://www-igm.univ-mlv.fr/~dr/XPOSE2002/Neurones/index.php?rubrique=Apprentissage
IV / Enseignements de la revue de littérature
4.1- Les limites du Scoring
Les limites d'une démarche de scoring sont nombreuses.
Comme nous l'avons déjà dit plus haut, sa mise en place est
souvent complexe d'un point de vue technique. De ce fait, les systèmes
de scoring ne peuvent pas être mis en oeuvre par toutes les institutions
financières qui le souhaitent, surtout de microfinance. Ils sont plus
accessibles pour les institutions de microfinance dont les procédures
d'octroi sont assez formalisées et qui ont aussi la possibilité
de reconstituer des bases de données riches d'un important historique de
prêts individuels.
Le principe est par ailleurs beaucoup plus adapté aux
prédictions portant sur les prêts individuels; les
prédictions sont beaucoup moins fiables et faciles sur les prêts
octroyés à des groupes solidaires. La détermination et
l'usage d'une classification qui établit des profils types de groupes
est effectivement aussi délicate qu'incertaine.
Autre limite, le futur n'est pas forcément
déductible du passé, ce qui reste pourtant l'un des postulats de
la démarche. Les tendances s'infléchissent parfois et un
environnement changeant ne répond plus aux mêmes
déterminismes. Le fait que toutes les caractéristiques de la
candidature du prêt et du risque ne soient pas quantifiables constitue
par ailleurs une autre limite de principe.
Enfin, si les démarches de scoring prédisent le
risque, elles ne disent pas forcément comment le gérer. La
responsabilité des managers de l'entreprise reste entière quand
il s'agit, in fine, de prendre la décision de financer ou non un
prêt. En ce sens, le scoring est une sorte de « troisième
voix » au sein du comité de crédit et elle ne saurait en
aucun cas remplacer les agents de l'IMF. Schreiner (2002) ne
manque pas d'évoquer alors le risque d'un mauvais usage du scoring si
l'on s'en sert pour exclure tous les risques en évitant de prêter
aux plus pauvres, et partant, en faire un outil de discrimination
négative au point que le microcrédit génère plus
d'exclusion qu'il ne prétend en combattre. Il insiste sur la
nécessité de réfléchir sur les
éléments d'une discrimination positive, sans forcément
faire porter à un individu le poids des déterminismes qui sont
supposés être les siens compte tenu de son appartenance à
la catégorie de clients à laquelle il est intégré.
Au lieu de procéder par exclusion, il s'agit alors de spécifier
l'accompagnement du client supposé vulnérable.
4.2- Les limites de la régression logistique
Le modèle LOGIT est tiré de
l'économétrie des variables qualitatives. La première
limite de la régression logistique est qu'elle nécessite des
échantillons de grande taille pour pouvoir prétendre un niveau
acceptable de stabilité. Un nombre minimal de cinquante (50)
observations par variables est en général nécessaire.
Une deuxième limite est que les catégories
auxquelles appartiennent les variables indépendantes doivent être
mutuellement exclusives et exhaustives, car un prédicteur ne peut pas
appartenir aux deux groupes Y0 et Y1 à la fois. Les deux groupes sont en
effet dichotomiques. Cette particularité s'avère très
sensible à la multicolinéarité entre les
prédicteurs, celle-ci pouvant se vérifier grâce à
une matrice de corrélation. D'où la nécessité
d'examiner les corrélations entre les variables prédicatrices
avant de procéder à l'élaboration du modèle, afin
d'éliminer celles qui semblent fortement corrélées entre
elles (risques de variables redondantes).
Dans la même lancée la régression
logistique présente aussi la limite de présumer que les
réponses sont non reliées. Ainsi si les variables
résultantes sont formées par la période de temps pendant
laquelle les mesures sont prises (avant et après traitement), ou si les
variables proviennent d'un groupe par couplage (chaque sujet du groupe
expérimental est jumelé à un sujet du groupe
contrôle), la régression logistique n'est plus licite compte tenu
des risques probables de biais liés aux corrélations
(Tabachnick & Fidell, 2000)18(*).
4.3- Les limites des réseaux neuronaux19(*)
Plusieurs limites dans l'utilisation des réseaux de
neurones peuvent être retenues.
D'abord on mentionnera qu'il n'existe pas encore de
théorie permettant de
déterminer la structure optimale d'un
réseau. En particulier la détermination du nombre de couches
cachées et du nombre de neurones sur chacune d'entre elles relève
encore largement de l'intuition de l'utilisateur et de sa capacité
à expérimenter plusieurs architectures, afin de retenir celle qui
donne les résultats les meilleurs. Plus le réseau est complexe,
c'est-à-dire plus il comporte de neurones cachés et de liens
synaptiques, plus il est capable de reconnaître les formes qui lui sont
présentées à travers l'échantillon
d'apprentissage.
Mais malheureusement, l'accroissement de la complexité
n'améliore pas nécessairement le taux de reconnaissance sur
l'échantillon test. Il faut cependant remarquer que cette critique doit
être nuancée, car plusieurs méthodes ont été
proposées pour aider l'utilisateur dans cette tâche. Celles-ci
s'appuient sur des techniques analytiques faisant intervenir la dimension du
vecteur d'entrée, ou sur des algorithmes qui permettent soit la
construction automatique pas à pas des couches cachées, soit
l'élagage des connexions les moins pertinentes dans un réseau
surdimensionné au départ.
Ensuite, un réseau de neurones reste encore en partie
aujourd'hui une « boîte noire » de laquelle il reste difficile
d'extraire les relations pertinentes entre les variables. De ce point de vue,
le système n'a donc qu'un pouvoir explicatif médiocre
contrairement aux systèmes experts qui sont capables de retracer le
cheminement suivi pour atteindre le résultat. Pourtant, le
phénomène de « boîte noire » n'est pas total
puisque des analyses de sensitivité sont possibles, en faisant varier
l'une des entrées pas à pas, de sa valeur minimale vers sa valeur
maximale, les autres entrées du réseau restant figées
à leur valeur moyenne.
Enfin, comme cela a été signalé pour ce
qui est du choix de l'architecture, ces
systèmes font toujours trop
largement appel à l'intuition de l'utilisateur. En particulier,
l'apprentissage est guidé par des paramètres qu'il convient de
régler manuellement.
Un taux d'apprentissage (paramètre
réglant la vitesse de convergence de l'algorithme) trop important peut
aboutir à une oscillation du système alors qu'un taux trop faible
se traduira par une convergence très lente, ce qui peut se
révéler prohibitif en temps de calcul.
Par ailleurs, il
revient encore à l'utilisateur de choisir le point d'arrêt de
l'apprentissage de façon à ce que le réseau conserve ses
capacités de généralisation.
CHAPITRE II : Problematique Generale
[...] L'homme du XXIe siècle baigne dans un flot
d'informations statistiques (...) dont il ne voit que l'écume sans en
soupçonner les lames de fond [...]
Gilbert SAPORTA, 2007
Conservatoire National des Arts et Métiers (CNAM),
Chaire de Statistique Appliquée,
in Préface of « Data Mining &
Statistique Décisionnelle »20(*)
I/ Problématique
1.1. Contexte et justification
1.1.1. Le contexte socio-économique, institutionnel,
sectoriel et technologique
Le contexte actuel de cette étude de data mining, en
vue de l'élaboration d'un modèle prédictif des
défaillances de remboursement dit « Score » chez les
clients de l'UMECUDEFS, peut être appréhendé selon trois
angles : le premier angle a trait à l'environnement
socio-économique, le deuxième est lié à
l'environnement institutionnel et politique, le troisième quant à
lui, concerne l'évolution conjoncturelle du secteur de la Microfinance
au niveau national et l'influence des avancées technologiques qu'il
subit.
Au plan socio-économique, cette
étude se fera alors que l'actualité au Sénégal est
marquée par une inflation galopante des denrées de
première nécessité. De 0% en 2003 ; 0,5% en 2004,
1,7% en 2005 et 2,1% en 2006, l'Agence Nationale de la Statistique et de la
Démographie (ANSD) comptabilise une hausse de l'indice harmonisé
des prix à la consommation de 6% entre septembre 2006 et septembre 2007.
Cette augmentation généralisée et durable des prix n'est
cependant pas une particularité de l'économie
sénégalaise. En effet, la hausse du prix du baril de
pétrole, associée à la financiarisation de
l'économie mondiale, font flamber les cours du maïs, du blé,
du riz, du coton,.. L'UMECUDEFS, dans ce contexte, voit sa clientèle
PME-PMI directement ou indirectement touchée par les implications d'une
telle inflation, dans la mesure où le coût des facteurs de
production est affecté. Or l'ampleur de tels impondérables
n'était pas forcément prévue dans les budgets
prévisionnels.
Au plan institutionnel, cette étude se
fera à l'UMECUDEFS dans le contexte du cadre réglementaire
régissant l'activité des Institutions de la Micro-Finance (IMF)
au Sénégal. Ce cadre est structuré autour de la loi 95-03
portant réglementation des institutions mutualistes d'Epargne et de
Crédit, elle-même découlant de l'intégration au
corpus juridique national de la loi PARMEC ou « Projet
d'Appui à la Réglementation des Mutuelles d'Épargne et de
Crédit » initiée par l'UEMOA. Aussi, les
principaux objectifs de la loi PARMEC tiennent à 04 points: i) la
protection des déposants, ii) la sécurité des
opérations, iii)la recherche d'autonomie financière des SFD,
iv)l'intégration de la finance informelle dans le cadre légal.
Dans cette lancée, la loi 95-03 a été renforcée par
certaines dispositions règlementaires d'accompagnement, telles que le
décret d'application de la loi 97-1106 du 11 Novembre 1997, ainsi que
les instructions de la BCEAO relatives aux normes et règles de gestion
des structures financières décentralisées. Ce cadre
institutionnel impose une plus grande rigueur de gestion des SFD, à
laquelle n'échappe pas l' UMECUDEFS. C'est donc dans le sillage du
deuxième objectif que s'assigne la loi PARMEC, à savoir oeuvrer
à l'amélioration de la sécurité des
opérations, que peut être appréhendé notre
mission.
Au plan de la prévention des risques
dans le secteur bancaire, le contexte est marqué par les
préconisations du Comité de Bâle dans la
perspective de la réforme du ratio Cooke, remplacé au 1er Janvier
2008 pat le ratio Mc Donough. En effet, bien que cette réforme ne
modifie pas la valeur du ratio de solvabilité (8%), elle diversifie les
risques pris en compte (en incluant les risques de taux et les risques
opérationnels) et affine la méthode de pondération des
risques, notamment en autorisant l'utilisation de systèmes de
classification des emprunteurs ("notations internes") à partir
des probabilités de défaillance prédites dans les
différents types de portefeuille de la banque: souverain, interbancaire,
entreprise, banque de détail (particuliers et professionnels),
affacturage, titrisation et actions.
Au Sénégal, de tels systèmes de
classification ne seraient en vigueur pour le moment, selon nos informations,
que dans une banque (la Société Générale de Banque
du Sénégal) sur une vingtaine. Le marché est ainsi
quasiment vierge au plan national, dans la mesure où toutes les banques
seront obligées dans un avenir proche a s'aligner sur ces normes de
Bâle II.
Au plan sectoriel, la microfinance est en
pleine évolution. En effet si l'on en croit les données de la
Lettre de politique sectorielle, Stratégie et plan d'action
2005-2010 (Ministère des PME, de l'entreprenariat féminin et de
la microfinance), le constat est clair : le secteur de la
microfinance gagne du terrain. En effet le nombre d'institutions a
été multiplié par 6 entre 1993 et 2003, atteignant les 620
Mutuelles d'Epargne et de Crédit. Dans la même période, le
nombre de points de services (caisses de base, agences et bureaux...) est
passé de 1136 à 2597; le nombre de clients/membres servis par ces
institutions est passé de 313 000 à 4 millions; les
dépôts collectés ont atteint 204,7 milliards FCFA; les
prêts octroyés ont été multipliés par 10,
passant de 19,4 milliards à 200 milliards FCFA à fin 2003. Plus proche de nous, le seul
réseau PAMECAS mobilisait 19 milliards CFA en 12 mois (2007). Aussi, le
secteur est marqué par la domination de quelques réseaux de MEC.
Avec le CMS, l'ACEP, l'UMPAMECAS et le REMECU, l' UMECUDEFS fait partie des
principaux acteurs du système financier décentralisé au
Sénégal.
Au plan technologique, cette étude
aura lieu alors que tous les secteurs d'activités, de l'agroalimentaire
à la banque, sont en proie au développement rapide des nouvelles
technologies de communication (Internet, téléphonie mobile,..) et
de traitement de l'information (entrepôts de données). La
mondialisation des facteurs de production (k, W, technologie), exacerbée
par les attentes plus exigeantes des clients sur la qualité des services
ainsi que par une concurrence « mondialisée », a
entraîné une sophistication des moyens de production, et plus
particulièrement des moyens de collecte, de traitement et d'analyse de
données, jusqu'à leur communication. Le secteur de la
microfinance n'est pas en marge de ces évolutions, et se voit
consacré de plus en plus d'applications qui sont propres à ses
spécificités.
1.1.2. La justification pour les managers, les
décideurs politiques et les chercheurs
L'objet de cette étude de data mining en vue de
l'élaboration d'un modèle prédictif des
défaillances de remboursement dit « Score » chez les
clients de l'UMECUDEFS, peut revêtir un intérêt pour les
managers, mais aussi pour les décideurs politiques.
Pour les managers de l'UMECUDEFS, recevoir
une étude de data mining se justifie par des impératifs à
la fois stratégique (réorientation/amélioration des
services vers une cible particulière) et opérationnelle
(réduction des impayés). En comparaison à
l'évaluation implicite ou subjective, l'évaluation statistique
quantifie le risque et présente de nombreux avantages potentiels. Aussi,
sans prétendre à l'exhaustivité, les dirigeants de
l'UMECUDEFS pourront bénéficier des attraits suivants
inhérents à notre étude21(*) :
§ La quantification du risque comme
probabilité. Le produit d'une évaluation statistique est
une probabilité, le produit d'une évaluation subjective est un
sentiment, et il est plus facile pour le microprêteur de gérer les
probabilités que les sentiments.
§ La cohérence de l'évaluation
statistique. Deux personnes ayant les mêmes
caractéristiques auront les mêmes risques estimés. Alors
que dans un système d'évaluation subjective, on pourrait obtenir
des variations selon les agents de crédit responsables ou même
l'humeur d'un responsable donné. La discrimination pour le sexe,
l'âge ou l'ethnie n'a pas de place dans l'évaluation statistique ;
les pondérations des caractéristiques sont basées sur des
données historiques sans l'influence des jugements subjectifs.
§ L'explicité de l'évaluation
statistique. Le procédé exact utilisé pour
pronostiquer les risques avec l'évaluation statistique est connu et peut
être communiqué. Par contre, l'évaluation subjective
dépend d'un procédé flou que même les utilisateurs
(les agents de crédit) auront du mal à expliquer.
§ La portée du nombre de facteurs
évalués. Les directives des manuels de
l'évaluation subjective peuvent spécifier qu'une candidature doit
correspondre à certains indices financiers et d'autres règles de
principes, mais contrairement à l'évaluation statistique,
l'évaluation subjective ne peut tenir compte de 30 à 50
caractéristiques.
§ La réduction du temps de
travail. La vertu majeure de l'évaluation statistique pour
l'agent de crédit est qu'il passera nettement moins de temps au
traitement des demandes de crédit, de même qu'au recouvrement.
§ L'influence sur les bénéfices
financiers. Le bénéfice financier est le nombre de
« mauvais » prêts qui seraient rejetés multiplié
par le bénéfice financier net d'un « mauvais »
prêt évité, ôté au nombre de « bons
» prêts qui seraient rejetés multiplié par le
coût financier net d'un « bon » prêt perdu. En effet, la
pratique a montré qu'il est bien plus grave d'octroyer un prêt
à une personne qui ne le remboursera pas (faux positif - erreur de type
1) que de ne pas octroyer un prêt à une personne fiable (faux
négatif - erreur de type 2).
Pour les décideurs politiques dont
l'une des préoccupations principales tient à
l'élargissement de l'accès du plus grand nombre d'agents
économiques à des services financiers adaptés et
sécurisés, cette étude de data mining est
intéressante à deux titres. En ce sens qu'à terme d'une
part, elle aura pour corollaire une amélioration de l'accès des
PME-PMI au crédit (donc à l'investissement), et d'autre part une
limitation du risque de surendettement des mutuelles face à un
portefeuille de crédit médiocre. En effet, un des axes de
développement formulés dans des politiques
macroéconomiques au Sénégal tient à l'accroissement
des investissements intérieurs, ajouté aux investissements
étrangers.
Cet accroissement est crucial pour atteindre un taux de
croissance accéléré et durable à même de
créer les conditions d'une économie émergente, via une
hausse des créations d'emploi, de la consommation, et donc une baisse de
la pauvreté (un des points des OMD). Or l'accroissement du niveau des
investissements intérieurs ne peut se faire sans l'amélioration
de l'accès au crédit des PME/PMI, qui représentent 80% du
tissu industriel sénégalais. Ceci alors qu'une autre
justification de cette étude, à l'endroit des décideurs,
est liée à la limitation du risque de surendettement qui est
à attendre, en ce sens que l'utilisation du score de risque dans le
domaine de crédit permet à l'institution financière
d'améliorer l'allocation de ses fonds propres, notamment relatif au
ratio de solvabilité.
Par ailleurs, le système bancaire étant
vulnérable au risque de crédit, un autre
intérêt de cette mission de data mining est d'ordre
monétaire, car les risques liés aux incidents de paiement qui
touchent directement la trésorerie des SFD seront mieux
appréhendés, et par conséquent mieux traités. Les
crises financières (susceptibles de se muer en crise de confiance de
plus grande empleur), qui pourraient être consécutives à
l'état de cessation de paiement d'un réseau mutualiste, n'en
seront que plus prévenues.
Pour les chercheurs, cette étude
pourrait trouver une justification dans leur tentative d'imitation des
organismes élémentaires, depuis une vingtaine d'année,
s'appuyant sur la thèse selon laquelle « la tâche la plus
ordinaire accomplie par l'insecte le plus infime le sera toujours plus
rapidement qu'il ne serait possible en employant la stratégie
computationnelle » (Varela, 1996, p. 56). Le bouleversement
méthodologique est en effet profond, puisque deux paradigmes se font
face : le constructivisme qui présuppose
l'existence d'un modèle par lequel la solution est estimée
(exemple le modèle par régression logistique), et le
connexionnisme qui privilégie les résultats par
apprentissage qui émergent de la coopération globale d'agents
multiples (exemple les réseaux de neurones).
1.2. Problème de recherche et résultats
attendus
Nous considérerons la problématique de
recherche, ainsi que le recommande GAYE (2004) dans
son « Cours de Méthodologie de la Recherche en
Sciences Sociales » p.29, comme
l'ensemble de l'exercice de réflexion qui inclut les étapes ou
points suivants :
F le thème de recherche qui nous intéresse;
F la pertinence du thème à travers la
préoccupation des chercheurs et/ou des décideurs ;
F le problème général et/ou la question
générale de recherche en rapport avec le thème de
recherche ;
F un cadre conceptuel établissant les théories
modèles ou relations présupposées ;
F le problème spécifique est
déterminé ;
F la question spécifique est clairement formulée
pour orienter la collecte de données dont la réponse permettra de
résoudre le problème spécifique ;
F des hypothèses clairement construites.
Nous avons choisis de travailler sur le thème du risque
de crédit bancaire chez la cible PME/PMI. Plus concrètement, le
sujet faisant l'objet du présent mémoire nous amènera
à identifier, expliquer et prévoir les déterminants du
risque de crédit chez les PME, grâce à une application
comparative de la régression par la modélisation statistique
(régression logistique) et par l'intelligence artificielle
(réseaux de neurones). Pour appliquer notre recherche, nous nous
appuierons sur l'historique client d'une Mutuelle d'Epargne et de Crédit
(MEC) Sénégalaise qui s'appelle UMECUDEFS (Union des Mutuelles
d'Epargne et de Crédit de l'UNACOIS).
La pertinence du sujet, ainsi que nous
l'évoquions supra, peut être
appréciée d'un point de vue scientifique tout d'abord, mais aussi
et surtout d'un point de vue pratique. Pour les chercheurs
d'abord, cette étude pourrait revêtir à notre sens un
double intérêt. Le premier tient à la comparaison
des capacités prédictives de deux techniques relativement
récentes et non moins à la pointes. Nous serons amenés,
grâce aux modèles de prévision issues de la
modélisation statistique et de l'intelligence artificielle, à
contribuer au débat actuel cherchant à trancher entre les
décisions s'appuyant sur les espaces fonctionnels (le raisonnement
logique formel) et celles s'appuyant davantage sur la perception et
l'apprentissage automatisé. En effet, au sortir de cette étude
seul le modèle le plus robuste sera retenu afin de constituer la
fonction score recherchée. Le second intérêt de
cette étude, à l'endroit des chercheurs est de contribuer
à savoir dans quelles mesures les modèles de score s'appuyant
uniquement sur des bases quantitatives, voire uniquement financières,
sont pertinents ou non, dès lors que l'analyse porte sur des PME issues
des pays du Sud.
Pour ce qui concerne les décideurs de
l'UMECUDEFS, en plus des points que nous avons déjà
évoqué supra (cf. justification de l'étude), nous pouvons
préciser que le souci de gestion au quotidien est de pourvoir minimiser
la sélection adverse afin de préserver la viabilité
financière, dans le contexte de ce que Morduch (2000) a
nommé le « schisme de la
microfinance »22(*). Pouvoir adapter les taux d'intérêt et
les rendre flexibles aux conditions d'octroi de crédit aux PME est une
question à la fois délicate au plan pratique, et sensible si l'on
considère les enjeux financiers engagés. Ainsi, les banquiers et
les micro-préteurs ont tendance à se protéger en adoptant
une stratégie de sélection adverse en majorant les taux
d'intérêt, compte tenu de la visibilité limitée sur
les capacités de remboursement de ses clients. Or il est maintenant
établit que seuls les promoteurs de projets les plus risqués
acceptent de contacter à des taux d'intérêts relativement
élevés. La conséquence d'une telle stratégie de
couverture de la part des préteurs est de ne finalement financer,
malgré eux, que les dossiers présentant le plus de risques de
défaillance. Par ailleurs, une autre préoccupation des
décideurs de l'UMECUDEFS reste la réduction et l'optimisation du
temps d'analyse et de traitement d'une demande de crédit, face à
des flux hebdomadaires relativement importants et à une concurrence
contraignante.
Notre problème général de
recherche s'est largement inspiré de ces préoccupations
à la fois scientifiques et managériales. Il est dans ce sens
question pour nous d'améliorer notre connaissance sur les
facteurs qui influencent le risque de crédit bancaire chez les PME, mais
aussi sur les techniques qui permettent d'appréhender un tel
risque. D'une manière générale donc, nous sommes
posés la question suivante : Quels sont les déterminants
d'une défaillance de remboursement lorsqu'une PME contracte un
crédit ?
Pour répondre à cette question, la
littérature fait état de certains éléments de
réponse. Par exemple, les principaux chercheurs qui ont tenté de
modéliser le non-remboursement (ou le risque que l'on peut y associer)
se sont basés sur des déterminants de type comptable et financier
dans les entreprises évaluées. C'est le cas des modèles de
Altman, Conan-Holder, AFDCC, Banque de France pour ne citer que ceux-là.
La logique de ces modèles est que le non-remboursement d'un
crédit contracté par une PME est intimement lié à
son risque de défaillance (son analogue juridique est la
faillite). Pour eux, si on peut prédire la probabilité de
faillite d'une entreprise grâce à certains indicateurs (ratios
financiers), alors on peut en déduire le risque de contrepartie
associable à la demande de crédit formulée par cette
entreprise. Seulement cette vision semble réductrice et simpliste. En
fait, il y'a des chances qu'une PME soit confrontée à des
difficultés de remboursement, même si au plan strictement
comptable ses indicateurs n'en présagent rien (les données
comptables peuvent être falsifiées dans ce genre d'entreprises).
De plus dans le contexte africain, la plus grande partie des PME
évoluent dans le secteur informel, c'est-à-dire qu'elles ne
peuvent produire, même si elles le souhaitaient, des états
financiers crédibles.
Pour ce qui concerne la mesure et la prévision des
déterminants du risque de crédit bancaire des PME, la principale
technique utilise dans la littérature est l'analyse discriminante,
parfois l'arbre de décision. Cependant d'autres techniques d'analyse et
de prévision dans le vaste champ des méthodes statistiques sont
de plus en plus utilisées. Au titre de celles-ci on relève le
succès de plus en plus grandissant de la fonction gaussienne du
modèle LOGIT, mais aussi du recours aux algorithmes d'apprentissage par
les réseaux de neurones artificiels (RNA).
Sous ce rapport, notre problème
spécifique de recherche consiste à interroger
d'autres déterminants que les indicateurs financiers pour expliquer le
risque de crédit bancaire chez les PME africaines notamment, et
à envisager d'autres techniques que l'analyse discriminante
pour expliquer et prévoir le risque de contrepartie (ou de
non-remboursement) chez les PME. Ce problème est d'autant plus
orienté au cas spécifique des PME africaines dont l'information
comptable et financière n'est que très peu souvent disponible.
Nous nous appuierons sur le Sénégal pour ce faire, en nous
interrogeant de la façon suivante : Les ratios financiers sont-ils
les véritables déterminants significatifs dans le
dénouement d'un prêt bancaire contracté par une PME
sénégalaise ? Une méthode de prévision de tels
déterminants par modélisation statistique est elle plus fiable
que par intelligence artificielle ?
II/ Cadre Conceptuel
Le cadre conceptuel nous aidera dans un premier temps à
repréciser les définitions des principaux mots-clés
utilisés tout au long du présent mémoire, et dans un
second temps de présenter l'hypothèse sous-jacente de
l'étude accompagnée du cadre opératoire qui traduit ses
concepts en indicateurs (ou variables) mesurables.
2.1- Définition des concepts
Ø Aléa moral (ou hasard
moral): Il s'agit d'une forme d'opportunisme post contractuel
qui survient lorsque les actions mises en oeuvres ne peuvent être
discernées. Les problèmes liés à l'aléa
moral apparaissent lorsqu'un individu entreprend une action inefficace, ou
procure une information inexacte parce que ses intérêts
individuels ne sont pas compatibles avec les intérêts collectifs
et parce que ni les informations données ni les actions entreprises ne
peuvent être contrôlées (K. Arrow, 1963).
Ø Dans le cadre du risque de
contrepartie, l'aléa moral se rapporte à toute situation
dans laquelle les résultats de la relation de crédit
dépendent d'actions entreprises par l'emprunteur après signature
du contrat et imparfaitement observables par le créancier. Ainsi, une
entreprise contractant un crédit pourra s'engager de façon plus
ou moins forte dans la réussite du projet. Les dirigeants pourront
accomplir des dépenses inutiles au développement de l'entreprise
en détournant à leur profit une part des résultats du
projet sous forme d'avantages en nature ou de rémunérations
excessives.
Ø Data Mining: littéralement
« fouille de données » ou « forage de
données », et connu dans le milieu francophone sous
l'appellation Extraction de Connaissances à partir de Données
(ECD), le data mining peut s'entendre de l' application des
techniques statistiques, d'analyse des données et d'intelligence
artificielle à l'exploration et l'analyse sans à priori de
grandes bases de données informatiques , en vue d'en extraire des
informations nouvelles et utiles pour le détenteur de ces données
(STUFFERY, 2007).
Ø Intelligence artificielle
(IA) : Ce terme renvoie à une discipline à cheval
entre statistique-mathématique d'une part et informatique d'autre part,
qui cherche à représenter la connaissance de l'homme et à
formaliser le raisonnement de façon à obtenir des algorithmes qui
simulent la réflexion humaine. Par extension elle est aussi devenue une
discipline qui cherche à simuler par les moyens de l'informatique des
mécanismes cognitifs et neuronaux. Selon le CNTRL,
l'IA est la « recherche de moyens susceptibles de
doter les systèmes informatiques de capacités intellectuelles
comparables à celles des êtres humains »
(source : La Recherche, janv. 1979, no 96, vol. 10, p. 61,
cité par le dictionnaire du CNTRL).
Ø Modélisation statistique :
Nous entendons par ce terme la conception d'un modèle, ou la
représentation simplifiée d'une réalité plus
complexe, dans l'optique d'analyser des phénomènes réels
et de prévoir des résultats à partir de l'application
d'une ou plusieurs théories à un niveau d'approximation
donné. Cette modélisation se fait par des méthodes
statistiques, parmi lesquelles on retrouve la régression logistique
(économétrie des variables qualitatives).
Ø PME, TPE, MPE : Dans notre
étude, nous entendons par PME toute personne physique ou morale,
productrice de biens ou de services marchands, dont les critères
sont pour les Petites Entreprises (PE) et les Moyennes Entreprises
(ME) : i) un effectif compris entre 01 et 250, ii) un chiffre d'affaires
hors taxe inférieur à 20 millions FCFA (PE) ou 15 milliards
CFA(ME), un investissement net inférieur ou égal à 1
milliard FCFA. (Source : Charte des Petites et Moyennes Entreprises du
Sénégal, 2003, pp.6 & 7). Dans la suite de notre
mémoire, nous utiliserons indifféremment les signes PME et TPE,
pour désigner la même réalité.
Ø Régression logistique :
Comme définit plus haut, la régression logistique (ou
régression par le modèle LOGIT) est une technique statistique qui
a pour objectif, à partir d'un fichier d'observations, de produire
un modèle permettant de prédire les valeurs prises par une
variable catégorielle, le plus souvent binaire, à partir d'une
série de variables explicatives continues et/ou binaires. (source :
wikipédia).
Ø Réseaux de neurones artificiels
(RNA) : Les RNA (ou
Bayesian
Machine Learning) sont des simulations logicielles qui
relèvent du champ de l'intelligence artificielle. Il s'agit d'ensembles
interconnectés de petites machines à additionner qui ont pour but
d'imiter le fonctionnement des cellules grises humaines. Selon une
définition proposée par A. Nigrin (1993)23(*), un réseau de
neurones est un circuit composé d'un nombre très important
d'unités de calcul simples basées sur des neurones. Dans la
même lancée, S. Haykin (1994)24(*), les RNA ressemblent
au cerveau sur deux aspects: i) la connaissance est acquise par le
réseau au travers d'un processus d'apprentissage, ii) les connexions
entre les neurones, connues sous le nom de poids synaptiques servent à
stocker la connaissance.
Ø Risque de contrepartie : Le
risque de contrepartie représente la perte potentielle
réalisée par la banque dans l'hypothèse d'une
défaillance future de sa contrepartie. Ce risque regroupe deux risques
de natures différentes : le risque de livraison et le risque de
crédit.
Ø Risque de livraison : Le risque
de livraison concerne toutes les opérations de marché
intégrant un échange simultané de devises ou de flux
d'intérêts. Ainsi, le type d'opération le plus sensible
est-il le change au comptant, mais le change à terme et certains swaps
de taux sont également concernés.
Ø Risque de crédit (couramment
désigné par risque de contrepartie) : Le
risque de crédit est le risque
http://fr.wikipedia.org/wiki/Risque
que l'emprunteur ne rembourse pas sa dette
http://fr.wikipedia.org/wiki/Dette
à l'échéance fixée (wikipédia). Le
risque est une perte
http://fr.wikipedia.org/wiki/Perte
potentielle, identifiée et quantifiable, inhérente à une
situation ou une activité, associée à la
probabilité
http://fr.wikipedia.org/wiki/Probabilit%C3%A9
de l'occurrence d'un évènement ou d'une série
d'événements. Le risque de crédit peut être
donc défini comme la perte totale enregistrée sur une
opération suite à la défaillance de la contrepartie. On
l'appelle aussi parfois risque de signature. Dans le cas d'un
crédit à taux révisable, cette perte est égale au
capital restant dû augmenté des intérêts courus non
échus.
Ø Scoring (crédit) : le
crédit scoring, ou scoring crédit, est compris selon R.
Anderson (2007) comme étant le recours aux modèles
statistiques en vue de transformer des données (qualitatives,
quantitatives) en indicateurs numériques mesurables à des fins
d'aide à la décision d'octroi ou de rejet de
crédit.
Ø Sélection adverse (ou
antisélection) : Les travaux de G. Akerlof (1970) ont
introduit la notion d'antisélection, appelée aussi
sélection adverse, qui peut être définie comme un ensemble
de stratégies complexes élaborées en vue d'anticiper des
phénomènes de fraude du co-contratactant. Il s'agit d'un
problème d'opportunisme pré contractuel induit par
l'incapacité d'obtenir une information exhaustive sur la partie qui
sollicite un crédit.
.
2.2- Objectifs de recherche
Les objectifs de notre recherche sont de trois 2 (deux)
ordres :
F La description et l'explication : nous
sommes intéressés par la distribution des clients (PME) au sein
des « bon clients » et des « mauvais
clients » de l'UMECUDEFS. En sus de la description nous avons un
objectif additionnel qui est de faire une assertion sur une telle distribution.
En pratique il s'agira d'examiner les relations entre le dénouement des
crédits octroyés (remboursés in fine ou non), et les
variables que nous avons prédéfinies. L'optique est de tenter
d'expliquer pourquoi certaines PME ont plus de chances de rembourser que
d'autres ;
F La prédiction : A partir de
notre description-explication, nous tenterons de prédire l'issue d'un
échantillon de dossiers tests prévus à cet effet.
L'idée est de pouvoir produire un modèle de régression
capable de prévoir le risque inhérent à un dossier de
demande de crédit, sur la base d'une pondération de la valeur de
ses caractéristiques.
Au plan opérationnel, les objectifs de notre
présente étude se présentent comme suit :
Tableau 3: Objectifs opérationnels de notre
étude
|
Objectif Général
|
Mise en place d'un modèle de prévision du risque
de crédit, dit « modèle de score », chez la
clientèle PME/PMI de l'UMECU
|
|
Objectif Spécifique I
(OS 1)
|
Explication des déterminants de la distribution des
dossiers de demande de crédit PME, en fonction de leur remboursement ou
de leur non-remboursement, chez l'UMECU entre 200 et 2007.
|
|
Objectif Spécifique II
(OS 2)
|
Prédiction du dénouement d'un échantillon
test et définition d'une équation de régression à
cet effet.
|
Source : Recherche de Fred Ntoutoume, Crefdes, 2007
2.3- Hypothèses et indicateurs
Notre étude est basée sur une seule
hypothèse principale qui est de type co-ralationnelle, et une
hypothèse secondaire qui est de type mathématique.
2.3.1) Hypothèses de recherche et cadre
opératoire
· Hypothèses de recherche
Au cours de notre étude nous tenterons de vérifiez
les hypothèses suivantes
Hypothèse 1: En dehors des ratios financiers, les
données démographiques du dirigeant, l'expérience du
dirigeant en matière de crédit, la forme juridique de la PME, le
secteur d'activité, le type de garantie, le facteur temps et le montant
de la demande de prêt influencent le risque de crédit de
manière significative.
Hypothèse 2: un modèle de
prévision du risque de crédit bancaire des PME chez l'UMECU par
la régression logistique a de meilleures performances
prévisionnelles qu'un modèle de prévision par la
régression neuronale.
· Cadre opératoire
La présente étude a pour objet de mettre en
place un algorithme de scoring crédit qui sera du type score
d'octroi (ou d'acceptation), type que l'on définit comme le
score de risque calculé pour un client (ancien ou
nouveau) qui sollicite un crédit. Une telle étude, puisque
descriptive et prédictive, se fait sur la base de l'historique clients
des 2 ou 3 dernières années de l'entreprise qui souhaite scorer
ses futurs demandeurs de crédit.
Ainsi, en vue de la constitution de cette base de
données historisées devant servir à
« entrainer » les différents modèles de
prévision retenus pour l'étude de scoring, il sera
nécessaire de disposer d'un certain nombre d'informations sous formes de
données qualitatives (catégorielles) et quantitatives
(numériques). Ces données constitueront
« l'échantillon d'apprentissage » et seront
classées selon une nomenclature divisée en 4 axes
descriptifs-prédicteurs sensés décrire la
PME (personne morale ou physique), encore appelé le demandeur de
crédit:
1- Qui est-il? = Identification
2- Que fait-il? = Description de
l'activité
3- Que possède t-il ? =
Garanties
4- Que veut t-il ? = Caractéristiques des
prets
Les concepts issus de ces axes, évoqués dans les
hypothèses, sont déclinés en indicateurs qui permettent de
les mesurer (Cf. Tableau ci-dessous). Le périmètre de la
clientèle à scorer définit par conséquent les
aspects suivants :
§ Population Cible : les PME qui
ont sollicité un crédit durant les 3 dernières
années, et dont le remboursement portait sur le moyen terme (entre 6
mois et 18 mois).
§ Individus statistiques :
l'entreprise.
§ Source de données :
Système d'information de la mutuelle.
§ Phénomène à
prédire : la défaillance de remboursement (le
« Mauvais dossier »).
§ Définition du « «Mauvais
Dossier » : Un mauvais dossier est
celui qui qui n'a pas remboursé intégralement son crédit,
intérêt et principal, au plus 3 mois après la
dernière échéance.
§ Nombre d'individus (PME) constituant
l'échantillon d'apprentissage : 212.
§ Répartition de l'échantillon
d'apprentissage :
F 36 Dossiers de crédits avérés
« bons »,
F 176 dossiers de crédit avérés
« mauvais »,
Tableau 4: Présentation du cadre
opératoire
|
N°
|
Axes descriptifs-prédicteurs
|
Concepts contenus dans l'hypothese
|
Indicateurs (variables)
|
|
1
|
AXE PREDICTEUR 1 : IDENTIFICATION DU DIRIGEANT
(Qui est le demandeur de crédit ?)
|
Données démographiques du dirigeant de
l'entreprise
|
§ Sexe
§ Age
§ Statut matrimonial
§ Nombre d'enfants
§ Nombre de personnes à charge (y compris les
épouses)
§ Nombre de personnes salariées dans le foyer
§ Lieu de domicile
§ Niveau d'étude
§ Niveau de revenus
|
|
2
|
Expérience passée du dirigeant en matière de
crédit
|
§ Nombre de prêts déjà contractés
par le dirigeant dans le passé
|
|
3
|
AXE PREDICTEUR 2 : DESCRIPTION de L'ACTIVITE
(Que fait le demandeur de crédit ?)
|
Forme et Activité de l'entreprise
|
§ Secteur d'activité
§ Durée d'existence de l'entreprise
|
|
4
|
AXE PREDICTEUR 3 : GARANTIES
(Que possède le demandeur de crédit ?)
|
Garanties
|
§ Type de garantie
§ Valeur de la garantie
|
|
5
|
AXE PREDICTEUR 4 : CARACTERISTIQUES DES PRETS
(Que possède le demandeur de crédit ?)
|
Indicateurs temporels du crédit
|
§ Durée écoulée entre demande de
crédit et réponse
|
|
6
|
Montant de la demande de crédit
|
§ Montant du crédit
§ Montant demandé = montant obtenu ?
§ Différence (en nombre de mois) entre nombre de
versements demandés et obtenus
|
|
7
|
VARIABLE DISCRIMINANTE
|
|
§ Le Client a-t-il remboursé intégralement son
crédit au plus 3 mois après la dernière
échéance prévue ?
|
Source : Recherche de Fred Ntoutoume, Crefdes, 2007
2.3.2) Outils de collecte, sources d'information et
difficultés rencontrées
Le principal outil de collecte d'information aura
été le questionnaire. Les données provenant de sources
secondaires (système d'information de l'institution de micro finance),
ont en effet dû faire l'objet d'un redimensionnement à notre
convenance par cette voie. Ces questionnaires ont été
renseignés par des agents de l'IMF commandités à cet
effet, à partir des informations contenues dans leurs bases de
données manuscrites.
Ainsi, à chaque dossier de client PME retenu dans
l'échantillon et ayant sollicité un prêt ces 3
dernières années, correspondait un questionnaire dont les
différentes modalités (issues de la traduction des concepts en
indicateurs empiriques) auront été renseignées par les
agents de crédit affectés à la tache.
La principale difficulté de cette étude est donc
provenue de l'indisponibilité, sous format informatique, des
données devants constituer notre base de données. Ce d'autant
plus que le remplissage des questionnaires dans ces conditions aura
nécessité un délai relativement important, en même
temps qu'il aura occasionné à n'en point douter des biais
certains.
III/ Cadre de l'étude : présentation de
l'UMECUDEFS
3.1. Historique et Activités25(*)
L'UMECUDEFS est la dénomination du réseau
mutualiste de caisses d'épargne et de crédit créées
depuis 1997 à l'initiative de l'UNACOIS (Union Nationale des
Commerçants et Industriels du Sénégal) suite au
regroupement et à la fédération des caisses de base en
novembre 2002 au sein d'une Union, UMECUDEFS. Le réseau dispose
depuis le 22 mars 2000 d'un agrément officiel (n° DK 1 00 003U)
délivré par le Ministère de l'Economie et des Finances en
conformité à la réglementation régissant les
institutions de microfinance du Sénégal.
L'Union dispose en son sein d'une Direction
Générale composée de différents services techniques
destinés à coordonner et superviser les actions du réseau.
Celui-ci est constitué en fin 2006 de 60 caisses créées de
manière endogène et sur fonds propres par l'UNACOIS sur toute
l'étendue du territoire national.
En effet, soucieuse, d'un développement
économique et financier sans faille dans les zones les plus
reculées du Sénégal, l'UMECUDEFS a décidé de
mener une politique d'extension de son réseau dans le but de se
rapprocher des populations où qu'ils se trouvent. C'est dans cette
perspective que l'Union a implanté des mutuelles dans les onze
régions du pays à savoir Dakar, Thiès, Kaolack, Fatick,
Diourbel, Saint-Louis, Matam, Ziguinchor, Tambacounda, Louga et Kolda et
éventuellement dans les nouvelles régions que sont
Sédhiou, Kaffrine et Kédougou.
Les caisses sont localisées en majorité dans des
centres commerciaux ou les marchés en référence au lien
commun du réseau (sociétariat constitué majoritairement de
commerçants, artisans et groupements féminins).
Actuellement le réseau dispose d'un potentiel important et
fait partie des IMF les plus importantes du Sénégal grâce
à une maîtrise de la croissance et à la qualité des
produits et services.
L'UMECUDEFS s'est fixé les missions suivantes :
· Encourager l'esprit mutualiste au
Sénégal;
· Faciliter l'accès au financement;
· Développer une culture d'entreprise chez les
sociétaires;
· Sécuriser l'épargne des membres;
· Lutter contre la pauvreté.
3.2. Structure organisationnelle
L'organigramme actuel de l'UMECUDEFS se présente comme
suit :
Figure : Organigramme de l'UMECUDEFS
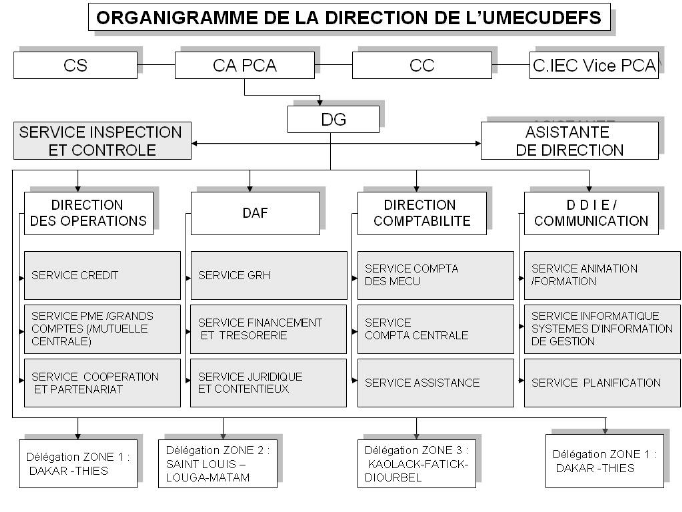
Source :
http://www.umecudefs.com/index.php?option=com_wrapper&Itemid=46
3.3. Caractéristiques de l'activité
La principale caractéristique à noter dans
l'activité de l'UMECUDEF tient au fait que les prêts
octroyés sont presque toujours de court terme, c'est-à-dire
à échéancier de remboursement de 12 mois maximum. Ceci
dans la mesure où les sommes prêtées n'excèdent pas
en générale les 3 millions de FCFA.
Par ailleurs, l'UMECUDEF n'ayant
bénéficié que très récemment d'un logiciel
de traitement des opérations bancaires dénommé
« E-BANKING », l'essentiel des données n'est de
disponible que sur version papier, et non numérique.
DEUXIEME PARTIE
METHODOLOGIE
&
ANALYSE DES RESULTATS
CHAPITRE III : Methodologie
I/ Les préalables au Scoring: Collecte et
préparation des données
Avant de présenter les résultats de notre
étude, il est nécessaire de préciser les
caractéristiques liées à l'échantillonnage
utilisé, à la préparation des données recueillies,
et au protocole de recherche qui sera mis en oeuvre.
1.1. L'échantillon
Malgré les difficultés rencontrées
(liées au format des données contenues dans des fiches
géographiquement éparpillées à travers les
mutuelles du réseau UMECU), nous avons pu renseigner les 20 variables
pour 212 entreprises toutes des TPE pour les années 2005, 2006 et 2007.
L'échantillon a été sélectionné par la
méthode de l'échantillonnage systématique.
Tableau 5 : Les 212 entreprises de l'échantillon
|
2005
|
2006
|
2007
|
|
Nombre
|
%
|
Nombre
|
%
|
Nombre
|
%
|
|
TPE
|
102
|
48
|
76
|
36
|
34
|
16
|
Source : Recherche de Fred Ntoutoume, Crefdes, 2007
1.2. Les paramètres analysés
L'originalité de notre étude, pour
mémoire, est basé sur l'hypothèse selon laquelle dans le
contexte africain où les TPE souvent dans l'informelle,
présentent la particularité de ne pas disposer de données
comptables sur lesquelles se baser pour une quelconque analyse, la
prévision des risques de contrepartie pourrait se faire à partir
de paramètres qualitatifs. Il s'agit notamment de critères
sociaux sur le dirigeant de l'entreprise, couplé aux conditions d'octroi
du crédit.
Ainsi, les paramètres utilisés, dont les
variables constitutives sont présentées plus haut dans le cadre
opératoire, sont :
Tableau 6: Les paramètres étudiés
|
Libellé des paramètres (concepts)
|
Nombre de
variables
|
|
1
|
données démographiques du dirigeant de
l'entreprise
|
9
|
|
2
|
expérience du dirigeant en matière de
crédit
|
1
|
|
3
|
forme et l'activité de l'entreprise
|
2
|
|
4
|
garanties proposées
|
2
|
|
5
|
indicateurs temporels du crédit
|
1
|
|
6
|
montant de la demande de crédit
|
3
|
|
7
|
Variables discrimante et nominative
|
2
|
|
TOTAL
|
20
|
Source : Recherche de Fred Ntoutoume, Crefdes, 2007
1.3. Le traitement des données
Après obtention des questionnaires dûment remplis
par les agents de crédit de l'UMECUDEFS, les données ont
été recueillies sur le logiciel SPSS version 10.0. La
stratégie de traitement des données a consisté, dans un
premier temps, à une analyse fréquentielle des
modalités prises pour chaque variable, afin de déceler des
variables non significatives. En effet, comme le recommande Saporta
(2006)26(*)
«le fichier brut une fois constitué doit d'abord être
«nettoyé» pour éliminer erreurs et incohérences.
Il comporte alors en général un trop grand nombre de
variables». Lors de cet examen dans notre cas, certaines variables
retenues au départ ont été supprimées, car les
réponses ne présentaient aucun intérêt dans la suite
de note étude. C'est le cas pour la question liée à la
présentation ou non d'une garantie, dont la réponse est
« OUI » pour tous les individus. Il en a été
ainsi pour 9 variables, qui ont été supprimées de notre
base de données. L'étude s'est donc poursuivie avec 20
variables.
Dans un second temps, pour faciliter les étapes
d'analyse factorielle et de
modélisation/classification/prédiction, les données
catégorielles ont fait l'objet d'une codification. L'idée est
d'obtenir un tableau de contingence, utile à une analyse factorielle
sensée réduire encore plus la dimension des variables.
II / Le protocole de recherche
2.1. Le protocole général
Le protocole général de recherche que nous nous
proposons de mettre en oeuvre est présenté dans le schéma
suivant :
Figure 5: Schéma du protocole général de
recherche
|
Collecte et préparation des données
(Logiciel SPSS)
|
|
Analyse Factorielle
(Logiciel SPSS)
|
Revue de la littérature, Problématique &
Cadre Opératoire
Modélisation et Prédiction par régression
logistique (Logiciel SPSS)
Modélisation et Prédiction par réseaux de
neurone
(Logiciel SPAD)
(F. B. Doucouré, 2006)
1- Génération des modalités
discriminantes
2- Estimation du modèle par le maximum de vraisemblance
3- Test de sigificativité globale
4- Validation du modèle
5- Vérification des taux de prédiction
(Asselin de Beauville et Zollinger, 1995)
1- le choix d'un type de réseau :
2- le choix d'une architecture du réseau ;
3- le choix des fonctions de transfert ;
4- le choix d'un algorithme d'apprentissage ;
5- le choix d'une base d'apprentissage ;
6- la fixation des paramètres du réseau
7- Apprentissage & Validation du modèle
prédictif
Comparaison de la performance des 2 modèles
prédictifs (Courbes ROC)

MODELE DE SCORING
FINAL
2.2. Le protocole de la réduction des variables par
l'analyse factorielle
L'étude de notre population statistique (les clients
PME de l'UMECUDEFS) de taille n passe par le recueil d'un nombre
élevé p de données quantitatives et qualitatives
par élément observé. L'analyse de ces données, dont
les qualitatives seront recodées, doit tenir compte de leur
caractère multidimensionnel et révéler les liaisons
existantes entre leurs composantes.
L'analyse factorielle des correspondances (AFC)27(*), est une méthode
très puissante pour explorer la structure de telles données
multidimensionnelles. Chaque donnée étant
représentée dans un espace à p dimensions,
l'ensemble des données forme un "nuage de n points" dans
Rp. Le principe de l'AFC est d'obtenir une représentation
approchée du nuage dans un sous-espace de dimension faible k par
projection sur des axes bien choisis. Les composantes principales sont les n
vecteurs ayant pour coordonnées celles des projections orthogonales des
n éléments du nuage sur les k axes principaux. On parle de
projection des variables de Rp sur R2 ou R3
.
Cette technique factorielle nous permettra surtout de pouvoir
réduire les dimensions de notre problème (19 variables
explicatives de départ), de sorte que nos modélisations
logistique et neuronale ne se fassent que sur la base les variables les plus
significatives de la défaillance des clients PME dans leur remboursement
de crédit.
2.2.1) La technique et l'interprétation
La technique d'analyse des données par correspondances
multiples que nous avons utilisé dans le présent mémoire
respecte les étapes suivantes :
1ère étape : les données sont
codées
· Les données quantitatives sont
découpées en classes
· Les données qualitatives sont codées.
Pour éviter des effectifs de classe trop faibles, on les regroupe des
modalités.
· Dans cette étape, les logiciels demandent
souvent de nommer les différentes modalités.
2ème étape : le tableau codé
est transformé en tableau de contingence
· Cette étape est souvent effectuée par les
logiciels sans intervention
de l'utilisateur.
3ème étape : une analyse des
correspondances est effectuée sur le tableau de contingence
· Réduction et quantification des
données
· Choix du nombre d'axes pertinents
· Sauvegarde des coordonnées factorielles et poids
des individus
· Représentations graphiques : cartes
factorielles et diagrammes interactifs
.
D'un point de vue mathématique, le traitement
opéré sur les données du tableau de contingence lors d'une
AFC nous a permis d'obtenir :
- des axes factoriels associés à des valeurs
propres ;
- pour chaque ligne (ou colonne) du tableau de contingence,
des coordonnées, des contributions à la formation des axes et des
qualités de représentation.
Le tableau de Burt étant symétrique, les profils
lignes et les profils colonnes sont identiques. Il en est de même des
coordonnées des individus-lignes et des individus-colonnes. L'inertie
totale du nuage des modalités a été
déterminée uniquement par le nombre total de modalités
q et le nombre de variables p. L'interprétation s'est
faite essentiellement à partir des modalités qui ont les
meilleures qualités de représentation selon chacun des septs axes
factoriels ou dans le premier plan factoriel. Enfin, l'inertie relative par
rapport à chaque axe nous a permi de retenir les modalités qui
ont le plus fortement contribué à la formation de cet axe.
2.3. Le protocole de prédiction par les
réseaux de neurone
Pour effectuer notre expérimentation par réseaux
neuronaux, nous nous proposons de préciser le type et l'architecture du
réseau, les paramètres caractéristiques et la base
d'apprentissage utilisée.
2.3.1) Le réseau utilisé: Perceptron
multicouches (PMC)
Compte tenu de la complexité des relations pouvant
exister entre les données, et de la dispersion statistique importante
des ratios aussi bien pour les entreprises défaillantes que pour les
entreprises non défaillantes (Malécot, 1997), le
réseau que nous avons utilisé est un réseau
supervisé à rétropropagation à deux couches. La
première couche est composée de 18 neurones. Le nombre de
neurones de la deuxième couche est égal à 2, il est
contraint par les valeurs cibles utilisées : « mauvais
payeur » ou « bon payeur »
2.3.2) Les paramètres
§ La fonction de transfert de la première
couche est logsigmoïde, la fonction de transfert de la deuxième
couche est la fonction linéaire. Ces fonctions permettent, dans une
architecture de taille suffisante, d'ajuster parfaitement toute fonction
comprenant un nombre fini de discontinuités.
§ L'apprentissage a été
réalisé par rétropropagation de l'erreur. De
façon à éviter les minima locaux dans la surface d'erreur,
nous avons utilisé un taux d'apprentissage variable et un moment.
L'avantage des réseaux multicouches à rétropropagation
réside dans leur faculté d'être très peu restrictifs
quant à la fonction à réaliser et d'être des
estimateurs très faiblement biaisés.
Les paramètres d'apprentissage du réseau sont les
suivants :
- Coefficient d'apprentissage : 0,1 0
- Momentum : 0,5
- Temperature de fonction sigmoide : 0,5
§ Trois critères peuvent être utilisés
pour définir l'arrêt de l'apprentissage (Asselin de
Beauville et Zollinger, 1995) :
1- un seuil d'erreur quadratique cumulée en sortie du
réseau : S.S.E.;
2- un nombre d'itérations préfixées ;
3- un seuil de taux d'efficacité du réseau sur la
base d'apprentissage.
Nous avons fixé la fin de l'apprentissage à une
valeur d'erreur de 0.01, critère numéro 1, à défaut
à un nombre défini d'itérations : 10 000, selon le
critère numéro 2
2.3.3) Apprentissage et généralisation
Deux tests différents ont été
menés, l'un sur les défaillances à un an, l'autre sur les
défaillances à deux ans et trois ans. Dans chacun des deux cas,
le nombre d'entreprises défaillantes a été partagé
en deux, une moitié pour l'apprentissage du réseau et une
moitié pour la phase de généralisation.
Durant la phase d'apprentissage, le caractère
« mauvais payeur » ou « bon payeur »
était donné au réseau et les poids des neurones
s'ajustaient au fur et à mesure des itérations. Puis les poids
des neurones ont été figés et nous avons
vérifié les performances du réseau. Nous avons
présenté au réseau la moitié des entreprises
défaillantes qui n'a pas été retenue pour la phase
d'apprentissage. Pour que le test soit complet, nous avons
présenté au réseau à la fois des entreprises
défaillantes et des entreprises non défaillantes et nous avons
relevé le nombre d'entreprises pour lesquelles le réseau
réalisait un diagnostic exact
2.4. Le protocole d'expérimentation par la
régression logistique28(*)
2.4.1) Génération des modalités
discriminantes
La modélisation mathématique requière le
choix d'une variable dépendante dont on aimerait connaître les
déterminants ou variables explicatives qui l'influencent. Pour notre
cas, les modalités « mauvais payeurs » et
« bons payeurs » sont générées
à partir de la variable dépendante
rem3mois (l'entreprise a-t-elle remboursé son
crédit 3 mois au plus après la dernière
échéance prévue ?). Pour la réponse
« non » à cette variable, l'individu est
classé « mauvais payeur ». Pour la réponse
« oui », l'individu est classé « bon
payeur ».
2.4.2) Estimation du modèle par le maximum de
vraisemblance
On a considéré que l'ajustement est satisfaisant si
:
1. La distance entre la variable de sortie observé
y et l'outcome prédit par le modèle y est
petite (test de Hosmer-Lemeshow).
2. Le modèle est bien « calibré »,
i.e. les fréquences prédites sont proches de celles
observées (test de Hosmer-Lemeshow)..
3. Le modèle permet de bien discriminer entre les
valeurs de y = 0 et y = 1 en fonction des variables
explicatives (matrice de confusions).
La démarche que nous avons adopté a
consisté à évaluer, d'abord, globalement
l'adéquation du modèle au moyen des différents tests de
« Goodness of fit », puis lorsqu'on a été satisfait de
la qualité de l'ajustement global, à déterminer s'il n'y a
pas localement des observations très mal ajustées et ayant
possiblement un effet important sur l'estimation des coefficients. Le but des
ces évaluations globale et locale est de s'assurer que l'ajustement du
modèle soit satisfaisant pour toutes les valeurs observées dans
l'échantillon des variables explicatives. Finalement,
l'évaluation du pouvoir discriminant du modèle nous a permis
d'appréhender si nous avons choisi les « bonnes » variables
explicatives ou s'il manque d'importants régresseurs pour arriver
à prédire avec suffisamment de précision la variable de
sortie.
2.4.3) Test de sigificativité globale (Evaluation
de la calibration du modèle : le test de Hosmer et Lemeshow)
Le test de Hosmer et Lemeshow a été basé
sur un regroupement des probabilités prédites par le
modèle. On a calculé ensuite, pour chacun des groupes le nombre
observé de réponses positives y = 1 et négatives
y = 0, que l'on a comparé au nombre espéré
prédit par le modèle. On a alors calculé une distance
entre les fréquences observées et prédites au moyen d'une
statistique du Khi 2. Lorsque cette distance est petite on considère que
le modèle est bien calibré
2.4.4) Evaluation du pouvoir discriminant du modèle
: sensibilité, spécificité
Il est intéressant de déterminer la performance
du classement et comment celui-ci dépend du seuil (ou de la
règle) choisi. Pour cela nous avons considéré les notions
de sensibilité et spécificité. La sensibilité est
définie comme la probabilité de classer l'individu dans la
atégorie y = 1 (on dit que le test est positif) étant
donné qu'il est effectivement observé dans celle-ci :
Sensibilité = P(test + | y = 1)
La spécificité est définie comme la
probabilité de classer l'individu dans la catégorie y =
0 (on
dit que le test est négatif) étant donné
qu'il est effectivement observé dans celle-ci :
Spécificité = P(test - | y = 0)
CHAPITRE IV : PRESENTATION & ANALYSE DES
RESULTATS
« Le Credit Scoring n'approuve, ni ne rejette une
demande de prêt,
il peut plutôt prédire la probabilité
d'occurrence de mauvaise performance (défaut)
telle que définie par le préteur »
(Caire et Kossmann, 2003)
I/ Résultats de l'analyse factorielle des
correspondances principales
Notre analyse va se baser sur nos données
décrivant des individus (clients PME de l'UMECUDEFS) à l'aide de
variables catégorielles (recodées en numériques) et
quantitatives décrivant leurs données démographiques, leur
expérience en matière de crédit, la forme et la nature de
leur activité, les garanties proposées, les indicateurs temporels
et le montant du crédit. Il y'a n=212 individus ou observations, et p=18
variables descriptives + une variable explicative
(rem3mois), la variable nom_entr
identifiant les 212 observations.
Tableau 6: Descriptif des variables initiales
|
Code
|
Nouveau
Code
|
Etiquette
|
Nombre de
modalités
|
|
nom_entr
|
Var1
|
Nom de l'entreprise (ou du dirigeant)
|
207
|
|
sexedir
|
Var2
|
Sexe du dirigeant de l'entreprise
|
2
|
|
statmat
|
Var3
|
Statut matrimonial du dirigeant de l'entreprise
|
4
|
|
age
|
Var4
|
Age du dirigeant de l'entreprise
|
11
|
|
nbenf
|
Var5
|
Nombre d'enfant du dirigeant de l'entreprise
|
2
|
|
persach
|
Var6
|
Nombre de personnes à charge dans le foyer du dirigeant
d'entreprise
|
3
|
|
perssal
|
Var7
|
Nombre de personnes salariées dans le foyer du dirigeant
d'entreprise
|
4
|
|
dom
|
Var8
|
Domicile du dirigeant d'entreprise
|
3
|
|
nivetude
|
Var9
|
Niveau d'étude du dirigeant de l'entr.
|
5
|
|
nivrev
|
Var10
|
Niveau de revenu du dirigeant de l'entr.
|
7
|
|
pretpass
|
Var11
|
Nombre de prêts déjà contractés par le
dirigeant de l'entreprise dans le passé
|
6
|
|
Sectact
|
Var12
|
Secteur d'activité de l'entreprise
|
10
|
|
duréexis
|
Var13
|
Durée d'existence de l'entreprise
|
4
|
|
typgar
|
Var14
|
Type de garantie proposé par le demandeur de
crédit
|
7
|
|
valgar
|
Var15
|
Valeur de la garantie proposée
|
8
|
|
durecoul
|
Var16
|
Durée écoulée entre demande de crédit
et réponse de l'UMECUDEFS
|
4
|
|
montant
|
Var17
|
Montant du crédit octroyé
|
6
|
|
democt
|
Var18
|
Montant demandé = montant octroyé ?
|
2
|
|
difdemre
|
Var19
|
Différence entre nombre de versements demandés
et obtenus
|
5
|
|
rem3mois
|
Var20
|
Le Client a-t-il remboursé intégralement son
crédit au plus 3 mois après la dernière
échéance prévue ?
|
2
|
Source : Recherche de Fred Ntoutoume, Crefdes, 2007
1.1. Dimensions de la solution et valeurs propres
(inerties)
La représentation graphique que l'on souhaite obtenir
de ces données en termes de catégories et d'objets, s'effectue
dans un repère orthonormé dont on doit préciser le nombre
d'axes a, appelé la dimension de la
solution. La dimension maximum du sous-espace de représentation
est égale au nombre de catégories
(m=95) moins le nombre de variables sans
valeurs manquantes (p=19). Cependant pour des raison pratiques, notre
représentation s'appuiera sur une solution à sept dimensions pour
synthétiser les traits essentiels le l'information recherchée.
Pour obtenir une analyse en composantes principales sous
SPSS, nous créons par recodage, à partir du tableau des
données alphanumériques, un tableau numérique comportant
l'ensemble des variables à analyser. Pour ce faire, nous utilisons la
procédure de recodage automatique <Recoder
Automatiquement> du menu de transformation
<Transformer>, créant ainsi la variable Var2
(codage numérique), à partir de
sexedir (codage alphanumérique),
jusqu'à la variable Var20 à partir de
rem3mois, par transformation des catégories
prises dans un ordre lexical croissant.
Après recodage automatique des données, nous
sélectionnons à partir du menu <Analyse>, la
procédure <Analyse Factorielle> du menu
<Factorisation>, en choisissant les options correspondantes
à la syntaxe suivante :
Tableau 7: Fichier de syntaxe de l'analyse factorielle
sous SPSS
FACTOR
/VARIABLES sexedir statmat age nbenf persachg perssal dom
nivetude nivrev
pretpass sectact duréexis typgar valgar durecoul montant
democt difdemre
/MISSING LISTWISE /ANALYSIS sexedir statmat age nbenf persachg
perssal dom
nivetude nivrev pretpass sectact duréexis typgar valgar
durecoul montant
democt difdemre
/PRINT INITIAL EXTRACTION FSCORE
/FORMAT SORT
/PLOT EIGEN
/CRITERIA MINEIGEN(1) ITERATE(25)
/EXTRACTION PC
/ROTATION NOROTATE
/SAVE REG(ALL)
/METHOD=CORRELATION .
Source : Recherche de Fred Ntoutoume, Crefdes, 2007
Le tableau des Eigenvalues ci-dessous rend compte des valeurs
propres (ou inerties) prises par chaque axe factoriel (ou composante), il rend
compte aussi des taux d'inertie (% de la variance) et des taux d'inertie
cumulés (% cumulés). En effet dans la solution initiale, nous
avons autant de composantes que de variables explicatives (au nombre de 18), la
colonne « Total » nous renseignant sur la contribution de
la variance dans chaque variable observée et expliquée par chaque
axe factoriel. Cette valeur est ensuite relativisée par rapport à
l'inertie totale, puis cumulée.
En observant les inerties des 3 premiers axes, on constate que
le premier représente 15,5% de l'inertie totale, le deuxième
représente 10,6% de l'inertie totale et le troisième 9,4%. Leur
cumul est de 35,6%, ce qui signifie qu'en s'appuyant sur une solution à
3 dimensions, nous résumerions 35,6% de l'information totale de
départ. Ce qui est relativement insuffisant pour nous permettre de
continuer. Nous retiendrons donc les sept premiers axes, dont l'inertie
cumulée est de 61,7%.
Tableau 8: Variance expliquée totale
(Eigenvalues)
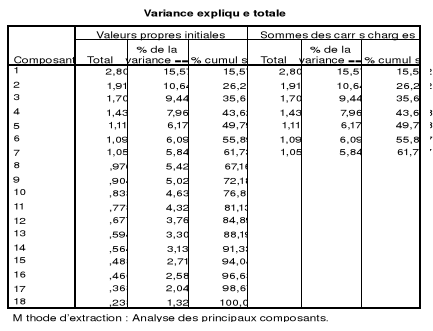
Source : Recherche de Fred Ntoutoume (logiciel SPSS),
Crefdes, 2007
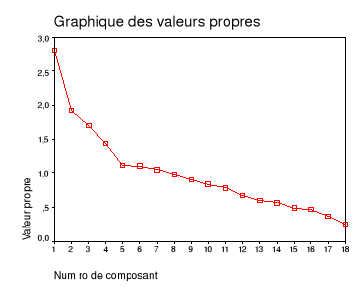
Le choix que nous faisons de retenir les 7 premiers axes de
l'analyse peut être conforté par le l'analyse du graphique
suivant, où l'on constate qu'après le septième composant,
la contribution reste marginale et décroissante.
Figure 6: Graphique des valeurs propres
Source : Recherche de Fred Ntoutoume
(logiciel SPSS), Crefdes, 2007
1.2 Qualité de représentation (Factor Analisys
Communalities)
La qualité de représentation indique la
contribution de chaque variable expliquée. Les qualités de
représentation initiales estiment la variance de chaque variable
expliquée par l'ensemble des facteurs (composants).
Pour l'ACP la représentation initiale est toujours
égale à 1 (analyse de corrélation) ou à la variance
de la variable (analyse de covariance).
Les extractions étant estimées de la variance de
chaque variable expliquée dans la solution factorielle, les plus petites
valeurs représentent les variables qui ne s'ajustent pas assez à
la solution factorielle, et qui peuvent par conséquent être
supprimées de l'analyse.
Ainsi, on remarque que les 12 premières variances
(inerties) les plus importantes sont, par ordre décroissant :
1-Nombre d'enfants..........................(0,803)
2-Nombre de personnes à charge ......... (0,775)
3-Sexe du dirigeant ......................... (0,697)
4-Secteur d'activité
..........................(0,662)
5-Montant du crédit octroyé
...............(0,654)
6-Durée entre demande et réponse
........(0,641)
7-Niveau de revenus du dirigeant ........(0,640)
8-Valeur estimée de la garantie ............(0,629)
9-Différence versements dem et obt.......(0,621)
10- Montant dem = montant octroyé ?.....(0,618)
11- Durée d'existence de l'entreprise .....(0,579)
12-Age du dirigeant de l'entreprise .......(0,569)
On en déduit que d'autres variables comme le type de
garantie ou le statut matrimonial du dirigeant de l'entreprise n'expliquent pas
assez la solution factorielle.
Tableau 9: Qualité de représentation des
variables
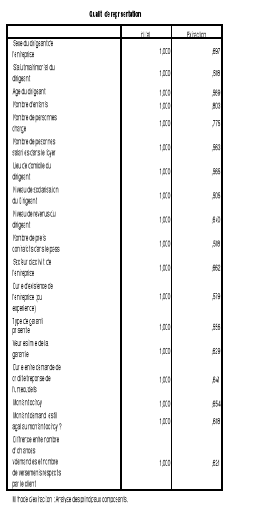
Source : Recherche de Fred Ntoutoume (logiciel SPSS),
Crefdes, 2007
Notre interprétation des inerties peut être
conforté à la lumière de l'analyse la matrice des
composantes, qui renseigne sur la contribution de chaque variable à
l'explication de chacun des 7 axes factoriels retenus.
Nous remarquons en effet, sur la ligne de la variable
« Nombre d'enfants », que les inerties sont assez fortes
pour chaque axe factoriel concerné. De même pour la variable
« Nombre de personnes à charges », qui a d'assez
bonnes contributions sur tous les sept axes. Par contre, la variable
« Type de garantie présentée », qui semble
pourtant bien expliquer l'axe 1, n'est pas assez explicative sur les 6 autres
composantes.
Source : Recherche de Fred Ntoutoume (logiciel SPSS),
Crefdes, 2007
Tableau 10: Matrice des composantes
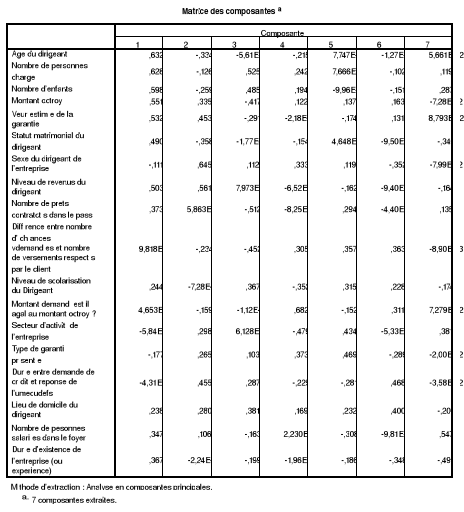
1.3. Les variables explicatives retenues
Suite à notre analyse factorielle des correspondances
principales, dont l'objectif de départ tenait à la
réduction des variables, nous avons constaté que certaines
d'entre les 18 variables explicatives de départ ne contribuaient pas
assez à l'explication de la solution factorielle. En effet, dans les
sept premières composantes, leurs taux d'inertie se sont
révélés marginaux par rapport à d'autres, ainsi que
nous l'avons présenté dans le tableau représentant la
matrice des composantes.
Sous ce rapport, nous avons procédé à une
sélection des principales variables qui nous semblent, au regard de leur
inertie, prendre en charge assez fortement l'essentiel de l'information
contenue dans notre échantillon de 212 PME. Leur composition, dont le
nombre est passé de 18 à 12, est présentée dans le
tableau qui suit:
Tableau 11: Les variables explicatives retenues apres
l'AFC
|
Code
|
Etiquette
|
Nombre de
modalités
|
|
1
|
sexedir
|
Sexe du dirigeant de l'entreprise
|
2
|
|
2
|
nbenf
|
Nombre d'enfant du dirigeant de l'entreprise
|
2
|
|
3
|
persach
|
Nombre de personnes à charge dans le foyer du dirigeant
d'entreprise
|
3
|
|
4
|
nivrev
|
Niveau de revenu du dirigeant de l'entr.
|
7
|
|
5
|
sectact
|
Secteur d'activité de l'entreprise
|
10
|
|
6
|
valgar
|
Valeur de la garantie proposée
|
8
|
|
7
|
durecoul
|
Durée écoulée entre demande de crédit
et réponse de l'UMECUDEFS
|
4
|
|
8
|
montant
|
Montant du crédit octroyé
|
6
|
|
9
|
democt
|
Montant demandé = montant octroyé ?
|
2
|
|
10
|
difdemre
|
Différence entre nombre de versements demandés
et obtenus
|
5
|
|
11
|
age
|
Age du dirigeant de l'entreprise
|
11
|
|
12
|
duréexis
|
Durée d'existence de l'entreprise
|
4
|
Source : Recherche de Fred Ntoutoume, Crefdes, 2007
II/ Résultats économétriques de la
modélisation par la régression logistique
Dans la mesure où notre étude, dont l'objectif
est la construction d'un modèle de score sensé prédire le
niveau de risque de contrepartie associé à un demandeur de
crédit, implique le recours à une variable endogène
qualitative discrète (Y = {0,1}), nous rappelons qu'un modèle
linéaire n'est pas licite.
En effet, la matrice (X'X) des variables explicatives
(exogènes) n'étant pas inversible, il n'est pas possible
d'estimer les paramètres du modèle de notre étude par la
méthode des moindres carrés ordinaires (MCO). Nous aurons recours
à l'économétrie des variables qualitatives, en particulier
à une méthode d'optimisation appelée la méthode du
maximum de vraisemblance (maximum likelihood).
2.1. Génération des modalités
« Bon payeur » et « mauvais
payeur »
En posant que :
1 si la TPE est « mauvais
payeur »
Y= probabilité de défaut (variable
endogène), avec Yi=
0 sinon
Définition (Rappel) : une entreprise est
« mauvais payeur » si elle n'a pas intégralement
remboursé son crédit, intérêt et principal, au plus
3 mois après la dernière date d'échéance
prévue.
Tableau 12: Codage de la varible dépendante (Y)

Source : Recherche de Fred Ntoutoume, Crefdes, 2007
On peut donc écrire pour le modèle logit auquel
nous aurons recours :
Probabilité de défaut de remboursement P(Y
=1) = 1- F(S - Xi â),
Avec F : la fonction de répartition du
modèle logit qui est égal à F(x) = 1/(1+e-x)
Xi â : vecteur des variables
exogènes (explicatives)
S : le seuil (constante)
Donc :
1
1 + e -S+Xiâ
§ P (Y=1) = 1 -
2.2. Spécification du modèle logit et
estimation des paramètres prédictifs
Figure 7: Procédure d'estimation du modèle
logistique sous SPSS
Pour obtenir une spécification et une estimation du
modèle par régression logistique sous SPSS, nous
sélectionnons à partir du menu <Analyse>, la
procédure <Logistique Binaire> du menu
<Régression>, en choisissant les options
« Diagramme de classement », « qualité
d'ajustement de Hosmer-Lemeshow », « correlation des
estimations » et « historique des
itérations ».
Source : Recherche de Fred Ntoutoume, Crefdes, 2007
Figure 8: Choix de la méthode logistique
« Descendante par rapport de vraisemblance »
Nous choisissons ensuite d'utiliser la méthode
« descendante par rapport de vraissemblance » de sorte que
SPSS ne sélectionne que les variables réellement significatives
dans le modèle final.
Source : Recherche de Fred Ntoutoume, Crefdes, 2007
Le tableau ci-dessous récapitule le traitement des
observations contenues dans notre base de données. Nous retrouvons nos
212 TPE inclues dans l'analyse.
Tableau 13: Récapitulatif du traitement des
observation

Source : Recherche de Fred Ntoutoume, Crefdes, 2007
Ce récapitulatif établi, il nous permet de
savoir qu'aucune observation n'a été retirée (omise) de
l'analyse suite à une probable valeur aberrante ou manquante. Nous
pouvons dès lors présenter les résultats de l'estimation
des paramètres du modèle Logit, par la méthode du
Maximum Likelihood (descendante):
Tableau 14: Estimation des paramètres du
modèle logistique
|
|
|
B
|
E.S.
|
Wald
|
ddl
|
Signif.
|
Exp(B)
|
|
Etape 12
|
AGE
|
0,316
|
0,144
|
4,818
|
1
|
0,028
|
1,372
|
|
|
NIVREV
|
-0,451
|
0,187
|
5,842
|
1
|
0,016
|
0,637
|
|
|
DURÉEXIS
|
-0,951
|
0,562
|
2,859
|
1
|
0,091
|
0,386
|
|
|
VALGAR
|
-0,273
|
0,154
|
3,129
|
1
|
0,077
|
0,761
|
|
|
MONTANT
|
0,888
|
0,327
|
7,378
|
1
|
0,007
|
2,43
|
|
|
DEMOCT
|
3,347
|
0,662
|
25,592
|
1
|
0
|
28,418
|
|
|
DIFDEMRE
|
1,268
|
0,321
|
15,636
|
1
|
0
|
3,554
|
|
|
Constante
|
-3,586
|
2,373
|
2,283
|
1
|
0,131
|
0,028
|
Source : Recherche de Fred Ntoutoume, Crefdes, 2007
En considérant P comme la
probabilité que la TPE soit un « mauvais payeur »,
l'estimation des paramètres du modèle permet d'aboutir à
la régression (Equation) suivante :
= (-3,586) +0,316.AGE
-0,451.NIVREV -0,951.DUREEXIS
-0,273.VALGAR +0,888.MONTANT
+3,347.DEMOCT + 1,268.DIFDEMRE
P
1-P
ln
D'où le modèle logistique P de
probabilité de défaut de remboursement (ou modèle de
crédit-scoring) dans notre présente étude peut finalement
s'écrire :
1
1+e (- 3,586
+0,316.AGE -0,451.NIVREV
-0,951.DUREEXIS -0,273.VALGAR
+0,888.MONTANT +3,347.DEMOCT
+1,268.DIFDEMRE)
P = 1-
A proprement parler, la valeur numérique des
paramètres estimés en eux même n'ont pas
d'intérêt dans une estimation logistique, dans la mesure où
« ils ne correspondent aux paramètres de d'équation
de la variable latente qu'à une constante multiplicative
près » (Doucouré, 2006).
La seule information réellement utilisable est donc le
signe des paramètres, car ceux-ci donnent une indication sur le sens de
l'influence que la variable associée a sur la probabilité de
non-remboursement à la hausse ou à la baisse. Par ailleurs, il
apparaît après l'estimation des paramètres par le maximum
de vraisemblance que seules sept variables sont réellement
significatives dans notre modèle logistique, au vu des valeurs de leur
probabilité (colonne « Signif. »). Il s'agit des
variable AGE (2,8%), NIVREV (1,6%),
DUREEXIS (« variable forcée »
à 9,1%), VALGAR (« variable
forcée » à 7,7%), MONTANT
(0,7%), DEMOCT (0%) et DIFDEMRE (0%). Pour
mémoire, on accepte l'hypothèse de non nullité du
coefficient dès que la probabilité critique
(significativité) est inférieure à 0,05, soit 5%.
Enfin, le logiciel SPSS indique à son 12e
pas qu'« aucune autre variable ne peut être supprimée ou
rajoutée au modèle en cours » (cf. tableau infra). En
effet, à chaque étape, l'algorithme du modèle logistique
élimine systématiquement les variables dont la
significativité est trop faible quant à la classification des
bons ou mauvais payeurs. Cette spécifié vient de l'option
« régression logistique descendante » pour laquelle
nous avons opté, en complément de notre analyse factorielle.
Ainsi, comme le présente le tableau récapitulatif ci-dessous, la
variable PERSACH a été « out » à
l'étape 1, suivie de la variable TYPGAR à l'étape 3, puis
de la variable NBENF à l'étape 4, et ainsi de suite jusqu'au
12e pas. Pour cette raison, nous ne discuterons infra que des
variables significatives (cf paragraphe 2.6).
Tableau 15: Récapitulatif des étapes de la
régression logistique
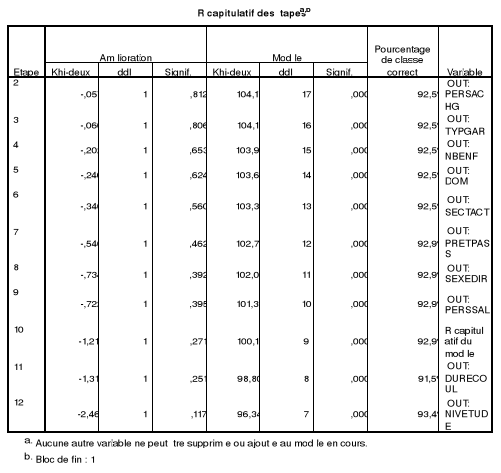
Source : Recherche de Fred Ntoutoume, Crefdes, 2007
2.3. Qualité du modèle (Test de
Significativité globale)
La qualité du modèle est évaluée
par le Log likelihood (ou log vraisemblance). Cet indicateur vaut 96,827
à la 12e étape. On en déduit que la
significativité globale du modèle est bonne.
Tableau 16: Test de Log vraisemblance
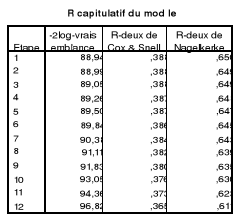
Source : Recherche de Fred Ntoutoume, Crefdes, 2007
2.4. Test de Hosmer-Lemeshow (test d'ajustement du
modèle)
Le test de Hosmer-Lemeshow permet de savoir si le modèle
spécifié est bon ou mauvais. Il s'appuie sur le test
d'hypothèse suivant :
H0 : ajustement bon (Goodness of fit)
H1 : ajustement mauvais
La règle de décision est :
§ On accepte l'hypothèse H0 si la
valeur de la probabilité (Significativité) est supérieure
à 5% ;
§ On refuse l'hypothèse dans le cas contraire.
Le logiciel SPSS nous fourni les résultats
ci-dessous :
Tableau 17: Test de Hosmer-Lemeshow
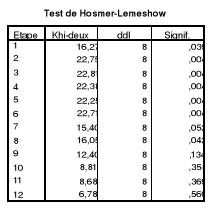
Source : Recherche de Fred Ntoutoume, Crefdes, 2007
Interprétation du test : au seuil de 5%,
l'ajustement du modèle est bon car la probabilité (ou
significativité) du Khi carré à 8 degrés de
liberté (ddl) vaut 0,56, soit 56%, d'où on accepte
l'hypothèse H0. Ce d'autant plus que la distance entre les
fréquences observées et prédites au moyen de la
statistique du Khi 2 est petite (6,788). Le modèle est donc bien
calibré.
2.5. Qualité de prédiction du modèle
(performance de classification)
La qualité de prédiction du modèle est
donnée par le tableau suivant
Tableau 18: Performances de classification du
modèle logit
Source : Recherche de Fred Ntoutoume (Logiciel SPSS),
Crefdes, 2007
Le modèle logit prédit correctement la
défaillance des TPE dans 93,4% des cas. Le
présent modèle de crédit scoring présente donc
d'excellentes qualités prédictives. Ce d'autant plus qu'il
prédit à 97,2 % les mauvais emprunteurs
(sensibilité), et à 75% les bons (spécificité). Or
les pertes financières issues d'un « mauvais
prêt » sont plus importantes que les pertes financières
issues du rejet par erreur d'un « bon prêt »29(*).
2.6. Discussions sur les déterminants du risque de
crédit du modèle Logistique
Pour mémoire, nous rappelons les signes des
coefficients dans le tableau qui suit :
Tableau 19 : Signe des coefficients et
significativité
|
|
B
|
Signif.
|
|
AGE
|
0,316
|
0,028
|
|
NIVREV
|
-0,451
|
0,016
|
|
DURÉEXIS
|
-0,951
|
0,091
|
|
VALGAR
|
-0,273
|
0,077
|
|
MONTANT
|
0,888
|
0,007
|
|
DEMOCT
|
3,347
|
0
|
|
DIFDEMRE
|
1,268
|
0
|
|
Constante
|
-3,586
|
0,131
|
Source : Recherche de Fred Ntoutoume, Crefdes, 2007
Notre discussion admettra systématiquement un test du
Khi 2 de Pearson, afin d'évaluer la relation entre la variable
endogène (non remboursement) et la covariable discutée. Le test
d'hypothèse généralement admis est le suivant :
H0 : La variable exogène et la variable
endogène ne sont pas dépendantes (aucun lien)
H1 : La variable exogène et la variable
endogène sont dépendantes
Nous nous baserons sur une signification asymptotique
(bilatérale) de 0,05 qui signifie qu'on a 5 chances sur 100 de se
tromper en rejetant l'hypothèse nulle, c'est-à-dire en admettant
que les colonnes et les lignes du cas traité sont indépendantes.
En conséquence, on accepte l'hypothèse d'indépendance des
variables si la signification asymptotique est supérieure à
5%.
2.6.1) Probabilité de non-remboursement et âge
du dirigeant de la PME
On remarque que le coefficient de la covariable AGE est
positif et significatif. Ainsi, l'âge du dirigeant de la TPE est une
fonction croissante de la probabilité de non-remboursement d'un
crédit, chez les chefs d'entreprises du portefeuille de l'UMECUDEFS. En
d'autres termes, plus le dirigeant se trouve dans une tranche d'âge
élevée, et plus il présente de risques de non
remboursement de la créance.
Cette relation entre l'age d'un client et le remboursement
d'un crédit n'est en fait pas propre à l'Afrique. La plupart des
banques ou IMF prennent en effet plus de précautions (souscription
d'assurance par exemple) à mesure que le demandeur de crédit se
révèle être avancé en age. Notre échantillon
montre que ce sont les clients de la tranche 30 à 50 ans qui sont les
plus nombreux dans l'effectif des mauvais payeurs, au prorata du profil de la
population mère, qui comptent en majorité des PME dont les
dirigeants appartiennent à cette tranche d'âge.
D'un point de vue purement statistique, il semble que
l'âge des dirigeants des PME, bien qu'ayant une influence sur le risque
de non-remboursement, n'en dépende pas pour autant. En effet, la
signification du test du Khi-deux de Pearson révèle une valeur de
9,396 significative à 49,5%, ce qui nous pousse à accepter
l'hypothèse d'indépendance entre les deux variables.
Tableau 20: Test du Khi Carré
REM3MOIS & AGE
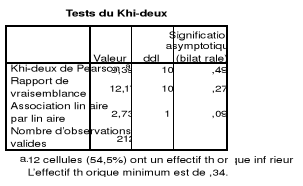
Source : Recherche de Fred Ntoutoume, Crefdes, 2007
2.6.2) Probabilité de non-remboursement et Niveau de
Revenu du dirigeant de la PME
En ce qui concerne le niveau de revenu du dirigeant de la PME,
les résultats de l'estimation logistique nous révèlent un
coefficient associé négatif. Cette influence en sens inverse
revenu sur le risque de contrepartie était aussi attendue. En effet, si
les revenus du client engagé auprès de la mutuelle augmentent, il
a d'autant moins de risques de ne pas rembourser dans la mesure où il
dispose d'une plus grande surface financière. Cette règle soutend
d'ailleurs le dicton populaire qui recommande de ne prêter qu'aux
riches.
La valeur du Khi-deux de Pearson est de 27,889. Au niveau de
0,005 de signification, l'hypothèse H0 d'indépendance des
variables est rejetée car la probabilité de signification vaut 0.
On en déduit que le niveau de revenu des dirigeants de TPE est bien
lié, du point de vue statistique, au risque de contrepartie que
présentent les individus de notre échantillon.
Tableau 21: Test du Khi Carré
REM3MOIS & NIVREV

Source : Recherche de Fred Ntoutoume,
Crefdes, 2007
2.6.3) Probabilité de non-remboursement et
Durée d'existence de la PME
De même que le niveau de revenu, la durée
d'existence de la PME (c'est-à-dire de
l'activité commerciale) influence négativement le risque
de crédit. Il est en effet négatif et significatif au seuil de
10%. Cette relation pourrait signifier que plus l'entreprise a acquis
d'expérience dans son secteur d'activité, et moins elle
présente de risques de défaillance dans le remboursement d'un
prêt. Cette relation non plus n'est pas nouvelle, et se situe d'ailleurs
au coeur de la sélection adverse que les prêteurs, banques et IMF,
développent à l'égard des entreprises naissantes ou en
phase de croissance.
D'un point de vue statistique toutefois, l'hypothèse
d'indépendance entre les deux variables est acceptée au regard
des résultats du test du Khi-deux. La signification asymptotique est en
effet égale à 34,6%, donc bien largement supérieur aux 5%
communément admisent comme seuil maximum de rejet de l'hypothèse
H0. On en déduit que la durée d'existence des PME de notre
échantillon n'admet aucune dépendance statistique avec le risque
de contrepartie qu'elles présentent.
Tableau 22: Test du Khi Carré
REM3MOIS & DUREEXIX
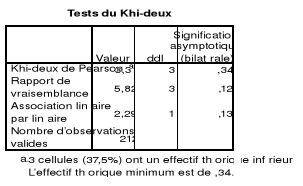
Source : Recherche de Fred Ntoutoume, Crefdes, 2007
2.6.4) Probabilité de non-remboursement et Valeur de
la garantie proposée
Pour ce qui est de la covariable VALGAR, elle est
négative et significative à 8%. Cela signifie que le risque de
contrepartie diminue à mesure que la valeur du type de garantie
proposée (hypothèque, caution,..) est élevée. Cette
relation aussi était plus ou moins attendue entre les deux variables,
même si les banquiers s'accordent à dire que « la
garantie ne fait pas le crédit ».En effet, dans la pratique
c'est moins la valeur de la garantie qui est regardée que sa
capacité à être réalisée.
Une garantie de grande valeur mais peu liquide n'est donc pas
une garantie de grande qualité. De plus, les types de garantie
proposées présentent souvent une valeur sociale importante,
à l'instar de la mise en hypothèque d'une maison, ce qui en rend
la réalisation parfois longue, difficile et non moins coûteuse
pour le créancier.
Le lien statistique entre la valeur de la garantie et le
risque de crédit n'est justement pas confirmé par le test du Khi
deux de Pearson. En effet, la signification asymptotique prise par la valeur du
test s'élevant à 31,1%, elle ne permet pas de conclure à
une quelconque dépendance statistique entre les deux variables.
Tableau 23: Test du Khi Carré
REM3MOIS & VALGAR
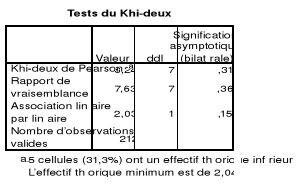
Source : Recherche de Fred Ntoutoume, Crefdes, 2007
2.6.5) Probabilité de non-remboursement et Montant
du crédit Octroyé
On constate que la variable MONTANT a un paramètre
associé dont le signe est positif et rès significatif (au seuil
de 0,008). Ce signe est conforme à nos attentes, car un montant de
crédit élevé diminue la probabilité pour le
créancier d'honorer son engagement, toutes choses étant
égales par ailleurs. Ce d'autant plus que les échéanciers
de remboursement appliqués par l'UMECUDEFS n'excèdent que
rarement les douze mois. Un montant élevé du principal, a par
conséquent tendance à « gonfler » les
échéances de remboursement, ajouté des
intérêts.
Le test du Khi-deux postule l'inexistence d'une
dépendance formelle entre le montant du crédit et la
probabilité de non remboursement chez les PME constitutives de notre
échantillon. En effet, la valeur de l'indicateur de Pearson vaut 6,416
à 5 degrés de liberté, mais n'est significative
qu'à 26,8%, ce qui est largement supérieur à 5%, seuil
requis pour rejeter l'hypothèse d'indépendance des variables.
Tableau 24: Test du Khi Carré
REM3MOIS & MONTANT

Source : Recherche de Fred Ntoutoume, Crefdes, 2007
2.6.6) Probabilité de non-remboursement et
sélection adverse
La variable DEMOCT
est significative et positive. L'analyse économétrique nous
révèle donc que la probabilité de non remboursement
augmente si le montant finalement octroyé par l'UMECUDEFS est
inférieur à celui initialement sollicité par le demandeur
de crédit. Ce résultat pourrait se justifier par le fait que le
montant de la demande de crédit est souvent associé à un
projet plus ou moins évalué par le client. Or, financer la
moitié ou le tiers de ce projet porte à l'évidence
atteinte au résultat dudit projet, et par conséquent à sa
viabilité.
Le principe qui pousse le microprêteur à baisser
le montant du crédit (ou à augmenter les taux
d'intérêt) sur un dossier est imputable à la notion de
sélection adverse, selon laquelle celui-ci espère réduire
le risque de contrepartie en corsant (ou
« sécurisant ») davantage l'opération. Or
cette option a pour effet de produire le strict contraire de celui
espéré : le risque de contrepartie augmente
significativement, dans la mesure où d'une part le projet amputé
d'une partie de son besoin de financement se retrouve compromis, et d'autre
part, ce sont les projets les plus risqués qui accepteraient les
conditions de crédit les plus contraignantes.
Le test du Khi-deux nous confirme avec un seuil de signification
de 0,05% que la sélection adverse est bel et bien liée à
la probabilité qu'un dirigeant de PME ne rembourse pas son
crédit. Sa valeur est de 43,190 à 1 degré de
liberté, ce qui nous permet d'accepter l'hypothèse de
dépendance entre les deux variables.
Tableau 25: Test du Khi Carré
REM3MOIS & DEMOCT

Source : Recherche de Fred Ntoutoume, Crefdes, 2007
2.6.7) Probabilité de non-remboursement et Respect
des échéances
Le respect ou non des
échéances semble jouer un rôle dans la probabilité
de remboursement, après l'octroi du crédit. En effet le
coefficient de DIFDEMRE étant significatif et positif, on en
déduit que la probabilité de défaut de remboursement
augmente si l'emprunteur présente de plus en plus de
différés de remboursement. Ce constat soulève en filigrane
la question du suivi des prêts et du recouvrement des
échéances dans la balance âgée.
La relation tient au fait qu'un client qui accumule les
échéances impayées augmente significativement son risque
de contrepartie, ce qui est tout à fait logique toutes choses
étant égales par ailleurs, dans la mesure où le coût
d'opportunité du remboursement sera inférieur au coût du
renoncement à un autre placement, ou à un autre poste de
dépense avec la même somme.
Au plan statistique, nous remarquons une dépendance
réciproque du respect des échéances et du risque de
crédit, avec un seuil d'erreur de 0,005%. En effet, le test du Khi-deux
de Pearson sur la variable exogène et la variable endogène prend
une valeur de 48,796 à 4 degré de liberté, ce qui nous
permet de rejeter l'hypothèse nulle d'indépendance des
variables.
Tableau 26: Test du Khi Carré
REM3MOIS & DIFDEMRE

Source : Recherche de Fred Ntoutoume, Crefdes, 2007
2.7. Simulations sur le modèle logistique binaire
Nous nous proposons, après avoir présenté
et discuté des déterminants du risque de crédit sur
l'échantillon de notre étude, de procéder à
quelques simulations du modèle sur 2 cas de demande de crédit
hors échantillon de départ. Il s'agit de tester le modèle
sur le plan empirique. Nous aurons donc recours à deux dossiers, pour
éprouver notre modèle de scoring dont la formule aura
été préalablement programmée dans un tableur, sous
le logiciel EXCEL.
Ainsi, calculons la probabilité de non remboursement
pour ces 2 cas:
§ 1er cas de demandeur de crédit :
soit le dirigeant d'une PME (Boucherie) âgé de 46 ans,
exerçant depuis 10 ans et percevant mensuellement un revenu compris
entre 150.000 et 200.000 Fcfa, présentant une garantie
(électroménager) d'une valeur estimée de 300.000 Fcfa, et
dont la demande de crédit a été traitée pour un
montant demandé et accordé de 500.000 FCFA. Le score de risque de
ce client est présenté dans le tableau ci-dessous avec une
première hypothèse sans retard de versement, puis une seconde
hypothèse avec 1 retard (le cas présenté dans la
figure) ;
§ 2e cas de demandeur de crédit :
soit la dirigeante d'une PME (Commerce de textile) agée de seulement 32
ans mais avec un niveau de revenu atteignant les 400.000 Fcfa mensuels,
exerçant dans le commerce depuis 6ans, proposant une garantie d'une
valeur estimée à plus de 3 millions Fcfa (stock de marchandises),
dont la demande de crédit initialement de 600.000 Fcfa, a
été traitée et accordée à 400.000 Fcfa. Le
score de risque de ce client est présenté dans le tableau
ci-dessous avec une première hypothèse sans retard, puis une
deuxième avec 1 retard (le cas présenté dans la
figure) ;
Figure 9: Simulation sur modèle de scoring
logistique
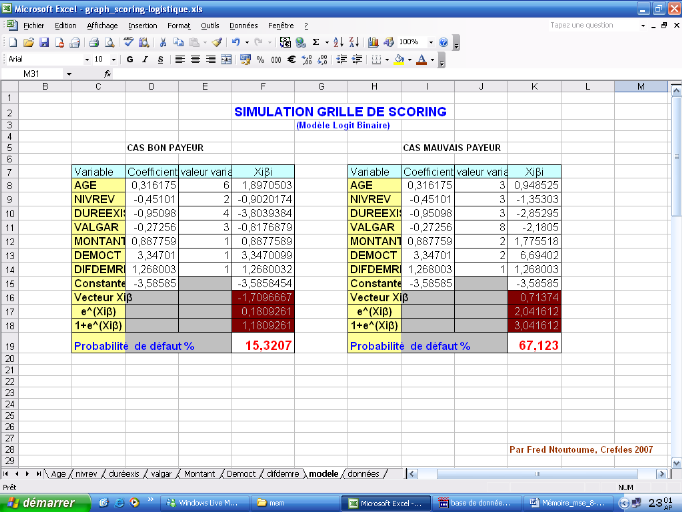
Source : Recherche de Fred Ntoutoume, Crefdes, 2007
Dans le premier cas, notre modèle de
scoring crédit associe au dirigeant de la PME demandeur de crédit
une probabilité de défaillance de 15,32%. En
d'autres termes, il y'aurait un peu plus de 8 chances sur 10 que ce client
rembourse son crédit au plus tard 3 mois après la date de la
dernière échéance prévue, toutes choses
étant égales par ailleurs. Mais compte tenu du niveau de
prédictions global du modèle qui est de 93%, cette
probabilité de 15,29% peut varier à la hausse ou à la
baisse d'à peu près 7 points. Ce qui reste très
appréciable comme risque à prendre.
Pour ce même cas, nous pouvons faire quelques
simulations avec notre modèle. Par exemple :
§ si le microprêteur décidait de ne pas
attribuer par prudence une probable échéance impayée dans
l'analyse du risque de ce client, et que par conséquent il admettait que
la valeur de la covariable DIFDEMRE était égale à zero, la
probabilité de défaut du dirigeant de la PME baisserait à
4,84%, toutes choses étant égales par ailleurs.
Ce qui nous confirme que la prise en compte ex-ante d'une probable
échéance impayée du demandeur de crédit a une
influence significative sur la probabilité de remboursement.
§ Si le montant du crédit s'élevait
à 600.000 FCFA (au lieu de 250.000 FCFA dans le cas
initial), toujours avec le même dirigeant de la PME (boucherie), et
toujours en admettant dans l'analyse que celui-ci aurait au moins une
échéance impayée, la probabilité de non
remboursement passerait à 51,64% (mais avec 100.000Fcfa
de moins, c-à-d un montant de crédit à 500.000, le risque
passe 30,53%). Cette augmentation du risque de contrepartie, d'environ 35
points au plus et 15 points au moins, à la suite d'une augmentation du
montant du crédit alloué, illustre bien la significativité
et la sensibilité de cette variable MONTANT dans l'influence
négative de la capacité de remboursement.
Du point de vue empirique, notre modèle logistique a
correctement classé le client de ce premier cas (à 15, 29% de
risque de non remboursement), puisque dans les faits cette PME a en effet
été en mesure de rembourser intégralement son
crédit, moins de trois mois après la dernière
échéance prévue.
Dans le second cas, le dossier du demandeur
de crédit est se voit attribuer une probabilité de non
remboursement de 67,12%, avec un seuil de plus ou moins 7 points. Ce client se
révèle donc être plus risqué que la moyenne, ce
malgré l'âge du dirigeant de la PME (32 ans), son niveau de
revenus (400.000Fcfa mensuel environ), et surtout la valeur de la garantie qui
semble importante (plus de 3 millions) alors que le crédit obtenu ne
s'élevait qu'à 400.000Fcfa. Cette probabilité
élevée de non remboursement est attribuable, selon notre
modèle :
§ d'abord à l'effet de sélection adverse
développé par le micropreteur qui en lieu et place des
600.000Fcfa demandés, a amputé la somme initiale de 30% à
400.000Fcfa. En effet, si le client avait obtenu le montant sollicité,
c'est-à-dire si la valeur de la variable DEMOCT était
égale à 1, notre modèle économétrique
calcule dans ce cas une probabilité de défaut de l'ordre de
7%, soit une différence de 60 points environ.
D'où l'on déduit la très grande significativité de
cette variable pour le risque de crédit présent dans notre
échantillon. En fait, la plupart des mauvais payeurs de l'UMECUDEFS
n'ont pas obtenu le montant du crédit sollicité au
départ.
§ Puis au différé d'un mois inclus dans
l'analyse, en admettant que ce client présenterait au moins un
défaut de paiement sur une échéance pendant le
remboursement du crédit. En l'absence de cette hypothèse, et
toutes choses étant égales par ailleurs, le score de cette
cliente reviendrait à 36,48%, avec plus ou moins 7 points de variation.
Ce qui l'aurait classée dans les « cas
médians » ni trop risqués, ni trop fiables.
Dans les faits cependant, la probabilité de
67,12% calculée par notre modèle a
été confirmée par l'issue réelle du cas N°2.
Cette PME n'avait pas remboursé son crédit en
intégralité, plus de trois mois après la dernière
échéance prévue.
III/ Résultats de la modélisation par les
réseaux de neurones
Après la modélisation logistique, notre
étude s'attachera dans cette section à tenter une
modélisation prédictive par la méthode neuronale. Pour
mémoire, nous rappelons que la fonction de transfert utilisée
dans la première couche cachée est la sigmoïde logistique ou
logsigmoide Y=F(x) = 1/(1+exp(-x)), similaire à celle
de la régression logistique que nous avons vu plus haut. Dans une
deuxième couche, il s'agira d'une fonction linéaire.
L'idée c'est d'obtenir une fonction qui présente un comportement
linéaire lorsque les poids des noeuds sont petits (au voisinage de
zero), et non linéaire lorsque l'on se situe aux
extrémités.
3.1. Identification des données en entrée et en
sortie.
Les données en entrées sont celles composant
notre échantillon après épurement de l'analyse
fréquentielle. En l'occurrence, il s'agit des 212 individus
décrits à travers leurs 18 variables explicatives, qui
constitueront les neurones input. Les données en sortie sont
soit la modalité 1 pour « bon payeur », ou la
modalité 2 pour « mauvais payeur ». Le type de
réseau qui sera utilisé est le perceptron multicouches (PMC),
encore appelé « Multi Layer Perceptron ». Celui-ci
semble adapté aux modèles non linéaires, et se compose en
plusieurs couches : les variables en entrée, les variables de
sortie, les niveaux cachés.
Tableau 27 : Caractéristiques du réseau
neuronal PMC utilisé
|
Libellé
|
caractéristiques
|
|
« poids »
|
Poids pi, et Poids qi
|
|
Couches cachées
|
Fonction de combinaison
|
Produit scalaire ?i
pixi
|
|
Fonction transfert
|
Logistique
F(X)= 1/(1+exp(-X))
|
|
Nombre de couches cachées
|
2
|
|
Couche de sortie
|
Fonction de combinaison
|
Produit scalaire ?k
pkxk
|
|
Fonction transfert
|
Logistique
F(X)= 1/(1+exp(-X))
|
|
Rapidité
|
Plus rapide en mode « application du
modèle »
|
|
Avantage
|
Meilleure généralisation
|
Source : Recherche de Fred Ntoutoume, Crefdes, 2007
(inspiré de Tufféry, 2006)
Nous avons augmenté le pouvoir de prédiction en
admettant deux couches cachées entre la couche d'entrée et la
couche de sortie. La structure générale de notre réseau
est de la forme :
Figure 10: Structure générale du
réseau neuronal PMC utilisé
Variables explicatives
(Couches d'entrée)
& Poids synaptiques (p et q)
Fonction de sortie (couche de sortie)
Fonction de combinaisaon
(couches cachées)
Source et Format
des données
(pi)
(qi)
SEXEDIR
(pi)
(qi)
STATMAT
Ó pi xi
(pi)
(qi)
AGE
Y=F(X)= 1/(1+exp(-X))
Base de données UMECUDEFS
(212 individus)
Ó qi xi
(pi)
(qi)
NBENF
.
.
.
.
.
.
.
.
(pi)
(qi)
Source :
Recherche de Fred Ntoutoume, Crefdes, 2007
DEMOCT
Pour procéder à l'identification des
données en entrée et en sortie sur le logiciel SPAD 5.5, nous
procédons par exportation de la base de données d'origine de SPSS
à SPAD, via une conversion en extension *.sba, puis par création
et enregistrement d'une filière, non sans avoir précisé la
méthode que nous souhaitions utiliser. Après un double clic sur
l'icône de la méthode, nous obtenons la boite de dialogue de
définition du modèle (cf figure ci-dessous).
Figure 11: procédure de définition du
modèle neuronal sous SPAD
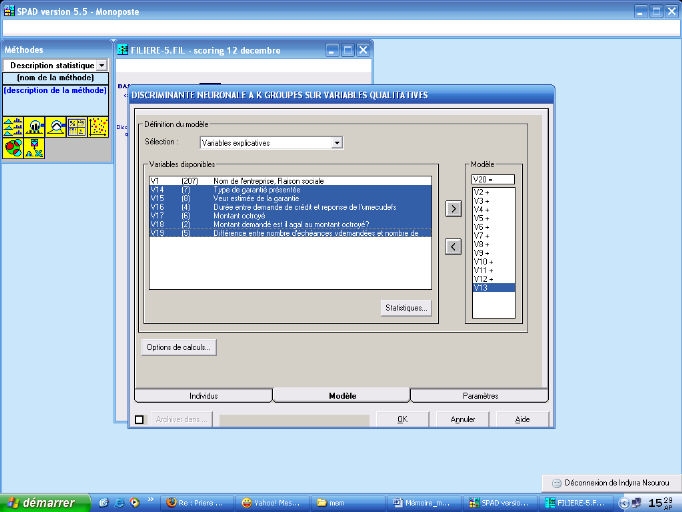
Source : Recherche de Fred Ntoutoume, Crefdes, 2007
Cette procédure SPAD nous permet, d'une part, de
définir la variable à discriminer (variable de sortie) qui
correspond dans notre cas à la variable REM3MOIS (remboursement
du crédit au plus 3 mois a près la dernière
échéance). Cette variable est codée en V20 sur SPAD.
D'autre part, le logiciel nous demande de spécifier les variables
explicatives du modèle, ou variables d'entrée. Celles-ci
correspondent aux variables V2 à V19.
Les réseaux de neurones souffrant fréquemment de
« sur-apprentissage » on a scindé l'échantillon de base
en deux : l'échantillon d'apprentissage et son complément
l'échantillon test. Par ailleurs, on utilise la fonction sigmoïde
et l'apprentissage s'effectue avec une fonction d'erreur quadratique (encore
appelée coût). La vitesse de convergence est alors sensible au
coefficient å.
3.2. La fixation des paramètres du réseau
Pour mémoire, nous rappelons que l'apprentissage a
été réalisé par rétropropagation de
l'erreur. De façon à éviter les minima locaux dans la
surface d'erreur, nous avons utilisé un taux d'apprentissage variable et
un moment. Nous avons admis deux couches cachées, en sus de la couche
d'entrée et de la couche de sortie. Les paramètres
d'apprentissage du réseau sont les suivants :
- Coefficient d'apprentissage : 0,1 0
- Momentum : 0,5
- Température de fonction sigmoïde : 0,5
Figures 12: Procédure de fixation des
paramètres du modèle neuronal sous SPAD
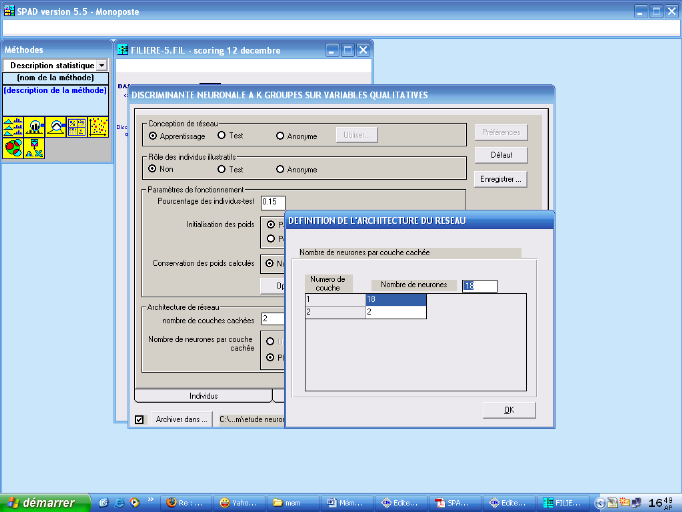
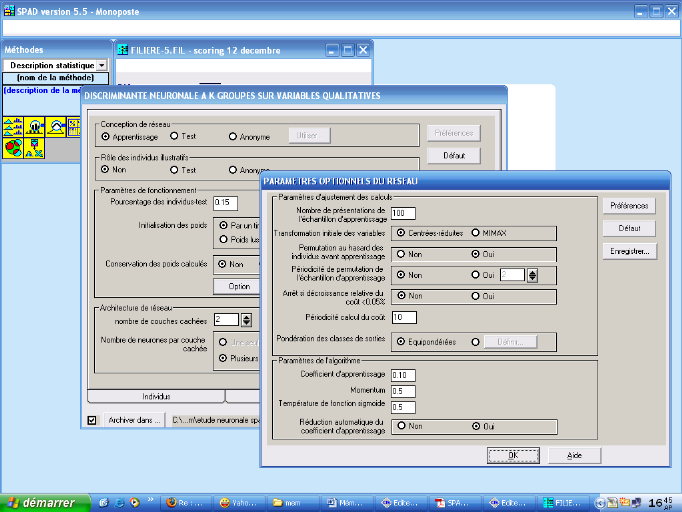
Source : Recherche de Fred Ntoutoume, Crefdes, 2007
3.3. Les résultats de la modélisation par
réseaux de neurones
La modélisation du risque de crédit à des
fins de prédiction par rétropropagation de gradient de l'erreur,
sur réseaux neuronaux, nous fournit les résultats
suivants :
Tableau 28: Matrice de confusion avec marge
(avec 2 neurones dans la 2e couche cachée)
DISCRIMINANTE NEURONALE A N GROUPES
INFORMATION SUR LE RESEAU UTILISE
ROLE DES INDIVIDUS ACTIFS : APPRENTISSAGE
NOMBRE DE COUCHES CACHEES : 2 COUCHES
NOMBRE DE NEURONES PAR COUCHE CACHEE
COUCHE 2 : 18
COUCHE 3 : 2
COEFFICIENT D'APPRENTISSAGE : 0.10000
MATRICE DE CONFUSION AVEC MARGES
EN LIGNE : Ce client a til remboursé integralement son
credit au plus 3
EN COLONNE : CLASSES DE SORTIE
+----------------------+------+------+------+
| |CLA 1|CLA 2| ENS |
+----------------------+------|------|------|
| oui | 29 | 7 | 36 |
| non | 18 | 158 | 176 |
+----------------------+------+------+------+
| ENSEMBLE | 47 | 165 | 212 |
+----------------------+------+------+------+
Source : Recherche de Fred Ntoutoume, Crefdes, 2007
La matrice des confusions calculée sur les
données d'apprentissage permet de mesurer le taux d'erreurs, ou taux de
mauvais classement. A la lumière des résultats observés
dans le tableau ci-dessus, nous constatons que les performances
prédictives du modèle neuronal ne sont pas assez satisfaisantes.
En effet, la proportion d'individus orientés vers la bonne classe de
sortie est de l'ordre de 88,21%, c'est-à-dire en deçà des
90%, seuil tolérable au grand maximum. Le tableau de pourcentages des
biens classés indique dans le détail, que les
« mauvais payeurs » classés par erreur chez les
« bon payeurs » est supérieur à 1/10 (cf
tablau ci-dessous).
Tableau 29: Performances de classement du réseau de
neurones
(avec 2 neurones dans la 2e couche cachée)
POURCENTAGE DE BIEN CLASSES
+----------------------+---------+---------+---------+---------+---------+
| | BIEN | MAL | | %BIEN
| |
| | CLASSES | CLASSES | TOTAL | CLASSES
| PURETE |
+----------------------+---------+---------+---------+---------+---------+
| oui | 29 | 7 | 36 | 80.56
| 61.70 |
| non | 158 | 18 | 176 | 89.77
| 95.76 |
+----------------------+---------+---------+---------+---------+---------+
| TOTAL | 187 | 25 | 212 | 88.21
| 88.21 |
+----------------------+---------+---------+---------+---------+---------+
Source : Recherche de Fred Ntoutoume, Crefdes, 2007
Compte tenu de ces premiers résultats relativement
insuffisants, nous nous proposons de réajuster la structure du
réseau, afin d'améliorer les performances prédictives.
Nous pouvons opter soit pour l'ajout d'une couche supplémentaire, soit
pour l'ajustement d'une couche déjà existante. La première
solution a cependant l'inconvénient de complexifier d'avantage le
réseau. Nous choisissons la seconde option, moins coûteuse.
3.4. Le réajustement de la structure du
réseau de neurones et les résultats
Le réajustement de la deuxième couche consiste
à lui retrancher un neurone, sur les deux de départ. Toutes
choses étant donc égales par ailleurs, nous relançons le
réseau et obtenons ce qui suit :
Tableau 30: Résultats de la modélisation
neuronale
(avec 1 neurone dans la 2e couche cachée)
INFORMATION SUR LE RESEAU UTILISE
ROLE DES INDIVIDUS ACTIFS : APPRENTISSAGE
NOMBRE DE COUCHES CACHEES : 2 COUCHES
NOMBRE DE NEURONES PAR COUCHE CACHEE
COUCHE 2 : 18
COUCHE 3 : 1
COEFFICIENT D'APPRENTISSAGE : 0.10000
MATRICE DE CONFUSION AVEC MARGES
EN LIGNE : Ce client a til remboursé integralement son
credit au plus 3
EN COLONNE : CLASSES DE SORTIE
+----------------------+------+------+------+
| |CLA 1|CLA 2| ENS |
+----------------------+------|------|------|
| oui | 28 | 8 | 36 |
| non | 10 | 166 | 176 |
+----------------------+------+------+------+
| ENSEMBLE | 38 | 174 | 212 |
+----------------------+------+------+------+
POURCENTAGE DE BIEN CLASSES
+----------------------+---------+---------+---------+---------+---------+
| | BIEN | MAL | | %BIEN |
|
| | CLASSES | CLASSES | TOTAL | CLASSES |
PURETE |
+----------------------+---------+---------+---------+---------+---------+
| oui | 28 | 8 | 36 | 77.78 |
73.68 |
| non | 166 | 10 | 176 | 94.32 |
95.40 |
+----------------------+---------+---------+---------+---------+---------+
| TOTAL | 194 | 18 | 212 | 91.51 |
91.51 |
+----------------------+---------+---------+---------+---------+---------+
Source : Recherche de Fred Ntoutoume, Crefdes, 2007
Suite de notre réajustement structurel du réseau
Perceptron Multicouches, nous observons que la performance globale des
classements a été améliorée de 3 points environ. En
effet, alors que le pourcentage des biens classés était de
l'ordre de 88,21% dans le premier cas, il se situe à présent au
niveau de 91,51%. Nous en déduisons que notre
réajustement a permis d'obtenir l'une des plus robustes performances de
classement possibles pour notre échantillon, et nous le gardons.
IV/ Comparaison des modèles logistique et neuronal
Après avoir procédé avec succès
à la modélisation par la régression logistique binaire
d'une part, et par les réseaux de neurones PMC d'autre part, nous nous
proposons de comparer les performances de classement prédictif des deux
modèles à des fin d'arbitrage.
4.1. Comparaison des matrices de confusion (pourcentage de
classement prédictif)
La règle de décision associée à un
score nous permet d'affecter chaque entreprise à un des groupes
« mauvais payeur », ou « bon payeur ».
Toutes les entreprises de notre base de données ont donc un groupe
auquel elles appartiennent réellement, et un groupe auquel elles sont
affectées. Le décompte des affectations correctes,
c'est-à-dire correspondant au groupe réel, nous a fournit les
pourcentages de bons classements, celui-ci dépendant du seuil de
décision. Les pourcentages de classement pour les deux méthodes,
sont comparés dans le tableau qui suit :
Tableau 31: Comparaison des pouvoirs discriminants
|
Classes à prédire
|
Modèles de classement prédictif
|
|
Régression Logistique binaire
|
RNA Perceptron Multicouches
|
|
« bons payeurs »
|
75,0
|
77,78
|
|
« mauvais payeurs »
|
97,2
|
94,32
|
|
Ensemble
|
93,4
|
91,51
|
Source : Recherche de Fred Ntoutoume, Crefdes, 2007
La comparaison des pourcentages des bons classements
prédictifs nous révèle que la modélisation du
risque de contrepartie issue de notre échantillon d'apprentissage est
plus fiable lorsque l'on se base sur une régression logistique,
plutôt que sur une régression neuronale. En effet, l'ensemble des
prédictions est correct à 93,4% dans le cas de la première
méthode, alors qu'il n'est fiable qu'à 91,51% dans le
deuxième cas. Ce constat nous suggère d'opter, dans le cadre du
choix de notre scoring final, pour l'équation de régression
définie par la procédure Logit.
La qualité de prédiction des mauvais payeurs,
qui sont correctement classés dans 97,2% des cas en régression
logistique conte 94,32% en régression neuronale, vient en appui à
notre décision en raison de la sensibilité. La sensibilité
est définie pour mémoire comme la probabilité de classer
l'individu dans la catégorie y = 1 (on dit que le test est
positif) étant donné qu'il est effectivement observé dans
celle-ci. En effet, nous l'avons dit, il est bien plus grave d'octroyer un
prêt à une personne qui ne le remboursera pas (faux positif -
erreur de type 1) que de ne pas octroyer un prêt à une personne
fiable (faux négatif - erreur de type 2).
Nous rappelons que nous avons fixé notre seuil à
0,5, cela signifie que l'on considère comme mauvais payeur tout individu
dont la probabilité de non-remboursement dépasse 0,5.
4.2. Choix du modèle de scoring final
A la lumière de la comparaison des matrices de
confusion, nous retenons le modèle logistique comme le meilleur
modèle prédictif sur notre échantillon. En l'occurrence le
modèle, non-linéaire qui servira de base à la grille de
scoring avec un seuil fixé à 0,5 est :
1
1+e (- 3,586
+0,316.AGE -0,451.NIVREV
-0,951.DUREEXIS -0,273.VALGAR
+0,888.MONTANT +3,347.DEMOCT
+1,268.DIFDEMRE)
P = 1-
TROISIEME PARTIE
RECOMMANDATIONS
CHAPITRE V : RECOMMANDATIONS
I/ Recommandations pour une utilisation du modèle de
score
Pour l'utilisation du modèle de scoring que nous avons
proposé, il est important que certaines mesures techniques soient
prises, afin d'en assurer la bonne mise en oeuvre. Ces mesures passent par i)
l'implémentation informatique, ii) la formation des utilisateurs du
modèle de score, ainsi que par un suivi du modèle soit iii)
ponctuel, soit iv) continue.
1.1. Implémentation informatique
Le préalable à l'utilisation des
résultats de notre data mining pour l'action et à la mise
à disposition du modèle aux utilisateurs est
l'implémentation informatique.
Nous notons d'abord qu'il est plus complexe, pour l'UMECUDEFS
de mettre à jour des fichiers poste de travail afin d'y
implémenter la nouvelle grille de score, dans la mesure où il
sera nécessaire de saisir de nouvelles informations par les
micropreteurs pour une exécution en temps réelle, grâce a
une remontée vers les fichiers centraux. Or le logiciel
« E-Banking » utilisé à présent par
l'IMF ne prévoit pas de tels aménagements.
Sous ce rapport, nous recommanderions donc :
§ l'utilisation dans un premiers temps d'un fichier de
tableur pour réaliser un publipostage, à l'aide d'un logiciel de
traitement de données (EXCEL par exemple) ;
§ la mise en test de cette configuration pendant 3
à 6 mois, avec une mise à jour hebdomadaire des bases de
données.
1.2. Formation des utilisateurs du modèle de score
Pour une bonne appropriation du nouvel outil d'aide à
la décision des micropreteurs et des analystes crédits, il serait
nécessaire d'envisager des séances de formation à leur
profit.
Les objectifs de ces séances de formation pourraient
être :
§ Présenter le but recherché par le scoring
et y adhérer
§ Présenter les principes de l'outil grille de
score et son fonctionnement
§ Présenter les limites de la grille de score
§ Présenter les apports de la grille de score dans
la mission de l'analyste crédit (opérationnel et
organisationnel)
1.3. Suivi ponctuel par évaluation des
utilisateurs
Il importe, après la mise en oeuvre du modèle,
de suivre et d'évaluer les résultats obtenus. Ce suivi peut se
faire dans le cadre d'un programme précis de prêts, à
l'instar des crédits « TAXI IRANIENS ».
L'idée est d'analyser les résultats obtenus après la
campagne d'octroi des crédits, en s'assurant que les taux de
remboursement sont bien en rapport avec les valeurs du score, et que ce sont
biens les demandeurs de crédit avec les scores les moins risqués
qui ont le mieux honoré leurs engagements.
Nous recommanderions par ailleurs de compléter cette
analyse quantitative, par une analyse qualitative basée sur l'avis des
agents de crédit ayant utilisé le score. Ceux-ci peuvent en effet
avoir une meilleure idée des phénomènes omis par le score
d'une part, ou bien avoir identifié par intuition des populations mal
scorées d'autre part.
En somme, nous recommanderions, dans le cas d'un suivi
ponctuel :
· une analyse quantitative basée sur une
comparaison du point de vue de la sensibilité et de la
spécificité du score ;
· une analyse qualitative basée sur une approche
participative des utilisateurs du modèle de score.
1.4. Suivi en continue par tableau de bord
En complément ou en substitut du suivi ponctuel, il serait
de même nécessaire de s'assurer des bonnes performances du score
de crédit et de sa bonne utilisation, par la mise en place d'un suivi
continue à travers des tableaux récapitulatifs. Le tableau
ci-dessous pourrait servir à surveiller le bon fonctionnement du score,
au fil des n premiers mois :
Tableau 32: Tableau de Bord de suivi du fonctionnement du
score
|
Mois M-1
|
Mois M-2
|
Mois M-3
|
...
|
|
Score
%
|
Nb de clients
|
% de clients / pop. Totale
|
Taux d'impayé
|
Nb de clients
|
% de clients / pop. Totale
|
Taux d'impayé
|
Nb de clients
|
% de clients / pop. Totale
|
Taux d'impayé
|
|
|
10
|
|
|
|
|
|
|
|
|
|
|
|
20
|
|
|
|
|
|
|
|
|
|
|
|
30
|
|
|
|
|
|
|
|
|
|
|
|
40
|
|
|
|
|
|
|
|
|
|
|
|
50
|
|
|
|
|
|
|
|
|
|
|
|
60
|
|
|
|
|
|
|
|
|
|
|
|
70
|
|
|
|
|
|
|
|
|
|
|
|
80
|
|
|
|
|
|
|
|
|
|
|
|
90
|
|
|
|
|
|
|
|
|
|
|
|
100
|
|
|
|
|
|
|
|
|
|
|
|
Total
|
|
|
|
|
|
|
|
|
|
|
Source : Recherche de Fred Ntoutoume, Crefdes, 2007
(inspiré de Tufféry, 2007, p.37)
Ce tableau, qui pourrait servir de support à un suivi en
continue des performances du modèle de Scoring, présente à
partir de sa deuxième colonne, pour le mois M-1 qui
précède l'analyse et pour chaque valeur du score :
§ le nombre de clients qui sont classés dans ce
score,
§ le rapport de ce nombre sur la population totale de
clients,
§ le taux d'impayés enregistrés par les
clients qui se sont vus attribués ce score.
Ces indicateurs valent pour les mois d'avant M-n, jusqu'au
3e mois (si l'on souhaite tester le score sur 3 mois), ou jusqu'au
12e mois (si l'on souhaite observer les performances du score sur
une année).
De même, le suivi de la bonne utilisation de la grille
est possible. L'idée est de vérifier que les agents de
crédit tiennent compte de la probabilité de non-remboursement
fournie par le score de risque, et limitent de ce fait leurs engagements avec
les clients les plus risqués. Dans ce cas, le tableau
précédent sert toujours, mais le taux d'impayé est
remplacé par le nombre et l'encours de crédit des dossiers
conclus durant le mois concerné.
Tableau 33: Tableau de Bord de suivi de l'utilisation du
score
|
Mois M-1
|
Mois M-2
|
Mois M-3
|
...
|
|
Score
%
|
Nb de clients
|
% de clients / pop. Totale
|
Nb de crédits alloués
|
encours
|
Nb de clients
|
% de clients / pop. Totale
|
Nb de crédits alloués
|
encours
|
Nb de clients
|
% de clients / pop. Totale
|
Nb de crédits alloués
|
encours
|
|
|
10
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
20
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
30
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
40
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
.
.
.
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
100
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Total
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Source : Recherche de Fred Ntoutoume, Crefdes, 2007
(inspiré de Tufféry, 2007, p.37)
II/ Recommandation sur les aspects organisationnels de
l'UMECUDEFS
Au plan organisationnel, nous recommanderions à
l'UMECUDEFS d'améliorer la traçabilité des dossiers de
crédit, afin de pouvoir assurer un meilleur suivi des tableaux de bord
proposés supra. La traçabilité des dossiers de
crédit est la capacité de l'UMECUDEFS à fournir aux
clients un service indiquant la position de l'ensemble de leurs dossiers
(clôturés ou en cours de traitement) dans l'espace (dans quelle
service ou chez quel agent traitant) et dans le temps (délai de
traitement déjà réalisé et estimation du
délai restant) au sein de la chaîne de traitement. Ainsi, nos
recommandations dans ce sens seront :
· étendre la notion de traçabilité
au delà du simple suivi de dossier ne donnant qu'a posteriori les
étapes qu'un dossier particulier a déjà franchie, et
fournir aux usagers un service indiquant en temps réel les étapes
que ses dossiers ont franchies, les étapes à venir et la position
des dossiers dans la chaîne complète du traitement ;
· identifier les dossiers à rendre traçable
en priorité et les connecter à leur processus de
traitement ;
· débuter par une analyse et une formalisation
métier des processus à rendre traçables ;
· identifier au sein de la formalisation métier
les étapes du processus à rendre visibles pour l'usager ;
· compléter par une formalisation sous l'angle
« système d'information » pour ce qui concerne les
étapes visibles pour l'usager ;
· permettre aux usagers d'accéder à
l'ensemble de leurs dossiers à partir du portail internet de
l'UMECUDEFS.
CONCLUSION
En définitive, il ressort de notre étude que la
prévision du risque de contrepartie, par la mise en place d'un scoring
dont les données de bases sont en grandes majorité nominales,
peut être fiable. L'idée que les modèles de scoring
crédit étaient difficilement approchables dans le contexte de
variables qualitatives, comme semblait le défendre l'esprit dans lequel
les plus célèbres modèles de score sont nés, nous
parait donc excessive du point de vue des résultats de notre
recherche.
En effet, cette appréhension a d'abord
été levée d'un point de vue méthodologique. Les
premiers modèles de scoring crédit admettaient une liaison
linéaire entre les « income » et les
« outcome », ce qui n'est pas toujours le cas, nous l'avons
vu. Or cette hypothèse de départ enferme de facto le
modélisateur dans le difficile compromis de l'indépendance des
observations et de normalité des variables explicatives, impossibles
à satisfaire si on possède au moins une variable explicative
qualitative. Nous avons donc opté pour une solution
méthodologique non paramétrique, admettant des relations non
linéaires entre variables exogènes et variable
endogène.
Cette appréhension a ensuite été
levée du point de vue de la performance statistique, puisque les
résultats obtenus, dans les deux modèles prédictifs
estimés étaient fiables à plus de 90%.. Ainsi, nous avons
pu atteindre, avec un bon seuil de confiance, nos objectifs de départ
qui tenaient à la description, à l'explication, puis à la
prédiction par la modélisation statistique et l'intelligence
artificielle.
Dans les deux premiers points en effet, nous nous sommes
intéressés à la distribution des clients (PME) de
l'UMECUDEFS au sein des « bon payeurs » et des
« mauvais payeurs ». Il en ressort que les clients
« mauvais payeurs » présents dans notre
échantillon comptent plus de cas dont l'age est compris entre 30 et 50,
et que le risque de crédit augmente avec l'âge. Il en ressort
aussi que la relation entre le niveau de revenu des dirigeant des PME et le
risque de crédit évolue en sens inverse, confirmant que
« mieux vaut ne prêter qu'aux riches », de même
d'ailleurs qu'entre la durée d'existence de l'entreprise elle-même
et la probabilité de défaut.
Nous observons par ailleurs que la distribution des PME est
plus forte chez les « mauvais payeurs » si la valeur de la
garantie proposée baisse, ou si le montant du crédit a une
tendance haussière. Enfin, la sélection adverse des agents de
crédits ainsi que le nombre d'échéances de retard que
peuvent accuser les débiteurs pendant le remboursement, ont une
importante influence positive sur la distribution des « mauvais
payeurs » de notre échantillon..
Dans le troisième point, l'objectif de
prédiction aura été atteint à travers une
régréssion logistique binaire, puis une régression
neuronale par parceptron multicouches. Le modèle de scoring finalement
retenu a confirmé notre hypothèse numero 1. En effet, nous avons
admis dans notre hyperplan que les données démographiques du
dirigeant, l'expérience du dirigeant en matière de crédit,
la forme juridique de la PME, le secteur d'activité, le type de
garantie, le facteur temps et le montant de la demande de prêt
influencent le risque de crédit de manière significative.
En outre, nous avons confirmé que le modèle
logistique présente de meilleures performances prédictives que le
modèle neuronal, dans le cadre de notre deuxième hypothèse
de recherche.
Cependant, cette étude tiendra son importance de
l'applicabilité de la grille de scoring crédit à laquelle
elle aura permis d'aboutir, via une implémentation informatique
progressive au sein de l'UMECUDEFS, et via un système de suivi
évaluation participatif continue ou ponctuel.

fred.ntoutoume@yahoo.fr
BIBLIOGRAPHIE
· Analyse de données et
statistiques
DESJARDINS,
« Tutorial in Quantitative Methods for Psychology »,
Université de Montréal, 2005, Vol. 1(1),
TABACHNICK, B.G. & Fidell, L.S.
«Using Multivariate statistics», Fourth Edition.
United State of America: Allyn and Bacon, 2000.
NIGRIN, A, «Neural Networks for Pattern
Recognition», Cambridge, MA: The MIT Press, (1993)
HAYKIN, S., «Neural Networks: A Comprehensive
Foundation», NY: Macmillan, (1994)
Source :
GAYE, I., «Cours de méthodologie de la recherche
en sciences sociales », Ecole Nationale d4economie
Appliquée, 2004.
SAPORTA, G., «
Probabilités,
analyses des données et statistiques » ,
Editions TECHNIP, Juin 2006
DROESBEKE, J.J. ;
LEJEUNE, M. ; SAPORTA, G., « Méthodes statistiques
pour données qualitatives », Editions TECHNIP, Septembre
2006
·
Scoring
SCHREINER, M. ,« Les Vertus et Faiblesses de
L'évaluation Statistique (Credit scoring en
Microfinance », Microfinance Risk Management, septembre 2003
SCHREINER, M. «Scoring: The Next Breakthrough in
Microfinance?» Occasional
Paper No. 7, Consultative Group to Assist the Poorest,
Washington, D.C, 2002
SCHREINER, M. «Credit Scoring for Microfinance: Can It
Work?», Journal of Microfinance,
Vol. 2, No. 2, 2000
SCHREINER, M. «A Scoring Model of the Risk of Arrears at a
Microfinance Lender in Bolivia», manuscrit, Center for Social Development,
Washington University de St.
Louis, 1999
FONG, G. & VASICEK, O. A. «A multidimensional
framework for risk analysis», Financial. Analyst Journal,
Juillet/Aout 1997
De SOUSA-SANTOS, F. « Le scoring est-il la
nouvelle révolution du microcrédit ? », in
BIM N°32, octobre 2002
SAUNDERS A.& ALLEN L., « Credit Risk
Measurement », John Wiley & Son (Ed), 2002
SCHREINER, M. « Scoring: the next breakthrough in
microcredit ? », CGAP, juin 2002
DIALLO, B. « Un modèle de `crédit
scoring' pour une institution de micro-finance africaine : le cas de
Nyesegisio au Mali », Laboratoire d'Economie d'Orléans
(LEO), Mai 2006.
ANDERSON, R. « The crédit scoring
Toolkit », Oxford University Press, 2007
· Réseaux de neurones et Régression
logistique
DOUCOURE, F.B., « Cours de Méthodes
économétriques », Centre de Recherche et de
Formation pour le Développement Economique et Social (CREFDES),
Université de Dakar, 2007
TAFFE, P., « Cours de Régression
logistique Appliquée », Institut Universitaire de
Médecine Sociale et Préventive (IUMSP),
Lausanne, Août 2004
NIGRIN, A, «Neural Networks for Pattern
Recognition», Cambridge, MA: The MIT Press, . (1993)
ROSENBLATT, F.. «The Perceptron: A Probabilistic
Model for Information Storage and Organization in the Brain» In,
Psychological Review, Vol. 65, No. 6, Novembre, 1958
TUFFERY,S. « Data Mining et Statistique
décisionnelle, l'intelligence des données », Editions
Technip, 2007
ESPAHBODI P., «Identification of problem banks and binary
choice models», Journal of Banking and Finance, N°15, 1991
· Articles complémentaires
MEDSKER L., TURBAN E. et TRIPPI R.R., «Neural Network
Fundamentals for Financial Analysts», «Neural Network in Finance and
Investing», The Journal of Investing, printemps 1993, p. 3-25.
FELDMAN K. and KINGDON J., «Neural networks and some
applications to finance» Applied Mathematical Finance, vol. 2, (1995), p.
17-42 (à la reserve)
ZHANG G., HU M.Y., PATUWO B.E. and INDRO D.C.,
«Artificial neural networks in bankruptcy prediction: General framework
and cross-validation analysis», European journal of operational research
116 (1999) p.16-32.
COATS P. K. et FANT L. F., «Recognizing Financial
Distress Patterns Using a Neural Network Tool«, Financial Management,
vol., 22, no. 3, automne 1993, p. 142-155.
KRYZANOWSKI L., GALLER M. et WRIGHT, D. W., «Using
Artificial Neural Networks to Pick Stocks«, Financial Analysts
Journal, juillet-août 1993, p. 21-27.
Charte des Petites et Moyennes Entreprises du
Sénégal, 2003, p.6
· Webographie
www.microfinance.com.
http://fr.wikipedia.org/wiki/R%C3%A9gression_logistique
http://fr.wikipedia.org/wiki/Neuronal_network
www.cedric.cnam.fr/
http://www.umecudefs.com/index.php?option=com_content&task=view&id=25&Itemid=43
http://www-igm.univ-mlv.fr/~dr/XPOSE2002/Neurones/index.php?rubrique=Apprentissage
www.pagesperso-orange.fr/levasseur.michel/ (Site
du professeur Levasseur, Spécialiste en réseaux de neurones)
www.vieartificielle.com/article/?id=54
http://www.emse.fr/~pbreuil/amv/nn/index.html
www.zonecours.hec.ca/documents/H2006-1-701647.401600H06_Seance11.ppt
www.federalreserve.gov
www.formation.creascience.com/regression-logistique-p-250.html
fr.wordpress.com/tag/regression-logistique/
etc.

* 1
http://www.federalreserve.gov
* 2 G. Fong & O. A. Vasicek
«A multidimensional framework for risk analysis», Financial.
Analyst Journal, July/August 1997, p. 52
* 3 Rayon Anderson,
« The crédit scoring Toolkit », Oxford
University Press, 2007, p. 6
* 4 Stéphane
Tufféry, « Data Mining et Statistique décisionnelle,
l'intelligence des données », Editions Technip, 2005, p.
141
* 5Fréderic De
Sousa-Santos, « Le scoring est-il la nouvelle révolution du
microcrédit ? », in BIM N°32, octobre 2002, p.2
* 6 Antony Saunders & Linda
Allen, « Credit Risk Measurement », John Wiley
& Son (Ed), 2002, p. 21
* 7 Mark Schreiner «
Scoring: the next breakthrough in microcredit ? », CGAP, juin 2002, 102
p.
* 8 9 Stéphane
Tufféry, « Data Mining et Statistique
décisionnelle, l'intelligence des données »,
Editions Technip (2e Ed), 2007
* 10 L'Association
Française des Crédits Managers (AFDCC) calcule elle-même
ses propres scores depuis les années 1997.
* 11 B. Diallo, « Un
modèle de `crédit scoring' pour une institution de micro-finance
africaine : le cas de Nyesegisio au Mali », Laboratoire
d'Economie d'Orléans (LEO), Mai 2006.
* 12 J. Desjardins,
« Tutorial in Quantitative Methods for Psychology »,
Université de Montréal,
2005, Vol. 1(1), p. 35,41
* 13
http://fr.wikipedia.org/wiki/R%C3%A9gression_logistique
(le 20 Novembre 2007)
* 14 A. Nigrin, (1993),
«Neural Networks for Pattern Recognition», Cambridge, MA:
The MIT Press, p. 11
* 15 ROSENBLATT, Frank.
«The Perceptron: A Probabilistic Model for Information Storage and
Organization in the Brain» In, Psychological Review, Vol. 65, No. 6,
pp. 386-408, Novembre, 1958
* 16Plusieurs autres
fonctions d'activation existent pour la transformation des données
d'entrée du neurone, on peut citer la fonction logistique Y = F(X) =
1/(1 + exp(-d*X) dont nous allons nous servir, la tangente hyperbolique Y = 2
/(1+ exp(-2* X) -1), la fonction gaussienne Y = exp(-(X^2) /2), ou la fonction
sigmoïde Y= (1 + e - âx) - 1
* 17
http://www-igm.univ-mlv.fr/~dr/XPOSE2002/Neurones/index.php?rubrique=Apprentissage
* 18 Tabachnick,
B.G. & Fidell, L.S. «Using
Multivariate statistics», Fourth Edition. United State of America:
Allyn and Bacon, 2000.
* 19 Source :
http://www.trader-workstation.com/finance/ia_critiques_reseaux_neurones.php
* 20 TUFFERY, Stéphane,
« Data Mining & Statistiques Décisionnelles :
l'intelligence des données », Technip (Ed), 2007
* 21 Schreiner, Mark
,« Les Vertus et Faiblesses de L'évaluation Statistique
(Credit scoring en Microfinance », Microfinance Risk Management,
septembre 2003
* 22 Il est en fait question
de choisir entre privilégier les résultats financiers et
comptables de l'IMF pour une pérennisation profitable à tous, ou
bien mettre en avant la rentabilité sociale en termes de
réduction de la pauvreté en assumant les risques de portefeuille
médiocre pouvant entraîner la fermeture de l'IMF. Même si la
question n'est pas tranchée entre les institutionnalistes (tenants de la
viabilité) et les welfaristes (tenants de la rentabilité
sociale), notre étude s'inscrit dans la ligne des premiers
cités.
* 23 Nigrin, A,
«Neural Networks for Pattern Recognition», Cambridge, MA:
The MIT Press, p. 11. (1993)
* 24 Haykin, S., Neural
Networks: A Comprehensive Foundation, NY: Macmillan, p. 2, (1994)
* 25 Source :
http://www.umecudefs.com/index.php?option=com_content&task=view&id=25&Itemid=43
* 26 SAPORTA, Gilbet,
« La notation statistique des emprunteurs ou `scoring' »,
Conservatoire National des Art et Métier, article paru en 2006.
(edusol.education.fr)
* 27 L'ACP a été
introduite en 1901 par K. Pearson et développée par H. Hotelling
en 1933.
* 28 TAFFE, Patrick,
« cours de Régression logistique Appliquée »,
Institut Universitaire de Médecine Sociale et Préventive
(IUMSP), Lausanne, Août 2004
* 29 En effet, il est bien
plus grave d'octroyer un prêt à une personne qui ne le remboursera
pas (faux positif - erreur de type 1) que de ne pas octroyer un prêt
à une personne fiable (faux négatif - erreur de type 2).
| 

