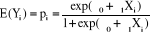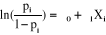Scoring crédit: une application comparative de la régression logistique et des réseaux de neurones( Télécharger le fichier original )par Fred NTOUTOUME OBIANG-NDONG Université Cheikh Anta Diop (UCAD) - Master Methodes Statistiques et Econometriques 2006 |

II/ Généralités sur la régression logistique2.1. Définition de la régression logistique binaireLa régression logistique se définit selon Desjardins (2005)12(*) comme une technique permettant d'ajuster une surface de régression à des données lorsque la variable dépendante est dichotomique. Cette technique est utilisée pour des études ayant pour but de vérifier si des variables indépendantes peuvent prédire une variable dépendante dichotomique. Selon Wikipédia en outre, la régression logistique peut correspondre à une technique statistique dont l'objet est, à partir d'un fichier d'observations, de produire un modèle permettant de prédire les valeurs prises par une variable catégorielle, le plus souvent binaire, en se basant sur une série de variables explicatives continues et/ou binaires13(*). Contrairement à la régression multiple et l'analyse discriminante, la régression logistique n'exige pas une distribution normale des prédicteurs ni l'homogéneité des variances. Par ses nombreuses qualités donc, cette technique est de plus en plus préférée à l'analyse discriminante par les statisticiens et les spécialistes du scoring. Ainsi dans le cadre du modèle linéaire généralisé, des perfectionnements ne cessent d'être apportés à la régression logistique (McFadden, prix Nobel d'économie en 2000 fut récompensé pour ses travaux à ce sujet), la confirmant comme l'une des méthodes de modélisation les plus fiables, et dont plusieurs indicateurs statistiques permettent d'en contrôler facilement la robustesse (LR ratio, R carré de McFadden, Test de Hosmer-Lemeshow). La régression logistique est enfin largement répandue dans des domaines nombreux et divers. D'abord utilisée dans la médecine (caractérisation des sujets malades par rapport aux sujets sains par exemple), cette technique de classement et de prédiction s'est rependue dans la banque assurance (détection des groupes à risque), la science politique (explication des intentions de vote), le marketing (fidélisation des clients).. 2.2. Principes et propriétés mathématiques de la régression logistique binaireLorsque nous voulons modéliser une variable à réponse binaire, la forme de la relation est souvent non linéaire. On recourt alors à une fonction non-linéaire, de type logistique par exemple, en pareils cas. Le principe de la régression logistique binaire est de considérer une variable à prévoir binaire (variable cible admettant uniquement deux modalités possibles) Y = {0,1} d'une part, et p variables explicatives notées X = (X1, X2, ..., Xj), continues, binaires ou qualitatives. L'objectif de la régression logistique est de modéliser l'espérance conditionnelle E(Y/X=x), par l'estimation d'une valeur moyenne de Y pour toute valeur de X. Pour une valeur Y valant 0 ou 1 (loi de Bernouilli), cette valeur moyenne est la probabilité que Y=1. On a donc : E (Y/X=x) = Prob (Y=1/X=x) Les propriétés principales de la régression logistique peuvent être exposées à travers l'exemple des deux graphiques ci-dessous (Cf. graphiques). On constate dans les deux cas de figure que la fonction logistique est monotone croissante ou décroissante, selon le signe de 1 d'une part, et que la fonction logistique est presque linéaire lorsque E(Y) est entre 0,2 et 0,8 et s'approche graduellement de 0 et 1 aux deux extrémités du support de X. Aussi, la distribution logistique est symétrique E (-Y) = 1 - E (Y), et de moyenne nulle ð2 / 6. (F. B. Doucouré, 2007).
Figures 1: Les propriétés de la régression logistique Une autre propriété de la régression logistique est qu'elle n'exige pas que les prédicteurs (variables indépendantes) suivent une loi normale, ou soient distribués de façon linéaire, ou encore qu'ils possèdent une variance égale entre chaque groupe. La forme de courbe (en « s ») que nous remarquons par ailleurs sur les deux graphiques est appelé sigmoïde, ou courbe logistique. Si l'on suit l'expression de cette courbe, on peut écrire la fonction logistique E(Y) = pi = prob (Y=1/X=x) sous la forme:
La probabilité d'occurrence selon la formule logistique s'écrit :
Equation équivalente par transformation à : En fait, en cherchant à expliquer la probabilité de réalisation de l'évènement Prob(Y=1/X=x), il nous faudrait une transformation de E(Y) qui étende l'intervalle de définition [0,1]. C'est le calcul des ratios de chance « odds ratio » qui permet d'envisager cette transformation. Ainsi le quotient pi /(1-pi) est appelé « odds », et la fonction f(p)=ln (pi/1-pi) est appelée « logit ». Le fonctionnement consiste à calculer des coefficients de régression de façon itérative. En d'autres termes le programme informatique, à partir de certaines valeurs de départ pour Y0 et Y1, vérifiera si les log chances (odd ratios) estimés sont bien ajustés aux données, corrigera les coefficients, réexaminera le bon ajustement des valeurs estimées, jusqu'à ce qu'aucune correction ne puisse atteindre un meilleur résultat (Howell, 1998). Sous ce rapport, le modèle logistique défini précédemment peut être utilisé pour : · décrire la nature de la relation entre la probabilité espérée d'un succès pour la variable réponse (ex: probabilité d'acheter, probabilité de s'abonner) et une variable explicative X; · prédire la probabilité espérée d'un succès étant donné la valeur de la variable X (ex: probabilité de rembourser un crédit étant donné les caractéristiques sociales, géo-marketing, etc de l'emprunteur, tel qu'est l'objet de notre présent mémoire). Mais au cours de la dernière décennie d'autres techniques de modélisation, regroupées sous le vocable « algorithmes d'apprentissage » et initialement utilisées en bio-physiologie, ont peu à peu émergé dans les milieux académiques et professionnels pour leurs capacités de prédiction. Nous porterons notre attention sur l'une de ces techniques venue de la neurophysiologie, et de plus en plus utilisée dans le domaine du scoring : les réseaux de neurones artificiels (RNA). * 12 J. Desjardins, « Tutorial in Quantitative Methods for Psychology », Université de Montréal, 2005, Vol. 1(1), p. 35,41 * 13 http://fr.wikipedia.org/wiki/R%C3%A9gression_logistique (le 20 Novembre 2007) |
|