3. Processus d'utilisation
3.1.Apprentissage des modèles des lettres
Dans cette partie nous allons extraire les modèles des
lettres pour chaque scripteur dans ses différentes formes. Nous allons
analyser chaque modèle et d'extraire leurs matrices de distributions
afin de les enregistrer dans la base de données d'apprentissage (figure
21). Le schéma général d'apprentissage est illustré
par la figure 20.
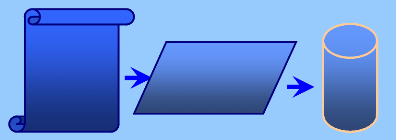
Modèles des
lettres des
différents
scripteurs
RIMA
Sous Système
d'Apprentissage
BD
XML
Figure 20 : Modèle d'apprentissage

Figure 21 : Portion de la base d'apprentissage
3.2.Reconnaissance des mots manuscrits arabes
Dans cette partie notre système va essayer de
reconnaître les mots entrés. Nous mesurons par la suite la
précision de reconnaissance pour chaque mot, qui est le pourcentage des
lettres reconnues par rapport au nombre totale des lettres de chaque mot
(figure 22).
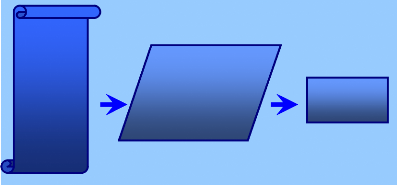
Liste des
mots
RIMA
Sous Système de
reconnaissance
Mesure de
la précision
Figure 22 : Modèle de reconnaissance
La figure 23 montre un exemple de reconnaissance du mot
«a+4Å», la reconnaissance se fait de façon
incrémentale caractère par caractère, en se basant sur la
base d'apprentissage précédemment construite. Cet exemple utilise
une reconnaissance supervisée.
En entré, on a une image nettoyée qui passera a
un processus de d'extraction incrémental des trames qui ce dernier se
charge de retrancher une trame du mot image et l'envoyer au processus de
correspondance qui effectuera la correspondance entre la trame extraite et les
modèles des lettres dans la base de données d'apprentissage avec
la prise en compte de la position au début et aussi dont les
modèles qui sont isolés. Une fois la première lettre
reconnue le système récupère l'identité du
scripteur qui a écrit cette lettre et le système enregistre dans
sa mémoire la première lettre. Le système modifie la
requête de sélection des modèles afin d'optimiser et
d'éviter le parcours de tous les modèles de tous les scripteurs.
Le système recommence le processus d'extraction en éliminant la
première partie dont elle correspond à la lettre trouvée.
Le système dans sa deuxième mission va chercher dans la base de
données tous les modèles qui sont au début puisqu'il
s'agit s'un nouveau psédo-mot, etc.
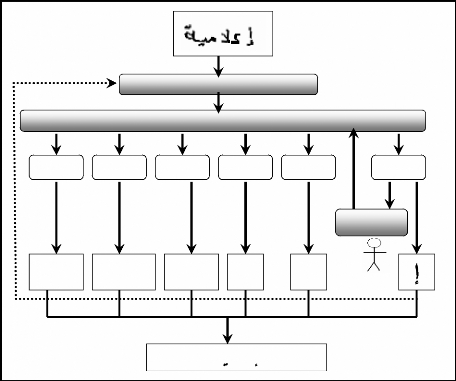
Sixième
Lettre
ÉÜ
Cinquième
Lettre
ÜíÜ
Extraction incrémentai des trames
Quatrième
Lettre
Üã
Correspondance
??????
Troisième
Lettre
?
Image
Deuxième
Lettre
?
Mot solution
Reconnaissance
du scripteur
Première
Lettre
Figure 23 : Exemple de reconnaissance de mot manuscrit
| 

