|
REMERCIEMENTS
Nos sinceres remerciements s'adressent à Allah le
tout Puissant pour son aide et son guide qui nous a permis de réaliser
ce travail.
Ce travail a été réalisé sous
la direction du Mr. ZOUACHE Djaafer notre promoteur, que nous tenons à
lui adresser notre égard pendant la période de réalisation
de ce mémoire, et pour ses conseils judicieux qui nous ont servi de
guide tout au long de notre travail.
Nos remerciements vont également Mr. LAALAMI
Fatih,
Mr .BENAMEUR Ziani, tous les enseignants du
département d'informatique et aux membres de jury qui ont
acceptés de juger ce modeste travail.
Enfin, nos sinceres remerciements s'adressent à tous
ceux qui
nous ont aidés de prés ou de loin à
réaliser notre travail.
Depuis la création du Web, il a connu un accroissement
important d'une manière phénoménale grace à
l'augmentation colossale du nombre de documents mis en ligne et des nouvelles
informations ajoutées chaque jour. En réalité, les usagers
d'un site Web apprécieront davantage la manière dont cette
information est présentée au sein du site alors que les
créateurs des sites Web intéressés par la
fidélisation des internautes fréquentant leurs sites et cherchant
à attirer de nouveaux visiteurs, ont besoin d'analyser le comportement
des internautes afin d'extraire des patrons d'accès au Web en vue d'une
amélioration et une personnalisation des sites. En effet, une grande
quantité de données peut être
récupérée suite à la navigation d'un utilisateur
sur un site. La taille sans cesse croissante de celles-ci et leur
diversité ne permet toutefois pas à l'être humain de
traiter de manière manuelle cette information.
L'accumulation de données a motivé le
développement d'un nouveau champ de recherche : l'Extraction de
Connaissances dans les bases de Données (ECD). L'ECD est un processus
itératif et interactif d'analyse d'un grand ensemble de données
brutes afin d'en extraire des connaissances exploitables par un
utilisateur-analyste qui y joue un rôle central [24].
Ce processus est itératif car les résultats
d'une étape peuvent remettre en cause les traitements effectués
durant les étapes précédentes, et il est interactif car la
qualité des résultats obtenus dépend en grande partie de
l'intervention des utilisateurs finaux. Le processus d'ECD se déroule en
trois étapes [25] :
La première étape décrit le
prétraitement de données qui consiste à nettoyer et
à mettre en forme les données (sélection des
données, élimination des doublons, élimination des valeurs
aberrantes, gestion des valeurs manquantes, transformation des variables,
création de nouvelles variables, etc.).
La fouille de données (data mining) représente
la deuxième étape du processus, c'est l'étape motrice de
l'ECD qui consiste à identifier les motifs qui structurent les
données, ou produire des modèles explicatifs ou prédictifs
des données.
La dernière étape présente le
post-traitement qui met en forme et évalue les résultats obtenus
(appelés connaissances), et à les faire interpréter et
valider par l'utilisateur.
Description du problème
L'approche que nous présentons : est une étude
de cas en fouille de données d'usage de web qui consiste à
analyser les données (les fichiers log ou bien le journal des connexion)
enregistrer au niveau du serveur de site web de CUBBA1 afin de
transformer ces données en des connaissances utiles pour
l'identification d'éventuels comportements typiques d'internautes selon
leur profil, s'est déroulée en trois étapes :
Elle consiste dans un premier temps à un
prétraitement des données qui servent à la
récupération et la concaténation des fichiers log afin que
les requêtes soient organisées en navigations.
Des paramètres introduits à partir des
statistiques sur les accès aux pages sont utilisés pour la
catégorisation des pages Web afin de sauvegarder les pages de contenu et
d'éliminer les pages auxiliaires qui ne présentent aucun
intérét, c'est la classification des pages qui est basée
sur deux méthodes hybrides à savoir l'analyse en composante
principale et le clustering k_means.ces pages de contenu permettent
l'extraction des profils.
À partir des résultats obtenus des deux
étapes précédentes, un regroupement des utilisateurs
basés sur la classification ascendante hiérarchie sont
appliqués aux bases de navigations afin de valider l'existence de
comportements particuliers chez les utilisateurs selon leur profil.
L'une des motivations principales de ce travail est qu'il
n'existe pas, à notre connaissance, des travaux similaires
déjà réalisés dans les institutions universitaires
algériennes. Pour ce faire, Il nous faut récupérer et
analyser les données concernant les requêtes des utilisateurs
stockées dans les fichiers log du serveur.
1 Centre Universitaire de Bordj Bou Arreridj
Organisation de mémoire
Pour conclure cette introduction, le présent
mémoire est réparti en deux grandes parties.
La première partie défini un état de
l'art contenant les chapitres 1, 2 et 3. La deuxième partie contient les
deux derniers chapitres présentent une série de résultats
d'expérimentation. Les chapitres sont organisés de la
façon suivante :
Dans le premier chapitre, on présente les
différentes étapes du processus de la fouille de données
d'usage du Web et un ensemble de concept utilisés dans ce domaine ainsi
ces différentes applications.
Dans le deuxième chapitre, on parle sur le
prétraitement des données qui décrit la première
étape de processus de la fouille d'usage du web, en présentant
les différentes heuristiques de prétraitement afin d'obtenir des
données structurées et prétes à l'application des
méthodes de fouille des données.
Dans le troisième chapitre , on définie les
différentes techniques de la fouille d'usage du web,
précisément une méthode factorielle et deux autres de la
classification non supervisée exploitées dans le présent
mémoire, à savoir les méthodes hiérarchiques et les
méthodes de partitionnement.
Le quatrième chapitre décrit
l'implémentation de prétraitement de données
réelles (les fichiers log de centre universitaire de Bordj Bou Arreridj)
ainsi les différents outils utilisés.
Le dernier chapitre exprime l'application de l'ensemble des
techniques d'analyse de fouille d'usage du web sur les fichiers log
structurés et prétraités.
Enfin nous concluons le mémoire on posant quelques
perspectives pour continuer ce travail.
Première partie
Chapitre 1
Fouille de données d'usage du Web
1. Web
Content Mining Web Structure Mining
Web Mining
Web Usage Mining
Introduction
Les sites Web représentent actuellement une
véritable source de production de grands volumes d'informations. La
recherche d'information, la consultation de données et l'achat en ligne,
sont des exemples de l'utilisation du Web. Dans le but d'améliorer ces
services et d'autres nous nous intéressons aux informations liées
au comportement des utilisateurs de cet environnement .C'est dans cet espace
que nous pouvons récupérer une quantité d'informations
pertinentes.
Pour fixer les idées, nous introduisons dans ce
chapitre la fouille de données du web et précisément la
fouille de donnée d'usage du web, les diverses définitions,
concepts, les données d'usage et quelque approches d'analyse que nous
utiliserons tout au long de ce mémoire.
2.
Fouille de données du Web
La fouille du Web (Web Mining (WM), en anglais) [01]
s'est développée à la fin des années 90 et
consiste à utiliser l'ensemble des techniques de la fouille de
données afin de développer des outils permettant l'extraction
d'informations pertinentes à partir de données du Web (documents,
traces d'interactions, structure des liens, etc.).
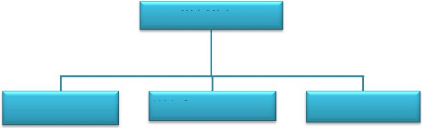
2.1. Taxonomie du Fouille de données du Web
Selon l'objectif visé plusieurs types d'études
peuvent être réalisés (FIG.1.1), à savoir :
a. L'analyse du contenu des pages Web (Web Content
Mining) :
C'est le processus d'extraction des connaissances à
partir du contenu réel des pages Web. Les informations provenant du Web
sont stockées dans des bases de données. Ces dernières
sont ensuite analysées en utilisant les langages d'interrogations des
bases de données et les techniques de fouille de données.
b. L'analyse des liens entre les pages Web (Web
Structure Mining) :
Il s'agit d'une analyse de la structure du Web, de
l'architecture et des liens qui existent entre les différents sites.
L'analyse des chemins parcourus permet par exemple de déterminer combien
de pages consultent les internautes en moyenne et ainsi d'adapter
l'arborescence du site pour que les pages les plus recherchées soient
dans les premières pages du site. De même, la recherche des
associations entre les pages consultées permet d'améliorer
l'ergonomie du site par création de nouveaux liens
c. L'analyse de l'usage des pages Web (Web Usage Mining)
:
Cette dernière branche du Web Mining consiste à
analyser le comportement de l'utilisateur à travers l'analyse de son
interaction avec le site Web. Cette analyse est notamment centrée sur
l'ensemble des clics effectués par l'utilisateur lors d'une visite au
site (on parle alors d'analyse du clickstream). L'intéret est d'enrichir
les sources de données utilisateur (bases de données clients,
bases marketing, etc.) à partir des connaissances extraites des
données brutes du clickstream et ce afin d'affiner les profils
utilisateur et les modèles comportementaux.
C'est précisément sur cet axe, exploité
plus en détail dans le présent chapitre que se focalise la
présente thèse.
3. Fouille de données d'usage du Web
3.1. Definition
La fouille de données d'usage du Web (Web Usage Mining
(WUM), en anglais) désigne l'ensemble de techniques basées sur la
fouille de données pour analyser l'usage d'un site Web [02, 03,
04]. En d'autres termes, le WUM correspond au processus d'Extraction
de Connaissances dans les Bases de Données (ECD) - ou Knowledge
Discovery in Databases (KDD), en anglais - appliqué aux données
d'usage du Web.
requetes (affichage d'une page du site,
téléchargement d'un fichier, identification de l'utilisateur via
un mot de passe, etc.) qui sont enregistrées en format texte et
stockées de manière standardisée dans un fichier qui
s'appelle log Web. Ce fichier est maintenu par le serveur HTTP qui
héberge le(s) site(s) en question.
Suivant la fréquentation du site, la taille du fichier
log peut atteindre des proportions importantes, pouvant croître de
quelques centaines de mégaoctets jusqu'à plusieurs dizaines de
gigaoctet par mois.
3.2. Processus de la MKIGeBSIBdIMAs Bd'KADTIBIK B
Ib
La fouille de données d'usage du Web (WUM) comporte trois
étapes principales :

Prétraitement


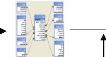
Extraction des motifs
Motifs
Fichiers log
Interprétation
Connaissance
FIG 1.2. Le schéma du processus WUM
[17].
a. Prétraitement
Le prétraitement du WUM (nettoyer et transformer les
données), qui est un processus fastidieux et complexe dû
principalement à la grande quantité de données (les
fichiers logs Web) et à la faible qualité de l'information qu'on
trouve dans les fichiers logs Web. Dans cette première étape,
plusieurs tâches doivent titre accomplies, comme le nettoyage des
données, l'identification des utilisateurs, l'identification des
sessions et l'identification des visites. La préparation des
données occupe environ 60 à 80% du temps impliqué dans le
processus du web usage mining.
b. Extraction des motifs
C'est l'étape qui constitue véritablement le
coeur du processus de fouille d'usage du Web. C'est ici qu'on va chercher
à extraire automatiquement des motifs ou des modèles à
partir des données. Cette étape est la plus critique du point de
vue algorithmique. Les méthodes de fouille de données permettent
de découvrir ce que contiennent les données exploitées et
filtrées résultantes de l'étape précédente
afin de découvrir des modèles comportementaux qui
décrivent les navigations des utilisateurs.
c. Interprétation
Interprétation des modèles est la
dernière étape globale du Web Usage Mining. Elle a comme objectif
de filtrer les modèles inintéressants de l'ensemble trouvé
dans la phase d'extraction des modèles. Ce filtrage dépend de
l'application finale que l'on souhaite faire du Web Usage Mining (adaptation
des sites web, système de recommandation, préchargement des
pages, etc. . .).
3.3. Sources de la TRXIODBGeBGRnnAsBG'XADTeBGX
Web
L'activité d'un serveur web est composée d'une
succession d'étapes : la réception d'une requête en
provenance d'un client, l'analyse de la requête, la création de la
réponse, l'envoi de cette dernière. La totalité de ces
informations peut être stockée dans un fichier d'enregistrements
(ou logs). il existe plusieurs formats des fichiers Logs Web mais le format le
plus courant est le CLF (Common Log file Format). Selon ce
format six informations sont enregistrées:
1. le nom du domaine ou l'adresse de Protocole Internet (IP) de
la machine appelante.
2. le nom et le login HTTP de l'utilisateur (en cas
d'accès par mot de passe).
3. la date et l'heure de la requête.
4. la méthode utilisée dans la requête (GET,
POST, etc.) et le nom de la ressource Web demandée (l'URL de la page
demandée).
5. le code de statut attribué à la requête
(prend la valeur 200 en cas de réussite).
6. la taille de la page demandée en octets.
Le format ECLF (Extended Common Log file
Format) représente une version plus complète du format CLF. En
effet, il indique en plus l'adresse de la page de référence (la
page précédemment visitée ou le moteur de recherche
utilisé pour rejoindre la page Web suivi des mots clés
demandés), la configuration du client, c'est-à-dire, son
navigateur Web (Firefox,
Internet Explorer, etc.) et son système d'exploitation
(Windows, Linux, Mac OS, etc.). Le format du fichier log a été
standardisé par W3C [05]. Le format ECLF:
[ip] [name] [date] [url] [statut] [taille] [refferer] [agent].
Exemple
41.98.239.119 - - [14/Mar/2010:04:20:39 +0100] "GET / HTTP/1.0"
200 25479 "-" "Mozilla/5.0 (Windows; U; Windows NT 5.1; fr; rv:1.9.0.11)
Gecko/2009060215 Firefox/3.0.11"
41.98.239.119 - - [14/Mar/2010:04:20:39 +0100] "GET /
HTTP/1.0" 200 25479 "-" "Mozilla/5.0 (Windows; U; Windows NT 5.1; fr; rv:
1.9.0.11) Gecko/2009060215 Firefox/3.0.11"
67.195.111.190 - - [14/Mar/2010:05:34:44 +0100] "GET /index.php?
View=weblink&catid=1%3Aliens-utiles&id=2%3Asite-delarn&option=com_weblinks&Itemid=52
HTTP/1.0" 301 - "-" "Mozilla/5.0 (compatible; Yahoo! Slurp/3.0;
http://help.yahoo.com/help/us/ysearch/slurp)"
FIG 1.3. Schéma illustratif des champs
d'un fichier log Web contenant trois requêtes.
3.4. Concepts de base de la fouille de données
d'usage du Web
La définition de certains termes qui se
répèteront tout au long de ce mémoire. Ces
définitions sont inspirées du travail de W3C sur la terminologie
de caractérisation du Web [06] :
|
concept
|
Définition
|
|
Ressource
|
une ressource R peut être tout objet ayant une
identité. Comme exemples de ressources nous pouvons citer: un fichier
html, une image ou un service Web.
|
|
Ressource
Web
|
une ressource accessible par une version du protocole HTTP ou un
protocole similaire (ex. HTTP-NG).
|
|
Serveur Web
|
un serveur qui donne accès à des ressources Web.
|
|
Requête Web
|
une requête pour une ressource Web faite par un client
(navigateur Web) à un serveur Web.
|
|
Page Web
|
ensemble des informations consistant en une (ou plusieurs)
ressource(s) Web, identifiée(s) par un seul URL. Exemple: un fichier
HTML, un fichier image et un applet Java accessibles par un seul URL
constituent une page Web.
|
|
Navigateur
Web
(Browser)
|
logiciel de type client chargé d'afficher des pages
à l'utilisateur et de faire des requêtes HTTP au serveur Web.
|
|
Session
utilisateur
|
un ensemble délimité des clics utilisateurs sur un
(ou plusieurs) serveur(s) Web.
|
|
Visite
|
L'ensemble des clics utilisateur sur un seul serveur Web (ou
sur plusieurs lorsque on a fusionné leurs fichiers logs) pendant une
session utilisateur. Les clics de l'utilisateur peuvent être
décomposés dans plusieurs visites en calculant la distance
temporelle entre deux requêtes HTTP consécutives et si cette
distance excède un certain seuil une nouvelle visite commence.
|
TAB 1.1. Les principaux termes utilisés
en Web Usage Mining.
3.5. Les applications de la TRKiOODIEeIERnWA IE'KADTeIdu
Web
Selon [22], l'analyse des fichiers log Web
est particulièrement utile car elle fournit des informations sur la
manière dont les utilisateurs naviguent réellement sur le site
Web. Après la réalisation d'une telle analyse, il est ainsi
possible de:
v mettre en évidence les fonctionnalités les plus
et les moins utilisées dans le site.
v chercher à comprendre les raisons pour lesquelles
les fonctionnalités les moins utilisées sont
délaissées par les utilisateurs afin, selon les cas, de les
améliorer ou de les supprimer.
v personnaliser la consultation, cet enjeu important pour de
nombreuses applications internet ou sites de e-commerce consiste à
proposer des recommandations dynamiques à un utilisateur en se basant
sur son profil et une base de connaissances d'usages connus.
Le WUM peut encore apporter des avantages à d'autres
domaines, comme par exemple, l'ajout dynamique de liens dans des pages Web, la
recommandation de produits, la caractérisation de groupes
d'utilisateurs, l'amélioration de politiques comme le caching , etc.
4. Conclusion
Au cours de ce chapitre, nous avons abordé quelques
points touchant le domaine de la fouille de données d'usage du web,
ainsi les différentes phases de son processus. Le chapitre suivant
illustre les différentes heuristiques de prétraitement qui
décrit le premier pas du processus de la fouille de données
d'usage du web.
.
CHAPITRE 2
Prétraitement des données
1. Introduction
Le processus du WUM comporte trois étapes principales :
le prétraitement des données, Extraction des motifs d'usage et
l'interprétation des résultats obtenus. La phase de
prétraitement des données est souvent la plus laborieuse et qui
demande le plus de temps, ceci dü en particulier à l'absence de
structuration et à la grande quantité de bruit existant dans les
données brutes d'usage.
Le prétraitement des fichiers log Web consiste à
nettoyer et structurer les données contenues dans ces fichiers afin de
les préparer à une future analyse. Les fichiers logs Web
étant souvent du type texte, l'un des objectifs de l'étape de
prétraitement est de transférer ces données dans un
environnement plus facile à exploiter (comme par exemple, dans une base
de données).
2. Le nettoyage des données
Le nettoyage des données vise à éliminer
toutes les requêtes considérées comme inutiles de
l'ensemble de logs de départ. En effet, une quantité non
négligeable des enregistrements d'un serveur web ne reflète pas
le comportement de l'internaute, nous expliquons donc les problèmes de
ces enregistrements en détail et ce que nous apportons pour leur
gestion.
Le serveur web permet de disposer des ressources de tout type
: page web, élément multimédia, programme, donnée
quelconque. Lors d'une requête correspondant à une page
intégrant d'autres ressources (généralement des images, ou
de petites animations), le client exécute effectivement plusieurs
requêtes vers le serveur: une pour la page (le contenant), une pour les
divers éléments (les contenus). Ainsi, pour une page
demandée, plusieurs requêtes peuvent aboutir au serveur.
En se référant au but de notre travail, à
savoir l'extraction de modèles d'utilisateurs pour l'amélioration
de services web, il nous parait judicieux de ne conserver que les pages web
(dites contenant), sans les éléments incorporés. Nous
simplifions les données des logs en enlevant tout ce qui ne correspond
pas à une page web. Certaines expériences ont montré que
la suppression des URL concernant des images réduisait la taille du
fichier log original de 40 % à 85 %. Le nettoyage des images consiste
à supposer qu'un utilisateur ne peut cliquer à la fois (au
même instant) sur plusieurs images pour les visualiser « FIG 3.1
», tenant compte de cette hypothèse, nous déterminons pour
chaque utilisateur l'ensemble des requêtes
effectuées au méme instant dont les extensions
connues d'images et autres composants multimédias sont
éliminées.
De plus, nous faisons le choix de ne garder pour la phase
d'apprentissage que les requêtes ayant abouti, c'est à dire
correspondant à une ressource valide. Le code de retour présent
dans les logs nous permet de filtrer ces requêtes. Par conséquent,
nous ne gardons que celles de code compris entre « 200 et 399 ».
Des données dites incohérentes peuvent subsister
: en effet, lors du traitement des logs, des requêtes d'annonces
apparaissent toutes seules dès que l'utilisateur se connecte sur le site
du CUBBA. De ce fait, ces requêtes correspondantes ne sont pas prises en
compte. Pour éliminer ces requêtes, il suffit de supprimer les
requêtes qui contiennent le mot clé « popups ».
Ainsi, nous faisons le choix que les requêtes
correspondantes d'une réponse de serveur à une requête d'un
client pour ça on va éliminer toute requête, dont sa
méthode différente de « Get », et voici le
type des différentes méthodes généralement
utilisées :
1' Get : est une requête d'information. Le
serveur traite la demande et renvoie le contenu
de l'objet
1' Head : est très similaire
à la méthode Get. Cependant, le serveur ne retourne que
l'entête de la ressource demandée sans les données.
1' Post : est utilisée pour envoyer des
données au serveur.
Un dernier type de requête, non seulement inutiles, mais
apportant un bruit dans les données, correspond à celles
effectuées de manière automatique par des robots web ne
reflétant pas le comportement de l'utilisateur. Il existe plusieurs
heuristiques pour considérer la requête correspondante comme
étant généré par un robot Web :
v' Identifier les adresses IP et les « User-Agents »
connus comme étant des robots Web.
Ces informations sont fournies généralement par les
moteurs de recherche. v' Identifier les adresses IP ayant fait une
requête à la page : « robots.txt ».
v' Identifier les « User-Agents» comportant l'un des
mots clés suivants : « crawler »,
« spider » ou « bot ».
v' Identifier les requêtes effectuées par des
aspirateurs de sites Web (HTTrack par exemple), ou par des modules de certains
navigateurs permettant la consultation de pages hors ligne tels que DigExt
d'Internet Explorer. L'identité de ces aspirateurs est effectuée
en se basant sur la durée de leurs requêtes
généralement nulle.
Exemple
Une simple vérification sur le site a montré que
plusieurs images sont contenues dans la page
FIG 2.1 Exemple de page contenant plusieurs
images.
3. Transformation des données
3.1. Identification des internautes
En ce qui concerne l'identification de l'utilisateur, pour les
sites Web, il est indispensable d'identifier clairement chaque utilisateur. Si
le serveur ne peut différencier les requêtes qui lui parviennent,
toute solution proposée n'est pas optimale.
3.1.1. Adresse IP
Sur Internet, les ordinateurs communiquent entre eux
grâce au protocole TCP/IP « Transmission Control Protocol ».
Chaque ordinateur appartenant au réseau est identifié par une
séquence unique de 32 bits (l'adresse IP) écrite à l'aide
de quatre nombres compris entre 0 et 255.
Les adresses IP ont l'avantage d'être toujours disponibles
et de ne nécessiter aucun
traitement préalable. En revanche, elles possèdent
principalement deux limites :
+ Premièrement, une adresse IP peut n'identifier qu'un
groupe d'ordinateurs « cachés »
derrière le serveur proxy d'un fournisseur d'accès
à Internet ou d'un réseau local. Rappelons qu'un serveur proxy a
une double fonction : il permet aux ordinateurs d'un réseau utilisant
des adresses IP privées d'accéder à Internet par son
intermédiaire. Il peut également servir de cache,
c'est-à-dire qu'il peut garder en mémoire les pages les
plus souvent visitées pour les fournir plus rapidement.
Ainsi, tous les internautes utilisant un serveur proxy seront identifiés
par l'unique adresse IP de ce serveur. Le site visité ne peut alors
déceler s'il a à faire à un ou plusieurs visiteurs.
Exemple :
IP des clients Proxy IP apparaissant dans le log

ch1smc.bellglobal.com
hse-montreal-ppp123456.sympatico.ca
hse-sherbrookeppp1236456.qc.sympatico.ca
hse-quecity-ppp123456.qc.sympatico.ca
FIG 2.2 Effet du proxy sur le contenu des
logs [16].
+ Le deuxième inconvénient de l'utilisation des
adresses IP comme identifiants vient de son inadéquation à la
rétribution dynamique. La majorité des internautes se voient en
effet prêter une adresse IP par leur fournisseur d'accès le temps
d'une connexion à Internet. Cet inconvénient est
particulièrement influant sur les sites ayant de nombreux visiteurs, les
adresses IP attribuées dynamiquement pouvant être
réutilisées immédiatement par d'autres utilisateurs. Par
ailleurs, l'attribution dynamique ne permet une identification valable que pour
une seule session ininterrompue : si l'internaute interrompt sa visite en se
déconnectant un bref instant, sa session sera toujours en cours, mais
son adresse IP aura changé, l'identification ne sera donc plus
possible.
3.1.2. Les sessions
a. Définition
Une session est composée de l'ensemble de pages
visitées par le même utilisateur durant la période
d'analyse, cependant, dans [12] la combinaison des champs IP
(adresse) et User Agent (le navigateur Web) d'un fichier log Web identifie
correctement l'utilisateur dans 92.02 % des cas et seul un nombre limité
de ces combinaisons (1.32 %) sont utilisés par plus de trois
utilisateurs. Chaque session est caractérisée par le nombre de
requêtes effectuées par l'utilisateur durant cette session, le
nombre de pages consultées (URLs2 différentes) et la
durée de la session. Nous pouvons considérer la combinaison
adresse IP plus navigatrice comme étant un critère acceptable
pour l'identification d'un utilisateur dans le cadre d'une activité
ponctuelle.
session1
session2
une base
de
données
session n
FIG 2.3 Le schéma d'identification de
session.
b. Algorithme d'identification
Afin de mieux identifier les sessions, nous adoptons l'algorithme
proposé ci-dessous. [13]
|
Tant qu'il y » a des enregistrements
dans la base faire lire l'enregistrement i
Récupérer l'adresse IPi et l'User-Agent UAi
Si (le couple (IPi, UAi) = (IPi-1, UA i-1))
Alors
Ajouter l'enregistrement i à la session S i-1
Sinon
Recommencer une nouvelle session Si FinSi
Fin Tant Que
|
FIG 2.4 Algorithme d'identification des
sessions.
3.2. Identification des visites des internautes
Une fois l'utilisateur (approximativement) identifié,
le problème consiste alors à détecter toutes les
requêtes en provenance de cet utilisateur. Concernant cette
problématique, la méthode la plus simple pour le groupement des
requêtes en sous-ensembles de requêtes appartenant au méme
utilisateur est d'utiliser le temps de latence maximum entre deux
requêtes successives. Selon [14] ce temps est
estimé de manière empirique à 25.5 minutes. La
majorité des méthodes d'analyse de l'usage du Web ont donc
adopté le temps de latence de 30 minutes. Dans [15] la
navigation définit comme l'ensemble de requêtes (clics) en
provenance d'un méme utilisateur séparées au-delà
de 30 minutes, et session comme l'ensemble de navigations d'un méme
utilisateur.
Cette stratégie serait capable d'identifier les
requêtes en provenance d'un méme utilisateur dans le contexte
d'une seule navigation. Cependant, on ne peut pas généraliser
cette combinaison pour l'identification de plusieurs navigations appartenant
à un méme utilisateur, puisque nous n'avons aucune garantie que
l'utilisateur d'avant aura les mémes valeurs pour le couple adresse IP
plus navigatrice lors d'une prochaine visite sur le site Web.
Une fois les visites identifiées, la durée de
consultation de la dernière page de chaque visite (la dernière
page de chaque session et les pages dont la durée de consultation a
dépassé 30 minutes celles qui ont permis la construction des
visites) est obtenue à partir de la moyenne des durées de
consultation des pages précédentes appartenant à la
même visite.
visite 1
une
session
visite2
visite n
FIG 2.5 Le schéma d'identification de
visite.
4. Conclusion
Dans ce chapitre, nous avons présenté les
problèmes de données inutiles ou incohérentes dans ces
derniers apparaissent comme rédhibitoires à l'utilisation dans le
processus de fouille d'usage du Web, très sensible aux données
bruitées. Nous avons présenté une méthode de
prétraitement des données avec une mise en place d'heuristiques
qui permettent de transformer l'ensemble de requêtes enregistrées
dans les fichiers Logs à des données structurées,
nettoyées et exploitables. Nous consacrons le chapitre suivant à
l'ensemble des techniques d'analyse faisant objet des expérimentations
réalisées dans le cadre de ce mémoire.
CHAPITRE 3
Techniques d'analyse de la fouille
d'usage du web
1. Introduction
Dans ce chapitre nous ne prétendons pas fournir une
liste exhaustive de l'ensemble des notions et méthodes existant dans le
cadre de l'analyse de la fouille d'usage de web. Il s'agit plutôt de
donner un aperçu général sur la notion d'une
méthode factorielle : l'analyse en composantes principales et deux
autres de classification non supervisé à savoir la classification
ascendante hiérarchique et la méthode de partitionnement
k-means.
2. Les méthodes factorielles
Les méthodes factorielles permettent de réduire
l'espace en fournissant des représentations graphiques, d'exploiter, de
fouiller, de représenter de grands ensembles de données.
2.1. / TQa3\111Q1FomSINQAW SLIQFISIXIITS
&3)
L'ACP est l'une des techniques des méthodes
factorielles qui est utile pour la compression et la classification des
données. Le problème consiste à réduire la
dimensionnalité d'un ensemble des données (échantillon) en
trouvant un nouvel ensemble de variables plus petit que l'ensemble original des
variables, qui néanmoins contient la plupart de l'information de
l'échantillon.
Etant donné un ensemble d'observations décrites
par des variables exclusivement numériques {x1, x2 , ..., xp}, l'ACP a
pour objectif de décrire ce même ensemble de données par de
nouvelles variables en nombre réduit. Ces nouvelles variables seront des
combinaisons linéaires des variables originales comme suit :
Ck == a1kx1 + a2k x2+ ... + apk xp, et porteront
le nom de Composantes Principales (CP). 2.1.1. Propriétés
des Composantes Principales
Nombre :
Bien que l'objectif soit en général de
n'utiliser qu'un petit nombre de Composantes Principales, l'ACP en construit
initialement p, autant que de variables originales. Ce n'est que par la suite
que l'analyste décidera du nombre de Composantes à retenir.
"Retenir k Composantes Principales" veut dire "Remplacer les observations
originales par leur projections orthogonales dans le sous-espace à k
dimensions défini par les k premières Composantes
Principales".
1' Orthogonalité :
Les Composantes Principales définissent des directions
de l'espace des observations qui sont deux à deux orthogonales.
Autrement dit, l'ACP procède à un changement de repère
orthogonal, les directions originales étant remplacées par les
Composantes Principales.
1' Décorrélation :
Les Composantes Principales sont des variables qui
s'avèrent être deux à deux
décorrélées.
1' Ordre et sous-espaces optimaux :
La propriété fondamentale des Composantes
Principales est de pouvoir être classée par ordre
décroissant d'importance dans le sens suivant : Si l'analyste
décide de décrire ses données avec seulement k (k < p)
combinaisons linéaires de ses variables originales tout en perdant le
moins possible d'information, alors ces k combinaisons linéaires sont
justement les k premières Composantes Principales.
2.1.2. Calcul matriciel
a. Matrice des covariances
+ La covariance
La covariance de deux variables v1 et v2 est un indicateur de
la variation simultanée. La covariance est positive quand v2 croît
chaque fois que v1 croit. Elle est négative quand v2
décroît chaque fois que v1 croit. Elle est nulle si v1 et v2 sont
indépendants.
Covariance et corrélation sont de même signe, la
covariance est fonction du coefficient de corrélation :
Cov (v1, v2) = écart-type (v1) * écart-type (v2) *
corrélation (v1, v2)
+ Choix de la matrice des covariances
Si on a des données homogènes avec des ordres de
grandeurs identiques (typiquement dans le cas de données physiques),
alors on a une métrique euclidienne et on travaille avec une matrice des
covariances.
A chaque couple de variables (v1, v2), la valeur de la case de la
matrice est celle de la covariance du couple (v1, v2).
b. Matrice des corrélations
+ La corrélation
A chaque couple de variables (v1, v2), la valeur de la case de la
matrice est celle du coefficient de corrélation entre v1 et v2.
+ Choix de la matrice des corrélations
Si on a des données hétérogènes
avec des ordres de grandeurs différents (typiquement dans le cas de
données économétriques), alors on a une métrique
« inverse des variances » et on travaille avec une matrice des
corrélations.
Corrélation (v1, v2) = cov (v1, v2) / (écart-type
(v1) * écart-type (v2))
2.1.3. Les composantes principales à
garder
Il y a 3 critères empiriques pour savoir combien de
composantes principales garder :
V' Le critère de Kaiser :
Si on a utilisé une matrice des corrélations (cas
le plus courant), on ne garde que les composantes principales dont la valeur
propre est > 1. Ce n'est pas un critère absolu.
V' Valeur du pourcentage :
La valeur propre est aussi donnée en pourcentage. On
peut garder les pourcentages significatifs. En regardant la courbe des
pourcentages cumulé, on peut faire apparaître un moment de flexion
significatif qui montre qu'à partir de là, il y a peu
d'information restituée.
V' Valeurs des coefficients de corrélation avec les
variables d'origine :
On peut aussi ne garder que les composantes principales qui ont
un coefficient de corrélation élevé avec au moins une
variable d'origine
2.1.4. Le cercle de corrélation
a. Présentation
On peut calculer le coefficient de corrélation de
chaque variable d'origine avec toutes les composantes principales. Le
coefficient de corrélation est une valeur comprise entre --1 et1.Le
cercle des corrélations ou bien l'espace des variables est le plan dont
les axes sont constitués par des composantes principales (la
première et la deuxième prioritairement). Chaque variable
d'origine a des coordonnées dans ce plan.
La projection des variables dans ce plan (nuage de points) permet
visuellement de : + Détecter les variables d'origine liées entre
elles.
+ Interpréter chaque composante principale d'après
ses corrélations avec les variables d'origine.
b. Interpretation
+ Des projections proches entre elles et proches du cercle des
corrélations correspondent à des variables
corrélées.
+ Des projections proches de l'horizontale montrent une
corrélation avec la composante principale horizontale.
+ Des projections proches de la verticale montrent une
corrélation avec la composante principale verticale.
3. La classification non supervisé
La classification non supervisé (classification
automatique, regroupement ou clustring, en anglais) a pour but de regrouper des
individus en classes homogènes en fonction de l'analyse des
caractéristiques qui décrivent les individus. Par classes
homogènes, on entend regrouper les individus qui se ressemblent et
séparer ceux qui sont dissemblables.
L'expression non supervisée fait
référence au fait qu'aucun superviseur ou label est
utilisé pour préciser à quelle classe appartient un
individu. En conséquence, le nombre de classes existant dans un ensemble
d'individus est a priori inconnu. De ce fait, l'un des problèmes les
plus délicats à propos des méthodes de classification non
supervisée concerne le choix du nombre de classes à retenir. Pour
palier cet écueil, il existe des artifices permettant d'approcher le bon
nombre de classes. Dans ce mémoire, nous nous intéressons
particulièrement à deux grandes familles de méthodes de
classification non supervisée : les méthodes hiérarchiques
et les méthodes de partitionnement.
3.1. Notion de similarité
Il s'agit de définir des groupes d'objets tels que la
similarité entre objets d'un méme groupe soit maximale et que la
similarité entre objets de groupes différents soit minimale.
La question est alors de définir cette similarité.
Pratiquement, la similarité entre objets est estimée par une
fonction calculant la distance entre ces objets.
Ainsi deux objets proches selon cette distance seront
considérés comme similaires, et au contraire, deux objets
séparés par une large distance seront considérés
comme différents.
Le choix de cette mesure de distance entre objets est alors
très important.
Très souvent il s'agit d'un choix arbitraire qui traite
tous les attributs de la méme manière [24].
3.2. Les mesures de distances
Nous exposons dans ce qui suit les distances les plus usuelles
pour les données quantitatives.
Soient I et J deux points dans un espace E d'individus
décrit par p variables quantitatives. On note i =
(xi1, xi2, ..., xip) et j =
(xj1, xj2, ..., xjp). La distance entre X
et Y peut se calculer selon
+ La distance Euclidienne : qui
calcule la racine carrée de la somme des carrés des
différences entre les coordonnées des deux points
:

+ La distance de Manhattan : qui
calcule la somme des valeurs absolues des différences entre les
coordonnées de deux points :
+ La distance de Chebychev : qui
calcule la valeur absolue maximale des différences entre les
coordonnées de deux points :
d(i, j) = max |xi - xj|
i={1...p} ;j{1....p}
3.3. Les méthodes hiérarchiques
La classification hiérarchique est une famille de
techniques qui génèrent des suites de classes
emboîtés les uns dans les autres. Les techniques de classification
existantes dans cette famille peuvent être classées dans deux
grands groupes : Classification Ascendante Hiérarchique (CAH) ou par
agrégation et Classification Descendante Hiérarchique (CDH) ou
par division.
Dans le groupe CAH, tous les individus sont initialement
considérés comme des classes ne contenant qu'un seul individu. A
chaque étape du processus de classification, les deux classes les plus
proches au sens d'une mesure d'agrégation sont fusionnées. Le
processus s'arrête quand les deux classes restantes
fusionnent dans l'unique classe contenant tous les individus.
Les techniques dans le groupe CDH partent de la partition
triviale à une seule classe (contenant toutes les observations). Le
processus de classification suit en effectuant de divisions successives des
classes jusqu'à ce que soit atteint la partition triviale où
chaque observation est une classe. La division d'une classe s'opère de
façon à ce que la mesure d'agrégation entre les deux
classes descendants soit la plus grande possible, de manière à
créer deux classes bien séparés.
Les classes résultants des méthodes de
classification hiérarchiques sont souvent représentés par
une structure graphique appelé dendrogramme. Les typologies qui
ont le plus de chance d'être significatives sont obtenues simplement en
traçant une ligne horizontale en travers du dendrogramme, et en retenant
dans la typologie les classes terminales justes audessus de cette ligne. En
changeant la hauteur de la ligne, l'on change le nombre de classes retenus.
Cette pratique constitue un moyen simple pour faire varier la
granularité de la typologie finale.
3.3.1. Classification Ascendante Hiérarchique
(CAH)
Dans ce groupe, il existe plusieurs méthodes
d'agrégation possibles entre deux classes. Le choix de la méthode
dépend de la problématique que l'on se pose. En ce qui concerne
la distance entre deux individus, la distance euclidienne est la plus
utilisée en général.
a. / 1-s 1P plid41-41WITIpITalidn
Parmi les méthodes d'agrégation existantes pour
chaque couple de classes, nous citons ciaprès les plus classiques :
v agrégation selon le lien minimum (single
linkage) : l'agrégation entre deux classes A et B
correspond au minimum des distances entre un élément du classe A
et un élément du classe B.
d (A; B) = min
i?A;j?B
|
d(xi; xj)
|
|
v agrégation selon le lien maximum
(complete linkage) : l'agrégation entre deux classes A et
B correspond au maximum des distances entre un élément du classe
A et un élément du classe B.
d (A;B) ==
maxxEA;xEB d(xi; xj)
+ agrégation selon le lien moyen (average
linkage) : l'agrégation entre deux classes A et B
correspond à la moyenne des distances entre un élément du
classe A et un élément du classe B.
d (A; B) = 1
|A||B| ??????;?????? ??(????;????)
+ la méthode de Ward : on
choisira de regrouper les deux classes qui génèrent le gain
d'inertie intra-classe minimum.
Selon le théorème de Huygens, l'inertie total T
d'un ensemble d'individus E est égale à la somme des inerties
intra-classe W et inter-classe B de cet ensemble d'individus regroupés
dans une partition P.
%7 L'inertie totale : T(E)
C'est la moyenne des carrées des distances des individus
au centre de gravité .ou T(E) = W(P) + B(P)
T(E) = 1 ?? ??(????, ??)2
??=1
??
Avec :
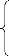
n : nombre d'individu de la population
x : valeur d'un individu
g : valeur du centre de gravité de la population %7
l'inertie intra-classes : W(P)
C'est la somme des inerties totales de chaque classe.
W(P) = ??(??)
??
??=1
Avec k : le nombre de classes de la population %7 inertie
inter-classes : B(P)
B(P) = [???? *
?? ??=1 (????,??)]2
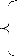
Avec :
k : le nombre de classe de la population initiale.
g: valeur du centre de gravité de la population initiale.
P : poids de la classe
L'inertie intra-classe d'une partition mesure
l'homogénéité de l'ensemble de classes. Une classe sera
d'autant plus homogène que son inertie intra-classe sera faible.
L'inertie interclasse d'une partition mesure la séparation entre les
classes qui la composent. Plus l'inertie
interclasse d'une partition est grande plus les classe sont
distinctement séparées. Deux cas particuliers sont à
considérer :
ü Si chaque classe de la partition contient un seul
individu, c'est-à-dire, K == n, alors W(P) = 0 et B(P)
= T(E).
ü Si la partition n'est composée que d'une seule
classe, c'est-à-dire, K = 1, alors B(P) == 0 et W(P)
== T(E).
L'inertie intra-classe d'une partition croit avec la
diminution du nombre de classes, où encore, l'inertie intra-classe
décroit avec l'augmentation du nombre de classes dans la partition.
Le but de l'algorithme CAH est de passer de la meilleure
partition de k classes à la meilleure partition de (k-1) classes selon
le critère d'agrégation adopté. Selon ce critère,
pour passer d'une partition PK à une partition
PK-1, on choisira de regrouper les deux classes qui
génèrent le gain d'inertie intra-classe minimum. Ce gain est
calculé de la façon suivante :
Gain == W (Pk-1) -W(Pk)
Soit A et B deux classes, uA et uB leurs respectifs poids. Le
gain d'inertie intra classe engendré par le regroupement de ces deux
classes est donné par l'écart de Ward. L'écart de Ward
peut être vu comme une distance entre deux classes si la distance entre
deux individus est la distance euclidienne.
|
Gain (A; B) =_ uAuB
uA+uB
|
d2 (gA ; gB)
|
|
iEA
iEB
|
xiwi
xiwi
|
1
Où uA=ZiEA wii et g A=
uA
1
uB=ZwiiEB et g B= uB
b. Nombre de classes à retenir
La recherche du nombre approprié de classes dans une
partition est une phase indispensable dans la construction d'une classification
de données, mais elle est souvent laborieuse et délicate. Si le
choix du nombre de classes dans une partition ne correspond pas au vrai nombre
de classes existantes dans un ensemble d'individus, alors la partition choisie
soit regroupe à tort des classes séparées (pas assez de
classes), soit découpe en plusieurs classes des classes homogènes
(trop de classes).
Dans les méthodes de classification
hiérarchiques, le dendrogramme indique l'ordre dans lequel les
agrégations (ou divisions) successives ont été
opérées ainsi que la valeur de l'indice à chaque niveau
d'agrégation (ou division). La problématique consiste à
trouver le meilleur couple de contraintes opposées : inertie
intra-classe et nombre de classes dans la partition, puisque à chaque
fois que l'on diminue le nombre de classes dans la partition, son inertie
intra-classe augmente.
Pour déterminer le bon nombre de classes, Il est
pertinent d'effectuer la coupure du dendrogramme après les
agrégations correspondant à des valeurs peu élevées
de l'indice utilisé et avant les agrégations correspondant
à des valeurs élevées de cet indice. En coupant le
dendrogramme au niveau d'un saut important de cet indice, on peut
espérer obtenir une partition de bonne qualité car les individus
regroupés en-dessous de la coupure seront proches, et ceux
regroupés au-dessus de la coupure seront éloignés.
D'après application de l'algorithme de CAH avec le
critère d'agrégation de Ward, on connait à chaque
étape les deux classes à rassembler et l'inertie intra-classe de
la partition ainsi composée. La meilleure coupure du dendrogramme sera
obtenue par un coude sur les valeurs du critère optimisé. Ce
critère est l'inertie intra-classe. L'on trace le graphique des n- 1
gains d'inertie intra-classe obtenus à chaque itération de
l'algorithme. Parmi les innombrables règles de détection du
nombre adéquat des classes, il y a la fameuse « loi du coude »
: nous cherchons visuellement la zone où la variation de courbure est la
plus importante, traduisant l'idée d'une modification significative des
proximités des variables à l'intérieur des groupes.
3.4. Méthodes de partitionnement
Les méthodes de partitionnement ont pour but de fournir
une partition des éléments à classer. Le nombre de classes
dans la partition à générer doit être fixé au
départ. Le principe des méthodes de partitionnement est le
suivant : à partir d'un ensemble E de n individus, on cherche à
construire une partition P = (C1, ,CK) contenant K classes homogènes et
distinctes, tout en respectant un critère basé sur une distance
entre les individus. Doivent se trouver dans une même classe les
individus qui se ressemblent et en classes différentes les individus
divergents en termes du critère adopté.
Une partition optimale peut être obtenue à partir
de l'énumération exhaustive de toutes les partitions, ce qui
devient cependant prohibitif en termes de temps de calcul. Comme solution
alternative à ce problème, des méthodes de partitionnement
basées sur l'optimisation itérative du critère à
respecter permettent d'obtenir des groupes bien distincts en un temps de
calcul raisonnable. Ces méthodes d'optimisation utilisent
une réaffectation afin de redistribuer itérativement les
individus dans les K classes.
3.4.1. Clustering K-means
Proposé en 1967 par MacQueen, l'algorithme des centres
mobiles (K-means) est l'algorithme de clustering le plus connu et le plus
utilisé, tout en étant très efficace et simple. Ce
succès est dû au fait que cet algorithme présent un rapport
coût/efficacité avantageux.
On considère l'espace de (n) points de dimension (p)
suivant :
X=
On suppose que les (n) points peuvent être regroupés
en (c) classes (c < n).
x Ck = [???? 1, ???? 2,???? 3, ., ???? ??]
. x ?
f 1
Les classes sont décrites par leurs centres :
... .. .. ... ...
? ?
+ S on note par d (i, k) la distance entre le point xi et le
centre Ck, alors le point xi est x .. x . x
i1 if p
affecté au classe dont le centre est le plus proche.
... .. ... .. ... ?
?
L'algorithme fonctionne selon les étapes suivantes :
? n nf p ?
1' On choisit d'abord K points représentant les K classes
recherchés et appelés centroides des classes (le nombre K est
fixé par l'utilisateur).
1' On assigne chaque point non classé au classe dont le
centroide est le plus proche. 1' On réévalue les nouveaux
centroides des classes.
1' On recommence (réassignation des points au classe
dont le centroide est le plus proche, et recalculé des centroides)
jusqu'à ce que les centroides ne changent plus significativement.
[24]
Entrée : k le nombre de clusters désiré.
Sortie : Une partition C = {C1, ...,Ck} Initialiser ì1, ...ìk {k
donné}
Répéter
Affecter chaque point à son cluster le plus proche C (xi)
= ming d (xi, ìg)
Recalculer le centre ìi de chaque cluster
|
ìg =
|
1
????
|
????????
|
????
|
Jusqu?`a ce que (|?ì|<??)
FIG 3.1. L'algorithme k-means.
Le principal inconvénient de l'algorithme est que la
partition finale dépend du choix de la partition initiale. L'algorithme
est sensible à la sélection initiale des centroides, et
nécessite que l'utilisateur lui fournisse le nombre K de classes
(information souvent peu disponible).
4. Conclusion
Dans le domaine de la fouille de données d'usage du
web, le but de ces méthodes d'analyse présentées est de
découvrir deux types de classes : classes d'usagers et classes de pages
qui seront présenté en détail dans notre
expérimentation (chapitre 5). Le chapitre suivant montre
l'expérimentation de prétraitement sur des données
réelles.
CHAPITRE 4
Prétraitement de fichiers log
du site CUBBA
1. Étude de cas
1.1. Analyse du site Web académique
Dans cette étude de cas sur des données
réelles, nous analysons les fichiers log du site Web de notre Centre
universitaire de Bordj Bou Arréridj3. La figure exhibe un
aperçu de la page de garde du site en question.
FIG 4.1. Aperçu de la page de garde du
site Web de Centre Universitaire de Bordj Bou Arrerridj.
1.2. Préparation des données
En collaboration avec les responsables du centre de calcul,
nous avons pu obtenir un jeu de données qui enregistre l'accès au
site pendant la période du 14 février 2010 jusqu'au 17 mars 2010.
Les différents fichiers log du format ECLF sont concaténés
en un seul fichier qui a constitué notre source de données. Le
tableau suivant indique la taille des différents fichiers log
récupérés sur la période étudiée.
3 Le site analysé est accessible à l'adresse
suivante :
http://www.univ-bba.dz
|
Période Taille
|
|
14 mars .17mars
|
1698 ko
|
|
07mars 14mars
|
4276 ko
|
|
28fev 07mars
|
2537 ko
|
|
21fev 28fev
|
1873 ko
|
|
14 fev 21 fev
|
3955 ko
|
|
Total
|
14339 ko
|
TAB 4.1. La taille des fichiers log
analysés.
2. Implémentation
2.1. Chargement du fichier Log et transformation en une
table d'une BDD
Le fichier LOG est un fichier texte, appelé aussi journal
des connexions. Généralement il est de la forme suivante :
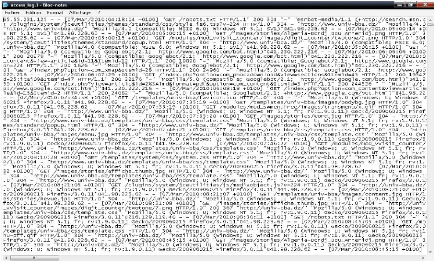
Le fichier Log se transforme en une table composée de
plusieurs colonnes. Chaque colonne correspond à un champ
spécifique du fichier Log :
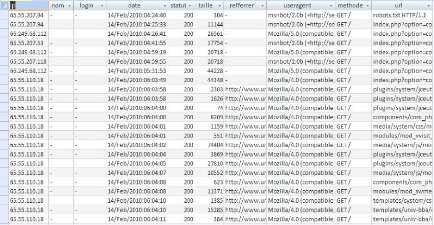
FIG 4.3. Base de données après
import.
2.2. Présentation de l'application de
prétraitement
Notre application est une petite démonstration aux
différentes étapes de prétraitement, c'est pour ça
on n'a pas besoin de réalisé une interface ergonomique, mais on a
mené à réaliser une interface plus au moins au
professionnel.

a. Nettoyage des données
Une fois les fichiers log importés dans les espaces de
stockage, les données concernant les pages possédants des
requêtes non valides, des images ou de fenêtre publicitaire ...etc
; n'apportent rien à l'analyse. Elles seront donc filtrées et
éliminées.
Pour cela on est amené à supprimer de notre base
de données les requêtes qui ont les formes suivantes :
+ Les requêtes correspondant aux statuts non valides par
la requête
("delete from LOGUNIV where statut<=200 ou statut>399
»)
+ Les requêtes correspondant aux méthodes
différentes de get' par la requête
("delete from LOGUNIV where methode < >`get' »)
+ Les requêtes correspondant aux fenêtres
publicitaires par la requête
("delete from LOGUNIV where url like %popus%')
L'étape qui concerne les pages provenant des robots
web nécessite l'établissement d'une liste des adresses
IP4 (4187 adresses collectées) et une liste
d'UserAgent5 (966 User- Agents collectés). Les requêtes
provenant d'une des adresses IP ou d'un des User-Agents présents dans
les deux listes sont supprimées.
b. Transformation des données
La transformation des données est une tache fastidieuse
car elle représente véritablement le visiteur. Notre analyse est
entièrement ne tient pas compte du fait que plusieurs requêtes
peuvent provenir d'un même utilisateur. Ceci réduit les
problèmes liés aux caches Web (Proxy), aux adresses IP dynamiques
et au partage d'ordinateurs.
+ L'identification des sessions
d'utilisateurs
Après le nettoyage des données et l'application
de l'algorithme d'identification des sessions d'utilisateurs « FIG 4.5
» on a obtenue 744 sessions. La figure ci dessous présente un
aperçu de sessions obtenues.
4
5
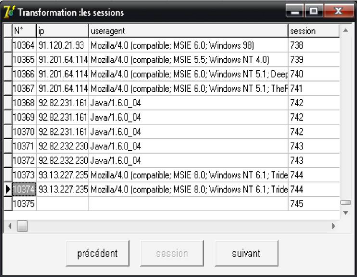
FIG 4.5. L'identification des sessions. +
L'identification des visites
Après la création des sessions et l'application de
l'algorithme d'identification des visites ci-dessous, nous obtenons 1826
visites d'après la base totale.
> Algorithme d'identification des visites
d'utilisateur
En premier temps on doit collecter des informations sur
l'identification des visites d'utilisateurs. Soit les variables suivantes :
v' Ri= Requête i
v' V [Ri] = Visite à laquelle appartient la
requête i v' S [Ri] = Session à laquelle appartient la
requête i v' T [Ri] = Temps de déclenchement de la requête
i. v' Durée [Ri] =Durée de la requête i.
v' Durée = Somme des durées de requêtes de
chaque visite. v' NV = Nombre de requêtes dans chaque visite.
1. Ordonner les requêtes suivant la variable S [Ri].
2. Détermination de la durée de chaque
requête.
3. Construction des visites.
4. Détermination de I a durée de I a
dernière requête de chaque visite.
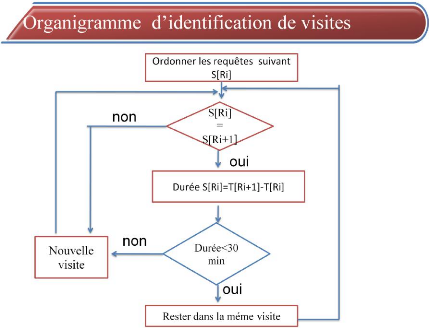
FIG 4.6 Algorithme d'identification des visites
d'utilisateur.
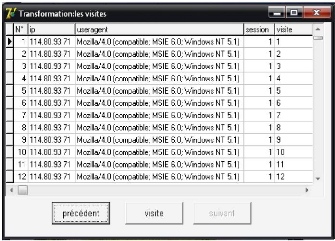
FIG 4.7. L'identification des visites.
c. Base de données final
Notre base de données qui constitue de 1826
requêtes est prête pour l'application de différentes
méthodes de fouille des données. La figure suivante montre la
base de données finale après l'étape de
prétraitement.
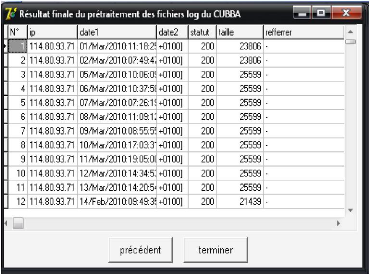
FIG 4.8. Résultat final de
prétraitement.
3. Résultats de l'analyse des fichiers Log du
CUBBA
La figure suivante illustre un résumé sur les
statistiques obtenues du prétraitement des fichiers log du centre
universitaire de Bordj Bou Arréridj
Fichiers log
|
requêtes non valides 1,27%
methode<>get 0,50%
robots.txt 1,22%
liste ips des robots web 0,16%
liste useragent robots web 0,10%
mots clés de robots web 3,88%
annonces 34,81%
images 39,26%
aspérateurs web 0,66%
requêtes valide 18,10%
|
nombre de sessions 744
nombre de visites 1826
FIG 4.9. Statistiques de prétraitement de
fichiers log
4. 2 XV013d01" Slé1" MAion
L'implémentation est une partie primordiale dans ce
travail. Au cours de cette partie, nous allons décrire brièvement
l'ensemble d'outils d'investigation utilisés durant les étapes de
prétraitement.
4.1. DELPHI 7:
Pour la réalisation de notre application, nous avons
choisi le langage de programmation DELPHI 7, qui est un outil de
développement puissant pour une programmation d'application sous
WINDOWS.
DELPHI 7 offre plusieurs avantages, on peut citer :
Il apporte une grande souplesse aux développements
lorsqu'il un fichier
exe.il s'agit d'un vrai exécutable,
aucun autre fichier n'est nécessaire pour l'exécution, vous
obtenez donc une application plus propre et plus facile à distribuer et
à maintenir.
v' L'emploi des tableaux à plusieurs dimensions.
1' DELPHI est doté d'outils de programmation tels que les
modèles d'application et des fichiers qui permettent de créer et
de tester une application.
v' Lors de la phase de transformation, nous pouvons visualiser
les données (réelles), nous pouvons ainsi savoir aussi si le
résultat de notes requis correspond à nos attentes.
4.2. Le langage SQL
Pour le nettoyage de données nous avons eu recours au
formalisme du langage de manipulation des données SQL, très
répandu et de compréhension facile.
SQL (Structured Query Language, en anglais, ou langage
structuré de requêtes, en français) est un langage standard
et normalisé, destiné à interroger ou à manipuler
une base de données relationnelle. SQL se décompose en 3 parties,
à savoir :
v' La définition de données: création,
suppression, modification de la structure des tables.
v' Les manipulations des bases de données :
Sélection, modification, suppression d'enregistrements.
v' La gestion des droits d'accès aux tables :
Contrôle des données : droits d'accès, validation des
modifications
5. Conclusion
Dans le cadre de ce chapitre, nous avons
présentés les différents résultats de la
méthodologie de prétraitement des fichiers Logs qui donne de bons
résultats expérimentaux (18.10 % de la taille de la base
après l'étape de nettoyage). A ce stade, la phase amont du
processus se termine. Les données du web sont prêtent bien
à La partie suivante qui constituant le coeur du processus,
décrit l'application des techniques de la fouille d'usage du web aux
fichiers log de CUBBA.
CHAPITRE 5
Classification des pages et d'internautes du
site CUBBA
1. Introduction
Dans ce chapitre, nous avons donné une série de
résultats d'expérimentation et leurs interprétations que
nous utilisons dans deux types de fouille : d'une part, les classes de pages
regroupant les pages dont les contenus sont sémantiquement proche, et
d'autre part, de définir les classes d'utilisateurs dont l'objectif est
de trouver des groupes d'internautes ayant des modèles de navigation
similaires.
Cependant ce chapitre n'a pas pour intention de
décrire les techniques de classifications présentées avec
plus de détail dans le chapitre 1. Il présent plutôt
comment ces techniques sont appliquées dans le domaine du fouille
d'usage du Web.
2. Classification des pages
La classification des pages a pour objectif de distinguer les
pages de contenu présentant l'information recherchée par
l'internaute des pages de navigation utilisée pour faciliter la
navigation de l'utilisateur sur le site de manière à ne garder
dans la base que les requêtes aux pages présentant un contenu
intéressant aux visiteurs. Notre approche consiste à
définir des variables servant à la caractérisation des
pages et les utiliser pour la classification des pages.
2.1. Variables statistiques pour la
caractérisation des pages
Afin de caractériser les pages visitées par les
internautes, les variables suivantes sont définies pour chaque page :
|
N0
|
variable
|
Signification
|
|
1
|
NV
|
Nombre de Visites effectuées à chaque page.
|
|
2
|
NI
|
Nombre des Inlinks qui mènent à la page en question
à partir des autres
pages.
|
|
3
|
NO
|
Nombre des Outlinks dans la page qui mènent vers d'autres
pages
|
|
4
|
DM
|
Durée Moyenne par page de visite de chaque page
|
TAB 5.1. Variables statistiques
décrivant les pages.
l'indexation des pages du site Web pour faciliter leur
manipulation et la construction de deux matrices : matrice d'hyperliens et
matrice d'accès.
a. 0 DtIiFIRdADFFgs
Cette matrice est utilisée pour déterminer le
nombre de visites effectuées par les internautes à chaque page.
Chaque entrée (i, j) de la matrice représente le nombre de
visites effectuées de la page i à la page j. Si cette
entrée est égale à zéro alors la page j n'a jamais
été visitée à partir de la page i.
|
Exemple :
|
|
|
A
|
B
|
C
|
D
|
E
|
F
|
G
|
SOM
|
|
A
|
0
|
42
|
14
|
29
|
17
|
9
|
0
|
111
|
|
B
|
0
|
1
|
19
|
2
|
3
|
1
|
0
|
26
|
|
C
|
0
|
0
|
1
|
12
|
3
|
1
|
0
|
17
|
|
D
|
0
|
3
|
2
|
0
|
11
|
6
|
0
|
22
|
|
E
|
0
|
4
|
0
|
5
|
1
|
12
|
0
|
21
|
|
F
|
0
|
0
|
1
|
1
|
4
|
0
|
14
|
20
|
|
G
|
0
|
0
|
0
|
0
|
0
|
3
|
0
|
3
|
TAB 5.2. Matrice d'accès.
b. 0 DtIiFIRdAN, slims
Cette matrice est utilisée pour calculer le nombre
d'inlinks et le nombre d'outlinks. En effet, le nombre d'inlinks est le total
sur les lignes alors que le nombre d'outlinks est le total sur les colonnes.
Chaque ligne de la matrice correspond à une page du site. Il en est de
même pour chaque colonne. Ainsi, s'il existe N pages différentes
visitées par les internautes, la matrice d'hyperliens sera de dimension
(N, N). Chaque entrée (i, j) de la matrice prend la valeur 1 si
l'utilisateur a visité la page j à partir de la page i et la
valeur 0 sinon.
Toutefois, il ne faut pas oublier que certaines pages du site
ne sont pas visitées par les internautes et que certains liens dans les
pages visitées ne sont pas utilisés. Ces pages et hyperliens ne
sont pas considérés dans cette représentation matricielle
qui ne prend que les accès enregistrés dans les fichiers Logs.
120,00%
100,00%
40,00%
80,00%
60,00%
20,00%
0,00%
0 1 2 3 4 5
% cumulated
% cumulated
Exemple
|
|
|
A
|
B
|
C
|
D
|
E
|
F
|
G
|
inlinks
|
|
A
|
1
|
1
|
0
|
0
|
1
|
0
|
1
|
4
|
|
B
|
1
|
1
|
0
|
0
|
1
|
1
|
0
|
4
|
|
C
|
1
|
1
|
0
|
1
|
1
|
1
|
1
|
6
|
|
D
|
1
|
0
|
1
|
1
|
0
|
0
|
0
|
3
|
|
E
|
1
|
1
|
1
|
0
|
1
|
1
|
0
|
5
|
|
F
|
1
|
1
|
0
|
1
|
1
|
0
|
1
|
5
|
|
G
|
1
|
0
|
1
|
1
|
0
|
0
|
1
|
4
|
|
outlinks
|
7
|
5
|
3
|
4
|
5
|
3
|
4
|
31
|
TAB 5.3. Matrice d'hyperlien.
2.2. Application de l'Analyse en Composantes Principale
(ACP)
A partir de l'application de l'Analyse en composante principale
sur l'ensemble des variables du tableau « TAB 5.1 » qui participe
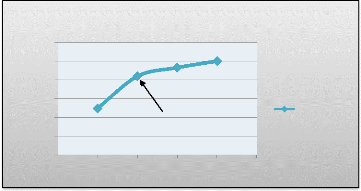
à la construction des axes, On a gardé selon le critère
« valeur du pourcentage » les deux premiers axes qui
représentent à 83 % près l'allure du nuage initial (FIG
5.1).
a. La projection des variables sur les axes
factoriels
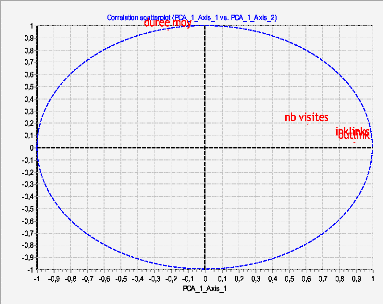
FIG 5.2. Projection des variables sur les axes
factoriels.
+ Interprétation
duree
Le premier axe traduit bien un effet de visite, il
oppose les pages ayant une valeur importante de « NI, NO et NV », ces
dernières sont corrélées positivement avec le premier axe.
Le second axe était plus associé à la DM des
visites.
b. la projection des individus sur les axes
factoriels
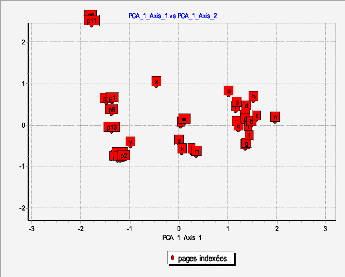
FIG 5.3. Projection des individus sur les axes
factoriels. ? Interprétation
d1
La popularité de l'ACP repose en grande partie sur les
représentations graphiques qu'elle propose. Elles nous permettent
d'apprécier visuellement les proximités entre les
p _
individus. Dans notre cas, nous projetons les individus dans le
plan factoriel. Nous voulons
p1
associer les individus aux classes.
À partir de la représentation obtenue (FIG 4.3) le
contenu du site peut être divisé en quatre classes dont les pages
dans chaque classe sont sémantiquement proches.
x
Pour aboutir à un meilleur résultat, nous avons
recourt à la combinaison de l'ACP avec
rp d
p
l'une des méthodes de partitionnement k-means. Les axes
factoriels obtenus sont utilisés
i
p13 o l
y
comme des variables d'entrée pour le k-means.
q g
k j m
10
2.3. clustering k-means
L'application de la méthode de clustering k-means met en
évidence quatre classes de pages.
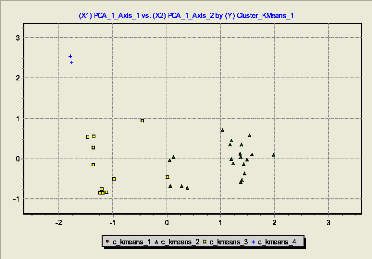
FIG 5.4. Résultat de classification de
pages
Nous intéressons notamment à
l'interprétation statistique des classes en fonction des variables les
plus discriminantes :
A
1. La première classe (09.1%) est composée de
pages visitées fréquemment et caractérisées par un
nombre important d'inlinks et d'outlinks. Elle correspond à la classe de
pages auxiliaires ou de navigation qui contiennent les hyperliens primaires aux
autres pages Web et utilisées pour la navigation.
2. La deuxième classe (15.9%) est celle de pages de
contenu caractérisées par une durée de consultation assez
élevée et contiennent des informations intéressantes aux
utilisateurs.
3. L'intersection de ces deux classes (38.6%) est
composée de pages présentant à la fois les
caractéristiques des pages de contenu et des pages auxiliaires. C'est la
classe de pages hybrides
4. La derniere classe (36.4%) est celle des pages
visitées rarement, qui ne pointent nulle part et vers lesquelles
pointent peu de pages. La durée moyenne de consultation de ces
pages est faible. Nous considérons que ces pages
correspondent à ce que [21] appelle « pages de
références » utilisées pour définir un concept
ou expliquer des acronymes. Cependant, nous considérons que ces pages
sont, dans une certaine mesure, des pages de contenu.
+ Résultat
A partir du total de pages, nous avons identifié 9.1 %
de pages auxiliaires. Les autres pages sont des pages de contenu, des pages
hybrides et des pages de référence. L'ensemble des pages
restantes est présentant un certain intérêt à
l'internaute fait l'objet de notre analyse.
3. Classification des utilisateurs
3.1. Modélisation des données
d'usage
|
N0
|
Variable
|
Signification
|
|
1
|
DureeTotale
|
Durée totale de la navigation (en secondes)
|
|
2
|
Nb Requêtes
|
Nombre de clics effectués durant la navigation
|
|
3
|
MDuree
|
Moyenne de la durée des requêtes (= DureeTotale /Nb
Requêtes)
|
|
4
|
Nb Répétitions
|
Nombre de requêtes répétées dans la
navigation
|
|
5
|
P_Repetitions
|
Pourcentage de répétitions (=Nb
Répétitions / Nb Requêtes)
|
|
6
|
Nb Requêtes OK
|
Nombre de requêtes réussies (statut = 200) dans la
navigation
|
|
7
|
P _Requêtes OK
|
Pourcentage de requêtes réussies (=Nb Requêtes
OK / Nb Requêtes)
|
TAB 5.4. Variables statistiques
décrivant les navigations.
Dans le but de mieux caractériser la navigation d'un
internaute, nous définissons un ensemble de sept variables statistiques
obtenues à partir des données d'usage prétraitées
et stockées dans une base de données. Ces variables sont
énumérées dans le tableau 5.4 et détaillées
dans les paragraphes suivants.
Durant la navigation sur un site Web, l'utilisateur peut faire
face à des messages d'erreur sur la page demandée (quand la page
n'a pas été retrouvée), de redirection (quand la page
requise a été physiquement déplacée), d'erreur sur
le serveur Web (quand le serveur en question est occupé ou hors
service), etc. Le code de retour d'une requête est identifié dans
les fichiers log Web par le champ statut. Les codes de retour de requête
assument des valeurs standardisées par le W3C6. Une
requête est dite réussie quand son code de retour est égal
à 200. Dans tous les autres cas, la requête est
considérée échouée. Dans le but de discriminer le
nombre de requêtes réussies durant une navigation, nous utilisons
respectivement les variables NbRequêtes_OK. La variable Nb
Requêtes représente le nombre total de clics effectués
pendant la navigation.
Durant la navigation, un internaute peut, pour un motif
quelconque, revenir sur une page déjà visitée. Les pages
revisitées durant une navigation sont souvent celles qui attirent le
plus l'attention de l'internaute. Les variables Nb
Répétitions et P_Repetitions contiennent
respectivement le nombre et le pourcentage de pages revisitées dans une
navigation.
La variable DureeTotale représente le temps
(en secondes) consacré par l'internaute à la visite du site Web
en question. La variable MDuree représente la moyenne de temps
consacré aux pages visitées durant la navigation.
Les variables présentées dans cette section ont
pour but de décrire la navigation des internautes d'un site Web
quelconque à partir des données extraites des fichiers log du
serveur Web qui héberge le site en question.
3.2. Construction de groupes d'utilisateurs
L'analyse proposée dans cette partie consiste une
classification non supervisée dans un premier temps à diviser
l'ensemble de variables à des groupes afin que Les résultats de
cette première classification sont injectés dans la base des
navigations utilisée pour classifier les internautes et découvrir
des groupes d'utilisateurs. Chaque navigation sera affectée à un
groupe contenant des navigations proches au sens de la distance
appliquée par la méthode de classification.
6 Une liste exhaustive des codes de retour de requête peut
être consultée à l'adresse suivante :
http://www.w3.org/Protocols/rfc2616/rfc2616-sec10.html
3.2.1. Classification hiérarchique ascendante
(CAH)
a. Classification des variables
La classification ascendante hiérarchique(CAH) des
variables permet d'agréger au fur et à mesure les groupes de
variables qui portent les mêmes informations (redondantes
corrélées), et dissocier les variables qui expriment des
informations complémentaires au sens de la minimisation de la perte
d'inertie à chaque étape. La classification de variable à
pour but de :
+ mieux comprendre ce qui rassemble ou distingue les groupes. +
Réduction du nombre de variables.
La classification des variables « DureeTotale,
MDuree, P_Repetitions, Nb Requêtes, P_RequêtesOK », Pour
la distance euclidienne et l'agrégation selon la méthode de Ward,
donne le dendrogramme suivant :
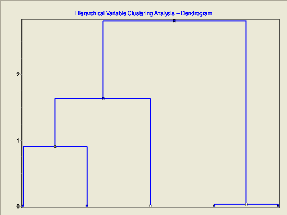
FIG 5.5. Dendrogramme de classification CAH
des variables
Nous avions vu dans le dendrogramme que les partitions en 3 ou
4 classes semblent les plus appropriées dans cette classification. Pour
acquérir le nombre de classe adéquat : on s'appuie sur la courbe
d'évolution de la variation de l'inertie intraclasse en fonction du
nombre de classes. Le premier coude apparus correspond de trois classes de
variable.
inertie intra classe
4
0
6
5
3
2
1
0 2 4 6
classe
inertie intra classe
FIG 5.6. La courbe de la variation de
l'inertie intraclasse
On voit sur le dendrogramme, trois groupes bien distincts de
variables : d'une part DureeTotal MDuree, d'autre part P_Repetition P
_Requête OK et le troisième groupe est représenté
par Nb Requêtes.
b. Classification des individus
Le graphique de la figure « FIG 5.7 » exhibe un
aperçu de La classification des individus basée sur le
résultat des classes obtenues de la classification des variables.
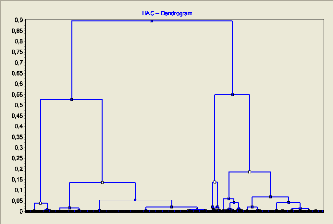
FIG 5.7. Dendrogramme de classification CAH des
individus
A partir d'un premier regard sur ce graphique, l'on imagine
aisément les difficultés rencontrées par les analystes
à la recherche de nombre de classes significatives. Le choix ici est
basé sur l'indice du saut le plus élevé.
La classification en deux classes a été
ignorée alors qu'elle correspond au saut le plus élevé,
cela est naturel car à l'usage on constate que cette subdivision en deux
classes proposera toujours le saut le plus élevé, ce qui est
normal dans le sens où il s'agit là de la première
subdivision possible de l'ensemble de données, la dispersion dans les
deux groupes produits chute mécaniquement sans que cela corresponde
forcément, dans la plupart des cas, à un partitionnement
intéressant. Dans le cas présent, le partitionnement en quatre
classes se démarque fortement des autres.
+ Interprétation statistique des
classes
Ce travail a aboutit à la découverte de quatre
groupes d'utilisateurs du site du CUBBA à savoir :
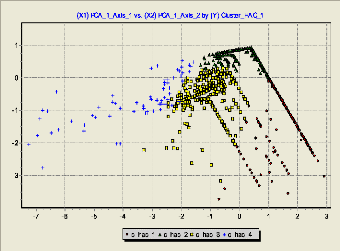
FIG 5.8. Résultat de classification des
navigations
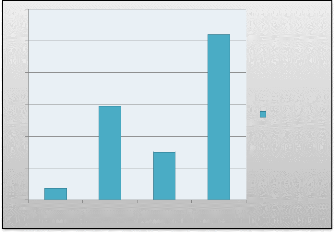
40
60
50
30
20
10
0
classe1 classe2 classe3 classe4
pourcentage
FIG 5.9. Interprétation statistique des
classes des individus.
1' Classe 1: Groupe d'internautes composées de
navigations dont le nombre de requête très important.
1' Classe 2: Groupe d'internautes composées de
navigations dont La durée de chaque navigation et moyenne de la
durée sont très élevées en comparaison avec les
autres classes.
v' Classe 3: Groupe d'internautes composées de
navigations dont toutes ces valeurs de variables sont faibles.
1' Classe 4: Groupe d'internautes composées de
navigations dont pourcentage de répétitions de requête de
chaque navigation et Pourcentage de requêtes réussies sont
élevées.
+ Interprétation sémantique des
classes
Dans le cadre de ce mémoire, on ne s'intéresse
pas uniquement à l'interprétation statistique des classes, mais
aussi et surtout à l'interprétation sémantique. En
d'autres termes, nous cherchons à comprendre ce qui se passe dans le
site afin d'identifier les informations pouvant être extraites une fois
toutes les navigations classées dans des classes, à savoir :
1' chaque classe rassemble des navigations appartenant à
des individus ayant visité de
pages similaires et qui partagent ainsi les mêmes
préférences.
1' Les Profils d'usages permettent de créer des
catégories de navigations dans les fichiers log. ils sont une
manière simple de grouper les pages du site pour une meilleure analyse.
Ces profils sont très intuitifs et peuvent être facilement
extraites à partir de la
60
50
40
30
20
10
0
classe1
classe2
classe3
classe4
profil1
profil2
profil3
profil1
profil2
profil3
classification des pages. Chaque classe de page possède un
profil différent des autres profils .dans notre expérimentation
on possède tois profils :
> le premier profil est celui de pages hybrides pour les
internautes ayant un centre d'intérêt les activités de
recherche des unités et laboratoires de recherche.
> le deuxième profil est celui des pages de contenus
dont l'objectif des internautes les activités des institutions
universitaires et le téléchargement des cours.
> le dernier profil représente les internautes ayant
pour objectif la découverte du site et qui ont visité les pages
de références.
v' Les classes ayant un effectif important correspondent aux
profils d'usage le plus populaires.
v' Les classes ayant un faible effectif correspondent aux
profils d'usage minoritaires.
Ces informations sont très intuitives et peuvent
être facilement extraites à partir d'une simple analyse sur la
partition de données.
Afin de mieux connaître les profils les plus typiques de
comportement d'internaute, nous avons eu recours à
l'interprétation des classes par les profils.
Résultat
La composition des classes en fonction des profils des
utilisateurs montrent bien que les classes trouvées ne se
détachent pas visiblement les unes des autres. Ce résultat
reflète un comportement assez homogène chez l'ensemble des
utilisateurs indépendamment de leurs profils.
4. 2 Xlil ENiP SlA)P 'nlalion
L'outil d'implémentation utilisé dans ce chapitre
est: TANAGRA version 1.4.33.
TANAGRA est un logiciel gratuit de data mining destiné
à l'enseignement et à la recherche, diffusé sur internet.
Il implémente une série de méthodes de fouilles de
données issues du domaine de la statistique exploratoire, de
l'apprentissage automatique et des bases de données.
v Son premier objectif est d'offrir aux étudiants et
aux chercheurs d'autres domaines (médecine, bioinformatique, marketing,
etc.) une plate-forme facile d'accès, respectant les standards des
logiciels actuels, notamment en matière d'interface et de mode de
fonctionnement, il doit etre possible d'utiliser le logiciel pour mener des
études sur des données réelles.
v Le second objectif est de proposer aux enseignants une
plate-forme entièrement fonctionnelle, le logiciel peut servir d'appui
pédagogique pour les illustrations et le traitement des jeux de
données en cours ou en TD.
v Enfin, le troisième objectif est de proposer aux
chercheurs une architecture leur facilitant l'implémentation des
techniques qu'ils veulent étudier, de comparer les performances de ces
algorithmes. TANAGRA se comporte alors plus comme une plate-forme
d'expérimentation.
Point très important à nos yeux, la
disponibilité du code source est un gage de crédibilité
scientifique, elle assure la reproductibilité des
expérimentations publiées, et surtout, elle permet la comparaison
et la vérification des implémentations.
Le site de diffusion du logiciel7 a
été mis en ligne en janvier 2004, il compte en moyenne une
vingtaine de visiteurs par jour. TANAGRA est également
référencé par les principaux portails de l'ECD.
7 (
http://eric.univ-lyon2.fr/~ricco/tanagra)
5. Conclusion
L'expérience de fouille de donnée a pour but de
valider ou d'invalider l'existence d'un comportement typique des utilisateurs
selon leur profil. Les différentes classes qui peuvent être
éventuellement identifiés présentent chacune un
intérêt pour une catégorie différente
d'utilisateurs. Ceci permet une bonne vision de l'ensemble des utilisateurs.
Conclusion
&
Perspective
Au cours de ce mémoire qui s'inscrit dans le cadre de
la préparation d'un Ingénieur informatique au CUBBA, on a
étudié le comportement des utilisateurs du site Web de notre
centre universitaire à partir de l'exploitation des données
d'usage disponibles dans les fichiers log gérés par le serveur.
Notre objectif est de proposer une approche permettant d'exploiter les
différentes informations relatives à l'usage d'un site Web en vue
d'extraire des connaissances pouvant servir à son
amélioration.
La partie d'expérimentation confirme l'étape de
préparation des données telle qui indiqué dans la
littérature consultée, et qui représente 60 à 80%
du processus de Fouille de données d'usage du Web. Cette phase sert de
construire un tableau de description des navigations permettant d'aller
à la phase de classification. L'objectif de cette classification est de
découvrir les différents comportements d'utilisateurs ou des
catégories de comportement de navigation et les résultats obtenus
ne montrent aucune différence significative dans le comportement chez
l'ensemble des utilisateurs.
Nous pensons que la validation des résultats obtenus
nécessite d'autres expérimentations dans le temps et
éventuellement, une comparaison avec des études similaires dans
des institutions universitaires. Ceci constitue un des perspectives du travail
réalisé.
Enfin, il nous semble intéressant de
généraliser l'analyse à des données autres que ceux
du Web. En particulier nous pensons à l'analyse des requêtes de
n'importe quel système d'informations. Les résultats obtenus
peuvent permettre une meilleure compréhension des utilisateurs de tels
systèmes et répondre au mieux à leurs attentes. Ceci nous
semble une bonne piste dans le domaine de l'application des techniques de
fouilles de données.
Bibliographie
[1] R. Kosala and H. Blockeel, «Web mining research : A
survey,» ACM SIGKDD Explorations :Newsletter of the Special Interest Group
on Knowledge Discovery and Data Mining, vol. 2,pp. 1-15, 2000.
[2] J. Srivastava, R. Cooley, M. Deshpande, and P.-N. Tan,
«Web usage mining: Discovery and applications of usage patterns from web
data,» SIGKDD Explorations, vol. 1, no. 2, pp. 12-23, 2000.
[3] R. Cooley, B. Mobasher, and J. Srivastava, «Data
preparation for mining world wide web browsing patterns,» Journal of
Knowledge and Information Systems, vol. 1, no. 1, pp. 5- 32,1999.
[4] M. Spiliopoulou, «Data mining for the web,»
Workshop on Machine Learning in User Modelling of the ACAI99, pp. 588-589,
1999.
[5] W3C, «Logging control in w3c httpd,» http: //
www.w3.org/TR/WD-logfile.
[06]B. Lavoie et H. F. Nielson, Web characterisation
terminology & definitions sheet
[7] Caractérisation d'usages et personnalisation d'un
portail pédagogique. État de l'art et expérimentation de
différentes méthodes d'analyse du Web UsageMining. Christine
MICHEL
[8] H. Samelides, P. Bouret, J. Reggia, Réseaux
neuronaux. Une approche connexionniste de l'intelligence artificielle.
Édition TEKNEA 1991.
[9] 4/5ème années - cours de Data
Mining -6 : Analyses factorielles -Bertrand LIADET
[10] M. Mc Cord Nelson, W.T. Illingworth A practical guide to
neural nets, Addison-Wesley Publishing ompany 1991.
[11] J. A. Freeman, D. Skapma, Neural Networks, Algorithms, and
programming technique, Addison-Wesley publishing company 1992
[12] B. Berendt, B. Mobasher, M. Spiliopoulou, and M.
Nakagawa, «The impact of site structureand user environment on session
reconstruction in web usage analysis,» in Proceedings of the 4th WebKDD
2002 Workshop, at the ACM-SIGKDD Conference on Knowledge Discovery in Databases
(KDD'2002), Edmonton, Alberta, Canada, July 2002.
[13] Malika Charrad: Techniques d'extraction de connaissances
appliquées aux données du Web .Thèse de
mastère.Université manouba Tunisie .2005
[14] L. D. Catledge and J. E. Pitkow, «Characterizing
browsing strategies in the world-wide web,»Computer Networks and ISDN
Systems, vol. 27, no. 6, pp. 1065-1073, 1995.
[15] D. Tanasa, «Web usage mining: Contributions to
intersites logs preprocessing and sequential pattern extraction with low
support,» Thèse de doctorat, University of Nice Sophia Antipolis, 3
June 2005.
[16] M. Michel Zins : Les outils et méthodes
destinés à l'analyse des logs de serveur Web ;
Méthodologie de la recherche en marketing (MRK-65384)
[17] Application des techniques de fouille de données aux
logs web : Etat de l'art sur le Web Usage Mining Doru Tanasa, Brigitte Trousse
et Florent Masséglia
[18] Data Mining et statistique décisionnel
.Stéphane TUFFERY.
[19] J. Srivastava, R. Cooley, M. Deshpande, et P. Tan,
»Web Usage Mining: discovery and applications of usage patterns from Web
data,» In SIGKDD Explorations, Volume1, Issue 2 editions ACM, pp. 12-23,
Jan 2000.
[20] Lebart L, Morineau A et Piron M - Statistique exploratoire
multidimensionnelle - Edition DUNOD, Paris 2000
[21] R. Rao, P. Pirolli, et J.Pitkow, »Silk from a sow's
ear: Extracting usable structures from the web. » In proc. ACM Conf. Human
Factors in Computing Systems, CHI, 1996.
[22] personnalisation des sites web : élaboration d'une
méthodologie de mise en oeuvre et application au cas autre directeur
:
jean vanderdonckt université catholique de louvain
2001-2002
[23] Tanagra, un logiciel de Data Mining gratuit pour
l'enseignement et la recherche Ricco Rakotomalala February 19, 2010
[24] Ziani b. Ouinten y : Etude de cas en Web Usage Mining :
Catégorisation des utilisateurs de la connexion Internet de l'UATL.
[25] W. Frawley, G. Piatetsky-Shapiro, et C. Matheus, Knowledge
Discovery in Databases, ch. Knowledge Discovery in Databases: An Overview, p.
1-27, AAAI/MIT Press, 1991.
[26] Zouache.Djaafer , chapitre1 Analyse en
composantes principales 1èreMaster Informatique.
Décisionnel.
.
| 

