Application du processus de fouille de données d'usage du web sur les fichiers logs du site cubba( Télécharger le fichier original )par Nabila Merzoug et Hanane Bessa Centre universitaire de Bordj Bou Arréridj Algérie - Ingénieur en informatique 2009 |

CHAPITRE 4Prétraitement de fichiers logdu site CUBBA1. Étude de cas1.1. Analyse du site Web académiqueDans cette étude de cas sur des données réelles, nous analysons les fichiers log du site Web de notre Centre universitaire de Bordj Bou Arréridj3. La figure exhibe un aperçu de la page de garde du site en question.
FIG 4.1. Aperçu de la page de garde du site Web de Centre Universitaire de Bordj Bou Arrerridj. 1.2. Préparation des donnéesEn collaboration avec les responsables du centre de calcul, nous avons pu obtenir un jeu de données qui enregistre l'accès au site pendant la période du 14 février 2010 jusqu'au 17 mars 2010. Les différents fichiers log du format ECLF sont concaténés en un seul fichier qui a constitué notre source de données. Le tableau suivant indique la taille des différents fichiers log récupérés sur la période étudiée. 3 Le site analysé est accessible à l'adresse suivante : http://www.univ-bba.dz
TAB 4.1. La taille des fichiers log analysés. 2. Implémentation2.1. Chargement du fichier Log et transformation en une table d'une BDDLe fichier LOG est un fichier texte, appelé aussi journal des connexions. Généralement il est de la forme suivante :
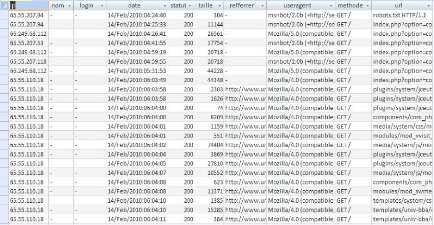
Le fichier Log se transforme en une table composée de plusieurs colonnes. Chaque colonne correspond à un champ spécifique du fichier Log :
FIG 4.3. Base de données après import. 2.2. Présentation de l'application de prétraitementNotre application est une petite démonstration aux différentes étapes de prétraitement, c'est pour ça on n'a pas besoin de réalisé une interface ergonomique, mais on a mené à réaliser une interface plus au moins au professionnel.
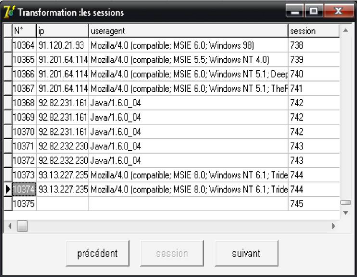
La transformation des données est une tache fastidieuse car elle représente véritablement le visiteur. Notre analyse est entièrement ne tient pas compte du fait que plusieurs requêtes peuvent provenir d'un même utilisateur. Ceci réduit les problèmes liés aux caches Web (Proxy), aux adresses IP dynamiques et au partage d'ordinateurs. + L'identification des sessions d'utilisateurs Après le nettoyage des données et l'application de l'algorithme d'identification des sessions d'utilisateurs « FIG 4.5 » on a obtenue 744 sessions. La figure ci dessous présente un aperçu de sessions obtenues. 4 5
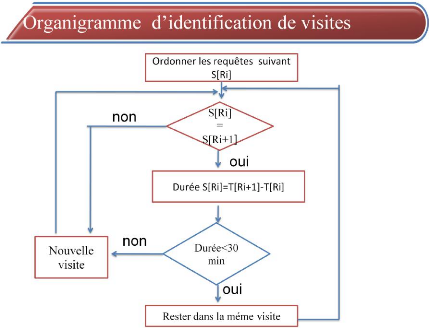
FIG 4.5. L'identification des sessions. + L'identification des visites Après la création des sessions et l'application de l'algorithme d'identification des visites ci-dessous, nous obtenons 1826 visites d'après la base totale. > Algorithme d'identification des visites d'utilisateur En premier temps on doit collecter des informations sur l'identification des visites d'utilisateurs. Soit les variables suivantes : v' Ri= Requête i v' V [Ri] = Visite à laquelle appartient la requête i v' S [Ri] = Session à laquelle appartient la requête i v' T [Ri] = Temps de déclenchement de la requête i. v' Durée [Ri] =Durée de la requête i. v' Durée = Somme des durées de requêtes de chaque visite. v' NV = Nombre de requêtes dans chaque visite.
FIG 4.6 Algorithme d'identification des visites d'utilisateur.
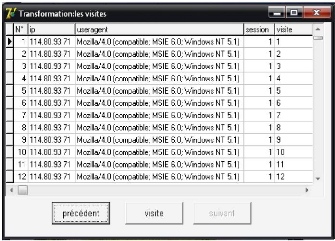
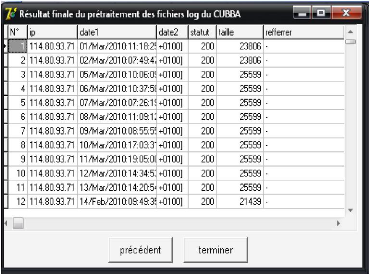
FIG 4.7. L'identification des visites. c. Base de données final Notre base de données qui constitue de 1826 requêtes est prête pour l'application de différentes méthodes de fouille des données. La figure suivante montre la base de données finale après l'étape de prétraitement.
FIG 4.8. Résultat final de prétraitement. |
| ||||||||||||||||||||||