Application du processus de fouille de données d'usage du web sur les fichiers logs du site cubba( Télécharger le fichier original )par Nabila Merzoug et Hanane Bessa Centre universitaire de Bordj Bou Arréridj Algérie - Ingénieur en informatique 2009 |

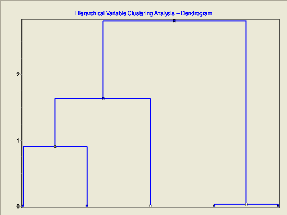
3.2.1. Classification hiérarchique ascendante (CAH)a. Classification des variables La classification ascendante hiérarchique(CAH) des variables permet d'agréger au fur et à mesure les groupes de variables qui portent les mêmes informations (redondantes corrélées), et dissocier les variables qui expriment des informations complémentaires au sens de la minimisation de la perte d'inertie à chaque étape. La classification de variable à pour but de : + mieux comprendre ce qui rassemble ou distingue les groupes. + Réduction du nombre de variables. La classification des variables « DureeTotale, MDuree, P_Repetitions, Nb Requêtes, P_RequêtesOK », Pour la distance euclidienne et l'agrégation selon la méthode de Ward, donne le dendrogramme suivant :
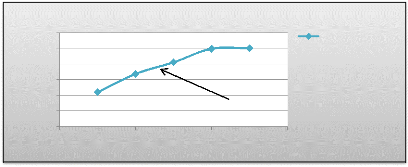
FIG 5.5. Dendrogramme de classification CAH des variables Nous avions vu dans le dendrogramme que les partitions en 3 ou 4 classes semblent les plus appropriées dans cette classification. Pour acquérir le nombre de classe adéquat : on s'appuie sur la courbe d'évolution de la variation de l'inertie intraclasse en fonction du nombre de classes. Le premier coude apparus correspond de trois classes de variable.
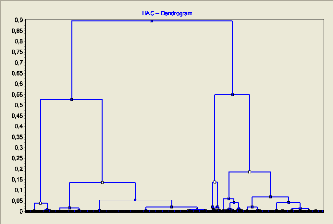
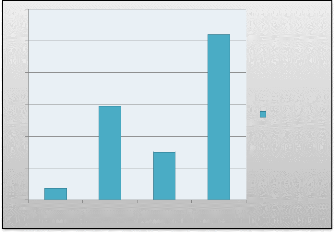
inertie intra classe 4 0 6 5 3 2 1 0 2 4 6 classe inertie intra classe FIG 5.6. La courbe de la variation de l'inertie intraclasse On voit sur le dendrogramme, trois groupes bien distincts de variables : d'une part DureeTotal MDuree, d'autre part P_Repetition P _Requête OK et le troisième groupe est représenté par Nb Requêtes. b. Classification des individus Le graphique de la figure « FIG 5.7 » exhibe un aperçu de La classification des individus basée sur le résultat des classes obtenues de la classification des variables.
FIG 5.7. Dendrogramme de classification CAH des individus A partir d'un premier regard sur ce graphique, l'on imagine aisément les difficultés rencontrées par les analystes à la recherche de nombre de classes significatives. Le choix ici est basé sur l'indice du saut le plus élevé. La classification en deux classes a été ignorée alors qu'elle correspond au saut le plus élevé, cela est naturel car à l'usage on constate que cette subdivision en deux classes proposera toujours le saut le plus élevé, ce qui est normal dans le sens où il s'agit là de la première subdivision possible de l'ensemble de données, la dispersion dans les deux groupes produits chute mécaniquement sans que cela corresponde forcément, dans la plupart des cas, à un partitionnement intéressant. Dans le cas présent, le partitionnement en quatre classes se démarque fortement des autres. + Interprétation statistique des classes Ce travail a aboutit à la découverte de quatre groupes d'utilisateurs du site du CUBBA à savoir :
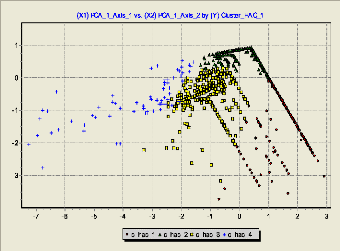
FIG 5.8. Résultat de classification des navigations
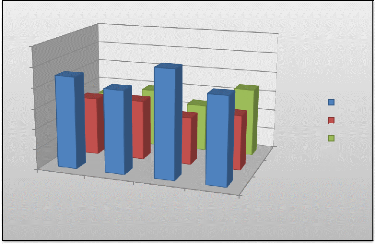
40 60 50 30 20 10 0 classe1 classe2 classe3 classe4 pourcentage FIG 5.9. Interprétation statistique des classes des individus. 1' Classe 1: Groupe d'internautes composées de navigations dont le nombre de requête très important. 1' Classe 2: Groupe d'internautes composées de navigations dont La durée de chaque navigation et moyenne de la durée sont très élevées en comparaison avec les autres classes. v' Classe 3: Groupe d'internautes composées de navigations dont toutes ces valeurs de variables sont faibles. 1' Classe 4: Groupe d'internautes composées de navigations dont pourcentage de répétitions de requête de chaque navigation et Pourcentage de requêtes réussies sont élevées. + Interprétation sémantique des classes Dans le cadre de ce mémoire, on ne s'intéresse pas uniquement à l'interprétation statistique des classes, mais aussi et surtout à l'interprétation sémantique. En d'autres termes, nous cherchons à comprendre ce qui se passe dans le site afin d'identifier les informations pouvant être extraites une fois toutes les navigations classées dans des classes, à savoir : 1' chaque classe rassemble des navigations appartenant à des individus ayant visité de pages similaires et qui partagent ainsi les mêmes préférences. 1' Les Profils d'usages permettent de créer des catégories de navigations dans les fichiers log. ils sont une manière simple de grouper les pages du site pour une meilleure analyse. Ces profils sont très intuitifs et peuvent être facilement extraites à partir de la
60 50 40 30 20 10 0 classe1 classe2 classe3 classe4 profil1 profil2 profil3 profil1 classification des pages. Chaque classe de page possède un profil différent des autres profils .dans notre expérimentation on possède tois profils : > le premier profil est celui de pages hybrides pour les internautes ayant un centre d'intérêt les activités de recherche des unités et laboratoires de recherche. > le deuxième profil est celui des pages de contenus dont l'objectif des internautes les activités des institutions universitaires et le téléchargement des cours. > le dernier profil représente les internautes ayant pour objectif la découverte du site et qui ont visité les pages de références. v' Les classes ayant un effectif important correspondent aux profils d'usage le plus populaires. v' Les classes ayant un faible effectif correspondent aux profils d'usage minoritaires. Ces informations sont très intuitives et peuvent être facilement extraites à partir d'une simple analyse sur la partition de données. Afin de mieux connaître les profils les plus typiques de comportement d'internaute, nous avons eu recours à l'interprétation des classes par les profils. Résultat La composition des classes en fonction des profils des utilisateurs montrent bien que les classes trouvées ne se détachent pas visiblement les unes des autres. Ce résultat reflète un comportement assez homogène chez l'ensemble des utilisateurs indépendamment de leurs profils. 4. 2 Xlil ENiP SlA)P 'nlalion L'outil d'implémentation utilisé dans ce chapitre est: TANAGRA version 1.4.33. TANAGRA est un logiciel gratuit de data mining destiné à l'enseignement et à la recherche, diffusé sur internet. Il implémente une série de méthodes de fouilles de données issues du domaine de la statistique exploratoire, de l'apprentissage automatique et des bases de données.
Point très important à nos yeux, la disponibilité du code source est un gage de crédibilité scientifique, elle assure la reproductibilité des expérimentations publiées, et surtout, elle permet la comparaison et la vérification des implémentations. Le site de diffusion du logiciel7 a été mis en ligne en janvier 2004, il compte en moyenne une vingtaine de visiteurs par jour. TANAGRA est également référencé par les principaux portails de l'ECD. 7 ( http://eric.univ-lyon2.fr/~ricco/tanagra) 5. Conclusion L'expérience de fouille de donnée a pour but de valider ou d'invalider l'existence d'un comportement typique des utilisateurs selon leur profil. Les différentes classes qui peuvent être éventuellement identifiés présentent chacune un intérêt pour une catégorie différente d'utilisateurs. Ceci permet une bonne vision de l'ensemble des utilisateurs. |
|