Application du processus de fouille de données d'usage du web sur les fichiers logs du site cubba( Télécharger le fichier original )par Nabila Merzoug et Hanane Bessa Centre universitaire de Bordj Bou Arréridj Algérie - Ingénieur en informatique 2009 |

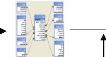
3. Fouille de données d'usage du Web3.1. DefinitionLa fouille de données d'usage du Web (Web Usage Mining (WUM), en anglais) désigne l'ensemble de techniques basées sur la fouille de données pour analyser l'usage d'un site Web [02, 03, 04]. En d'autres termes, le WUM correspond au processus d'Extraction de Connaissances dans les Bases de Données (ECD) - ou Knowledge Discovery in Databases (KDD), en anglais - appliqué aux données d'usage du Web. requetes (affichage d'une page du site, téléchargement d'un fichier, identification de l'utilisateur via un mot de passe, etc.) qui sont enregistrées en format texte et stockées de manière standardisée dans un fichier qui s'appelle log Web. Ce fichier est maintenu par le serveur HTTP qui héberge le(s) site(s) en question. Suivant la fréquentation du site, la taille du fichier log peut atteindre des proportions importantes, pouvant croître de quelques centaines de mégaoctets jusqu'à plusieurs dizaines de gigaoctet par mois. 3.2. Processus de la MKIGeBSIBdIMAs Bd'KADTIBIK B Ib La fouille de données d'usage du Web (WUM) comporte trois étapes principales :
Prétraitement
Extraction des motifs Motifs Fichiers log Interprétation
Connaissance FIG 1.2. Le schéma du processus WUM [17]. a. Prétraitement Le prétraitement du WUM (nettoyer et transformer les données), qui est un processus fastidieux et complexe dû principalement à la grande quantité de données (les fichiers logs Web) et à la faible qualité de l'information qu'on trouve dans les fichiers logs Web. Dans cette première étape, plusieurs tâches doivent titre accomplies, comme le nettoyage des données, l'identification des utilisateurs, l'identification des sessions et l'identification des visites. La préparation des données occupe environ 60 à 80% du temps impliqué dans le processus du web usage mining.
Interprétation des modèles est la dernière étape globale du Web Usage Mining. Elle a comme objectif de filtrer les modèles inintéressants de l'ensemble trouvé dans la phase d'extraction des modèles. Ce filtrage dépend de l'application finale que l'on souhaite faire du Web Usage Mining (adaptation des sites web, système de recommandation, préchargement des pages, etc. . .). 3.3. Sources de la TRXIODBGeBGRnnAsBG'XADTeBGX Web L'activité d'un serveur web est composée d'une succession d'étapes : la réception d'une requête en provenance d'un client, l'analyse de la requête, la création de la réponse, l'envoi de cette dernière. La totalité de ces informations peut être stockée dans un fichier d'enregistrements (ou logs). il existe plusieurs formats des fichiers Logs Web mais le format le plus courant est le CLF (Common Log file Format). Selon ce format six informations sont enregistrées:
Le format ECLF (Extended Common Log file Format) représente une version plus complète du format CLF. En effet, il indique en plus l'adresse de la page de référence (la page précédemment visitée ou le moteur de recherche utilisé pour rejoindre la page Web suivi des mots clés demandés), la configuration du client, c'est-à-dire, son navigateur Web (Firefox, Internet Explorer, etc.) et son système d'exploitation (Windows, Linux, Mac OS, etc.). Le format du fichier log a été standardisé par W3C [05]. Le format ECLF: [ip] [name] [date] [url] [statut] [taille] [refferer] [agent]. Exemple 41.98.239.119 - - [14/Mar/2010:04:20:39 +0100] "GET / HTTP/1.0" 200 25479 "-" "Mozilla/5.0 (Windows; U; Windows NT 5.1; fr; rv:1.9.0.11) Gecko/2009060215 Firefox/3.0.11" 41.98.239.119 - - [14/Mar/2010:04:20:39 +0100] "GET / HTTP/1.0" 200 25479 "-" "Mozilla/5.0 (Windows; U; Windows NT 5.1; fr; rv: 1.9.0.11) Gecko/2009060215 Firefox/3.0.11" 67.195.111.190 - - [14/Mar/2010:05:34:44 +0100] "GET /index.php? View=weblink&catid=1%3Aliens-utiles&id=2%3Asite-delarn&option=com_weblinks&Itemid=52 HTTP/1.0" 301 - "-" "Mozilla/5.0 (compatible; Yahoo! Slurp/3.0; http://help.yahoo.com/help/us/ysearch/slurp)" FIG 1.3. Schéma illustratif des champs d'un fichier log Web contenant trois requêtes. |
|