Monitoring d'une infrastructure informatique Linux sur
base d'outils libres

Travail de fin d'études présenté par
Geoffrey Lemaire en vue de l'obtention du grade de
Bachelier en Informatique
Industrielle
Remerciements
Je remercie tout d'abord la société Manex, qui a eu
la gentillesse de m'accueillir et de me donner tout ce dont j'avais besoin pour
que mon stage se déroule pour le mieux.
Je pense tout particulièrement à Vincent Keunen,
qui m'a parrainé au sein de la société, et à David
Wery, mon guide durant ces quelques mois.
Merci également à mon superviseur, Pierre De Fooz,
pour son suivi et ses bons conseils quant à la rédaction de mon
TFE.
Merci à tous ceux qui ont participé de près
ou de loin à ce projet et merci à Coralie.
Table des matières
1 MANEX 8
1.1 PERSONNEL 8
1.2 DOMAINES DE PRÉDILECTIONS : 8
1.3 OUTILS ET TECHNOLOGIES 8
1.4 COORDONNÉES 9
1.5 LEURS PRODUITS 9
1.6 LEURS RÉFÉRENCES 10
1.6.1 Systèmes Internet 10
1.6.2 Systèmes de sécurité 10
1.6.3 Systèmes mobiles 10
2 LES OBJECTIFS DU TRAVAIL 11
2.1 L'ENVIRONNEMENT TECHNIQUE ET LES OUTILS 11
2.2 AU NIVEAU DES LOGICIELS 11
2.3 AU NIVEAU DU MATÉRIEL 11
2.4 LEUR RÉSEAU 12
3 LES OUTILS DE MONITORING 13
3.1 NAGIOS 13
3.2 MANAGEENGINE OPMANAGER 16
3.2.1 Trois versions 16
3.2.2 Caractéristiques 16
3.2.3 Conclusion 18
3.2.4 Captures d'écran 19
3.3 CACTI 20
3.3.1 Pré requis 20
3.3.2 Installation 20
3.3.3 Configuration 20
3.3.4 Contrôles des hôtes 20
3.3.5 Conclusion 20
3.3.6 Captures d'écran 21
3.4 OREON 22
3.4.1 Pré requis 22
3.4.2 Installation 23
3.4.3 Configuration 23
3.4.4 Contrôles des hôtes 23
3.4.5 Gestions des utilisateurs 23
3.4.6 Conclusion 23
3.4.7 Captures d'écran 24
3.5 TABLEAUX RÉCAPITULATIFS DES OUTILS DE
MONITORING 25
4 LES OUTILS DE SÉCURITÉ 26
4.1 LE FIREWALL (OU PARE-FEU) 26
4.1.1 Présentation 26
4.1.2 Les catégories 26
4.2 SYSTÈME DE DÉTECTION D'INTRUSIONS
(IDS) 28
4.2.1 Une petite histoire : le voleur, le videur et la
caméra cachée 28
4.2.2 Les deux familles de systèmes de
détection d'intrusion 28
4.3 NESSUS 30
4.3.1 Pré requis 30
4.3.2 Installation 30
4.3.3 Configuration 30
4.3.4 Particularité 30
4.3.5 Fonctionnement 30
4.3.6 Deux versions 30
4.3.7 Tests 31
4.3.8 Conclusion 31
4.3.9 Captures d'écran 32
4.4 SNORT 33
4.4.1 L'abonnement 33
4.4.2 Pré requis 33
4.4.3 Installation 33
4.4.4 Configuration 34
4.4.5 Tests avec Nessus 34
4.4.6 Conclusion 36
4.5 NMAP 37
4.5.1 Installation 37
4.5.2 Fonctionnement 37
4.5.3 Les premiers scans 37
4.5.4 D'autres options 39
4.5.5 Conclusion 40
4.6 MBSA DE MICROSOFT 41
4.6.1 Présentation 41
4.6.2 Installation 41
4.6.3 Tests 41
4.6.4 Conclusion 41
4.6.5 Captures d'écran 41
5 LES OUTILS INDISPENSABLES 43
5.1 NET-SNMP 43
5.2 MRTG 44
5.3 RRDTOOL 44
5.4 LE CHOIX DES OUTILS 44
6 PRÉSENTATION DE NAGIOS 45
6.1 CARACTÉRISTIQUES 45
6.2 PRÉ REQUIS 46
6.3 INSTALLATION 46
6.3.1 Ajout des dépôts 46
6.3.2 Modification des iptables 46
6.3.3 Téléchargement et installation
46
6.4 STRUCTURE DES RÉPERTOIRES ET EMPLACEMENT
DES FICHIERS 46
6.5 ACCÈS À L'INTERFACE WEB 47
6.6 DESCRIPTION DES FICHIERS DE CONFIGURATIONS 48
6.6.1 Configuration principal 48
6.6.2 Configuration des CGIs 49
6.6.3 Configuration d'un vhost dans Apache 49
6.6.4 Les contacts et groupes de contacts 50
6.6.5 Définition des périodes de
vérifications et de notifications 51
6.6.6 Définition des groupes d'hôtes et des
templates hôtes 51
6.6.7 Définition des hôtes 52
6.6.8 Définition des ressources 52
6.6.9 Définition des commandes 53
6.6.10 Configuration des informations étendues
53
6.7 LES SERVICES 55
6.7.1 Les services publics 55
6.7.2 Les services privés 55
6.7.3 Définition des templates et des services
55
6.7.4 Déclaration d'un autre service 56
6.7.5 Un dernier... 57
6.8 MÉTHODES POUR DÉMARRER NAGIOS 57
6.9 PLUGINS 58
6.9.1 Différentes sources 59
6.9.2 Le principe de fonctionnement 59
6.9.3 Utilisation des Plugins pour Contrôler des
Services 59
6.9.4 Utilisation des Plu gins pour contrôler des
hôtes 59
6.9.5 L'analyse d'un plugin 60
6.10 CONTRÔLE DES HÔTES 64
6.10.1 NRPE 64
6.10.2 NSCA 64
6.10.3 Conclusion 65
6.11 TYPES DE MONITORING 65
6.11.1 Monitoring actif 66
6.11.2 Monitoring passif 66
6.12 DÉTECTION ET GESTION DES CHANGEMENTS
D'ÉTATS 66
6.13 L'ESCALADE DES NOTIFICATIONS 66
6.13.1 Recoupement des portées des escalades
66
6.13.2 Notifications de reprise d'activité
67
6.13.3 Intervalles de notification 67
6.14 LES DÉPENDANCES 67
6.14.1 Aperçu des dépendances de services
67
6.14.2 Comment les dépendances d'un service
sont-elles testées ? 67
6.14.3 Exemple de dépendance de service 68
6.14.4 Dépendances d'exécution 68
6.14.5 Dépendances de notification 68
6.14.6 Dépendances d'hôtes 69
6.15 L'HÉRITAGE 69
6.16 LES NOTIFICATIONS PAR MAIL 69
6.16.1 Son fichier de configuration 69
6.16.2 Les mails de Nagios 70
6.17 UTILISATION DU PROTOCOLE SNMPV3 71
6.18 DES TAS D'AUTRES POSSIBILITÉS ! 71
6.19 NAGIOS CHECKER 71
6.20 CONCLUSION 72
7 PRÉSENTATION DU PROTOCOLE SNMP 73
7.1 EN PRATIQUE 73
7.2 LES TRAMES 74
7.3 SA 3ÈME VERSION 75
7.3.1 USM - User-based Security Model 75
L'authentification : 75
1. Le transmetteur groupe des informations à
transmettre avec le mot de passe. 75
2. On passe ensuite ce groupe dans la fonction de hachage
à une direction. 75
3. Les données et le code de hachage sont ensuite
transmis sur le réseau. 75
4. Le receveur prend le bloc des données, et y ajoute
le mot de passe 75
5. On passe ce groupe dans la fonction de hachage à
une direction. 75
6. Si le code de hachage est identique à celui
transmis, le transmetteur est authentifié. 75
Le cryptage : 76
L'estampillage du temps : 76
7.3.2 VACM - View- based Access Control Model 77
7.4 LA TRAME SNMPV3 77
7.5 SON UTILISATION DANS MON STAGE 78
7.6 SA CONFIGURATION 78
7.6.1 Création d'un utilisateur v3 78
7.6.2 Le fichier snmpd.conf 78
7.6.3 Le test 79
7.7 ANALYSE AVEC WIRESHARK 79
7.7.1 Tests avec SNMPv2c 79
7.7.2 Test avec le SNMPv3 81
8 UPS 83
8.1 LE MATÉRIEL 83
8.2 LA CONNECTIQUE 83
8.3 LES LOGICIELS 83
8.3.1 UPSmon 83
8.3.2 Drivers Nut 83
8.4 NAGIOS DANS TOUT CELA 84
8.4.1 Présentation du plugin 84
8.4.2 Définition de la commande 84
8.4.3 Définition du service 84
8.4.4 Le résultat 84
9 LES IMPRIMANTES 85
9.1 ACTIVER LE PROTOCOLE SNMP 85
9.2 UN SNMPWALK DE L'IMPRIMANTE 86
9.3 INTÉGRATION DANS NAGIOS 87
9.3.1 Le contrôle du niveau d'encre 87
9.3.2 Le contrôle du statut 87
10 UTILISATION DE SNMP POUR LANCER UN SCRIPT À
DISTANCE 88
10.1 DES PLUGINS SUPPLÉMENTAIRES 88
10.2 LA CONFIGURATION DE L'AGENT SNMP 88
10.3 DÉFINITION DE LA COMMANDE ET DES SERVICES
SUR LE SERVEUR 88
10.4 LE POURQUOI ET LE COMMENT ? 89
11 UTILISATION DES TRAPS AVEC NAGIOS 90
11.1 CONFIGURATIONS 90
11.1.1 Coté client (l'agent) 90
11.1.2 Coté serveur 90
11.2 NAGIOS DOIT COMPRENDRE, SNMPTT L'AIDE. 91
11.2.1 Fonctionnement général 91
11.2.2 Configuration 91
11.3 A NOTER : 92
11.4 COMPILATION DES MIBS 93
11.5 DANS NAGIOS 93
11.6 QUELQUES TESTS 94
Introduction
La gestion d'un parc de serveur est un travail de chaque
instant. Un bon administrateur système doit savoir à tout moment
l'état des différentes machines et des différents
services. Un autre aspect clé est que l'administrateur ne peut pas se
permettre de passer son temps devant un tableau avec des voyants verts en
attendant qu'un voyant passe au rouge pour agir. Son temps est occupé
à d'autres tâches et il ne peut donc pas surveiller le tableau de
statut en permanence.
L'examen journalier des logs systèmes est un bon
début. Cependant, si un problème survient, on s'en rend compte
seulement le lendemain. Ce qui peut être trop tard. Tout problème
ou panne peut avoir de lourdes conséquences aussi bien
financières qu'organisationnelles. La supervision des réseaux est
alors nécessaire et indispensable. Elle permet entre autres d'avoir une
vue globale du fonctionnement et des problèmes pouvant survenir sur un
réseau mais aussi d'avoir des indicateurs sur la performance de son
architecture.
De nombreux logiciels, qu'ils soient libres ou
propriétaires, existent sur le marché. La plupart s'appuient sur
le protocole SNMP. Pour simplifier le travail, nous allons utiliser un moniteur
de supervision. Le but d'un tel programme est de surveiller les services et les
machines se trouvant sous notre responsabilité. Si un problème
survient, le moniteur de supervision nous prévient (email, SMS, coup de
téléphone,...) ou peut entreprendre certaines actions par
lui-même (relancer un service, tuer un processus, demander un
reboot,...).
Manex, la société dans laquelle j'ai
été accueilli, avait besoin d'une solution pour monitorer son
parc informatique afin de soulager la tâche des employés
suffisamment occupés au développement de leurs produits.

Chapitre 1

Présentation de l'entreprise

1 Manex
Depuis 1986, Manex propose des services de consultance et
développement pour la mise en oeuvre de solutions logicielles et
réseaux.
1.1 Personnel
Cette société est dirigée par Vincent
Keunen et est présidée par Nicolas Keunen. En plus des trois
informaticiens qui y travaillent à plein temps, la société
Manex travaille avec plusieurs indépendants. À cette
équipe s'ajoute une assistante de direction.
1.2 Domaines de prédilections :
Les systèmes internet : sites web
transactionnels, applications « web », connexions bases de
données, systèmes de messagerie, échanges B2B, ...
Les systèmes de sécurité :
Cryptographique, infrastructures à clés publiques,
certificats et signatures électroniques, ...
Les Systèmes mobiles : Palm, iPaq,
Psion, J2ME, GSM, SMS, ...
1.3 Outils et technologies
La société Manex s'est spécialisée
dans le domaine Java et développe, grâce à ce langage,
aussi bien des applications classiques que des applications Web.
L'utilisation de ce langage n'est pas anodine. En effet,
grâce à la machine virtuelle de Java, les applications pourront
être utilisées aussi bien sur un ordinateur équipé
d'un système d'exploitation Microsoft, Linux/Unix ou bien encore Mac.
De plus, la société Manex favorise l'Open Source en
utilisant des produits tels que Jboss, Hibernate ou bien encore Jasper
Report.
Elle maîtrise aussi les protocoles tels que :
HTTP : le protocole utilisé pour les communications web
;
SOAP : le protocole d'échanges utilisé pour la
communication avec un service Web ; LDAP : le protocole de communication avec
des annuaires ;
SMTP/POP/IMAP : les protocoles utilisés pour le transfert
du courrier électronique ; ...

1.4 Coordonnées
Rue Wagner 127
BE-4100 Boncelles, Belgique Tel. : +32 (0) 4 330 37 30 Fax. : +32
(0) 4 338 06 06 Mail :
info@manex.be
Web :
http://www.manex.be
1.5 Leurs produits
Inter Business Automated Transport System
Ibats est un système de messagerie Internet
sécurisée, automatisée et ouverte.
· :. Sécurisée, car il
utilise une infrastructure clés publiques - clés privées,
qui apporte :
> l'authenticité à la fois de
l'émetteur et du récepteur ;
> la confidentialité, du fait que
toute communication est cryptée, elle ne pourra être comprise que
par le destinataire ;
> l'intégrité du message,
car si une modification ou altération du message se produit
lors du transfert, alors il sera illisible par le récepteur, et donc
tout message interprété correctement est obligatoirement
identique à celui que l'émetteur a transmis ;
> la non-répudiation, car par le
système de signature électronique, le message a été
signé grâce à la clé privée, mais sera
vérifié par la clé publique associée. Donc, si la
signature est vérifiée par la clé publique de
l'émetteur que possède le récepteur, il peut prouver
l'origine du message ;
· :. Automatisée
> tout document déposé dans le
répertoire d'envoi sera envoyé automatiquement, selon une
fréquence déterminée ;
> le système gère les éventuels conflits
lors de la réception des documents ;
> Ibats se met automatiquement à jour via le
réseau.
· :. Ouverte car :
> gestion des formats : Ibats possède un convertisseur
qui adapte les formats de fichiers entre l'émetteur et le
récepteur ;
> portabilité : grâce à la machine
virtuelle Java, Ibats fonctionne sur les divers systèmes d'exploitation
(Windows, Unix, Mac, AS400) ;
> standard : Ibats fonctionne sur les standards Internet tel
que IMAP, SMTP, LDAP;
> complémentaire : il ne remplace pas votre logiciel
de messagerie actuelle, mais le complète.
La technologie qui est au coeur d'Ibats est utilisée
aujourd'hui par les deux principales messageries médicales de Belgique
et couvre près de 10 000 utilisateurs. Au niveau international, Ibats
est en cours d'implémentation dans plusieurs pays.
Site Web du produit :
http://www.ibats.biz
Java Advanced Facilities for Audit and Reporting ( Jafar
)

Jafar est la réponse à une demande d'Idewe,
leader dans le secteur de la médecine du travail en Belgique. En effet,
avant l'arrivée de Jafar, les observations des auditeurs étaient
inscrites sur papier, et une numérisation de cette méthode
s'avérait nécessaire. C'est alors que Manex a
développé un produit appelé Jaws (Java Workstation),
adaptable à divers appareils, capable de centraliser et de traiter les
données collectées, et de générer des rapports sur
base de celles-ci.
Afin de trouver de nouveaux débouchés, Manex a
développé un nouveau logiciel, qui reprend les mêmes
fonctionnalités que Jaws, mais qui en élargit le domaine
d'activité. Ce nouveau logiciel est Jafar.
Fonctionnalités

Faire des audits et recueillir des données en ce qui
concerne un champ d'activité. Générer
instantanément des rapports en fonction de ces audits.
Synchroniser les données recueillies avec un serveur
central.
Site Web du produit :
http://www.jafar.biz
1.6 Leurs références
1.6.1 Systèmes Internet

Commerce électronique : Disteel Cold, IBM, ChemResults
,... Extranets : GV comÐany, SMAP,...
Web : Docs.be, Mosacier, diverses PME,...
1.6.2 Systèmes de
sécurité

Consultance et implantations : Dresdner Bank, diverses
PME
PKI dans le monde médical : Conception et
réalisation de meXi, +1000 utilisateurs
1.6.3 Systèmes mobiles

Système d'audit et reporting : Prévention,
médecine du travail, Idewe, 300 utilisateurs Systèmes
mobiles pour vendeurs et techniciens : Olympian Games, Disteel Cold,
dossier
médical,...
Chapitre 2
Cahier des charges
2 Les objectifs du travail
L'objectif de ce travail est de monitorer et centraliser toutes
les informations concernant une infrastructure informatique à plusieurs
niveaux :
o Services (vérifier que les services sont bien
fonctionnels) ;
o Sécurité (monitoring de firewall,
détection d'intrusions) ;
o Machine (état du système de fichiers, chargement
mémoire et CPU, ...) ;
o Réseau (engorgement du réseau, bande passante,
table de routage, ...) ;
2.1 L'environnement technique et les outils
La plate-forme de travail sera composée des distributions
Linux Red Hat Entreprise, Fedora, Ubuntu et Microsoft Windows.
Les outils : Bash (PuTTY1), Apache, SNMP, Iptables
ainsi que tous les outils standards du monde Linux.
2.2 Au niveau des logiciels
Au départ, j'ai dû effectuer une recherche sur les
divers outils de monitoring et de sécurité disponibles sur les
plateformes Linux Red Hat Entreprise. Les résultats de ma recherche
sont
? pour le monitoring :
Nagios, AdventNet ManageEngine OpManager, Cacti, Oreon,
Utilisation du protocole SNMP (via Net-SNMP), RRDTool/MRTG (pour la
génération de graphiques).
? pour la sécurité :
Nessus (leader dans le domaine des scanners de
sécurité2), Snort+BASE
Bien entendu, il en existe bien d'autres (Big Brother,
OpenNMS, Scotty, Hobbit, nMap,...), mais ce sont les plus utilisés.
Sinon, il existe des solutions payantes et professionnelles dont HP OpenView,
Cisco Works, IBM Tivoli, ... A la fin du chapitre 3 sur la présentation
des outils, se trouve un tableau comparatif des divers outils en licence
ouverte/libre et commerciale.
2.3 Au niveau du matériel
Pour l'élaboration de ma recherche, j'ai eu ã ma
disposition un serveur tournant sous RHEL (Red Hat Entreprise Linux 4 update
5), une imprimante HP Officejet 7100 series et mon ordinateur portable sous
Windows XP Pro SP2.
1 Putty : Client Telnet/SSH pour les plateformes Windows et Unix
http://www.chiark.greenend.org.uk/~sgtatham/putty
2 Un top 100 des outils de sécurité réseau
est disponible à cette adresse :
http://sectools.org
Monitoring d'une infrastructure Linux sur base d'outils
libres 2.4 Leur réseau

Figure 2.3-1 : Topologie Manex réalisée
avec Dia
Le réseau de Manex est divisé en trois parties :
> La DMZ : oz se trouvent les serveurs de productions (Web,
Mail, DNS, iBats, SVN, ?)
> L'intranet Servers : où se trouve le serveur LDAP,
Backup, Dasys et le serveur de Monitoring > L'intranet Users : où se
trouvent les 3 imprimantes réseaux et les différentes stations
de
travail.
Le serveur mxisrv4 a été mis
ã ma disposition lors de mes différents tests et pour
l'installation complète de celui-ci avec RHEL 4u5.
+ La majorité des serveurs sont installés sous Red
Hat Entreprise Linux - ES 4 ou 5 et sont de marque IBM de la série 306,
335, 345, 346.
+ Les stations de travail, quant à elles, sont sous Mac
OS X ou Windows XP.
+ Les switchs sont de marque 3Com série 2824 non
manageable.
+ Cisco ASA 5510
+ Un PABX Forum 500 pour les communications
téléphoniques.
Lors de mon arrivée chez Manex, un serveur Linux
équipé de la distribution RHEL 4 servait de routeur/firewall. Un
mois après mon arrivée, il a été remplacé
par un ASA 5510 pour faciliter le management du réseau de Manex
grâce à une interface graphique très agréable
à configurer et dont les opérations de maintenance étaient
hautement simplifiées.
Chapitre 3
Présentation des outils de monitoring
3 Les outils de monitoring
Voici la liste des outils qui ont fait état d'un rapport
dans la société oz j'étais en stage.
3.1 Nagios

Nagios (anciennement appelé NetSaint
développé par Ethan Galstad), est un logiciel qui permet de
superviser un système d'information complet. C'est un logiciel libre, il
est sous licence GPL. Les fonctionnalités de Nagios sont
nombreuses3. La première particularité de Nagios est
la modularité. En effet, des plugins peuvent être ajoutés
pour effectuer des tâches spécifiques. De nombreux plugins sont
déjà écrits par la communauté Nagios.
La signification officiel de N.A.G.I.O.S. est un acronyme
récursif pour « Nagios Ain't Gonna Insist On Sainthood
»4. C'est un charrier sur le
précédent nom du logiciel NetSaint. Une signification alternative
proposée par SAM Tilders : « Notices Any Glitch In Our System
»5.
La version actuelle est la 2.9 mais une version
3.0 (déjà en version beta 4) ne tardera pas
à sortir. Une analyse plus approfondie sera effectuée au
chapitre 5.
Site Web du produit :
http://www.nagios.org
3 Et seront décrites au chapitre 5.
4 Traduction littérale : Nagios ne va pas insister pour
Sainthood
5 Traduction littérale : Note n'importe quel
problème dans notre système
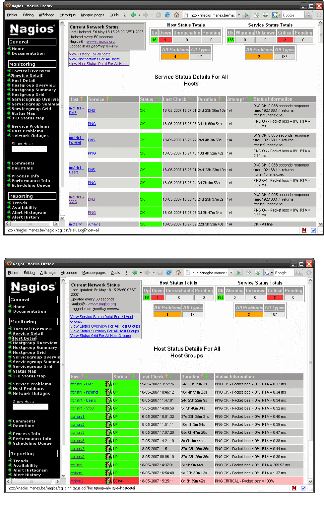
3.1-1 : Statut des services dans Nagios
3.1-2 : Statut des hôtes dans Nagios

3.1-3 : Liste des problèmes des
services
3.1-4 : « Status Map » des hôtes
monitorés par Nagios
Monitoring d'une infrastructure Linux sur base d'outils
libres 3.2 ManageEngine OpManager

ManageEngine OpManager est un logiciel complet de surveillance
de réseau qui offre une surveillance combinée d'applications, du
réseau à grande échelle et des serveurs avec des
fonctionnalités intégrées de service d'assistance,
d'administration et d'analyse du trafic sur le réseau. OpManager
automatise plusieurs tâches de surveillance du réseau et
élimine la complexité associée à l'administration
réseau.
Site Web du prod uit :
http://www.manageengine.fr/opmanager/
3.2.1 Trois versions Il existe trois
versions.
|
Gratuite : Possède les même fonctionnalités
que la payante mais ne peut monitorer que 10 périphériques. Cette
version ne possède pas la découverte automatique des
périphériques. Edition Professionnelle (à partir de 795$)
: Toutes les fonctionnalités + découverte automatique + support
(à partir de 299$ annuel).
Premium Edition (à partir de 1995$) : Idem + d'autres
monitorings évolués + support (à partir de 399$
annuel).
|
3.2.2 Caractéristiques

3.2-1 Map des serveurs
3.2.2.1 Surveillance réseau
Détecte les problèmes de performance du
réseau avant que se crée des indisponibilités
coûteuses.
La Surveillance WAN

3.2-2 : Graphiques de l'utilisation du
réseau
OpManager permet de transformer une collection logique de
périphériques en une entité physique en créant des
cartes avec la position des centres, des routeurs, serveurs ou autres.
Il monitore de manière autonome le réseau et
s'assure qu'il ait une disponibilité maximum. On peut configurer des
valeurs de seuils pour prévenir une éventuelle panne. Par exemple
en mesurant l'engorgement d'un réseau. Si les pings entre deux routeurs
par exemple, dépassent un certain seuil, on peut être
prévenu de diverses manières (mail, SMS, ...).
Surveillance des équipements réseaux (switchs,
routers, UPS,...)
OpManager permet de monitorer les ressources des routers, des
switchs et des autres équipements réseaux comme la charge CPU, la
mémoire de l'équipement, ainsi que ses tensions, les erreurs sur
les interfaces, etc... Toutes ces vérifications se font via le
3.2-3 : Vérification de divers paramètres
d'un UPS
protocole SNMP. Analyse NetFlow
OpManager s'intègre sans problème avec NetFlow
Analyzer, un produit de ManageEngine qui offre une surveillance de la bande
passante basée sur la technologie Cisco NetFlow. Lorsqu'on utilise ces
deux produits, on peut obtenir automatiquement une interface
détaillée avec les rapports de trafic de NetFlow Analyzer
à partir d'OpManager.
3.2.2.2 Surveillance serveur
Améliore la disponibilité et les performances de
l'infrastructure serveur.
Surveillance serveur
OpManager fournit des graphiques de disponibilité
détaillés et des rapports quotidiens, hebdomadaires, mensuels et
trimestriels de la disponibilité des serveurs. Les
fonctionnalités de rapport d'OpManager fournissent également un
rapport de disponibilité détaillé de tous les
composants.
Voir image « 3.2-4 : Monitoring des serveurs »
Surveillance du journal des évènements (pour
Windows)
En utilisant OpManager, les administrateurs peuvent surveiller
les journaux d'événements de Windows sur les ordinateurs locaux
ou distants et chercher les sources, les catégories, les
identités d'événements et les motifs
d'événements spécifiques dans la description de
l'événement. Avec OpManager, on peut protéger le
réseau des attaques internes et surveillez la disponibilité des
applications en contrôlant les journaux d'événements de
Windows.
Surveillance des services
OpManager surveille la disponibilité et le temps de
réponse des services fonctionnant sur les serveurs. La
fonctionnalité de surveillance des services vous fournit des graphiques
et des rapports détaillés sur la disponibilité des
services que l'on surveille.
3.2.2.3 Surveillance d'application
Identifie les problèmes de performance des applications
avant qu'ils ne touchent les utilisateurs finaux.
Moniteur Exchange (Microsoft)
OpManager permet de surveiller ã l'aide d'une extension,
Microsoft Exchange pour prévenir l'indisponibilité et
réparer rapidement les problèmes dès leur apparition.
Surveillance URLs
OpManager aide à surveiller la disponibilité des
sites Web ou des pages intranet et vérifie si les pages sont
affichées en temps réel.
Surveillance des Applications
OpManager surveille par défaut Microsoft exchange, MySQL,
Lotus notes, MSSQL, Oracle,?
3.2.2.4 Pré requis
OpManager requiert, tout comme Nagios, plusieurs librairies :
1 XFree86 (et ses dépendances), pour
l'utilisation de l'interface graphique
1 Fontconfig, nécessaire pour certaines polices de
caractères
1 freetype-devel, pour le rendu de polices True-Type gratuites
1 compat-libstdc++, nécessaire pour l'exécution de
certains plugins interne à OpManager 1 compat-libs, un paquet de
librairies pour l'exécution d'OpManager
1 java, OpManager exploite majoritairement Java pour son
exécution
1 NET-SNMP, utilisé pour obtenir les ressources de divers
composants réseaux (routers, switchs, servers si le protocole SNMP est
installé et utilisable).
3.2.2.5 Installation
L'installation est un vrai plaisir. Elle peut se faire via une
interface graphique (si un serveur X tourne) ou en ligne de commande.
Après quelques réponses à des questions
très simples, nous pouvons directement avoir accès à
l'interface Web (port 9090).
3.2.2.6 Configuration
La configuration est très simple. Le système de
découverte est vraiment très performant. Il suffit d'indiquer le
réseau et son masque et le programme se charge de tout trouver.
Comparativement à Nagios, on ne doit pas éditer des
fichiers de configurations, tout se fait via l'interface Web.
3.2.2.7 Contrôle des
hôtes
Le contrôle des hôtes se fait majoritairement via
SNMP bien que pour les OS sous Linux, il existe un Agent que l'on peut
installer.
3.2.3 Conclusion
OpManager est un merveilleux programme. Tout se configure en
quelques clics. L'interface graphique est très réussie. Il est
régulièrement mis à jour. Un support technique qui
répond dans les 24-48h même lorsque l'on n'a pas encore
enregistré sa copie. Au niveau évolutivité, il est
possible de rajouter des MIB ã l'intérieur via l'interface
graphique du programme. Le seul point noir est qu'il est payant, mais quoi de
plus normal vu la qualité de celui-ci ? Tout comme Nessus (que l'on
décrira plus tard), OpManager n'est plus Open-Source.
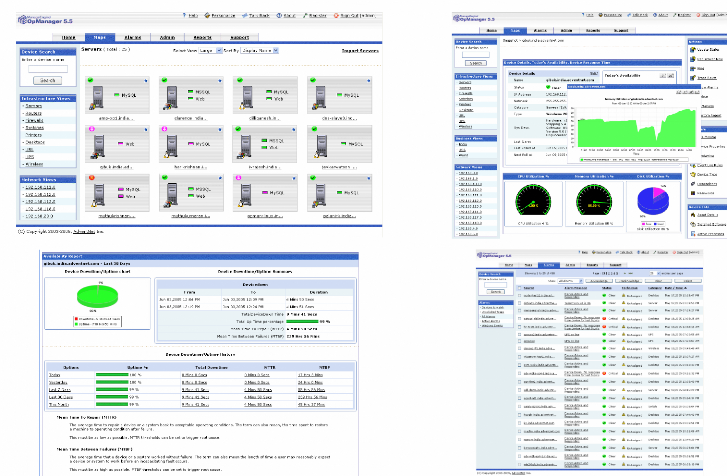
3.2.4 Captures d'écran
3.2-5 : Monitoring des serveurs 3.2-6 : État d'un
hôte
3.2-7 : Journal de l'utilisation CPU 3.2-8 : Les ala
rmes
Monitoring d'une infrastructure Linux sur base d'outils
libres 3.3 Cacti

Cacti est une solution complète de
génération de graphiques réseaux destiné à
démontrer la puissance de RRDTool6 dans le stockage de
données et les fonctionnalités graphiques.
Cacti fournit un poller rapide, des Template de graphiques
avancés, des méthodes multiples d'acquisition de données,
et des dispositifs de gestion d'utilisateurs extérieurs. Des droits
peuvent être attribués en fonction de leur poste dans le
management du réseau. Tout cela est enveloppé dans une interface
intuitive, facile à utiliser, pour les installations de taille LAN
jusqu'aux réseaux complexes avec des centaines de dispositifs.
Site Web du produit :
http://cacti.net
3.3.1 Pré requis
? RRDTool, pour la génération des graphiques
? MySQL, pour stocker les informations
? PHP, pour l'affich age des pages
? Apache, pour consulter le site
3.3.2 Installation
L'installation est relativement simple et rapide... Une base
de données ã créer, quelques droits sur les
répertoires, paramétrage d'un device et voilã, cinq
minutes plus tard, les premiers graphiques apparaissent. Cependant,
l'installation de RRDTool fut un peu plus laborieuse, mais raisonnable.
3.3.3 Configuration
La configuration est simple en elle-même. On ajoute les
devices que l'on souhaite monitorer ainsi que les services. On définit,
les résultats que l'on souhaite transformer en graphique et quelques
minutes plus tard, les premiers résultats apparaissent.
3.3.4 Contrôles des hôtes
Comme les autres outils de monitoring, tout se fait via des
requêtes SNMP (v1, v2c, v3). Cependant, le choix des services à
monitorer est assez restreint comparé à Nagios et OpManager. Il
s'agit simplement de monitoring SNMP, donc avoir des graphiques
représentant la consommation des interfaces, la variation de
température, l'occupation des disques dur,... Bref tout ce qui est
monitorable via SNMP. Cela dit, il existe plusieurs plugins7 que
l'on peut éventuellement greffer. On peut aussi définir
soi-même les services à monitorer si on sait où trouver les
informations qui nous intéressent dans la MIB du protocole SNMP.
3.3.5 Conclusion
Cacti a l'air assez complet comme programme et possède
une interface très jolie. Les graphiques sont clairs, mais il reste
juste une démonstration des possibilités offertes par RRDTool. Ce
que l'on appel communément un « Front-End ».
6 Sera présenté plus loin dans ce chapitre.
7 Disponible ici :
http://www.cacti.net/additional
scripts.php

3.3.6 Captures d'écran
3.3-1 : Dual Panel Tree View 3.3-2: Graph View - Tree
Mode
3.3-3 : Edition des templates des graphiques 3.3-4 :
Edition des sources des graphiques
Monitoring d'une infrastructure Linux sur base d'outils
libres 3.4 Oreon

Oreon est un logiciel de surveillance et de supervision
réseau, basé sur le moteur de supervision Open Source le plus
performant : Nagios. Oreon lui offre une nouvelle interface et lui apporte
de
nouvelles fonctionnalités.
L'installation de l'interface Oreon permet de gagner du temps
dans l'utilisation de Nagios, mais aussi
de la rendre disponible ã un plus grand nombre
d'utilisateurs. En effet, n'importe qui peut dorénavant utiliser
Oreon/Nagios et comprendre facilement à l'aide de graphiques et de
représentations, les informations remontées. Les techniciens, de
leurs cotés, ont toujours accès aux
informations techniques de Nagios.
Lancé depuis trois ans, Oreon a su convaincre un grand
nombre d'utilisateurs et fait figure maintenant d'interface de
référence pour l'outil Nagios. Ce couple est la solution
adoptée par un
grand nombre d'utilisateurs, aguerris ou novices dans la
supervision, connaisseurs de Nagios ou non.
Voici une liste non exhaustive des fonctionnalités
présentes dans Oreon :

U ne interface multi-utilisateurs intuitive et personnalisable
Une interface de configuration évoluée pour
configurer le périmètre à superviser Des aides à la
configuration
Une gestion des fichiers de configuration de Nagios
(cgi.cfg, nagios.cfg, resources.cfg,...) Un module de chargement de
configuration de Nagios
Une compatibilité Nagios 1.x, Nagios 2.x
Un test de validité des configurations avec le debugger
de Nagios
Des fiches d'identités serveurs/équipements
réseaux regroupant les informations de base sur ces types de
ressource
Des représentations graphiques élaborées et
personnalisables
Une gestion des accès très fine, comprenant les
ressources comme les pages de l'interface Et bien d'autres choses...
Site web du prod uit :
http://www.oreon-project.org
3.4.1 Pré requis
1 Nagios 1.x /2.x
1 Nagios-plugins 1.3.x / 1.4.x
1 Apache 2.x
1 MySQL 3.x / 4.x / 5.x 1 PHP 4.x /5.x
1 GD
1 GD-devel
1 RRDTool
1 Net-SNMP
1 Des tas de librairies !
1 PEAR Packages (beaucoup) !
Monitoring d'une infrastructure Linux sur base d'outils
libres 3.4.2 Installation
L'installation d'Oreon est relativement simple lorsque toutes
les librairies et programmes tiers sont installés. Elle se
déroule via une interface Web en dix étapes. La grosse
difficulté a été d'installer tous
les packages PEAR (pour PHP Extension and Application
Repository est un framework de composants PHP) sans la procédure
automatique des téléchargements des dépendances. Un autre
problème, non résolu pour le moment, est l'utilisation de
Perfparse qui permet de générer des graphiques dans Oreon.
3.4.3 Configuration
Oreon est donc une belle interface graphique au-dessus de
Nagios. Toutes les configurations d'Oreon sont identiques à Nagios sauf
que celles-ci se font via une interface Web beaucoup plus agréable que
les modifications directes dans les fichiers de configurations de Nagios. Cela
dit, les configurations d'Oreon sont stockées dans une base de don
nées MySQL.
3.4.4 Contrôles des hôtes
Identique ã Nagios, Oreon n'est juste qu'une apparence
graphique un peu plus jolie que ce qui est offert par défaut avec
Nagios.
3.4.5 Gestions des utilisateurs
Encore une fois, comme Nagios (raÐÐelons qu'Oreon
n'est juste qu'une interface graÐhique au-dessus de Nagios), on peut
paramétrer les droits d'un ensemble d'utilisateurs8.
3.4.6 Conclusion
Oreon est difficile à faire fonctionner correctement.
Des bugs de session qui renvoient toujours vers l'interface de login. Un
Perfparse très dur ã installer. L'obligation d'avoir une base de
données MySQL pour stocker les configurations et données
statistiques. Bref beaucoup de petits problèmes mais je suis convaincu
qu'une fois bien configuré, cet outil sera indissociable de Nagios.
8 La gestion des utilisateurs sera expliquée dans les
configurations de Nagios.

3.4.7 Captures d'écran

3.4-1 : Aperçu du monitoring des services et des
hôtes 3.4-2 : Rapports et vues des problèmes
3.4-3 : Configuration d'Oreon 3.4-4 : Informations d'un
hôte
Monitoring d'une infrastructure Linux sur base d'outils
libres
3.5 Tableaux récapitulatifs des outils de
monitoring
Voici deux tableaux récapitulatifs des différents
logiciels testés précédemment.
Nom Installation Configuration Plugins Alertes
Plateformes Particularités Prix
(version/année) (dépôts)
(langage)
Nagios (v2.9/2007)
|
Via RPM (Dag Wieers)
|
Via fichiers textes Nombreux
développés en C ou Perl.
Nombreux tutos disponible sur Internet.
|
Mail, Pager, SMS, Voice,
NagiosChecker, Web, ?
|
Linux, compatible Unix
(C/Cgi)
|
Énormément de plugins créés par
les utilisateurs
|
Gratuit
|
OpManager (v7/2007)
|
Installateur .bin Via interface Web Pas de
possibilité
d'en développer mais achats possibles de plugins
pa rticu l iers.
|
Mail, Pager, SMS, Web, ?
|
Windows, Linux
(Java)
|
Payant A partir de 800€
|
Cacti Via RPM (Dag Via interface Web Plusieurs
plugins Pas d'alerte, juste Unix/Linux avec Utilise Gratuit
(v0.8.6j) Wieers) mais pas vraiment
création des Apache, Windows abondamment
de tutos. graphiques avec IIS (PHP) RRDTool
|
|
Oreon A compiler Via interface Web Idem Nagios
Idem à Nagios Idem Nagios Couche au-dessus Gratuit
(v1.4) (mélange de de Nagios
PH P/Perl)
A coté de cela, il existe des solutions commerciales : HP
OpenView, IBM Tivoli & NetView, Cisco Works, Sun Net Manager, Mercury, ?
Leurs avantages Leurs inconvénients


Solutions globales et sûres.
Périmètre techniques et fonctionnels
étendus. Support
Coût d'acquisition et de support (surtout pour de
petites PME) Incompatibilités entre les fournisseurs (un seul
doit être installé) Développement additionnel
restreint et coûteux.
Au niveau des coûts, les solutions d'entrées de
gamme d'HP OpenView commencent dans les environs des 8 000€ (pour 250
noeuds) HT jusqu'ã 40 000€ HT pour un nombre illimité de
noeuds. Pour IBM Tivoli dans sa version Express pour les PME/PMI, les
premières licences commencent à environ 900€ HT.
Chapitre 4
Présentation des outils des outils de
sécurité
4 Les outils de sécurité
Avant de présenter les outils suivants, un petit rappel
sur les notions de firewall et d'IDS est nécessaire.
4.1 Le firewall (ou pare-feu)
Le firewall est un élément du réseau
informatique, logiciel et/ou matériel (dans le cas de Manex, il
s'agit d'un ASA 5510), qui a pour fonction de faire respecter la politique
de sécurité du réseau, celleci définissant quels
sont les types de communication autorisés ou interdits.
4.1.1 Présentation
Le pare-feu est aujourd'hui considéré comme un
outil indispensable dans la sécurité d'un réseau
informatique. Il permet d'appliquer une politique d'accès aux ressources
réseau (serveurs).
Il a pour principale tâche de contrôler le trafic
entre différentes zones de confiance, en filtrant les flux de
données qui y transitent. Généralement, les zones de
confiance incluent Internet (une zone dont la confiance est nulle), et
au moins un réseau interne (une zone dont la confiance est plus
importante).
Le but est de fournir une connectivité
contrôlée et maîtrisée entre des zones de
différents niveaux de confiance, grâce à l'application de
la politique de sécurité et d'un modèle de connexion
basé sur le principe du moindre privilège.
Le filtrage se fait selon divers critères. Les plus
courants sont :
|
l'origine ou la destination des paquets (adresse IP, ports
TCP ou UDP, interface réseau, etc.) les options contenues dans les
don nées (fragmentation, validité, etc.)
les données elles-mêmes (taille, correspondance
à un motif, etc.)
les utilisateurs, pour les plus récents
|
|
Un pare-feu fait souvent office de routeur et permet ainsi
d'isoler le réseau en plusieurs zones de sécurité
appelées zones démilitarisées ou DMZ. Ces zones sont
séparées suivant le niveau de confiance qu'on leur porte.
4.1.2 Les catégories
Les pare-feux sont le plus vieil équipement de
sécurité et comme tel, ils ont été soumis à
de nombreuses évolutions. Suivant la génération du
pare-feu ou son rôle précis, on peut les classer en
différentes catégories.
4.1.2.1 Pare-feu sans états (stateless
firewall)
C'est le plus vieux dispositif de filtrage réseau,
introduit sur les routeurs. Il regarde chaque paquet
indépendamment des autres et le compare à une
liste de règles préconfigurées.

Monitoring d'une infrastructure Linux sur base d'outils
libres

Ces règles peuvent avoir des noms très
différents en fonction du pare-feu: "ACL" pour Access Control List
(certains pare-feux Cisco) ;
politiq ue ou policy (pare-feux Juniper/Netscreen) ;
filtre...
La configuration de ces dispositifs est souvent complexe et
l'absence de prise en compte des machines à états des protocoles
réseaux ne permet pas d'obtenir une finesse du filtrage très
évoluée. Ces pare-feu ont donc tendance à tomber en
désuétude mais restent présents sur certains routeurs ou
systèmes d'exploitation.
4.1.2.2 Pare-feu à états (stateful
firewall)
Certains protocoles dits « à états »
comme TCP introduisent une notion de connexion. Les pare-feu à
états vérifient la conformité des paquets pour une
connexion en cours. C'est-à-dire qu'ils vérifient que chaque
paquet d'une connexion est bien la suite du précédent paquet et
la réponse à un paquet dans l'autre sens. Ils savent aussi
filtrer intelligemment les paquets ICMP qui servent à la signalisation
des flux IP.
4.1.2.3 Pare-feu applicatif
Dernière mouture de pare-feu, ils vérifient la
complète conformité du paquet à un protocole attendu. Par
exemple, ce type de pare-feu permet de vérifier que seul du HTTP passe
par le port TCP 80. Ce traitement est très gourmand en temps de calcul
dès que le débit devient très important; il est
justifié par le fait que de plus en plus de protocoles réseaux
utilisent un tunnel TCP pour contourner le filtrage par ports.
|
Conntrack (suivi de connexion) et l7 Filter
(filtrage applicatif) sur Linux Netfilter CBAC sur Cisco IOS
Fixup puis inspect sur Cisco PIX
|
|
4.1.2.4 Pare-feu personnel
Les pare-feu personnels, généralement
installés sur une machine de travail, agissent comme un pare-feu
à états. Bien souvent, ils vérifient aussi quel programme
est à l'origine des données. Le but est de lutter contre les
virus et les spywares.
Zone Alarm
Look'n'StoÐ
Kaspersky Internet Security
?
4.2 Système de détection d'intrusions
(IDS)
Un système de détection d'intrusions (ou IDS :
Intrusion Detection System) est un mécanisme destiné à
repérer des activités anormales ou suspectes sur la cible
analysée (un réseau ou un hôte). Il permet ainsi d'avoir
une action de prévention sur les risques d'intrusion.
4.2.1 Une petite histoire : le voleur, le videur et la
caméra cachée
Pour illustrer ces notions de sécurité, une petite
analogie9 :

Dans cette histoire, le videur peut être faillible et
ne voit pas tout car il y a toujours des malins qui grâce à de
divers techniques tels l'attaque à fragmentation IP, usurpation ou vol
d'identité (adresse IP), trompent le videur.
On peut voir le pare-feu comme un videur devant un casino qui
peut décider d'autoriser ou non en regardant sa tête (ou
en-tête dans le cas d'un pare-feu du type packet filtering)
l'entrée d'une personne, tandis que la détection d'intrusion
serait plutôt une caméra cachée qui peut être
placée à l'entrée ou à l'intérieur du
casino.
Si la caméra cachée filme la personne qui entre et
en procédant à une analyse reconnaît
cette personne, elle va alerter la direction la présence
d'un intrus potentiellement dangereux pour le casino.
La caméra cachée apporte donc un rôle
complémentaire au rôle joué par le videur.
4.2.2 Les deux familles de systèmes de
détection d'intrusion
Il existe deux grandes familles distinctes d'IDS :
|
Les N-IDS (Network Based Intrusion Detection System),
qui surveillent l'état de la sécurité au niveau du
réseau.
Les H-IDS (HostBased Intrusion Detection System), qui
surveillent l'état de la sécurité au niveau des
hôtes.
|
|
Ce qui distingue fondamentalement ces deux types d'IDS, c'est
leur mode de fonctionnement :
Le premier mode s'appuie sur des
bibliothèques de signatures (approche par scénario). La
démarche d'analyse est similaire ã celle de l'antivirus quand
ceux-ci s'appuient sur des signatures d'attaques. Ainsi, l'IDS est efficace
s'il connaît l'attaque, mais inefficace dans le cas contraire. Les outils
commerciaux ou libres ont évolué pour proposer une
personnalisation de la signature afin de faire face à des attaques dont
on ne connaît qu'une partie des éléments. Les outils
à base de signatures requièrent des mises à jour
très régulières.
Le second mode de fonctionnement
des IDS s'appuie sur une analyse comportementale. Un H-IDS se comporte comme un
daemon ou un service standard sur un système hôte qui
détecte une activité suspecte en s'appuyant sur une norme. Si les
activités s'éloignent de la norme, une alerte est
générée. Au préalable, l'IDS doit alors apprendre
le comportement du réseau pour établir la norme. L'analyse porte
sur l'usage du réseau (protocoles, volumétrie, horaires
d'activité, congestion et erreurs), l'activité d'une machine
(nombre et listes de processus et d'utilisateurs, et ressources
9 J'ai trouvé cette petite analogie sur
http://www-igm.univ-mlv.fr/~dr/XPOSE2001/liyun/IDS.html
qui m'a bien
fait comprendre le but d'un IDS.
Monitoring d'une infrastructure Linux sur base
d'outils libres
consommées) et l'activité d'un
utilisateur (horaires et durée des connexions, commandes
utilisées, messages envoyés, programmes activés, etc.).
Ces outils s'appuient essentiellement sur des calculs statistiques.
Un autre type d'H-IDS cherche les intrusions dans le «
noyau » (kernel) du système, et les modifications qui y
sont apportées. Certains appellent cette technique « analyse
protocolaire ». Très rapide, elle ne nécessite pas de
recherche dans une base de signature.
Chacun de ces deux types d'IDS s'adresse ã des besoins
spécifiques. Les H-IDS sont particulièrement efficaces pour
déterminer si un hôte est contaminé et les N-IDS permettent
de surveiller l'ensemble d'un réseau contrairement ã un H-IDS qui
est restreint à un hôte.
Snort est un IDS.
4.3 Nessus

Nessus est un outil de sécurité informatique. Il
signale les faiblesses potentielles ou avérées sur les machines
testées.
Ceci inclut, entre autres :


les services vulnérables à des attaques
permettant la prise de contrôle de la machine, l'accès à
des informations sensibles (lecture de fichiers confidentiels par exemple),
des dénis de service...
les fautes de configuration (relais de messagerie ouvert par
exemple)
les patchs de sécurité non appliqués, que
les failles corrigées soient exploitables ou non dans la configuration
testée
les mots de passe par défaut, quelques mots de passe
communs, et l'absence de mots de passe sur certains comptes systèmes.
Nessus peut aussi appeler le programme externe Hydra pour attaquer les mots de
passe à l'aide d'un dictionnaire.
les services jugés faibles (on suggère par
exemple de remplacer Telnet par SSH) les dénis de service contre la
pile TCP/IP
support multiplateformes : Linux, FreeBSD, Solaris, Mac OS X,
Windows
Site web du produit :
http://www.nessus.org
4.3.1 Pré requis
? nessus-libraries
? libnasl
? nessus-core
? nessus-plugins
4.3.2 Installation
L'installation est rapide et simple. Il faut juste l'installer
dans l'ordre ci-dessus.
4.3.3 Configuration
Tout d'abord, nous devons ajouter des utilisateurs qui
possèderont des droits. Les utilisateurs
peuvent se connecter via mot de passe ou par certificat (non
testé). Nessus permet éventuellement
d'en créer.
Une fois cette tâche accomplie, nous pouvons lancer un scan
des PC que l'on souhaite interroger.
4.3.4 Particularité
Nessus se compose d'un serveur et d'un client. Le serveur est
celui qui va scanner les divers ports du PC cible et le client, quant à
lui, donnera les ordres au serveur. Le client peut se trouver sur le serveur ou
être distant.
Il existe des clients sous Windows, Linux et autres OS avec
interface graphique ou en mode console.
4.3.5 Fonctionnement
Lorsqu'un test (testé avec le client Windows) est
terminé, Nessus nous retourne une page web de
résultats avec les différents ports ã
problèmes trouvés. Nessus est composé d'une multitude
de
plugins qui viennent augmenter le nombre de tests vers la machine
cible.
4.3.6 Deux versions
Il existe deux versions de Nessus. Une payante et une gratuite.
La différence se trouve principalement sur les plugins. Lorsqu'on prend
la version payante (1200$), on a accès directement
Monitoring d'une infrastructure Linux sur base d'outils
libres
aux dernières mises à jour et plugins. La version
gratuite sera toujours sept jours en retard par
rapport à la version payante. De plus, avec la version
payante, nous bénéficions du support technique, un accès
ã un portail d'utilisateurs, la possibilité d'avoir des plugins
pour les périphériques
SCADA, et enfin des tests automatiques réguliers vers les
serveurs.
4.3.7 Tests
Voici différents tests que j'ai effectués contre
Windows et Linux.
4.3.7.1 Contre Windows XP SP2
Comme premier test, j'ai essayé d'attaquer un ordinateur
sur réseau local avec le firewall XP SP2
désactivé. Les résultats ne se sont pas fait
attendre : 4 Open Ports (139 - netbios-ssn, 135 - epmap,
icmp, 137 - netbios-ns), 20 Notes, 2 Warnings, 1 Holes
(445 microsoft-ds).
Deuxième test, réactivons le firewall d'XP SP2... A
l'étonnement de tout le monde, aucun problème n'a
été découvert par Nessus.
Troisième test, Windows XP SP2 avec Kaspersky Security
6.0.2 dont le firewall est réglé en mode protection Maximale
(Bloquer toutes les connexions qui ne sont pas autorisées par les
règles). Résultats similaire. Aucun problème si le
firewall est activé.
4.3.7.2 Contre Windows XP SP2 en
local
Tests suivants, ce test un peu plus particulier car il est
effectué en local sur ma machine disposant de Kaspersky.
Premier test, en local avec Kaspersky désactivé :
6 Open Ports, 21 Notes, 1 Warnings, 1 Holes.
Deuxième test, en local avec Kaspersky activé en
Protection Maximale : 2 Open Ports, 15 Notes, 1 Warnings, 1 Holes.
Dernier test, en local avec Kaspersky activé et en
Bloquant tout les trafics : le scan de Nessus ne
voulait tout simplement pas se lancer.
4.3.7.3 Contre des serveurs Linux
J'ai effectué des tests ã l'encontre des serveurs
de la DMZ de chez Manex.
Nessus détectait les ports volontairement ouverts que se
soit HTTP, IMAP(S), SMTP(S), ... Cela dit, les serveurs sont tous
équipés d'iptables rigoureusement paramétrés et de
l'ASA pour le reste. Les seuls réels problèmes, c'est que Nessus
recommandait de désactiver le service SMTP ou de
passer à un service SMTPS.
4.3.8 Conclusion
Dans le rapport que Nessus nous donne après un scan, s'y
trouve non seulement la liste des ports
ouverts, mais aussi des conseils pour régler ces trous de
sécurité. Il est bien entendu possible d'archiver les
résultats, de définir ses propres tests sur des plages de ports
ou via certains types
d'attaques.

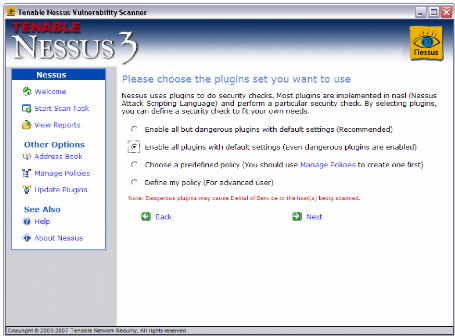
4.3.9 Captures d'écran
4.3-1 : Le client Nessus pour Windows 4.3-2 :
Résultats d'un scan (IMAPS)
4.3-3 : Vérifications des patchs de mise à
jour Microsoft 4.3-4 : Différentes possibilités de
scan
Lemaire Geoffrey 32 Haute Ecole Rennequin Sualem
4.4 Snort

Snort est capable d'effectuer en temps réel des
analyses de trafic et de logger les paquets sur un réseau IP. Il peut
effectuer des analyses de protocole, recherche/correspondance de contenu et
peut être utilisé pour détecter une grande
variété d'attaques et de sondes comme des dépassements de
buffers, scans, attaques sur des CGI, sondes SMB, essai d'OS fingerprintings et
bien plus. Cependant, comme tout logiciel, Snort n'est pas infaillible et
demande une mise à jour régulière.
Snort peut également être utilisé avec
d'autres projets open sources tels que SnortSnarf, ACID, sguil et BASE
(Basic Analysis and Security Engine) afin de fournir une
représentation visuelle des données concernant les
éventuelles intrusions.
Dans notre cas, j'utilise BASE pour la représentation
visuelle.
Site web du prod uit :
http://www.snort.org
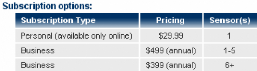
4.4.1 L'abonnement
Il existe trois types d'utilisateurs pour Snort au niveau des
règles de sécurités.
Le premier est pour l'utilisateur non enregistré
sur le site reçoit un set de sécurité statique pour
chaque Release Majeur de Snort.
Le second (dans mon cas) est l'utilisateur enregistré
sur le site. On peut dès lors avoir accès à des
règles mises à jour tout les 30 jours après les
utilisateurs abonnés.
Enfin, le troisième, l'utilisateur abonné.
Ce dernier recevra en temps réel les mises à jour dès
qu'elles sont disponibles.
Voici les prix :
4.4.2 Pré requis
SNORT requiert peu de chose pour pouvoir s'installer. Par
contre BASE (v1.3.6) requiert une base de données MySQL et
plusieurs packages de PEAR sont requis. Une petite modification dans iptables
est requise aussi. Il s'agit d'ouvrir tout les ports en entrée et en
sortie pour que Snort puisse recevoir et analyser les paquets.
4.4.3 Installation
Comme spécifié dans le pré requis, SNORT
ne requiert que peu de choses à faire. Il est disponible sur les
dépôts de Dag Wieers (v. 2.3.3) mais suite à quelques
problèmes notamment du coté des «Configure dynamic loaded
libraries» qui ne voulaient pas se charger, j'ai décidé
d'aller chercher les RPMs pour RHEL4 sur le site de Snort et j'ai
installé Snort à partir de là. Quand à BASE, une
fois
SNORT configuré en daemon, il s'installe via une interface
Web sans encombre si le compte MySQL est bien réglé.
4.4.4 Configuration
Aucune configuration particulière. Juste dans le
fichier de configuration, on peut définir l'adresse du réseau que
Snort doit monitorer et l'endroit où se trouvent les règles de
sécurités. On doit ensuite indiquer à Snort qu'il doit
envoyer ses logs vers une base de données MySQL. Enfin, on lance le
daemon SNORT et quelques heures plus tard, il ne se passe rien...
4.4.5 Tests avec Nessus
Si rien ne se passe, provoquons des attaques?
L'attaquant : 192.168.1.14 L'attaqué : 192.168.1.11
Le résultat ne s'est pas fait attendre :
# tail -f /var/log/snort/alert
05/23-15:29:47.059534 (**] (1:1418:11] SNMP request tcp (**]
(Classification: Attempted Information Leak] (Priority: 2] {TCP}
192.168.1.14:4647 -> 192.168.1.11:161
05/23-15:29:47.059559 (**] (1:1420:11] SNMP trap tcp (**]
(Classification: Attempted Information Leak] (Priority: 2] {TCP}
192.168.1.14:4647 -> 192.168.1.11:162
Monitoring d'une infrastructure Linux sur base d'outils
libres
05/23-15:35:34.893804 [**] [116:54:1] (snort_decoder): Tcp
Options found with bad lengths [**] {TCP} 192.1 68.1 .14:22362 -> 192.1 68.1
.11:389
05/23-15:35:34.893839 [**] [116:54:1] (snort_decoder): Tcp
Options found with bad lengths [**] {TCP} 192.1 68.1 .14:22362 -> 192.1 68.1
.11:389
05/23-15:35:44.928871 [**] [116:4:1] (snort_decoder): Ipv4
Options found with bad lengths [**] {TCP} 192.1 68.1 .14:80 -> 192.1 68.1
.11:80
05/23-15:35:44.928909 [**] [116:4:1] (snort_decoder): Ipv4
Options found with bad lengths [**] {TCP} 192.1 68.1 .14:80 -> 192.1 68.1
.11:80
05/23-15:35:44.928941 [**] [116:4:1] (snort_decoder): Ipv4
Options found with bad lengths [**] {TCP} 192.1 68.1 .14:80 -> 192.1 68.1
.11:80
05/23-15:35:44.928974 [**] [116:4:1] (snort_decoder): Ipv4
Options found with bad lengths [**] {TCP} 192.1 68.1 .14:80 -> 192.1 68.1
.11:80
05/23-15:35:44.929057 [**] [116:4:1] (snort_decoder): Ipv4
Options found with bad lengths [**] {TCP} 192.1 68.1 .14:80 -> 192.1 68.1
.11:80
05/23-15:35:44.929100 [**] [116:4:1] (snort_decoder): Ipv4
Options found with bad lengths [**] {TCP} 1 92.1 68.1 .14:80 -> 192.1 68.1
.11:80
05/23-15:35:44.929132 [**] [116:4:1] (snort_decoder): Ipv4
Options found with bad lengths [**] {TCP} 192.1 68.1 .14:80 -> 192.1 68.1
.11:80
05/23-15:35:44.9291 79 [**] [116:4:1] (snort_decoder): Ipv4
Options found with bad lengths [**] {TCP} 1 92.1 68.1 .14:80 -> 192.1 68.1
.11:80
05/23-15:35:44.929211 [**] [116:4:1] (snort_decoder): Ipv4
Options found with bad lengths [**] {TCP} 192.1 68.1 .14:80 -> 192.1 68.1
.11:80
05/23-15:35:44.929242 [**] [116:4:1] (snort_decoder): Ipv4
Options found with bad lengths [**] {TCP} 192.1 68.1 .14:80 -> 192.1 68.1
.11:80
05/23-15:35:54.931508 [**] [116:54:1] (snort_decoder): Tcp
Options found with bad lengths [**] {TCP} 192.1 68.1 .14:31658 -> 192.1 68.1
.11:31658 05/23-15:35:55.932433 [**] [116:4:1] (snort_decoder): Ipv4 Options
found with bad lengths [**] {PROTO170} 192.1 68.1 .14 -> 192.1 68.1
.11
05/23-15:35:55.932465 [**] [116:4:1] (snort_decoder): Ipv4
Options found with bad lengths [**] {PROTO170} 192.1 68.1 .14 -> 192.1 68.1
.11
05/23-15:35:55.932495 [**] [116:4:1] (snort_decoder): Ipv4
Options found with bad lengths [**] {PROTO170} 192.1 68.1 .14 -> 192.1 68.1
.11
05/23-15:35:55.932524 [**] [116:4:1] (snort_decoder): Ipv4
Options found with bad lengths [**] {PROTO170} 192.1 68.1 .14 -> 192.1 68.1
.11
05/23-15:35:55.932592 [**] [116:4:1] (snort_decoder): Ipv4
Options found with bad lengths [**] {PROTO170} 192.1 68.1 .14 -> 192.1 68.1
.11
05/23-15:35:55.932632 [**] [116:4:1] (snort_decoder): Ipv4
Options found with bad lengths [**] {PROTO170} 192.1 68.1 .14 -> 192.1 68.1
.11
05/23-15:35:55.932662 [**] [116:4:1] (snort_decoder): Ipv4
Options found with bad lengths [**] {PROTO170} 192.1 68.1 .14 -> 192.1 68.1
.11
05/23-15:29:48.052402 [**] [1 :1421:11] SNMP AgentX/tcp
request [**] [Classification: Attempted Information Leak] [Priority: 2] {TCP} 1
92.1 68.1 .14:4 64 7 -> 192.168.1.11:705 05/23-15:29:50.053122 [**] [1
:1421:11] SNMP AgentX/tcp request [**] [Classification: Attempted Information
Leak] [Priority: 2] {TCP} 1 92.1 68.1 .14:4 64 7 -> 192.168.1.11:705
05/23-15:29:50.315235 [**] [1 :1420:11] SNMP trap tcp [**] [Classification:
Attempted Information Leak] [Priority: 2] {TCP} 192.168.1.14:4647 -> 192.1
68.1 .11:1 62
05/23-15:29:50.316245 [**] [1 :1418:11] SNMP request tcp [**]
[Classification: Attempted Information Leak] [Priority: 2] {TCP}
192.168.1.14:4647 -> 192.1 68.1 .11:1 61 05/23-15:29:52.053797 [**] [1
:1421:11] SNMP AgentX/tcp request [**] [Classification: Attempted Information
Leak] [Priority: 2] {TCP} 1 92.1 68.1 .14:4 64 7 -> 192.168.1.11:705
05/23-15:29:52.316913 [**] [1 :1420:11] SNMP trap tcp [**] [Classification:
Attempted Information Leak] [Priority: 2] {TCP} 192.168.1.14:4647 -> 192.1
68.1 .11:1 62 05/23-15:29:52.317919 [**] [1 :1418:11] SNMP request tcp [**]
[Classification: Attempted Information Leak] [Priority: 2] {TCP}
192.168.1.14:4647 -> 192.1 68.1 .11:1 61 05/23-15:30:19.043407 [**] [1 :4 69
:4] ICMP PING NMAP [**] [Classification: Attempted Information Leak] [Priority:
2] {ICMP} 192.1 68.1 .14 -> 192.1 68.1 .11 05/23-15:30:33.410074 [**] [1
:1444:3] TFTP Get [**] [Classification: Potentially Bad Traffic] [Priority: 2]
{UDP} 192.1 68.1 .14:11670 -> 192.168.1.11:69
05/23-15:30:34.416906 [**] [1 :1444:3] TFTP Get [**]
[Classification: Potentially Bad Traffic] [Priority: 2] {UDP} 192.1 68.1
.14:11670 -> 192.168.1.11:69
05/23-15:30:35.42373 7 [**] [1 :1444:3] TFTP Get [**]
[Classification: Potentially Bad Traffic] [Priority: 2] {UDP} 192.1 68.1
.14:11670 -> 192.168.1.11:69
05/23-15:30:48.020705 [**] [1 :524:8] BAD-TRAFFIC tcp port 0
traffic [**] [Classification: Misc activity] [Priority: 3] {TCP} 192.1 68.1
.14:29019 -> 192.1 68.1 .11:0
05/23-15:30:50.02 73 71 [**] [1 :524:8] BAD-TRAFFIC tcp port
0 traffic [**] [Classification: Misc activity] [Priority: 3] {TCP} 192.1 68.1
.14:29019 -> 192.1 68.1 .11:0 05/23-15:30:52.035044 [**] [1 :524:8]
BAD-TRAFFIC tcp port 0 traffic [**] [Classification: Misc activity] [Priority:
3] {TCP} 192.1 68.1 .14:29019 -> 192.1 68.1 .11:0 05/23-15:33:20.013863 [**]
[1 :221:5] DDOS TFN Probe [**] [Classification: Attempted Information Leak]
[Priority: 2] {ICMP} 192.1 68.1 .14 -> 192.1 68.1 .11
05/23-15:33:56.69904 7 [**] [1 :4 75 :4] ICMP traceroute
ipopts [**] [Classification: Attempted Information Leak] [Priority: 2] {ICMP}
192.1 68.1 .1 1 -> 1 92.1 68.1 .14 05/23-15:35:34.893696 [**] [116:54:1]
(snort_decoder): Tcp Options found with bad lengths [**] {TCP} 1 92.1 68.1
.14:22362 -> 192.168.1.11:389
05/23-15:35:34.893735 [**] [116:54:1] (snort_decoder): Tcp
Options found with bad lengths [**] {TCP} 1 92.1 68.1 .14:22362 ->
192.168.1.11:389
05/23-15:35:34.893772 [**] [116:54:1] (snort_decoder): Tcp
Options found with bad lengths [**] {TCP} 1 92.1 68.1 .14:22362 ->
192.168.1.11:389
Monitoring d'une infrastructure Linux sur base d'outils
libres
05/23-15:35:55.932702 [**] [116:4:1] (snort_decoder): Ipv4
Options found with bad lengths [**] {PROTO1 70} 192.168.1.14 -> 1 92.1 68.1
.1 1
05/23-15:35:55.932731 [**] [116:4:1] (snort_decoder): Ipv4
Options found with bad lengths [**] {PROTO1 70} 192.168.1.14 -> 1 92.1 68.1
.1 1
05/23-15:35:55.932759 [**] [116:4:1] (snort_decoder): Ipv4
Options found with bad lengths [**] {PROTO170} 192.1 68.1 .14 -> 192.1 68.1
.11
05/23-15:36:05.934681 [**] [1 :525:9] BAD-TRAFFIC udp port 0
traffic [**] [Classification: Misc activity] [Priority: 3] {UDP} 192.1 68.1
.14:1234 -> 192.1 68.1 .11:0 05/23-15:36:05.934714 [**] [1 :525:9]
BAD-TRAFFIC udp port 0 traffic [**] [Classification: Misc activity] [Priority:
3] {UDP} 192.1 68.1 .14:1234 -> 192.1 68.1 .11:0 05/23-15:36:05.934742 [**]
[1 :525:9] BAD-TRAFFIC udp port 0 traffic [**] [Classification: Misc activity]
[Priority: 3] {UDP} 192.1 68.1 .14:1234 -> 192.1 68.1 .11:0
05/23-15:36:05.934771 [**] [1 :525:9] BAD-TRAFFIC udp port 0 traffic [**]
[Classification: Misc activity] [Priority: 3] {UDP} 192.1 68.1 .14:1234 ->
192.1 68.1 .11:0 05/23-15:36:05.934823 [**] [1 :525:9] BAD-TRAFFIC udp port 0
traffic [**] [Classification: Misc activity] [Priority: 3] {UDP} 192.1 68.1
.14:1234 -> 192.1 68.1 .11:0 05/23-15:36:05.934854 [**] [1 :525:9]
BAD-TRAFFIC udp port 0 traffic [**] [Classification: Misc activity] [Priority:
3] {UDP} 192.1 68.1 .14:1234 -> 192.1 68.1 .11:0 05/23-15:36:05.934882 [**]
[1 :525:9] BAD-TRAFFIC udp port 0 traffic [**] [Classification: Misc activity]
[Priority: 3] {UDP} 192.1 68.1 .14:1234 -> 192.1 68.1 .11:0
05/23-15:36:05.934910 [**] [1 :525:9] BAD-TRAFFIC udp port 0 traffic [**]
[Classification: Misc activity] [Priority: 3] {UDP} 192.1 68.1 .14:1234 ->
192.1 68.1 .11:0 05/23-15:36:05.93493 7 [**] [1 :525:9] BAD-TRAFFIC udp port 0
traffic [**] [Classification: Misc activity] [Priority: 3] {UDP} 192.1 68.1
.14:1234 -> 192.1 68.1 .11:0 05/23-15:36:05.934966 [**] [1 :525:9]
BAD-TRAFFIC udp port 0 traffic [**] [Classification: Misc activity] [Priority:
3] {UDP} 192.1 68.1 .14:1234 -> 192.1 68.1 .11:0 05/23-15:36:35.945745 [**]
[1 :2 74:6] DOS ath [**] [Classification: Attempted Denial of Service]
[Priority: 2] {ICMP} 192.1 68.1 .14 -> 192.168.1.11
05/23-15:38:20.82 6466 [**] [116:151:1] (snort decoder) Bad
Traffic Same Src/Dst IP [**] {TCP} 192.1 68.1 .11:389 ->
192.168.1.11:389
4.4.6 Conclusion
Du fait de l'environnement de test dans lequel je suis, je
n'ai pas pu réellement tester SNORT. Beaucoup d'attaques étant
filtrées par l'ASA et par les iptables. Cependant, grâce à
Nessus, j'ai pu simuler des attaques à l'encontre d'un serveur et c'est
justement le rôle de Snort, voir des paquets pas très logique
à l'encontre du serveur et les répertorier.
On peut voir que Nessus fait bien son travail. On retrouve
donc notamment des attaques DOS (Denial of Service), il essaye de
récupérer diverses informations via SNMP, envois des paquets
traffiqués (avec des options de tailles différentes)
pour s'introduire dans le serveur, des attaques ICMP,? Cependant, Base ne
relève rien du tout ni dans la base de donnée MySQL...
Peut-être un petit problème entre Snort et Mysql...
4.5 Nmap

Nmap est un scanner de ports open source créé
par Fyodor et distribué par
Insecure.Org. Il est conçu pour
détecter les ports ouverts, les services hébergés et les
informations sur le système d'exploitation d'un ordinateur distant. Ce
logiciel est devenu une référence pour les administrateurs
réseaux car l'audit des résultats de Nmap fournit des indications
sur la sécurité d'un réseau.
Site web du logiciel :
http://www.insecure.org/nmap/
4.5.1 Installation
Il s'installe très facilement via les dépôts
de Red Hat (v4.11). Il est utilisable sans configuration
particulière hormis des iptables oz j'ai dû ouvrir tout les ports
en sortie.
4.5.2 Fonctionnement
Pour scanner les ports d'un ordinateur distant, Nmap utilise
diverses techniques d'analyse basées sur
des protocoles tels que TCP, IP, UDP ou ICMP.
De même, il se base sur les réponses
particulières qu'il obtient à des requêtes
particulières pour obtenir une empreinte de la pile IP, souvent
spécifique du système qui l'utilise. C'est par cette
méthode que l'outil permet de reconnaitre la version d'un système
d'exploitation et aussi la version
des services en écoute.
Le code source est disponible sous la licence GNU GPL.
4.5.3 Les premiers scans
Effectuons un premier scan. Le côté pratique de nMap
est qu'il permet de scanner une plage d'IP et d'indexer tout les ports
ouverts.
Tout d'abord qui a-t-il sur notre réseau ?
# nmap -sP 192.1 68.1 .0/24
Starting Nmap 4.11 (
http://www.insecure.org/nmap/
) at 2007-05-22 14:20 CEST
Host
mx1rtr1.manex.be
(192.1 68.1 .1) appears to be up. MAC Address: 00:19:2F:83:65:86
(Unknown)
Host
mxisrv1.manex.be
(192.1 68.1 .11) appears to be up. MAC Address: 00:14:5E:29:9A:A4
(IBM)
Host
mxisrv2.manex.be
(192.1 68.1 .12) appears to be up. MAC Address: 00:11:25:AC:B4:C1
(IBM)
Host
mxisrv3.manex.be
(192.1 68.1 .13) appears to be up. MAC Address: 00:0D:93:9E:82:B8 (Apple
Computer) Host
mxisrv4.manex.be
(192.1 68.1 .14) appears to be up. Host
mxisrv6.manex.be
(192.1 68.1 .1 6) appears to be up.
MAC Address: 00:0A:EB:2F:A2:D2 (Shenzhen Tp-Link
Technology Co;) Nmap finished: 256 IP addresses (6 hosts up) scanned in 4.970
seconds
Monitoring d'une infrastructure Linux sur base d'outils
libres Voyons le résultat des ports ouverts avec :
8009/tcp open ajp13
8080/tcp open http-proxy
12345/tcp open NetBus
MAC Address: 00:0D:93:9E:82:B8 (Apple
Computer)
Interesting ports on
mxisrv4.manex.be
(1 92.1 68.1 .14): Not shown: 1675 closed ports
PORT STATE SERVICE
22/tcp open ssh
80/tcp open http
199/tcp open smux
1241/tcp open nessus
3306/tcp open mysql
Interesting ports on
mxisrv6.manex.be
(1 92.1 68.1 .1 6):
Not shown: 1669 filtered ports PORT STATE
SERVICE
20/tcp closed ftp-data
21/tcp open ftp
80/tcp open http
88/tcp closed kerberos-sec 135/tcp open
msrpc
139/tcp open netbios-ssn 389/tcp closed
ldap
445/tcp open microsoft-ds 548/tcp open afpovertcp
1026/tcp closed LSA-or-nterm 3389/tcp open ms-term -serv
MAC Address: 00:0A:EB:2F:A2:D2 (Shenzhen Tp-Link
Technology Co;) Nmap finished: 20 IP addresses (6 hosts up) scanned in 54.935
seconds
# nmap 192.168.1.1-20
Starting Nmap 4.11 (
http://www.insecure.org/nmap/
) at 2007-05-22 14:24 CEST
All 1680 scanned ports on
mx1rtr1.manex.be
(192.1 68.1 .1) are closed MAC Address: 00:19:2F:83:65:86
(Unknown)
Interesting ports on
mxisrv1.manex.be
(1 92.1 68.1 .11): Not shown: 1679 filtered ports
PORT STATE SERVICE
389/tcp open ldap
MAC Address: 00:14:5E:29:9A:A4 (IBM)
All 1680 scanned ports on
mxisrv2.manex.be
(192.1 68.1 .12) are filtered MAC Address: 00:11:25:AC:B4:C1
(IBM)
Interesting ports on
mxisrv3.manex.be
(1 92.1 68.1 .13):
Not shown: 1661 closed ports PORT STATE SERVICE
22/tcp open ssh
80/tcp open http
106/tcp open pop3pw 111/tcp open rpcbind 311/tcp open
asip-webadmin 427/tcp open svrloc 548/tcp open afpovertcp 625/tcp open unknown
749/tcp open kerberos-adm 1012/tcp open unknown 1014/tcp open unknown 1015/tcp
open unknown 2049/tcp open nfs
4444/tcp open krb524 5432/tcp open postgres 5900/tcp
open vnc
4.5.4 D'autres options
On Ðeut demander ã nMaÐ de déterminer quel
est l'OS des systèmes scannés avec l'oÐtion « -O »
ainsi que l'identification des services « -sV ».
Voici ce que cela donne pour un serveur : # nmap -O
-sV 192.168.1.16
Starting Nmap 4.11 (
http://www.insecure.org/nmap/
) at 2007-05-22 16:03 CEST Interesting ports on
mxisrv6.manex.be
(192.1 68.1 .16):
Not shown: 1669 filtered ports
PORT STATE SERVICE VERSION
20/tcp closed ftp-data
21/tcp open ftp Microsoft ftpd
80/tcp open http Microsoft IIS webserver
5.1
88/tcp closed kerberos-sec
135/tcp open msrpc Microsoft Windows
RPC
139/tcp open netbios-ssn 389/tcp closed ldap
445/tcp open netbios-ssn 548/tcp open afpovertcp? 1026/tcp
closed LSA-or-nterm
3389/tcp open microsoft-rdp Microsoft Terminal
Service
MAC Address: 00:0A:EB:2F:A2:D2 (Shenzhen Tp-Link Technology
Co;)
Device type: general purpose
Running: Microsoft Windows NT/2K/XP
OS details: Microsoft Windows XP Pro SP1 or Windows
2000 Advanced Server SP3
Service Info: OS: Windows
Nmap finished: 1 IP address (1 host up) scanned in 126.166
seconds
Réessayons sur un serveur linux?
# nmap -O -sV 192.168.1.14
Starting Nmap 4.11 (
http://www.insecure.org/nmap/
) at 2007-05-22 16:09 CEST Interesting ports on
mxisrv4.manex.be
(192.1 68.1 .14):
Not shown: 1675 closed ports
PORT STATE SERVICE VERSION
22/tcp open ssh OpenSSH 3.9p1 (protocol
1.99)
80/tcp open http Apache httpd
199/tcp open smux Linux SNMP
multiplexer
1241/tcp open ssl/unknown
3306/tcp open mysql MySQL
(unauthorized)
Device type: general purpose
Running: Linux 2.4.X|2.5.X|2.6.X
OS details: Linux 2.5.25 - 2.6.8 or Gentoo 1.2 Linux
2.4.19 rc1-rc7, Linux 2.6.3 - 2.6.10 Uptime 12.976 days (since Wed May 9
16:43:23 2007)
Service Info: OS: Linux
Nmap finished: 1 IP address (1 host up) scanned in 8.132
seconds
Monitoring d'une infrastructure Linux sur base d'outils
libres On peut aussi demander à scanner un range de ports ou
tous (65535) : # nmap -p U:53,111,137,
T:21-25,80,139,8080
# nmap -p1-65535 192.1 68.1 .11
4.5.5 Conclusion
nMap est un outil pratique pour une indexation rapide des
ordinateurs présents sur le réseaux et de
leurs ports ouverts.
4.6 MBSA de Microsoft
Il m'a été demandé de tester aussi une des
solutions de Microsoft pour comparer aux résultats de Nessus. Voyons
cela?
4.6.1 Présentation
Pour répondre à la demande formulée par
certains clients d'une méthode rationnelle d'identification des erreurs
de configuration de la sécurité les plus fréquentes,
Microsoft a développé Microsoft Baseline Security Analyzer
(MBSA). La version 2.0.1 de MBSA comprend une interface graphique et une
interface de ligne de commande qui peuvent effectuer l'analyse locale ou
distante de systèmes Windows. MBSA s'exécute sur Windows Server
2003, Windows 2000 et Windows XP et peut repérer des failles dans la
configuration de sécurité des produits suivants : Windows 2000,
Windows XP, Windows Server 2003, Internet Information Server (IIS) 5.0 et 6.0,
SQL Server 7.0 et 2000, Internet Explorer 5.01 et versions ultérieures,
ainsi qu'Office 2000, 2002 et 2003. MBSA recherche également les mises
à jour de sécurité, correctifs cumulatifs et Service Packs
publiés par Microsoft Update qui ne sont pas installés.
4.6.2 Installation
On peut télécharger gratuitement la dernière
version du MBSA sur le site de Microsoft à condition bien entendu
d'avoir une version originale de Windows.
4.6.3 Tests
Testons le MBSA sur mon portable qui a servi
précédemment pour Nessus. Le test a été
effectué sans
firewall et avec firewall Kaspersky. Résultat, rien de
bien alarmant, les résultats sont les mêmes avec ou sans la
présence de Kaspersky.
4.6.4 Conclusion
MBSA est un produit Microsoft donc que pour ses derniers OS. Le
logiciel est clair, l'analyse rapide et de bons conseils sont donnés
quant à la résolution d'éventuels problèmes.
4.6.5 Captures d'écran
Résultats avec et sans firewall :

4.6-1 : Résultats du MBSA
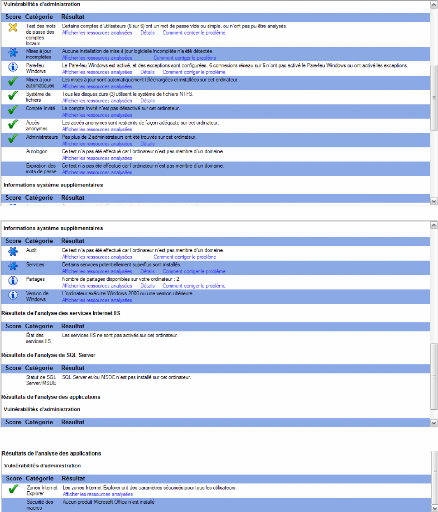
4.6-2 : Suite des résultats
4.6-3 : Suite des résultats
4.6-4 : Fin des résultats
Chapitre 5
d'autres outils
5 Les outils indispensables 5.1
Net-SNMP
Net-SNMP est un ensemble d'applications utilisées pour
implémenter le protocole SNMP (v1, v2c & v3) utilisant ã la
fois l'IPv4 & IPv6. La suite inclut :


Des applications en ligne de commande :
o Rechercher des informations SNMP en employant des demandes
simples (snmpget, snmpgetnext), ou des demandes multiples (snmpwalk, snmptable,
snmpdelta)
o Manipuler des informations de configuration sur des
périphériques compatibles SNMP (snmpset)
o Recevoir une collection fixée d'informations d'un
périphérique compatible SNMP (snmpdf, snmpnetstat, snmpstatus)
o Convertir entre les formes numériques et textuelles
d'OIDs de MIB et montrer le contenu de MIB et la structure (snmptranslate).
Un daemon pour recevoir des interruptions SNMP (snmptrad).
Un agent extensible pour répondre aux questions SNMP
(snmpd).
?
Il sera fort utilisé pour monitorer les ressources
des serveurs et présenté dans un chapitre
ultérieur.
Site web du produit :
http://www.net-snmp.org
Monitoring d'une infrastructure Linux sur base d'outils
libres 5.2 MRTG

MRTG est un logiciel dédié à la
supervision réseau. Il permet d'obtenir toute une série de
statistiques (visualisation de charge sur un réseau, utilisation de
bande passante...) concernant un appareil informatique (tels que
routeurs, serveurs, ou PC) sous forme de représentations
graphiques. Il va pour cela chercher des informations directement sur les
interfaces des machines du réseau via le protocole SN M P (Simple
Network Management Protocol, protocole facilitant l'administration de
systèmes à distance).
Outil connu des grandes entreprises, entièrement
configurable et gratuit, MRTG (Multi Router Traffic Grapher) est un
Freeware constitué de scripts en langage Perl, distribué
librement sur le Web. Il présente les résultats de ses recherches
sur des pages Web classiques, ce qui facilite nettement l'accès à
un utilisateur quelconque, quelle que soit la machine utilisée.
Site web du produit :
http://www.mrtg.org
5.3 RRDTool

RRDtool est un outil sous licence GNU GPL de gestion de base
de données RRD créé aussi par Tobi Oetiker. Cet outil est
dédié au développement des outils de supervision. Il
permet de stocker et de visualiser, sous forme graphique, différents
types de données provenant des équipements (serveurs, switchs,
routers...), tels que la charge CPU, ou l'utilisation de bande passante. Il est
nécessaire pour cela de collecter les données via une application
(ex : Cacti) ou un processus extérieur, qui pourra
récupérer périodiquement l'état des indicateurs en
utilisant par exemple le protocole SNMP.
Site web du produit :
http://www.rrdtool.com
5.4 Le choix des outils
Lors du rapport que j'ai effectué auprès de Manex,
Nagios et Nessus ont été choisi pour être
implémentés dans le réseau de l'entreprise.
Chapitre 6
L'analyse de Nagios
6 Présentation de Nagios
Nagios est un moniteur d'hôtes et de services
destiné ã nous informer des problèmes du réseau
avant les clients, les utilisateurs finaux et les managers. Il a
été créé pour fonctionner sous des systèmes
d'exploitations de type Linux, mais il fonctionne très bien sous la
majorité des variantes *NIX.
Le service de monitoring fonctionne par des
vérifications intermittentes sur les hôtes et les services que
l'on spécifie en utilisant des « plugins ? externes qui retournent
des informations d'états vers Nagios.
Quand des problèmes sont rencontrés, le service
de monitoring peut envoyer des notifications vers des contacts par divers
moyens (email, message instantané, SMS, etc.). Les informations
sur le statut actuel, les logs, et rapports peuvent tous être atteints
via un navigateur Internet.
6.1 Caractéristiques
Nagios a un tas de caractéristiques faisant de lui un
excellent outil de monitoring. Les possibilités majeures sont
listées ci-dessous :


Surveillance des services réseaux (SMTP, POP3, HTTP,
NNTP, PING, etc.)
Surveillance des ressources des hôtes (charge
processeur, utilisation des disques, etc.) Monitoring des facteurs
environnementaux comme la température
Système simple de plugins permettant aux utilisateurs de
développer facilement leurs propres vérifications de services.
Parallélisassions des vérifications des
services.
Possibilité de définir la hiérarchie du
réseau en utilisant des hôtes "parents", ce qui permet la
détection et la distinction entre les hôtes qui sont à
l'arrêt et ceux qui sont injoignables. Notifications des contacts quand
un hôte ou un service a un problème et quand celui-ci est
résolu (via email, pager, sms, ou par tout autre méthode
définie par l'utilisateur) Possibilité de définir des
gestionnaires d'évènements qui s'exécutent pour des
évènements sur des hôtes ou des services, pour une
résolution proactive des problèmes
Support pour l'implémentation de serveurs de monitoring
redondants et distribués
Interface de commandes externes qui permet des modifications
rapides d'être faite vers le monitoring et le comportement des
notifications ã travers l'utilisation de gestionnaires
d'évènements, de l'interface Web , et d'applications tierces.
Conserve le statut des hôtes et de services après un
redémarrage
Coupure planifiée pour la suppression des notifications
d'hôtes et de services pendant les périodes de maintenance
Capacité de confirmer un problème via
l'interface
Interface Web pour voir le statut actuel du réseau,
notification et historique des problèmes, fichiers de logs, etc.
Organisation simple des autorisations qui permet de restreindre
ce que les utilisateurs peuvent voir et faire ã partir de
l'interface.
6.2 Pré requis
? Noyaux Linux 2.6, Apache
? NET-SNMP
? Libraire GD, Perl, Compilateur C (si non installé via
les RPM)
6.3 Installation
Il existe deux possibilités d'installation : en manuel par
compilation des sources et via les packages RPM (dépôts de Dag
Wieers10).
Pour des raisons de facilité de maintenance, il m'a
été demandé de l'installer en automatique via
dépôts.
6.3.1 Ajout des dépôts
Nagios n'étant pas disponible sur les dépôts
officiels de Red Hat Entreprise Linux, j'ai dû rajouter le
dépôt de Dag Wieers en modifiant le fichier
/etc/sysconfig/rhn/ sources et en rajoutant ###
Dag RPM Repository for Red Hat Enterprise Linux
yum dag
http://apt.sw.be/redhat/el4
/en/$ARCH/dag
Suivi d'un # up2date -u
6.3.2 Modification des iptables
IP_DAG=1 93.1 .193.67
iptables-A OUTPUT -d $IP_DAG -p tcp --syn --dport
http -j LOG_OUTGOING
iptables -A OUTPUT -d $IPRANGE_INTRANET_SERVERS -p
udp --dport snmp -j LOG_OUTGOING iptables -A OUTPUT -d $IPRANGE_DMZ -p udp
--dport snmp -j LOG_OUTGOING
L'avantage de cette méthode est lors de la
présence de mise ã jour, tout se fera automatiquement via un
up2date. La méthode manuelle entrainait quand à
elle, une recompilation obligatoire de Nagios et des plugins additionnels.
6.3.3 Téléchargement et
installation
# up2date -i nagios nagios-plugins net-snmp
net-snmp-utils
|
Nagios est donc le noyau du monitoring. Il inclut l'interface Web
qui permet de consulter les alertes.
Nagios-plugins comportent une collection des plugins
développés par Nagios et d'autres plugins les plus
utilisés issus de contribution des utilisateurs.
Net-snmp et net-snmp-utils qui seront utilisés plus tard
par plusieurs plugins pour obtenir
des informations (CPU Load, Memory, Disk Space,...).
|
6.4 Structure des répertoires et emplacement des
fichiers
Nagios s'installe par défaut dans plusieurs
répertoires :
Sous-répertoires Contenus
/usr/bin/nagios/ Ensemble des programmes
Nagios
/etc/nagios/ Les fichiers de configurations
principaux, des ressources, des objets,
et des CGI doivent être mis
ici
|
/usr/lib/nagios/plugins/ Les plugins sont des
scripts ou des binaires qui réalisent les contrôles
des
services et des hôtes pour la supervision.
|
/usr/sbin/nagios/ CGIs
10 Dag Johan Maarten Wieers :
http://dag.wieers.com/
Monitoring d'une infrastructure Linux sur base d'outils
libres
/usr/share/nagios/ fichiers HTML (pour
l'interface web et la documentation en ligne)
/var/log/nagios/ Répertoire vide pour les
fichiers de log, les fichiers de statuts, les
fichiers de rétention,
etc.
/var/log/nagios/archives Répertoire vide
pour les logs arch ivés
/var/log/nagios/rw Répertoire vide pour
le fichier de commandes externes
6.5 Accès à l'interface Web
L'accès ã l'interface Web se fait par
défaut sur le port 80 et est protégé par un
.htaccess. Avec un des employés de Manex, nous avons
rendu l'accès ã Nagios via une authentification LDAP. Ce point
sera expliqué plus tard.
On peut spécifier des droits d'accès aux
différentes parties de l'interface.
|
Données des CGI
|
Contacts authentifiés
|
Autres utilisateurs authentifiés
|
|
Information sur l'état des hôtes
|
Oui
|
Non
|
|
Information sur la configuration des
hôtes
|
Oui
|
Non
|
|
Historique des hôtes
|
Oui
|
Non
|
|
Notifications des hôtes
|
Oui
|
Non
|
|
Commande des hôtes
|
Oui
|
Non
|
|
Information sur l'état des
services
|
Oui
|
Non
|
|
Information sur la configuration des services
|
Oui
|
Non
|
|
Historique des services
|
Oui
|
Non
|
|
Notifications des services
|
Oui
|
Non
|
|
Commandes des services
|
Oui
|
Non
|
|
Toutes informations de configuration
|
Non
|
Non
|
|
Information sur le système/processus
|
Non
|
Non
|
|
Commandes système/processus
|
Non
|
Non
|
Les Contacts authentifiés ont
les droits suivants sur chaque service dont ils sont un contact (mais pas
sur ceux dont ils ne sont pas un contact)...
( Droit de voir l'état du service
( Droit de voir la configuration du service
( Droit de voir l'historique et les notifications de ce
service
( Droit de passer des commandes à ce service
Les Contacts authentifiés ont
les droits suivants sur chaque hôte dont ils sont un contact (mais pas
sur ceux dont ils ne sont pas un contact)...
( Droit de voir l'état de l'hôte
( Droit de voir la configuration de l'hôte
( Droit de voir l'historique et les notifications de cet
hôte
( Droit de passer des commandes à cet hôte
( Droit de voir l'état de tous les services de cet
hôte
( Droit de voir la configuration de tous les services de cet
hôte
( Droit de voir l'historique et les notifications de tous les
services de cet hôte
( Droit de passer des commandes à tous les services de
cet hôte
6.6 Description des fichiers de
configurations
Il existe une dizaine de fichiers de configurations dans
/etc/nagios/ dont le principal est nagios.cfg.
Il contient un certain nombre de directives qui affectent la
manière dont Nagios fonctionne. Ce fichier est lu par le processus
Nagios et par les CGIs.
6.6.1 Configuration principal
Le fichier principal est nagios.cfg11.
C'est ce fichier que le daemon Nagios va lire en tout premier. Il
contient divers paramètres pour le daemon en lui-même ainsi que
les références vers les autres fichiers de configurations.
Les variables importantes (à décommenter) :
cfgjile=/etc/nagios/contactgroups.cfg
cfgjile=/etc/nagios/contacts.cfg cfgjile=/etc/nagios/hostgroups.cfg
cfgjile=/etc/nagios/hosts.cfg
cfgjile=/etc/nagios/services.cfg
cfgjile=/etc/nagios/timeperiods.cfg
cfgjile=/etc/nagios/dependencies.cfg
En fait, pour plus de clarté, j'ai suivi le
modèle de configuration recommandé par Nagios à savoir
bien séparer les différentes configurations. Je les
détaillerai après. Cela dit, rien n'empêche de regrouper
toutes les configurations dans un seul et même fichier... <= bonjour
la maintenance ;o)
Nagios permet aussi de lire la configuration de plusieurs
fichiers dans un répertoire. Utile pour regrouper par exemple tout les
serveurs d'un même LAN, ou encore d'une DMZ. Seule obligation pour que
les fichiers quÐ l'on y mettra soient pris en compte, c'est qu'ils portent
l'extension .cfg
cfg_dir=/etc/nagios/servers
cfg_dir=/etc/nagios/DMZ
Le fichier resource.cfg est très
important ! Il nous permettra de stocker les diverses Macros utiles dans la
définition de commandes.
resourcejile=/etc/nagios/resource.cfg
Si l'on souhaite pourvoir utiliser les diverses commandes via
l'interface Web de Nagios, il est obligatoire de mettre cette variable à
112.
check_external_commands=1
Il s'agit en fait d'un fichier nagios.cmd qui
sera placé (par les scripts CGI gérés par le daemon) dans
/var/log/nagios/rw où toutes les commandes
passées par l'interface Web seront écrites dedans jusqu'à
leur exécution. Le fichier peut être lu autant que possible ou
toutes les x secondes. La variable suivante défini la chose.
command_check_interval=10s # remplacer 10s par -1 si
check autant que possible
Et on peut changer (si on le souhaite) l'emplacement du fichier
précédemment cité...
commandjile=/var/log/nagios/rw/nagios.cmd
11 Plus d'infos :
http://nagios.sourceforge.net/docs/2
0/configmain.html
12 Plus d'infos :
http://nagios.sourceforge.net/docs/2
0/extcommands.html
6.6.2 Configuration des CGIs
Le fichier de configuration des CGIs
cgi.cfg13 contient un certain nombre de directives
qui affectent le
mode de fonctionnement des CGIs.
Il existe plusieurs façons de restreindre l'accès
à Nagios. Par défaut, il s'agit du couple :
.htaccess/.htpassword .
Quel qu'en soit le choix, il faut modifier les lignes suivantes
:
use_authentication=1 # Forcera Nagios à
demander une
authentification
authorizedjor_system_information=*
authorizedjor_configuration_information=*
authorizedjor_system_commands=* authorizedjor_all_services=*
authorizedjor_all_hosts=*
authorizedjor_all_service_commands=*
authorizedjor_all_host_commands=*
Dans notre cas, on autorise tout le monde car nous allons
utiliser le LDAP pour restreindre l'accès.
Mais pour ceux qui utilisent simplement le couple
.htaccess/.htpassword on peut spécifier l'accès
à certaines choses et pas à d'autres allant du simple affichage
des pages Nagios à la capacité de
arrêter/redémarrer le processus Nagios.
6.6.3 Configuration d'un vhost dans Apache
Nous allons créer le fichier suivant :
/etc/httpd/vhosts.d/
nagios.manex.be.conf
Voici son contenu :
<VirtualHost 192.168.1.14:80>
ServerName
nagios.manex.be
ScriptAlias /nagios/cgi-bin
"/usr/lib/nagios/cgi"
ServerAdmin
infrastructure-managers@manex.be
ErrorLog
/var/log/httpd/nagios.manex.be-error_log
CustomLog /var/log/httpd/nagios.manex.be-access_log
common
<Directory
"/usr/lib/nagios/cgi">
Options ExecCGI
AllowOverride None
Order deny,allow
Allow from all
AuthType Basic
AuthName
nagios.manex.be
AuthLDAPEnabled on
AuthLDAPURL
ldap://192.168.1.11/dc=manex,dc=be?uid?sub?(objectclass=person) AuthLDAPBindDN
"uid=apache,ou=special users,dc=manex,dc=be" AuthLDAPBindPassword
apache
Require group cn=
nagios.manex.be,ou=web,ou=Applications,dc=manex,dc=be
Require valid-user
</Directory>
Alias /nagios "/usr/share/nagios"
13 Plus d'infos :
http://nagios.sourceforge.net/docs/2
0/configcgi.html
<Directory
"/usr/share/nagios">
Options None
AllowOverride None
Order deny,allow
Allow from all
AuthType Basic
AuthName
nagios.manex.be
AuthLDAPEnabled on
AuthLDAPURL
ldap://192.168.1.11/dc=manex,dc=be?uid?sub?(objectclass=person) AuthLDAPBindDN
"uid=apache,ou=special users,dc=manex,dc=be" AuthLDAPBindPassword
apache
Require group cn=
nagios.manex.be,ou=web,ou=Applications,dc=manex,dc=be
Require valid-user
</Directory>
RedirectMatch ^(/)$ /nagios
</VirtualHost>
Prendre soin de donner les droits dans le LDAP.
6.6.4 Les contacts et groupes de contacts
Les contacts sont les personnes qui seront prévenues lors
d'un évènement (alerte warning, critical,
...). Commençons par créer un groupe
d'utilisateurs dans le fichier contactgroups.cfg.
define contactgroup{
contactgroup_name admins
alias Nagios Administrators
members nagios-admin
I
On a dès lors un groupe nommé « admins »
qui possède un alias (une description en fait) et un contact
« nagios-admin ». Allons configurer ce contact dans le fichier
contacts.cfg14.
define contact{
contact_name nagios-admin
alias LE Big Boss de Nagios
service_notification_period 24x7
host_notification_period 24x7
service_notification_options w,u,c,r
host_notification_options d,r
service_notification_commands
notify-by-email
host_notification_commands
host-notify-by-email
email
infrastructure-managers@manex.be
I
Ici, on se retrouve avec nagios-admin et son alias. Ensuite, la
période pendant laquelle il peut être prévenu pour les
services et les hôtes. Suivi des options de notification respectivement
pour les
services et les hôtes (Warning, Unknown, Critical,
Recovery, Down, Flapping,...). Ensuite, la
commande ã utiliser
pour envoyer les notifications des services ou des hôtes. Enfin,
l'adresse e-mail à
conta cter.
14 Plus d'infos :
http://nagios.sourceforge.net/docs/2
0/xodtemplate.html#contact
6.6.5 Définition des périodes de
vérifications et de notifications
On peut spécifier facilement des périodes dans le
fichier timeperiods.cfg15 qui
seront utilisées par les
services lors des contrôles ou des notifications.
|
define timeperiod(
timeperiod_name
|
24x7
|
|
alias
|
24 Hours A Day, 7 Days A Week
|
|
sunday
|
00:00-24:00
|
|
monday
|
00:00-24:00
|
|
tuesday
|
00:00-24:00
|
|
wednesday
|
00:00-24:00
|
|
thursday
|
00:00-24:00
|
|
friday
|
00:00-24:00
|
|
saturday
|
00:00-24:00
|
|
}
define timeperiod(
timeperiod_name
|
workhours
|
|
alias
|
"Normal" Working Hours
|
|
monday
|
09:00-1 7:00
|
|
tuesday
|
09:00-1 7:00
|
|
wednesday
|
09:00-1 7:00
|
|
thursday
|
09:00-1 7:00
|
|
friday
|
09:00-1 7:00
|
|
}
define timeperiod(
timeperiod_name
|
nonworkhours
|
|
alias
|
Non-Work Hours
|
|
sunday
|
00:00-24:00
|
|
monday
|
00:00-09:00,17:00-24:00
|
|
tuesday
|
00:00-09:00,17:00-24:00
|
|
wednesday
|
00:00-09:00,17:00-24:00
|
|
Thursday
|
00:00-09:00,17:00-24:00
|
|
friday
|
00:00-09:00,17:00-24:00
|
|
Saturday
|
00:00-24:00
|
}
Il est toujours utile de spécifier plusieurs
périodes de temps. Prenons le cas du monitoring des imprimantes... Il
n'est pas important d'être prévenu le week-end si l'imprimante
s'est mise en veuille
ou si elle n'a plus d'encre... Et inutile aussi d'exécuter
certaines vérifications durant le week-end.
6.6.6 Définition des groupes d'hôtes et des
templates hôtes
Commençons par créer les groupes d'hôtes dans
le fichier hostgroups.cfg16.
define hostgroup(
hostgroup_name thelanservers
alias SERVERS Intranet
members mxisrv1,mxisrv2,mxisrv4
}
15 Plus d'infos :
http://nagios.sourceforge.net/docs/2
0/xodtemplate.html#timeperiod
16 Plus d'infos :
http://nagios.sourceforge.net/docs/2
0/xodtemplate.html#host
define hostgroup{
hostgroup_name thedmzservers
alias SERVERS DMZ
members
mx1srv1,mx1srv2,mx1srv3,mx1srv6,mx1srv7,mx1srv9
}
Et les Templates d'hôtes dans le fichier
hosts.cfg17. Ces Templates sont utiles pour
définir une
configuration identique pour plusieurs hôtes.
define host{
name generic-host ; The name of this host
template
notifications_enabled 1 ; Host notifications are
enabled
event_handler_enabled 1 ; Host event handler is
enabled
flap_detection_enabled 1 ; Flap detection is
enabled
failure_prediction_enabled 1 ; Failure prediction is
enabled
process_perf_data 1 ; Process performance
data
retain_status_information 1 ; Retain status
information across program restarts
retain_nonstatus_information 1 ; Retain
non-status information across program restarts
notification_period 24x7 ; Send host notifications at
any time
register 0 ; DONT REGISTER THIS DEFINITION - ITS NOT
A REAL HOST, JUST A TEMPLATE! }
6.6.7 Définition des hôtes
Pour définir un hôte, rien de plus simple :
define host{
use linux-server ; Name of host template to
use
host _name mxisrv4
alias mxisrv4 (Monitoring)
address
mxisrv4.manex.be
}
L'emplacement de ces lignes est un peu plus particulier. Dans
mon cas, j'ai suivi un certain nombre de personnes dont l'avis est de
créer un fichier par hôte. Dans ce cas-ci, j'ai
créé un répertoire « servers » dans lequel j'ai
placé le fichier mxisrv4.cfg.
6.6.8 Définition des ressources
Les fichiers des ressources resource.cfg18
sont utilisés pour stocker les macros définies par
les
utilisateurs. Ces fichiers peuvent aussi contenir d'autres
informations (telle que la configuration des connexions de la base de
données), bien que ceci dépend de la manière dont
Nagios aura été compilé.
L'avantage de ces fichiers est de pouvoir y mettre des
données sensibles de configuration qui ne seront pas accessibles
à travers les CGIs.
Le fichier des ressources est bien utile car il permet de
définir des macros qui seront utilisées dans les
différentes commandes19.
# Sets $USER1$ to be the path to the
plugins
$USER1$=/usr/lib/nagios/plugins
17 Plus d'infos :
http://nagios.sourceforge.net/docs/2
0/xodtemplate.html#host
18 Plus d'infos :
http://nagios.sourceforge.net/docs/2
0/macros.html 19 Seront présentées juste après.
# Macro - SNMPv3 ; chaine de connexion
utilisée par le plugin ./check_snmp
$USER4$=-P 3 -L authPriv -U UnUtilisateur -A
UnBeauMot2Passe -X UnAutreBeauMot2Passe
# Macro - SNMPv3 Login/Password => MD5 ; contenu
CRYPTE => DES (ou AES) $USER5$=-l UnUtilisateur -x UnBeauMot2Passe -X
UnAutreBeauMot2Passe -L md5,des
# Macro - Authentification http
$USER6$=-a
UnUtilisateur:Encore1Mot2Passe
La définition de macro est vraiment très
pratique, notamment dans le cas des Logins/Mots de Passe
utilisés par le ÐrotocolÐ SNMPv3 s'ils sont
communs ÐntrÐ Ðux.
6.6.9 Définition des commandes
Les commandes sont utilisées par les services et
définies dans le fichier commands.cfg20.
C'est une
couche intermédiaire entre le Plugin en lui-même qui
sera utilisé et le service. C'est ici que l'on va indiquer les
paramètres que l'on passe au Plugin.
Il y a deux sortes de Plugins, les locaux qui sont
destinés à une utilisation locale. Donc pas besoin de renseigner
l'adresse de la machine, ils ne donneront que les résultats de la
machine sur laquelle ils se
trouvent.
define command{
command_name check_local_load
command_line $USER1$/check_load -w $ARG1$ -c
$ARG2$
I
Ensuite, les Plugins qui vont récupérer des
informations sur d'autres serveurs. define
command{
command_name check_imaps
command_line $USER1$/check_simap -H $HOSTADDRESS$ -S
-w $ARG1$ -c $ARG2$
I
Les champs $HOSTADDRESS$ $ARG1$ $ARG2$ sont des
macros. Ils servent d'intermédiaire dans la définition.
6.6.10 Configuration des informations
étendues
Les fichiers de configuration des informations étendues
(hostextinfo.cfg21 &
serviceextinfo.cfg) sont
utilisés pour définir des informations
supplémentaires pour les hôtes et les services qui doivent
être utilisés par les CGI. On peut notamment y définir des
petites images et des coordonnées pour la Map.
define hostextinfo{
host _name mxisrv4
notes Serveur de Monitoring - Nagios
notes_url
http://nagios.manex.be/nagios/cgi-bin/status.cgi?host=mxisrv4
icon_image redhat.jpg
icon_image_alt Red Hat Entreprise
Linux
vrml_image redhat.jpg
statusmap_image redhat.jpg
2d_coords 100,250
3d_coords 1 00.0,50.0,75.0
I
Après beaucoup de chipotage, on arrive à une Map
dans ce genre :
20 Plus d'infos :
http://nagios.sourceforge.net/docs/2
0/xodtemplate.html#command
21 Plus d'i nfos :
http://nagios.sourceforge.net/docs/2
0/xodtemplate. html#hostexti nfo
6.6-1 : Petit réseau de Manex
6.6-2 : Le réseau d'une entreprise
inconnue
Pour l'image de droite, je l'ai obtenu via une recherche sur
Google démontrant la capacité de ce créateur de Map. Bien
entendu, il existe encore des plus grandes? avec ce genre d'outils, il est
difficile de se limiter.
Monitoring d'une infrastructure Linux sur base d'outils
libres 6.7 Les services
Il existe deux sortes de services : publics et privés.
6.7.1 Les services publics
Les services dits Ðubliques sont ceux que Nagios Ðeut
monitorer sur les hôtes distants en n'ayant
comme information, que leur adresse IP.
Par exemple : HTTP, SMTP, DNS, IMAP,
LDAP, ?
6.7.2 Les services privés
Les services dits Ðrivés sont ceux qui demandent
l'utilisation du Ðrotocole SNMP ou l'exécution des
plugins sur les hôtes monitorés via NRPE, NSCA ou
par SSH.
Par exemple : Charge CPU, utilisation
du disque, utilisation de la mémoire virtuelle/SWAP,
utilisateurs
connectés, ?
6.7.3 Définition des templates et des
services
Tout comme les hôtes, il est utile de définir des
templates pour les services. Ils permettent, je le
rappelle, de faire une configuration similaire pour plusieurs
services. La configuration se déroule dans le fichier
services.cfg22.
define service{
name generic-service ; The 'name' of this service
template
active_checks_enabled 1 ; Active service checks are
enabled
passive_checks_enabled 0 ; Passive service checks are
enabled/accepted
parallelize_check 1 ; Active service checks should be
parallelized
obsess_over_service 1 ; We should obsess over this
service (if necessary)
checkjreshness 0 ; Default is to NOT check service
'freshness'
notifications_enabled 1 ; Service notifications are
enabled
event_handler_enabled 1 ; Service event handler is
enabled
flap_detection_enabled 1 ; Flap detection is
enabled
failure_prediction_enabled 1 ; Failure prediction is
enabled
process_perf_data 1 ; Process performance
data
retain_status_information 1 ; Retain status
information across program restarts
retain_nonstatus_information 1 ; Retain
non-status information across program restarts
is_volatile 0 ; The service is not
volatile
register 0 ; DONT REGISTER THIS DEFINITION - ITS NOT
AREAL
SERVICE, JUST A TEMPLATE!
}
define service{
name local-service ; The name of this service
template
use generic-service ; Inherit default values from the
generic-service definition
check_period 24x7 ; The service can be checked at any
time of the day
max_check_attempts 4 ; Re-check the service up to 4 times in
order to determine its final (hard) state
normal_check_interval 5 ; Check the service every
5 minutes under normal conditions retry_check_interval 1 ; Re-check the service
every minute until a hard state can be determined
contact_groups admins ; Notifications get sent out to
everyone in the 'admins'
group
notification_options w,u,c,r ; Send notifications
about warning, unknown, critical, and
recovery events
22 Plus d'infos :
http://nagios.sourceforge.net/docs/2
0/xodtemplate.html#service
Monitoring d'une infrastructure Linux sur base d'outils
libres
notification_interval 60 ; Re-notify about service
problems every hour
notification_period 24x7 ; Notifications can be sent
out at any time
register 0 ; DONT REGISTER THIS DEFINITION - ITS NOT
A REAL SERVICE, JUST
A TEMPLATE!
}
Le template host-service est le même local-service. C'est
juste prévu si on souhaite modifier les
paramètres globaux du service...
La définition des services n'est pas des plus
compliquée. Il suffit de néanmoins respecter la façon dont
on a défini la commande avant. Voici pour le service local.
define service(
use local-service ; Name of service template to
use
host _name mxisrv4
service_description CPU Load
check_command
check_local_load!10.0,10.0,10.0!20.0,20.0,20.0
}
Et pour l'autre :
define service(
use host-service
host _name mx1srv1
service_description IMAPS
check_command check_imaps!10!20
}
On peut éventuellement définir des groupes de
services dans le fichier
servicegroups.cfg23, mais je
n'ai pas encore vu d'intérêt à cela.
6.7.4 Déclaration d'un autre service
Voici la déclaration d'un service qui contrôle la
SWAP pour le localhost :
define service (
use local-service
host _name localhost
service_description SWAP
check_command check_local_swap!90!80
}
Le service utilise un Template local-service qui
permet de définir une foule de paramètres.
define command (
command_name check_local_swap
command_line $USER1$/check_swap -w $ARG1$ -c
$ARG2$
}
Dans la définition de la commande, on retrouve le nom
de la commande check_local_swap et sa ligne de commande. Pour
la ligne de commande, on utilise des macros qui sont définies dans le
fichier des ressources. $USER1$ pointe vers le path où
se trouvent les plugins. $ARG1$ et $ARG2$
sont les arguments passés au plugin check_swap.
Ils correspondent dans ce cas-ci aux valeurs dit warning et
critical qui sont des niveaux d'alertes en fonction de l'utilisation
de la SWAP.
23 Plus d'infos :
http://nagios.sourceforge.net/docs/2
0/xodtemplate.html#servicegroup
Monitoring d'une infrastructure Linux sur base d'outils
libres 6.7.5 Un dernierg
Voici la déclaration d'un service qui contrôle la
mémoire virtuelle sur un ordinateur distant sous Windows XP Pro SP2 :
define service {
use host-service
host _name HOST A
service_description Taille memoire
Virtuelle
check_command check_snmp_storage_v1 !public!"^
Virtual Memory$ "!80!90
}
Le service utilise un autre Template que
précédemment, host-service qui permet notamment
de définir la période où le service doit être
utilisé. Cette fois-ci, on attache le service à HOST A, mon
portable et du fait qu'il est sous Windows XP, on utilise le
Ðrotocole SNMP (v1 dans ce cas-ci).
define command {
command_name check_snmp_storage_v1
command_line $USER1$/check_snmp_storage.pl -H
$HOSTADDRESS$ -C $ARG1$ -m
$ARG2$ -w $ARG3$ -c $ARG4$
$ARG5$
}
Ci-dessus, la définition de la commande qui se rapporte
au service. On utilise plusieurs macros.
Comme précédemment, $USER1$.
Ensuite $HOSTADDRESS$ qui indique qui on va
interroger.
Cette fois-ci, $ARG1$ indiquera la
communauté utilisé pour SNMP. Ensuite, $ARG2$
indiquera quel disque on souhaite interroger (dans le cas de ce
plugin, la mémoire virtuelle est considérée comme
un
disque dur à part). $ARG3$ et
$ARG4$ sont les valeurs warning et critical.
On peut ajouter un $ARG5$ qui pourra
éventuellement servir pour paramétrer plus
précisément le service.
6.8 Méthodes pour démarrer
Nagios
Bien que lors de chaque chargement de Nagios, celui-ci fasse une
vérification sur les fichiers de
configurations, il est néanmoins recommandé de
faire une vérification manuelle : # nagios -v
/etc/nagios/nagios.cfg
Nagios 2.9
Copyright (c) 1 999-2007 Ethan Galstad (
http://www.nagios.org)
Last Modified: 04-10-2007
License: GPL
Reading configuration data...
Running pre-flight check on configuration
data...
Checking services...
Checked 187 services. Checking
hosts...
Checked 17 hosts.
Checking host groups...
Checked 3 host groups. Checking service
groups...
Checked 0 service groups. Checking
contacts...
Checked 3 contacts. Checking contact groups...
Checked 1 contact groups.
Monitoring d'une infrastructure Linux sur base d'outils
libres
Checking service escalations...
Checked 0 service escalations.
Checking service dependencies...
Checked 271 service dependencies. Checking host
escalations...
Checked 0 host escalations.
Checking host dependencies...
Checked 2 host dependencies.
Checking commands...
Checked 47 commands.
Checking time periods...
Checked 4 time periods.
Checking extended host info
definitions...
Checked 17 extended host info definitions. Checking
extended service info definitions...
Checked 0 extended service info definitions. Checking
for circular paths between hosts...
Checking for circular host and service
dependencies... Checking global event handlers...
Checking obsessive compulsive processor commands...
Checking misc settings...
Total Warnings: 0 Total Errors: 0
Things look okay - No serious problems were detected
during the pre-flight check Il y a cinq moyens différents
de lancer Nagios:


Manuellement, en tant que processus prioritaire (utile pour
les tests initiaux et le débogage) # nagios
/etc/nagios/nagios.cfg
Manuellement, en tant que processus d'arrière-plan
# nagios /etc/nagios/nagios.cfg &
Manuellement, en tant que un daemon # nagios -d
/etc/nagios/nagios.cfg
Manuellement via un script de démarrage
Lors dÐ l'installation, un script dÐ démarragÐ
Ðst placé dans le /etc/init.d/. On peut dès
lors le lancer ainsi :
# /etc/init.d/nagios
Usage: nagios {start|stop
|restart|reload|force-reload|status}
Automatiquement au démarrage (boot) du
système
Pour qu'il démarre à chaque redémarrage du
serveur, il suffit de taper cette commande :
# chkconfig -level 345 nagios on 6.9
Plugins
Les plugins sont des programmes compilés (C dans la
majorité des cas) ou des scripts (Perl, Shell, etc..) qui
peuvent être exécutés en ligne de commande pour tester
l'état d'un hôte ou d'un service. Nagios utilise le
résultat des plugins pour déterminer le statut actuel des
hôtes ou services sur le
réseau.
Monitoring d'une infrastructure Linux sur base d'outils
libres 6.9.1 Différentes sources
Il existe un tas de plugins officiels et non officiels. Tout
d'abord, les plugins officiels fournis par Nagios, sans quoi ce dernier ne
fonctionnerait pas. Ensuite, il y a les plugins de Manubulon24
permettant d'effectuer des requêtes en utilisant le protocole SNMP
(v1, 2c, 3). Enfin, il existe des sites communautaires dont
NagiosExchange.org fait partie,
qui regroupe les plugins développés par d'autres personnes.
6.9.2 Le principe de fonctionnement
Nagios exécutera un plugin dès qu'il a besoin de
vérifier un service ou un hôte supervisé. Le plugin fait
quelque chose pour exécuter le contrôle et simplement renvoyer le
résultat à Nagios. Nagios analysera le résultat provenant
du plugin et prendra les mesures nécessaires (lancer les
gestionnaires d'évènements, envoyer des notifications,
etc).

6.9-1 : Montre comment les Ðlugins sont
séÐarés du coeur logique de Nagios
Nagios exécute les plugins qui vérifient ensuite
des services ou des ressources locales ou distantes. Lorsque les plugins ont
fini de vérifier la ressource ou le service, ils transmettent simplement
le résultat de la vérification à Nagios.
Avantages Inconvénients
|
Contrôle n'importe quoi Nagios n'a absolument aucune
idée de ce qui est
supervisé
|
Superviser des tâches automatisées avec Nagios Ne
peut pas créer des graphes des ressources
supervisées
Beaucoup de plugins créés pour superviser les
ressources basiques (CPU, Mem, Disk, Ping,...)
Peut seulement suivre les changements d'état de ces
ressources
Seul les plugins savent exactement ce qu'ils supervisent et
comment ils réalisent les vérifications
6.9.3 Utilisation des Plugins pour Contrôler des
Services
Quand Nagios a besoin de vérifier l'état d'un
service défini, il exécutera le plugin spécifié
dans
l'argument « check_command » de la définition du
service. Le plugin vérifiera l'état du service ou de la ressource
et retournera le résultat à Nagios.
6.9.4 Utilisation des Plugins pour contrôler des
hôtes
Dans chaque définition d'hôte on utilise
l'argument « host_check_command » pour spécifier un plugin qui
devra être utilisé pour vérifier l'état de
l'hôte. Les contrôles des hôtes ne sont pas effectués
régulièrement : ils sont exécutés uniquement au
besoin, typiquement lorsqu'il y a des
problèmes avec un ou plusieurs services associés
à l'hôte.
24 Manubulon est le pseudonyme de Patrick PROY :
http://www.manubulon.com/nagios
Monitoring d'une infrastructure Linux sur base d'outils
libres
Les contrôles des hôtes peuvent s'effectuer avec les
mêmes plugins que les contrôles des services. La
seule réelle différence entre les deux types de
contrôles est l'interprétation des résultats du plugin. Si
le résultat d'un plugin utilisé pour le contrôle d'un
hôte est un état différent d'OK, alors Nagios croira que
l'hôte n'est pas actif. Dans la plupart des cas, on peut utiliser un
plugin permettant de contrôler si l'hôte répond à une
requête ICMP (exemple : il répond au "ping") car c'est la
méthode la plus courante pour savoir si un hôte est actif ou
non.
6.9.5 L'analyse d'un plugin
6.9.5.1 Présentation
Le code source qui suit est le code en langage C du plugin «
check_users », plugin officiel de Nagios Ðermettant d'obtenir le
nombre de Ðersonnes connectées sur la machine locale et
générant un
évènement si ce nombre est supérieur
à un range défini.
6.9.5.2 Utilisation
Pour afficher l'aide sur le fonctionnement, les
Ðaramètres, etc. du plugin, il suffit de taper la
commande suivante : #
/usr/lib/nagios/plugins/check_users --help
check_users (nagios-plugins 1.4.8)
1.22
Copyright (c) 1999 Ethan Galstad
Copyright (c) 2000-2006 Nagios Plugin Development
Team <
nagiosplug-devel@lists.sourceforge.net>
This plugin checks the number of users currently
logged in on the local
system and generates an error if the number exceeds
the thresholds specified.
Usage:check_users -w <users> -c
<users>
Options:
-h, --help
Print detailed help screen
-V, --version
Print version information
-w, --warning=INTEGER
Set WARNING status if more than INTEGER users are
logged in -c, --critical=INTEGER
Set CRITICAL status if more than INTEGER users are
logged in
Send email to
nagios-users@lists.sourceforge.net
if you have questions regarding use of this software. To submit patches or
suggest improvements, send email to
nagiosplug-devel@lists.sourceforge.net
Il suffit de taper la ligne de commande du plugin ainsi que les
paramètres appropriés pour avoir le résultat :
# /usr/lib/nagios/plugins/check_users -w 2 -c 5 USERS
OK - 1 users currently logged in |users=1;2;5;0
Sur le site nous avons :
6.9-2 : Vue de l'état des utilisateurs
connectés sur la machine
Monitoring d'une infrastructure Linux sur base d'outils
libres Effectuons un autre test, connectons nous une deuxième
fois sur ce serveur
# /usr/lib/nagios/plugins/check_users -w 2 -c
5
USERS WARNING - 2 users currently logged in
|users=2;2;5;0
Comme on Ðeut le voir, nous avons un Warning? allons voir du
coté du site :

6.9-3 : Un état Warning pour le nombre
d'utilisateurs connectés
6.9.5.3 Le mail d'alerte ***** Nagios
2.9 *****
Notification Type: PROBLEM
Service: Users logged
Host: mxisrv4 (Monitoring) Address:
mxisrv4.manex.be State: WARNING
Date/Time: Fri May 25 11:37:53 CEST 2007
Additional Info:
USERS WARNING - 2 users currently logged in
6.9.5.4 Analyse
Le Ðlugin est donc écrit en langage C. Il va tout
d'abord vérifier les Ðaramètres qu'on lui a soumis lors de
l'exécution. En fonction de ces Ðaramètres, il
exécutera une fonction ou retournera une valeur. Ensuite, il
créera un processus fils qui sera chargé d'aller
récuÐérer (ã l'aide d'une boucle While) le
résultat retourné par la commande linux :
# who
geoffrey pts/1 May 25 09:10 (192.1
68.2.32)
Enfin, il comÐarera en fonction des Ðaramètres
Warning et Critical, la valeur qu'il a Ðrécédemment
comptée et retournera un état ainsi que le résultat sur la
console.
6.9.5.5 Son code source
En raison de la grandeur du code (pourtant le plus petit en
nombre de ligne), je l'ai mis ã la suite sur
deux pages.
Monitoring d'une infrastructure Linux sur base d'outils
libres
/*************************************************** *
* Nagios check_users plugin
*
* License: GPL
* Copyright (c) 2000-2006 nagios-plugins team
*
* Last Modified: $Date: 2007/01/28 21:46:41 $
*
const char *progname = "check_users";
const char *revision = "$Revision: 1.22 $";
const char *copyright = "2000-2006";
const char *email = "
nagiosplug-devel@lists.sourceforge.net";
#include "common.h" #include "popen.h" #include "utils.h"
if (child_stderr == NULL)
printf (_("Could not open stderr for %s\n"), WHO_COMMAND);
users = 0;
while (fgets (input_buffer, MAX_INPUT_BUFFER - 1, child_process))
{
* Description: #define possibly_set(a,b) ((a) == 0 ? (b) : 0) /*
increment 'users' on all lines except total
* user count */
* This file contains the check_users plugin
*
* This plugin checks the number of users currently logged in on
the local
* system and generates an error if the number exceeds the
thresholds specified.
*
* License Information:
*
* This program is free software; you can redistribute it and/or
modify
* it under the terms of the GNU General Public License as
published by
* the Free Software Foundation; either version 2 of the License,
or
* (at your option) any later version.
*
* This program is distributed in the hope that it will be
useful, * but WITHOUT ANY WARRANTY; without even the implied warranty of
* MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See
the
* GNU General Public License for more details.
*
* You should have received a copy of the GNU General Public
License
* along with this program; if not, write to the Free Software
* Foundation, Inc., 675 Mass Ave, Cambridge, MA 02139, USA. *
* $Id: check_users.c,v 1.22 2007/01/28 21:46:41 hweiss Exp $ *
***************************************************/
int process_arguments (int, char **); void print_help (void);
void print_usage (void);
int wusers = -1; int cusers = -1;
int
main (int argc, char **argv)
{
int users = -1;
int result = STATE_UNKNOWN;
char input_buffer[MAX_INPUT_BUFFER]; char *perf;
setlocale (LC_ALL, "");
bindtextdomain (PACKAGE, LOCALEDIR); textdomain (PACKAGE);
perf = strdup("");
if (process_arguments (argc, argv) == ERROR) usage4 (_("Could not
parse arguments"));
/* run the command */
child_process = spopen (WHO_COMMAND); if (child_process == NULL)
{
printf (_("Could not open pipe: %s\n"), WHO_COMMAND);
return STATE_UNKNOWN;
}
child_stderr = fdopen (child_stderr_array[fileno
(child_process)], "r");
if (input_buffer[0] != '#') {
users++;
continue;
}
/* get total logged in users */
if (sscanf (input_buffer, _("# users=%d"),
&users) == 1)
break;
}
/* check STDERR */
if (fgets (input_buffer, MAX_INPUT_BUFFER - 1, child_stderr))
result = possibly_set (result,
STATE_U NKNOWN);
(void) fclose (child_stderr);
/* close the pipe */
if (spclose (child_process))
result = possibly_set (result, STATE_U NKNOWN);
/* else check the user count against warning and critical
thresholds */
if (users >= cusers)
result = STATE_CRITICAL;
else if (users >= wusers)
result = STATE_WARNING;
else if (users >= 0)
result = STATE_OK;
Monitoring d'une infrastructure Linux sur base d'outils
libres
if (result == STATE_UNKNOWN) switch (c) { usage4 (_("Warning
threshold
printf ("%s\n", _("Unable to read output")); case '?': must be a
positive integer"));
else { /* print short else
asprintf(&perf, "%s", perfdata ("users", usage statement if
args not parsable */ cusers = atoi (argv[c]);
users, "", usage5 (); }
TRUE, wusers,
TRUE, cusers,
TRUE, 0,
FALSE, 0));
printf (j "USERS %s - %d users currently logged in |%s\n"),
state_text (result),
users, perf);
}
return result;
}
/* process command-line arguments */ int
process_arguments (int argc, char **argv) {
int c;
int option = 0;
static struct option longopts[] = {
{"critical", required_argument, 0, 'c'}, {"warning",
required_argument, 0, 'w'}, {"version", no_argument, 0, 'V'},
{"help", no_argument, 0, 'h'},
{0, 0, 0, 0}
};
if (argc < 2)
usage ("\n");
case 'h':
/* help */
print_help ();
exit (STATE_OK);
case 'V':
/* version */
print_revision (progname,
revision);
exit (STATE_OK);
case 'c':
/* critical */
if (!is_intnonneg (optarg))
usage4 (_("Critical threshold must be a positive integer"));
else
cusers = atoi (optarg);
break;
case 'w':
/* warning */
if (!is_intnonneg (optarg))
usage4 (_("Warning threshold must be a positive integer"));
else
wusers = atoi (optarg);
break;
}
}
c = optind;
if (wusers == -1 && argc > c) {
if (is_intnonneg (argv[c]) == FALSE) usage4 (_("Warning
threshold
return OK;
}
void
print_help (void)
{
print_revision (progname, revision);
printf ("Copyright (c) 1999 Ethan Galstad\n"); printf (COPYRIGHT,
copyright, email);
printf ("%s\n", _("This plugin checks the number of users
currently logged in on the local"));
printf ("%s\n", _("system and generates an error if the number
exceeds the thresholds specified."));
printf ("\n\n");
print_usage ();
printf (_(UT_HELP_VRSN));
printf (" %s\n", "-w, --warning=I NTEG ER");
printf (" %s\n", _("Set WARNING status if more than INTEGER users
are logged in"));
printf (" %s\n", "-c, --critical=INTEG ER");
printf (" %s\n", _("Set CRITICAL status if more than INTEGER
users are logged in"));
printf (_(UT_SUPPORT));
}
|
while (1) {
c = getopt_long (argc, argv, "-i-hVvc:w:", longopts,
&option);
|
must be a positive integer"));
else
wusers = atoi (argv[c-i--i-]);
}
|
void
print_usage (void) {
|
|
if (c == -1 || c == EOF || c == 1) break;
|
if (cusers == -1 && argc > c) {
if (is_intnonneg (argv[c]) == FALSE)
|
printf (_("Usage:"));
printf ("%s -w <users> -c <users>\n", progname);
}
|
6.10 Contrôle des hôtes
Pour le monitoring des hôtes, il existe 3
possibilités :
1. Par l'utilisation du protocole SNMP (v1,
v2c, v3)
2. Via NRPE : Permet d'exécuter des
plugins sur des machines distantes de manière transparente et
relativement aisée
3. Via NSCA : Permet d'envoyer des
résultats de contrôles passifs de services à un autre
serveur sur le réseau sur lequel tourne Nagios
6.10.1 NRPE
Les fichiers qui le constituent :
Fichiers Description
check_nrpe Plugin utilisé pour envoyer
des requêtes sur l'agent nrpe de la machine distante.
nrpe Agent qui tourne sur la machine distante et
exécute les requêtes du plugin.
nrpe.cfg Fichier de configuration pour les
agents des machines distantes.
Cet ajout est conçu pour permettre l'exécution
de plugins sur une machine distante. Le plugin check_nrpe tourne sur la machine
Nagios et est utilisé pour envoyer les requêtes d'exécution
du plugin à l'agent nrpe de la machine distante. L'agent nrpe
exécutera le plugin approprié sur la machine distante, et
retournera les données de sortie et le code de retour au plugin
check_nrpe de la machine Nagios. Le plugin check_nrpe envoit la sortie du
plugin distant et le code de retour à Nagios comme si c'était le
sien. Cela permet d'exécuter les plugins de manière transparente
sur les machines distantes. L'agent nrpe peut soit fonctionner en mode daemon
standalone, soit comme un service i netd.
6.10.2 NSCA
Les fichiers qui le constituent :
Fichiers Description
|
nsca Daemon qui tourne sur le serveur central de
Nagios et qui traite les résultats
des contrôles faits sur les
services passifs soumis par les clients.
|
nsca.cfg Fichier de Configuration pour le daemon
nsca.
|
send_nsca Programme client
exécuté à partir des machines distantes, et qui envoie des
informations de contrôles de services passifs au daemon nsca sur le
serveur principal Nagios.
|
send_nsca.cfg Fichier de configuration pour le
client send_nsca.
Cet ajout permet d'envoyer des résultats de
contrôles de services passifs à partir de machines distantes
à une machine centrale sur laquelle Nagios tourne. Le client peut
être utilisé comme un programme séparé, ou peut
être intégré dans des serveurs NAGIOS distants qui
exécutent la commande ocsp pour créer un environnement de
contrôles distribués. La communication entre le client et le
daemon peut être cryptée par différents algorithmes
(DES, 3DES, CAST, xTEA, Twofish, LOKI97, RJINDAEL, SERPENT, GOST,
SAFER/SAFER+, etc.) si les bibliothèques mcrypt
sont installées sur les systèmes.
6.10.3 Conclusion
Par facilité et compatibilité, j'ai utilisé
la première solution car :
|
SNMP est un protocole standard fonctionnant sous divers OS et
dont les échanges peuvent être sécurisés et
cryptés (via la version 3)
SNMP permet d'exécuter lui aussi des scripts ã
distance
NRPE et NSCA ne sont disponibles que sous les environnements UNIX
à première vue
NRPE et NSCA ne permettent pas le monitoring d'hôtes genre
imprimantes, router, etc. (SNMP le permet)
NRPE et NSCA nécessitent que les plugins soient
installés sur les machines en questions pour fonction ner.
Cela dit, l'utilisation de NRPE/NSCA pourra être
envisagée sur certaines machines dans des cas particulier.
|
6.11 Types de monitoring
Il existe deux types de monitoring, actif et passif.

6.11-1: Utiliser les vérifications actives et
passives
Monitoring d'une infrastructure Linux sur base d'outils
libres 6.11.1 Monitoring actif
Le monitoring est actif lorsqu'il est demandé par Nagios.
Nagios peut monitorer le server sur lequel il est ou des hôtes locaux ou
distants.
6.11.2 Monitoring passif
Le monitoring est passif lorsque le résultat est
envoyé vers Nagios ã l'initiative du client. On utilise
dès lors, soit le protocole SNMP Traps, soit le plugin
NSCA (uniquement machine de type Linux).
6.12 Détection et gestion des changements
d'états25
Nagios supporte la détection des hôtes et des
services qui "oscillent". L'oscillation intervient quand un service ou un
hôte change d'état trop fréquemment, provoquant une
avalanche de notifications de problèmes et de rétablissement.
L'oscillation peut être l'indice de problèmes de configuration ou
de vrais problèmes sur le réseau.
Exemple : des seuils positionnés
trop bas (ce qui a été souvent mon cas).
L'élaboration de cette technique a demandé,
ã l'auteur, beaucoup de temps et de recherches. Je vous invite ã
consulter la page suivante pour l'explication de la technique qu'il a dû
élaborer.
LIEN :
http://nagios.sourceforge.net/docs/2
0/flapping.html
6.13 L'escalade des notifications
Nagios supporte l'escalade des notifications envoyées aux
contacts pour des services ou des hôtes.
En résumé, on peut définir qu'au bout de 3
notifications, un premier groupe de contact sera prévenu. Ensuite au
bout de 5 notifications, un autre groupe sera prévenu et ainsi de
suite.
6.13.1 Recoupement des portées des
escalades
Les définitions d'escalade de notification peuvent avoir
des portées qui se recoupent. Par exemple,
définissons une escalade pour le service Status (En
attente, Mode veille, Impression en cours,
RemÐlacer cartouches, ...) de
l'imprimante26 printer1 :
define serviceescalation(
host_name printer1
service_description Status
first _notification 3
last _notification 5
notification_interval 20
contact_groups secretaire,users
I
define serviceescalation(
host_name printer1
service_description Status
first _notification 4
last _notification 0
notification_interval 120
contact_groups nagios-admin
I
Dans l'exemple ci-dessus :
25 En anglais, on utilise le terme : « flapping »
26 Le procédé pour monitorer les imprimantes
réseaux sera expliqué ultérieurement dans un chapitre
dédié.
|
Les deux premières notifications ne seront pas prises en
compte par l'escalade, le
groupe de contacts prévenu sera celui
spécifié dans la définition du service Les groupes de
contact secretaire et users reçoivent la
troisième notification Les trois groupes de contact reçoivent les
quatrième et cinquième notifications
Seul le groupe de contact nagios-admin reçoit les
notifications à partir de la sixième notification
|
6.13.2 Notifications de reprise
d'activité
Les notifications de reprise d'activité sont
légèrement différentes des notifications de
problème lorsqu'il s'agit d'escalade. Reprenons l'exemple d'avant...
Admettons qu'après trois notifications de
problème, une notification de reprise d'activité est
envoyée au service qui reçoit la notification. La reprise
d'activité est la quatrième notification envoyée.
Cependant, le code d'escalade est suffisamment bien fait pour que seules les
personnes qui ont reçu la troisième notification reçoivent
celle de reprise d'activité. Dans ce cas, seul les groupes de contact
secretaire et users recevront la notification de reprise
d'activité.
6.13.3 Intervalles de notification
Nous pouvons modifier la fréquence à laquelle les
notifications escaladées sont émises pour un hôte ou un
service particulier (avec notification_interval). Reprenons une
dernière fois l'exemple d'avant.
Admettons que l'intervalle de notification par défaut
du service Status de l'imprimante printer1 soit 60 minutes.
Quand la notification de ce service est escaladée lors des 3ème,
4ème, et 5ème notifications, un intervalle de 45 minutes sera
utilisé entre les notifications. Lors de la 6ème notification et
des suivantes, l'intervalle de notification sera de 120 minutes, comme il est
spécifié dans la seconde définition d'escalade.
6.14 Les dépendances
Les dépendances d'hôtes et de services sont une
fonctionnalité avancée qui permet de contrôler le
comportement des hôtes et des services selon l'état d'un ou
plusieurs autres hôtes ou services.
6.14.1 Aperçu des dépendances de
services
1. Un service peut être dépendant d'un ou plusieurs
autres services
2. Un service peut être dépendant de services qui
ne sont pas associés au même hôte
3. Les dépendances de service ne se sont pas
héritées (à moins que ce ne soit explicitement
spécifié)
4. Les dépendances de service permettent de supprimer
l'exécution de services et de notifications de service selon
différents critères (états OK, WARNING, UNKNOWN, et/ou
CRITICAL)
6.14.2 Comment les dépendances d'un service
sont-elles testées ?
Avant que Nagios n'exécute un contrôle de service
ou n'envoie des notifications concernant un service, il vérifiera si le
service comporte des dépendances. Si ce n'est pas le cas, le
contrôle est exécuté ou la notification est envoyée
comme en temps normal. Si le service a bien une ou plusieurs
dépendances, Nagios vérifiera chacune de la manière
suivante :
1. Nagios récupère l'état courant du
service dont il dépend.
2. Nagios compare l'état courant du service dont il
dépend aux options d'échec soit d'exécution soit de
notification dans la définition de dépendance (selon ce qui
est adapté).
3. Si l'état courant du service dont il dépend
correspond à une des options d'échec, la dépendance est
réputée avoir échoué et Nagios sortira de la boucle
de vérification des dépendances.
Monitoring d'une infrastructure Linux sur base d'outils
libres
4. Si l'état courant du service dont il dépend ne
correspond à aucune des options d'échec de la
dépendance, la dépendance est réputée
avoir réussi et Nagios continuera avec la prochaine
dépendance.
Ce cycle continue jusqu'à ce que toutes les
dépendances du service aient été vérifiées,
ou jusqu'à ce qu'une dépendance échoue.
6.14.3 Exemple de dépendance de service define
servicedependency {
host _name HOST A
service_description PING
dependent_host_name HOST A
dependent_service_description CPU Load,Process
List,Memory
notificationjailure_criteria w,u
executionjailure_criteria c,u
}
Dans cet exemple, admettons que le service PING de
l'hôte A est en état Warning ou Unknown. Les notifications pour
les services CPU Load, Process List et Memory sur l'hôte A seront
désactivées. Dans le cas où le PING de l'hôte A est
en Critical ou Unknown, l'exécution des services (CPU Load, ?) ne
s'effectuera pas.
6.14.4 Dépendances
d'exécution
Les dépendances d'exécution permettent de limiter
les vérifications de services actifs. Les vérifications de
services passifs ne sont pas affectées par les dépendances
d'exécution.
Si tous les tests de dépendance d'exécution du
service réussissent, Nagios exécute le contrôle du service
comme d'habitude. Si ne serait-ce qu'une dépendance d'exécution
du service échoue, Nagios arrêtera temporairement
l'exécution des contrôles pour ce service
(dépendant).
Par la suite, les tests des dépendances d'exécution
du service vont réussir. Alors, Nagios recommencera les contrôles
de ce service de manière normale.
Dans l'exemple ci-dessus, les dépendances
d'exécution des services CPU Load, Process List, Memory
échoueraient si le service PING est dans un état CRITICAL ou
UNKNOWN. Si c'était le cas, le contrôle de service ne serait pas
réalisé et serait prévu pour une future exécution
(potentielle).
6.14.5 Dépendances de
notification
Si tous les tests de dépendance de notification du
service réussissent, Nagios enverra les notifications pour ce service
comme à l'accoutumée. Si, ne serait-ce qu'une dépendance
de notification du service échoue, Nagios arrêtera temporairement
l'émission de notifications pour ce service (dépendant).
Plus tard, les tests des dépendances de notifications du service
vont réussir. Alors, Nagios recommencera à envoyer des
notifications pour ce service de manière normale.
Dans l'exemple ci-dessus, les dépendances de
notification des services CPU Load, Process List, Memory échoueraient si
le service PING est dans un état WARNING, UNKNOWN. Si
c'était le cas, les notifications pour ce service ne seraient pas
envoyées.
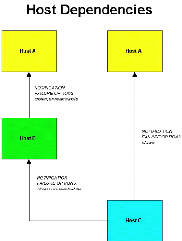
6.14-1 : Dépendances des hôtes
6.14.6 Dépendances d'hôtes
Les dépendances d'hôtes fonctionnent d'une
manière similaire à celles de services. La principale
différence est que ce sont des hôtes et pas des services. Une
autre différence est que la dépendance d'hôte ne sert
qu'à supprimer des notifications d'hôtes et non pas des
contrôles d'hôtes.
define hostdependency (
host _name HOST A
dependent_host_name HOST B
notificationjailure_criteria d,u
}
Les dépendances de notifications d'hôtes marchent
d'une manière similaire à celles des services. Si toutes les
notifications de
dépendance d'un hôte réussissent, Nagios
enverra les notifications comme à l'accoutumée. Si ne serait-ce
qu'une de ces dépendances échoue, Nagios supprimera
temporairement toutes les notifications
pour cet hôte (dépendant). Par la suite,
les dépendances réussiront à nouveau. Nagios recommencera
alors à envoyer les notifications de manière habituelle.
6.15 L'héritage
Il est possible de créer des relations d'héritage
entre hôtes. Notamment entre des routeurs, switchs,
firewalls. Dans ce cas, le simple ajout d'une ligne dans la
configuration de l'hôte :
define host(
...
parents asa5510
...
}
Si cet hôte est sur le même segment que l'hôte
de supervision (sans routeur intermédiaire, etc.), il est
considéré comme étant sur le réseau local et n'aura
pas d'hôte parent. Laissez cette valeur vide si
l'hôte n'a pas d'hôte parent (c.à.d. s'il est
sur le même segment que l'hôte de Nagios).
6.16 Les notifications par mail
Lors d'un évènement dans Nagios, il nous notifie
par mail. Pour ce faire, il est nécessaire de
configurer le serveur en conséquence. Dans le cas du
serveur de monitoring, on m'a demandé d'installer Postfix pour sa
simplicité de configuration et d'utilisation.
6.16.1 Son fichier de configuration
Voici les lignes à modifier dans le fichier
/etc/postfix/
main.cf
:
myhostname =
mxisrv4.manex.be
mydomain =
manex.be
myorigin = $mydomain
mydestination = $myhostname, localhost.$mydomain,
localhost relayhost = $mydomain
Monitoring d'une infrastructure Linux sur base d'outils
libres
6.16.2 Les mails de Nagios
Voici un exemple de mail lorsque Nagios n'arrive pas ã
accèder ã un site hébergé chez Manex (leur site
Web) :
To:
geoffrey.lemaire@manex.be
Subject: ** PROBLEM alert - mx1srv9 (Web)/
manex.be is CRITICAL **
Date: Thu, 17 May 2007 03:44:41 +0200 (CEST)
From:
nagios@manex.be (nagios)
***** Nagios 2.9 ***** Notification Type: PROBLEM
Service:
manex.be
Host: mx1srv9 (Web) Address: 217.117.50.179 State: CRITICAL
Date/Time: Thu May 17 03:44:41 CEST 2007
Additional Info:
CRITICAL - Socket timeout after 10 seconds
Ou lorsqu'un hôte est injoignable. Par exemple, une
imprimante :
To:
geoffrey.lemaire@manex.be
Subject: Host DOWN alert for mxiprn2!
Date: Fri, 18 May 2007 09:00:10 +0200 (CEST)
From:
nagios@manex.be (nagios)
***** Nagios 2.9 *****
Notification Type: PROBLEM
Host: mxiprn2
State: DOWN
Address: 192.168.0.22
Info: PING CRITICAL - Packet loss = 100%
Date/Time: Fri May 18 09:00:10 CEST 2007
Un problème de PING trop élevé pour
accèder ã un serveur distant?
To:
geoffrey.lemaire@manex.be
Subject: ** PROBLEM alert - mx2rtr1 (ViKe)/PING
is WARNING ** Date: Wed, 23 May 2007 18:37:27 +0200 (CEST)
From:
nagios@manex.be (nagios)
***** Nagios 2.9 ***** Notification Type: PROBLEM
Service: PING
Host: mx2rtr1 (ViKe)
Address:
mx2rtr1.manex.be State: WARNING
Date/Time: Wed May 23 18:37:27 CEST 2007 Additional Info:
PING WARNING - Packet loss = 0%, RTA = 474.21 ms Enfin, quand
l'état change et revient ã la normal :
To:
geoffrey.lemaire@manex.be
Subject: ** RECOVERY alert - mx2rtr1 (ViKe)/PING
is OK ** Date: Tue, 29 May 2007 21:29:20 +0200 (CEST)
From:
nagios@manex.be (nagios)
***** Nagios 2.9 ***** Notification Type: RECOVERY
Service: PING
Host: mx2rtr1 (ViKe)
Address:
mx2rtr1.manex.be State: OK
Date/Time: Tue May 29 21:29:20 CEST 2007 Additional Info:
PING OK - Packet loss = 0%, RTA = 50.31 ms

6.17 Utilisation du protocole
SNMPv327
Avec les plugins de Manubulon, il est possible de monitorer via
le protocole SNMPv3. Il peut se faire selon les deux modes : authNoPriv
et authPriv.
Pour authNoPriv, le login et le mot de passe de
connexion sera encrypté en MD5 ou en SHA-1 et pour authPriv,
les informations récupérées du protocole SNMPv3 sera
encryptée en DES ou AES.
6.18 Des tas d'autres possibilités !
Du fait que je devais tester plusieurs programmes de monitoring,
je n'ai pas eu le temps d'approfondir et tester certains plugins. Par exemple
:
Interception de Traps SNMP
Utilisation de NMAP pour check les intrusions
Monitoring du matériel (UPS28, switch,
température matériel et ambiante, ?) Notification par SMS
Utilisation d'Oreon (interface Web pour configurer les fichiers
de Nagios) ?
Il existe une grande communauté d'utilisateurs,
développeurs, etc. autour de Nagios. La confection de plugins ã
l'air simple vu les nombreux tutoriaux et la disponibilité de quasi tous
en open source.
|
6.19 Nagios Checker
Une extension Firefox pour afficher les alertes de Nagios.
Ce plugin s'installe dans la barre de statut de Nagios et
indique les évènements réseaux en provenance de Nagios.
Ces informations sont prises de l'interface Web de Nagios. Son installation est
très simple, il suffit juste de renseigner l'adresse du site où
on consulte le statut de Nagios, de cliquer sur un bouton qui permet de
localiser le fichier « status.cgi ».
|
|
|
6.19-1 : Ce qu'affiche le Ðlugin une fois
installé et configuré dans sa version anglaise.
|
Ce plugin fonctionne depuis les premières versions de
Nagios.
LIEN :
https://addons.mozilla.org/fr/firefox/addon/3607
J'ai soumis plusieurs « issues ? ã l'auteur de ce
plugin pour la correction de bugs sous le pseudo « geolem1903 ».

LIEN :
http://code.google.com/p/nagioschecker/issues/detail?id=17
27 Le chapitre suivant traitera du protocole SNMPv3 et de
l'interaction avec Nagios.
28 Un chapitre traitera de cette configuration.

6.19-2 : Je fais partie des contributeurs du
projet.
6.20 Conclusion
Nagios a besoin de plusieurs programmes, librairies tierces
qui elles aussi ont besoin d'autres librairies etc. mais une fois que l'on a
tout, c'est relativement simple ã installer et d'autant plus simple si
on installe via les dépôts (ce qui était mon
cas).
Au niveau de la configuration, on modifie directement les
fichiers de configurations et on recharge la configuration au niveau de daemon.
Pas très pratique car on doit à chaque fois revérifier la
configuration.
Cela dit, il est très modulaire et peut s'adapter ã
énormément de type de réseaux. Il est puissant,
léger et gratuit.
On pourrait aussi envisager le développement de plugin
pour les logiciels Ibats,
etc. et la vente de services de
monitoring.
Chapitre 7
Le protocole SNMP
7 Présentation du protocole SNMP
Le système de gestion de réseau est basé
sur trois éléments principaux: un superviseur, des noeuds (ou
nodes) et des agents. Dans la terminologie SNMP, le synonyme manager est plus
souvent employé que superviseur. Le superviseur est la console qui
permet à l'administrateur réseau d'exécuter des
requêtes de management. Les agents sont des entités qui se
trouvent au niveau de chaque interface, connectant l'équipement
managé (noeud) au réseau et permettant de
récupérer des informations sur différents objets.
Switchs, hubs, routeurs et serveurs sont des exemples
d'équipements contenant des objets manageables. Ces objets manageables
peuvent être des informations matérielles, des paramètres
de configuration, des statistiques de performance et autres objets qui sont
directement liés au comportement en cours de l'équipement en
question. Ces objets sont classés dans une sorte de base de
données appelée MIB (« Management Information Base
»). SNMP permet le dialogue entre le superviseur et les agents afin
de recueillir les objets souhaités dans la MIB.
L'architecture de gestion du réseau proposée par
le protocole SNMP est donc fondée sur trois principaux
éléments :


Les équipements managés (managed devices)
sont des éléments du réseau (ponts, hubs,
routeurs ou serveurs), contenant des « objets de gestion »
(managed objects) pouvant être des informations sur le
matériel, des éléments de configuration ou des
informations statistiques ;
Les agents, c'est-à-dire une application de gestion de
réseau résidant dans un périphérique et
chargé de transmettre les données locales de gestion du
périphérique au format SNMP ; Les systèmes de management
de réseau (network management systems notés NMS),
c'està-dire une console à travers laquelle les
administrateurs peuvent réaliser des tâches d'administration.
7.1 En pratique
Concrètement, dans le cadre d'un réseau, SNMP est
utilisé:
|
pour administrer les équipements
pour surveiller le comportement des équipements.
|
Une requête SNMP est un datagramme UDP habituellement
à destination du port 161. Les schémas de sécurité
dépendent des versions de SNMP (v1, v2 ou v3). Dans les
versions 1 et 2, une requête SNMP contient un nom appelé
communauté, utilisé comme un mot de passe. Il y a un nom de
communauté différent pour obtenir les droits en lecture et pour
obtenir les droits en écriture. Dans bien des cas, les colossales
lacunes de sécurité que comportent les versions 1 et 2 de SNMP
limitent l'utilisation de SNMP à la lecture des informations car la
communauté circule sans chiffrement avec ces deux protocoles. Un grand
nombre de logiciels libres et payants utilisent SNMP pour interroger
régulièrement les équipements et produire des graphes
rendant compte de l'évolution des réseaux ou des systèmes
informatiques (MRTG, Cacti, Nagios,...).
Monitoring d'une infrastructure Linux sur base d'outils
libres
Le protocole SNMP définit aussi un concept de Trap. Une
fois défini, si un certain évènement se produit, comme par
exemple le dépassement d'un seuil, l'agent envoie un paquet UDP à
un serveur. Ce processus d'alerte est utilisé dans les cas où il
est possible de définir simplement un seuil d'alerte. Dans nombre de
cas, hélas, un alerte réseau ne devrait être
déclenchée qu'en corrélant plusieurs
événements.
7.2 Les trames
La trame SNMPv1 est complètement encodée en ASN.1
[ISO 87]. Les requêtes et les réponses ont le même format
:

7.2-1 : Paquet SNMP


La version la plus utilisée est encore la version 1.
Plusieurs versions 2 ont été proposées par des documents
de travail, mais malheureusement, aucune d'entre elles n'a jamais
été adoptée comme standard. La version 3 est actuellement
en voie d'être adoptée. On place la valeur zéro dans le
champ version pour SNMPv1, et la valeur 3 pour SNMPv3.
La communauté permet de créer des domaines
d'administration. La communauté est décrite par une chaîne
de caractères. Par défaut, la communauté est « PUBLIC
».
Le PDU (Packet Data Unit)

7.2-2 : Le PDU
7.3 Sa 3ème version
Cette nouvelle version du protocole SNMP vise essentiellement
à inclure la sécurité des transactions. La
sécurité comprend l'identification des parties qui communiquent
et l'assurance que la conversation soit privée, même si elle passe
par un réseau public.
Cette sécurité est basée sur 2 concepts :
|
USM (User-based Security Model)
VACM (View- based Access Control Model)
|
7.3.1 USM - User-based Security Model
Trois mécanismes sont utilisés. Chacun de ces
mécanismes a pour but d'empêcher un type
d'attaque.
L'authentification : Empêche un intrus
vienne changer le paquet SNMPv3 en cours de route et de valider le mot de passe
de la personne qui transmet la requête.

7.3-1 : Schéma d'authentification du
SNMPv3
1. Le transmetteur groupe des informations à transmettre
avec le mot de passe.
2. On passe ensuite ce groupe dans la fonction de hachage
à une direction.
3. Les données et le code de hachage sont ensuite
transmis sur le réseau.
4. Le receveur prend le bloc des don nées, et y ajoute le
mot de passe.
5. On passe ce groupe dans la fonction de hachage à une
direction.
6. Si le code de hachage est identique à celui transmis,
le transmetteur est authentifié.
Monitoring d'une infrastructure Linux sur base d'outils
libres
Le cryptage : Empêche quiconque de lire
les informations de gestions contenues dans un paquet SNMPv3.
Avec SNMPv3, le cryptage de base se fait sur un mot de passe
« partagé » entre le manager et l'agent. Ce mot de passe ne
doit être connu par personne d'autre. Pour des raisons de
sécurité, SNMPv3 utilise deux mots de passe : un pour
l'authentification et un pour le cryptage. Ceci permet au système
d'authentification et au système de cryptage d'être
indépendants. Un de ces systèmes ne peut pas compromettre
l'autre.
SNMPv3 se base sur DES (Data Encryption Standard) pour
effectuer le cryptage.

7.3-2 : Schéma du cryptage des données
du SNMPv3
On utilise une clé de 64 bits (8 des 64 bits sont des
parités, la clé réelle est donc longue de 56 bits) et DES
encrypte 64 bits à la fois. Comme les informations que l'on doit
encrypter sont plus longues que 8 octets, on utilise du chaînage de blocs
DES de 64 bits.
Une combinaison du mot de passe, d'une chaîne
aléatoire et d'autres informations forme le « Vecteur
d'initialisation ». Chacun des blocs de 64 bits est passé par
DES et est chaîné avec le bloc précédent avec un
XOR. Le premier bloc est chaîné par un XOR au vecteur
d'initialisation. Le vecteur d'initialisation est transmis avec chaque paquet
dans les « Paramètres de sécurité », un
champ qui fait partie du paquet SNMPv3.
Contrairement à l'authentification qui est
appliquée à tout le paquet, le cryptage est seulement
appliqué sur le PDU.
L'estampillage du temps : Empêche la
réutilisation d'un paquet SNMPv3 valide déjà transmis par
quelqu'un.
Par exemple, si l'administrateur effectue l'opération
de remise à jours d'un équipement, quelqu'un peut saisir ce
paquet et tenter de le retransmettre à l'équipement à
chaque fois que cette personne désire faire une mise à jour
illicite de l'équipement. Même si la personne n'a pas
l'autorisation nécessaire, elle envoie un paquet, authentifié et
encrypté correctement pour l'administration de l'équipement.
On appelle ce type d'attaques le « Replay Attack
». Pour éviter ceci, le temps est estampillé sur chaque
paquet. Quand on reçoit un paquet SNMPv3, on compare le temps actuel
avec le temps dans le paquet. Si la différence est plus que
supérieur à 150 secondes, le paquet est ignoré.
SNMPv3 n'utilise pas l'heure normale. On utilise plutôt
une horloge différente dans chaque agent. Ceux-ci gardent en
mémoire le nombre de secondes écoulées depuis que l'agent
a été mis en circuit.
Monitoring d'une infrastructure Linux sur base
d'outils libres
Ils gardent également un compteur pour connaître
le nombre de fois où l'équipement a été mis en
fonctionnement. On appelle ces compteurs BOOTS (Nombre de fois ou
l'équipement a été allumé) et TIME (Nombre
de secondes depuis la dernière fois que l'équipement a
été mis en fonctionnement).
La combinaison du BOOTS et du TIME donne une valeur qui
augmente toujours, et qui peut être utilisée pour l'estampillage.
Comme chaque agent a sa propre valeur du BOOTS/TIME, la plate-forme de gestion
doit garder une horloge qui doit être synchronisée pour chaque
agent qu'elle contacte. Au moment du contact initial, la plateforme obtient la
valeur du BOOTS/TIME de l'agent et synchronise une horloge distincte.
7.3.2 VACM - View- based Access Control
Model
Permet le contrôle d'accès au MIB. Ainsi on a la
possibilité de restreindre l'accès en lecture et/ou
écriture pour un groupe ou par utilisateur.
7.4 La trame SNMPv3
Le format de la trame SNMPv3 est très différent
du format de SNMPv1. Ils sont toutefois codés tous deux dans le format
ASN.1 [ISO 87]. Ceci assure la compatibilité des types de données
entres les ordinateurs d'architectures différentes.
Pour rendre plus facile la distinction entre les versions, le
numéro de la version SNMP est placé tout au début du
paquet. La figure suivante montre la trame SNMPv3:

7.4-1 : Trame SNMPv3
Ce schéma montre clairement les différents
champs du paquet SNMPv3. Toutefois, le contenu de chaque champ varie selon la
situation. Selon que l'on envoie une requête, une réponse, ou un
message d'erreur, les informations placées dans le paquet respectent des
règles bien définies dans le standard.
Monitoring d'une infrastructure Linux sur base d'outils
libres 7.5 Son utilisation dans mon stage
Pour monitorer les différents équipements,
j'utilise donc le protocole SNMP. Pour ce faire, il faut installer sur les
machines Net-SNMP29. Net-SNMP est une collection d'applications
utilisées pour implémenter SNMP v1, SNMP v2c, SNMP v3 en
utilisant à la fois IPv4 et IPv6.
J'ai rapatrié les packages Net-SNMP suivant via les
dépôts de Red Hat :


Net-snmp
o Snmpd (daemon) : agent qui répondra aux
requêtes SNMP
o Snmptrapd (daemon) : application qui recevra les
notifications SNMP Net-snmp-utils : contient les divers outils (snmpwalk,
snmpget, ?)
Une fois les packages installés, il suffit de lancer le
daemon snmpd et on peut déjà interroger l'agent avec des petits
utilitaires du genre de Getif30.
7.6 Sa configuration
7.6.1 Création d'un utilisateur v3
Pour créer un utilisateur v3 (snmpd doit être
arrêté). Il suffit d'ajouter les lignes suivantes au tout
début du fichier /etc/snmp/snmpd.conf
createUser MonUtilisateur MD5 "MonMot2passe" DES
MonMot2PasseDES rouser MonUtilisateur
|
MonUtilisateur : nom d'utilisateur
MonMot2passe : authentication protocol pass phrase (qui se
transformera en MD5)
MonMot2PasseDES : privacy protocol pass phrase (qui
servira pour le cryptage des don nées en DES)
|
7.6.2 Le fichier snmpd.conf Ensuite, modifier le
fichier comme suit :
####
# First, map the community name "public" into a "security
name"
# sec.name source community
com2sec Local monserveur.domain.tld
ma_communaute_ro
####
# Second, map the security name into a group name:
# groupName securityModel securityName
group LocalGroup usm Local
####
# Third, create a view for us to let the group have rights
to:
# Make at least snmpwalk -v 1 localhost -c public system fast
again.
# name incl/excl subtree mask(optional)
view allview included .1.3.6
view systemview included
.1.3.6.1.2.1.1
view systemview included
.1.3.6.1.2.1.25.1.1
29 Net-SNMP :
http://www.net-snmp.org
30 Getif :
http://www.wtcs.org/snmp4tpc/getif.htm
####
# Finally, grant the group read-only access to the systemview
view.
# group context sec.model sec.level prefix read write
notif
access LocalGroup "" usm authPriv exact allview none
none
|
chercher les mots : syslocation et
syscontact et les modifier en conséquence :
syslocation Rack 6, Armoire 9, Societe, Ville, Province,
Pays
syscontact Departement Informatique
<adresse-mail@domain.tld> lancer le service snmpd (
# /etc/init.d/snmpd start )
rééditer le fichier précédent et
supprimer la ligne « create user? »
|
7.6.3 Le test
Pour tester, nous pouvons lancer cette commande :
# snmp get -v 3 -u MonUtilisateur -l authPriv -a MD5
-A MonMot2passe -X MonMot2PasseDES localhost sysUpTime.0
Si on a l'heure (SNMPv2-MIB::sysUpTime.0 = Timeticks:
(42388) 0:07:03.88 ) c'est bon, continuons avec ceci :
# snmpwalk -v 1 -c manex_ro
localhost
Si Timeout: No Response from localhost
apparait, tant mieux :o) Plus de SNMPv1.
7.7 Analyse avec WireShark
WireShark va nous permettre d'analyser les paquets et de voir que
les informations demandées passent réellement en clair sur le
réseau lorsqu'on utilise les versions 1 et 2c du protocole SNMP et
qu'elles sont cryptées avec la version 3 de SNMP.
7.7.1 Tests avec SNMPv2c
Voici une capture ã l'aide du logiciel Wireshark. Comme on
peut le remarquer, la communauté passe
en clair vers l'agent que l'on souhaite interroger. Voici le
get-request :
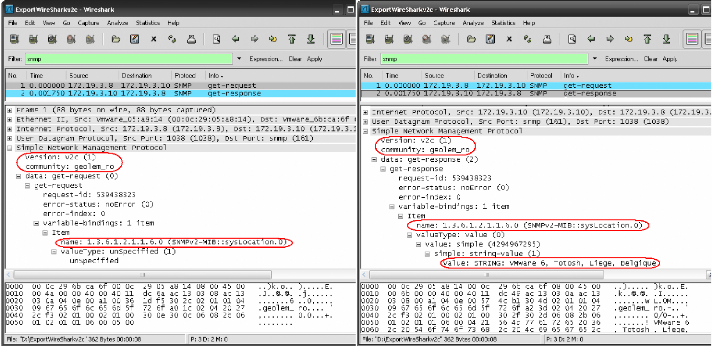
7.7-1 : get-request, SNMPv2c 7.7-2 : get-response ;
SNMPv2c
Sur l'image de gauche, nous voyons donc la version
utilisée (SNMPv2c), le nom de ma communauté
(geolem_ro) et l'OID avec sa traduction des informations
demandées.
Ensuite sur l'image de droite, la réponse de l'agent.
Encore une fois la communauté est en clair, mais aussi ses informations.
Sinon, dans ce cas-ci, j'avais demandé la localisation du serveur. Des
informations tels que les services fonctionnant sur la machine peuvent
être consulté avec parfois la version de ceuxci. Il ne reste plus
qu'ã effectuer une petite recherche sur Internet pour trouver les
failles de ce dernier.Voyons ce que cela donne avec le SNMPv3?

7.7.2 Test avec le SNMPv3
7.7-3 : get-request ; SNMPv3 7.7-4 : report ;
SNMPv3
Ici, nous utilisons le SNMPv3. La procédure pour
obtenir des informations est un peu différente. Pour obtenir le
« syslocation » du test précédent,
nous devons passer par 4 paquets au lieu de 2. Il s'agit en fait de la
procédure d'authentification qui permettra d'obtenir le «
msgAuthoritativeEngineID » qui, comme on le verra, reste le
même tout le long des paquets.
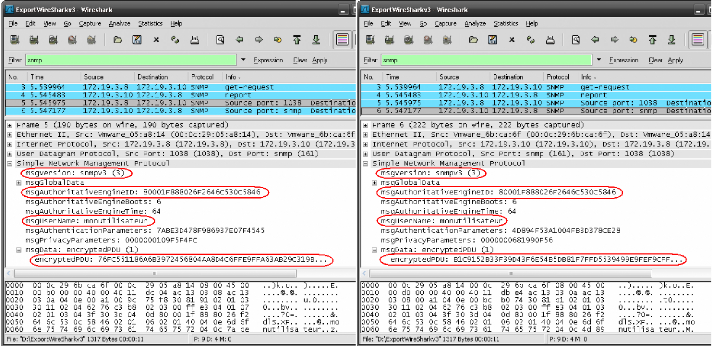
7.7-5 : Demande des informations cryptées 7.7-6 :
La réponse cryptée
A gauche, nous avons la demande, à droite la
réponse. Le « msgAuthoritativeEngineID » est
resté comme prévu le même. On peut apercevoir que le «
UserName » passe en clair. Enfin, on peut voir les informations
encryptées.
Chapitre 8
Le monitoring des UPS
8 UPS
Les UPS sont un des éléments importants dans une
infrastructure de serveurs. Lors d'une coupure de courant, ils prennent
instantanément le relais le temps que le courant revienne ou au pire des
cas peuvent arrêter les serveurs de manière « propre ».
Il est important dès lors, de vérifier leur état de
fonction nement.
8.1 Le matériel
Chez Manex, les serveurs sont protégés par deux UPS
de marque MGE UPS SYSTEMS et le modèle
Pulsar Evolution.

LIEN :
http://www.mgeups.com/products/pdt230/smallups/evol/index.htm
8.2 La connectique
Les UPS peuvent être reliés par câble
séries ou USB. Dans mon cas, mon serveur dispose d'une prise USB et d'un
connecteur série ã l'arrière. Suite ã quelques
problèmes avec le câble série, j'ai relié le premier
UPS en USB.
8.3 Les logiciels
Pour monitorer les UPS deux logiciels sont nécessaires
:
8.3.1 UPSmon
Upsmon est un processus client qui a la responsabilité de
la partie la plus importante du monitoring - couper correctement le
système quand le courant est épuisé. Il peut faire appel
ã d'autres
programmes dans le but de notifier des évènements
de l'alimentation.
8.3.2 Drivers Nut31
Le driver libre NUT (Network UPS Tools) est un logiciel
libre largement soutenu par le fabricant MGE
qui y contribue beaucoup, dont les 2 atouts principaux sont :
|
Universalité : fonctionne avec la plupart des UPS du
marché32, quelque soit leur connectique (liaison
série, USB, ...)
Client/serveur : un serveur tourne sur la machine ã
laquelle est branchée l'UPS, ce qui permet ã tout le
réseau de connaître ã tout moment l'état du
système, et éventuellement d'envisager les actions
nécessaires le cas échéant (batterie faible ?
extinction propre).
|
LIEN :
http://www.networkupstools.org
31 Un tutorial pour son installation peut être
consulté ici :
http://linux.developpez.com/cours/upsusb/
32 Un liste peut être consultée ici :
http://eu1.networkupstools.org/compat/stable.html
8.4 Nagios dans tout cela
Le monitoring de l'UPS est très simple ã mettre en
oeuvre avec Nagios.
8.4.1 Présentation du plugin
Il existe un plugin officiel du coté de Nagios qui permet
de monitorer les UPS ã l'aide de Nut. Ce plugin essaye de
déterminer le statut de l'UPS sur une machine locale ou distante. Si
l'UPS est en
ligne ou en calibrage, le plugin retournera un état OK.
Si la batterie est en fonctionnement, il retournera un état Warning.
Si l'UPS est coupé ou a une batterie faible, le plugin retournera
un état Critical.
La définition du service approprié est aussi simple
que pour le reste. Cependant, il faut bien entendu définir la
commande.
8.4.2 Définition de la commande
Voici la définition de la commande :
define command(
command_name check_ups
command_line $USER1$/check_ups -H $HOSTADDRESS$ -u
$ARG1$
I
Le plugin prend comme argument l'adresse de l'hôte et le
nom de l'UPS. Voyons ensuite la définition du service.
8.4.3 Définition du service
Rien de bien compliqué :
define service(
use local-service
host _name HOST A
service_description UPS
check_command check_ups!myups
I
Un service local, sur le serveur HOST A. Une courte description
du service et enfin la ligne de
commande.
8.4.4 Le résultat

Capture d'écran deÐuis l'interface Web de
Nagios
Nous pouvons constater que le plugin monitore la charge utile, le
pourcentage de charge et l'utilisation de celle-ci.
Chapitre 9
Le monitoring des imprimantes réseaux
9 Les imprimantes
A priori, monitorer des imprimantes est peu utile car dans
beaucoup de cas, l'utilisation d'une imprimante, même via réseau,
nécessite l'installation d'un driver même si celui-ci est
générique. Lorsque l'on imprime, on reçoit une alerte de
la part de l'imprimante comme quoi les cartouches d'encres sont bientôt
vides. Cela dit, la maintenance des imprimantes est souvent confiée
ã d'autres personnes que l'utilisateur lui-même. Par exemple
à la secrétaire ou à un chef de département. Pour
connaître l'état de l'imprimante, plusieurs solutions s'offrent
ã nous :
|
Se déplacer devant l'imprimante et voir le statut de
celle-ci.
Les imprimantes réseaux sont généralement
fournies avec une interface Web où on peut obtenir divers renseignements
et les paramétrer en conséquence.
|
Seulement, quand on possède plusieurs imprimantes, cela
devient dur ã gérer d'oz l'intérêt de centraliser
tout çà.
9.1 Activer le protocole SNMP
A l'aide du protocole SNMP, on va pouvoir monitorer son statut
et le niveau des cartouches d'encre ou toners. D'autres choses peuvent bien
entendu être monitoré. Il est donc nécessaire d'activer ce
protocole sur les imprimantes et ce via l'interface Web de l'imprimante. Dans
notre cas, cela se fera via le protocole SNMP v1/v2? Il n'y a que peu
d'intérêt de faire cela via SNMPv3. A noter que j'utilise
seulement l'accès « read-only ». Pour obtenir des
informations, c'est suffisant.

9.2 Un SNMPwalk de l'imprimante
Utilisons la commande snmpwalk :
# snmpwalk -v 2c -c public
mxiprn2.manex.be
Lorsqu'on analyse le résultat, on peut trouver ceci :
SNMPv2-SMI::mib-2.43.11.1.1.6.1.1 = STRING: "black
ink" SNMPv2-SMI::mib-2.43.11.1.1.6.1.2 = STRING: "cyan ink"
SNMPv2-SMI::mib-2.43.11.1.1.6.1.3 = STRING: "magenta ink"
SNMPv2-SMI::mib-2.43.11.1.1.6.1.4 = STRING: "yellow ink"
Nous avons trouvez les couleurs, maintenant trouvons le
pourcentage d'utilisation des cartouches... continuons donc plus loin dans le
résultat du snmpwalk. On peut trouver ceci :
SNMPv2-SMI::mib-2.43.11.1.1.9.1.1 = INTEGER: 82
SNMPv2-SMI::mib-2.43.11.1.1.9.1.2 = INTEGER: 9
SNMPv2-SMI::mib-2.43.11.1.1.9.1.3 = INTEGER: 9
SNMPv2-SMI::mib-2.43.11.1.1.9.1.4 = INTEGER: 9

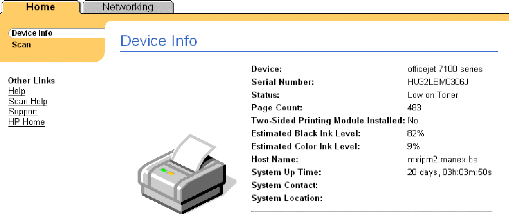

Si on regarde de plus près le statut des encres via
l'interface Web...
On remarque que les valeurs trouvées via SNMP
correspondent aux valeurs reprises dans l'interface. Cela dit, j'émets
une réserve quant ã la véracité de ces valeurs car
c'est bien connu, les couleurs Magenta, Cyan et Jaune ne s'usent pas en
même temps. Enfin, quoi qu'il arrive, il s'agit d'une estimation ayant
pour but de nous prévenir d'imprimer un trop gros document s'il n'y
avait plus d'encre. Voyons comment incorporer ces résultats dans
Nagios.
9.3 Intégration dans Nagios
Encore une fois, rien de bien compliqué.
9.3.1 Le contrôle du niveau d'encre
Pour contrôler le niveau d'encre dans Nagios, il faut tout
d'abord définir une commande :
define command(
command_name check_snmp_color
command_line $USER1$/check_snmp -H $HOSTADDRESS$ -o
$ARG1$ -w '$ARG2$' -
c '$ARG3$' $USER3$ -l '$ARG4$' -u
'$ARG5$'
I
Nous passons donc par le plugin check_snmp. En argument,
on passe l'adresse de l'imprimante, l'OID que nous avons trouvé
précédemment, les valeurs Warning et Critical,
la communauté. Dans ce cas-
ci, j'utilise une macro $USER3$ défini dans
resource.cfg où il est simplement indique
« public » et la version du protocole SNMP ainsi que d'autres
paramètres propres aux plugins check_snmp.
Les services quant à eux (par exemple pour la couleur
noir) :
define service(
use printers-remote
host_name mxiprn2
service_description Black Color
check_command
check_snmp_color!.1.3.6.1.2.1.43.11.1.1.9.1.1!0:96!0:99!Status!percent
I
9.3.2 Le contrôle du statut
Il existe parmi les plugins officiels de Nagios, un plugin qui
vérifie par lui-même le statut des
imprimantes connectées via le HP JetDirect card. Sa
commande :
define command(
command_name check_hpjd
command_line $USER1$/check_hpjd -H $HOSTADDRESS$ -C
public
I
Son service :
define service(
use printers-remote
host_name mxiprn2
service_description Status
check_command check_hpjd
I
Chapitre 10
Utilisation d'un script à distance via SNMP
10 Utilisation de SNMP pour lancer un script à
distance
Le protocole SNMP permet d'obtenir un nombre incroyable
d'informations sur l'hôte distant.
Malheureusement, on ne peut pas obtenir toutes les informations
que l'on souhaite... Cela peut s'arranger en ajoutant des informations
simplement dans la MIB.
10.1 Des plugins supplémentaires
Dans notre cas, j'utilise deux PlugIns. Il est nécessaire
de les placer soi-même sur les hôtes distants.
Le premier Plugin est check_connections.pl. Il
fait partie des PlugIns officiels de Nagios. Il permet d'obtenir le nombre de
connections TCP ouverts pour un processus et/ou un utilisateur.
Le deuxième Plugin est check_diskio. Il
est téléchargeable ici :
LIEN :
http://www.id.ethz.ch/people/allid
list/corti/gnu software
Il permet de connaître le nombre de secteurs lus par
seconde.
Les PlugIns peuvent être placés où on le
souhaite sur l'hôte. Dans notre cas, je les ai placé dans
/usr/lib(64)/nagios/plugins.
10.2 La configuration de l'agent SNMP
On peut placer les lignes suivantes où on le souhaite.
Mais par rapport aux commentaires déjà présents dans le
fichier, j'ai préféré mettre les lignes qui suivent
après les commentaires sur :
# Executables/scripts
exec 1.3.6.1.4.1.17259.100 ldaptcpconn-check
/usr/lib64/nagios/plugins/check_connections.pl -C ns-slapd -w 500 -c
800
exec 1.3.6.1.4.1.17259.101 DiskIOsda
/usr/lib64/nagios/plugins/check_diskio -w 100 -c 200 -d sda
10.3 Définition de la commande et des services sur
le serveur
Bien entendu, il faut définir la commande et le service
respectif aux lignes précédentes.
define command(
command_name check_snmp
command_line $USER1$/check_snmp -H $HOSTADDRESS$ -o
$ARG1$ -r "OK" $USER4$ }
define service(
use ldap-service
host _name mxisrv1
service_description LDAP Connections
check_command check_snmp!1.3.6.1 .4.1 .1 7259.100.1
01 .1 }
define service{
use host-service
host _name
mx1srv1,mx1srv2,mx1srv3,mx1srv7,mx1srv9,mxisrv1,mxisrv2 service_description
DiskIOsda
check_command check_snmp!1.3.6.1 .4.1 .1 7259.101.1
01 .1
I
10.4 Le pourquoi et le comment ?
Certaines informations que l'on souhaite obtenir de la machine
nécessitent donc le lancement d'un Plugin à distance. Seulement,
il serait absurde que le Plugin tourne 24h/7j.
Le protocole SNMP permet d'exécuter à distance des
scripts notamment. Ce qui est notre cas avec les deux PlugIns plus haut.
Lorsque Nagios fera une requête SNMP sur l'OID
1.3.6.1.4.1.17259.100.101.1 sur mxisrv1 (par exemple),
le daemon snmpd va interpréter ce message, va se renseigner dans sa
MIB pour obtenir les informations demandées. Pour les obtenir, il va
exécuter le Plugin adéquat. Ce Plugin va renvoyer des
informations que le daemon va capturer et renvoyer au serveur de
monitoring qui lui les analysera et réagira en fonction.
Chapitre 11
Les traps
11 Utilisation des traps avec nagios
Le protocole SNMP définit aussi un concept de trap.
Une fois défini, si un certain évènement se produit,
comme par exemple le dépassement d'un seuil, l'agent envoit un paquet
UDP (port 162) à un serveur. Ce processus d'alerte est
utilisé dans les cas où il est possible de définir
simplement un seuil d'alerte. Dans nombres de cas, hélas, un alerte
réseau ne devrait être déclenchée qu'en unissant
plusieurs événements.
11.1 Configurations
Une petite configuration est nécessaire coté
serveur et coté client pour que les traps puissent fonctionner.
Commençons par le client.
11.1.1 Coté client (l'agent)
Tout d'abord, il faut éditer le fichier
/etc/snmp/snmpd.conf et ajouter les lignes suivantes à
la fin du fichier. Pour nos tests, nous utiliserons la communauté «
public ».
# Définit la communauté par défaut
à utiliser quand des traps seront envoyées. trapcommunity
public
# Envois des traps de version 1 - HOTE où se trouve le
daemon snmptrad [Community [Port]] trapsink 192.1 68.88.129 public
162
# Envois des traps de version 2
trap2sink 192.1 68.88.129 public 162
#Utilisé lors d'envois d'inform ã la place des
traps
informsink 192.1 68.88.129 public
162
# Envois de traps lors d'authentification
ratée
authtrapenable 1
# Permet d'envoyer des traps lors du changement d'état
(Down/Up) des interfaces réseaux
linkUpDownNotifications yes
# Envois des traps pour une liste de problèmes
généraux defaultMonitors yes
11.1.2 Coté serveur
Premièrement, il faut créer (ou éditer)
le fichier /etc/snmp/snmptrapd.conf et ajouter les
lignes
suivantes à la fin du fichier.
# On traite de la même façon toutes les
interruptions : avec SNMPTT
traphandle default /usr/sbin/snmptt
# On accepte toutes les interruptions
disableAuthorization yes
#on ne journalise pas les interruptions reçues (c'est
SNMPTT qui s 'en chargera). On aura quand même une trace de snmptrapd
dans syslog, grâce à l'option -Lsd du lanceur (voir ci-dessous).
donotlogtraps yes
Pour la petite histoire, snmptrad passe à SNMPTT les
éléments de l'interruption qu'il a reçus via les
paramètres de la ligne de commande.
Le lanceur du service snmptrapd doit être modifié
pour ne pas traduire les OID, mais les laisser sous forme numérique.
C'est SNMPTT qui fera la traduction. Il faut modifier
/etc/init.d/snmptrapd :
OPTIONS="-On -Lsd -p /var/run/snmptrapd.pid"
# Il faut rajouter le -On
Après modification, il suffit de redémarrer le
daemon snmptrapd.
11.2 Nagios doit comprendre, SNMPTT l'aide.
SNMPTT (SNMP Trap Translator v1.2beta2) est un handler de trap
écrit en Perl pour être utilisé avec
le programme snmptrapd de Net-SNMP.
Site Web du logiciel :
http://www.snmptt.org
11.2.1 Fonctionnement général
1. Un hôte sur le réseau (ou plutôt une
application de cet hôte) envoit une interruption SNMP
au serveur qui héberge Nagios. Celui-ci la reçoit
via le service snmptrapd (qui est en écoute sur le
port UDP 162).
2. Snmptrapd la passe ensuite à SNMPTT,
dont le rôle est de rendre intelligible l'interruption.
Pour cela, il se base sur la MIB de l'aÐÐlication
émettrice, que l'on aura bien sûr
récuÐérée et transformée au préalable
pour en nourrir SNMPTT.
3. SNMPTT envoit enfin l'interruption interprétée
à Nagios, via le fichier de commandes
externes de celui-ci. Il utilise pour cela la commande Nagios
submit_check_result.
Dans ma configuration de Nagios, il n'y a qu'un service par
hôte qui reçoit les traps SNMP. Cela signifie que si plusieurs
traps sont reçus en provenance d'un même hôte, seul le
dernier sera affiché.
Par contre, chaque trap reçu générera bien
une notification.
Pour acquitter une interruption dans Nagios, il faut soit forcer
un check immédiat du service (qui fera
un ping et remettra l'état à OK), soit soumettre
manuellement un check passif, avec l'intitulé "Init", ou "RAZ", par exem
ple.
11.2.2 Configuration
Nous allons faire fonctionner SNMPTT en mode "stand-alone" ; il
sera appelé chaque fois que nécessaire par le gestionnaire
d'interruptions snmptrapd. L'initialisation est plus longue dans ce cas,
mais le paramétrage plus simple.
Le fichier de configuration /etc/snmp/snmptt.ini
doit contenir : [General]
mode = standalone
multiple_event = 1
dns_enable = 1
strip_domain = 1
strip_domain_list = <<END
mon.domaine
END
Monitoring d'une infrastructure Linux sur base d'outils
libres
resolve_value_ip_addresses = 0
net_snmp_perl_enable = 1
net_snmp_perl_best_guess = 0 translate_log_trap_oid = 0
translate_value_oids = 1
translate_enterprise_oid_format = 1 translate_trap_oid_format = 1
translate_varname_oid_format = 1 translate_integers = 1
wildca rd_expansion_separator = " " allow_unsafe_regex = 0
remove_backslash_from_quotes = 0 dynamic_nodes = 0
description_mode = 0
description_clean = 1
[Logging]
stdout_enable = 0
log_enable = 1
log_file = /var/log/snmptt.log
unknown_trap_log_enable = 1
unknown_trap_log_file = /var/log/snmpttunknown.log
statistics_interval = 0
syslog_enable = 1
syslog_facility = local0
syslog_level_debug = <<END
END
syslog_level_info = <<END
END
syslog_level_notice = <<END
END
syslog_level_warning = <<END
END
syslog_level_err = <<END
END
syslog_level_crit = <<END END
syslog_level_alert = <<END END
syslog_level = info
syslog_system_enable = 1 syslog_system_facility = local0
syslog_system_level = warning
[Exec]
exec_enable = 1
pre_exec_enable = 0 unknown_trap_exec =
[Debugging]
DEBUGGING = 0
DEBUGGING_FILE =
DEBUGGING_FILE_HANDLER =
[TrapFiles]
snmptt_conf_files = <<END /etc/snmp/snmptt.conf END
11.3 A noter :

le nom de domaine à supprimer pour ne garder que le nom
d'hôte, qui dÐvra êtrÐ adaÐté ã
l'ÐnvironnÐmÐnt oz on travaillÐ,
et le fait que le module Perl net-snmp est activé. Il
permet l'interprétation étendue des OID.
11.4 Compilation des mibs
Il faut maintenant récupérer le ou les fichiers
MIB des équipements à superviser, pour les convertir au format
SNMPTT. Le but est d'extraire ce qui dans le fichier MIB est un commentaire,
pour que SNMPTT le mette en correspondance avec l'OID qui sera reçu.
snmpttconvertmib --in=<fichier MIB>
--out=/etc/snmp/snmptt.conf.<equipement> \
--exec='/usr/local/nagios/libexec/eventhandlers/submit_check_result $r TRAP
1'
Dans le cas où on aurait trop de MIB, on peut
exécuter le petit script suivant en tenant compte que toutes les mibs se
trouvent dans /usr/share/snmp/mibs/ :
for i in /usr/share/snmp/mibs/ *.txt
> do
> /usr/sbin/snmpttconvertmib --in=$i
--out=/etc/snmp/snmptt.conf \
--exec='/usr/lib/nagios/plugins/eventhandlers/submit_check_result $r TRAP
1
> done
Ce qui va donc permettre de prendre en compte toutes les mibs
dans le répertoire précédemment
cité et les ajouter dans le fichier snmptt.conf.
On aura quelques lignes dans le genre :
EVENT coldStart .1.3.6.1.6.3.1.1.5.1 "Status Events"
Normal
FORMAT A coldStart trap signifies that the SNMP
entity, $*
EXEC
/usr/lib/nagios/plugins/eventhandlers/submit_check_result $r TRAP 1 "A
coldStart trap signifies that the SNMP entity, $*"
SDESC
A coldStart trap signifies that the SNMP
entity,
supporting a notification originator application,
is
reinitializing itself and that its configuration
may
have been altered.
Variables:
EDESC
11.5 Dans Nagios
Le principe est d'utiliser, pour recevoir les interruptions SNMP,
des services passifs mais aussi volatiles, car si nous recevons une
deuxième interruption pour le même hôte avant que la
première
ait été remise à OK, nous voulons être
notifié à nouveau.
Pour cela, il faut (par exemple) définir un
service générique pour les traps SNMP, dérivé de
mon service générique général :
define service{
name snmptrap-service
use generic-service
register 0
service_description TRAP
is_volatile 1
check_command check-host-alive
max_check_attempts 1
normal_check_interval 1
retry_check_interval 1
passive_checks_enabled 1
check_period none
notification_interval 31536000
contact_groups admins
}
Monitoring d'une infrastructure Linux sur base d'outils
libres Et le dériver pour chaque machine supervisée, par
exemple :
define service{
host _name Ubuntu
use snmptrap-service
contact_ groups admins
}
Tout d'abord, il y a la commande check-host-alive
(un simple ping) qui permet de remettre à OK
l'état du service en forçant un contrôle actif. D'autre
part, l'intervalle de notification est
artificiellement long : un an ici. Il permet d'éviter
de recevoir régulièrement des notifications pour la même
interruption (tant que le service n'est pas ramené à
l'état OK), laissant penser qu'une nouvelle interruption, identique
à la précédente, a été reçue. Le
problème est qu'il faut redémarrer Nagios au
moins une fois par an.
11.6 Quelques tests
Coté client (agent), il suffit de
redémarrer simplement le daemon SNMPD pour qu'un évènement
se produise dans les logs du serveur (manager) :
# tail -f /var/lo g/snmptt.log
Tue May 29 14:20:38 2007 .1.3.6.1.4.1.8072.4.0.2
Normal "Status Events" 192.1 68.88.1 28 - An indication that the agent is in
the process of being shut down.
Tue May 29 14:20:40 2007 .1.3.6.1.6.3.1.1.5.1 Normal
"Status Events" 192.1 68.88.128 - A coldStart trap signifies that the SNMP
entity,
Allons voir sur Nagios :

Le trap est répertorié 3 secondes après dans
Nagios. Le trap décrit un peu plus haut.
Conclusion
Professionnelle :
Ce stage m'a permis de me familiariser avec le système
d'exploitation linux dont la maîtrise est nécessaire pour
travailler dans les réseaux informatiques.
La mise en place du service de surveillance Nagios permet
actuellement ã l'administrateur, ã l'ensemble du service
informatique, ainsi qu'aux dirigeants d'être informé de la
santé du réseau en temps réel. Depuis la mise en place de
Nagios, certains problèmes réseau ont été
traités plus ra pidement.
Personnelle :
Ces quatre mois au sein de Manex m'ont permis
d'acquérir une bonne expérience professionnelle. Les
dernières semaines chez Manex ont été des semaines de
défi. En fait, lorsque Manex avait besoin de monitorer quelque chose en
particulier, on me mettait un peu « au défi » de trouver une
solution à leur besoin. Par exemple :


vérifier le nombre d'IO sur les disques durs ã
l'aide de Nagios (réussi) ;
vérifier si ClamAV (un antivirus pour Linux)
était à jour (réussi) ;
vérifier si SpamAssassin fonctionnait (réussi)
;
vérifier si Amavis (lien entre ClamAV et un serveur de
mail) fonctionnait (réussi). La
vérification s'effectuait ã l'aide du virus EICAR
;
vérifier l'état du RAID ã l'aide d'SNMP
sur certains serveurs (raté) - pour monitorer cela, il
était nécessaire d'installer un logiciel de management
propriétaire ã IBM utilisant Java. Après plusieurs essais
avec un employé de Manex, nous ne sommes pas arrivés à le
faire fonctionner ;
vérifier l'état des UPS (réussi
avec l'aide d'un employé de Manex) ;
vérifier l'état des imprimantes (réussi)
;
vérifier l'état des sauvegardes ã l'aide du
client Bacula33 (presque réussi) - du
côté du serveur de Monitoring, tout est en ordre. Manque de temps
pour l'implémenter correctement.
De plus, la mise en place du système de surveillance du
réseau m'a permis de découvrir comment se déroulait la
gestion d'un travail d'équipe au sein d'un service informatique, car
étant donné la complexité du projet, il a
été nécessaire d'effectuer ce travail en équipe
afin de pouvoir connaître tout le réseau et de respecter les
objectifs et le délai.
Ce projet professionnel m'a donc apporté une grande et
enrichissante expérience puisqu'il s'agissait d'un projet important pour
Manex.
33 Le couplage Nagios/Bacula est relativement simple, pour plus
d'infos :
http://www.devco.net/pubwiki/Bacula/MonitoringWithNagios
Bibliographie
Nagios :



http://www.nagios.org
http://nagios.sourceforge.net/docs/2_0
http://forums.bfl-solutions.eu
Oreon :
http://oreon-project.org
http://forum.oreon-project.org
Cacti :
http://cacti.net OpManager :

http://manageengine.adventnet.com/products/opmanager
http://www.manageengine.fr/opmanager
SNMP / Traps :

http://fr.wikipedia.org/wiki/Simple_Network_Management_Protocol
http://christian.caleca.free.fr/snmp
http://www.frameip.com/snmp
http://www.supinfo-projects.com
http://linuxtips.castres-wireless.org/article.php3?id_article=16
http://xavier.dusart.free.fr
http://www.net-snmp.org/wiki/index.php/TUT:snmptrap
RRDtool / MRTG:
Nessus :




http://www.nessus.org
Snort :
http://www.snort.org
http://www-igm.univ-mlv.fr/~dr/XPOSE2001/liyun/IDS.html
MBSA :
http://www.microsoft.com/technet/security/tools/mbsahome.mspx
UPS :

http://linux.developpez.com/cours/upsusb/
Lexique
.htaccess : Les fichiers .htaccess
sont des fichiers de configuration des serveurs web Apache. Ils peuvent
être placés dans n'importe quel répertoire du site web (la
configuration s'applique au répertoire et à tous les
répertoires qu'il contient) et peuvent être modifiés alors
que le serveur est en cours d'exécution.
On peut les utiliser pour modifier les droits d'accès,
créer des redirections, écrire des messages d'erreurs
personnalisés, associer les extensions de fichier à des types
MIME, etc.
LIEN :
http://httpd.apache.org/docs/2.0/howto/htaccess.html

DMZ : Une zone
démilitarisée est un sous-réseau (DMZ) isolé par
deux pare-feux (firewall). Ce sousréseau contient des machines se
situant entre un réseau interne (LAN - postes clients) et un
réseau externe (typiquement, Internet).
La DMZ permet à ces machines d'accéder à
Internet et/ou de publier des services sur Internet sous le contrôle du
pare-feu externe. En cas de compromission d'une machine de la DMZ,
l'accès vers le réseau local est encore contrôlé par
le pare-feu interne.
Le DMZ est aussi (sur certain routeurs) le fait de rediriger
tout les ports vers un pc précis sur un réseau local.

LIEN :
http://fr.wikipedia.org/wiki/Sécurité
informatique
GPL : La Licence publique
générale GNU, ou GNU GPL pour GNU General Public License en
anglais, est une licence qui fixe les conditions légales de distribution
des logiciels libres du projet GNU. Richard Stallman et Eben Moglen, deux des
grands acteurs de la Free Software Foundation, en furent les premiers
rédacteurs. Sa dernière version est la GNU GPL version 2 de 1991
et une troisième version est en cours d'écriture.
Elle a depuis été adoptée, en tant que
document définissant le mode d'utilisation, donc d'usage et de
diffusion, par de nombreux auteurs de logiciels libres. La principale
caractéristique de la GPL est le copyleft, ou gauche d'auteur, qui
consiste à « détourner » le principe du copyright (ou
droit d'auteur) pour préserver la liberté d'utiliser,
d'étudier, de modifier et de diffuser le logiciel et ses versions
dérivées.
LIEN :
http://www.gnu.org/licenses/gpl.html
LDAP : Lightweight Directory Access
Protocol (LDAP) est un protocole permettant l'interrogation et la modification
des services d'annuaire. Ce protocole repose sur TCP/IP.
LIEN :
http://www.cru.fr/ldap/
Monitoring d'une infrastructure Linux sur base d'outils
libres
IMAP : Internet Message Access
Protocol (IMAP) est un protocole utilisé par les serveurs de messagerie
électronique, fonctionnant pour la réception.
Ce protocole permet de laisser les e-mails sur le serveur dans
le but de pouvoir les consulter de différents clients e-mails ou
webmail. Il comporte des fonctionnalités avancées, comme les
boîtes aux lettres multiples, la possibilité de créer des
dossiers pour trier ses e-mails? Le fait que les messages soient
archivés sur le serveur fait que l'utilisateur peut accéder
à tous ses messages depuis n'importe où sur le réseau et
que l'administrateur peut facilement faire des copies de sauvegarde.
IMAP utilise le port TCP 143. Il est particulièrement
bien adapté à l'accès à travers des connexions
lentes. IMAPS (IMAP over SSL) permet l'accès sécurisé au
serveur en utilisant SSL. Il utilise le port TCP 993. L'utilisation du
protocole IMAP au dessus de SSL est décrite dans la RFC 2595.
MIB : Une MIB (Management
Information Base, base d'information pour la gestion du réseau) est un
ensemble d'informations structuré sur une entité réseau,
par exemple un routeur ou un commutateur. Ces informations peuvent être
récupérées, ou parfois modifiées, par un protocole
comme SNMP.

LIEN :
http://christian.caleca.free.fr/snmp/la
mib.htm
SMTP : Le Simple Mail Transfer
Protocol (littéralement « Protocole simple de transfert de courrier
»), généralement abrégé SMTP, est un protocole
de communication utilisé pour transférer le courrier
électronique vers les serveurs de messagerie électronique.
SMTP est un protocole assez simple (comme son nom l'indique).
On commence par spécifier le ou les destinataires d'un message puis,
l'expéditeur du message, puis, en général après
avoir vérifié leur existence, le corps du message est
transféré. Il est assez facile de tester un serveur SMTP en
utilisant telnet sur le port 25.
LIEN :
http://stielec.ac-aix-marseille.fr/cours/caleca/smtp/index.html
SNMP : Le sigle SNMP signifie Simple
Network Management Protocol (protocole simple de gestion de réseau en
Français). Il s'agit d'un protocole de communication qui permet aux
administrateurs réseau de gérer les équipements du
réseau et de diagnostiquer les problèmes de réseau
à distance.
LIEN :
http://www.snmp.com
WAN : Un réseau
étendu, souvent désigné par l'acronyme anglais WAN de Wide
Area Network, est un réseau informatique couvrant une grande zone
géographique, typiquement à l'échelle d'un pays, d'un
continent, voire de la planète entière. Le plus grand WAN est le
réseau Internet.

LIEN :
http://fr.wikipedia.org/wiki/Wan


