EPIGRAPHIE
« Si tu n'arrives pas à marcher sur la
terre, ne rêve jamais de courir sur la lune »
Proverbe africain
IN MEMORIAM
A mon feu oncle paternel Justin MUKENDI MWAMBA
KABONDO Joad à qui j'ai beaucoup de l'estime pour tout ce qu'il avait
toujours fait pour moi il y a dès cela dix ans alors que son âme
continue à reposer en paix.
A mes feux grands parents : KAPENA MUSAMPA, KANKU
MAMPUYA, MUKUNA RAPHAEL, Fidèle KALEKA pour m'avoir donné des
parents si aimables, gentils et compétents, veillant toujours à
mon éducation que leurs âmes reposent en paix à jamais.
DEDICACE
A Dieu soit rendue
la gloire.
A mes parents :
Donatien MULAMBA MPOYI Elie et Marthe NTANGA NGALULA Marie pour tout l'amour et
les sacrifices consentis pour mon éducation, vos sages conseils ont
fait de moi une personne respectueuse dans ce monde.
A mes frères et
soeurs : Pépin KAPENA, Abel MUTOMBO, Jordan MWANZA, Naomi MPEMBA,
Ramia MULAMBA, Prisca NGALULA pour tant d'affectation et attachement dont vous
avez témoignés à mon égard.
A mes neveux et nièces : Ma joie ILUNGA, Daniel
KABUYA, Marthe NTANGA, Blessing KAPENA, La Précieuse MPEMBA, Djovinah
BIABOLA.
A mes cousin(e)s, tantes, Oncles, belles soeurs : Mea gloria
MUKENDI, Grâce KUKIMUNU, Ma joie MPONGO, Dieu Donné KANTSHESSA,
Maman BIBOMBA, Joseph KASONGO, Patience MULANGA, Joëlle MUSHIYA, Sarah
BIJANU, Naomi BIBOMBA, Isaac KALAMBI, Colonel François KALONJI, Marie
NKULA, Maman BIABOLA, Djony TSHAMULANGA, B. Davis INGA, Valentin KABONGO, M.
Fubu MULAMBA, M. Volcan BANZA, Mamou MUSUAMBA, Mireille OMOY, Dorcas SAMBA,
Vinah MWADI et autres de leur assistance.
A tous, nous dédions ce travail.
AVANT - PROPOS
Le couronnement de nos efforts a été possible
grâce à la contribution de plusieurs personnes. De prime à
bord nous rendons grâce à DIEU tout puissant qui a bien voulu nous
donner le souffle de vie.
A toutes les autorités académiques et au corps
professoral pour l'encadrement à notre formation.
Nos remerciements s'adressent au Professeur PUNGA KUMANENGE
Doyen de la faculté des Sciences, au professeur Léonard MANYA
NDJADI Vice-Doyen de la faculté des Sciences, au professeur MUBENGA
KAMPOTU Chef du Département des Mathématiques et Informatique,
à tous les professeurs, chefs de travaux et assistants du
Département des Mathématiques et Informatique.
Que le Professeur Eugène MBUYI MUKENDI trouve ici nos
sentiments de référence car en dépit de ses multiples
occupations à bien voulu accepter d'assurer la direction du
présent travail et au Chef des Travaux Pierre KAFUNDA qui, ses remarques
et orientations scientifiques ont donné à cette étude la
forme qu'elle revêt présentement.
Nous n'allons pas passer cette étape sans pour autant
remercier Monsieur Yves KOTA qui nous a beaucoup aidé avec les
données qui constituent l'objet du présent travail.
A mes ami(e)s et connaissances : Erick MAMBINZI, Grâce
KITIAKA, 2Kaz KAZADI, Didel NSONGA, Bruce MAZUNDA, Papy LUSHIMA, Brady MALEMBE,
Nina KANGALA, Fresty MAUTU, Charry NSASI, Jireh IKOLI, Anthony MULUMBA, Olivier
BUYAMA, Ruddy NDOMA, Glody Parker NSILULU, Michael TALUSHIMA, Morgan DHANDU,
Ali Djogo BUANA, Kam's KANYINDA, Bill MADUDA, Pape KAMAKONDI, Lilya MULEKO,
Emilien DIABONDA, Patrick MONDOMBA, Yves KATSIAKA, Fanny WUMBA, Marie France
TSHIBOLA, Laetitia MASENGU pour tous les moments de joie partagés,
leurs attachements et estime en ma personne.
Nous remercions, tous ceux qui ont contribué de loin ou
de près à la matérialisation de ce travail et dont nous
avons oublié de citer leurs noms trouvent à travers cette ligne
l'expression de notre sincère reconnaissance.
LISTE DES ABREVIATIONS
MCD : Modèle Conceptuel de Données
MLD : Modèle Logique de Données
MPD : Modèle Physique de Données
CENI : Commission Electorale Nationale et
Indépendante
CI : Centre d'Inscription
RDC : République Démocratique du Congo
SGBD : Système de Gestion de Base de Données
SGBDR : Système de Gestion de Base de Données
Réparties
SQL : Structured Query Language
DBMS : Data Base Management System
LMD : Langage de Manipulation de données
IBM : International Business Machines
FTP : File Transfer Protocol
HTTP : Hypertext Transfer Protocol
SMTP : Simple Message Transfer Protocol
BCCE : Banque Congolaise du Commerce Extérieure
LISTE DES FIGURES
Figure I. 1. Approche Descendante
Figure I. 2. Approche Ascendante
Figure I. 3. Fragmentation Horizontale
Figure I. 4. Fragmentation Verticale
Figure I. 5. SGBD Hiérarchique
Figure I. 6. SGBD Réseau
Figure I. 7. SGBD Relationnel
Figure I. 8. SGBDR Homogène
Figure I. 9. SGBDR Hétérogène
Figure II. 1. Architecture à deux-tiers
Figure II. 2. Architecture à trois-tiers
Figure III. 1. Réplication Asymétrique
Synchrone
Figure III. 2. Réplication Asymétrique
Asynchrone
Figure III. 3. Réplication Symétrique
Synchrone
Figure III. 4. Réplication Symétrique
Asynchrone
Figure IV. 1. Topologie de la Configuration de la
Réplication
INTRODUCTION
1. Généralités
Le processus électoral en République
démocratique du Congo exige à ce jour une révision du
fichier électoral. De la qualité de ce fichier dépendent,
en grande partie, la crédibilité, la transparence et
l'appropriation, par les différents acteurs, des résultats qui
sortiront des urnes. Dans cette perspective et en prélude aux prochaines
élections locales et générales, la CENI s'apprête
à mettre à jour le fichier électoral notamment par la
prise en compte les congolais remplissant les conditions requises par les
textes en vigueur.
Aujourd'hui, la haute disponibilité des données
est un problème récurrent dans le monde de l'informatique en
général, et des Systèmes de Gestion de Bases de
données Répartis en particulier. La réplication consiste
à copier les informations d'une base de données à une
autre et vice-versa. Les copies effectuées doivent être les
différentiels, de façon à obtenir deux bases de
données identiques sur les sites distants reliés par ces
opérations.
La réplication qui est un processus de partage
d'informations pour assurer la cohérence de données entre
plusieurs sources de données redondantes répondant à ces
exigences. Elle améliore la fiabilité des dites données,
la tolérance aux pannes et l'accessibilité.
La Commission Electorale Nationale et
Indépendante « CENI » possède plusieurs
serveurs dont de mail(ou messagerie), de web, d'applications et des bases de
données et c'est dans ce dernier où sont stockées les
bases de données utilisées pour les opérations
d'identification et d'enrôlement des électeurs. La CENI
possède en dehors de son siège central en ville province de
Kinshasa, des sites locaux dans différentes provinces de la RDC y
compris dans cette dernière qui, effectuent leurs opérations dans
des bases locales lors des opérations d'identification et
d'enrôlement des électeurs dont les données doivent
être transférées après au siège central.
C'est dans cette optique que nous sommes appelés à mettre en
place un système de réplication qui facilitera le transfert des
données.
Le but du présent travail est de permettre aux lecteurs
de comprendre le concept général de «
réplication » et de démontrer les avantages
qu'offre ce système non moins gourmand en ressources matérielles
et logicielles, mais efficace.
La réplication présente des avantages
différents selon le type de réplication et les options choisies,
mais l'intérêt général de la réplication est
la disponibilité des données à tout moment et à
travers divers sites distants.
En général, la réplication comprend les
étapes suivantes : configuration de la réplication,
génération et application de la capture instantanée
initiale, modification des données répliquées, puis
synchronisation et propagation des données.
2. Problématique
Nous cherchons à mettre en place une technique de
réplication pour la gestion des opérations d'identification et
d'enrôlement des électeurs à la Commission Electorale
Nationale et Indépendante « CENI-Kinshasa ».
Les questions fondamentales seront de savoir :
ü Serait-il possible de configurer une
réplication à temps différé entre différents
sites rapprochés et enfin celui du central ?
ü Si c'est possible, alors quelle est la
démarche à suivre ?
ü Et dans le cas des opérations
concurrentes, comment gérer la cohérence des données dans
ce système ?
Elle pose directement le problème d'un retour sur
investissement, même si l'investissement a des chances de ne jamais
être consommé (absence d'incident).
3. Hypothèse du Sujet
L'usage de la réplication dans cette entreprise pour la
gestion des opérations d'identification et d'enrôlement des
électeurs apportera certes, des maints avantages non seulement de la
disponibilité, confidentialité et intégrité des
données en permanence dans différents sites mais aussi,
l'allègement de dépenses en énergie de son personnel dans
la réalisation des tâches hebdomadaires.
4. Choix du Sujet
Concernant la réalisation de notre travail de fin
d'étude du second cycle en sciences informatiques, la gestion des
opérations d'identification et d'enrôlement des électeurs a
retenu notre attention. Ainsi, le sujet de notre réflexion scientifique
se présente comme suit : « Etude de la Réplication
Symétrique Asynchrone dans une base de données répartie.
Application à l'enrôlement des électeurs
».
5. Intérêt du Sujet
Notre travail a pour objet de mettre en place une technique de
réplication des données sur la gestion des opérations
d'identification et d'enrôlement des électeurs de la CENI, afin de
proposer un logiciel d'application, de permettre à chaque
électeur de voter peu importe l'endroit où il va se trouver.
6. Délimitation du Sujet
Tout travail qui se veut scientifique doit être
délimité et dans le temps et dans l'espace. Nous avons
circonscrit ce travail selon deux approches :
Ø Dans l'approche temporelle, notre étude couvre
une période d'une année qui est de 2011.
Ø Quant à l'approche spatiale, la CENI sous
étude est localisée géographiquement dans la ville
province de Kinshasa, précisément sur le boulevard du 30 juin
occupant le bâtiment ex. BCCE en face de l'ONATRA et à
proximité de la gare centrale
7. Méthodes et Techniques
utilisées
Il y a lieu souvent de noter la confusion qui existerait dans
l'emploi de ces deux concepts « méthodes et techniques ».
Pour ce qui nous concerne, nonobstant la confusion
constatée, nous avons utilisé la méthode de traitement
automatique basée sur la création de logiciel adéquat. Et
en ce qui concerne les techniques utilisées, nous avons fait recours aux
techniques documentaires et interview.
Quant aux techniques documentaires, nous avons consulté
toute la documentation liée à la gestion des opérations
d'identification et d'enrôlement des électeurs.
8. Subdivision du Travail
En plus de l'introduction et la conclusion pour un bon
traitement de notre sujet, nous l'avons articulé autour de deux
axes :
1ère Partie : CONCEPTS
THEORIQUES
Chapitre I : Bases de données Réparties et
SGBD Répartis (Ce chapitre porte sur les concepts théoriques des
bases de données Système de gestion de base de données,
Bases de données Réparties et Système de gestion de base
de données Réparti)
Chapitre II : Architecture Client-Serveur (Ce chapitre
aborde les théories sur les types d'architectures client)
Chapitre III : Réplication des données
2ème Partie : IMPLEMENTATON DU
SYSTEME ET APPLICATION
Chapitre IV : Présentation de l'entreprise
Chapitre V : Implémentation du système de
réplication et Application
PREMIERE PARTIE :
CONCEPTS THEORIQUES
CHAPITRE I : BASE DE
DONNEES REPARTIES ET SGBD Répartis [3][6][7][9][10]
I.1. INTRODUCTION AUX BASES
DE DONNEES
I.1.1. DÉFINITION
a) Une base de données :
ü Est l'ensemble cohérent, intégré
et partagé des informations nécessaire au fonctionnement de
l'entreprise.
ü Est une grande quantité des données,
centralisée ou non, servant pour des besoins d'un ou de plusieurs
applications interrogeables et modifiables par un groupe d'utilisateur
travaillant en parallèle.
b) Une base de données
informatisée :
Est un ensemble structuré de données
enregistrées sur des supports accessibles par l'ordinateur pour
satisfaire simultanément plusieurs utilisateurs de manière
sélective en un temps opportun.
I.1.2. CARACTÉRISTIQUES
D'UNE BASE DE DONNÉES
Une base de données étant une collection de
données est caractérisée par :
L'intégrité
La sécurité
La confidentialité
La concurrence
L'intégrité :
Les données enregistrées dans la base de
données doivent respecter un certain nombre des contraintes
d'intégrité et assurer le respect de celles-ci.
La sécurité :
La base de données doit être restaurée
après une panne qui soit d'origine logicielle ou matérielle par
le SGBD.
La concurrence :
La base de données doit être cohérente
lorsque plusieurs transactions se font et lorsque plusieurs utilisateurs se
partagent la même base de données.
La confidentialité :
Le SGBD doit permettre d'interdire à
certaines personnes de réaliser certaines opérations sur une
partie ou toute la base de données.
I.1.3. UTILITÉ D'UNE
BASE DE DONNÉES
Une base de données permet de stocker
de données de façon structurée et avec le moins de
redondance possible. Il permet de mettre des données à la
disposition de l'utilisateur pour la consultation, la saisie ou voir même
la mise à jour tout en s'assurant des droits accordés à ce
dernier.
Une base de données offre aux utilisateurs la
possibilité d'accéder simultanément aux données.
I.1.4. TYPES DE BASE DE
DONNÉES
· Une base de données Centralisée
· Une base de données Répartie
a) Une base de données
centralisée
La base de données est dite
centralisée lorsque les informations sont
centralisées dans une seule machine et d'autres utilisateurs distants y
accèdent.
b) Une base de données
répartie
La base de données est dite
répartie lorsque les informations sont stockées
sur des machines distantes et accessibles par un réseau. Elle rassemble
de données plus ou moins hétérogènes,
partagées dans un réseau d'ordinateurs sous forme d'une base de
données globales homogènes et intégrées.
I.1.5. CONCEPTION D'UNE BASE DE
DONNÉES
A. Modèle conceptuel de données
(MCD)
Le modèle conceptuel de données (MCD) a pour but
d'écrire de façon formelle les données qui seront
utilisées par le système d'information. Il s'agit donc d'une
représentation des données, facilement compréhensible,
permettant de décrire le système d'information à l'aide
d'entités.
B. Modèle logique de données
(MLD)
Le modèle logique de données consiste à
décrire la structure de données utilisée sans faire
référence à un langage de programmation. Il s'agit donc de
préciser le type de données utilisées lors des
traitements.
Ainsi, le modèle logique est dépendant du type
de base de données utilisé.
C. Modèle Physique de données
(MPD)
Cette étape consiste à implémenter le
modèle dans le SGBD, c'est-à-dire le traduire dans un langage de
définition de données. Le langage généralement
utilisé pour ce type d'opération est le SQL, et plus
spécialement le langage de définition de données du
SQL.
I.2. BASE DE DONNEES
REPARTIE
I.2.1. DÉFINITION
Une base de données répartie
est :
ü Un ensemble de bases de données
localisées sur différents sites, perçues par l'utilisateur
comme une base unique.
ü Aussi vue comme une collection de bases de
données logiquement reliées, distribuées sur un
réseau.
Une base de données répartie diffère
d'une base de données fédérée et d'une multi
base.
Une multi base : est un ensemble de plusieurs
bases de données (hétérogènes ou non) inter
opérant avec une application via un langage commun et sans modèle
commun.
Une base de données
fédérée : est un ensemble de plusieurs bases de
données hétérogènes capables d'inter opérer
via une vue commune (modèle commun).
Elle donne aux utilisateurs une vue unique des données
implémentées sur plusieurs systèmes à priori
hétérogènes (plate-forme et SGBD), c'est le cas
rencontré lors de la concentration d'entreprises : faire cohabiter les
différents systèmes tout en leur permettant d'inter
opérer.
Schéma d'une relation : est la
description de la relation, c'est-à-dire son nom, les noms, les types et
la potée des attributs.
Schéma relationnel : c'est l'ensemble
des schémas des relations.
Vue : est la partie visible d'un
schéma relationnel qui correspond à une espèce de
fenêtre qui montre les données accessibles par l'usager de la vue,
elle peut être un sous-ensemble d'un schéma relationnel.
Relation de base : est une relation
décrite dans le schéma conceptuel qui peut être
découpée en fichiers ou en relation interne.
Relation interne : est une relation
décrite dans le schéma interne et caractérise la structure
du fichier qui contient l'occurrence physique de la relation.
Relation abstraite : est une relation
définie soit sur une relation de base, soit sur une autre relation, elle
se caractérise par l'expression qu'il faut appliquée pour
créer son occurrence.
Relation fragmentée ou partitionnée
: est une relation abstraite composée par un ou plusieurs
relations ou sous-relations appelées « fragment ».
Partitionnement ou fragmentation : est
l'action de séparer ou découper une relation abstraite en
plusieurs fragments.
Localisation : est l'action de prendre en
compte la situation des fragments.
Relation répartie : est une relation
fragmentée dont les fragments se trouvent sur les différents
sites du système.
Schéma interne : décrit
l'accès physique aux occurrences de la relation.
Schéma conceptuel : est l'ensemble des
schèmes de relations de base, c'est la vue de toute la base de
données.
Schéma externe : c'est un
sous-schéma du schéma conceptuel, il est composé de
l'ensemble des schèmes de relations abstraites, définies sur les
relations de base du schéma conceptuel.
I.2.2. CARACTÉRISTIQUES
D'UNE BASE DE DONNÉES RÉPARTIE
ü La distribution de données : les données
ne résident pas dans le même site.
ü Corrélation logique des données: les
données possèdent les propriétés qui les tiennent
ensemble.
ü Une structure de contrôle hiérarchique
basée sur un administrateur des bases de données globales qui est
le responsable central sur les bases de données réparties
entières et sur les administrateurs des bases de données locales,
qui ont la responsabilité de leur base de données respective.
ü L'indépendance des données et la
transparence de répartition.
ü La redondance des données qui permet
l'accroissement de l'autonomie des applications et la disponibilité des
informations en cas de panne d'un site.
ü Un plan d'accès réparti écrit soit
par le programmeur ou produit automatiquement par un optimiseur.
I.2.3. CONCEPTION DE LA BASE DE
DONNÉES RÉPARTIE
La conception d'une base de données répartie
peut être le résultat de deux approches totalement distinctes,
soit d'une part la nécessité de connecter la multitude de base de
données existantes, ainsi que la disponibilité nécessaire
à la globalisation des systèmes informatiques. D'où, la
mise en place d'une base de données répartie se résume en
quatre étapes :
ü La conception du schéma globale
ü La conception de base de données physique locale
dans chaque site
ü La conception de la fragmentation
ü La conception de l'allocation des fragments
A. La conception du schéma globale
Dans une entreprise, privée ou publique, les bases de
données réparties ou distribuées (distributed data bases,
en anglais) permettent de réaliser des applications qui
nécessitent le stockage, la maintenance et le traitement des
données en plusieurs endroits différents.
Une base de données est décentralisée ou
répartie lorsqu'elle est modélisée par un seul
schéma logique de base de données, mais implémentée
dans plusieurs fragments de tables physiques sur des ordinateurs
géographiquement dispersés.
L'utilisateur d'une base de données répartie se
focalise sur sa vue logique des données et n'a pas besoin de se
préoccuper des fragments physiques.
C'est le système de bases de données qui se
charge lui-même d'exécuter les opérations, soit localement,
soit en les distribuant sur plusieurs ordinateurs en cas de besoin.
La définition du schéma global de
répartition est la partie la plus délicate de la phase de
conception d'une base de données car il n'existe pas de méthode
miracle pour trouver la solution optimale.
L'administrateur doit donc prendre des décisions dont
l'objectif est de minimiser le nombre de transferts entre sites, les temps de
transfert, le volume de données transférées, les temps
moyens de traitement des requêtes, le nombre de copies de fragments,
etc...
Le schéma global se subdivise en trois schémas
qui sont :
Le Schéma interne
Le Schéma conceptuel
Le Schéma Externe
Schéma Interne
Le schéma interne décrit l'accès physique
aux occurrences des relations, il est constitué de l'ensemble des
descriptions des fichiers et/ou par un ensemble des Schémas de relations
internes.
Schéma conceptuel
Le schéma conceptuel est l'ensemble des schémas
des relations de base et l'ensemble des contraintes d'intégrités,
c'est la vue globale de la base de données.
Le schéma conceptuel est composé de relations
fragmentées ou d'une relation composée d'une ou de plusieurs
sous-relations, la distinction de deux approches dans sa mise en oeuvre.
Schéma externe
Le schéma conceptuel est un sous-ensemble du
schéma conceptuel composé de l'ensemble des schémas de
relations abstraites définies sur la relation de base du schéma
conceptuel.
1. Approche descendante
Dans l'approche descendante, on commence par définir un
schéma conceptuel global de la base de données répartie en
respectant les règles de la normalisation. Cependant pour de raison de
performance, les relations sont découpées horizontalement par des
restrictions simple ou verticalement par des projections puis réparties
sur les différents sites en schémas conceptuels locaux.
L'approche descendante permet de maitriser la
complexité de la répartition (fragmentation, duplication,
placement) et la définition des schémas locaux à partir du
schéma global.
Schéma Conceptuel Global
Schéma Conceptuel Local 1
Schéma Conceptuel Local 2
Schéma Conceptuel Local 3
Figure 1.1. Approche Descendante
2. Approche ascendante
Elle se base sur le fait que la répartition est
déjà faite, mais il faut réussir à intégrer
les différentes bases de données existantes en une seule base de
données globale c'est-à-dire que les relations du schéma
conceptuel sont définies à partir des schémas externes ou
conceptuels des bases de données déjà en exploitation et
que l'on ne veut pas modifier.
Schéma Conceptuel Global
Schéma Conceptuel Local 1
Schéma Conceptuel Local 2
Schéma Conceptuel Local 3
Figure 1.2. Approche Ascendante
La différence la plus importante avec l'approche
descendante précédente est que la fragmentation est
conditionnée par la structure des fragments. On rencontre deux
problèmes importants, celui de duplication partielle de n-uplets et
celui des valeurs indéfinies des certains attributs.
B. La conception de la fragmentation
La fragmentation est un processus de décomposition
d'une base de données logique en un ensemble de
« sous » base de données logiques appelées
« fragments », donc d'un schéma global en un
ensemble des schémas locaux sans perte d'informations
c'est-à-dire qu'on peut recomposer le schéma conceptuel global en
partant des schémas conceptuels locaux.
Cette décomposition est assurée par une fonction
de définition qui préserve les arguments lors de son
application.
De plus, les différents fragments doivent de
préférence être exclusifs (leur intersection est vide)
puisqu'une fragmentation non exclusive implique une duplication. D'où,
il faudra affiner la fragmentation en produisant des fragments plus petits.
1. Règles de fragmentation
Les fragments sont déterminés en tenant compte
de :
ü La complétude : pour toute
donnée de la relation globale R, il existe un fragment Ri de
la relation qui possède cette donnée c'est-à-dire toutes
les données de la relation globale doivent être reprises dans les
fragments.
ü La reconstruction : pour toute
relation globale R décomposée en un ensemble de fragments
Ri, il existe une opération de reconstruction c'est à
dire qu'il y a une possibilité de reconstruction de chaque relation
globale à partir de ses fragments.
ü La disjonction : permet de
contrôler la redondance au niveau d'allocation, il est souhaitable
d'avoir de fragment disjoint.
2. Technique de fragmentation
Il existe plusieurs techniques de fragmentation
définies par unité de fragment :
a) Fragmentation horizontale
La fragmentation horizontale consiste à partitionner
les n-uplets d'une relation globale en des sous-ensembles. Une relation globale
est fragmentée horizontalement lorsqu'elle est formée par l'union
des fragments des relations locales qui peuvent être
considérés comme des restrictions de la relation globale.
ü L'opération de partitionnement est la
sélection
ü L'opération de recomposition est l'union
Client 1
Client
Client 2
|
Numéro
|
Nom
|
Localité
|
|
1
|
APOULAH
|
KINSHASA
|
|
2
|
DJEDJE
|
KINSHASA
|
|
3
|
MAMIE
|
LUBUMBASHI
|
|
4
|
YANNICK
|
LUBUMBASHI
|
|
Numéro
|
Nom
|
Localité
|
|
1
|
APOULAH
|
KINSHASA
|
|
2
|
DJEDJE
|
KINSHASA
|
|
Numéro
|
Nom
|
Localité
|
|
3
|
MAMIE
|
LUBUMBASHI
|
|
4
|
YANNICK
|
LUBUMBASHI
|
Figure 1.3. Fragmentation Horizontale
b) Fragmentation verticale
La fragmentation verticale est la subdivision de certains
attributs de la relation globale en groupe. Les fragments sont obtenus par
projection de la relation globale sur chaque groupe, donc une relation globale
est fragmentée verticalement quand elle est formée par une
composition de plusieurs relations locales.
La fragmentation verticale est utile pour distribuer les
parties des données sur les sites ou chacune de ces parties est
utilisée.
ü L'opération de partitionnement est la
projection
ü L'opération de recomposition est la jointure
Commande
|
Code_cmde
|
Client
|
Produit
|
quantité
|
|
001
|
01
|
Sucre
|
100
|
|
002
|
02
|
Maïs
|
500
|
|
003
|
03
|
Manioc
|
200
|
|
004
|
04
|
Arachide
|
150
|
Commande 1
|
Code_cmde
|
Produit
|
|
001
|
Sucre
|
|
002
|
Maïs
|
|
003
|
Manioc
|
|
004
|
Arachide
|
Commande 2
|
Code_cmde
|
Produit
|
Quantité
|
|
001
|
Sucre
|
100
|
|
002
|
Maïs
|
500
|
|
003
|
Manioc
|
200
|
|
004
|
Arachide
|
150
|
Figure 1.4. Fragmentation Verticale
c) Fragmentation mixte
La fragmentation mixte est la combinaison de deux
fragmentations précédentes, dont l'opérateur de
partitionnement est la combinaison de la projection et de la sélection
et celui de la recomposition, la combinaison de la jointure et de l'union.
D. Allocation des fragments
L'allocation des fragments est une méthode qui permet
d'affecter les fragments sur les sites donnés en fonction de l'origine
(sites d'émission) des requêtes enfin de minimiser les transferts
des données entre les sites.
L'allocation peut se faire de deux manières,
l'allocation sans réplication et l'allocation avec
réplication.
a) Allocation sans réplication
L'allocation sans réplication est facile à
réaliser, il suffit d'associer à chaque allocation une mesure et
à chaque site une meilleure mesure. C'est une solution qui ne tient pas
compte de l'effet naturel, il faut placer un fragment dans un site donné
si un autre fragment apparenté est aussi dans ce site.
b) Allocation avec réplication
L'allocation avec réplication est
réalisée en appliquant l'une de deux méthodes suivantes
:
ü Déterminer l'ensemble de tous les sites dont
l'importance d'allouer une copie est d'intérêt plus
élevé que le coût de transfert puis allouer une copie de
fragment à chaque élément de cet ensemble.
ü Déterminer premièrement la solution du
problème qui n'est pas la réplication et introduire
progressivement les copies en commençant par celles qui sont plus
avantageuses. Le processus prend fin si aucune réplication additionnelle
n'est avantageuse.
L'allocation avec réplication favorise les performances
des requêtes et la disponibilité de données.
c) Technique de répartition
avancée
Dans le cas où la méthode classique d'allocation
des fragments ne s'avèrent pas satisfaisante, des techniques plus
puissantes mais aussi complexes à mettre en oeuvre doivent être
envisagées :
ü Allocation avec duplication des fragments
ü Allocation dynamique des fragments
ü Fragmentation dynamique
ü Clichés
a. Allocation avec duplication
Certains fragments peuvent être dupliqués sur
plusieurs sites (éventuellement sur tous les sites) ce qui procure
l'avantage d'améliorer les performances en termes de temps
d'exécution des requêtes (en évitant certains transferts de
données). Elle permet aussi une meilleure disponibilité des
informations (connues de plusieurs sites), et une meilleure fiabilité
contre les pannes. Par contre, l'inconvénient majeur est que les mises
à jour doivent être effectuées sur toutes les copies d'une
même donnée. En conséquence, moins un fragment est sujet
à des modifications, plus il est prédisposé à la
duplication.
b. Allocation dynamique
Avec cette technique, l'allocation d'un fragment peut changer
en cours d'utilisation de la BDR. Ce peut être le cas suite à une
requête par exemple. Dans ce cas, le schéma d'allocation et les
schémas locaux doivent être tenus à jour. Cette technique
est une alternative à la duplication qui se révèle plus
efficace lorsque la base de données est sujette à de nombreuses
mises à jour.
c. Fragmentation dynamique
Dans le cas où le site d'allocation peut changer
dynamiquement, il est possible que deux fragments complémentaires
(verticalement ou horizontalement) se retrouvent sur le même site. Il est
alors normal de les fusionner. A l'inverse, si une partie d'un fragment est
appelé sur un autre site, il peut être intéressant de
décomposer ce fragment et de ne faire migrer que la partie
concernée. Ces modifications du schéma de fragmentation se
répercutent sur le schéma d'allocation et sur les schémas
locaux.
d. Clichés
Un cliché (snapshot) est une copie figée d'un
fragment. Il représente l'état du fragment à un instant
donné et n'est jamais mis à jour contrairement aux vues et aux
copies qui répercutent toutes les modifications qui ont lieu sur le
fragment original.
L'intérêt d'un cliché diminue donc au fur
et à mesure que le temps passe. L'utilisation des clichés est
intéressante lorsque l'on juge que la gestion de copies multiples se
révélerait trop lourde pour la base de données
considérée alors que des copies même peu anciennes et non
à jours seraient largement suffisantes.
On peut en effet se passer de l'information exacte pour
diverses raisons. D'une part l'information contenue dans la base de
données peut ne pas refléter tout à fait la
réalité (cas d'un changement d'adresse non signalé, par
exemple).
D'autre part, certaines informations ne subissent pas souvent
de modification (comme le nom de famille, l'adresse ou le nombre d'enfants des
employés) et par conséquent une copie même ancienne de ces
informations est, dans sa grande majorité, encore exacte.
Enfin, certaines informations dans un certain contexte ne sont
pas de caractère sensible et par conséquent une information
erronée n'aura pas de répercussion grave : le changement
d'adresse d'un employé non répercuté n'aura pas
d'incidence, les services postaux se chargeant du bon acheminement du courrier
pendant plusieurs semaines.
Les deux critères qui sont à prendre en compte
pour définir l'intérêt d'un cliché sont d'une part
l'ancienneté du cliché, et d'autre part le temps d'attente qui
serait nécessaire avant d'obtenir l'information originale (à
jour).
Ces deux informations, l'ancienneté et le temps
d'attente, peuvent être pondérées par un taux de
satisfaction pour le système d'information.
I.3. Gestion des
transactions
I.3.1. INTRODUCTION
Une transaction est un ensemble d'opérations
cohérentes et fiables menées sur une base de données qui
la transforme d'un état stable et cohérent en un autre
état stable et cohérent. C'est un ensemble d'ordres SQL.
Une transaction est constituée de quatre types
d'opérations qui sont : le début, l'écriture, la lecture
et la fin (terminaison).
Une transaction peut ou ne pas arriver à son terme,
elle peut être interrompu pour diverses raisons. Pour assurer la
cohérence de la base de données, il y a quatre ordres de
transaction :
Begin : cet ordre permet de démarrer
de manière explicite une transaction.
Commit : permet de mettre fin avec
succès à une transaction, c'est-à-dire la conservation de
l'ensemble de modifications effectuées dans la transaction.
Roll back : permet de terminer une
transaction en annulant toutes les modifications de données
effectuées.
Save : permet de définir un point
d'arrêt, donc donne la possibilité d'annuler une partie de la
transaction en cours. Il est possible de définir plusieurs points
d'arrêt sur une même transaction.
I.3.2.
PROPRIÉTÉS
La cohérence et la fiabilité d'une transaction
sont garanties par quatre propriétés :
a. Atomicité
La transaction ne peut pas être divisée en une
partie qui réussit et une autre qui échoue, donc tout ou rien.
On rencontre deux types de problèmes durant
l'exécution de la transaction :
ü La transaction peut s'interrompre
d'elle-même ;
ü La transaction peut également être
interrompue en raison d'une panne du système réseau.
b. Cohérence
Une fois qu'une transaction prend fin ou termine, la base de
données rentre de nouveau à un état cohérent.
c. Isolation
Lorsqu'une transaction considère que, pendant son
exécution, les données qu'elle manipule ne sont pas
modifiées par une autre transaction.
d. Durabilité
Lorsque les modifications opérées par la
transaction sont enregistrées de façon permanente (et
recouvrables en cas de reconstruction de la base).
I.3.3. DIFFÉRENT NIVEAU
DE FRAGMENTATION DE LA RÉPARTITION
La transparence est la caractéristique principale d'un
système distribué dans lequel l'utilisateur doit se voir
travailler sur un énorme ordinateur personnel constitué de tous
les ordinateurs connectés.
Nous distinguons plusieurs niveaux de transparence de
répartition qui sont indépendantes du programme d'application de
la répartition :
a. Transparence globale
La transparence globale définit toutes les
données contenues dans la base de données réparties comme
si cette base était définie exactement comme dans une base de
données non réparties.
b. Transparence de fragmentation
Une relation globale peut être répartie en
plusieurs fragments, une transparence de fragmentation définit une
fonction entre la relation globale et les fragments.
Cette fonction est multivaluée c'est à dire
plusieurs fragments correspondent à une relation globale, mais une seule
relation globale correspond à un seul fragment.
c. Transparence d'allocation
Les fragments sont des portions logiques des relations
globales qui sont uniquement situées dans un ou plusieurs sites du
réseau. La transparence d'allocation définit le site dans lequel
est situé un fragment. La relation définit dans la transparence
d'allocation détermine si la base de données répartie est
redondante ou pas.
d. Transparence conceptuelle locale
Transparence conceptuelle locale définit une fonction
qui associe chaque image physique aux objets qui sont manipulés par les
systèmes de gestion de base de données locaux. Cette transparence
dépend du type de système de base de données locale.
II. SYSTEME DE GESTION DE
BASE DE DONNEES (SGBD)
II.1. Définition
Un système de gestion de base de données (SGBD)
en anglais « data base management system (DBMS) »:
ü Est un outil informatique permettant aux utilisateurs
de structurer, d'insérer, de modifier et de chercher de manière
efficace des données spécifiques dans une grande quantité
d'informations stockées sur les mémoires secondaires (disques
magnétiques) partagées de manière transparente par
plusieurs utilisateurs.
ü Est un logiciel permettant d'interagir avec une base de
données.
ü Est un service ou un ensemble des services (application
logicielle) permettant de gérer la base de données.
II.1.1. OBJECTIF
Des objectifs principaux ont été fixés
aux systèmes de gestion de base de données afin de
résoudre les problèmes causés par la démarche
classique. Ces objectifs sont les suivants :
ü L'indépendance physique : La façon dont
les données sont définies doit être indépendante des
structures des stockages utilisées.
ü L'indépendance logique : Un même ensemble
de données peut être vu différemment par les utilisateurs
différents.
ü L'accès aux données : Il se fait par
l'intermédiaire d'un langage de manipulation de données (LMD)
permettant d'obtenir des réponses aux requêtes en un temps
raisonnable.
ü L'administration centralisée des données
(intégration) : Toutes les données doivent être
centralisées dans un réservoir unique, commun à toutes les
applications permettant de résoudre plus facilement des
différentes versions des données.
ü Le non redondance de données : Il permet
d'éviter les problèmes lors de la mise à jour, chaque
donnée ne doit être présentée qu'une seule fois dans
la base de données.
ü La cohérence de données : Les
données sont soumises à un certain nombre de contraintes
d'intégrité qui définissent un état cohérent
de la base de données.
ü Le partage de données : Il s'agit de permettre
à plusieurs utilisateurs d'accéder aux mêmes données
au même moment de manière transparente.
ü La sécurité de données : Les
données doivent être protégées contre les
accès non autorisés, pour cela, il faut pouvoir associer à
chaque utilisateur le droit d'accès aux données.
II.1.2. PRINCIPE DE
FONCTIONNEMENT
Le système de gestion de base de données
héberge généralement plusieurs bases de données,
destinées à des logiciels différents.
Actuellement, la plupart des systèmes de gestion de
base de données fonctionnent selon le mode ou architecture
client-serveur. Le serveur (sous-entendu la machine qui stocke les
données) reçoit des requêtes de plusieurs clients de
manière concurrente, les analyse, les traite puis retourne le
résultat au client.
II.1.3. TYPE DE SYSTÈME
DE GESTION DE BASE DE DONNÉES
Depuis leur apparition jusqu'aujourd'hui, nous distinguons
plusieurs types de SGBD qui sont :
ü Le SGBD hiérarchique
ü Le SGBD réseau
ü Le SGBD relationnel
ü Le SGBD objet
a) Le SGBD hiérarchique
Dans ce modèle, les données sont classées
hiérarchiquement selon une arborescence descendante. Chaque noeud de
l'arbre correspond à une classe d'entité du monde réel et
les chemins entre les noeuds représentent des liens entre les objets.
Figure 1.5. SGBD Hiérarchique
b) Le SGBD réseau
Ce modèle utilise des pointeurs vers les
enregistrements comme le modèle précédent, mais il n'y a
pas forcement la structure d'arborescence descendante. Ce modèle est
inventé par C. Bachmann.
Figure 1.6. SGBD Réseau
c) Le SGBD relationnel
Le modèle relationnel est basé sur le principe
de l'algèbre relationnel. Le père du modèle relationnel
est Edgar Franck Codd chercheur chez IBM, à
la fin des années 1960, il étudiait alors les nouvelles
méthodes pour gérer des grandes quantités de
données, car les modèles et les logiciels de l'époque ne
le faisaient pas, il s'était persuadé qu'il pouvait utiliser des
branches spécifique de la mathématique notamment théorie
des ensembles et la logique de prédicats du premier ordre pour
résoudre des difficultés telles que la redondance des
données, l'intégrité de données ou
l'indépendance de la structure de la base de
données avec sa mise en oeuvre.
Figure 1.7. SGBD Relationnel
III. Système de
Gestion de Base de Données Répartis (SGBDR)
III.1.
Définition
Un SGBDR est un logiciel qui se charge de la création
et de la maintenance des bases de données réparties.
Un SGBDR est constitué de composantes suivantes :
ü La composante de gestion de base de données
ü La composante de communication de données
ü Le dictionnaire de données qui peut
représenter l'information à propos de la répartition des
données dans le réseau informatique.
ü La composante de base de données répartie
qui contient le logiciel qui s'occupe du parallélisme, de
l'exécution mutuelle et de la synchronisation.
III.2. Fonctions
ü L'accès lointain par un programme d'application
rendu possible grâce à la composante de base de données
répartie.
ü Garantir certains degrés de transparences
réparties.
ü Le support d'administration et de contrôle de
base de données. Le contrôle, l'utilisation des bases de
données et la vue globale des fichiers existants dans les divers
sites.
ü Le contrôle de concurrence et la
rentabilité des transactions réparties.
III.3. Remarque
SGBDR Homogène
Schéma global
Schéma de fragmentation
Schéma d'allocation
Schéma Conceptuel Local 3
Schéma Conceptuel Local 2
Schéma Conceptuel Local 1
SGBD
SQL SERVER
SGBD
SQL SERVER
SGBD
SQL SERVER
BD
BD
BD
Un SGBDR est dit homogène s'il utilise le même
SGBD dans chaque site, il est dit hétérogène s'il utilise
au moins deux SGBD différents, c'est le cas du service web de
l'Internet.
Figure 1.8. SGBDR Homogène
SGBDR Hétérogène
Schéma global
Schéma de fragmentation
Schéma d'allocation
Schéma Conceptuel Local 3
Schéma Conceptuel Local 2
Schéma Conceptuel Local 1
SGBD
POSTGRESQL
SGBD
ACCESS
SGBD
MY SQL
BD
BD
BD
Figure 1.9. SGBDR Hétérogène
CHAPITRE II : ARCHITECTURES
CLIENT - SERVEUR [2][4][5][8][9]
II.1. PRESENTATION DE
L'ARCHITECTURE CLIENT - SERVEUR
De nombreuses applications fonctionnent selon un environnement
client - serveur, cela signifie que des machines clientes (des machines faisant
partie du réseau) contactent un serveur, une machine
généralement très puissante en termes de capacités
d'entrée-sortie, qui leur fournit des services. Ces services sont des
programmes fournissant des données telles que l'heure, des fichiers, une
connexion, etc.
Les services sont exploités par des programmes,
appelés programmes clients, s'exécutant sur les machines
clientes. On parle ainsi de client FTP, client de messagerie, etc., lorsque
l'on désigne un programme, tournant sur une machine cliente, capable de
traiter des informations qu'il récupère auprès du serveur
(dans le cas du client FTP, il s'agit de fichiers tandis que pour le client
messagerie il s'agit de courrier électronique)
II.1.1. DÉFINITION
L'architecture client-serveur est une architecture de
réseau dans laquelle les traitements sont répartis entre les
clients qui demandent aux serveurs les informations dont ils ont besoin.
C'est une architecture qui désigne un mode de
communication entre plusieurs ordinateurs d'un réseau qui distingue un
ou plusieurs postes clients du serveur.
Les acteurs principaux de l'architecture client-serveur sont
au nombre de trois :
a) Client
Un client est un système (programme, ordinateur)
demandant l'exécution d'une opération à un fournisseur des
services par l'envoi d'un message contenant le descriptif de l'opération
à exécuter et attendant la réponse à cette
opération par un message en retour.
Nous distinguons trois types de client :
ü Client léger :
Est une application accessible via une interface web
consultable à l'aide d'un navigateur web.
ü Client lourd :
Est une application cliente graphique exécuté
sur le système d'exploitation de l'utilisateur possédant les
capacités de traitement évoluées.
ü Client riche :
Est l'assemblage du client léger et client lourd dans
lequel l'interface graphique est décrite avec une grammaire basée
sur la syntaxe XML.
b) Serveur
Un serveur est un système (programme, ordinateur de
grande capacité) détenant des ressources qu'il met à la
disposition des autres ordinateurs (clients) d'un réseau. Nous
distinguons plusieurs types de serveur en fonction des services rendus :
Serveur d'application, serveur de base de données, serveur des
fichiers...
c) Middleware
Le middleware est l'ensemble des services logiciels qui
assurent l'intermédiaire entre les applications et le transport de
données dans le réseau afin de permettre les échanges des
requêtes et des réponses entre client et serveur de manière
transparente.
II.1.2. FONCTIONNEMENT DE
L'ARCHITECTURE CLIENT - SERVEUR
L'architecture client-serveur fonctionne selon le
schéma suivant :
ü Le client émet une requête vers le serveur
grâce à son adresse IP et le port, qui désigne un service
particulier du serveur.
ü Le serveur reçoit la demande et répond
à l'aide de l'adresse IP de la machine cliente et son port.
II.2. TYPE D'ARCHITECTURE
CLIENT - SERVEUR
II.2.1. ARCHITECTURE À
UN - TIERS
Dans une approche d'application de type 1-tiers, les trois
couches sont fortement et intimement liées, et s'exécutent sur la
même machine. Dans ce cas, on ne peut pas parler d'architecture
client-serveur mais d'informatique centralisée.
Dans un contexte simple utilisateur, la question ne se pose
pas, mais dans un contexte multiutilisateurs, on peut voir apparaître
deux types d'architectures mettant en oeuvre des applications Un - tiers : des
applications sur site central ; des applications réparties sur des
machines indépendantes communiquant par partage de fichiers.
II.2.2. ARCHITECTURE À
DEUX - TIERS
Ce système est dit 2-tiers pour le fait qu'il
permet deux niveaux de traitement applicatif. Dans les systèmes à
deux niveaux (2-tiers), la logique applicative est en fouie soit dans
l'interface utilisateur chez le client, soit dans la base de données
chez le serveur (ou dans les deux à la fois). L'accès aux
données est direct et n'a pas besoin d'un niveau intermédiaire.
Ils ont comme avantages :
ü La possibilité de l'utilisation d'une interface
utilisateur riche ;
ü Niveau 1
Niveau 2
Données
Messages
Réponse
Client
Serveur
Requête
http,
Fichier,
SQL ...
La réalisation de l'appropriation des applications par
l'utilisateur.
Figure 2.1. Architecture à Deux-Tiers
Jusqu'alors une majorité d'application web pouvait se
ramener à une architecture à deux niveaux, avec d'un
côté un client (dans la plupart des cas un navigateur) et de
l'autre côté un serveur web. Les deux communiquant au travers du
protocole http. Les insuffisances de ce modèle sont les suivants
:
· L'expérience a démontré qu'il
était coûteux et contraignant de vouloir faire l'ensemble des
traitements applicatifs par le poste client. On en arrive à un client
lourd.
· On ne peut pas soulager la charge du poste client, qui
supporte la grande majorité des traitements applicatifs.
· Les mises à jour régulières pour
répondre au besoin des utilisateurs.
· Les applications se prêtent assez mal aux fortes
montées en charge car il est difficile de modifier l'architecture
initiale.
· La relation étroite qui existe entre le
programme client et l'organisation de la partie serveur complique les
évolutions de cette dernière.
· Ce type d'architecture et grandement rigidifié
par les coûts et la complexité de sa maintenance.
II.2.3. ARCHITECTURE À
TROIS-TIERS
Pour faire face au tournant évoqué dans le
système 2-tiers et pour répondre à des exigences de
sécurité par exemple celles demandées par des applications
prenant en charge des électeurs ou aux transactions électorales
depuis le domicile, on assiste de plus en plus au déploiement
d'architectures n-tiers où n'est généralement égal
à trois.
Niveau 1
Niveau 2
Données
Messages
Réponse
Client
Serveur d'application
Requête
http,
Fichier,
SQL ...
Niveau 3
Serveur de Base de données
Ces architectures 3-tiers se distinguent, comme leur nom le
laisse entendre, trois niveaux. Celui dit de présentation (niveau 1),
celui dit de logique applicative (niveau 2) et celui des données (niveau
3), nous pouvons le comprendre par la figure ci-après :
Figure 2.2. Architecture à trois-tiers
a) Le premier niveau est chargé de gérer la
logique de navigation à l'aide de composants de
présentation ;
b) Le deuxième regroupe un ensemble de composants
gérant la logique métier dans un serveur dit
d'application ;
c) Le troisième abrite les données des
systèmes existants.
CHAPITRE III : REPLICATION
[6][8][9][10][11][12][13]
III.1. INTRODUCTION AUX
REPLICATIONS
Le terme « réplication » a
été emprunté à la biologie. On aurait pu dire
simplement « duplication ». Dans le jargon informatique en
général, et dans celui des bases de données en
particulier, ce terme désigne un mécanisme de copie automatique
d'une base de données vers une autre, permettant de rapprocher des
données de l'utilisateur, dans un système distribué.
La réplication utilise la technologie de base de
données distribuée pour partager les données entre
multiples sites mais une base de données répliquée et une
base de données distribuée sont différentes. Pour les
bases de données distribuées, les données sont disponibles
à plusieurs endroits mais une table particulière réside
à un seul site. La réplication signifie que les mêmes
données sont disponibles à multiples endroits.
III.2. AVANTAGES ET
DESAVANTAGES
La réplication présente des avantages
différents selon le type de réplication et les options choisies,
mais l'intérêt général de la réplication est
la disponibilité des données à tout moment et en tout
lieu.
Les autres avantages sont les suivants :
· Possibilité pour plusieurs sites de conserver
des copies des mêmes données. Cela est utile lorsque plusieurs
sites ont besoin de lire les mêmes données ou requièrent
des serveurs différents pour les applications de création de
rapport.
· Autonomie accrue. Les utilisateurs peuvent manipuler
des copies de données hors connexion, puis propager leurs modifications
aux autres bases de données lorsqu'ils sont connectés.
· Davantage de méthodes pour accéder aux
données, comme l'exploration de données à l'aide
d'applications Web par exemple.
· Amélioration des performances de lecture des
agrégats.
· Rapprochement des données par rapport aux
utilisateurs individuels ou aux groupes. Cela permet de réduire les
conflits liés aux modifications de données et requêtes
impliquant plusieurs utilisateurs. En effet, les données peuvent
être distribuées sur l'ensemble du réseau et
partitionnées en fonction des besoins des différents utilisateurs
ou unités de l'entreprise.
· Utilisation de la réplication dans le cadre
d'une stratégie de serveur en attente personnalisée. La
réplication est l'une des options de la stratégie de serveur en
attente.
Parmi les autres options disponibles dans certains SGBD,
figurent l'envoi de journaux et la gestion de clusters avec basculement qui
fournissent des copies des données en cas de défaillance d'un
serveur.
La mise à jour des bases de données des
électeurs se fait manuellement en ce moment. Pour ce faire, à la
fin de chaque semaine un agent habilité à ce travail est
obligé de se déplacer avec les données sur CD-RW pour
aller remettre au siège central pour les mises à jour. Plusieurs
drames sont à prévoir quand même avec un système de
réplication :
ü Consommation élevée des ressources du
serveur suivant la position du distributeur ;
ü Les modifications de schéma peuvent ne pas
être prises en compte suivant le mode de réplication ;
ü Les problèmes de réplication suivants
affectent la performance de vos réseaux :
Volume et taille usuelle des données circulant sur le
réseau.
Nombre d'abonnés à un éditeur
particulier.
Vitesse de la connexion.
Capacité de traitement de l'éditeur, du
distributeur et des abonnés
III.3. DEFINITION
En informatique, la réplication est un processus de
partage d'informations pour assurer la cohérence de données entre
plusieurs sources de données redondantes, pour améliorer la
fiabilité, la tolérance aux pannes ou l'accessibilité.
On parle de réplication de données si les
mêmes données sont dupliquées sur plusieurs
périphériques. Une application de base de données repose
sur un modèle client-serveur. Dans ce modèle, le client se
connecte au SGBD pour passer des ordres. Ces ordres sont de deux natures :
lecture (on parle alors de requêtes) ou mise
à jour (on parle alors de transactions). Pour les transactions,
il y a une modification des données sur le serveur, mais cela reste des
ordres de courte durée.
A l'inverse, dans le cas d'une lecture, il n'y a pas de
modification des données mais les traitements peuvent être longs
et porter sur une grande masse de données. On comprend donc
aisément que, dans le cadre d'un site web par exemple, un nombre
important de requêtes peut surcharger partiellement (ou
complètement) le serveur. Il existe plusieurs solutions pour
remédier à ce genre de problèmes et, ça tombe bien,
la réplication en est une.
La réplication n'est pas à confondre avec une
sauvegarde : les données sauvegardées ne changent pas dans le
temps, reflétant un état fixe des données, tandis que les
données répliquées évoluent sans cesse à
mesure que les données sources changent.
La réplication est aussi considérée comme
la capacité à maintenir à jour une base de données
distribuée sur plusieurs machines reliées en réseau, en
recopiant à intervalles réguliers des morceaux ou
l'intégralité de la base d'une machine à l'autre.
Plusieurs méthodes de réplication existent selon la configuration
matérielle présente.
III.4. PRINCIPES DE LA
REPLICATION
L'objectif principal de la réplication est de faciliter
l'accès aux données en augmentant la disponibilité. Soit
parce que les données sont copiées sur différents sites
permettant de répartir les requêtes, soit parce qu'un site peut
prendre la relève lorsque le serveur principal s'écroule.
Une autre application tout aussi importante est la
synchronisation des systèmes embarqués non connectés en
permanence. Ce qui peut se résumer à l'aide des trois types de
scénario suivants :
ü Deux serveurs distants sur lesquels les données
doivent être consistantes ;
ü Deux serveurs, un comme serveur principal, l'autre
comme serveur de backup à chaud ;
ü Plusieurs serveurs en cluster utilisés pour de
l'équilibrage de charge et de la tolérance à la panne.
Le principe de la réplication, qui met en jeu au
minimum deux SGBD, est assez simple et se déroule en trois temps :
· La base « maître » reçoit un
ordre de mise à jour (INSERT, UPDATE ou DELETE).
· Les modifications faites sur les données sont
détectées et stockées (dans une table, un fichier, une
queue) en vue de leur propagation.
· Un processus de réplication prend en charge la
propagation des modifications à faire sur une seconde base dite esclave.
Il peut bien entendu y avoir plus d'une base esclave.
Bien entendu, il est tout à fait possible de faire de
la réplication dans les deux sens (de l'esclave vers le maître et
inversement). On parlera dans ce cas-là de réplication
bidirectionnelle ou symétrique.
Dans le cas contraire la réplication est
unidirectionnelle (seulement du maître vers l'esclave) et on parle de
réplication en lecture seule ou asymétrique.
De plus, la réplication peut être faite de
manière synchrone ou asynchrone. Dans le premier cas, la
résolution des conflits éventuels entre deux sites intervient
avant la validation des transactions ; Dans le second cas, la résolution
est faite dans des transactions séparées. Il est donc possible
d'avoir quatre modèles de réplication :
ü Réplication asymétrique avec propagation
asynchrone ;
ü Réplication asymétrique avec propagation
synchrone ;
ü Réplication symétrique avec propagation
asynchrone ;
ü Réplication symétrique avec propagation
synchrone.
Mise à jour synchrone et asynchrone
Jusque-là, nous avons supposé que toute mise
à jour de la base demandée depuis un noeud était
effectuée en temps réel sur les autres noeuds,
c'est-à-dire pour le compte de la même transaction atomique. Ceci
correspond au mode de mise à jour synchrone qui s'avère souvent
trop contraignant pour les applications.
Mise à jour synchrone
C'est le mode de distribution dans lequel toutes les sous
opérations locales effectuées suite à une mise à
jour globale sont accomplies pour le compte de la même transaction.
Dans le contexte des copies, ce mode de distribution est
très utile lorsque les mises à jour effectuées sur un site
doivent être prises en compte immédiatement sur les autres sites.
L'avantage essentiel de la mise à jour synchrone est de
garder toutes les données au dernier niveau de mise à jour. Le
système peut alors garantir la fourniture de la dernière version
des données quel que soit la copie accédée.
Les inconvénients sont cependant multiples, ce qui
conduit beaucoup d'application à éviter la gestion de copies
synchrones. Ce sont d'une part, la nécessité de gérer des
transactions multiples coûteuses en ressources et d'autre part, la
complexité des algorithmes de gestion de concurrence et de panne d'un
site. C'est pour cela que l'on préfère souvent le mode de mise
à jour asynchrone (encore appelé mise à jour
différée)
Mise à jour asynchrone
C'est le mode de distribution dans lequel certaines sous
opérations locales effectuées suite à une mise à
jour globale sont accomplies dans des transactions indépendantes en
temps différé. Le temps de mise à jour des copies peut
être plus au moins différé : les transactions de
report peuvent être lancées dès que possible ou à
des instants fixes, par exemple le soir ou en fin de semaine.
Les avantages sont la possibilité de mettre à
jour en temps choisi des données, tout en autorisant l'accès aux
versions anciennes avant la mise à niveau.
Les inconvénients sont bien sûr que
l'accès à la dernière version n'est pas garanti. Ce qui
limite les possibilités des mises à jour.
Technique de diffusion des mises à
jour
La diffusion automatique des mises à jour
appliquée à une copie aux autres copies doit être
assurée par le SGBD réparti. Plusieurs techniques de diffusion
sont possibles parmi lesquelles, on distinguera celles basées sur la
diffusion de l'opération de mise à jour, de celles basées
sur la diffusion du résultat de l'opération.
Diffuser le résultat présente l'avantage de ne
pas devoir ré exécuter l'opération sur le site de la
copie, mais l'inconvénient de nécessité un ordonnancement
identique des mises à jour en tous les sites afin d'éviter les
pertes de mises à jour. Le report d'opération est plus flexible,
notamment dans le cas d'opérations commutatives.
Réplication asymétrique
C'est une technique de gestion de copie basée sur un
site primaire seul autorisé à mettre à jour et
chargé de diffuser les mises à jour aux autres copies dites
secondaire. Le site primaire effectue les contrôles et garantit
l'ordonnancement correct des mises à jour.
A noter que le choix d'une technique asymétrique est
orthogonal au choix d'un mode de diffusion synchrone ou asynchrone des mises
à jour et on peut donc distinguer l'asymétrique synchrone et
l'asymétrique asynchrone.
SITES SECONDAIRES






SITE PRIMAIRE
La première technique est illustrée Fig. 3.1
où un site primaire pousse les mises à jour en temps réel
vers deux sites secondaires. La deuxième est illustrée Fig. 3.2
cette fois, les mises à jour sont poussées en temps
différé via une file persistante. Dans les deux cas, de
problèmes surviennent lorsque le site primaire tombe en panne.
Figure 3.1. Réplication Asymétrique Synchrone


SITES SECONDAIRES




SITE PRIMAIRE
Ici, toute mise à jour est d'abord appliquée au
site maître puis diffusée à temps réel aux sites
secondaires.
Figure 3.2. Réplication Asymétrique Asynchrone
Par contre ici, la mise à jour se s'effectue d'abord au
site primaire puis se diffuse à temps différé aux sites
secondaires.
Un problème de la gestion de copie asymétrique
est donc la panne du site primaire. Dans ce cas, il faut choisir un
remplaçant si l'on veut continuer les mises à jour et celui-ci
peut être fixé par l'administrateur ou élu par un protocole
spécifique de vote majoritaire.
On aboutit alors à une technique asymétrique
mobile dans laquelle le site primaire change dynamiquement selon de
critères qui peuvent être liés à l'application. Le
droit de mise à jour se déplace de site en site par exemple au
fur et à mesure de l'évolution des données.
Réplication symétrique
A l'opposé de la réplication asymétrique
ne privilégie aucune copie. Elle permet les mises à jour
simultanées de toutes les copies par des transactions
différentes.
Réplication symétrique
C'est une technique de gestion de copies ou chaque copie peut
être mise à jour à tous instant et assure la diffusion des
mises à jour aux autres copies.






SITE MAITRE
SITE MAITRE
SITE MAITRE
A noter aussi que le choix d'une technique symétrique
est orthogonal au choix d'un mode de diffusion synchrone ou asynchrone des
mises à jour et on peut donc distinguer la symétrique synchrone
et la symétrique asynchrone.
Figure 3.3. Réplication Symétrique Synchrone






SITE MAITRE
SITE MAITRE
SITE MAITRE
Ici, les mises à jour s'effectuent à partir de
n'importe quel site maitre et se diffusent à temps réel.
Figure 3.4. Réplication Symétrique Synchrone
DEUXIEME PARTIE :
IMPLEMENTATION ET APPLICATION
CHAPITRE IV. PRESENTATION
DE L'ENTREPRISE
I. ANALYSE PREALABLE
I.1. PRÉSENTATION ET
ANALYSE DE LA STRUCTURE DU SYSTÈME (CENI)
Dans cette partie nous aurons à analyser les
informations concernant juste l'organisation structurelle de la CENI telles
que :
ü Historique
ü Situation géographique
ü Objectif
ü Organisation
A. Historique
Depuis son indépendance, le 30 juin 1960, la RDC est
confrontée à des crises politiques récurrentes dont l'une
des causes fondamentales est la contestation de la légitimité des
institutions et de leurs animateurs. Cette contestation a pris un relief
particulier avec les guerres qui ont déchiré le pays de 1996
à 2003.
En vue de mettre fin à cette crise chronique de
légitimité et de donner au pays toutes les chances de se
reconstruire, les délégués de la classe politique et de la
société civile, forces vives de la Nation, réunies en
Dialogue inter congolais, ont convenu, dans l'Accord Global et inclusif
signé à Pretoria en Afrique du Sud le 17 décembre 2002, de
mettre en place un nouvel ordre politique, fondé sur une nouvelle
Constitution démocratique sur base de laquelle le peuple congolais
puisse choisir souverainement ses dirigeants, au terme des élections
libres, pluralistes, démocratiques, transparentes et
crédibles.
A l'effet de matérialiser la volonté politique
ainsi exprimée par les participants au Dialogue inter congolais, le
sénat, issu de l'Accord Global et inclusif précité, a
déposé, conformément à l'article 104 de la
Constitution de la transition, un avant-projet de la nouvelle Constitution
à l'Assemblée nationale qui l'a adopté sous forme de
projet de Constitution soumis au référendum populaire.
La Constitution ainsi approuvée s'articule pour
l'essentiel autour des idées forces ci-après :
1. DE L'ETAT ET DE LA SOUVERAINETE
Dans le but d'une part, de consolider l'unité nationale
mise à mal par des guerres successives et, d'autre part, de créer
des centres d'impulsion et de développement à la base, le
constituant a structuré administrativement l'Etat congolais en 25
provinces plus la ville de Kinshasa dotées de la personnalité
juridique et exerçant des compétences de proximité
énumérées dans la présente Constitution.
En sus de ces compétences, les provinces en exercent
d'autres concurremment avec le pouvoir central et se partagent les recettes
nationales avec ce dernier respectivement à raison de 40 et de 60%.
En cas de conflit de compétence entre le pouvoir
central et les provinces, la cour constitutionnelle est la seule
autorité habilitée à les départager. Au demeurant,
les provinces sont administrées par un Gouvernement provincial et une
Assemblée provinciale. Elles comprennent, chacune, des entités
territoriales décentralisées qui sont la ville, la commune, le
secteur et la chefferie.
Par ailleurs, la présente Constitution réaffirme
le principe démocratique selon lequel tout pouvoir émane du
peuple en tant que souverain primaire.
Ce peuple s'exprime dans le pluralisme politique garanti par
la Constitution qui érige, en infraction de haute trahison,
l'institution d'un parti unique.
En ce qui concerne la nationalité, le constituant
maintient le principe de l'unicité et de l'exclusivité de la
nationalité congolaise.
2. DES DROITS HUMAINS, DES LIBERTES FONDAMENTALES ET
DES DEVOIRS DU CITOYEN ET DE L'ETAT
Le constituant tient à réaffirmer l'attachement
de la RDC aux Droits humains et aux libertés fondamentales tels que
proclamés par les instruments juridiques internationaux auxquels elle a
adhéré. Aussi, a-t-il intégré ces droits et
libertés dans le corps même de la Constitution? A cet
égard, répondant aux signes du temps, l'actuelle Constitution
introduit une innovation de taille en formalisant la parité
homme-femme.
3. DE L'ORGANISATION ET DE L'EXERCICE DU
POUVOIR
Les nouvelles institutions de la République
Démocratique du Congo sont :
ü Le Président de la République ;
ü Le Parlement ;
ü Le Gouvernement ;
ü Les Cours et Tribunaux ;
Les préoccupations majeures qui président
à l'organisation de ces institutions sont les suivantes :
1. Assurer le fonctionnement harmonieux des institutions de
l'Etat ;
2. Eviter les conflits ;
3. Instaurer un Etat de droit ;
4. Contrer toute tentative de dérive
dictatoriale ;
5. Garantir la bonne gouvernance ;
6. Lutter contre l'impunité ;
7. Assurer l'alternance démocratique ;
C'est pourquoi non seulement le mandat du Président de
la République n'est renouvelable qu'une seule fois, mais aussi, il
exerce ses prérogatives de garantir de la Constitution, de
l'indépendance nationale, de l'intégrité territoriale, de
la souveraineté nationale, du respect des accords et traités
internationaux ainsi que celles de régulateur et d'arbitre du
fonctionnement normal des institutions de la République avec
l'implication du Gouvernement sous le contrôle du Président.
Les actes réglementaires qu'il signe dans les
matières relevant du Gouvernement ou sous gestion ministérielle
sont couverts par le contreseing du Premier ministre qui en endosse la
responsabilité devant l'Assemblée nationale.
Bien plus, les affaires étrangères, la
défense et la sécurité, autrefois domaines
réservés du Chef de l'Etat, sont devenues des domaines de
collaboration.
Cependant, le Gouvernement, sous l'impulsion du Premier
ministre, demeure le maitre de la conduite de la politique de la Nation qu'il
définit en concertation avec le Président de la
République.
Il est comptable de son action devant l'Assemblée
nationale qui peut le sanctionner collectivement par l'adoption d'une motion de
censure.
L'Assemblée nationale peut, en outre, mettre en cause
la responsabilité individuelle des membres du Gouvernement par une
motion de défiance.
Réunis en congrès, l'Assemblée nationale
et le Sénat ont la compétence de déférer le
Président de la République et le Premier ministre devant la cour
constitutionnelle, notamment pour haute trahison et délit
d'initié.
Par ailleurs, tout en jouissant du monopole du pouvoir
législatif et du contrôle du Gouvernement, les parlementaires ne
sont pas au-dessus de la loi ; leurs immunités peuvent être
levées et l'Assemblée nationale peut être dissoute par le
Président de la République en cas de crise persistante avec le
Gouvernement.
La présente Constitution réaffirme
l'indépendance du pouvoir judiciaire dont les membres sont
gérés par le Conseil supérieur de la magistrature
désormais composé des seuls magistrats.
Pour plus d'efficacité, de spécialité et
de célérité dans le traitement des dossiers, les cours et
tribunaux ont été éclatés en trois ordres
juridictionnels :
ü Les juridictions de l'ordre judiciaire placées
sous le contrôle de la cour de cassation ;
ü Celles de l'ordre administratif coiffées par le
Conseil d'Etat ;
ü La cour Constitutionnelle
Des dispositions pertinentes de la Constitution
déterminent la sphère d'action exclusive du pouvoir central et
des provinces ainsi que la zone concurrente entre les deux échelons du
pouvoir d'Etat.
Pour assurer une bonne harmonie entre les provinces
elles-mêmes d'une part, et le pouvoir central d'autre part, il est
institué une conférence des Gouverneurs présidée
par le Chef de l'Etat et dont le rôle est de servir de conseil aux deux
échelons de l'Etat.
De même, le devoir de solidarité entre les
différentes composantes de la Nation exige l'institution de la Caisse
nationale de péréquation placée sous la tutelle du
Gouvernement.
Compte tenu de l'ampleur et de la complexité des
problèmes de développement économique et social aux quels
la République Démocratique du Congo est confrontée, le
constituant crée le conseil économique et social, dont la mission
est de donner des avis consultatifs en la matière au Président de
la République, au Parlement et au Gouvernement.
Pour garantir la démocratie en République
Démocratique du Congo, la présente Constitution retient deux
institutions d'appui à la démocratie, à savoir la
Commission Electorale Nationale et Indépendante chargée de
l'organisation du processus électoral de façon de permanente et
le Conseil supérieur de l'audiovisuel et de la communication dont la
mission est d'assurer la liberté et la protection de la presse ainsi que
tous les moyens de communication des masses dans le respect de la loi.
4. DE LA REVISION CONSTITUTIONNELLE
Pour préserver les principes démocratiques
contenus dans la présente Constitution contre les aléas de la vie
politique et les révisions intempestives, les dispositions relatives
à la forme républicaine de l'Etat, au principe du suffrage
universel, à la forme représentative du Gouvernement au nombre et
à durée des mandats du Président de la République,
à l'indépendance du pouvoir judiciaire, au pluralisme politique
et syndical ne peuvent faire l'objet d'aucune révision
constitutionnelle. Telles sont les lignes maîtresses qui
caractérisent la présente Constitution.
B. Situation géographique
La Commission Electorale Nationale et Indépendante est
située dans la ville province de Kinshasa, précisément sur
le boulevard du 30 juin occupe maintenant le bâtiment ex. BCCE en face de
l'ONATRA et à proximité de la gare centrale.
C. Objectif
La Commission Electorale Nationale et Indépendante
comme toute autre entreprise a comme objectif de permettre à la
population de s'enrôler pour avoir une carte d'identité principale
appelée « Carte d'électeur » et d'organiser
les élections dans le pays.
D. Organisation
1. Tableau des anciennes provinces et nouvelles
provinces
|
Anciennes Provinces
|
Nouvelles Provinces
|
|
1. Kinshasa
|
Kinshasa
|
|
2. Bas-Congo
|
Kongo central
|
|
3. Bandundu
|
Kwango
|
|
Kwilu
|
|
Mai-Ndombe
|
|
4. Equateur
|
Equateur
|
|
Nord-Ubangi
|
|
Sud-Ubangi
|
|
Mongala
|
|
Tshuapa
|
|
5. Province Orientale
|
Tshopo
|
|
Bas-Uele
|
|
Haut-Uele
|
|
Ituri
|
|
6. Nord-Kivu
|
Nord-Kivu
|
|
7. Sud-Kivu
|
Sud-Kivu
|
|
8. Maniema
|
Maniema
|
|
9. Katanga
|
Haut-Katanga
|
|
Haut-Lomami
|
|
Lualaba
|
|
Tanganika
|
|
10. Kasaï-Oriental
|
Kasaï-Oriental
|
|
Sankuru
|
|
Lomami
|
|
11. Kasaï-Occidental
|
Kasaï
|
|
Kasaï-Central
|
2. Les Organigrammes de la CENI
a) ORGANIGRAMME DU CNT
Directeur
Directeur Adjoint
Assistant Administratif
Assistant logistique
Programmation
Superviseur
Opérations
Administration Système et Réseau
Administration Base de Données
Technicien Support
DBA
Administrateur Système et Réseau
Programmeurs
Programmeurs
Technicien d'appui
DBA
Technicien Support
Webmaster
Superviseur Technicien d'appui
b) ORGANIGRAMME DE LA CENI
SEP
SEP
SEP
ANTENNE
ANTENNE
ANTENNE
BUREAU
SEN
c) ORGANIGRAMME DU BUREAU DE LA CENI
Président
Vice-Président
Rapporteur
Questeur Adjoint
Questeur
2ème Rapporteur Adjoint
1er Rapporteur Adjoint
d) ORGANIGRAMME DU SEN
SEN
SENA
Assistant
Dir. Fin
Télécom
Sensibilisation
Dir. Cab
Formation
CNT
Dir. Adm
Dir. Ops
I.2. DESCRIPTION DES
ACTIVITÉS
a. Activité dans l'enceinte du Centre
d'inscription (CI)
Le Président du Centre d'inscription et l'un de ses
opérateurs de saisie établissent des jetons
numérotés à un ordre croissant des nombres qui seront
remis aux différents candidats qui se présenteront pour
s'enrôler.
Le Requérant à son tour dès qu'il arrive
dans le Centre d'inscription, se place sur la file d'attente en attendant qu'on
lui remette le jeton.
Dès qu'il reçoit son jeton
numéroté, il attend qu'on appelle son numéro et dès
que se fait, il peut aller s'asseoir dans la salle pour attendre à se
faire enrôler.
b. Activité dans le Centre
d'inscription
Le Requérant entre dans la salle, présente sa
pièce d'identité (ancienne carte d'électeur ou toutes
autres cartes pièces validées par la CENI) à
l'opérateur de saisie. Si c'est une ancienne carte d'électeur
prouvant qu'il était déjà enrôlé alors
ça sera pour lancer directement la recherche des informations à
partir du numéro de la carte ou des autres champs.
Dans le cas contraire, ça sera pour un nouveau
processus d'enrôlement, en enregistrant étape par étape les
informations du requérant nom, post-nom, prénom, etc.
jusqu'à sortir la carte.
II. Etude de
l'Opportunité
II.1. Besoin d'un
système de réplication
La mise à jour de la base de données au niveau
du siège central se fait hebdomadairement c.-à-d. qu'à la
fin de chaque semaine (7 jours), on est obligé de graver des
données sur CD-RW et il y a des personnes habilitées à
ramener les CD-RW gravés au siège central en ville. Il se pose
alors un sérieux problème dans le cas où on ignorait que
la gravure n'a pu réussir ou le CD-RW a été abimé
ou encore lorsqu'il arrive que le support a été perdu et puis le
fichier comportant les mises à jour de la base de données
étant sous PostgreSQL qui est un SGBD libre téléchargeable
par tout le monde sur internet, une personne connaissant que la CENI utilise
comme SGBD PostgreSQL peut le télécharger pour enfin avoir la
possibilité d'ouverture et de faire n'importe quoi. Pour plus
d'efficacité, il faudra donc penser à une nouvelle méthode
pour obtenir les données provenant des sites.
Il convient aussi de prendre en compte la force et la
gravité d'un incident comme critère à intégrer dans
le processus de haute disponibilité. Il n'est pas toujours possible, de
prendre en compte tous les incidents sans tenir compte du coût ou de la
logistique globale de mise en oeuvre de la solution de dépannage.
I. Topologie de la Configuration de la
Réplication
Serveur 2
Serveur 3
Serveur 1
Siège Central
Figure 4.1. Topologie de la Configuration de la
Réplication
Dans notre travail, nous avons choisis de configurer une
réplication symétrique asynchrone des sites locaux vers le
siège central et une réplication symétrique asynchrone
entre les sites locaux suite aux données volumineuses qui seront
stockées dans la base lors des opérations d'identification et
d'enrôlement des électeurs. En fait, l'idée est de placer
entre les sites les plus rapprochés un serveur à partir duquel,
ils vont commencer à y accéder par une application cliente pour
enregistrement et autres opérations dans la base.
CHAPITRE V. IMPLEMENTATION
DU SYSTEME ET APPLICATION [6][7]
V. 1. Conception d'une
base de données étape conceptuelle
Cette étape a pour but de recenser les entités
conceptuelles (objets, associations), la détermination des règles
d'intégrité et la production du modèle conceptuel.
V. 1. 1. RECENSEMENT DES
OBJETS / ENTITÉS
1. Personnes
2. Adresse
3. Categories
4. Village
5. Groupement
6. Secteur
7. Territoire
8. Nvelle_province
9. Province
10. Centre_enrolement
Après notre analyse sur terrain, nous avons pu retenir
dix entités pour constituer notre base de données globale. Ces
différentes entités sont les suivantes :
V. 1. 2. RECENSEMENT DES
ASSOCIATIONS
Pour réaliser notre base de données globale,
nous avons retenu les suivantes ci-après :
1. S'enrôler
2. Contenir (1, 2, 3, 4)
3. Correspondre
4. Retrouver
5. Provenir
6. Habiter
7. Comporter
V. 1. 3. DESCRIPTION DES
ATTRIBUTS
Nous décrivons les attributs par à leurs objets
et leurs associations
|
Objets
|
Nom des Propriétés
|
Abréviations
|
Identifiants
|
|
Personnes
|
Code de la Personne
Nom de la Personne
Post nom de la Personne
Prénom de la Personne
Sexe de la Personne
Sa Date de naissance
Nom de son Père
Nom de la Mère
Photo de la Personne
Son Empreinte digitale droite
Son Empreinte digitale gauche
|
# Code_pers
Nom
Post_nom
Prénom
Sexe
Datenais
Nom_pere
Nom_mere
Photo
Empr_droit
Empr_gauch
|
OK
|
|
Categories
|
Code de la Categorie
Description de l'adresse
|
# Code_cat
Description
|
OK
|
|
Adresse
|
Code de l'adresse
Description de l'adresse
|
# Code_adr
Description
|
OK
|
|
Centre_enrol
|
Code du Centre d'enrôlement
Description du Centre
|
# Code_ce
Description
|
OK
|
|
Provinces
|
Code de la Province
Description de la Province
|
# Code_prov
Description
|
OK
|
|
Nvel_provinces
|
Code de la Nouvelle Province
Description de la N_Province
|
#Code_nprov
Description
|
OK
|
|
Territoire
|
Code du Territoire
Description du Territoire
Type = « Territoire »
/ « Ville »
|
# Code_tv
Description
Type
|
OK
|
|
Groupement
|
Code du Groupement
Description du Groupement
Type= « Groupement » /
« Quartier »
|
# Code_qg
Description
Type
|
OK
|
|
Secteur
|
Code du Secteur
Description du Secteur
Type= « Chefferie » /
« Cité » / « Secteur »
/ « Commune »
|
# Code_scc
Description
Type
|
OK
|
|
Village
|
Code du Village
Description du Secteur
|
# Code_villa
Description
|
OK
|
V. 1. 4. CONSTRUCTION DU
MODÈLE CONCEPTUEL DE DONNÉES
Nous présentons maintenant le modèle conceptuel
de données conçu à partir des entités et
associations prélevées :
Personnes (# Code_Pers, Nom, Post-nom,
Prénom, Sexe, Datenais, Nom_pere, Nom_mere, Photo, Empr_droit,
Empr_gauche, Date_enrol)
Adresse (# Code_adr, Description)
Categories (# Code_cat, Description)
Village (# Code_villa, Description, Code_adr,
Code_group)
Secteur (# Code_sect, Description, Type)
Territoire (# Code_territ, Description,
Type)
Groupement (# Code_group, Description,
Type)
Nvel_province (#Code_nprov, Description)
Province (#Code_prov, Description)
Centre_enrol (#Code_ce, Description,
President)
Centre_enrol (# Code_ce, Description)
|
Territoire/Ville
|
|
#Code_tv
Description
Type
|
|
Groupement/Quartier
|
Contenir 1
Type
|
|
Secteur/Chefferie/Commune
|
|
#Code_scc
Description
Type
|
|
Personnes
|
|
#Code_pers
Nom
Postnom
Prenom
Sexe
Datenais
Nom_pere
Nom_mere
Photo
Empr_droit
Empr_gauch
Date_enrol
|
|
Nvel_province
|
|
#Code_nprov
Description
|
|
Categories
|
|
#Code_cat
Description
|
|
Adresse
|
|
#Code_adr
Description
|
|
Provinces
|
|
#Code_prov
Description
|
|
1, N
|
|
1, 1
|
|
Centre_enrol
|
|
#Code_ce
Description
President
|
|
1, 1
|
|
1, N
|
S'enrôler
Contenir 2
Contenir 3
|
1, 1
|
|
1, N
|
|
1, N
|
|
1, N
|
|
1, 1
|
|
1, N
|
|
1, 1
|
|
1, N
|
|
1, 1
|
|
1, 1
|
|
1, N
|
|
1, N
|
|
1, N
|
|
1, N
|
|
Village
|
|
#Code_villa
Description
|
|
1, 1
|
|
1, N
|
|
1, 1
|
|
1, 1
|
|
1, N
|
Comporter
Habiter
Correspondre
Retrouver
Provenir
Contenir 4
|
Groupement/Quartier
|
|
#Code_qg
Description
Type
Code_scc
|
|
Secteur/Chefferie/Commune
|
|
#Code_scc
Description
Type
Code_tv
|
|
Categories
|
|
#Code_cat
Description
Code_adr
|
|
Centre_enrol
|
|
#Code_ce
Description
President
Code_scc
Code_tv
Code_adr
Code_qg
|
|
Personnes
|
|
#Code_pers
Nom
Postnom
Prenom
Sexe
Datenais
Nom_pere
Nom_mere
Photo
Empr_droit
Empr_gauch
Date_enrol
Code_villa
Code_cat
Code_ce
|
|
Comporter
Provenir
Habiter
Correspondre
|
Territoire/Ville
|
|
#Code_tv
Description
Type
Code_nprov
|
|
Nvel_province
|
|
#Code_nprov
Description
Code_prov
|
|
Provinces
|
|
#Code_prov
Description
|
|
Village
|
|
#Code_villa
Description
Code_qg
|
|
Adresse
|
|
#Code_adr
Description
|
V. 1. 5. CONSTRUCTION DU
MODÈLE PHYSIQUE DE DONNÉES
Pour une base de données, nous distinguons
clairement deux choses : sa structure et son contenu.
Le schéma d'une base de données est
défini par sa structure en terme de ses tables, leurs colonnes avec le
type de valeurs, leurs identifiants primaires et secondaires, les contraintes
référentielles.
Personnes
|
Nom du Champ
|
Type de données
|
Taille
|
Observations
|
|
# Code_Pers
|
Alphanumérique
|
10
|
Clé primaire
|
|
Nom
|
Alphanumérique
|
20
|
|
|
Post-nom
|
Alphanumérique
|
20
|
|
|
Prénom
|
Alphanumérique
|
20
|
|
|
Sexe
|
Alphanumérique
|
20
|
|
|
Datenais
|
Alphanumérique
|
20
|
|
|
Nom_pere
|
Alphanumérique
|
20
|
|
|
Nom_mere
|
Alphanumérique
|
20
|
|
|
Photo
|
Image
|
|
|
|
Empr_droit
|
Image
|
|
|
|
Empr_gauche
|
Image
|
|
|
|
Code_villa
|
Alphanumérique
|
20
|
Clé secondaire
|
|
Code_adr
|
Alphanumérique
|
20
|
Clé secondaire
|
|
Code_cat
|
Alphanumérique
|
20
|
Clé secondaire
|
|
Code_ce
|
Alphanumérique
|
20
|
Clé secondaire
|
|
Date_enrol
|
Date
|
20
|
|
Provinces
|
Nom du Champ
|
Type de données
|
Taille
|
Observations
|
|
Code_prov
|
Alphanumérique
|
10
|
Clé primaire
|
|
Description
|
Aplhanumérique
|
20
|
|
Nvel_provinces
|
Nom du Champ
|
Type de données
|
Taille
|
Observations
|
|
Code_nprov
|
Alphanumérique
|
10
|
Clé primaire
|
|
Description
|
Alphanumérique
|
20
|
|
|
Code_prov
|
Alphanumérique
|
10
|
Clé sécondaire
|
Village
|
Nom du Champ
|
Type de données
|
Taille
|
Observations
|
|
Code_villa
|
Alphanumérique
|
10
|
Clé primaire
|
|
Description
|
Alphanumérique
|
20
|
|
|
Code_qg
|
Alphanumérique
|
10
|
Clé secondaire
|
Groupement
|
Nom du Champ
|
Type de données
|
Taille
|
Observations
|
|
Code_group
|
Alphanumérique
|
10
|
Clé primaire
|
|
Description
|
Alphanumérique
|
20
|
|
|
Type
|
Alphanumérique
|
20
|
|
|
Code_scc
|
Alphanumérique
|
10
|
Clé secondaire
|
Adresse
|
Nom du Champ
|
Type de données
|
Taille
|
Observations
|
|
Code_adr
|
Alphanumérique
|
10
|
Clé primaire
|
|
Description
|
Alphanumérique
|
20
|
|
Categories
|
Nom du Champ
|
Type de données
|
Taille
|
Observations
|
|
Code_cat
|
Alphanumérique
|
10
|
Clé primaire
|
|
Description
|
Alphanumérique
|
20
|
|
|
Code_adr
|
Alphanumérique
|
10
|
Clé secondaire
|
Territoire
|
Nom du Champ
|
Type de données
|
Taille
|
Observations
|
|
Code_tv
|
Alphanumérique
|
10
|
Clé primaire
|
|
Description
|
Alphanumérique
|
20
|
|
|
Type
|
Alphanumérique
|
20
|
|
|
Code_nprov
|
Alphanumérique
|
10
|
Clé secondaire
|
Secteur
|
Nom du Champ
|
Type de données
|
Taille
|
Observations
|
|
Code_sect
|
Alphanumérique
|
10
|
Clé primaire
|
|
Description
|
Alphanumérique
|
20
|
|
|
Type
|
Alphanumérique
|
20
|
|
|
Code_territ
|
Alphanumérique
|
10
|
Clé secondaire
|
Centre_enrol
|
Nom du Champ
|
Type de données
|
Taille
|
Observations
|
|
Code_ce
|
Alphanumérique
|
10
|
Clé primaire
|
|
Description
|
Alphanumérique
|
20
|
|
|
Président
|
Alphanumérique
|
20
|
|
|
Code_scc
|
Alphanumérique
|
10
|
Clé secondaire
|
|
Code_adr
|
Alphanumérique
|
10
|
Clé secondaire
|
|
Code_tv
|
Alphanumérique
|
10
|
Clé secondaire
|
|
Code_qg
|
Alphanumérique
|
10
|
Clé secondaire
|
V.1. Application et
Implémentation du Système
Dans cette partie du travail, nous avons choisis comme
Système de gestion de base de données réparties pour la
configuration de notre réplication, le SQL Server Management Studio 2008
et comme outil d'application cliente un des produits de Microsoft Visual Studio
qui est le C Sharp (C#).
Code de génération de la Base de
données Globale
USE [CENI-KIN]
GO
/****** Object: Table [dbo].[Centre_enrol] Script Date:
02/21/2012 12:09:17 ******/
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
SET ANSI_PADDING ON
GO
CREATE TABLE [dbo].[Centre_enrol](
[code_ce] [varchar](10) NOT NULL,
[description] [varchar](20) NULL,
[president] [varchar](20) NULL,
[code_qg] [varchar](10) NULL,
[code_adr] [varchar](10) NULL,
[code_scc] [varchar](10) NULL,
[code_tv] [varchar](50) NULL,
CONSTRAINT [PK_Centre_enrol] PRIMARY KEY CLUSTERED
(
[code_ce] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF,
IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON
[PRIMARY]
) ON [PRIMARY]
GO
SET ANSI_PADDING OFF
GO
/****** Object: Table [dbo].[Categorie] Script Date:
02/21/2012 12:09:17 ******/
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
SET ANSI_PADDING ON
GO
CREATE TABLE [dbo].[Categorie](
[code_cat] [varchar](10) NOT NULL,
[description] [varchar](20) NULL,
[code_adr] [nchar](10) NULL,
CONSTRAINT [PK_Adresse_Urbaine] PRIMARY KEY CLUSTERED
(
[code_cat] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF,
IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON
[PRIMARY]
) ON [PRIMARY]
GO
SET ANSI_PADDING OFF
GO
/****** Object: Table [dbo].[Adresse] Script Date:
02/21/2012 12:09:17 ******/
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
SET ANSI_PADDING ON
GO
CREATE TABLE [dbo].[Adresse](
[code_adr] [varchar](10) NOT NULL,
[description] [varchar](20) NULL,
CONSTRAINT [PK_Adresse_Rurale] PRIMARY KEY CLUSTERED
(
[code_adr] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF,
IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON
[PRIMARY]
) ON [PRIMARY]
GO
SET ANSI_PADDING OFF
GO
/****** Object: Table [dbo].[Province] Script Date:
02/21/2012 12:09:17 ******/
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
SET ANSI_PADDING ON
GO
CREATE TABLE [dbo].[Province](
[code_prov] [varchar](10) NOT NULL,
[description] [varchar](20) NULL,
CONSTRAINT [PK_Province] PRIMARY KEY CLUSTERED
(
[code_prov] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF,
IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON
[PRIMARY]
) ON [PRIMARY]
GO
SET ANSI_PADDING OFF
GO
/****** Object: Table [dbo].[Personnes] Script Date:
02/21/2012 12:09:17 ******/
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
SET ANSI_PADDING ON
GO
CREATE TABLE [dbo].[Personnes](
[matr] [varchar](25) NOT NULL,
[nom] [varchar](20) NULL,
[postnom] [varchar](20) NULL,
[prenom] [varchar](20) NULL,
[sexe] [varchar](20) NULL,
[datenais] [varchar](20) NULL,
[nom_pere] [varchar](20) NULL,
[nom_mere] [varchar](20) NULL,
[date_enrol] [varchar](20) NULL,
[lieu] [varchar](50) NULL,
[photo] [image] NULL,
[empr_droit] [image] NULL,
[empr_gauch] [image] NULL,
[code_adr] [varchar](10) NULL,
[code_villa] [varchar](10) NULL,
[code_ce] [varchar](10) NULL,
[code_cat] [varchar](10) NULL,
CONSTRAINT [PK_Personnes] PRIMARY KEY CLUSTERED
(
[matr] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF,
IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON
[PRIMARY]
) ON [PRIMARY] TEXTIMAGE_ON [PRIMARY]
GO
SET ANSI_PADDING OFF
GO
/****** Object: Table [dbo].[Nvel_Province] Script Date:
02/21/2012 12:09:17 ******/
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
SET ANSI_PADDING ON
GO
CREATE TABLE [dbo].[Nvel_Province](
[code_nprov] [varchar](10) NOT NULL,
[description] [varchar](20) NULL,
[code_prov] [varchar](10) NULL,
CONSTRAINT [PK_Nvel_Province] PRIMARY KEY CLUSTERED
(
[code_nprov] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF,
IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON
[PRIMARY]
) ON [PRIMARY]
GO
SET ANSI_PADDING OFF
GO
/****** Object: Table [dbo].[Territoire] Script Date:
02/21/2012 12:09:17 ******/
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
SET ANSI_PADDING ON
GO
CREATE TABLE [dbo].[Territoire](
[code_tv] [varchar](10) NOT NULL,
[description] [varchar](20) NULL,
[type] [varchar](20) NULL,
[code_nprov] [varchar](10) NULL,
CONSTRAINT [PK_Territoire] PRIMARY KEY CLUSTERED
(
[code_tv] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF,
IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON
[PRIMARY]
) ON [PRIMARY]
GO
SET ANSI_PADDING OFF
GO
/****** Object: Table [dbo].[Secteur] Script Date:
02/21/2012 12:09:17 ******/
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
SET ANSI_PADDING ON
GO
CREATE TABLE [dbo].[Secteur](
[code_scc] [varchar](10) NOT NULL,
[description] [varchar](20) NULL,
[type] [varchar](20) NULL,
[code_territ] [varchar](10) NULL,
CONSTRAINT [PK_Secteur] PRIMARY KEY CLUSTERED
(
[code_scc] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF,
IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON
[PRIMARY]
) ON [PRIMARY]
GO
SET ANSI_PADDING OFF
GO
/****** Object: Table [dbo].[Groupement] Script Date:
02/21/2012 12:09:17 ******/
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
SET ANSI_PADDING ON
GO
CREATE TABLE [dbo].[Groupement](
[code_qg] [varchar](10) NOT NULL,
[description] [varchar](20) NULL,
[type] [varchar](20) NULL,
[code_scc] [varchar](10) NULL,
CONSTRAINT [PK_Groupement] PRIMARY KEY CLUSTERED
(
[code_qg] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF,
IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON
[PRIMARY]
) ON [PRIMARY]
GO
SET ANSI_PADDING OFF
GO
/****** Object: Table [dbo].[Village] Script Date:
02/21/2012 12:09:17 ******/
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
SET ANSI_PADDING ON
GO
CREATE TABLE [dbo].[Village](
[code_villa] [varchar](10) NOT NULL,
[description] [varchar](20) NULL,
[code_qg] [varchar](10) NULL,
CONSTRAINT [PK_Village] PRIMARY KEY CLUSTERED
(
[code_villa] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF,
IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON
[PRIMARY]
) ON [PRIMARY]
GO
SET ANSI_PADDING OFF
GO
/****** Object: ForeignKey [FK_Groupement_Secteur] Script
Date: 02/21/2012 12:09:17 ******/
ALTER TABLE [dbo].[Groupement] WITH CHECK ADD CONSTRAINT
[FK_Groupement_Secteur] FOREIGN KEY([code_scc])
REFERENCES [dbo].[Secteur] ([code_scc])
ON UPDATE CASCADE
ON DELETE CASCADE
GO
ALTER TABLE [dbo].[Groupement] CHECK CONSTRAINT
[FK_Groupement_Secteur]
GO
/****** Object: ForeignKey [FK_Nvel_Province_Province]
Script Date: 02/21/2012 12:09:17 ******/
ALTER TABLE [dbo].[Nvel_Province] WITH CHECK ADD CONSTRAINT
[FK_Nvel_Province_Province] FOREIGN KEY([code_prov])
REFERENCES [dbo].[Province] ([code_prov])
ON UPDATE CASCADE
ON DELETE CASCADE
GO
ALTER TABLE [dbo].[Nvel_Province] CHECK CONSTRAINT
[FK_Nvel_Province_Province]
GO
/****** Object: ForeignKey [FK_Secteur_Territoire] Script
Date: 02/21/2012 12:09:17 ******/
ALTER TABLE [dbo].[Secteur] WITH CHECK ADD CONSTRAINT
[FK_Secteur_Territoire] FOREIGN KEY([code_territ])
REFERENCES [dbo].[Territoire] ([code_tv])
ON UPDATE CASCADE
ON DELETE CASCADE
GO
ALTER TABLE [dbo].[Secteur] CHECK CONSTRAINT
[FK_Secteur_Territoire]
GO
/****** Object: ForeignKey [FK_Territoire_Nvel_Province]
Script Date: 02/21/2012 12:09:17 ******/
ALTER TABLE [dbo].[Territoire] WITH CHECK ADD CONSTRAINT
[FK_Territoire_Nvel_Province] FOREIGN KEY([code_nprov])
REFERENCES [dbo].[Nvel_Province] ([code_nprov])
ON UPDATE CASCADE
ON DELETE CASCADE
GO
ALTER TABLE [dbo].[Territoire] CHECK CONSTRAINT
[FK_Territoire_Nvel_Province]
GO
/****** Object: ForeignKey [FK_Village_Groupement] Script
Date: 02/21/2012 12:09:17 ******/
ALTER TABLE [dbo].[Village] WITH CHECK ADD CONSTRAINT
[FK_Village_Groupement] FOREIGN KEY([code_qg])
REFERENCES [dbo].[Groupement] ([code_qg])
ON UPDATE CASCADE
ON DELETE CASCADE
GO
ALTER TABLE [dbo].[Village] CHECK CONSTRAINT
[FK_Village_Groupement]
GO
Images de mes Bases de données et tables ainsi
de ma Configuration
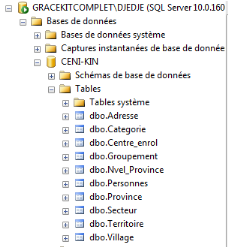
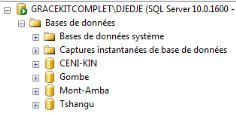
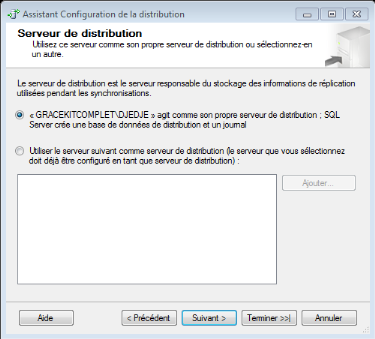
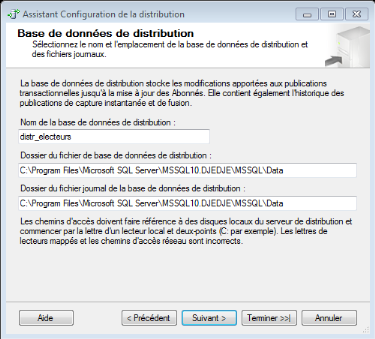
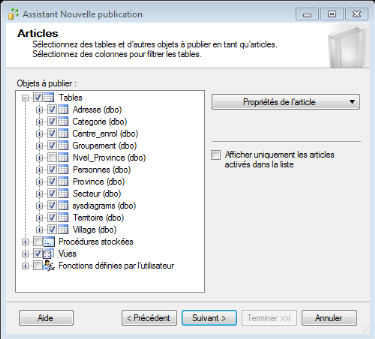
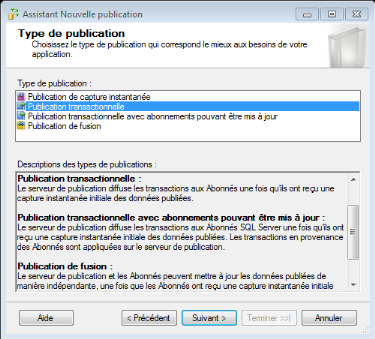
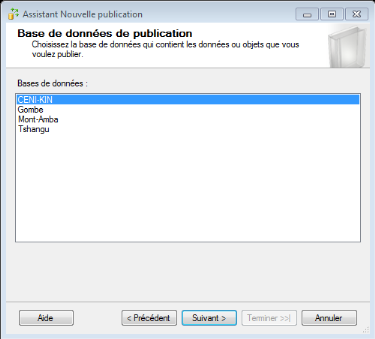
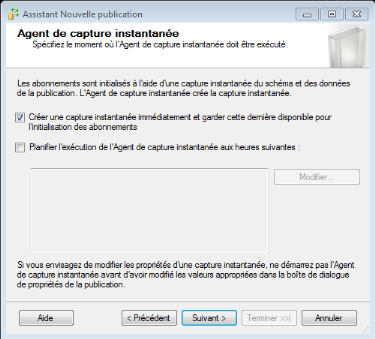
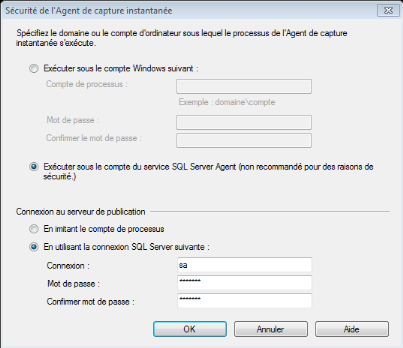
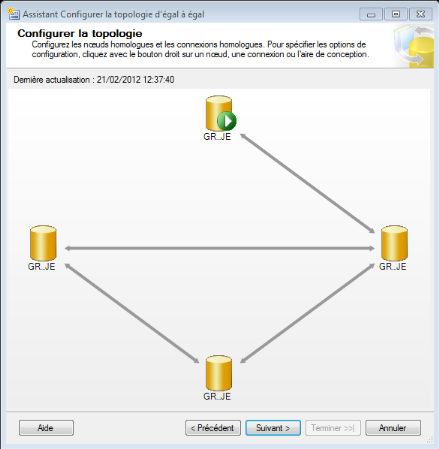
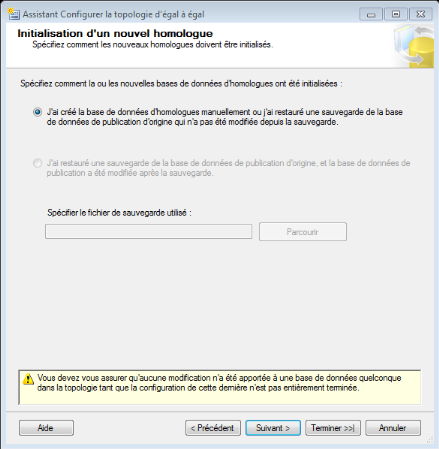
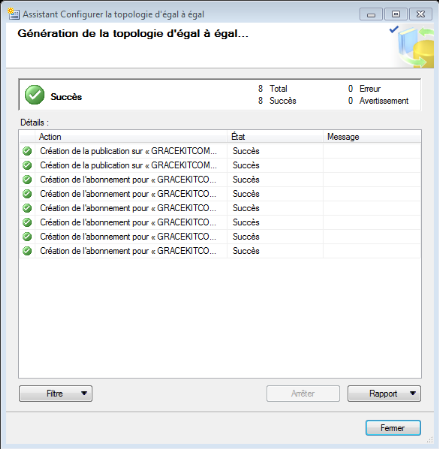
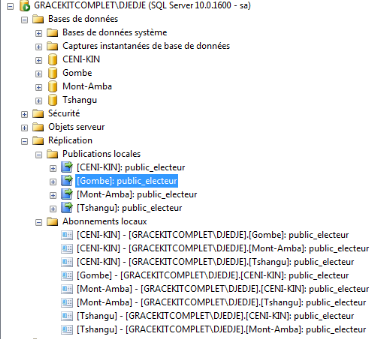
CONCLUSION
Nous voici arrivée au terme de notre étude
portant sur « l'étude de la réplication
symétrique asynchrone dans une base de données répartie.
Application à l'enrôlement des
électeurs » à la direction
générale de la CENI située dans la ville province de
Kinshasa occupant présentement le bâtiment ex. BCCE
précisément sur le boulevard du 30 juin en face de l'ONATRA et
à proximité de la gare centrale.
Nous voyons que la réplication se présente comme
un avantage par rapport à la méthode de mise à jour
utilisée actuellement à la CENI-Kinshasa.
Au-delà des besoins d'investissements
supplémentaires à prévoir pour l'implémentation
réelle de cette solution, la réplication est une
nécessité qui rentre dans la même lignée que celle
de la connexion à établir entre les différents sites pour
l'enregistrement des électeurs.
La réalisation de ce projet résoudra à la
fois des problèmes de sécurité, de disponibilité
des données et sans oublier ceux des doublons, permettrait aux
différents électeurs de voter à n'importe quel endroit et,
obligerait l'Entreprise à établir une connexion entre ses
différents sites d'enrôlement pendant ses opérations
« d'Identification et d'enrôlement des
électeurs ».
Toutefois à ne pas oublier que la mise à niveau
de l'environnement matériel et logiciel est à prévoir car
les versions plus récentes des SGBD et autres logiciels offrent des
outils qui simplifient encore davantage certains traitements.
Quoi qu'il en soit notre travail est une oeuvre humaine qui
contient aussi des faiblesses. C'est pourquoi nous restons attentifs à
toutes les remarques et suggestions possibles venant de vous afin de corriger
pour qu'à la prochaine occasion nous puissions réaliser un bon
travail.
BIBLIOGRAPHIE
I. OUVRAGES
[1] GABILLAUD J.,
« SQL Server 2008, administration d'une Base de
données avec SQL Server Management Studio », Edition ENI Juin
2010.
[2] GARDARIN O. et GEORGES,
« Client - Serveur », Edition Eyrolles, Paris
1996.
[3] GARDARIN O. et GEORGES,
« Base de données - Objet/relationnel », Edition
Eyrolles, Paris 1999.
[4] LEFEBVRE A., « Client -
Serveur, guide de suivi », Edition Armand Colin 1994.
II. NOTES DE COURS
[5] KASENGEDIA MUTUMBE P.,
« Système d'Objet Réparti »,
Université de Kinshasa, année 2010.
[6] MBUYI MUKENDI E., «
Système d'information et Base de données »,
Université de Kinshasa, année 2011.
[7] MBUYI MUKENDI
E., Notes de Cours, Base de Données et SQL, G3 Info,
Université de Kinshasa, année 2009.
III. MEMOIRES ET THESES
[8] Christelle Pierkot,
« Gestion de la Mise à jour de Données
Géographiques Répliquées », Université de
Toulouse, Juillet 2008.
[9] Djedje NKONGOLO, «Réalisation
d'une application de gestion des malades par l'approche base de données.
Cas de la Polyclinique aux bons soins », Université de
Kinshasa, 2009.
[10] Felly Manda, « Etude sur la
mise en place d'un environnement de gestion et de déploiement
collaboratif dans une entreprise à plusieurs succursales. Cas de figure
d'une banque », Université de Kinshasa, année 2010.
IV. ARTICLES SCIENTIFIQUES
[11] A. Luna-Almeida, JP. Briot, J. Mal enfant, S.
Aknine, « Méthode de réplication basée
sur les plans pour la tolérance aux pannes des systèmes
multi-agents », Edition Université de Paris 6.
[12] Lambert SONNA MOMO,
« Réplication et Durabilité dans les
systèmes répartis », Edition, Février 2001.
V. WEBOGRAPHIE
[13]
www.memoireonline.com
(le 23 Août 2011)
[14]
www.wikepedia.com
(le 15 novembre 2011)
[15]
www.commentçamarche.com
(le 02 janvier 2012)
TABLE DES MATIERES
EPIGRAPHIE
I
IN MEMORIAM
II
AVANT - PROPOS
IV
LISTE DES ABREVIATIONS
V
LISTE DES FIGURES
VI
INTRODUCTION
1
1. Généralités
1
2. Problématique
2
3. Hypothèse du Sujet
2
4. Choix du Sujet
2
5. Intérêt du Sujet
3
6. Délimitation du Sujet
3
7. Méthodes et Techniques
utilisées
3
8. Subdivision du Travail
4
CHAPITRE I : BASE DE DONNEES REPARTIES ET
SGBD RÉPARTIS [3][6][7][9]
6
I.1. INTRODUCTION AUX BASES DE DONNEES
6
I.1.1. Définition
6
I.1.2. Caractéristiques d'une base de
données
6
I.1.3. Utilité d'une base de
données
7
I.1.4. Types de base de données
7
I.1.5. Conception d'une base de
données
8
I.2. BASE DE DONNEES REPARTIE
8
I.2.1. Définition
8
I.2.2. Caractéristiques d'une base de
données répartie
10
I.2.3. Conception de la base de données
répartie
10
I.3. Gestion des transactions
19
I.3.1. Introduction
19
I.3.2. Propriétés
20
I.3.3. Différent niveau de fragmentation
de la répartition
21
II. SYSTEME DE GESTION DE BASE DE DONNEES
(SGBD)
22
II.1. Définition
22
II.1.1. Objectif
22
II.1.2. Principe de fonctionnement
23
II.1.3. Type de système de gestion de
base de données
24
III. Système de Gestion de Base de
Données Répartis (SGBDR)
25
III.1. Définition
25
III.2. Fonctions
26
III.3. Remarque
26
CHAPITRE II : ARCHITECTURES CLIENT -
SERVEUR [2][4][5][8][9]
28
II.1. PRESENTATION DE L'ARCHITECTURE CLIENT -
SERVEUR
28
II.1.1. Définition
28
II.1.2. Fonctionnement de l'architecture Client
- Serveur
29
II.2. TYPE D'ARCHITECTURE CLIENT - SERVEUR
30
II.2.1. Architecture à Un - tiers
30
II.2.2. Architecture à Deux - tiers
30
II.2.3. Architecture à Trois-tiers
31
CHAPITRE III : REPLICATION
[6][8][9][10][11][12][13]
33
III.1. INTRODUCTION AUX REPLICATIONS
33
III.2. AVANTAGES ET DESAVANTAGES
33
III.3. DEFINITION
34
III.4. PRINCIPES DE LA REPLICATION
35
CHAPITRE IV. PRESENTATION DE
L'ENTREPRISE
42
I. ANALYSE PREALABLE
42
I.1. Présentation et analyse de la
structure du système (CENI)
42
A. Historique
42
B. Situation géographique
46
C. Objectif
46
D. Organisation
46
I.2. Description des activités
52
II. Etude de l'Opportunité
52
II.1. Besoin d'un système de
réplication
52
CHAPITRE V. IMPLEMENTATION DU SYSTEME ET
APPLICATION [6][7]
54
V. 1. Conception d'une base de données
étape conceptuelle
54
V. 1. 1. Recensement des Objets /
Entités
54
V. 1. 2. Recensement des Associations
54
V. 1. 3. Description des Attributs
55
V. 1. 4. Construction du Modèle
Conceptuel de Données
56
V. 1. 5. Construction du Modèle Physique
de Données
59
V.1. Application et Implémentation du
Système
62
CONCLUSION
74
BIBLIOGRAPHIE
75
TABLE DES MATIERES
77
| 

