2.4 : Méthodologie
2.4.1 : Présentation des données
Les données de la présente étude
proviennent de la troisième Enquête Démographique et de
Santé (EDS-III) au Bénin réalisée en 2006 par
sondage, où ont été interviewés 17675
ménages à base du questionnaire ménage et du questionnaire
communautaire ; 17794 femmes âgées de 15 à 49 ans
à l'aide du questionnaire femme ; 5321 hommes âgés de
15 à 69 ans à l'aide du questionnaire homme. Ces données
sont extraites de la base concernant les femmes principalement de la section
relative à leur grossesse. Précisons que les questions sur les
soins prénatals portent sur la grossesse du dernier enfant né au
cours de la période 2001- 2006.
Qualité des données
Avant toute analyse, il est important d'évaluer la
qualité des données. Pour être acceptable, les
données à utiliser doivent avoir un taux de non-réponse
inférieur à 10 %. Le taux de non-réponse pour les
questions clés (variables) de notre étude est faible. Il est
inférieur à 1% pour certaines variables. On peut alors dire que
les informations collectées sur ces variables sont susceptibles de
permettre la vérification des hypothèses de l'étude.
2.4.2 : Méthodes d'analyse
Dans le cadre de cette étude, nous utiliserons les
méthodes d'analyse descriptive, factorielle et
économétrique.
L'analyse descriptive nous permettra
de faire ressortir l'ampleur du recours aux soins prénatals selon les
différentes caractéristiques de la femme et les aspects
différentiels selon les régions. Cette première partie
concerne l'examen des associations entre chaque variable indépendante et
le recours aux soins prénatals. Il s'agit de produire des tableaux
croisés entre chaque variable indépendante et la variable
dépendante. Cela permet de voir les relations éventuelles entre
ces variables, la mesure du degré d'association qui se fera à
l'aide de la statistique de khi-deux.
Pour l'analyse factorielle, nous
ferons recours à l'Analyse des Correspondances Multiples (ACM).
L'utilisation de l'ACM dans la présente étude est
justifiée par le fait que, la plupart des variables sont qualitatives,
et qu'elle permet d'étudier les relations existantes entre plusieurs
variables à la fois. Elle nous permettra d'étudier les
associations existantes d'une part, entre les variables indépendantes et
la variable dépendante et d'autre part, entre les variables
indépendantes (entre elles), et de ce fait, elle met en évidence
des types d'individus ayant des profils semblables aux attributs choisis pour
leur description.
Principes d'interprétation de l'ACM
Les interprétations s'effectuent à l'aide du
plan factoriel (formés par deux axes) qui explique mieux les relations
entre les modalités insérées dans la méthode. On
interprète :
? La proximité entre individus en terme de
ressemblance : deux individus se ressemblent s'ils ont globalement les
mêmes modalités ;
? La proximité entre modalités de
variables différentes en terme d'association : ces modalités
correspondent aux points moyens des individus qui les ont choisies et sont
proches parce qu'elles concernent globalement les mêmes individus ou des
individus semblables ;
? La proximité entre deux modalités
d'une même variable en termes de ressemblance : par construction,
les modalités d'une même variable s'excluent. Si les variables
sont proches, cette proximité s'interprète en termes de
ressemblance entre les groupes d'individus qui les ont choisies.
? Analyse économétrique
Compte tenu de notre objectif de mettre en évidence les
déterminants de l'irrégularité aux soins prénatals
et de la nature dichotomique de notre variable dépendante
(irrégularité ou régularité), nous aurons recours
à une régression d'un modèle logistique.
Les éléments de base de ce modèle sont :
? un événement : variable à
expliquer codée Y,
pour N individus indicés i = 1, ...,
N
1, si l'événement
s'est réalisé pour l'individu i
Y =
0, si
l'événement ne s'est pas réalisé pour l'individu
i ;
? des caractéristiques : K modalités
(variables explicatives),
Xik = 1, si l'individu i a
cette caractéristique
Xik = 0, sinon ;
? Pi = P (Y=1/
Xi) la probabilité (chance) qu'a l'individu
i de connaître l'événement Y, (Yi
=1), ses caractéristiques étant connues.
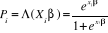
Où 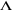 (.) est la fonction de répartition de la loi logistique, (.) est la fonction de répartition de la loi logistique, 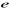 représente la fonction exponentielle et â le vecteur des
coefficients des modalités qui sont des paramètres à
estimer. représente la fonction exponentielle et â le vecteur des
coefficients des modalités qui sont des paramètres à
estimer.
Ici la variable dépendante est
l'irrégularité aux soins prénatals (irreg) :
irregi =1, si la femme i n'a pas effectué
quatre CPN et irregi =0, si elle a effectué au moins
quatre CPN. Les modalités retenues sont les caractéristiques.
Principes d'interprétation des
résultats :
La régression logistique fournit, entre autres, la
probabilité du Khi-deux associée au modèle, le pouvoir
prédictif du modèle (pseudo R2), le seuil de
significativité (P>|z|) des paramètres â et les rapports
de chance (odds ratios) pour chacune des modalités introduites dans le
modèle, qui facilitent l'interprétation des résultats.
La probabilité du Khi-deux associée au
modèle permet de se prononcer sur l'adéquation du modèle
utilisé.
Dans le cas de la présente étude, le
modèle sera jugé adéquat lorsque la probabilité
associée au Khi-deux sera inférieure à 5% voire 10%. Le
pseudo R² détermine le pouvoir prédictif du modèle,
c'est-à-dire la contribution du modèle dans l'explication de
l'irrégularité aux CPN (ce qui nous aidera à
hiérarchiser les déterminants). Par ailleurs, en ce qui concerne
le risque d'irrégularité aux CPN, le modèle de
régression logistique fournit pour chaque variable introduite dans
l'équation une probabilité (P>|t|) qui indique la
probabilité de significativité du paramètre relatif
à la modalité considérée. Lorsque cette
probabilité est inférieure à 5%, nous considérons
qu'il existe une irrégularité différentielle aux CPN
significative entre les femmes présentant la caractéristique de
la modalité considérée et celle de la modalité de
référence.
L'écart de risque est calculé à partir
des rapports de chance (Odds ratio ou OR). Lorsque le rapport de chance est
inférieur à 1, les femmes ayant la caractéristique de la
modalité considérée de la variable explicative ont [(1 -
OR)*100)] % moins de risque (ou de chance) que leurs homologues de la
modalité de référence de réaliser
l'événement. Lorsque le rapport de risque est supérieur
à 1, cela signifie que les femmes appartenant à la
modalité considérée de la variable explicative courent OR
fois plus le risque de subir l'évènement
irrégularité ou [(OR - 1)*100)] % fois moins le risque de subir
cet évènement.
| 

