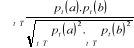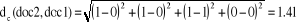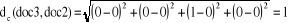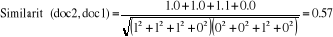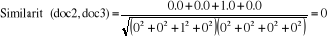Algorithmes d'apprentissage pour la classification de documents( Télécharger le fichier original )par yasmine Hanane zeggane Mokhtar - Université de Mostaganéme -Algérie- - Licence 2009 |

CHAPITRE II1- Introduction : En apprentissage automatique, différents types de classificateurs ont été mis au point, et cela dont le but d'atteindre un degré maximal de précision et d'efficacité, chacun ayant ses avantages et ses inconvénients. Mais, ils partagent toutefois des caractéristiques communes. Parmi la panoplie de classificateurs existants, on peut faire des regroupements et distinguer des grandes familles. Dans les pages qui suivent, nous allons exposer quelques algorithmes en détail, le classificateur bayésien naïf algorithme surpassé par d'autres mais il est souvent utilisé comme point de référence à cause de sa simplicité, l'algorithme de Rocchio. Puis, les machines à support vectoriel et l'algorithme des k-voisins les plus proches, qui représentent vraisemblablement à l'heure actuelle les deux meilleurs choix en catégorisation de textes. 2- Classificateur bayésien naïf : Comme son nom l'indique, ce classificateur se base sur le théorème de Bayes permettant de calculer les probabilités conditionnelles. Dans un contexte général, ce théorème fournit une façon de calculer la probabilité conditionnelle d'une cause sachant la présence d'un effet, à partir de la probabilité conditionnelle de l'effet sachant la présence de la cause ainsi que des probabilités a priori de la cause et de l'effet. On peut résumer son utilisation lorsqu'il est appliqué à la classification de textes ainsi : - On cherche la classification qui maximise la probabilité d'observer les mots du document. - Lors de la phase d'entraînement, le classificateur calcule les probabilités qu'un nouveau document appartienne à telle catégorie à partir de la proportion des documents d'entraînement appartenant à cette catégorie. Il calcule aussi la probabilité qu'un mot donné soit présent dans un texte, sachant que ce texte appartient à telle catégorie. - Par la suite, quant un nouveau document doit être classé, on calcule les probabilités qu'il appartienne à chacune des catégories à l'aide de la règle de Bayes et des chiffres calculés à l'étape précédente. La probabilité à estimer est donc : P( cj | a1 , a2 , a3 , ..., an ) Où: · cj est une catégorie · ai est un attribut A l'aide du théorème de Bayes, on obtient :
On peut omettre de calculer le dénominateur, qui reste le même pour chaque catégorie. En guise de simplification, on calcule P
(a1, a2, a3, ...,
an | cj) ainsi : La probabilité qu'un mot apparaisse dans un texte est indépendante de la présence des autres mots du texte. On sait que cela est faux. Par exemple, la probabilité de présence du mot «artificielle» dépend partiellement de la présence du mot «intelligence». Pourtant, cette supposition n'empêche pas un tel classificateur de présenter des résultats satisfaisants. Et surtout, elle réduit de beaucoup les calculs nécessaires. Sans elle, il faudrait tenir compte de toutes les combinaisons possibles de mots dans un texte, ce qui d'une part impliquerait un nombre important de calculs, mais aussi réduirait la qualité statistique de l'estimation, puisque la fréquence d'apparition de chacune des combinaisons serait très inférieure à la fréquence d'apparition des mots pris séparément. [Sim, 2005]. Pour estimer la probabilité P (ai | cj), on pourrait calculer directement dans les documents d'entraînement la proportion de ceux appartenant à la classe cj qui contiennent le mot ai. Cependant, l'estimation ne serait pas très valide pour des numérateurs petits. Dans le cas extrême où un mot ne serait pas du tout rencontré dans une classe, sa probabilité de 0 dominerait les autres dans le produit ci-dessus et rendrait nulle la probabilité globale. Pour pallier ce problème, une bonne façon de faire est d'utiliser le m-estimé qui est calculé ainsi :
Où · nk est le nombre d'occurrences du terme dans la classe cj · n est le compte total des mots dans le corpus d'entraînement. · |Vocabulaire| : Le nombre de mots clés. 3- Méthode de Rocchio : La méthode de Rocchio est un classifieur linéaire proposé dans [Rocchio, 1971], un des plus vieux algorithmes de classification déstiné à l'amélioration des systèmes de recherche documentaires. L'avantage de ce type de classifieurs est la simplicité et l'interprétabilité. Pour un expert, ce profil prototype est plus compréhensible qu'un réseau de neurones par exemple. L'apprentissage de ce type de classifieur est souvent précédé par une sélection et une réduction de termes. Ce classifieur s'appuie sur une représentation vectorielle des documents : chaque document dj est représenté par un vecteur dj de Rn (n est le nombre de termes après sélection et réduction); chaque coordonnée tkj se déduit du nombre d'occurrences # (tk, dj) du terme tk dans dj , par :
Avec : · # (tk, dj) : Nombre d'apparition de terme tk dans le document dj. · |Tr| : le nombre de documents du corpus d'apprentissage · #Tr(tk) : le nombre de documents dans lesquels apparaît au moins une fois le terme tk. Un terme tk se voit donc attribuer un poids d'autant plus fort qu'il apparaît souvent dans le document et rarement dans le corpus complet. Chaque vecteur dj est ensuite normalisé, par la normalisation en cosinus, afin de ne pas favoriser les documents les plus longs.
Selon la méthode de Rocchio, Chaque catégorie est représentée par un profil «prototypique». Un profil de la classe ci est une liste de termes pondérés, dont la présence et l'absence discriminent au mieux cette classe ci. [Mat, 2003]. Pour chaque catégorie ci, les coordonnées tki du profil prototypique ci = (t1i, · · · , t|T|i) sont calculé ainsi : Où : Nc : le nombre de documents dans C
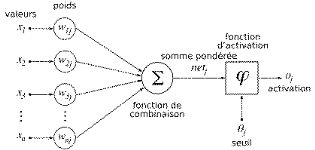
t : un paramètre du modèle compris entre 0 et 1. Dans les situations où un document peut être attribué à une seule classe, t est souvent positionné à 1. di : Poids des termes dans les documents de la classe i. Ci : Profil prototypique de la classe i. Les profils prototypes ci correspondent donc aux barycentres des exemples (avec un coefficient positif pour les exemples de la classe, et négatif pour les autres). Le classement de nouveaux documents s'opère en calculant la distance euclidienne entre la représentation vectorielle du document et celle de chacune des classes ; le document est assigné à la classe la plus proche. [Mat, 2003]. 4- Algorithme des k-voisins les plus proches : L'algorithme des k-voisins les plus proches («k-nearest neighbors» ou kNN) est une méthode d'apprentissage à base d'instances. La méthode ne nécessite pas de phase d'apprentissage; c'est l'échantillon d'apprentissage, associé à une fonction de distance et à une fonction de choix de la classe en fonction des classes des voisins les plus proches, qui constitue le modèle. Lorsqu'un nouveau document à classer arrive, il est comparé aux documents d'entraînement à l'aide d'une mesure de similarité. Ses k plus proches voisins sont alors considérés : on observe leur catégorie et celle qui revient le plus parmi les voisins est assignée au document à classer. C'est là une version de base de l'algorithme que l'on peut raffiner. Souvent, on pondère les voisins par la distance qui les sépare du nouveau texte. 5- Réseaux de neurones : Un réseau de neurones (ou Artificial Neural Network en anglais) est un modèle de calcul dont la conception est très schématiquement inspiré du fonctionnement de vrais neurones (humains ou non). Les réseaux de neurones sont généralement optimisés par des méthodes d'apprentissage de type statistique grâce à leur capacité de classification et de généralisation, tels que la classification automatique de codes postaux ou la prise de décision concernant un achat boursier en fonction de l'évolution des cours. Ils enrichissent avec un ensemble de paradigmes permettant de générer de vastes espaces fonctionnels, souples et partiellement structurés .Ils appartient d'autre part à la famille des méthodes de l' intelligence artificielle qu'ils enrichissent en permettant de prendre des décisions s'appuyant davantage sur la perception que sur le raisonnement logique formel . Exemple : Une banque peut générer un jeu de données sur les clients qui ont effectué un emprunt constituées : de leur revenu, de leur âge, du nombre d'enfants à charge... et s'il s'agit d'un bon client. Si ce jeu de données est suffisamment grand, il peut être utilisé pour l'entraînement d'un réseau de neurones. La banque pourra alors présenter les caractéristiques d'un potentiel nouveau client, et le réseau répondra s'il sera bon client ou non, en généralisant à partir des cas qu'il connaît. Structure du réseau : Un réseau de neurone est en général composé d'une succession de couches dont chacune prend ses entrées sur les sorties de la précédente. Chaque couche (i) est composée de Ni neurones, prenant leurs entrées sur les Ni-1 neurones de la couche précédente. À chaque synapse est associée un poids synaptique, de sorte que les Ni-1 sont multipliés par ce poids, puis additionnés par les neurones de niveau i, ce qui est équivalent à multiplier le vecteur d'entrée par une matrice de transformation. Mettre l'une derrière l'autre, les différentes couches d'un réseau de neurones reviendrait à mettre en cascade plusieurs matrices de transformation et pourrait se ramener à une seule matrice, produit des autres, s'il n'y avait à chaque couche, la fonction de sortie qui introduit une non linéarité à chaque étape. Ceci montre l'importance du choix judicieux d'une bonne fonction de sortie : un réseau de neurones dont les sorties seraient linéaires n'aurait aucun intérêt [1]. Au delà de cette structure simple, le réseau de neurones peut également contenir des boucles qui en changent radicalement les possibilités mais aussi la complexité. De la même façon que des boucles peuvent transformer une logique combinatoire en logique séquentielle, les boucles dans un réseau de neurones transforment un simple dispositif de reconnaissance d'inputs en une machine complexe capable de toute sortes de comportements [1].
Figure 6. Vue simplifiée d'un réseau artificiel de neurones Exemple : Ce neurone calcule la somme de ses entrées puis cette valeur passe à travers la fonction d'activation pour produire sa sortie.
Figure7. Exemple d'un réseau de neurone 6- Machines à support vectoriel :
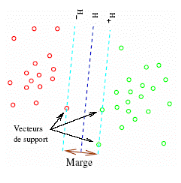
Les machines à support vectoriel («Support Vector Machines» ou SVM) proposée dans [Vapnik, 1995] forment une classe d'algorithmes d'apprentissage qui peuvent s'appliquer à tout problème qui implique un phénomène f et qui, à partir d'un jeu d'entrées x, produit une sortie y = f(x), et où le but est de retrouver f à partir de l'observation d'un certain nombre de couples entrée/sortie. Le problème revient à trouver une frontière de décision qui sépare l'espace en deux régions, à trouver l'hyperplan qui classifie correctement les données et qui se trouve le plus loin possible de tous les exemples. On dit qu'on veut maximiser la marge, la marge étant la distance du point le plus proche de l'hyperplan. (Figure 5) [Sim, 2005].
Figure8Maximisation de la marge avec les SVM Des techniques de programmation quadratique permettent de résoudre ce problème. Une propriété intéressante des SVM est que la surface de décision est déterminée uniquement par les points qui en sont les plus proches de vecteurs de support. En présence de ces seuls exemples d'entraînement, la même fonction serait apprise. Même s'ils cherchent l'hyperplan séparant l'espace vectoriel en deux, l'avantage des SVM est qu'ils s'adaptent facilement aux problèmes non linéairement séparables. Avant de procéder à l'apprentissage de la meilleure séparation linéaire, on transforme les vecteurs d'entrée en vecteurs de caractéristiques de dimension plus élevée. De cette façon, un séparateur linéaire trouvé par un SVM dans ce nouvel espace vectoriel devient un séparateur non linéaire dans l'espace original. Cette transformation des vecteurs se fait à l'aide des foncions appelées fonctions noyaux. [Sim, 2005]. Dans le cas de la classification de textes, les entrées sont des documents et les sorties sont des catégories. En considérant un classificateur binaire, on voudra lui faire apprendre l'hyperplan qui sépare les documents appartenant à la catégorie et ceux qui n'en font pas partie. Les SVM conviennent bien pour la classification de textes [Joa98a]. Une dimension élevée ne les affecte pas puisqu'ils se protègent contre le sur-apprentissage. Dans le même sens, il affirme que peu d'attributs sont totalement inutiles à la tâche de classification et que les SVM permettent d'éviter une sélection agressive qui aurait comme résultat une perte d'information. On peut se permettre de conserver plus d'attributs. Egalement, une caractéristique des documents textuels est que lorsqu'ils sont représentés par des vecteurs, une majorité des entrées sont nulles. Or, les SVM conviennent bien à des vecteurs dits clairsemés. [Sim, 2005]. 7- Choix de classifieur : La catégorisation de textes nécessite un choix de technique d'apprentissage (classifieur). Parmi les méthodes d'apprentissage les plus utilisées figurent le classifieur de Rocchio, Classifieur bayésien naïf, les k-plus proches voisins, et plus récemment les machines à vecteurs supports (SVM). Nous avons choisi la méthode des k plus proche voisins (k-PPV) pour de nombreuses raisons, que nous expliquerons dans les sections qui suivent. 8- La méthode k-PPV en détail : L'idée de base de l'algorithme des k-plus proches voisins (kPPV), traduction de nearest neighbor (kNN) en anglais, est de prédire la classe d'un texte t en fonction des k textes les plus proches voisins déjà étiquetés en mémoire. L'algorithme 1 montre comment classer un nouvel exemple par la méthode k-PPV. Algorithme 1 Algorithme de classification par k-PPV Paramètre : le nombre k de voisins Contexte : un échantillon de (l) textes classés en C = c1, c2, ..., cn classes 1: pour chaque texte t faire 2: transformer le texte t en vecteur t = (x1, x2, ..., xm) 3: déterminer les k plus proches textes du texte t selon une métrique de distance 4: combiner les classes de ces k exemples en une classe c 5: fin pour Sortie : le texte t associé à la classe c. Le choix de la distance et du paramètre k est primordial pour le bon fonctionnement de la méthode. Nous présentons maintenant les différents choix possibles pour la distance et pour le mode de sélection de la classe du cas présenté. [Rad, 2003]. 8-1- Définition de la distance Soit E : un ensemble de textes. Soient a, b, c trois points de l'espace E (Les points sont des textes). Une distance est une application de E × E dans R+ qui vérifie les propriétés suivantes:
On peut noter qu'un point A peut avoir un plus proche voisin B qui, lui-même, possède de nombreux voisins plus proches que A (Figure 6). A B × × × × ×
Figure 9 : (A) a un plus proche voisin (B), (B) a de nombreux voisins proches autres que (A) La distance entre un texte et ses voisins se fait via une métrique de distance. Cette métrique peut être la métrique de Minkowski : [Rad, 2003] (9)
Selon la valeur de p, on retrouve plusieurs distances connues : (10) 1. Si p = 1 cette distance est la distance de Manhattan définie par dm(a,b)= {|a1 - b1| + |a2 - b2| + ... + |an - bn|} 2. Si p = 2 c'est la distance euclidienne définie par : (11)
Choix de k : La valeur de k est un des paramètres à déterminer lors de l'utilisation de ce type de classificateur. La valeur que l'on choisit pour k va être plus critique, plus déterminante en rapport avec la performance du classificateur. On peut se permettre de considérer un plus grand nombre de voisins, sachant que plus ils diffèrent du document à classer, moins ils ont d'impact sur la prise de décision. Cependant, il demeure nécessaire de limiter le nombre de voisins pour s'en tenir à un temps de calcul raisonnable. [Sim, 2005]. Mesure de similarité : Une des caractéristiques fondamentales de ce type de classificateur est l'utilisation d'une mesure de similarité entre les documents. Les textes étant représentés sous forme vectorielle, donc comme des points dans un espace à n dimensions. 1) On peut au premier abord penser à déterminer les voisins les plus proches en calculant la distance euclidienne entre ces points. Distance euclidienne entre deux
documents a et b : Où : · T est l'ensemble des attributs · pt(a) est le poids du terme t dans le document a · pt(b) est le poids du terme t dans le document b 2) Une autre façon : de calculer la similarité des documents : (13) Similarité
cosinusoïdale entre deux documents a et b :
Où : · T est l'ensemble des attributs · pt(a) est le poids du terme t dans le document a · pt(b) est le poids du terme t dans le document b La similarité cosinusoïdale est préférable en classification de textes pour plusieurs raisons : - Elle permet de comparer des textes de longueurs différentes en normalisant leur vecteur. - Elle met l'accent plutôt sur la présence de mots que sur l'absence de mots. (La présence de mots est probablement plus représentative de la catégorie du texte que l'absence de mots). [Sim, 2005]. Illustration : Regardons à l'aide d'un exemple pourquoi la similarité cosinusoïdale est préférable à la distance euclidienne. Nous allons considérer le vocabulaire et les trois documents suivants : · Vocabulaire : <classification, automatique, similarité, document> · Document 1 : <1, 1, 1, 0> · Document 2 : <0, 0, 1, 0> · Document 3 : <0, 0, 0, 0> 1 : signifie que le mot et présent dans le document. 0 : signifie l'absence de mot. Par exemple le mot « classification » est présent dans le document 1 (indiqué par 1) et absent dans les documents 2 et 3 (indiqué par 0) La mesure de distance euclidienne indique que le document 3 est moins distant (plus similaire) du document 2 (distance de 1) que le document 2 ne l'est du document 1 (distance de 1.41). Pourtant, les documents 2 et 3 n'ont aucun mot en commun, alors que les documents 1 et 2 partagent le mot «similarité».
La mesure de similarité cosinusoïdale, pour sa part, retourne une similarité nulle (0) entre les documents 2 et 3, mais positive (0.57) entre les documents 1 et 2. Ces derniers résultats sont plus représentatifs de la réalité, puisque les documents 1 et 2 partagent au moins un mot, donc présentent une certaine similarité et sont plus susceptibles d'être classés dans la même catégorie que les documents 2 et 3 qui ne partagent aucun mot. [Sim, 2005]. Comme il a déjà été mentionné, le classificateur kNN n'implique pas de phase d'entraînement en tant que telle. La seule opération préalable est le stockage des exemples d'entraînement. L'apprentissage est repoussé au moment où un nouveau document à classer arrive. Par le fait même, la plus grosse part de l'effort requis en termes de temps de calcul est fourni au moment même de la classification. Une des caractéristiques de l'apprentissage à base d'instances est qu'il n'y a pas de construction d'une description explicite de la fonction à apprendre (dans notre cas, l'appartenance à une catégorie). L'avantage est qu'on n'estime pas qu'une seule fois la fonction pour tout l'espace, mais on l'estime plutôt localement et différemment pour chaque nouvelle instance. [Sim, 2005]. 8-2- Mise en place de la méthode : La méthode ne nécessite pas de phase d'apprentissage. Le modèle est constitué de trois éléments : 1) l'échantillon d'apprentissage, 2) la distance ou Similarité, 3) la méthode de combinaison des voisins. L'efficacité de la méthode dépend de ces trois éléments. Il faut choisir l'échantillon, c'est-à-dire les attributs pertinents pour la tâche de classification considérée et l'ensemble des enregistrements. Il faut veiller à disposer d'un nombre assez grand d'enregistrements par rapport au nombre d'attributs et à ce que chacune des classes soit bien représentée dans l'échantillon choisi. La distance par variable et le mode de combinaison de ces distances sont choisis en fonction du type des variables et des connaissances préalables concernant le domaine. Une heuristique fréquemment utilisée pour le choix du nombre k de voisins est de prendre k égal au nombre d'attributs plus 1. L'emploi de k voisins, au lieu d'un seul, assure une plus grande robustesse à la prédiction. Classiquement, dans le cas où la variable à prédire comporte deux étiquettes, ce paramètre k est une valeur impaire afin d'avoir une majorité plus facilement décidable. [Rad, 2003]. |
|


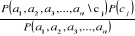 (5)
(5)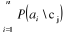 (6)
(6)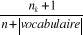 (7)
(7)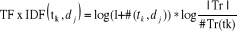 (3)
(3)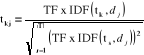 (4)
(4)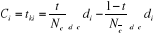 (8)
(8) : le nombre de documents n'appartenant pas à C
: le nombre de documents n'appartenant pas à C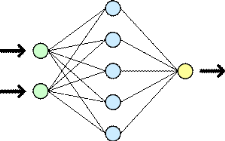
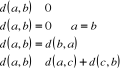
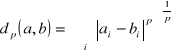
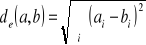
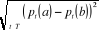 (12)
(12)