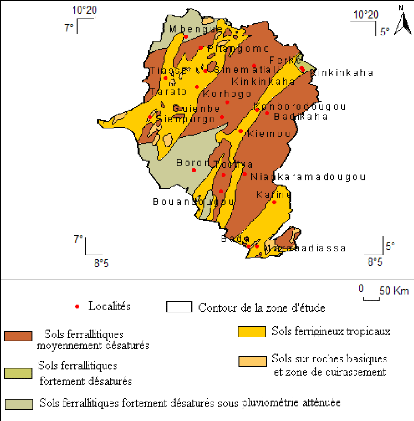
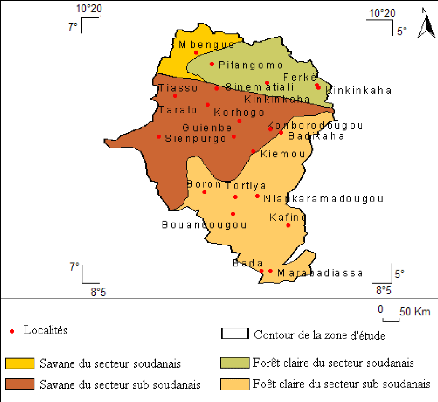
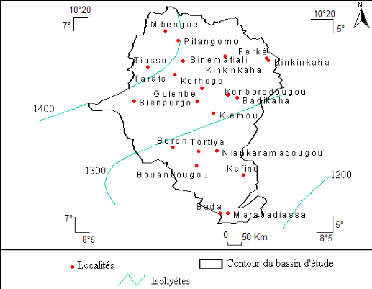
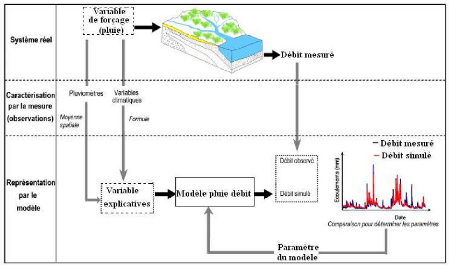
Etude du calage, de la validation et des performances des réseaux de neurones formels à partir des données hydro-climatiques du bassin versant du Bandama blanc en Côte d'Ivoire( Télécharger le fichier original )par Yao Blaise KOFFI Université de Cocody Abidjan - Doctorat 2007 |

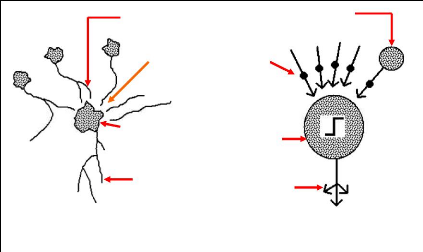
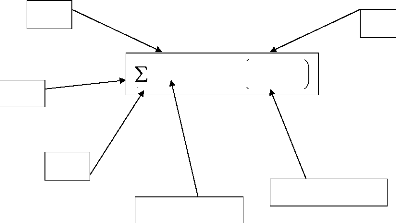
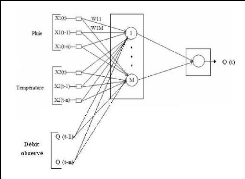
des connexions (Wij, i=1, m). Wij est le poids de la connexion qui lie l'entrée Xi au neurone nj. Wij est positif, si la série Xi doit augmenter la sortie du neurone nj et Wij est négatif, si Xi doit la diminuer ; ii. la fonction neurone (fj) sert à limiter la sortie du neurone nj dans un intervalle prédéfini et/ou augmenter la non linéarité du neurone. Le modèle du neurone peut inclure une valeur limite appelée Seuil (S). Dans la littérature le mot seuil est souvent remplacé par le terme biais. Lorsque le niveau d'activation, (la somme pondérée WijXi) atteint ou dépasse ce biais, alors l'argument de la fonction d'activation devient positif ou nul ; sinon, il est négatif (Parizeau, 2004). L'équation de la sortie calculée est donnée par la relation (1). Outj = fj(In j ) (1) Inj = WijXi-Si (2) Avec : Inj : l'entrée de la fonction d'activation du neurone j ; Outj : la sortie de la fonction d'activation du neurone j ; Xi : l'entrée i connectée au neurone j ; Wij : le poids de la connexion entre l'entrée Xi et le neurone j ; Sj : le seuil du neurone j ; m : le nombre d'entrées connectées au neurone j ; f : la fonction d'activation du neurone j. Le schéma d'un neurone formel adapté des travaux d'Awadallah (1999) est présenté à la figure 19.
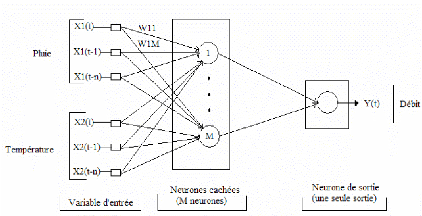
S Xi Xi+1 i m = 1 W X ij i / Out f W X S = ij i i - m i = 1 Xm Unité d'addition Unité d'activation Figure 19 : Schéma d'un neurone formel La modélisation pluie-débit, objectif de ce travail de recherche ne s'intéresse pas aux neurones pris individuellement mais plutôt à leurs différentes combinaisons en réseaux. 3.5. ORGANISATION DES NEURONES EN RÉSEAUXUn réseau de neurones est un maillage de plusieurs neurones, généralement organisés en couches. Les connexions entre les neurones, définies précédemment, qui composent le réseau décrivent la topologie ou l'architecture du modèle. Elle peut être quelconque, mais le plus souvent, dans la littérature, il est possible de distinguer une certaine régularité, (Touzet ,1992). Selon le chemin suivi par l'information dans le réseau on peut classer les réseaux de neurones en deux grandes catégories : les réseaux «feed-forward» et les réseaux «feed-back». 3.5.1. Réseaux «feed-forward»Les réseaux «feed-forward» ou réseaux «nourrir en avant» appelés aussi «réseaux de type Perceptron», sont des réseaux dans lesquels l'information se propage de couche en couche, sans retour possible en arrière. Nous pouvons citer parmi ces réseaux les Perceptrons (objet de cette étude) et les réseaux à fonction radiale. 3.5.1.1. Modèle perceptronsIl existe deux modèles Perceptrons : les modèles Perceptrons Monocouches et les modèles Perceptrons Multicouches (PMC). Le Perceptron Monocouche est historiquement le premier réseau de neurones, c'est le Perceptron de Rosenblatt. C'est un réseau simple, puisqu'il ne se compose que d'une couche d'entrée et d'une couche de sortie. Il est calqué, à la base, sur le système visuel et de ce fait a été conçu dans un but premier de reconnaissance des formes. Cependant, il peut aussi être utilisé pour faire de la classification et/ou pour résoudre des opérations logiques simples («ET» ou «OU»). Sa principale limite est qu'il ne peut résoudre que des problèmes linéairement séparables, ce qui diffère de la relation pluie-débit qui est non-linéaire. Il suit généralement un apprentissage de type supervisé selon la règle de correction de l'erreur (ou selon la règle de Hebb (Parizeau, 2004)). La typologie des apprentissages sera détaillée dans la suite de cette étude. La figure 20 représente un Perceptron Multicouches simplifié avec une seule couche de neurones cachés. Les variables d'entrée sont la pluie et la température et la variable cible est le débit.
Figure 20 : Perceptron Multicouche simplifié avec une seule couche de neurones cachés Le Perceptron Multicouches (PMC) est une extension du précédent, avec une ou plusieurs couches cachées entre l'entrée et la sortie. Chaque neurone dans une couche est connecté à tous les neurones de la couche précédente et de la couche suivante (excepté pour les couches d'entrée et de sortie) et il n'y a pas de connexions entre les cellules d'une même couche. Ce type de réseaux a été récemment classé comme outil de prévision et de simulation des débits (Fortin et al., 1997). Cependant, ces applications se sont largement diversifiées et les fonctions d'activation utilisées dans ce type de réseaux sont principalement les fonctions à seuil ou sigmoïdes. Il peut résoudre des problèmes non-linéairement séparables et des problèmes logiques plus compliqués comme la relation pluie-débit. Il suit aussi un apprentissage supervisé selon la règle de correction de l'erreur. Le Perceptron Multicouches est le Réseau de neurones le plus utilisé en modélisation hydrologique (Coulibaly et al., 1999). Plusieurs auteurs considèrent que ce type de réseau comprend trois groupes de neurones. Par exemple, Awadallah, (1999) identifie trois groupes de neurones : un groupe d'entrée, un groupe intermédiaire et un groupe de sortie. Cette considération, faite notamment par plusieurs auteurs, paraît «impropre» ; car, d'après Dreyfus et al. (2004), la couche des entrées n'effectue aucune modification de l'information donc ne fait aucun calcul. L'équation générale d'un réseau de neurones formels de type Perceptron Multicouches, avec une seule couche cachée et une seule sortie scalaire, est formulée comme suit : m n (3) Y f Wo f Wh X b b = * + + 2 j * 1 ij i 1 2 j= 1 i = 1 Où : Y : est la sortie calculée par le réseau, f2 : est la fonction d'activation du neurone de la couche de sortie, m : est le nombre de neurones cachés, n : est le nombre de variables d'entrée Woj : est le poids de la connexion entre la jième neurone sur la couche cachée et le neurone de sortie, f1 : est la fonction d'activation du neurone de la couche cachée, Whij : est le poids entre la iième entrée et le jième neurone sur la couche cachée, Xi : est la matrice d'entrée, b1 : est le biais de la fonction d'activation du jième neurone caché, b2 : est le biais de la fonction d'activation du neurone de sortie. Pour la classification des Perceptrons Multicouches deux critères peuvent être considérés :
3.5.1.2. Architecture des Réseaux de neurones FormelsUn réseau de neurones formels, comme déjà mentionné, est un ensemble de neurones formels associés sous forme de couches. Les réseaux de neurones formels ont la capacité de stocker de la connaissance empirique et de la rendre disponible pour un usage donné. La connaissance du réseau va être stockée dans les coefficients synaptiques, calculés par des processus d'adaptation ou d'apprentissage (encore appelé adaptation ou calage). En ce sens, les réseaux de neurones formels ressemblent donc à un cerveau car non seulement, la connaissance est acquise au travers d'un apprentissage mais plus, cette connaissance est soit stockée dans les
- 45 - connexions entre les entrées, soit dans les coefficients synaptiques. Deux (2) architectures générales se distinguent : le réseau non bouclé et le réseau bouclé.
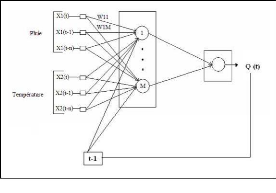
Dans les réseaux bouclés, la sortie de certains neurones est renvoyée sur l'entrée de neurones de la même couche ou d'une couche inférieure. Ce bouclage donne un comportement dynamique au réseau, la sortie ne dépend plus seulement des entrées du réseau, mais également de sa sortie aux instants précédents. Deux types de bouclages peuvent être réalisés, ce qui constitue deux types de réseaux distincts : les réseaux bouclés non dirigés et les réseaux bouclés dirigés. Les réseaux bouclés non dirigés (Figure 21) réalisent un bouclage avec les débits calculés. Ces modèles sont particulièrement intéressants, car lors de la simulation ou la prévision d'un événement (après apprentissage), la connaissance de la sortie à un pas de temps ultérieur permet de recadrer la sortie prévue. Ces modèles donnent de bons résultats notamment dans l'étude de la relation pluie-débit. Il s'agit du modèle le plus intéressant en matière de prévision des crues (Eurisouké, 2006) car les débits calculés par le réseau sont réinjectés et donc ne nécessitent pas d'autres données. Les Réseaux Bouclés Dirigés réalisent un bouclage, non plus sur la sortie calculée par le modèle à un temps t-1, mais par la sortie désirée à un temps t-1 sur les débits observés (Figure 22). Figure 21 : Réseau Bouclé Non Dirigé
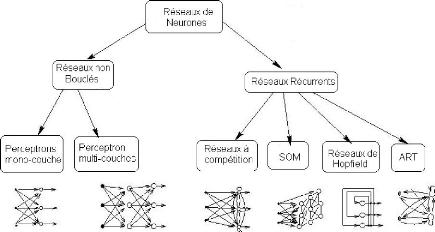
Figure 22 : Réseau Bouclé Dirigé Ce bouclage permet au réseau de pouvoir se caler après son apprentissage sur les vraies valeurs. Les résultats de prévisions et/ou de simulations avec ce type de réseau donne généralement d'excellents résultats, notamment dans le cadre de la prévision pluie-débit (Eurisouké, 2006). Toutefois l'intérêt de ce type de réseau dans le cadre de la prévision reste limité si le délai de prévision et/ou de simulation est proche. Les réseaux non bouclés et les réseaux bouclés présentés précédemment comprennent comme variables explicatives la pluie et la température. La variable cible est le débit. Le présent travail de recherche s'intéressera à ces deux modèles, plus particulièrement à ces deux types de réseau : les Réseaux Non Bouclés et les Réseaux Bouclés Dirigés. Les Réseaux Non Bouclés utilisés seront nommés Perceptrons Multicouches Non Dirigés(PMCND) et les réseaux dirigés, Perceptrons Multicouches Dirigés (PMCD). 3.5.2. Réseaux à fonction radialeLes réseaux à fonction radiale sont les réseaux que l'on reconnaît aussi sous le vocable RBF pour «Radial Basic Functions». L'architecture est la même que pour les PMC, cependant, les fonctions de base utilisées ici sont des fonctions Gaussiennes. Les RBF seront donc employés dans les mêmes types de problèmes que les PMC à savoir la classification et l'approximation de fonctions (Parizeau, 2004). L'apprentissage le plus utilisé pour les RBF est le mode hybride qui fait intervenir les modes supervisés et non supervisés définis dans les paragraphes suivants et les règles sont soit la règle de correction de l'erreur, soit la règle d'apprentissage par compétition. 3.5.3. Réseaux "feed - back"Appelés aussi «réseaux récurrents», ce sont des réseaux dans lesquels il y a retour en arrière de l'information. Ces réseaux ramènent l'information en arrière de manière inverse par rapport au sens de propagation défini dans un réseau Multicouche. Ces connexions sont le plus souvent locales, (Touzet, 1992). 3.5.4. Cartes auto - organisatrices de KohonenCe sont des réseaux à apprentissage non-supervisé qui modifient leurs paramètres en fonction des régularités statistiques des entrées et établissent des catégorisations. Ils génèrent à la fin une carte discrète ordonnée topologiquement en fonction des différentes données d'entrée. Le réseau forme ainsi une sorte de treillis dont chaque noeud est un neurone associé à un vecteur de poids. La correspondance entre chaque vecteur de poids est calculée pour chaque entrée. Par la suite, le vecteur de poids ayant la meilleure corrélation, ainsi que certains de ses voisins, vont être modifiés afin d'augmenter encore cette corrélation (Parizeau, 2004 ; Dreyfus et al., 2004). 3.5.5. Réseaux de HopfieldLes réseaux de Hopfield sont des réseaux récurrents et entièrement connectés (Johannet, 2006). Dans ce type de réseau, chaque neurone est connecté à chaque autre neurone et il n'y a aucune différenciation entre les neurones d'entrées et de sorties. Ils fonctionnent comme une mémoire associative non-linéaire et sont capables de trouver un objet stocké en fonction de représentations partielles ou bruitées. L'application principale des réseaux de Hopfield est l'entrepôt de connaissances, mais aussi la résolution de problèmes d'optimisation. Le mode d'apprentissage utilisé ici est le mode non-supervisé. 3.5.6. Réseaux à apprentissage par compétition ou « Adaptative Resonnance Theory » (ART)Les réseaux ART « Adaptative Resonnance Theory » sont des réseaux à apprentissage par compétition. Le problème majeur qui se pose dans ce type de réseaux est le dilemme "stabilité/plasticité". En effet, dans un apprentissage par compétition, rien ne garantit que les catégories formées resteront stables. La seule possibilité, pour assurer la stabilité, serait que le coefficient d'apprentissage tende vers zéro, mais le réseau perdrait alors sa plasticité. Les ART ont été conçus spécifiquement pour contourner ce problème. Dans ce genre de réseau, les vecteurs de poids ne seront adaptés que si l'entrée fournie est suffisamment proche, d'un prototype déjà connu par le réseau ; on parlera alors de résonnance. A l'inverse, si l'entrée s'éloigne trop des prototypes existants, une nouvelle catégorie va alors se créer, avec pour prototype, l'entrée qui a engendrée sa création. Il est à noter qu'il existe deux principaux types de réseaux ART : les ART-1 pour des entrées binaires et les ART-2 pour des entrées continues. Le mode d'apprentissage des ART peut être supervisé ou non. Les différents réseaux de neurones peuvent être résumés comme ce qu'indique la figure 23.
Figure 23 : Récapitulatif des
Principales architectures des réseaux de neurones formels
(RNF) 3.6. APPRENTISSAGE DES RÉSEAUX DE NEURONESPour un modèle type réseau de neurones, l'apprentissage peut être considéré comme le problème de la mise à jour des poids des connexions au sein du réseau, afin de réussir la tâche qui lui est demandée. En effet, parmi les propriétés des réseaux de neurones, la plus fondamentale est sûrement la capacité d'apprendre, et donc d'améliorer sa performance à travers un processus d'apprentissage ou de calage. Cependant, dans la littérature, il n'existe pas de définition générale, universellement acceptée ; car, ce concept touche, d'après Parizeau (2004), à trop de notions distinctes qui dépendent du point de vue du modélisateur. Il donne alors la définition suivante : "L'apprentissage est un processus dynamique et itératif permettant de modifier les paramètres d'un réseau de neurones en réaction avec les stimuli qu'il reçoit de son environnement". L'apprentissage étant la caractéristique principale des réseaux de neurones formels, il peut se faire de différentes manières et selon différentes règles. C'est le lieu ici de faire la part des choses entre mode d'apprentissage et règle d'apprentissage. Le mode d'apprentissage intéresse la manière dont les changements de paramètres surviennent pendant le processus ; et, la règle d'apprentissage concerne le type d'algorithme mathématique utilisé. Au niveau du mode d'apprentissage, Roussillon, (2004) détermine deux classes à savoir l'apprentissage supervisé et l'apprentissage non supervisé. Parizeau (2004), va plus loin et détermine trois types d'apprentissage : le mode supervisé, le mode renforcé et le mode non-supervisé. On peut ajouter à ces trois types d'apprentissage, le mode hybride. Concernant les règles d'apprentissage, on en dénombre quatre : la règle de correction de l'erreur, la règle de Boltzmann, la règle de Hebb et enfin la règle par compétition. 3.6.1. Différentes approches d'apprentissageLes quatre modes d'apprentissage pour les réseaux de neurones sont ici présentés :
communs aux exemples présentés, et modifier les poids, afin de fournir la même sortie pour les entrées aux caractéristiques proches (Roussillon, 2004) ; iv. Mode hybride. : Le mode hybride comprend à la fois l'apprentissage supervisé et l'apprentissage non - supervisé. 3.6.2. Règles d'apprentissageLes quatre règles précédemment énoncées sont ici successivement énoncées. 3.6.2.1. Règle de correction d'erreursCette règle s'inscrit dans le paradigme d'apprentissage supervisé, c'est-à-dire dans le cas où l'on fournit au réseau une entrée et la sortie correspondante. Si on considère la variable y comme étant la sortie calculée par le réseau, et la variable d la sortie désirée, le principe de cette règle est d'utiliser l'erreur (d-y), afin de modifier les connexions et de diminuer ainsi l'erreur globale du système. Le réseau va donc s'adapter jusqu'à ce que y soit égal à d ou très proche. Ce principe est notamment utilisé dans le modèle Perceptron. 3.6.2.2. Règle de BoltzmannLes réseaux de Boltzmann sont des réseaux symétriques récurrents. Ils possèdent deux sousgroupes de cellules, le premier étant relié à l'environnement (cellules dites visibles) et le second ne l'étant pas (cellules dites cachées). Cette règle d'apprentissage est de type stochastique, relevant partiellement du hasard et consiste à ajuster les poids des connexions, de telle sorte que l'état des cellules visibles satisfasse une distribution probabiliste souhaitée. 3.6.2.3. Règle de HebbLa règle de Hebb, basée sur des données biologiques, modélise le fait que si des neurones, de part et d'autre d'une synapse, sont activés de façon synchrone et répétée, la force de la connexion synaptique augmente. Il est à noter ici que l'apprentissage est localisé, c'est-à-dire que la modification d'un poids synaptique wij ne dépend que de l'activation d'un neurone i et d'un autre neurone j. 3.6.2.4. Règle par compétitionsLa particularité de cette règle vient du fait que l'apprentissage ne concerne qu'un seul neurone. Le principe de cet apprentissage est de regrouper les données en catégories. Les patrons similaires vont donc être rangés dans une même classe, en se basant sur les corrélations des données, et seront représentés par un seul neurone, on parle de "winner-take- all". Dans un réseau à compétition simple, chaque neurone de sortie est connecté aux neurones de la couche d'entrée, aux autres cellules de la couche de sortie (connexions inhibitrices) et à elle-même (connexion excitatrice). La sortie va donc dépendre de la compétition entre les connexions inhibitrices et excitatrices. 3.7. DOMAINES D'APPLICATION DES RÉSEAUX DE NEURONESSe trouvant à l'intersection de différents domaines (informatique, électronique, sciences cognitives, neurobiologie et même philosophie), l'étude des réseaux de neurones formels (RNF) est une voie prometteuse de l'Intelligence Artificielle (IA), qui a des applications dans de nombreux domaines tels que l'industrie, les télécommunications, les sciences hydrologiques, etc.
Les paragraphes développés jusqu'à présent ont montré que les réseaux de neurones formels sont utilisés, avec succès, dans plusieurs domaines. Mais pourquoi est-ce que ces modèles arrivent à donner de très bons résultats ? L'objet du chapitre suivant est d'apporter des éléments de réponse à cette question. 3.8. PROPRIÉTÉS DES RÉSEAUX DE NEURONESLes nombreuses performances obtenues avec les modèles à base de réseaux de neurones sont généralement le fait des propriétés qu'ils possèdent. Mangeas (1997) et Haykin (1999) font la description de certaines propriétés telles que : la non linéarité ; la tolérance au manque d'information ; la résistance aux entrées aberrantes ; la possibilité de se passer de pré requis ; la non-unicité du modèle par rapport aux paramètres ; l'adaptabilité ; l'utilisation des données à leur état brut ; l'universalité et l'analogie avec la neurobiologie. 3.8.1. Non-linéaritéEtant donné que le neurone est un élément
non linéaire et que les neurones sont
parallèlement entrées et les sorties sont non linéaires comme c'est le cas entre la pluie et le débit mesurée en un point d'un bassin versant donné. Mais, cette non-linéarité ne dépend pas uniquement de la fonction d'activation, mais également de la norme des poids. Plus cette norme est petite, plus les entrées (In) parvenant aux neurones se situent au voisinage de zéro et plus les fonctions sigmoïdes utilisées sont proches des fonctions linéaires. 3.8.2. Tolérance au manque d'informationVu que la distribution de l'information est parallèle, l'endommagement d'un neurone, ou d'une connexion, ou bien la perte de données, ne provoque pas un échec irrémédiable dans la performance du réseau, mais seulement une dégradation moins sérieuse dans les résultats. Ceci est seulement vrai si la couche cachée est munie de suffisamment de neurones. Le calcul de la sortie étant mené par plusieurs neurones, il y a différents chemins pour relier l'entrée à la sortie. 3.8.3. Résistance aux entrées aberrantesDu fait des filtres saturants que constituent les fonctions d'activation sigmoïde, le réseau est résistant aux valeurs aberrantes qui pourraient se glisser dans les différentes séries hydroclimatiques dont nous disposons. Néanmoins, un réseau de neurones est prisonnier des données qui ont servi à sa calibration (apprentissage). Pour cette raison, des analyses statistiques sont nécessaires afin de détecter et de remplacer les données aberrantes de nos différentes séries. Si ces données ne sont pas réparties sur tout le continuum de leur variabilité, le réseau sera incapable d'extrapoler sur les données. Par contre, pour un modèle linéaire, il suffit que, les exemples pour l'estimation des paramètres se situent sur les extrémités de ce continuum. 3.8.4. Possibilité de se passer de pré requisLe Réseau de neurones est en principe capable de faire correspondre à un ensemble de sorties, un ensemble de données d'entrée, sans avoir recours pour cette opération à une distribution de probabilité des variables du modèle ou à un pré requis des relations entre elles, (Haykin, 1999). Cette notion, bien que présente dans plusieurs références de base sur les réseaux de neurones formels, n'est pas partagée par les statisticiens évoluant dans ce domaine. En fait, Bishop (1995) démontre que les Réseaux de neurones Formels requièrent les mêmes hypothèses de distribution que les autres modèles statistiques pour obtenir des estimations efficaces et optimales. 3.8.5. Non-unicité des modèles neuronaux par rapport aux paramètresDans les modèles neuronaux, on peut trouver deux ensembles de poids différents qui génèrent la même sortie. De même, un même ensemble d'entrées et de sorties peut aboutir à des ensembles de paramètres très différents à chaque fois que le réseau est entraîné. Les performances de ces différents modèles peuvent cependant être identiques. 3.8.6. AdaptabilitéLes modèles neuronaux pourraient être conçus de manière à changer les poids de leurs synapses en temps réel, en fonction des changements environnementaux. Ils peuvent donc opérer dans un environnement non stationnaire. 3.8.7. Utilisation des données dans leur état bruteEn principe, le Réseau de neurones fonctionne avec les données telles qu'elles sont, sans transformation pour rendre leur série homogène ou stationnaire, ou pour changer leur échelle. Néanmoins, il est préférable de standardiser les entrées et les sorties. Cette transformation permet au réseau de mieux éviter les minima locaux et d'avoir, pour une valeur d'initialisation des poids et seuils proches de zéro, une valeur plus proche du minimum global. Ceci est d'autant plus vrai pour les méthodes d'apprentissage de type gradient de la plus forte pente, telle que la rétro propagation définie dans la suite de ce mémoire. Ces méthodes sont très sensibles aux valeurs initiales. 3.8.8. Propriété d'universalité et analogie avec la neurobiologieL'universalité des analyses et des conceptions des
réseaux de neurones est la possibilité de différentes applications. En ce qui concerne l'analogie avec la neurobiologie, la science neurobiologique inspire le développement d'autres réseaux de neurones formels qui sont, à leur tour, des outils de recherche pour interpréter les phénomènes neurobiologiques. Malgré la grande variété des propriétés des réseaux de neurones, ci-dessus énumérées, qui permettent d'obtenir de très bons résultats lorsqu'ils sont utilisés en simulation et en prévision ; il est bon de remarquer que, ces modèles, tout comme les autres modèles hydrologiques, présentent toutefois des limites. Pour pallier à certaines de ces limites qui feront l'objet de la section cidessous, des précautions sont à prendre. 3.9. LIMITES ET PRÉCAUTIONS DANS LA MODÉLISATION AVEC LESRÉSEAUX DE NEURONES FORMELSDans la modélisation avec les Réseaux de neurones Formels, deux questions reviennent de façons récurrentes. La problématique des minima locaux et celle de la généralisation. 3.9.1. Problème des minima locauxPendant l'apprentissage, les paramètres tels que les poids et les biais peuvent converger vers des valeurs qui représentent des minima locaux de la fonction coût et non un minimum global. Atteindre le minimum global est une utopie, à cause de la complexité de la surface de la fonction de coût. Il faut, cependant y être le plus près possible pour représenter fidèlement les variables cibles à simuler ou à prévoir. Chitra, (1993) préconise trois approches pour éviter le plus possible les minima locaux et s'approcher des minima globaux :
La modélisation avec les réseaux de neurones formels est un compromis entre le sous apprentissage et le sur apprentissage. Il s'agit généralement d'éviter les minima locaux et de se rapprocher des maxima globaux. Le sou apprentissage est facile à résoudre, grâce à l'augmentation de la taille du réseau. Concernant le sur-apprentissage, plusieurs méthodes ont tenté de le résoudre, notamment l'élagage, l'arrêt prématuré et la régularisation (Awadallah, 1999). 3.9.2.1. ElagageL'élagage est une méthode d'élimination par pas descendant (stepwise en anglais) qui tend à éliminer les poids d'un réseau de neurones formels entièrement connecté. Cette méthode admet deux variantes, le dommage optimal du cerveau (optimal brain damage) et la variante du chirurgien optimal du cerveau (optimal brain surgeon). La première variante est basée sur le calcul de la matrice de dérivées secondes de la fonction coût en fonction des paramètres ; tandis que la seconde variante est basée sur le calcul de l'augmentation minimale de la fonction coût due à l'élimination d'un poids. Le réseau ainsi allégé est entraîné à nouveau et sa capacité de généralisation est testée à chaque fois. Cette méthode est coûteuse du point de vue temps et il existe un risque de tomber sur des réseaux instables pendant le processus. Dans la littérature, une méthode inverse existe (Awadallah, 1999). Avec cette méthode inverse, on commence par un réseau simple et on le rend complexe en ajoutant des neurones cachés. Le réseau de neurones formels retenu à la fin de tous ces processus est celui qui minimise au mieux l'erreur de généralisation. 3.9.2.2. Arret prematuréL'arrêt prématuré ou précoce (utilisé dans ce travail) consiste à utiliser beaucoup de neurones cachés pour éviter les minima locaux et en même temps réduire le temps d'apprentissage. Cette méthode agit indirectement sur le nombre effectif de paramètres. Elle est basée sur le concept statistique de la division d'échantillon (split-sampling). Les données d'entrée du modèle sont subdivisées en trois ensembles : un premier groupe pour l'apprentissage, un deuxième groupe pour la validation (pour arrêter l'apprentissage) et un troisième groupe pour le test (pour tester la généralisation du modèle). L'apprentissage est arrêté, avant qu'il atteigne le minimum, lorsque le critère d'erreur, mesuré sur l'ensemble de validation, commence à augmenter de façon constante. Le résultat obtenue avec cette méthode est biaisée vers l'ensemble de validation. Elle est très critiquée ; car, ni l'ensemble d'apprentissage, ni celui de validation, n'utilise l'échantillon dans sa totalité (Awadallah, 1999). 3.9.2.3. RégularisationLa troisième méthode joue sur les normes de la matrice des paramètres. Elle consiste à introduire un terme de pénalité dans la fonction coût pour restreindre progressivement l'espace du vecteur des paramètres dans un voisinage de zéro. L'expression de la fonction coût résultant est détaillée dans les travaux d'Awadallah (1999), McKay (1992) et Neal (1996). Ces travaux ont élaboré un cadre statistique basé sur la théorie baryesienne pour la détermination d'un coefficient de régularisation. 3.9.3. Limites conceptuelles pour la modélisation pluie-débitOutre les limites des réseaux de neurones ci-dessus signalées, liées généralement au processus d'apprentissage, la conception de ces modèles pour la modélisation pluie-débit pose d'autres problèmes à cause de leur appartenance aux modèles "boites noires". En effet, ces modèles ne permettent pas de cerner tout le processus qui a lieu en leur sein. Au stade actuel des recherches, aucun modélisateur ne peut donc donner une signification physique des différents poids de ces modèles. A cette limite, s'ajoute également celles de la qualité des données, des longues chroniques nécessaires, de l'impossibilité d'utiliser actuellement ces modèles sur des bassins versants non jaugés, etc. Toutefois, les recherches sont en cours pour tenter de remédier à ces limites et transformer les Réseaux de neurones Formels en des modèles "boites grises" avec moins de limites possibles. 3.10. ÉTAT DE LA MODÉLISATION PLUIE-DÉBIT AVEC LES RÉSEAUX DENEURONES FORMELS OU ARTIFICIELSDepuis les travaux de Mac Culloch et Pitts (1943), les modèles connexionnistes ont eu plusieurs applications dans différents domaines notamment l'hydrométéorologique où de bons résultats ont été obtenus dans les domaines de :
Depuis 1997 plusieurs centaines d'articles ont été publiés sur l'application des réseaux de neurones formels à la gestion des ressources en eau nécessaire à un Développement Durable. La moitié des applications hydrologiques des Réseaux de neurones Formels concernent la modélisation des débits, crues et étiages des cours d'eau. La période 2000 à 2005 fut marquée par la publication de nombreux travaux dans le domaine de la modélisation pluie-débits par Réseaux de neurones. On peut citer notamment les travaux de Li-chiu et al. (2004) ; Ashu et al. (2004) ; Young (2003) ; Masiyandina et al. (2003) ; Gunnar et Uhlenbrook (2003) ; Sudheer et al. (2003) ; Sudheer et al. (2002) ; Cameron et al. (2002) ; Abrahart et See (2000) et Schumann et al. (2000). Toujours dans le même axe de recherche que les auteurs cités ci-dessus, Wenri et al. (2004) ont développé un modèle de neurones pour la prévision des débits du fleuve Apalachicola (USA, Floride). Il s'agissait d'un modèle de type "feed-forward" entraîné avec la rétro propagation de l'erreur sur la période 1939-2000. Ce modèle a donné de très bons résultats au pas de temps journalier, mensuel, trimestriel et annuel avec respectivement 0,98 ; 0,95 ; 0,91 et 0,83 comme coefficients de corrélation de Pearson. Pour valider ces résultats, ces auteurs ont utilisé sur la même période un autre modèle de type ARIMA. Après comparaison des deux modèles, il ressort que le Réseau de neurones Formel est plus performant. De ces résultats, on peut donc dire que les Réseaux de neurones sont utilisables à tous les pas de temps en simulation et en prévision. Dechemi et al. (2003) ont utilisé les réseaux de neurones artificiels pour modéliser le binôme pluie-débit au pas de temps mensuel sur le bassin versant de la Cheffia du Nord Est algérien. L'architecture du réseau utilisé est de type (2-4-1) avec pour règle d'apprentissage l'algorithme de Levenberg Marquard qui est un apprentissage supervisé en bloc. Les résultats obtenus par ces auteurs ont été comparés à deux types de modèles : un modèle hydride neuronale-logique floue et des modèles conceptuels (modèles de Thornthwaite et GR2M). Ils conclurent que tous les modèles donnent de bonnes valeurs mais que le modèle hybride donne les meilleurs résultats, car ce modèle permet de décomposer le processus complexe en un processus physique plus simple. Sur le même bassin versant de Cheffia en Algérie, Tarik et Dechemi (2004), ont testé quatre modèles pluie-débit au pas de temps journalier. Ces modèles appartiennent à deux catégories : les modèles conceptuels, que sont le modèle GR3j, le modèle CREC à huit paramètres ; et les modèles de type «boîte noire», représentés par le modèle ARMAX (modèle autorégressif à moyenne mobile avec variables exogènes) et par un modèle neuroflou, qui combine un modèle structure neuronale et la logique floue. Les modèles ont été testés sur deux périodes, l'une sèche et l'autre humide. Ces auteurs, après comparaison des différents résultats, proposent une meilleure modélisation de la relation pluie-débit, au pas de temps journalier, en combinant l'approche conceptuelle et le modèle du système neuroflou. Une autre étude significative a été réalisée par Hsu et al. (1995). Ces auteurs ont proposé une procédure nommée LLSSIM pour « Linear Least Squares Simplex » pour une identification automatique des paramètres du RNA. Trois modèles neuronaux identifiés à l'aide de la technique LLSSIM sont comparés à deux autres modèles de prévisions classiques : ARMAX, SAC-SMA « Sacramento Soil Moisture Input Model », (U.S. National Weather Service). Les données hydrologiques (pluies et débits journaliers) utilisées sont celles du "Leaf River Basin " dans le Mississipi. En utilisant une seule année hydrologique pour la calibration des différents modèles (ARMAX, SAC-SMA, RNA) et cinq années pour leur validation, les résultats obtenus accordent les meilleures performances aux RNA aussi bien pour la calibration que pour la validation. De même, en calibrant les modèles sur 5 ans et en les validant sur 1 année, les meilleurs résultats sont obtenus par les RNA. Cependant, dans les deux cas, les "meilleurs résultats" obtenus par les modèles neuronaux sont variables de bon à mauvais : la prévision des débits de pointe est bonne, mais celle des périodes de récession est mauvaise. Ces résultats sont néanmoins meilleurs que ceux obtenus par les modèles ARMAX et SAC-SMA pour ces mêmes périodes. Cette étude indique que lorsque très peu de données sont disponibles, le modèle neuronal serait préférable au modèle ARMAX pour la prévision des débits. Par contre, une bonne application du modèle SAC-SMA nécessiterait au moins 8 années d'observations. Karunanithi et al. (1994) ont appliqué le réseau en cascade, "Cascade Network", utilisant l'algorithme dit de " Cascade-Corrélation" (Fahlman et Lebiere, 1990) pour la prévision des débits de la rivière Huron dans l'état du Michigan. Cet algorithme a l'avantage de modifier la topologie du modèle lors de l'apprentissage. Les données hydrologiques utilisées sont les débits journaliers observés sur 13 ans (1960-1972). Dans un premier modèle, les variables d'entrées sont les débits des jours j-5 à j-1 (j étant l'horizon de prévision), tandis que pour le second modèle, les variables d'entrées sont les moyennes mobiles des débits des jours j-5 à j-1. Ces deux modèles sont calibrés à l'aide de 11 ans d'observations et validés sur 2 ans. Les résultats de ces deux modèles neuronaux sont comparés à ceux d'un modèle de puissance (Chow, 1964). Les valeurs de l'erreur quadratique moyenne pour la période de test ou de validation indiquent que les modèles neuronaux sont de meilleurs prédicteurs que le modèle de puissance. La comparaison des erreurs relatives indique que les modèles neuronaux sont surtout meilleurs pour la prévision des débits de pointe. L'analyse de la taille du réseau montre que l'algorithme de "cascade-corrélation" est capable d'adapter la complexité du Réseau de neurones artificiel (RNA) à celle de l'ensemble d'apprentissage. Cette étude a aussi le mérite de montrer que l'utilisation des débits du jour j5 à j-1 comme entrées du RNA est meilleure à celle des débits moyens de j-5 à j-1. De nombreuses autres applications des Perceptrons Multicouches (PMC) à la modélisation de la relation pluie-débits et à la prévision des crues ont été proposées. On peut citer les travaux de Buch et al. (1993); Crespo et Mora (1993); Liong et al. (1994); Zhu et Fujita (1994); Smith et Eli (1995); Dimopoulos et al. (1996); Zhang et Trimble (1996); Asaad et Shamseldin (1997); Huttunen et al. (1997); Clair et Ehrman (1998); Thirumalaiah et Deo (1998). 3.11. CONCLUSION PARTIELLED'après les paragraphes précédents, il ressort que les réseaux de neurones sont des modèles inspirés du fonctionnement du cerveau humain, composé de plusieurs unités de calcul simple appelées neurones et fonctionnant en parallèle. C'est un assemblage d'éléments, d'unités ou de noeuds processeurs pour lequel un sous-groupe fait un traitement indépendant et passe le résultat à un deuxième sous-groupe. Le but de ces modèles est de traiter des informations de façon analogue au système biologique. Il existe alors une analogie entre les deux types de neurones. En effet, les synapses, les axones, les dendrites et le soma, des neurones biologiques correspondent respectivement aux poids des connexions, aux signaux de sortie, aux signaux d'entrée, et à la fonction d'activation, dans les neurones artificiels. Il a été également possible de voir que l'évolution des recherches sur les réseaux de neurones Formels ou Artificiels a connu trois grandes étapes : la naissance ou le début des recherches en 1890, le ralentissement des travaux en 1969 et la renaissance en 1982. La manière dont ces neurones sont disposés définit les différentes architectures des réseaux de neurones formels (RNF) utilisés pour la résolution de problème non-linéaire dans plusieurs disciplines, notamment l'industrie, la télécommunication, l'informatique et les sciences hydrologiques. En effet, plusieurs réseaux de neurones existent : les réseaux feed-forward, les réseaux à fonction radiale, les réseaux feed-back, les cartes auto-organisatrices de Kohonen, les réseaux de hopfield et les réseaux à apprentissage par compétition. Parmi tous ces réseaux, seuls les Perceptrons Multicouches (PMC) sont les plus utilisés pour la prévision et la simulation de la relation pluie-débit. Ces modèles doivent ces différentes performances à leurs innombrables propriétés citées précédemment. Malgré ces différentes propriétés, les réseaux de neurones ne sont fonctionnels que s'ils sont calibrés grâce aux différentes approches d'apprentissage comme le mode supervisé, le mode renforcé, le mode non-supervisé et le mode hybride. Cependant, il faut noter que la bonne applicabilité de ces modèles nécessite le respect d'un certain nombre de règles afin d'éviter les problèmes des minima locaux qui sont les causes de certaines mauvaises performances des modèles de réseaux de neurones. Pour éviter ces problèmes, la généralisation apparaît comme une solution idoine. Le chapitre III qui vient de s'achever a traité de la problématique des réseaux de neurones. Le chapitre IV, de la deuxième partie de ce mémoire, sera consacré au matériel et aux méthodes utilisées pour atteindre les objectifs de cette étude. DEUXIEME PARTIE : MATÉRIEL ET
MÉTHODES
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Stations hydrométriques |
Période d'observation |
Nombre d'années d'observation |
|
Bada |
1962 à 1997 |
36 |
|
Marabadiassa |
1974 à 1995 |
22 |
|
Tortiya |
1960 à 1997 |
38 |
|
Bou |
1976 à 1997 |
22 |
|
Tawara |
1976 à 1997 |
22 |
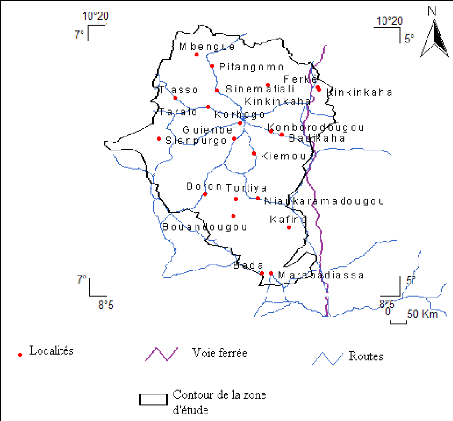
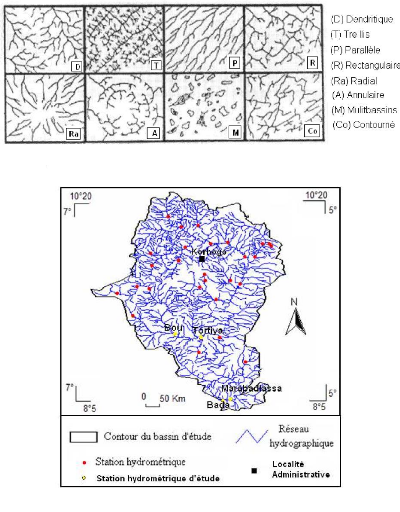
Les series de débits disponibles présentent des données manquantes (lacunes). A la station de Bada, on en dénombre 64, soit 14,81% ; à Marabadiassa, 51 soit 19,31%, à Tortiya 72 soit 15,79% et à Bou 43 lacunes, soit 14,25%. Il convient de noter que la zone d'étude compte en principe 32 stations hydrométriques (Figure 25) mais seulement cinq sont suivies de façon régulière par les services nationaux d'hydrologie. Dans cette étude, seules les stations qui sont supposées fortement perturbées par les barrages agropastoraux feront l'objet de l'étude. Il s'agit des stations de Bada, Marabadiassa, Tortiya et de Bou. La station de Tawara, la plus en amont sur le bassin versant d'étude a été écarté dans cette étude.
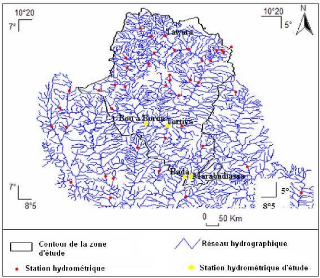
Figure 25 : Localisation des stations hydrométriques les plus suivies de la zone d'étude
Pour les variables explicatives de cette étude (pluie et température), nous disposons de deux séries de données différentes. Une première série collectée au près de la Société d'Exploitation et de Développement Aéroportuaire, Aéronautique et Météorologique (SODEXAM) et une deuxième série téléchargée du site Internet du Système d'Information Intégré de Base de Données (IDIS). L'adresse électronique ce site est : ( http://dw.iwmi.org/dataplatform/Links.aspx).
4.2.1.2.1. Données fournies par la SODEXAM
Les données de pluies et de températures fournies par la SODEXAM concernent celles des stations synoptiques de Korhogo et de Katiola (Figure 26).
Pour la station de Korhogo l'étendue de la série des précipitations mensuelles obtenues est de
29 ans (de 1971 à 2000). Cette série de
données comporte des lacunes. En effet, 12,9 3% des
données de
pluie collectées sont aberrantes. En ce qui concerne les
températures à Korhogo,
30 ans de mesures (de 1971 à 2001) sont disponibles.
Pour la station de Katiola, les pluies journalières de 1949 à 2000 ont pu être collectées soit 51 années d'observation. Ces pluies journalières ont été transformées en pluies mensuelles en faisant leur somme. Il faut signaler que les irrégularités observées dans la série de pluie de la station de Korhogo n'apparaissent pas au niveau de la station de Katiola.
Les données de pluie de la station de Katiola sont attribuées aux deux bassins délimités par rapport aux exutoires du Bandama Blanc à Bada et à Marabadiassa à cause de leur proximité. Pour les même raisons, les données de pluie de la station de Korhogo sont affectés aux bassins versants délimités par rapport aux exutoires du Bandama Blanc à Bou et à Tortiya.
4.2.1.2.2. Données fournies par le système IDIS
Le Système d'Information Intégré de Base de Données (IDIS) fournit des données en ligne partageant la plate-forme qui permet d'accéder aux données scientifiques sur l'eau, l'agriculture et l'environnement pour l'allégement de la pauvreté. Le but principal d'IDIS est d'aider les scientifiques de l'International Water Management Institute (IWMI) et du Challenge Program on Water and Food (CPWF). Le système IDIS contient plus d'un milliard de séries chronologiques mensuelles sur les zones géographiques étudiées par IWMI et CPWF. Cette base de données contient les valeurs de précipitation mensuelles de 1900 à 2002 sur la zone d'étude (Tableau II). Elle fournit également la température, au pas de temps mensuel, de 25 localités réparties de façon homogène sur la zone d'étude.
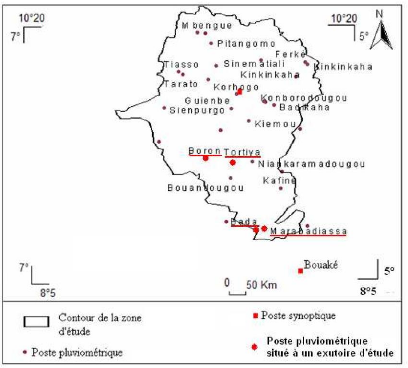
Figure 26 : Répartition de
quelques stations pluviométriques
de la zone d'étude dans la
base IDIS
Les températures et les pluies des localités, résumées dans le tableau II et représentées sur la figure 26, ont permis de déterminer les différentes valeurs mensuelles de ces variables explicatives aux stations de Bada, Marabadiassa, Tortiya et Bou. Les moyennes arithmétiques sont utilisées à cet effet.
Pour la station hydrométrique de Bou, les données de température utilisées dans cette étude sont les températures des localités de Boron, Sienpurgo et de Guiebé ; pour la station hydrométrique de Tortiya. Les températures sont celles des localités de Boron, Sienpurgo, Guienbe, Kiemou, Badikaha, Konborodougou, Korhogo, Tarato, Tiasso, Sinematiali, Kinkinkaha, Ferkessedougou, Pitangomo et de Mbengue ; pour la station de Marabadiassa, les localités sont celles listées précédemment plus la localité de Marabadiassa et ; pour la station hydrométrique de Bada, il s'agit des localités de Boron, Sienpurgo, Guienbe, Kiemou,
Badikaha, Konborodougou, Korhogo, Tarato, Tiasso, Sinematiali, Kinkinkaha, Ferkessedougou, Pitangomo, Mbengue, Marabadiassa, et de Bada.
Tableau II : Présentation de quelques localités extraites de la base de données IDIS
|
Localités |
Période |
Nombre |
|||
|
Localités |
Période |
Nombre |
d'observation |
d'année |
|
|
d'observation |
d'année |
||||
|
Bada |
1900-2002 |
102 |
Korahaha |
1900-2002 |
102 |
|
Badikaha |
1900-2002 |
102 |
Kiemou |
1900-2002 |
102 |
|
Marabadiassa |
1900-2002 |
102 |
Pitangomo |
1900-2002 |
102 |
|
Binguedougou |
1900-2002 |
102 |
Boron |
1900-2002 |
102 |
|
sinématiali |
1900-2002 |
102 |
Bouandougou |
1900-2002 |
102 |
|
Tortiya |
1900-2002 |
102 |
Ferké |
1900-2002 |
102 |
|
Niankaramandougou |
1900-2002 |
102 |
Kinkinkaha |
1900-2002 |
102 |
|
Konborodougou |
1900-2002 |
102 |
Korhogo |
1900-2002 |
102 |
|
Tiébela |
1900-2002 |
102 |
Konbolokoura |
1900-2002 |
102 |
|
Kafine |
1900-2002 |
102 |
Tawara |
1900-2002 |
102 |
|
Tiasso |
1900-2002 |
102 |
Sienpurgo |
1900-2002 |
102 |
|
Guienbe |
1900-2002 |
102 |
Tarato |
1900-2002 |
102 |
|
Mbengue |
1900-2002 |
102 |
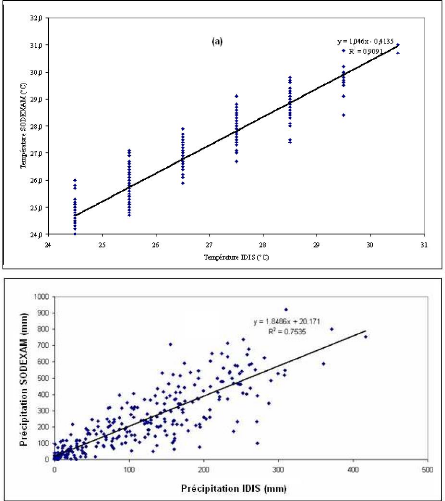
Les pluies et les températures du système IDIS sont comparées à celles fournies par la
SODEXAM à la station de Korhogo, choisie comme station de référence. Les graphes (a) et (b) de la Figure 27 illustrent respectivement la corrélation entre les températures du système IDIS et les températures SODEXAM d'une part et les pluies IDIS et les pluies SODEXAM d'autre part. Ces graphes montrent que les variables mesurées par les deux systèmes sont, dans l'ensemble, très corrélées. En effet, les températures sont corrélées à 95% et les pluies à 87%. Il faut cependant remarquer que les pluies fournies par la SODEXAM semblent généralement deux fois plus grandes que les pluies fournies par la base IDIS (cf. Figure 28 b avec l'équation y = 1,8x +20). Entre les pluies SODEXAM et les pluies IDIS, la relation suivante peut alors être établie : Pluie SODEXAM = 1, 8486Pluie IDIS + 20,1 7 1
(b)
Figure 27 : Relation entre les
données climatiques. (a) Corrélation température IDIS et
température
SODEXAM, (b) corrélation pluie IDIS et pluie
SODEXAM
Il faut toutefois noter, malgré cette corrélation au niveau des données de pluie et de température des deux systèmes, les irrégularités au niveau des pluies fournies par la SODEXAM. Cette étude n'a pas pour objet de remettre en cause les compétences de la SODEXAM au niveau de la fourniture des données climatiques telles que la température et la
pluie. Mais, on peut tout de même faire certaines remarques pour justifier les différents choix opérés dans la suite de l'étude. En effet, sur la période 1971-1997, certaines irrégularités apparaissent dans la série de pluie de la SODEXAM. Certaines de ces irrégularités sont résumées dans le tableau III.
Tableau III : Récapitulatif de certaines irrégularités dans la série des pluies fournies par la SODEXAM sur la période d'étude (1971-1997)
|
Année |
Mois |
Pluies par le |
Pluies |
Année |
Mois |
Pluies par le |
Pluies |
|
1984 |
Décembre |
0 |
12 |
||||
|
1971 |
Janvier |
0 |
1 |
1985 |
Janvier |
0 |
1 |
|
1972 |
Janvier |
0 |
1 |
1985 |
Décembre |
0 |
12 |
|
1973 |
Janvier |
0 |
1 |
1986 |
Janvier |
0 |
1 |
|
1973 |
Février |
0 |
2 |
1986 |
Décembre |
0 |
12 |
|
1973 |
Décembre |
6 |
12 |
1987 |
Décembre |
2 |
12 |
|
1974 |
Janvier |
0 |
1 |
1988 |
Janvier |
0 |
1 |
|
1974 |
Février |
0 |
2 |
1988 |
Février |
0 |
2 |
|
1974 |
Décembre |
0 |
12 |
1988 |
Décembre |
0 |
12 |
|
1975 |
Janvier |
0 |
1 |
1989 |
Janvier |
0 |
1 |
|
1975 |
Février |
0 |
2 |
1989 |
Février |
3 |
2 |
|
1976 |
Décembre |
0 |
12 |
1990 |
Janvier |
29 |
1 |
|
1977 |
Décembre |
0 |
12 |
1990 |
Décembre |
3 |
12 |
|
1978 |
Janvier |
4 |
1 |
1991 |
Janvier |
0 |
1 |
|
1978 |
Février |
0 |
2 |
1991 |
Décembre |
0 |
12 |
|
1978 |
Décembre |
7 |
12 |
1992 |
Janvier |
4 |
1 |
|
1980 |
Février |
22 |
2 |
1992 |
Décembre |
0 |
12 |
|
1981 |
Janvier |
0 |
1 |
1993 |
Janvier |
0 |
1 |
|
1981 |
Décembre |
0 |
12 |
1993 |
Décembre |
0 |
12 |
|
1982 |
Janvier |
0 |
1 |
1994 |
Décembre |
0 |
12 |
|
1982 |
Décembre |
0 |
12 |
1995 |
Janvier |
0 |
1 |
|
1983 |
Janvier |
0 |
1 |
1995 |
Février |
0 |
2 |
|
1984 |
Janvier |
0 |
1 |
1996 |
Janvier |
0 |
1 |
|
1984 |
Février |
0 |
2 |
1997 |
Février |
0 |
2 |
|
1997 |
Décembre |
4 |
12 |
En analysant le tableau III, il est évident que des valeurs de pluies de certains mois concernés ont été remplacées par le code du mois correspondant. Ainsi pour le mois de janvier la pluie est de 1 mm, pour le mois de février, elle est de 2 mm et pour le mois de décembre la pluie mesurée est de 12 mm. Cette irrégularité se répète pour plusieurs années. Ces irrégularités constatées dans les pluies fournies par la SODEXAM peuvent être en partie imputable à des erreurs de report ou à la défaillance des instruments de mesure.
Les différentes statistiques calculées et consignées dans les tableaux IV et V résument les données fournies par les deux systèmes. Ces tableaux témoignent de la similitude des données fournies, notamment pour les températures.
Tableau IV : Statistiques des températures à Korhogo
Nom des Températures du Température de la
statistiques système IDIS en °C SODEXAM en °C
Min 24 24
Max 30 31
Moyenne 26 27
Ecart type 1,51 1,66
Concernant les données de pluies, le tableau V et la figure 27 montrent que les données SODEXAM sont généralement deux fois plus grandes que les données IDIS.
Tableau V : Statistiques des pluies à Korhogo
Nom des Pluie du système Pluie de la SODEXAM
statistiques IDIS en mm en mm
Min 0 1
Max 417 919
Moyenne 100 206
Ecart type 91,69 195,26
Au niveau de la température, les valeurs estimées par les deux méthodes semblent très proches parce que les statistiques calculées sont du même ordre de grandeur. On note que l'écart moyen entre les valeurs et la moyenne des températures est respectivement de 1,51 pour les températures IDIS et de 1,66 pour celles de la SODEXAM. En ce qui concerne les pluies, les statistiques présentées dans le tableau V sont différentes pour les deux méthodes. Les différentes statistiques ne sont pas de même ordre de grandeur.
Dans un travail de modélisation pluie-débit comme c'est le cas ici, il serait intéressant
d'utiliser des variables climatiques issues d'une même
base de données dans la mesure du
possible. Mais, dans notre
situation, les données de pluie et de température fournies par
la
SODEXAM présente beaucoup de lacunes et assez de données aberrantes. Pour résoudre ce problème de données, il est donc fait recours dans ce travail à la base de donnée IDIS, qui donne des séries de pluies et de températures sans données manquantes et pour plusieurs localités réparties sur l'ensemble du bassin versant d'étude.
Les pluies IDIS sont utilisées pour combler les lacunes dans les séries de pluies de la SODEXAM à la station synoptique de Korhogo. En ce qui concerne les températures IDIS, elles sont utilisées comme entrée des différents modèles développés (réseaux de neurones et modèle à réservoir, GR2M) dans la suite de ce travail. Deux raisons majeures motivent le choix des températures IDIS comme entrée des modèles. En effet, d'après les analyses statistiques, ces températures sont similaires à celles fournies par la SODEXAM et elles sont disponibles pour plusieurs localités du bassin versant d'étude, ce qui permet la détermination de températures moyennes plus représentatives que celles de la SODEXAM qui ne concernent que quelques stations synoptiques.
Mesurer les précipitations revient à mesurer une hauteur d'eau pendant un intervalle de temps donné. On a l'habitude d'exprimer les cumuls de pluies journaliers, mensuels ou annuels respectivement en millimètre (mm) par jour, par mois ou par an, réservant généralement l'expression en intensité de précipitation (mm/h) à des intervalles de temps plus courts (horaire, minute, etc.). L'usage a également consacré la pluviométrie comme l'étude de la répartition et du régime des précipitations. Dans cette étude, la pluviométrie (P) est exprimée en mm par le pas de temps du modèle, ici en mm/mois. Elle représente la hauteur d'eau moyenne tombée sur le bassin d'étude et intégrant la distribution spatio-temporelle. Elle est notée P dans cette étude.
La température exprime la valeur de la chaleur ou le froid de l'atmosphère ou de l'air ambiant d'un lieu donné et est exprimée en degré Celsius (°C). La température de l'air influence directement la température des eaux, et par conséquent, la tension de vapeur saturante de l'eau (Rousselle et El-Jabi, 1987). Elle est de plus liée à d'autres facteurs météorologiques qui influencent eux aussi l'évaporation, comme le rayonnement solaire ou la sécheresse de l'air et est notée T dans cette étude.
L'évapotranspiration potentielle est la quantité d'eau susceptible d'être évaporée par une surface d'eau libre ou par un couvert végétal dont l'alimentation en eau n'est pas le facteur limitant. Pour Margat (1999) la valeur de l'évapotranspiration potentielle est fonction de l'énergie disponible. Elle est mesurée par un évaporomètre ou déduite par des formules empiriques telles que celles de Thornthwaite (1948), Turc (1963), Penman (1946), Morton (1983), etc. La méthode de Thornthwaite présentée dans les sections suivantes sera utilisée pour la détermination de l'évapotranspiration potentielle (ETP) dans la mesure où elles ne nécessitent pas beaucoup de paramètres. L'unité de l'évapotranspiration est le millimètre sur le pas de temps désiré (jour, mois, an). Tout le long de cette étude, l'unité utilisée est le mm/mois et elle est notée ETP.
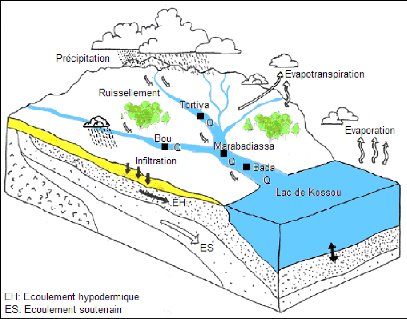
Suite à une pluie tombée sur le bassin versant du Bandama Blanc, tout un mécanisme complexe d'interaction de phénomènes hydrologiques et climatologiques se met en oeuvre. Il se traduit par une circulation, directe ou indirecte, de l'eau, en surface, à travers le sol ou le sous-sol en passant par les cours d'eau secondaires puis principaux, pour finir à l'exutoire. A l'échelle locale du bassin d'étude, le débit traduit la réaction du bassin versant suite à un phénomène pluvieux. Il est mesuré par différentes techniques hydrométriques, par exemple, le jaugeage par moulinet ou le jaugeage chimique en vue d'établir une courbe de tarage mettant en relation hauteur d'eau et débit au niveau de la station de mesure. C'est le cas des débits mesurés par les services de la sous direction de l'hydrologie de la direction de l'hydraulique humaine sur les stations limnimétriques retenues pour cette étude. Le débit est exprimé en mètre cube par seconde (m3/s). Il est représenté par la lettre Q dans ce travail et est également au besoin exprimé en lame d'eau (mm).
Comme déjà annoncé dans les sections précédentes, les données hydrométriques présentent plusieurs lacunes. L'utilisation de ces données à l'état brute sans traitement est une source d'erreur, même si les modèles Perceptrons Multicouches (PMC) pourraient intégrer ces "lacunes" (données manquantes) en les considérants comme des valeurs nulles (zéro) pendant le processus d'apprentissage. Pour remédier à cette éventualité, ces lacunes méritent d'être comblées à l'aide des techniques adaptées dans ces circonstances.
Pour réconstituer les données de débit manquantes plusieurs techniques existent dans la littérature. On peut utiliser des critères de proportionnalité analogues dans le cas de stations hydrométriques placées sur un même cours d'eau (transposition géographique, conservation des volumes, etc.). Les méthodes basées sur l'analyse des régressions et des corrélations (relation pluie-pluie ou pluie-débit, relations inter-postes) peuvent également être utilisées à cet effet (Musy et Higy, 2003). Pour cette étude, les données de débit, mesurées aux stations hydrométriques de Bada, Marabadiassa, Tortiya et Bou, ont été reconstituées à l'aide de la première méthode citée : la méthode du critère de proportionnalité analogue. Les différentes surfaces des sous bassins ont été calculés et les rapports ci-dessous ont été déterminés et utilisés :
|
Concernant les données de pluies aberrantes répertoriées au niveau de la station de Korhogo, elles ont été remplacées par leur équivalent dans la base de données de pluies fournie par le système IDIS en les multipliant par un facteur de 2. Il faut cependant noter que cette multiplication n'a eu aucun effet sur les valeurs complétées car elles étaient toutes nulles.
Les données ainsi harmonisées sont analysées dans la section suivante afin de déterminer des biais éventuels qui pourraient être présents dans ces séries chronologiques.
Dans les sciences hydrologiques, il est souvent nécessaire de contrôler un seul type de données (pluie, température, évaporation) à l'échelle locale (à l'endroit où la mesure a été effectuée) ou à l'échelle régionale (d'un bassin versant où plusieurs sites de mesures ont été établis). La comparaison des données IDIS et SODEXAM trouve ici son importance. C'est la méthode du double cumul qui consiste à vérifier la proportionnalité des valeurs mesurées à deux stations qui a été utilisée. L'une des stations (station X) est la station de base ou station de référence, supposée correcte. L'autre station (Y) est la station à contrôler. Un effet de lissage est obtenu en comparant, au pas de temps choisi (année, saison, mois, décade), non pas
les valeurs observées, mais leur cumul. Dans cette étude, les données IDIS représentent la station (Y) et les données SODEXAM la station X. Les auteurs tels que Musy et Higy (2003) propose les relations suivantes :
t
X t
( ) = x i
( ) (8)
i = 0 t
Y t
( ) = y i
( ) (9)
i = 0
Le cumul est établi sur 27 ans avec les valeurs mensuelles des précipitations et des températures. Les pluies et les températures issues de la base de données IDIS et celles fournies par les services de la SODEXAM sont comparées. Les figures 28 et 29 illustrent respectivement les comparaisons avec les pluies et les températures.
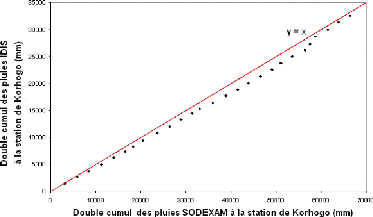
Figure 28 : Double cumul des précipitations SODEXAM et IDIS à Korhogo
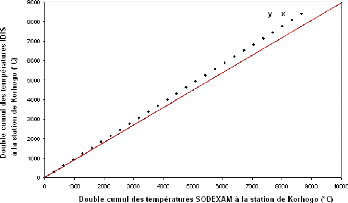
Figure 29 : Double cumul des températures SODEXAM et IDIS à Korhogo 4.2.6.2. Données hydrométriques
Comme pour la pluie et la température, le cumul des débits mensuels est établi sur 27 ans. Les débits des stations de Marabadiassa, Tortiya et Bou (stations à contrôler) sont comparés aux débits de la station de Bada (station de référence) d'une part (Figure 30 à 32) et d'autre part les débits à la station de Bou (station contrôlée) aux débits de la station de Tortiya (station de référence) (Figure 33).
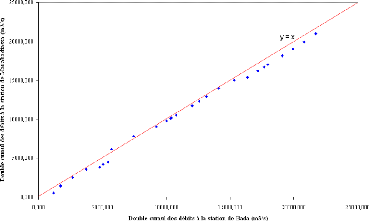
Figure 30 : Double cumul des débits aux stations de Bada et de Marabadiassa
La figure 30 compare des bassins versants de taille voisine et assez proche géographiquement (les superficies sont de 24 050 km2 pour la station de Bada et de 22 293 km2 pour la station de Marabadiassa). La figure 31 compare les stations de Bada et de Tortiya qui sont deux stations très éloignées l'une de l'autre. Ici on note une différence notable entre les superficies des deux sous bassins (24 050 km2 pour la station de Bada et 14 500 km2 pour la station de Tortiya).
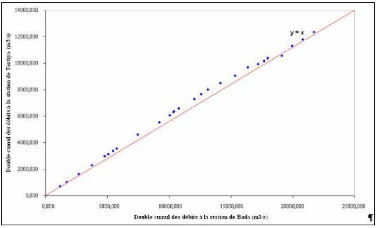
Figure 31 : Double cumul des débits des stations de Bada et de Tortiya
Comme précédemment, la figure 32 compare des bassins versants trop différents (24 050 km2 pour la station de Bada et 3 710 km2 pour la station de Bou).
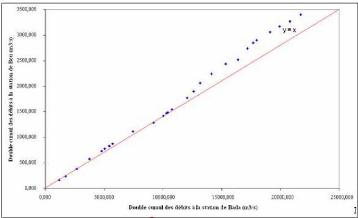
Figure 32 : Double cumul des
débits des stations de Bada et de Bou
- 74 -
Quant à la figure 33 elle paraît plus intéressante, car elle compare des bassins versants assez proches par la taille et par leur position géographique (Tortya et Bou).
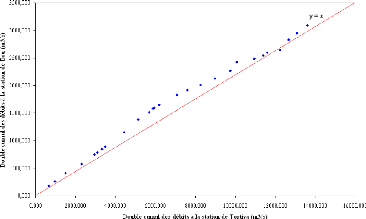
Figure 33 : Double cumul des debits des stations de Tortiya et de Bou
On note que quelque soit la différence de superficie des bassins versants et l'éloignement des stations de mesures, il ne se dégage aucune tendance comme par exemple une rupture de pente significative. Il ressort que la méthode du double cumul suggérée par Musy et Higy (2003) ne permet pas de détecter des biais significatifs au niveau des données hydrométriques disponibles pour cette étude. Cependant, il est bon de remarquer que lorsqu'on compare les débits de la station de Bou à ceux des stations de Bada et de Tortiya, on observe de légers changements de pente.
Cette partie du travail a pour objectif d'apprécier de façon globale la dynamique de l'évolution des précipitations par rapport aux lames d'eau écoulées aux stations de Bada, Marabadiassa, Tortiya et de Bou. Les figures 34 à 37 illustrent respectivement l'évolution des lames d'eau écoulées, des précipitations et des déficits d'écoulements moyens à ces différentes stations hydrométriques.
En Annexe B, les chroniques de pluies et débits sont représentées pour chaque année et pour chacune des 4 stations.
|
Quantite d'eau (mm) |
350,00 300,00 250,00 200,00 150,00 100,00 50,00 0,00 |
||
|
Lame d'eau écoulée (mm) Précipitation (mm) Déficit d'écoulement (mm) |
|||
mars
mai
avril
juin
octobre
juillet
janvier
aoat
fewier
novembre
decembre
septembre
Mois
Figure 34 : Évolution des
lames d'eau écoulées, des précipitations et des
déficits d'écoulements
moyens à la station de Bada
|
Quantite d'eau (mm) |
350,00 300,00 250,00 200,00 150,00 100,00 50,00 0,00 |
||
|
Lame d'eau écoulée (mm) Précipitation (mm) Déficit d'écoulement (mm) |
|||
mars
mai
avril
juin
octobre
juillet
janvier
aoat
Wrier
novembre
decembre
septembre
Mois
Figure 35 : Évolution des
lames d'eau écoulées, des précipitations et des
déficits d'écoulements
moyens à la station de
Marabadiassa
|
Quantite d'eau (mm) |
600,00 |
||
|
300,00 |
Lame d'eau écoulée (mm) Précipitation (mm) Déficit d'écoulement (mm) |
||
|
200,00 100,00 0,00 |
mars
mai
awll
juin
octobre
juillet
janvier
aoat
fewier
novembre
decembre
septembre
Mois
Figure 36 : Évolution des
lames d'eau écoulées, des précipitations et des
déficits d'écoulements
moyens à la station de
Tortiya
|
Quantite d'eau (mm) |
600,00 |
||
|
300,00 |
Lame d'eau écoulée (mm) Précipitation (mm) Déficit d'écoulement (mm) |
||
|
200,00 100,00 0,00 |
mars
mai
avril
juin
acid
fevrier
juillet
octobre
janvier
novembre
decembre
septembre
Mois
Figure 37 : Évolution des
lames d'eau écoulées, des précipitations et des
déficits d'écoulements
moyens à la station de Bou
La
lecture de ces figures ci-dessus montre généralement que pendant
toute la période de
décembre à juin, les rivières du bassin
versant du Bandama Blanc, situées en amont du
barrage de Kossou,
réagissent faiblement aux évènements pluvieux. C'est
seulement à partir
de juin jusqu'à décembre qu'on peut
apprécier une quantité d'eau écoulée non
négligeable
avec un maximum atteint en septembre. Ces faibles écoulements du Bandama blanc à Bada, Marabadiassa, Tortiya et à Bou peuvent être le fait de trois facteurs : (i) l'évapotranspiration intense pendant la saison sèche, (ii) les fortes infiltrations des eaux de pluie pour alimenter les nappes profondes et (iii) l'utilisation des eaux pour les activités anthropiques (agriculture et élevage) à travers la création de barrage agro pastoraux.
4.2.6.4.1. Évapotranspiration potentielle
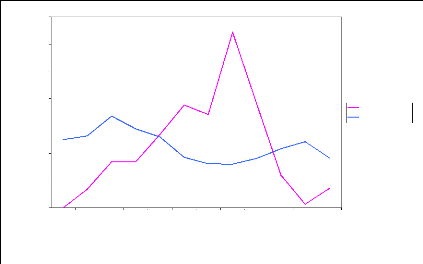
Sur l'ensemble de la période d'étude (1971 à 1997), la plus grande valeur d'évapotranspiration potentielle, déterminée en mars 1983 et 1990 avec la méthode de Thornthwaite, est égale à 220 mm et la plus petite valeur est de 80 mm, déterminer en Août 1971. L'étendue est donc estimée à 140 mm. Cela montre une très grande dispersion des ETP sur l'ensemble de la période d'étude. La lecture de la figure 38 montre que l'ETP présente généralement deux grandes évolutions au cours de l'année sur l'ensemble de la zone d'étude. En effet, de janvier à mars, l'ETP et les précipitations évoluent de façon proportionnelle. Après mars, les deux variables sont inversement proportionnelles ; car, lorsque l'ETP augmente, la pluie diminue et vis- versa.
Quantite Beau en mm
350,00
300,00
250,00
200,00
150,00
100,00
50,00
0,00
janvier
fevrier
mars
avril
mai
juin
Mois
juillet
adit
septembre
octobre
novembre
decembre
Précipitation (mm) ETP (mm)
Figure 38 : Évolution des ETP et des précipitations sur la zone d'étude
4.2.6.4.2. Variable temporelle (le mois)
Les chiffres affectés aux différents mois sont compris entre 0,08 et 1. La figure 39 donne les différentes valeurs des mois qui ont été codés en fonction des températures enrégistrées à la station de Bada.
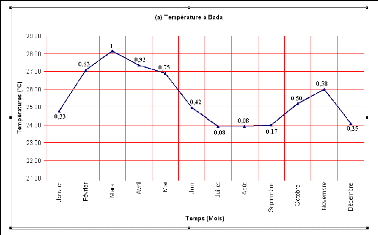
Figure 39 : Codage des mois à partir des températures moyennes mensuelles de la station de Bada
Les mois ainsi codés sont introduits dans les modèles de réseaux de neurones développés dans ce mémoire.
Cette section présente le compilateur RNF PRO et le tableur EXCEL qui ont servi au développement respectivement des réseaux de neurones formels et du modèle GR2M.
Plusieurs environnements sont disponibles pour le développement des Réseaux de neurones notamment Matlab, Statistica, Scilab, RNF PRO, etc. Le compilateur "RNF PRO" développé à l'Ecole des Mines d'Alès (France) sera utilisé de préférence dans cette étude à cause de son usage facile. Il faut préciser que ce compilateur est en amélioration perpétuelle et que le langage de programmation utilisé pour son développement est « Java » à cause de sa flexibilité. En effet, cet environnement permet au logiciel "RNF PRO" d'être utilisable sur plusieurs plates formes (Windows, Unix, etc.) et sur plusieurs PC. Pour optimiser l'utilisation de l'environnement de travail, les paramètres à faire varier sont (Eurisouke, 2006) :
i. l'initialisation avec le choix de la suite aléatoire ;
ii. le choix de la méthode de minimisation de la fonction coût qui est l'erreur quadratique moyenne ;
iii. le pas de gradient ;
iv. le nombre de présentation des événements de l'apprentissage, qui est évalué en fonction de l'allure de la courbe du critère de test. Si ce critère se met à augmenter, l'apprentissage est arrêté car il se spécialise (apprentissage par "coeur" sur les exemples d'apprentissage et donc la qualité de test se dégrade) ;
v. la période d'affichage, si cette période est de p, le critère d'apprentissage est affiché toutes les p présentations de l'ensemble d'apprentissage. Dans cette étude, la période d'apprentissage est égale à 10 ;
vi. le critère lambdaä , si on utilise l'algorithme de Levenberg Marquarld (LM). Les modèles neuronaux construits avec le logiciel "RNF PRO" se présente sous la forme suivante (Figure 40).
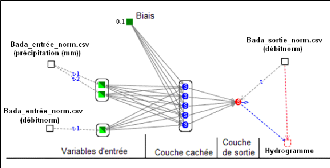
Figure 40 : Présentation d'un
modèle Perceptron multicouche à cinq (5) neurones sur la
couche
cachée
La figure 40 représente un
modèle Perceptron Bouclé Dirigé, de prévision. La
variable
d'entrée est la pluie mensuelle et la variable cible, le débit mensuel. Dans le compilateur RNF PRO, les entrées et les sorties sont rangées dans une matrice. Cette matrice représentée à la figure 41 contient autant de colonnes et de lignes qu'il y a de données. La première colonne porte le nom "action" et les lignes sont occupées par les lettres A pour apprentissage et T pour test. Les autres colonnes portent les noms des variables correspondantes et lorsqu'une colonne est sélectionnée, elle prend la couleur rose.
Si les données ne sont pas déjà normées, cette fenêtre permet leur normalisation en choisissant la méthode dans le menu "normaliser" situé au bas de la matrice.
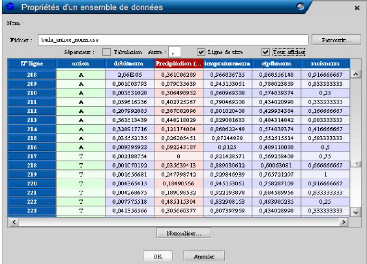
Figure 41 : Matrice d'entrée
des variables dans le logiciel "RNF PRO"
Une fois les données
formatées et rangées dans la matrice ci-dessus
présentée, le programme
peut alors être « lancé ». Pendant ce processus d'apprentissage, l'évolution des critères d'apprentissage et de validation ou test sont visibles grâce aux fenêtres, d'optimisation des paramètres, représentées par les figures 42 et 43. Ces figures sont respectivement les fenêtres d'optimisation utilisées pour l'apprentissage par la méthode de la rétropropagation de l'erreur et de celle de Levenberg Marquarld (LM).
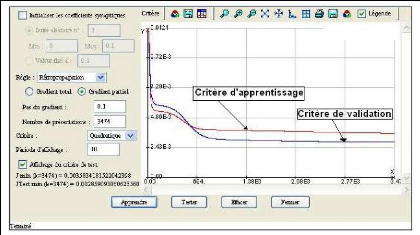
Figure 42 : Fenêtre de saisie des paramètres dans "RNF PRO" pour la retropropagation de l'erreur
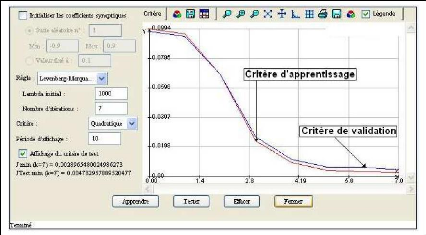
Figure 43 : Fenêtre de saisie des paramètres dans "RNF PRO" pour la Levenberg Marquarld
En plus des différents paramètres cités plus haut, les fenêtres d'optimisation affichent également, à la fin de l'apprentissage, les erreurs quadratiques moyennes (MSE) les plus faibles des phases de calage et de validation (ou test). A la fin de cette phase d'optimisation ou d'apprentissage, l'évolution des hydrogrammes (hydrogrammes mesuré et calculé) en apprentissage et en validation sont représentés respectivement par les figures 44 et 45.
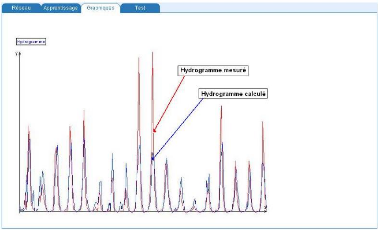
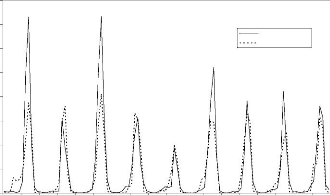
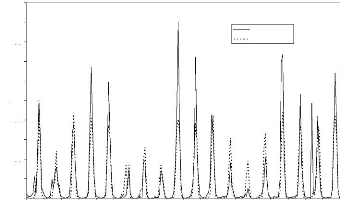
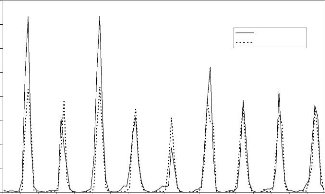
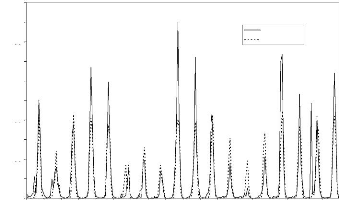
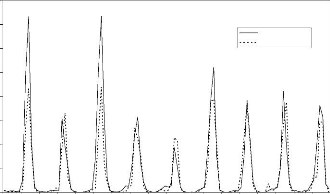
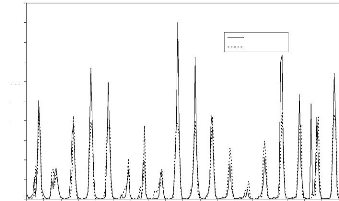
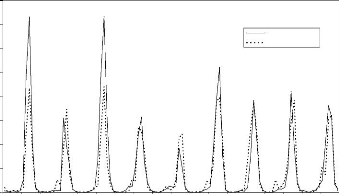
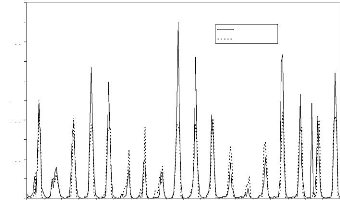
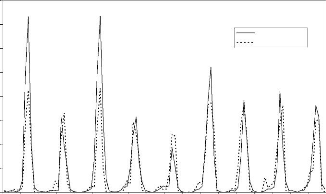
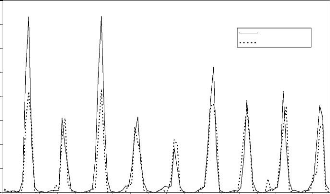
Figure 44 : Hydrogrammes mesuré et calculé sous le logiciel "RNF PRO"en apprentissage
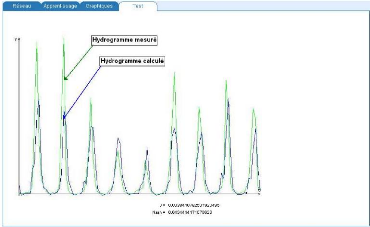
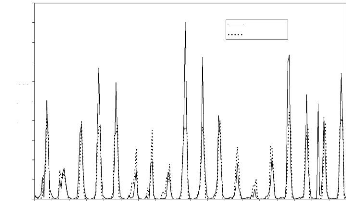
Figure 45 : Hydrogrammes mesuré et calculé sous le logiciel "RNF PRO" en validation
Que se soit en apprentissage ou en validation, les modèles développés sont meilleurs si et seulement si les hydrogrammes calculés et les hydrogrammes mesurés se superposent.
En vue d'apprécier les résultats obtenus avec les réseaux de neurones, une approche avec un modèle conceptuel à réservoir, GR2M, a été développée. Cette étape de modélisation est ici présentée. Pour fixer les idées sur les modèles GR, quelques travaux ayant contribué au développement des modèles GR sont présentés dans les paragraphes suivants :
i. Modèles pluie-débit au pas de temps journalier
La conception des modèles GR au pas de temps journalier a débuté dans les années 80 au Cemagref avec les travaux de Claude Michel (1983). Cet auteur a engagé une réflexion sur la modélisation pluie-débit à partir du modèle CREC, un modèle à neuf paramètres développés au Laboratoire d' Hydrologie de l'Université de Montpellier (Cormary et Guilbot, 1973). Se basant sur cette structure, des simplifications ont été faites, dans le but d'obtenir un modèle à peu de paramètres, sans amoindrir les performances du modèle initial en terme de simulation des débits. Une structure simple à deux réservoirs a ainsi été proposée avec un seul paramètre correspondant à une capacité maximale identique de ces
deux réservoirs dans le cas du bassin versant de l'Orgeval (Michel, 1983). Le modèle à deux paramètres, GR2, avec un paramètre pour chaque capacité de réservoir, venait de naître. Après avoir été utilisé par Loumagne (1988) et Devred (1989), GR2 a ensuite été repris et amélioré par Edijatno (1987, 1991) pour obtenir le modèle GR3. Il a modifié la fonction de production et a ajouté un troisième paramètre. Le nouveau modèle journalier GR3 (Edijatno et Michel, 1989) fut testé sur un échantillon de 110 bassins versants français et donna des résultats satisfaisants. Dans une perspective de constante amélioration de cette structure, Nascimento (1991, 1995) a isolé des bassins intermittents pour lesquels le modèle avait du mal à fournir des résultats corrects, et a introduit dans le modèle un quatrième paramètre gouvernant des échanges "souterrains" pour répondre aux exigences de bonne reproduction des débits. Le nouveau modèle GR4 a fourni sur un échantillon de 120 bassins de meilleures performances que la version antérieure à trois paramètres. Parallèlement aux travaux de Nascimento (1995), Makhlouf (1994) a mené des recherches sur l'explication des paramètres du modèle GR4J sur des bassins de Moselle et de Bretagne et a également donné quelques voies pour le traitement de la neige sur les bassins de la Moselle. Plus récemment, Edijatno et al. (1999) ont proposé une nouvelle version à trois paramètres du modèle journalier. Cette version, dans laquelle la capacité du réservoir de production est fixe, est très similaire à la version proposée par Nascimento (1995) avec des fonctions de production et d'échange légèrement modifiées. Enfin, Perrin (2000) et Perrin et al. (2003) ont proposé une version améliorée de ce modèle journalier, comportant quatre paramètres et permettant notamment d'améliorer la simulation des étiages avec l'introduction d'une percolation issue du réservoir de production du modèle.
ii. Modèles pluie-débit au pas de temps mensuel et annuel
Les travaux de Kabouya (1990) ont permis de mettre au point un modèle mensuel GR3M à trois paramètres pour l'appliquer à des problèmes d'évaluation de la ressource en eau en Algérie septentrionale (Kabouya et Michel, 1991). Makhlouf (1994) a également travaillé sur un modèle mensuel en proposant une version à deux paramètres, le modèle GR2M (Makhlouf et Michel, 1994) qui a par la suite été améliorée par Mouelhi (2003). Au pas de temps annuel, les travaux de Bouabdallah (1997) ont permis de jeter les premières bases d'un modèle pluie-débit annuel, avec deux versions, à un paramètre (GR1A) et deux paramètres (GR2A). Par la suite, Mouelhi (2003) a repris la chaîne de modélisation à pas de temps mensuel, annuel et pluriannuel, en essayant d'identifier l'adaptation des structures
des modèles au pas de temps de fonctionnement, et en recherchant les cohérences de structures entre ces différents pas de temps. Il a ainsi pu proposer un modèle mensuel (GR2M) à deux paramètres, un modèle annuel (GR1A) à un paramètre et un modèle interannuel sans paramètres à caler.
Le modèle GR2M est développé sous plusieurs environnements. On a les compilateurs Scilab, le Fortran et le tableur ExcelTM utilisé dans ce travail. Le modèle GR2M développé sous le tableur ExcelTM comprend six feuilles :
i. la feuille "Readme", contient les détails sur l'architecture du modèle, les données à rentrer, la manière de faire les simulations, les critères de performance et sur les graphiques ;
ii. la feuille "GR2M", permet de faire les simulations de débit au pas de temps mensuel ;
iii. la feuille "S", donne l'évolution du taux de remplissage du réservoir de production;
iv. la feuille "R", donne l'évolution du taux de remplissage du réservoir de routage;
v. la feuille "Hydrogramme", présente les hydrogrammes observés et calculés ainsi que la pluie et ;
vi. la feuille "Débit XY", présente la courbe de corrélation entre les débits observés et les débits simulés par le modèle GR2M.
En ce qui concerne les données utilisées dans le modèle GR2M, elles sont toutes exprimées en mm (précipitations, évapotranspirations potentielles et débits). En pratique, les précipitations et les évapotranspirations potentielles sont fournies ou calculées et l'unité est directement le mm. Quant aux débits, ils sont fournis en m3/s et il faut alors les diviser par la surface du bassin concerné et multiplier ce quotient par le temps afin de les avoir en mm.
Au terme de ce chapitre, il convient de noter que les variables explicatives retenues sont la pluie (P), la température (T), l'évapotranspiration potentielle (ETP), estimée avec la méthode de Thornthwaite, et le mois (M) qui a été codé par rapport à la température. Les variables cibles sont les débits mensuels mesurés aux stations hydrométriques de Bada, Marabadiassa, Tortiya et Bou sur le Bandama Blanc en amont de la retenue d'eau du barrage de Kossou. Ces données débimétriques collectées sur ces stations s'étendent généralement de 1962 à 1997 et
présentent des lacunes. En effet, à la station de Bada, on en dénombre 64, soit 14,81% ; à Marabadiassa, 51 soit 19,31%, à Tortiya 72 soit 15,79% et à Bou 43 lacunes, soit 14,25%.
En ce qui concerne les données de pluie et de température, elles proviennent de la SODEXAM et du Système IDIS. Les stations de la SODEXAM retenues pour cette étude sont les stations de Korhogo et de Katiola.
En vue de minimiser les valeurs aberrantes, les pluies de la station de Korhogo ont été affectées aux stations de Bou et de Tortiya qui lui sont plus proches et les pluies de la station de Katiola aux localités de Bada et de Marabadiassa pour les mêmes raisons.
A Korhogo, l'étendue de la série des pluies mensuelles collectées est de 29 ans (de 1971 à 2000) et comporte des lacunes. En effet, sur l'ensemble des pluies collectées sur cette station, 12,93% sont des valeurs aberrantes. Ces dernières ont donc été remplacées par leurs homologues de la base de données du système IDIS en les multipliant par un facteur de 2, car, les pluies du système IDIS sont de moitiés inférieures à celles de la SODEXAM. Les pluies IDIS sont donc utilisées dans cette étude pour combler les lacunes au niveau des séries de pluies de la SODEXAM. En ce qui concerne les températures IDIS, elles sont entièrement utilisées comme entrée des différents modèles développés (Réseaux de neurones et GR2M). Il faut également noter que les séries de pluies et de températures, de 24 localités de la base de données IDIS, disponibles, s'étendent généralement de 1900 à 2002. En ce qui concerne les températures, elles sont celles de la période 1971 à 2001.
Pour la station de Katiola, les pluies journalières de 1949 à 2000 ont pu être collectées soit 51 années d'observations. Les irrégularités observées dans la série de pluie à la station de Korhogo n'apparaissent pas à la station de Katiola.
Après analyse et contrôle des données hydroclimatiques avec la méthode du double cumul, aucun biais ne se dégage au niveau des pluies, des températures et des débits. On admet alors que les données rassemblées pour cette étude semblent homogènes. Une autre analyse, celle de la chronique précipitation-lame d'eau écoulée, a permis d'observer la répartition mensuelle des écoulements sur l'ensemble de la zone d'étude. Il ressort de cette étude que c'est seulement à partir de juin jusqu'à décembre qu'on peut apprécier une quantité d'eau écoulée non négligeable avec un maximum atteint en septembre.
Les environnements scientifiques retenus pour traiter ces
données sont le compilateur RNF
PRO développé sous Java
par l'Ecole des Mines d'Alès (Fance) pour la mise en place des
modèles neuronaux et le tableur EXCEL pour le modèle GR2M développé par le CEMAGREF (France).
L'objectif de ce chapitre est de mettre en place la méthodologie de développement et d'optimisation des modèles utilisés dans ce travail. Pour cela il est subdivisé en quatre grandes sections. La première section présente la méthode de détermination des ETP et du codage du mois. La deuxième section donne les objectifs de la modélisation entrepris dans ce mémoire et précise le pas de temps utilisé. La troisième section s'intéresse à la sélection des variables pertinentes, au choix et à la conception des modèles. Une fois les modèles mis en place par les sections précédentes, la dernière section présente les critères de performance de ces modèles.
L'évaporation représente le processus au cours duquel l'eau liquide se transforme en vapeur. L'ensemble des processus d'évaporation et de transpiration est connu sous le nom d'évapotranspiration. Elle est une des composantes fondamentales du cycle hydrologique et la précision de son estimation est essentielle pour le calcul du bilan en eau, de l'irrigation et de la gestion des ressources en eau, ainsi que pour les travaux d'aménagement. L'agronome américain Thornthwaite proposa en 1931 une expression de l'évapotranspiration ne tenant compte que de la température mensuelle :
ETP = × ) a × a ×
10
1,6 ( t f (10)
I
où :
ETP : évapotranspiration mensuelle (cm)
I : indice thermique annuel défini comme la somme des indices thermiques mensuels i,
déc
(11)
I = i , 1 , 5 1 4
i = ( t )
jan
5
t : température moyenne mensuelle (°C)
a : coefficient fonction de I a (0, 0675 3 7 ,7 1 2 1792 ) 10 5
-
= × - × +
I I × ×
I
f : facteur fonction de la durée réelle du mois et de l'éclairement ( f = N × ñ avec N : durée astronomique du jour pendant le mois considéré (heure/jour), ñ : paramètre dépendant du nombre de jours par mois).
D'autres méthodes existent dans la littérature. On peut citer entre autres :
· La formule de Turc (1963) ;
· Les méthodes basées sur le bilan hydrique (Mermoud, 1998) ;
· Les méthodes basées sur le bilan d'énergie ;
· Les méthodes basées sur le transfert de masse.
L'évapotranspiration potentielle peut également être estimée à partir de mesures directes sur des bacs d'évaporation. Les valeurs de ce coefficient sont tabulées pour différentes conditions climatiques et environnementales. Une autre méthode d'évaluation directe est l'utilisation de cases lysimétriques. Dans ce cas, le taux d'évapotranspiration est déterminé par la mesure des pertes d'eau.
De toutes ces méthodes, il est très difficile de choisir la meilleure pour estimer l'évapotranspiration. D'une part, les équations existantes sont multiples et, d'autre part, les données climatiques ne sont pas toujours disponibles. En l'absence de mesures directes d'évaporation sur notre site d'étude, compte tenu des données disponibles (température, etc.) et de la difficulté d'estimation du rapport durée réelle d'insolation/durée maximale possible
( h ) dans la méthode de Turc, la méthode de Thornthwaite a été utilisée pour calculer l'ETP. H
Il s'agit d'un codage effectué en utilisant les courbes d'évolution des températures moyennes mensuelles mesurées sur les sous bassins versants objets de cette étude. Ce codage répond à l'exigence de fournir au réseau, la température sous une autre forme. Pour ce faire, le codage le plus simple serait d'attribuer le chiffre 1 au mois de janvier ; le chiffre 2 au mois de février ainsi de suite jusqu'au mois de décembre. Mais, cette manière de coder les mois ne permet pas d'apprécier la variation de la température d'un mois à un autre. Ainsi dans cette étude, le codage réalisé se base t-il sur les chiffres 1 à 12, mais affecte le rapport 1/12 (code 0,08) au mois le moins chaud et le rapport 12/12 (code 1) au mois le plus chaud.
Plusieurs auteurs ont proposé une méthodologie pour la conception de modèles. On peut citer comme exemple les travaux de Refsgaard (1997) et ceux de Dreyfus et al., (2004).
Pour Dreyfus et al., (2004) la conception d'un modèle non linéaire type « boîte noire » peut comprendre trois grandes parties :
i. la sélection des entrées du modèle qui comprend la réduction de la dimension des données d'entrée (c'est-à-dire la réduction de la dimension de l'espace de représentation des variables du modèle) et l'élimination des variables non pertinentes ;
ii. l'estimation des paramètres du modèle avec le choix du type de modèle (par exemple les modèles de Réseaux de neurones, les fonctions polynômes, etc.) et l'apprentissage ou le calage du modèle précédemment choisi ;
iii. la sélection du meilleur modèle et l'estimation des performances des modèles. Si le modèle estimé meilleur n'est pas satisfaisant, on choisit une famille de fonctions plus ou moins complexe et on revient à la seconde étape de la tâche précédente.
Cette méthodologie bien qu'elle permette le développement de modèles, souffre cependant du manque d'une étape importante : la définition de l'objectif de la modélisation. En effet, tout modèle est construit pour la résolution de tâches bien précises. On parle de modèle de simulation ou de modèle de prévision. L'objectif assigné au modèle peut alors orienter le modélisateur dans le choix des variables explicatives et des variables cibles. Pour combler cette insuffisance, il est intéressant de considérer les étapes proposées par Refsgaard (1997) qui prend en compte, en plus des étapes décrites par Dreyfus (2004), la définition de l'objectif du modèle. Pour cette étude, la méthodologie, représentée sur la figure 46 suivante, inspirée des deux auteurs précédemment cités a été adoptée.
Figure 46 : Protocole de
modélisation adopté des méthodologies de Dreyfus et
al., (2004) et de
Refsgraad (1997)
Le développement d'un modèle débute toujours par la définition de ses objectifs. Cette thèse vise la modélisation de la rélation pluie-débit dans un contexte perturbé. Il s'agit de mettre en place des réseaux de neurones capables de :
· Reconstituer des valeurs manquantes dans les séries de débits sur le Bandama Blanc
(faciliter la réalisation de certains projets de développement sur la zone d'étude) ;· (ii) Prévoir les périodes de basses eaux et les périodes de hautes eaux sur l'ensemble de la zone d'étude. Ceci permettra d'aider la classe paysanne dans la gestion de la ressource en eau. On pourra alors gérer les conflits opposants agriculteurs et éleveurs dans le Nord de la Côte d'Ivoire. Ce travail vise aussi à aider la Société de
Distribution d'Eau de la Côte d'Ivoire (SODECI) dans l'alimentation en eau des localités concernées par l'étude.
Cette modélisation peut s'effectuer selon plusieurs pas de temps. Le pas de temps choisi est toujours lié aux objectifs de la modélisation comme définit précédemment. En hydrologie, les pas de temps fréquemment utilisés sont l'heure, le jour, le mois et l'année. Les travaux de Mouelhi (2002) se sont intéressés à la modélisation au pas de temps pluriannuel, annuel, mensuel et journalier dans ses travaux de Thèse. Son objectif était de tirer profit de l'échelle de temps dans la modélisation pluie-débit en vue d'obtenir des modèles plus efficaces et plus cohérents entre eux. Huang et al. (2004) ont fait de la prévision de la rivière Apalachicola (Floride, USA) au pas de temps journalier, mensuel, trimestriel et annuel. Quant à Solomatine et Dibike (1999), ils ont fait de la prévision au pas de temps hebdomadaire en utilisant la pluie, l'évapotranspiration et les débits. Tous ces exemples montrent que la modélisation pluie-débit peut se faire sur de nombreux pas de temps.
Une analyse des données de débits fournies par la Direction de l'Eau (DE) donne les observations suivantes :
i. au pas de temps horaire, les données n'existent pas ;
ii. au pas de temps journalier, les données existent mais présentent beaucoup de lacunes ;
iii. au pas de temps mensuel, les données sont obtenues en calculant la moyenne des débits journaliers. Les séries obtenues présentant peu de lacunes ;
iv. au pas de temps annuel, les données sont obtenues en calculant les moyennes des débits mensuels. Les débits obtenus représentent les moyennes des débits mensuels. Les différentes valeurs de débits sont très lissées au pas de temps annuels. Les séries de débits annuels obtenues présentent peu de lacunes.
Il ressort de cette analyse que la Direction de l'Eau ne dispose que des données au pas de temps journalier et que les données au pas de temps mensuel et annuels sont obtenues par calcul. Vu ce qui précède, c'est la modélisation au pas de temps mensuel qui a été choisie. En effet, ce pas de temps semble être un bon compromis permettant d'intégrer des données avec peu de lacunes sans qu'elles soient trop lissées. Le pas de temps mensuel peut également être considéré comme opérationnel pour les acteurs concernés par la gestion de la ressource en eau.
D'après les travaux de Lachtermacher et Fuller (1994) et de Dimopoulos et al., (1996), le choix de données d'entrée du modèle doit tenir compte de la disponibilité de ces données, des facteurs déterministes ou de toute information connue à priori. Toutefois, ce choix doit tenir compte des autocorrélations, des corrélations croisées et de l'analyse de causalité (Awadallah, 1999). Dans cette étude, le choix des variables explicatives pertinentes se fonde sur les données disponibles et sur les objectifs précédemment définis. Les variables retenues sont donc la pluie, la température, l'évapotranspiration et le mois comme variables explicatives d'une part et les débits aux stations hydrométriques de Bada, Marabadiassa, Tortiya et Bou comme variables cibles d'autre part. L'objectif majeur d'un modèle pluie-débit est d'arriver à estimer des débits qui soient les plus proches possibles des débits observés que ce soit en simulation qu'en prévision. Ces modèles doivent donc être capables de simuler et de prévoir des débits dans des situations très contrastées c'est-à-dire en période humide et en période sèche. Le modélisateur doit de ce fait prendre en compte d'une façon relativement uniforme toutes les classes de débits (Mouelhi, 2002). Plusieurs auteurs ont utilisé diverses transformations du débit et ont obtenu de très bons résultats.
La transformation logarithmique du débit a été utilisée par Ambroise et al., (1995). Ces auteurs ont pu niveler les valeurs des débits et faire varier les erreurs du modèle dans un même ordre de grandeur pour toutes les classes de débits. Une autre possibilité est de diviser les débits par les pluies correspondantes pour obtenir un paramètre qui correspond au coefficient d'écoulement. Cette transformation de la variable cible pose un certain nombre de problèmes. En effet, le débit et les pluies sont des variables entachées d'un certain nombre de bruits (incertitudes sur la mesure, courbes de tarage, etc.). En calculant le rapport de ces deux variables, on contribue à augmenter le bruit. Cette méthode augmente le risque de biaiser les estimations des débits en simulation ou en prévision. Une solution intermédiaire se situant entre la transformation logarithmique et la solution de prendre directement la variable cible existe. Il s'agit de la transformation puissance des débits (ou transformation racine carrée). Chiew et al., (1993), Perrin (2000) et Mouelhi (2003) ont utilisé cette transformation intermédiaire avec des résultats très satisfaisants. En modélisation avec les Réseaux de neurones, cette transformation des variables cibles qui s'étend aussi aux variables explicatives est la "normalisation ". Elle est nécessaire car pendant l'apprentissage ou le calage, si les
variables explicatives et les variables à expliquer sont très différentes, les plus petites valeurs n'ont pas d'influence sur l'apprentissage. Différentes "normalisation " utilisées en modélisation avec les Réseaux de neurones, existent. Dans cette étude on a divisé les données par leurs valeurs maximales. On retrouve ainsi une "normalisation " où toutes les valeurs des différentes variables sont comprises entre 0 et 1. L'équation de cette normalisation peut se
V ànormer
traduire par : V normée = ; avec V normée , la valeur de la donnée normée ; V ànormer , une des
Vmax
données à normer ; Vmax , la valeur maximale des données.
Le tableau VI donne les statistiques des variables normées aux différentes stations de la zone d'étude.
Tableau VI : Statistiques des variables normées aux stations de Bada, Marabadiassa, Tortiya et Bou
|
Débit |
||||
|
Bada |
Marabadiassa Tortiya |
Bou |
||
|
Moyenne |
0,08 |
0,08 |
0,09 |
0,08 |
|
Pluie |
||||
|
Moyenne |
0,17 |
0,17 |
0,25 |
0,26 |
|
Température |
||||
|
Moyenne |
0,86 |
0,86 |
0,86 |
0,86 |
|
Evapotranspiration |
||||
|
Moyenne |
0,57 |
0,57 |
0,57 |
0,57 |
Le développent d'un réseau de neurones se heurte à l'absence d'une méthodologie précise et rigoureuse (Awadallah, 1999). La démarche que suit tous les modélisateurs est la méthode "essais-erreur" qui est un processus par tâtonnement. Cette difficulté est rendue possible à cause de la flexibilité inhérente aux réseaux de neurones, à son caractère intrinsèquement non linéaire et à la difficulté de déterminer la signification statistique des paramètres estimés (poids).
Une fois l'objectif défini et les variables pertinentes sélectionnées, il faut choisir le type d'approche qui soit le plus en adéquation avec cet objectif.
Ce choix a été dicté par le contexte du travail, le type, la quantité et la qualité des observations de terrain dont on dispose et enfin la qualité des résultats que l'on peut en attendre.
5.3.3.2.1. Choix de la structure et de la topologie des modèles
Dans la mise au point des réseaux de neurones, la partie qui semble la plus difficile est la détermination de l'architecture. En effet, la détermination de la topologie d'un réseau revient à faire un choix très judicieux du vecteur d'entrée et de la taille du réseau. Rumelhart et al., (1986) reconnaissent le niveau de difficulté dans le choix de la topologie d'un réseau de neurones adaptée à la résolution d'un problème donné tel que la simulation ou la prévision des débits d'une rivière dans un contexte perturbé.
La topologie d'un réseau de neurones est déterminée par le nombre de couches cachées, l'existence de connexions entre les neurones et le nombre de neurones sur les couches cachées. La complexité du modèle neuronal dépend aussi bien de la valeur des poids et des biais que de leur nombre (Vapnik, 1992). Que ce soit en simulation ou en prévision, une seule couche cachée est suffisante. En effet, le Perceptron multicouche (PMC) à une couche cachée est un approximateur universel capable de modéliser n'importe quelle fonction continue (Hornik et al., 1989). Cependant cela ne garantit pas qu'un modèle de ce type arrive à modéliser une fonction quelconque avec un nombre raisonnable de neurones, ni qu'il sera possible de déterminer ce nombre (Fortin et al., 1997). Plusieurs travaux ont tenté de résoudre la détermination de la topologie des modèles perceptrons multicouches, mais la question est loin d'être résolue. Comment arriver à déterminer le nombre minimal et adéquat de neurones cachés ? Cette question demeure jusqu'à présent sans réponse véritable, malgré de nombreuses approches empiriques. Un réseau incapable de modéliser la complexité d'un système, que cela soit faute de neurones cachés ou de temps suffisant d'apprentissage, est qualifié de réseau sous-entraîné (underfitting). Par contre, un réseau qui donne de bonnes performances sur son ensemble d'apprentissage, mais qui donne de moins bonnes performances en validation, que cela soit dû à trop de neurones cachés ou à un apprentissage excessif, est qualifié de réseau sur-entraîné (overfitting). Un modèle Perceptron sur-entraîné fait une mauvaise évaluation de la variance de la perturbation aléatoire associée au phénomène étudié, et par conséquent, produit des sorties avec une variance excessive (Geman et al., 1992). Le choix de la structure des modèles neuronaux est donc un compromis entre le sous-apprentissage et le sur apprentissage (Awadallah, 1999). Plusieurs règles heuristiques existent pour suggérer à priori un nombre de neurones cachés en fonction du nombre d'observations en apprentissage et du nombre d'entrée du modèle. Cependant, ces règles empiriques dépendent de la nature des données utilisées et du bruit qui entache ces données. Elles ne sont donc pas à généraliser (Sarle, 1999). Il faut pour ce faire procéder avec une démarche du type "essais-erreurs".
5.3.3.2.2. Détermination de l'architecture des modèles 5.3.3.2.2.1. Nombre de retard
Le retard ou délais est la fénêtre temporelle qu'on donne au réseau de neurones afin de lui permettre de prendre en compte les évenements passés (pluies, températures, évapotranspirations potentielles, mois, débits, etc.). Ce retard est déterminé par plusieurs méthodes dont les méthodes empiriques. Dans cette étude, la méthode utilisée consiste à faire varier le nombre de retards de 1 à n ( n ? R) et de fixer le nombre de neurones cachés. Ici, n est égal à 13 et le nombre de neurones cachés est fixé à 5. Une fois le nombre de retards optimaux obtenus pour le nombre de neurones fixé à 5, on fixe ce nombre de retards et on fait varier le nombre de neurones cachés de 1 à 12.
5.3.3.2.2.2. Nombre de neurones cachés
Dans la littérature il existe plusieurs méthodes de détermination du nombre de neurones dans la couche cachée (Roussillon, 2004) : l'approche par sélection (a), l'approche incrémentale (b) et l'approche par expérience (c).
Approche par sélection
L'approche par sélection ou approche destructive consiste à commencer par la construction d'un réseau complexe qui contient un grand nombre de neurones, puis d'essayer de réduire le nombre de neurones inutiles et supprimer les connexions redondantes pendant ou à la fin de l'apprentissage. Cette méthode présente deux variantes : l'optimal Cell Damage (OCD) et l'utilisation de la dérivée de la sortie.
i) Optimal Cell Damage (OCD)
Cette méthode qui est directement inspirée de l'Optimal Brain Damage (OBD) proposé par Le Cun (1990) consiste à supprimer des cellules durant l'apprentissage.
Une cellule est supprimée si sa "sensibilité" est faible. La sensibilité d'une cellule est définie
|
n par : ( j ) SC i = S i W |
(18) |
j = 1
Où Ci représente la cellule i du réseau de neurones, représente la connexion sortante j de la cellule Ci et S i (W j ) représente la sensibilité de la connexion Wj .
1 ? 2 MSE
Cette sensibilité est définie par : ( )
S W = × × W 2 j (19)
i j W 2
2 ? j
Avec MSE est la moyenne des carrées des erreurs.
Cibas (1996) propose de faire d'abord converger le Réseau de neurones, puis de calculer la sensibilité pour chaque entrée du réseau, de classer les entrées par ordre croissant de sensibilité et enfin de supprimer les entrées pour lesquelles la sensibilité est inférieure à un seuil donné. Le processus sera répété jusqu'à aboutir à une architecture optimale.
ii) Utilisation de la dérivée de la sortie
Cette technique de sélection de variables est basée sur l'influence de l'entrée Xi sur la sortie
du réseau de neurones.
Le principe consiste à calculer la dérivée
?F de la sortie du réseau par rapport à l'entrée Xi
?Xi
pour toutes les observations. Si la valeur de cette dérivée est faible pour toutes les observations, on conclut que la sortie ne dépend pas de l'entrée Xi .
Approche incrémentale
Dans l'approche incrémentale (ou approche constructive), à l'inverse de l'approche précédente, on commence par un réseau le plus simple possible, puis on y ajoute des neurones ou des couches, jusqu'à obtenir une architecture optimale.
On peut citer la méthode de Fahlman (1989) qui commence par un réseau initialisé à un seul neurone. Une fois que le neurone est bien entraîné, une nouvelle unité sera ajoutée dans le réseau et ainsi de suite. L'inconvénient de l'approche de Fahlman est qu'elle peut générer un réseau dont le nombre de neurones et/ou de couches est très élevé.
Approche relevant des expériences antérieures
Pour l'optimisation d'un réseau de la forme (V , N , S ) où V est le nombre de variables d'entrée, N le nombre de neurones dans la couche cachée et S le nombre de variables de sortie, les différentes méthodes sont ici codées de Me1 à Me4.
i. Me1 fixe N égale à V ;
ii. Me2 utilise la relation suivante : N = 0,75 × V ;
iii. Me3 est la méthode dite de racine carrée où N est obtenu par la formule :
N = V × S ;
( ) 2
1
iv. Me4 attribue à N la moyenne de V et S .
L'approche par sélection paraît peu pertinente
pour la problématique de ce travail de
recherche, qui a pour objectif
de développer un modèle opérationnel et donc
économe en
temps de calcul. Ce sont donc les approches
incrémentales (Fahlman, 1989) et empiriques qui
seront utilisées, ce qui permettra in fine de vérifier dans quelle mesure la méthode empirique est efficace.
5.3.3.2.3. Choix de la fonction d'activation
Le choix du modèle neuronal comprend toujours celui de la fonction d'activation ou fonction neurone. Celle-ci est essentielle pour introduire la non linéarité dans les modèles. En effet, sans la non-linéarité, les réseaux de neurones formels ne seront pas plus puissants qu'un modèle linéaire généralisé, parce que la combinaison de fonctions linéaires reste toujours une fonction linéaire (Awadallah, 1999). Les propriétés de la fonction d'activation influent en effet sur celle du neurone formel et il est donc important de bien choisir celle-ci pour obtenir un modèle bien construit. Quand les neurones sont combinés en un réseau de neurones, il est important par exemple que la fonction d'activation de certains d'entre eux ne soit pas un polynôme sous réserve de limiter la puissance de calcul du réseau obtenu. Une revue bibliographique a permis de savoir que les trois fonctions les plus utilisées sont les fonctions "seuil" (limit), linéaire et sigmoïde. Ces fonctions sont résumées dans le tableau VII.
La fonction "seuil" applique un palier sur son entrée. Plus précisément, si une entrée négative ne passe pas le palier fixé, la fonction retourne alors la valeur 0, alors que pour une entrée qui dépasse cette limite, la fonction retourne 1. Cette fonction permet donc de prendre des décisions binaires. Les débits à modéliser par les différents modèles à développer et à optimiser dans ce travail de recherche prennent tous des valeurs discrètes et continues. Pour cette raison cette fonction d'activation a été écartée dans le cadre de cette étude.
En ce qui concerne la fonction linéaire, elle est très simple. Cette fonction affecte directement son entrée à sa sortie. La relation pluie-débit étant une relation non-linaire, utiliser la fonction linéaire supposerait que la pluie et le débit évoluent linéairement, ce qui n'est pas le cas. Cette fonction tout comme la précédente n'a pas été utilisée ici.
Il reste alors les fonctions sigmoïdes qui présentent deux variantes : la fonction sigmoïde de type logistique et la fonction sigmoïde de type tangentiel. Ces fonctions ressemblent soit à la fonction seuil, soit à la fonction linéaire, selon que l'on est, respectivement loin ou proche du seuil. Les fonctions sigmoïdes apparaissent donc comme un compromis intéressant entre les deux autres fonctions. Des deux variantes, la fonction Sigmoïde de type logistique bornée de 0 à 1 a été utilisée dans ces travaux.
Tableau VII : Typologie des fonctions d'activation les plus utilisées (Roussillon, 2004)
|
Catégorie |
Type |
Equation |
Allure |
Dérivée |
||||
|
Seuil |
Binaire (fonction |
f(x) = 1 si x > 0 f(x) = 0 si x <= 0 |
- |
|||||
|
Signe |
f(x) = 1 si x > 0 f(x) = -1 si x <= 0 |
- |
||||||
|
Linéaire |
Identité |
f(x) = x |
f'(x) = 1 |
|||||
|
Saturé positif |
f(x,k) = 0 si x < 0 f(x,k) = 1 si x >= 1/k f(x,k) = k.x sinon |
f(x,k) = 0 si x < 0 f(x,k) = 0 si x >= 1/k f(x,k) = k sinon |
||||||
|
Saturé symétrique |
f(x,k) = -1 si x < -1/k f(x,k) = 1 si x >= 1/k f(x,k) = k.x sinon |
f(x,k) = 0 si x < - 1/k f(x,k) = 0 si x >= 1/k f(x,k) = k sinon |
||||||
|
Sigmoïde |
Positive (type |
|||||||
|
Symétrique (type tanh) |
||||||||
Plusieurs méthodes existent en hydrologie pour le choix des périodes de calage/validation des modèles développés. On trouve entre autres :
i. la méthode la plus simple qui consiste à diviser la période de mesures disponibles en
deux parties pas forcément égales. La première partie sert à calibrer le modèle et la seconde à tester ou à valider le modèle calibré. Cette méthode, appelée "simple split-sample test" (Klemes, 1986a) » est la plus utilisée en hydrologie ;
ii. la méthode appelée "differential split-sample test" (Klemes, 1986a) qui consiste à
diviser la période de mesures disponibles en deux, mais cette fois-ci en fonction d'un critère comme l'intensité des précipitations, de façon à tester la capacité du modèle à reproduire les observations dans un contexte climatique différent de celui sur lequel il a été calibré. On pourra par exemple calibrer le modèle sur une saison déficitaire et le valider sur une saison excédentaire.
Ces deux premières méthodes permettent de tester le modèle sur le bassin versant sur lequel il a été calibré. Il est également possible de les combiner avec les données d'un autre bassin versant lorsqu'elles sont disponibles. Parmi ces méthodes on peut citer la méthode "proxy-catchment" qui consiste à calibrer le modèle sur un bassin versant et à le valider sur un autre pour la même période de mesure ; la méthode "differential proxy-catchment" est plus exigeante puisqu'elle teste le modèle sur un autre bassin avec des conditions différentes de celles avec lesquelles le modèle a été calibré.
Les méthodes "simple split-sample" sont généralement utilisées lorsque l'on veut utiliser le modèle sur des bassins versants qui risquent d'être peu modifiés. Les méthodes différentielles ont été présentées comme valables lorsque l'objectif est de prédire l'impact des changements climatiques. Or, il a été prouvé que les variations climatiques importantes n'ont pas toujours eu un impact visible sur le régime hydrologique d'un bassin (Ewen et Parkin, 1996). Les méthodes "simple split-sample" et "proxy-catchment" sont celles qui sont généralement utilisées. Dans cette étude, la méthode du "simple split-sample test" a été utilisée, notamment parce qu'elle est simple et fréquement utilisée en hydrologie. Ainsi les 2/3 des données (1971- 1988) seront choisies pour la phase d'apprentissage et les 1/3 (1989-1997) pour la phase de validation (Figure 47).

Figure 47 : Diagramme de
séparation des données d'apprentissage et de validation des
modèles
développés
Le choix des 2/3 des données disponibles pour le calage
et des 1/3 de ces mêmes données
pour la validation est
raisonnable dans la mesure où dans l'optimisation d'un modèle
Réseaux
de neurones Formel, plus la phase d'apprentissage est longue et plus il est possible d'espérer de meilleurs résultats.
L'apprentissage (ou la calibration) représenté sur la figure 48 consiste en un entraînement du réseau. Des entrées (variables) sont présentées au réseau pour modifier sa pondération de telle sorte que l'on trouve la sortie correspondante. L'algorithme consiste dans un premier temps à propager vers l'avant les entrées jusqu'à obtenir une sortie par le réseau. La seconde étape compare la sortie calculée à la sortie réelle connue. les poids (weight) sont alors modifiés de telle sorte qu'à la prochaine itération, l'erreur commise entre la sortie calculée et mesurée soit minimisée. Malgré tout, il ne faut pas oublier que l'on a des couches cachées. L'erreur commise est rétropropagée vers l'arrière jusqu'à la couche d'entrée tout en modifiant la pondération. Ce processus est répété sur tous les exemples jusqu'à ce que l'on obtienne une erreur de sortie considérée comme acceptable par le modélisateur. Quand l'erreur devient suffisamment petite, le réseau ainsi optimisé est utilisé pour calculer les sorties en introduisant de nouvelles entrées inconnues par le modèle : c'est la validation (test ou contrôle selon les auteurs).
Entrées
Nouvelles
entrées
Réseaux de neurone formel (RNF)
Réseau de neurone
formel (RNF)
Déterminer
les poids
Indiquer la sortie
Sortie prévue
Figure 48 : Stratégie d'apprentissage des modèles neuronaux
L'estimation des paramètres comporte plusieurs choix : le critère d'erreur à atteindre ; l'algorithme d'optimisation de ce critère et ; les paramètres de l'algorithme et l'ensemble des valeurs initiales aléatoires des poids et des biais. Pour ce faire, certains choix ont été opérés. Avant d'être développés dans les sections suivantes, ils sont ici présentés :
i. le critère d'erreur est l'erreur quadratique;
ii. la méthode du gradient de l'erreur (avec un gradient partiel et le pas du gradient fixé à 0,1) est choisie pour optimiser les différents modèles développés. ;
iii. la fonction d'activation est la sigmoïde logistique bornée de 0 à 1 ;
iv. les poids initiaux des réseaux sont fixés à 0,1
v. le biais est fixé à 0,1.
Toute la puissance des réseaux de neurones réside dans leur capacité d'apprentissage. Cet apprentissage se fait par une rétropropagation de l'erreur commise par le réseau par rapport à la sortie désirée. Il se fait selon une approche déterministe où les poids sont modifiés après présentation de l'ensemble ou partie de la base d'apprentissage. Le critère à minimiser est l'erreur quadratique moyenne î :
|
MSE = î ( w) = E d - ? ( w , x ) ( 2) |
(20) |
Où ö est une fonction dépendante du réseau, w le vecteur contenant les différents poids et les biais du réseau, x les exemples présentés aux réseaux et d les sorties désirées. On modifie le vecteur w de façon à minimiser cette erreur. Pour l'optimisation des modèles en général et des modèles hydrologiques en particulier, deux grandes familles de méthodes existent dans la littérature : les méthodes locales et les méthodes globales.
5.3.3.4.1. Méthodes locales
La méthode locale exige le choix d'un point de l'espace des paramètres comme point de départ et le déplacement dans une direction qui améliore continuellement le critère de performance. Deux variantes de cette méthode existent. Ce sont les méthodes directes et les méthodes du gradient. Les méthodes directes se basent plus sur le choix de la direction et du pas de recherche. Là encore de nombreuses variantes existent : la méthode de Rosenbroch (1960), la méthode du Pattern Search (PS), (Hooke et Jeeves, 1961), la méthode du Simplex (Nelder et Mead, 1965) et la méthode "pas a pas" (Michel, 1989 ; Nascimento, 1995).
En ce qui concerne les méthodes du gradient, elles utilisent en plus de la valeur de la fonction critère, la valeur de son gradient pour décider de la stratégie d'évolution dans l'espace des paramètres (Perrin, 2000). Dans cette catégorie, on a les méthodes de 1er ordre (Retro propagation de l'erreur et ses dérivées) et les méthodes de 2eme ordre (Gradient conjugué + Fletcher-Reeves (CCGF) et Levenberg-Marquardt (LM)).
5.3.3.4.2. Méthodes globales
Pour Perrin (2000), les méthodes globales permettent de
traiter efficacement des problèmes
où la fonction à
optimiser est multi modale. Ces méthodes sont différentes des
premières par
le fait qu'elles explorent une partie beaucoup plus grande de l'espace des paramètres. Trois variantes existent : les méthodes déterministes, les méthodes stochastiques et les méthodes combinatoires. Pour plus de détail sur ces méthodes, consulter les travaux de Perrin (2000). La méthode locale du gradient (la rétro-propagation de l'erreur) est utilisée dans ce mémoire. La qualité des paramètres d'un modèle dépend de la puissance et de la robustesse de l'algorithme utilisé (Duan et al., 1992). En modélisation, l'optimisation n'est pas un problème hydrologique mais un corollaire mathématique lié à la nature et à la complexité intrinsèque du modèle. Comme mentionné au chapitre II, les algorithmes d'apprentissage sont des règles à partir desquelles les modèles neuronaux vont apprendre à se comporter, à se construire. Ils fonctionnent par minimisation de l'erreur d'un critère imposé. La méthode du gradient peut être :
i. totale, dans le cas de l'utilisation d'un critère total : celui-ci prend en compte tous les exemples en même temps ;
ii. partielle, dans le cas d'utilisation d'un critère partiel : celui-ci considère chaque exemple pris séparément.
Cette méthode nécessite l'emploi d'une fonction sigmoïde dérivable. Elle utilise un développement de Taylor à l'ordre 1 de l'erreur quadratique. Il a été développé par Rumelhart et Parkenet le Cun en 1985 et repose sur la minimisation de l'erreur quadratique entre les débits calculés et les débits mesurés aux différentes stations. Le terme rétropropagation du gradient provient du fait que l'erreur calculée en sortie est retransmise en sens inverse vers l'entrée. Dans cette méthode, la stratégie de mise à jour des poids est différente selon qu'on se trouve à la sortie des réseaux où à l'intérieur de ceux-ci. Pour plus de compréhension, on considère un réseau comportant n variables d'entrée, m variables de sortie et plusieurs couches cachées. Supposons qu'on dispose d'un ensemble d'apprentissage composé de k paires de vecteurs :
( x 1 , o 1), ( x2, o 2) , ,( xk ,o k) (21)
Avec :
= , 0 , 1 , , 0 , 2 , ..., , 0 , ? (Vecteur d'entrée) ;
n
( ) t
x x x x R
p p p p n
o p = o p , 1 , op,2 ,..., op,m ? R (Vecteur de sortie) ;
m
( ) t
= , , , , 1 , 2 ,..., , , ? (Vecteur des sorties réelles du réseau)
m
y y y
( ) t
y R
p p l l p p l m
On pose
Cj , k , i : La connexion entre le neurone k de la couche j-1 et le neurone i de la couche j :
yp,j, k : L'entrée totale du neurone k pour l'échantillon p de la couche j :
Cj , k, 0=èj,k : Le poids fictif du neurone k de la couche j correspondant à un biais dont l'entrée
est fixée à 1.
L'entrée totale du k noeud pour la couche j est :
n
y p , j , k = E Wj,k , i X p,j -1 , i (22)
i
=
0
La sortie de ce noeud sera :
n
|
Out |
Wj , k ,i X |
+ è - j , p j i , 1 , |
k |
(23) |
i
=
1
X p , j , k = F(Yp,j , k ) , F étant la fonction d'activation sigmoïde présentée ci-dessus.
Pour la mise à jour des différents poids, on pose que l'erreur commise sur le kième noeud de
sortie est définie par : äp ,k = O p , k- X p,l , k
2
m m
(24)
Il vient que l'erreur totale est : (
1 1
J = ä p k
2 = O X
- )
, p k
, p l k
, ,
2 k=1 2 k=1
Pour minimiser J, on calcule son gradient par rapport à chaque poids C, puis on modifie les poids dans le sens du gradient. Selon qu'il s'agisse des couches de sortie ou des couches cachées, l'équation de mise à jour des poids est différente. Elle est facile à mettre en place pour la couche de sortie et plus difficile dans l'autre cas. La modification des poids est fonction du calcul du gradient. Ainsi, les poids sur la couche de sortie sont mis à jour de la façon suivante :
C t
l k j+ 1 ) = C l,k , j (t )+ ( )(25)- ( t) =ìOp, k X p,l , k ) f' frp,l , k * p,l -1 ,j (26)
Avec ì le pas d'apprentissage compris entre 0 et 1. Finalement :
ep l , k = (Op,k - Xp,l , k ' , , avec ep, l , k l'erreur de signal du kieme noeud de la couche de
sortie, l'équation des modification des poids :
(27)
(28)
Cl ,k , j ( t + 1 ) = C l,k , j ( t ) + ìe p,l ,k X p,l -1 ,k
En ce qui concerne la mise à jour des couches cachées
Cl - 1 , j , ( t + 1 ) = C l-1, j, i ( t ) + ì e X
p,l -1 , j p,l -2 ,i
L'un des inconvénients majeurs de cet algorithme est qu'il risque de converger vers un minimum local de la surface d'erreur, d'où un choix non neutre des conditions initiales, fixées à 0,1 pour le poids et le biais.
Les critères de performance d'un modèle hydrologique peuvent être simples (rapport des volumes d'eau simulés et observés), ou faire l'objet de calculs en général inspirés par des méthodes statistiques visant à normaliser la comparaison entre le résultat de la simulation ou de la prévision et les observations. On peut trouver des descriptions détaillées de ces critères dans les travaux de Nash et Sutchiffe (1970), Beven et Binley (1992), Franchini et al., (1996) et Siebert, (1999). Pour quantifier les performances des modèles, il n'y a pas de critère universel d'évaluation. Le principe général est de comparer les débits calculés aux débits observés. On peut interpréter les critères en termes de qualité (ajustement du modèle à la réalité), de robustesse (conservation des performances d'un modèle de la phase de calage à la phase de contrôle), et de fiabilité (conservation des performances d'un modèle d'un bassin à un autre), Miossec (2004). De nombreux critères sont utilisés en hydrologie pour évaluer la sensibilité des modèles, notamment :
i. le Critère de Nash ;
ii. le coefficient de corrélation R ;
iii. le coefficient de détermination R2 ;
iv. l'erreur quadratique moyenne (Mean Square Error) (MSE) ;
v. la racine carrée de l'erreur quadratique moyenne (Mean Square Error) (RMSE) Les paragraphes développés ci-dessous essaieront de décrire ces critères afin de faciliter leur utilisation dans la suite de ce mémoire de Thèse.
Le critère de Nash (Nash-Sutchiffe, 1970) varie entre -8 et 1. L'asymétrie de la distribution du critère de Nash-Sutcliffe peut poser des problèmes, par exemple si le modèle est très mauvais, il y aura des valeurs négatives très grandes en valeur absolue qui constituent un obstacle au calcul d'une moyenne. De plus, le critère de Nash-Sutcliffe accorde plus d'importance aux erreurs sur les forts débits. En pratique, il convient de garder cette propriété à l'esprit pour l'interprétation des performances des modèles ou de transformer les variables sur lesquels on calcule le critère (par exemple en calculant le critère sur les racines carrées des débits, on accordera la même importance à toutes les classes de débit). Kachroo (1986) a donné l'échelle suivante quand aux valeurs prises par le critère de Nash :
i. = 90% le modèle est excellent ;
ii. 80% à 90%, le modèle est très bon ;
iii. 60% à 80%, le modèle est bon ; et
iv. = 60% , le modèle est mauvais.
Le critère de Nash-Sutcliffe est donné par la formule suivante :
|
( ) T P - i i |
2 |
i
Nash = (1 00) (1
× - 2) (29)
-
|
i |
T 1 |
- |
P
avec :
-
Ti et Pi respectivement les débits mesurés (observés) et calculés pour les i =1 , .. . , N, P est la moyenne des débits calculés.
R )
(30)
Le coefficient de corrélation de Pearson est habituellement utilisé pour évaluer la performance des modèles hydrogéologiques et hydrologiques (Legates et McCabe, 1999). Il est obtenu en calculant la régression linéaire entre les valeurs (débits) calculées et les valeurs (débits) observées ou mesurées. Sa formulation est la suivante :
N
i = 1
tP
R
i i


N 2
( t ) ( 2 )
i P i
i = 1
avec :
-
Ti et Pi respectivement les débits observés et calculés pour les i =1 , .. . , N, T et P sont les moyennes respectives des débits observés et calculés.
- -
N , le nombre d'entrées; t i = Ti- T , p i = Pi- P ,
La corrélation entre les débits observés et les débits calculés est (Legates et McCabe, 1999) :
i. parfaite si R = 1 ;
ii. très forte si R > 0,8 ;
iii. forte si R se situe entre 0,5 et 0,8 ;
iv. d'intensité moyenne si R se situe entre 0,2 et 0,5 ;
v. faible si R se situe entre 0 et 0.2 ;
vi. nulle si R = 0 ;
Si R est positif et proche de 1, la relation entre les débits mesurés et les débits calculés par les modèles est de type linéaire, elle est croissante et le nuage de point est très concentré autour de la droite de régression. Il est cependant impossible de tirer une conclusion ferme et définitive sur la linéarité de la relation tant que le graphique n'a pas été réalisé (méthode empirique), ou qu'un test sur la linéarité de la relation n'a pas été effectué (méthode statistique). Le coefficient de détermination ( 2
R ) mesure la qualité de l'ajustement des estimations de l'équation de régression. Il est utilisé à la fois en régression simple et en régression multiple. Il permet d'avoir une idée globale de l'ajustement du modèle. Il s'interprète comme la part de la variance de la variable Y expliquée par la régression varie entre 0 et 1 et s'exprime souvent en pourcentage. En régression simple, un 2
R proche de 1 est suffisant pour dire que l'ajustement est bon. En régression multiple, une valeur élevée du coefficient de détermination n'est pas suffisante pour affirmer que le modèle est bon, il est nécessaire d'effectuer un test sur la signification de 2
R afin de savoir s'il existe une relation entre les débits calculés et les débits mesurés ou observés. Ce test revient à effectuer un test de significativité globale du modèle à l'aide du test de Fisher. Il faut savoir que de faibles valeurs du F statistique sont associées à des valeurs du 2
r proche de 0, et de fortes valeurs du
F à des valeurs de R2 proches de 1. L'expression de R2 est donnée par l'équation :
N
(P i - T _ )2
2 i
R = (1 00 ).( ) (31)
N
( )2
T T
-
i
i
avec :
-
Ti et Pi respectivement les débits observés et calculés pour les i =1 , . . . , N, T est la moyenne des débits mesurés ou observés
N , le nombre d'entrées.
Lorsque le coefficient de détermination 2
R vaut environ K% par exemple. L'interprétation à donner est la suivante: "Si la relation entre Ti et Pi est de type linéaire, le modèle mathématique Pi =a Ti +b peut expliquer à lui seul K% de la variabilité observée. Les (100- K)% restants représentent les erreurs de mesures et toutes les imprécisions engendrées lors de l'expérience. Comme précédemment, sans la visualisation graphique de l'expérience, ou un
test statistique sur la linéarité, il est impossible d'affirmer avec certitude que la relation est bien linéaire.
L'erreur quadratique moyenne (MSE en anglais) est généralement utilisée pour mesurer la performance de l'étape de calage pendant le développement du modèle.
Les auteurs, Hagan et al., (1996) et Principe et al., (1999) s'accordent sur l'expression suivante de l'Erreur quadratique moyenne (MSE) :

2
N
1
MSE
1
=
Ni
( )
T i P i
-
(32)
N
2
1
RMSE = ( ( ) 1 / 2
T i P i
- ) (33)
N i = 1
avec :
Ti et Pi respectivement les débits observés et calculés pour les i =1 , .. . , N
N , le nombre d'entrées.
Deux types d'architectures de réseaux de neurones sont présentés dans ces paragraphes. Il s'agit des Perceptrons Multicouches Non Dirigés(PMCND) et des Perceptrons Multicouches Dirigés (PMCD) dont les architectures générales ont déjà été présentées dans la première partie de ce mémoire. Ces modèles seront indexés par la lettre "s" pour signifier qu'il s'agit de modèles de simulation. La nomenclature des différentes architectures de modèles Perceptrons Multicouches développés dans ce mémoire sera fonction des variables explicatives. En effet, on aura le modèle :
i. PMCD1s avec la pluie comme variable explicative ;
ii. PMCND1s avec la pluie comme variable explicative ;
iii. PMCD2s avec la pluie et le mois comme les variables explicatives ;
iv. PMCD3s avec la pluie et l'ETP comme les variables explicatives ;
v. PMCD4s avec comme variables explicatives la pluie et la température ;
vi. PMCD5s avec comme variables explicatives la pluie, la température et le mois et ;
vii. PMCD6s avec la pluie l'ETP et le mois comme variables explicatives.
Au total sept architectures différentes de
modèles Perceptrons Multicouches de simulation ont
été
utilisées dans ce travail. Une fois la structure des modèles
définie, il reste alors la
détermination du nombre de couches cachées, du nombre de neurones sur ces couches cachées et le nombre de mois de retard. La détermination du nombre de couches cachées est très importante dans la mise en place des modèles Perceptrons Multicouches (PMC). La figure 50 illustre l'évolution de la performance en fonction du nombre de couches cachées. D'après la figure 49, les modèles Perceptrons avec une seule couche de neurones sont plus performants que ceux qui possèdent deux, trois couches de neurones ou plus. Tous les modèles Perceptrons développés dans ce travail ont été donc à une seule couche cachée de neurones. La figure 50 présente l'évolution du Nash en fonction du nombre de retard. Les graphes (a) sont obtenus avec les modèles non dirigés(PMCND1s) et les graphes (b) sont ceux obtenus avec les modèles boucles dirigés (PMCD1s).
|
Valeurs du critere |
80 70 60 50 |
|||
|
40 |
PMC avec 1 couche cachée PMC avec 2 couches cachées PMC avec 3 couches cachées |
|||
|
30 20 10 0 |
2 3 4 5 6 7 8 9 10 11 12
Nombre de neurones sur la couche cachée
Bada
|
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
11 |
12 |
13 |
Bada Marabadiassa Tortiya
Bou
080
(a)
70
0,60
0,50
0,40
Nash
0,30
0,20
0,10
0,00
-0,10
Nombre de retard
|
(b) |
90 0,80 0,70 0,60 |
||||
|
Nash |
0,50 |
Bada Marabadiassa Tortiya Bou |
|||
|
0,30 0,20 0,10 0,00 |
1 2 3 4 5 6 7 8 9 10 11 12 13
Nombre de retard
Figure 50 : Évolution du
critère de Nash en fonction du nombre de retard aux stations de
Bada,
Marabadiassa, Tortiya et Bou :(a) MODÈLES NON
DIRIGÉS(PMCND1s), (b) MODÈLES DIRIGÉS
(PMCD1s)
Avec les Perceptrons Multicouches Non Dirigésayant pour entrée la pluie (PMCND1s), le nombre de retard optimal, exprimé en mois, est de 13 mois pour les stations de Bada, Marabadiassa et Tortiya et de 11 mois pour la station de Bou. En ce qui concerne les Perceptrons Multicouches Dirigés avec la pluie en entrée (PMCD1s), ce retard reste constant et égal à 13 mois pour la station de Bada et diminue pour les autres stations. Il est de 9 mois
0,80
0,70
0,60
0,50
Nash
0,40
0,30
0,20

pour la station de Marabadiassa, de 6 mois pour la station de Tortiya et de 4 mois pour la station de Bou.
La figure 51 représente l'évolution du critère de performance de Nash en fonction du nombre de neurones cachés.
0,90
(a)
Bada Marabadiassa Tortiya
Bou

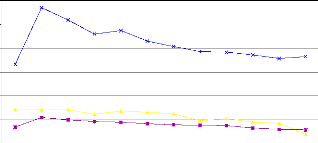
0,10
0,00
1 2 3 4 5 6 7 8 9 10 11 12
Neurone caché
|
(b) |
0,90 0,80 0,70 0,60 |
|||
|
Nash |
0,50 |
Bada Marabadiassa Tortiya Bou |
||
|
0,30 0,20 0,10 0,00 |
1 2 3 4 5 6 7 8 9 10 11 12
Nombre de neurone caché
Figure 51 : Évolution du
critère de Nash en fonction du nombre de neurones cachés aux
stations de
Bada, Marabadiassa, Tortiya et Bou : (a) modèles non
dirigés(PMCND1s), (b) modèles dirigés
(PMCD1s)
La lecture des graphes (a) et (b) de la figure 51 montre que lorsque le nombre de neurones cachés passe de 1 à 12, la performance des Perceptrons Multicouches Non Dirigésavec la pluie comme entrée (PMCND1s) et des Perceptrons Multicouches Dirigés (PMCD1s) augmente, atteint une valeur optimale et diminue par la suite.
La valeur optimale du nombre de neurones cachés varie en fonction de la station et du modèle considéré. Cette valeur est pour le modèle :
i. PMCND1s, égal à 1 à la station de Marabadiassa et 2 aux autres stations ;
ii. PMCD1s, égal à 3 aux stations de Bada et Tortiya et 2 aux stations Marabadiassa et de Bou.
Le nombre de retard optimal est généralement élevé avec les Perceptrons Multicouches Non Dirigés(PMCND1s) et moins élevés avec les Perceptrons Multicouches Dirigés (PMCD1s) à toutes les stations. Les retards élevés observés avec les modèles PMCND1s expriment le fait que les pluies de plusieurs mois soient utilisées par le réseau pour faire la simulation. Ces retards élevés pourraient être le fait de l'influence des multiples barrages agropastoraux présents sur l'ensemble de la zone d'étude. En effet, les eaux tombées seraient retenues dans ces barrages, s'infiltreraient lentement et atteindraient tardivement l'exutoire considéré. Cette hypothèse paraît réaliste à cause de la géologie du terrain qui laisse entrevoir des formations perméables. En ce qui concerne les faibles retards obtenus avec les modèles PMCD1s, il est possible d'attribuer cela à l'ajout de la seconde information apportée par le débit. Le bouclage donne en effet une information supplémentaire au réseau de l'état dans lequel il se trouve : s'il est confronté à des débits d'étiage, à des débits moyens ou à des débits de crues, ce qui fait que le réseau n'est plus obligé d'avoir recours à plusieurs mois pour extraire les singularités au niveau des données de débit. Les résultats ont montré que les modèles avec une seule couche cachée sont plus performants que les modèles avec deux ou trois couches cachées. Le nombre de couches cachées utilisées dans ce travail corrobore les résultats obtenus par Mamdouh et al. (2006). Selon ces auteurs, l'utilisation de plusieurs couches cachées (2,3,.., n), demande beaucoup d'espace mémoire au niveau des ordinateurs et diminue la performance des modèles en généralisation. Le nombre de neurones cachés optimal est généralement faible, compris entre 1 et 3, pour tous les Réseaux de neurones utilisés. La valeur la plus fréquente est égale à 2 neurones cachés. La démarche précédemment utilisée pour la détermination des architectures des modèles PMCND1s et PMCD1s est appliquée aux modèles PMCD2s, PMCD3s, PMCD4s, PMCD5s, et PMCD6s et les résultats sont les suivants :
i. pour le modèle PMCD2s, les retards sont de 1 ; 2 ; 5 et 8 mois respectivement aux stations de Bada, Marabadiassa, Tortiya et de Bou. Le nombre de neurones cachés à ces stations est de 4 ; 7 pour les stations de Bada et de Marabadiassa et de 2 pour Tortiya et Bou ;
ii. pour le modèle PMCD3s, les retards sont de 6 ; 1 ; 12 et 6 mois respectivement aux stations de Bada, Marabadiassa, Tortiya et de Bou. Le nombre de neurones cachés à ces stations est de 4 ; 3 ; 5 et 2 respectivement pour les stations de Bada, Marabadiassa, Tortiya et Bou ;
iii. pour le modèle PMCD4s, les retards sont de 7 ; 10 mois à Bada et à Marabadiassa et de 2 mois à Tortiya et à Bou. Le nombre de neurones cachés à ces stations est de 6 ; 5 ; 3 et 4 respectivement pour les stations de Bada, Marabadiassa, Tortiya et Bou ;
iv. pour le modèle PMCD5s, les retards sont de 1 ; 6 ; 5 et 10 mois respectivement aux stations de Bada, Marabadiassa, Tortiya et de Bou. Le nombre de neurones cachés à ces stations est de 3 ; 5; respectivement pour les stations de Bada et de Marabadiassa, et de 2 pour Tortiya et Bou ;
v. pour le modèle PMCD6s, les retards sont de 1 ; 3 ; 4 et 5 mois respectivement aux stations de Bada, Marabadiassa, Tortiya et de Bou. Le nombre de neurones cachés à ces stations est de 3 ; 10 ; 4 et 5; respectivement pour les stations de Bada, Marabadiassa, Tortiya et Bou.
Les figures 52 à 57 présentent de façon simplifiée les différentes architectures des modèles de prévision développés dans ce mémoire.
Les modèles développés dans ce paragraphe sont uniquement des modèles Perceptrons Multicouches Dirigés (PMCD). Six modèles de ce type, différents du point de vue du nombre de retard, du nombre de neurones cachés et des variables explicatives utilisées, sont présentés. Les mêmes méthodes de détermination des retards et du nombre de neurones cachés que celles utilisées pour les modèles de simulation, sont appliquées pour développer ces modèles de prévision.
5.3.5.2.1. Modèle PMCD1p
Les entrées, du modèle PMCD1p
représenté à la figure 52, sont les
précipitations et le débit
mesuré. Les retards de ces
entrées sont égaux à 12 et 1 respectivement pour les
pluies et les
débits mesurés. On dénombre 3 neurones
sur la couche cachée de ce réseau. Le réseau prend
en compte les pluies des 12 derniers mois et des débits du mois qui précède les trois mois avant le mois de la prévision.
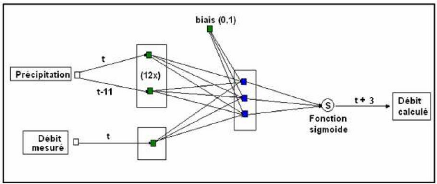
Figure 52 : Architecture simplifiée du modèle PMCD1p 5.3.5.2.2. Modèle PMCD2p
L'architecture du modèle PMCD2p (Figure 53) comprend trois entrées : la pluie, le mois et le débit. Le nombre de retard est égal à 4 mois pour les variables d'entrée et de 1 mois pour les débits mesurés et le nombre de neurones sur la couche cachée est égal à 2.
Le réseau utilise donc les pluies des 4 derniers mois et des débits mesurés du mois qui précède le mois de la prévision pour faire la prévision. Le réseau prend en compte les précipitations et les mois des 2 derniers mois et des débits du mois qui précède les trois mois avant le mois de la prévision. On remarque que, par rapport au modèle précédent, le nombre de retard a diminué avec l'ajout du mois en entrée. On est passé de 11 à 4 mois de retard.
Figure 53 : Architecture
simplifiée du modèle PMCD2p
- 114 -
5.3.5.2.3. Modèle PMCD3p
La figure 54 représente le modèle de prévision PMCD3p avec trois variables en entrée.
Figure 54 : Architecture simplifiée du modèle PMCD3p
Ces variables explicatives sont la pluie, l'évapotranspiration potentielle et les débits mesurés. Pour ce modèle, le nombre de retard est estimé à 3 mois pour la pluie et l'évapotranspiration potentielle et de 1 mois pour les débits mesurés. En ce qui concerne le nombre de neurones sur la seule couche cachée, il est égal à 5. Le réseau prend en compte les précipitations et les évapotranspirations des 3 derniers mois et des débits du mois qui précède les trois mois avant le mois de la prévision. Dans ce modèle également, on observe une diminution du retard des variables explicatives avec l'ajout de l'évapotranspiration potentielle qui passe de 11 mois pour le modèle PMCD1p à 3 mois pour le modèle PMCD3p.
5.3.5.2.4. Modèle PMCD4p
Tout comme les modèles PMCD2p et PMCD3p, le modèle PMCD4p, représenté à la figure 55, possède trois variables en entrée : la pluie, la température et le débit.
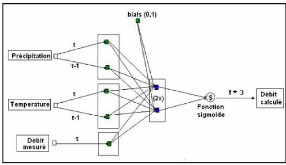
Figure 55 : Architecture
simplifiée du modèle PMCD4p
- 115 -
L'architecture de ce modèle laisse apparaître 2 mois de retard au niveau de la pluie et de la température et 1 mois pour les débits mesurés. Ce réseau présente également 3 neurones sur la couche cachée. Le réseau prend en compte les précipitations et les températures des 2 derniers mois et les débits du mois qui précède les trois mois avant le mois de la prévision. On assiste toujours à une diminution du retard qui est passé de 11 pour le modèle PMCD1p à 1 pour le présent modèle. Les modèles PMCD5p et PMCD6p (Figure 56 et 57), sont à quatre variables explicatives.
5.3.5.2.5. Modèle PMCD5p
Le modèle PMCD5p (Figure 56) comprend en entrée la pluie, le mois, la température et les débits mesurés.
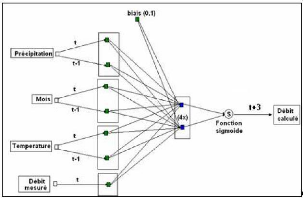
Figure 56 : Architecture simplifiée du modèle PMCD5p
Le nombre de retard au niveau des précipitations, des mois et des températures est égal à 2 mois. Pour les débits mesurés, ce retard n'est que de 1 mois. Ce réseau présente sur sa couche cachée 4 neurones. Le réseau prend en compte les précipitations, les mois et les températures des 2 derniers mois et des débits du mois qui précède les trois mois avant le mois de la prévision.
5.3.5.2.6. Modèle PMCD6p
Les entrées du modèle PMCD6p (Figure
57) sont les précipitations, les mois,
les
évapotranspirations potentielles et les débits
mesurés. Les retards sont de 1 mois pour les
débits
mesurés et de 2 mois pour autres variables en entrée. Sur la
couche cachée de ce réseau,
le nombre de neurones est égal à 2. Le réseau prend en compte les mois, les précipitations et les évapotranspirations des 2 derniers mois et des débits du mois qui précède les trois mois avant le mois de la prévision.
Figure 57 : Architecture simplifiée du modèle PMCD6p
En conclusion, on note qu'à part le modèle PMCD1p qui comporte un nombre élevé de retard (12 mois), le reste des modèles a un nombre de retard compris généralement entre 2 et 4 mois. En ce qui concerne le nombre de neurones cachés, il varie entre 2 et 5.
Les travaux de recherche menés au Cemagref d'Antony, signalés aux paragraphes précédents, ont montré que la structure optimale d'un modèle ne peut être discutée indépendamment de son pas de temps de fonctionnement. Une augmentation du pas de temps (équivalente à regarder le fonctionnement du bassin versant avec une résolution temporelle plus grossière) doit s'accompagner d'une simplification de la structure du modèle. Des structures de modèle ont donc été développées particulièrement pour les pas de temps journalier, mensuel et annuel. Les structures les plus récentes de ces modèles, jugées comme les plus performantes actuellement, sont :
i. GR4J: modèle du Génie Rural à 4 paramètres au pas de temps Journalier ;
ii. GR2M: modèle du Génie Rural à 2 paramètres au pas de temps Mensuel ;
iii. GR1A: modèle du Génie Rural à 1 paramètre au pas de temps Annuel.
Des trois modèles GR, seul le modèle GR2M a été utilisé dans cette Thèse. La version utilisée dans ce travail de recherche et présentée dans ces paragraphes qui suivent, est la dernière version mise au point par Mouelhi (2003). Cette version (Figure 58) comprend deux paramètres (la capacité du réservoir de production ( X1 ) (en mm) et le coefficient d'échanges
souterrains ( X2 ) (sans unité).
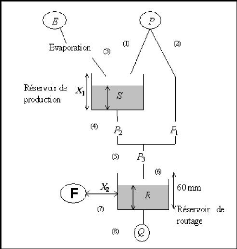
Figure 58 : Représentation du modèle conceptuel global GR2M selon Mouelhi et al. (2006)
Le modèle GR2M est caractérisé par deux fonctions (Mouelhi, 2003) : une fonction de production et une autre de transfert.
Une fonction de production qui s'articule autour d'un réservoir "sol" de capacité
maximale X1 , paramètre à optimiser. Cette version ne présente ni phase d'interception partielle comme pour le cas du modèle GR3M, ou comme pour le modèle GR4J. Une percolation du réservoir sol vers le transfert est assurée par une fonction dépendant de l'état du stock "S" ;
La fonction de transfert représentée par un réservoir à vidange quadratique de capacité fixée
à 60 mm. Ce réservoir est modifié par un échange souterrain, dont le coefficient ( X2 ) est le deuxième paramètre à optimiser.
|
Les calculs se présentent comme suit : Posant |
? |
tanh |
P X1 |
, le niveau S dans le réservoir |
devient S1 sous l'action de la pluie P (opération (1) de la figure 58) 1

S X
+ 1 ?
S
S1
?
1 +
X1
(34)
S1
( )
1 ? Ø
=
S1
S2
1+Ø 1
X1
Ou le paramètre X1, capacité du réservoir, est positif et exprimé en mm. Il s'ensuit une contribution à l'écoulement P1 (opération (2) de la figure 58) par
P1 = P+S-S 1 (35)
Ø = tanh E
Posant X1 , le niveau S1 devient S2 sous l'effet de l'évapotranspiration E
(opération (3) de la figure 58) :
(36)
Le réservoir se vidange ensuite en une percolation P2 (opération (4) de la figure 58) et son niveau S, prêt pour les calculs du mois suivant, est alors donné par :
|
S |
S 2 |
||
|
1/ 3 |
|||
|
1 + |
S 2 |
X1 (37)
P 2 = S2-S (38)
La pluie totale P3 qui atteint le réservoir de routage (opération (5) de la figure 58) est donnée par :
P 3 = P 1 + P 2 (39)
Le réservoir R, dont le niveau en début du mois est R devient R1 (opération (6) de la figure 58)
R 1 = R+( P 3 ) (40)
L'échange, F (opération (7) de la figure 58), qui agit sur le réservoir R est donnée par :
F = ( X2 - 1) . R1
(41)
Le paramètre X2 est positif et adimensionnel.
Le niveau dans le réservoir devient :
R2 = X2.R1 (42)
Le réservoir, de capacité fixe égale à 60 mm, se vidange suivant une fonction quadratique (opération (8) de la figure 58) et le débit est donné par :
Q =
R
R2
2 +
2
60
(43)
Pour déterminer les valeurs optimale des paramètres X1 et X2 , la méthode "pas à pas" est utilisée. Cette méthode est une maximisation ou une minimisation de la fonction d'erreur, qui est ici le critère de Nash-Stucliffe (1970). Les travaux de Perrin (2000) traitent de cette méthode. Elle a été toutefois simplifiée dans ce travail et utilisée pour optimiser les paramètres X1 et X2 du modèle GR2M. En effet, au début de l'optimisation les valeurs
initiales de X1 et X2 sont respectivement fixées égales à 1 et 0,6. Une fois X2 fixé, on fait varier X1 jusqu'à sa valeur maximale. Une fois cette valeur atteinte, on la fixe et on fait varier aussi X1 jusqu'à sa valeur maximale.
L'une des techniques les plus utilisées pour évaluer la robustesse des modèles est la technique du double échantillon. Elle permet de tester l'adaptabilité des modèles quelle que soit leur complexité. Si l'on dispose d'observations chronologiques au pas de temps mensuel et annuel par exemple, il suffira de subdiviser la période d'observation de chaque bassin versant en sous-périodes, avec calage sur une période et validation sur le reste des observations. Dans cette étude, la robustesse est évaluée en faisant la différence des valeurs des Nash obtenus en calage et en validation (Klemes, 1986 in Perrin, 2000).
Pour tester si les débits obtenus par un modèle de simulation ou de prévision sont significativement différents de ceux obtenus par un autre modèle, plusieurs tests sont disponibles : celui du quotient de vraisemblance (Rao, 1973) ou bien encore les tests non paramétriques comme celui de Wilcoxon (1945). Ces tests donnent bien souvent les mêmes résultats (Berthier, 2005). C'est pourquoi Hipel et McLeod (1994) ont recommandé l'utilisation du Test de Pitman (1939), équivalent au test du quotient de vraisemblance, plus rapide et aussi efficace. Le test de Pitman consiste à vérifier si la variance des erreurs de
simulation (ou de prévision) produite par un
modèle est significativement différente de celle
d'un autre
modèle. Cela revient à tester si le coefficient de
corrélation de Pitman rp , entre St
(somme des erreurs de simulation ou de prévision des deux modèles comparés, S t = e1 , t+ e2 , t ) et Dt (différence entre les erreurs de simulation ou de prévision des deux modèles comparés, D t = e1 , t- e2 , t ) est significativement différent de zéro. A condition que le nombre (nf) de valeurs simulées pour le test dépasse 25, les deux modèles de simulation (ou de prévision)
comparés sont considérés significativement différents à 95% si rp
1,96
= . (44)
n f
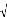
Le test de Pitman a pour but de comparer les modèles de simulation ou de prévision deux à deux. Les résultats de ce test sont tabulés et les modèles sont facilement comparables deux à deux.
Tout modélisateur sait que son modèle est incorrect, car ce dernier donne des résultats plus ou moins éloignés de la réalité. Pour utiliser le modèle et prendre des décisions, l'utilisateur doit donc connaître l'ordre de grandeur des incertitudes du modèle et ainsi quantifier et apprécier ces incertitudes (Berthier, 2005). Les origines de ces incertitudes peuvent être diverses (Perrin, 2002). Le tableau VIII fait correspondre le type d'erreur à la nature de l'erreur.
Tableau VIII : Correspondance entre le type d'erreur et sa nature (Perrin, 2002).
Type d'erreur Nature de l'erreur
Incertitude des données d'entrée Erreurs au moment de la collecte des données
et de leurs traitements, mauvaise
représentation de
la variabilité spatio-
temporelle.
Incertitude du modèle Le modèle reste une représentation grossière
d'un système naturel complexe.
Incertitude des paramètres du modèle Dépend du choix de la fonction objective, des
performances d'optimisation, des échantillons
des
données de calage.
Plusieurs méthodes existent dans la littérature
pour estimer et représenter les incertitudes d'un
modèle en
hydrologie : i) la méthode GLUE (l'échantillonnage par ordre
d'importance) ; ii) la
méthode dérivée de Monte-Carlo
fondée sur une approximation linéaire des écarts-types
des
paramètres du modèle ; et iii) la méthode basée sur le rapport des débits observés et des débits calculés
La méthode Generalized Likelihood Uncertainty Estimation (GLUE) a été développée par
Beven et Binley (1992) et consiste à tirer un échantillon aléatoire de la fonction de vraisemblance et à pondérer les résultats par ordre d'importance (le meilleur résultat aura un poids maximal et le pire un poids minimal). La fonction de vraisemblance pourra être remise à jour lorsque de nouvelles données seront disponibles (Chahinian, 2004). Cette méthode gère la multiplicité possible des jeux de paramètres acceptables en les classant selon une mesure subjective traduisant l'ajustement aux données observées, tel le critère de Nash et Sutcliffe (1970) par exemple. Le succès de cette méthode dépend du choix de la fonction de vraisemblance et de la taille de l'échantillon (Kuczera et Parent, 1998). Elle est onéreuse en temps de calcul. La méthode GLUE rejette le principe du paramètre optimal unique. En effet, elle n'est pas réellement une méthode de calage dans la mesure où elle ne détermine pas un jeu de paramètres qui l'emporte sur un autre. En réalité un grand nombre de jeux de paramètres sont retenus, ce qui permet d'obtenir non pas un hydrogramme à comparer avec l'hydrogramme des débits mesurés, mais "n" hydrogrammes, ce qui permet le calcul d'un intervalle de confiance.
Développée par Stanislaw Ulam et Nicholas Metropolis en 1949, la méthode dérivée de
Monte-Carlo a pour but de quantifier les incertitudes des paramètres en reconstituant la distribution des variables de sortie. Elle nécessite des simulations répétées en tirant aléatoirement la valeur de la variable d'entrée. C'est une méthode facile mais longue à concevoir. Cependant, en hydrologie, elle donne des résultats avec des bornes d'erreurs très faibles, ce qui la rend quasi inutilisables en pratique (Tuffin, 1997).
Les écarts entre les débits observés et les débits calculés sont le plus souvent représentés
comme des différences. Les différents critères utilisés en hydrologie (MSE, Nash, etc.) en témoignent. Mais cette représentation est limitée dans le cadre d'une utilisation pratique, car une même erreur absolue peut-être mineure pour une pointe de crue et excessive pour un étiage. Il est donc plus approprié de calculer les erreurs en faisant le rapport débit
observé/débit calculé (Berthier, 2005). C'est cette dernière méthode qui a été utilisée ici compte tenu de sa facilité de mise en place et des bons résultats qu'elle donne.
L'objectif de ce travail de recherche est de mettre en place des modèles neuronaux capables de : (i) reconstituer des valeurs manquantes dans les séries de débits sur le Bandama Blanc (faciliter la réalisation de certains projets de développement sur la zone d'étude) et (ii) de faire la prévision des périodes de basses eaux et de hautes eaux sur l'ensemble de la zone d'étude afin d'aider la classe paysanne dans la gestion de la ressource en eau, donc participer à la diminution des conflits opposants agriculteurs et éleveurs. La modélisation se fera en considérant le mois comme pas de temps. La transformation des variables cibles et des variables explicatives effectuée dans ce mémoire est la "normalisation ". Elle sera nécessaire ; car, pendant l'apprentissage ou le calage, si les séries sont très différentes, les plus petites valeurs n'ont pas d'influence sur l'apprentissage. Chaque série hydro-climatique est donc distribuée de sorte que les valeurs soient comprises entre 0 et 1. Cette transformation a permis d'obtenir des séries hydro-climatiques dont les valeurs sont très proches. Le Perceptron Multicouche (PMC) à une couche cachée est le réseau utilisé pour cette étude. Le nombre de neurones dans la couche cachée est déterminé avec l'approche de Fahlman. La fonction Sigmoïde de type logistique bornée de 0 à 1 est retenue dans cette étude où la méthode du "simple split-sample" est utilisée pour séparer les différentes bases d'apprentissage et de validation. Les 2/3 de chaque série hydro-climatique (1971-1988) seront choisis pour la phase d'apprentissage et les 1/3 (1989-1997) pour la phase de validation.
Dans ce mémoire, la méthode locale du gradient (la rétropropagation de l'erreur ou du gradient) est retenue pour entraîner les différents modèles développés. L'évaluation de la performance est assurée par le critère de Nash, le coefficient de corrélation R, le coefficient de détermination 2
R , l'erreur quadratique moyenne (Mean Square Error) (MSE) et la racine carrée de l'erreur quadratique moyenne (RMSE). Après l'exposé sur la méthodologie de conception des modèles Perceptrons Multicouches, le chapitre suivant présente l'environnement scientifique, les modèles Perceptrons Multicouches et le modèle GR2M ainsi que les différents outils d'analyse statistique.
Ce premier chapitre des résultats a pour but de présenter les performances des réseaux de neurones avec uniquement la pluie comme variable explicative et les débits du Bandama Blanc mesurés aux stations de Bada, Marabadiassa, Tortiya et Bou comme variables cibles. Les modèles développés sont des Perceptrons Multicouches Non Dirigés(PMCND1s) et des modèles Perceptrons Multicouches Dirigés (PMCD1s). Comme déjà mentionné, ces modèles Perceptrons sont, indexés par la lettre "s" pour signifier qu'il s'agit de modèles de simulation et sont développés sous le logiciel "RNF PRO" avec les caractéristiques suivantes :
i. l'algorithme d'apprentissage est la rétro propagation avec gradient partiel ;
ii. le pas du gradient est fixé à 0,1 ;
iii. le critère de performance pendant l'apprentissage est l'erreur quadratique (MSE) ;
iv. la période d'affichage est de 10 ;
v. les poids initiaux sont fixés à 0,1 ;
vi. le biais est fixé à 0,1.
Bien que théoriquement, rien n'empêche de développer et d'optimiser directement des réseaux de neurones avec plusieurs variables explicatives, commencer par construire des MODÈLES NON DIRIGÉSet des MODÈLES DIRIGÉS avec la pluie comme seule variable, permet de comprendre par la suite l'apport des autres variables comme la température, l'évapotranspiration potentielle et le mois dans le comportement de ces modèles. Les résultats des modèles qui intègrent plusieurs variables explicatives seront présentées dans le chapitre VII. Dans le present chapitre, la première section présente les différentes performances des modèles développés à travers les critères de Nash, l'erreur quadratique moyenne (MSE), la racine carrée de l'erreur quadratique moyenne (RMSE), le coefficient de détermination multiple (R2) et le coefficient de corrélation de Pearson (R). En ce qui concerne la deuxième section, elle compare les performances des Perceptrons Multicouches Non Dirigés(PMCND1s) et des Perceptrons Multicouches Dirigés (PMCD1s).
Les critères de performance déjà
présentés sont utilisés pour étudier la
capacité des
Perceptrons Multicouches Non Dirigés(PMCNDs) et
des Perceptrons Multicouches Dirigés
(PMCDs) à simuler les débits du Bandama Blanc aux stations hydrométriques de Bada, Marabadiassa, Tortiya et de Bou.
L'erreur quadratique moyenne (MSE), la racine carrée de l'erreur quadratique moyenne (RMSE) et le critère de Nash sont calculés à la fois pour les débits réels (Tableau IX) et pour la racine carrée de ces débits (Tableau X). Ces différents critères de performance sont renforcés par la représentation des nuages de points traduisant la corrélation entre les débits mesurés et les débits simulés par les différents modèles pour la station de Tortiya.
La lecture du Tableau IX montre des fortes valeurs de l'erreur quadratique moyenne (MSE) calculée avec les débits sans aucune transformation, pour tous les modèles, tant en calage qu'en validation. En comparant les racines carrées des erreurs quadratiques moyennes (RMSE), on se rend compte que le Perceptrons Multicouche Non Dirigé(PMCND1s) donne les plus grandes valeurs comprises entre 10 et 85 en calage et entre 12 et 96 en validation. Pour le Perceptron Multicouche Dirigé (PMCD1s), les valeurs de RMSE sont les plus faibles et varient entre 7 et 69 en calage et entre 9 et 71 en validation. Ces grandes valeurs de MSE et de RMSE trouveront leur explication dans le chapitre destiné à la discussion.
L'analyse de ce même tableau montre que, en validation et en considérant les critères de Nash, le Perceptron Multicouche Non Dirigé (PMCND1s) est seulement bon (Nash compris entre 60% et 80%) pour la simulation des débits à la station de Tortiya et mauvais pour les autres stations. Les valeurs de Nash, avec ce modèle non bouclé, sont de 76% à la station de Tortiya et de 39%, 44%, et 52% respectivement aux stations de Bada, Marabadiassa et Bou. Quant au Perceptron Multicouche Dirigé (PMCD1s), il est un bon modèle pour simuler les débits mensuels du Bandama Blanc aux stations d'étude, les Nash sont compris entre 60% et 80% soit, 67%, 67%, 81% et 71% respectivement aux stations de Bada, Marabadiassa, Tortiya et Bou. Que se soit l'erreur quadratique ou le critère de Nash qu'on considère, il est bon de noter que tous les modèles développés (PMCND1s et PMCD1s) simulent bien les débits mensuels du Bandama Blanc à la station de Tortiya. Les Nash obtenus sont toujours supérieurs à 60% tant en calage qu'en validation. Les valeurs de Nash ont permis de construire les histogrammes de la figure 59 qui traduisent les robustesses des deux modèles étudiés
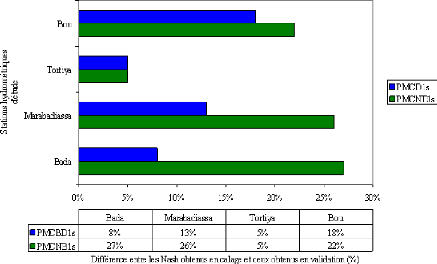
Figure 59 : Robustesses des modèles PMCND1s et PMCD1s
La lecture de ces histogrammes montre que le modèle PMCD1s est plus stable que le modèle PMCND1s à toutes les stations d'étude. Cependant, à la station de Tortiya, les deux modèles ont la même stabilité.
Les résultats obtenus et analysés par les Perceptrons Multicouches Dirigés (PMCD1s) et les Perceptrons Multicouches Non Dirigés(PMCND1s) sont expliqués au niveau du chapitre discussion.
Tableau IX : Performance des MODÈLES NON DIRIGÉS(PMCND1s) et des MODÈLES DIRIGÉS (PMCD1s) avec les débits réels
|
PMCND1s |
PMCD1s |
||||||||
|
Bada |
Marabadiassa Tortiya |
Bou |
Bada |
Marabadiassa Tortiya |
Bou |
||||
|
Calage |
|||||||||
|
MSE |
7169,02 |
6947,96 |
2070,25 |
105,71 |
4739,54 |
4680,34 |
1694,19 |
56,6 |
|
|
RMSE |
84,67 |
83,35 |
45,5 |
10,28 |
68,84 |
68,41 |
41,16 |
7,52 |
|
|
Nash (%) |
66 |
70 |
71 |
74 |
75 |
80 |
76 |
89 |
|
|
2 R (%) |
82 |
79 |
90 |
90 |
90 |
89 |
91 |
95 |
|
|
R |
0,76 |
0,74 |
0,86 |
0,85 |
0,85 |
0,83 |
0,87 |
0,91 |
|
|
Validation |
|||||||||
|
MSE |
9077,06 |
7068,99 |
1391,45 |
137,93 |
4989,17 |
4203,31 |
1107,71 |
81,93 |
|
|
RMSE |
95,27 |
84,08 |
37,30 |
11,74 |
70,63 |
64,83 |
33,28 |
9,05 |
|
|
Nash (%) |
39 |
44 |
76 |
52 |
67 |
67 |
81 |
71 |
|
|
2 R (%) |
72 |
85 |
92 |
81 |
89 |
89 |
95 |
88 |
|
|
R |
0,63 |
0,67 |
0,90 |
0,73 |
0,82 |
0,82 |
0,91 |
0,84 |
|
Les paragraphes précédents ont permis d'apprécier les performances des modèles PMCND1s et PMCD1s sans toutefois modifier l'ordre de grandeur des débits ayant servi à calculer ces performances. Comment évolueront les performances de ces modèles si les débits subissaient une transformation puissance ? Les paragraphes suivants se chargent de répondre à cette préoccupation. En effet, en intégrant la racine carrée des débits mesurés et calculés, on obtient de très bonnes valeurs des critères de performance consignées dans le tableau X. Les erreurs quadratiques moyennes ont diminué de façon drastique. Cette transformation des débits améliore également les valeurs du critère de Nash à toutes les stations sauf à la station de Bou où avec le modèle Perceptrons Multicouche Dirigé (PMCD1s) en validation, on assiste à une diminution du Nash qui passe de 89% à 83%. On note tout de même que ces performances sont toujours du même ordre de grandeur. Les raisons de l'amélioration des critères de performance par la transformation puissance des débits seront exposées dans la discussion.
Tableau X : Performance des modèles non dirigés(PMCND1s) et des modèles dirigés (PMCD1s) avec la racine carrée des débits
|
PMCND1s |
PMCD1s |
||||||||
|
Bada |
Marabadiassa Tortiya |
Bou |
Bada |
Marabadiassa |
Tortiya |
Bou |
|||
|
Calage |
|||||||||
|
MSE |
15,51 |
14,46 |
6,72 |
1,21 |
8,95 |
9,2 |
5,25 |
76,6 |
|
|
RMSE |
3,94 |
3,80 |
2,59 |
1,1 |
2,99 |
3,03 |
2,29 |
8,75 |
|
|
Nash (%) |
74 |
73 |
77 |
80 |
85 |
84 |
82 |
83 |
|
|
Validation |
|||||||||
|
MSE |
20,88 |
16,74 |
4,28 |
1,29 |
11,25 |
8,76 |
3,30 |
0,99 |
|
|
RMSE |
4,57 |
4,09 |
2,07 |
1,13 |
3,35 |
2,96 |
1,81 |
0,99 |
|
|
Nash (%) |
41 |
48 |
80 |
76 |
68 |
73 |
85 |
74 |
|
Malgré les mauvaises performances des modèles PMCND1s, on remarque au niveau des coefficients de corrélation de Pearson, qu'ils varient de forts à très forts pour tous les modèles et pour toutes les phases (calage et validation). La plus faible corrélation, estimée à 0,63, est obtenue à la station de Bada avec le Perceptron Multicouche Non Dirigé (PMCND1s) en validation. La plus forte corrélation dont la valeur est 0,91 est obtenue à la station de Bou avec le Perceptrons Multicouche Dirigé (PMCD1s) en calage et à la station de Tortiya avec le modèle Dirigé en validation. Les hydrogrammes mesurés et calculés pour la phase de calage (1971-1988) et pour la phase de validation (1989-1997) sont illustrés respectivement sur les figures 60 à 63 aux stations de Bada, Marabadiassa, Tortiya et Bou. Ces figures montrent que les modèles non dirigéset les modèles dirigés reproduisent bien la dynamique des écoulements du Bandama Blanc aux stations d'étude. Malgré cette bonne représentation des hydrogrammes par les modèles neuronaux développés, il faut cependant noter qu'on observe des décalages entre les débits mesurés et les débits calculés, tant pendant la phase de calage que pendant la phase de validation. Ces décalages sont plus accentués avec les Perceptrons Multicouches Non Dirigés qu'avec les Perceptrons Multicouches Dirigés. Il faut aussi remarquer qu'à la station de Tortiya, les décalages entre les hydrogrammes mesurés et calculés sont encore moins marqués par rapport aux hydrogrammes des autres stations. L'un des objectifs de ce travail de recherche est de mettre au point des modèles opérationnels pouvant servir à la gestion rationnelle des ressources en eau superficielle de notre zone d'étude. Pour cela, il s'avère nécessaire d'accorder plus d'importance à l'étude des débits extrêmes, c'est-à-dire les débits de crue et les débits d'étiage. Les débits de pointe observés généralement pendant le mois de septembre, à toutes les stations, sont mal simulés. On note par exemple à la station de Bada, avec le Perceptron Multicouche Bouclé Dirigé, que seules les crues de septembre 1992 et septembre 1995 sont surestimées et celles des autres années sont sous estimées. Il en est de même pour les crues des stations de :
i. Marabadiassa, septembre 1990 ;
ii. Tortiya, septembre 1990 et 1992 ;
iii. Bou, septembre 1991, 1992 et 1994.
Au niveau des débits d'étiages on remarque aussi une mauvaise simulation par les deux modèles étudiés à maints endroits. En observant les hydrogrammes mesurés des figures 60 à 63, de la période de calage (1971-1988), on remarque que ces hydrogrammes présentent des anomalies caractérisées par des oscillations de 1971 à 1973 pour les stations de Bada, Tortiya et de Bou et de 1971 à 1972 pour la station de Marabadiassa. En ce qui concerne la période de validation (1989-1997), c'est seulement à la station de Marabadiassa qu'on observe ces
oscillations. Ces anomalies rencontrées en calage et en validation sont généralement corrigées par les modèles non dirigés(PMCND1s) et les modèles dirigés (PMCD1s). Cette correction se ressent au niveau des hydrogrammes calculés qui essaient de lisser les parties des hydrogrammes où l'on constate ces oscillations.
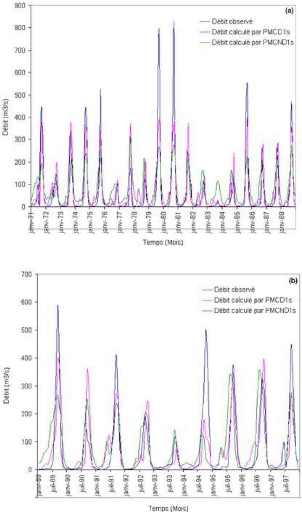
Figure 60: Hydrogrammes mesuré
et calculé avec les modèles PMCD1s et PMCND1s en calage (a)
et
en validation (b) à la station de Bada
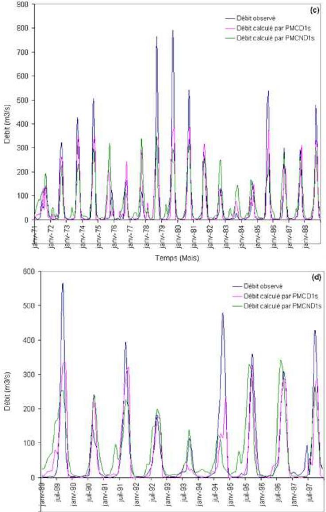
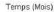
Figure 61 : Hydrogrammes
mesuré et calculé avec les modèles PMCD1s et PMCND1s en
calage (c)
et en validation (d) à la station de Marabadiassa
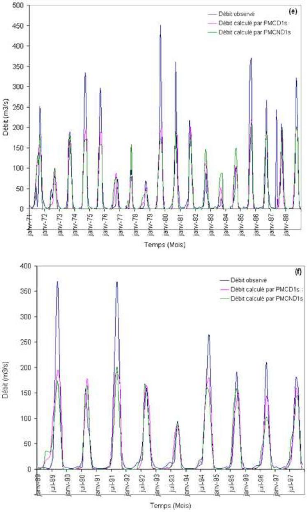
Figure 62 : Hydrogrammes
mesuré et calculé avec les modèles PMCD1s et PMCND1s en
calage (e)
et en validation (f) à la station de Tortiya
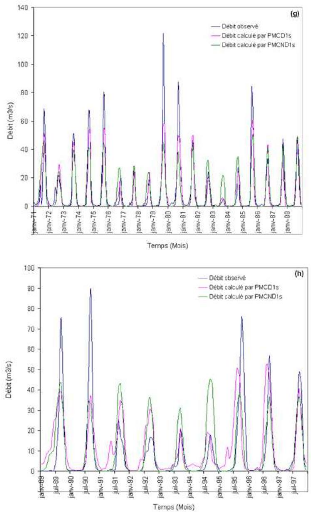
Figure 63 : Hydrogrammes
mesuré et calculé avec les modèles PMCD1s et PMCND1s en
calage (g)
et en validation (h) à la station de Bou
Les paragraphes suivants présentent respectivement les résultats des analyses de variance, de résidus et les incertitudes sur les débits simulés par les deux modèles de simulations étudiés. 6.3.1. Présentation des résultats de l'analyse des résidus
Dans cette section la matrice de Pitman n'est pas établie ; car, il s'agit d'un cas très simple qui est la comparaison de deux modèles PMCND1s et PMCD1s. Les résultats de l'analyse des résidus (les coefficients de corrélations de Pitman ( rp )) sont consignés dans le tableau XI. Il montre que les coefficients de corrélation de Pitman sont de même grandeur pour toutes les stations. La station de Marabadiassa enregistre la plus grande valeur (0,36) tandis que les autres stations présentent approximativement les mêmes valeurs.
Tableau XI : Récapitulatif des coefficients de corrélations de Pitman ( rp )
|
Stations |
2 rp |
rp |
||||||
|
Bada |
0,05 |
0,23 |
||||||
|
Marabadiassa |
0,13 |
0,36 |
||||||
|
Bou |
0,04 |
0,20 |
||||||
|
Tortiya |
0,04 |
0,20 |
||||||
|
coefficients |
rp |
du tableau XI au coefficient |
rp |
critique |
, Il apparaît clairement que les |
|||

rp
critique
1,96 = 1,96 =
est égale à : 0,1 8 8
108
n
f
La valeur du coefficient
. En comparant les
coefficients de Pitman calculés aux différentes stations hydrométriques d'étude sont généralement supérieurs à la valeur critique qui est de 0,188. Cela signifie que les Perceptrons Multicouches Non Dirigés(PMCND1s) et les Perceptrons Multicouches Dirigés (PMCD1s) sont significativement différents au seuil de 95% aux stations de Bada, Marabadiassa, Tortiya et de Bou. On peut donc affirmer à 95% de chance de ne pas se tromper que les débits simulés par les deux modèles Perceptrons Multicouches sont différents à toutes les stations. Malgré le fait que ces modèles simulent des débits proches des débits mesurés, ils sont significativement différents entre eux.
Les incertitudes sont calculées et représentées seulement pour la station de Bada qui est la station située à l'exutoire du bassin versant d'étude. Ce choix se justifie pour éviter de répéter des figures de même signification et de même importance. C'est le Perceptron Multicouche Dirigé (PMCD1s) qui est utilisé ; car, des deux modèles développés dans ce chapitre, c'est le modèle qui arrive à mieux simuler les débits du Bandama Blanc aux stations de Bada, Marabadiassa, Tortiya et Bou.
L'intérêt de ce paragraphe réside dans le
fait qu'il permet d'apprécier les incertitudes sur les
débits
calculés par les modèles de simulation pendant l'apprentissage et
la validation. Les
rapports Qobs /
Qcal sur la période de calage (1971-1988) et les
rapports Qobs / Qcal sur la
période de validation (1989-1997) par tranche de débit calculé seront utilisés. 6.3.2.1.1. Hydrogrammes observé et calculé
Dans ce paragraphe, il est utilisé comme exemple la station de Bada qui est la station en aval de la zone d'étude. Il est décrit les différentes étapes permettant une représentation simplifiée et pratique des résultats de simulations avec le modèle PMCD1s afin de quantifier et de visualiser graphiquement les incertitudes sur les débits simulés. Après le calage où les paramètres du modèle sont déterminés, le Perceptrons Multicouche Dirigé (PMCD1s) calcule les débits, qui sont alors comparés aux débits observés sur la même période (1971-1988). Les hydrogrammes de la figure 64 illustrent cette comparaison. De l'analyse de cette figure, il ressort que certains débits sont sous estimés et que d'autres sont, au contraire, surestimés. Mais cette figure n'arrive pas à montrer clairement tous les débits qui sont effectivement sous estimés et ceux qui sont surestimés. Une analyse plus profonde à l'aide d'autres figures permettra de lever cette inquiétude.
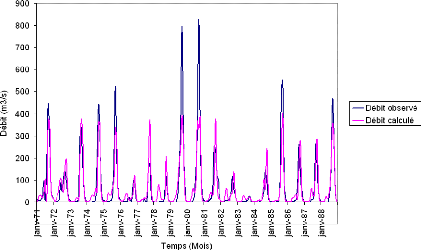
Figure 64 : Hydrogrammes observé et calculé à la station de Bada avec le modèle PMCD1s
6.3.2.1.2. Rapport Qobs / Qcal sur la période de calage (1971-1988)
Pour des raisons signalées précédemment, les erreurs relatives représentées par les rapports Qobs / Qcal ont été utilisées en lieu et place des différences Qobs - Qcal. En effet, à chaque
observation (la moyenne par mois), le rapport débit mesuré sur le débit calculé du même mois est calculé et les valeurs sont représentées à la figure 65. Elle illustre les écarts entre les hydrogrammes mesurés et les hydrogrammes simulés par le modèle neuronal. Son analyse montre bien que la majorité des rapports Qobs / Qcal est comprise entre 0 et 1.
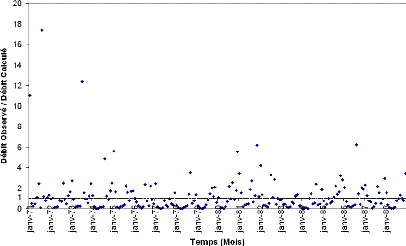
Figure 65 : Rapport des débits
observés sur les débits calculés à la station de
Bada avec le modèle
PMCD1s
Un dénombrement de ces
débits permet d'avoir les statistiques suivantes. En effet, 62,5% des
débits observés sont surestimés et 36,5% de ces débits sont sous estimés par le modèle PMCD1s. A elle seule, la figure 65 ne peut pas donner des informations sur la manière dont les débits extrêmes sont simulés par le modèle PMCD1s. Il faut alors superposer les figures 64 et 65 afin d'obtenir la figure 66, qui est plus explicite.
|
D6bits (m3/s) |
900 800 700 600 |
100 10 1 |
||||
|
500 400 300 200 100 0 |
0,1 0,01 0,001 0,0001 |
Qobs/Qcal |
Qobs Qcal Qobs/Qcal |
|||
janv-71 janv-72 janv-73 janv-74 janv-75 janv-76 janv-77 janv-78 janv-79 janv-80 janv-81 janv-82 janv-83 janv-84 janv-85 janv-86 janv-87 janv-88
Temps (Mois)
Figure 66 : Superposition des Figures 65 et 66
De façon générale, la lecture de la figure 66 montre que pour les débits de crue, la majorité des points correspondants aux rapports Qobs / Qcal est située au-dessous de la droite d'équation y = 1 . En ce qui concerne les débits d'étiages, les points correspondants aux rapports Qobs / Qcal sont situés au dessus de la droite d'équation y = 1 . En conclusion, on constate, grâce à cette figure que, pendant le calage du modèle, les débits de pointes sont fortement sous estimés ( Qobs / Qcal = 1) et que les débits d'étiage sont également, fortement surestimés ( Qobs / Qcal = 1). La figure 67 regroupe sur un fond logarithmique l'ensemble des rapports ( Qobs / Qcal) en fonction des débits calculés (en abscisse). Ici encore, comme déjà signalé, la majorité des rapports Qobs / Qcal est inférieure à 1. C'est-à-dire qu'il y a plus de débits qui sont surestimés que de débits sous estimés.
1 10 100 1000





100
0,0001
10
1
Debitobseme/DeMcWcWe
0,1
0,01
0,001



Débit calculé (Qcal) (m3/s)
Figure 67 : Rapport des débits
observés sur les débits calculés (
Qobs / Qcal) à la station de Bada
avec
les modèles PMCD1s en fonction des débits
calculés
Sur cette figure certains débits sont jusqu'à dix fois sous estimé et jusqu'à mille fois surestimés par le modèle PMCD1s. Toutefois, ce nuage de point représenté reste difficile à interpréter. En effet, les valeurs extrêmes, des rapports sont peu nombreuses. Cette étude s'est donc intéressée à la dispersion des points. Cette dispersion est mesurée avec les quartiles 0,15 et 0,85 qui engloberaient 70% des effectifs autour des valeurs centrales. Les paragraphes suivants résument les résultats de cette analyse statistique.
6.3.2.1.3. Rapport Qobs / Qcal sur la période de calage (1971-1988) par tranche de débit calculé
Les rapports Qobs/Qcal sont regroupés par tranches de débits calculés pour calculer les quartiles. Chaque fourchette de débit calculé est équivalente à 1/7 d'unité logarithmique Les résultats sont présentés dans le tableau XII. Les débits allant de 1 à 1000 m3/s sont regroupés en 7 intervalles. Pour chacune de ces 7 fourchettes les quartiles (0,15 ; 0,50 et 0,85) sont calculés pour chaque tranche de débits calculés pour la période de calage 1971-1988. En statistique descriptive, un quartile représente chacune des 3 valeurs qui divisent les données triées en 4 parts égales, de sorte que chaque partie représente 1/4 de l'échantillon de population. On utilise généralement les quartiles 0,25 ; 0,50 et 0,75.
Tableau XII : Récapitulatif des quartiles pour la phase de calage
|
Intervalles (m3/s) |
Effectifs |
Quartiles 0,15 |
Quartiles 0,50 |
Quartiles 0,85 |
|
|
0,0 |
1 |
0 |
|||
|
1 |
5 |
51 |
0,284 |
1,215 |
2,761 |
|
5 |
10 |
27 |
0,188 |
0,628 |
1,523 |
|
10 |
50 |
83 |
0,139 |
0,945 |
2,015 |
|
50 |
100 |
18 |
0,196 |
0,407 |
1,538 |
|
100 |
500 |
37 |
0,542 |
0,854 |
1,307 |
|
500 |
1000 |
0 |
|||
La représentation de ces résultats est faite
à la figure 68. On remarque qu'entre les
deux
courbes on a 70% des effectifs autours des valeurs centrales pour
chacun des intervalles. Les
triangles rouges situés au dessus de la
droite d'équation y = 1 correspondent au quartile 0,85
et ceux situés en dessous de cette droite, le quartile 0,15.
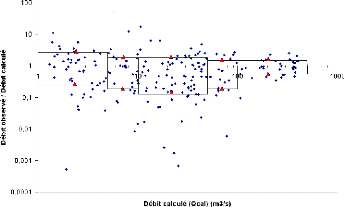
Figure 68 : Encadrement de 50% des
rapports Qobs / Qcal pour chaque
fourchette de débit calculé sur
la période de calage
(1971-1988)
Pour clarifier la représentation des incertitudes, il est présenté à la figure 69 la répartition des rapports Qobs / Qcal entre les deux courbes en pointillés.
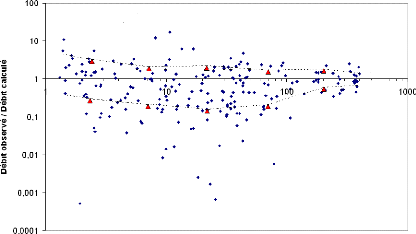
Figure 69 : Rapport
Qobs / Qcal pour chaque fourchette de
débit calculé avec le modèle PMCD1s sur
la
période de calage (1971-1988)
Les incertitudes déterminées sur les débits calculés par le modèle PMCD1s pendant le calage
sont-elles pareilles ou différentes de celles qu'on obtiendrait en validation ? Les paragraphes suivants s'intéressent à cette problématique en utilisant la même démarche que précédemment.
6.3.2.2.1. Hydrogrammes mesuré et calculé
Tout comme en calage, les hydrogrammes représentés à la figure 70 traduisent bien la dynamique des écoulements mais ne montrent pas combien de débits extrêmes sont sous estimés ou surestimés par le modèle Perceptron Multicouche. Cependant, la lecture de cette figure montre que les débits de pointe des années 1989, 1991, 1994, 1995 et 1997 sont surestimés. En ce qui concerne les débits de pointe des autres années (1990, 1992,1993 et 1996) ils sont sous estimés par le modèle PMCD1s.
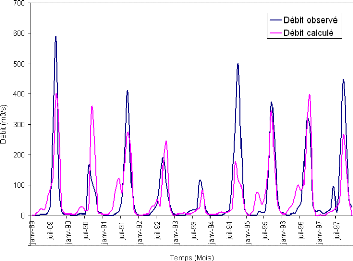
Figure 70 : Hydrogrammes mesuré et calculé par le modèle PMCD1s en validation (1989-1997)
L'analyse de cette figure demeure difficile. Le recourt aux rapports Qobs / Qcal est donc nécessaire comme ce fut le cas en calage.
6.3.2.2.2. Rapport Qobs / Qcal sur la période de validation (1989-1997)
Comme précédemment le rapport débit mesuré sur le débit calculé du même mois est calculé et les valeurs sont représentées sur la figure 71. Cette figure illustre les écarts entre les hydrogrammes mesurés et les hydrogrammes simulés par le modèle PMCD1s. On observe sur cette figure presque le même nombre de points de part et d'autre de la droite d'équation y = 1 .
Cela signifie qu'il y a autant de débits sous
estimés (50%) que de débits surestimés (50%) par
le
modèle PMCD1s. En superposant les figures 70 et 71, on
obtient la figure 72. Sur cette
figure on peut observer que
les débits de pointes sont fortement sous estimés (
Qobs / Qcal = 1)
et que les débits d'étiage sont surestimés ( Qobs / Qcal = 1) comme c'était le cas pendant le calage.
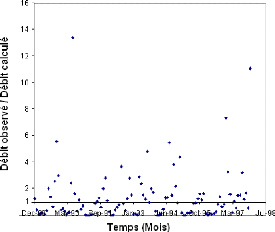
Figure 71 : Rapport des débits
observés sur les débits calculés à la station de
Bada par le modèle
PMCDs
|
Debit (m3/s) |
700 600 500 400 300 |
100 10 1 |
Qobs/Qcal |
|||||||||||||
|
0.1 |
Qobs Qcal Qobs/Qcal |
|||||||||||||||
|
200 |
0.01 0.001 |
|||||||||||||||
|
Jan-89 |
Sep-89 |
Jan-91 |
Sep-91 |
Jan-93 |
Sep-93 |
Jan-95 |
Sep-95 |
Jan-97 |
Sep-97 |
|||||||
Temps (Mois)
Figure 72 : Superposition des Figures 71 et 72
La figure 73 regroupe sur un fond logarithmique l'ensemble des rapports ( Qobs / Qcal = 1) en
fonction des débits calculés (en abscisse). De la même manière que précédemment, on peut observer sur la figure 73 que les débits compris entre 1 et 100 m3/s sont jusqu'à 14 fois sousestimés. Toute fois, ce nuage de point représenté à la figure 73 reste difficile à interpréter
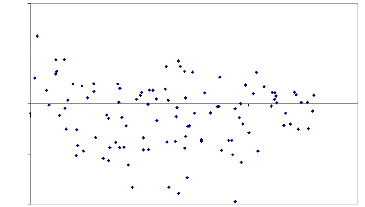
Debit observe / Debit calcule
0,01
100
0,1
10
1
10 100 1000
Débit calculé (Qcal) (m3/s)
Figure 73 : Rapport des débits
observés sur les débits calculés (
Qobs / Qcal = 1) à la station de
Bada
avec les modèles PMCDs en fonction des débits
calculés
En effet, les valeurs extrêmes, des rapports sont peu nombreuses. Cette étude s'est donc intéressée à la dispersion des points, à partir des quantiles 0,15 et 0,85 qui engloberait 70% des effectifs autour des valeurs centrales comme précédemment.
6.3.2.2.3. Rapport Qobs / Qcal sur la période de validation (1989-1997) par tranche de débit calculé
Les rapports Qobs / Qcal = 1 sont regroupés par tranches de débits pour calculer les quantiles 0,15, 0,50 et 0,85 (Tableau XIII).
Tableau XIII : Récapitulatif des quartiles pour la phase de validation
|
Intervalles (m3/s) |
Effectifs |
Quartiles 0,15 |
Quartiles 0,50 |
Quartiles 0,85 |
|
|
0,0 |
1 |
0 |
|||
|
1 |
5 |
23 |
0,312 |
1,319 |
2,884 |
|
5 |
10 |
15 |
0,135 |
0,366 |
0,843 |
|
10 |
50 |
34 |
0,184 |
0,663 |
1,681 |
|
50 |
100 |
14 |
0,136 |
0,467 |
0,904 |
|
100 |
500 |
22 |
0,465 |
1,066 |
1,579 |
|
500 |
1000 |
0 |
|||
La représentation de ces résultats est faite sur la figure 74 et améliorée sur la figure 75. On remarque qu'entre les deux courbes de la figure 75 on a 70% des effectifs autours des valeurs centrales pour chacun des intervalles.
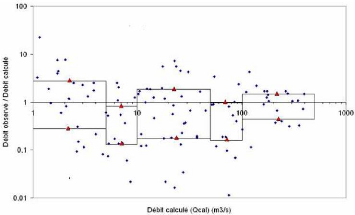
Figure 74 : Encadrement de 50% des rapports Qobs / Qcal = 1 pour chaque fourchette de débit calculésur la période de validation (1989-1997)
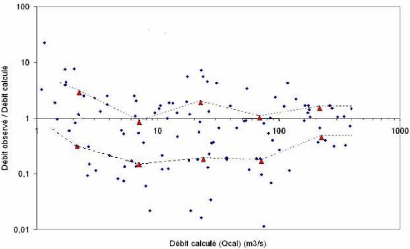
Figure 75 : Rapport Q obs /
Q cal =1 pour chaque fourchette de débit
calculé avec le modèle PMCD1s
sur la période de
validation (1989-1997)
Comme précédemment, entre les deux courbes on a 70% des effectifs autours des valeurs centrales pour chacun des intervalles. Les Différents encadrements des débits mesurés sont résumés dans le Tableau XIV.
Tableau XIV : Récapitulatifs des encadrements des débits mesurés par tranche de débit calculé en calage et en validation
Intervalles de débit (m3/s) Encadrement des débits Encadrement des débits
observés par les débits observés par les débits
(m3/s) simulés en calage (m3/s) simulés en validation
|
1 et 5 m3/s 5 et 10 m3/s 10 et 50 m3/s 50 et 100 m3/s 100 et 500 m3/s |
0,3 . Qcal =Q 0,2 . Qcal = Q 1,1 4 . Qcal = Qobs = 2. Qcal 0,1 8 .Qcal = Qobs =1,7 . Qcal 0,2 . Q cal = Q 0,5 . Q cal = Qobs =1,3 . Qcal 0,5 . Qcal = Qobs =1,6 . Qcal |
D'après le tableau XIV, les
encadrements des débits mesurés ou observés en calage et
en
validation sont similaires pour les faibles débits simulés
(1 à 5 m3/s) et pour les forts débits
simulés (100 à 500 m3/s). En ce qui concerne les autres fourchettes de débits on assiste à quelques légères différences.
Ce premier chapitre des résultats a permis de démontrer que les Perceptrons Multicouches avec une seule couche cachée sont capables de simuler des débits avec de très bonnes performances. Cette étude a également montré qu'avec la pluie seule comme entrée des réseaux de neurones, le nombre de mois de retard à considérer est dans l'ensemble élevé. Les modèles non dirigés(PMCND1s) contenaient plus de neurones sur leur couche cachée que les modèles dirigés (PMCD1s). Au niveau de la performance des modèles développés, les Perceptrons Multicouches Dirigés (PMCD1s) sont plus performants que les Perceptrons Multicouches Non Dirigés (PMCND1s). En effet, en validation pour les modèles PMCD1s, les valeurs de Nash aux stations de Bada, Marabadiassa, Tortiya et de Bou sont respectivement de 67%, 67%, 81% et de 71%. On remarque donc que ces modèles reproduisent plus de 60% des variances des débits. La comparaison faite entre les Nash calculés sans transformation des débits et avec transformation puissance des débits a révélé que la transformation puissance des débits améliore les valeurs des critères de performance des modèles de façon générale en validation.
Pour le modèle PMCND1s, les gains en performance sont de 4 unités aux stations de Marabadiassa (44% à 48%) et Tortiya (76% à 80%). Aux stations de Bada (39% à 41%) et de Bou (52% à 76%) on a respectivement des gains de 3 et 14 unités. En ce qui concerne le modèle PMCD1s, les gains en performance sont les suivants : 1 unité à la station de Bada (67% à 68%) ; 6 unités à la station de Marabadiassa (67% à 73%) ; 4 unités à la station de Tortiya (81% à 85%) et ; 3 unités à a station de Bou (71% à 74%). Malgré la supériorité du modèle Dirigé (PMCD1s) sur le modèle Non Dirigé (PMCND1s) déterminée avec le Test de Pitman, on constate que les deux modèles arrivent à approcher plus ou moins les débits du Bandama Blanc mesurés aux stations de Bada, Marabadiassa, Tortiya et de Bou. L'utilisation de la pluie seule comme variable explicative dans une modélisation avec les réseaux de neurones est possible à condition d'arriver à choisir judicieusement l'architecture convenable (nombre de retard et nombre de neurones optimal). Toutefois cette étude a montré qu'avec la pluie seule comme variable explicative, les réseaux de neurones développés n'arrivent pas à simuler correctement les débits extrêmes (étiages et crues) en calage et en validation. En effet, les modèles développés surestiment généralement les faibles débits et sous estiment les forts débits. Malgré les décalages constatés en calage et en validation, les incertitudes représentées
permettent de donner plus de crédibilités aux différents résultats obtenus. L'intégration de nouveaux paramètres aux données d'entrée des modèles ici développés est la piste de recherche qui va être suivie en vue d'améliorer les simulations obtenues.
Le but de ce 7ème chapitre est d'étudier l'apport des variables comme la température, l'évapotranspiration potentielle, le mois et leurs différentes combinaisons dans les performances des Perceptrons Multicouches Dirigés (PMCD) dans la simulation des débits mensuels sur un bassin versant et la comparaison de ces modèles au modèle GR2M. Il a été déjà démontré dans le chapitre VI, la capacité des Perceptrons Multicouches Dirigés à simuler les débits mensuels du Bandama Blanc, aux stations de Bada, Marabadiassa, Tortiya et Bou, avec en entrée la pluie. La démarche adoptée pour la construction des modèles de simulation est identique à celle appliquée au chapitre précédent. Les modèles dont les résultats sont présentés dans ce chapitre sont :
o le Perceptron Multicouche Dirigé de simulation avec en entrée la pluie (PMCD1s) ;
o ii) le Perceptron Multicouche Dirigé de simulation avec en entrée la pluie et le mois (PMCD2s) ;
o iii) le Perceptron Multicouche Dirigé de simulation avec en entrée la pluie et l'ETP (PMCD3s) ;
o iv) le Perceptron Multicouche Dirigé de simulation avec en entrée la pluie et la température (PMCD4s) ;
o v) le Perceptron Multicouche Dirigé de simulation avec en entrée la pluie, la température et le mois (PMCD5s) et ;
o vi) le Perceptron Multicouche Dirigé de simulation avec en entrée la pluie l'ETP et le mois (PMCD6s).
Ce chapitre comprend trois (3) sections. La première section présente les performances du modèle global GR2M avec le critère de Nash, l'erreur quadratique moyenne (MSE), la racine carrée de l'erreur quadratique moyenne (RMSE), le coefficient de détermination multiple (R2) et le coefficient de corrélation de Pearson (R) comme critères de peformance. La deuxième section s'intéresse à l'évolution de la performance du modèle PMCDs chaque fois qu'on ajoute une ou deux autres variables explicatives en entrée. En ce qui concerne la troisième section, elle compare le modèle GR2M au meilleur modèle Perceptron Multicouche Bouclé Dirigés de simulation.
Les résultats présentés ici sont obtenus avec l'optimisation par la méthode "pas à pas". Il
s'agit de déterminer les valeurs optimales des paramètres X1 et X2 . Comme déjà présenté dans chapitre du matériel et des méthodes, les données sont subdivisées en deux parties : 2/3 pour le calage (1971-1988) et 1/3 pour la phase de validation (1989-1997). Dans le tableau XV sont résumés les paramètres X1 (mm) et X2 du modèle GR2M ainsi que les différents critères de performance (Nash (%), R2 (%), R, MSE et RMSE).
Tableau XV : Récapitulatif des valeurs des paramètres du modèle GR2M et de ces performances
|
Stations |
Superficie |
Paramètres du modèle |
Critères de performance |
|||||
|
X1 (mm) |
X2 |
Nash (%) |
R2 (%) |
R |
MSE |
RMSE |
||
|
Calage (1971-1988) |
||||||||
|
Bada |
24050 |
1211,97 |
0,54 |
67,10 |
67 |
0,81 |
61,64 |
7,85 |
|
Marabadiassa |
22293 |
1339,43 |
0,58 |
51,10 |
45 |
0,65 |
101,04 |
10,05 |
|
Tortiya |
14500 |
1339,43 |
0,55 |
72 |
71 |
0,83 |
55,59 |
7,46 |
|
Bou |
3710 |
1480,3 |
0,54 |
69,70 |
69 |
0,81 |
47,11 |
6,86 |
|
Validation (1989-1997) |
||||||||
|
Bada |
24050 |
1211,97 |
0,54 |
63,30 |
68 |
0,81 |
59,77 |
7,73 |
|
Marabadiassa |
22293 |
1339,43 |
0,58 |
69,30 |
74 |
0,85 |
50,46 |
7,1 |
|
Tortiya |
14500 |
1339,43 |
0,55 |
71 |
75 |
0,85 |
51,43 |
7,17 |
|
Bou |
3710 |
1480,3 |
0,54 |
20,70 |
42 |
0,63 |
99,97 |
10 |
Les paramètres X1 (mm) et
X2 du modèle ont été obtenus
après une étape d'optimisation et
de calage. Le
paramètre X1 (mm) est la capacité maximale du
réservoir (sol) et le paramètre
X2 traduit
le paramètre d'échange souterrain au niveau du réservoir
(eau gravitaire). Le taux
d'humectation des sols est un facteur qui conditionne plus ou
moins fortement leur aptitude au
ruissellement et à l'infiltration en
fonction du type de sol et de son état de surface.
Le
paramètre X1 permet donc au modèle de
s'adapter à la demande évaporatoire brute qui lui est
présentée. Les approches conceptuelles globales apparaissent comme une solution pragmatique pour prendre en compte l'effet de l'humidité du sol sur sa réponse hydrologique (Loumagne et al., 1991). En ne tenant compte que des valeurs pour lesquelles on enregistre des performances jugées satisfaisantes, le paramètre X1 (mm) varie de 1 211,97 à 1 480,30
mm. La capacité maximale du réservoir (sol) varie
d'un sous bassin versant à un autre. Le
paramètre
X2 oscille entre les valeurs 0,54 et 0,58. Ces valeurs
restent inférieures à 1, ce qui
implique des apports d'eau au niveau des différents bassins. En effet, lorsque X2 est supérieur
à 1, on assiste à une perte d'eau du réservoir R vers les autres bassins versant et dans le cas contraire, c'est plutôt un apport vers le réservoir R qu'il traduit. La lecture du tableau XV montre que le modèle conceptuel global GR2M donne de bonnes performances aux différentes stations d'étude. Il illustre bien les performances du modèle GR2M. En effet, en calage, les Nash obtenus aux stations de Bada, Tortiya et Bou sont supérieurs à 60%. A la station de Marabadiassa, il n'est que de 51,1%. En ce qui concerne les coefficients de corrélation de Pearson, ils varient de forts à très forts. En validation, tous les Nash sont supérieurs à 60% sauf celui déterminé à la station de Bou qui est de 20,7%. Le coefficient de corrélation de Pearson varie toujours de forts à très forts avec des valeurs généralement supérieures à 0,80. Cependant, on observe une instabilité du modèle GR2M à Marabadiassa, en calage, et à Bou, en validation, où le coefficient de corrélation de Pearson est respectivement de 0,65 et 0,63. En effet, on note une dégradation de la performance du modèle à la station de Bou et une amélioration de la performance du modèle à la station de Marabadiassa. Pour les autres stations le modèle est généralement robuste. Ces mêmes remarques sont valables pour le coefficient de détermination (R2) et de l'erreur quadratique moyenne. En ce qui concerne le coefficient de détermination (R2), les valeurs extrêmes sont : i) en calage, le maximum est de 0,75 obtenu à la station de Tortiya et le minimum de 0,45 à la station de Marabadiassa ; ii) en validation, le maximum est obtenu toujours à Tortiya et est égal à 0,75 et le minimum est de 0,42 obtenu à la station de Bou.
Les bonnes valeurs des critères de performance (Nash, R2 (%), R, MSE, RMSE) ne suffisent pas pour dire que tel ou tel modèle calcule très bien les débits mensuels au niveau d'une station hydrométrique. Il faut alors associer à ces critères les hydrogrammes pour pouvoir apprécier la représentativité de ces derniers par ces modèles de simulation. Dans cette étude, les hydrogrammes mesurés et simulés en calage et en validation sont représentés respectivement par les figures 76 et 77. Une lecture de ces figures montre que la dynamique des écoulements, à travers l'évolution des hydrogrammes, est bien représentée par le modèle conceptuel global GR2M. Cependant, en regardant de plus près on s'aperçoit qu'il existe un certain décalage entre les hydrogrammes mesurés et les hydrogrammes calculés par le modèle GR2M. Ces décalages sont plus marqués au niveau des débits de pointe qui sont généralement mal reproduits tant en phase de calage qu'en phase de validation par le modèle GR2M. On
remarque également que les périodes de grande pluie coincident avec les pics des hydrogrammes mesurés et calculés à toutes les stations hydrométriques.
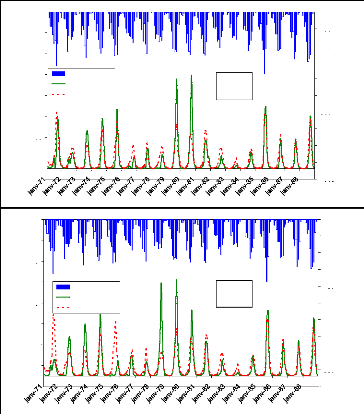
Debit (mm/mois)
Debit (mm/mois)
150 0
130
110
-10
90
70
50
30
150 0
130
110
10
-10
90
70
50
30
10
Pluie
Débit observé Débit simulé
Pluie
Débit observé Débit simulé
(a)
(c)
200
400
300
500
600
700
800
900
100
1000
400
200
300
500
600
700
800
900
100
1000
Pluie (mm/mois)
Pluie (mm/mois)
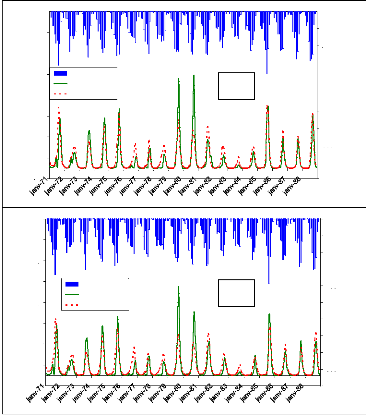
Debit (mm/mois)
Debit (mm/mois)
150 0
130
110
-10
90
70
50
30
150 0
130
110
10
-10
90
70
50
30
10
Pluie
Débit observé Débit simulé
Pluie
Débit observé Débit simulé
(b)
(d)
400
200
300
500
600
700
800
900
100
1000
200
400
300
500
600
700
800
900
100
1000
Pluie (mm/mois)
Pluie (mm/mois)
Figure 76 : Hydrogrammes observés et simulés en phase de calage par GR2M à Bada (a), Marabadiassa (b), Tortiya (c) et à Bou (d)
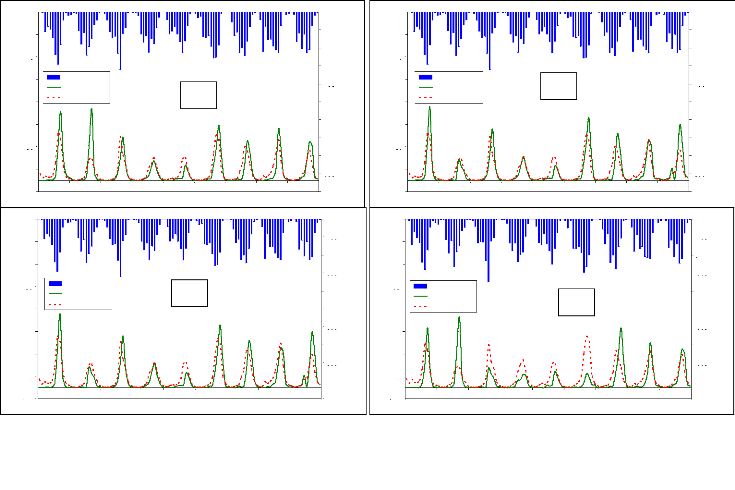
- 154 -
Debit (mm/mois)
Debit (mm/mois)
150
130
110
150
130
110
-10
janv-89 janv-90 janv-91 janv-92 janv-93 janv-94 janv-95 janv-96 janv-97
-10
janv-89 janv-90 janv-91 janv-92 janv-93 janv-94 janv-95 janv-96 janv-97
90
70
50
30
10
90
70
50
30
10
Pluie
Débit observé Débit simulé
Pluie
Débit observé Débit simulé
(c)
(a)
200
400
0
300
500
600
700
800
900
100
1000
200
400
0
300
500
600
700
800
900
100
1000
Pluie (mm/mois)
Pluie (mm/mois)
Debit (mm/mois)
Debit (mm/mois)
150
130
110
-10
janv-89 janv-90 janv-91 janv-92 janv-93 janv-94 janv-95 janv-96 janv-97
150
130
110
90
70
50
30
-10 janv-89 janv-90 janv-91 janv-92 janv-93 janv-94 janv-95 janv-96 janv-97
10
90
70
50
30
10
Pluie
Débit observé Débit simulé
Pluie
Débit observé Débit simulé
(b)
(d)
200
400
0
300
500
600
700
800
900
100
1000
400
0
200
300
500
600
700
800
900
100
1000
Pluie (mm/mois)
Pluie (mm/mois)
Figure 77 : Hydrogrammes observés et simulés en phase de validation par GR2M à Bada (a), Marabadiassa (b), Tortiya (c) et à Bou (d)
Après avoir présenté les performances du modèle conceptuel GR2M, le paragraphe suivant étudier la relation entre ces performances (Nash (%) et R2 (%) et les différentes superficies des sous bassins d'étude (sous bassin de Bada, sous bassin de Marabadiassa, sous bassin de Tortiya et le sous bassin de Bou). La lecture de la figure 78 ne signale aucune tendance quant à une éventuelle relation entre les critères de performance et les différentes superficies des sous bassins versants d'étude.
|
80 |
30000 |
(a) |
||||
|
Critete de performance |
60 |
20000 |
superficies des sous bassins d'etucle (Kmz) |
|||
|
40 |
15000 |
Nash (%) r2 (%) superficie (km2) |
||||
|
30 20 10 0 |
10000 5000 0 |
|||||
|
Sous bassin de Bada Sous bassin de Marabadiassa |
Sous bassin de Tortiya Sous bassin de Bou |
|||||
Sous bassins versants d'étude
|
80 |
30000 |
(b) |
||||
|
60 |
Superficies des sous bassins d'etude (Kmz) |
|||||
|
Criteres de performance (%) |
50 |
20000 |
||||
|
40 |
15000 |
Nash (%) r2 (%) superficie (km2) |
||||
|
30 20 10 0 |
10000 5000 0 |
|||||
|
Sous bassin de Bada Sous bassin de Marabadiassa |
Sous bassin de Tortiya Sous bassin de Bou |
|||||
Sous bassins versants d'étude
Figure 78 : Diagramme comparatif des
critères de performances et des superficies des sous
bassins
d'étude : (a) calage et (b) validation
En effet, que se soit en calage ou en validation, les performances du modèle GR2M ne dépendent pas de la superficie du sous bassin versant considéré.
Dans la présente section, il est résumé les performances des Perceptrons Multicouches Dirigés (PMCDs après ajout des autres variables explicatives comme l'évapotranspiration potentielle (ETP), la température (T), le mois et leurs différentes combinaisons. Le critère de Nash est utilisé comme critère d'évaluation de performance des modèles pendant la phase de validation comme dans le chapitre précédent.
Les retards et le nombre de neurones cachés varient en fonction des variables d'entrée. En effet, on remarque que :
i. l'ajout du mois à la pluie en entrée du modèle Perceptron Multicouche a fortement diminué le nombre de retard. On est passé avec cet ajout de 2 mois à 1 mois de retard à Bada, de 10 mois à 4 mois de retard à Marabadiassa, de 11 mois à 3 mois de retard à Tortiya et de 7 mois à 1 mois de retard à Bou. En ce qui concerne la variation du nombre de neurones cachés, on note une hausse sensible à toutes les stations hydrométriques sauf à la station de Bou. En effet, on est passé de 3 à 4 neurones cachés à la station de Bada, de 2 à 7 neurones cachés à la station de Marabadiassa, de 3 à 2 neurones cachés à la station de Tortiya. Pour la station de Bou, le nombre de neurones cachés reste identique, donc ne subit pas d'augmentation ;
ii. l'ajout de l'évapotranspiration à la pluie en entrée du modèle Perceptron a fortement diminué le nombre de retard à toutes les stations sans exception. On est passé pour ce modèle de : 2 mois à 1 mois de retard à la station de Bada ; de 10 mois à 2 mois de retard à la station de Marabadiassa ; de 11 mois à 2 mois de retard à la station de Tortiya et ; de 7 mois à 1 mois de retard à la station de Bou. Pour le nombre de neurones cachés, l'ajout de l'ETP à la pluie en entrée a favorisé son augmentation à toutes les stations sauf à la station de Bou où le nombre de neurones cachés est resté identique et égale à 2 neurones cachés. Pour les autres stations, le nombre de neurones cachés est passé de 3 à 4 à la station de Bada ; de 2 à 3 à la station de Marabadiassa ; de 3 à 5 à la station de Tortiya ;
iii. l'ajout de la température à la pluie en entrée du modèle Perceptron Multicouche se comporte sur le nombre de retard comme l'ajout de l'évapotranspiration. Pour la
variation du nombre de neurones cachés, on note une hausse sensible. En effet, on passe de 3 à 6 neurones cachés à la station de Bada ; de 2 à 5 neurones cachés à la station de Marabadiassa ; de 2 à 4 neurones cachés à la station de Bou. Pour la station de Tortiya, le nombre de neurones cachés reste identique et égale à 3 ;
iv. l'ajout de la température et du mois à la pluie en entrée du modèle Perceptron a fortement diminué le nombre de retard pour l'ensemble des stations étudiées. Le nombre de retard est passé : de 2 à 0 mois de retard à la station de Bada ; de 10 à 4 mois de retard à la station de Marabadiassa ; de 11 à 1 mois de retard à la station de Tortiya et ; de 7 à 1 mois de retard à la station de Bou. En ce qui concerne la variation du nombre de neurones cachés, on note une hausse sensible aux stations de Marabadiassa, Tortiya et Bou. A la station de Bada, on n'enregistre aucun changement du nombre de neurones cachés ;
v. l'ajout de l'évapotranspiration et du mois à la pluie en entrée du modèle Perceptron Multicouche a fortement diminué le nombre retard. Le nombre de retard est passé : de 2 à 0 mois de retard à la station de Bada ; de 10 à 2 mois de retard à la station de Marabadiassa ; de 11 à 1 mois de retard à la station de Tortiya et ; de 7 à 1 mois de retard à la station de Bou. En ce qui concerne la variation du nombre de neurones cachés, on note une hausse sensible seulement à la station de Marabadiassa où le nombre de neurones cachés est passé de 2 à 5. A la station de Tortiya on assiste à une diminution du nombre de neurones qui passe de 3 à 2. Pour la station de Bou, et de Bada le nombre de neurones cachés reste identique, donc ne subit pas d'augmentation.
De façon générale, les résultats montrent que l'ajout de nouvelles variables explicatives à la
pluie diminue le nombre de retard et augmente le nombre de neurones cachés au niveau des
modèles Perceptrons Multicouches Dirigés de simulation (PMCDs) à toutes les stations
hydrométrique d'étude.
Le tableau XVI résume les performances obtenues par les modèles Perceptrons Multicouches Dirigés de simulation (PMCDs) après les ajouts en entrée du mois, de la température, de l'ETP et de leurs différentes combinaisons. Les modèles expriment plus de 60% de la variabilité des débits quelque soit la station d'étude considérée.
De façon générale, tous les ajouts ont contribué à améliorer les performances des modèles. Une analyse plus détaillée permet de faire les remarques suivantes :
i. l'ajout du mois améliore la performance du modèle aux stations Bada et Marabadiassa et a au contraire, contribué à dégrader la performance du modèle à la station de Bou. A la station de Tortiya, la variation au niveau de la performance du modèle est faible de l'ordre de 0,01. Ceci se traduit par des valeurs du rapport Nash Modèle PMCD1s /Nash Modèle PMCD3s inférieures à 1 aux stations de Bada et de Marabadiassa et supérieures à 1 à la station de Bou ;
ii. les ajouts des variables comme, l'évapotranspiration et la température, améliorent la performance des modèles aux stations qui drainent la plus grande superficie (Bada et Marabadiassa) et a, au contraire, contribué à dégrader la performance du modèle à la station de Bou qui est la plus petite des stations du point de vue superficie. Cependant, à la station de Tortiya on ne constate aucun changement dans la performance du modèle. Ceci se traduit par des valeurs du rapport Nash Modèle PMCD1s /Nash Modèle PMCD3s inférieures à 1 aux stations de Bada et de Marabadiassa ; égales à 1 à la station de Tortiya et supérieures à 1 à la station de Bou ;
iii. l'ajout de la température et du mois en entrée améliore les performances à toutes les
stations. Il faut cependant remarquer que l'amélioration du modèle au niveau de la station de Bou est minime de l'ordre de 0,01%. A la station de Tortiya on enregistre toujours la même performance malgré l'ajout de la température et du mois ;iv. l'ajout de l'évapotranspiration et du mois améliore la performance du modèle aux stations Bada et Marabadiassa et a, au contraire, contribué à dégrader la performance du modèle à la station de Bou. A la station de Tortiya, on ne constate aucun changement dans la performance du modèle. Ceci se traduit par des valeurs du rapport Nash Modèle PMCD1s /Nash Modèle PMCD6s inférieures à 1 aux stations de Bada et de Marabadiassa, et supérieures à 1 à la station de Bou.
Tableau XVI : Résumé des performances des modèles Perceptrons Multicouches de simulations
|
Stations |
Rapports de |
Modèles |
Nash (%) |
Nash PMCD 1 ) ( s Nash PMCDx ( s ) |
|
PMCD1s |
67 |
- |
||
|
PMCD2s |
77 |
0,87 |
||
|
PMCD3s |
74 |
0,90 |
||
|
Bada |
1 |
PMCD4s |
72 |
0,93 |
|
PMCD5s |
73 |
0,92 |
||
|
PMCD6s |
81 |
0,83 |
||
|
PMCD1s |
67 |
|||
|
PMCD2s |
80 |
0,84 |
||
|
PMCD3s |
69 |
0,97 |
||
|
Marabadiassa |
0,93 |
PMCD4s |
72 |
0,93 |
|
PMCD5s |
72 |
0,93 |
||
|
PMCD6s |
70 |
0,96 |
||
|
PMCD1s |
81 |
- |
||
|
PMCD2s |
82 |
0,99 |
||
|
PMCD3s |
81 |
1 |
||
|
Tortiya |
0,60 |
PMCD4s |
81 |
1 |
|
PMCD5s |
81 |
1 |
||
|
PMCD6s |
82 |
0,99 |
||
|
PMCD1s |
71 |
- |
||
|
PMCD2s |
68 |
1,04 |
||
|
PMCD3s |
61 |
1,16 |
||
|
Bou |
0,15 |
PMCD4s |
68 |
1,04 |
|
PMCD5s |
72 |
0,99 |
||
|
PMCD6s |
64 |
1,11 |
Au niveau de la performance des modèles, on note une
amélioration, à presque toutes les
stations, sauf à la
station de Bou où l'ajout de ces variables explicatives
dégrade
considérablement les critères de Nash en validation. Ceci est traduit par l'équation définie cidessous :
Nash PMCD 1
( )
s Nash PMCDx
( s ) (avec x variant de 2 à 6 et traduisant l'indice qui permet de
définir les différents modèles engendrés par les ajouts des variables climatiques).
Il est aussi utile de signaler qu'à la station de Tortiya, l'ajout de ces variables explicatives et de leur combinaison n'influencent pas fortement la qualité des résultats car les rapports précédemment définis sont égaux ou proche de 1. En définitive, en comparant les différents modèles issus des ajouts de variables climatiques, on se rend compte qu'à la station de Bada, c'est le modèle PMCD6s qui est le meilleur avec un Nash de 81% ; à la station de Marabadiassa, c'est le modèle PMCD2s avec un Nash de 80% apparaît comme le plus performant ; à la station de Tortiya, les modèles PMCD2s et PMCD6s sont les meilleures avec des Nash de 82% et ; à la station de Bou, le Nash le plus bon est obtenu avec le modèle PMCD5s.
Le chapitre VII et les sections précédentes ont présenté les performances du modèle GR2M et des modèles neuronaux (PMCD1s, PMCD2s, PMCD3s, PMCD4s, PMCD5s, PMCD6s). La section suivante se charge de comparer les performances des modèles GR2M, PMCD1s et PMCD3s. Cette comparaison est réalisée sur l'ensemble des périodes de calage (1971-1988) et de validation (1989-1997). Pourquoi comparer spécifiquement les modèles PMCD1s et PMCD3s au modèle GR2M ? Le choix de ces modèles repose sur le simple fait que les modèles GR2M et PMCD3s ont les mêmes variables explicatives en entrée (la pluie mensuelle et l'évapotranspiration potentielle mensuelle) et que la variable explicative utilisée par le modèle PMCD1s est uniquement la pluie mensuelle. Cette étude comparative à deux principaux buts : i) voir lequel des modèles GR2M et PMCD3s est le meilleur et ; vérifier si le modèle PMCD1s à une seule entrée est plus performant. La figure 79 représente les valeurs de Nash (%) obtenues en calage et en validation avec les modèles comparés (GR2M, PMCD1s et PMCD3s). En ce qui concerne les figures 80, 81, 82 et 83, elles représentent les hydrogrammes mesurés et calculés obtenus en validation avec les modèles GR2M et PMCD3S, respectivement aux stations de Bada, Marabadiassa, Tortiya et Bou.
La lecture de la figure 79 montre que
: i) en calage ou en validation, tous les
modèles
comparés donnent de très bonnes valeurs de Nash
à la station de Tortiya ; ii) en calage, tous
les modèles
donnent de bonnes valeurs de Nash à toutes les stations, sauf à
la station de
Marabadiassa où le modèle GR2M donne un Nash inférieur à 60%, donc jugé mauvais sur l'échelle de Kachroo (1986) ; iii) ce même constat est fait en validation à la station de Bou où le Nash calculé avec le modèle GR2M est très faible et égal à 21% et ; iv) le modèle PMCD1s avec la pluie seulement en entrée donne toujours de bonnes valeurs de Nash comprises généralement entre 60% et 80%, ce qui permet de dire que le Perceptron Multicouche Bouclé Dirigé, avec en entrée la pluie est un bon modèle tout comme son homologue qui a en entrée la pluie et l'évapotranspiration potentielle (ETP).
En définitive, on note que le modèle Perceptron Multicouche Dirigé avec en entrée la pluie mensuelle est plus performant que le modèle GR2M qui utilise deux variables en entrée (la pluie et l'évapotranspiration potentielle mensuelle).
Au niveau de la dynamique des écoulements, représentée par les figures 80 à 83, on note une bonne reproduction de ces hydrogrammes par les modèles GR2M et PMCD3s à toutes les stations hydrométriques d'étude. Les hydrogrammes mesurés et simulés par les deux modèles sont en effet très bien synchrones avec les mois où apparaissent les crues et les étiages bien marqués. Malgré cette synchronisation des débits mesurés et simulés, on observe quelques décalages entre ces hydrogrammes, qui sont plus marqués avec les hydrogrammes simulés par le modèle GR2M. A l'actif des imperfections des modèles GR2M et PMCD3s, il faut ajouter les surestimations et les sous estimations de certaines classes de lames d'eau écoulées aux différentes stations d'étude. En effet, on observe au niveau des figures présentées ci-dessous que le modèle GR2M surestime plus les faibles lames d'eau écoulées que le modèle PMCD3s à toutes les stations hydrométriques d'étude. En ce qui concerne l'estimation des débits de pointes par les deux modèles, la lectures des hydrogrammes ci-dessous permet de faire les observations suivantes par stations : i) aux stations de Bada et de Marabadiassa, la crue de 1993 est surestimée par le modèle GR2M et sous estimée par le modèle PMCD3s ; ii) á la station de Tortiya, les crues des années 1990, 1992 et 1993 sont surestimées par les modèles GR2M et PMCD3s et ; iii) à la station de Bou, les crues des années 1991, 1992 et 1993 sont surestimées par les modèles GR2M et PMCD3s ; mais, on constate que, des deux modèles, le modèle GR2M surestime plus ces lames d'eau écoulées pendant ces années. Pour ce qui est de la crue de 1994, le modèle GR2M surestime les lames d'eau écoulées à environ 3 fois leurs valeurs tandis que le modèle PMCD3s les surestime à environ 2 fois.
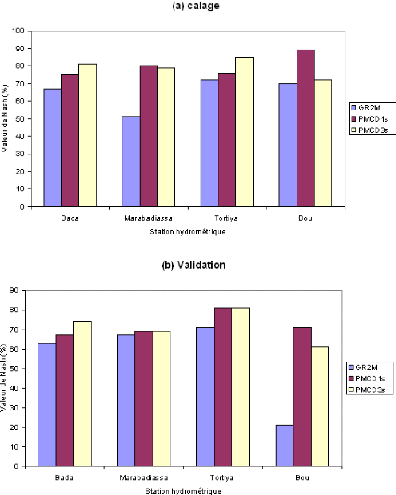
Figure 79 : Représentation des valeurs de Nash (%) obtenues avec les modèles GR2M, PMCD1s et PMCD3s en calage et en validation
A part les quelques cas de sur-estimation et de sous-estimation signalés, les crues sont généralement sous estimées par les modèles GR2M et PMCD3s. Ces décalages et ces problèmes de sur-estimation et de sous-estimation des lames d'eau écoulées aux différentes stations hydrométriques d'étude seront interprétés dans le chapitre discussion.
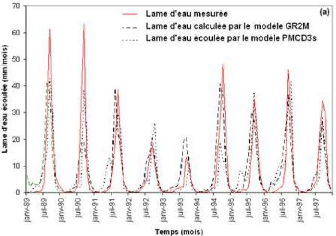
Figure 80 : Hydrogrammes mesurés et calculés par les modèles GR2M et PMCD3s à la station de Baba
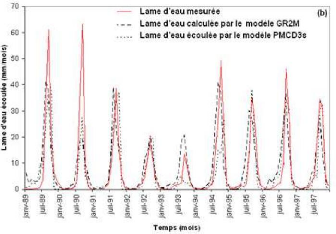
Figure 81 : Hydrogrammes mesurés et calculés par les modèles GR2M et PMCD3s à la station de Marabadiassa
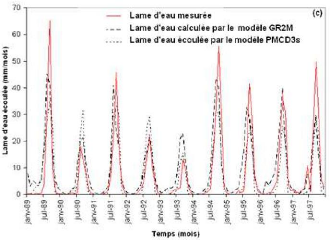
Figure 82 : Hydrogrammes mesurés et calculés par les modèles GR2M et PMCD3s à la station de Tortiya
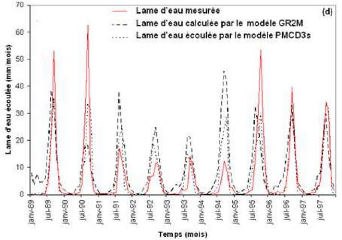
Figure 83 : Hydrogrammes mesurés et calculés par les modèles GR2M et PMCD3s à la station de Bou
Tout au long de ce chapitre VII, il a été mis au point deux (2) types de modèles : le modèle conceptuel global GR2M et les modèles Perceptrons Multicouches Dirigés (PMCD1s, PMCD2s PMCD4s, PMCD5s PMCD6s). Ces modèles ont permis d'obtenir en général de très bonnes performances tant en calage qu'en validation.
En validation, à la station de Tortiya, les valeurs de Nash obtenues avec les modèles GR2M, PMCD1s et PMCD3s sont respectivement de 71%, 81% et 81%. En comparant le modèle conceptuel GR2M et les modèles neuronaux, il apparaît dans cette étude que les derniers cités sont les plus performants et les plus parcimonieux pour la simulation des débits des cours d'eau. On peut aussi retenir de ce chapitre que la performance des modèles neuronaux est fortement liée aux stations d'étude, donc directement liée à la qualité des données collectées. Toutefois, il est bon de signaler que les Réseaux de neurones sont plus aptes à modéliser les données hydroclimatiques bruitées que le modèle conceptuel global, GR2M.
Les chapitres VI et VII précédents ont traité de la simulation des débits des eaux du Bandama Blanc à l'aide des modèles globaux. Il s'agit des Perceptrons Multicouches et du modèle conceptuel GR2M du CEMAGREF utilisé pour apprécier les résultats obtenus avec les Réseaux de neurones. Les débits mensuels du Bandama Blanc à Bada, Marabadiassa, Tortiya et à Bou ont été simulés avec de bons résultats. Mais, parmi ces stations, la station de Tortiya s'est révélée être celle où les deux types de modèles globaux développés et optimisés ont donné les meilleures performances. Pour cette raison, la station de Tortiya sera celle utilisée dans ce chapitre pour tester la capacité des Réseaux de neurones à faire de la prévision dans un contexte perturbé avec, notamment la présence de plusieurs barrages agropastoraux. Les modèles utilisés dans ce chapitre ont été largement présentés dans la deuxième partie de ce mémoire. Cependant, pour faciliter la compréhension des paragraphes qui vont suivre, ils sont rappelés ici. On a donc:
o le Perceptron Multicouche Dirigé de prévision avec en entrée la pluie (PMCD1p) ;
o le Perceptron Multicouche Dirigé de prévision avec en entrée la pluie et le mois (PMCD2p) ;
o le Perceptron Multicouche Dirigé de prévision avec en entrée la pluie et l'ETP (PMCD3p) ;
o le Perceptron Multicouche Dirigé de prévision avec en entrée la pluie et la température (PMCD4p) ;
o le Perceptron Multicouche Dirigé de prévision avec en entrée la pluie, la température et le mois (PMCD5p) et ;
o le Perceptron Multicouche Dirigé de prévision avec en entrée la pluie l'ETP et le mois (PMCD6p).
Pour tous ces modèles, l'horizon de prévision est de trois mois. En effet, on donne aux différents réseaux le débit un mois avant la prévision et on lui demande de faire la prévision du troisième mois. Un seul horizon de prévision est choisi ; car, l'objectif de ce présent chapitre est de montrer seulement que les modèles Perceptrons Multicouches sont aussi
capables de faire de la prévision. Il s'agira donc de montrer que les Réseaux de neurones en général et les Perceptrons Multicouches en particulier peuvent être exploités convenablement tant en simulation qu'en prévision. Pour atteindre cet objectif, ce chapitre est subdivisé en trois (3) sections. La première section présente les performances des modèles de prévision en calage et en validation à travers le critère de Nash, le coefficient de détermination multiple et le coefficient de corrélation de Pearson. La deuxième section est consacrée à la présentation des résultats du test de comparaison entre les prévisions des différents Perceptrons Multicouches utilisés. La troisième section compare les performances des modèles en simulation et en prévision afin de voir à quel niveau de modélisation ils sont plus performants.
Les résultats présentés dans cette section ont été obtenus par optimisation des modèles de prévision présentés largement dans la deuxième partie de ce mémoire et annoncés ci-dessus. Les résultats de cette optimisation sont consignés dans le tableau XVII. La lecture de ce tableau montre que tous les modèles expriment plus de 70% de la variation des débits du Bandama Blanc à Tortiya. On note également que pour tous les modèles, les Nash calculés sont nettement supérieurs à 70% et les coefficients de corrélation de Pearson sont très forts, supérieurs à 0,80, et cela en calage et en validation. Il est bon de remarquer que tous les modèles semblent plus performants en validation qu'en calage. Toutefois, les performances (Nash et coefficient de Pearson) en calage et en validation sont du même ordre de grandeur, ce qui signifierait que les différents modèles sont très robustes donc stables. Pour les deux phases phases (calage et validation), les modèles PMCD2p et PMCD3p donnent les mêmes valeurs de Nash, du coefficient de détermination et du coefficient de corrélation de Pearson. Au vu des valeurs des critères de performance consignés dans le tableau XVII, on se rend compte aussi que les modèles PMCD2p et PMCD3p sont les meilleurs.
Tableau XVII : Performance des modèles PMCD1P, PMCD 2P, PMCD 3P, PMCD4P, PMCD5P, PMCD6P
|
Calage |
Validation |
||||||||||||
|
Modèles |
Nash (%) |
R2 (%) |
R |
Nash (%) |
R2 (%) |
R |
|||||||
|
PMCD1P |
72 |
79 |
0,88 |
77 |
82 |
0,89 |
|||||||
|
PMCD2P |
74 |
85 |
0,91 |
79 |
83 |
0,90 |
|||||||
|
PMCD3P |
74 |
85 |
0,91 |
79 |
85 |
0,90 |
|||||||
|
- 167 - |
|||||||||||||
|
Calage |
Validation |
||||||||||||
|
Modèles |
Nash (%) |
R2 (%) |
R |
Nash (%) |
R2 (%) |
R |
|||||||
|
PMCD4P |
73,6 |
79 |
0,88 |
78,2 |
82 |
0,89 |
|||||||
|
PMCD5P |
73 |
79 |
0,88 |
78,4 |
82 |
0,89 |
|||||||
|
PMCD6P |
71,6 |
76 |
0,86 |
79 |
84 |
0,90 |
|||||||
Les figures 86 à 91 représentent les hydrogrammes mesurés et calculés en calage (a) et en validation (b) respectivement pour les modèles de prévision PMCD1p, PMCD2p, PMCD3p, PMCD4p, PMCD5p, PMCD5p. L'analyse de ces hydrogrammes montre bien que les modèles de prévision, tout comme les modèles de simulation développés aux chapitre VI et VII, reproduisent bien la dynamique des écoulements du Bandama Blanc à la station hydrométrique de Tortiya. On peut cependant, remarquer quelques décalages entre les débits mesurés et les débits prédits par ces modèles de prévision à la station de Tortiya. Les graphes (b) en validation, des figures 84 à 89, montrent que tous les modèles sous-estiment à au moins 2/3 les débits de pointes mesurés au mois de septembre qui correspond au mois des débits de crues. Les mois de septembre des années suivantes sont concernés par cette remarque :
· 1989, 1991, 1994 et 19 97 avec le modèle PMCD1p ;
· 1989 et 1991 avec les modèles PMCD2p, PMCD3p, PMCD4p, PMCD5p et PMCD6p. Ces observations permettent de voir que l'ajout des variables explicatives, comme la température, l'évapotranspiration et le mois ainsi que leurs différentes combinaisons, améliore la capacité des modèles neuronaux à reproduirent la dynamique des écoulements du Bandama Blanc à Tortiya.
Debit (m3/s)
450
400
500
350
300
250
200
150
100
50
0
(a)
Débit mesuré Débit calculé
janv-71 janv-72 janv-73 janv-74 janv-75 janv-76 janv-77 janv-78 janv-79 janv-80 janv-81 janv-82 janv-83 janv-84 janv-85 janv-86 janv-87 janv-88
Temps en Mois
Debit (m3/s)
400
350
300
250
200
150
100
50
0
(b)
Débit mesuré Débit calculé
janv-89 juil-89 janv-90 juil-90 janv-91 juil-91 janv-92 juil-92 janv-93 juil-93 janv-94 juil-94 janv-95 juil-95 janv-96 juil-96 janv-97 juil-97
temps en mois
Figure 84 : Hydrogrammes mesurés et prédits en calage (a) et en validation (b) par le modèle neuronal PMCD1P
Debit(m3/s)
450
400
350
300
250
200
150
100
50
0
(a)
Débit mesuré Débit calculé
janv-71 janv-72 janv-73 janv-74 janv-75 janv-76 janv-77 janv-78 janv-79 janv-80 janv-81 janv-82 janv-83 janv-84 janv-85 janv-86 janv-87 janv-88
Temps en Mois
Debit (m3Is)
400
250
200
350
300
150
100
50
0
(b)
Débit mesuré Débit calculé
janv-89 juil-89 janv-90 juil-90 janv-91 juil-91 janv-92 juil-92 janv-93 juil-93 janv-94 juil-94 janv-95 juil-95 janv-96 juil-96 janv-97 juil-97
Temps en Mois
Figure 85 : Hydrogrammes mesurés et prédits en calage (a) et en validation (b) par le modèle neuronal PMCD2P
Debit (m3/s)
450
400
250
200
500
350
300
150
100
50
0
(a)
Débit mesuré Débit calculé
janv-71 janv-72 janv-73 janv-74 janv-75 janv-76 janv-77 janv-78 janv-79 janv-80 janv-81 janv-82 janv-83 janv-84 janv-85 janv-86 janv-87 janv-88
Temps en Mois
Debit (m3Is)
400
350
300
250
200
150
100
50
0
(b)
Débit mesuré Débit calculé
janv-89 juil-89 janv-90 juil-90 janv-91 juil-91 janv-92 juil-92 janv-93 juil-93 janv-94 juil-94 janv-95 juil-95 janv-96 juil-96 janv-97 juil-97
Tem ps en Mois
Figure 86 : Hydrogrammes mesurés et prédits en calage (a) et en validation (b) par le modèle neuronal PMCD3P
Debit (m3/s)
450
400
500
350
300
250
200
150
100
50
0
(a)
Débit mesuré Débit calculé
janv-71 janv-72 janv-73 janv-74 janv-75 janv-76 janv-77 janv-78 janv-79 janv-80 janv-81 janv-82 janv-83 janv-84 janv-85 janv-86 janv-87 janv-88
Temps en Mois
Debit (m3/s)
400
350
300
250
200
150
100
50
0
(b)
Débit mesuré Débit calculé
janv-89 juil-89 janv-90 juil-90 janv-91 juil-91 janv-92 juil-92 janv-93 juil-93 janv-94 juil-94 janv-95 juil-95 janv-96 juil-96 janv-97 juil-97
Temps en Mois
Figure 87 : Hydrogrammes mesurés et prédits en calage (a) et en validation (b) par le modèle neuronal PMCD4P
Debits (m3/s)
450
400
500
350
300
250
200
150
100
50
0
(a)
Débit mesuré Débit calculé
janv-71 janv-72 janv-73 janv-74 janv-75 janv-76 janv-77 janv-78 janv-79 janv-80 janv-81 janv-82 janv-83 janv-84 janv-85 janv-86 janv-87 janv-88
Temps en Mois
Debit (m3/s)
400
350
300
250
200
150
100
50
0
(b)
Débit mesuré Débit calculé
janv-89 juil-89 janv-90 juil-90 janv-91 juil-91 janv-92 juil-92 janv-93 juil-93 janv-94 juil-94 janv-95 juil-95 janv-96 juil-96 janv-97 juil-97
Temps en Mois
Figure 88 : Hydrogrammes mesurés et prédits en calage (a) et en validation (b) par le modèle neuronal PMCD5P
Debit (m3/s)
450
400
500
350
300
250
200
150
100
50
0
(a)
Débit mesuré Débit calculé
janv-71 janv-72 janv-73 janv-74 janv-75 janv-76 janv-77 janv-78 janv-79 janv-80 janv-81 janv-82 janv-83 janv-84 janv-85 janv-86 janv-87 janv-88
Temps en Mois
Debit (m3/s)
400
350
300
250
200
150
100
50
0
(b)
Débit mesuré Débit calculé
janv-89 juil-89 janv-90 juil-90 janv-91 juil-91 janv-92 juil-92 janv-93 juil-93 janv-94 juil-94 janv-95 juil-95 janv-96 juil-96 janv-97 juil-97
Tem ps en Mois
Figure 89 : Hydrogrammes mesurés et prédits en calage (a) et en validation (b) par le modèle neuronal PMCD6P
Malgré tout ce qui précède, il est difficile d'apprécier la tendance générale quand à la surestimation ou à la sous-estimation des débits du Bandama Blanc à la station de Tortiya par les modèles Perceptrons Multicouches développés. Il est donc plus commode de superposer les hydrogrammes afin d'obtenir les figures 90 à 95 présentés comme déjà utilisé au chapitre VII.
|
|
|
|
|||||
|
||||||||
mars-
ao0t-janv-94 juin-94 nov-94 avr-95 sept-95 fevr-96 juil-96 dec-96 mai-97 oct-97
janv-89 juin-89 nov-89 avr-90 sept-90 fevr-91 juil-91 dec-91 mai-92 oct-92
Temps (Mois)
Figure 90 : Superposition des hydrogrammes mesurés et calculés en validation avec le modèle PMCD1p et des rapports Qobs/Qcal
|
|
|
|
|||||
|
||||||||
janv-89 juin-89 nov-89 avr-90 sept-90 fevr-91 juil-91 dec-91 mai-92 oct-92
mars-ao0t-janv-94 juin-94 nov-94 avr-95 sept-95 fevr-96 juil-96 dec-96 mai-97 oct-97
Temps (Mois)
Figure 91 : Superposition des hydrogrammes mesurés et calculés en validation avec le modèle PMCD2p et des rapports Qobs/Qcal
|
|
|
|
|||||
|
||||||||
janv-89 juin-89 nov-89 avr-90 sept-90 fevr-91 juil-91 dec-91 mai-92 oct-92
mars-
ao0t-janv-94 juin-94 nov-94 avr-95 sept-95 fevr-96 juil-96 dec-96 mai-97 oct-97
Temps (Mois)
Figure 92 : Superposition des hydrogrammes mesurés et calculés en validation avec le modèle PMCD3p et des rapports Qobs/Qcal
|
|
|
|
|||||
|
||||||||
janv-89 juin-89 nov-89 avr-90 sept-90 fevr-91 juil-91 dec-91 mai-92 oct-92
mars-ao0t-janv-94 juin-94 nov-94 avr-95 sept-95 fevr-96 juil-96 dec-96 mai-97 oct-97
Temps (Mois)
Figure 93 : Superposition des hydrogrammes mesurés et calculés en validation avec le modèle PMCD4p et des rapports Qobs/Qcal
|
|
|
|
|||||
|
||||||||
janv-89 juin-89 nov-89 avr-90 sept-90 fevr-91 juil-91 dec-91 mai-92 oct-92
mars-
ao0t-janv-94 juin-94 nov-94 avr-95 sept-95 fevr-96 juil-96 dec-96 mai-97 oct-97
Temps (Mois)
Figure 94 : Superposition des hydrogrammes mesurés et calculés en validation avec le modèle PMCD5p et des rapports Qobs/Qcal
|
|
|
|
|||||
|
||||||||
janv-89 juin-89 nov-89 avr-90 sept-90 fevr-91 juil-91 dec-91 mai-92 oct-92
mars-
ao0t-janv-94 juin-94 nov-94 avr-95 sept-95 fevr-96 juil-96 dec-96 mai-97 oct-97
Temps (Mois)
Figure 95 : Superposition des hydrogrammes mesurés et calculés en validation avec le modèle PMCD6p et des rapports Qobs/Qcal
Modèles PMCD1P PMCD2P PMCD3P PMCD4P PMCD1P _ 0,21(+) 0,069 (=) 0,088 (=)
PMCD2P 0,134 (-) 0,106 (=)
|
|
|
|||
|
|
|
|||
L'analyse des figures présentées ci-dessus montre que les débits de pointes extrêmes sont dans leur majeure partie sous estimés ( = 1
Qobs ) et que les débits d'étiages extrêmes sont
Qcal
quant à eux surestimés ( = 1
Qobs ) par les modèles Perceptrons Multicouches Dirigés.
Qcal
Le test de Pitman est déjà décrit dans la deuxième partie de ce mémoire. Ici, il est appliqué pendant les phases de calage et de validation des modèles Perceptrons Multicouches Dirigés, de prévision, à la station de Tortiya. Le tableau XVIII montre les valeurs calculées du coefficient de corrélation r de Pitman. Il faut rappeler qu'en calage, pour nf = 216, la différence de l'erreur quadratique moyenne de prévision de deux modèles est significative au seuil de 95%, si rp = 0,1 3 3 . Si rp = -0,1 3 3 , le premier modèle (ligne) est meilleur et si rp = 0,1 3 3 , le second modèle (colonne) est meilleur.
Les résultats du Test de Pitman pour la période de calage (1971-1988) sont résumés dans le tableau XVIII avec 15 comparaisons entre 6 modèles développés. Les modèles sont comparés deux à deux avec le premier sur une ligne et le second sur une colonne. Ces résultats s'accordent pour dire que la différence entre les prévisions des modèles comparés deux à deux n'est pas significatif au seuil de 95%.Toutefois il est important de remarquer que :
· le modèle PMCD2P est meilleur que le modèle PMCD1P ;
· le modèle PMCD2P est meilleur que le modèle PMCD3P ;
· le modèle PMCD2P est meilleur que le modèle PMCD5P ;
· le modèle PMCD2P est meilleur que le modèle PMCD6P ;
· le modèle PMCD4P est meilleur que le modèle PMCD6P ;
· le modèle PMCD5P est meilleur que le modèle PMCD6P.
Tableau XVIII : Résultats de la comparaison par paires de modèles entre les cinq modèles de réseaux de neurones, utilisant le Test de Pitman, en phase de calage
Modèles
Modèles
|
|
|
|
|
|
|
|
|
|
||
|
|
|
|||
|
|
||||
|
|||||
(=) : la différence entre les prévisions des deux (2) modèles comparés n'est pas significative ; (-) : le modèle de la ligne est plus performant que celui de la colonne ;
(+) : le modèle de la colonne est plus performant que celui de la ligne ;
De ce qui précède, on peut affirmer que le modèle PMCD2p est le meilleur de tous avec les plus fortes valeurs de Nash (74%) et des coefficients de corrélation de Pearson très élevés (R=0,91). On remarque qu'en calage tous les modèles donnent de bons résultats avec le modèle PMCD2p en tête. En est-il de même pour la phase de validations ? C'est à cette question que le paragraphe suivant tentera d'apporter une réponse. Pour cela, les différentes valeurs calculées du coefficient de corrélation rp de Pitman sont consignées dans le tableau
XIX. En effet, pour nf = 108, la différence de l'erreur quadratique moyenne de prévision de
deux modèles est significative au seuil de 95%, si rp = 0,1 89 . La lecture du tableau XXI,montre comme précédemment que le modèle PMCD2P est le meilleur de tous les modèles développés malgré le fait que tous les modèles semblent donner approximativement les mêmes débits prédits. Ces résultats sont pareils à ceux présentés à la section 9.2 de ce chapitre, qui traite de l'ordre de grandeur des différents critères de performance.
Tableau XIX : Résultats de la comparaison par paires de modèles entre les cinq modèles de réseaux de neurones, utilisant le test de Pitman, en phase de validation
Modèles
Modèles PMCD1P PMCD2P PMCD3P PMCD4P PMCD5P PMCD6P
PMCD1P _ 0,0141 (=) 0,291(-) 0,3(-) 0,1018(=) 0,357(-)
PMCD2P 0,354(-) 0,337(-) 0,373(-) 0,416(-)
PMCD3P 0,03(=) 0,051(=) 0,0735(=)
PMCD4P 0,0387(=) 0,047(=)
PMCD5P _ 0,02(=)
PMCD6P
_
(=) : la différence entre les prévisions des deux (2) modèles comparés n'est pas significative ; (-) : le modèle de la ligne est plus performant que celui de la colonne ;
(+) : le modèle de la colonne est plus performant que celui de la ligne ;
Le tableau XX récapitule les performances des Perceptrons Multicouches Dirigés (PMCDs) d'une part et des Perceptrons Multicouches Dirigés (PMCDp) d'autre part pour la station de Tortiya choisie comme la station de référence où tous les modèles développés et optimisés présentent de très bonnes performances.
Tableau XX : Résumé de la performance des modèles de simulation et des modèles de prévision à la station de Tortiya
Phase de validation (1989-1997)
|
|
||
|
|||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|||
|
|||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|||
Prévision
Nash (Q) (%)
77
79
7978
7879
Nash ( Q ) (%)
81
83
8382
8283
Les modèles de simulation sont plus sensibles à l'ajout de variables explicatives en entrée que
les modèles de prévision. On peut aussi remarquer qu'à part le modèle PMCD1s qui est moins
performant que le modèle PMCD1p, les autres modèles de simulation sont plus ou moins
aussi performants que les modèles de prévision. Il apparaît généralement qu'au niveau de chaque type de modèle (modèle de simulation et modèle de prévision), les modèles donnent sensiblement les mêmes valeurs du critère de Nash ; sauf avec le modèle PMCD1 où on constate un écart un peu plus important avec les autres valeurs. Il faut aussi remarquer que tous les modèles expriment au moins 65% des variances des débits à la station de Tortiya comme précédemment annoncé. D'après le tableau XX, les racines carrées des débits améliorent considérablement les performances des modèles de simulation et de prévision. Les valeurs des Nash sont augmentées d'environ trois unités pour tous les modèles.
Au terme de ce chapitre, On constate que les Perceptrons Multicouches Dirigés (PMCDp) sont utilisables tant en simulation qu'en prévision. Les résultats obtenus avec les modèles de prévision sont satisfaisants dans l'ensemble. En effet, en se referant à l'échelle de Kachroo (1986) on se rend compte que les modèles développés sont de bon modèles car les critères de Nash sont supérieurs à 70% en calage et en validation. Le maximum des Nash est de 74 en calage et de 79 en validation ; et le minimum est de 71,6% en calage et de 77% en validation. Au niveau des coefficients de corrélation de Pearson, la valeur maximale en calage est de 0,91 et de 0,90 en validation ; et la valeur minimum est de 0,86 en calage et de 0,89 en validation. Malgré les bonnes performances des modèles Perceptrons Multicouches en prévision, ce chapitre a montré que les débits extrêmes étaient mal modélisés. En effet, les débits de pointes extrêmes (les débits de crue) sont dans leur majeure partie sous estimés ( = 1
Qobs ) et que les
Qcaldébits d'étiages extrêmes sont quant à eux surestimés ( = 1
Qobs ). Il est aussi apparu dans
Qcal
cette étude que pour la prévision, les modèles neuronaux développés sont des modèles très simples. En effet, un Perceptron Multicouches avec une seule couche cachée et quelques neurones suffisent pour faire la prévision des débits du Bandama Blanc sur un mois avec de très bonnes performances. Le nombre de neurones sur les couches cachées des réseaux développés sont de :
· 3 neurones pour les modèles PMCD1p et PMCD4p ;
· 2 neurones pour les modèles PMCD2p et PMCD6p ;
· 5 neurones pour le modèle PMCD3p;
· 4 neurones pour le modèle PMCD5p.
Aussi, faudrait-il noter que cette étude a permis aussi d'apprécier l'apport des variables telles que la température, l'évapotranspiration et le mois ainsi que leurs combinaisons dans la prévision des débits mensuels du Bandama Blanc. Il ressort que la pluie et l'évapotranspiration potentielle sont suffisantes comme entrée des Perceptrons Multicouches Dirigés pour faire la prévision des débits mensuels du Bandama Blanc.
Les réseaux de neurones développés dans le premier chapitre de ce mémoire, avec une seule variable explicative en entrée, ont donné de bons résultats. Ces résultats sont expliqués et confrontés à d'autres résultats obtenus par différents travaux dans le même domaine. Les performances des modèles montrent que la transformation puissance des débits (racine (Q)) observés et calculés améliore les critères de performances utilisés. En effet, la transformation puissance donne le même poids à tous les débits. Elle permet donc au modèle de ne pas donner trop de poids aux erreurs associées aux événements de crue pendant le calage. On a remarqué aussi que les Perceptrons Multicouches Dirigés (PMCD) étaient plus performants que les Perceptrons Multicouches Non Dirigés(PMCND). En effet, le bouclage avec les débits mesurés en entrée permet au Réseau de neurones Formel de situer son état et de s'auto corriger comme précédemment signalé. C'est ce qui explique les bons résultats obtenus avec les modèles dirigés (PMCDs). Les résultats obtenus dans cette étude sont aussi semblables à ceux obtenus par Eurisouké (2006) pendant la modélisation des crues éclairs du bassin versant du Gardon de Saint-Jean à Saumane par les Réseaux de neurones Formels, si l'on considère les valeurs du critère de Nash. Ces valeurs montrent que le modèle Non Dirigé (PMCNDs) est moins performant que le modèle Dirigé (PMCDs) avec respectivement des Nash compris entre 0,58 et 0,86. Mais lorsqu'on analyse les débits de crue et les débits d'étiage, on se rend compte que les résultats obtenus dans ces présents travaux sont différents de ceux obtenus par Eurisouké (2006). En effet, les travaux présentés ici montrent que les débits extrêmes sont sous estimés et que les débits d'étiage sont surestimés. Eurisouké (2006) dans ces travaux a démontré que les débits de crues étaient très bien estimés par les Réseaux de neurones Formels sur le Gardon de Saint-Jean à Saumane. La différence entre les deux résultats pourrait s'expliquer par le fait que les données d'entrée utilisées par Eurisouké (2006) sont plus nombreuses (Imagerie radar à la place des données pluviographiques) que celles utilisées dans ce présent mémoire. Les Perceptrons Multicouches peuvent donc être plus performants lorsque les données qui participent à leur optimisation sont plus nombreuses.
De façon générale, les débits de crue sont sous estimés et les débits d'étiage sont surestimés. En effet, les Réseaux de neurones Formels sont des modèles à apprentissage, c'est-à-dire qu'ils se familiarisent aux données pendant le calage afin d'extraire une certaine singularité dans ces données. Au niveau des séries de débits utilisées dans cette étude, les débits extrêmes (crue et étiages) sont en nombre restreint par rapport aux autres débits. Les crues par exemple s'observent une seule fois par année (généralement en août-septembre). Il apparaît donc que les modèles disposent de peu de débits de cette catégorie en apprentissage pour pouvoir
extraire la singularité signalée déjà dans la première partie de ce mémoire. La mauvaise simulation des débits extrêmes par les réseaux de neurones dans cette étude pourrait être aussi due à la séparation des bases de calage et de validation (2/3 pour le calage et 1/3 pour la validation). Une sépartion aléatoire pourrait peut être amélioré les performances de ces modèles.
Malgré la bonne représentativité des hydrogrammes mesurés par les Perceptrons Multicouches Dirigés, il apparaît un décalage entre les hydrogrammes mesurés et les hydrogrammes calculés tant en calage qu'en validation. Ces décalages sont le fait de l'incapacité des modèles développés à reproduire certains débits aux différentes stations d'étude. En effet, les débits à l'exutoire d'une rivière comme le Bandama Blanc ne sont pas seulement le fait des seules pluies tombées sur le bassin versant. Ces débits sont aussi influencés par d'autres variables explicatives comme la température et l'évapotranspiration potentielle par exemple. L'intégration de ces variables comme entrée de ces modèles sera l'objet du chapitre VII et permettra d'apprécier leur apport dans la simulation des débits aux stations de Bada, Marabadiassa, Tortiya et Bou. Les mauvaises performances des modèles développés pourraient être imputées à l'algorithme d'apprentissage (Koffi et al., 2006). En effet, les algorithmes du 1er ordre comme la rétro propagation par erreur du gradient (GD) sont très souvent piégés dans des minima locaux comme l'illustre la figure 96. Ils n'arrivent donc pas à atteindre les vrais minima de la fonction de coût.
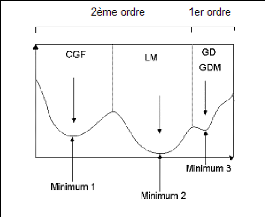
Figure 96 : Evolution des minima locaux en fonction des algorithmes
En n'atteignant pas le minimum global escompté, les algorithmes de 1er ordre donneraient des
débits simulés qui s'éloigneraient des
débits observés. Mais, ici les causes des
mauvaises
performances des Réseaux de neurones Formels sont ailleurs
; car, les minima locaux ont pu
être évités grâce à la réinitialisation et à l'augmentation plusieurs fois des différents poids suivis du recommencement perpétuel des processus d'apprentissage. Ce qui évite normalement l'algorithme d'être piégé dans ces minima locaux. Les mauvaises performances sont probablement liées au nombre et à la qualité des donnés hydroclimatiques disponibles dans cette étude. Les critères de Nash calculés entre les débits mesurés et les débits calculés varient en calage et en validation de 0,63 à 0,91. A ces valeurs de Nash correspond aussi une variation des coefficients de corrélation de Pearson de 0,63 à 0,91. A ce pas de temps mensuel, les résultats semblent satisfaisants. A ce même pas de temps, Achite et Mania (2000) dans l'application des modèles neuronaux à la détermination des débits de l'Oued Haddad avec seulement les pluies en entrée, ont obtenu des coefficients de corrélation compris entre 0,61 à 0,90, soit dans la même gamme que ceux de cette étude.
Les résultats des simulations avec le modèle GR2M sont généralement satisfaisants. En calage, les Nash obtenus aux stations de Bada, Tortiya et Bou sont supérieurs à 60 %. A la station de Marabadiassa, elle n'est que de 51 % (juste la moyenne). En validation, tous les Nash sont supérieurs à 60 % sauf celui déterminé à la station de Bou qui est de 21 %. Les coefficients de corrélation (R) déterminés sont positifs et proche de 1 à toutes les stations. En validation par exemple, ce coefficient est de 0,81 ; 0,85 ; 0,85 et 0,63 respectivement à Bada, Marabadiassa, Tortiya et à Bou. Cela signifie que les relations entre les débits mesurés et les débits calculés par le modèle GR2M sont de type linéaire à toutes les stations hydrométriques d'étude. Les coefficients de détermination (r2) sont tous supérieurs à 60% sauf à la station de Bou où il est égal à 42%. L'interprétation à donner est que, les relations entre les débits mesurés et les débits simulés par le modèle GR2M étant de type linéaire, les modèles mathématiques Qs = a. Qm + b peuvent expliquer à eux seuls en validation : 68%, 74%, 75%
et 42% des variabilités observées et les 32%, 26%, 25% et 58% restants représentent les erreurs de mesures et toutes les imprécisions engendrées lors de l'optimisation du modèle respectivement pour les stations de Bada, Marabadiassa, Tortiya et Bou. Les mauvais résultats enregistrés à la station de Bou sont probablement liés à la qualité des données hydroclimatiques de cette station. En effet, dans la deuxième partie de ce mémoire, un contrôle des données hydrométriques avait permis de détecter des légers changements de pente lorsqu'on compare les débits de la station de Bou à ceux des stations de Bada et de Tortiya. Ces changements de pentes traduisent souvent des irrégularités dans les différentes séries de données comme c'est peut être le cas des données de la station de Bou. On remarque que le modèle global conceptuel GR2M est plus performant en calage qu'en validation sauf à
la station de Marabadiassa où l'on ne fait pas cette observation. Les travaux de Tarik (2006) ont permis d'aboutir à ce même type de résultats sur les bassins versants de Cheffia, Lakhdaria, La Traille, Sebbaou et Tafoura en Algérie. Le modèle GR2M est instable à Bou et à Marabadiassa. On observe une dégradation de la performance de ce modèle à la station de Bou et une amélioration de la performance du modèle à la station de Marabadiassa. La station de Tortiya est la station où le modèle GR2M est le plus performant avec des Nash en validation et en calage supérieurs à 70%. Tout comme le modèle GR2M, les modèles Perceptrons Multicouches Dirigés (PMCD) développés au chapitre VII de ce mémoire présentent de bonnes performances. En effet, l'ajout d'autres variables explicatives en entrée du réseau et leur combinaison augmente généralement le nombre de neurones cachés. En effet, en ajoutant ces variables, on augmente la quantité de données à traiter par le réseau. Or ce sont les neurones de la couche cachée qui font le traitement. Il s'en suit que pour plus de données à traiter, il faut au réseau plus de neurones dans la couche cachée. Dans le cas contraire il fallait ajouter d'autres couches cachées. Or on sait que le perceptron multicouche à une seule couche cachée est capable de résoudre les problèmes de modélisation hydrologique (Hornik, 1991). L'ajout des variables explicatives (Température, évapotranspiration potentielle et mois) et de leur combinaison a amélioré les performances des modèles Perceptrons Multicouches Dirigés aux stations de Bada, Marabadiassa et de Tortiya et a dégradé celles de la station de Bou. En effet, les variables ajoutées expriment certaines pertes d'eau au niveau du bassin versant d'étude. Ce sont des informations complémentaires qu'on apporte aux réseaux de neurones pour leurs permettre de simuler correctement les débits aux différentes stations d'étude. Normalement, leurs ajouts en entrée devraient améliorer les performances des modèles à toutes les stations. Mais, à la station de Bou, compte tenu des irrégularités constatées au niveau des données hydrométriques, leur ajout a au contraire, provoqué la dégradation des performances des modèles développés. Parmi ces station, c'est la station de Tortiya qui offre les meilleures performances des modèles jusqu'à 80% pour le critère de Nash quelque soient les variables considérées en entrée. En effet, les coefficients d'inter corrélation entres les autres variables et le débit à la station de Tortiya sont plus élevés que ceux calculés sur les autres stations. Les résultats obtenus avec les modèles Perceptrons Multicouches Dirigés étaient forts satisfaisants et sont différents de ceux obtenus par Tarik (2006). Les résultats obtenus par cet auteur avec le réseau de neurones à une seule couche cachée comportant quatre neurones sont résumés dans le tableau XXI. Cet auteur a attribué ces résultats non satisfaisants au type d'apprentissage en block (batch training) et il a conclu que l'utilisation des réseaux de neurones en block, soit au pas de temps mensuel ou journalier,
n'est pas adaptée à la modélisation pluie-débit qui est un processus se calculant en temps réel. Il faut ajouter à cette justification le nombre réduit de données utilisé en calage et en validation par Tarik (2006) et la qualité des données hydroclimatiques utilisées. Les résultats obtenus dans ce travail de recherche semblent bien meilleurs que ceux de Tarik (2006) grâce notamment au calage qui a été réalisé sur 18 ans et la validation sur 7 ans. On a donc pu présenter aux réseaux une large variété de données afin de faciliter le processus d'apprentissage qui est aussi un apprentissage en block ; ce qui n'est pas le cas avec les 7 et 8 ans utilisés par Tarik (2006). Bien que les deux zones d'étude soient différentes au niveau de leurs géologies et de leurs hydrographies, cette comparaison a néanmoins son sens dans la mesure où les deux études s'intéressent à la modélisation pluie-débit au pas de temps mensuel à l'aide des Réseaux de neurones avec l'apprentissage en block.
Tableau XXI : Résumé des performances obtenues avec Tarik (2006).
|
Station |
Cheffia |
Lakhdaria |
La Traille |
Sebbaou |
Tafia |
|
Période de |
(1978-1984) |
(1980-1987) |
(1970-1977) |
(1980-1987) |
(1980-1987) |
|
Nombre |
7 ans |
8 ans |
8 ans |
8 ans |
8 ans |
|
Nash (%) |
63,9 |
45,6 |
61,4 |
41,8 |
-1,0 |
|
Validation |
Cheffia |
Lakhdaria |
La Traille |
Sebbaou |
Tafia |
|
Période de |
(1985-1991) |
(1988-1995) |
(1979-1985) |
(1988-1995) |
(1988-1995) |
|
Nombre |
7 ans |
8 ans |
7 ans |
8 ans |
8 ans |
|
Nash (%) |
41,9 |
45,5 |
41,5 |
41,9 |
5,0 |
En plus d'être plus performants, les Réseaux de neurones Formels (RNF) seraient économiquement plus rentables que le modèle conceptuel global GR2M. En effet, avec seulement la pluie en entrée, le modèle PMCD1S apparaît plus performant que le modèle GR2M qui intègre à la fois la pluie et l'évapotranspiration en entrée. En ajoutant l'évapotranspiration à la pluie pour obtenir le modèle PMCD3S, la performance du modèle s'améliore davantage. Ce qui veut dire que pour un résultat plus satisfaisant, le modélisateur
dépense moins avec le modèle PMCD1S qu'avec le modèle conceptuel global GR2M. Il serait alors moins coûteux pour l'ingénieur d'utiliser le modèle PMCD1S que le modèle GR2M. En effet, si on considère que le coût des températures et des pluies mensuelles avec la SODEXAM est de 600 F CFA l'unité et que les débits mensuels sont fournis gratuitement par la Direction de l'eau (comme c'est le cas dans cette présente étude), pour une simulation de débit mensuel sur une période de 10 ans et sur 10 bassins versant, le modélisateur fera un bénéfice de 720 000 F CFA. Le détail du calcul est présenté comme suit :
Les résultats obtenus au niveau du dernier chapitre de ce mémoire montrent que tous les modèles de prévision expriment plus de 70% de la variation des débits du Bandama Blanc à Tortiya. Pour tous les modèles, les Nash calculés sont nettement supérieurs à 70% et les coefficients de corrélation de Pearson sont très forts, supérieurs à 0,80, et cela quelque soit la phase de développement considérée (calage et validation). Ces très forts coefficients de corrélation de Pearson montrent que les débits mesurés et les débits prédits par les modèles de prévisions (PMCD1p, PMCD2p, PMCD3p, PMCD4p, PMCD5p, PMCD6p) sont liés par des relations de type linéaire. Cette étude a également montré que les coefficients de détermination 2
R sont tous supérieurs à 75% en calage et supérieurs à 80% en validation. L'interprétation donnée est que, les relations entre les débits mesurés et les débits calculés par les modèles de prévision étant de type linéaire, les modèles mathématiques Q p = a. Qm + b
( Qp , débit prédit et Qm , débit mesuré) peuvent expliquer à eux seuls :
iii) en calage, 79%, 85%, 85%, 79%, 79% et 76% des variabilités observées et les 21%, 15%, 15%, 21%, 21% et 24% restants représentent les erreurs de mesures et toutes les imprécisions engendrées lors de l'optimisation respectivement des modèles de prévision PMCD1p, PMCD2p, PMCD3p, PMCD4p, PMCD5p et PMCD6p ;
iv) en validation, 82%, 83%, 85%, 82%, 82% et 84% des variabilités observées et les 18%, 17%, 15%, 18%, 18% et 16% restants représentent les erreurs de mesures et toutes les imprécisions engendrées lors de l'optimisation respectivement des modèles de prévision PMCD1p, PMCD2p, PMCD3p, PMCD4p, PMCD5p et PMCD6p.
Malgré ces bonnes performance tant en calage qu'en validation, il faut cependant noter que les performances obtenues en validation sont nettement supérieures à celles obtenues en calage quel que soit le modèle de prévision et le critère de performance considéré. Cette situation pourrait simplement s'expliquer par le fait que, la base d'apprentissage (18 ans)
contient plus de débits extrêmes (débits de crue et débit d'étiage) que la base de validation (9 ans). En effet, les études effectuées dans ce chapitre ont montré que les débits extrêmes étaient relativement mal calculés par les Perceptrons Multicouches de prévision. Les débits de pointes extrêmes sont tous sous estimés.
En effet, les modèles de prévision sous estiment à au moins 2/3 les débits de pointes mesurés au mois de septembre qui correspond au mois des débits de crues et les débits d'étiages extrêmes sont quant à eux surestimés par les modèles.
Pendant le calibrage de ces modèles de prévision, on aura donc plus de débits mal calculés qu'en phase de validation. Le calcul des critères de performance tel que le critère de Nash sera donc fortement influencé par ces mauvais débits qui auront tendance à agir sur la qualité de ce critère. Pour améliorer les performances des modèles, les critères de Nash sont recalculés avec cette fois ci la racine carrée des débits et les résultats sont édifiants. En effet, les valeurs de Nash ont été augmentées d'environ trois unités. Cela a été possible ; car, en calculant le critère de Nash sur les racines carrées des débits, on accorde la même importance aux erreurs sur les forts débits. Les critères de performance (Nash et coefficient de Pearson) en calage et en validation sont du même ordre de grandeur quel que soit le critère considéré. On peut donc dire que les différents modèles de prévision (PMCD1p, PMCD2p, PMCD3p, PMCD4p, PMCD5p, PMCD6p) sont très robustes donc stables. Il est donc possible que ces modèles développés puissent s'appliquer à d'autres données qui n'ont pas participé au calage avec de très bonnes performances. Des six modèles développés, les modèles de prévision PMCD2p et PMCD3p donnent approximativement les mêmes performances (critères de Nash, coefficient de détermination et coefficient de corrélation de Pearson). Au vu des valeurs de ces critères de performance, on se rend aussi compte que ces modèles sont les meilleurs des modèles de prévision développés. Les types de variables en entrée pourraient expliquer ces résultats. En fait, le mois qui est la deuxième variable explicative du modèle PMCD2p exprime également, sous une autre forme, l'ETP qui est la deuxième variable explicative du modèle PMCD3p. En effet, le codage du mois s'est effectué par rapport aux valeurs moyennes mensuelles interannuelles des températures qui ont aussi servi à calculer les évapotranspirations potentielles. Les modèles PMCD2p et PMCD3p peuvent donc être qualifiés de "modèles jumelles". Les meilleurs résultats obtenus par ces modèles de prévisions sont le fait que les combinaisons "pluie-ETP" et "pluie-mois" exprimeraient mieux la dynamique du cycle de l'eau sur le bassin versant d'étude que les autres combinaisons à savoir : pluie-température ; pluie-température-mois et ; pluie-ETP-mois. Les modèles de prévision reproduisent bien la dynamique des écoulements du Bandama Blanc à la station hydrométrique de Tortiya. Et,
l'ajout des variables explicatives comme la température, l'évapotranspiration et le mois ainsi que leurs différentes combinaisons améliore la capacité des modèles Perceptrons Multicouches à la prévision des débits du Bandama Blanc à Tortiya. Cependant, quelques décalages existent entre les hydrogrammes mesurés et calculés à la station hydrométrique de Tortiya par les modèles de prévision. Ces décalages pourraient être le fait du nombre réduit de données utilisées pendant l'apprentissage (18 mois) de ces modèles de prévision. En effet, des études similaires ont montrées que, plus on dispose de données pour l'apprentissage et plus les modèles arrivaient à reproduire fidèlement les débits. Parmi ces études, on peut citer celle de Wenrui et al., (2004) sur la prévision des débits de la rivière Apalachicola (Floride, USA) avec les Réseaux de neurones Artificiels. En effet, ces auteurs ont fait la prévision des débits au pas de temps journalier, mensuel, trimestriel et annuel avec des coefficients de corrélation de Pearson respectives de 0,98 ; 0,95 ; 0,91 et 0,83. On remarque que plus le pas de temps est petit, ce qui est équivalent à un nombre élevé de données, les modèles de prévision développés donnent de très bonnes valeurs du coefficient de corrélation. Ces bonnes valeurs du coefficient de corrélation de Pearson pourraient être en phase avec les hydrogrammes prédits qui se rapprocheraient davantage des hydrogrammes mesurés.
Au cours de ce travail de recherche, il a été mis au point deux types de modèles neuronaux de simulation et de prévision : les modèles Perceptrons Multicouches Non Dirigés(PMCNDs) (développés uniquement en simulation) et les Perceptrons Multicouches Dirigés (PMCDs) (développés en simulation et en prévision). Les variables hydro-climatiques mensuelles utilisées sont les pluies, les températures, les évapotranspirations potentielles (calculées avec la méthode de Thornwaithe) et les débits du Bandama Blanc mesurés aux stations de Bada, Marabadiassa, Tortiya et Bou. Les résultats obtenus avec ces modèles neuronaux sont généralement forts satisfaisants par rapport à ceux obtenus avec le modèle conceptuel global GR2M.
Simulation des débits avec les réseaux de neurones formels avec la pluie comme variable explicative
Les Perceptrons Multicouches avec une seule couche cachée ont été les plus aptes à simuler les débits. Cette étude a montré qu'avec la pluie seule comme entrée des réseaux de neurones formels, le nombre de mois de retard à considérer était dans l'ensemble élevé. Les modèles non dirigés (PMCNDs) contenaient plus de neurones sur leur couche cachée que les modèles dirigés (PMCDs). Au niveau de la performance des modèles développés, les Perceptrons Multicouches Dirigés (PMCDs) étaient plus performants que les Perceptrons Multicouches Non Dirigés(PMCNDs). En effet, en validation pour les modèles PMCDs, les valeurs de Nash aux stations de Bada, Marabadiassa, Tortiya et de Bou étaient respectivement de 67%, 67%, 81% et de 71%. On a donc remarqué que ces modèles reproduisaient plus de 60% des variances des débits.
La comparaison faite au cours de cette étude entre les Nash calculés sans transformation des débits et avec transformation puissance des débits a révélé que la transformation puissance des débits améliorait les valeurs des critères de performance des modèles de façon générale en validation.
Pour le modèle PMCND1s, les gains en performance
étaient de 4 unités aux stations de
Marabadiassa (44% à
48%) et Tortiya (76% à 80%). Aux stations de Bada (39% à 41%) et
de
Bou (52% à 76%) on avait respectivement des gains de 3 et 14
unités. En ce qui concerne le
modèle PMCD1s, les gains en performance étaient les suivants : 1 unité à la station de Bada (67% à 68%) ; 6 unités à la station de Marabadiassa (67% à 73%) ; 4 unités à la station de Tortiya (81% à 85%) et ; 3 unités à a station de Bou (71% à 74%).
Malgré la supériorité du modèle Dirigé (PMCDs) sur le modèle Non Dirigé (PMCNDs) déterminée avec le Test de Pitman, on a constaté que les deux modèles arrivent à approcher plus ou moins les débits du Bandama Blanc mesurés aux stations de Bada, Marabadiassa, Tortiya et de Bou.
En définitive, cette étude a montré que l'utilisation de la pluie comme variable explicative dans une modélisation avec les Réseaux de neurones Formels est possible à condition d'arriver à choisir judicieusement l'architecture convenable (nombre de retard et nombre de neurones optimal). Toutefois, avec la pluie comme variable explicative, les Réseaux de neurones Formels développés n'arrivaient pas à simuler correctement les débits extrêmes (étiages et crues) en calage et en validation. En effet, les modèles de simulation développés surestiment généralement les faibles débits et sous estiment les forts débits.
Ajouts et influences des variables climatiques sur la performance des modèles de simulation Le modèle conceptuel global GR2M et les modèles Perceptrons Multicouches Bouclés (PMCD1s, PMCD2s PMCD4s, PMCD5s et PMCD6s) ont obtenu en général de très bonnes performances tant en calage qu'en validation pendant de cette étude.
En validation, à la station de Tortiya, les valeurs de Nash obtenues avec les modèles GR2M, PMCD1s et PMCD3s étaient respectivement de 71%, 81% et 81%. En comparant le modèle conceptuel GR2M et les modèles neuronaux, il est apparu dans cette étude que les derniers cités sont les plus performants et les plus parcimonieux pour la simulation des débits des cours d'eau. On peut aussi retenir que la performance des modèles neuronaux était fortement liée aux stations d'étude, donc directement liée à la qualité des données collectées. Toutefois, il est bon de signaler que les Réseaux de neurones étaient plus aptes à modéliser les données hydroclimatiques bruitées que le modèle conceptuel global, GR2M.
Prévision des débits du Bandama Blanc avec les Réseaux de neurones Formels
Au terme de la prévision des débits du Bandama Blanc à la station de Tortiya, on a constaté que les Perceptrons Multicouches Dirigés (PMCDp) étaient utilisables tant en simulation qu'en prévision.
Les résultats obtenus avec les modèles de
prévision étaient satisfaisants dans l'ensemble. En
effet, en
se referant à l'échelle de Kachroo (1986) on s'est rendu compte
que les modèles
développés sont de bons modèles car les critères de Nash étaient supérieurs à 70% en calage et en validation. Le maximum des Nash était de 74 en calage et de 79 en validation ; le minimum était de 71,6% en calage et de 77% en validation. Au niveau des coefficients de corrélation de Pearson, la valeur maximale en calage était de 0,91 et de 0,90 en validation ; la valeur minimum était de 0,86 en calage et de 0,89 en validation.
Malgré les bonnes performances des modèles Perceptrons Multicouches en prévision, on a pu constater que les débits extrêmes étaient mal modélisés.
En effet, les débits de pointes extrêmes (les débits de crue) étaient dans leur majeur partie sous estimés ( = 1
Qobs ) et que les débits d'étiages extrêmes sétaient quant à eux surestimés
Qcal
( = 1
Qobs ). Il est aussi apparu dans cette étude que pour la prévision, les modèles neuronaux
Qcal
développés étaient des modèles très simples. En effet, un Perceptron Multicouches avec une seule couche cachée et quelques neurones a suffi pour faire la prévision des débits du Bandama Blanc sur trois mois avec de très bonnes performances. Le nombre de neurones sur les couches cachées des réseaux développés était de :
· 3 neurones pour les modèles PMCD1p et PMCD4p ;
· 2 neurones pour les modèles PMCD2p et PMCD6p ;
· 5 neurones pour le modèle PMCD3p ;
· 4 neurones pour le modèle PMCD5p.
Aussi, faudrait-il noter que cette étude a permis aussi d'apprécier l'apport des variables telles que la température, l'évapotranspiration et le mois ainsi que leurs combinaisons dans la prévision des débits mensuels du Bandama Blanc. Il est ressorti de cette étude que la pluie et l'évapotranspiration potentielle étaient suffisantes comme entrée des Perceptrons Multicouches Dirigés pour faire la prévision des débits mensuels du Bandama Blanc. En définitive, on retiendra de cette Thèse que les réseaux de neurones formels (RNF) sont de très bons modèles de simulation et de prévision au pas de temps mensuel. En effet, que se soit en calage ou en validation, ces modèles donnent de très bonnes performances. Cependant, ils ont du mal à simuler et à prévoir les débits extrêmes (débits de crue et débits d'étiage) lorsque le modélisateur ne dispose pas d'assez de données en calage comme ce fut le cas dans ce mémoire.
Suite aux résultats présentés et discutés dans ce mémoire, les perceptives de recherche se situent essentiellement à trois niveaux :
i. améliorer les modèles neuronaux de simulation et de prévision ;
ii. concevoir un logiciel de simulation et de prévision afin d'obtenir des modèles neuronaux de simulation et de prévision type "boite grise";
iii. développer des réseaux de neurones formels utilisables sur des cours d'eau non jaugés. Pour ce qui est de l'amélioration des modèles de simulation et de prévision, on pourrait développer des modèles hybrides en combinant les réseaux de neurones avec les modèles de la logique floue. On aura alors des modèles dénommés "fuzzy logic neural networks" Ces modèles hybrides auront comme entrée les variables climatiques (pluies, évapotranspirations potentielles, etc.). En ce qui concerne la conception d'un logiciel de simulation et de prévision, il s'agira de proposer une architecture logicielle et de développer le code correspondant à l'intégration des débits observés, de la végétation, des pluies, des températures, des évapotranspirations potentielles et d'un modèle numérique de terrain (MNT) dans un réseau de neurones formel afin de simuler ou de prédire des débits sur un bassin versant donné. Les réseaux de neurones comme modèles distribués permettront de simuler et de faire la prévision des débits des rivières non jaugées. Il s'agira d'ajouter les caractéristiques physiques des bassins versants d'études aux variables explicatives des modèles à développer. La recherche en hydrologie globale à l'aide des Réseaux de neurones Formels n'est qu'au début. L'augmentation de la vitesse et de la capacité de stockage des ordinateurs permettront dans les années à venir d'intégrer dans les réseaux de neurone de très grandes quantités de données et de développer des algorithmes d'optimisation qui convergeront plus rapidement et qui donneront de très bonnes performances.
ABRAHART, R.J. et SEE, L. (2000). Comparing neural network and autoregressive moving average techniques for the prevision of continuous river flow forecasts in two contrsting catchments. Hydrological Processes, Vol. 14, pp. 2157-2172.
ACHITE, M., et MANIA, J. (2000). Modélisation de la relation pluie-débit par les Réseaux de neurones Artificiels (RNA): Cas du bassin versant de l'Oued Haddad (Nord Ouest de l'Algérie), Hydrological Processes, Vol. 11, pp. 154-166.
AMBROISE, B. (1998). Genèse des débits dans les petits bassins versants ruraux en milieu tempéré: processus et facteur, Revue des sciences de l'eau, pp. 471-495.
AMBROISE, B., GOUNOT, M., et MERCIER, J. L. (1982). Réflexion sur la modélisation mathématique du cycle hydrologique à l'échelle d'un bassin versant. Rech. Géogr. A Strasbourg, France, pp. 5-24.
AMBROISE, B., et REUTENAUER, D. (1995). Multicriterion validation of a semi-distributed conceptual model of the water cycle in the Fecht catchment (Vosges Massif, France). Water resources Research, Vol. 31, n°6, pp. 1467-1481.
AUBIN J. P. (2007). Réseaux de neurones Formels et Biologiques. Fond de cours, France, 6 p.
ASHU, J., SUDHEER, K. P. et SANAGA, S. (2004). Identification of physical processes inherent in artificial neural network rainfall-runof models. Hydrological processes, Vol 18, pp. 571-581
ASSAD, Y. et SHAMSELDIN, X. (1997). Application of a neural network technique to rainfall-runoff modelling. Journal of hydrology, Vol. 199, pp. 272-294.
AWADALLAH, A. G. (1999). Hydro-climatologie globale pour la prévision des crues du Nil au moyen de fonction de transfert avec bruit et de Réseaux de neurones Artificiels. Thèse de Doctorat, Université de Montréal, Québec, Canada, 220 p.
AYRAL, P. A. (2005). Contribution à la spatialisation du modèle de prévision des crues éclaires ALHTAIR. Approche spatiale et expérimentale, application au bassin versant du Gardon d'Anduze. Thèse de Doctorat, Université de Provence, Aix-Marseille 1, LGEI, Ecole des Mines d'Alès, Alès, France, 311 p.
BERTHIER, C. H. (2005). Quantification des incertitudes des débits calculés par un modèle empirique. Master II, Sciences de la terre spécialité hydrologie, hydrogéologie des sols, Université Paris-Sud 11, France. 50 p.
BESSOLES, B. (1977). Géologie de l'Afrique de l'Ouest. Le craton Ouest africain. Mémoires B.R.G.M., n°88, Paris, France, 402 p.
BEVEN, K. J. (1989). Distributed models. Hydrological forecasting, New York, USA, pp. 405-435.
BEVEN, K. J. (1993). Prophecy, reality and uncertainty in distributed hydrological modelling. Advances in Water resources, Vol. 16, pp. 41-51.
BEVEN, K. J. (1995). Linking parameters across scales: sub-grid parameterisations and scale dependent hydrological models. Hydrological Processes, Vol. 9, pp. 507-526.
BEVEN, K. J. et BINLEY, A. (1992). The future of distributed models: model calibration and uncertainty prediction. Hydrological Processes, Vol.6, pp. 279-298.
BIEMI, J. (1992). Contribution à l'étude géologique, hydrogéologique par télédétection des bassins versants subsahéliens du socle précambrien d'Afrique de l'Ouest: Hydrostructurale, hydrodynamique, hydrochimie et isotopie des aquifères discontinus de sillons et aire granitique de la haute Marahoué (Côte d'Ivoire). Thèse de Doctorat ès Sciences Naturelles, Université d'Abidjan, Cocody, Côte d'Ivoire, 479 p.
BISHOP, C. M. (1995). Neural networks for pattern recognition. Oxford University press, Oxford, USA, 482 p.
BOUABDALLAH, F. (1997). Mise au point d'un modèle de transformation pluie-débit au pas de temps annuel. DEA Hydrogéologie-Hydrologie filière Géochimie isotopique, Paris Sud Orsay, Cemagref Antony, France, 45 pp.
BOUVIER, C. (1994). MERCEDES : Principes du modèle et notice d'utilisation, Editions de l'Orstom, 40 p.
BUCH, A. M., MAZUMDAR, H.S., et PANDEY, PC (1993). Application of artificial neural networks in hydrological modelling: a case study of runoff simulation of a Himalayan basin. Proceedings of the International Joint Conference on Neural Networks, vol. 1, pp. 971- 974.
CAMERON, D., KNEALE, P. et SEE, L. (2002). An evaluation of a traditional and a neural network modelling approach to flood forecasting for an upland catchment. Hydrological Processes, Vol. 16, pp. 1033-1046.
CAMIL, J. (1984). Pétrographie,
chronologie des ensembles granulitiques archéens et
formations
associées de la région de Man (Côte d'Ivoire). Implication
pour l'histoire
géologique du craton Ouest africain. Thèse de Doctorat ès Sciences Naturelles, Université. d'Abidjan, Cocody, Côte d'Ivoire, n° 79, 306 p.
CAMUS, H. (1972). Hydrologie du Bandama. Rapport de l'ORSTOM, Adiopodoumé, Côte d'Ivoire, Vol. 2, 150 p.
CASTANY, G. (1982). Principes et méthodes de l'hydrogéologie, Dunod Université, Paris, France, 238 p.
CHAHINIANN, N. (2004). Développement de méthodes de paramétrisation multi-critère et multi échelle d'un modèle hydrologique spatialisé de crue en milieu agricole. Université de Montpellier II, Sciences et techniques du Languedoc, Spécialité Science de la Terre et de l'Eau, France, 258 p.
CHIEW, F., et MACMAHON, T. A. (1993). Detection of trend or change in annual flow of Australian rivers. International Journal of Climatology, Vol. 13. pp. 643-653.
CHITRA, S. P. (1993). Use neural network for problem solving. Chemical Engineering Progress, Vol. 2, pp. 44-51.
CHOW, D. (1964). Handbook of applied hydrology Chapter 15. New York. USA, pp. 114- 225.
CIBAS, T. (1996). Contrôle de la Complexité dans les Réseaux de neurones: Régularisation et Sélection de Caractéristiques, Unité de Formation et de Recherche Scientifique D'Orsay, Vol. 204, n° 15, pp. 452-478.
CIRIANI, T. A., MAIONE, U. et WALLIS, J. R. (1977). Mathematical Models for Surface Water Hydrology, Wiley, Chichester, UK, 146 p.
CLAIR, T. A. et EHRMAN, J. M. (1998). Using neural networks to assess the influence of changing seasonal climates in modifying discharge, dissolved organic carbon, and nitrogen export in eastern Canadian rivers. Water resources Research, Vol. 4, n°3, pp. 447-455. COULIBALY, P. ANCTIL, F. et BOBÉE, B. (1998). Real time neural network-based forecasting system for hydropower reservoirs. Procedings of the First International Conference on New Information Technologies for Decision Making in Civil Engineering, Ecole de Technologie Supérieure, Montréal, Canada. Vol. 2, pp. 1001-1011.
COULIBALY, P., ANCTIL, F., et Bobee, B. (1999). Prévision hydrologique par réseaux de neurones artificiels : Etat de l'art. Revue canadienne de génie civil, Vol. 26, pp. 293-304. COULIBALY, P., ANCTIL, F., RASMUSSEN, P.et BOBEE, B. (2000). A recurrent neural networks approach using indices of low-frequency climatic variability to forecast regional annual runoff. Hydrological Processes, Vol. 14, pp. 2755-2777.
CORMARY, Y. et DUILLOT, A. (1969). Ajustement et réglage des modèles déterministes. Méthode de calage des paramètres. La houille blanche, pp. 131-140.
CORMARY, Y. et GUILBOT, A. (1973). Etude des relations pluie-débit sur trois bassins versants d'investigation. Proceedings of the IAHS Madrid Symposium. IAHS Publication, Vol. 108, pp. 265-279.
CRAWFORD, N. H. et LINSLEY, R. K. (1966). Digital Simulation in Hydrology: Stanford Watershed Model IV. Technic Report. Departement of Civil Engineering, Université de Stanford, Stanford, Vol. 39, 210 p.
CRESPO, J. L., et MORA, E. (1993). Drought estimation with neural networks. Advances In Engineering Software, Vol. 18, n° 3, pp. 167-170.
DALLMEYER, R. D. et LECORCHE, J. P. (1990). Enregistrement d'un âge minéral argon 39-argon 40 polyorogénique dans la partie nord de l'orogène des Mauritanides, Afrique occidentale. Univ. Georgia, dep. geology, Athens GA 30602, Etats-Unis. CongrèsTerranes. In the Variscan blet of Europe and circum-Atlantic Paleozoic orogens : selected papers, Montpellier, France, August 1988International IGCP conference project 233 : terranes in the Variscan belt of France and Western Europe, Montpellier , France, vol. 177, no 1 et 3, pp. 81- 107.
DARPA NEURAL NETWORK STUDY (1988). Alexandria, VA: AFCEA International Press, 60 p.
DATIN, R., (1999). Développement d'outils opérationnels pour la prévision des crues rapides. Prise en compte de la variabilité spatiale de la pluie dans TOPMODEL, La Houille Blanche, n°7 et 8, pp. 13-20.
DEFFONTAINES, B., (1990). Développement d'une méthodologie morphotectoniqueAnalyse de surfaces enveloppes du réseau hydrographique et des MNT. Thèse de Doctorat, Université Paris VI, France, 225 p.
DECHEMI, N., TARIK, B. A. et ISSOLAH, A. (2003). Modélisation des débits mensuels par les modèles conceptuels et les systèmes neuro-flous. Revue des Sciences de l'Eau. Vol. 16 n°4, pp. 407-424.
DE MARSILY, G. (1981). Hydrogéologie quantitative. Edition Masson. Paris, France, 215 p.
DEVRED, D. (1989). Etude pluviométrique du bassin de la Sambre. Etude hydrologique du sous-bassin de la Solre. Thèse de Doctorat, Université des Sciences et Techniques de LilleFlandre-Artois, France, 382 p.
DIBIKE, Y. B. et SOLOMATINE, D. P. (2001). River flow forecasting using Artificial Neural Networks. Physical chemical Earth, Vol. 26, n°1, pp. 1-7.
DIMOPOULOS, L., LECK, S., et LAUGA, J. (1996). Modélisation de la rélation pluiedébit par les réseaux connexionnistes et le filtre de Kalman. Journal des Sciences Hydrologiques, Vol. 41, n°2, pp. 179-193.
DJRO, S. C. (1998). Evolution tectono-métamorphiques des gneiss granulitiques archéens du secteur de Biankouma. Thèse de Doctorat ès Sciences Naturelles, Université de Cocody, Abidjan, Cote d'Ivoire, 171 p.
DREYFUS, G., MARTINEZ, J. M., SAMUELIDES, M., GORDON, M. B, BADRAN, F., THIRIA, S., et HERAULT, L. (2004). Réseaux de neurones : Méthodologie et application. 2ème édition, Groupe Eyrolles, 374 p.
DUAN, Q., SOROOSHIAN, S., et GUPTA, V. K. (1992). Effective and efficient global optimization for conceptual rainfall-runoff models. Water resources Research, Vol. 28, pp. 1015-1031.
EDIJATNO (1987). Amélioration des modèles simples de transformation pluie-débit au pas de temps journalier sur des petits bassins versants. Mémoire de DEA, Université Louis Pasteur (Strasbourg), Cemagref (Antony), France, 67 p.
EDIJATNO (1991). Mise au point d'un modèle élémentaire pluie-debit au pas de temps journalier (Elaboration of a simple daily rainfall-runoff model). Thèse de Doctorat, Université Louis Pasteur (Strasbourg) et Cemagref (Antony), France, 625 p.
EDIJATNO et MICHEL, C. (1989). Un modèle pluie-débit à trois paramètres. La houille Blanche, Vol. 2. pp. 113-121.
EDIJATNO, NASCIMENTO, N.O., YANG, X., MAKHLOUF, Z. et MICHEL, C. (1999). GR3J: a daily watershed model with three free parameters. Hydrological Sciences Journal, Vol. 44, n°2, pp. 263-278.
EL-JABI, N. et ROUSSELLE, J. (1987). Hydrologie fondamentale. Département de génie civil. Ecole Polytechnique de montréal. 2ème édition. 234 p.
ENGLAND, C. B. (1975). Soil moisture accounting component of the USDAHL-74 model of watershed hydrology. Water Res. Bull. Vol. 11, n° 3, pp. 559-567.
ESTUPINA-BORREL, V., et DARTUS, D. (2003). La télédétection au service de la prévision opérationnelle des crues éclaires, Société Française de photogrammétrie et Télédétection, Hydrosystèmes et Télédétection à haute résolution, n°172, pp. 21-39. EURISOUKE, S. (2006). Prévision des crues par réseaux de neurones formels. Rapport de stage, Master Professional en Géotechnologie Environnementale, Ecole des Mines d'Alès, France, 50 p.
EWEN, J. et PARKIN, G. (1996). Validation of catchment models for predicting land-use and climate change impacts. Journal of hydrology, Vol. 175, no1 et 4, pp. 583-594.
FABRE, R. (1985). Caractérisation géochimique du magmatisme birimien dans le centre Côte d'Ivoire (Afrique de l'Ouest) : ses implications géodynamiques. CIFEG, publication Occasionnelle, n°12, 47 p.
FAHLMAN, S. E. (1989). Faster-learning variations on back-propagation: an ampirical study. In Proceedings of the 1988 Connectionist Models Summer School, Tourezky, D., Hinton, G., et Sjnowski, T. Morgan Kaufmann, pp. 38-51.
FAHLMAN, S.E., et LEBIERE, C. (1990). The cascade-correlation learning architecture. Technical report CMU-CS-90-100, Carnegie Mellon University, Pittsburgh, 134 p.
FORTIN, V., OURDA, T. B. M. J., RASMUSSEN, P.F., et BOBEE, B. (1997). Revue bibliographique des méthodes de prévision des débits. Revue des sciences de l'eau, Vol.10, n°4, pp. 461-487.
FRANCHINI, M. (1996). Use of a genetic algorithm combined with a local search method for the automatic calibration of conceptual rainfall-runoff models. Hydrological Sciences Journal, Vol. 41, n°1, pp. 21-39.
FRÄMLING, K. (1992). Les réseaux de neurones comme outils d'aide à la décision floue. Stage effectué au Département Stratégie du Développement (Equipe Ingénierie de l'Environnement) Ecole Nationale Supérieure des Mines de Saint-Etienne. DEA. I.N.S.A de Lyon Département Informatique (France), 55p.
FREAD, D. L. (1985). Channel routing. In: Hydrological Forecasting. M. G. Anderson et T. P. Burt. John Wiley et Sons Inc., New York. pp. 437-503.
FRIEDMAN, J. H. (1991). Multivariate adaptive regression splines. Annals of Statistics, Vol. 19, pp. 1-142.
GAUME, E. (2004). Sécheresse et étiage : Quelques réflexions . La houille blanche, Vol. 4, pp. 77-83.
GAUME, E., VILLENEUVE, J. P, et DESBORDES, X. (1998). Uncertainty assessment and analysis of the calibrated parameter values of an urban torm water quality model. Journal of Hydrology, Vol. 210, pp. 38-50.
GEMAN, S., BIENENSTOCK, E., et DOURSAT, R. (1992). Neural networks and the bias/variance dilemma. Neural Computation, Vol. 4, pp. 1-58.
GIRARD, G., CHARBONNEAU, R., et MORIN, G. (1972). Modèle hydrophysiographique. Comptes rendus Symposium international sur les techniques de modèles mathématiques appliquées aux systèmes de ressources en eau. Environnement Canada, Ottawa, Vol. 1, pp. 190-205.
GUNNAR, L. et UHLENBOOK, S. (2003). Cheching a process-based catchment model by artificial neural networks. Hydrological processes, Vol. 17, pp. 265-277.
GUILLOT, P., et DUBAND, D., (1967). La méthode du GRADEX pour le calcul de la probabilité des crues rares à partir des pluies, Publication AISH, n°84, pp. 560-569. GUILLOT, P. et DUBAND, D. (1980). Une méthode de transfert pluie-débit par régression multiple. Prévision hydrologique. Actes du colloque d'Oxford, AISH Publication, n° 129, pp. 177-195.
GUYOT, J. L. (1997). Hidro-climatologia da região. Goiás 94 et 95, J.L. Guyot, Brasília, pp. 23-30.
HAAN, C. T. (1977). Statistical methods in Hydrology. Iowa State University Press, Ames (Ia, USA), 378 p.
HAGAN, M. T., DEMUTH, H. B. et BEALE, M. H. (1996). Neural network design, PWS, Boston, MA, 259 p.
HAYKIN, S. (1994). Neural networks: a comprehensive foundation. Macmillan College Publishing Company Inc., New York, 134 p.
HAYKIN, S. (1999). Neural Networks : A Comprehensive Foundation, Prentice-Hall, Old Tappan, N. J., 350 p.
HIPEL, K. W. et MCLEOD, A. I. (1994). Developpment in water sciences. Time Series Modelling of Water Resources and Environmental Systems, Elsevier, Amsterdam, 1013 p. HOOKE, R., et JEEVES, T. A. (1961). Direct Search Solution of Numerical and Statistical Problems. ACM Journal, Vol 8, pp. 212-229.
HORNIK, K. (1991). Approximation capabilities of multilayer feedforward networks, Neural Networks, Vol. 4, pp. 251-257.
HORNIK, K., STINCHCOMBE, M., et WITHE, H. (1989). Multilayer feedforward networks are universal approximators. Neural Network, Vol. 2, pp. 359-366.
HSU, K.L., GUPTA, H.V., et SOROOSHIAN, S. (1995). Artificial neural network modelling of the rainfall-rainoff process. Water Resources Research, Vol. 31, n°10, pp. 2517- 2530.
HUANG, W. F., TSAI, S. J., LO, C. F., SOICHI, Y. et WANG, C. H. (2004). The novel organization and complete sequence of the ribosomal gene of Nosema bombycis. Fung. Genet. Biol., Vol. 41, pp.473-481.
HSU, K. L., GUPA, H. V., et SOROOSHIAN, S. (1995). Artificial neural network modeling of the rainfall-rainoff process. Water Resources Research, Vol. 31, n° 10, pp. 2517- 2530.
HUTTUMEN, M., VEHVILAINEN, B., et UKLONEN, E. (1997). Neural network in the ice-correction of discharge observations. Nordic Hydrology, Vol. 28, n°4, pp. 283-296. INSTITUT NATIONALE DE LA STATISTIQUE (INS) (2000). Recensement Général de la population et des habitats de la Côte d'Ivoire.
IVAKHNENKO, A. G. (1971). Polynomial theory of complex systems. IEEE Transactions on System, Man and Cybernetics, Vol. 12, pp. 364-378.
JAMES, A. A. et ROSENFELD, E. (1988). Neurocomputing : fondations of Research. MIT Press Cambridge, MA, USA, 729 p.
JOHANNET, A. (2006). Les réseaux de neurones formels. Cours, Travaux dirigés et travaux pratiques. Ecole des Mines d'Alès, Alès, France, 54 p.
JOURDAN, F. (2007). Modèle de prévision et de gestion des crues optimisation des opérations des aménagements hydroélectriques à accumulation pour la réduction des débits de crue. Thèse de Doctorat Es-Science, École Polytechnique Fédérale de Lausanne, Suisse, 269 p.
KABOUYA, M. (1990). Modélisation pluie-débit aux pas de temps mensuel et annuel en Algérie septentrionale. Thèse de Doctorat, Université Paris Sud Orsay, France, 347 p.
KABOUYA, M. et MICHEL, C. (1991). Monthly water resources assessment, application to a semi-arid country. Revue des sciences de l'Eau, Vol. 4, n°4, pp. 569-587.
KACHROO, R. K. (1986). HOMS workshop on river flow forecasting, Nanjing, China. Unpublished internal report, Dep. Eng. Hydrol., University College Galway, Irelan, 149 p.
KARUNANITHIK, N., GRENNEY, W. J., WITHNEY, D., et BOVEE, K. (1994). Neural networks for river flow prediction. Journal of Computing in Civil Engeneering, ASCE, Vol. 8; n°2, pp. 201-220.
KLEMES, V. (1986a). Operational testing of hydrological simulation models. Journal des sciences hydrologiques, Vol. 31, pp. 13-24.
KOFFI, Y. B., (2002). Contribution à l'analyse des méthodes d'interprétation des essais de pompage : Cas des méthodes dérivées de la solution de Théis (Méthodes grapho-analytiques et méthodes numériques) ; application aux secteurs de Biankouma-Man et de Dabou. Mémoire de Diplôme d'Etude Approfondie, Université de Cocody, Abidjan, Côte d'Ivoire, 53 p.
KOFFI, Y. B., LASM, T., AYRAL, P. A., JOHANNET, A., KOUASSI, A. M., ASSIDJO, E., et BIEMI, J. (2006). Optimisation des modèles Perceptrons Multicouches avec les algorithmes de premier et de deuxième ordre. Application à la modélisation de la relation pluie-débit du Bandama Blanc, nord de la Côte d'Ivoire. European Journal of Scientific Research. Vol. 17, n° 3, pp.13-328.
KOUAMELAN, A. N. (1996): Géochronologie et géochimie des formations Archéennes et Protérozoïques de la dorsale de Man en Côte d`Ivoire. Implications pour la transition Archéenne-protérozoique. Thèse de Doctorat ès Sciences Naturelles. Université de Rennes I. 277 p.
KUCZERA, G. et PARENT, E. (1998). Monte Carlo assessment of parameter uncertainty in conceptual catchment models: the Metropolis algorithm, Journal of Hydrology, Vol. 211, n°1 et 4, pp 69-85.
LADJADJ, R. (2003). Les réseaux de neurones, Ingénieur 2000, Cours de la Filière Informatique et Réseaux, 79 p.
LACHTERMACHER, G. et FULLER, J. D. (1994). Backpropagation in hydrological time series forecasting. In Stochastic and statistical methods in hydrology and environmental engineering. Time series analysis in hydrology and environmental engineering. K. W. Hipel, A. I. McLeod, U. S. Panu et V. P. Singh. Kluwer Academic Publishers, Dordrecht, Hollande. pp. 229-242.
LAFONT, D. (2005). Prise en Compte des Hétérogénéités dans la Restitution de l'Eau Nuageuse et des Précipitations par Radiométrie Micro-Onde Passive. Thèse de Doctorat, Université Blaise Pascal (Ecole Doctorale des Sciences Fondamentales), n° 1558, France, 192 p.
LAM, R. BEVEN, K. et MYRABO, S (1998). Use of spatially distributed water table observations to constain uncertainly in a rainfall-runoff model. Adavances in water resources, Vol. 11, n°4, pp. 305-317.
LASM, T. (2000). Hydrogéologie des réservoirs fracturés : analyse statistique et géostatistique de la fracturation et des propriétés hydrauliques. Application à la région des Montagnes de Côte d'Ivoire (domaine Archéen). Thèse de Doctorat Unique, Université de Poitiers, France, 273 p.
LE CUN, Y. DENKER, J. S. et SOLLA, S. A. (1990). Optimal brain damage. In advances in Neural information System 2, Touretzsky, D., ed., Denver, Co, Morgan Faufmann, pp. 598- 605.
LEGATES, X. et MCCABE, J. (1999). Evaluating the use of "goodness-of-fit" measures in hydrologic and hydroclimatic model validation. Water Resources Research, Vol. 35, n°1. pp. 233-241.
LEMOINE, S. (1988): Evolution de la région de Dabakala (NE de la Côte d'ivoire) au Protérozoïque inférieur. Possibilités d'extension au reste de la Côte d`Ivoire et au Burkina Faso. Similitudes et différences; les linéaments de Greenville-Ferkessedougou et grand CessNiakaramandougou. Thèse de Doctorat ès Sciences Naturelles, Université Clermont Ferrand II, France, n° 92, 334 p.
LERAY, P. (2000). Quelques Types de Réseaux de neurones. La Rétropropagation. Fond de Cours. INSA Rouen -Département ASI-Laboratoire PSI, France, 52 p.
LETTENMAIER, D. P. et WOOD, E. F. (1993). Hydrologic forecasting. Dans Handbook of hydrology. D. R. Maidment. McGraw-Hill, New York, pp. 164-184.
LÉVÊQUE, C., DEJOUX, C. et ILTIS, A. (1983). Limnologie du fleuve Bandama, Côte d'Ivoire. O.R.S.T.O.M., Hydrobiologie, 24 rue Bayard, Paris (France). Hydrobiologia, Vol. 100, pp. 113-141.
LEWIS, P. A. W. et STEVENS, J. C. (1991). Nonlinear modeling of time series using multivariate adaptive regression splines (MARS). Journal of the American Statistical Association, Vol. 87, pp. 864-877.
LOUMAGNE, C. (1988). Prise en compte d'un indice de l'état hydrique du sol dans la modélisation pluie-débit. Thèse de Doctorat, Université de Paris-Sud (Orsay), Cemagref (Antony), France, 200 p.
LI-CHIU, C., JOHN, C. et YEN-MING, C. (2004). A two-step-ahead recurrent neural network for stream-flow forecasting. Hydrological Processes, Vol. 18, pp. 81-92.
LIONG, S. Y., NGUYEN, V. T.V., CHAN, W.T., et CHIA, Y.S. (1994). Regional estimation of floods for ungaged catchments with neural networks. 9th Congress of the Asian and Pacific Division of the International Association for hydraulic Research , Singapour. Comptes rendus. Asian Pacific Division of the International Association for hydraulic Research Singapour, Vol 1, pp. 372-378.
LOUMAGNE, C., MICHEL, C., et NORMAND, M. (1991). Etat hydrique du sol et prévision des débits, Journal of Hydrology, Vol. 123, pp.1-17.
Malin, F. (1992) : Comment préserver le cycle de l'eau» dans M. Barrère, Terre, patrimoine commun : la science au service de l'environnement et du développement Paris, La Découverte/ Descartes, France, pp. 45-54.
MAMDOUH, A. A., IBRAHIM, E., et MOHAMED, N.A. (2006). Rainfall-runoff modelling using artificial neural networks technique: a Blue Nile catchment case study. Hydrological, Processes, Vol. 20, pp. 1201-1216.
MANGEAS, M. (1997). Propriétés statistiques des modèles paramétriques non-linéaires de prévision de series temporelles. Application aux réseaux de neurones à propogation directe. Report n° 97NJ00017, Electricité de France, Clamart, France, 205 p.
MAKHLOUF, Z. (1994). Compléments sur le modèle pluie-débit GR4J et essai d'estimation de ses paramètres. Thèse de Doctorat. Université de Paris XI Orsay / Cemagref (Antony), France, 228 pp.
MASIYANDINA, M. C., GIESEN, N. V., DIATTA, S., WINDEMEIJER, P. N. et STEENHUIS, T. S. (2003). The hydrology of inland valleys in the sub-humid zone of West Africa : rainfall-runof processes in the M'bé expérimental watershed. Hydrological processes, Vol. 17, pp. 1213-1225.
MAKHLOUF, Z. et MICHEL, C. (1994). A two-parameter monthly water balance model for French watersheds. Journal of Hydrology, Vol. 162, pp. 299-318.
MC CULLOCH, W. S., et PITTS, W. H. (1943). A logical calculus ideas immanent in nervous activity. Bulletin of Mathematical Biophysics, Vol. 5, pp. 115-133.
MCKAY, D. J. C. (1992). Bayesian interpolation, Neural Computation, Vol. 4, n°3, pp. 415- 447.
MERMOUD, A. (1998). Eléments de physique du sol, Ed. H. G. A., Bucarest, 132 p. MICHEL, C. (1989). Hydrologie appliquée aux petits bassins ruraux. Rapport technique CEMAGREF-Antony. Report, n°5, 189 p.
MICHEL, C. (1983). Que peut-on faire en hydrologie avec un modèle conceptuel à un seul paramètre. La Houille Blanche, Vol. 1, pp. 39-44.
MICHEL, C. et MAILHOL, J.C. (1989). Hydrologie appliquée aux bassins ruraux. CEMAGREF, Antony, France, 528 p.
MIOSSEC, M. P. (2004). Apport des multi-modèles pour la modélisation sur des basins versants non jaugés. DEA Hydrologie, hydrogéologie, géostatistique et géochimie. Université Pierre et Marie Curie, Université de Paris-sud, Ecole Nationale du Génie Rural des eaux et des Forêts. CEMAGREF, Antony, France, 43 p.
MORIN, G., FORTIN, J. P., LARDEAU, J. P., SOCHANSKA, W. et PAQUETTE, S., (1981). Modèle CEQUEAU : manuel d'utilisation. INRS-Eau, Ste-Foy, Rapport scientifique, Québec, Canada, n° 93, 449 p.
MONTEITH, J. L. (1980). The development and extension of Penman's evaporation formula. Academi Press, New York, USA, 138 p.
MOUELHI, S. (2003). Vers une chaîne cohérente de modèles pluie-débit conceptuels globaux aux pas de temps pluriannuel, annuel, mensuel et journalier. Thèse de doctorat de l'Ecole Nationale du Génie Rural, des Eaux et des Forêts, CEMAGREF, France, 263 p. MOUELHI, S., MICHEL, C., PERRIN, C., et ANDRÉASSIAN, V. (2006). Linking stream flow to rainfall at the annual time step: the Manabe bucket model revisited. Journal of hydrology, (sous presse).
MUSY, A. et HIGY, C. (2003). Hydrologie, Une science de la nature. Presses Polytechniques et Universitaires Romandes, Vol. 1, 309 p.
NASH, J. E., et STUCLIFFE, J. V. (1970). River flow forecasting through conceptual models. Part 1. A discussion of principles. Journal of Hydrology, Vol. 10, pp. 282-290.
NASCIMENTO, N. O. (1991). Adaptation d'un modèle conceptuel journalier (GR3J) aux bassins versants de cours d'eau intermittents. Mémoire de DEA, ENPC, ENGREF, Université Paris Val de Marne, France, 89p.
NASCIMENTO, N. O. (1995). Appréciation à l'aide d'un modèle empirique des effets d'actions anthropiques sur la relation pluie-débit à l'échelle du bassin versant. Thèse de doctorat, CERGRENE/ENPC. Paris, France, 550 p.
NEAL, R. M. (1996). Bayesian learning for neural networks, Springer-Verlag, New York, 183 p.
NELDER, J. A. et MEAD, R. (1965). A simplex method for function optimization. Computer Journal, Vol. 7, 308 p.
NIGRIN, A. (1993), Neural Networks for Pattern Recognition, Cambridge, MA: The MIT Press, 11 p.
ORSTOM (1989). Précipitations journalières de 1966 à 1980: République de Côte d'Ivoire. Montpellier, France, 594 p.
PARIZEAU, M. (2004). Réseaux de neurones. GIF-21140 et GIF-64326. Université Laval. 115 p.
PERRAUD, A. (1971). Les sols, in le milieu naturel de la Côte d'Ivoire, Mémoire ORSTOM, 50 p.
PERRIN, C. (2000). Vers une amélioration d'un modèle global pluie-débit au travers d'une approche comparative. Thèse de Doctorat, CEMAGREF. Antony, Institut National Polytechnique de Grenoble, France, 530 p.
PERRIN, C., MICHEL, C. et ANDREASSIAN, V. (2002). Improvement of a parsimonious model for streamflow simulation. Journal of Hydrology, pp. 125-149.
PERRIN, C., MICHEL, C., et ANDRÉASSIAN, V. (2003). Improvement of a parsimonious model for streamflow simulation. Journal of Hydrology, Vol. 279, n°1 et 4, pp.275-289.
PITMAN, E. J. G. (1939). A note on normal correlation. Biometrika, Vol. 31, pp. 9-12. PREISSMANN, M. (1971). A note on strong perfectness of graphs. Mathematical programming, Ecole polytechnique Fédérale de Lausanne, SUISSE, Vol. 31, no3, pp. 321- 326.
PRINCIPE, J. C, EULIANO, N. R, et LEFEBVRE, W.C. (2000). Neural and Adaptive Systems: Fundamentals throught Simulation, John Wiley and Sons, Inc. Stil, J. M., Irwin, J. 563 p.
QUAEGHEBEUR, R. (2002). Analyse et prédiction de débit de rivières par des méthodes non linéaires. Masters Thesis, Université catholique de Louvain, Louvain-la-Neuve, Belgium, 52 p.
RAO, C. R. (1973). Linear statistical inference an applications, John Wiley, New York, USA, 522 p.
REFSGAARD, J. C. (1997). Parameterisation, calibration and validation of distributed hydrology models. Journal of Hydrology, Vol. 198, n°1 et 4, pp. 69-97.
REFSGAARD, J. C., et ABOTT, M. B. (1996). The role of distributed hydrologycal modelling in water resources management. In Distributed hydrologycal modelling, Abott, M.B., et Refsgaard, J.C. (Eds.), Kluwer, the netherlands, pp. 1-16.
ROCHE, M. (1971). Les divers types de modèles déterministes. La houille Blanche, Vol. 2. pp. 111-129.
ROSENBROCH, K. H. (1960). An automatic method for finding the greatest of least value of a function. The Computer Journal, pp. 3-7.
ROUSSELLE, J. et EL-JABI, N. (1987). Hydrologie fondamentale. Ecole Polytechnique de Montréal, Canada, 234 p.
ROUSSILLON, C. (2004). Prévision de température par Réseaux de neurones. Lycée Victor Hugo, BESANCON, 48 p.
RUMELHART, D. E, et MCCLELLAND, J. L. (1986). Parallel distributed processing: Axploration in the Microstructure of Cognition. MIT Press. Cambridge, USA. 137 p.
SARLE, W. S. (1994). Neural networks and statistic models. Proceedings of the 9th Annual SAS Users Group International Conference (SAS Institute), Cary, North Carolina, pp. 1538- 1550.
SARLE, W. S. (1999). Neural network FAQ, Introduction, periodic posting to the Usenet newsgroup comp.ai.neural-nets, pp. 1-7.
SCHUMANN, A. H.; FUNKE, R. et SCHULZ, G. A. (2000).Application of a geographic information system for conceptual rainfall-runoff modelling. Journal of Hydrology, Vol. 240, pp. 45-61.
SIEBERT, X. (2000). Multi-criteria calibration of a conceptual runoff model using genetic algorithm. Hydrology and Earth System Sciences, Vol. 4, n°2, pp.215-224.
SMITH, J. et ELI, R. N. (1995). Neuronal-network models of rainfall-runoff process. Journal of Water Resources planning and Management, Vol. 121, n°6, pp. 499-508.
SMITH, R. E., et HEBBERT, R. H. B. (1983). Mathematical simulation of interdependent surface and subsurface. Hydrologic Processes, Vol. 19, n°4, pp. 987-1001.
SOLOMATINE, D. P (1999). Two strategies of adaptative cluster covering with descent and their comparison to other algorithms, J. of Global Optimization, Vol. 14, n°1, pp 55-78. SUDHEER, K. P., GOSAIN, A K et RAMASASTRI, K S (2002). A data-driven algorithm for constructing artificial neural network rainfall-runoff models. Hydrological Processes, Vol. 16, pp. 1325-1330.
SUDHEER, K. P. et JAIN, A. (2004). Explaining the Internal Behaviour of Artificial Neural Network River Flow Models. Hydrological Processes, Vol. 18, n°4, pp. 833-844.
SUDHEER, K.P., NAYAK, P.C. et RAMASASTRI, K. S. (2003). Improving peak flow estimates in artificial neural network river flow models. Hydrological Processes, Vol. 17, pp. 677-686.
TAGINI, B. (1971). Esquisse structurale de la Côte d'Ivoire. Essai géotechnique régional. Thèse de Doctorat es-Sciences Naturelles, Université de Lausanne, Suisse, n°88, 266 p. TAPSOBA, S. A. (1995). Contribution à l'étude géologique et hydrogéologique de la région de Dabou (Sud de la Côte d'Ivoire): Hydrochimie, Isotopie et Indice cationique de vieillissement des eaux souterraines. Thèse de Doctorat de 3ème cycle. Université d' Abidjan, Cote d'Ivoire, n°75, 200 p.
TARIK, B. A. (2006). Modélisation pluie-débit mensuelle et journalière par les modèles conceptuels et les systèmes neuro-flous (application aux bassins Algériens). Thèse de Doctorat d'Etat, Institut National Agronomique d'Alger, Algérie, 242 p.
TARIK, B. A. et DECHEMI, N. (2004). Modélisation pluie-débit journalière par des modèles conceptuels et «boîte noire»; test d'un modèle neuroflou / Daily rainfall-runoff modelling using conceptual and black box models; testing a neuro-fuzzy model. Journal des Sciences Hydrologiques, Vol. 49, pp. 919-930.
TASTET, J. P. (1979). Environnements sédimentaires et structuraux quaternaires du littoral du golfe de Guinée (Côte d'Ivoire, Togo, Bénin). Thèse de doctorat d'Etat, Université de Bordeau I, France, n° 621, 181 p.
THIRUMALAIAH, K. et DEO, M. C. (1998). River stage forecasting using artificial neural networks. ASCE Journal of Hydrologic Engineering, Vol. 3, n°1, pp. 26-32.
Tong, H. (1983). Threshold models in nonlinear time series analysis. Springer-Verlag, Berlin, Allemagne, pp. 552-670.
TOUZET, C. (1992). Les réseaux de neurones artificiels. Introduction au connexionnisme. Cours, exercice et travaux pratiques, 58 p.
TROMPETTE, R. (1973). Précambrien (le) supérieur et le paleozoique inferieur de l'ADRAR de Mauritanie (bordure occidentale du bassin de Taoudeni, Afrique de l'ouest) un exemple de sédimentation de craton. Etude stratigraphique et sédimentologique. L.A. CNRS 132 (Travaux des laboratoires des sciences de la terre, Saint-Jérôme Marseille), Vol. 3, 765 p.
TUFFIN, B. (1997). Variance Reductions applied to Product-Form Multi-Class Queuing Networks. ACM Transactions on Modeling and Computer Simulation, Vol.7, n°4, pp 478- 500.
UNESCO-OMM (1992). Glossaire international d'hydrologie, en quatre langues (Anglais, Espagnol, Français, Russe), 2ème édition, UNESCO-OMM, Paris/Genève, 497 p.
VAPNIK, V. (1992). Principles of risk minimization for learning theory. In Advances in Neural Processing System 4, Denver, 245 p.
WENRI, H., XU, B., et AMY, C. H. (2004). Forecasting flows in Apalachicola river using neural networks. Hydrological Processes, Vol. 18, pp. 2545-2564.
WERBOS, P. J. (1974). Beyond regression: new tools for prediction and analysis in the behavioral sciences. Thèse de Doctorat, Committe on Applied Mathematics, Harvard University, Cambridge, Massachusetts, 256 p.
WERBOS, P. J. (1981). Applications of advances in nonlinear sensitivity analysis. Dans System modeling and optimization. Drenick R. et Kozin F. Springer-Verlag, New York, pp. 762-770.
WINTERS, P. R. (1960). Forecasting sales by exponentially weighted moving averages. Management Sciences, Vol. 6, pp. 324-342.
WMO (1994). Guide to hydrological practics. WMO, n° 168, Genève, suisse, 560 p. WILCOXON, F. (1945). Individual comparisons by ranking methods. Biometrics, Vol. 1, pp. 80-83.
YOUNG, P. (2003). Top-down and data-based mechanistic modelling of rainfall-flow dynamics at the catchment scale. Hydrological Processes, Vol. 17, pp. 2195-2217.
ZHANG, E. Y., et TRIMBLE, P. (1996). Forecasting water availability by appliying neural network with global and solar indices. Proceedings of the sixteenth annual American Geophysical Union Hydrology Days. Ed. H.J. Morel-Seytoux. Hydrology Days Publications, Washington, D.C, pp. 559-570.
ZHU, M. L. et FUJITA, M. (1994). Comparison between fuzzy reasoning and neural network methods to forecast runoff discharge. Journal of Hydroscience and Hydraulic Engineering, Vol. 12, n°2, pp. 131-141.
ZURADA, J. M. (1992). Introduction to artificial neural system. West Publishing Co., Saint Paul, Minnesota, 327 p.