3.2 Plate-forme de migration (« Migration
Platform »)
La Figure 15 représente les principaux cas d'utilisation
du système « Migration Platform ». Ils sont
répartis de la manière suivante :
· La cartographie de l'application représente la
base de l'ensemble et contiendra tous les composants applicatifs du projet
(fenêtres, composants graphiques, classes, fonctions).
· La cartographie des tests intègre les
différentes données propres aux tests et s'appuie sur
la
cartographie de l'application pour indiquer quels sont les composants
utilisés par les tests.
· Le suivi d'intégration quant à lui permet
d'avoir un historique des niveaux d'intégration par composant.
· Ensuite vient l'automatisation des tests qui s'appuie
sur la cartographie des tests. Elle permet, comme on le verra un peu plus loin,
de spécifier une relation entre les composants sources et cibles
présents dans la cartographie de l'application.
Les différents acteurs sont l'architecte, qui a pour
rôle principal d'initialiser et de vérifier que la cartographie de
l'application est correcte ; le testeur qui alimente la cartographie des tests
d'une part, et génère les scripts de tests d'autre part ; le chef
de projet qui utilise la cartographie de l'application pour obtenir
différentes visions de celle-ci, et qui se sert du suivi
d'intégration pour avoir une idée réaliste de
l'état d'avancement de l'intégration. Ces différents cas
d'utilisation sont détaillés dans les paragraphes suivants.
La Figure 16 représente la répartition des
paquetages constituant le système plate-forme de migration («
Migration Platform »). On peut remarquer que les deux principaux
paquetages coeur (« Core ») et éléments de
code (« CodeItems ») forment un noyau autonome. Les autres
« fonctionnalités » viennent se greffer sur ce noyau et sont
indépendantes entre elles, mis à part les deux paquetages
architecture de test (« Testing.Architecture ») et
données de test (« Testing.Data ») qui sont
regroupées au sein du paquetage test.
CNAM de Nantes - 2010 / 2011 - Mémoire
d'ingénieur
|
|
|
3.2.1 La cartographie des applications
Avant d'approfondir les deux principaux objectifs de ce
mémoire, se pose le problème essentiel de la cartographie des
applications. En effet, pour pouvoir indiquer quels composants sont
utilisés par un scénario de test, il faut déjà
pouvoir lister de manière exhaustive l'ensemble des composants de
l'application et les identifier de manière unique.
Comme indiqué dans l'état de l'art, nous ne
nous sommes pas servis de KDM. Cependant, bien que fortement
simplifié, nous nous en sommes grandement inspirés pour concevoir
le métamodèle « Migration Platform ». La
réalisation de ce métamodèle est le fruit d'un travail
commun entre mon responsable, M. Breton, un collègue, M. Pacaud et
moi-même. Plus précisément, mon rôle a
été de concevoir les parties afférentes aux tests :
· Le paquetage architecture des tests (« Testing
Architecture », cf. Figure 20)
· Le paquetage données de test (« Testing
Data », cf. Figure 21)
· Le paquetage traçabilité («
Traceability », cf. Figure 28)
Ces diagrammes de classe sont détaillés dans les
§ 3.2.2 et 3.2.3.
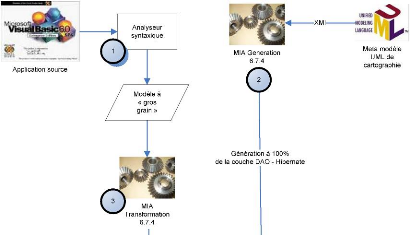
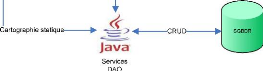
Figure 17 : Processus d'alimentation de la cartographie
d'application
CNAM de Nantes - 2010 / 2011 - Mémoire
d'ingénieur
|
|
|
Le métamodèle « Migration
Platform » a été réalisé avec le modeleur
UML MagicDraw, sous la forme d'un modèle UML. Il est
décrit principalement par des paquetages, des classes, des attributs et
des relations. MIA Generation permet d'importer un fichier
XMI15 exporté depuis MagicDraw. Nous nous en sommes
servi afin de générer entièrement la couche de persistance
DAO16 Hibernate dans le langage Java17 (cf. Figure 17
étape 2). Nous remplissons ainsi deux des contraintes initialement
fixées, à savoir une façon simple d'exposer les
données aux outils de la chaîne d'évolution d'architecture.
Mais aussi, une solution performante, car même en cas de
volumétrie importante, c'est sur le moteur de base de données
relationnelle (SGBDR18) que repose principalement ce
problème, or il est justement prévu pour ça. Cette couche
de persistance sera intégrée aux outils sous la forme d'une
archive Java (Jar) déposée dans des répertoires
prédéfinis, par exemple : <répertoire installation
MIA Generation>\tools\lib.
La Figure 17 qui présente le processus de cartographie
des applications, permet de voir l'ensemble des actions qui, en partant de
l'analyse du code source, permet de peupler la base de données «
Migration Platform ». En premier lieu se déroule l'analyse
syntaxique du code source (cf. Figure 17, étape 1) afin de produire un
modèle de l'application à « gros grain ». Ce
modèle est du même niveau que KDM et ne descend pas
jusqu'aux instructions mais s'arrête aux méthodes et aux relations
qui les unissent. On évite aussi, grâce à ce niveau de
modèle, des problèmes de volumétrie. En effet, il n'est
pas rare d'avoir à « découper » des applications
sources en plusieurs parties afin que le volume des modèles soit
compatible avec les outils MIA, on parle ici de modèles XMI d'environ
une centaine de mégaoctets. Ce découpage pose de sérieux
problèmes de résolution de type à l'analyseur, lorsqu'une
classe qui est décrite dans un modèle est utilisée dans un
autre.
Après avoir déposé l'archive Java issue
de l'étape 2 dans le répertoire prévu à cet effet,
et effectué quelques paramétrages (adresse de la base de
données, type de serveur), MIA Transformation peut lire le
modèle de l'application source fourni par l'analyseur syntaxique, et
peupler la base de données « Migration Platform »
(cf. Figure 17, étape 3).
15 XMI : XML Metadata Interchange
16 DAO : Data Access Object
17 Java : langage de programmation orienté
objet
18 SGBDR : Système de Gestion de Base de
Données Relationnelle.
CNAM de Nantes - 2010 / 2011 - Mémoire
d'ingénieur
|
|
|

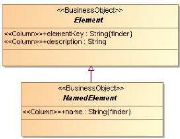



Figure 18 : Diagramme de classe du paquetage « Core
»
(source Sodifrance, extrait du métamodèle «
Migration Platform »)
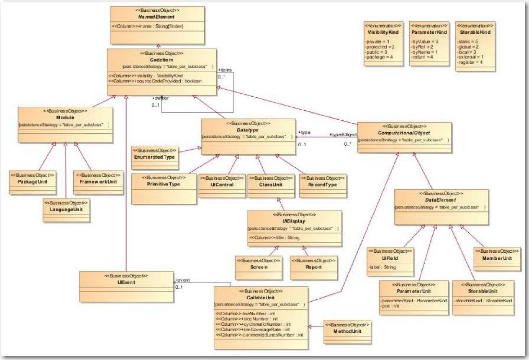
Figure 19 : Diagramme de classe du paquetage « CodeItems
»
(source Sodifrance, extrait du métamodèle «
Migration Platform »
CNAM de Nantes - 2010 / 2011 - Mémoire
d'ingénieur
|
|
|
Attardons-nous un instant sur la manière dont sont
identifiés les éléments au sein de la base. Les classes
servant à la cartographie héritent de la classe «
Element » (cf. Figure 18 et Figure 19). Cette classe
possède une propriété « elementKey »
qui est essentielle. En effet, c'est elle qui assure l'identification de
manière unique de chaque élément. La construction de cette
clé répond à des règles très strictes qui,
on le verra par la suite, devront être respectées à tous
les niveaux du processus de migration. Ce formalisme consiste à
reprendre l'ensemble de la clé de l'élément parent, et
à y ajouter l'identifiant de l'élément courant.
Tableau 1 : Exemples de clefs
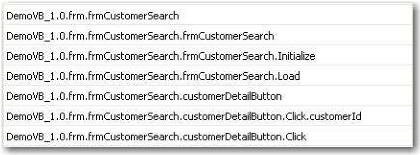
Le Tableau 1 montre un exemple concret de cette notation avec
le modèle « DemoVB_1.0 ». Le conteneur «
frmCustomerSearch » se trouve dans le répertoire «
frm ». L'écran « frmCustomerSearch »
contient les événements « Initialize » et
« Load », et a aussi un contrôle graphique
nommé « customerDetailButton ». Ce dernier a un
événement « Click » qui utilise une variable
« customerId ».
Ce système de classification arborescente permet de
lister l'ensemble des composants de l'application de manière exhaustive.
L'élément racine correspond au modèle présent en
base et représente l'application, vient ensuite s'il y a lieu,
l'arborescence des répertoires, puis les fichiers. Dans le modèle
de l'application source, le type du fichier : écran, classe, module,
etc., a déjà été déterminé par
l'analyseur syntaxique. Enfin, on retrouve les méthodes, leurs
propriétés, et le type de retour s'il s'agit des fonctions. Le
fait d'avoir intégré l'arborescence complète des fichiers,
permet de prendre en compte plusieurs fichiers portant le même nom mais
présents dans des répertoires différents.

CNAM de Nantes - 2010 / 2011 - Mémoire
d'ingénieur
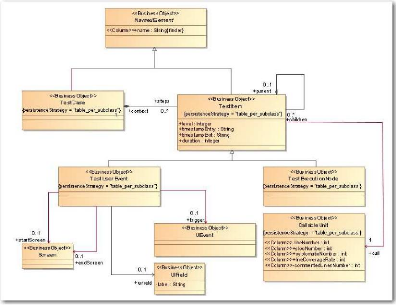
Figure 20 : Les classes du paquetage architecture des tests
(« Testing.Architecture »)
du métamodèle
« Migration Platform »
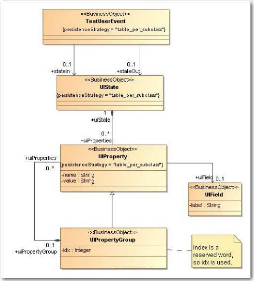
Figure 21 : Les classes du paquetage données de test
(« Testing.Data »)
du métamodèle «
Migration Platform »
CNAM de Nantes - 2010 / 2011 - Mémoire
d'ingénieur
|
|
|
| 

