|

Rapport de Projet J2EE
Site de E-Commerce
Hibernate - Struts - Spring
Olivier Ferran - Guillaume Papon 08/01/2008

Rapport de Projet J2EE Site de E-Commerce
janv. 8

2
I.
|
II.
|
Introduction
L'environnement de développement
|
3
3
|
|
1.
|
Eclipse Europa
|
3
|
|
2.
|
Apache Tomcat
|
4
|
|
3.
|
SVN
|
4
|
|
III.
|
|
Le modèle MVC
|
5
|
|
1.
|
Spring : Faciliter le développement et les tests
|
5
|
|
2.
|
Struts : Mettre en place le MVC
|
5
|
|
3.
|
Hibernate : La persistance des objets
|
6
|
|
a.
|
Pourquoi Hibernate ?
|
6
|
|
b.
|
Configuration d'Hibernate
|
7
|
|
c.
|
Utilisation d'Hibernate
|
7
|
|
IV.
|
|
Le site de E-Commerce
|
8
|
|
1. Architecture 3-tier et mise en place du modèle MVC
|
8
|
|
2.
|
Configuration de l'application
|
9
|
|
3.
|
Les contrôleurs
|
10
|
|
4.
|
La couche Web
|
13
|
|
a.
|
JSTL
|
13
|
|
b.
|
Ajax
|
17
|
|
|
5.
|
La couche service
|
19
|
|
a.
|
Synchronisation
|
19
|
|
b.
|
Le framework Spring
|
20
|
|
6.
|
La couche d'accès aux données (DAO)
|
21
|
|
a.
|
La persistance des objets en via Object/Relational Mapping (ORM)
|
21
|
|
b.
|
Hibernate
|
22
|
|
|
V.
|
Conclusion
|
27
|

Introduction
Notre objectif en choisissant ce projet était de se
familiariser avec toute l'architecture J2EE et de découvrir les
frameworks les plus couramment dans le développement web en java. Pour
ce faire, nous avons choisi de les mettre en oeuvre dans un site de type
e-commerce. Néanmoins, le véritable objectif reste la
manipulation de toutes ces technologies en vue de nous futurs stages.
L'environnement de développement
1. Eclipse Europa
Eclipse Europa (Ex Callisto) est une version de l'IDE d'IBM
auquel ont été ajoutés plus de 21 projets pour un total de
plus de 500 plugins, allant de l'édition de fichier xml a la gestion de
serveurs d'applications en passant par la création de JSP, d'EJB, de JSF
et bien d'autres.
Nous avons choisi cette distribution car son projet Web Tools
(WTP) permet de gérer a l'intérieur de l'IDE toutes les
étapes du développement, notamment tout ce qui concerne la
publication automatique du projet web sur le serveur d'application.

2.
4
Apache Tomcat
Tomcat est un conteneur de Servlet J2EE issu du projet
Jakarta, Tomcat et est désormais un projet principal de la fondation
Apache. C'est un conteneur de Servlet J2EE qui implémente la
spécification des Servlets et des JSP de Sun Microsystems. Tomcat est en
fait chargé de compiler les pages JSP avec Jasper pour en faire des
Servlets (une servlet étant une application Java qui permet de
générer dynamiquement des données au sein d'un serveur
http). Généralement, ces données sont
présentées sous forme de page HTML coté client.
3. SVN
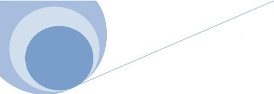
Subversion est un système de gestion de version,
conçu pour remplacer CVS. Concrètement, ce système permet
aux membres d'une équipe de développeur de modifier le code du
projet quasiment en même temps. Le projet est en effet enregistré
sur un serveur SVN (le notre sur
https://opensvn.csie.org/) et
à tout moment, le développeur peut mettre à jour une
classe avant de faire des modifications pour bénéficier de la
dernière version et a la possibilité de comparer deux versions
d'un même fichier.
Le principe de fonctionnement est le suivant :

Rapport de Projet J2EE Site de E-Commerce
janv. 8

III. Le modèle MVC
1. Spring : Faciliter le développement et les
tests
Le framework Spring est un conteneur dit « léger
», c'est-à-dire une infrastructure similaire à un serveur
d'application J2EE. Il prend donc en charge la création d'objets et la
mise en relation d'objets par l'intermédiaire d'un fichier de
configuration qui décrit les objets à fabriquer et les relations
de dépendances entre ces objets (IoC - Inversion of Control). Le gros
avantage par rapport aux serveurs d'application est qu'avec SPRING, les classes
n'ont pas besoin d'implémenter une quelconque interface pour être
prises en charge par le framework. C'est en ce sens que SPRING est
qualifié de conteneur « léger ». L'idée du
pattern IoC est très simple, elle consiste, lorsqu'un objet A à
besoin d'un objet B, à déléguer à un objet C la
mise en relation de A avec B.
2. Struts : Mettre en place le MVC
Apache Struts est un framework libre pour développer
des applications web J2EE. Il utilise et étend l'API Servlet Java afin
d'encourager les développeurs à adopter l'architecture
Modèle-VueContrôleur. Struts permet la structuration d'une
application Java sous forme d'un ensemble d'actions représentant des
événements déclenchés par les utilisateurs de
l'application. Ces actions sont décrites dans un fichier de
configuration de type XML décrivant les cheminements possibles entre les
différentes actions. En plus de cela, Struts permet d'automatiser la
gestion de certains aspects comme par exemple la validation des données
entrées par les utilisateurs via l'interface de l'application. Ainsi, il
n'est plus besoin de venir coder le contrôle de chaque donnée
fournie par un utilisateur, il suffit de décrire les
vérifications à effectuer dans un fichier XML dédié
à cette tâche.
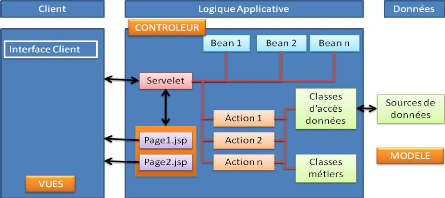
Le contrôleur est le coeur de l'application. Toutes les
demandes du client transitent par lui. C'est une servlet
générique fournie par STRUTS. Cette servlet
générique prend les informations dont elle a besoin dans un
fichier le plus souvent appelé struts-config.xml. Si la requête du
client contient des paramètres de formulaire, ceux-ci sont mis par le
contrôleur dans un objet javaBean héritant de la classe
ActionForm. Dans le fichier de configuration struts-config.xml, à chaque
URL devant être traitée par programme on associe certaines
informations :
1 Le nom de la classe étendant Action chargée de
traiter la requête.
1 Si l'URL demandée est paramétrée (cas de
l'envoi d'un formulaire au contrôleur), le nom du bean chargé de
mémoriser les informations du formulaire est indiqué.
Muni de ces informations fournies par son fichier de
configuration, à la réception d'une demande d'URL par un client,
le contrôleur est capable de déterminer s'il y a un bean à
créer et lequel. Une fois instancié, le bean peut vérifier
que les données qu'il a stockées et qui proviennent du
formulaire, sont valides ou non. Pour cela, une méthode du bean
appelée validate est appelée automatiquement (si le
développeur le souhaite et la définie) par le contrôleur et
renvoie éventuellement une liste des erreurs. Dans ce cas là, le
contrôleur n'ira pas plus loin et passera la main à une vue
déterminée dans son fichier de configuration pour informer
l'utilisateur des erreurs qu'il a commis lors de la saisie de son
formulaire.
Si les données du bean sont correctes, ou s'il n'y a
pas de vérification ou s'il n'y a pas de bean, le contrôleur passe
la main à l'objet de type Action associé à l'URL. Il le
fait en demandant l'exécution de la méthode execute de
cet objet à laquelle il transmet la référence du bean
qu'il a éventuellement construit. C'est ici que le développeur
fait ce qu'il a à faire : il devra éventuellement faire appel
à des classes métier ou à des classes d'accès aux
données. A la fin du traitement, l'objet Action rend au contrôleur
le nom de la vue qu'il doit envoyer en réponse au client.
Le contrôleur envoie cette réponse. L'échange
avec le client est terminé.
3. Hibernate : La persistance des objets
a. Pourquoi Hibernate ?
Hibernate est un framework open source gérant la
persistance des objets en base de données relationnelle. La manipulation
de SQL dans le langage de programmation JAVA est rendue possible par
l'utilisation du JDBC. Puisque, chaque requête est effectuée sur
le modèle logique de la base de données, cette approche
présente l'inconvénient de lier très fortement le code de
l'application au schéma de la base de données. En
conséquence, toute évolution apportée au modèle
logique doit être répercutée sur le code de
l'application.

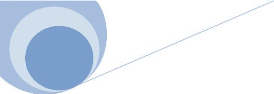
L'outil Hibernate propose une solution à ce
problème. Celleci consiste à définir, dans des fichiers de
configurations, le lien entre le diagramme de classes de l'application qui
exploite une base de données et le modèle logique de cette base
de données. Il permet ensuite de manipuler les données de la base
de données sans faire la moindre référence au
schéma de la base de données en utilisant l'API fournie par cet
outil grâce au lien établi dans les fichiers de configuration.
b.

Rapport de Projet J2EE Site de E-Commerce
janv. 8

7
Configuration d'Hibernate
Hibernate est conçu pour pouvoir être utilise
dans différents types d'architectures d'application. Pour cela, chaque
application doit indiquer à Hibernate comment celui-ci peut
accéder et manipuler la source de données dans un fichier de
configuration nommé hibernate.cfg.xml.
Les principaux éléments à paramétrer
sont les suivantes :
( Le SGDB utilisé. Chaque SGBD propose une
implémentation du langage SQL qui diffère souvent de la norme
SQL. Hibernate doit connaitre le type de SQL qu'il doit
générer.
( La Connexion à la base de données. Si la
connexion à la base de données se fait en utilisant JDBC, il faut
indiquer à Hibernate, le driver JDBC, l'url de connexion ainsi qu'un nom
d'utilisateur et un mot de passe permettant de se connecter `a la base de
données. Les connexions peuvent également être
gérées par un serveur d'application. Dans ce cas, il faut
indiquer à Hibernate comment il peut accéder aux connexions
créées par ce serveur (Annuaire JNDI).
( Les Services tiers. Hibernate a besoin de gérer un
ensemble (pool) de connexions à la base de données et un cache de
données. Pour cela, Hibernate propose une implémentation
rudimentaire de ces services mais peut aussi utiliser des services tiers plus
performants.
Pour résumer, le paramétrage de Hibernate
nécessite :
( La définition du modèle de classes exploitant la
base de données ;
1 Une correspondance (mapping) entre le modèle de classes
et la base de données ; 1 Une configuration au niveau système de
l'accès.
c. Utilisation d'Hibernate
L'utilisation de Hibernate se fait principalement au travers de
la classe Session qu'il fournit. Un objet session offre les
fonctionnalités suivantes :
1 Rendre persistant un objet d'une classe. C'est la
méthode save qui offre cette fonctionnalité. Elle prend
en paramètre l'objet a rendre persistant.
( Charger un objet d'une classe à partir de la base de
données. La méthode load est utilisée à
cette fin. Elle prend en paramètre la classe de l'objet a charger ainsi
que la valeur de l'identifiant (clé primaire) de cet objet.
1 Modification d'un objet persistant. Il suffit pour cela de
modifier la valeur des propriétés d'un objet puis d'appeler la
méthode flush de l'objet session.
( Suppression d'un objet persistant. L'appel de la
méthode delete avec en paramètre un objet
persistant se charge d'effectuer la suppression dans la base de
données.
( Rechercher des objets. Hibernate propose un langage de
requête orienté objets nommé HQL dont la syntaxe est
similaire au SQL et qui permet d'effectuer des requêtes sur le
modèle objet.

IV. Le site de E-Commerce

1. Architecture 3-tier et mise en place du modèle
MVC Une application web possède souvent une architecture 3-tier
:
1 la couche dao s'occupe de l'accès aux données, le
plus souvent des données persistantes au sein d'un SGBD.
1 la couche métier implémente les algorithmes "
métier " de l'application. Cette couche est indépendante de toute
forme d'interface avec l'utilisateur. Ainsi elle doit être utilisable
aussi bien avec une interface console, une interface web, une interface de
client riche. Elle doit ainsi pouvoir être testée en-dehors de
l'interface web et notamment avec une interface console. C'est
généralement la couche la plus stable de l'architecture. Elle ne
change pas si on change l'interface utilisateur ou la façon
d'accéder aux données nécessaires au fonctionnement de
l'application.
1 la couche interface utilisateur qui est l'interface (graphique
souvent) qui permet à l'utilisateur de piloter l'application et d'en
recevoir des informations.
Les couches métier et dao sont normalement
utilisées via des interfaces Java. Ainsi la couche métier ne
connaît de la couche dao que son ou ses interfaces et ne connaît
pas les classes les implémentant. C'est ce qui assure
l'indépendance des couches entre-elles : changer l'implémentation
de la couche dao n'a aucune incidence sur la couche métier tant qu'on ne
touche pas à la définition de l'interface de la couche dao. Il en
est de même entre les couches interface utilisateur et métier.
L'architecture MVC prend place dans la couche interface
utilisateur lorsque celle-ci est une interface web
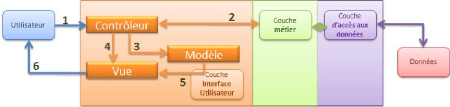
Le traitement d'une demande d'un client se déroule selon
les étapes suivantes :
1. Le client fait une demande au contrôleur. Celui-ci voit
passer toutes les demandes des clients. C'est la porte d'entrée de
l'application. C'est le C de MVC.
2. Le contrôleur C traite cette demande. Pour ce faire,
il peut avoir besoin de l'aide de la couche métier. Une fois la demande
du client traitée, celle-ci peut appeler diverses réponses. Un
exemple classique est :
1 une page d'erreurs si la demande n'a pu être
traitée correctement 1 une page de confirmation sinon
3. Le contrôleur choisit la réponse (une vue)
à envoyer au client. Choisir la réponse à envoyer au
client nécessite plusieurs étapes:

9
( choisir l'objet qui va générer la
réponse. C'est ce qu'on appelle la vue V, le V de MVC. Ce
choix
dépend en général du résultat de l'exécution
de l'action demandée par l'utilisateur.
( lui fournir les données dont il a besoin pour
générer cette réponse. En effet, celle-ci contient le plus
souvent des informations calculées par le contrôleur. Ces
informations forment ce qu'on appelle le modèle M de la vue, le M de
MVC. L'étape 3 consiste donc en le choix d'une vue V et en la
construction du modèle M nécessaire à celle-ci.
4. Le contrôleur C demande à la vue choisie de
s'afficher. Il s'agit le plus souvent de faire exécuter une
méthode particulière de la vue V chargée de
générer la réponse au client.
5. Le générateur de vue V utilise le
modèle M préparé par le contrôleur C pour
initialiser les parties dynamiques de la réponse qu'il doit envoyer au
client. 6. la réponse est envoyée au client. La forme exacte de
celle-ci dépend du générateur de vue. Ce peut être
un flux HTML, PDF, Excel...
Dans notre application, et pour plus de simplicité, la
couche métier est intégrée au générateur de
vue.
2. Configuration de l'application
Chacun des frameworks que nous avons utilisés
nécessite sa propre configuration, en plus de celle requise par le
moteur de servlet. Généralement, cette configuration se fait via
l'utilisation de fichiers XML, bien qu'il soit également possible
d'utiliser d'autres types de fichiers ou de l'effectuer par programmation.
C'est néanmoins la première solution que nous avons retenu.
Globalement, l'architecture d'un projet web Java EE dans eclipse
est la suivante :
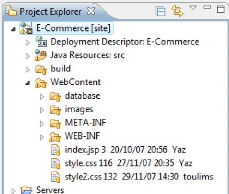
On trouve d'abord le repertoire src, qui contient les
packages et les sources java de l'application ainsi que certains fichiers de
configuration, dont ceux d'hibernate (hibernate.cfg.xml) et de spring
(springconfig.xml).
Ensuite, on a le répertoire build, qui
correspond à la version compilée du répertoire
src . En J2EE, quand une page est demandée par l'utilisateur,
le moteur de servlet regarde la version compilée de la servlet qu'il
possède pour cette page et détermine s'il a besoin ou non de
recompiler une version plus récente de
la source correspondant. C'est dans ce répertoire
build que vont toutes ces classes une fois
compilées, ainsi que les copies des fichiers de
configuration présent dans le répertoire src.
Le répertoire WebContent contient quant à lui
toutes les données relatives à une application web classique,
c'est-à-dire que c'est ici que l'on va retrouver nottament les images,
les feuilles de style, les jsp , etc...

Rapport de Projet J2EE Site de E-Commerce
janv. 8
On y trouve également contenu dans le répertoire
WEB-INF , plusieurs éléments importants :
( Un répertoire classes, qui correspond au
répertoire build précédent.
( Un répertoire lib, qui contient tous les jar
nécessaires a l'exécution de l'application. Dans notre cas, entre
les frameworks que nous utilisions et leur dépendances, le nombre
d'archives s'éleve à plus de 40, pour un taille de 10Mo.
( Le fichier de configuration de struts
(struts-config.xml)
( Le fichier de configuration de l'application, nécessaire
pour le fonctionnement du moteur de serlet (web.xml)
En fait, le répertoire WebContent représente,
comme son nom l'indique, le contenu complet nécessaire pour faire
tourner le site web sur un serveur d'application. On se rend plus facilement
compte de cela si l'on exporte notre projet dans un fichier WAR (pour Web
Archive) afin de le mettre en production sur notre serveur Tomcat ou sur un
autre serveur compatible J2EE, tels que Glassfish, le serveur utilisé
par Sun, ou d'autres tels que JBoss, Jonas ou autres. Cette archive ne comporte
dès lors plus que le contenu du répertoire WebContent,
le répertoire classes contenant toutes la partie applicative
écrite en java.
3. Les contrôleurs
Notre contrôleur est le point d'entrée dans notre
application. C'est un des premiers modules que nous avons
développé car il a été nécessaire dès
le début de trouver une méthode unifiée pour dispatcher
les requêtes (les pages demandées) des utilisateurs vers les
servlets traitant ces demandes.
Dans le but de nous familiariser avec l'architecture et pour
appréhender son fonctionnement, nous avons décidé de coder
notre propre moteur. Comme dans les frameworks récents, nous avons
développé une servlet unique (architecture de type MVC-2) qui
réceptionne toutes les requêtes et qui, suivant l'uri
demandée, transmet la vue a une classe qui s'occupe de lui renvoyer la
jsp correspondante.
Nous avons choisi de gérer tout le paramétrage dans
un fichier xml nommé config-servlet.xml dont le contenu est de
la forme suivante :
<delegate
id="main"
uri="/main"
jsp="/WEB-INF/vues/main.jsp" spring-id="delegate-main"
default="true" />
Ainsi, chaque page peut posséder son
élément « delegate » qui permet, grâce à
Spring, de charger automatiquement le générateur de vue
approprié pour retourner la page au client. Ce système permet
également d'utiliser le même générateur de vue pour
plusieurs pages.
Ensuite, dans le fichier spring-config-servlet.xml, on
trouve la correspondance entre l'identifiant passé dans
l'élément « delegate » précédent et la
classe à faire instancier à Spring.

10
<bean id=" delegate-main"
class="yaz.ecommerce.controleur.delegate.DelegateMain"/>
Cette classe est l'implémentation d'une interface
(IDelegate) possédant une méthode « process >
appelée par notre contrôleur pour générer la vue a
renvoyer a l'utilisateur
void process( HttpServletRequest
request, HttpServletResponse response,
ServletContext context, ServletConfig config, String
jsp)
throws AccesNonAuthoriseException,
ServletConfigInitialisationException;.
L'intérêt de notre contrôleur est qu'il
permet au générateur de vue de lancer des exceptions
correspondant a la logique métier de notre application. Ainsi, une page
nécessitant que l'utilisateur soit identifié va lancer une
exception de type AccesNonAuthoriseException pour signifier que l'utilisateur
n'a pas le droit d'accéder a cette page. Le contrôleur se chargera
alors de transmettre le traitement à la delegate appropriée pour
ce genre de cas, ce qui au final, enrichie notre contrôleur de nombreuses
possibilités d'extensions.
Nous avons également utilisé le contrôleur
de servlet de Struts pour gérer tous les formulaires présent dans
notre application. Pour ce faire, pour chaque formulaire, nous
définissions dans le fichier struts-config.xml les paramètres
suivant :
<form-beans>
<form-bean
name="formInscription"
type="yaz.ecommerce.formulaire.bean.InscriptionBean" />
<form-beans>

<action
name="formInscription"
path="/inscription"
scope="request"
type="yaz.ecommerce.formulaire.action.InscriptionAction"
validate="true" input="/WEB-INF/vues/inscription.jsp"
parameter="/WEB-INF/vues/main.jsp">
<forward name="success" path="/WEB-INF/vues/main.jsp"/>
</action>

Tout d'abord, on définit le « form-bean >.
L'attribut « name > donne le nom du bean et « type > le bean
étendant ActionForm contenant les membres correspondant aux
éléments du formulaire.
Ensuite, on définit l'action a appliquer une fois le
formulaire validé. On retrouve le paramètre « name >
précédent, pour faire la correspondance entre l'ActionForm
(le bean contenant les données du formulaire) et la classe
Action (la classe contenant les actions à effectuer une fois le
bean correctement rempli). Viennent ensuite l'uri a laquelle on trouve le
formulaire (attribut « path >), la portée dans laquelle sont
transmises les données entre le formulaire et l'ActionForm
(attribut « scope >, pouvant prendre les valeurs de «
application >, « session >, ou « request >), la classe

12


14
Action (propriété « type »), la
demande de valider ou non les données du formulaire en appelant la
fonction validate ,la page vers laquelle rediriger l'utilisateur en
cas d'erreur dans la valorisation de l'ActionForm (attribut «
input ») et enfin un ou plusieurs forwards permettant de déterminer
quelle va être la jsp à afficher.
Ainsi, au bean InscriptionBean correspond le formulaire
suivant :
public class InscriptionBean
extends ActionForm{
private String civilite;
private String nom;
private String prenom;

public String getCivilite(){ return
this.civilite; }
~
<html:form action="/inscription" >
<html:select property="civilite">
<html:option value="Monsieur"></html:option>
<html:option value="Madame"></html:option>
<html:option value="Madamoiselle"></html:option>
</html:select><br/>
<html:text property="nom" maxlength="20"/><br/>
<html:text property="prenom" maxlength="20"/><br/> <html:submit
value="Soumettre" >
<html:reset value="Reset" >
</html:form>
Il est intéressant de noter que dans la jsp, il est
obligatoire d'utiliser les balises de la taglib html de Struts et non pas les
éléments html classiques (input*text+ input*submit+, select,
etc...) afin que le contrôleur de Struts puisse correctement
récupérer les valeurs des champs afin de valoriser les membres
correspondant dans l'ActionForm.
Une fois validées par le client, les données
sont transmises a l'ActionForm qui, avant de rendre la main à la classe
Action, va tenter de vérifier si elles sont bien valides. Dans le cas
contraire, la fonction validate retourne un objet de type
ActionErrors contenant la liste des erreurs et redirige vers la jsp
spécifiée par l'attribut input dans son fichier de configuration.
Ce mécanisme est très puissant et très simple à
utiliser car le framework Struts propose dans sa taglib html un tag
nommé « html:errors » qu'il suffit d'appeler pour afficher la
liste des erreurs.
On l'utilise simplement comme suit :
<div id="inscriptionErreurs">
<html:errors />
</div>
En réalité, en appelant ce tag, le
contrôleur de Struts va analyser le contenu de l'objet
ActionErrors et pour chaque erreur désignée par un
ActionMessage, va aller chercher le code html à afficher
correspondant dans le fichier /classes/erreur.properties.
errors.header=<h1>Erreurs</h1><ul>
errors.footer=</ul>
inscription.nom.vide=<li>Veuillez renseigner votre
nom</li> inscription.nom.long=<li>Le nom ne doit pas excéder
20 caractères</li>
inscription.prenom.vide=<li>Veuillez renseigner votre
prénom</li> inscription.prenom.long=<li>Le prénom ne
doit pas excéder 20 caractères</li>
Ainsi, une erreur dans la saisie générera
automatiquement le code html suivant :
<div id="inscriptionErreurs">
<h1>Erreurs</h1>
<ul>
<li>Veuillez renseigner votre nom</li> </ul>
</div>
De plus, la classe ActionForm possède une
deuxième méthode intéressante, la méthode
reset. Cette méthode est appelée a chaque fois avant que
le formulaire ne soit affiché dans la page web, d'oi son utilisation
pour pré-remplir les champs. Par exemple, nous proposons à nos
utilisateurs une page (/ECommerce/editInfos) leur permettant de
modifier leurs coordonnées personnelles. Dès l'accès a
cette page, et puisqu'ils sont identifiés nous savons qui ils sont, nous
pouvons afficher leurs informations complètes grâce à cette
méthode afin de leur faciliter la saisie. La méthode
reset est également appelée lorsque l'utilisateur clique
sur un bouton de type input*reset+.
4. La couche Web
La couche web est composée de tout le coté html
de l'application, c'est-à-dire les Jsp, les feuilles de style css, le
javascript, ainsi que des contrôles nécessaires à charger
le modèle de chaque page à afficher.
a. JSTL
Le but de la JSTL est de simplifier le travail des auteurs de
page JSP, c'est à dire la personne responsable de la couche
présentation d'une application web J2EE. En effet, un web designer peut
avoir des problèmes pour la conception de pages JSP du fait qu'il est
confronté à un langage de script complexe qu'il ne maîtrise
pas forcément.
La JSTL permet de développer des pages JSP en utilisant
des balises XML, donc avec une syntaxe proche des langages utilisés par
les web designers, et leur permet donc de concevoir des pages dynamiques
complexes sans connaissances du langage Java.
Sun a donc proposé une spécification pour une
librairie de tags standards : la Java Standard Tag Library (JSTL). C'est
à dire qu'il spécifie les bases de cette librairie, mais qu'il
laisse l'implémentation libre (de la même manière que pour
les serveurs J2EE qui sont des implémentations de la
spécification J2EE).
La JSTL se base sur l'utilisation des Expressions Languages
(EL) en remplacement des scriptlets Java. L'exemple suivant tiré de la
page de commandes permet de se rendre compte de la puissance des Expressions
Languages :
<c:forEach var="item" varStatus="iter"
items="${facture.pannier.contenu}">
...
<td>${item.portable.stockage.taille}Go
(${item.portable.stockage.rotation}tr/min) </td>
...
</c:forEach>
Tout d'abord, on remarque qu'une EL commence par un « $
'> et que le contenu de l'expression doit se trouver a l'intérieur
d'accolades. La page JSP va chercher un attribut s'appelant "item"
successivement et dans l'ordre dans :
1 l'objet « request > qui représente la
requête transmise par le contrôleur :
request.getAttribute("item")
1 l'objet « session > qui représente la session du
client : session.getAttribute("item")
1 l'objet « application > qui représente le
contexte de l'application web :
application.getAttribute("item")
Puisque l'expression fait référence a un
attribut composé, JSTL va chercher un membre de l'objet « item >
qui s'appellerait « portable > (un membre public, ou accessible par un
getter), puis va faire de même en cherchant un « membre '>
stockage du type de l'objet « portable >, puis de même avec
« taille '>. Une fois l'objet d'extrémité trouvé,
la JSP l'affiche en utilisant la méthode « toString > de cet
objet. Ainsi, on aura parcouru toute l'arborescence de l'objet très
simplement, sans surcharge de code.
Dans le code précédent, on peut également
observer l'utilisation d'un tag <c :forEach>.Ce tag fait partie
d'une des quatre taglibs que propose JSTL, la taglib « Core > (les
trois autres étant Format, XML, SQL), et propose de nombreuses actions
de base tels que l'affichage de variables, la création ou la
modification de variables de scope, la gestion d'exceptions, etc ~
Une taglib intéressante que nous avons également
testée est la taglib Format (fmt) qui permet de simplifier la
localisation et le formatage des données.
La première utilisation que nous en avons faite
concerne la gestion des dates, dans notre module de news. En effet, les dates
étant enregistrées dans notre base de données de
façon non formatée, il nous faut les traiter avant leur
affichage. Pour cela, la taglig Format propose deux tags :
<fmt:parseDate value="${news.date}" pattern="yyyy-MM-dd"
var="date"/> <fmt:formatDate value="${date}" dateStyle="full"/>
Le premier permet de construire le modèle d'affichage
de la date, en utilisant un pattern personnalisé. Il prend en
paramètre la date à parser, le pattern à suivre, et le nom
de la variable dans laquelle il placera le résultat.
Le tag « formatDate '> n'as plus alors qu'à
afficher le résultat contenu dans la variable « date >.
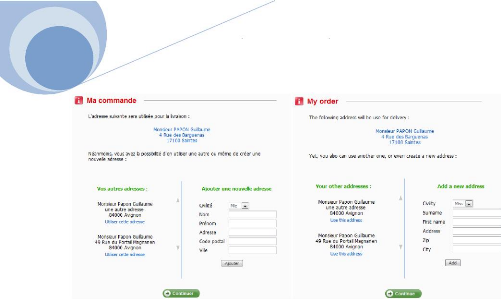
Mais la principale utilité de cette taglib
réside dans sa faculté d'internationaliser une application,
c'est-à-dire d'afficher indifféremment tous les messages contenus
sur un site dans différentes langues. Nous avons mis en place ce concept
sur les premières étapes d'une commande.
La JSTL utilise les classes standards de Java pour la gestion
de l'internationalisation. Ainsi la classe java.util.Locale permet de
représenter les spécificités régionales, ainsi que
la classe java.util.ResourceBundle pour accéder aux données des
fichiers de localisation.
Un ResourceBundle permet de gérer un ensemble de
fichier *.properties contenant les ressources localisées. Par exemple
pour gérer les langues françaises et anglaises, nous avons les
fichiers suivants:
1 messages_fr_FR.properties
1 messages_en_US.properties

pannierVide=Il n'y a pas d'items dans votre pannier
quantite=Quantite
prixTTC=Prix TTC
Alors que le fichier « message_en_US.properties »
contient pour sa part :
pannierVide=There is no item in your cart
quantite=Quantity
prixTTC=IAT Price
Dès lors, l'utilisation est très simple puisqu'il
suffit de choisir à un moment quelle est la langue à utiliser et
de placer cette locale dans un objet de la session :
String langue = request.getParameter("langue");
if (langue != null){
if (langue.equals("FR"))
request.getSession().setAttribute("langue","fr_FR");
if (langue.equals("EN"))
request.getSession().setAttribute("langue","en_US");
}
Puis de rajouter dans les jsp concernées les deux lignes
suivantes:
<fmt:setLocale value="${sessionScope.langue}"/>
<fmt:setBundle basename="messages" var="maLocale"
scope="session"/>
Le tag « setLocale ~ permet d'aller chercher dans le
scope session la variable représentant la langue a utiliser, celle que
nous lui avons donné précédemment, et le tag setBundle
spécifie le nom du fichier de base contenant les messages (on ajoute
« basename »+ « locale » pour construire «
messages_fr_FR.properties »).
Il ne suffit plus alors qu'à accéder a nos messages
en utilisant le tag « message » en spécifiant la clé
voulue.
<fmt:message bundle="${maLocale}" key="pannierVide"/>
1 Les fichiers *.properties comportent un ensemble de couples
clef/valeur contenant l'ensemble des messages possibles a afficher. On
accède aux données localisées grâce aux
différentes clefs. Par exemple, le fichier «
messages_fr_FR.properties » contient :
Rapport de Projet J2EE Site de E-Commerce
janv. 8

16
Pour avoir mis en place ce mécanisme, nous nous sommes
rendus compte de la puissance de la JSTL, et notamment de la taglib Format car
en à peine plus d'une demi heure, il est possible de rendre son site
complètement multilingue, ce qui crée une forte valeur
ajoutée à une application.
Il est également possible de créer sa propre
bibliothèque de tags. Nous avons également testé cette
possibilité en créant plusieurs tags que nous avons réunis
dans une customTag. Par exemple, nous avons créé un tag
nommé PromoTag dont le résultat est représenté par
la capture suivante.
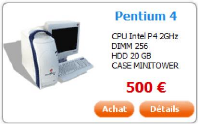
La construction d'un tel tag se fait en deux étapes. Tout
d'abord, il faut décrire les paramètres de ce tag dans une
tld.
<tag>
<name>promo</name>
<tag-class>yaz.ecommerce.taglib.PromoTag</tag-class>
<bodycontent>scriptless</bodycontent>
<description>
Utilisé pour afficher une offre spéciale
</description>
<attribute>
<name>image</name>
<required>true</required>


<rtexprvalue>false</rtexprvalue>
</attribute>

<attribute>
<name>titre</name>
<required>true</required>
<rtexprvalue>false</rtexprvalue>
</attribute>
</tag>
On y trouve le nom du tag, le chemin vers la classe qui
correspond au code du tag, un paramètre spécifiant si le tag
accepte ou nom des expression language ainsi que la liste complete des
attributs du tag.
L'écriture du code du tag est très simple, il sufit
de créer une classe héritant de
javax.servlet.jsp.tagext.SimpleTagSupport, contenant un membre par
propriété spécifiée avec ses setters puis de se
servir du l'objet JSPWriter qui représente le flux de sortie de la jsp
pour écrire le code html du tag.
public void doTag() throws
JspException, IOException{ JspWriter writer = getJspContext().getOut();
writer.println ("<div class=\"produit1\">"); writer.println (" <div
class=\"caracteristiques\">"); writer.println (" <div
class=\"photo\"><img
src=\"images/"+image+"\"
alt=\""+altImage+"\"/></div>");
writer.println (" <div class=\"description\">");
writer.println (" <h1>"+titre+"</h1>");
Même si dans notre cas, les tags que nous avons
créés ont plus une visée pédagogique que pratique,
on peut quand même entr'apercevoir de nombreuses utilisations de ce
mécanisme. Par exemple, les taglibs de Struts sont construites de cette
façon.
b. Ajax
De toutes les technologies en vogue en ce moment, Ajax est sans
doute l'une des plus prometteuses. Nous n'avons pas dérogé
à cette mode et avons testé son implémentation dans un
site en java. Puisqu'étant déjà familiers du concept et de
son implémentation en php, la retranscription en java est assez
rapide.
Nous avons placé notre requête après
l'affichage des résultats d'une recherche de produits, afin d'ajouter un
produit au panier.
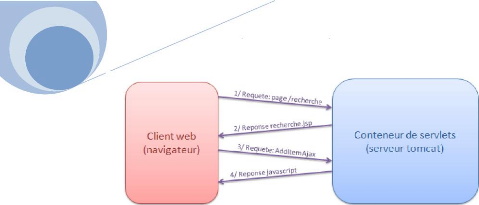
janv. 8
Rapport de Projet J2EE Site de E-Commerce

18
Dans un premier temps (1), l'utilisateur demande la page
/recherche. Le conteneur de servlet donne la main au contrôleur pour
traiter la demande et renvoie finalement le code html de la page
désiré que le navigateur web affiche au client (2). Alors que
cette première partie de l'échange est terminé,
l'utilisateur va déclencher une fonction javascript qui, via une
requête http sur une url bien précise, constituera la demande
d'ajout d'un item dans son pannier (3). Le serveur traitera cette requête
http et retournera non pas une page à afficher, mais du code javascript
(4) que le navigateur pourra exécuter.
Dans notre cas, quand l'utilisateur clique sur le lien pour
ajouter un objet a son panier, il déclenche en fond une requête
vers l'uri AddItemAjax avec deux paramètres : l'identifiant du produit
et la quantité à ajouter.
function doAjouterPannier(id, qte){
var xhr = getXHR();
if (xhr){
// true : requête asynchrone
xhr.open( "POST",
"./addItemAjax?portable="+id+"&quantite="+qte, true);
xhr.onreadystatechange = function() {
if (xhr.readyState ==
4){
eval(xhr.responseText);
}
}
// envoie la requete au serveur xhr.send(null);
}
}
Coté serveur, une fois la requête reçue les
paramètres récupérés, on se contente
d'exécuter les fonctions nécessaires a l'ajout du produit au
panier et on retourne quelques lignes de javascript que le client
exécutera pour signifier a l'utilisateur que sa requête s'est
déroulée avec succès en écrivant dans le flux de
sortie de la servlet.
/* ajoute le portable au panier */
pannier.ajouterProduit(idPortable, quantite);
try{
PrintWriter pw = response.getWriter();
pw.println("var p =
document.getElementById('ajoutPannierResponse"+idPortable+"');");
pw.println("p.innerHTML = '(" + quantite + " Article
ajouté au pannier)'");

}
catch(IOException ex){
ex.printStackTrace();
}
5. La couche service
a. Synchronisation
La couche service est une couche clé de l'application
puisque c'est par elle que transitent les informations entre la couche
contrôleur et la couche d'accès aux données (dao). Son
existence provient d'un constat simple : il est nécessaire de
protéger la couche dao de possibles accès concurrentiels sur la
base de données.
Considérons la situation suivante. Imaginons que nous
possédions dans notre module de news une partie administration qui
permettrait d'éditer le contenu d'une news, ou de la supprimer
complètement. Imaginons maintenant que nous avons deux administrateurs
qui tentent de modifier la même news en même temps. On sent bien
qu'il peut arriver un problème entre le moment oi la première
personne commence l'exécution de la fonction d'édition et le
moment ou l'exécution se termine. Si la news a été
supprimée par le deuxième administrateur entre temps, le
programme va tenter de modifier un objet qui n'existe plus.
Pour résoudre ce problème, on a besoin de
synchroniser l'accès aux méthodes de la couche dao afin de
s'assurer qu'un seul thread les exécute a la fois. Pour cela, les
classes du package dao ne sont instanciées qu'un un seul exemplaire.
C'est ce que l'on appelle des « singletons ». Ces singletons sont
répartis sur plusieurs classes, chacune d'entre elle gérant une
seule table en base de données, ce qui rend possible un tel
découpage.
Puisque pendant le déroulement normal de l'application,
il existe de nombreux threads lancés en même temps et
potentiellement concurrents, il faut trouver un moment oi il n'y a qu'un seul
thread de lancé pour instancier nos objets dao. Cet instant a lieu
pendant la phase d'initialisation de la servlet, lors de l'appel a la
méthode init.
Chacune de nos classes dao est alors instanciée une seule
fois et la référence ainsi créée est stockée
en mémoire dans un objet accessible depuis le « scope application
».
/* construit une hashmap qui va contenir toutes les instances de
la couche service */
HashMap<String,Object> mapService = new
HashMap<String,Object>();

/* met la hashmap dans le scope de l'application */
getServletContext().setAttribute("mapService", mapService);

Rapport de Projet J2EE Site de E-Commerce
janv. 8
Nous mettons ainsi dans cette HashMap tous nos objets de la
couche service dont les méthodes synchronisées permettent
d'accéder a la couche dao.
public class LivraisonServiceImpl
implements ILivraisonService{
private ILivraisonDao dao;
public LivraisonServiceImpl(){}
public synchronized void
ajouterLivraison(Livraison livraison){ dao.ajouterLivraison(livraison);
}
public synchronized ArrayList<Livraison>
getAllLivraisons(Integer id){ return
dao.getAllLivraisons(id);
}
public synchronized Livraison
getDefaultLivraison(Integer id){ return
dao.getDefaultLivraison(id);
}
public ILivraisonDao getDao() {
return dao;
}
public void setDao(ILivraisonDao dao) {
this.dao = dao;
}
}
b. Le framework Spring
Lorsque nous ajoutons des objets dans la HashMap
précédente, ce sont toujours des objets implémentant une
interface contenant le prototype des méthodes proposées.
Considérons la classe LivraisonServiceImpl en la
modifiant comme suit :
public LivraisonServiceImpl(){
dao = new LivraisonDaoImpl();
}

20
Si nous avions écrit ceci, notre classe
LivraisonServiceImpl aurait été dépendante de la
classe LivraisonDaoImpl puisque pour utiliser une autre classe
implémentant l'interface ILivraisonDao, nous aurions du
modifier l'objet a la main et recompiler la classe. Pour remédier
à ce problème, nous avons choisi d'utiliser le framework Spring
notamment pour ses fonctions d'Inversion of Control (Injection de
Dépendance en français).
Spring IoC nous permet de créer une application 3tier
où les couches sont indépendantes des autres, c'est a dire que
changer l'une ne nécessite pas de changer les autres. Cela apporte une
grande souplesse dans l'évolution de l'application.
Avec Spring IoC, la classe LivraisonServiceImpl va
obtenir la référence dont il a besoin sur la couche dao de la
façon suivante :
2.
1. Dès que besoin, nous demandons à Spring IoC de
nous donner une référence vers un objet implémentant
l'interface ILivraisonService.

Spring va alors exploiter un fichier XML de configuration qui lui
indique quelle classe doit être instanciée et comment elle doit
être initialisée.
3. Spring IoC nous rends alors la référence de la
couche ainsi créée.
L'avantage de cette solution est que désormais le nom
des classes instanciant les différentes couches n'est plus codé
en dur mais simplement présent dans un fichier de configuration. Changer
l'implémentation d'une couche induira un changement dans ce fichier de
configuration mais pas dans les classes appelantes.
L'instanciation des beans lors de l'initialisation se fait
dès lors de la façon suivante :
/* charge toutes les instances de la couche service dans la
hashmap */ mapService.put("LivraisonServiceImpl",
(ILivraisonService)new XmlBeanFactory(
new ClassPathResource("spring-config.xml"))
.getBean("livraison-service"));
La configuration de Spring s'effectue dans le fichier
spring-config.xml de la façon suivante :
<bean id="livraison-dao"
class="yaz.ecommerce.dao.LivraisonDaoImpl" init-method="init"
destroy-method="close"/>
<bean id="livraison-service"
class="yaz.ecommerce.service.LivraisonServiceImpl"> <property
name="dao">
<ref local="livraison-dao" />
</property>
</bean>
Le premier bean définit un objet de type
LivraisonDapImpl. C'est l'objet que nous allons passer a comme
référence de la couche dao à la couche service. Les
attributs « init-method » et « destroy-method »
spécifient respectivement la méthode à appeler à la
création du bean et à sa destruction.
Le deuxième bean est celui de notre couche service.
Nous lui donnons la classe à instancier et définissons comment
valoriser le membre « dao » en lui disant de prendre le bean local
créé juste avant, dont l'id est « livraison-dao ». De
cette façon, nous obtenons automatiquement un objet java prêt a
l'emploi dont la configuration est aisément modifiable par simple
modification d'un fichier xml.
6. La couche d'accès aux données
(DAO)
a. La persistance des objets en via Object/Relational
Mapping (ORM)
Pour faire court, la notion d'ORM est le fait d'automatiser la
persistance des objets java dans les tables d'une base de données
relationnelle, ainsi que son contraire, récupérer les
données des tables directement dans des objets java.

Rapport de Projet J2EE Site de E-Commerce
janv. 8
Pour implémenter ce concept, un framework doit être
composé des quatre éléments suivants :

22
( Une api pour effectuer les opérations CRUD (Create,
Retrieve, Update, Delete) de base sur les objets des classes persistantes
( Un langage ou une api pour créer des requêtes qui
se réfèrent aux classes et à leurs
propriétés.
( Un moyen simple de spécifier les
métadonnées pour le mapping
( L'implémentation de concepts tels que l'automatic
dirty checking (mise à jour automatique des tables quand les objets
java correspondants sont modifiés), le lazy loading (chargement
des propriétés des objets uniquement des qu'ils sont
accédés) ainsi que d'autres fonctions d'optimisation.
b. Hibernate
Parmi de nombreuses solutions répondant à cette
attente (EJB, iBatis, JDO, Cayenne, Castor, etc..), nous avons choisi
d'utiliser le framework Hibernate car c'est a l'heure actuelle le framework le
plus puissant, le plus complet, et surtout le plus utilisé dans le monde
professionnel.
Néanmoins, son utilisation est assez complexe
malgré le grand nombre de documentations disponibles sur internet. Dans
notre cas, nous nous sommes contenter d'utiliser les fonctions de bases
nécessaires pour la persistance de nos données, sans nous
préoccuper de toute la problématique concernant les
performances.
Tout d'abord, avant d'utiliser Hibernate, il est
nécessaire de modéliser les données que l'on va vouloir
stocker. Cette étape consiste à construire des objets java dont
les membres seront porteurs des informations à stocker. Chaque membre
doit posséder un getter et un setter.
public class Commande {
private Integer id;
private Date dateCommande;
private Date datePreparation; private Date
dateExpedition; private Integer client;
private Livraison livraison;
private Float port;
private Float tva;
public Commande(){}
/* getters, setters */
}
On peut noter en regardant cette simple entité qu'outre
les types primitifs (ou les wrappers), il est également possible de
mapper des types complexes (des objets de la classe Livraison). De
plus, Hibernate est non intrusif, c'est-à-dire qu'il ne nécessite
pas l'implémentation d'une quelconque interface ou héritage.
La deuxième étape consiste à mapper nos
entités dans les tables de la base de données. Pour cela,
Hibernate utilise deux types de fichiers de configuration.
<hibernate-configuration>
<session-factory>
<property name="hibernate.dialect">
org.hibernate.dialect.PostgreSQLDialect
</property>
<property name="hibernate.connection.driver_class">
org.postgresql.Driver
</property>
<property name="hibernate.connection.url">
jdbc:postgresql://localhost/e-commerce
</property>
<property name="hibernate.connection.username">
Postgres
</property>
<property name="hibernate.connection.password">
Administrateur
</property>
<property name="show_sql">true</property>
<property
name="hibernate.jdbc.batch_size">0</property>
<mapping resource="yaz/ecommerce/entite/commande.hbm.xml"/>
</session-factory>
</hibernate-configuration>
La propriété hibernate.dialect sert
à configurer le dialecte SQL de la base de données. Ce dialecte
va servir à Hibernate pour optimiser certaines parties de
l'exécution en utilisant les propriétés spécifiques
à la base. Cela se révèle très utile pour la
génération de clé primaire et la gestion de concurrence.
Chaque base de données à son dialecte propre.
La propriété
hibernate.connection.driver_class permet de renseigner quel est le
driver jdbc à utiliser. Ce driver est fournit par l'éditeur de la
base de données.
La propriété hibernate.connection.url
renseigne sur l'adresse de la base de données.
Les propriétés
hibernate.connection.username et hibernate.connection.pasword
correspondent aux identifiants du compte avec lequel Hibernate va
accéder à la base de données.
Les deux propriétés suivantes sont optionnelles,
le première permettant d'afficher les requêtes crées par
Hibernate dans la console au moment de l'exécution, et la
deuxième désactive les traitements par batch.
Ensuite, il faut ajouter tous les mappings des entités
dont nous avons besoin grâce aux « balises mapping ressource ».
En général, chaque objet persistant possède son fichier de
mapping.
Le contenu d'un tel fichier pour la classe Commande est le
suivant :
Le premier, hibernate.cfg.xml, regroupe les
paramètres ayant trait à la base de données
elle-même (son type, comment y accéder, etc...).
<hibernate-mapping package="yaz.ecommerce.entite">
<class name="Commande" table="commandes">
<id name="id" type="integer">
<generator class="sequence">
<param name="sequence">commandes_id_seq</param>
</generator>

</id>
<property name="dateCommande" column="date_commande"
type="date" />
<property name="datePreparation" column="date_preparation"
type="date" />
<property name="dateExpedition" column="date_expedition"
type="date" />
<property name="client" type="integer" />
<component name="livraison"
class="yaz.ecommerce.entite.Livraison">
<property name="civilite" column="livraison_civilite"
type="string" />
<property name="nom" column="livraison_nom" type="string"
/>
<property name="prenom" column="livraison_prenom"
type="string" />
<property name="adresse" column="livraison_adresse"
type="string" />
<property name="cp" column="livraison_cp" type="integer"
/>
<property name="ville" column="livraison_ville" type="string"
/>
</component>
<property name="port" type="float" /> <property
name="tva" type="float" /> </class>
</hibernate-mapping>
La balise class définit le mapping de la classe
Commande (l'attribut package sert de raccourci pour le package de
cette classe) et l'attribut « table » donne la table dans la base de
donnée qui va être concernée par cette classe.
On doit ensuite mapper tous les champs de la classe un par un,
avec certaines spécificités.
Les classes mappées doivent déclarer la
clé primaire de la table en base de données. Toutes nos classes
ont ainsi une propriété présentant l'identifiant unique
d'une instance. L'élément <id> sert à
définir le mapping entre cette propriété et la clef
primaire en base. L'élément fils <generator> nomme
une classe Java utilisée pour générer les identifiants
uniques pour les instances des classes persistantes. Certaines applications
peuvent proposer leurs propres implémentations
spécialisées pour le générateur de clés mais
pour notre utilisation, nous nous servons d'une des implémentations
intégrées à Hibernate. Il est bien sûr
également possible d'utiliser des clés composées en
mappant plusieurs attributs de la classe comme propriétés
identifiantes mais nous ne les avons pas utilisées.
Toutes les propriétés simples se mappent
aisément en spécifiant d'un coté le nom de la
propriété dans la classe java et de l'autre le nom de la colonne
dans la base de données.
Pour les propriétés complexes, on utilise
l'élément <component> en lui passant en
paramètre le nom de la propriété java dans l'objet et le
chemin vers la classe correspondant a cet objet. Les paramètres sont
alors mappés de la même façon que pour la classe
englobante.
L'utilisation que nous avons faite d'Hibernate est assez
rudimentaire puisque globalement, tous nos objets sont mappés de cette
façon. Néanmoins, après avoir commencé la lecture
du livre Hibernate in Action, nous nous sommes aperçus que la
meilleure façon de modéliser les classes était
différente de la notre, et qu'elle impliquait de nombreux autres
éléments dans les fichiers de configuration.

24

Ainsi, même si notre mapping est fonctionnel, nous nous
sommes rendu compte sur le tard de ses limites lorsque nous avons eu besoin de
mapper des objets plus complexes qu'une simple classe contenant uniquement des
types simples. Ce fut notamment le cas pour mapper les objets
représentant les commandes, puisque ceux-ci comportaient des tableaux
d'objets complexes représentant le contenu de la commande.
Néanmoins, c'est une fois le mapping effectué que
l'on se rend compte de la puissance d'Hibernate. Pour manipuler les objets
persistants, tout passe par l'objet Hibernate Session.
public void enregistrerCommande(
Integer idClient,
Livraison livraison,
Double tva,
Double port,
ArrayList<PannierItem> listePortables){
Transaction tx = null;
(1) session = sessionFactory.openSession();
Commande commande = new Commande(idClient,
livraison,
25.0f , 19.6f);
try {
(2) tx = session.beginTransaction();
(3) session.save(commande);
for (Iterator it = listePortables.iterator();
it.hasNext();){
CommandeContenu contenu =
new CommandeContenu((PannierItem)it.next());
contenu.setCommande(commande.getId()); session.save(contenu);
}
(4) tx.commit();
}
catch (HibernateException e) {
e.printStackTrace();
if (tx != null &&
tx.isActive())
(5) tx.rollback();
}
finally {
session.close();
sessionFactory.close();
}
}
Tout d'abord, on récupère une session Hibernate
(1) grâce a une fabrique qui analyse les fichiers xml de configuration et
qui retourne un objet prêt a l'emploi. Ensuite, on débute une
transaction (2), qui représente une unité de travail,
c'est-à-dire toutes les instructions à réaliser pour
compléter une tâche. En (3), nous constatons qu'il suffit d'une
simple ligne pour insérer notre objet java dans la base de
données ! En (4), nous flushons la session et terminons notre
unité de travail. Il est remarquable de voir que si une exception s'est
produite pendante la durée de la transaction, l'api Hibernate est
capable d'annuler toutes les modifications qui se sont déroulé
durant cette période (5).
Dès lors, on se rend bien compte des raisons qui ont
menés au succès d'Hibernate par ce simple exemple.
tx = session.beginTransaction();
Commande commande =
(Commande)session.get(yaz.ecommerce.entite.Commande.class,id);
tx.commit();
Un simple appel à la fonction « get » avec en
paramètre la classe de l'objet persistant et la clé primaire de
l'objet en base permet de récupérer une instance persistance
java. De même que si l'on utilise le code suivant durant une session:
tx = session.beginTransaction();
Commande commande =
(Commande)session.get(yaz.ecommerce.entite.Commande.class,id)
Commande.setPort(12f);
tx.commit();
L'api Hibernate va détecter le changement d'une des
propriétés de l'objet commande et va mettre a jour
automatiquement l'enregistrement correspondant en base de données.
En ce qui concerne le requêtage, Hibernate est aussi bien
capable d'utiliser le langage SQL
tx = session.beginTransaction();
Query q = session.createQuery("select * from commandes_contenu
where
commande=:id");
q.setInteger("id",id);
contenu = (ArrayList<CommandeContenu>)q.list();
tx.commit();
Que le langage HQL (Hibernate Query Language). Ce dialecte
orienté objet a été développé au
dessus du langage SQL afin de récupérer des objets
en base de données (le R de CRUD).
tx = session.beginTransaction();
Query q = session.createQuery("from Commande as c where c.client
=
?").setInteger(0, id);
liste = q.list();
tx.commit();
La différence entre les deux précédentes
requêtes est qu'en HQL, la requête retourne une liste non pas
d'Object mais de Commande.
Hibernate propose même un autre type de requêtage,
via l'api Query By Criteria (QBC) qui permet de construire ses
requêtes en spécifiant les contraintes dynamiquement sans
manipulation de chaines de caractères comme on serait obligé de
le faire en HQL ou en SQL.
Criteria crit =
session.createCriteria(yaz.ecommerce.entite.News.class);
crit.addOrder(Order.desc("date"));
crit.setMaxResults(10);
liste = (ArrayList)crit.list();

Rapport de Projet J2EE Site de E-Commerce
janv. 8
De la même façon, pour récupérer un
objet persistant, on utilisera la fonction suivante :

26

V. Conclusion

Ce projet, malgré la courte duré dont nous avons
disposé, nous a été d'un grand bénéfice. En
effet, lorsqu'au mois de Septembre nous avons choisi comme sujet le
développement J2EE, l'un des principaux objectifs était de
proposer un profil extrêmement attractif sur nos CV puisque le
marché de l'emploi dans le domaine de l'informatique est aujourd'hui
dominé par le développement Java/J2EE. La facilité avec
laquelle nous avons tous les deux trouvé notre stage confirme que ce
choix était pertinent.
Sur un plan plus technique, nous avons découvert le
monde du développement web dans un langage que nous connaissions
déjà. Néanmoins, la spécificité de J2EE fait
que nous avons du apprendre toutes les bases de cette nouvelle architecture ce
qui nous a pris plus de temps que nous ne l'escomptions. Finalement, une fois
maitrisé, nous nous sommes rendu compte de la puissance de l'outil et
avons compris pourquoi, pour des sites de grosse audience nécessitant de
fréquentes mises à jour et proposant des services complexes, le
mode est aujourd'hui au J2EE plutôt qu'a un langage comme PHP.
Nous avons pu apprendre les bases des frameworks les plus
couramment utilisés tels que Struts, Spring et Hibernate. Compte tenu de
la complexité de ces APIs, et du peu de temps dont nous disposions, nous
n'avons pas pu pousser notre approche trop loin mais nous avons quand
même eu le temps de juger de leur utilité.
Struts est aujourd'hui l'un des frameworks incontournables
dans le monde J2EE, comme peut l'être Hibernate (et dans une moindre
mesure Spring) et son utilisation, relativement aisée, améliore
grandement la facilité de développement. Sa gestion façon
MVC 2 avec un contrôleur unique et ses taglibs utilisées pour la
gestion des formulaires en font un allié presque indispensable pour une
application de grande envergure.
Hibernate quant à lui est beaucoup plus complexe
à maitriser et nécessiterait un projet complet pour en maitriser
toutes les facettes. Malgré cela, il nous est apparu comme étant
une alternative extrêmement puissante au requêtage classique en SQL
comme on le connait en PHP par exemple. Son efficacité est d'ailleurs
reconnue a tel point que le framework a été porté en C#
pour être utilisé dans l'environnement .NET (tout comme l'a
été Spring IoC).
Avec un peu plus de temps, nous aurions également
aimé tester des frameworks comme Tiles pour ajouter à notre
application un système de template ou JSF, le futur standard proposant
un modèle basé sur les composants graphiques et non plus sur le
paradigme MVC.
| 

