0. INTRODUCTION
0.1 Problématique
De nos jours on parle de plus en plus de
l'insécurité dans divers secteurs ainsi que des moyens
informatiques à mettre en oeuvre pour contrer cette tendance : le
contrôle d'accès aux ordinateurs, l'e-commerce, les
opérations bancaires basées sur l'identification du demandeur,
etc.
Parlant des opérations bancaires, une institution
bancaire est amenée à effectuer ses activités quotidiennes
en assurant des services à ses clients. Ces services rendus par une
institution bancaire la conduisent à être en contact physique
fréquent (à part quelques exceptions à l'exemple du
commerce par internet) avec ses clients.
Les clients qui vont déposer, retirer des sommes
d'argent, effectuer des virements bancaires, des transferts d'argent,...
doivent se présenter physiquement dans cette institution afin
d'être servis. Ceci fait que cette institution bancaire doit recevoir
nombreuses gens de toute catégorie, de tout genre, de toute couche de la
population par jour et encore plus par semaine, par mois, par an.
Les mesures de sécurité mises en place par nos
institutions bancaires de la place ne leur garantissent pas la protection
totale contre les espions, contre les braqueurs, contre les escrocs. Comme
preuve, ici dans la province du Sud-Kivu, principalement dans notre ville de
Bukavu, nous avons assisté à un braquage en pleine journée
de l'une des institutions bancaires. Ces braqueurs ne se sont pas
inquiétés des mesures de sécurité utilisées
par cette institution bancaire (comme tant d'autres institutions bancaires de
la ville de Bukavu qui utilisent seulement les agents de sécurité
en uniforme).
Ces auteurs, les braqueurs pouvaient être
découverts (s'ils ne le sont pas encore bien sûr) le plus vite
possible, si les mesures préventives de sécurité pouvaient
être mises au point avant cet événement (cette
période) de braquage.
Une préoccupation nous vient en première vue:
- Comment nos institutions bancaires, en particulier de la
ville de Bukavu peuvent-elles assurer le control, la surveillance, le suivi de
toutes les visites dans ces dernières de personnes
considérées comme clients pour afin garantir leur
sécurité?
- Mais aussi, même si elles arrivaient à
contrôler toutes ces visites, quelle est le moyen efficace à
utiliser pour mieux identifier toutes les personnes visitant ces institutions
bancaires et ainsi assurer la sécurité individuelle à
chacune de ces institutions?
Nous tacherons de répondre à ces questions tout
au long de notre travail et ceci pourra même constituer la base de notre
sujet de recherche.
0.2 Hypothèse
Alors que l'informatique est devenue pour l'entreprise un
outil incontournable de gestion, d'organisation, de production et de
communication, les échanges internes et externes de cette entreprise
sont exposés aux actes de malveillance de
différentes natures et sans cesse changeants.
Il convient en dépit de tout ce qui
précède de ne pas renoncer aux bénéfices de
l'informatisation, et pour cela de faire appel à des outils
informatiques qui apportent une garantie contre les risques.
D'une manière concrète pour lutter contre ces
visites incontrôlées, nous proposons comme hypothèse ce qui
suit :
- La mise en place d'un système de contrôle des
"personnes extérieures" (ici les clients) à nos institutions
bancaires de la ville de Bukavu peut les aider à assurer et à
garantir leur sécurité. Ceci pourra être possible
grâce à l'utilisation des cameras de surveillance placées
à l'intérieur comme à l'extérieur, dans
différents coins (dans toutes les positions) de bâtiment des
institutions bancaires et à leurs différentes entrées pour
accéder à l'intérieur de ces institutions.
- En plus de cela, une application permettant de
détecter la présence de visage d'une personne se
présentant devant ces cameras et plus que cela, de reconnaitre de quelle
visage s'agit-il peut être un moyen efficace à utiliser pour
garantir une forte sécurité. Tous ces différents visages
seront stockés dans une base de données pour ainsi permettre leur
exploitation pour de fins palpables futures.
Les visages ainsi découverts peuvent alors faire
l'objet d'un suivi d'une image à l'autre, suivi permettant de les
retrouver plus rapidement et de pérenniser leurs caractéristiques
à l'aide d'une moyenne calculée sur les observations
effectuées de ce visage.
0.3 Choix et
intérêt du sujet
Notre investissement dans le domaine de la reconnaissance de
visages est sans doute motivé par la multiplicité et la
variété des champs d'application entre-autre : haute
sécurité, télésurveillance et contrôle
d'accès, etc.
Parmi ses applications les plus concrètes
rencontrées dans la vie courante, peut-on citer à titre
d'exemple : authentification de visage d'un utilisateur d'un compte de
Windows pour accéder à ses données personnelles dans ce
dernier, recherche des individus dans une foule par reconnaissance de leur
visage par des cameras de surveillance, étude des émotions par
analyse des expressions faciales, protection d'identité des personnes
pour livrer les cartes d'identités surs et fiables mais aussi de permis
de conduire.
0.4 Délimitation du
sujet
Notre sujet de recherche porte sur l'identification des
personnes par reconnaissance de visage pour la sécurité d'une
institution bancaire.
Dans le présent travail, nous n'abordons que la
détection et la reconnaissance du visage humain par accession dans des
institutions bancaires. Nous nous arrêtons qu'à capturer les
visages et les stocker dans l'ordinateur mais cette action est possible
à une seule condition : il faut que le visage capturé ne
soit déjà capturé une autre fois, donc ne puisse pas
exister dans la liste des visages prédéfinis (dans la base de
données des visages).
En ce qui concerne la délimitation spatiale, nos
recherches ne concernent que les instituions bancaires de la province du
Sud-Kivu et plus particulièrement de la ville de Bukavu.
0.5 Méthodologie
Nous visons à développer un système de
reconnaissance faciale par authentification de visage. Ainsi, nous avons
commencé par développer une technique « bas niveau »
pour la localisation et la détection du visage dans un flux
vidéo. Nous avons utilisé les méthodes globales (ou
holistiques) et là nous avons utilisé l'une de ces techniques
linéaires qui est l'Analyse en Composantes Principales mais qui
est bidimensionnelle.
La méthode scientifique utilisée est la
méthode comparative :
Celle-ci nous a aidé pour arriver à comparer
deux visages (celui qui se présente devant la camera et celui
déjà capturé dans la base de données des
visages).
Nous avons utilisé la distance de Mahalanobis pour
effectuer une mesure de distance (divergence) entre deux visages. Si cette
distance est élevée (ici supérieur à zéro),
nous prenions la décision de ne pas capturer le visage devant la
caméra. La capture du visage devant la caméra était
conditionnée par la distance (divergence) égale à
zéro. Ainsi la sécurité est certaine si un visage ne peut
être capturé qu'une seule fois et ce visage peut subir de suivi
pour de fins quelconques.
0.6 Etat de la question
D'après nos recherches, nous n'avons pas trouvé
d'autres travaux parlant de l'identification des personnes par reconnaissance
de visage pour la sécurité d'une institution bancaire.
Les seuls travaux approchant notre sujet de recherche et
parlant de la reconnaissance faciale trouvés sont :
1) Authentification d'individus par reconnaissance
de caractéristiques biométriques liées aux visages
2D/3D : thèse présentée et soutenue par
SOUHILA GUERFI ABABSA en vu de l'obtention du titre de Docteur de
l'Université Evry Val d'Essonne, spécialité des
Sciences de l'Ingénieur.
Dans ce travail, l'auteur traite de deux problématiques
majeures et complémentaires rencontrées en reconnaissance de
visage qui sont : l'extraction automatique de visage et de ses
régions caractéristiques, et la reconnaissance du visage. Il
arrive au résultat selon lequel, le choix d'un domaine variable pour la
couleur de la peau peu améliorer la robustesse de la méthode de
détection vis-à-vis des changements d'illumination.
Quant à nous, avons fait usage de l'un de classifieurs
d'OpenCV pour arriver à détecter le visage humain mais avons
utilisé les la distance de Mahalanobis pour authentifier la
reconnaissance faciale.
2) Capteur Intelligent pour la Reconnaissance du
visage : thèse présentée et soutenue
par Walid Hizem en vu de l'obtention du titre de Docteur de l'Institut
national des télécommunications et l'Université Pierre et
Marie Curie - Paris 6, spécialité d'Electronique/Informatique.
Cet auteur présente dans ce travail un nouveau capteur
atténuant l'illumination ambiante. Ce capteur se base sur la
réduction de temps de pose pour ne capturer qu'une faible
quantité de la lumière ambiante mais aussi facilite la
délivrance en simultané d'une image en proche infrarouge et d'une
image normale acquise avec la lumière ambiante.
Grâce à ce capteur et avec utilisation des points
caractéristiques détectés et l'image de contours, un
algorithme de reconnaissance de visage s'inspirant de l'elastic grap
matching pour construire un modèle du visage a été
mis au point.
Quant à nous, avons tenu compte de l'environnement
changeant et par conséquent avons converti toutes les images de figures
détectées en niveau gris égalisé.
3) Reconnaissance des personnes par le visage dans
les séquences vidéo : Rapport de projet de fin
d'études élaboré par Riadh HAMZAOUI de l'Institut
Supérieur des Sciences Appliquées et de Technologies de
Sousse.
L'auteur du présent travail aboutit au résultat
qui est la conception d'une application de reconnaissance de visage dans une
séquence vidéo. Pour lui, il faut que la vidéo soit
déjà enregistrée dans l'ordinateur bien avant.
En ce qui concerne notre travail par rapport à
celui-ci, nous avons utilisé les caméras comme source directe
d'acquisition de vidéo. Ce qui nous a permis le vrai traitement des
images en temps réel assurant une vrai sécurité des nos
institutions bancaires.
0.7 Difficultés
rencontrées
Malgré notre motivation portée au choix de ce
sujet, nous nous sommes heurté à quelques difficultés:
La documentation livresque a été difficile. Nous
avons été obligé de faire toutes nos recherches sur
internet, ce qui nous a couté extrêmement cher du faite que nous
devrions surfer à tout moment.
En plus de ce qui suit, la plus part de documentations
trouvées étaient en langue anglaise, ce qui nous a semblé
difficile dans notre recherche.
0.8 Plan sommaire du travail
Nous avons choisi d'articuler notre étude autour de
trois chapitres principaux hormis l'introduction et la conclusion:
Dans le premier chapitre, nous parlons de
généralités sur la bibliothèque OpenCV. Dans le
présent chapitre, nous décrivons cette bibliothèque en
donnant son historique, ses fonctionnalités, sa structure et sa
configuration dans différents systèmes d'exploitation (Microsoft
Windows et Linux dans sa distribution Ubuntu) ainsi que sa configuration sous
différents compilateurs.
Le deuxième chapitre est consacré à la
notion sur la reconnaissance faciale. Nous y parlons d'abord de la
détection de visage et en suite de la reconnaissance du visage
proprement dite.
En ce qui concerne le troisième chapitre qui est
d'ailleurs le dernier, nous parlons de la mise en place d'une application de
surveillance et identification de personnes par reconnaissance de visage pour
la sécurité d'une institution bancaire.
Nous y décrivons la procédure suivie pour
arriver à mettre en place une application de reconnaissance faciale
pouvant nous aider à assurer une sécurité dans d'un
bâtiment (ou sale).
Nous y présentons les explications de
différentes fonctions utilisées et tout l'algorithme
utilisé.
CHAPITRE PREMIER :
GENERALITES SUR OPENCV
1.1. Histoire
OpenCV (Open Computer Vision) est une bibliothèque
graphique libre. Elle est conçue pour le traitement d'image en temps
réel. Il est utilisable sous Windows, sous Linux et sous MacOS.
Officiellement lancé en 1999, le projet OpenCV est
développé initialement par Intel pour optimiser les applications
gourmandes en temps processeur. Cela faisait partie d'une série de
projets tel que l'affichage d'un mur en 3 dimensions. Cette bibliothèque
est distribuée sous licence BSD.
Les principaux acteurs du projet sont l'équipe de
développement de bibliothèque de chez Intel ainsi qu'un certain
nombre d'experts dans l'optimisation de chez Intel Russie.
Les objectifs de base du projet étaient :
· Faire des recherches sur la vision par ordinateur en
vue de fournir un logiciel libre et optimisé.
· Établir une infrastructure commune s'appuyant
sur les développeurs pour obtenir un code plus lisible et
transférable.
· Continuer à développer en rendant le
code portable et permettre des performances optimisées gratuites avec
une licence qui est libre de toutes contraintes commerciales.
La première version alpha d'OpenCV fut
présentée lors de la conférence IEEE sur la vision par
ordinateur et la reconnaissance de formes en 2000. Après cela, cinq
versions bêta ont été publiées entre 2001 et 2005 et
la première version 1.0 a été publiée en 2006.
Au milieu de l'année 2008, OpenCV obtient l'appui de la
société de robotique Willow Garage et la bibliothèque est
encore développée à ce jour. Une version 1.1 est sortie en
Octobre 2008 et un livre écrit par deux auteurs d'OpenCV, publié
par O'Reilly Media est sorti sur le marché ce même mois.
La deuxième version majeure d'OpenCV née en
octobre 2009. Il s'agit d'OpenCV 2 incluant des changements majeurs au niveau
du langage C++ servant à faciliter le développement de nouvelles
fonctions et améliorant les performances.
Voici en liste toutes les versions d'OpenCV
téléchargeables pour le système d'exploitation Linux
(Ubuntu) et Windows (1(*)):
1. OpenCV 1.0
2. OpenCV 1.1pre1
3. OpenCV 2.1
4. OpenCV 2.2
5. OpenCV 2.3
6. OpenCV 2.3.1
1.2. Fonctionnalités
La bibliothèque OpenCV met à disposition de
nombreuses fonctionnalités très diversifiées permettant de
créer des programmes partant des données brutes pour aller
jusqu'à la création d'interfaces graphiques basiques.
a)
Traitement d'images
Elle propose la plupart des opérations classiques en
traitement bas niveau des images :
· lecture, écriture et affichage d'une
image ;
· calcul de l'
histogramme
des niveaux de gris ou d'histogrammes couleurs ;
· lissage, filtrage ;
· binarisation, segmentation en composantes
connexes ;
·
morphologie mathématique.
b)
Traitement vidéos
Elle met également à disposition de
l'utilisateur quelques fonctions d'interfaces graphiques, comme les curseurs
à glissière, les contrôles associés aux
événements souris, ou bien l'incrustation de texte dans une
image.
Cette bibliothèque s'est imposée comme un
standard dans le domaine de la recherche parce qu'elle propose un nombre
important d'outils issus de l'état de l'art en vision des ordinateurs
tels que :
· lecture, écriture et affichage d'une
vidéo (depuis un fichier ou une caméra)
· détection de droites, de segment et de cercles
par
Transformée
de Hough
· détection de visages par la
méthode
de Viola et Jones
·
cascade de classifieurs boostés
· détection de mouvement, historique du mouvement
· poursuite d'objets par
mean-shift
ou
Camshift
· détection de points d'intérêts
· estimation de
flux optique (tracker
de Kanade-Lucas)
·
triangulation de Delaunay
· diagramme de
Voronoi
· enveloppe convexe
· ajustement d'une ellipse à un ensemble de points
par la méthode des moindres carrés
c)
Algorithmes d'apprentissage
Certains algorithmes classiques dans le domaine de
l'apprentissage artificiel sont aussi disponibles :
· K-means
· AdaBoost
·
Réseau de neurones artificiels
·
Machine à vecteurs de support
·
Estimateur (statistique)
d)
Calculs Matriciels
Depuis la version 2.1 d'OpenCV l'accent a été
mis sur les matrices et les opérations sur celles-ci. En effet, la
structure de base est la matrice. Une
image peut
être considérée comme
une matrice de
pixel. Ainsi, toutes les opérations de bases des matrices sont
disponibles, notamment:
· la transposé
· calcul du déterminant
· inversion
· multiplication (par une matrice ou un scalaire)
· calcul des valeurs propres
1.3. Structure de la
librairie OpenCV
La librairie OpenCV se présente de la manière
suivante :
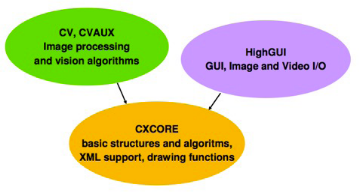
Figure 1. Structure de la bibliothèque d'OpenCV
a) CV & CVAUX :
Cette partie de la bibliothèque permet le traitement
d'images. Voici en liste quelques unes de ses applications :
· Gradient, contours, coins et contours actifs,
· Morphomath (érosion, dilatation,
fermeture...)
· Filtrages divers (lissage, rehaussement de
contraste, suppression de fond...)
· Conversion d'espace couleur (RGB, HSV,...)
· Étiquetage, manipulation de contours,
Transformations diverses (Fourier, Hough...)
· Histogrammes
· Analyse de mouvement et suivi
· Suivi d'objets, flot optique...
· Reconstruction
· Calibration, mise en correspondance...
· Détection et reconnaissance de formes
· Détection de visages et autres formes
particulières.
b) HIGHGUI :
En plus de traitement d'images, celle-ci permet le traitement
des vidéos en temps réel. En voici, ses applications :
· Structures élémentaires
· matrices, tableaux, listes, files, graphes,
arbres...
· opérateurs standards sur ces structures,
· Dessin de primitives géométriques
· lignes, rectangles, ellipses, polygones... et
texte.
· Manipulation des images et des séquences
· lecture, écriture...
· Interface utilisateur
· fenêtre, entrées/sorties
utilisateur.
c) CXCORE :
Cette partie regorge nombreuses fonctions de dessin dont en
voici quelques applications :
· lignes, cercles, ellipses, arcs, ...
· Polygone plein ou contours
· Textes (avec différentes fonts)
· Trousse à outils pour gérer les
couleurs, les tailles,...
1.4. Installation
d'OpenCV
1.4.1 Sous Windows
Sous Windows, nous allons présenter la configuration
d'OpenCV sous Visual Studio (la version 6) mais aussi sous Dev-C++.
a) OpenCV 1.0 sous Visual Studio 6
Ce qu'il faut d'abord faire avant tout :
· Installer la bibliothèque en double-cliquant sur
le fichier téléchargé, comme un programme classique.
· Depuis le nouveau menu créé dans le menu
Démarrer, lancer le workspace liée à son EDI (VS6)
· Afficher le menu Build (Clic droit dans la
barre de menu en haut) et régler le mode de compilation sur
Debug
· Compiler la solution (F7)
· Régler le mode de compilation sur
Release
· Compiler à nouveau la solution (F7)
Maintenant les différents fichiers nécessaires
au fonctionnement d'OpenCV sont installés.
Pour faire la configuration proprement-dite, il y a deux
étapes :
· La configuration générale, qui est
à faire une seule fois.
· La configuration nécessaire pour chaque nouveau
projet
v Configuration générale
Il s'agit d'indiquer à Visual Studio les nouveaux
répertoires où sont disponibles les fichiers .h et .lib d'OpenCV.
(Remarque: l'aspect du menu peut varier en fonction de votre version de
Visual Studio)
· Aller dans Tools, Options.
· Rechercher le sous-menu VC++ Directories dans
Projects and Solutions
· Choisir Include files pour Show
directories
· Ajouter les 4 sous-répertoires comme sur l'image
suivante :
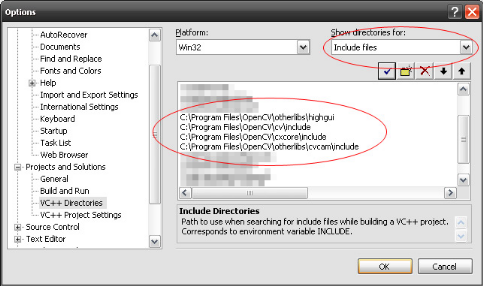
Le chemin C:\program files\opencv peut varier en fonction de
ce que vous avez choisi lors de l'installation.
· Choisir ensuite Library files
· Rajouter la ligne C:\Program Files\OpenCV\lib
· Valider avec OK
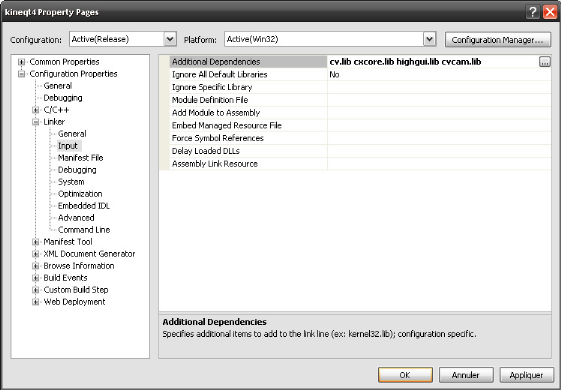
v Configuration pour chaque projet
Cette étape est à recommencer pour chaque
nouveau projet.
· Aller dans les propriétés de votre projet
(ALT+F7 ou menu Project, Properties)
· Rechercher le sous-menu Linker (voir image)
· Rajouter les fichiers lib comme sur l'image.
o cv.lib et cxcore.lib sont
à ajouter dans tous les cas
o highgui.lib : à ajouter si vous
utilisez le gestionnaire de fenêtre d'OpenCV
o cvcam.lib : à ajouter si vous
manipulez une webcam à l'aide d'OpenCV.
· Valider avec OK
b) OpenCV1.0 sous Dev-C++ 4.9.9.x
(installé en langue anglaise)
L'installation sous Windows est un peu plus simple. OpenCV est
distribué en tant que package binaire prêt à l'emploi. On a
aussi besoin d'un compilateur C++. L'environnement de développement
libre Dev-C++ fera très bien l'affaire. Voici en quelques lignes la
procédure :
- Dans le menu Tools de Dev-C++, choisissez Compiler
Options. Dans le premier onglet Compiler, cochez Add these
commands to the linker command line et saisissez ceci dans le
champ de texte : -lhighgui -lcv -lcxcore -lcvaux -lcvcam
- Cliquez maintenant sur l'onglet Directories et dans la
section Libraries ajoutez le chemin suivant : C:\Program
Files\OpenCV\lib
- Il reste à lister les chemins qui contiennent les
fichiers headers d'OpenCV, rajoutez pour cela dans les sections à C
Includes et C++ Includes tout ce qui suit :
C:\Program Files\OpenCV\cxcore\include
C:\Program Files\OpenCV\cv\include
C:\Program Files\OpenCV\otherlibs\highgui
C:\Program Files\OpenCV\cvaux\include
C:\Program Files\OpenCV\otherlibs\cvcam\include
Avant de le lancer, il reste à informer le
système d'exploitation du chemin contenant les fichiers DLL d'OpenCV.
Depuis les Propriétés système de Windows accessibles avec
un clic droit sur le Poste de travail, cliquez sur l'onglet Avancé puis
sur le bouton Variables d'environnement et dans la partie Variables
système, sélectionnez la variable Path, cliquez sur le bouton
Modifier et ajouter ceci à la fin du champ de saisie Valeur de la
variable (n'oubliez pas le point-virgule qui sert de séparateur) :
;C:\Program Files\OpenCV\bin
Il est à signaler qu'il y a une petite
différence dans l'installation des versions supérieures d'OpenCV
(depuis la version 2.0), cela est du à la structure de leur dossier
contenant les fichiers nécessaires à la compilation des
programmes utilisant cette bibliothèque.
Par exemple pour OpenCV2.x (x
représente le chiffre suivant d'une version donnéé),
après avoir coché Add these commands to the linker
command line et on saisit plutôt ce qui suit:
-L"C:\Program Files\OpenCV2.x\lib" -lcxcore2xx -lcv2xx
-lcvaux2xx -lhighgui2xx -lml2xx
Dans les onglets des includes de C et C++, on
augmente seulement une seul ligne qui est la suivante : C:\Program
Files\OpenCV2.x\include\opencv.
Pour les onglets Binaries et Libraries, on augmente
successivement ce qui suit :
C:\Program Files\OpenCV2.x\bin et C:\Program
Files\OpenCV2.x\lib
1.4.2 Sous Linux
OpenCV ne sait pas exploiter directement un flux
vidéo, pour ce faire il utilise ffmpeg, une solution complète de
traitement audio/vidéo. Nous allons ici détailler l'installation
de ffmpeg et d'OpenCV. Comme on ne dispose pas des droits super-utilisateurs
sur la machine, on installe tout ça dans une arborescence fictive du
système au sein même de notre répertoire personnel.
La procédure d'installation nécessite
l'utilisation d'environ 190 Mo d'espace disque dans /tmp, qui pourront
être libéré par la suite. Les fichiers qui seront
installés dans votre répertoire personnel occuperont environ 60
Mo, qui ne devront pas être libéré tant que vous souhaitez
continuer à utiliser OpenCV.
On commence par récupérer et extraire les
sources de ffmpeg et d'OpenCV 1.0.
$ cd /tmp && mkdir `whoami` && cd
`whoami`
$ wget
http://ffmpeg.mplayerhq.hu/ffmpeg-checkout-snapshot.tar.bz2
$ tar xvf ffmpeg-checkout-snapshot.tar.bz2
$wget
ttp://kent.dl.sourceforge.net/sourceforge/opencvlibrary/opencv-1.0.0.tar.gz
$ tar xvzf opencv-1.0.0.tar.gz
On installe ffmpeg dans notre répertoire personnel
avec l'option --enable-shared.
$ cd ffmpeg-checkout-* && ./configure
--prefix=$HOME/root/usr/local --enable-shared
$ make && make install
On configure l'installation d'OpenCV, il faut respecter
à la lettre l'énumération de chaque paramètre tel
qu'il est donné ci-dessous:
$ ./configure --prefix=$HOME/root/usr/local --enable-apps
--enable-shared
--with-ffmpeg --with-gnu-ld --with-x
--without-quicktime
CXXFLAGS=-fno-strict-aliasing
CFLAGS=-I$HOME/root/usr/local/include
CPPFLAGS=-I$HOME/root/usr/local/include
LDFLAGS=-L$HOME/root/usr/local/lib
Vérifier que ffmpeg a bien été
détecté sur le système et qu'il sera utilisé pour
patcher la compilation d'OpenCV. Il suffit pour cela de regarder dans les
dernières lignes qui ont été écrites à
l'écran. Si apparait ffmpeg: yes, vous pouvez alors continuer
l'installation.
$ make && make install
Il ne reste plus qu'à rajouter ces trois lignes
à la fin de votre ~/.bashrc :
#OPENCV
export LD_LIBRARY_PATH=~/root/usr/local/lib
export
PKG_CONFIG_PATH=~/root/usr/local/lib/pkgconfig
Pour utiliser OpenCV tout de suite, il faut également
recharger le ~/.bashrc en tapant ceci :
$ . ~/.bashrc
Pour les versions supérieures (2.0 et plus), tout a
été réduit en quelques lignes de commande après
avoir installé tout les atouts (c'est-à-dire mettre à jour
tout le système d'exploitation et installer en particulier
cmake). Taper le commande ci-dessous dans la console d'éditeur
de commande unix:
1. tar -xjf OpenCV-2.x.x.tar.bz2
2. mkdir opencv.build
3. cd opencv.build
4. cmake [<extra_options>] ../OpenCV-2.x.x #
CMake-way
5. make -j 2
6. sudo make install
7. sudo ldconfig # linux only
Remarque : Comme nous
l'avons supposé ci-haut, x représente le chiffre de la
suite de la version d'OpenCV.
Pour compiler un programme C ou C++ utilisant la
bibliothèque OpenCV, on utilise cette ligne de commande :
- g++ `pkg-config --cflags opencv` `pkg-config --libs
opencv` -o Execucable Programme.c (Pour C)
- g++ `pkg-config --cflags opencv` `pkg-config --libs
opencv` -o Execucable Programme.cpp(Pour C++)
CHAPITRE DEUXIEME:
RECONNAISSANCE DU VISAGE
La reconnaissance du visage est un domaine très actif
dans la Vision par Ordinateur et dans la Biométrie. Elle a
été étudiée vigoureusement il y a
déjà 25 ans et sa finalité est de produire des
applications de sécurité, des applications en robotique,
d'interface homme-machine, applications pour les appareils photo
numériques, jeux et divertissement.
La reconnaissance du visage implique
généralement deux étapes:
· La détection de visage
qui consiste à chercher et à détecter un ou plusieurs
visages en parcourant une image numérique ou une vidéo.
· La reconnaissance de visage
qui consiste à comparer le visage détecté à celui
se trouvant dans la base de données de visages reconnus afin de savoir
quel est ce visage reconnu ou à qui appartient-il.
2.1 DETECTION DE
VISAGE
La détection de visage est un domaine de la
vision par
ordinateur consistant à détecter un
visage humain dans une
image
numérique. C'est un cas spécifique de
détection
d'objet, où l'on cherche à détecter la présence
et la localisation précise d'un ou plusieurs visages dans une image.
C'est l'un des domaines de la vision par ordinateur parmi les plus
étudiés, avec de très nombreuses publications, brevets, et
de conférences spécialisées. La forte activité de
recherche en détection de visage a également permis de faire
émerger des méthodes génériques de détection
d'objet.
La détection de visage est un sujet difficile,
notamment dû à la grande variabilité d'apparence des
visages dans des conditions sans contraintes:
· Variabilité intrinsèque des visages
humains (couleur, taille, forme)
· Présence ou absence de caractéristiques
particulières (
cheveux,
moustache,
barbe,
lunettes...)
· Expressions faciales modifiant la
géométrie du visage
· Occultation par d'autres objets ou d'autres visages
· Orientation et pose (de face, de profil)
· Conditions d'illumination et qualité de
l'image
2.1.1 Applications
La détection de visage a de très nombreuses
applications directes en
vidéo-surveillance,
biométrie,
robotique, commande d'
interface
homme-machine,
photographie,
indexation d'images et de vidéos,
recherche
d'images par le contenu, etc... Elle permet également de faciliter
l'automatisation complète d'autres processus comme la reconnaissance de
visage ou la reconnaissance d'expressions faciales.
Parmi les applications directes, la plus connue est sa
présence dans de nombreux
appareils
photo numérique, où elle sert à effectuer la
mise au point
automatique sur les visages. C'est également une technique importante
pour les
interfaces
homme-machine évoluées, afin de permettre une interaction
plus naturelle entre un humain et un ordinateur.
La détection de visage est aussi utilisée en
indexation d'images et
recherche
d'information, où elle peut être utilisée pour
rechercher des images contenant des personnes, associer automatiquement un
visage à un nom dans une
page web, identifier les
principales personnes dans une vidéo par
clustering.
La détection de visage peut aussi servir à
déterminer l'attention d'un utilisateur, par exemple face à un
écran dans l'espace public, qui peut également, une fois le
visage détecté, déterminer le sexe et l'âge de la
personne afin de proposer des
publicités
ciblées. Cela peut également servir à savoir si une
personne est bien présente devant une
télévision
allumée, et dans le cas contraire mettre l'appareil en veille ou
réduire la luminosité afin d'économiser de
l'énergie.
De façon plus indirecte, la détection de visage
est la première étape vers des applications plus
évoluées, qui nécessitent la localisation du visage, comme
la
reconnaissance
de visage, la reconnaissance d'expression faciales, l'évaluation de
l'âge ou du sexe d'une personne, le
suivi de visage ou
l'estimation de la direction du regard et de l'attention visuelle.
2.1.2 Méthode de
détection de visage
La méthode la plus utilisée est celle de Viola
et Jones (2(*)).
Elle est une méthode de
détection
d'objet dans une
image
numérique, proposée par les chercheurs Paul Viola et Michael
Jones en 2001. Elle fait partie des toutes premières méthodes
capables de détecter efficacement et en temps réel des objets
dans une image. Inventée à l'origine pour
détecter des
visages, elle peut également être utilisée pour
détecter d'autres types d'objets comme des
voitures ou des
avions. La méthode de
Viola et Jones est l'une des méthodes les plus connues et les plus
utilisées, en particulier pour la détection de visages et la
détection
de personnes.
En tant que procédé d'
apprentissage
supervisé, la méthode de Viola et Jones nécessite de
quelques centaines à plusieurs milliers d'exemples de l'objet que l'on
souhaite détecter, pour entraîner un
classifieur.
Une fois son apprentissage réalisé, ce classifieur est
utilisé pour détecter la présence éventuelle de
l'objet dans une image en parcourant celle-ci de manière exhaustive,
à toutes les positions et dans toutes les tailles possibles.
Considérée comme étant l'une des plus
importantes méthodes de détection d'objet, la méthode de
Viola et Jones est notamment connue pour avoir introduit plusieurs notions
reprises ensuite par de nombreux chercheurs en
vision par
ordinateur, à l'exemple de la notion d'
image
intégrale ou de la méthode de
classification
construite comme une cascade de classifieurs
boostés.
Cette méthode bénéficie d'une
implémentation sous
licence BSD dans
OpenCV qui est comme nous
l'avons vu, une
librairie
très utilisée en
vision par
ordinateur.
2.1.2.1 Historique
Paul Viola et Michael Jones, alors au Cambridge Research
Laboratory de la société américaine
Compaq, publient la
méthode qui porte leur nom pour la première fois le
13
juillet
2001 dans le
journal
scientifique
International
Journal of Computer Vision (IJCV). Les deux auteurs publient ensuite deux
autres articles sur la méthode : une version moins
détaillée, présentée à la
Conference
on Computer Vision and Pattern Recognition (CVPR) en décembre 2001
et une version révisée en 2004, toujours dans IJCV.
Les
caractéristiques
extraites par cette méthode sont inspirées des travaux de
Papageorgiou, Oren et Poggio, datant de 1998, qui utilisent des
caractéristiques construites à partir d'
ondelettes de
Haar. La méthode s'inspire également de
précédents travaux de Paul Viola et Kinh Tieu dans un autre
domaine, celui de la
recherche
d'image par le contenu, en reprenant l'idée de sélection de
caractéristiques par
AdaBoost. Parmi les
nombreuses méthodes de
détection de
visages publiées à l'époque, Viola et Jones
considèrent en particulier celle de Rowley-
Kanade : en raison
de ses excellents résultats et de sa rapidité, ils la prennent
comme référence pour les comparaisons. À performances
équivalentes, Viola et Jones notent que la détection par leur
méthode est 15 fois plus rapide que le détecteur de
Rowley-Kanade.
La méthode, considérée comme l'une des
plus efficaces en détection de visage, devient rapidement un standard
dans ce domaine. Les travaux de Viola et Jones sont parmi les plus
utilisés et les plus cités par les chercheurs, et de nombreuses
améliorations sont ainsi proposées. Leurs travaux sont
également étendus à d'autres types d'objets que les
visages et la méthode devient ainsi un standard en
détection
d'objet. La méthode est par ailleurs reconnue comme étant
celle ayant eu le plus d'impact dans le domaine de la détection de
visage dans les
années 2000.
2.1.2.2
Éléments de la méthode
La méthode de Viola et Jones est une approche
basée apparence, qui consiste à parcourir l'ensemble de l'image
en calculant un certain nombre de
caractéristiques
dans des zones rectangulaires qui se chevauchent. Elle a la
particularité d'utiliser des caractéristiques très simples
mais très nombreuses. Une première innovation de la
méthode est l'introduction des
images
intégrales, qui permettent le calcul rapide de ces
caractéristiques. Une deuxième innovation importante est la
sélection de ces caractéristiques par
boosting, en
interprétant les caractéristiques comme des classifieurs. Enfin,
la méthode propose une architecture pour combiner les classifieurs
boostés en un processus en cascade, ce qui apporte un net gain en temps
de détection.
La méthode, en tant que méthode d'
apprentissage
supervisé, est divisée en deux étapes : une
étape d'apprentissage du classifieur basé sur un grand nombre
d'exemples positifs (c'est-à-dire les objets d'intérêt, par
exemple des visages) et d'exemples négatifs, et une phase de
détection par application de ce classifieur à des images
inconnues.
a)
Caractéristiques
Description
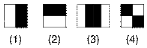
Figure 1- Un exemple des types de
caractéristiques
utilisées par Viola et Jones.
Source :
http://fr.wikipedia.org/wiki/Méthode_de_Viola_et_Jones,
valide le 10/10/2011
Plutôt que de travailler directement sur les valeurs de
pixels, et pour être à la fois plus efficace et plus rapide, Viola
et Jones proposent d'utiliser des
caractéristiques,
c'est à dire une représentation synthétique et
informative, calculée à partir des valeurs des pixels. Viola et
Jones définissent des caractéristiques très simples, les
caractéristiques
pseudo-Haar, qui sont calculées par la différence des sommes
de pixels de deux ou plusieurs zones rectangulaires adjacentes. La figure
ci-contre donne des exemples des caractéristiques proposées par
Viola et Jones à 2, 3 ou 4 rectangles, dans lesquelles la somme de
pixels sombres est soustraite de la somme des pixels blancs. Leur nom vient de
leur similitude avec les
ondelettes de
Haar, précédemment proposées comme
caractéristiques par Papageorgiou et dont se sont inspirés Viola
et Jones.
Pour calculer rapidement et efficacement ces
caractéristiques sur une image, les auteurs proposent également
une nouvelle méthode, qu'ils appellent «
image
intégrale ». C'est une représentation sous la forme
d'une image, de même taille que l'image d'origine, qui en chacun de ses
points contient la somme des pixels situés au-dessus de lui et à
sa gauche. Plus formellement, l'image intégrale ii au point
(x,y) est définie à partir de l'image
i par :
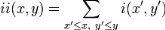
Grâce à cette représentation, une
caractéristique formée de deux zones rectangulaires peut
être calculée en seulement 6 accès à l'image
intégrale, et donc en un temps constant quelle que soit la taille de la
caractéristique.
b) Calcul
Les caractéristiques sont calculées à
toutes les positions et à toutes les échelles dans une
fenêtre de détection de petite taille, typiquement de 24 × 24
pixels ou de 20 × 15
pixels. Un très grand nombre de caractéristiques par
fenêtre est ainsi généré, Viola et Jones donnant
l'exemple d'une fenêtre de taille 24 × 24 qui génère
environ 160 000 caractéristiques.
En phase de détection, l'ensemble de l'image est
parcouru en déplaçant la fenêtre de détection d'un
certain pas dans le sens horizontal et vertical (ce pas valant 1 pixel dans
l'algorithme original). Les changements d'échelles se font en modifiant
successivement la taille de la fenêtre de détection
[. Viola
et Jones utilisent un facteur multiplicatif de 1,25, jusqu'à ce que la
fenêtre couvre la totalité de l'image.
Finalement, et afin d'être plus robuste aux variations
d'illumination, les fenêtres sont normalisées par la
variance.
La conséquence de ces choix techniques, notamment le
recours aux
images
intégrales, est un gain notable en efficacité, les
caractéristiques étant évaluées très
rapidement quelle que soit la taille de la fenêtre.
c) Sélection de
caractéristiques par boosting
Le deuxième élément clé de la
méthode de Viola et Jones est l'utilisation d'une méthode de
boosting afin de
sélectionner les meilleures caractéristiques. Le boosting est un
principe qui consiste à construire un classifieur
« fort » à partir d'une combinaison
pondérée de classifieurs « faibles »,
c'est-à-dire donnant en moyenne une réponse meilleure qu'un
tirage aléatoire. Viola et Jones adaptent ce principe en assimilant une
caractéristique à un classifieur faible, en construisant un
classifieur faible qui n'utilise qu'une seule caractéristique.
L'apprentissage du classifieur faible consiste alors à trouver la valeur
seuil de la caractéristique qui permet de mieux séparer les
exemples positifs des exemples négatifs. Le classifieur se réduit
alors à un couple (caractéristique, seuil).
L'algorithme de boosting utilisé est en pratique une
version modifiée d'
AdaBoost, qui est
utilisée à la fois pour la sélection et pour
l'apprentissage d'un classifieur « fort ». Les classifieurs
faibles utilisés sont souvent des
arbres de
décision. Un cas remarquable, fréquemment rencontré,
est celui de l'arbre de profondeur 1, qui réduit l'opération de
classification à un simple seuillage.
L'algorithme est de type
itératif, à
nombre d'itérations déterminé. À chaque
itération, l'algorithme sélectionne une caractéristique,
qui sera ajoutée à la liste des caractéristiques
sélectionnées aux itérations précédentes, et
le tout va contribuer à la construction du classifieur fort final. Cette
sélection se fait en entraînant un classifieur faible pour toutes
les caractéristiques et en élisant celle de ces dernières
qui génère l'erreur la plus faible sur tout l'ensemble
d'apprentissage. L'algorithme tient également à jour une
distribution
de probabilité sur l'ensemble d'apprentissage,
réévaluée à chaque itération en fonction des
résultats de classification. En particulier, plus de poids est
attribué aux exemples difficiles à classer, c'est à dire
ceux dont l'erreur est élevée. Le classifieur
« fort » final construit par AdaBoost est composé de
la somme pondérée des classifieurs sélectionnés.
Plus formellement, on considère un ensemble de
n images  et leurs étiquettes associées et leurs étiquettes associées  , qui sont telles que yi = 0 si l'image
xi est un exemple négatif et yi
= 1 si xi est un exemple de l'objet à
détecter. L'algorithme de boosting est constitué d'un nombre
T d'itérations, et pour chaque itération t et
chaque
caractéristique
j, on construit un classifieur faible hj.
Idéalement, le but est d'obtenir un classifieur h qui
prédise exactement les étiquettes pour chaque échantillon,
c'est-à-dire yi = h(xi) , qui sont telles que yi = 0 si l'image
xi est un exemple négatif et yi
= 1 si xi est un exemple de l'objet à
détecter. L'algorithme de boosting est constitué d'un nombre
T d'itérations, et pour chaque itération t et
chaque
caractéristique
j, on construit un classifieur faible hj.
Idéalement, le but est d'obtenir un classifieur h qui
prédise exactement les étiquettes pour chaque échantillon,
c'est-à-dire yi = h(xi)
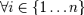 . En pratique, le classifieur n'est pas parfait et l'erreur
engendrée par ce classifieur est donnée par : . En pratique, le classifieur n'est pas parfait et l'erreur
engendrée par ce classifieur est donnée par :
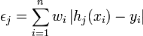 , ,
les wi étant les poids
associés à chaque exemple et mis à jour à chaque
itération en fonction de l'erreur obtenue à l'itération
précédente. On sélectionne alors à
l'itération t le classifieur ht
présentant l'erreur la plus faible : åt =
minj(åj).
Le classifieur fort final h(x) est construit
par seuillage de la somme pondérée des classifieurs faibles
sélectionnés :
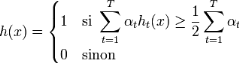
Les át sont des coefficients
calculés à partir de l'erreur åt.
d) Cascade de
classifieurs
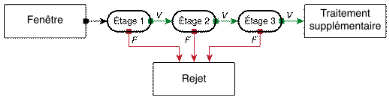
Figure 2 - Illustration de
l'architecture de la cascade : les fenêtres sont traitées
séquentiellement par les classifieurs, et rejetées
immédiatement si la réponse est négative (F).
La méthode de Viola et Jones est basée sur une
approche par
recherche
exhaustive sur l'ensemble de l'image, qui teste la présence de
l'objet dans une fenêtre à toutes les positions et à
plusieurs échelles. Cette approche est cependant extrêmement
coûteuse en calcul. L'une des idées-clés de la
méthode pour réduire ce coût réside dans
l'organisation de l'algorithme de détection en une cascade de
classifieurs. Appliqués séquentiellement, ces classifieurs
prennent une décision d'acceptation -- la fenêtre contient l'objet
et l'exemple est alors passé au classifieur suivant --, ou de rejet --
la fenêtre ne contient pas l'objet et dans ce cas l'exemple est
définitivement écarté --. L'idée est que l'immense
majorité des fenêtres testées étant négatives
(c.-à-d. ne contiennent pas l'objet), il est avantageux de pouvoir les
rejeter avec le moins possible de calculs. Ici, les classifieurs les plus
simples, donc les plus rapides, sont situés au début de la
cascade, et rejettent très rapidement la grande majorité des
exemples négatifs. Cette structure en cascade peut également
s'interpréter comme un
arbre de
décision dégénéré, puisque chaque noeud
ne comporte qu'une seule branche.
En pratique, la cascade est constituée d'une succession
d'étages, chacune étant formée d'un classifieur fort
appris par
AdaBoost. L'apprentissage
du classifieur de l'étage n est réalisé avec les
exemples qui ont passé l'étage n - 1 ; ce
classifieur doit donc faire face à un problème plus
difficile : plus on monte dans les étages, plus les classifieurs
sont complexes.
Le choix du nombre K d'étages est fixé
par l'utilisateur ; dans leur méthode originale, Viola et Jones
utilisent K = 32 étages. L'utilisateur doit également
spécifier le
taux de
détection minimal di et le taux de
fausse alarme maximal
fi à atteindre pour l'étage i. Le
taux de détection de la cascade est alors donné par :
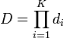
et le taux de fausse alarme par :
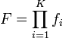
Source :
http://fr.wikipedia.org/wiki/Méthode_de_Viola_et_Jones,
valide le 10/10/2011
En pratique, les taux di et
fi sont les mêmes pour tous les étages.
Indirectement, ces taux déterminent également le nombre de
caractéristiques utilisées par les classifieurs forts à
chaque étage : les itérations d'Adaboost continuent
jusqu'à ce que le taux de fausse alarme cible soit atteint. Des
caractéristiques/classifieurs faibles sont ajoutés jusqu'à
ce que les taux cibles soient atteints, avant de passer ensuite à
l'étage suivant.
Pour atteindre des taux de détection et de fausse
alarme corrects en fin de cascade, il est nécessaire que les
classifieurs forts de chaque étage aient un bon taux de
détection ; ils peuvent par contre avoir un taux de fausses alarmes
élevé. Si l'on prend l'exemple d'une cascade de 32 étages,
pour obtenir une performance finale D = 0.9 et F = 10 -
6, chaque classifieur fort doit atteindre di = 0,997.
Chaque étage ajouté diminue donc non seulement le nombre de
fausses alarmes, mais aussi le taux de détection.
Plusieurs chercheurs font remarquer que cette idée de
filtrer rapidement les exemples négatifs les plus simples n'est pas
nouvelle. Elle existe dans d'autres méthodes sous forme d'
heuristiques, comme la
détection de la couleur chair ou une étape de
pré-classification.
2.1.3 Étapes clés
de la méthode
a) Apprentissage
L'apprentissage est réalisé sur un très
large ensemble d'images positives (c'est-à-dire contenant l'objet) et
négatives (ne contenant pas l'objet). Plusieurs milliers d'exemples sont
en général nécessaires. Cet apprentissage
comprend :
1. Le calcul des
caractéristiques
pseudo-Haar sur les exemples positifs et négatifs ;
2. L'entraînement de la cascade : à chaque
étage de la cascade, un classifieur fort est entraîné par
AdaBoost. Il est construit par ajouts successifs de classifieurs faibles
entraînés sur une seule caractéristique, jusqu'à
l'obtention de performances conformes aux taux de détection et de fausse
alarme souhaités pour l'étage.
b) Détection
La détection s'applique sur une image de test, dans
laquelle on souhaite déceler la présence et la localisation d'un
objet. En voici les étapes :
· parcours de l'ensemble de l'image à toutes les
positions et échelles, avec une fenêtre de taille 24 × 24
pixels, et application de la cascade à chaque sous-fenêtre, en
commençant par le premier étage :
· calcul des caractéristiques pseudo-Haar
utilisées par le classifieur de l'étage courant,
· puis calcul de la réponse du classifieur,
· passage ensuite à l'étage
supérieur si la réponse est positive, à la
sous-fenêtre suivante sinon,
· et enfin l'exemple est déclaré positif si
tous les étages répondent positivement ;
· fusion des détections multiples : l'objet
peut en effet générer plusieurs détections, à
différentes positions et échelles ; cette dernière
étape fusionne les détections qui se chevauchent pour ne
retourner qu'un seul résultat.
2.1.4 Limitations et extensions
de la méthode
Figure 3 - L'extension des
caractéristiques
pseudo-Haar proposée par Lienhart.
Source :
http://fr.wikipedia.org/wiki/Méthode_de_Viola_et_Jones,
valide le 10/10/2011
De très nombreuses améliorations ont
été proposées par la suite, visant à
améliorer le paramétrage de la méthode, ou à en
combler un certain nombre de limitations.
L'une des premières améliorations est
apportée par Lienhart et Maydt en 2002. Ils proposent d'étendre
l'ensemble de
caractéristiques
pseudo-Haar utilisé de 4 à 14 caractéristiques. De
même, ils introduisent des caractéristiques « de
biais » (tournées de 45°), ainsi qu'une méthode
pour les calculer basée sur une extension des
images
intégrales.
D'autres types de caractéristiques ont également
été utilisés en remplacement des caractéristiques
de Haar : les
histogrammes
de gradients orientés, les
motifs binaires
locaux ou la covariance de région. Les chercheurs ont
également proposé d'utiliser des variantes de l'algorithme de
boosting, notamment
RealBoost, qui produit un
indice de confiance à
valeurs réelles,
en plus de la classification. Plusieurs travaux ont ainsi montré la
supériorité de RealBoost sur
AdaBoost dans le cadre de
l'algorithme de Viola et Jones.
Viola et Jones étendent en 2003 leur système
à la
détection
de piétons dans des vidéos, en incluant une information de
mouvement en plus de l'information d'apparence.
Une des limitations de la méthode est son manque de
robustesse à la
rotation, et sa
difficulté à apprendre plusieurs vues d'un même objet. En
particulier, il est difficile d'obtenir un classifieur capable de
détecter à la fois des visages de face et de profil. Viola et
Jones ont proposé une amélioration qui permet de corriger ce
défaut, qui consiste à apprendre une cascade dédiée
à chaque orientation ou vue, et à utiliser lors de la
détection un
arbre de
décision pour sélectionner la bonne cascade à
appliquer. Plusieurs autres améliorations ont été
proposées par la suite pour apporter une solution à ce
problème.
Une autre limitation importante de la méthode de Viola
et Jones concerne le temps d'apprentissage de la cascade, compris
généralement entre plusieurs jours et plusieurs semaines de
calcul, ce qui limite sévèrement les possibilités de tests
et de choix des paramètres.
Un des problèmes majeurs de la méthode
proposée par Viola et Jones est qu'il n'existe pas de méthode
optimale pour choisir les différents paramètres régissant
l'algorithme : le nombre d'étages, leur ordre ou les taux de
détection et de fausses alarmes pour chaque étage doivent
être choisis par
essais et erreurs.
Plusieurs méthodes sont proposées pour déterminer certains
de ces seuils de manière automatique.
Un reproche également fait à la méthode
concerne la perte d'information subie au passage d'un étage à
l'autre de la cascade, perte due à l'effet couperet des décisions
d'acceptation ou de rejet prises à chaque étage. Certains
chercheurs proposent la solution de garder l'information contenue dans la somme
pondérée des classifieurs faibles, par exemple le
« boosting chain » de Xiao. Une modification plus radicale
de structure est proposée par Bourdev et sa notion de cascade souple,
qui consiste essentiellement à supprimer le concept d'étages, en
formant un seul classifieur fort, donc une seule somme, et en permettant de
prendre une décision à chaque évaluation de classifieur
faible et de s'affranchir de la contrainte des taux de détection et de
fausses alarmes cibles.
2.2 LA RECONNAISSANCE DU
VISAGE
La reconnaissance faciale est une tâche que les humains
effectuent naturellement et sans effort dans leurs vies quotidiennes. La grande
disponibilité d'ordinateurs puissants et peu onéreux ainsi que
des systèmes informatiques embarqués ont suscité un
énorme intérêt dans le traitement automatique des images et
des vidéos numériques au sein de nombreuses applications,
incluant l'identification biométrique, la surveillance, l'interaction
homme-machine et la gestion de données multimédia. La
reconnaissance faciale, en tant qu'une des technologies biométriques de
base, a pris une part de plus en plus importante dans le domaine de la
recherche, ceci étant dû aux avances rapides dans
des technologies telles que les appareils photo numériques, Internet et
les dispositifs mobiles, le tout associé à des besoins en
sécurité sans cesse en augmentation.
La reconnaissance faciale possède plusieurs avantages
sur les autres technologies biométriques: elle est
naturelle, non intrusive et facile
à utiliser.
Parmi les six attributs biométriques
considérés par Hietmeyer (3(*)), les caractéristiques faciales marquent
un score de compatibilité le plus élevé dans un
système MRTD («Machine Readable Travel
Documents») (4(*)), ce score étant basé sur plusieurs
facteurs d'évaluation tels que l'enrôlement, le renouvellement des
données, les requis matériels et la perception des utilisateurs
(Figure 4)..
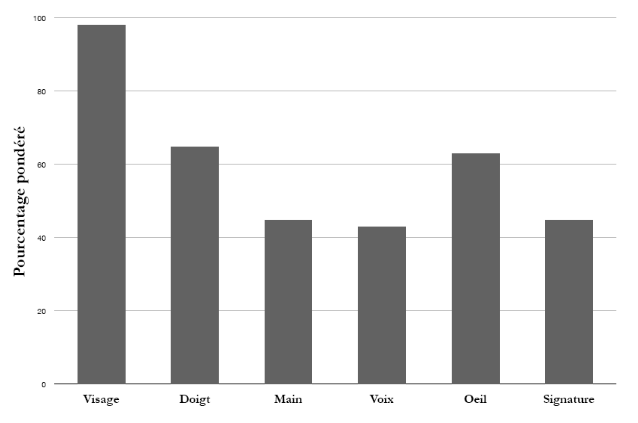
Figure 4 - Scores de compatibilité pour
différentes technologies biométriques dans un système
MRTD.
Idéalement, un système de reconnaissance faciale
doit pouvoir identifier des visages présents dans une image ou une
vidéo de manière automatique. Le système peut
opérer dans les deux modes suivants : authentification ou identification
; on peut également noter qu'il existe un autre type de scénario
de reconnaissance faciale mettant en jeu une vérification sur une liste
de surveillance («watch-list»), où un individu est
comparé à une liste restreinte de suspects. Le principe de
fonctionnement de base d'un système de reconnaissance faciale (Figure 5)
peut être résumé en quatre étapes :
les deux premières s'effectuent en amont du système
(détection (5(*))et normalisation du visage
(6(*))) et les deux
dernières représentent la reconnaissance à
proprement dit (extraction et comparaison des caractéristiques).
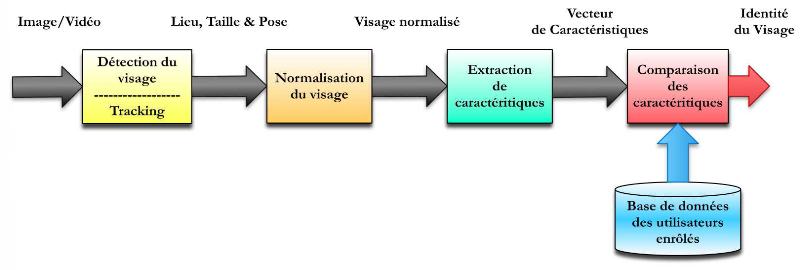
Figure 5 - Principe de fonctionnement de base d'un
système de reconnaissance faciale.
La performance des systèmes de reconnaissance faciale
s'est significativement améliorée depuis les premiers travaux qui
ont été menés dans les années 1960-1970(7(*)) et de nombreux algorithmes de
reconnaissance du visage ont été proposés depuis.
Certaines méthodes se basent sur une photographie (2D) du visage tandis
que d'autres méthodes prennent en compte des informations 3D de
celui-ci. On peut également noter qu'il existe d'autres méthodes
(parfois appelées 2.5D) qui effectuent la reconnaissance du visage en se
basant la plupart du temps sur l'information de profondeur.
Cependant, ces dernières méthodes peuvent
demander un coup de déploiement élevé dû à
l'investissement de scanners 3D coûteux. Un autre inconvénient
majeur concerne le grand volume de données tridimensionnelles qu'il est
souvent nécessaire de convertir afin de pouvoir les traiter
convenablement, ce qui implique une utilisation encore relativement
inadaptée à des contraintes temps-réel, contrairement au
traitement de photographies 2D. Enfin, à notre connaissance, il n'existe
pas de bases de données officielles 3D comprenant un nombre suffisamment
élevé d'utilisateurs pour pouvoir évaluer le rapport entre
la performance gagnée par l'utilisation d'une troisième dimension
et les coûts supplémentaires en termes de ressources et de temps
de calcul. Par conséquent, pour la partie concernant la reconnaissance
faciale, nous privilégierons l'étude des méthodes 2D.
Les méthodes de reconnaissance faciales peuvent
être séparées en deux grandes familles, les
méthodes globales (ou holistiques) et
les méthodes locales, basées sur des
modèles. Le choix a été fait de se concentrer sur
ces deux types d'approches fondamentales et de n'aborder ni les
réseaux neuronaux (8(*)) (plus adaptés à la
détection des visages), ni les modèles cachés de
Markov (9(*)) (plus
utilisés en reconnaissance de la parole) car ces deux dernières
techniques rencontrent des problèmes lorsque le nombre d'individus
augmente (les calculs deviennent très importants) ; de plus elles ne
conviennent pas pour les systèmes de reconnaissance basés sur une
seule "image modèle" car de nombreuses images par personne sont
nécessaires pour entraîner les systèmes afin de configurer
leurs paramètres de façon "optimale".
2.2.1 Méthodes
globales
Les méthodes globales sont basées sur des
techniques d'analyse statistique bien connues. Il n'est pas nécessaire
de repérer certains points caractéristiques du visage (comme les
centres des yeux, les narines, le centre de la bouche, etc.) à part pour
normaliser les images. Dans ces méthodes, les images de visage (qui
peuvent être vues comme des matrices de valeurs de pixels) sont
traitées de manière globale et sont généralement
transformées en vecteurs, plus faciles à manipuler.
L'avantage principal des méthodes globales est qu'elles
sont relativement rapides à mettre en oeuvre et que les
calculs de base sont d'une complexité moyenne. En revanche, elles sont
très sensibles aux variations d'éclairement, de pose et
d'expression faciale.
Ceci se comprend aisément puisque la moindre variation
des conditions de l'environnement ambiant entraîne des changements
inéluctables dans les valeurs des pixels qui sont traités
directement.
Ces méthodes utilisent principalement une analyse de
sous-espaces de visages. Cette expression repose sur un fait relativement
simple : une classe de "formes" qui nous intéresse (dans notre
cas, les visages) réside dans un sous-espace de l'espace de
l'image d'entrée.
Par exemple, considérons une petite image de
64×64, en niveaux de gris codés sur 8 bits (donc de 0 à
255). Cette dernière possède 4096 pixels qui peuvent exprimer un
grand nombre de classes de formes, comme des arbres, des maisons ou encore des
visages.
Cependant, parmi les 2564096 > 109864
"configurations" possibles, seulement une petite quantité peut
correspondre à des visages. Ainsi, la représentation de l'image
originale est très redondante et la dimensionnalité de cette
représentation pourrait être grandement réduite si l'on se
concentre uniquement sur les formes qui nous intéressent. L'utilisation
de techniques de modélisation de sous-espace a fait avancer la
technologie de reconnaissance faciale de manière significative.
Nous pouvons distinguer deux types de techniques parmi les
méthodes globales : Les techniques linéaires
et les techniques non linéaires.
Les techniques linéaires projettent linéairement
les données d'un espace de grande dimension (par exemple, l'espace de
l'image originale) sur un sous-espace de dimension inférieure.
Malheureusement, ces techniques sont incapables de préserver les
variations non convexes des variétés
(géométriques donc au sens mathématique du terme) de
visages afin de différencier des individus.
Dans un sous-espace linéaire, les distances
euclidiennes (cfr. Annexe A.1) et plus généralement les
distances de Mahalanobis (cfr. Annexe A.2), qui sont normalement
utilisées pour faire comparer des vecteurs de données, ne
permettent pas une bonne classification entre les classes de formes "visage" et
"non-visage" et entre les individus eux-mêmes. Ce facteur crucial limite
le pouvoir des techniques linéaires pour obtenir une détection et
une reconnaissance du visage très précises.
La technique linéaire la plus connue et sans aucun
doute l'Analyse en Composantes Principales (abrégé PCA
en anglais), également appelée
transformée de Karhunen-Loeve. Le PCA fut d'abord
utilisé afin de représenter efficacement des images de visages
humains (10(*)).
En 1991, cette technique a été reprise dans le
cadre plus spécifique de la reconnaissance faciale sous le nom de
méthode des Eigenfaces (11(*)) (on en trouvera une explication approfondie en
Annexe B.1).
Cependant, le PCA classique nécessite que les images de
visage soient mises sous formes de vecteurs, ce qui a pour effet de
détruire la structure géométrique de l'image.
Pour ne pas perdre les informations de voisinage lors du
passage de l'image en vecteur, une méthode PCA bi-dimensionnelle
(2-D PCA) a été étudiée. Cette
méthode prend en entrée des images et non plus des vecteurs.
Il existe d'autres techniques également construites
à partir de décompositions linéaires comme
l'analyse discriminante linéaire (abrégé
LDA en anglais) ou encore l'analyse en composantes
indépendantes (abrégé ICA en
anglais).
Tandis que le PCA construit un sous-espace pour
représenter de manière "optimale" (mathématiquement
parlant) seulement "l'objet" visage, le LDA construit un sous-espace
discriminant pour distinguer de façon "optimale" les visages de
différentes personnes.
Elle permet donc d'effectuer une véritable
séparation de classes (une explication détaillée du LDA
pourra être consultée en Annexe B.2). Des études
comparatives montrent que les méthodes basées sur le LDA donnent
généralement de meilleurs résultats que les
méthodes basées sur le PCA.
L'algorithme ICA, quant à lui, est une
généralisation de l'algorithme PCA avec lequel il coïncide
dans le cas de données gaussiennes. L'algorithme ICA
est basé sur le concept intuitif de contraste et permet
d'éliminer la redondance statistique des données de
départ. Ce dernier a été rendu célèbre
notamment avec l'expérience de la «cocktail party»
(12(*))qui met en avant la
résolution d'un problème de séparation
(décorrélation) de sources audio. Bartlett et al. ont
fourni deux architectures différentes pour l'ICA : une
première architecture (ICA I) qui construit une base d'images
statistiquement indépendantes et une deuxième architecture (ICA
II) qui fournit une représentation en code factoriel des
données.
Bien que ces méthodes globales linéaires
basées sur l'apparence évitent l'instabilité des toutes
premières méthodes géométriques qui ont
été mises au point, elles ne sont pas assez précises pour
décrire les subtilités des variétés
(géométriques) présentes dans l'espace de l'image
originale. Ceci est dû à leurs limitations à gérer
la non-linéarité en reconnaissance faciale : les
déformations de variétés non linéaires peuvent
être lissées et les concavités peuvent être remplies,
causant des conséquences défavorables.
Afin de pouvoir traiter ce problème de
non-linéarité en reconnaissance faciale, de telles
méthodes linéaires ont été étendues à
des techniques non linéaires basées sur la notion
mathématique de noyau («kernel») comme le Kernel PCA
(13(*)) et le Kernel LDA
(14(*)).Ici, une
projection non linéaire (réduction de dimension) de l'espace de
l'image sur l'espace de caractéristiques («feature
space») est effectuée ; les variétés
présentes dans l'espace de caractéristiques résultant
deviennent simple, de même que le subtilités des
variétés qui sont préservées. Bien que les
méthodes basées sur le noyau peuvent atteindre une bonne
performance sur les données d'entraînement, il ne peut pas en
être de même pour de nouvelles données en raison de leur
plus grande flexibilité ; contrairement aux méthodes
linéaires.
2.2.2 Méthodes
locales
Les méthodes locales, basées sur des
modèles, utilisent des connaissances a priori que l'on possède
sur la morphologie du visage et s'appuient en général sur des
points caractéristiques de celui-ci. Kanade présenta un des
premiers algorithmes de ce type en détectant certains points ou traits
caractéristiques d'un visage puis en les comparant avec des
paramètres extraits d'autres visages. Ces méthodes constituent
une autre approche pour prendre en compte la non-linéarité en
construisant un espace de caractéristiques local et en utilisant des
filtres d'images appropriés, de manière à ce que les
distributions des visages soient moins affectées par divers
changements.
Les approches Bayesiennes, les machines à vecteurs de
support, la méthode des modèles actifs d'apparence ou encore la
méthode «local binary pattern» ont été
utilisées dans ce but.
Toutes ces méthodes ont l'avantage de pouvoir
modéliser plus facilement les variations de pose, d'éclairage et
d'expression par rapport aux méthodes globales. Toutefois, elles sont
plus lourdes à utiliser puisqu'il faut souvent placer manuellement un
assez grand nombre de points sur le visage alors que les méthodes
globales ne nécessitent de connaître que la position des yeux afin
de normaliser les images, ce qui peut être fait automatiquement et de
manière assez fiable par un algorithme de détection.
2.2.3 Méthodes
hybrides
Les méthodes hybrides permettent d'associer les
avantages des méthodes globales et locales en combinant la
détection de caractéristiques géométriques (ou
structurales) avec l'extraction de caractéristiques d'apparence locales.
Elles permettent d'augmenter la stabilité de la performance de
reconnaissance lors de changements de pose, d'éclairement et
d'expressions faciales.
L'analyse de caractéristiques locales et les
caractéristiques extraites par ondelettes de Gabor (comme l'Elastic
Bunch Graph Matching, dont on trouvera une présentation plus
détaillée en Annexe B.3), sont des algorithmes hybrides
typiques.
Plus récemment, l'algorithme LogGabor PCA effectue une
convolution avec des ondelettes de Gabor orientées autour de certains
points caractéristiques du visage afin de créer des vecteurs
contenant la localisation et la valeur d'amplitudes énergétiques
locales ; ces vecteurs sont ensuite envoyés dans un algorithme PCA afin
de réduire la dimension des données.
La figure 6 fournit une classification des algorithmes
principaux de reconnaissance faciale.
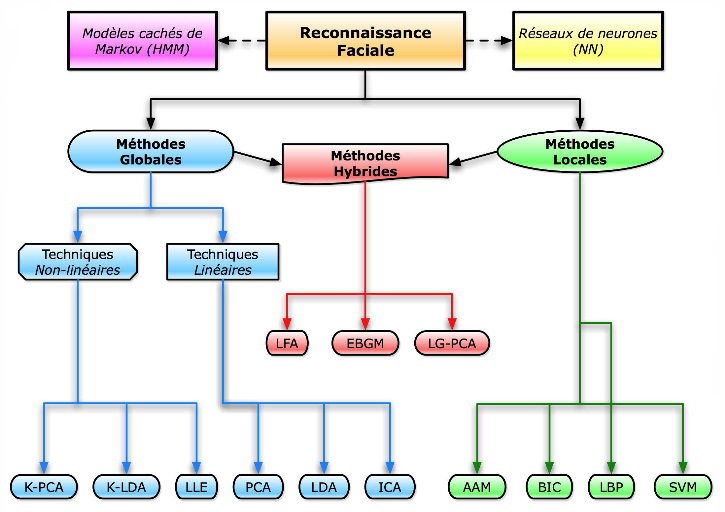
Figure 6 - Une
classification des algorithmes principaux utilisés en reconnaissance
faciale.
Comme nous l'avons signalé dans la partie introductive,
nous avons utilisé la méthode globale (ou holistique). Dans cette
dernière, nous avons utilisé l'une de ces techniques
linéaires qui est l'Analyse en Composantes Principales mais qui
est bidimensionnelle.
CHAPITRE TROISIEME :
MISE EN PLACE D'UNE APPLICATION D'IDENTIFICATION DE PERSONNES PAR
RECONNAISSANCE DE VISAGE POUR LA SECURITE D'UNE INSTITUTION BANCAIRE
3.1 ENVIRONNEMENT
UTILISE
Notre sujet de recherche nous a permis d'aboutir à la
conception d'une application permettant d'assurer la sécurité
d'une institution bancaire.
Notre application tourne sous un ordinateur ayant les
caractéristiques suivantes :
a. Environnement matériel ou le hardware
· Toshiba satellite C660
· Capacité du disque dur : 500 gigaoctet
· Modèle du processeur : Intel Celeron
· Vitesse du processeur : 2,30 gigahertz
· Mémoire RAM : 2 gigaoctet
b. Environnement immatérielle ou le
software
· Système d'exploitation : Linux dans sa
distribution Ubuntu 10.10
· Version d'OpenCV : 2.3.1
· Version cmake : 2.8.2
· Version ffmpeg : 0.6-4 :0.6-2ubuntu6.3
Ceci étant l'environnement sous lequel a tourné
notre application, il est à signaler qu'elle peut aussi tourner sur
d'autres ordinateurs à technologie moderne.
3.2 PROGRAMMATION
Nous avons commencé par importer les
bibliothèques suivantes que nous allons préciser leur utilisation
au fur et à mesure que nous avançons dans notre programmation.
Voici les bibliothèques utilisées :· <cv.h>
· <highgui.h>
· <cvaux.h>
· <stdio.h>
· <stdlib.h>
· <string.h>
· <assert.h>
· <math.h>
· <float.h>
· <limits.h>
· <time.h>
· <ctype.h>· Détection de
visage
Pour que l'application parvienne à détecter le
visage humain, il faut d'abord qu'il parvienne à lire à partir
d'une camera (webcam). Nous savons aussi qu'un flux est une succession d'images
(appelées frames) qui ont été prises à intervalles
de temps réguliers.
Pour arriver à capturer les éléments qui
passent devant la caméra, nous avons utilisé la fonction
cvCaptureFromCAM et nous avons stocké cette donnée dans
la variable capture qui est du type Iplimage.
Une condition a été utilisée pour
vérifier si la capture a été réalisée.
Si oui, ouverture d'une boucle infinie et dans cette
dernière nous avons utilisé la fonction cvGrabFrame pour
saisir des frames de la caméra et nous les stockons dans la variable
frame.
Si non, chargement d'un fichier image d'une personne qui se
trouve dans un emplacement de l'ordinateur à l'aide de la fonction
cvLoadImage.
Toujours dans la boucle infinie, nous avons alloué une
image de même dimension que la frame saisie et nous avons crée une
copie bien sûr avec la fonction cvCopy et c'est sur cette copie
que nous avions à appliquer la détection du visage. Dans cette
même boucle (infinie), nous y avons mis la condition d'arrêt de la
boucle au cas où on appuyait sur n'importe quelle touche du clavier avec
la fonction cvWaitKey.
A la fin de cette boucle, nous avons détruit la frame
et la copy de la frame (qui sont considérées ici comme
étant déjà des images) à l'aide de la fonction
cvReleaseImage . Pour ainsi tout afficher dans une fenêtre et
donner le nom à cette dernière, nous avons utilisé la
fonction cvNamedWindow, cette fenêtre est détruite
à la fin de la boucle par la fonction cvDetroyWindow au cas
où on quittait le programme en l'arrêtant.
Nous avons pu afficher un message sur la fenêtre de la
vidéo créée grâce à la fonction
cvPutText.
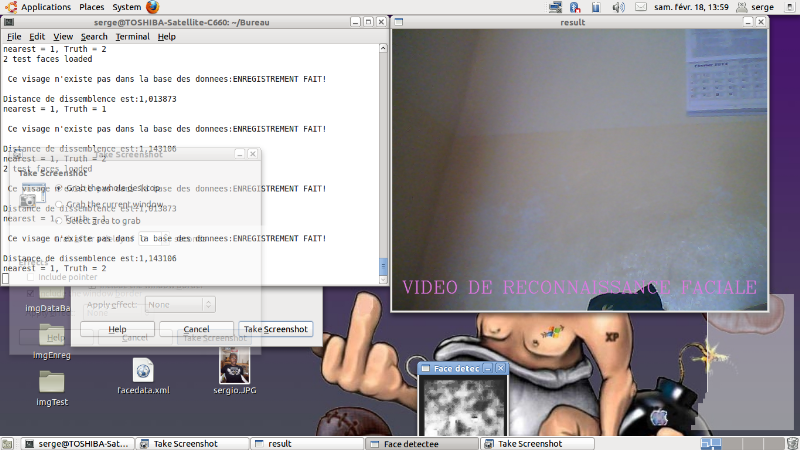
Cette partie expliquée étant la partie
principale du programme (le main en anglais), nous a permis d'aboutir
au résultat suivant et qui est représenté par l'image
ci-dessous :
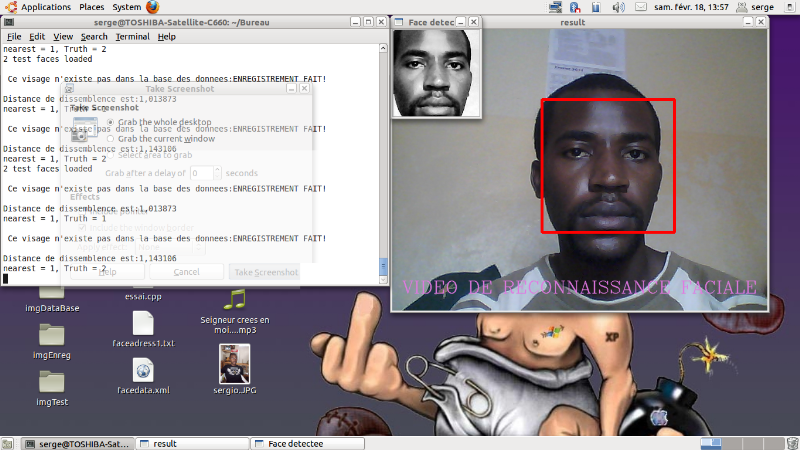
Pour arriver à détecter le visage présent
devant la camera, nous avons fait usage de la fonction
cvHaarDetectObjects.
Cette fonction fait appel à un classifieur qui permet
de détecter le visage d'une personne devant la camera.
NB : Il est à noter que ces classifieurs ne sont
pas les mêmes parce que sont crées pour des fins
différentes : pour détecter les personnes, détecter
les voiture, détecter les plaques des voitures,...
OpenCV vient déjà avec différents
classifieurs du visage (face) humain dès son installation. Ces
différents classifieurs sont situés dans le dossier data/
haarcascades/. Voici en exemple les classifieurs que nous trouvons dans OpenCV
de sa version 2.2.0 :
haarcascade_eye
haarcascade_eye_tree_eyeglasses
haarcascade_frontalface_alt
haarcascade_frontalface_alt_tree
haarcascade_frontalface_alt2
haarcascade_frontalface_default
haarcascade_fullbody
haarcascade_lefteye_2splits
haarcascade_lowerbody
haarcascade_mcs_eyepair_big
haarcascade_mcs_eyepair_small
haarcascade_mcs_lefteye
haarcascade_mcs_mouth
haarcascade_mcs_nose
haarcascade_mcs_righteye
haarcascade_mcs_upperbody
haarcascade_profileface
haarcascade_righteye_2splits
haarcascade_upperbody
Etant donné que nous avions à détecter le
visage humain, nous avons fait usage du classifieur
haarcascade_frontalface_alt.xml.
C'est ainsi que nous avons crée une fonction
appelée detecte_et_dessine qui détecte le visage et
dessine un rectangle autour du visage comme son nom l'indique. Dans cette
dernière, nous chargeons le classifieur qui a été
stocké dans une variable. Si le chargement réussit, nous
parcourons les frames avec la fonction cvHaarDetectObjects pour
chercher à détecter tout visage devant la camera. Une fois le
visage détecté, nous le parcourons en considérant ses
différents cotés et nous y traçons un rectangle avec la
fonction cvRectangle. Pour mieux voir le visage
détecté, nous l'affichons dans une autre fenêtre Windows.
Nous savons que la reconnaissance faciale a ses limites entre
autre les conditions d'éclairage pour mieux assurer la reconnaissance de
visage. Pour contourner cette difficulté, nous avons converti cette
figure détectée en image grise sur laquelle nous appliquons
l'égalisation d'histogramme pour rendre la surbrillance et le contraste
consistants à l'aide de la fonction cvEqualizeHist.
Ainsi la détection est réalisée et nous
aboutissons au résultat suivant représenté par
l'image ci-dessous:
Voici en quelques lignes le code utilisé pour la
détection de visage :
Nous avons crée deux autres fonctions nommées
Enreg_faceImg1 et Enreg_faceImg2. La première fait
l'enregistrement de visages dans le dossier des visages temporaires dans et la
deuxième le dossier considéré comme la base de
données des visages sélectionnés. Ces deux fonctions nous
ont permis d'enregistrer chaque fois 3 images successivement après
chaque seconde à l'aide de la fonction cvSaveImage dans des
emplacements différents ci-haut signalés.
Dans ces fonctions, nous avons utilisé le format de la
date/heure pour donner le nom aux figures capturées. Ceci nous a permis
de capturer une ou plusieurs images de figures ayant chacune un nom
différent de l'autre.
C'est ainsi que nous avions à stocker les figures sur
le disque dur dans un emplacement précis. En plus de cela, chaque
enregistrement était accompagné par l'ouverture,
l'écriture dans un fichier texte (d'extension .txt) et la fermeture de
cet dernier. L'écriture dans le fichier texte est du format :
1 imgDataBase/face_16-01-2012_12:57:36.bmp
1 imgDataBase/face_16-01-2012_12:57:37.bmp
2 imgDataBase /face_02-02-2012_05:50:14.bmp
2 imgDataBase /face_02-02-2012_05:50:15.bmp
3 imgDataBase /face_02-02-2012_05:50:56.bmp
3 imgDataBase /face_02-02-2012_05:50:57.bmp
Ceci veut dire au programme que toutes les images (figures)
ayant le même nombre entier désigne les figures d'une même
personne, une fois ce nombre change c'est-à-dire par exemple passe de 1
à 2, les figures deviennent d'une autre personne qui n'est plus la
première.
Nous tenons à préciser que nous avions
utilisé deux fichiers de type texte : l'un nommé bdd.txt
qui stocke les adresses des figures sélectionnées dan la
base de données et l'autre nommé test.txt qui stocke les
adresses des figures capturées temporairement qui vont subir le teste
avant d'être stockées et considérées comme images de
la base de données.
· Reconnaissance du visage
Pour parvenir menant à assurer une reconnaissance pour
mieux sélectionner les visages à enregistrer une et une seule
fois dans la base de données (ne pas enregistrer le visage d'une
personne au cas où il est existe déjà dans la base de
données), nous avons utilisé une autre fonction nommée
apprentissage.
Dans cette fonction, nous avons commencé par charger
les visages stockés dans la base de données (bien sûr par
ouverture en lecture du fichier contenant les adresses des figures
stockées sur le disque dur) à l'aide de la fonction
loadFaceImgArray. Cette fonction permet de lire ligne par ligne dans
le fichier texte bdd.txt et ainsi compter le nombre de figures
chargées, ceci étant possible du fait que chaque tour de lecture
d'une ligne équivaut est stocké dans une variable nommée
nTrainFaces de type integer (entier). Toutes ces
figures chargées sont projetées dans la fonction
doPCA.
Cette fonction, n'est que celle qui permet de
régénérer d'autres figures appelées ici dans notre
programmation eigenface. Ces figures
régénérées sont issues de la première figure
capturée permettant ainsi d'avoir une multitude de figures peu
semblables à la figure d'origine. En confrontant ces différentes
figures, nous parvenons à reconnaitre la première figure
d'origine.
Cette opération se fait de la manière suivante
suivant cet exemple :
(FaceOriginale) + (13.5% de la face
régénérée0) - (34.3% de la face
régénérée1) + (4.7% de la face
régénérée2) + ... + (0.0% de la face
régénérée20).
Une fois il a résolu ceci, il peut penser à
cette image source de la formation comme les 20 proportions: {13.5, -34.3, 4.7,
..., 0.0}.
Dans cette fonction apprentissage fait aussi appel
à une autre fonction nommée storeTrainingData . Quant
à cette dernière fonction, elle permet de créer un
fichier de stockage d'extension xml. Ce fichier sert à stoker toutes les
données que nous avions à utiliser et que nous aurons aussi
à utiliser mais qui y sont stockées comme des entiers. Ces
données sont : les différentes figures
régénérées par la fonction doPCA, les
figures originales, le nombre entier qui représente le nombre de visage
stockées pour chaque personne, ...
Par la suite, nous avons aussi utilisé une autre
fonction nommée reconnaissance. Cette fonction nous a permis
aussi de charger les figures contenues dans le fichier test.txt (bien
sûr avec la fonction loadFaceImgArray) pour enfin comparer la
ressemblance entre les figures déjà stockées dans la base
de données et les figures vouées au teste avant d'être
considéré comme figures de la base de données existante.
Cette fonction nous a permis aussi de calculer le pourcentage de
rapprochement entre les visages.
Il faut aussi signaler qu'une autre fonction nommée
loadTrainingData a été utilisée pour charger
les données (visages et autres) stockées dans le fichier xml et
ainsi faire la comparaison avec ceux qui vont subir le teste.
Il convient aussi de signaler que c'est dans la fonction
findNearestNeighbor qu'a été calculée la distance de
Mahalanobis pour effectuer une mesure de distance (divergence) entre toutes
les figures (visages) détectée (cfr. Annexe A.2).
Nous avons estimé ce taux de divergence en terme de
pourcentage et avons considéré 10,00% comme seuil. Ceci veut
signifier que, chaque fois que la comparaison de distance entre deux visages
est au-delà de ce 10,00% (c'est-à-dire 10,01% et plus), les deux
visages sont différents et par conséquent le visage
détecté est enregistré dans la base de données.
Ainsi la condition remplie, une capture de trois images était
possible.
Dans le cas contraire (c'est-à-dire entre 0,00% et
10,00%), le visage détecté existe déjà dans la base
de données et par conséquent il n'est pas enregistré.
CONCLUSION
Dans ce mémoire, nous avons traité de
l'identification des personnes par reconnaissance de visage pour la
sécurité d'une institution bancaire.
Comme nous l'avons vu, nous avions comme problématique
le control des `'personnes étrangers'' (clients) visitant une
institution bancaire par jour, par semaine, par mois,... du faite que leurs
visites peuvent conduire au braquage, escroquerie et espionnage. S'ils ne sont
pas reconnus, aucun suivi ne pourra être fait pour arriver à les
arrêter.
Notre hypothèse avait stipulé que, la mise en
place d'un système de contrôle par caméras de surveillance
et ces dernières assistées par une application de
détection et reconnaissance faciale (des visages) afin que les figures
capturées puissent subir de suivi, serait un moyen efficace pour contrer
ces actes d'espionnage, d'escroquerie et de braquage.
Nous avons commencé par présenter les outils
à utiliser pour nous aider à arriver à nos fins dans le
premier chapitre dont la bibliothèque d'OpenCV ; ensuite nous avons
montré en quoi consiste la reconnaissance faciale (du visage) en
théorie et comment fonctionne-t-elle dans le chapitre deuxième.
Dans le troisième chapitre, nous avons mis en place une
application de reconnaissance faciale pouvant nous aider dans la
sécurité par caméra de surveillance pour les institutions
bancaires de la ville de Bukavu.
D'après nos résultats, nous avons utilisé
la méthode comparative pour comparer les visages déjà
capturés et ceux se présentant devant la caméra. Pour
arriver à faire cette comparaison, nous avons fait usage de la distance
de Mahalanobis et grâce à cette dernière, nous
établissions la distance de divergence existant entre deux visages.
D'après nos expériences et testes, nous
confirmons que cette application de reconnaissance faciale est à la
hauteur de la sécurité par caméra de surveillance pour les
institutions bancaires de la ville de Bukavu tout en considérant le
seuil de confiance de 0,10 soit 10,00%. C'est-à-dire l'enregistrement du
visage est conditionné par une distance de divergence supérieure
à 10,00%.
Nous confirmons encore notre hypothèse en disant que,
la reconnaissance du visage contribue de manière efficace à la
sécurité des institutions bancaires de la ville de Bukavu du
faite que les visages détectés automatiquement portent comme nom,
la date et l'heure de la détection.
Ceci pourra contribuer au suivi de visages capturés
tout en étant sûr de la date et de l'heure que les institutions
bancaires de la ville de Bukavu ont connu des événements
d'escroquerie, d'espionnage et de braquages.
Néanmoins, nous suggérons une bonne position
devant la caméra pour une bonne détection de visage mais aussi
l'environnement bien éclairé (si pas ceci, faire usage de cameras
infrarouges) pour que cette distance de divergence ne soit pas
influencée par ces deux facteurs.
Le résultat offert par l'application que nous avons
réalisée confirme bien notre hypothèse.
Toutes fois, un vaste champ de recherche reste ouvert aux
futurs chercheurs, qui voudraient faire le suivi des visages capturés
mais aussi l'amélioration les conditions de capture de visage en
utilisant les outils que nous offre la bibliothèque d'OpenCV.
Tout travail humain étant sujet à des
imperfections, nous disons bienvenues aux suggestions et remarques d'autres
chercheurs qui pourront élargir de plus les frontières de la
science.
BIBLIOGRAPHIE
A. Ouvrages
BRADSKI G. et KAEBLER A.; Learning
OpenCV ; O'Reilly Media; 2008;
B. Thèses et mémoires
· Souhila GUERFI ABABSA ;
Authentification d'individus par reconnaissance de
caractéristiques biométriques liées aux visages
2D/3D ; Thèse; UNIVERSITE EVRY VAL D'ESSONNE;
Ile-de-France; 2008.
· Walid HIZEM ; Capteur Intelligent pour
la Reconnaissance du visage ; UNIVERSITE PIERRE ET MARIE
CURIE - PARIS 6 ; Thèse ; Paris ; 2009.
· Nicolas MORIZET ; Reconnaissance
Biométrique par Fusion Multimodale du Visage et de
l'Iris ; Ecole Nationale Supérieure des
Télécommunications ; Paris ; 2009.
C. Netographie
-
http://www.faceRecognition.html/ valide le 11/10/2011
- http://www.face-rec.org/
valide le 16/08/2011
-
http://opencv.willowgarage.com/ valide 10/10/2011
- http://www.siteduzero.com/
valide le 20/07/2011
- http://www.cppfrance.com/
valide le 5/09/2011
TABLE DES MATIERES
PRELUDE.................................................................................................I
IN
MEMORIAM.........................................................................................II
DEDICACE.............................................................................................III
REMERCIEMENTS..................................................................................IV
SIGLES ET
ABREVIATIONS.....................................................................VI
0. INTRODUCTION
1
0.1 Problématique
1
0.2 Hypothèse
2
0.3 Choix et intérêt du sujet
3
0.4 Délimitation du sujet
3
0.5 Méthodologie
4
0.6 Etat de la question
4
0.7 Difficultés rencontrées
6
0.8 Plan sommaire du travail
6
CHAPITRE PREMIER : GENERALITES SUR OPENCV
7
1.1 Histoire
7
1.2 Fonctionnalités
8
a) Traitement d'images
8
b) Traitement vidéos
8
c) Algorithmes d'apprentissage
9
d) Calculs Matriciels
9
1.3 Structure de la librairie OpenCV
10
1.4 Installation d'OpenCV
12
1.4.1 Sous Windows
12
a) OpenCV 1.0 sous Visual Studio 6
12
b) OpenCV1.0 sous Dev-C++ 4.9.9.x
(installé en langue anglaise)
15
1.4.2 Sous Linux
16
CHAPITRE DEUXIEME: RECONNAISSANCE DU VISAGE
19
2.1 DETECTION DE VISAGE
19
2.1.1 Applications
20
2.1.2 Méthode de détection de
visage
21
2.1.2.1 Historique
21
2.1.2.2 Éléments de la
méthode
22
a) Caractéristiques
23
b) Calcul
24
c) Sélection de caractéristiques par
boosting
25
d) Cascade de classifieurs
27
2.1.3 Étapes clés de la
méthode
29
a) Apprentissage
29
b) Détection
29
2.1.4 Limitations et extensions de la
méthode
30
2.2 LA RECONNAISSANCE DU VISAGE
32
2.2.1 Méthodes globales
35
2.2.2 Méthodes locales
39
2.2.3 Méthodes hybrides
40
CHAPITRE TROISIEME : MISE EN PLACE D'UNE
APPLICATION D'IDENTIFICATION DE PERSONNES PAR RECONNAISSANCE DE VISAGE POUR LA
SECURITE D'UNE INSTITUTION BANCAIRE
42
3.1 ENVIRONNEMENT UTILISE
42
3.2 PROGRAMMATION
42
CONCLUSION
50
BIBLIOGRAPHIE
52
TABLE DES MATIERES
53
Annexes...............................................................................................................................................................55

* 1
http://sourceforge.net/projects/opencvlibrary/files/
, valide le 10/06/2011 a 15h20
* 2
http://fr.wikipedia.org/wiki/Méthode_de_Viola_et_Jones,
valide le 10/10/2011
* 3R. Hietmeyer, «Biometric
identification promises fast and secure processing of airline passengers».
The International Civil Aviation Organization Journal, Vol. 17, No. 9,
pp. 10-11, 2000.
* 4 «Machine Readable
Travel Documents (MRTD)». 2008.
http://www2.icao.int/en/mrtd/Pages/default.aspx.
valide le 12/07/2011
* 5 Y. Hori, M. Kusaka, et T.
Kuroda. «A 0.79mm2 29mW Real-Time Face Detection Core». Symposium
on VLSI Circuits Digest of Technical Papers, pp. 188-189, June 2006.
* 6 D. Bolme, J. Beveridge, M.
Teixeira, et B. Draper. «The CSU Face Identification Evaluation System :
Its Purpose, Features, and Structure». In : Proceedings of the 3rd
International Conference on Computer Vision Systems (ICVS), pp. 304-313,
2003.
* 7 T. Kanade. «Computer
Recognition of Human Faces». Interdisciplinary Systems Research,
Vol. 47, 1977.
* 8 S. Lin, S. Kung, and L. Lin.
«Face Recognition/Detection by Probabilistic Decision-Based
Neural-Network». Transactions on Neural Networks, Vol. 8, No. 1,
pp. 114-132, Janvier 1997.
* 9 A. Nefian and M. Hayes.
«Face Detection and Recognition Using Hidden Markov Models». In :
International Conference on Image Processing (ICIP), pp. 141-145,
1998.
* 10L. Sirovich et M. Kirby.
«Low-dimensional procedure for the characterization of human faces».
Journal of Optical Society of America, Vol. 4, No. 3, pp. 519-524,
1987.
* 11 M. Turk et A. Pentland,
«Eigenfaces for recognition». Journal of Cognitive
Neuroscience, Vol. 3, No. 1, pp. 71-86, 1991.
* 12 G. Brown, S. Yamada, and
T. Sejnowski. «Independent Component Analysis at the Neural Cocktail
Party». Trends in Neuroscience, Vol. 24, pp. 54-63, 2001.
* 13 B. Schölkopf, A.
Smola, and K.-R. Müller. «Nonlinear component analysis as a kernel
eigenvalue problem». Neuralomputation, Vol. 10, No. 5, pp. 1299-
1319, 1998.
* 14 S. Mika, G. Ratsch,
J.Weston, B. Schölkopf, and K.-R. Müller. «Fisher Discriminant
Analysis With Kernels». In : Neural Networks for Signal Processing
IX,v pp. 41-48, 1999.
| 

