Identification des personnes par reconnaissance de visage pour la sécurité d'une institution bancaire( Télécharger le fichier original )par Serge KOMANDA BASEMA Institut supérieur pédagogique de Bukavu- RDC - Licence en informatique de gestion option pédagogie appliquée 2010 |

b) CalculLes caractéristiques sont calculées à toutes les positions et à toutes les échelles dans une fenêtre de détection de petite taille, typiquement de 24 × 24 pixels ou de 20 × 15 pixels. Un très grand nombre de caractéristiques par fenêtre est ainsi généré, Viola et Jones donnant l'exemple d'une fenêtre de taille 24 × 24 qui génère environ 160 000 caractéristiques. En phase de détection, l'ensemble de l'image est parcouru en déplaçant la fenêtre de détection d'un certain pas dans le sens horizontal et vertical (ce pas valant 1 pixel dans l'algorithme original). Les changements d'échelles se font en modifiant successivement la taille de la fenêtre de détection [. Viola et Jones utilisent un facteur multiplicatif de 1,25, jusqu'à ce que la fenêtre couvre la totalité de l'image. Finalement, et afin d'être plus robuste aux variations d'illumination, les fenêtres sont normalisées par la variance. La conséquence de ces choix techniques, notamment le recours aux images intégrales, est un gain notable en efficacité, les caractéristiques étant évaluées très rapidement quelle que soit la taille de la fenêtre. c) Sélection de caractéristiques par boostingLe deuxième élément clé de la méthode de Viola et Jones est l'utilisation d'une méthode de boosting afin de sélectionner les meilleures caractéristiques. Le boosting est un principe qui consiste à construire un classifieur « fort » à partir d'une combinaison pondérée de classifieurs « faibles », c'est-à-dire donnant en moyenne une réponse meilleure qu'un tirage aléatoire. Viola et Jones adaptent ce principe en assimilant une caractéristique à un classifieur faible, en construisant un classifieur faible qui n'utilise qu'une seule caractéristique. L'apprentissage du classifieur faible consiste alors à trouver la valeur seuil de la caractéristique qui permet de mieux séparer les exemples positifs des exemples négatifs. Le classifieur se réduit alors à un couple (caractéristique, seuil). L'algorithme de boosting utilisé est en pratique une version modifiée d' AdaBoost, qui est utilisée à la fois pour la sélection et pour l'apprentissage d'un classifieur « fort ». Les classifieurs faibles utilisés sont souvent des arbres de décision. Un cas remarquable, fréquemment rencontré, est celui de l'arbre de profondeur 1, qui réduit l'opération de classification à un simple seuillage. L'algorithme est de type itératif, à nombre d'itérations déterminé. À chaque itération, l'algorithme sélectionne une caractéristique, qui sera ajoutée à la liste des caractéristiques sélectionnées aux itérations précédentes, et le tout va contribuer à la construction du classifieur fort final. Cette sélection se fait en entraînant un classifieur faible pour toutes les caractéristiques et en élisant celle de ces dernières qui génère l'erreur la plus faible sur tout l'ensemble d'apprentissage. L'algorithme tient également à jour une distribution de probabilité sur l'ensemble d'apprentissage, réévaluée à chaque itération en fonction des résultats de classification. En particulier, plus de poids est attribué aux exemples difficiles à classer, c'est à dire ceux dont l'erreur est élevée. Le classifieur « fort » final construit par AdaBoost est composé de la somme pondérée des classifieurs sélectionnés. Plus formellement, on considère un ensemble de
n images
les wi étant les poids associés à chaque exemple et mis à jour à chaque itération en fonction de l'erreur obtenue à l'itération précédente. On sélectionne alors à l'itération t le classifieur ht présentant l'erreur la plus faible : åt = minj(åj). Le classifieur fort final h(x) est construit par seuillage de la somme pondérée des classifieurs faibles sélectionnés :
Les át sont des coefficients calculés à partir de l'erreur åt. |
|


 et leurs étiquettes associées
et leurs étiquettes associées  , qui sont telles que yi = 0 si l'image
xi est un exemple négatif et yi
= 1 si xi est un exemple de l'objet à
détecter. L'algorithme de boosting est constitué d'un nombre
T d'itérations, et pour chaque itération t et
chaque
, qui sont telles que yi = 0 si l'image
xi est un exemple négatif et yi
= 1 si xi est un exemple de l'objet à
détecter. L'algorithme de boosting est constitué d'un nombre
T d'itérations, et pour chaque itération t et
chaque
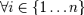 . En pratique, le classifieur n'est pas parfait et l'erreur
engendrée par ce classifieur est donnée par :
. En pratique, le classifieur n'est pas parfait et l'erreur
engendrée par ce classifieur est donnée par :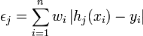 ,
,