Conclusion
Les regroupements en cliques sont une étape
d'étude. Les cliques relevées n'ont pas donné satisfaction
en de nombreux points.
Tout d'abord, la taille « maximale » des cliques est
très faible.
4.4 : Résultats des regroupements et validation
sémantique 152
Chapitre 4. Expérimentations, validations
sémantiques et résultats de mesure
Ensuite, plus de 70 % des cliques ne sont en fait que le
résultat d'une requête. En effet, il suffit d'une requête de
neuf mots pour créer une clique d'autant de mots. Chacun des neuf mots
de la requête a bien été utilisé avec les huit
autres. Il n'y a pas, avec cette méthode, de pondération et donc
de seuil de validation des liaisons.
Par ailleurs, une vérification manuelle rapide nous
montre que les agrégats ne sont pas sémantiquement
cohérents. La non prise en compte de la pondération des liens
permet de créer des ensembles non significatifs. (cf. figure 4.11). Les
éléments utilisés une fois conjointement créent
forcément une clique. Les mots les plus utilisés servent de hubs
à des cliques dans lesquelles les autres mots se sont trouvés
simplement une fois « au contact » de tous les autres. Ceci
n'est pas représentatif des « véritables » usages. Une
utilisation exceptionnelle ou erronée, d'un terme provoque des liens
tout aussi valides que des utilisations nombreuses.
Enfin, sur ce réseau, nous avons dû supprimer
préalablement les mots vides pour éviter des agrégats
encore moins cohérents. Ce type de regroupement n'est pas efficace sur
des réseaux de cette nature (cf. figure 4.11). En revanche, sur d'autres
réseaux, notamment sur des réseaux possédant la
caractéristique d'imposer un degré limité à chaque
noeud, ils peuvent être très efficaces. Le travail de Palla &
all [Palla&al-2005] (cf. paragraphe 2.3.1) utilisant la
notion d'agrégation de cliques a, sur des réseaux biologiques,
donné d'excellents résultats.
4.4.2 Agrégation par la méthode de
Rigidification Simple sur réseaux AOL-17/04/2006 et AOL-17/03/2006 -
Validation par MCCVS
Matériel et conditions de test
Pour cette validation nous travaillons sur les réseaux
: AOL-17/04/2006 et AOL-17/03/2006.
Définition des paramètres de
l'algorithme
Après plusieurs essais sur des échantillons,
nous avons défini les valeurs des seuils : Valeur Minimale de CFL ou
Val-Min-CFL à 5 % du poids du mot-clé et la Valeur
d'Activation ou Val-Activ-CFL à 20 % du poids du mot-clé
(cf. paragraphe 3.3).
Ces essais, effectués par approximations successives
sur des échantillons du graphe, ont permis de définir des valeurs
qui, tout à la fois, autorisent la création d'agrégats et
limitent la taille maximale des agrégats à des valeurs qui,
intuitivement, semblent correctes. Nous avons considéré que la
taille maximale devait être inférieure à un millier de
mots.
Ces valeurs pourront être modifiées lors de
prochaines expérimentations ; ici, elles servent d'exemples et ne
constituent pas le sujet de l'étude. Elles doivent cependant nous
permettre de valider la méthode en créant suffisamment
d'agrégats pour étudier ceux-ci, c'est ce qui a été
validé par les essais préliminaires.
4.4 : Résultats des regroupements et validation
sémantique 153
Chapitre 4. Expérimentations, validations
sémantiques et résultats de mesure
Nombre et nature des agrégats
créés
La démarche implantée a permis de former 9 556
agrégats construits avec 38 621 mots-clés dont 24 537
mots-clés différents dans l'ensemble des agrégats (cf.
figure 4.12). Le nombre moyen de mots-clés par agrégat est de
4,04. L'agrégat le plus important contient 133 mots-clés.
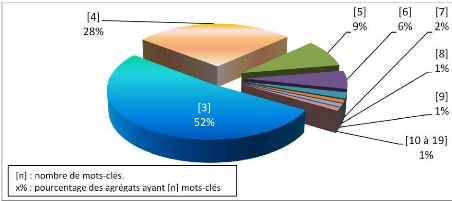
Figure 4.12 : Répartition des agrégats en
fonction du nombre de mots-clés
Estimation de la qualité sémantique des
agrégats
40
70
60
50
30
20
10
0
A
B
Trios de mots aléatoires
Triades existantes dans une requête utilisateur au moins
C
D
Figure 4.13 : Comparaison des réponses aux
requêtes susceptibles d'être les plus éloignées
sémantiquement (cf. 4.3.1) et détermination de la zone à
plus forte divergence.
Nous comparons ici les deux courbes de réponses des
deux espaces les plus éloignés sémantiquement selon le
postulat posé en section 4.3.1. Nous comparons la courbe issue des mots
combinés aléatoirement (excluant des triades de mots
utilisées dans une recherche) avec la courbe de référence
issue du test de triades de mots pour lesquelles il existe au moins une
4.4 : Résultats des regroupements et validation
sémantique 154
Chapitre 4. Expérimentations, validations
sémantiques et résultats de mesure
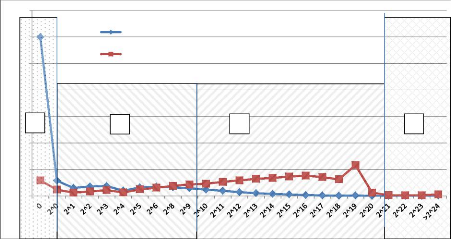
recherche incluant ces trois mots-clés. Sur la figure
4.13, nous distinguons quatre zones clairement identifiables, la zone A de 0,
la zone B de 2^1 à 2^9, la zone C de 2^10 à 2^20 (cf. figure
4.14) et la zone D supérieure à 2^20. Les zones « B »
et « D » ne présentent pas beaucoup d'intérêt,
les courbes n'ayant pas de différence notable. La zone « A »
est limitée à une seule valeur et ne peut donc représenter
une étendue suffisante pour mener notre étude. La zone « C
» est la zone la plus singulière avec une plage suffisante pour
avoir un sens. Afin de mieux percevoir l'importance de la zone « C »,
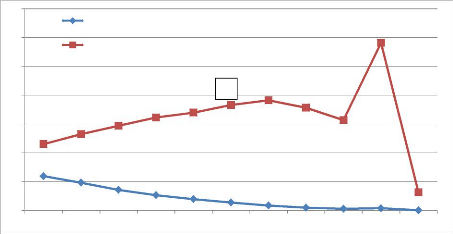
reprenons une lecture du graphique en omettant les zones A, B et D.
14
12
10
4
8
0
6
2
2^10 2^11 2^12 2^13 2^14 2^15 2^16 2^17 2^18 2^19 2^20
Trios de mots aléatoires
Triades existantes dans une requête utilisateur au moins
C
Figure 4.14 : Zoom sur la zone « C »
sélectionnée comme zone d'étude.
La zone « C » nous sert de zone de validation
sémantique. Afin de pouvoir élaborer une comparaison rapide et
arithmétique, nous définissons un coefficient
approprié.
Calcul du Coefficient de Validation Sémantique
Comparée (CVSC)
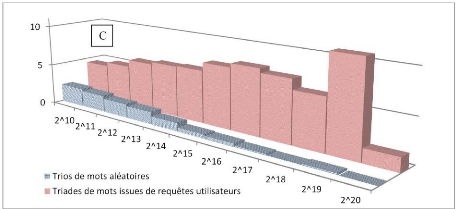
Figure 4.15 : Représentation de la Zone C en
aires couvertes par les deux courbes de référence.
4.4 : Résultats des regroupements et validation
sémantique 155
Chapitre 4. Expérimentations, validations
sémantiques et résultats de mesure
Nous considérons que les classes en puissance de deux
forment une échelle d'indice « un » et comparons l'aire prise
par les deux histogrammes. Le CVSC, ou Coefficient de Validation
Sémantique Comparé, a alors la valeur « 1 » pour
l'équivalence de l'histogramme des triades (de trois mots-clés)
ayant été au moins une fois utilisées dans une même
recherche et 0 pour la valeur de l'histogramme des trios aléatoires.
Où AR définit l'aire de l'histogramme
des triades dont tous les mots sont inclus au moins une fois tous ensemble dans
une recherche selon la formule CVSCX = (AX - AA) /
(AR - AA) (cf. paragraphe 4.31) :
Où AA définit la valeur de l'aire de
l'histogramme des triades aléatoires :
Où Ax définit la valeur de l'aire de
l'histogramme des triades à comparer :
Comparaison des coefficients CVSC pour des
agrégats de tailles différentes
Dans un premier temps nous étudions le comportement des
agrégats en fonction de leur taille. Pour plus de lisibilité nous
les regroupons en cinq familles correspondant aux cinq décades : les
agrégats de moins de 10 mots, ceux de moins de 20 mots et plus de 9,
ceux de moins de 30 mots et plus de 19, ceux de moins de 40 mots et plus de 29
et enfin ceux de plus de 39 mots.
Le but de ce test est de détecter s'il existe une
corrélation entre la taille des agrégats et la valeur du
CVSC.
4.4 : Résultats des regroupements et validation
sémantique 156
Chapitre 4. Expérimentations, validations
sémantiques et résultats de mesure
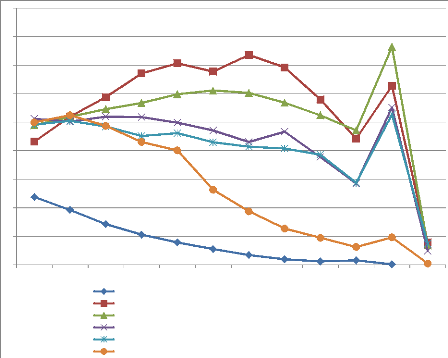
4
9
8
0
7
6
5
3
2
1
2^10 2^11 2^12 2^13 2^14 2^15 2^16 2^17 2^18 2^19 2^20
Trios de mots aléatoires
Trios de mots pris dans des agrégats de 3 à 9
mots-clés
Trios de mots pris dans des agrégats de 10 à 19
mots-clés
Trios de mots pris dans des agrégats de 20 à 29
mots-clés
Trios de mots pris dans des agrégats de 30 à 39
mots-clés
Trios de mots pris dans des agrégats de 40 et plus
mots-clés
Figure 4.16 : Représentation graphique des
CVSC en fonction de la taille des agrégats en zone « C
» de validation sémantique.
|
Taille des agrégats en nombre de
mots-clés
|
CVSC
|
|
De 3 à 9
|
0.89
|
|
De 10 à 19
|
0.80
|
|
De 20 à 29
|
0.61
|
|
De 30 à 39
|
0.57
|
|
Plus de 39
|
0.29
|
Tableau 4.7. Valeur des CVSC en fonction de la
taille des agrégats en zone « C » de validation
sémantique.
L'analyse des courbes présentées et des valeurs
de CVSC montre une forte corrélation entre la taille des
agrégats et les valeurs du coefficient. Si la taille des agrégats
est inversement proportionnelle aux CVSC mesurés, on note un
écroulement à partir de 40 mots et au-delà.
Borner la taille des agrégats est donc un moyen pour
limiter le nombre des agrégats ayant une faible cohérence
sémantique.
Comparaison des coefficients CVSC en excluant les
recherches utilisateurs
Afin d'estimer la perte de cohérence sémantique
liée à la notion d'agrégat, il est pertinent de comparer
les coefficients sémantiques obtenus pour les mêmes classes
d'agrégats
4.4 : Résultats des regroupements et validation
sémantique 157
Chapitre 4. Expérimentations, validations
sémantiques et résultats de mesure
en excluant les triades utilisées dans une recherche au
moins. Ainsi, les coefficients obtenus ne doivent leur valeur qu'à des
combinaisons créées par la méthode de Rigidification
Simple.
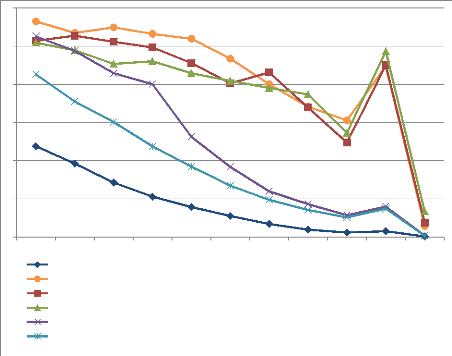
4
0
6
5
3
2
1
2^10 2^11 2^12 2^13 2^14 2^15 2^16 2^17 2^18 2^19 2^20
Trios de mots aléatoires
Trios de mots dans des agrégats de 3 à 9
mots-clés jamais utilisés dans une requête
Trios de mots dans des agrégats de 10 à 19
mots-clés jamais utilisés dans une requête
Trios de mots dans des agrégats de 20 à 29
mots-clés jamais utilisés dans une requête
Trios de mots dans des agrégats de 30 à 39
mots-clés jamais utilisés dans une requête
Trios de mots dans des agrégats de 40 mots-clès
et plus jamais utilisés dans une requête
Figure 4.17 : Représentation graphique des CVSC
en fonction de la taille des agrégats en zone « C » de
validation sémantique en excluant les triades incluses dans une
requête d'utilisateur.
L'observation des chiffres du CVSC (cf. tableau 4.8)
des trios issus d'agrégats et n'ayant jamais été
utilisés dans une recherche par un utilisateur nous conforte sur le
seuil à ne pas dépasser. En effet, les agrégats de moins
de 30 mots gardent un ratio supérieur à la moyenne.
Il est difficile de déterminer sans une étude
détaillée au cas par cas les raisons de la baisse du coefficient.
Cependant, la possibilité qu'un mot soit utilisé dans des
acceptions différentes peut en être une des causes.
|
Taille des agrégats en nombre de
mots-clés
|
CVSC
|
Perte
|
|
De 3 à 9 mots
|
0.62
|
0.27
|
|
De 10 à 19 mots
|
0.57
|
0.23
|
|
De 20 à 29 mots
|
0.56
|
0.05
|
|
De 30 à 39 mots
|
0.28
|
0.29
|
|
De 40 à 49 mots
|
0.17
|
0.12
|
Tableau 4.8. Valeur des CVSC en fonction de la
taille des agrégats.
4.4 : Résultats des regroupements et validation
sémantique 158
Chapitre 4. Expérimentations, validations
sémantiques et résultats de mesure
Ainsi, que ce soit de manière graphique (cf. figure
4.17) ou par le calcul du CVSC (cf. Tableau 4.8), on peut conclure que
plus le nombre de mots-clés est important plus le CVSC a
tendance à baisser. Cette étude révèle finalement
que les agrégats d'une taille supérieure à 30 mots
possèdent un CVSC inférieur ou égal à
0.5.
Placer une limite absolue sur une qualité aussi
subjective que la cohérence sémantique d'un groupe de mots n'a
bien sûr aucun sens si cela n'est pas fait de manière statistique
et seulement dans le but d'étudier le comportement des
agrégats.
En fixant un seuil de qualité au niveau de la valeur
médiane (0.5 comme on le fait pour valider un examen), on
considère que statistiquement les agrégats de plus de 30
mots-clés ne présentent pas un CVSC acceptable.
Mais plus que la valeur du CVSC elle-même,
c'est la baisse brutale de cette valeur qui est intéressante. Tandis
qu'entre des agrégats de 3 à 9 et 20 à 29 le coefficient
baisse seulement de 9.6%, entre les agrégats de 20 à 29 et ceux
de 30 à 39 le coefficient s'écroule de 50 %. La chute
s'accentuant encore de 39% supplémentaire entre les agrégats de
30 à 39 et ceux de 40 à 49.
Ce test révèle donc la baisse brutale de
CVSC pour les agrégats de taille supérieure à 30
mots.
Comparaison entre les réseaux
AOL-17/04/2006 et AOL-17/03/2006
Afin de savoir si ces résultats sont liés au
contexte comme, par exemple, le jour choisi dans le fichier de log, nous avons
rejoué notre test sur un autre jour du fichier du log d'AOL, le
17/03/2006.
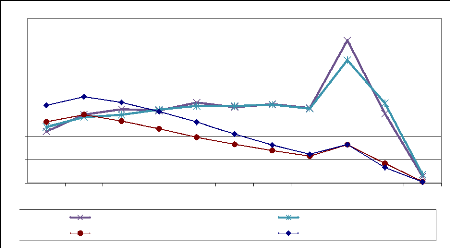
14
12
10
4
8
6
2
0
2^10 2^11 2^12 2^13 2^14 2^15 2^16 2^17 2^18 2^19 2^20
Moins de 30 du 17 03 Moins de 30 du 17 04
30 et plus du 17 03 30 et plus du 17 04
Figure 4.18 : Comparaison des courbes de CVSC
pour les agrégats de moins et de plus de 30 mots-clés sur
les deux réseaux différents.
4.4 : Résultats des regroupements et validation
sémantique 159
| 

