L'objet de ce travail était l'étude de
regroupements d'objets dans les réseaux de grandes tailles.
Dans une première partie, après une
brève présentation des caractéristiques des grands graphes
de terrain et des petits mondes, nous avons exposé un éventail
des techniques de regroupement de noeuds existantes. Nous avons plus
particulièrement insisté sur les techniques permettant des
recouvrements d'agrégats de noeuds.
Dans une seconde partie correspondant à notre
contribution, nous avons décrit plusieurs algorithmes permettant de
créer ou d'enrichir des agrégats de mots issus de réseaux
provenant de fichiers de log de moteurs de recherche (
AOL.com, Edonkey). L'évolution de
ces algorithmes a permis de proposer une méthode capable d'extraire des
agrégats d'un méga-graphe de terrain, sans que celui-ci ait
à être préalablement filtré. Par la reconnaissance
et l'éviction de noeuds concentrateurs ou « hubs » et de
noeuds présentant des liens faibles nous avons pu contenir la taille des
agrégats de façon à en garantir la cohérence
sémantique.
Certains résultats sont à considérer
comme acquis. Cependant, les techniques d'agrégation
présentées, comme celles de validation sémantique, sont le
début d'une recherche à approfondir.
À propos des techniques d'agrégation dans les
graphes de mots utilisés conjointement dans des requêtes nous
pouvons conclure que :
? les algorithmes d'agrégation ne peuvent être
génériques et se doivent de considérer et la nature des
réseaux étudiés et la nature des regroupements à
créer ;
? dans les grands graphes de terrain de mots, si l'on cherche
à créer des ensembles sémantiquement cohérents, les
techniques séparatistes et
185
Conclusion générale et perspectives
déterministes ou encore ne travaillant pas en
respectant la pondération des graphes sont à écarter. Les
techniques agglomératives sont préférables ;
? il existe statistiquement un nombre maximal de mots
à ne pas dépasser dans un ensemble si l'on veut conserver une
bonne qualité sémantique sur l'ensemble des agrégats
créés (dans les réseaux étudiés ce nombre
est entre 30 et 40 mots) ;
? il est possible de créer des agrégats
présentant statistiquement une bonne cohérence
sémantique.
Les méthodes de rigidification constituent une base
qui est ouverte aux modifications ; le choix de créer des
agrégats comme des composantes bi-connexes n'est qu'une des
possibilités ; ce choix pouvant être même modifié
dynamiquement de telle manière qu'un graphe trop grand puisse se voir
imposer comme règle d'être tri-connexe et ensuite quadri-connexe
s'il est encore trop important et ainsi de suite. La souplesse de cette
méthode et le support de différentes contraintes possibles de
l'opérateur d'extension en fait une excellente base d'étude.
Les validations humaines ne présentent souvent que peu
d'intérêt pour faire évoluer les méthodes. Elles
demandent beaucoup d'efforts. Sans références comparatives
mesurables, elles ne sont qu'un avis. Quand elles ont pour but la comparaison
de différentes méthodes, elles ne parviennent le plus souvent
qu'à un classement des dites méthodes. Pourtant, ce type de
validation est indispensable. En effet, puisqu'il n'existe pas, à ce
jour, de système étalonné de mesure de la cohérence
sémantique des agrégats, seul le jugement d'un esprit humain,
expert du domaine, peut fournir un avis de référence.
Il est parfois possible d'utiliser des systèmes de
satisfaction étalonnés, comme nous l'avons fait avec TREC-Eval,
et d'en tirer alors des conclusions plus précises.
Une mesure incontestable reste celle de la satisfaction
d'usage. Pour l'obtenir, il est nécessaire de passer par une utilisation
fonctionnelle des agrégats, comme la création de
communautés dynamiques d'utilisateurs (cf. Avant-propos). La
satisfaction d'usage des utilisateurs d'un tel système devient ainsi la
mesure indiscutable de la qualité sémantique des
agrégats.
La comparaison de comportements d'ensembles
d'éléments déterminés reste à nos yeux la
solution la plus efficace. Il convient bien sûr de posséder un
échantillon suffisant et des éléments aux
caractéristiques fortement identifiées. Si les résultats
ne sont pas différentiables la mesure n'a alors pas lieu d'être.
Dans le cas contraire, on peut estimer qu'elle possède une vraie valeur.
Cette valeur doit cependant être relativisée en fonction : de la
taille de l'échantillon, de la distance entre les populations
identifiées et des critères ou comportements observés. Il
est important ici de noter que les mesures de moyenne, d'écart type ou
de variance ne sont pas toujours à considérer. L'observation de
la distribution des valeurs retournées par la mesure des
différentes populations permet de détecter des zones plus
distantes. Ces zones sont alors un espace valide dans la comparaison de ces
populations prédéterminées et des agrégats.
186
Conclusion générale et perspectives
Ces algorithmes qui ont, dans une certaine mesure, fait la
preuve de leur efficacité peuvent être validés par des
utilisateurs intégrés aux communautés ; une
communauté d'utilisateurs pouvant alors se définir comme un
système interactif toujours en évolution. En proposant,
pondérant ou écartant des mots, les adhérents d'une
communauté peuvent la faire vivre et améliorer la pertinence des
agrégats et donc la manière dont la communauté peut se
proposer à de nouveaux membres. Il reste là tout un
équilibre à inventer entre interactions humaines et
agrégations algorithmiques.
En plus de la participation des utilisateurs, les pistes
d'amélioration de la qualité des agrégats sont très
nombreuses. Il est possible de créer des liens supplémentaires
entre des mots par l'utilisation de dictionnaires, de sites
encyclopédiques ou encore de dictionnaires ontologiques. Dans ce cas, le
lien serait porteur, par sa pondération, de la signification de la
précédence d'un mot dans la définition d'un autre. Des
algorithmes comme celui de « Porter » [Sparck&al-1997]
permettraient de créer des liens supplémentaires entre
des mots ayant une racine commune. Ainsi, de nouveaux graphes seraient
créés puis combinés entre eux pour trouver les
agrégats. En effet, si la pondération de liaisons
hyper-définies est un élément qui a permis
d'améliorer la qualité des agrégats, elle est aussi
responsable de certaines limitations. Une fois définie et
pondérée elle ne peut représenter qu'un seul type de
relation. D'un autre côté, il n'est pas question de revenir
à des liaisons non spécifiées et donc non
pondérées.
Au contraire, notre conviction est que la qualité des
agrégats ne saura progresser qu'en affinant le plus possible les
informations que sous-tendent les liaisons. Nous pensons qu'une des pistes
permettant de mieux cerner ces relations est de combiner plusieurs graphes.
Nous entendons par « combinaison » l'ensemble des opérations
mathématiques possibles.
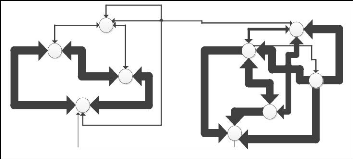
Pour expliciter notre propos, nous proposons en conclusion de
ce travail et pour sourire, un petit jeu utilisant ce type de raisonnement :
Notre graphe représente un réseau social. C'est
en fait une soirée où « il faut être ». Nous
désirons identifier des communautés « d'affection
réciproque » (sans plus les définir), présentes dans
cette soirée. Nous nous fondons pour cela sur les éléments
verbaux échangés. Le graphe est dirigé et
pondéré selon le sens de « qui parle à qui » et
le temps de parole est représenté par l'épaisseur du
trait. Pour simplifier on suppose ce temps de parole équitablement
partagé si les flèches vont dans les deux sens.
2
4
1
3
9
8
7
5
6
Figure C.1 : Cherchez la ou les communautés dans
une soirée - « Qui parle à qui ? ».


