|
Nous allons nous allons relever quelques causes dans ce
service qui nous a un peut pousser à réaliser cette
application.
1
0. INTRODUCTION GENERALE
L'informatique reste actuellement une science incontournable
qui amène l'homme à une évolution dynamique et
scientifique étant donné qu'elle est comme « « la
science du traitement rationnel de données notamment par des machines
automatiques , considéré comme support des connaissances humaines
dans le domaine technique et économico-social » ».
Le programme de l'enseignement supérieur et
universitaire et la recherche prévoit qu'à la fin de chaque cycle
d'études, l'étudiant doit rédiger son travail de fin de
cycle , pour bénéficier de ce dernier une qualification
équivalente.
Alors nous étant qu'étudiant finaliste du cycle
de graduat en sciences informatiques à l'université Notre - dame
du Kasaï ( U.KA), nous n'avons pas fait exception à cette
règle.
Dans ce travail, nous allons décortiquer tous ces
mécanismes entrant en ligne de compte pour la gestion automatisée
de charroi automobile au sein d'une entreprise.
0.1. CHOIX ET INTERET DU SUJET
Notre sujet est intitulé : « « la Mise en
place d'une Application pour la Gestion de charroi automobile de la CARITAS /
KANANGA. » »
Intérêt à ce sujet est de mettre en place
une Application pouvant aider cette entreprise plus précisément
dans la gestion de charroi automobile.
Autres intérêts :
V' Sur le plan pratique de la CARITAS comme utilisateur, ce
travail lui servira d'outil de gestion par excellence de charroi automobile.
V' Sur le plan scientifique, ce travail ouvre la voie à
tout chercheur d'en tirer des références sur la manière de
gérer le système d'information au sein d'une entreprise et sur
les méthodes et modèles de conception en informatique .
V' En fin, pour l'auteur que nous sommes , ce travail nous
permet d'approfondir notre connaissance théoriques et pratiques acquises
en informatique de gestion.
0.2. PROBLEMATIQUE ET HYPOTHESE
2
0 .2 .1. PROBLEMATIQUE
Compte tenu la mauvaise gestion des véhicules qui s'est
posé dans cette entreprise, un jour il y'avait un véhicule marque
LAND CRUISER qui avait fait un petit déplacement vers un village
quelconque avait causé une crise des carburant et ce véhicule
était partit et en retour le chauffeur n'était pas
enregistré même le véhicule aussi, peut il possible de
résoudre ce problème ?.
0.2.2. HYPOTHESE
Nous entant qu'informaticien nous sommes capable de
résoudre ce problème en concevra une Base de données qui
peut vous aidez à, enregistré tous les véhicules
même leur chauffeurs et plus de concevoir une application qui peut aider
plus à saisir toutes les informations dans la Base de données.
0.3 .DELIMITATION DU SUJET
Notre travail va concerner la gestion du charroi de
l'année passée jusque dans les années suivantes
0.4. METHODES ET TECHNIQUES
UTILISEES
0.4.1 .METHODES
Dans ce cadre de notre travail, nous nous sommes servis de la
méthode MERISE pour la conception de notre application ; parce qu'elle
est une méthode de conception de système d'information et
d'analyse informatique.
0.4.2 .TECHNIQUES UTILISEES
Pour arriver à récolter les données
utiles à notre modélisation, nous avons utilisés les
techniques que voici :
? Technique documentaire : cette technique nous a permis de
nous documenter, c'est -à-dire de nous atteler aux archives de la
CARITAS pour nous procurer des informations , les ouvrages , les
mémoires et d'autres travaux de fin de cycle(TFC) qui nous ont fournis
les informations.
? Technique d'interview : cette technique , par la
réalisation
d'une suite des questions , nous a permis de poser
quelques questions possibles pour récolter les informations claires et
véritables.
? Technique d'enquête : cette dernière nous aide
à descendre sur
terrain de la CARITAS pour voir comment est
l'évolution de la gestion de charroi automobile, tout ça pour
avoir les informations toujours fiables ,claires et véritables.
3
0.5 .SUBDIVISION DU TRAVAIL
Hormis l'introduction et la conclusion, notre travail comprend
quarts chapitres :
? Le chapitre 1 intitulé :Architecture client serveur
qui montre et explique le modèle de fonctionnement de l'architecture
client serveur .
? Le chapitre 2 intitulé : système d'information
et base de données
? Le chapitre 3 intitulé : la modélisation et
l'implémentation, dans le quel nous allons prendre connaissance du
système existant dans l'Enterprise en fin de connaitre de quelle
manière les informations circulent.
4
CHAPITRE I. L'ARCHITECTURE CLIENT SERVEUR
I.1. INTRODUCTION
Dans ce monde ou la cause à la productivité
conduit les technologies à évoluer de plus vite, le client
serveur s'est taillé une part de choix depuis le début des
années 90.
Ainsi, dès nos jours , de nombreuses applications
fonctionnent selon le mode client serveur qui désigne un mode de
communication à travers un réseau en très plusieurs
programmes ou logiciels l'un appelé client et l'autre serveur.
Ce chapitre se propose donc de présenter la vue
d'ensemble du modèle client serveur et quelques notions de base
indispensables à la compréhension dudit concept.
Il traite dans respectivement des définitions des concepts
des
principes généraux, des différents types
d'architectures des avantages et désavantages des architectures client
serveur , de leurs caractéristiques , de type de client serveurs et des
techniques de dialogues client serveur.
I.2 DEFINITIONS
Le client serveur désigne un mode de communication
à travers un réseau entre plusieurs programmes ou logiciels ,
l'un
qualifié des serveurs attendent les requêtes des
clients et y
répondaient.
Le client désigne également l'ordinateur sur le
quel est exécuté le logiciel client et le serveur est
l'ordinateur sur le quel est exécuté les logiciels qui viennent
du serveur central.
Les définitions de quelques mots de l'architecture client
serveur :
? Client : processus demandant l'exécution d'une
opération à
un autre processus par envoi d'un message contenant le
descriptif de l'opération à exécuter et attendant la
réponse à cette opération par un message en retour .
? Serveur : processus accomplissant une tache ou
une
opération sur une demande d'un client et transmet la
réponse à ce dernier.
? la requête : message transmis par un client à
un serveur
décrivant l'opération à exécuter pour
le compte du client.
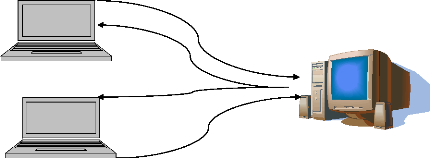
CLIENT 1
CLIENT 2
Réponse
Requête
Requête
SERVEUR CENTRAL
5
? Réponse : message transmis par un serveur
à un client suit
à l'exécution d'une opération contenant
les paramètres de retour de l'opération .
Les appels au service de transport mis en jeux sont au nombre
de 4 que voici :
V' sendRequest () ; permet au client d'émettre
le message
décrivant la requête à une correspondante
à la porte d'écoute du serveur.
V' ReceiveReply() ;permet au client de recevoir la
réponse en
provenance du serveur
V' ReciveRequest() ;Permet au serveur de recevoir la
requête sur
la porte d'écoute du client .
V' SendReply() ;Permet au serveur d'envoyer la
réponse à la porte
d'écoute du client.
L'élément important dans cette architecture est
l'utilisation du mécanisme de communication entre les deux applications
.le dialogue qui se fait par les applications expliqué par :
? Le client demande à un serveur un service ;
? Le serveur à son tours, il prend cette demande et
réalise un service et renvoi le résultat au client.
L'un des principes fondamentaux est que le serveur
réalise un traitement pour le client.
A. LE FONCTIONNEMENT D'UN SYSTEME CLIENT SERVEUR
Dans ce système client serveur le fonctionnement se
fait de la manière suivante :
1. Le client émet une requête vers le serveur
grâce à son adresse IP et son Port.
2. Le serveur à son tours reçoit la demande et
renvoi une réponse chez client à l'aide de son adresse IP et son
Port.
6
I.3. LES PRINCIPES GENERAUX
Il n'y pas trop des définitions exhaustives de la
notion de client serveur, mais des principes peuvent très
montrées ce que c'est le modèle client serveur :
1. SERVICE
A ce qui concerne le service, c'est le serveur qui est
fournisseur de service tandis que le client est un consommateur de service .
c'est toujours client qui déclenche la demande de service. le serveur
lui attend simplement les demandes ou les requêtes de client.
2. PARTAGE DES RESSOURCES
Un serveur traite les requêtes des plusieurs clients en
même temps et contrôle leurs accès aux ressources.
3. LOCALISATION
Pour la localisation, c'est le logiciel client serveur qui
montre aux clients la localisation du serveur. Il est possible d'ajouter et de
retirer des stations clientes, il est possible de faire évoluer les
serveurs .
4. INTEGRITE
Les données qui sont au serveur sont
gérées sur les serveurs de façon centralisée,
Les clients restent individuels et indépendants.
Dans l'architecture client serveur, une application est
constituée des 3 parties qui sont :
? L'interface utilisateur ;
? Le logiciel des traitements ; ? La gestion de
données.
I.4. LES DIFFERENTS TYPES D'ARCHITECTURES
I.4.1.L'ARCHITECTURE A DEUX NIVEAUX
L'architecture à deux niveaux(aussi appelée
architecture à 2-tiers),cette architecture est
caractérisée par le système client serveur dans le quel le
client fait une demande d'une ressource au serveur et ce dernier ne fait aucun
appel à un autre serveur pour fournir une partie de service.
7
La représentation de cette architecture se fait de cette
manière :
Requête SQL
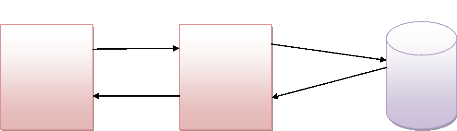
Niveau 1 Envoi des Niveau 2
requête
Envoi des
réponses
requête
résultat
Figure 2.1 : Architecture client serveur 2-tiers
I.4.2.L'ARCHITECTURE A 3 NIVEAUX
Cette architecture est appelée aussi architecture
à 3-tiers, ici nous avons un intermédiaire .voici ces
différents niveaux qui constituent ce type d'architecture :
? UN CLIENT : qui est un ordinateur ou une machine qui demande
des ressources, équipé d'une interface utilisateur
(généralement un navigateur).
? LE SERVEUR D'APPLICATION :(appelé également
middleware) ; il est chargé d fournir des ressources mais faisant appel
à un autre serveur.
? LE SERVEUR DE DONNEES : c'est celui qui prend les
requêtes venant du serveur d'application et lui fournit les
données dont il à besoin.
Envoi des
Niveau1 requête Niveau 2 Niveau 3

CLIENT
Envoi des réponses
Serveur D'applica tion
Serveur
de base
de
données
SQL
Figure 2.2 : Architecture client serveur 3-tiers
Dans cette architecture chaque serveur est
spécialisé dans une tâche (Serveur Web, Serveur de Base de
données).
L'architecture à 3 niveaux permet :
8
? Une plus grande flexibilité ou une souplesse,
? Une sécurité accrue car la
sécurité peut être définie indépendamment
pour chaque service et à chaque niveau ;
? Des meilleurs performances , étant donné le
partage des tâches entre les différents serveurs.
I.4.3.L'ARCHITECTURE MULTINIVEAUX
Dans cette architecture multi-niveaux, chaque serveur effectue
une tâche (un service) spécialisé.
Un serveur peut donc utilisé les services d'un ou
plusieurs autres services en fin de fournir son propre service.
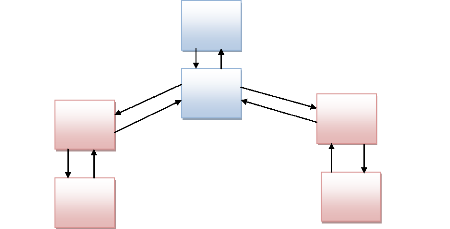
Niveau 1
le client
Niveau 2 Serveur
Serveur
Niveau 3
Serveur
Niveau N
Figure 2.3 : Architecture client serveur Multi niveaux
Plusieurs applications client-serveur fonctionnent selon cet
environnement client serveur, c'est -à-dire des machines faisant partis
au réseau contactent un serveur qui est une machine très
puissante en capacité d'entrée-sortie, qui leur fournit des
services, Ces derniers sont des programmes fournissant des données.
Les services sont exploités par des programmes,
appelés programme clients, qui s'exécutent sur les machines
clientes. on parle ainsi de client (clients FTP, client de messagerie, etc....)
, lorsqu'on désigne un programme
9
tournant sur une machine cliente capable de traiter des
informations qu'il récupèrent auprès d'un serveur.
I.5.AVANTAGES ET DESAVANTAGES DE L'ARCHITECTURE
CLIENT SERVEUR
I.5.1.AVANTAGES
Dans ce type d'architecture :
> Toutes les données sont centralisées sur un
seul serveur, ce qui veut les contrôles de sécurité,
l'administration, la mise à jour des données et des logiciels.
> Toutes les technologies supportant l'architecture client
serveur sont plus naturelles que les autres.
> La complexité du traitement et la puissance de
calcul sont à la charge du/ou des services, les utilisateurs utilisant
simplement un client léger sur un ordinateur terminal.
> Recherche d'information , les serveurs étant
centralisés, cette architecture est particulièrement
adaptée pour retrouver et comparer de vaste quantité
d'informations.
I.5.2.LES DESAVANTAGES
Pour les désavantages de cette architecture client
serveur, interviennent :
+ Si plusieurs clients veulent dialogués avec le
serveur au même moment , le serveur peut avoir un problème de
n'est pas supporter la charge.
+ Si le serveur n'est pas en ligne ou disponible, aucune des
machines ne fonctionne.
+ Les coûts de mise en place et de maintenance peuvent
être élevés.
I.6.QUELQUES CARACTERISTIQUES CLIENT SERVEUR
I.6.1.CARACTERISTIQUES D'UN PROCESSUS SERVEUR
Nous allons énumérer quelques
caractéristiques de ce processus :
a. Le serveur attend une connexion entrant sur un ou
plusieurs ports réseaux ;
b. S'il est à la connexion d'un client sur le port en
écoute, il ouvre un socket local au système d'exploitation ;
c. Suite à la connexion , le processus serveur
communique avec le client suivant le protocole prévu par la couche
application du n modèle OSI.
1
I.6.2.CARACTERISTIQUESS D'UN PROCESSUS CLIENT
Nous allons énumérer quelques
caractéristiques de ce processus :
a. Il établit une connexion au serveur à
destination d'un ou des plusieurs ports réseaux ;
b. Lorsque la connexion est acceptée par le
réseau, il communique comme le prévoit la couche applicative du
modèle OSI.
Les clients et les serveurs doivent bien sûr utiliser le
même protocole de communication au niveau de la couche transport du
modèle OSI. Un serveur est généralement capable de servir
plusieurs clients au même moment.
On parle aussi souvent d'un service pour designer la
fonctionnalité offerte par un processus serveur.
Ici on peut encore éxploité le mot serveur comme
étant un ordinateur spécialisé ou une machine virtuelle
ayant pour unique tâche l'exécution d'un ou des plusieurs
processus serveurs.
I.7.TYPES DES CLIENTS I.8.1.CLIENT
LEGER
Le post client accède à une application
située sur un ordinateur dit « « SERVEUR » » via une
interface et un navigateur web. L'application fonctionne entièrement sur
le serveur, le post client reçoit la réponse concernât sa
requête qu'il avait formulée.
I.8.2.CLIENT LOURD
Le post client doit comporté un système
d'exploitation capable d'exécuter localement une partie de traitement,
le traitement de la réponse à la requête du client
utilisateur , va mettre en oeuvre un travail combiné entre l'ordinateur
serveur et post client.
I.8.3.CCLIENT RICHE
Dans ce client riche, il a une interface graphique qui aide
à mettre en oeuvre des fonctionnalités capables à celles
d'un « « CLIENT LOURD » »
I.9.LES DIFFERENTS TYPES DE CLINT-SERVEUR
Selon la nature des services accomplis par le serveur pour un
client, différents types de client-serveur ont été
distingués, on distingue les différents types de client-serveur
décrit ci-dessous.
I.9.1.CLIENT-SERVEUR DE PRESENTATION
1
C'est un types dans le quel un processus exécute
seulement les fonctions de dialogue avec l'utilisateur, l'autre gérant
les données et exécutant le codes applicatifs.
I.9.2.CLIENT-SERVEUR DE REHABILITATION
Type de client-serveur dans le quel un processus
exécute les fonctions de dialogue, sophistique avec l'utilisateur,
l'autre gérant les données et l'exécution de codes
applicatifs.
I.9.3.CLIENT-SERVEUR DE DONNEES
C'est un modèle dans le quel un programme applicatif
contrôlé par une interface de présentation sur une machine
cliente accède des données sur une machine serveur par des
requêtes de recherche et mise à jour souvent exprimé avec
le langage SQL.
Le serveur de données en globe une ou plusieurs bases
de données. La base de données est accédée par un
langage SQL (Structureed Query Languages).
I .9.4.CLIENT-SERVEUR DE PROCEDURES
Type de client -serveur dans le quel un programme applicatif
contrôlé par une interface de présentation sur une machine
cliente sous-traite l'exécution de procédures applicatives
à une machine serveur, les procédures encapsulant une base de
données.
I.9.5.CLIENT-SERVEUR DE DONNEES ET PROCEDURES
De plus en plus souvent ce type de client-serveur permet de
mettre en commun des procédures communes autour de la base de
données au niveau du serveur, donc de repartir les traitements entre le
client et le serveur.
Les composants d'une telle architecture sont les suivantes :
? Les clients ; ? Les serveurs ; ? Le réseau.
a. LES CLIENTS
Ils supportent le code de l'application non lié
directement aux données , le code est réalisé grâce
à un outil de développement d'application.
Il implémente le dialogue inter actif avec les
utilisateurs, le traitement spécialisé de message, l'affichage de
résultat.
b. LE SERVEUR
1
Dans ce paragraphe du serveur, le dernier assure le stockage, la
distribution, la gestion de disponibilité et se la
sécurité de données.
Il permet l'accès transactionnel, décisionnel des
informations
classiquement, il regroupe les fonctions du SGBD et sera
aujourd'hui bâti autour du modèle relationnel.
c. LE RESEAU
Avec les protocoles réseau de transport et
d'échanger de requête, il permet le transfert des demandes et des
résultats.
Il assure la connectivité des outils clients au serveur
; l'outil de connectivité permet l'encodage des requêtes en
message sur le client, et le décodage sur le réseau et vice versa
pour les réponses.
Client
Réseau Requête
Outil de connectivité
Protocole Réseau
Outil application
Application
Résultat
serveur
|
|
Protocole Réseau
Outil de
Connectivité
Serveur Base de Données
|
|
|
Base de Données
|
I.10. DIALOGUE SYNCHRONE ET ASYNCHRONE
I.10.1.DIALOGUE SYNCHRONE
Type de dialogue géré sans fils d'attente ou les
commandes d'émission et de réception sont bloquantes,
typiquement, dans le cas synchrone, le client attend le serveur pendant que
celui-ci exécute une opération pour lui.
1
I.10.2.DIALOGUE ASYNCHRONE
Type de dialogue géré avec fils d'attente ou
l'une au moins de commande d'émission ou de réception non
bloquante.
Le dialogue asynchrone permet au client au client d'effectuer
une tâche pendent que le serveur exécute la première
opération pour lui.
Il permet aussi, le biais de fils d'attente, de demander
plusieurs opérations au serveur avant de recevoir les
opérations.
I.11.LES INTERETS TECHNIQUES D'UNE ARCHITECTURE
CLIENT-SERVEUR
Les intérêts sont multiples :
> La sécurité des accès aux
données ;
> L'optimisation et l'administration centralisée de
données ;
> La Gestion de transaction fiable de données ;
> La diminution de trafic réseau ;
> La mise en commun des procédures utilisables ;
> La diminution de codage des applications.
CONCLUSION
Ayant compris sur l'architecture client-serveur, son corps et son
fonctionnement et tout autre, cela nous aidera à passer à notre
deuxième chapitre intitulé « « Système
d'information et Base de données « « qui va nous
éclairé encore plus quelques points essentiels.
Cette information peut se présenter sous diverses
formes, les trois principales formes rencontrées dans une entreprise
sont la forme
1
CHAPITRE II : SYSTEME D'INFORMATION ET
BASES DE DONNEES II.1.SYSTEME D'INFORMATION
II.1.0.INTRODUCTION
L'entreprise est un système complexe, dans le quel
transite des très nombreux flux d'information, sans un dispositif de
maitrise de ces flux, l'entreprise peut être vite dépassée,
elle ne peut plus fonctionner avec une qualité de service
satisfaisante.
L'engin des toutes entreprises consiste donc en mettre en
place un système destiné à collecter, mémoriser,
traiter et distribuer l'information avec un temps de réponse
suffisamment bref. Ce système d'information assurera le lien entre deux
autres systèmes de l'entreprise :
V' Le système de pilotage ; V' Le système
opérant.
II.1.1. DEFINITION DES QUELQUES CONCEPTS II.1.1.1.
INFORMATION
L'information est une donnée qui a un sens et un impact
sur le récepteur. Sa valeur est proportionnelle à son impact et
à son potentiel de surprise. La valeur d'une information est quelque
chose de très difficile à quantifier. Cette valeur dépend
de plusieurs facteurs : de l'écoulement du temps (une information
fraîche vaut beaucoup plus qu'une information périmée), du
récepteur de l'information (une bourse ou un résultat sportif ont
une valeur différente selon son potentiel de surprise telle une qu'une
information secrète ou inattendue)...etc.
La récolte, le stockage et la diffusion de
l'information est devenue une industrie à part entière.
Et toute organisation quelle qu'elle soit, doit consacrer une
partie de son effort à récolter, traiter, stocker et diffuser
l'information issue de son propre fonctionnement. Ainsi l'information est
l'élément conceptuel permettant le transfert, le stockage et
traitement de la connaissance.
L'information est indispensable dans le processus de
décision d'une organisation ; l'information est aussi un
élément qui permet de compléter notre connaissance sur un
objet, un événement, un concept, etc.
1
écrite (fiche papiers, documents écrits, etc.),
la forme symbolique (une étoile sur une fiche, un cube de couleur sur
une table, etc.), ou la forme orale (de bouche à l'oreille).
Ainsi, pour une automatisation réussie, l'information
devra être cernée et classifiée de manière
très précise et devra également pouvoir être
représentable dans le système informatique.
II.1.1.2. Classification des informations
Pour se présenter dans un ensemble important des
informations qui constituent le système d'information de l'entreprise ou
du système étudié, on est amené à
procéder à une certaine classification.
Ainsi, l'information peut se présenter sous les
diverses catégories suivantes :
a. Informations élémentaires
Une information élémentaire est une information
dont on ne peut inventer la ou les valeurs. Pour s'en servir, on doit,
connaître sa valeur.
Exemple : le nom d'un étudiant
b. Informations paramètres
Un paramètre est une rubrique dont la valeur est
constante et prévisible. On peut estimer que sa valeur est connue et la
même pour tout ou pour tous.
Exemple un taux de TVA connu est indiqué pour tous les
articles et pour tous les clients...
c. Informations résultantes
Une information résultante est obtenue par un
traitement arithmétique et un traitement logique.
Exemple : Résultat d'un traitement arithmétique
: la moyenne d'un étudiant.
Résultat d'un traitement logique : compte tenu du
montant des achats, le client a droit à une remise ou non.
d. Informations de commande
1
L'information de commande est celle ayant permis, à
partir d'informations invariantes, d'obtenir une information résultante.
Ce sont les traitements (calculs, comparaison ...) à effectuer.
On emploie également les termes de règles de
gestion règles de calcul, pour désigner ces informations de
commande
II.1.1.3. Autre classification des
informations
- informations externes ou internes
L'information est dite interne si elle reste à
l'intérieur du
domaine étudié, alors qu'elle est dite externe
si elle provient de l'extérieur ou lui est destiné
- information quantitative ou
qualitative
Une information quantitative se présente sous forme
chiffrable alors que l'information qualitative va être non
chiffrée.
Exemple : la note d'un élève est une information
quantitative alors que le fait qu'il soit fille ou garçon est
qualitatif.
- Information permanente ou temporaire
(signalétique ou de situation)
Une information permanente est une information qui ne va
pas varier dans le temps, alors qu'une information temporaire
va être soumise à une variation régulière.
Exemple : le nom d'un élève est une information
permanente, alors que sa moyenne en mathématique est une information
temporaire.
II.1.1.4. Valeur de l'information
Toutes les activités humaines de travail font
naître des besoins en données, en information et en connaissance
qui sont des représentations de quelque chose par quelqu'un. Ainsi,
l'information n'a de valeur qu'en fonction de l'utilisation qui en est fait
dans des processus de travail et comportementaux.
Par exemple pour un processus décisionnel, les
critères de valorisations d'une information sont entre autre ;
? la réduction de l'incertitude : une information n'a
de valeur que si elle contribue à réduire l'incertitude.
? La modification de la décision : une information
additionnelle n'a de valeur que si elle peut affecter la décision.
1
· . Les conséquences de la décision : une
information n'a de valeur que si elle contribue à modifier
significativement les conséquences d'une action.
a. Importance
L'information est indispensable dans le processus de
décision
d'une organisation
b. But
· . Diminution de l'incertitude
· . Liberté de choix
· . Cohésion de l'organisation
· . Evolutivité par rapport à
l'environnement
c. Les qualités requises
Une bonne information doit avoir les
qualités suivantes :
1. La Pertinence
2. La Précision
3. La Sécurité
4. L'intégrité
5. La Confidentialité
6. Non redondance
7. La Convivialité
8. L'âge
9. La Fréquence
10. Cohérence
11. Rentabilité
II.1.1.5. Mode de représentation de
données
En vue de traiter de manière automatisée, les
données
doivent être représentables sous formalisme
acceptable par le système informatique qui sera employé.
Les formes de représentation (type ou format) classiques
rencontrées en informatique sont :
· Alphabet (des lettres uniquement) ;
· Alphabet (lettre, chiffre, symbole, etc.)
;
· Numérique (nombre)
· Date ;
· Logique booléen (vrai, faux, oui, non).
1
II.2. SYSTEME
Tous les travaux informatiques s'effectuent dans un
système. Ainsi, il existe plusieurs définitions du mot SYSTEME.
Le système est un ensemble d'éléments en interaction
dynamique, dont les éléments sont organisés et
coordonnées en vue d'atteindre un objectif, qui évolue dans un
même environnement.
Jean Louis LEMOIGNE définit un système comme suit
:
· Quelque chose (n'importe quoi identifiable) ;
· Qui fait quelque chose (activité ou fonction) ;
· Qui est doté d'une structure ;
· Qui évolue dans le temps ;
· Dans quelque chose ;
· Pour quelque chose ;
Ainsi la faculté de sciences peut être
considérée comme un système constitué
d'éléments en interaction dynamiques.
Du point de vue de la structuration, le système
d'entreprise est définit comme suit
Système de pilotage
Système d'information
|
Informations collectées
|
|
FLUX D'ENTREE
|
Système Opérant
|
FLUX DE SORTIE
|
Figure 1 : Approche systématique de
l'entreprise
1° Le système de Pilotage
Définit la politique de développement de
l'entreprise, les stratégies qui peuvent être à court,
moyen ou long terme pour atteindre ses objectifs. Il décide des actions
à conduire sur le système opérant en fonction des
objectifs et des politiques de l'entreprise.
1
Ainsi, le système de pilotage à pour rôle
la prise de décision. Une décision est un choix parmi plusieurs
autres. Elle est constituée du comité (les membres du
comité de gestion) ou des membres décisionnels. Il transmet au
sous système opérant
2° Le système opérant
Concerne l'ensemble des activités, opérations,
effectuées dans l'entreprise. C'est le système qui exécute
les ordres provenant du système de pilotage.
Il est constitué des exécutants. En d'autres
termes le système opérant englobe toutes les fonctions
liées à l'activité propre de l'entreprise
Exécute les tâches, produits les biens selon les
besoins des utilisateurs, au système de pilotage Système de
décision (ou pilotages, management, etc.). Guide de l'organisation vers
ses objectifs (activités de planifications et de contrôle.
Système opérant ou logistique, technologies, physique, de
production, etc.
3° Le système d'information
C'est le trait d'union entre le système de pilotage et
le système opérant
Ainsi, le système d'information peut être
définit comme l'ensemble des informations internes et externes
circulants dans l'entreprise.
II.4. LES DIFFERENTS TYPES DE SYSTEMES
a. systèmes naturels : Sont les systèmes
crées par Dieu. Par ex : l'être humain ;...
b. Systèmes artificiels : ce sont les systèmes
crées par l'homme à l'imitation de système naturel.
Par ex : la robotique ;...
c. Systèmes ouverts : sont les systèmes qui
communiquent ou interagissent avec l'extérieur.
d. Systèmes fermés : sont les systèmes
qui se communiquent entre eux.
Par ex : réseaux de malfaiteur ;...
2
II.5. Système d'information
a. Définition
Le système d'information est un ensemble des moyens
(humains et matériels) et des méthodes se rapportant au
traitement de l'information d'une organisation. Ou encore l'ensemble des
informations circulant dans l'organisation, elle est le trait d'union entre le
système de pilotage et le système opérant.
? Le système de pilotage décide des actions
à conduire sur le système opérant en fonction des
objectifs et des politiques de l'entreprise,
? Le système opérant englobe toutes les
fonctions liées à l'activité propre de l'entreprise
? Le système d'information assurera le lien entre deux
autres systèmes de l'entreprise : le système opérant et le
système de pilotage.
b. Rôle du système
d'information
On attribue quatre rôles principaux à un
système d'information :
? Produire les informations légales ou quasis
légales réclamées par l'environnement
socio-économique : les factures, les bulletins de salaire ;
? Déclencher les décisions non programmables :
ex : émission d'un ordre d'approvisionnement lorsqu'un stock atteint son
point de commande,...
? Aider à la prise de décision non programmable
en fournissant au décideur de l'organisation un ensemble d'information
brute ou modélisée (statistique, tableau de bord, modèle,
simulation, ...)
? Assurer la coordination des tâches en permettant les
communications entre les individus du système organisationnel.
c. Qualité d'un Système
D'information
Un système d'information doit posséder les
qualités ci-
après :
? La fiabilité : le système
d'information doit fournir les informations fiables, sans erreurs, autrement un
bon système d'information doit contenir moins d'erreurs possibles.
2
· La rapidité : un bon
système doit mettre à temps, dans un délai court les
informations ou les résultats à la disposition des
utilisateurs.
· La pertinence : un bon système
doit être capable d'assurer une sécurité pour les
informations en son sein.
· La sécurité : un bon
système d'information ne peut être accédé que par
les utilisateurs prédéfinis.
d. Classification des systèmes
d'informations
La classification des systèmes d'informations tient
compte
des types de traitements. Ainsi, on a :
1. Selon le degré d'automatisation, on
distingue
· Le système manuel
: le traitement des informations s'effectue à
l'aide de la main (stylo, crayons, etc.).
· Le système mécanique
: le traitement des informations utilisant des
instruments auxiliaires tels que les machines à écrire.
· Le système informatique
: dans ce cas, on utilise comme auxiliaire de traitement
les moyens électroniques, tels que des ordinateurs.
2. Selon le degré d'intégration des
informations, on distingue :
Système indépendant :
Dans le système indépendant,
chaque service a son propre système informatique,
c'est-à-dire chaque système développe ses propres
applications. Il peut avoir aussi ses matériels et logiciels propres et
pro logiciels ses propres matériels)
- Avantages : chaque service est autonome -
Désavantages : multiplicité des
matériels
|
SERVICE COMMERCIAL
|
SERVICE COMPTABLE
|
|
SERVICE
DESAPPROVISIONNEMENTS
|
SERVICE DES RESSOURCES HUMAINES
|
2
? Système dépendant ou
intégré : il y a intégration au niveau
d'échange des informations entre différents services.
Dans le système intégré les
différents services ou départements
sont reliés entre eux, ainsi l'intégration consiste
par exemple à l'organisation d'un seul site de traitement.
D'où le système intégré
recourt à l'approche base de données ou l'approche
réseau
SERVICE COMMERCIAL
SERVICE DES
APPROVISIONNEMENTS
SERVICE COMPTABLE
SERVICE DES RESSOURCES
HUMAINES
3. Selon l'architecture de traitement Dans ce
cas, on distingue :
? Le traitement centralisé (informations
centralisées) : dans ce cas, le traitement, la saisie et la diffusion
s'effectuent dans un seul site. Qui peut être le centre de traitement
informatique.
? Le traitement décentralisé (informations
décentralisées ou reparties) : le traitement et la diffusion
s'effectuent dans différents sites, appelé aussi postes.
Ce type d'information est avantageux parce que les différents postes
peuvent être reliés sous forme des réseaux. Dans ce cas,
chaque poste de travail a son micro-ordinateur. Les ordinateurs des
différents postes peuvent être connectés en réseau.
Cette tendance de traiter les informations utilise l'approche base de
données dans l'organisation des informations.
? Le traitement mixte (informatique mixte ou
distribuée) : la saisie et la diffusion des informations s'effectue dans
des sites secondaires, tandis que le traitement s'effectue dans le site
principal, c'est-à-dire il y a mariage de l'informatique
centralisé.
II.5. CONNAISSANCE.
La connaissance peut être considérée comme
une combinaison d'intuitions, de modèles, de méthodes de
règles de
2
gestion, de programme et de principes d'utilisation qui
guident les décisions et les actions.
On distingue deux types de connaissance :
? La connaissance formalisée ou explicite : c'est une
connaissance qui peut se transmettre notamment lors de formations ou dans les
ouvrages, documents, Internet, tec.
? La connaissance tactile : c'est une connaissance qui
s'acquiert principalement par la pratique.
? Par exemple : savoir conduire une automobile ou savoir
nager. II.5.1. Système informatisé
Les systèmes informatisés sont définis
comme l'ensemble de moyens matériels (ordinateur +
périphérique) des moyens humains (informaticiens), des
algorithmes, des méthodes, procédures permettant le traitement
des informations d'une façon automatique.
Ainsi, le système informatisé est un sous
système du système d'information.
II.4.2. Relation entre Donnée, Information et
Connaissance
Tout système d'information commence par une
codification des événements et des objets du monde réel
à l'aide de différents symboles (chiffres, lettres,
photographies, sons, etc.) afin de présenter des objets ou des
événements qui ont de l'intérêt à un ou
plusieurs membres d'une organisation (une commande, un client ou une facture).
Même l'acquisition et l'organisation des données ne sont pas les
fruits du hasard elles passent des mécanismes de filtrages reliés
à la connaissance individuelle ou collective.
Cette codification des événements et des objets
permet de stocker des données brutes.
Ensuite, les informations sont des données brutes qui
ont été traitées, filtrées, organisées et
formatées sous une forme significative et utile. Le passage des
données brutes demande un modèle d'interprétation issu des
connaissances de l'utilisateur de cette information. Par exemple, gestionnaire
de vente s'informe quotidiennement des résultats des ventes par
territoire, par client et par vendeur afin de mieux comprendre les
activités commerciales de l'organisation, de les
interprétés en les comparant aux résultats
planifiés et de les utiliser pour les actions à mettre en oeuvre.
Ainsi, en
2
utilisant sa connaissance de la vente, le gestionnaire filtre
des événements et faits. Il utilise un modèle
interprétatif, à savoir des analyses écarts entre les
résultats planifiés et les résultats
réalisés, comme source interne d'information. Ce système
d'information est une source parmi plusieurs autres (discussions avec des
clients, des représentations, journaux d'affaires etc.) pour comprendre
les situations du marché et leurs évolutions.
Finalement, le gestionnaire utilise encore sa connaissance
pour décider des actions, des stratégies, et des plans aptes
à lui donner les résultats voulus. L'évaluation des
résultats planifiés par rapport aux résultats réels
permet un retour d'expérience qui devrait favoriser une meilleure
connaissance.
II.6.LES FONCTIONS D'UN SYSTEME D'INFORMATION
1°.Collectes de données
: ici le système dispose deux grandes sources
d'alimentation en informatique :
? Les sources externes ; ? Les sources internes.
2°.mémoriser
l'information
Une fois saisie, l'information doit être stockée
de manière durable et stable.
Il ya deux moyens technique et organisationnel, mais
actuellement sa se fait par deux techniques :
- Les fichiers ;
- Les bases de données.
3°.Exploiter l'information
Une fois mémoriserons peut appliquer à
l'information une série d'opérations de traitement qui consiste
à :
? Consulter les informations : consiste à rechercher,
sélectionné,... ? Organiser les informations :
c'est-à-dire on peut trier ; fusionner et les partitionner.
? Mise a jour des informations : c'est-à-dire on peut
les modifiées ; les supprimées ou on peut ajouter les autres.
2
4°.Communiquer ou diffuser
l'information
Consiste a mettre à la disposition de ceux qui en ont
besoin au moment opportun sous une forme directement exploitable .
? Le support oral :
? Le support papier :
? Le support électronique ou magnétique
II.7.LES FINALITES D'UN SYSTEME D'INFORMATION
1. Aider à la prise de décision
: cette finalité a la disposition du décideur les
informations s nécessaires à la prise de décision, permet
d'étudier les conséquences prévisibles des
décisions et l'automatisation des certaines décisions.
2. Contrôler l'évolution de
l'organisation :le système permet de détecter les
disfonctionnements internes et les situations anormales de l'entreprise.
3. Cordonner l'activité de l'entreprise :
le système permet de cordonner l'activité du service par
le billet de flux d'informations internes.
II.2.BASES DE DONNEES II.2.1 Introduction
II.2.3. DEFINITION D'UNE BASE DES DONNEES
Une base de données (son abréviation est BD, en
anglais DB, data base) est une entité dans laquelle il est
possible de stocker des données de façon structurée et
avec le moins de redondance possible. Ces données doivent pouvoir
être utilisées par des programmes, par des utilisateurs
différents. Ainsi, la notion de base de données est
généralement couplée à celle de
réseau, afin de pouvoir mettre en commun ces informations,
d'où le nom de base. On parle généralement de
système d'information pour désigner toute la structure regroupant
les moyens mis en place pour pouvoir partager des données.
II.2.4. UTILITE D'UNE BASE DE DONNEES
Une base de données permet de mettre des données
à la disposition d'utilisateurs pour une consultation, une saisie ou
bien une mise à jour, tout en s'assurant des droits accordés
à ces derniers. Cela est d'autant plus utile que les données
informatiques sont de plus en plus nombreuses.
2
Une base de données peut être locale,
c'est-à-dire utilisable sur une machine par un utilisateur, ou bien
répartie, c'est-à-dire que les informations sont stockées
sur des machines distantes et accessibles par réseau.
L'avantage majeur de l'utilisation de bases de données
est la possibilité de pouvoir être accédées par
plusieurs utilisateurs simultanément.
II.2.5. SYSTEME DE GESTION DE BASE DE DONNEES
Afin de pouvoir contrôler les données ainsi que
les utilisateurs, le besoin d'un système de gestion s'est vite fait
ressentir. La gestion de la base de données se fait grâce à
un système appelé SGBD (système de gestion de
bases de données) ou en anglais DBMS (Data base management system). Le
SGBD est un ensemble de services (applications logicielles) permettant de
gérer les bases de données, c'est-à-dire :
? permettre l'accès aux données de façon
simple
? autoriser un accès aux informations à de
multiples utilisateurs
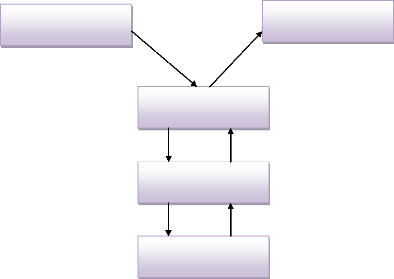
APPLICATION
TERMINAL
SGBD EXTERNE
SGBD INTERNE
GESTION DE FICHIER
? manipuler les données présentes dans la base
de données (insertion, suppression, modification)
Elle est représentée par une boite rectangulaire
subdivisée en deux parties :
2
II.2.6.LE SYSTEME DE GESTION DE BASE DES DONNEES(SGBD)
II.2.6.1.LES OBJECTIFS DE SGBD
Le SGBD permet :
1°.d'offrir les différents niveaux d'abstraction,
parmi les quels on retrouve :
? le niveau physique ? le
niveau conceptuel ? le niveau vu
2°.d'assurer l'indépendance physique de
données ; 3°.d'assurer l'indépendance logique de
données ; 4°.de contrôler la redondance de données
;
5°.à tout type d'utilisateur de manipuler les
données ;
6°.d'assurer l'intégrité de données ;
7°.d'assurer le partage de données ; 8°.d'assurer la
sécurité de données ; 9°.d'optimiser l'accès
aux données. II.2.6.2.MODELE RELATIONNEL (modèle
entité et association)
Est l'ensemble des concepts et de règles de composition
qui permettent de décrire les données.
A .entité : un ensemble des informations
existantes dans une organisation étudie et repérer par le
responsable de l'étude à raison de son utilité dans la
gestion.
Ex : entité fournisseur (id_four,
nom_four, sexe_four,...), B. Représentation d'une
entité
|
2
|
|
|
Nom_ entité
|
Une entité
|
|
Attribut1
|
|
|
Les attributs
|
|
Attribut2
|
|
C. Attribut d'une entité : c'est une
information élémentaire qui décrit une entité.
Ex : nom, sexe, adressen, telphone,... ce sont des attributs
d'une entité
D. Identifiant d'une entité
C'est un attribut dont la valeur particulier permet
d'identifier une
E.
|
occurrence de l'entité.
|
Client
|
|
|

L'identifiant d'une entité
Id client
Nom_client
Les relations
V' la relation unaire : c'est une relation qui
s'appuyé sur une seule entité.
Une seule entité : Avion
Id avion
N°avion
V' La relation binaire : c'est une relation qui relie
deux entités. Deux entités
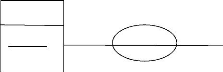
Id avion N°avion
Avion
vol
PILOTE
Idpilote
N°pilote
2
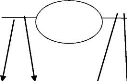
( , ) RELATIO ( , )
N
ID_B
Maxi de A Mini de B Maxi de B
A
IDA
Mini de A
B
V' La relation ternaire : c'est une relation qui relie
trois entités Trois entités
PILOTE
Id pilote Nompilote
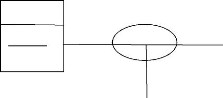
Id avion N°avion
Avion
vol
DESTINATION
IdDEST
LIBELLE
F. CARDINALITE : une cardinalité dans une
association exprime le nombre de partition possible d'une occurrence de chaque
entité à l'association.
Les cardinalités (0,1) et (1,1) sont appelées
cardinalités fils c'est-à-dire cardinalités minimales.
Les cardinalités (0, n) et (1, n) sont appelées
cardinalités père c'est-à-dire cardinalités
maximales.
II.2.6.3.LE MODELE CONCEPTUEL DE DONNEES (MCD)
1°.Définition du MCD: est un modèle qui
traduit la réalité, pour arriver à repérer les
entités a travers un problème posé.
2° .Démarche pour élaborer un bon
schéma du MCD :
V' Repérage des entités
V' Après le repérage des entités
chaque entité doit posséder ses
propriétés ou ses attributs,
V' La définition des relations,
V' La définition des branches de
cardinalité.
3
II.2.6.4 LE MODELE LOGIQUE DE DONNES (MLD)
1°.Définition du MLD : c'est un modèle qui
se rapproche du matériel informatique, c'est un modèle que le
SGBD traite.
Los qu'on a un schéma du MCD pour passer au MLD, on
applique les règles suivantes :
? On change l'appellation de l'entité en table,
? On change l'appellation de propriété ou attribut
en champ,
? On change l'appellation de l'identifiant en clé
primaire,
? Les relations peuvent changées soit en un lien, soit en
une table.
Par ex : Pour les cardinalités père fils le passage
de MCD au MLD est :
FILS
ID FILS
ID PERE
PERE
(1, n) (1,1)
AVOIR
Ex : pour les cardinalités père père le
passage de MCD au MLD est :
? Le MCD
PERE
ID PERE
PERE
ID PERE

(1, n) (1, n)
AVOIR
? LE MLD
|
PERE
ID PERE
|
|
|
AVOIR
ID PERE
ID PERE
|
|
|
PERE
ID PERE
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
3
II.2.7. LES PRINCIPAUX SGBD
Les principaux systèmes de gestion de bases de
données sont les suivantes :
> Borland Paradoxe ;
> File marker ;
> IBM ;
> Ingres ;
> Inter base ;
> Microsoft SQL server ;
> Microsoft Access ;
> Microsoft Foxpro ;
> Oracle ;
> Sybase ;
> MySQL ;
> postgreSQL ;
> MySQL ;
> SQL server.
II.2.7. LES DIFFERENTS MODELES DE BASES DE DONNEES
Les bases de données sont apparues à la fin des
années 60, à une époque où la
nécessité d'un système de gestion de l'information souple
se faisait ressentir. Il existe cinq modèles de SGBD,
différenciés selon la représentation des données
qu'elle contient :
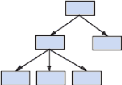
? le modèle hiérarchique :
sont classées hiérarchiquement, selon une
arborescence descendante. Ce modèle utilise des pointeurs entre les
différents enregistrements. Il s'agit du premier modèle de SGBD
les données
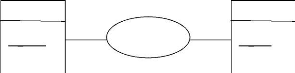
? le modèle réseau
comme le modèle hiérarchique ce modèle
utilise des pointeurs vers des enregistrements. Toutefois la structure n'est
plus forcément arborescente dans le sens descendant
3
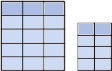
? le modèle relationnel
(SGBDR, Système de gestion de
bases de données relationnelles) les données sont
enregistrées dans des tableaux à deux dimensions (lignes et
colonnes). La manipulation de ces données se fait selon la
théorie mathématique des relations
? le modèle déductif
les données sont représentées sous forme de
table, mais leur manipulation se fait par calcul de prédicats
? le modèle objet
(SGBDO, Système de gestion de
bases de données objet) : les données sont stockées sous
forme d'objets, c'est-à-dire de structures appelées classes
présentant des données membres. Les
champs sont des instances de ces classes
A la fin des années 90 les bases relationnelles sont
les bases de données les plus répandues (environ trois quarts des
bases de données).
LA CONCLUSION
Nous voici au terme de notre de notre chapitre qui nous a trop
parlé du fonctionnement de la base de données relationnelle dans
la quelle on peut stocké les informations et le système
d'information sur le quel on va l'ensemble des informations qui circulent dans
une entité.
3
CHAPITRE .III. MODELISATION ET IMPLEMENTATION DE LA
CARITAS
III .0.INTRODUCTION III .1.ETUDE PREABLE
Dans cette partie nous parlerons de l'historique de la
Caritas, de la situation géographique et des objectifs poursuivit par la
Caritas, Nous vous présenterons les différentes
difficultés concernant le système existent de la Caritas, les
pistes de solutions suivrons pour clore.
III.1.1.CADRE HISTORIQUE
Il est crée au sein de l'archidiocèse de
Kananga, conformément à la mission sociale de l'église
Catholique, à la pastorale de Mgr l'archevêque N°5 de 28
Août 2008 et la note de restriction CARITAS DEVELOPPEMENT KANANGA en
cigle CDKA.
Durée : La CDKA est créée
pour une durée indéterminée.
? Définition de la CDKA
La CDKA est un instrument de la pastorale sociale de
l'archevêque ASBL, appelée à travers ses intervention sur
terrain, les orientation et les directeurs de l' archevêque en rapport
avec la promotion et le Développement intégral de l'homme et de
la femme créée à l'image de Dieu dans les domaines
spécifiques de la lutte contre la faim et la pauvreté, de la
promotion de la solidarité et du partage, de la santé et du
développement humain.
La Caritas s'instruise dans les axes d'assurances
humanitaires, de santés et développements
socio-économiques tels que :
? Le bureau diocésain de Caritas (BDC)
? Le bureau diocésain des OEuvres Médicales
(BDOM)
? Le bureau diocésain de Développement (BDD)
III.1.2.CADRE GEOGRAPHIQUE
Le siège de la Caritas Développement Kananga et
situé au numéro 96, Avenue du commerce, Quartier TSHISAMBI, comme
de Kananga, Ville de Kananga, Province du Kasaï occidental.
Il peut être transféré à un autre
endroit sur décision de l'archevêque de Kananga.
Il est entouré à L'Est par une l'École
lumière des nations à L'ouest par une église de Bima au
Sud par une église Orthodoxe, et au Nord par une grande Route de
L'avenue lulua et l'Institut Kelekele.
III.1.3.LES OBJECTIFS POURSUIVIS
La CDKA à pour mission :
3
? Augmenter, par la réflexion et les actions,
l'efficacité de la contribution de l'église aux efforts de la
promotion intégrale de la personne et de la communauté humaine
sans exception, conformément à la doctrine sociale de
l'église, aux options fondamentales aux directeurs pastorales de la
commission Caritas Développement de la CENCO.
? Mener la communauté humaine et chacun de ses membre
à l'accroissement de la charité et de la solidarité, de la
justice et de la paix.
? D'encourage et soutenir la promotion de l'homme par
lui-même. ? Promouvoir la santé de tout homme, dans sa
communauté toute entière.
35
III.1.4.ORGANIGRAMME FONCTIONNEL
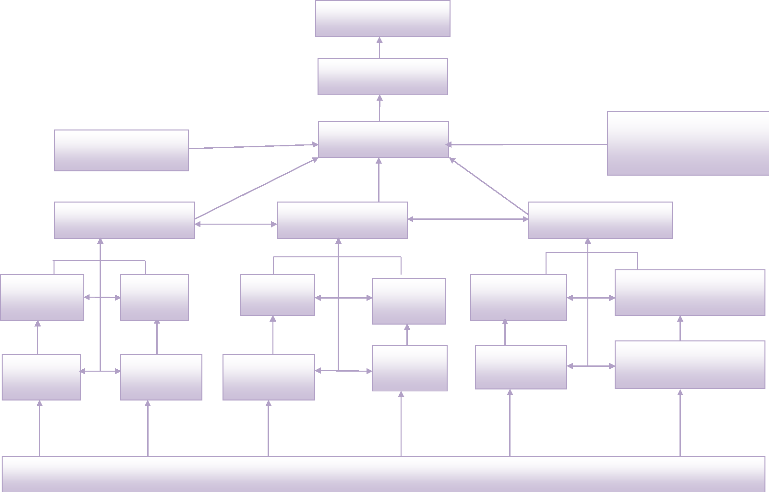
SUPERVISION
FORMATIONS SANITAIRES
COMMISSARIAT AUX COMPTE
DIRECTION BDOM
PROJETS DE SANTE
CHARGES DE PROJET
COMITES PAROISSIAUX DE CARITAS DEVELOPPEMENT
(CPCD)
OEUVRES SOCIALES ET CARITATIVES
ANIMATEUR ET ENCADEUR
DIRECTION BDC
COORDINATION DE LA CDKA
CONSEIL D'ADMINISTRATION
ARCHEVEQUE
CHARGES DE PROJETS
PROJET
D'URGENCE
STRUCTURE DE DEVELOPPEMENT
ANIMATEUR ENCADREURS
DIRECTION BDD
CHARGES DE PROJETS
- SERVICE ADMINISTRATIF - SERVICE DE
LOGISTIQUE - SERVICE DES FINANCES ET COMPTABILITE
PROJET DE DEVELOPPEMENT DURABLE
36
III.1.5.ORGANOGRAMME DE L'EXISTANT
SECRETARIAT GENERAL
LOGISTIQUE
CHAUFFEUR
MECANICIEN
37
III.2.ANALYSE DE DIFFRENTES POSTES DE
TRAVAIL
Notre étude nécessite une analyse des
différentes postes de travail de la CARITAS pour observer un peu comment
ils sont organisés et comment ses postes communiquent.
|
No
|
Intitulé de
poste de
travail
|
Moyen de
traitement
(matériel)
|
Nombres
des
personnes
|
Observation
|
|
1
|
Secrétariat
Général
|
ordinateur
|
1
|
Plus rapide
|
|
2
|
logistique
|
Manuel
|
1
|
perte des
informations trop fréquentes.
|
|
3
|
comptabilité
|
ordinateur
|
1
|
Lenteur dans la
transmission des
rapports
|
|
4
|
caisse
|
ordinateur
|
1
|
Surcharge par le
nombre
d'informations
à
traiter
|
38
III.3.ANALYSE DE FLUX D'INFORMATION
L'analyse des étapes essentielles du système actuel
est définie comme étant l'ensemble d'informations qui circule
dans organisation notamment entre les différents services ou
départements.
III.3.1.TABLEAU DE FLUX D'INFORMATION
Géstion : charroi Analyste : Mfumu
junior
Application : charroi automobile Date : le...... /....../ 2014
Flux
|
Listes des
chauffeurs Données véhicules
|
|
Matricule Nom
Age Origine
|
|
Secrétariat Général Destination
|
|
Comptabilité Logistique
|
Nom Post nom
|
Fiche de payes
|
|
Fiches de chauffeurs
|
|
Secrétariat Général
|
|
Logistique
|
|
Caisse
|
|
Secrétariat Général Caisse
|
|
Liste des chauffeurs
à payés
|
Nom
Post nom Prénom sexe
|
Caisse
|
Secrétariat Général Logistique
|
39
III.3.2.MATRICE D'INFORMATION
Le tableau suivant constitue la matrice des flux d'information
qui se présente en ligne par les services origines sources, tandis qu'en
colonne ce sont les services destinateurs.
|
Secrétariat Général
|
logistique
|
Comptabilité
|
Caisse
|
|
Secrétariat
Général
|
-
|
Liste des
chauffeurs
engagés
|
liste des agents dans chaque bureau
|
Fiche des
chauffeurs
engagés
|
|
Logistique
|
-
|
-
|
-
|
Listez des
agents sur le
point de
payement
|
|
Comptabilité
|
Listez des
agents sur le
point de
payement
|
-
|
-
|
-
|
|
Caisse
|
Fiches de fin
de mois pour
le payement
|
-
|
-
|
-
|
40
III.3.3. Narration de charroi Automobile de la CARITAS
Chaque matin le chauffeur se présente à la
CARITAS à la réception avec son document de son véhicule,
il signe à la fiche après il donne ses document au
récepteur, ce dernier à son tour il vérifier les documents
de véhicule puis il enregistre le numéro de la plaque du
véhicule dans son registre, le récepteur élabore une fiche
avec deux copies, après le récepteur remet l'une chez logisticien
et garde l'autre copie pour le chauffeur lui -même et cette même
fiche est remise encore au récepteur .
A la fin de la journée le récepteur fait un
rapport journalier pour aller donner le responsable de la
société.
III.3.4.SHEMA DE FLUX
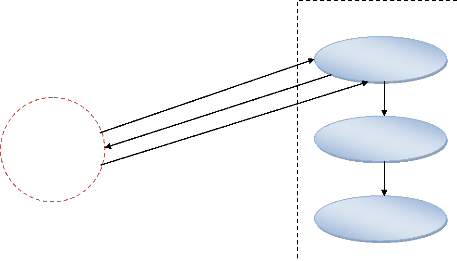
RECEPTION
LOGISTIQUE
CHAUFFEUR
RSPONSABLE
Le circuit d'information, s'indique comment les informations
circulent dans une entreprise.
41
III.3.5.ANALYSE DU SCHMA DE CIRCULATION D'INFORMATION
C'est un modèle organique de traitement de données
dans un ordinateur.
|
100 CHAUFFEUR
|
200 RECEPTION
|
300 LOGISTIQUE
|
400
RESPONSABLE
|
|
|
201
|
|
|
202
|
|
|
|
|
101
|
Registre
|
|
|
101
|
|
401
|
|
|
|
|
|
201
|
|
301
|
|
|
|
|
|
Document
|
|
|
|
|
|
|
Document
|
|
|
|
Rapport
|
X
|
|
|
|
|
|
Rapport
|
X
|
|
|
201
|
|
|
|
|
|
Fiche
|
|
|
|
102
|
|
|
|
|
301
102
|
|
Fiche
202
|
|
|
|
|
|
202
|
|
|
|
|
|
Fiche
|
|
|
|
|
|
X
|
|
|
Rapport
401
|
|
|
42
III.4. CRITIQUE DIAGNOSTIQUE DE L'EXISTANT
Nous résumons de tous les travails effectués au
niveau de l'analyse de l'existant. Ainsi, la critique ou le diagnostic de
l'existant permettra de dénicher les points forts et faibles du
système actuel.
III.4.1. LES POINTS FAIBLES DU SYSTEME
Après une analyse la circulation faite sur le lieu,
voici les éléments constatés qui rendent le système
inefficace et entraîne des difficultés dans la gestion de la
faculté :
? Malgré la présence de l'outil informatique,
nombre de traitements se font encore manuellement ce qui prouve que cet outil
n'est pas bien utilisé,
? Manque du personnel qualifié en informatique,
? Insuffisance des moyens techniques pour le traitement et la
diffusion de l'information aux utilisateurs de ce système.
III.4.2. SOLUTIONS INFORMATIQUES APPORTEES
La solution informatique est fiable, car elle tient compte de
l'intérêt général, présentant plus d'avantage
par rapport aux autres. Le type de système informatique adopté
à cette situation est un système informatique qui s'effectue au
niveau de chaque poste de travail, les informations sont traitées d'une
façon ordinaire sans une application, nous allons nous servir d'une Base
de données et une interface de la saisie conçu d'un langage de
programmation C#.
III.4.3. RAPPORT DE LA SOLUTION
Cette solution apportera une petite modification des
tâches, changement d'activité des agents travaillants dans les
postes de travail concernées par l'application. Les agents
concernés doivent suivre une petite formation pour l'utilisation des
équipements informatiques et logiciels installés dans ces
domaines.
III .5. CONCEPTION DE LA BASE DE
DONNEES
III.5.1 CONCEPTION DE LA BASE DE DONNEES
Comme nous utilisons la méthode de conception MERISE, elle
nous aidera de séparer les données et le traitement, on aura les
modèles suivants pour cette conception :
43
· Modèle conceptuelle de données ;
· Modèle logique de données ;
· Etape physique de données.
III.5.1.1 Modèle conceptuel de données
(MCD)
Cette étape a pour objectif de mettre en place des
données
appropriées pour la gestion automatisée. Nous y
présentons les entités manipulés dans notre application
ainsi que les relations les reliant.
a. Les entités trouvées
Pour notre application de la gestion de charroi automobile,
nous
aurons comme entités suivantes :
· Chauffeur ;
· matériels ;
· Société ;
· Garage ;
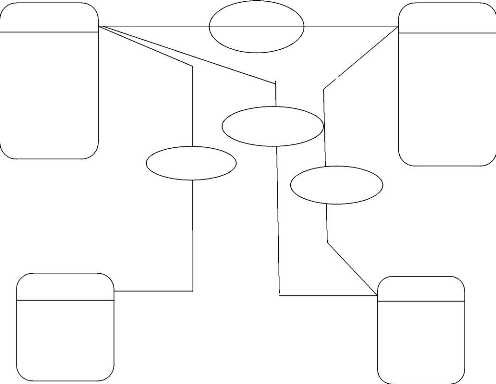
1, n
1, 1
Id_materiel Type_materil Marque Date_dachat Date_fabricatio n
Maison_fabricat Couleur
Id_chauffeur Nom_chauf Postnom_chauf Prenom_chauf Sexe
Age Niveau_etude Adresse Id_societe
1, n
1, n
MATERIEL
Conduire
CHAUFFEUR
Date
Gérer
Acheter
Engager
Id_garage Nom
GARAGE
1, n
SOCIETE
Id_societe Nom
adresse
1, n
1, n
b. Description des ces entités
44
III.5.1.2 Modèle logique de données (MLD)
A ce niveau, nous montrerons quelques informations qui serons
prêtes à être traiter à l'ordinateur.
1. Passage du MCD au MLD
La transformation d'une structure conceptuelle à une
structure logique nous présenterons quelques règles, dont les
voici :
? les individus (objets) sont transformés en tables ;
les propriétés des attributs et les identifiants deviennent des
clés primaires,
? les relations sont transformées en relation du type
père-fils ; les CIF
disparaissent et le père envoie sa clé au fils
qui devient une clé étrangère ; ? les relations du type
père-père deviennent aussi des tables et prennent les
identifiant ces deux entités associés.
2. Présentation du MLD
C'est un modèle relationnel conçu
dans le Microsoft Access.
45
III.5. 1.3. Modèle physique de données
(MPD)
Cette étape consiste en la prise en compte des
contraintes physiques liées au matériel de traitement et au
logiciel choisi. Le modèle physique de données est le passage du
MLD à la structure de la machine.
Tout SGBD doit pouvoir permettre entre autre : la
création d'une base de données par son langage de
définitions de données le chargement de la base de
données, la mise à jour des données et la structure par le
langage de manipulations de données l'interrogation par les
utilisateurs.
a) Règles du passage du MLD au MPD
A ce niveau les tables deviendrons des fichiers et les
attributs des champs ou rubriques). La structure de cette base de
données dépendra du type de SGBD choisi
b) Présentation du MPD
A ce stade, nous signions qu'il n'existe pas d'approche
normalisée de description et de présentation du niveau physique
de données.
Le modèle Physique de données se présente
de la manière suivant pour toutes les tables concernées.
46
|
TABLES
|
CHAMPS
|
TYPE
|
TAILLE
|
OBSERVATION
|
|
MATERIEL
|
Id_materiel
|
Texte
|
15
|
Primary Key
|
|
Nom_materil
|
Texte
|
15
|
Champ
|
|
Date_dachat
|
Date
|
15
|
Champ
|
|
Maison_fabrication
|
Texte
|
15
|
Champ
|
|
Marque
|
Texte
|
15
|
Champ
|
|
Couleur
|
texte
|
10
|
champ
|
|
CHAUFFEUR
|
Id_chauffeur
|
Texte
|
15
|
Primary key
|
|
Nom_chauf
|
Texte
|
15
|
Champ
|
|
Postnom_chauf
|
Texte
|
15
|
Champ
|
|
Prenom_chauf
|
Texte
|
15
|
Champ
|
|
Sexe
|
Texte
|
5
|
Champ
|
|
Age
|
Numerique
|
5
|
Champ
|
|
Niveau_etude
|
Texte
|
10
|
Champ
|
|
Adresse
|
Texte
|
20
|
Champ
|
|
Id_societe
|
texte
|
15
|
Foreign key
|
|
GARAGE
|
Id_garage
|
Texte
|
15
|
Primary key
|
|
Nom
|
texte
|
15
|
champ
|
|
SOCIETE
|
Id_societe
|
Texte
|
15
|
Primary key
|
|
Nom
|
Texte
|
15
|
Champ
|
|
adresse
|
texte
|
20
|
champ
|
|
GARER
|
Id_garage
|
Texte
|
15
|
Foreign key
|
|
Id_materiel
|
texte
|
15
|
Foreign key
|
|
CONDUIRE
|
Id_materiel
|
Texte
|
15
|
Foreign key
|
|
Id_chauffeur
|
Texte
|
15
|
Foreign key
|
|
date
|
texte
|
10
|
|
|
ACHETER
|
Id_materiel
|
texte
|
15
|
Foreign key
|
|
Id_societe
|
texte
|
15
|
Foreign key
|
47
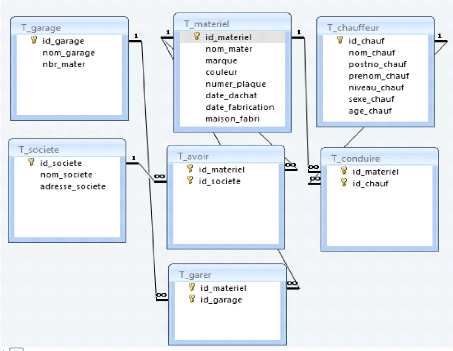
III.6.APPLICATION INFORMATION (Programmation)
1 .FORMULAIRE D'ACCUEIL
Le Formulaire d'accueil qui contient les différents
contrôles, après le chargement de ce dernier un formulaire
d'authentification apparait.

2 .FORMULAIRE D'AUTHENTIFICATION
Ce formulaire vous aide à vous identifier si vous
êtes concerne ou pas par l'application.
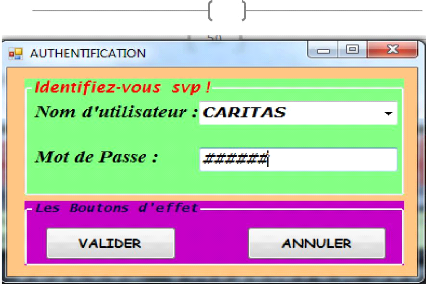
48
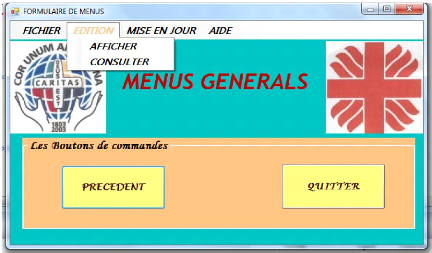
3 .FORMULAIRE DE MENUS GENERALS
Ce dernier vous aide à choisir un menu les autres
formulaires de l'application.
4 .FORMULAIRE DES CHAUFFEURS
Celui-ci nous aide plus d'enregistrer les chauffeurs d'une
entreprise CARITAS, pas seulement l'ajout de chauffeur mais encore d'autres
opérations.
49
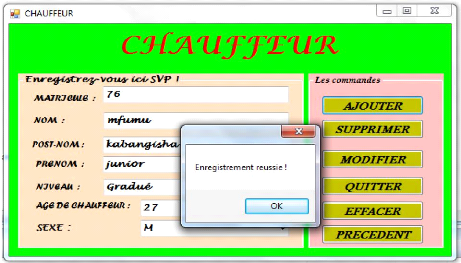
5 .FORMULAIRE DES ENGINS
Ce formulaire joue le même rôle que le formulaire des
enregistrements des chauffeurs.
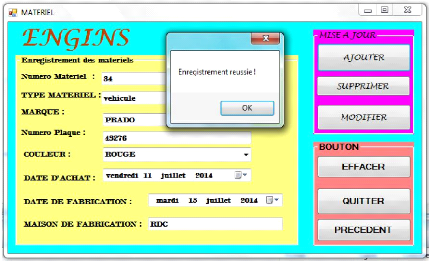
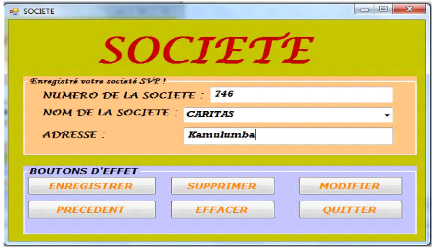
Ce dernier exploite les mêmes opérations que les
précédents, mais celui-ci fait l'enregistrement des
différentes sociétés.
6 .FORMULAIRE SOCIETE
50
7 .FORMULAIRE DE GARAGE
Ce dernier exploite les mêmes opérations que les
précédents, mais celui-ci fait l'enregistrement des
différents garages.
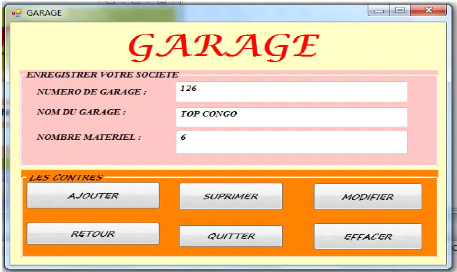
? QUELQUES CODES DE L'APPLICATION Pour l'Appel
d'un formulaire :
}
51
private void button1_Click(object sender, EventArgs e)
{
Form form = null;
Form Form2 = new Form2();
form = Form2; Form2.Show(); this.Hide();
}
Pour une classe ( classe de la table chauffeur)
:
class Class_chauffeur
{
private string Id_chauf;
private string Nom_chauf; private string Postnom_chauf; private
string Prenom_chauf; private string Sexe_chauf; private string Niveau_chauf;
private string Age_chauf;
public string id_chauf
{
get { return Id_chauf; } set { Id_chauf = value; }
}
public string nom_chauf
{
get { return Nom_chauf; } set { Nom_chauf = value; }
}
public string postnom_chauf
{
get { return Postnom_chauf; } set { Postnom_chauf = value; }
}
public string prenom_chauf
{
get { return Prenom_chauf; } set { Prenom_chauf = value; }
}
public string sexe_chauf
{
get { return Sexe_chauf; } set { Sexe_chauf = value; }
}
public string niveau_chauf
{
get { return Niveau_chauf; } set { Niveau_chauf = value; }
}
public string age_chauf
{
get { return Age_chauf; } set { Age_chauf = value; }
}
52
Pour le Bouton Enregistrer (Table Matériel)
:
public Form5()
{
InitializeComponent();
}
string chaine = @"Provider=microsoft.ACE.OLEDB.12.0;Data
source=c:\\tfc_mfumu\\gestion_charroi.accdb";
public void ajoutmateriel()
{
Class_materiel nouv_matet = new Class_materiel();
nouv_matet.id_materiel = textBox1.Text; nouv_matet.nom_mater = textBox2.Text;
nouv_matet.marque = textBox3.Text; nouv_matet.couleur = comboBox1.Text;
nouv_matet.numer_plaque = textBox4.Text; nouv_matet.date_dachat =
dateTimePicker1.Value; nouv_matet.date_fabrication = dateTimePicker2.Value;
nouv_matet.maison_fabri = textBox5.Text; OleDbConnection conn = new
OleDbConnection(chaine); DialogResult junior = MessageBox.Show("voulez-vous
enregistrer
?", "Avertissement", MessageBoxButtons.OKCancel,
MessageBoxIcon.Information);
if (junior == DialogResult.OK)
{
OleDbCommand cmd = new OleDbCommand("insert into T_materiel
values('" + nouv_matet.id_materiel + "','" + nouv_matet.nom_mater
+ "','" + nouv_matet.marque + "','" + nouv_matet.couleur + "','" +
nouv_matet.numer_plaque + "','" + nouv_matet.date_dachat + "','" +
nouv_matet.date_fabrication + "','" + nouv_matet.maison_fabri + "')");
cmd.Connection = conn;
conn.Open();
cmd.ExecuteNonQuery();
conn.Close();
MessageBox.Show("Enregistrement reussie !");
|
textBox1.Text
|
=
|
"";
|
|
textBox2.Text
|
=
|
"";
|
|
textBox3.Text
|
=
|
"";
|
|
textBox4.Text
|
=
|
"";
|
|
textBox5.Text
|
=
|
"";
|
|
comboBox1.Text
|
=
|
"";
|
}
}
Pour le bouton Surimer :
public void supprimer()
{
string jesus = textBox1.Text;
OleDbConnection conn = new OleDbConnection(chaine); OleDbCommand
cmd = new OleDbCommand();
DialogResult juni = MessageBox.Show("Etes-vous autoriser de
supprimer ?", "Avertissement", MessageBoxButtons.OKCancel,
MessageBoxIcon.Information);
if (juni == DialogResult.OK)
{
}
53
cmd.CommandText = "delete from T_materiel where
id_materiel='" + jesus + "'";
cmd.Connection = conn;
conn.Open();
cmd.ExecuteNonQuery();
conn.Close();
MessageBox.Show("la suppression Reussie ! !");
textBox1.Text = "";
textBox2.Text = "";
textBox3.Text = "";
textBox4.Text = "";
textBox5.Text = "";
comboBox1.Text = "";
}
}
Pour Bouton Modifier :
public void modifier()
{
string jesus = textBox1.Text;
OleDbConnection conn = new OleDbConnection(chaine);
OleDbCommand cmd = new OleDbCommand();
cmd.Connection = conn;
cmd.CommandText = "delete from T_materiel where id_materiel='"
+ jesus + "'";
conn.Open();
cmd.ExecuteNonQuery();
conn.Close();
Class_materiel nouv_matet = new Class_materiel();
nouv_matet.id_materiel = textBox1.Text;
nouv_matet.nom_mater = textBox2.Text;
nouv_matet.marque = textBox3.Text;
nouv_matet.numer_plaque = textBox4.Text;
nouv_matet.maison_fabri = textBox5.Text;
nouv_matet.couleur = comboBox1.Text;
nouv_matet.date_dachat = dateTimePicker1.Value;
nouv_matet.date_fabrication = dateTimePicker2.Value;
OleDbConnection conne = new OleDbConnection(chaine);
OleDbCommand junior = new OleDbCommand();
cmd.Connection = conne;
cmd.CommandText="insert into T_materiel values('" +
nouv_matet.id_materiel + "','" + nouv_matet.nom_mater + "','" +
nouv_matet.marque + "','" + nouv_matet.numer_plaque + "','" +
nouv_matet.maison_fabri + "','" + nouv_matet.couleur + "','" +
nouv_matet.date_dachat + "','" + nouv_matet.date_fabrication + "')";
conne.Open();
cmd.ExecuteNonQuery();
conne.Close();
MessageBox.Show("la modification a reussie avec succé
!");
textBox1.Text = "";
textBox2.Text = "";
textBox3.Text = "";
textBox4.Text = "";
textBox5.Text = "";
comboBox1.Text = "";
textBox1.Focus();
}
ce dit travail.
54
CONCLUSION GENERALE
Etant donné que toute chose qui commence a toujours eu
une fin ; nous voici au terme de notre travail. Nous avons eu l'honneur de
présenter ce travail qui manifeste la fin de notre cycle de graduat.
Dans les pages précédentes ; nous avons eu à parler
différents points dont le premier chapitre intitulé Architecture
client-serveur, dans lequel nous avons mis en évidence les
différents types d'architecture client-serveur existant notamment
l'architecture deux et trois tiers, ainsi que quelques définitions y
afférentes.
Le deuxième chapitre intitulé Système
d'information et Base de données, dans lequel nous avons
épinglé et défini quelques concepts principaux en rapport
avec les bases de données ; ainsi que quelques règles à
suivre pour la conception d'une base de données.
Pour y arriver, nous avons fait usage d'un système de
gestion de base de données Microsoft Access ainsi que le langage de
programmation C#(C-SHARP).
L'objectif principal de la mise en place de cette application
était de pouvoir réveiller les esprits sur quelques notions
liées à l'informatique. C'est pourquoi nous étions
obligés de parler du modèle client-serveur, donner beaucoup plus
d'éclaircissement sur les notions de système d'information et
base de données en suite nous avons répondu à notre
problématique.
Enfin nous avons mis en place une base de données qui
nous permettra de stocker toutes les informations en rapport avec la gestion de
charroi automobile. Sans plus tarder nous avons passés a la
programmation informatique en vue de garantir la sécurité de
données. Avec le SGBD ACCESS 2007 qui nous a aidé à mettre
en place notre base et avec un langage de programmation que nous venons de
souligner.
Nous invitons d'autres chercheurs et réalisateurs de
consulter
55
BIBLIOGRAPHIE
I. OUVRAGE :
ACSIOME : Modélisation dans la conception des
systèmes d'information MASSON, 1989
M. ADIBA, C. DELOBEL : Base de données et
systèmes relationnels DUNOD, 1983
M. BOUZEGHOUB, GARGARIN et P. VALDURIEZ : Les Objets :
concepts, langages, bases de données, méthodes,
interfaces AYROLLES, 1987
GALACSI : Les systèmes d'information : analyse et
conception DUNOD, 1984 G. GARGARIN : Base de données :
les systèmes et leurs langages EYROLLES,
Arnold rochfeld et José morejon : La méthode
MERISE, les éditions
d'organisation
DI GALLO FREDERIC, méthodologie de système
d'information - Merise, CNAM,
ANGOULEME 2000-2001
George Gardarin : base de données et objet
relationnelle, Eyrolles, Paris 1999
GARDARIN, le Client-serveur, Eyrolles,
Paris 1996.
GADARIN G., Maitriser les bases de données,
Eyrolles, Paris 1993
RGG cattel : bases de données orienté objet
Jacques Alphonse vibudula et louis Denis konkie IPEPE :
technique de base de
donnés études et cas, criged, janvier 2010
RGG CATTEL : les systèmes des bases de données
traditionnelles
II. NOTES DE COURS
? Cours de MERISE avec le Professeur Pierre KAFUNDA
? INFORMATIQUE GENERALE avec l'assistant Anaclet TSIKUTU
III. SITE INTERNET
http://www.commencamarche.net
23/02/2014 15h45',
http://www.nitropdf.com 02/03/2014
10h30',
http://www.wikipedia.com
14/05/2014 09h36',
56
TABLE DES MATIERES
0. INTRODUCTION GENERALE 1
CHAPITRE I. L'ARCHITECTURE CLIENT SERVEUR 4
I.1. INTRODUCTION 4
I.2 DEFINITIONS 4
I.3. LES PRINCIPES GENERAUX 6
I.4.LES DIFFERENTS TYPES D'ARCHITECTURES 6
I.4.1.L'ARCHITECTURE A DEUX NIVEAUX 6
I.4.2.L'ARCHITECTURE A 3 NIVEAUX 7
I.4.3.L'ARCHITECTURE MULTINIVEAUX 8
I.5.AVANTAGES ET DESAVANTAGES DE L'ARCHITECTURE CLIENT
SERVEUR 9
I.5.1.AVANTAGES 9
I.5.2.LES DESAVANTAGES 9
I.6.QUELQUES CARACTERISTIQUES CLIENT SERVEUR 9
I.6.1.CARACTERISTIQUES D'UN PROCESSUS SERVEUR 9
I.6.2.CARACTERISTIQUESS D'UN PROCESSUS CLIENT 10
I.7.TYPES DES CLIENTS 10
I.8.1.CLIENT LEGER 10
I.8.2.CLIENT LOURD 10
I.8.3.CCLIENT RICHE 10
I.9.LES DIFFERENTS TYPES DE CLINT-SERVEUR 10
I.9.1.CLIENT-SERVEUR DE PRESENTATION 10
I.9.2.CLIENT-SERVEUR DE REHABILITATION 11
I.9.3.CLIENT-SERVEUR DE DONNEES 11
I .9.4.CLIENT-SERVEUR DE PROCEDURES 11
I.9.5.CLIENT-SERVEUR DE DONNEES ET PROCEDURES 11
I.10. DIALOGUE SYNCHRONE ET ASYNCHRONE 12
I.10.1.DIALOGUE SYNCHRONE 12
I.10.2.DIALOGUE ASYNCHRONE 13
I.11.LES INTERETS TECHNIQUES D'UNE ARCHITECTURE
CLIENT-SERVEUR 13
CONCLUSION 13
CHAPITRE II : SYSTEME D'INFORMATION ET BASES DE DONNEES 14
II.1.SYSTEME D'INFORMATION 14
II.1.0.INTRODUCTION 14
II.1.1. DEFINITION DES QUELQUES CONCEPTS 14
II.1.1.1. INFORMATION 14
II.2. SYSTEME 18
II.4. LES DIFFERENTS TYPES DE SYSTEMES 19
II.5. CONNAISSANCE. 22
II.6.LES FONCTIONS D'UN SYSTEME D'INFORMATION 24
II.7.LES FINALITES D'UN SYSTEME D'INFORMATION 25
II.2.BASES DE DONNEES 25
II.2.1 Introduction 25
II.2.3. DEFINITION D'UNE BASE DES DONNEES 25
II.2.4. UTILITE D'UNE BASE DE DONNEES 25
II.2.5. SYSTEME DE GESTION DE BASE DE DONNEES 26
II.2.6.LE SYSTEME DE GESTION DE BASE DES DONNEES(SGBD) 27
57
II.2.6.1.LES OBJECTIFS DE SGBD 27
II.2.6.2.MODELE RELATIONNEL (modèle entité et
association) 27
II.2.6.3.LE MODELE CONCEPTUEL DE DONNEES (MCD) 29
II.2.6.4 LE MODELE LOGIQUE DE DONNES (MLD) 30
II.2.7. LES PRINCIPAUX SGBD 31
II.2.7. LES DIFFERENTS MODELES DE BASES DE DONNEES 31
CHAPITRE .III. MODELISATION ET IMPLEMENTATION DE LA CARITAS
33
III .0.INTRODUCTION 33
III .1.ETUDE PREABLE 33
III.1.1.CADRE HISTORIQUE 33
III.1.2.CADRE GEOGRAPHIQUE 33
III.1.3.LES OBJECTIFS POURSUIVIS 33
III.1.4.ORGANIGRAMME FONCTIONNEL 35
III.1.5.ORGANOGRAMME DE L'EXISTANT 36
III.2.ANALYSE DE DIFFRENTES POSTES DE TRAVAIL 37
III.3.ANALYSE DE FLUX D'INFORMATION 38
III.3.1.TABLEAU DE FLUX D'INFORMATION 38
III.3.2.MATRICE D'INFORMATION 39
III.3.3. Narration de charroi Automobile de la CARITAS 40
III.3.5.ANALYSE DU SCHMA DE CIRCULATION D'INFORMATION 41
III.4. CRITIQUE DIAGNOSTIQUE DE L'EXISTANT 42
III.4.1. LES POINTS FAIBLES DU SYSTEME 42
III.4.2. SOLUTIONS INFORMATIQUES APPORTEES 42
III.4.3. RAPPORT DE LA SOLUTION 42
III .5. CONCEPTION DE LA BASE DE DONNEES 42
III.5.1 CONCEPTION DE LA BASE DE DONNEES 42
III.6.APPLICATION INFORMATION (Programmation) 47
1 .FORMULAIRE D'ACCUEIL 47
2 .FORMULAIRE D'AUTHENTIFICATION 47
3 .FORMULAIRE DE MENUS GENERALS 48
4 .FORMULAIRE DES CHAUFFEURS 48
6 .FORMULAIRE SOCIETE 49
CONCLUSION GENERALE 54
BIBLIOGRAPHIE 55
| 

