DEDICACES
Je dédie ce travail à mes chers parents qui se
sont sacrifiés pour ma réussite,
Mon père Moctar Gueye, celui qui m'a toujours soutenu
moralement et financièrement
A ma très chère Maman, RoghayaDièye,
celle qui n'a jamais cessé de me soutenir, grâce à elle je
ne baisserai jamais les bras, je t'adore maman.
A mes tantes et oncles pour le soutien qu'ils m'ont
fourniquelque soit la nature
A mes chers frères et soeurs : Awa, Ndery,
Cheikh, Fallou, Mariam(Mah), Arame, Malick, Aboulahad, Roghaya, Mariam(Mami)
et DAM
A tous mes amis qui ont toujours été là
pour moi à savoir ceux qui sont avec moi au Maroc et ceux qui sont
ailleurs. Je ne saurais citer tous les noms de peur d'en oublier mais je vous
remercie du fond du coeur.
REMERCIEMENTS
Tous mes remerciements à Monsieur Moustapha directeur
de la prestigieuse école (MIAGE Kenitra).
Je remercie mon encadrant et professeur Mr Mounji qui s'est
fatigué autant pour ce travail que pour notre formation.
Merci à tous les professeurs et à toute
l'administration de l'école MIAGE Kenitra qui m'ont permis d'atteindre
ce niveau ainsi que tous mes promotionnaires.
Sans oublier Amina Hamoud et Cheikh OuldMehlou pour leur
aide
Je crois que sans vous ce travail n'aurait abouti à
temps
SOMMAIRE
DEDICACES
1
REMERCIEMENTS
2
INTRODUCTION
6
I. LA
SÉCURITÉ INFORMATIQUE
7
I.1. Objectif
7
I.2. Enjeux de la
sécurité au sein de l'entreprise
8
I.2.1. La
sécurité informatique : C'est quoi ?
8
I.2.2. La
sécurité informatique : Pourquoi ?
10
I.2.3. La
sécurité informatique : Comment ?
11
I.3. Les
Menaces
12
I.3.1. E-mails
forgés
12
I.3.2.
Spamming
12
I.3.3. Virus,
Chevaux de Troie et autres Malwares
14
I.3.3.1.
Virus
15
I.3.3.2.
Ver :
16
I.3.3.3. Cheval de
Troie :
16
I.3.3.4.
Backdoor
16
I.3.4. 3.4
SNIFFING
17
I.3.5. 3.5 IP
SPOOFING
19
I.4.
Définition des technologies oeuvrant pour la
sécurité
22
I.4.1. La
Cryptographie
22
I.4.1.1.
Cryptographie Symétrique
22
I.4.1.2.
Cryptographie Asymétrique
23
I.4.1.3.
Cryptographie numérique
23
I.4.2. Les
Firewalls
23
I.4.2.1.
Définition
23
I.4.2.2.
Fonctionnement d'un système Firewall
26
I.4.2.2.1. Le
filtrage simple de paquets
26
I.4.2.2.2. Limites
de filtrage de paquets
27
I.4.2.2.3. Le
filtrage dynamique
28
I.4.2.2.4. Le
filtrage applicatif
29
I.4.3. Les
différents types de Firewalls
31
I.4.3.1. Les
Firewalls BRIDGE
31
I.4.3.1.1. Les
Firewalls personnels
34
I.4.3.1.2. Les Firewalls plus
sérieux
34
I.4.3.2. DMZ (
demilitarized zone)
35
I.4.3.2.1. Notion
de cloisonnement
35
I.4.3.2.2.
Architecture DMZ
36
I.4.3.3. NAT
« Network Address Translation »
37
I.4.3.3.1.
Principe
37
I.4.3.3.2. Espaces
d'adressages
38
I.4.3.3.3.
Translation statique
39
I.4.3.3.4.
Translation dynamique
40
II. LES IDS
41
II.1.
Définition
41
II.2. Les
différentes sortes d'IDS
42
II.2.1. La détection d'intrusion
basée sur l'hôte
42
II.2.2.
Détection d'Intrusion basée sur une
application(ABIDS)
45
II.2.3. La
Détection d'Intrusion Réseau (NIDS)
45
II.2.3.1. Les
capteurs :
46
II.2.3.2. Placement
des capteurs
47
II.3. Mode de
fonctionnement d'un IDS
50
II.3.1. Modes de
détection
51
II.3.1.1. La
détection d'anomalies :
51
II.3.1.2. La
reconnaissance de signature :
51
II.3.2.
Réponse active et passive
53
II.3.2.1.
Réponse passive :
53
II.3.2.2.
Réponse active :
53
II.4. . Points
forts et Points faibles des IDS
54
II.4.1. Points
forts
54
II.4.1.1. Une
surveillance continue et détaillée :
54
II.4.1.2. La
modularité de l'architecture :
55
II.4.1.3. La
complémentarité des NIDS et des HIDS :
56
II.4.2. Points
faibles
56
II.4.2.1. Besoin de
connaissances en sécurité :
56
II.4.2.2.
Problème de positionnement des sondes :
57
II.4.2.3.
Vulnérabilités des sondes NIDS :
57
II.4.2.4.
Problèmes intrinsèques à la
plateforme :
58
III. SNORT
59
III.1.
L'architecture de SNORT
60
III.2. Le
décodeur de paquets.
61
III.3. Les
pré-processeurs.
62
III.4. Moteur de
détection.
63
III.5.
Système d'alerte et d'enregistrement des logs.
64
CONCLUSION
66
INDEX DES FIGURES
67
INDEX DES TABLEAUX
68
BIBLIOGRAPHIE 6
8
I.
INTRODUCTION
La croissance de l'Internet et l'ouverture des systèmes
ont fait que les attaques dans les réseaux informatiques soient de plus
en plus nombreuses. Les vulnérabilités en matière de
sécurité s'intensifient, d'une part au niveau de la conception
des protocoles de communication ainsi qu'au niveau de leur implantation et
d'autre part, les connaissances, les outils et les scripts pour lancer les
attaques sont facilement disponibles et exploitables. D'où la
nécessité d'un système de détection d'intrusions
(IDS).
Cette technologie consiste à rechercher une suite de mots
ou de paramètres caractérisant une attaque dans un flux de
paquets. Les systèmes de détection d'intrusion sont devenus un
composant essentiel et critique dans une architecture de sécurité
informatique.
Un IDS doit être conçu dans une politique globale de
sécurité. L'objectif d'un IDSest de détecter toute
violation liée à la politique de sécurité, il
permet ainsi de signaler les attaques.
Ainsi pour créer un IDS nous allons utiliser un logiciel
open source nommé SNORT.
Dans le cas du système SNORT, la reconnaissance des
attaques est basée sur le concept d'analyse de chaînes de
caractères présentes dans le paquet. Pour que le système
puisse être capable de détecter une attaque, cette dernière
doit être décrite par une signature. C'est avec cette signature
qu'on pourra d'écrire la règle que l'IDS va utiliser pour la
détection.
II. LA SÉCURITÉ INFORMATIQUE
La sécurité est un enjeu majeur des technologies
numériques modernes. Avec le développement de l'Internet et de la
notion du partage en général, les besoins en
sécurité sont de plus en plus importants. Le développement
d'applications Internet telles que le commerce électronique, les
applications médicales ou la vidéoconférence, impliquent
de nouveaux besoins comme, l'identification des entités communicantes,
l'intégrité des messages échangés, la
confidentialité de la transaction, l'authentification des
entités, l'anonymat du propriétaire du certificat, l'habilitation
des droits, la procuration, etc..
II.1. Objectif
« La sécurité informatique est tout un
processus ». Afin de garder un très bon niveau de
sécurité, il faut des contrôles réguliers (audits /
tests d'intrusion), des règles respectées (politiques de
sécurité) et des solutions intelligemment déployées
(Firewalls applicatifs, proxy, etc.). Le tout fait que la
sécurité converge vers des niveaux satisfaisants mais jamais
parfaits. Si une composante s'affaiblit c'est tout le processus qui est en
danger.
Nous allons essayer de répondre à une partie de
la problématique de la sécurité Informatique dans les
entreprises. La solution proposée au niveau de ce projet ne cadre que la
partie liée à l'architecture réseau, qui représente
un maillon parmi d'autres dans la politique de sécurité de
l'entreprise. Cette solution a été conçue de façon
modulaire dans le but de respecter les différents besoins des
entreprises. Allant de la simple utilisation d'un Firewall jusqu'à
l'utilisation des certificats avec les PKI« Public Key
Infrastructure » pour l'authentification, le VPN « Virtual
Private Network » - IPSEC pour le cryptage des données et les
IDS «Intrusion Detection System » pour la détection des
intrusion.
II.2. Enjeux de la
sécurité au sein de l'entreprise
Avant d'aborder le domaine technique, il est
préférable de prendre un peu de recul et de considérer la
sécurité dans son ensemble, pas comme une suite de technologies
ou de processus remplissant des besoins bien spécifiques, mais comme une
activité à part entière pour laquelle s'appliquent
quelques règles simples.
· Pour une entreprise ou une institution connectée
à l'Internet, le problème n'est pas de savoir si on va se faire
attaquer mais quand cela va-t-il arriver ? Une solution est donc de
repousser le risque dans le temps et dans les moyens à mettre en oeuvre
en augmentant le niveau de sécurité permettant d'écarter
les attaques quotidiennes, pas forcément anodines et non
spécifiquement ciblées.
· Aucun système d'information n'est 100%
sûr.
Ces deux premières règles ne sont pas du tout
les manifestations d'une paranoïa mais bien un simple constat qu'il est
bon d'avoir toujours en tête pour ne pas se sentir à tort
à l'abri de tout « danger ». En
sécurité informatique, on ne parle pas d'éliminer
complètement les risques mais de les réduire au minimum par
rapport aux besoins/contraintes d'affaires. Il ne faut pas oublier non plus de
considérer les actions provenant de l'intérieur de
l'organisation, qui forment une partie (la majorité selon certaines
données) non négligeable des sources d'attaques.
II.2.1. La sécurité informatique : C'est
quoi ?
Nous pouvons considérer que la sécurité
informatique est divisée en deux grands domaines :
La sécurité organisationnelle
La sécurité technique
La sécurité organisationnelle concerne la
politique de sécurité d'une société (code de bonne
conduite, méthodes de classification et de qualification des risques,
plan de secours, plan de continuité, ...).
Une fois la partie organisationnelle traitée, il faut
mettre en oeuvre toutes les recommandations, et plans dans le domaine technique
de l'informatique, afin de sécuriser les réseaux et
systèmes : cet aspect relève de la sécurité
technique.
Le périmètre de la sécurité est
très vaste :
La sécurité des systèmes
d'information
La sécurité des réseaux
La sécurité physique des locaux
La sécurité dans le développement
d'applications
La sécurité des communications
La sécurité personnelle
Un risque se définit comme une combinaison de menaces
exploitant une vulnérabilité et pouvant avoir un impact. De
manière générale, les risques sont soit des causes
(attaques, pannes, ...) soit des conséquences (fraude, intrusion,
divulgation ...).
Les objectifs de la sécurité sont simples :
empêcher la divulgation de données confidentielles et la
modification non autorisée de données.
Nous retrouvons ainsi les principes fondamentaux de la
sécurité :
La confidentialité,
L'intégrité,
L'authentification,
Le contrôle d'accès,
La non répudiation.
Une seule entrave à l'un de ces principes remet toute
la sécurité en cause
II.2.2. La sécurité informatique :
Pourquoi ?
Une politique de sécurité informatique mal
gérée peut conduire à trois types d'impacts
négatifs :
La pénétration d'un réseau,
Le vol ou détérioration d'informations,
Les perturbations.
La pénétration d'un réseau ou d'un
système peut se faire soit par vol d'identité soit par intrusion.
Ce vol d'identité peut se faire par vol du « nom d'utilisateur/mot
de passe » de connexion au système d'information. Tous les moyens
sont bons pour obtenir des informations. On peut citer à titre
d'exemples :
L'écoute des réseaux,
L'ingénierie sociale,
Ou tout simplement le fait de regarder par-dessus
l'épaule de l'utilisateur qui s'authentifie.
La pénétration d'un réseau ou
système peut aussi se faire à distance ; par exemple un hacker
peut pénétrer le réseau via un serveur de messagerie. Mais
il existe d'autres méthodes moins visibles, comme l'installation d'un
logiciel à l'insu de l'utilisateur, suite à la lecture d'une page
web sur un site. Ainsi un script contenu dans la page web chargée, peut
envoyer des messages de votre logiciel de messagerie vers d'autres
personnes.
II.2.3. La sécurité informatique :
Comment ?
Des produits existent sur le marché et permettent
d'éviter des problèmes de sécurité. Nous trouverons
par exemple des antivirus, des Firewall, du VPN, de la signature
numérique, du proxy, etc.
Chacune de ces technologies ou produits disposent d'une
couverture spécifique. Par exemple, l'antivirus va permettre de bloquer
les virus ou Chevaux de Troie entrants par la messagerie ou par échange
de fichiers.
Le très connu firewall, dont la configuration n'est ni
simple, ni rapide va permettre de filtrer les échanges entre deux
réseaux afin de limiter les accès, et de détecter les
éventuelles tentatives d'intrusion.
Une fonctionnalité supplémentaire a tendance
à se retrouver intégrée dans les firewalls : le VPN.
Celui-ci permet de garantir la confidentialité des échanges
d'informations passant par son intermédiaire en chiffrant le flux
d'informations.
Il est possible de mettre en outre une signature
numérique en place. Ainsi, dans le système de messagerie, le
destinataire du message sera certain de l'identité de l'émetteur
et de l'intégrité du message. Il pourra être le seul
lecteur si le message a été chiffré (clef
privée/clef publique).
Le serveur Web reste vulnérable, car accessible
directement depuis l'extérieur du réseau. La mise en place d'un
reverse proxy résout l'affaire. En effet, toute tentative de connexion
au serveur Web parvient au serveur proxy, qui lui-même envoie une
requête au serveur Web. Ainsi le serveur Web n'est plus accessible depuis
l'extérieur du réseau.
II.3. Les Menaces
Afin de mieux comprendre les menaces auxquelles sont
exposés les systèmes informatiques, nous allons analyser en
détail quelques attaques courantes.
II.4. E-mails
forgés
La falsification du courrier électronique est une des
attaques les plus faciles à réaliser. Bien qu'elle paraisse
anodine, elle peut être utilisée de manière criminelle pour
du harcèlement, de la diffamation ou du chantage.
La raison pour laquelle la falsification des e-mails est possible
est que le protocole utilisé par les serveurs de mail pour transmettre
le courrier (SMTP) n'effectue aucune vérification des adresses source
des messages, à l'image des bureaux de poste qui ne vérifient pas
l'adresse d'expéditeur inscrite sur les lettres ou colis.
Le protocole SMTP est basé sur cinq commandes principales:
HELO, MAIL FROM,RCPT TO,DATA, QUIT
II.4.1. Spamming
Le fait que l'on puisse envoyer du courrier électronique
anonyme ou avec des adresses falsifiées est exploitée par des
individus peu scrupuleux pour faire des envois de publicité
non-ciblées non-sollicitée et à très large
diffusion (plusieurs millions d'adresses e-mail). Ces messages non
sollicitées sont appelées du "spam" et le fait de les envoyer est
appelé le "spamming". Pour se mettre à l'abri des destinataires
qui sont frustrés d'éliminer chaque jour du spam de leur
boîte aux lettres et qui doivent parfois payer le prix d'une
communication téléphonique pour recevoir ces messages non
désirées, leurs auteurs se cachent derrière de fausses
adresses.
Si le fait de recevoir du spam est plus une
contrariété qu'un risque de sécurité, la
manière dont le spam est distribué crée des risques
réels. En effet, les ressources pour envoyer un même message
à des millions d'adresses e-mails coûteraient bien trop cher aux
spammers et ils n'auraient probablement pas le temps de terminer leurs envois
avant que leur fournisseur de service ne coupe la ligne. Il est beaucoup plus
efficace alors pour un spammer de choisir une centaine de serveurs de mail et
d'envoyer à chacun une copie du message avec une liste de distribution
d'une dizaine de milliers d'adresses.
Pour l'entreprise dont le serveur de messagerie est abusé
de telle sorte, les conséquences peuvent être les suivantes:
ü Le serveur est complètement surchargé par la
tâche de distribution du courrier pendant plus d'une journée. S'il
s'agit d'une petite entreprise avec un seul serveur, c'est non seulement la
messagerie Internet qui est bloqués, mais aussi la messagerie
interne.
ü Les disques du serveur se remplissent de logs confirmant
l'envoi des messages (risque de blocage de la machine).
ü La boîte aux lettres de l'administrateur est
inondée de messages d'erreur à propos de toutes les adresses
e-mail qui n'étaient pas atteignables.
ü Le fournisseur d'accès à Internet peut
menacer de couper la ligne s'il n'arrête pas de recevoir des
réclamations.
ü Le serveur de messagerie risque d'être inclus dans
les listes noires des serveurs participant au spam, rendant ainsi impossible
l'échange de courrier électronique avec des entreprises qui
consultent cette liste avant d'accepter du courrier d'un autre serveur.
La seule protection possible contre les abus de spam est de
configurer les serveurs de messagerie de manière à ce qu'ils
n'acceptent pas de relayer du courrier externe. Pour cela il faut appliquer au
minimum les deux règles suivantes au traitement des messages:
· Pour qu'il soit accepté par le serveur de
messagerie, l'expéditeur ou le destinataire d'un message doit faire
partie du domaine auquel appartient le serveur.
· Seules les machines faisant partie du domaine du serveur
de messagerie ont le droit de déposer des messages avec un
expéditeur qui fait partie du domaine.
La première règle permet d'éviter que le
serveur de messagerie soit utilisé pour relayer des messages qui n'ont
rien à voir avec le domaine (entreprise, unité) pour lequel il a
été mis en service. La deuxième est une règle
générale qui permet d'éviter qu'une personne externe ne
fasse relayer du courrier en prétendant que l'expéditeur
appartient au domaine du serveur.
II.4.2. Virus, Chevaux de Troie et autres Malwares
Les virus sont des programmes qui ont la capacité de se
répliquer et de se propager à travers les réseaux
informatiques. En réalité, il existe plusieurs types de logiciel
de ce genre qui peuvent compromettre la sécurité dans un
réseau informatique. Ils peuvent agir de manière
indépendante ou combinée. Voici quelques exemples :
II.4.2.1. Virus
Un fragment de logiciel qui se propage avec l'aide d'un autre
programme. Il peut détruire des données de manière directe
ou indirecte et dégrader les performances d'un système en
monopolisant certaines de ces ressources.
Certains virus n'ont comme fonction que de se répliquer
alors que d'autres sont programmées avec des actions destructives
(élimination de fichiers, redémarrage de
l'ordinateur, ...). Quoi qu'il en soit, il est important de se
protéger des virus car ils peuvent aussi créer des
dégâts indirects.
· Perte de données : Les virus modifient
des fichiers pour les infecter. Par cette opération, le contenu original
du fichier peut être perdu. D'autre part, certains virus sont
programmés pour effacer des fichiers.
· Perte de temps de travail : Les personnes dont
le poste de travail est infecté ne peuvent plus travailler
jusqu'à ce que le virus soit éliminé. Les administrateurs
ne peuvent pas faire leur travail quotidien pendant qu'ils éliminent les
virus des postes de travail et des serveurs.
· Perte de fonctionnalité : L'infection
par un virus peut rendre inutilisable une fonctionnalité d'un
système (messagerie, traitement de texte, accès Internet). Cette
perte de fonctionnalité peut par exemple empêcher une entreprise
de conduire ses affaires.
· Perte d'image de marque : Une entreprise peut
souffrir d'une perte d'image de marque, par exemple si un virus se propage par
son système de messagerie vers tous les clients de l'entreprise.
· Vol d'informations : Les virus peuvent rendre
un ordinateur vulnérable à du vol d'information (par exemple en
installant un backdoor) ou carrément envoyer une copie des fichiers se
trouvant sur l'ordinateur infecté vers un pirate.
II.4.2.2. Ver :
Un programme indépendant qui se reproduit en se copiant
d'un système à un autre par exemple à travers le
réseau. Comme les virus, les vers peuvent détruire des
données ou dégrader les performances d'un système en
consommant des ressources.
II.4.2.3. Cheval de Troie :
Un programme indépendant qui paraît avoir une
fonction utile et qui contient un programme malveillant. Quand un utilisateur
exécute la fonction utile, le cheval de Troie exécute aussi la
fonction malveillante.
II.4.2.4. Backdoor
Littéralement appelé porte arrière est un
programme permettant à un pirate de contrôler un ordinateur
à distance. Ces programmes étant souvent installés par des
chevaux de Troie sont aussi souvent classés comme tel. Ils ont trois
caractéristiques variables qui sont :
· La taille : Plus un backdoor est petit, plus
il est facile d'être installé par un cheval de Troie, un virus, ou
un ver.
· Les fonctionnalités : Les
fonctionnalités minimales sont par exemple la possibilité de
transférer un fichier exécutable sur la machine infectée
et de l'exécuter. Ceci permet d'installer un backdoor plus complet
à partir d'un backdoor minimal. Les backdoors
Les plus évolués permettent d'exécuter des
commandes arbitraires en ligne, d'espionner le réseau, le clavier et
l'écran.
· Le mode de communication : Les backdoors les
plus classiques ouvrent simplement un port TCP ou UDP prédéfini
et attendent qu'un pirate distant se connecte pour leur transmettre des ordres.
Les backdoors plus évolués peuvent envoyer un message à
une adresse e-mail ou dans un système de conversation en ligne pour
signaler qu'ils sont prêts à recevoir des ordres. Ils peuvent
ainsi aussi communiquer l'adresse IP de la machine infectée et le port
sur lequel ils attendent les commandes. Dans ce cas, le port peut être
choisi aléatoirement, ce qui rend plus difficile la détection du
backdoor. Certains backdoors utilisent des moyens de communication plus
discrets comme par exemple des paquets ICMP de requêtes et de
réponse (Ping). Finalement, ces communications peuvent aussi être
chiffrées.
Parmi les backdoors les plus complets on trouve "Back Orifice
2000" développé par le Cult of the Dead Cow, NetBus de
Carl-Fredrik Neikter et Subseven de MobMan.
Ils contiennent toutes les options décrites plus haut, la
possibilité de créer des extensions modulaires (plug-ins) ainsi
que des outils pour créer un cheval de Troie qui va les installer.
II.5. 3.4 SNIFFING
Le sniffing consiste simplement à capturer une image du
trafic qui circule sur un brin d'un réseau. Le but du sniffing est
d'exploiter le fait que beaucoup de méthodes d'authentification
transmettent les mots de passe en clair sur le réseau. Le sniffing est
typiquement utilisé par les pirates pour étendre leurs attaques.
Une fois qu'ils ont pris possession d'une machine, le sniffing leur permet de
trouver des mots de passe leur donnant accès à des machines
supplémentaires. Le sniffing est le plus efficace dans des
réseaux locaux qui utilisent un média partagé (par
exemple, l'Ethernet classique sans commutation). Dans ce cas le sniffer peut
voir le trafic de toutes les machines connectées au réseau local
et sa chance de trouver un mot de passe est plus grande. Les réseaux
locaux récents sont souvent commutés plutôt que
partagés. Dans ce cas chaque machine est connectée
séparément à un commutateur. Le commutateur ne propage les
paquets que vers les machines qui peuvent potentiellement être leur
destinataire. Ceci augmente largement les performances du réseau,
puisque chaque machine a à sa disposition la bande passante totale du
média. L'efficacité du sniffer est par contre fortement
réduite puisqu'il ne voit que le trafic concernant la machine sur
laquelle il est installé. Certains sniffers avancés permettent de
forger des messages du protocole de résolution d'adresses Ethernet (ARP)
afin de recevoir du trafic qui ne leur est pas destiné, même sur
un réseau commuté. On parle alors d'empoisonnement de la
résolution d'adresses (ARP poisoning).
La plupart des systèmes d'exploitation ne permettent
l'exécution de sniffers que par des utilisateurs ayant des
privilèges d'administrateur. En utilisant un sniffer sur une machine, le
pirate peut éventuellement trouver le mot de passe d'un administrateur
d'une autre machine et installer un sniffer sur cette nouvelle cible.
Plus souvent, le pirate découvre des mots de passe
d'utilisateurs qui ne sont pas administrateurs. Ces mots de passe lui donnent
accès à de nouvelles machines, mais il doit encore trouver une
vulnérabilité dans sa nouvelle cible et d'obtenir les
privilèges d'administrateur.
Pour information, les protocoles d'authentification les plus
courants qui transmettent des mots de passe en clair sont donnés dans le
tableau 1

Figure 1 : PROTOCOLES
ÉCHANGEANT DES MOTS DE PASSE EN CLAIR
II.5.1. IP SPOOFING
Le terme "IP Spoofing" se réfère à la
falsification d'adresses source IP. Dans de nombreux cas, des paquets de
données sont traités différemment en fonction de leur
adresse source. Dans les réseaux, un routeur ou un firewall peut laisser
passer des paquets dont l'adresse source indique qu'ils proviennent d'un site
ami. De même, certaines applications offrent des privilèges aux
connexions qui émanent de sites connus. Par exemple
rsh, sous Unix, peut permettre l'exécution de commandes
sans demander de mot de passe, à condition que la requête vienne
d'un site se trouvant sur une liste de sites amis.
Typiquement, les attaques de Spoofing exploitent des relations de
confiance entre des machines qui appartiennent à une même
entité. Par exemple, les machines d'une salle informatique peuvent
être configurées de manière à ce qu'on n'ait pas
besoin de s'authentifier si on se connecte à une machine de la salle
à partir d'une autre machine de la salle. Un pirate peut exploiter cette
relation de confiance en essayant de se faire passer pour une machine de la
salle lorsqu'il se connecte à une autre machine de la salle. La
difficulté avec le Spoofing est que le pirate qui envoie des paquets
avec des adresses source falsifiées ne voit pas les réponses
à ces paquets, puisque la cible répondra à l'adresse
falsifiée se trouvant dans les paquets. Ceci est d'autant plus difficile
que la plupart des attaques se basent sur des connexions TCP et que pour
établir une connexion, TCP exige que trois paquets soient
échangés.
Pour comprendre les tenants et aboutissants d'une telle attaque
il faut se rappeler quelques notions de base de TCP. TCP est un protocole
à fenêtre coulissante. Il utilise donc un numéro de
séquence pour chaque direction, indiquant le numéro du premier
byte envoyé dans la trame courante et le numéro du prochain byte
attendu. Pour éviter que des paquets retardés d'une ancienne
connexion soient confondus avec des paquets d'une connexion courante, les
numéros de séquence ne commencent pas à zéro, mais
à une valeur initiale qui est incrémentée dans le temps.
Lors de l'établissement d'une connexion, la machine initiante envoie une
demande de synchronisation (paquet syn.) en indiquant le numéro de
séquence initial qu'elle va utiliser. La machine destination
répond avec une confirmation de synchronisation (synack) qui contient
son numéro de séquence initial. La machine initiante peut ensuite
envoyer le premier paquet faisant partie du protocole à fenêtre,
un acquittement (ack), qui contient le numéro de séquence du
prochain byte attendu, éventuellement des données et le
numéro de séquence du premier byte transmis (ou à
transmettre). Cet échange est décrit à la figure
Imaginons maintenant le cas d'un pirate sur la machine A qui veut
se faire passer pour un utilisateur sur la machine C. Dans ce cas il
crée des paquets TCP dont l'adresse source est
C.
Quand la machine B va recevoir les paquets du pirate, elle va,
de bonne foi, répondre à la machine C. Le pirate ne verra donc
pas le numéro de séquence initial de B et ne peut continuer le
dialogue que s'il est capable de le deviner. Ce dialogue de sourds est
illustré à la figure 2
Pour réussir son attaque le pirate a besoin de deux
informations :
1. Le numéro de séquence initial utilisé
pour la dernière connexion établie par la cible
2. L'incrément qui va être utilisé pour
générer le numéro de séquence initial de la
prochaine connexion.
Pour obtenir la première information, le pirate n'a
qu'à faire une tentative de connexion en donnant sa vraie adresse source
(si le réseau est surveillé alors il sera démasque).
L'acquittement que la cible lui envoie contient le numéro de
séquence initial actuel. La deuxième information,
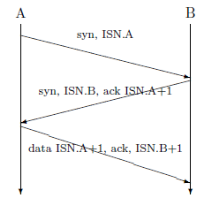
Figure 2 : ECHANGE
DES NUMÉROS DE SÉQUENCE INITIAUX LORS DE L'ÉTABLISSEMENT
D'UNE CONNEXION TCP
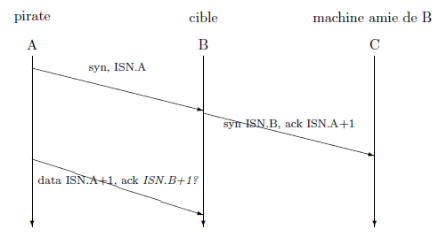
Figure 3 : TENTATIVE
D'ETABLISSEMENT D'UNE CONNEXION PAR UN PIRATE. POUR QUE L'ATTAQUE REUSSISSE, LE
PIRATE DOIT DEVINER LE NUMERO DE SEQUENCE INITIAL PROPOSE PAR
B.
Pour obtenir la deuxième information, l'incrément,
est plus difficile à obtenir. Initialement, la plupart des
implémentations de TCP utilisaient des incréments fixes. Suite
aux attaques de Spoofing, les incréments fixes ont été
remplacés par des incréments aléatoires. Quand le
générateur de nombres aléatoires utilisé est trop
simple, le pirate arrive quand-même à prédire le prochain
numéro de séquence initial. Il faut noter que le pirate n'a pas
besoin de connaître la valeur exacte du numéro de séquence.
Il peut envoyer une multitude de paquets avec une série de
numéros de séquence initiaux parmi lesquels il suppose que se
trouve le bon numéro. Les paquets avec les mauvais numéros seront
rejetés, et le paquet avec le bon numéro établira la
connexion.
Il existe une difficulté supplémentaire à
part le fait que le pirate doive deviner le numéro de séquence
initial de sa cible. En effet, la machine pour laquelle le pirate se fait
passer va recevoir un acquittement de synchronisation (syn-ack), alors qu'elle
n'a jamais demandé de synchronisation. Dans ce cas elle va envoyer un
paquet d'annulation (reset, rst), pour invalider la connexion. Le pirate doit
donc soit envoyer son paquet de données avant que la machine C ait pu
répondre, soit choisir comme machine C une machine hors service (mais
tout de même amie de B), quitte à mettre hors service cette
machine lui-même.
II.6. Définition des technologies oeuvrant pour la
sécurité
II.6.1. La Cryptographie
La cryptographie permet l'échange sûr des
renseignements privés et confidentiel. Un texte compréhensible
est converti en texte inintelligible (chiffrement), en vue de sa transmission
d'un poste de travail à un autre. Sur le poste récepteur, le
texte chiffré est reconverti en format intelligible
(déchiffrement). On peut également utiliser la cryptographie pour
assurer l'authentification, la non-répudiation et
l'intégrité de l'information, grâce à un processus
cryptographique spécial appelé signature numérique.
Celle-ci permet de garantir l'origine et l'intégrité de
l'information échangée, et aussi de confirmer
l'authenticité d'un document.
II.6.1.1. Cryptographie
Symétrique
La cryptographie symétrique encore appelée
cryptographie classique repose sur l'utilisation d'une
« clef » mathématique qui sert au chiffrement et au
déchiffrement des données. Ainsi, pour faire parvenir un message
de façon sûre, il faut le chiffrer à l'aide d'une clef
connue uniquement de l'expéditeur et du destinataire, puis faire
parvenir au destinataire prévu à la fois le message et la clef de
façon à ce que seul celui-ci puisse décoder le message.
II.6.1.2. Cryptographie
Asymétrique
La cryptographie asymétrique encore appelée
cryptographie à clef publique utilise deux clefs. La première
demeure privée, tandis que la seconde est publique. Si l'on utilise la
clef publique pour chiffrer un message, la clef privée permet de le
déchiffrer. Autrement dit, il suffit de chiffrer un message à
expédier à l'aide de la clef publique du destinataire, et ce
dernier peut ensuite utiliser la clef privée pour le
déchiffrer.
II.6.1.3. Cryptographie
numérique
La cryptographie à clef publique rend possible
l'utilisation des signatures numériques. Celles-ci permettent de
corroborer l'origine d'un message. Pour «signer» un message, on
utilise une fonction mathématique qui produit un résumé du
message (Hash). Le résumé obtenu est chiffré à
l'aide de la clef privée de l'expéditeur. Le résultat, qui
constitue la signature numérique, est annexé au message. Le
destinataire du message peut ensuite s'assurer de l'origine du message et de
l'intégrité de l'information qu'il contient en déchiffrant
la signature numérique au moyen de la clef publique de
l'expéditeur, puis en comparant le résultat avec le
résumé obtenu en appliquant la même fonction
mathématique au message reçu. Cela semble un peu
compliqué, mais en pratique, il suffit de cliquer sur une icône
à l'écran pour lancer tout le processus.
II.6.2. Les Firewalls
II.6.2.1. Définition
Aujourd'hui, toutes les entreprises possédant un
réseau local disposent aussi d'un accès à Internet, afin
d'accéder à la manne d'information disponible sur le
réseau des réseaux, et de pouvoir communiquer avec
l'extérieur. Cette ouverture vers l'extérieur est
indispensable... et dangereuse en même temps. Ouvrir l'entreprise vers le
monde signifie aussi laisser place ouverte aux étrangers pour essayer de
pénétrer le réseau local de l'entreprise, et y accomplir
des actions douteuses, parfois gratuites, de destruction, vol d'informations
confidentielles, ... Les mobiles sont nombreux et dangereux.
Pour parer à ces attaques, une architecture
sécurisée est nécessaire. Pour cela, le coeur d'une telle
architecture est basé sur un firewall. Cet outil a pour but de
sécuriser au maximum le réseau local de l'entreprise, de
détecter les tentatives d'intrusion et d'y parer au mieux possible.
Cela représente une sécurité
supplémentaire rendant le réseau ouvert sur Internet beaucoup
plus sûr. De plus, il peut permettre de restreindre l'accès
interne vers l'extérieur.
En effet, des employés peuvent s'adonner à des
activités que l'entreprise ne cautionne pas, le meilleur exemple
étant le jeu en ligne. En plaçant un firewall limitant ou
interdisant l'accès à ces services, l'entreprise peut donc avoir
un contrôle sur les activités se déroulant dans son
enceinte.
Le firewall propose donc un véritable contrôle
sur le trafic réseau de l'entreprise. Il permet d'analyser, de
sécuriser et de gérer le trafic réseau, et ainsi
d'utiliser le réseau de la façon pour laquelle il a
été prévu et sans l'encombrer avec des activités
inutiles, et d'empêcher une personne sans autorisation d'accéder
à ce réseau de données. Il s'agit ainsi d'une passerelle
filtrante comportant au minimum les interfaces réseaux suivantes telles
que montrées dans la Figure 3 :
Une interface pour le réseau à protéger
(réseau interne)
Une interface pour le réseau externe
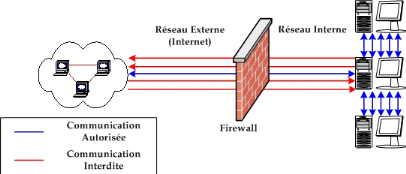
Figure 4: Schéma
d'une architecture réseau utilisant un Firewall
Le système firewall est un système logiciel,
reposant parfois sur un matériel réseau dédié,
constituant un intermédiaire entre le réseau local (ou la machine
locale) et un ou plusieurs réseaux externes. Il est possible de mettre
un système Firewall sur n'importe quelle machine et avec n'importe quel
système pourvu que :
La machine soit suffisamment puissante pour traiter le
trafic ;
Le système soit sécurisé ;
Aucun autre service que le service de filtrage de paquets ne
fonctionne sur le serveur.
Dans le cas où le système Firewall est fourni
dans une boîte noire « clef en main », on utilise le
terme d'« Appliance ».
II.6.2.2. Fonctionnement d'un
système Firewall
Un système Firewall contient un ensemble de
règles prédéfinies permettant :
D'autoriser la connexion (allow)
De bloquer la connexion (deny)
De rejeter la demande de connexion sans avertir
l'émetteur (drop).
L'ensemble de ces règles permet de mettre en oeuvre une
méthode de filtrage dépendant de la politique de
sécurité adoptée par l'entité. On distingue
habituellement deux types de politiques de sécurité
permettant :
Soit d'autoriser uniquement les communications ayant
été explicitement autorisées :
« TOUT CE QUI N'EST PAS EXPLICITEMENT
AUTORISÉ EST INTERDIT »
Soit d'empêcher les échanges qui ont
été explicitement interdits.
La première méthode est sans nul doute la plus
sûre, mais elle impose toutefois une définition précise et
contraignante des besoins en communication.
II.6.2.2.1. Le filtrage simple de paquets
Un système Firewall fonctionne sur le principe du
filtrage simple de paquets (en anglais « Stateless Packet
Filtering »). Il analyse les en-têtes de chaque paquet de
données (datagramme) échangé entre une machine du
réseau interne et une machine extérieure.
Ainsi, les paquets de données échangées
entre une machine du réseau extérieur et une machine du
réseau interne transitent par le Firewall et possèdent les
en-têtes suivants, systématiquement analysés par le
firewall :
Adresse IP de la machine émettrice ;
Adresse IP de la machine réceptrice ;
Type de paquet (TCP, UDP, etc.) ;
Numéro de port (un port est un numéro
associé à un service ou une application réseau).
Les adresses IP contenues dans les paquets permettent
d'identifier la machine émettrice et la machine cible, tandis que le
type de paquet et le numéro de port donnent une indication sur le type
de service utilisé.
Les ports reconnus (dont le numéro est compris entre 0
et 1023) sont associés à des services courants (les ports 25 et
110 sont par exemple associés au courrier électronique, et le
port 80 au Web). La plupart des dispositifs Firewall sont au minimum
configurés de manière à filtrer les communications selon
le port utilisé. Il est généralement conseillé de
bloquer tous les ports qui ne sont pas indispensables (selon la politique de
sécurité retenue).
Le port 23 est par exemple souvent bloqué par
défaut par les dispositifs Firewall car il correspond au protocole
Telnet, permettant d'émuler un accès par terminal à une
machine distante de manière à pouvoir exécuter des
commandes à distance. Les données échangées par
Telnet ne sont pas chiffrées, ce qui signifie qu'un individu est
susceptible d'écouter le réseau et de voler les éventuels
mots de passe circulant en clair. Les administrateurs lui
préfèrent généralement le protocole SSH (Secure
Shell), réputé sûr et fournissant les mêmes
fonctionnalités que Telnet.
II.6.2.2.2. Limites de filtrage de paquets
Le premier problème vient du fait que l'administrateur
réseau est rapidement contraint à autoriser un trop grand nombre
d'accès, pour que le Firewall offre une réelle protection. Par
exemple, pour autoriser les connexions à internet à partir du
réseau privé, l'administrateur devra accepter toutes les
connexions TCP provenant de l'internet avec un port supérieur à
1024. Ce qui laisse beaucoup de choix à un éventuel pirate.
Il est à noter que de définir des ACL sur des
routeurs haut de gamme n'est pas sans répercussion sur le débit
lui-même. Enfin, ce type de filtrage ne résiste pas à
certaines attaques de type IP Spoofing ou IP Flooding, la mutilation de paquets
ou encore certaines attaques de type DOS. Ceci est vrai sauf dans le cadre des
routeurs fonctionnant en mode distribué. Ceci permettant de gérer
les ACL directement sur les interfaces sans remonter à la carte de
traitement central. Les performances impactées par les ACL sont alors
quasi nulles.
II.6.2.2.3. Le filtrage dynamique
Le filtrage simple de paquets ne s'attache qu'à
examiner les paquets IP indépendamment les uns des autres, ce qui
correspond au niveau 3 du modèle OSI. Or, la plupart des connexions
reposent sur le protocole TCP, qui gère la notion de session, afin
d'assurer le bon déroulement des échanges. D'autre part, de
nombreux services (le FTP par exemple) initient une connexion sur un port
statique, mais ouvrent dynamiquement (c'est-à-dire de manière
aléatoire) un port afin d'établir une session entre la machine
faisant office de serveur et la machine cliente. La figure suivante illustre
l'échange entre un Client et un Serveur FTP.
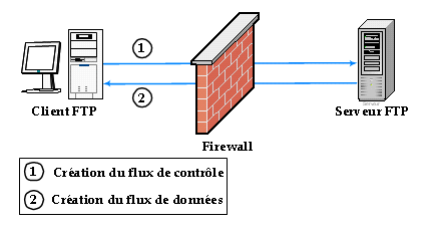
Figure 5 :
Etablissement de la connexion entre un client et serveur FTP en passant par
un Firewall
Ainsi, il est impossible avec un filtrage simple de paquets de
prévoir les ports à laisser passer ou à interdire. Pour y
remédier, le système de filtrage dynamique de
paquets est basé sur l'inspection des couches 3 et 4 du
modèle OSI, permettant d'effectuer un suivi des transactions entre le
client et le serveur. Le terme anglo-saxon est « Stateful
inspection » ou
« Statefulpacketfiltering », qui se
traduit en « filtrage de paquets avec état ».
Un dispositif pare-feu de type « Stateful
inspection » est ainsi capable d'assurer un suivi des
échanges, c'est-à-dire de tenir compte de l'état des
anciens paquets pour appliquer les règles de filtrage. De cette
manière, à partir du moment où une machine
autorisée initie une connexion à une machine située de
l'autre côté du pare-feu; l'ensemble des paquets transitant dans
le cadre de cette connexion seront implicitement acceptés par le
pare-feu.
Si le filtrage dynamique est plus performant que le filtrage
de paquets basique, il ne protège pas pour autant de l'exploitation des
failles applicatives, liées aux vulnérabilités des
applications. Or ces vulnérabilités représentent la part
la plus importante des risques en termes de sécurité.
Limites du filtrage dynamique
Tout d'abord, il convient de s'assurer que les deux techniques
sont bien implémentées par les Firewalls, car certains
constructeurs ne l'implémentent pas toujours correctement. Ensuite une
fois l'accès à un service a été autorisé, il
n'y a aucun contrôle effectué sur les enquêtes et
réponses des clients et serveurs. Un serveur http pourra donc être
attaqué impunément.
Enfin les protocoles maisons utilisant plusieurs flux de
données ne passeront pas, puisque le système de filtrage
dynamique n'aura pas connaissance du protocole.
II.6.2.2.4. Le filtrage applicatif
Le filtrage applicatif permet de filtrer les communications
application par application. Le filtrage applicatif opère donc au niveau
7 « Couche application » du modèle OSI,
Contrairement au filtrage de paquets simple « Niveau
4 ». Le filtrage applicatif suppose donc une connaissance des
protocoles utilisés par chaque application.
Le filtrage applicatif permet, comme son nom l'indique, de
filtrer les communications application par application. Le filtrage applicatif
suppose donc une bonne connaissance des applications présentes sur le
réseau, et notamment de la manière dont elle structure les
données échangées (ports, etc.).
Un firewall effectuant un filtrage applicatif est
appelé généralement « passerelle
applicative » ou « proxy », car il sert de relais
entre deux réseaux en s'interposant et en effectuant une validation fine
du contenu des paquets échangés. Le proxy représente donc
un intermédiaire entre les machines du réseau interne et le
réseau externe, subissant les attaques à leur place. De plus, le
filtrage applicatif permet la destruction des en-têtes
précédant le message applicatif, ce qui permet de fournir un
niveau de sécurité supplémentaire.
Il s'agit d'un dispositif performant, assurant une bonne
protection du réseau, pour peu qu'il soit correctement
administré. En contrepartie, une analyse fine des données
applicatives requiert une grande puissance de calcul et se traduit donc souvent
par un ralentissement des communications, chaque paquet devant être
finement analysé.
Par ailleurs, le proxy doit nécessairement être
en mesure d'interpréter une vaste gamme de protocoles et de
connaître les failles afférentes pour être efficace.
Limites du filtrage applicatif
Le premier problème qui se pose est la finesse du filtrage
réalisé par le proxy. Il ets extrêmement difficile de
pouvoir réaliser un filtrage qui ne laisse rien passer, vu le nombre de
protocoles de niveau 7. En outre le fait de devoir connaître les
règles protocolaires de chaque protocole filtré pose des
problèmes d'adaptabilité à de nouveaux protocoles ou des
protocoles maison.
Mais il est indéniable que le filtrage applicatif apporte
plus de sécurité que le filtrage de paquets par état, mais
cela se paie en performance. Ce qui exclut l'utilisation d'une technologie 100
% proxy pour les réseaux à gros trafic au jour d'aujourd'hui.
Néanmoins d'ici quelques années, le problème technologique
sera sans doute résolu.
Enfin, un tel système peut potentiellement comporter une
vulnérabilité dans la mesure où il interprète les
requêtes qui transitent par son biais. Ainsi, il est recommandé de
dissocier le pare-feu (dynamique ou non) du proxy tel que montré dans la
Figure 4, afin de limiter les risques de compromission.
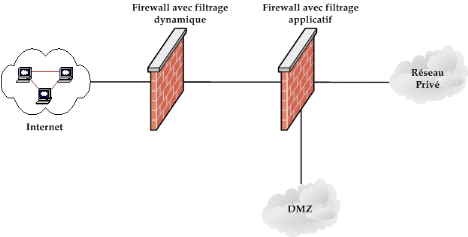
Figure 6 : Choix des
Firewalls dans une architecture réseau
II.6.3. Les différents types de
Firewalls
II.6.3.1. Les Firewalls BRIDGE
Ces derniers sont relativement répandus. Ils agissent
comme de vrais câbles réseau avec la fonction de filtrage en plus,
d'où leur appellation de Firewall. Leurs interfaces ne possèdent
pas d'adresse IP, et ne font que transférer les paquets d'une interface
a une autre en leur appliquant les règles prédéfinies.
Cette absence d'adresse IP est particulièrement utile, car cela signifie
que le Firewall est indétectable pour un hacker lambda. En effet, quand
une requête ARP est émise sur le câble réseau, le
Firewall ne répondra jamais. Ses adresses Mac ne circuleront jamais sur
le réseau, et comme il ne fait que « transmettre » les
paquets, il sera totalement invisible sur le réseau.
Cela rend impossible toute attaque dirigée directement
contre le Firewall, étant donnévqu'aucun paquet ne sera
traité par ce dernier comme étant sa propre destination. Donc, la
seule façon de le contourner est de passer outre ses règles de
drop. Toute attaque devra donc « faire » avec ses règles, et
essayer de les contourner.
Dans la plupart des cas, ces derniers ont une interface de
configuration séparée. Un câble vient se brancher sur une
troisième interface, série ou même Ethernet, et qui ne doit
être utilisée que ponctuellement et dans un environnement
sécurisé de préférence.
Ces Firewalls se trouvent typiquement sur les switchs.
|
Avantages
|
Inconvénients
|
|
Impossible de l'éviter (les paquets passeront par ses
interfaces)
Peu coûteux
|
Possibilité de le contourner (il suffit de passer
outre ses règles)
Configuration souvent contraignante
Les fonctionnalités présentes sont très
basiques (filtrage sur adresse IP, port, le plus souvent en Stateless)
|
Tableau 1 : Avantages et
inconvénients d'un Firewall Bridge
II.6.3.2. Les Firewalls
matériels
Ils se trouvent souvent sur des routeurs achetés dans
le commerce par de grands constructeurs comme Cisco ou Nortel.
Intégrés directement dans la machine, ils font office de «
boite noire », et ont une intégration parfaite avec le
matériel. Leur configuration est souvent relativement ardue, mais leur
avantage est que leur interaction avec les autres fonctionnalités du
routeur est simplifiée de par leur présence sur le même
équipement réseau. Souvent relativement peu flexibles en terme de
configuration, ils sont aussi peu vulnérables aux attaques, car
présent dans la « boite noire » qu'est le routeur.
De plus, étant souvent très liés au
matériel, l'accès à leur code est assez difficile, et le
constructeur a eu toute latitude pour produire des systèmes de codes
« signés » afin d'authentifier le logiciel (système RSA
ou assimilés).
Ce système n'est implanté que dans les
firewalls haut de gamme, car cela évite un remplacement du logiciel par
un autre non produit par le fabricant, ou toute modification de ce dernier,
rendant ainsi le firewall très sûr. Son administration est souvent
plus aisée que les Firewalls bridges, les grandes marques de routeurs
utilisant cet argument comme argument de vente. Leur niveau de
sécurité est de plus très bon, sauf découverte de
faille éventuelle comme tout firewall. Néanmoins, il faut savoir
que l'on est totalement dépendant du constructeur du matériel
pour cette mise à jour, ce qui peut être, dans certains cas, assez
contraignant. Enfin, seules les spécificités prévues par
le constructeur du matériel sont implémentées. Cette
dépendance induit que si une possibilité nous intéresse
sur un firewall d'une autre marque, son utilisation est impossible. Il faut
donc bien déterminer à l'avance ses besoins et choisir le
constructeur du routeur avec soin.
|
Avantages
|
Inconvénients
|
|
Intégré au matériel réseau
Administration relativement simple
Bon niveau de sécurité
|
Dépendant du constructeur pour les mises à
jour
Souvent peu flexible
|
Tableau 2 :Avantages
et inconvénients d'un Firewall matériel
II.6.3.3. Les Firewalls logiciels
Présents à la fois dans lesserveurs et routeurs
« faits maison », on peut les classer en plusieurs
catégories :
II.6.3.3.1. Les Firewalls personnels
Ils sont assez souvent commerciaux et ont pour but de
sécuriser un ordinateur particulier, et non pas un groupe d'ordinateurs.
Souvent payants, ils peuvent être contraignants et quelque fois
très peu sécurisés. En effet, ils s'orientent plus vers la
simplicité d'utilisation plutôt que vers l'exhaustivité,
afin de rester accessible à l'utilisateur final.
|
Avantages
|
Inconvénients
|
|
Sécurité en bout de chaîne (Poste
Client)
Personnalisable assez facilement
|
Facilement contournable
Difficiles à départager de par leur nombre
énorme
|
Tableau 3 : Avantages
et inconvénients d'un Firewall personnel.
II.6.3.3.2. Les Firewalls plus sérieux
Tournant généralement sous linux, car cet OS
offre une sécurité réseau plus élevée et un
contrôle plus adéquat, ils ont généralement pour but
d'avoir le même comportement que les firewalls matériels des
routeurs, à ceci prêt qu'ils sont configurables à la main.
Le plus courant est iptables (anciennement ipchains), qui utilise directement
le noyau linux.
Toute fonctionnalité des firewalls de routeurs est
potentiellement réalisable sur une telle plateforme.
|
Avantages
|
Inconvénients
|
|
Personnalisables
Niveau de sécurité très bon
|
Nécessite une administration système
supplémentaire
|
Tableau 4 : Avantages
et inconvénients d'un Firewall plus sérieux.
Ces firewalls logiciels ont néanmoins une grande
faille : ils n'utilisent pas la couche bas réseau. Il suffit donc de
passer outre le noyau en ce qui concerne la récupération de ces
paquets, en utilisant une librairie spéciale, pour
récupérer les paquets qui auraient été normalement
« droppés » par le Firewall. Néanmoins, cette faille
induit de s'introduire sur l'ordinateur en question pour y faire des
modifications... chose qui induit déjà une intrusion dans le
réseau, ou une prise de contrôle physique de l'ordinateur, ce qui
est déjà Synonyme d'inefficacité de la part du
firewall.
II.6.3.4. DMZ (demilitarized zone)
II.6.3.4.1. Notion de cloisonnement
Les systèmes
pare-feu
permettent de définir des règles d'accès entre deux
réseaux. Néanmoins, dans la pratique, les entreprises ont
généralement plusieurs sous-réseaux avec des politiques de
sécurité différentes. C'est la raison pour laquelle il est
nécessaire de mettre en place des architectures de systèmes
pare-feux permettant d'isoler les différents réseaux de
l'entreprise : on parle ainsi de « cloisonnement des
réseaux » (le terme isolation est parfois
également utilisé).
II.6.3.4.2. Architecture DMZ
Figure 7 :
Architecture d'une DMZ
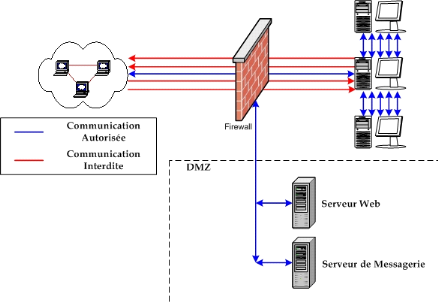
Lorsque certaines machines du réseau interne ont besoin
d'être accessibles de l'extérieur (serveur web, un serveur de
messagerie, un serveur FTP public, etc.), il est souvent nécessaire de
créer une nouvelle interface vers un réseau à part,
accessible aussi bien du réseau interne que de l'extérieur, sans
pour autant risquer de compromettre la sécurité de l'entreprise.
On parle ainsi de « zone
démilitarisé » (notée
DMZ pour Demilitarized Zone) pour désigner
cette zone isolée hébergeant des applications mises à
disposition du public. La DMZ fait ainsi office de « zone
tampon » entre le réseau à protéger et le
réseau hostile. La figure ci-dessous montre la position d'une DMZ au
sein d'un réseau.
Les serveurs situés dans la DMZ sont appelés
« bastions » en raison de leur position d'avant-poste dans
le réseau de l'entreprise.
La politique de sécurité mise en oeuvre sur la
DMZ est généralement la suivante :
Trafic du réseau externe vers la DMZ
autorisé ;
Trafic du réseau externe vers le réseau interne
interdit ;
Trafic du réseau interne vers la DMZ
autorisé ;
Trafic du réseau interne vers le réseau externe
autorisé ;
Trafic de la DMZ vers le réseau interne
interdit ;
Trafic de la DMZ vers le réseau externe
interdit.
La DMZ possède donc un niveau de sécurité
intermédiaire, mais son niveau de sécurisation n'est pas
suffisant pour y stocker des données critiques pour l'entreprise.
Il est à noter qu'il est possible de mettre en place
des DMZ en interne afin de cloisonner le réseau interne selon
différents niveaux de protection et ainsi éviter les intrusions
venant de l'intérieur.
II.6.3.5. NAT « Network
Address Translation »
II.6.3.5.1. Principe
Le mécanisme de translation d'adresses
« NAT » a été mis au point
afin de répondre à la pénurie d'adresses IP avec le
protocole IPv4 (le protocole IPv6 répondra à terme à ce
problème).
En effet, en adressage IPv4 le nombre d'adresses IP routables
(donc uniques sur la planète) n'est pas suffisant pour permettre
à toutes les machines nécessitant d'être connectées
à internet de l'être.
Le principe du NAT consiste donc à utiliser une adresse
IP routable (ou un nombre limité d'adresses IP) pour connecter
l'ensemble des machines du réseau en réalisant, au niveau de la
passerelle de connexion à internet, une translation
(littéralement une « traduction ») entre l'adresse
interne (non routable) de la machine souhaitant se connecter et l'adresse IP de
la passerelle. Cette passerelle peut être un routeur tel que
montré dans la figure suivante.
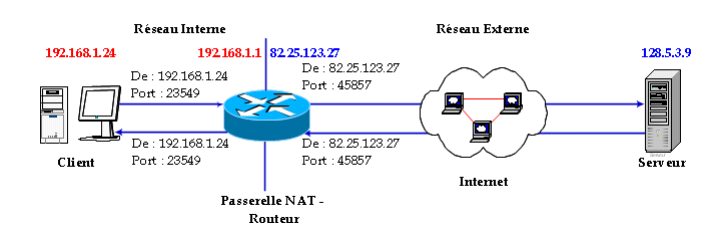
Figure 8 :
Fonctionnement de NAT
D'autre part, le mécanisme de translation d'adresses
permet de sécuriser le réseau interne
étant donné qu'il camoufle complètement l'adressage
interne. En effet, pour un observateur externe au réseau, toutes les
requêtes semblent provenir de la même adresse IP.
II.6.3.5.2. Espaces d'adressages
L'organisme gérant l'espace d'adressage public
(adresses IP routables) est l'IANA. La RFC 1918 définit
un espace d'adressage privé permettant à toute organisation
d'attribuer des adresses IP aux machines de son réseau interne sans
risque d'entrer en conflit avec une adresse IP publique allouée par
l'IANA. Ces adresses dites non-routables correspondent aux plages d'adresses
suivantes :
Classe A : plage de 10.0.0.0 à
10.255.255.255 ;
Classe B : plage de 172.16.0.0 à
172.31.255.255 ;
Classe C : plage de 192.168.0.0 à
192.168.255.55 ;
Toutes les machines d'un réseau interne,
connectées à internet par l'intermédiaire d'un routeur et
ne possédant pas d'adresse IP publique doivent utiliser une adresse
contenue dans l'une de ces plages. Pour les petits réseaux domestiques,
la plage d'adresses de 192.168.0.1 à 192.168.0.255 est
généralement utilisée.
II.6.3.5.3. Translation statique
Le principe du NAT statique consiste à
associer une adresse IP publique à une adresse IP privée interne
au réseau. Le routeur (ou plus exactement la passerelle) permet donc
d'associer à une adresse IP privée (par exemple 192.168.0.1) une
adresse IP publique routable sur Internet et de faire la traduction, dans un
sens comme dans l'autre, en modifiant l'adresse dans le paquet IP.
La translation d'adresse statique permet ainsi de connecter
des machines du réseau interne à internet de manière
transparente mais ne résout pas le problème de la pénurie
d'adresse dans la mesure où n adresses IP routables sont
nécessaires pour connecter n machines du réseau interne.
Avantages et inconvénients du NAT statique
En associant une adresse IP publique à une adresse IP
privée, nous avons pu rendre une machine accessible sur Internet. Par
contre, on remarque qu'avec ce principe, on est obligé d'avoir une
adresse publique par machine voulant accéder à Internet. Cela ne
va pas régler notre problème de pénurie d'adresses IP...
D'autre part, tant qu'à donner une adresse publique par machine,
pourquoi ne pas leur donner cette adresse directement plutôt que de
passer par un intermédiaire ? A cette question, on peut apporter
plusieurs éléments de réponse. D'une part, il est souvent
préférable de garder un adressage uniforme en interne et de ne
pas mêler les adresses publiques aux adresses privées. Ainsi, si
on doit faire des modifications, changements, interventions sur le
réseau local, on peut facilement changer la correspondance entre les
adresses privées et les adresses publiques pour rediriger les
requêtes vers un serveur en état de marche.
D'autre part, on gâche un certain nombre d'adresses
lorsqu'on découpe un réseau en sous-réseaux (adresse de
réseau, adresse de broadcast...), comme lorsqu'on veut créer une
DMZ pour rendre ses serveurs publiques disponibles. Avec le NAT statique, on
évite de perdre ces adresses. Malgré ces quelques avantages, le
problème de pénurie d'adresses n'a toujours pas été
réglé. Pour cela, on va se pencher sur la NAT dynamique.
II.6.3.5.4. Translation dynamique
Le NAT dynamique permet de partager une
adresse IP routable (ou un nombre réduit d'adresses IP routables) entre
plusieurs machines en adressage privé. Ainsi, toutes les machines du
réseau interne possèdent virtuellement, vu de l'extérieur,
la même adresse IP. C'est la raison pour laquelle le terme de
« mascarade IP » est parfois
utilisé pour désigner le mécanisme de translation
d'adresse dynamique.
Afin de pouvoir « multiplexer » (partager)
les différentes adresses IP sur une ou plusieurs adresses IP routables,
le NAT dynamique utilise le mécanisme de translation de port
(PAT - Port Address Translation), c'est-à-dire
l'affectation d'un port source différent à chaque requête
de telle manière à pouvoir maintenir une correspondance entre les
requêtes provenant du réseau interne et les réponses des
machines sur Internet, toutes adressées à l'adresse IP du
routeur.
Avantages et inconvénients du NAT dynamique
Comme nous l'avons vu, le NAT dynamique permet à des
machines ayant des adresses privées d'accéder à Internet.
Cependant, contrairement au NAT statique, il ne permet pas d'être joint
par une machine de l'Internet. Effectivement, si le NAT dynamique marche, c'est
parce que le routeur qui fait le NAT reçoit les informations de la
machine en interne (Adresse IP, port TCP/UDP). Par contre, il n'aura aucune de
ces informations si la connexion est initialisée de
l'extérieur... Le paquet arrivera avec comme adresse de destination le
routeur, et le routeur ne saura pas vers qui rediriger la requête en
interne.
La NAT dynamique ne permet donc que de sortir sur Internet, et
non pas d'être joignable. Il est donc utile pour partager un accès
Internet, mais pas pour rendre un serveur accessible. De plus, étant
donné que l'on peut "cacher" un grand nombre de machines derrière
une seule adresse publique, cela permet de répondre à notre
problème de pénurie d'adresses.
Par contre, les machines n'étant pas accessibles de
l'extérieur, cela donne un petit plus au niveau de la
sécurité.
Nous allons à présent parler d'un autre
système de sécurité (Les IDS) dans notre prochain
chapitre.
III. LES IDS
III.1. Définition
Tout d'abord, IDS (Intrusion Detection System) signifie
système de détection d'intrusion. Il s'agit d'un
équipement permettant de surveiller l'activité d'un réseau
ou d'un hôte donné, afin de détecter toute tentative
d'intrusion et éventuellement de réagir à cette
tentative.
Pour présenter le concept d'IDS, nous allons tout d'abord
présenter les différentes sortes d'IDS, chacun intervenant
à un niveau différent.
Nous étudierons ensuite leur mode de fonctionnement, c'est
à dire les modes de détection utilisés et les
réponses apportées par les IDS. Enfin, nous détaillerons
les points forts et les points faibles des IDS.
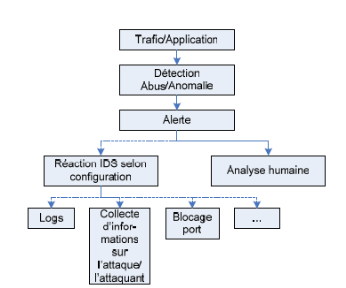
Figure 9 :
Fonctionnement d'un IDS
III.2. Les différentes sortes
d'IDS
Les différents IDS se caractérisent par leur
domaine de surveillance. Celui-ci peut se situer au niveau d'un réseau
d'entreprise, d'une machine hôte, d'une application...
Nous allons tout d'abord étudier la détection
d'intrusion basée sur l'hôte (HIDS), puis basée sur une
application, avant de nous intéresser aux IDS réseaux (NIDS).
III.2.1. La
détection d'intrusion basée sur l'hôte
Les systèmes de détection d'intrusion basés
sur l'hôte ou HIDS (Host IDS) analysent exclusivement l'information
concernant cet hôte. Comme ils n'ont pas à contrôler le
trafic du réseau mais "seulement" les activités d'un hôte,
ils se montrent habituellement plus précis sur les types d'attaques
subies.
De plus, l'impact sur la machine concernée est sensible
immédiatement, par exemple dans le cas d'une attaque réussie par
un utilisateur. Ces IDS utilisent deux types de sources pour fournir une
information sur l'activité de la machine : les logs et les traces
d'audit du système d'exploitation.
Chacun a ses avantages : les traces d'audit sont plus
précises et détaillées et fournissent une meilleure
information alors que les logs qui ne fournissent que l'information essentielle
sont plus petits.
Ces derniers peuvent être mieux contrôlés et
analysés en raison de leur taille, mais certaines attaques peuvent
passer inaperçues, alors qu'elles sont détectables par une
analyse des traces d'audit.
Ce type d'IDS possède un certain nombre d'avantages : il
est possible de constater immédiatement l'impact d'une attaque et donc
de mieux réagir. Grâce à la quantité des
informations étudiées, il est possible d'observer les
activités se déroulant sur l'hôte avec précision et
d'optimiser le système en fonction des activités
observées.
De plus, les HIDS sont extrêmement complémentaires
des NIDS. En effet, ils permettent de détecter plus facilement les
attaques de type "Cheval de Troie", alors que ce type d'attaque est
difficilement détectable par un NIDS. Les HIDS permettent
également de détecter des attaques impossibles à
détecter avec un NIDS, car elles font partie de trafic crypté.
Néanmoins, ce type d'IDS possède également
ses faiblesses, qui proviennent de ses qualités : du fait de la grande
quantité de données générées, ce type d'IDS
est très sensible aux attaques de type DoS, qui peuvent faire exploser
la taille des fichiers de logs.
Un autre inconvénient tient justement à la taille
des fichiers de rapport d'alertes à examiner, qui est très
contraignante pour le responsable sécurité. La taille des
fichiers peut en effet atteindre plusieurs Mégaoctets.
Du fait de cette quantité de données à
traiter, ils sont assez gourmands en CPU et peuvent parfois altérer les
performances de la machine hôte.
Enfin, ils ont moins de facilité à détecter
les attaques de type hôte que les IDS réseaux.
Les HIDS sont en général placés sur des
machines sensibles, susceptibles de subir des attaques et possédant des
données sensibles pour l'entreprise. Les serveurs, web et applicatifs,
peuvent notamment être protégés par un HIDS.
Pour finir, voici quelques HIDS connus: Tripwire, WATCH,
DragonSquire, Tiger,
Security Manager...
Avantages :
· Pouvoir surveiller des événements locaux
jusqu'au host et détecter des attaques qui ne sont pas vues par les
NIDS.
· Marcher dans un environnement dans lequel le trafic de
réseau est encrypté.
· HIDS n'est pas atteint par le réseau
commuté.
· Lors que HIDS marche sur la traînée de
l'audit de SE, ils peuvent détecter les Chevaux de Troie ou les autres
attaques concernant la brèche d'intégrité de logiciel.
Inconvénients :
· HIDS est difficile à gérer, et des
informations doivent être configurées et gérées pour
chaque host surveillé.
· Puisqu'au moins des sources de l'information pour HIDS se
résident sur l'host de la destination par les attaques, l'IDS peut
être attaqué et neutralisé comme une partie de l'attaque.
· HIDS n'est pas bon pour le balayage de réseau tel
que la surveillance qui s'adresse au réseau entier parce que les HIDS ne
voient que les paquets du réseau reçus par ses hosts.
· HIDS peuvent être neutralisés par certaines
attaques de DoS.
· Lorsque les HIDS emploient la traînée de
l'audit du SE comme des sources des informations, la somme de l'information est
immense, alors ils demandent le stockage supplémentaire local dans le
système.
III.2.2.
Détection d'Intrusion basée sur une application(ABIDS)
Les IDS basés sur les applications sont un sous-groupe des
IDS hôtes(HIDS).
Ils contrôlent l'interaction entre un utilisateur et un
programme en ajoutant des fichiers de log afin de fournir de plus amples
informations sur les activités d'une application particulière.
Puisque vous opérez entre un utilisateur et un programme, il est facile
de filtrer tout comportement notable. Un ABIDS se situe au niveau de la
communication entre un utilisateur et l'application surveillée.
L'avantage de cet IDS est qu'il lui est possible de
détecter et d'empêcher des commandes particulières dont
l'utilisateur pourrait se servir avec le programme et de surveiller chaque
transaction entre l'utilisateur et l'application. De plus, les données
sont décodées dans un contexte connu, leur analyse est donc plus
fine et précise.
Par contre, du fait que cet IDS n'agit pas au niveau du noyau, la
sécurité assurée est plus faible, notamment en ce qui
concerne les attaques de type "Cheval de Troie".
De plus, les fichiers de log générés par ce
type d'IDS sont des cibles faciles pour les attaquants et ne sont pas aussi
sûrs, par exemple, que les traces d'audit du système.
Ce type d'IDS est utile pour surveiller l'activité d'une
application très sensible, mais son utilisation s'effectue en
général en association avec un HIDS. Il faudra dans ce cas
contrôler le taux d'utilisation CPU des IDS afin de ne pas compromettre
les performances de la machine.
III.2.3. La
Détection d'Intrusion Réseau (NIDS)
Le rôle essentiel d'un IDS réseau est l'analyse et
l'interprétation des paquets circulant sur ce réseau.
L'implantation d'un NIDS sur un réseau se fait de la
façon suivante : des capteurs sont placés aux endroits
stratégiques du réseau et génèrent des alertes une
fois qu'ils détectent une attaque. Ces alertes sont envoyées
à une console sécurisée, qui les analyse et les traite
éventuellement. Cette console est généralement
située sur un réseau isolé, qui relie uniquement les
capteurs et la console.
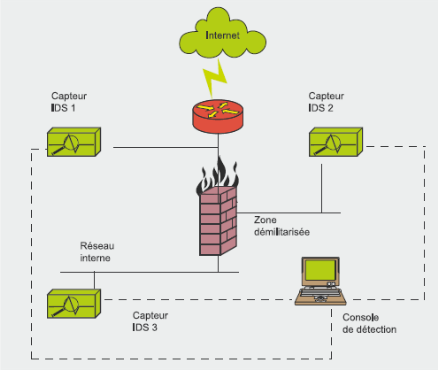
Figure 10 :
Système de détection d'intrusion réseau
III.2.3.1. Les
capteurs :
Les capteurs placés sur le réseau sont
placés en mode furtif (ou stealth mode), de façon à
être invisibles aux autres machines. Pour cela, leur carte réseau
est configurée en mode "promiscuous", c'est à dire le mode dans
lequel la carte réseau lit l'ensemble du trafic est confus, de plus
aucune adresse IP n'est configurée.
Un capteur possède en général deux cartes
réseaux, une, placée en mode furtif sur le réseau, l'autre
permettant de le connecter à la console de sécurité.
Du fait de leur invisibilité sur le réseau, il est
beaucoup plus difficile de les attaquer et de savoir qu'un IDS est
utilisé sur ce réseau.
III.2.3.2.
Placement des capteurs
Il est possible de placer les capteurs à différents
endroits, en fonction de ce que l'on souhaite observer. Les capteurs peuvent
être placés avant ou après le pare-feu, ou encore dans une
zone sensible que l'on veut protéger spécialement appelée
zone démilitarisée ou plus amplement DMZ (demilitarized zone).
Si les capteurs se trouvent après un pare-feu, il leur est
plus facile de dire si le pare-feu a été mal configuré
ou de savoir si une attaque est venue par ce pare-feu.
Les capteurs placés derrière un pare-feu ont pour
mission de détecter les intrusions qui n'ont pas été
arrêtées par ce dernier. Il s'agit d'une utilisation courante d'un
NIDS.
Il est également possible de placer un capteur à
l'extérieur du pare-feu (avant le firewall). L'intérêt de
cette position est que le capteur peut ainsi recevoir et analyser l'ensemble du
trafic d'Internet. Si vous placez le capteur ici, il n'est pas certain que
toutes les attaques soient filtrées et détectées.
Pourtant, cet emplacement est le préféré de nombreux
experts parce qu'il offre l'avantage d'écrire dans les logs et
d'analyser les attaques (vers le pare-feu...), ainsi l'administrateur voit ce
qu'il doit modifier dans la configuration du pare-feu.
Les capteurs placés à l'extérieur du
pare-feu servent à détecter toutes les attaques en direction du
réseau, leur tâche ici est donc plus de contrôler le
fonctionnement et la configuration du firewall que d'assurer une protection
contre toutes les intrusions détectées (certaines étant
traitées par le firewall).
Il est également possible de placer un capteur avant le
firewall et un autre après. En fait, cette variante réunit les
deux cas mentionnés ci-dessus. Mais elle est très dangereuse si
on configure mal les capteurs et/ou le pare-feu. En effet, on ne peut pas
simplement ajouter les avantages des deux cas précédents à
cette variante.
Les capteurs IDS sont parfois situés à
l'entrée de zones du réseau particulièrement sensibles
(parcs de serveurs, données confidentielles...), de façon
à surveiller tout trafic en direction de cette zone.
Les avantages des NIDS sont les suivants : les capteurs peuvent
être bien sécurisés puisqu'ils se contentent d'observer le
trafic et permettent donc une surveillance discrète du réseau,
les attaques de type scans sont facilement détectées, et il est
possible de filtrer le trafic.
Les NIDS sont très utilisés et remplissent un
rôle indispensable, mais ils présentent néanmoins de
nombreuses faiblesses. En effet, la probabilité de faux négatifs
(attaques non détectées comme telles) est élevée et
il est difficile de contrôler le réseau entier.
De plus, ils doivent principalement fonctionner de manière
cryptée d'où une complication de l'analyse des paquets. Pour
finir, à l'opposé des IDS basés sur l'hôte, ils ne
voient pas les impacts d'une attaque.
Voici quelques exemples de NIDS : Dragon, ISSRealSecure,
NetRanger, NFR, Snort.
Même si nous distinguons HIDS et NIDS, la différence
devient de plus en plus réduite puisque les HIDS possèdent
maintenant les fonctionnalités de base des NIDS. Des IDS bien connus
comme ISS RealSecure se nomment aujourd'hui "IDS hôte et réseau".
Dans un futur proche la différence entre les deux systèmes
deviendra de plus en plus faible (ces systèmes évolueront
ensemble).
Voici un exemple de mise en place d'un IDS RealSecure avec des
IDS hôtes et réseaux connectés à une console de
management centrale (sur le schéma, les HIDS sont appelés
RealSecure Server Sensor et les NIDS RealSecure Network Sensor).
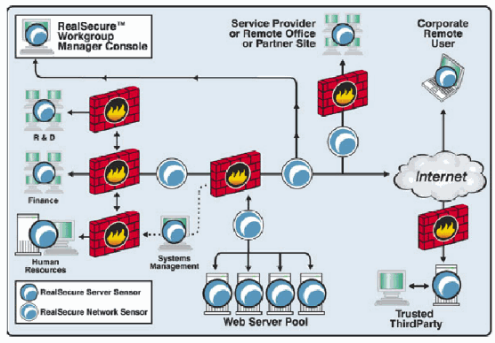
Figure 11: Exemple
d'architecture HIDS/NIDS
Avantages :
· Les NIDS peuvent surveiller un grand réseau.
· Le déploiement de NIDS a peu d'impact sur un
réseau existant. Les NIDS sont habituellement des dispositifs passifs
qui écoutent sur un fil de réseau sans interférer
l'opération normale d'un réseau. Ainsi, il est habituellement
facile de monter en rattrapage un réseau pour inclure IDS avec l'effort
minimal.
· NIDS peut être très sûr contre
l'attaque et peut être invisible pour beaucoup d'attaquants.
Inconvénients :
· Il est difficile à traiter tous les paquets
circulant sur un grand réseau. De plus il ne peut pas reconnaître
des attaques pendant le temps de haut trafic.
· Plusieurs des avantages des NIDS ne peuvent pas être
appliqués pour les commutateurs modernes. La plupart des commutateurs ne
fournissent pas des surveillances universelles des ports et limitent la gamme
de surveillance des NIDS .Même lorsque les commutateurs fournissent de
tels ports de surveillance, souvent le port simple ne peut pas refléter
tout le trafic traversant le commutateur.
· NIDS ne peut pas analyser des informations
chiffrées (cryptées). Ce problème a lieu dans les
organisations utilisant le VPN.
· La plupart de NIDS ne peuvent pas indiquer si une attaque
est réussie ou non. Ils reconnaissent seulement qu'une attaque est
initialisée. C'est-à-dire qu'après les NIDS
détectent une attaque, l'administrateur doit examiner manuellement
chaque host et vérifier s'il a été en effet
pénétré.
· Quelques NIDS provoquent des paquets en fragments. Ces
paquets mal formés font devenir les IDS instables.
III.3. Mode de fonctionnement d'un
IDS
Il faut distinguer deux aspects dans le fonctionnement d'un IDS :
le mode de détection utilisé et la réponse apportée
par l'IDS lors de la détection d'une intrusion.
Il existe deux modes de détection, la détection
d'anomalies et la reconnaissance de signatures. D'eux-mêmes, deux types
de réponses existent, la réponse passive et la réponse
active. Il faut noter que les différents IDS présents sur le
marché ne disposent pas toujours de l'ensemble des
fonctionnalités présentées ici.
Nous allons tout d'abord étudier les modes de
détection d'un IDS, avant de présenter les réponses
possibles à une attaque.
III.3.1. Modes de
détection
Nous notons deux modes de détection qui sont :
· La détection d'anomalies
· La reconnaissance de signature
Il faut noter que la reconnaissance de signature est le mode de
fonctionnement le plus implémenté par les IDS du marché.
Cependant, les nouveaux produits tendent à combiner les deux
méthodes pour affiner la détection d'intrusion.
III.3.1.1. La
détection d'anomalies :
Elle consiste à détecter des anomalies par rapport
à un profil "de trafic habituel". La mise en oeuvre comprend toujours
une phase d'apprentissage au cours de laquelle les IDS vont découvrir le
fonctionnement normal des éléments surveillés. Ils sont
ainsi en mesure de signaler les divergences par rapport au fonctionnement de
référence.
Les modèles comportementaux peuvent être
élaborés à partir d'analyses statistiques. Ils
présentent l'avantage de détecter des nouveaux types d'attaques.
Cependant, de fréquents ajustements sont nécessaires afin de
faire évoluer le modèle de référence de sorte qu'il
reflète l'activité normale des utilisateurs et réduire le
nombre de fausses alertes générées.
Dans le cas d'HIDS, ce type de détection peut être
basé sur des informations telles que le taux d'utilisation CPU,
l'activité sur le disque, les horaires de connexion ou d'utilisation de
certains fichiers (horaires de bureau...).
III.3.1.2. La
reconnaissance de signatures :
Cette approche consiste à rechercher dans
l'activité de l'élément surveillé les empreintes
(ou signatures) d'attaques connues. Ce type d'IDS est purement réactif ;
il ne peut détecter que les attaques dont il possède la
signature.
De ce fait, il nécessite des mises à jour
fréquentes. De plus, l'efficacité de ce système de
détection dépend fortement de la précision de sa base de
signature. C'est pourquoi ces systèmes sont contournés par les
pirates qui utilisent des techniques dites "d'évasion" qui consistent
à maquiller les attaques utilisées. Ces techniques tendent
à faire varier les signatures des attaques qui ainsi ne sont plus
reconnues par l'IDS.
Il est possible d'élaborer des signatures plus
génériques, qui permettent de détecter les variantes d'une
même attaque, mais cela demande une bonne connaissance des attaques et du
réseau, de façon à stopper les variantes d'une attaque et
à ne pas gêner le trafic normal du réseau.
Une signature permet de définir les
caractéristiques d'une attaque, au niveau des paquets (jusqu'à
TCP ou UDP) ou au niveau des protocoles (HTTP, FTP...).
· Au niveau paquet, l'IDS va analyser les différents
paramètres de tous les paquets transitant et les comparer avec les
signatures d'attaques connues.
· Au niveau protocole, l'IDS va vérifier au niveau du
protocole si les commandes envoyées sont correctes ou ne contiennent pas
d'attaque. Cette fonctionnalité a surtout été
développée pour HTTP actuellement.
Il faut savoir que les signatures sont mises à jour en
fonction des nouvelles attaques identifiées.
Néanmoins, plus il y a de signatures différentes
à tester, plus le temps de traitement sera long. L'utilisation de
signatures plus élaborées peut donc procurer un gain de temps
appréciable.
Cependant, une signature mal élaborée peut ignorer
des attaques réelles ou identifiées du trafic normal comme
étant une attaque. Il convient donc de manier l'élaboration de
signatures avec précaution, et en ayant de bonnes connaissances sur le
réseau surveillé et les attaques existantes.
Une fois une attaque détectée, un IDS a le choix
entre plusieurs types de réponses, que nous allons maintenant
détailler.
III.3.2.
Réponse active et passive
Il existe deux types de réponses, suivant les IDS
utilisés. La réponse passive est disponible pour tous les IDS
alors que la réponse active est elle plus ou moins
implémentée.
III.3.2.1.
Réponse passive :
La réponse passive d'un IDS consiste à enregistrer
les intrusions détectées dans un fichier de log qui sera
analysé par le responsable de sécurité.
Certains IDS permettent de logger l'ensemble d'une connexion
identifiée comme malveillante.
Ceci permet de remédier aux failles de
sécurité pour empêcher les attaques enregistrées de
se reproduire, mais elle n'empêche pas directement une attaque de se
produire.
III.3.2.2.
Réponse active :
La réponse active, au contraire a pour but de stopper une
attaque au moment de sa détection. Pour cela on dispose de deux
techniques : la reconfiguration du firewall et l'interruption d'une connexion
TCP.
La reconfiguration du firewall permet de bloquer le trafic
malveillant au niveau du firewall, en fermant le port utilisé ou en
interdisant l'adresse de l'attaquant. Cette fonctionnalité dépend
du modèle de firewall utilisé, tous les modèles ne
permettant pas la reconfiguration par un IDS. De plus, cette reconfiguration ne
peut se faire qu'en fonction des capacités du firewall.
L'IDS peut également interrompre une session
établie entre un attaquant et sa machine cible, de façon à
empêcher le transfert de données ou la modification du
système attaqué. Pour cela l'IDS envoie un paquet TCP reset aux
deux extrémités de la connexion (cible et attaquant). Un paquet
TCP reset a le flag RST de positionner, ce qui indique une déconnexion
de la part de l'autre extrémité de la connexion. Chaque
extrémité en étant destinataire, la cible et l'attaquant
pensent que l'autre extrémité s'est déconnectée et
l'attaque est interrompue.
Dans le cas d'une réponse active, il faut être
sûr que le trafic détecté comme malveillant l'est
réellement, sous peine de déconnecter des utilisateurs
normaux.
En général, les IDS ne réagissent pas
activement à toutes les alertes. Ils ne répondent aux alertes que
quand celles-ci sont positivement certifiées comme étant des
attaques. L'analyse des fichiers d'alertes générés est
donc une obligation pour analyser l'ensemble des attaques
détectées.
III.4. . Points forts et Points faibles
des IDS
Nous allons pour finir cette présentation des IDS,
résumer les points forts et les points faibles de ces
équipements.
III.4.1. Points
forts
III.4.1.1. Une
surveillance continue et détaillée :
Dans cette optique, nous nous intéressons aux flux
valides, mais aussi aux flux non valides qui transitent sur le réseau
dont nous avons la responsabilité.
Comment savoir si les règles d'un firewall sont valides ?
Comment savoir le nombre d'attaques subies au cours de la
dernière semaine ?
Comment différencier une surcharge normale du
réseau d'une attaque par DoS ?
Les IDS vont permettre de répondre à ces questions.
Ce sont des sondes en mode promiscuité. Ils peuvent donc analyser tout
le trafic (dans le même domaine de collision), et relever des attaques,
alors même qu'ils n'en sont pas la cible directe.
Bien sûr, nous évoquons ici le fonctionnement des
NIDS. Les HIDS vont au contraire établir une surveillance unique du
système sur lequel ils sont installés. De plus, toutes les
alertes sont stockées soit dans un fichier, soit dans une base de
données, ce qui permet de concevoir un historique, et d'établir
des liens entre différentes attaques.
Ainsi, le responsable sécurité n'a pas besoin de
surveiller le réseau en permanence pour être au courant de ce qui
se passe. Une attaque de nuit ne passera plus inaperçue. Tous les IDS
renvoient de nombreuses informations avec une alerte. Le type supposé
d'attaque, la source, la destination, ... Tout cela permet une bonne
compréhension d'un incident de sécurité, et en cas de
faux-positif, de le détecter rapidement.
Un autre point important dans la sécurité : nous
avons maintenant des outils de filtrage très intéressants qui
nous permettent de faire du contrôle par protocole
(ICMP, TCP, UDP), par adresse IP, jusqu'à du suivi de
connexion (couches 3 et 4).
Même si cela écarte la plupart des attaques, cela
est insuffisant pour se protéger des attaques passant par des flux
autorisés. C'est aussi assez marginal, car difficile à mettre en
place, l'ouverture de l'informatique au grand public et l'augmentation de ce
type de connaissances font qu'il faudra un jour savoir s'en protéger
efficacement.
III.4.1.2. La
modularité de l'architecture :
Il y a plusieurs solutions pour le positionnement de sondes
réseaux. Il peut être intéressant de positionner les sondes
pour étudier l'efficacité des protections mises en place.
Par exemple dans un réseau se cachant derrière un
firewall, nous mettrons une sonde côté extérieur du
firewall, et une autre côté intérieur du firewall. La
première sonde permet de détecter les tentatives d'attaques
dirigées contre le réseau surveillé.
La seconde sonde va remonter les attaques (préalablement
détectées par la première sonde) qui ont réussi
à passer le firewall. On peut ainsi suivre une attaque sur un
réseau, voir si elle arrive jusqu'à sa victime, en suivant quel
parcours a été emprunté.
Il est aussi intéressant de définir des
périmètres de surveillance d'une sonde. Ce sera en
général suivant un domaine de collision, ou sur des
entrées uniques vers plusieurs domaines de collision (par exemple
à l'entrée d'un commutateur).
Par cette méthode, nous réduisons le nombre de
sondes, car il n'y a pas de doublons dans la surveillance d'une partie du
réseau. Une alerte n'est remontée qu'une seule fois ; ce qui
allège l'administration des IDS. Et pour finir, le fait de placer les
sondes après les protections est plus logique, car le but premier des
IDS est d'étudier les intrusions malgré les protections.
III.4.1.3. La
complémentarité des NIDS et des HIDS :
Nous avons évoqué jusqu'ici principalement le cas
des NIDS. Les IDS se cantonnent à la surveillance des systèmes
sur lesquels ils sont hébergés. Mais ils sont extrêmement
utiles. Par exemple dans le suivi d'une attaque évoqué
précédemment, grâce aux sondes NIDS, nous pouvons suivre
son parcours. Mais quel est l'impact final sur la machine ?
Un NIDS ne peut pas répondre à cela, car il ne
gère pas les équipements terminaux. C'est ici que le HIDS se
révèle utile. De plus, la remontée d'alerte est locale et
vers un manager ainsi, la surveillance réseau et des équipements
terminaux est centralisée.
III.4.2. Points
faibles
III.4.2.1. Besoin
de connaissances en sécurité :
La mise en place d'une sonde de sécurité fait appel
à de bonnes connaissances en sécurité.
L'installation en elle-même des logiciels est à la
portée de n'importe quel informaticien. En revanche, l'exploitation des
remontées d'alertes nécessite des connaissances plus
pointues.
Les interfaces fournissent beaucoup d'informations, et permettent
des tris facilitant beaucoup de travail, mais l'intervention humaine est
toujours indispensable.
A partir des remontées d'alertes, quelle mesure prendre
?
Est-il utile de relever des alertes dont toutes les machines sont
protégées?
Comment distinguer un faux-positif d'un véritable incident
de sécurité ?
Toutes ces questions et bien d'autres doivent se poser au
responsable de sécurité en charge d'un IDS.
La configuration, et l'administration des IDS nécessitent
beaucoup de temps, et de connaissances. C'est un outil d'aide, qui n'est en
aucun cas complètement automatisé.
III.4.2.2.
Problème de positionnement des sondes :
La mise en place est importante. Il faut bien définir
là où placer les sondes. Il ne s'agit pas de mettre une sonde
partout où l'on veut surveiller. Il faut étudier les champs de
vision des sondes suivant leur placement, si on veut recouper ces champs de
vision (pour par exemple faire des doublons de surveillance ou faire un suivi
d'attaque), quel détail d'analyse (à l'entrée d'un
réseau, ou dans chaque domaine de collision). On découpe souvent
le réseau global en un LAN, une DMZ, puis Internet.
Mais il faut aussi envisager les domaines de collisions, les
sous-réseaux, ...
Les connaissances réseaux sont importantes. Il faut aussi
faire attention à comment sont remontées les alertes (passage par
un réseau sécurisé et isolé du réseau
surveillé).
III.4.2.3.
Vulnérabilités des sondes NIDS :
De par leur fonctionnement en mode promiscuité, les sondes
sont vulnérables. Elles captent tout le trafic, et même si un Ping
flood est réalisé sur une autre machine, les sondes NIDS le
captureront aussi et donc en subiront les conséquences, comme si
l'attaque leur était directement envoyée. Les DoS classiques
seront donc très nocifs pour les sondes NIDS.
Le point fort de certains IDS qui est d'archiver aussi le contenu
des trames ayant levées une alerte, peut aussi s'avérer un point
faible. Un hôte flood avec un paquet chargé de 64000 octets, ou
encore des trames de 1500 octets pour les SYN flood vont faire exploser la
taille des fichiers de logs des sondes en quelques minutes.
C'est une attaque qui porte le nom coke qui consiste à
saturer le disque dur.
La seule façon de parer cette attaque est de
prévoir d'importants espaces de stockages, et gérer le stockage
des fichiers de logs.
III.4.2.4.
Problèmes intrinsèques à la plateforme :
Beaucoup d'IDS (et plus particulièrement les IDS libres)
sont des logiciels reposant sur un système d'exploitation non
dédié aux IDS. Ainsi, la faiblesse d'un IDS est liée
à la faiblesse de la plate-forme.
Un même logiciel sera par exemple plus vulnérable
sur un PC Win98 que sur un PC Open BSD, de par la solidité de la pile IP
face aux attaques, ou tout simplement de par la stabilité du
système. La mise en place d'un IDS requiert donc des compétences
dans la sécurisation de la plate-forme.
Une saturation de la mémoire, de la carte réseau,
ou du processeur porte atteinte directement au bon fonctionnement de tout le
système et donc du logiciel IDS de la machine.
Le problème de ces dysfonctionnements est que si la sonde
ne peut plus remplir son rôle, le réseau n'en est pas coupé
pour autant. Le responsable sécurité ne peut donc pas voir que,
la sonde étant tombée, une partie du réseau n'est plus
surveillée. Une redondance des surveillances sur certaines zones devrait
momentanément résoudre le problème.
Comme nous venons de le voir, les IDS sont des outils
indispensables à la bonne sécurité d'un réseau,
néanmoins leur utilisation reste complexe et contraignante. Ces outils
sont malgré tout fiables et plutôt sûrs.
IV. SNORT
SNORT est une open source du système de détection
des intrusions de réseau (NIDS). Il est capable d'analyser le trafic sur
le réseau en temps réel et des paquets circulant sur le
réseau IP. Il peut exécuter l'analyse de protocole, en cherchant
le contenu et peut être employé pour détecter une
variété d'attaques, des tentatives comme des débordements
d'amortisseur, des balayages de port de dérobée, des attaques de
CGI, des sondes de SMB, des tentatives d'empreinte de OS, et beaucoup plus.
SNORT est un IDS gratuit. A l'origine, ce fut un sniffer qui par
la suite connut une telle évolution qu'il fut vite adapté et
utilisé dans le monde de détection d'intrusion en s'appuyant sur
une base de signatures régulièrement enrichie par « le
monde du libre ».
SNORT emploie un langage flexible de règles pour
décrire le trafic qu'il devrait se rassembler ou passer, aussi bien
qu'un moteur de détection qui utilise une architecture plug-in
modulaire. SNORT a des possibilités en temps réel d'alerter et
d'incorporer des mécanismes pour le système
d'événement, un dossier indiqué par utilisateur, un socket
d'Unix, ou des messages de WinPopup aux clients de Windows en utilisant la
smbclient.
SNORT a trois utilisations primaires. Il peut être
employé en tant qu'un renifleur de paquet (Sniffer) comme tcpdump(1), un
enregistreur de paquet (logs) (utile pour le trafic de réseau
corrigeant, etc....), ou comme plein système soufflé de
détection d'intrusion de réseau.
Figure 12 : Les
plateformes pour installer SNORT
IV.1. L'architecture de SNORT
L'architecture de SNORT est organisée en modules, elle est
composée de quatre grands modules : Le décodeur de paquets, les
préprocesseurs, le moteur de détection et le système
d'alerte et d'enregistrement de log.
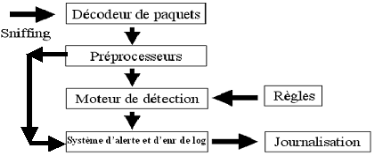
Figure 13: Architecture de
SNORT
IV.2. Le décodeur de paquets.
Un système de détection d'intrusion active un ou
plusieurs interfaces réseau de la machine en mode espion (promiscuous
mode), ceci va lui permettre de lire et d'analyser tous les paquets qui passent
par le lien de communication. SNORT utilise la bibliothèque libpcap pour
faire la capture des trames.
Un décodeur de paquets est composé de plusieurs
sous décodeurs qui sont organisés par protocole (Ethernet, IP,
TCP..), ces décodeurs transforme les éléments des
protocoles en une structure de données interne. (Voir figure 14).
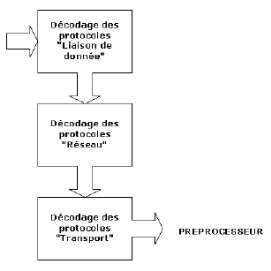
Figure 14 : Le
décodeur de paquets.
IV.3. Les pré-processeurs.
Les pré-processeurs s'occupent de la détection
d'intrusion en cherchant les anomalies. Un pré-processeur envoie une
alerte si les paquets ne respectent pas les normes des protocoles
utilisées. Un pré-processeur est différent d'une
règle de détection, il est un programme qui vise à aller
plus en détail dans l'analyse de trafic.
Les préprocesseurs permettent aussi d'étendre les
fonctionnalités de SNORT. Ils sont exécutés avant le
lancement du moteur de détection et après le décodage du
paquet IP. Le paquet IP peut être modifié ou analysé de
plusieurs manières en utilisant le mécanisme de
pré-processeur. Les pré-processeurs sont chargés et
configurés avec le mot-clé préprocessor.
IV.4. Moteur de détection.
C'est la partie la plus importante dans un IDS. Le moteur de
détection utilise les règles pour faire la détection des
activités d'intrusion. Si un paquet correspond à une
règle, alors une alerte est générée. Les
règles sont groupées en plusieurs catégories sous forme de
fichiers. SNORT vient avec un ensemble de règles
prédéfini.
Ces règles ne sont pas activées automatiquement, il
faut les activer dans le fichier de configuration snort.conf. Chaque fichier
contient des règles décrit en type de trafic à
signaler.
(Voir figure 15).
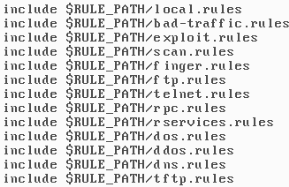
Figure 15 : Une
partie du fichier snort.conf.
IV.5. Système d'alerte et d'enregistrement des
logs.
Le système d'alerte et d'enregistrement des logs s'occupe
de la génération des logs et des alertes. Les alertes sont
stockées par défaut dans le répertoire
C:\Snort\log.
Dés que le système devient opérationnel, on
pourra consulter les alertes générées directement dans les
fichiers textes ou bien utiliser une console de gestion. ACID (Analysis Console
for Intrusion Detection), est une application qui fournie une console de
gestion et qui permet la visualisation des alertes en mode graphique. Les
alertes dans ce cas sont stockées dans une base de données
MySQL.
Voici une maquette qui nous permettra de tester Snort afin de
mettre en avant ses fonctions.
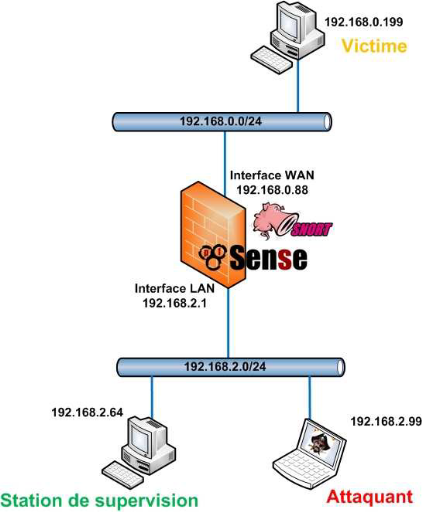
Figure 16 :Maquette
de test des fonctions de Snort
V. CONCLUSION
La sécurité reste encore un sujet à
discussion vu qu'aucune solution fiable à part entière n'a encore
été trouvée.
Nous venons de montrer que la détection d'intrusion sur les réseaux ne vient pas
concurrencer les autres systèmes de sécurité mais au
contraire les compléter.
On a également présenté les principes mises
en oeuvre par les IDS pour atteindre leur but.
Cependant le seul bémol est qu'un système ne peut
jamais être sécurisé à 100 %, alors le but
recherché serait de pouvoir détecter le maximum d'intrusions et
de toutes les boquer dans le futur ; C'est dans ce cas que Snort est
déclaré efficace.
Capable de détecter et de bloquer plusieurs intrusions
à la fois de par ses règles régulièrement mises
à jour par « le monde du gratuit », Snort est un
vrai portail anti-intrusion.
Cependant, comme tout autre système de
sécurité, cette technologie (les IDS) n'est pas encore
arrivée à maturité et les outils existants tels que Snort
ne sont pas toujours à la hauteur des besoins
INDEX DES FIGURES
Figure 1 : PROTOCOLES
ÉCHANGEANT DES MOTS DE PASSE EN CLAIR
3
Figure 2 : ECHANGE DES NUMÉROS DE
SÉQUENCE INITIAUX LORS DE L'ÉTABLISSEMENT D'UNE CONNEXION TCP
21
Figure 3 : TENTATIVE D'ETABLISSEMENT D'UNE
CONNEXION PAR UN PIRATE. POUR QUE L'ATTAQUE REUSSISSE, LE PIRATE DOIT DEVINER
LE NUMERO DE SEQUENCE INITIAL PROPOSE PAR B.
22
Figure 4 : Schéma d'une architecture
réseau utilisant un Firewall
26
Figure 5 : Etablissement de la connexion entre
un client et serveur FTP en passant par un Firewall
29
Figure 6 : Choix des Firewalls dans une
architecture réseau
32
Figure
7 Architecture d'une DMZ
37
Figure 8 : Fonctionnement de NAT
39
Figure 9 : Fonctionnement d'un IDS
43
Figure 10 : Système de
détection d'intrusion réseau
47
Figure 11 : Exemple d'architecture HIDS/NIDS
50
Figure 12 : Les plateformes pour installer
SNORT
61
Figure 13: Architecture de SNORT
62
Figure 14 : : Le décodeur de
paquets.
63
Figure 15 : : Une partie du fichier
snort.conf.
64
_Toc296727848
INDEX DES TABLEAUX
Tableau 1 : Avantages et inconvénients
d'un Firewall Bridge
3
Tableau 2 ; Avantages et inconvénients
d'un Firewall matériel
34
Tableau 3 : Avantages et inconvénients
d'un Firewall personnel.
35
Tableau 4 : Avantages et inconvénients
d'un Firewall plus sérieux.
35
VI. BIBLIOGRAPHIE
v
Les Firewalls par Alban Jacquemin et Adrien Mercier
v
Secuser (fr) : infos sur les virus et autres...
v
La sécurité des réseaux
| 

