2.3.1.2 Mesures basées sur les motifs
topologiques
Considérant un simple réseau social qui ne
contient aucun attribut sur les noeuds ou sur les liens, ils existent beaucoup
de mesures qui permettent de calculer les similarités entre les paires
de noeuds, la plupart concentrent sur l'information de
la structure ou bien de la topologie d'un réseau social.
Les auteurs ont montréque la structure joue encore un
rôle important sur l'évolution des liens dans un
réseau social, par conséquent, beaucoup de
mesures de similaritéen se basant sur la topologie d'un réseau
social ont étéproposé, dans la section suivante, nous
donnons une vue systématique sur les mesures les plus populaires dans la
prédiction des liens. Ce qu'il nous faut prendre en considération
que ces mesures se distinguent en trois grandes catégories :
1. Les mesures locales basées sur le voisinage des
noeuds.
2. Les mesures globales basées sur les distances entre les
noeuds.
3. Les mesures basées sur les marches
aléatoires.
· Chapitre 2. État de l'art 21
Mesures de similaritélocales
Dans les réseaux sociaux, les personnes tendent de
créer des relations avec des personnes proche de celui-ci, les voisins
sont les plus proches, pour cela, les chercheurs ont définit beaucoup de
mesures basées sur les voisins d'un noeud, ces mesures attribuent des
scores aux paires de noeuds non connectés seulement en fonction de leurs
voisins et ne considèrent pas l'information sur tous les noeuds de
réseau social, une grande valeur de similaritéentre les noeuds
non connectésignifie qu'il y a une grande probabilitéque ce pair
soit connectédans le futur.
Attachement préférentiel (PA)
:[New01] et [Ba02] considèrent qu'il existe une forte
probabilitéque deux noeuds se connectent, si ces noeuds, appelés
également «hubs», sont déjàconnectés
à un nombre élevéde noeuds . Cette idée rejoint le
principe du «rich-get-richer». Le score associéà la
possibilitéd'existence d'un lien entre x et y est le suivant :
L'attachement préférentiel a toutefois
l'inconvénient d'obtenir des valeurs de similarités
élevées concernant les utilisateurs non connectés, au
détriment des utilisateurs peu connectés dans le réseau.
Cet inconvénient relève du fait que les relations entre les
utilisateurs dépendent uniquement de leur connectivité. Or, notre
but est de trouver de nouveaux voisins aux noeuds qui en ont peu. En outre, une
autre limite de cette méthode est la création de plusieurs liens
entre les noeuds et la maximisation de la connectivitédu
réseau.
Voisins communs (CN) :[New01] définit
une mesure qui est l'une les plus utilisées dans le problème de
prédiction des liens principalement en raison de sa simplicité.
Pour les deux noeuds, x et y, le CN est définie comme le nombre de
noeuds que x et y ont une interaction directe c'est-à-dire sont des
voisins communs. Un plus grand nombre des voisins communs facilite l'apparition
d'un lien entre X et Y, cette mesure est définie comme suit :
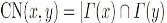
Chapitre 2. État de l'art 22
Comme nous avons dit, cette méthode considère
que plus les utilisateurs partagent des voisins, plus ils sont
corrélés. Or, comme pour l'attachement
préférentiel, l'in-convénient de cette méthode est
sa tendance à attribuer des similarités élevées aux
utilisateurs ayant de nombreux voisins. De ce fait, la similaritéentre
les utilisateurs disposant de peu de voisins tend à être faible,
voire nulle.
Coefficient de Jaccard (JC) : le coefficient
de Jaccard est une amélioration de la méthode voisins communs, Il
mesure la similaritéentre deux noeuds par le nombre de voisins en commun
divisépar le nombre total de voisins de ces noeuds. Il affecte des
valeurs plus élevées aux paires de noeuds qui ont une grande
proportion de voisins communs par rapport au total du nombre de voisins qu'ils
ont. Cette mesure est définie comme suit :
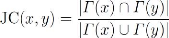
Comparéaux deux méthodes
précédentes, Jaccard a l'avantage de ne pas augmenter l'influence
des utilisateurs disposant d'un grand nombre de voisins.
Adamic et Adar (AA) : [Ada03] à
l'origine, cette une méthode est pour calculer la similaritéentre
deux pages Web au premier à travers ces items en prenant en compte les
items que ces deux utilisateurs ont en commun. La particularitéde cette
méthode est que les items qui sont partagés par peu
d'utilisateurs, ont un poids plus important que les items dont les occurrences
sont élevées (i.e. les items
qui sont communs à plusieurs paires d'utilisateurs),
après il a étélargement utilisédans les
réseaux sociaux :
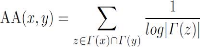
Selon l'équation, au lieu de considérer les
items, nous considérons les voisins qu'au x et y ont en commun.
L'idée de cette mesure consiste à introduire une
pondération en fonction du nombre de voisins des voisins communs. Ainsi
les voisins communs les moins connectés sont associés à un
poids plus important.
Chapitre 2. État de l'art 23
Dans le tableau 2.1, nous comparons les mesures les plus
populaires qui sont basées sur le voisinage selon trois principaux
critères : la normalisation, la com-plexitétemporelle et leurs
caractéristiques. Il existe en effet 3 mesures qui ne sont pas
normalisées, c'est-à-dire la similaritéest
calculéen utilisant ces mesures ayant une signification seulement si on
construit une liste des scores ordonnées et il nous ne donne aucune
information sur la topologie par exemple leurs degrés, proportion de
leurs voisins communs par rapport aux tous les voisins etc.
La complexitétemporelle est un facteur important pour
choisir des mesures en fonction de la taille d'un réseau social.
Supposant que la moyenne de nombre de voisins d'un noeud dans un réseau
social est n, pour deux noeuds x et y, la com-plexitétemporelle pour
trouver tous les voisins d'un noeud est O(n), et la
com-plexitétemporelle de l'intersection ou l'union de deux ensembles est
O(n2). CN (Voisins communs) , AP (Attachement
préférentiel) , JC (Coefficient de Jaccard) ont O(n2)
par ce qu'ils ont besoin de calculer l'intersection et l'union de deux
ensembles. AA (Adamic et Adar) a besoin de calculer l'intersection de deux
ensembles et de trouver les voisins des voisins communs, par conséquent,
la complexitétem-porelle sera O(2n2). Les
caractéristiques de ces mesures sont aussi discutédans le tableau
suivant.
Mesure
|
ou non
|
NormaliséComplexitéCaractéristiques
|
|
AP
|
Non
|
O(n2)
|
Simple, des noeuds ayant des degrés élevés
sont plus susceptible d'être liée
|
CN
|
Non
|
O(n2)
|
Simple et intuitive
|
JC
|
Oui
|
O(n2)
|
Proportion des voisins communs sur les voisins total
|
AA
|
Non
|
O(2n2)
|
Voisins communs ayant moins de voisins sont
pondérées plus lourdement
|
|
TABLE 2.1 - Quelques caractéristiques des mesures de
similaritélocale [Wp15]
Finalement, nous devons prendre en compte qu'il existe un
nombre important des algorithmes de prédiction de liens qui sont
basés sur le voisinage, mais pour des expérimentations
réels, plusieurs études ont montréqu'il n'existe pas une
mesure de similaritéabsolu donne des bonnes prédictions pour
n'importe quel réseau social.
· Chapitre 2. État de l'art 24
Mesures de similaritéglobales
Contrairement aux mesures de similaritélocales, les
mesures globales nécessitent de connaître toute l'information
topologique du réseau social. Ces approches se basent
généralement sur l'hypothèse que dans le cas oùil
existe plusieurs relations de longueurs différentes
(3ème degréou plus), cela peut
conduire à une relation entre ces deux personnes dans le futur.
Plus court chemin :[Win14] La mesure la plus directe pour
calculer la simila-ritéentre deux noeuds est la distance entre eux. Il
est défini comme la plus courte distance qui sépare x à y.
Plus précisément, nous initialisons S = {x} et D = {y} . A chaque
étape, nous élargissons les deux ensembles en incluant les
voisins directes pour chaque noeud de manière récursive. Nous
arrêtons si nous trouvons au moins un élément appartient
à ces deux ensembles: S et D c'est-à-dire S nD =6 Ø, le
plus court chemin dans ce cas est le nombre d'itérations. Une grande
distance indique une faible similaritétandis qu'une courte distance
indique une grande similarité.
Local path : [Lu09] Cette mesure prend en
considération l'information des chemins locales entre les noeuds de
longueurs 2 et 3 contrairement aux mesures qui prennent en compte que les
voisins les plus proches, cette mesure exploite des informations additionnelles
avec un chemin de longueur 3 depuis le noeud courant, évidement, les
chemins de longueur 2 sont plus importants par rapport aux chemins de longueur
3 donc il y a un facteur d'ajustement appliquédans cette mesure.
Katz :[Kat53] Cette mesure basésur le principe que
deux personnes dans un réseau social peuvent utiliser tous les chemins
qui les relie surtout si ses chemins sont nombreux par rapport aux chemins de
longueur inferieur, donc elle compte tous les chemins de différentes
longueurs qui relient les pairs de noeuds, en utilisant une pondération
en fonction de la longueur d'un chemin, tel que les chemins courts ont un poids
élevépar rapport aux chemins longs qu'en lui affectant des poids
faible.
·
Chapitre 2. État de l'art 25
Mesures basées sur les marches
aléatoires
Les interactions entre les noeuds au sein d'un réseau
social peuvent être aussi modélisées par des chaines
Markoviennes, en affectant une probabilitéde transition a chaque lien
entre chaque deux noeuds, la marche aléatoire saute d'un noeud à
un autre et ce dernier représente un état d'une chaine de Markov,
il existe un nombre assez important de mesures pour calculer la
similaritéentre deux noeuds en se basant sur les marches
aléatoires.
Hitting Time (HT) : [Fou07] Ht(x,y) est le
nombre des étapes pour effectuer une marche aléatoires en partant
d'un noeuds x à un noeud y.
Commute time(CT) : puisque la mesure Hitting
time n'est pas symétrique, la mesure CT est symétrique
c'est-à-dire elle considère le nombre des étapes pour
partir d'un x jusqu'au noeud y est le même pour une marche
aléatoire allant de y à x. CT(x,y) : Ht(x, y) = Ht(y,
x)
SimRank (SR) : [JG02] est une adaptation de
l'algorithme de Google qui permet de trier les pages web en selon leurs
importance en fonction du nombre de pages qu'ils la référence.
simRank est une mesure de similaritédans un graphe orienté, elle
est basésur une idée simple : deux noeuds sont similaire s'ils
référencent des noeuds qui sont aussi similaires, sachant que la
similaritéd'un seul noeud égal à 1, elle calcule ce score
à travers le nombre de leur voisins entrants et ces voisins à
travers leurs voisins entrants et ainsi de suite jusqu'àarriver à
un seul noeud.
La valeur de simRank peut être calculéavec deux
marches aléatoires, l'une part d'un noeud x et l'autre à partir
un noeud y, elle mesure après combien de temps les deux marches
aléatoire stationnent sur le même noeud, le cas le plus favorable
c'est que ce dernier est un voisin commun directe et dans ce cas la
similaritéest maximale.
| 

