CHAPITRE 3. CONSTRUCTION D'UN SYSTÈME
D'INTÉGRATION DE DONNÉES
ainsi nous utilisons les concepts d'ontologies en basant sur les
sémantiques des informations dont nous obtenons les synonymes, en
construction un dictionnaire des données contient les termes et leurs
sens, sur lequel nous fusionnons les termes qui ayant la même
sémantique.
2. Charge:
Cette fonction fait après l'intégration de sources
de données dans un schéma global, tel qu'un source global
homogène résulte depuis l'intégration des sources
hétérogènes a étè
chargée dans un entrepôt de données, dans
notre travail c'est le XML fichier global.
Technique de rapprochement
Les algorithmes de technique de rapprochement consacrent de
trouver les simulations entre les caractères des termes. Dans notre
travail nous implémentons un algorithme qui est l'optimisation des deux
algorithmes de cette technique pour faire la comparaison dans l'objectif de
trouver les termes semblables dont nous validons l'intégration entre les
sources qui contiennent ces termes.
-- Algorithme LCS « Longest Common Susbtring
»
LCS problème consiste à trouver la plus longue
sous séquence commune entre les deux chaînes de séquences,
l'algorithme de LCS permet de comparer deux chaînes de caractères
pour trouver la divergence entre eux selon les caractères
trouvés, jusqu'à trouver la plus longue chaîne commune.
Cet algorithme est plus performant pour le cas d'une
divergence ou une simulation des caractères entre les termes.
La mesure de similarité se calcule par;
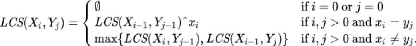
Telque :
Xi, Yj : deux
chaînes de caractéres.
i,j : les deux longueurs de X,Y par ordre, tel que.
-- Algorithme de Jaro-Winkler
Cet algorithme correspond de calculer la distance de simulation
entre deux termes, Jaro
propose une formule de calcul basé sur le poids de
caractères dans la longueur des termes
parmi les deux chaînes de caractères.
La mesure de similarité se calculer par :
Jaro(Q1, Q2) = 1 3(
C
S1 + C
S2 +
C-P
C )
Telque :
C :le nombre de caractères communs.
P : le nombre de permutations.
38
| 

