CHAPITRE 3. CONSTRUCTION D'UN SYSTÈME
D'INTÉGRATION DE DONNÉES
ent
|
Attribut
|
EmployeeNumber
|
EmploymentStatus
|
DateofHire
|
Depart
|
|
Department
|
88.0
|
88.0
|
88.0
|
100.0
|
|
DateFirstHired
|
82.0
|
94.0
|
86.0
|
87.0
|
|
FullName
|
86.0
|
86.0
|
88.0
|
91.0
|
|
AssignmentCategory
|
84.0
|
82.0
|
82.0
|
87.0
|
|
OvertimePay2017
|
86.0
|
86.0
|
96.0
|
87.0
|
|
Division
|
86.0
|
84.0
|
86.0
|
86.0
|
|
Gender
|
88.0
|
90.0
|
90.0
|
91.0
|
|
GrossPayReceived2017
|
74.0
|
78.0
|
78.0
|
81.0
|
|
EmployeePositionTitle
|
83.0
|
83.0
|
85.0
|
88.0
|
|
PositionUnderFilled
|
77.0
|
81.0
|
79.0
|
82.0
|
|
CurrentAnnualSalary
|
83.0
|
75.0
|
79.0
|
80.0
|
|
Attribut
|
State
|
DOB
|
MaritalDesc
|
ReasonForTerm
|
EmployeeName
|
Age
|
RaceDesc
|
|
Department
|
91.0
|
89.0
|
90.0
|
82.0
|
87.0
|
87.0
|
92.0
|
|
DateFirstHired
|
85.0
|
86.0
|
82.0
|
83.0
|
83.0
|
84.0
|
87.0
|
|
FullName
|
86.0
|
86.0
|
88.0
|
91.0
|
97.0
|
81.0
|
|
|
AssignmentCategory
|
81.0
|
84.0
|
78.0
|
81.0
|
81.0
|
84.0
|
85.0
|
|
OvertimePay2017
|
85.0
|
86.0
|
80.0
|
85.0
|
85.0
|
92.0
|
87.0
|
|
Division
|
89.0
|
93.0
|
90.0
|
80.0
|
85.0
|
85.0
|
88.0
|
|
Gender
|
93.0
|
90.0
|
86.0
|
87.0
|
89.0
|
94.0
|
95.0
|
|
GrossPayReceived2017
|
79.0
|
78.0
|
76.0
|
77.0
|
75.0
|
80.0
|
81.0
|
|
EmployeePositionTitle
|
84.0
|
85.0
|
79.0
|
82.0
|
84.0
|
87.0
|
84.0
|
|
PositionUnderFilled
|
80.0
|
81.0
|
77.0
|
78.0
|
78.0
|
79.0
|
80.0
|
|
CurrentAnnualSalary
|
78.0
|
79.0
|
77.0
|
80.0
|
78.0
|
81.0
|
80.0
|
TABLE 3.1 - Les valeurs de similarite par
wrinkler-jarro
Les trois tables affichent les distances de similarité
calculées par wrinkler-jaro sur 2 sources de données par
sélectionner leurs attributs, dans le but d'évaluer la
performance de cet algorithme dans notre algorithme de méditer
[Algorithme de médiateur, algorithme 7] nous utilisons la matrice de
confusion.
Matrice de confusion
La matrice de confusion est un sommaire pour prédire
les résultats d'une performance pour un algorithme, elle contient les
valeurs de quatre classifications :[22]
-- les vrais positifs VP :sont les valeurs correctes toutes les
valeurs,
-- les vrais négatifs VN : sont les valeurs incorrectes
mais en posant comme des valides valeurs, -- les faux positifs FP : ce sont les
valeurs qui sont incorrectes et considèrent comme des incorrectes
valeurs,
49
CHAPITRE 3. CONSTRUCTION D'UN SYSTÈME
D'INTÉGRATION DE DONNÉES
-- les faux négatifs FN : sont les valeurs incorrectes
mais en considérant comme des valeurs correctes.
Selon les trois tables précidentes nous produisons la
matrice de confusion et calculer leur matrice de classifications.
Nous basons dans notre algorithme une expression qui s'agit de
poser que les deux attributs sont simulés sémantiquement ou non
par presise si la distance de wrinkler-jarro supérieur au
80.7
Pour calculer les quatre valeurs VP,VN,FP,FN nous utilisons le
langage R pour donne des résultats bien présises, le
logiciel R utilise la librarie scikit-learn qui ayant la
fonction de calculer la matrice de confusion prédéfinit nous
trouvons comme suit :
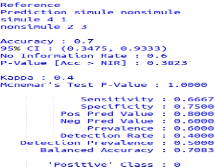
FIGURE 3.9 - Résultats de la matrice de
confusion par R
la figure3.9affiche les résultats de matrice de
confusion avec des valeurs très importantes sur la performance de notre
algorithme, la valeur Accuracy c'est-à-dire quelles sont les cas ou
l'algorithme travaille dans la manière correcte, dans notre algorithme
nous avons la valeur 0.70 qui donne 70%.
Comparaison avec dictionnaire de
données
Le dictionnaire de données se produit par extraction
des ontologies pour chaque source de données et de prendre des synonymes
parmi Word Net, nous utilisons ce dictionnaire dans notre algorithme comme un
autre cas dans la fusion si les techniques de rapprochement ne travaillent
pas.
Nous étudions le cas d'utilisation de dictionnaire de
données, la fonction principale dans l'algorithme c'est l'obtention des
synonymes corrects parmi les attributs de notre source de données, pour
calculer sa performance.
50
| 

