|
Dédicaces
A ma famille :
A mon épouse Catherine MIANDA BILE
A mon fils Gabriel ASSASSE BILE
A ma fille Joëlle MANYONGA BILE
Remerciements
Je tiens tout d'abord à remercier l'Ecole
Supérieure des Métiers d'Informatique et de Commerce sans
laquelle ce mémoire n'aurait jamais vu le jour.
Je remercie également mon directeur Monsieur le
Professeur Simon NTUMBA de l'Université de Kinshasa pour son orientation
et sa disponibilité, qui m'ont permis de franchir des multiples
obstacles et d'atteindre l'objectif initial.
Merci en particulier à mon co-directeur Monsieur Jean
PUKUTA MAMBUKU le Secrétaire Général de l'Ecole
Supérieure des Métiers d'Informatique et de Commerce pour son
encadrement, son soutien et son influence plus que positive pendant toute la
durée de ce mémoire.
Mes remerciements à tout le corps enseignant de l'Ecole
Supérieure des Métiers d'Informatique et de Commerce pour la
formation donnée au courant du cycle de licence, sans laquelle la
gestation de ce mémoire aurait été impossible.
Merci à Monsieur Jean Jacques MBULU pour ses multiples
conseils et son assistance inégalés au cours de notre
formation.
Je remercie de même mes collègues pour leur
collaboration et assistance qui ont fait de nous tous ce que nous sommes
aujourd'hui. Mes remerciements en particulier à Daniel OLUEMBO OKENDE,
Jhaunel MASIA MANGALA, Joselly PIALOU, Erick MUANDA DEKO, Jules MUSONGIELA
MULEMBWE, Christian DIFUMBA WETSHI, Sami YAKAWETU NZEMBA, Luc ABWASSAMBWA
YOGOSI, Avi DIAFWANA SAWA-YIMBI, Hans NGOMA NZITA.
Je ne saurais ne pas remercier très profondément
Maître Papi OKOTA DJELO pour sa disponibilité, sa
compréhension et son orientation sans lesquelles la réalisation
de ce mémoire n'était qu'herbe morte.
Merci également à tous ceux que je ne cite pas
ici mais qui ont participé de près ou de loin à cette
tâche et qui ont de ce fait contribué à sa
réussite.
Merci enfin à Catherine MIANDA pour tout ce que tu
m'apportes au quotidien, pour ta patience et ton soutien pendant cette
période, tant physique, morale que spirituel et pour tout le reste
...
Liste des
abréviations et sigles
ACID : Atomicité, Cohérence, Isolationet
Durabilité
AGB1 : Agent de Bureau de première classe
AGB2 : Agent de Bureau de deuxième classe
ANSI : Amercan National Standard Institute
APEX : Application Express
APJ : Agent de la Police Judiciaire
ATB1 : Attaché de Bureau de première
classe
ATB2 : Attaché de Bureau de deuxième classe
BD : Base de Données
CENTOS : Community Enterprise Operating System
DBA : DataBase Administrator
ESMICOM : Ecole Supérieure des Métiers
d'Informatique et de Commerce
IBM : International Business Machines
IDE : Environnement de Développement
Intégré
IPJ : Inspecteur de la Police Judiciaire
LDD : Langage de Description de Données
LMD : Langage de Manipulation de Données
MP : Ministère Public
OLAP : online analytical processing
OMP : Officier du Ministère Public
OPJ : Officer de la Police Judiciaire
PG : Parquet Général
PGA : Program Global Area
PGI : Parquet de Grande Instance
PGR : Parquet Général de la République
PL/SQL : Procedural Language / Structured Query
Language
PROREP : Procureur de la République
PSC : Parquet Secondaire
PV : Procès-Verbal
RAC : Real Application Cluster
RAP : Registre des Autres Parquets
RAT : Registre des Amendes Transactionnelles
RDC : République Démocratique du Congo
RDP : Registre de Détention Préventive
RFNI : Registre des Faits Non-Infractionnels
RI : Registre d'Informations
RMP : Registre du Ministère Public
RMPED : Registre du Ministère Public de l'Enfance
Déliquante
ROS : Registre des Objets Saisis
ROWA : Read-One/Write
All
ROWAA : Read-One/Write All Available
RSI : Relational Software Inc
RT : Registre de Tutelle
SDL : Software Development Laboratories
SGA : System Global Area
SGBD : Système de Gestion de Bases de Données
SGBD-RO : SGBD Relationnel Objet
SGBDO : SGBD Objet
SGBDR : SGBD Relationnel
SGBDR : SGBD Réparti
SQL : Structured Query Language
UML : Unified Modeling Language
UNIKIN : Université de Kinshasa
VPN : Virtual Private Network
XML : eXtensible Markup Language
Liste des figures
Figure 1. Conception d'une base de données répartie
: Approche ascendante
13
Figure 2. Conception d'une base de données répartie
: Approche descendante
13
Figure 3. Architecture d'une base de données
répartie (ANSI-SPARC)
14
Figure 4. Structure de stockage d'Oracle
26
Figure 5. Relation entre structure physique et structure logique
d'Oracle
27
Figure 6. Une instance Oracle
27
Figure 7. Organisation de l'Ordre judiciaire du Parquet congolais
39
Figure 8. Organigramme du Parquet de Grande Instance
40
Figure 9. Le graphe ordonné du projet
52
Figure 10. Le graphe complet du projet
53
Figure 11. Diagramme de flux d'informations
57
Figure 12. Diagramme de classe d'analyse
61
Figure 13. Diagramme de classe de conception
64
Figure 14.Aperçu du réseau privé virtuel
dans le terminal Linux
82
Figure 15. Aperçu des tables sous SQLDevelopper
83
Figure 16.Aperçu des vues sous SQLDevelopper
83
Figure 17. Aperçu de la table Parquet sous Oracle Apex
84
Figure 18. Aperçu de la vue Personne_Physique sous Oracle
Apex
84
Liste des tableaux
Tableau 1. Chronologie des versions d'Oracle database.
24
Tableau 2. Types de vues
34
Tableau 3. Liste de phases et tâches du projet
51
Tableau 4. Dictionnaire des données
63
INTRODUCTION GENERALE
1. Problématique
L'ordre judiciaire Congolais est constitué, à
chaque niveau de sa hiérarchie, des juridictions dont dépendent
des parquets.
Le parquet de grande instance près le tribunal de
grande instance comprend un secrétariat lui permettant d'accomplir sa
mission de ministère public dans la gestion des dossiers judiciaires.
Le secrétariat est le pivot moteur autour duquel
s'articulent toutes les activités du parquet, divisé en quatre
section chacune avec un rôle bien spécifique, ces dernières
détiennent des registres permettant de conserver les données
inhérentes aux dossiers judiciaires pour le bon fonctionnement du
parquet.
Certaines données généralement
confidentielles doivent être transmises ou partagées sans
incohérence entre les sections internes au parquet ou entre
différents parquets dans le délai prescrit.
En observant ce fonctionnement, par rapport à la
gestion des dossiers judiciaires, nos préoccupations sont les
suivantes :
· la gestion manuelle des données est
efficace ?
· L'accès aux données est-elle
performante ?
· N'y aurait-il pas risque de redondances voire
incohérences de données ?
· Quel serait niveau de partage et de
disponibilité des données ?
· Les données sont-elles réellement fiables
et sécurisées ?
Voilà autant des préoccupations aux quelles
notre mémoire tentera de répondre.
2. Hypothèse
Au regard de la problématique posée ci-haut,
nous osons croire que la mise en place d'une base de données
répartie permettra :
· une gestion efficace des données relatives aux
dossiers judiciaires ;
· une amélioration du partage des
données ;
· une disponibilité des données
acceptable ;
· un accroissement des performances à
l'accès aux données ;
· une amélioration de la cohérence et de la
sécurité des données.
3. Choix et intérêt du
sujet
Le parquet de grande instance constitue l'une des
pièces tournantes du ministère de justice qui, dépendant
du ministère de l'intérieur, joue un rôle
prépondérant dans la sécurité des personnes et de
leurs biens.
Cette étude serait en cela notre modeste contribution
à l'amélioration du fonctionnement du parquet de grande instance
et indirectement des performances de toutes les branches dépendantes du
ministère de l'intérieur et des affaires coutumières que
sont : le ministère de justice, l'Agence Nationale des
Renseignements et la Police Nationale Congolaise.
4. Délimitation du sujet
Du point de vue spatial, notre travail concerne les parquets
de grande instance de la ville de Kinshasa.
Sur le plan temporel, il couvre la période de notre
année académique soit du mois de septembre 2014 au mois de
juillet 2015.
Notre mémoire ne traite ni des juridictions dont
dépendent ces parquets (Tribunaux de grande instance), ni des parquets
généraux.
Du point de vue métier, notre mémoire se limite
à la mise en place d'une base de données répartie et n'est
donc pas le développement d'une application logicielle.
5. Méthodologie
Notre mémoire a été mise en oeuvre
grâce aux techniques et méthodes suivantes :
a) Techniques :
§ La revue de la
littérature
Elle a consisté à :
* collecter la documentation susceptible de fournir des
informations pertinentes afin d'éclairer notre démarche pour
l'atteinte des objectifs visés ;
* voir ce qui a été fait pour les sujets
similaires et évaluer les mérites des uns et des autres ;
* s'inspirer des études et recherches analogues afin de
mettre en place une étude originale.
Les recherches ont été menées dans
plusieurs centres d'informations documentaires, dont le Centre de Documentation
de l'Enseignement Supérieur, Universitaire et de Recherche à
Kinshasa (cedesurk) et la Bibliothèque Urbaine de Kinshasa (BUK).
§ Les entretiens et
interviews
Afin de comprendre le fonctionnement des parquets et des
juridictions de Kinshasa, nous avons eu des entretiens et des interviews avec
des personnes travaillant dans ce domaine.
C'est ainsi que Maître Papi OKOTA DJELO nous a
porté main forte en disposant de son temps et de ses connaissances pour
nous éclairer sur ce vaste domaine de droits.
b) Méthodes :
§ Méthode descriptive
Elle nous a permis, sur base de la description faite sur le
parquet de grande instance, de mieux comprendre et cerner les points
nécessaires qui concernent son organisation et son fonctionnement.
§ Méthode analytique
Elle nous a permis de bien comprendre et expliquer les
différents problèmes liés aux dossiers judiciaires.
§ Méthode Pert
Elle nous a permis de découper, estimer, planifier et
évaluer notre projet.
§ La méthode de
modélisation.
Nous nous sommes inspirés des étapes du
Processus Unifié avec l'utilisation du langage de modélisation
UML pour modéliser notre solution.
6. Subdivision du travail
Ce mémoire est structuré en six chapitres,
hormis l'introduction et la conclusion générales.
· Le premier chapitre présente les notions
générales sur les bases de données
réparties ;
· le deuxième chapitre présente les bases
de données réparties sous Oracle ;
· le troisième chapitreprésente les
parquets de grande instance de la ville de Kinshasa ;
· le quatrième chapitre présente la
gestiondu projet ;
· le cinquième chapitre présente l'analyse
et la conception du futur système informatisé ;
· le sixième chapitre présente son
implémentation sous Oracle dans sa version 11g.
7. Difficultés
rencontrées
Dans le cadre de notre étude nous avons eu à
faire face à des multiples contraintes :
· difficulté d'accès aux exemplaires des
données relatives aux dossiers judiciaires des parquets ;
· lors des entretiens et interviews, le manque de
maîtrise des termes juridiques engendrait au départ des
imprécisions et confusions entrainant de la sorte un retard à
l'avancement de notre mémoire;
· familiarisation au langage UML pour la
modélisation des bases de données, alors que nous étions
habitués à la méthode Merise ;
· familiarisation au SGBD Oracle et à la
plate-forme Linux avec CentOS.
CHAPITRE I. GENERALITES SUR
LES BASES DE DONNEES REPARTIES
Introduction
Dans ce chapitre seront traitées les notions
fondamentales d'une base de données répartie. Une série
des définitions des termes inhérents et complémentaires
à la base de données répartie sera abordée, suivie
de la présentation des avantages, inconvénients et des
propriétés requises d'une base de données répartie.
Y sera présentée ensuite la méthode de conception
descendante de base de données distribuée, en vue de rester dans
le contexte de notre mémoire, l'architecture d'une base de
données répartie et les techniques de fragmentation, d'allocation
et de réplication y seront présentées. La
réplication sera présentée avec un accent sur les
améliorations qu'elle apporte par rapport à la
disponibilité des données, l'autonomie locale et à la
performance globale du système, sans toutes fois oublier de mentionner
la difficulté qu'elle introduit pour le maintien de la cohérence
transactionnelle.
Le développement de l'informatique, la puissance des
micro-ordinateurs et les performances des réseaux des
télécommunications depuis ces dernières décennies
ont permis la gestion des grands volumes de données physiquement
dispersées dans plusieurs sites avec une certaine disponibilité
et une certaine performance remédiant ainsi aux problèmes
liés à la centralisation des données, et ce en
répartissant les ressources informatiques tout en préservant leur
cohérence.
Les bases de données réparties sont donc un
moyen rassurant que les données seront toujours rapidement disponibles
contrairement à une approche centralisée, mais ne restent pas
sans failles.
I.1. Définitions
I.2.1. Base de données
répartie
Une base de données répartie est une base de
données logique dont les données sont distribuées sur
plusieurs SGBD (sites) et visibles comme un tout. Chaque site peut être
une base de donnée centralisée, une base de données
parallèle ou encore une base de données répartie qui
stocke une portion de la base de données.
Une base de données répartie présente les
caractéristiques suivantes :
Ø Plusieurs bases de données sur plusieurs
sites, mais une seule BD « logique ».
Ø Les sites (SGBD) communiquent via le réseau
informatique et sont faiblement couplés.
Ø Chaque site contient une portion de la base de
données répartie, peut exécuter des transactions locales
et participer à l'exécution de transactions globales
Ø La répartition affecte les données, les
traitements, les contrôles
Ø La topologie des BD réparties est semblable
à celles des réseaux : anneau, étoile, arbre, ...
Une base de données répartie est
gérée par un SGBD réparti.
I.2.2. SGBD réparti
SGBD réparti est un système gérant une
collection de BD logiquement reliées, réparties sur
différents sites en fournissant un moyen d'accès rendant la
répartition (distribution) transparente à l'utilisateur.
I.2. Quelques définitions complémentaires
Un système de bases
de données réparties ne doit donc en aucun cas être
confondu avec un système dans lequel les bases de données sont
accessibles à distance. Il ne doit non plus être confondu avec une
BD centralisée, une multibase, une BD fédérée ou
une BD parallèle.
I.3.1. Base de données
centralisée
Une base de données centralisée est
gérée par un seul SGBD, est stockée dans sa
totalité à un emplacement physique unique et ses divers
traitements sont confiés à une seule et même unité
de traitement. Par opposition, une base de données répartie
(distribuée) est gérée par plusieurs processeurs, sites ou
SGBD.
I.3.2. Multibase
Dans une multibase, plusieurs bases de données
(hétérogènes ou non) inter opèrent avec une
application via un langage commun et sans modèle commun.
I.3.3. Base de données
fédérée
Dans une base de données fédérée,
plusieurs bases de données hétérogènes sont
accédées comme une seule via une vue commune.
I.3.4. Traitement
distribué
Il est essentiel de distinguer un SGBD distribué du
traitement distribué. Traitement distribué : Une base de
données centralisée accessible par le biais d'un réseau
informatique.
I.3.5. SGBD parallèle
Nous marquons également une distinction entre un SGBD
distribué et un SGBD parallèle. SGBD parallèle: Un SGBD
fonctionnant sur plusieurs processeurs et plusieurs disques, conçu pour
exécuter des opérations autant en parallèle que possible,
de façon à améliorer les performances. Les SGBD
parallèles associent plusieurs machines plus modestes pour atteindre le
même débit qu'une seule machine plus ambitieuse, offrant en outre
une meilleure évolutivité et une meilleure fiabilité que
les SGBD monoprocesseurs.
I.3. Avantages et inconvénients d'une base de
données repartie
I.4.1. Avantages
· Reflète une structure organisationnelle :
Amélioration du partage et de l'autonomie locale
· Disponibilité améliorée : la
réplication de données avec placement (allocation)
améliore la disponibilité d'une base de données
répartie, une panne dans un site d'un SGBDR ou une rupture de ligne de
communication isolant un ou quelques sites n'immobilise pas l'ensemble du
système
· Performances améliorées : l'accès
concurrent à plusieurs copies de données réparties sur
différents sites améliore le temps de réponse et favorise
un équilibrage de charge totale du système. les services de
l'unité centrale et des entrées sorties se trouvent nettement
réduite par rapport à un SGBD centralisé.
· Économie : l'ajout de stations de travail
à un réseau est nettement moins coûteux que l'extension
d'un gros système centralisé.
· Passage à l'échelle :
Facilité d'accroissement (scalability), l'extension du système
existant se fait de manière transparente sans perturbations.
I.4.2. Inconvénients
· Complexité : une base de données
répartie masque sa nature répartie aux yeux des utilisateurs et
fournit un niveau acceptable de performances, de fiabilité et de
disponibilité
· Sécurité: Dans un système
centralisé, l'accès aux données est d'un contrôle
facile, tandis que dans un système distribué, non seulement il
faut contrôler l'accès aux données dupliquées dans
des emplacements multiples, mais le réseau lui-même doit
être sécurisé.
· Contrôle d'intégrité de
données plus difficile : L'intégrité de base de
données fait référence à la validité et
à la cohérence des données stockées
· Complexité plus grande du design de bases de
données : le design d'une base de données distribuée doit
prendre en considération la fragmentation des données,
l'allocation des fragments à des sites spécifiques et la
réplication des données.
· Coût : la distribution entraîne des
coûts supplémentaires en termes de communication, et en gestion
des communications (hardware et software à installer pour gérer
les communications et la distribution).
I.4. Les propriétés requises d'une base de
données repartie
Une base de données répartie doit assurer
plusieurs propriétés pour être considérée
comme performante. Nous ne citerons que celles que nous trouvons les plus
connexes à notre contexte d'études : la transparence, le passage
à l'échelle, la disponibilité et l'autonomie.
I.5.1. Transparence
La transparence permet de cacher aux utilisateurs les
détails techniques et organisationnels d'une base de données
répartie. Ceci rend plus simple, le développement des
applications mais aussi leur maintenance évolutive ou corrective.
La transparence a plusieurs niveaux :
· accès : cacher l'organisation logique des
données et les moyens d'accès à une donnée;
· localisation : l'emplacement d'une donnée du
système n'a pas à être connu ;
· migration : une donnée peut changer
d'emplacement sans que cela ne soit aperçu ;
· relocalisation : cacher le fait qu'une donnée
peut changer d'emplacement au moment où elle est utilisée ;
· réplication : les données sont
dupliquées mais les utilisateurs n'ont aucune connaissance de cela ;
· panne : si un noeud (site) est en panne, l'utilisateur
ne doit pas s'en rendre compte et encore moins de sa reprise après panne
;
· concurrence : rendre invisible le fait qu'une
donnée peut être partagée ou sollicitée
simultanément par plusieurs utilisateurs.
I.5.2. Passage à
l'échelle
Le concept de passage à l'échelle désigne
la capacité d'un système à continuer à
délivrer avec un temps de réponse constant un service même
si le nombre de clients ou de données augmente de manière
importante. Le passage à l'échelle peut être mesuré
avec au moins trois dimensions :
· le nombre d'utilisateurs et/ou de processus (passage
à l'échelle en taille) ;
· la distance maximale physique qui sépare les
noeuds ou ressources du système (passage à l'échelle
géographique) ;
· le nombre de domaines administratifs (passage à
l'échelle administrative).
I.5.3. Disponibilité
Un système est dit disponible s'il est en mesure de
délivrer correctement le ou les services de manière conforme
à sa spécification. Pour rendre un système disponible, il
faut donc le rendre capable de faire face à tout obstacle qui peut
compromettre son bon fonctionnement. En effet, l'indisponibilité d'un
système peut être causée par plusieurs sources parmi
lesquelles nous pouvons citer :
· les pannes qui sont des conditions ou
évènements accidentels empêchant le système, ou un
de ses composants, de fonctionner de manière conforme à sa
spécification ;
· les surcharges qui sont des sollicitations excessives
d'une ressource du système entraînant sa congestion et la
dégradation des performances du système ;
· les attaques de sécurité qui sont des
tentatives délibérées pour perturber le fonctionnement du
système, engendrant des pertes de données et de cohérences
ou l'arrêt du système.
I.5.4. Autonomie
Un système ou un composant est dit autonome si son
fonctionnement ou son intégration dans un système existant ne
nécessite aucune modification des composants du système
hôte. L'autonomie des composants d'un système favorise
l'adaptabilité, l'extensibilité et la réutilisation des
ressources de ce système.
I.5. Conception d'une base de données repartie
Une base de données répartie reprend les
mêmes principes que ceux d'une base de données centralisée
mais en étendant les techniques existantes ou en proposant certains
concepts nouveaux qui sont particuliers à la répartition des
données.
Il existe deux approches de conception d'une base de
données réparties, pour rester dans le contexte de ce
mémoire seule l'approche descendante sera
détaillée :
I.6.1. Approche ascendante (BD
Fédérées, Bottom up design)
BD
fédérées
BD
Locale 1
BD
Locale 2
BD
Locale 3
Figure 1. Conception d'une base
de données répartie : Approche ascendante
Dans cette approche on part de l'existant (Figure 1).
L'objectif principal est d'intégrer les bases locales dans schéma
global. Elle nécessite une consolidation, uniformisation
c'est-à-dire :
· Réconciliation sémantique
· Identifier les données semblables
· Accorder leurs types, gérer leur
cohérence...
· Interfacer ou adapter les SGBD...
I.6.2. Approche descendante (BD
Réparties, Top down design) :
BD
réparties
BD
Locale 1
BD
Locale 2
BD
Locale 3
Figure 2. Conception d'une base
de données répartie : Approche descendante
Dans cette approche on part du schéma global en le
scindant en schémas locaux (Figure 2).Les points suivants sont
présents dans cette approche :
· Conception du schéma conceptuel global
· Distribution pour obtenir des schémas
conceptuels locaux
· Les tables du schéma global sont
fragmentées (processus de fragmentation)
· Les fragments sont donc placés sur des sites
(processus d'allocation)
1. Conception du schéma conceptuel
globale
On commence par définir un schéma conceptuel
global de la base de données répartie, puis on distribue sur les
différents sites en des schémas conceptuels locaux
Figure 3. Architecture d'une
base de données répartie (ANSI-SPARC)
(Figure 3).
Schéma
de mapping local 1
Schéma
Conceptuel local 1
Schéma
Interne local 1
BD1
Schéma
de mapping local n
Schéma
Conceptuel local n
Schéma
Interne local n
BDn
Schéma
de mapping local 2
Schéma
Conceptuel local 2
Schéma
Interne local 2
BD2
. . .
. . .
. . .
. . .
Schéma
de fragmentation
Schéma
d'
allocation
Schéma
Externe
Global n
Schéma
Externe
Global 1
Schéma
Externe
Global 2
. . .
Schéma
Conceptuel
Global
La répartition se fait donc en deux étapes, en
première étape la fragmentation, et endeuxième
étape l'allocation de ces fragments aux sites.
La répartition d'une base de données intervient
dans les trois niveaux de son architecture en plus de la répartition
physique des données :
· Niveau externe: les vues sont distribuées sur
les sites utilisateurs.
· Niveau conceptuel: le schéma conceptuel des
données est associé, par l'intermédiaire du schéma
de répartition (lui-même décomposé en un
schéma de fragmentation et un schéma d'allocation), aux
schémas locaux qui sont réparties sur plusieurs sites, les sites
physiques.
· Niveau interne : le schéma interne global n'a
pas d'existence réelle mais fait place à des schémas
internes locaux répartis sur différents sites.
2. Processus de fragmentation ou
partitionnement
a)
Définition
La fragmentation (le partitionnement) est le processus de
décomposition d'une base de données logique en un ensemble de
"sous" bases de données. Cette décomposition doit être sans
perte d'information.
b) Les
règles de fragmentation
Les règles à appliquer sont :
· La complétude : pour toute donnée d'une
relation R, il existe un fragment Ri de la relationR qui possède cette
donnée.
· La reconstruction : pour toute relation
décomposée en un ensemble de fragments Ri, ilexiste une
opération de reconstruction. Pour les fragmentations horizontales,
l'opération dereconstruction est l'une union. Pour les fragmentations
verticales c'est la jointure.
· La Disjonction : assure que les fragments d'une
relation sont disjoints deux à deux.
c) Techniques de
Fragmentation
Fragmentation horizontale
Décomposition de la table en groupes de lignes.
Exemple
Table Client (NCL, Nom, Ville)
Il existe deux types de fragmentation horizontale :
· Primaire
· Dérivée
Fragmentation horizontale primaire
La Fragmentation horizontale est définie par
l'opération de sélection
Exemple
Client (NCL, Nom, Ville) peut être fragmenté :
Client1= SELECT * FROM Client WHERE Ville =
«Kinshasa»
Client2= SELECT * FROM Client WHERE Ville <>
«Kinshasa»
Reconstruction de la relation initiale :
Client = Client1 ? Client2
Fragmentation horizontale
dérivée
La Fragmentation d'une table en fonction des fragments
horizontaux d'une autre table. (Cette fragmentation est obtenue dans le cas de
lien père-fils)
Exemple
Commande (NCL, N°Produit, Date, Qte,
N°Représentant)
Commande1= SELECT * FROM Commande
WHERE NCL IN
(SELECT NCL FROM CLIENT1)
Commande2= SELECT * FROM Commande
WHERE NCL IN
(SELECT NCL FROM CLIENT2)
Reconstruction de la relation initiale :
Commande = Commande1 ? Commande2
Fragmentation verticale
La fragmentation verticale est obtenue par
décomposition de la table en groupes de colonnes.Fragmentation verticale
est définie par l'opération de projection.
Table Client (N°Client, Nom, Sexe, Ville)
Exemple
Client (N°Client, Nom, Sexe, Ville) peut être
fragmentée :
Client1= SELECT N°Client, Nom FROM Client
Client2= SELECT N°Client, Sexe, Ville FROM Client
Reconstruction de la relation initiale :
Client = Client1 join Client2
Fragmentation mixte
La Fragmentation mixte résulte de l'application
successive d'opérations de fragmentation horizontale et de fragmentation
verticale.
Avantages et inconvénients de la fragmentation
Avantages
· Réduction des accès non pertinents
· Parallélisme intra-requête
· Combinée avec d'autres techniques d'optimisation
(index, vues matérialisées, etc.)
Inconvénients
· génération des fragments disjoints est un
problème difficile
· Accès multiples aux fragments nécessitent
des opérations de jointure et d'union
· La migration des données (conséquence
d'une mauvaise fragmentation horizontale)
3. Processus d'allocation des fragments
(Le placement)
L'affectation des fragments sur les sites est
décidée en fonction de l'origine prévue des requêtes
qui ont servi à la fragmentation. Le but est de placer les fragments
pour minimiser les transferts de données entre les sites. L'allocation
peut se faire avec réplication ou sans réplication. Sachant que
la réplication favorise les performances des requêtes et augmente
la disponibilité des données, mais est coûteuse en mise
à jour des différents fragments. (Utilisation des triggers «
Déclencheurs » pour détecter des mises à jour)
a) Problème
d'allocation
Entrées:
F = {F1, F2, ..., Fn} - ensemble de fragments
S = {S1, S2, ..., Sm} - ensemble de sites
Q = {Q1, Q2, ..., Ql} - ensemble de requêtes
Le problème d'allocation consiste à trouver une
distribution optimale de F sur S afin d'améliorer la performance (temps
de réponse, données transférées, etc.)
b) Contraintes
Stockage, équilibrage de la charge entre les sites
c) Allocation de
fragments aux sites
· Réplication totale : Chaque fragment est
répliqué sur tous les sites
· Réplication partielle : chaque fragment est
répliqué sur quelques sites
· Aucune réplication : Chaque fragment
réside dans un et un seul site.
4. Gestion de transaction
Une transaction peut être considérée comme
une unité de traitement cohérente et fiable. Une transaction
prend un état d'une base de données, effectue une ou des actions
sur elle et génère un autre état de celle-ci. Les actions
effectuées sont des opérations de lecture ou d'écriture
sur les données de la base. Par conséquent, une transaction peut
être définie comme étant une séquence
d'opérations de lecture et d'écriture sur une base de
données, qui termine en étant soit validée soit
abandonnée.
La notion de cohérence recouvre plusieurs
dimensions :
· Du point de vue des demandes d'accès, il s'agit
de gérer l'exécution concurrente de plusieurs transactions sans
que les mises à jour d'une transaction ne soient visibles avant sa
validation, on parle de cohérence transactionnelle ou isolation.
· Du point de vue des données
répliquées, il consiste à garantir que toutes les copies
d'une même donnée soient identiques, on parle de cohérence
mutuelle.
La cohérence transactionnelle est assurée
à travers quatre propriétés, résumées sous
le vocable ACID :
· Atomicité : toutes les opérations de la
transaction sont exécutées ou aucune ne l'est. C'est la loi du
tout ou rien.
· Cohérence : La cohérence signifie que la
transaction doit être correcte du point de vue de l'utilisateur,
c'est-à-dire maintenir les invariants de la base ou contraintes
d'intégrité. Une transaction cohérente transforme une base
de données cohérente en une base de données
cohérente. En cas de non succès, l'état cohérent
initial des données doit être restauré.
· Isolation : elle assure qu'une transaction voit
toujours un état cohérent de la base de données. Pour ce
faire, les modifications effectuées par une transaction ne peuvent
être visibles aux transactions concurrentes qu'après leur
validation. En outre, une transaction a une opération marquant son
début (begin transaction) et une autre indiquant sa fin (end
transaction). Si la transaction s'est bien déroulée, la
transaction est terminée par une validation (commit), dans le cas
contraire, la transaction est annulée (rollback, abort).
· Durabilité : une fois que la transaction est
validée, ses modifications sont persistantes et ne peuvent être
défaites.
Les propriétés ACID sont très difficiles
à maintenir car elles représentent un frein aux performances du
système.
Si une transaction contient au moins une opération qui
effectue des modifications sur les données de la base, la transaction
est dite transaction d'écriture ou de mise à jour. Si toutes les
opérations ne font que des lectures sur les données de la base,
la transaction est dite transaction de lecture.
Un autre classement peut être fait à partir de la
durée de la transaction. Avec ce critère, une transaction peut
être classée on-line ou batch. Les transactions on-line,
communément appelées transactions courtes, sont
caractérisées par un temps de réponse relativement court
(quelques secondes) et accèdent à une faible portion des
données.Les transactions batch, appelées transactions longues,
peuvent prendre plus de temps pour s'exécuter (minutes, heures, jours)
et manipulent une très grande quantité des données.
5. Processus de réplication
a. Définition
La réplication consiste à copier les
informations d'une base de données sur une autre.
b. Motivation
La motivation principale de la réplication est la
disponibilité et la performance pour les bases de données.
c. Gestion de la réplication
Dans le contexte de notre mémoire, la gestion de la
réplication sera représentée suivant quatre concepts
à savoir la distribution ou placement des données, la
configuration (rôle) des répliques, la stratégie de la
propagation des mises à jour et enfin la stratégie de maintien de
la cohérence.
· Placementdes données : Les données
peuvent être répliquées partiellement ou totalement. La
réplication totale stocke entièrement la base de données
sur chaque site. La réplication partielle nécessite une partition
des données en fragments. Chaque fragment est stocké par la suite
sur plusieurs noeuds.
· Configuration des répliques : Les mises
à jour peuvent être effectuées sur une seule
réplique (appelée maître) avant d'être
propagées vers les autres (esclaves). Une telle configuration est
appelée mono-maître (primary copy) car les autres répliques
ne sont utilisées que pour les requêtes de lecture seule, ce qui
améliore les performances des opérations de lecture seule. Une
approche multi-maîtres (update anywhere), dans laquelle les mises
à jour peuvent être exécutées sur n'importe quelle
réplique, permet d'améliorer aussi bien les performances des
transactions de lecture seule que d'écriture.
· Stratégies de rafraîchissement
(propagation) : Elles définissent comment la propagation va
être effectuée en précisant le contenu à propager,
le modèle de communication utilisé, l'initiateur et le moment du
déclenchement. Le rafraîchissement est fait grâce à
une transaction appelée transaction de rafraîchissement dont le
contenu peut être les données modifiées (writesets en
anglais) ou le code de la transaction initiale. La caractéristique
principale d'une transaction de rafraîchissement est qu'elle est
déjà exécutée sur au moins une réplique.
· Maintien de la cohérence. : La
cohérence peut être gérée de manière stricte
(réplication synchrone) ou relâchée (réplication
asynchrone). Avec la réplication synchrone, toutes les répliques
sont mises à jour à l'intérieur de la transaction. Cette
approche a l'avantage de garder toutes les copies cohérentes à
chaque instant, mais nécessite que toutes les répliques soient
disponibles et synchronisées au moment de l'exécution de la
transaction (ROWA pour Read-One/ Write-All). Une amélioration de cette
approche est de synchroniser uniquement les répliques disponibles au
moment de l'exécution d'une transaction (ROWAA pour Read-One/
Write-All-Available). La réplication asynchrone est plus souple car une
transaction est d'abord validée sur une seule réplique avant
d'être propagée sur les autres répliques dans une autre
transaction. L'inconvénient de cette approche est que les copies peuvent
diverger. Cette divergence a pour impact de retourner aux utilisateurs des
résultats faux. En effet, il est possible d'effectuer des transactions
de lectures sur des copies pas nécessairement fraîches pour
accélérer l'exécution des transactions de lecture.
Néanmoins, l'obsolescence des copies doit être
contrôlée en fonction des exigences des applications. Par
ailleurs, on peut classer la réplication asynchrone en deux familles :
réplication optimiste et réplication pessimiste. Avec la
réplication pessimiste, les transactions sont ordonnées à
priori avant d'être envoyées sur les répliques en
respectant leurs contraintes conflictuelles. La réplication asynchrone
optimiste autorise l'exécution de plusieurs transactions
simultanément sur plusieurs sites.
d. Avantages de la
réplication
La réplication est largement exploitée en vue
d'améliorer les performances des applicationscomplexes. Plusieurs
avantages plaident pour son adoption :
· La disponibilité : En effet, la duplication des
données augmente la disponibilité. Les utilisateurs et les
applications ont une multitude de chemins d'accès à une
même donnée. Ainsi, si un site devient inaccessible pour une
raison ou pour une autre. Le système peut continuer à
répondre aux requêtes des usagers, en les redirigeant vers un
autre site encore accessible, qui va prendre le relais. Notons que la
redirection est transparente à l'usager.
· La fiabilité : Il est évident que copier
une même donnée sur plusieurs emplacements distants,
réduitconsidérablement la chance qu'elle soit
définitivement perdue. La défaillance d'un site n'impliquepas
l'arrêt du système. Les utilisateurs connectés au site
défaillant sont immédiatement servis par unautre en marche, et
les données stockées dessus sont facilement
récupérables à partir d'un autre emplacement du moment que
les données sont dupliquées sur chaque site.
· Les performances : Dans un système
centralisé caractérisé par une forte charge de travail. La
réplication constitue unealternative incontestable en vue
d'accélérer l'exécution des requêtes utilisateurs.
La réplication offre,en effet, un accès local, rapide à
des données partagées, parce qu'elle équilibre la
répartition desactivités sur plusieurs sites. Certains
utilisateurs peuvent dès lors accéder à plus d'un serveur,
tandisque d'autres utilisateurs accèdent à des serveurs
différents, ce qui restitue des niveaux de performances acceptables sur
tous les serveurs.
· Vues de donnés selon utilisation : Il est devenu
commun que une organisation déploie plusieurs applicatifs qui manipulent
la mêmecollection de données (souvent la même base de
données). En plus de la haute disponibilité, laréplication
permet de créer plusieurs copiés hébergées sur des
sites distincts, ou chaque site seracomplément dédié
à répondre aux requêtes d'un type d'applicatif bien
précis.
· Une autonomie accrue: Dans une infrastructure de
réplication réelle, les sites ne sont pas forcément
liés par un réseau local.Rien n'empêche d'utiliser un
réseau plus étendu comme intranet, VPN, ou même internet.
Dans telcontexte, les ruptures de connexion sont plus que probables, et un
système de réplication basiquedevient dramatiquement inefficace.
Les techniques de réplication notamment celles asynchrones
yremédient, en exploitant le concept de snapshot (copie
instantané), implémenté par plusieursSGBDs. Un
instantané (snapshot) est une copie complète ou partielle
(c'est-à-dire uneréplique) d'une relation cible, prise à
un moment précis et unique. Les instantanés permettent à
desutilisateurs de travailler sur des sous-ensembles d'une base de
données d'entreprise, alors qu'ils sont déconnectés du
serveur de base de données central. Par la suite, dès que la
connexion est rétablie,les utilisateurs synchronisent
(rafraîchissent) leurs instantanés avec le contenu de la base de
données centrale, si nécessaire. Ceci peut signifier que les
instantanés reçoivent les mises à jour issues de labase de
données centrale, mais aussi la base de données centrale
reçoive des mises à jour en provenance des instantanés.
Quelle que soit l'action menée, les données de
l'instantané et de la base de données d'entreprise retrouvent
périodiquement leur cohérence.
e. La haute
performance par la réplication
Bien que l'objectif principal de la réplication soit la
haute disponibilité, la haute performance peutêtre
réalisée en exploitant l'architecture distribuée du
système. Les requêtes des utilisateurs peuventpotentiellement
s'exécuter en parallèle, du fait que les données sont
dupliquées sur plusieurs sites. Les travaux menés dans ce sens
ont essayé de transposer les techniques de parallélisme,
employéesdans les bases de données fragmentées vers les
bases de données répliquées. Le parallélisme
inter-requêtes est la première issue explorée. En effet, la
réplication favorise naturellement ce type du parallélisme. Les
requêtes des usagers sont lancées simultanément sur des
sites distincts, aucuneforme de communication n'est requise, du moment
où la totalité de la base de données est
répliquée sur chaque site. Certes, le parallélisme
inter-requête améliore le débit du système en
servant plus de clients par unité de temps, mais le temps
d'exécution des requêtes individuelles reste intact, les
systèmes recevant des requêtes complexes ne peuvent pas tirer
profit de ce genre du parallélisme.Pour remédier à
ça, le parallélisme intra-requête est introduit.
Typiquement, le parallélisme inter-requête est
implémenté à l'aide d'une couche logicielle sous forme
d'un middleware, qui constitue le seul point d'accès au système
de réplication. Le middleware intercepte les requêtes soumises, et
les transformes en un ensemble de sous-requêtes, qui seront
exécutées parallèlement sur les différents sites,
les résultats locaux seront consolidés pour former le
résultat final.
Conclusion
Une base de données répartie est une collection
de sites connectés par un réseau de communication. Chaque site
est une base de données centralisée qui stocke une portion de la
base de données.
La gestion d'une base de données répartie est
gérée de manière transparente par un SGBD réparti.
Pour améliorer les performances, les données peuvent être
répliquées sur plusieurs sites. La principale motivation de la
réplication des données est l'augmentation de la
disponibilité. En stockant les données critiques sur plusieurs
sites, la base de données répartie peut fonctionner même
si certains sites tombent en panne. Un second avantage de la réplication
consiste à l'amélioration des temps de réponses des
requêtes grâce aux traitements parallèles et un accès
plus facile et rapide des données.
CHAPITRE II. BASES DE
DONNEES REPARTIES SOUS ORACLE
II.1. Introduction
Dans ce chapitre seront présentés les
mécanismes de répartition et de réplication des bases de
données sous Oracle dans le contexte de notre mémoire. Une
présentation d'Oracle et une chronologie des versions seront
abordées, suivie de la présentation de l'architecture d'Oracle,
structure de stockage, structure de mémoire, structure de processus et
structure application et réseau. Y sera présentée ensuite
la sécurisation de la base de de données par le contrôle
d'accès aux données au niveau utilisateur, profil,
privilège et rôle et par la confidentialité des
données au travers de vue. En vue de rester dans le contexte de notre
mémoire, les objectifs de bases de données réparties
liées à la transparence vis-à-vis de la localisation, de
la fragmentation et de la réplication y seront présentés
(lien des bases de données, synonyme, vue, déclencheur,
procédure, la commande copy, snapshot et vue
matérialisée). Enfin une présentation non exhaustive des
différents outils d'administration, de développement et de
configuration réseau fournis par Oracle pour faciliter l'administration
des bases de données aux différents utilisateurs.
Oracle est un système de gestion de bases de
données relationnelles-objet en perpétuelle évolution
à l'exemple de l'informatique et des télécommunications.
Comme nous le verrons, les fonctionnent d'Oracle tendent évolues tout en
respectant les normes de sécurité des données.
II.2. Présentation
d'Oracle
Oracle Corporation, société américaine
située en Californie, développe et commercialise un SGBD et un
ensemble de produits de développement. Oracle a des filiales dans un
grand nombre de pays.
En 1977, Larry Ellison, Bob Miner et Ed Oates fondent la
société Software Development Laboratories (SDL). L'article
d'Edgar Frank Codd (1923-2003), « A Relational Model of Data for Large
Shared Data Banks », Communications of the ACM paru en 1970, fait devenir
le mathématicien et ancien pilote de la RAF durant la Seconde Guerre
mondiale, inventeur du modèle relationnel et de SQL. Les associés
de SDL devinent le potentiel des concepts de Codd et se lancent dans l'aventure
en baptisant leur logiciel « Oracle ». En 1979, SDL devient
Relational Software Inc. (RSI) qui donnera naissance à la
société Oracle Corp. en 1983. La première version du SGBD
s'appelle RSI-1 et utilise SQL. Le tableau suivant résume la chronologie
des versions (Tableau 1).
|
Année
|
Version
|
Brève description
|
|
1979
|
Oracle 2
|
Première version commerciale écrite en
C/assembleur pour Digital - pas de mode transactionnel.
|
|
1983
|
Oracle 3
|
Réécrit en C - verrous.
|
|
1984
|
Oracle 4
|
Portage sur IBM/VM, MVS, PC - transaction (lecture
consistante).
|
|
1986
|
Oracle 5
|
Architecture client-serveur avec SQL*Net - version pour
Apple.
|
|
1988
|
Oracle 6
|
Verrouillage niveau ligne - sauvegarde/restauration - AGL -
PL/SQL.
|
|
1991
|
Oracle 6.1
|
Parallel Server sur DEC.
|
|
1992
|
Oracle 7
|
Contraintes référentielles - procédures
cataloguées - déclencheurs - version Windows en 1995.
|
|
1994
|
|
Serveur de données vidéo.
|
|
1995
|
|
Connexions sur le Web.
|
|
1997
|
Oracle 8
|
Objet-relationnel - partitionnement - LOB - Java.
|
|
1998
|
Oracle 8i
|
i comme Internet, SQLJ - Linux - XML.
|
|
2001
|
Oracle 9i
|
Services Web - serveur d'applications - architectures sans
fil.
|
|
2004
|
Oracle 10g
|
g comme Grid computing (ressources en clusters).
|
|
2007
|
Oracle 11g
|
Auto-configuration.
|
|
2013
|
Oracle 12c
|
c comme Cloud computing
|
Tableau 1. Chronologie des
versions d'Oracle database.
Avec IBM, Oracle a fait un pas vers l'objet en 1997, mais
cette approche ne compte toujours pas parmi les priorités des clients
d'Oracle. L'éditeur met plus en avant ses aspects transactionnels,
décisionnels, de partitionnement et de réplication. Les
technologies liées à Java, bien qu'elles soient largement
présentes sous Oracle9i, ne constituent pas non plus la majeure partie
des applicatifs exploités par les clients d'Oracle.
La version 10g renforce le partage et la coordination des
serveurs en équilibrant les charges afin de mettre à disposition
des ressources réparties (répond au concept de l'informatique
à la demande). Cette idée est déjà connue sous le
nom de « mise en grappe » des serveurs (clustering). Une partie des
fonctions majeures de la version 10g est présente dans la version 9i RAC
(Real Application Cluster).
La version 11g Oracle insiste sur les capacités
d'auto-diagnostic, d'auto-administration et d'auto-configuration pour optimiser
la gestion de la mémoire et pour pouvoir faire remonter des alertes de
dysfonctionnement. En raison des exigences en matière de
traçabilité et du désir de capacité de
décision (datamining), la quantité de données
gérées par les SGBD triplant tous les deux ans, 11g met aussi
l'accent sur la capacité à optimiser le stockage.
Oracle Database est disponible en plusieurs versions
qualifiées de « Standard » ou « Enterprise ». Le nom
du produit monoposte pour Windows ou Linux est Personal Oracle.
Plusieurs options permettent de renforcer les performances, la
sécurité, le traitement transactionnel et le datawarehouse.
Citons Oracle Data Guard, Oracle Real Application Clusters, Oracle
Partitioning, Oracle Advanced Security, Oracle Label Security, Oracle
Diagnostics Pack, Oracle Tuning Pack, Oracle OLAP, Oracle Data Mining, Oracle
Spatial.
II.3. Architecture
d'Oracle
II.3.1. Structure de
stockage
Un serveur de base de données Oracle est
constitué de deux types de structures : structure physique et
structure logique. Les structures physiques sont en relation avec le
système d'exploitation, tels que les fichiers physiques
enregistrés sur un disque dur. Les structures logiques sont
créées et reconnues par le serveur de base de données
Oracle et ne sont pas connues du système d'exploitation.
II.3.1.1. Structure
physique
Un serveur de base de données Oracle est
constitué des fichiers enregistrés sur un disque de stockage
(Figure 4). A la création d'une base de données les fichiers
suivants sont créés :
· fichiers de données (Data files), fichiers
temporaires (temp files), Data file est un fichier créé sur un
disque par le serveur de base de données Oracle et qui contient la
structure des données telles que tables et indexes.
· Fichiers de contrôle (Control files), Control
file trace les composants physiques de la base de données.
· Fichiers journaux (Online redo log files), est un
ensemble de fichiers contenant les enregistrements des changements
effectués sur les données.
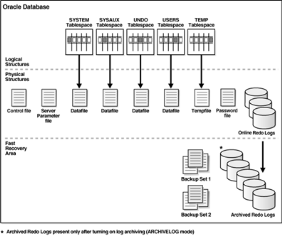
Figure 4. Structure de stockage
d'Oracle
II.3.1.2. Structure
logique
Un serveur de base de données Oracle alloue un espace
logique à toutes les données de la base de données. Les
unités logiques d'une base de données sont : data blocks,
extents, segments, et tablespaces (Figure 5).
II.3.2. Structure de
mémoire
Quand un serveur de base de données oracle est
démarré, il alloue un espace mémoire et lance des
processus en arrière-plan. La structure de mémoire basique
associée à une base de données Oracle inclut :
· System global area (SGA), est un groupe de structures
de mémoire partagée, appelées composants du SGA, il
contient les informations de données et de contrôle d'une instance
de base de données Oracle. SGA est partagée par les processus
serveurs et les processus en arrière-plan.
· Program global area (PGA), est la zone de
mémoire non partagée contenant les informations de données
et de contrôle allouées exclusivement à un processus
Oracle. Le PGA est créé par Oracle quand un processus Oracle est
démarré. Un PGA existe pour chaque processus serveur et processus
en arrière-plan. L'ensemble des des PGAs constitue une instance PGA.
· User Global Area (UGA), est la mémoire
associée à chaque session utilisateur.
· Software code areas, sont des portions de
mémoire utilisées par les processus.
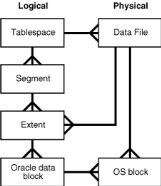
Figure 5. Relation entre
structure physique et structure logique d'Oracle
II.3.3. Structure des
processus
Un processus est un mécanisme dans un système
d'exploitation qui peut exécuter une série d'étapes.
Une instance de base de données contient deux types de
processus :
· Le processus client qui exécute une application
Oracle.
· Le processus Oracle qui exécute le code de la
base de données. Le processus Oracle est composé de :
· Processus en arrière-plan : démarre
la base de données et effectue des tâches de maintenance.
· Processus serveur qui répond aux requêtes
du processus client.
· Processus esclave qui accomplit des tâches
additionnelles aux processus en arrière-plan et serveur.
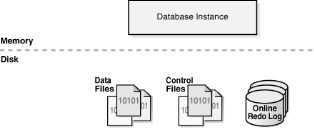
Figure 6. Une instance
Oracle
Une instance de base de données est l'ensemble de la
structure de mémoire gérée par les Data files (Figure
6).
II.4. Contrôle des
données
Comme dans tout système multi-utilisateur, l'usager
d'un SGBD doit être identifié avant de pouvoir utiliser des
ressources. L'accès aux informations et à la base de
données doit être contrôlé à des fins de
sécurité et de cohérence.
II.4.1. Gestion de
l'utilisateur
Un utilisateur (user) est identifié au niveau de la
base par son nom et peut se connecter puis accéder aux objets de la base
sous réserve d'avoir reçu un certain nombre de privilèges.
Un schéma est une collection nommée (du nom de l'utilisateur qui
en est propriétaire) d'objets (tables, vues, séquences, index,
procédures, etc.).
II.4.1.1. Classification
Les types d'utilisateurs, leurs fonctions et leur nombre
peuvent varier d'une base à une autre. Néanmoins, pour chaque
base de données en activité, on peut classifier les utilisateurs
de la manière suivante :
· Le DBA (DataBase Administrator). Il en existe au moins
un. Une petite base peut n'avoir qu'un seul administrateur. Une base importante
peut en regrouper plusieurs qui se partagent les tâches suivantes :
- installation et mises à jour de la base et des outils
éventuels ;
- gestion de l'espace disque et des espaces pour les
données (tablespaces) ;
- gestion des utilisateurs et de leurs objets (s'ils ne les
gèrent pas eux-mêmes) ;
- optimisation des performances ;
- sauvegardes, restaurations et archivages ;
- contact avec le support technique d'Oracle.
· L'administrateur réseaux (qui peut être le
DBA) se charge de la configuration de l'intergiciel (middleware) Oracle Net au
niveau des postes clients.
· Les développeurs qui conçoivent et
mettent à jour la base. Ils peuvent aussi agir sur leurs objets
(création et modification des tables, index, séquences, etc.).
Ils transmettent au DBA leurs demandes spécifiques (stockage,
optimisation, sécurité).
· Les administrateurs d'applications qui gèrent
les données manipulées par l'application ou les applications.
Pour les petites et les moyennes bases, le DBA joue ce rôle.
· Les utilisateurs qui se connectent et interagissent
avec la base à travers les applications ou à l'aide d'outils
(interrogations pour la génération de rapports, ajouts,
modifications ou suppressions d'enregistrements). Tous seront des utilisateurs
(au sens Oracle) avec des privilèges différents.
II.4.1.2. Création d'un
utilisateur
Pour pouvoir créer un utilisateur vous devez
posséder le privilège CREATE USER.
La syntaxe SQL de création d'un utilisateur est la
suivante :
CREATE USER utilisateur IDENTIFIED
{ BY motdePasse | EXTERNALLY | GLOBALLY AS 'nomExterne' }
[ DEFAULT TABLESPACE nomTablespace
[QUOTA { entier [ K | M ] | UNLIMITED } ON nomTablespace ]
]
[TEMPORARY TABLESPACE nomTablespace
[QUOTA { entier [ K | M ] | UNLIMITED } ON nomTablespace
].]
[PROFILE nomProfil ] [PASSWORD EXPIRE ] [ ACCOUNT { LOCK
|UNLOCK } ] ;
II.4.1.3. Suppression d'un
utilisateur
Pour pouvoir supprimer un utilisateur vous devez
posséder le privilège DROP USER. La syntaxe SQL pour supprimer un
utilisateur est la suivante :
DROP USER utilisateur [CASCADE];
II.4.2. Profil
Un profil regroupe des caractéristiques système
(ressources) qu'il est possible d'affecter à un ou plusieurs
utilisateurs. Un profil est identifié par son nom. Un profil est
créé par CREATE PROFILE, modifié par ALTER PROFILE et
supprimé par DROP PROFILE.
II.4.3. Privilège
Un privilège (sous-entendu utilisateur) est un droit
d'exécuter une certaine instruction SQL ou un droit d'accéder
à un certain objet d'un autre schéma.
Les privilèges sont de deux types :
· Les privilèges de niveau système :
Qui permettent la création, modification, suppression, exécution
de groupes d'objets, les privilèges CREATE TABLE, CREATE VIEW, CREATE
SEQUENCE par exemple permettent à l'utilisateur qui a reçu de
créer des tables, des vues et des séquences
· Les privilèges de niveau objet : Qui
permettent les manipulations sur des objets spécifiques, les
privilèges SELECT, INSERT, UPDATE, DELETE sur la table SCOTT.EMP par
exemple permettent à l'utilisateur qui les a reçu de
sélectionner, ajouter, modifier et supprimer des lignes dans la table
EMP appartenant à l'utilisateur SCOTT.
Lorsqu'un utilisateur est créé avec
l'instruction CREATE USER, il ne dispose encore d'aucun droit car aucun
privilège ne lui a encore été assigné, Il ne peut
même pas se connecter à la base, il faut donc lui assigner les
privilèges nécessaires, Il doit pouvoir se connecter,
créer des tables, des vues, des séquences. Pour lui assigner ces
privilèges de niveau système il faut utiliser l'instruction
GRANT.
II.4.4. Rôle
L'instruction GRANT permet d'assigner un ou plusieurs
privilèges système ou objet. Cependant, lorsque la liste des
privilèges est importante, il est souhaitable de pouvoir regrouper des
privilèges identiques dans un même ensemble. Cet ensemble
s'appelle un rôle et se créé avec l'instruction CREATE
ROLE. Une fois le rôle créé, il peut être
assigné à un utilisateur ou à un autre rôle.
La liste des rôles assignés à un
utilisateur s'obtient via les vues DBA_ROLE_PRIVS et USER_ROLE_PRIVS ;
La liste des privilèges objet assignés à
un utilisateur s'obtient en interrogeant les vues DBA_TAB_PRIVS, ALL_TAB_PRIVS
et USER_TAB_PRIVS ;
La liste des privilèges objet sur les colonnes de
tables assignés à un utilisateur s'obtient en interrogeant les
vues DBA_COL_PRIVS, ALL_COL_PRIVS et USER_COL_PRIVS ;
La liste des rôles assignés à
l'utilisateur au cours de sa session est visible via la vue
SESSION_ROLES ;
La liste des privilèges assignés à
l'utilisateur au cours de sa session est visible via la vue SESSION_PRIVS.
Un rôle peut être supprimé en utilisant
l'instruction DROP ROLE.
Les privilèges système qui ont été
assignés à des utilisateurs ou à des rôles peuvent
être retirés avec l'instruction REVOKE.
II.4.5. Vue
Outre le contrôle de l'accès aux données
(privilèges), la confidentialité des informations est un aspect
important qu'un SGBD relationnel doit prendre en compte. La
confidentialité est assurée par l'utilisation de vues (views),
qui agissent comme des fenêtres sur la base de données.
II.5. Oracle et les objectifs
d'une base de données répartie
Oracle Net services fournit des solutions de
connectivité dans des environnements distribués.
II.5.1. Oracle Net
Listener
Oracle Net Listener, aussi appelé listener, est un
processus serveur qui écoute les requêtes entrantes des connexions
clientes et gère le trafic vers la base de données.
II.5.2. Nom de service
Dans le contexte des services réseaux, un service est
un ensemble d'une ou plusieurs instances. Un nom de service est une
représentation logique des services utilisés par les connections
clientes.
II.5.3. Transparence vis-à-vis de la
localisation
II.5.3.1. Lien des bases de
données
Pour interroger une BD distante, il faut créer un lien
de base de données. Un lien de base de données est un chemin
unidirectionnel d'un serveur à un autre. En effet, un client
connecté à une BD A, peut utiliser un lien stocké dans la
BD A pour accéder à la BD distante B, mais les utilisateurs
connectés à B ne peuvent pas utiliser le même lien pour
accéder aux données sur A. Lorsqu'un lien est
référencé par une instruction SQL, Oracle ouvre une
session dans la base distante et y exécute l'instruction. La session
demeure ouverte au cas où elle serait de nouveau nécessaire.
En créant un lien de BD, on doit indiquer le nom du
compte auquel on se connecte, le mot de passe de ce compte, et le nom de
service associé à la base distante. En l'absence d'un nom de
compte, Oracle utilise le nom et le mot de passe du compte local pour la
connexion à la base distante.
La syntaxe pour la création d'un lien est la
suivante:
CREATE [SHARED|PUBLIC|PRIVATE] DATABASE LINK NomLien
CONNECT TO ..... [CURRENT_USER|User] IDENTIFIED BY password
USING connect_string
Un lien est soit privé ou public. Seul l'utilisateur
qui a créé un lien privé peut l'utiliser, alors qu'un lien
public est utilisé par tous les utilisateurs de la base de
données. Le lien partagé est propre à la configuration de
serveur multithreaded.
La clause CONNECT TO active une session vers la base
distante.
La clause CURRENT_USER crée un lien BD pour
l'utilisateur courant. L'utilisateur doit disposer d'un compte valide dans la
base distante.
La clause USING connect_string spécifie le nom de
service d'une base distante. Les noms de service d'instances sont
stockés dans le fichier de configuration « tnsnames.ora » du
serveur distant localisé dans le dossier
«$ORACLE_HOME/Network/Admin/ ». Ce fichier spécifie
l'hôte, le port, et l'instance associés à chaque nom de
service.
Des informations sur les liens de BD publics et privés,
figurent respectivement dans les vues du dictionnaire de données :
DBA_DB_LINKS et USER_DB_LINKS.
La syntaxe pour la suppression du lien est la suivante:
DROP [SHARED|PUBLIC|PRIVATE] DATABASE LINK nom_du_lien;
II.5.3.2. Synonyme
Pour référencer une base de données dans
un système distribué, on utilise le nom global ou le lien de base
de données. Mais afin de converger plus vers l'un des objectifs de la
répartition des bases de données qui est la transparence
vis-à-vis de la localisation, Oracle utilise des synonymes. Un synonyme
est un alias d'un objet (table, vue, séquence, procédure,
fonction ou paquetage).
Les avantages d'utiliser des synonymes sont les suivants :
· simplifier l'accès aux objets en
abrégeant les noms de tables, par exemple, ou en regroupant dans un
même alias les noms du schéma et de l'objet, pour les objets qui
ne vous appartiennent pas, mais dont vous avez accès ;
· masquer le vrai nom des objets ou la localisation des
objets distants (réunis par liens de base de données : database
links) ;
· améliorer la maintenance des applications dans
la mesure où la nature du synonyme peut être modifiée sans
mettre à jour tous les programmes qui l'utilisent (le synonyme garde le
même nom tout en référençant un nouvel objet).
Il est ainsi possible d'attribuer plusieurs noms à un
même objet. Il est aussi permis de créer des synonymes publics (en
utilisant la directive PUBLIC) qui seront visibles et utilisables par tous. Les
autres synonymes (privés) ne seront pas accessibles par d'autres
utilisateurs à moins de donner les autorisations nécessaires (par
GRANT). Pour pouvoir créer un synonyme dans votre schéma, il faut
que vous ayez reçu le privilège CREATE SYNONYM. Si vous avez le
privilège CREATE ANY SYNONYM, vous pouvez créer des synonymes
dans tout schéma. Enfin, pour pouvoir créer un synonyme public,
il faut que vous ayez reçu le privilège CREATE PUBLIC SYNONYM.
La syntaxe pour la création de synonyme est la suivante
:
CREATE [OR REPLACE] [PUBLIC] SYNONYM
[schéma.]nomSynonyme
FOR [schéma.]nomObjet[@lienBaseDonnées];
Pour pouvoir supprimer un synonyme, il faut qu'il se trouve
dans votre schéma ou que vous ayez reçu le privilège DROP
ANY SYNONYM. Pour pouvoir supprimer un synonyme public il faut que vous ayez
reçu le privilège DROP PUBLIC SYNONYM.
La syntaxe SQL est la suivante :
DROP [PUBLIC] SYNONYM [schéma.]nomSynonyme [FORCE];
II.5.3.3. Procédure
Les unités de programmes PL/SQL, peuvent servir
à référer à des données distantes, appeler
des procédures distantes, utiliser des synonymes pour
référer à des procédures distantes. On peut
utiliser une procédure locale pour appeler une procédure
distante. La procédure distante pourra exécuter les instructions
LMD requises. L'emplacement approprié pour une procédure
dépend de la distribution et de l'utilisation des données.
L'objectif étant de limiter le trafic sur le réseau pour
résoudre les requêtes.
II.5.4. Transparence
vis-à-vis de la fragmentation
II.5.4.1. Vue
Un des principaux objectifs de bases de données
réparties est la transparence à la fragmentation. Ainsi,
même fragmentés, les enregistrements doivent apparaître
comme sur un seul site. Pour cela, on utilise les vues : View.
Les utilisateurs pourront consulter la base, ou modifier la
base (avec certaines restrictions) à travers la vue, c'est-à-dire
manipuler la table résultat du SELECT comme si c'était une table
réelle.
Les vues correspondent à ce qu'on appelle le niveau
externe qui reflète la partie visible de la base de données pour
chaque utilisateur. Seules les tables contiennent des données et
pourtant, pour l'utilisateur, une vue apparaît comme une table. En
théorie, les utilisateurs ne devraient accéder aux informations
qu'en questionnant des vues. Ces dernières masquant la structure des
tables interrogées. Outre le fait d'assurer la confidentialité
des informations, une vue est capable de réaliser des contrôles de
contraintes d'intégrité et de simplifier la formulation de
requêtes complexes.Utilisées conjointement avec des synonymes et
attribuées comme des privilèges (GRANT), les vues
améliorent la sécurité des informations
stockées.
Pour pouvoir créer une vue dans votre schéma
vous devez posséder le privilège CREATE VIEW. Pour créer
des vues dans d'autres schémas, le privilège CREATE ANY VIEW est
requis.La syntaxe SQL de création d'une vue est la suivante :
CREATE [OR REPLACE] [[NO]FORCE] VIEW [schéma.]nomVue
[ ( { alias [ContrainteInLine [ContrainteInLine]...] |
ContrainteOutLine }
[, { alias ContrainteInLine [ContrainteInLine]... |
ContrainteOutLine } ] ) ]
AS requêteSELECT [ WITH { READ ONLY | CHECK OPTION
[CONSTRAINT nomContrainte] } ];
On distingue les vues simples des vues complexes en fonction
de la nature de la requête de définition (Tableau 2).
|
Requête de définition
|
Vue simple
|
Vue complexe
|
|
Nombre de table
|
1
|
1 ou plusieurs
|
|
Fonction
|
Non
|
Oui
|
|
Regroupement
|
Non
|
Oui
|
|
Mises à jour possibles ?
|
Oui
|
Pas toujours
|
Tableau 2. Types de
vues
a) Vues monotables
Une vue monotable est définie par une requête
SELECT ne comportant qu'une seule table dans sa clause FROM. L'objet source
d'une vue est en général une table mais peut aussi être une
vue ou un cliché.
b) Vues en lecture seule
L'option WITH READ ONLY déclare la vue non modifiable
par INSERT, UPDATE, ou DELETE.
c) Vues modifiables
Lorsqu'il est possible d'exécuter des instructions
INSERT, UPDATE ou DELETE sur une vue, cette dernière est dite modifiable
(updatable view). Vous pouvez créer une vue qui est modifiable
intrinsèquement. Si elle ne l'est pas, il est possible de programmer un
déclencheur INSTEAD OF qui permet de rendre toute vue modifiable. Les
mises à jour sont automatiquement répercutées au niveau
d'une ou de plusieurs tables.
d) Vues complexes
Une vue complexe est caractérisée par le fait de
contenir, dans sa définition, plusieurs tables (jointures), et une
fonction appliquée à des regroupements, ou des expressions. La
mise à jour de telles vues n'est pas toujours possible.
Modification d'une vue (ALTER VIEW). Pour pouvoir modifier une
vue, vous devez en être propriétaire ou posséder le
privilège ALTER ANY VIEW.
La syntaxe SQL est la suivante :
ALTER VIEW [schéma.]nomVue
{ ADD ContrainteOutLine | DROP
{ CONSTRAINT nomContrainte | PRIMARY KEY | UNIQUE(col1 [,
col2]... ) }
COMPILE ;
Pour pouvoir supprimer une vue, vous devez en être
propriétaire ou posséder le privilège DROP ANY VIEW. La
suppression d'une vue n'entraîne pas la perte des données qui
résident toujours dans les tables. La syntaxe SQL est la suivante :
DROP VIEW [schéma.]nomVue [CASCADE CONSTRAINTS];
II.5.5. Transparence
vis-à-vis à la réplication
Afin de réduire la quantité de données
transmises sur le réseau, et améliorer la disponibilité
des données et par conséquent les performances des
requêtes, plusieurs options de réplication peuvent être
envisagées.
II.5.5.1. copy
La commande COPY de SQL*Plus permet de copier des
données entre deux SGBD's. La meilleure utilisation est
d'exécuter cette commande sur la machine où réside la base
de données.La syntaxe est la suivante :
COPY {FROM database | TO database | FROM database TO
database}
{APPEND|CREATE|INSERT|REPLACE} destination_table [(column,
column, column, ...)]
USING query
· database a la syntaxe suivante:
username[/password]@connect_identifier
· APPEND : si la table n'existe pas (CREATE + INSERT)
sinon (INSERT)
· CREATE : si la table n'existe pas (CREATE + INSERT)
sinon (erreur)
· REPLACE : si la table n'existe pas (CREATE + INSERT)
sinon (DROP + CREATE + INSERT)
· INSERT : si la table n'existe pas (ERREUR) sinon
(INSERT)
II.5.5.2. Snapshots
Un snapshot est une copie conforme (cliché) d'une table
(ou plusieurs) située sur une base de donnée du système
distribué. Il permet de diminuer les coûts réseau, en
rendant locales les données situées à distance. Afin
d'assurer la cohérence de données, une mise à jour
régulière et automatique est effectuée à partir du
site d'origine ou MASTER.
Il existe deux types de snapshot : en lecture seule
(read-only) ou mis à jour (updateable).
a. Les read-only Snapshots
: non modifiables à partir du site esclave.
La syntaxe pour la creation de snapshot en lecture seule est
:
CREATE SNAPSHOT nom_snapshot
[REFRESH FAST | COMPLETE | FORCE]
START WITH date_de_debut_de_synchronisation
NEXT date_de_la_prochaine_synchronisation
AS requéte_select;
· FAST: Le mode rapide permet de faire un
rafraîchissement en tenant compte seulement des mises à jour
effectuées sur le site Maître.
Un SNAPSHOT LOG doit être crée pour la table
Maître afin de noter les différents changements subvenus qui
seront répercutés sur le snapshot:
CREATE SNAPSHOT LOG ON nom_de_la_table;
· COMPLETE: à chaque rafraîchissement, toute
la table est transférée.
Ce mode est obligatoire pour les snapshots complexes,
b. Les updateable Snapshots :
Les snapshots de mise à jour peuvent être
directement modifiés. Dans ce cas, les données mises à
jour à leur niveau sont répliquées vers le site Master
lors du processus de rafraîchissement.
La syntaxe pour la creation de updateable snapshot est :
CREATE SNAPSHOT nom_snapshot
[REFRESH FAST | COMPLETE | FORCE]
START WITH date_de_debut_de_synchronisation
NEXT date_de_la_prochaine_synchronisation
ENABLE QUERY REWRITE
AS requéte_select;
II.5.5.3. Vues
matérialisées
Une vue matérialisée peut apporter plusieurs
avantages au niveau performances. Selon la complexité de la
requête, on peut la remplir avec des changements incrémentiels,
à l'aide du journal de vues matérialisées (MATERIALIZED
VIEW LOG), au lieu de la recréer.
A l'inverse des snapshots, les vues
matérialisées peuvent être utilisées directement par
l'optimiseur, afin de modifier les chemins d'exécution des
requêtes. Pour ce, il faut disposer du privilège QUERY REWRITE
pour pouvoir réécrire la requête, et que
QUERY_REWRITE_ENABLED soit TRUE (ALTER SESSION SET QUERY_REWRITE_ENABLED =
TRUE).
Une vue matérialisée crée une table
locale pour stocker les données, et une vue qui y accède.La
syntaxe SQL pour la creation d'une vue matérialisée est la
suivante :
CREATE MATERIALIZED VIEW NomDeLaVue
TABLESPACE NomTablespace
{ NEVER REFRESH | [REFRESH FAST | COMPLETE | FORCE]}
START WITH date_de_debut_de_synchronisation
NEXT date_de_la_prochaine_synchronisation
ENABLE QUERY REWRITE
AS requéte_select;
· La clause ENABLE QUERY REWRITE permet à
l'optimiseur de rediriger les requêtes émises sur la table vers la
vue matérialisée s'il le juge approprié.
· La clause NEVER REFRESH empêche tout type
d'actualisation de la vue matérialisée.
Une vue matérialisée ne peut pas contenir les
op. UNION, MINUS, INTERSECT. Les vues DBMS_MVIEW, ALL_MVIEW_ANALYSIS
détaillent les caractéristiques des vues
matérialisées créées.
II.6. Outils d'Oracle
Oracle fournit une suite d'utilitaires en vue de faciliter et
améliorer l'utilisation des bases de données aux utilisateurs.
II.6.1. Outils
d'administration
II.6.1.1. sqlplus
SQL*Plus est un utilitaire en line des commandes qui
être utilisé pour envoyer des requêtes SQL et PL/SQL
à la base de données.
II.6.1.2. sqldeveloper
SQL Developer est un utilitaire graphique d'administration du
serveur de base de données Oracle. SQL Developer est également un
outil de développement en langage SQL et PL/SQL.
II.6.2. Outils de
configuration réseau
Oracle fournit des outils suivants pour la gestion de la
configuration réseau :
· Net Configuration Assistant
· Oracle Enterprise Manager
· Oracle Net Manager
II.6.3. Outils de
développement
Oracle fournit plusieurs outils de
développement des applications des bases de données :
II.6.3.1. SQL Developer
SQL Developer est la version graphique de SQL*Plus,
écrit en Java.
II.6.3.2. Oracle Application Express
Oracle Application Express (APEX) est un outil web de
développement des applications des bases de données.
II.6.3.3. Oracle JDeveloper
Oracle JDeveloper est un environnement de développement
intégré (IDE) des applications en Java, XML, Web et SQL. Oracle
JDeveloper supporte le cycle complet du génie logiciel.
II.6.3.4. Oracle JPublisher
Java Publisher (JPublisher) est utilitaire de création
des programmes en Java.
II.6.3.5. Oracle Developer pour Visual Studio .NET
Oracle Developer utilitaire pour Visual Studio .NET est une
suite d'applications intégrées à l'environnement Visual
Studio
II.7. Conclusion
Oracle offre des nombreuses fonctionnalités qui ne
sauront être détaillées dans notre mémoire. La mise
en place d'une base de données répartie sécurisée,
transparente, performante, fiable et disponible est possible avec Oracle au
travers d'une gestion de contrôle de données pour chaque
utilisateur en spécifiant son rôle bien précis, en lui
fournissant une vue adéquate, en lui offrant une disponibilité
des données acceptable tout en garantissant la cohérence globale
du système.
CHAPITRE III : PRESENTATION
DU PARQUET DE GRANDE INSTANCE
III.1. Introduction
Ce chapitre aborde la présentation du parquet de grande
instance. Il débute par une présentation de l'Ordre judiciaire en
République Démocratique du Congo (RDC), suivie de la
présentation de l'organisation du Parquet de Grande Instance, le
sous-système administration y est décrit ainsi que ses
différents composants (ceux-ci constituant le secrétariat du
PGI). Ensuite un aperçu du fonctionnement du PGI et de l'instruction
d'un dossier judiciaire (ouverture et enregistrement du dossier, lancement des
procédures, suites réservées au dossier et inventaires) au
sein de l'administration dont la gestion est actuellement manuelle.
Le domaine judiciaire ne peut être abordé en
totalité car complexe, ce chapitre s'efforce de présenter le
fonctionnement d'un Parquet de Grande Instance d'un oeil d'informaticien.
III.2. Présentation de l'Ordre judiciaire du Parquet
congolais
La Constitution du 18 février 2006 institue trois
ordresdejuridictions :
· laCourconstitutionnelle ;
· les juridictions del'Ordrejudiciaire placées
sous le contrôle de la Courdecassation ;
· juridictions de l'Ordre administratif coiffées
parleConseild'Etat
Au sommet de l'Ordre judicaire du Parquet en RDC est
institué le Parquet Général de la République,
ensuite viennent le Parquet Général, le Parquet de Grande
Instance et le Parquet Secondaire (figure 7).
Figure 7. Organisation de
l'Ordre judiciaire du Parquet congolais
1) Le Parquet Général de
la République
Ce Parquet est près la Courdecassation. Il est
dirigé par le Procureur Général de la République
assisté des premiers avocats généraux de la
République. Ce Parquet couvre l'étendue de toute la RDC.
2) Le Parquet Général
Le Parquet Général est institué dans
chaque province et est près la Cour d'Appel et la Cour de
Sûreté de l'Etat. Il est dirigé par un Procureur
Général assisté des avocats généraux et les
Substituts du Procureur Général.
3) Le Parquet de Grande Instance
Il se retrouve dans chaque district et il est près le
Tribunal de Grande Instance. Il est dirigé par un Procureur de la
République secondé par les Premiers Substituts du Procureur de la
République et les Substituts du Procureur de la République.
4) Le Parquet Secondaire
Pour assurer un bon fonctionnement de la justice et son
effectivité sur toute l'étendue du territoire de la RDC, il est
prévu des Parquets Secondaires dans les coins les plus reculés de
la République.
III.3. Organisation du Parquet de Grande Instance
Le PGI est composé pour son fonctionnement de la
Magistrature, la Police Judicaire et l'Administration (figure 8).
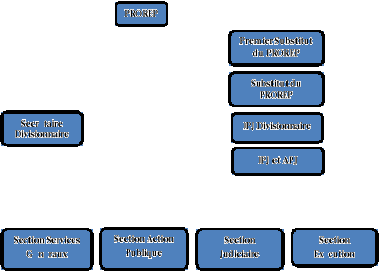
Figure 8. Organigramme du
Parquet de Grande Instance
A. La Magistrature
A ce niveau du PGI, trois catégories des magistrats
exercent, à savoir le Procureur de la République, les Premiers
Substituts Procureur de la République et les Substituts du Procureur de
la République.
B. La police Judicaire
Les Inspecteurs de la Police Judiciaire (IPJ) et les Agents de
la Police Judiciaire (APJ) composent la police judiciaire.
C. L'Administration
Elle est composée des fonctionnaires et agents de
l'Etat du Ministère de la justice relevant de la fonction publique.
L'administration du Parquet est dirigée par un fonctionnaire
revêtu du grade de Chef de Division et comme tous ces agents et
fonctionnaires sont des Secrétaires du Parquet. Il est appelé
Secrétaire Divisionnaire. Il coordonne tous les services du
Secrétariat du Parquet.
III.4. Fonctionnement du Parquet de Grande Instance
Dans l'administration du Parquet de Grande Instance, le
Secrétariat est le pivot moteur autour duquel s'articulent les
différentes actions du Parquet et est composé de quatre services
appelés « section », dirigé chacun par les
attachés de bureau (ATB1, ATB2), des agents de bureau (AGB1, AGB2), les
auxiliaires et huissiers.
Les quatre sections du secrétariat sont :
· La section de services généraux ;
· La section de l'action publique ;
· La section de l'instruction judiciaire ;
· La section de l'exécution du jugement.
a) La section de services généraux
Cette section s'occupe de la gestion du personnel judiciaire.
Elle dispose de plusieurs attributions en son sein ; il s'agit notamment :
· du budget (besoins du Parquet évalués en
chiffre) ;
· du service de l'économat et de l'intendance,
· de la relation publique et du protocole ;
· du service courriers
En tête de cette section, se trouve le Secrétaire
de première classe. Il a le devoir de réceptionner tous les
courriers et plaintes qui entrent et sortent du Parquet. La section services
généraux détient des registres d'entrées et de
sorties.
b) La section de l'action publique
Elle s'occupe de la réception et de l'enregistrement de
PV transmis au MP par les différents officiers de police judiciaire (Il
y a des PV avec l'inculpé et le PV sans l'inculpé). Elle
réceptionne les dossiers du Tribunal et communique à l'OMP pour
avis écrit. Ensuite elle dresse les statistiques mensuelles et annuelles
de tous les dossiers reçus et enregistrés au Parquet.
c) La section de l'instruction judiciaire
Cette section est qualifiée d'instruction judiciaire
puisqu'elle s'occupe du suivi de l'instruction du dossier au niveau de l'OMP.
Par là on veut tout simplement dire que tous les actes posés par
l'OMP lui sont communiqués. Les actes suivis par cette section sont de
deux manières, à savoir :
· L'instruction du dossier
· La suite à réserver au dossier
d) La section de l'exécution du jugement
Elle s'occupe de l'exécution de toutes les
décisions prises au Tribunal de Grande Instance au premier degré
comme au second degré. Pour ce faire, elle établit le mandat de
prise de corps si le prévenu est en liberté, ou la
réquisition aux frais d'emprisonnement si le prévenu est en
détention préventive. Elle dispose de deux registres à
savoir :
· Le registre audiencier
· Le registre
d'exécution des jugements
III.5. Gestion du dossier judiciaire
1. Ouverture du dossier
Avant l'instruction d'un dossier le Ministère Public ou
toute autre autorité judicaire doit être saisi. Les actes qui
donnent lieu à un dossier judiciaire sont les suivants :
· la plainte ;
· la dénonciation ;
· le PV de l'OPJ ;
· la saisie d'office.
Plainte
La plainte est une simple correspondance de la partie
lésée adressée au PROREP et qui relate les faits dont elle
a été victime.
Elle comprend l'identité de la partie
lésée, son adresse, la date, l'objet, le nom de l'accusé
et son adresse; elle se termine par une signature du plaignant.
Dénonciation
Une partie tierce porte à la connaissance du Parquet
des infractions qui se sont commises et dont elle n'est pas victime.
PV de L'OPJ
C'est un écrit par lequel l'officier de police
judiciaire rend compte d'une infraction pour laquelle il est
spécialement désigné comme compétent par un texte
pour le faire. Il relate tout ce qu'il a vu, fait et entendu.
Saisie d'office
C'est lorsque l'OMP verbalise les parties avant l'ouverture
d'un dossier au secrétariat. Elle consiste pour l'OMP à se saisir
des faits infractionnels dans son cabinet et sans que le dossier puisse passer
préalablement par la police ou par le secrétariat.
Par instruction du dossier, il faudra s'en tenir au fait que
le Ministère Public entende le plaignant, le prévenu et les
témoins ; et de faire ressortir tous les moyens de preuve afin de
permettre au juge de se décider. Si le dossier lui
présenté est un dossier avec prévenu, il doit dresser un
billet d'extraction pour extraire le prévenu de l'Amigo.
2. Instruction du dossier
judiciaire :
a) Enregistrement du dossier
Avant de procéder à
la lecture et à l'audition des parties, l'Officier du Ministère
Public devra mentionner la date de la réception du dossier sur la farde.
Ensuite il doit lire le dossier à fond.
b) Lancement des pièces de procédure
Après avoir lu et
enregistrer le dossier, le magistrat saisi du dossier procédera au
lancement des pièces de procédure pour faire comparaître
les parties.
Pour un dossier RMP : l'OMP lance les pièces de
procédure pour appeler les parties, il peut s'agir de :
· Mandant d'amener selon qu'il s'agit du plaignant, du
prévenu ou des témoins dans les circonstances bien
indiquées par la loi
· Mandant de comparution.
c) L'audition ou l'interrogation
Le Ministère Public
distingue l'interrogatoire selon qu'il s'agit de la victime ou du
prévenu.
C'est pour cette raison qu'il est recommandé au
magistrat instructeur de lire à fond le dossier qui lui est
attribué avant de l'instruire pour mieux poser des questions en tenant
compte des éléments en sa possession.
· S'il s'agit d'un dossier RMP, l'interrogatoire doit
surtout porter sur les éléments constitutifs de l'infraction
(élément moral et matériel).
· Quant aux dossiers RI, l'interrogatoire se passe autour
de l'information reçue. Et notons en passant que cela peut donner lieu
à un dossier RMP si les faits infractionnels mis à la charge de
l'inculpé sont établis ou non.
· Dans le cas d'un dossier avec prévenu en
détention, l'Officier du Ministère Public est dans l'obligation
de faire rapport au Procureur en lui informant de tout ce qui s'est
passé dans son office. Et de préciser la raison pour laquelle il
décide de relâcher ou de détenir le prévenu sous
mandat d'arrêt préventif.
3. Clôture du dossier judiciaire
Lorsque l'instruction est
clôturée, le magistrat doit décider du sort du dossier.
C'est la suite à donner au dossier, qui est inscrite sur la farde du
dossier.
- La transmission
du dossier à un autre office du Parquet :
Lorsque l'inculpé dans un dossier RMP réside
dans le ressort d'un autre Parquet, le magistrat instructeur transmettra le
dossier par la lettre de transmission à cet office du Parquet
territorialement compétent.
- La conversion du
dossier RI en dossier RMP :
Pour convertir un dossier RI en un dossier pénal RMP,
il faut que l'OMP établisse un rapport au Procureur selon lequel les
faits mis à charge de l'inculpé puissent s'avérer
infractionnels. C'est sur la farde qu'est marquée la mention : «
Dos RI converti en Dos RMP ».
- L'envoi du
dossier en fixation devant le Tribunal compétent :
La requête aux fins de fixation est établie
lorsqu'il s'agit d'une infraction alternative dont la solution n'a pas
été trouvée au niveau du Parquet ou tout simplement d'une
infraction cumulative. Dans ce cas le magistrat rédige la requête
aux fins de fixation d'audience qui saisit le Tribunal. La requête
comprend deux rubriques : l'identité du prévenu et le
libellé de la prévention en charge du prévenu.
- Le classement par
amende transactionnelle :
Il peut arriver que l'Officier du Ministère Public
après instruction du dossier propose au prévenu de payer une
amende transactionnelle pour mettre fin aux poursuites judiciaires lorsqu'il
s'agit d'une infraction alternative et que les intérêts civils ont
trouvé satisfaction. Dans ce cas, l'action publique sera close et le
dossier sera classé pour cette raison.
- Le classement
sans suite :
Un dossier peut être classé sans suite pour les
raisons suivantes :
· Faits bénins (préjudice mineur ou anodin)
;
· pours faits non-établis ;
· pour vétusté des faits ;
· pour inopportunité des poursuites ;
· pour prescription de l'action publique ;
· pour insuffisance des charges ;
· pour difficultés d'enquêtes ;
· Double emploi ;
· Cause du décès du
prévenu ;
4. Inventaire des pièces du dossier
L'instruction étant
clôturée après que le magistrat instructeur ait
décidé de la suite à réserver au dossier, le
magistrat doit procéder à l'inventaire des pièces du
dossier en regroupant les éléments selon leur nature respective
de la manière suivante :
· sous farde I : la plainte
· sous farde II : les procès-verbaux de l'OPJ ou
IPJ ;
· sous farde III : les procès-verbaux de l'OMP
;
· sous farde III : les pièces de
procédure ;
· sous farde V : les pièces à
conviction ;
· sous farde VI : les pièces de
détention ;
· sous farde VII : correspondances diverses ;
· dossiers administratifs (D.A).
III.6. Les parquets de grande
instance de la ville de Kinshasa
La ville de Kinshasa compte quatre parquets de grande
instance :
· Parquet de grande instance de Matete couvrant le
district du mont Amba qui est composé des communes
ci-après : Matete, Lemba, Limete, Ngaba, Makala et
Kisenso ;
· Parquet de grande instance de Kalamu dans le district
de la Funa avec les communes suivantes : Selembao, Bumbu, Ngiri-ngiri,
bandalungwa, Kalamu et Kasa-Vubu ;
· Parquet de grande instance de la Gombe pour le
district de la Lukunga avec les communes de : Ngaliema, Kitambo, Mont
Ngafula, Lingwala, Kinshasa, Barumbu et Gombe;
· Parquet de grande instance de N'djili couvrant le
district de la Tshangu constitué des communes : N'djili,
Kimbanseke, Masina, N'sele et Maluku.
Les parquets de grande instance de Kalamu et Gombe sont sous
l'autorité hiérarchique du parquet général de la
Gombe près la cour d'appel de la Gombe.
Les parquets de grande instance de Matete et N'djili sont sous
l'autorité hiérarchique du parquet général de
Matete près la cour d'appel de Matete.
III.7. Conclusion
Nous venons de présenter succinctement un Parquet de
Grande Instance, il est constitué de la magistrature, de la police
judiciaire et de l'administration. L'administration constituant le
secrétariat est sa pièce motrice et est composée de
quatre sections chacune ayant une mission bien précise pour la gestion
complète d'un dossier judiciaire.
CHAPITRE IV : GESTION
DU PROJET
IV.1. Introduction
Ce chapitre traite de la gestion de notre projet. Il
présente d'abord les notions théoriques sur la gestion du projet
et passe concrètement à la gestion de notre projet en suivant les
étapes y afférentes.
La gestion de projet recouvre l'ensemble des activités
et des produits attachés à la gestion économique et
administrative du projet afin de rationaliser les efforts de
développement (optimisation des ressources en fonction de la charge de
travail à effectuer) et de maîtriser les coûts et les
délais afférents.
IV.2. Notions
théoriques
Le processus de conduite de projet fait l'objet de la norme
ISO 12207 (de 1995) reprise par AFNOR sous la référence
Z67-150.
Quelle que soit la méthode de conduite de projet
considérée, elle possède une organisation
générale à 2 niveaux :
Ø un niveau macroscopique : grandes divisions
du cycle de vie du logiciel, découpage en phases ou étapes selon
la méthode utilisée,
Ø un niveau microscopique : précise,
pour chaque division du cycle, l'ensemble des traitements
élémentaires appelés tâches (ou
activités).
Chaque division du cycle comprend généralement
:
- 1 tâche de lancement : précise les ressources
nécessaires à partir de l'évaluation de la charge de
travail,
- N tâches opératoires,
- 1 tâche terminale : produisant par exemple un document
final.
Chaque phase du cycle de développement possède
les 3 types d'activités suivantes :
- les activités de réalisation,
permettant de construire petit à petit le logiciel,
- les activités de gestion, permettant de
maîtriser le déroulement du projet
- les activités qualité, permettant
d'assurer la bonne qualité et de vérifier la conformité
des produits réalisés à chaque phase et en fin de
développement.
IV.2.1. Identification des
actions principales
La gestion de projet se résume en 7 actions :
* Découper :
* Evaluer
* Organiser
* Planifier
* Suivre
* Ajuster
* Terminer
1) Décomposer (ou
découper)
Décomposer pour estimer.
Décomposer permet :
Ø de maîtriser la complexité et diminuer
les risques,
Ø d'optimiser :
- L'estimation, la planification et le suivi,
- Les ressources, les délais, les charges, les
coûts.
2) Evaluer (ou estimer)
Estimer pour planifier.
3) Organiser
Cette action consiste à créer une structure
indispensable pour mener le projet à son terme.
4) Planifier
Cette action a pour but d'ordonnancer les activités les
unes par rapport aux autres et de les placer dans le temps.
Méthodes d'ordonnancement
Jusqu'en 1958, les problèmes d'ordonnancement
étaient traités à l'aide de diagrammes de GANTT (ou
planning à barres).
Cette année-là, se sont
développées parallèlement 2 méthodes pour
ordonnancer les tâches de projets complexes :
- la méthode des potentiels,
- la méthode PERT (Program Evaluation and Review
Technic ou Program Evaluation Research Task).
Il sera fait usage de la méthode PERT dans notre
projet.
Méthode PERT
a. Origine
- Issue de l'US Navy en 1958-1959,
- appelée aussi méthode américaine ou
méthode des potentiels « Etapes »,
- à l'origine de la méthode PERT, la
méthode CPM (Critical Path Method) permettant de résoudre
uniquement des problèmes pour lesquels les durées des
tâches sont certaines; en pratique les 2 sigles CPM et PERT sont devenus
synonymes, PERT étant le plus fréquemment utilisé.
b. Principes
1. Représentation et
symbologie
- représentation graphique de l'enchaînement
logique des activités appelée réseau logique (ou graphe ou
réseau)
- les sommets (ou noeuds) du graphe, représentés
par des ronds (ou avales); symbolisent des étapes (ou
évènements ou jalons)
- les sommets sont reliés entre eux par des
flèches (ou arcs) qui symbolisent les opérations (ou tâches
ou activités); une flèche est soit en trait plein
(tâche réelle) soit en pointillé (tâche
fictive : généralement tâche de durée nulle et
ne nécessitant aucun moyen; elle permet uniquement de concrétiser
des contraintes temporelles comme séparer les chronologies entre
certaines suites de tâches)
- une opération nécessite des ressources
diverses (dont la main d'oeuvre) et consomme du temps,
- une étape marque le début ou la fin d'une
opération; elle ne consomme aucune ressource et est de durée
nulle; elle doit cependant correspondre à un état significatif de
l'ensemble du travail,
2. Règles
- le graphe possède un sommet initial et un sommet
final,
- le graphe orienté ne doit pas comporter de
circuit,
- une flèche n'a qu'une origine et qu'un destinataire
(elle ne se décompose pas et ne correspond à aucun
regroupement)
- une étape est atteinte si toutes les
opérations qui convergent vers elle sont terminées,
- une opération partant d'une étape ne peut
démarrer que si l'étape est atteinte,
- la durée de chaque opération est
supposée unique et connue (PERT déterministe ou classique),
- on suppose qu'il n'y a aucun conflit de ressources entre les
tâches exécutées simultanément
3. Algorithme
- la durée de chaque opération étant
connue, il est possible de déterminer de proche en proche, à
partir de l'étape de début, quelle sera la date "au plus
tôt" où l'on atteindra toute étape du réseau
(relativement au début du projet qui commence au temps 0) ;
- inversement, une fois fixée la date de fin "au plus
tôt" de l'ensemble des activités, on peut en remontant de proche
en proche calculer les dates de début "au plus tard" de chaque
opération;
- le délai entre le début "au plus tard" et le
début "au plus tôt" pour atteindre une étape, appelé
marge (ou battement, qui peut être positif, négatif ou nul),
permet de déterminer le chemin critique ou ensemble des arcs (donc des
tâches) allant du début à la fin du réseau pour
lequel la somme des marges est la plus faible; tout retard d'une tâche
appartenant au chemin critique retarde la fin du projet,
5) Suivre
Maîtriser l'avancement et permettre d'effectuer les
ajustements nécessaires
6) Ajuster
- Prendre en compte la réalité du projet
(dérive mesurée et expliquée lors de l'action suivre),
- Décider et mettre en oeuvre les actions correctives
pour diminuer voire annuler la dérive par rapport au plan de
développement prévisionnel (référentiel
théorique élaboré au début du projet et respectant
les contraintes contractuelles)
7) Terminer
- valider les résultats de la phase en cours,
- préparer la (ou les) phases suivantes.
IV.3. La gestion du projet
proprement dite
IV.3.1. Découpage du
projet
IV.3.1.1. Phases du projet
Notre projet est découpé en phases
ci-après :
1) La phase d'initialisation, elle conduit à
définir la « vision » du projet, sa portée, sa
faisabilité, son business case, afin de pouvoir décider au mieux
de sa poursuite ou de son arrêt.
2) La phase d'élaboration, elle poursuit trois
objectifs principaux en parallèle :
a) identifier et décrire la majeure partie des besoins
des utilisateurs,
b) construire (et pas seulement décrire dans un
document !) l'architecture de base du système,
c) lever les risques majeurs du projet.
3) La phase de construction, elle consiste surtout à
concevoir et implémenter l'ensemble des éléments
opérationnels (autres que ceux de l'architecture de base).
4) Enfin, la phase de transition permet de faire passer le
système informatique des mains des développeurs à celles
des utilisateurs finaux.
IV.3.1.2. Tâches du
projet
Chaque phase a été découpée en
tâche élémentaire (Tableau 3).
|
Phase
|
Tâche
|
Libellé
|
Durée
(jour)
|
Coût
($)
|
Tâche
antérieure
|
|
Initialisation du projet
|
|
|
|
|
|
|
A
|
Analyse de l'existant
|
7
|
700
|
|
|
B
|
Spécification
des besoins
|
3
|
300
|
A
|
|
C
|
Choix de solution
|
1
|
100
|
B
|
|
Elaboration du projet
|
|
|
|
|
|
|
D
|
Modélisation de la base de
données répartie
|
30
|
8100
|
C
|
|
E
|
Validation des
modèles
|
6
|
2250
|
D
|
|
Construction
|
|
|
|
|
|
|
F
|
Implémentation du serveur Oracle
|
3
|
5000
|
C
|
|
G
|
Implémentation
de base de données répartie
|
4
|
1600
|
E, F
|
|
H
|
Tests, corrections et
validation
|
4
|
1600
|
G
|
|
Transition
|
|
|
|
|
|
|
I
|
Déploiement du
système
|
21
|
19100
|
H
|
|
J
|
Formation des
utilisateurs
|
20
|
8500
|
C, E
|
Tableau 3. Liste de phases et
tâches du projet
IV.3.2. Organisation
Ce projet s'organise autour d'une équipe
composée comme-suit :
· un concepteur de la base de données
répartie ;
· un administrateur de bases de données
Oracle ;
· un administrateur du réseau informatique et du
système CentOS-Linux ;
· un développeur d'application logicielle.
Dans le cadre de notre mémoire, nous avons dû
jouer plusieurs rôles à la fois.
IV.3.3. Planification
a) Détermination des niveaux de
tâches :
R0 ={A}
R1={B}
R2 ={C}
R3 ={D,F}
R4 ={E}
R5 ={G,J}
R6 ={H}
R7 ={I}
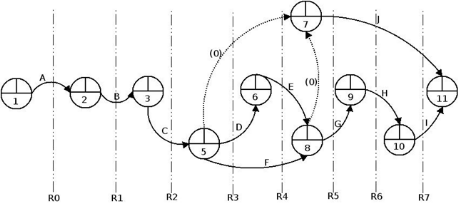
b) Figure 9. Le graphe
ordonné du projet
Mise enordredu graphe du projet
c) Délai de réalisation du
projet
1) Calcul des dates au plus
tôt
Pour une étape donnée, cette information
détermine à quelle date minimum depuis le début du projet
sera atteinte, au plus tôt, l'étape considérée.
Ø Pour le cas d'une seule tâche :
c'est-à-dire qu'il n'a qu'un seul chemin possible pour atteindre
l'étape :
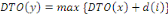
Ø Pour le cas de plusieurs tâches :
c'est-à-dire qu'il y a plusieurs chemins possibles pour atteindre
l'étape :
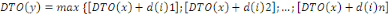
DTO(1) = 0
DTO(2) = 7
DTO(3) = 10
DTO(5) = 11
DTO(6) = 41
DTO(7) = 47
DTO(8) = 47
DTO(9) = 51
DTO(10) = 55
DTO(11) = 76
2) Calcul des dates au plus tard
Ø Pour une étape donnée, cette
information détermine à quelle date maximum, depuis le
début du projet, doit être atteinte, au plus tard, l'étape
considérée, afin que le délai de l'ensemble du projet ne
soit pas modifié.
Ø Pour le cas d'une seule tâche :
c'est-à-dire qu'il n'a qu'un seul chemin possible pour atteindre
l'étape :
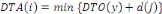
Ø Pour le cas de plusieurs tâches :
c'est-à-dire qu'il y a plusieurs chemins possibles pour atteindre
l'étape :
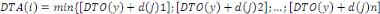
DTA(11) = 76
DTA(10) = 55
DTA(9) = 51
DTA(8) = 47
DTA(7) = 47
DTA(6) = 41
DTA(5) = 11
DTA(3) = 10
DTA(2) = 7
DTA(1) = 0
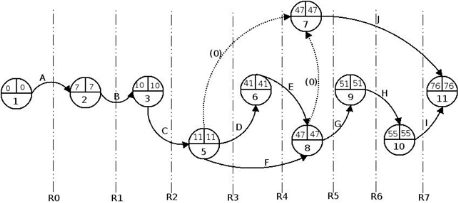
Figure 10. Le graphe complet du
projet
3) Calcul des marges libres
Le délai dont on dispose pour la mise en route de la
tache sans modifier la date au plus tard de l'étape y.
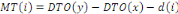
ML(A) = 0
ML(B) = 0
ML(C) = 0
ML(D) = 0
ML(E) = 0
ML(F) = 33
ML(G) = 0
ML(H) = 0
ML(I) = 0
ML(J) = 0
4) Calcul des marges totales
C'est le délai dont on dispose pour la mise en route de
la tache sans modifier la date au plus tard de l'étape y.
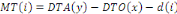
MT(A) = 0
MT(B) = 0
MT(C) = 0
MT(D) = 0
MT(E) = 0
MT(F) = 33
MT(G) = 0
MT(H) = 0
MT(I) = 0
MT(J) = 0
5) Détermination du chemin
critique
Le chemin critique est : A-B-C-D-G-H-I
6) Durée globale du projet
Durée globale du projet = 76 jours
d) Coût total du projet
Cout total du projet : 47250$
IV.4. Conclusion
Notre projet a été découpé en
phases, ces dernières à leur tour divisées en tâches
pour nous permettre une organisation et une planification optimales. La
durée globale du projet, son chemin critique et le coût total ont
été calculés à l'aide de la méthode PERT. Le
chapitre suivant présente l'analyse et la conception de notre futur
système automatisé.
CHAPITRE V : ANALYSE ET CONCEPTION
V.1. Introduction
Ce chapitre présente les étapes d'analyse et de
conception de notre base de données répartie. Il débute
par l'analyse des parquets de grande instance. Cette analyse à travers
l'étude des postes de travail et des documents du parquet nous
mène à spécifier le besoin et à proposer une
solution. L'informatisation d'un système d'information recourt à
des méthodes normalisées, étant donné notre choix
d'UML pour la modélisation, celui-ci n'étant pas une
méthode mais plutôt un langage, une brève
présentation d'UML par rapport à la conception d'une base de
données suivra. Et puis notre conception se servira des
différents schémas d'une base de données tels que
définis par ANSI et des différents diagrammes de classes UML pour
permettre de définir le schéma global, ainsi le schéma
local de notre future base de données répartie. Ensuite vient une
brève présentation des stratégies de
sécurité des données et de communication. Enfin ce
chapitre se clôt par une conclusion.
La conception d'un système d'information est une
tâche bien complexe qui nécessite des méthodes strictes
aboutissant à des solutions au-moins fidèles à la
réalité. Le langage de modélisation UML, bien que
spécifié à l'origine pour les applications logicielles, a
été progressivement adopté par la majorité des SGBD
existants pour la conception des bases de données.
V.2. Analyse de besoin
Chaque parquet de grande instance est doté d'un
secrétariat qui lui sert d'administration. Le but de ce mémoire
est de mettre en place une base de données lui permettant une gestion
efficace des données relatives aux dossiers judiciaires. Le
secrétariat comporte des postes et manipule divers documents qui
permettent au parquet de jouer son rôle de ministère public
(rechercher les infractions et les promoteurs, instruire les dossiers
judiciaires et exécuter les décisions des différentes
juridictions).
V.3. Etude des postes de
travail
Le parquet de grande instance est composé de la
magistrature, de la police judiciaire et du secrétariat.
Le secrétariat, constituant la pièce motrice,
est composé de quatre sections :
· Section des services généraux, qui
s'occupe de la gestion du personnel, du budget, de l'économat et de
l'intendance. Elle se charge en plus des courriers et plaintes transmis au
parquet ;
· Section de l'action publique, elle s'occupe de tous les
procès-verbaux provenant des sous-commissariats de la police de son
ressort ;
· Section de l'instruction judiciaire, appelée
section-mère, elle s'occupe de l'instruction du dossier judiciaire
(ouverture, enregistrement et clôture) ;
· Section de l'exécution du jugement, elle
s'occupe de l'exécution de toutes les décisions prises au
tribunal de grande instance, établit différents mandats.
Le personnel judiciaire du parquet de grande instance comprend
les magistrats, les agents et officiers de la police judiciaire du parquet et
les secrétaires.
Le secrétariat est placé sous la direction d'un
secrétaire divisionnaire assisté d'un ou plusieurs adjoints.
V.3.1. Diagramme de flux
d'informations
Figure 11. Diagramme de flux
d'informations
Personnes
Mandats
Autres parquets
Mandats,
Commissions rogatoires,
Avis de recherche
Personnes
Courriers,
Plaintes,
Dénonciations
Sous-commissariats
Procès-verbaux,
Rapports
Parquet de grande instance
Magistrature
- Procureur
- 1st Substituts
- Substituts
Police judiciaire
- IPJ
- OPJ
- APJ
Administration
- Secrétaire divisionnaire
- adjoints (ATB1, ATB2)
Services généraux
Action publique
Instruction judiciaire
Exécution de jugement
V.4. Etude des documents
Les données persistantes des dossiers judiciaires sont
stockées dans des registres détenus par les différentes
sections du secrétariat du parquet de grande instance.
· La section des services généraux
détient les registres indicateurs d'entrée et de sortie ayant les
rubriques ci-après : n° d'ordre (caché), n° de la
lettre, date d'entrée, les annexes, nom de l'expéditeur, l'objet,
observation (réservée au procureur de la république).
L'expéditeur peut être une personne physique ou morale.
· La section de l'action publique détient le
registre de procès-verbaux structuré comme-suit : date de
réception du PV, le n° du PV, le nom de l'OPJ de la provenance, le
nom du sous-commissariat.
· La section de l'instruction judiciaire détient
ce qui-suit :
- Le Registre du Ministère Public (RMP)
- Le Registre d'Information (R.I)
- Le Registre des Autres Parquets (RAP)
- Le Registre des Faits Non-Infractionnels (RFNI)
- Registre d'Amendes Transactionnelles (RAT)
- Le Registre des Objets Saisis (ROS)
- Le Registre de Tutelle (RT)
- Le Registre de Détention Préventive (RDP)
- Le Registre du Ministère Public pour l'Enfance
Délinquante (RMPED)
· La section de l'exécution du jugement
détient le registre audiencier et le registre d'exécution des
arrêts et jugements. Le registre audiencier reprend les colonnes
suivantes : Rôle pénal, n° RMP, Rôle pénal
en appel, nom du prévenu, la prévention, le réquisitoire
du ministère public, la décision du tribunal, observation,
n° RMP en appel. Le registre d'exécution des arrêts et
jugements : n° RMP, n° d'écrou, nom du condamné,
nationalité, date.
V.5. Spécification de
besoin
Le secrétariat du parquet de grande instance
reçoit des informations, les échange entre différentes
sections internes et avec d'autres parquets manuellement par le biais des
registres détenus par des sections bien spécifiques.
De ce fait, il l'en découle les lacunes
suivantes :
· lenteur dans la manipulation des données :
recherche manuelle des références relatifs aux dossiers
judiciaires ;
· Redondance possible des données : les
mêmes données peuvent se répéter et conduire
à une incohérence et à une utilisation accrue des
matériels bureautiques (papiers, encre ...).
· Partage de données moins efficace :
transmission manuelle (non automatisée) des dossiers entre services
internes ou avec d'autres parquets;
· Pas de possibilité d'accès concurrent
à une même donnée par différents intervenants du
système judiciaire ;
· Sécurité des données moindre :
dispositif de sécurité actuellement en place (cacher les
numéros de dossiers et autre) moins efficace, les dossiers peuvent
être sabotés, falsifiés ou simplement consulter à
des fins non justes. Sans parler des catastrophes naturelles (incendie,
inondation, vieillissement) qui peuvent supprimer complètement les
dossiers.
De ce qui précède, il paraît donc utile de
proposer une solution non pas la meilleure mais plus efficace que l'actuelle en
vue d'automatiser une partie ou toute la gestion de dossiers judiciaires.
V.6. Solution
proposée
La solution est de recourir à un système de
gestion de bases de données. Ce dernier ayant prouvé au fil du
temps son efficacité par rapport aux systèmes de gestion des
archives-papiers et aux systèmes de gestion des fichiers :
· Indépendance physique : Le SGBD offre une
structure canonique permettant la représentation des données
réelles sans se soucier de l'aspect matériel.
· Indépendance logique : Chaque service doit
pouvoir se concentrer sur ce qui l'intéresse uniquement. Il doit pouvoir
arranger les données comme il le souhaite même si d'autres
utilisateurs ont une vue différente.
· Manipulable facilement, même par des
non-informaticiens.
· Accès aux données efficace.
· Administration centralisée des données.
Le SGBD offre aux administrateurs des outils de vérification de
cohérence des données, de restructuration éventuelle de la
base, de sauvegarde ou de réplication.
· Non redondance des données. Le SGBD permet
d'éviter la duplication d'informations qui, outre la perte de place
mémoire, demande des moyens humains importants pour saisir et maintenir
à jour plusieurs fois les mêmes données.
· Cohérence des données. Cette
cohérence est obtenue par la vérification des contraintes
d'intégrité.
· Partage des données. Le SGBD permet à
plusieurs personnes (ou applications) d'accéder simultanément aux
données tout en conservant l'intégrité de la base. Chacun
a l'impression qu'il est seul à utiliser les données.
· Sécurité des données. Les
données sont protégées des accès non
autorisés ou mal intentionnés.
Il existe actuellement plusieurs types de bases de
données, le choix a été porté sur la base de
données relationnelle répartie qui permet une bonne
disponibilité et une meilleure performance d'accès aux
données tout en assurant la sécurité et la
cohérence locales et globales.
La ville de Kinshasa avec ses quatre parquets de grande
instance et deux parquets généraux permettra la mise en
place d'une base de données répartie sur les différents
PGI et le parquet général de la Gombe avec une manipulation
fiable, efficace, sécurisée des dossiers judiciaires hautement
disponibles.
V.7. Conception
Pour la conception de notre future base de données
répartie, il est fait appel au langage UML.Trois niveaux d'abstraction
(conceptuelle, logique et physique) ont été définis en
1974 pour la conception d'une base de données. Un découpage
légèrement différent a ensuite été
proposé par l'ANSI, en 1975, qui fait désormais
référence en la matière. Ce dernier décrit un
niveau externe, un niveau conceptuel et un niveau interne. Nombre de
méthodes de conception ont vu le jour et ont associé une forme de
représentation appelée « schéma » à
chacun de ces niveaux. Un niveau logique est présent dans certaines de
ces méthodes.
V.7.1. UML et les bases de
données
En UML, Le niveau conceptuel décrit une
représentation abstraite de la base de données à l'aide de
diagrammes de classes d'analyse. Le niveau logique détaille une
représentation intermédiaire entre le niveau conceptuel et le
niveau physique. Les diagrammes logiques peuvent être exprimés
soit à l'aide d'une notation mathématique, soit à l'aide
d'un diagramme de classes de conception. Quant au niveau physique, il concerne
les structures de données qui seront à mettre en oeuvre dans la
base de données relationnelle. Le schéma physique traduit,
à l'aide du langage SQL2 ou SQL3, le schéma logique. Le niveau
externe inclut des sous-schémas qui assurent la sécurité
et la confidentialité de la base de données.
Alors qu'UML 1.x définit neuf diagrammes : cinq pour
les aspects statiques (classes, objets, cas d'utilisation, composants et
déploiement) et quatre pour les aspects dynamiques (séquence,
collaboration, états-transition, activités), UML 2 ajoute ceux
d'interaction, de structure composite et le timing diagram. Ce mémoire
ne s'intéressera qu'à celui convenant à la conception
d'une base de données, à savoir le diagramme de classes, qui fait
partie de l'aspect statique d'UML.
Bien que la notation UML ait été proposée
tout d'abord pour la spécification d'applications, il n'en reste pas
moins que les concepts relatifs au diagramme de classes peuvent s'adapter
à la modélisation d'une base de données relationnelle.
UML 2 reprend les concepts du modèle
entité-association et propose en plus des artifices pour
améliorer la sémantique d'un schéma conceptuel
(contraintes, classe-association, stéréotype...).
De ce fait, cette notation est très complète et
puissante et peut s'adapter parfaitement à la description statique d'une
base de données.
V.7.2. Modèle
d'analyse
a) Règles de gestion
Notre système est régi par les règles
suivantes :
· une personne est exclusivement physique ou
morale ;
· une personne saisit la justice par un ou plusieurs
moyens (plainte, dénonciation ...) ;
· l'infraction est individuelle, ce qui fait qu'un fait
concerne une et une seule personne, même si le fait a été
commis en groupe chaque personne sera condamnée individuellement suivant
sa participation ;
· plusieurs faits peuvent constituer une seule
infraction ;
· un acte n'ouvre qu'un seul dossier et peut annexer
plusieurs éléments ;
· un dossier peut être à partir de plusieurs
actes (procès-verbal de l'OPJ, plainte, rapport, dénonciation
...) ;
· il existe des faits qui ne constituent pas
d'infraction, ils ne sont donc pas punissables par loi pénale ;
· une commune est sous la compétence territoriale
d'un seul parquet ;
· un parquet de grande instance couvre un seul district,
donc plusieurs communes ;
· le personnel judiciaire est affecté à un
seul parquet ;
· le personnel judiciaire du parquet est constitué
de plusieurs agents ;
· le dossier confirme une seule infraction, pour les
infractions alternatives plusieurs dossiers sont ouverts
automatiquement ;
· une personne (physique ou morale) possède une
seule adresse principale, par contre ne peut être interpelée par
le parquet de son district (commune), si le fait est commis dans le district
d'un autre parquet son dossier est transféré par mandat, avis ou
commission rogatoire ;
· un parquet reçoit les mandats de
plusieurs ;
· un mandat est envoyé à un parquet bien
précis ;
· une personne peut répondre à plusieurs
mandats ;
· un mandat est envoyé à une personne bien
déterminée.
b) Diagrammedeclassed'analyse
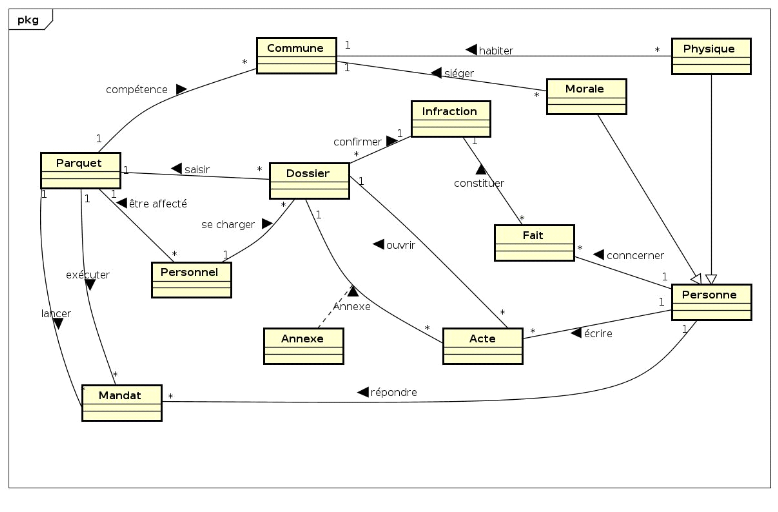
Figure 12. Diagramme de classe
d'analyse
V.7.3. Modèle
conceptuel
a. Dictionnaire des données
|
Code mnémonique
|
Libellé
|
Type
|
Format
|
Cat.
|
|
id_personne
|
Numéro d'ordre personne
|
N
|
38
|
I
|
|
Nom
|
Nom personne
|
AN
|
32
|
|
|
postnom
|
Post-nom personne
|
AN
|
32
|
|
|
prenom
|
Prénom personne
|
AN
|
32
|
|
|
datenaiss
|
Date de naissance
|
Date
|
10
|
|
|
aptitude
|
Aptitude personne
|
Booléen
|
|
|
|
Genre
|
Genre de la personne
|
A
|
1
|
|
|
villenaiss
|
Ville de naissance
|
AN
|
32
|
|
|
nationalite
|
Nationalité personne
|
AN
|
32
|
|
|
profession
|
Profession personne
|
AN
|
32
|
|
|
numidentif
|
Numéro national d'identification personne
|
AN
|
20
|
I
|
|
formejurid
|
Forme juridique
|
AN
|
128
|
|
|
datecreation
|
Date de création
|
Date
|
10
|
|
|
datefait
|
Date du fait
|
Date
|
10
|
|
|
Recit
|
Retranscription fait
|
AN
|
|
|
|
nomparquet
|
Nom parquet
|
AN
|
32
|
|
|
codeparquet
|
Code parquet
|
AN
|
10
|
I
|
|
typeparquet
|
Type parquet
|
AN
|
32
|
|
|
matricule
|
Matricule agent
|
AN
|
16
|
I
|
|
Service
|
service agent
|
AN
|
3
|
|
|
Grade
|
Grade agent
|
AN
|
32
|
|
|
fonction
|
Fonction agent
|
AN
|
32
|
|
|
Num_ordre
|
Numéro d'ordre acte
|
N
|
38
|
I
|
|
typeacte
|
Type d'acte
|
N
|
1
|
|
|
daterecept
|
Date de réception acte
|
Date
|
10
|
|
|
Objet
|
Objet acte
|
AN
|
64
|
|
|
id_dossier
|
Numéro d'ordre dossier
|
N
|
38
|
I
|
|
dateinscript
|
Date d'ouverture dossier
|
Date
|
10
|
|
|
observation
|
Observation sur dossier
|
AN
|
|
|
|
ordonnance
|
Ordonnance sur dossier
|
AN
|
|
|
|
codecom
|
Code commune
|
AN
|
10
|
|
|
nomcom
|
Nom commune
|
AN
|
32
|
|
|
id_mandat
|
Numéro d'ordre mandat
|
N
|
|
I
|
|
datenvoie
|
Date transmission mandat
|
Date
|
10
|
|
|
typemandat
|
Type mandat
|
AN
|
32
|
|
|
libelmandat
|
Libellé mandat
|
AN
|
|
|
|
article
|
Article code pénal
|
N
|
|
|
|
codepenal
|
Code pénal
|
AN
|
|
|
|
gravite
|
Gravité infraction
|
N
|
1
|
|
|
Sanction
|
Sanction pénale
|
N
|
1
|
|
|
mdprevent
|
Mise en détention préventive
|
Booléen
|
1
|
|
|
codeparexp
|
Code parquet expéditeur mandat
|
AN
|
10
|
|
|
codepardes
|
Code parquet destinataire mandat
|
AN
|
10
|
|
|
Ville
|
Ville parquet
|
AN
|
32
|
|
|
Nomperso
|
Nom agent
|
AN
|
32
|
|
|
Postperso
|
Post-nom agent
|
AN
|
32
|
|
|
Datearrest
|
Date arrestation
|
Date
|
10
|
|
|
Typepiece
|
Type pièce annexée
|
N
|
1
|
|
|
Element
|
Elément annexé
|
Fichier
|
|
|
|
Num_acte
|
Numéro d'acte
|
AN
|
20
|
|
|
Delaiprescipt
|
Délai de prescription
|
AN
|
|
|
|
typersonne
|
Type de personne
|
N
|
1
|
|
Tableau 4. Dictionnaire des
données
b. Domaines
L'acte pouvant ouvrir un dossier peut être :
· 1 : une plainte ;
· 2 : un procès-verbal de l'OPJ ;
· 3 : une dénonciation ;
· 4 : un rapport de l'OPJ.
Les infractions pénales sont classées selon leur
gravité (0 : nulle, 1 : moyenne, 2 : forte) et les peines
sont classées par niveau :
· 0 : classement sans suite ;
· 1 : la mort (remplacé par la servitude
pénale à perpétuité);
· 2 : les travaux forcés;
· 3 : la servitude pénale;
· 4 : l'amende;
· 5 : la confiscation spéciale;
· 6 : l'obligation de s'éloigner de certains
lieux ou d'une certaine région;
· 7 : la résidence imposée dans un
lieu déterminé;
· 8 : la mise à la disposition de la
surveillance du gouvernement.
Les articles qui définissent les infractions et les
peines relatives sont des entiers, où l'article 1 représente les
faits non infractionnels.
Les personnes sont classifiées par type :
· 1 : prévenu
· 2 : victime
· 3 : dénonciateur
· 4 : témoin
· 5 : personne morale
Le personnel du parquet est classifié par
service : mag(magistrature), pol(police judiciaire) et
sec(secrétariat) avec les fonctions suivantes : sec(
secrétaire), sed(secrétaire divisionnaire), opj(Office de la
Police Judiciaire), ipj(Inspecteur de la Police Judiciaire), ins(Magistrat
Instructeur) et omp(Officier du Ministère Public) relativement à
leur grade.
· gravite ? {0, 1, 2}
· peine ? {0, 1, 2, 3, 4, 5, 6, 7, 8}
· article ?N?
· typersonne ? {1, 2,3, 4, 5}
· typeacte ? {1, 2, 3, 4}
· service ? {`mag', `pol', `sec'}
· fonction ? {`sec', `sed', `opj', `ipj', `ins',
`omp'}
c. Diagramme de classe de conception
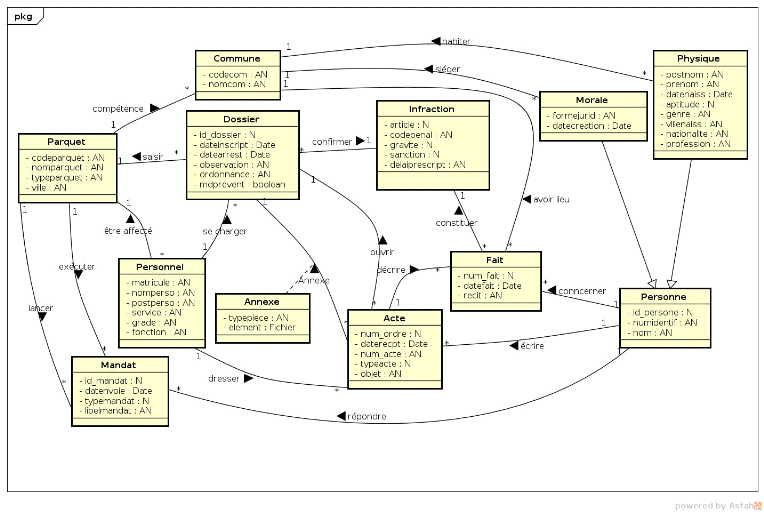
Figure 13. Diagramme de classe
de conception
V.7.4. Modèle
logique
1) Règles de passage
schéma conceptuel - schéma logique
Les quatre règles suivantes permettent de traduire un
schéma conceptuel UML en un schéma relationnel équivalent.
a) Transformation des classes
R1 : Chaque classe du diagramme UML devient une
relation. Il faut choisir un attribut de la classe pouvant jouer le rôle
d'identifiant. Si aucun attribut ne convient en tant qu'identifiant, il faut en
ajouter un de telle sorte que la relation dispose d'une clé primaire.
b) Transformation des associations
Les règles de transformation dépendent des
multiplicités maximales des associations. Nous distinguons trois
familles d'associations :
un-à-plusieurs ;
plusieurs-à-plusieurs ou classes-associations, et
n-aires ;
un-à-un.
1. Associations
un-à-plusieurs
R2 : Il faut ajouter un attribut de type clé
étrangère dans la relation fils de l'association. L'attribut
porte le nom de la clé primaire de la relation père de
l'association.
2. Associations
plusieurs-à-plusieurs et n-aires
R3 : L'association (classe-association) devient une
relation dont la clé primaire est composée par la
concaténation des identifiants des entités (classes)
connectés à l'association. Chaque attribut devient clé
étrangère si l'entité (classe) connectée dont il
provient devient une relation en vertu de la règle R1. Les attributs de
l'association (classe-association) doivent être ajoutés à
la nouvelle relation. Ces attributs ne sont ni clé primaire, ni
clé étrangère.
3. Associations un-à-un
La règle est la suivante, elle permet d'éviter
les valeurs NULL dans la base de données.
R4 : Il faut ajouter un attribut clé
étrangère dans la relation dérivée de
l'entité ayant la cardinalité minimale égale à
zéro. Dans le cas de UML, il faut ajouter un attribut clé
étrangère dans la relation dérivée de la classe
ayant la multiplicité minimale égale à un. L'attribut
porte le nom de la clé primaire de la relation dérivée de
l'entité (classe) connectée à l'association. Si les deux
cardinalités (multiplicités) minimales sont à zéro,
le choix est donné entre les deux relations dérivées de la
règle R1. Si les deux cardinalités minimales sont à un, il
est sans doute préférable de fusionner les deux entités
(classes) en une seule.
2) Schéma relationnel :
· parquet(codeparquet,
nomparquet, typeparquet, ville)
· infraction(article,
codepenal, gravite, sanction, delaiprescript)
· commune(codecom,
nomcom, #codeparquet)
·
personne(id_personne,
numidentif, nom, postnom, prenom, typersonne,
datenaiss, datecreation, aptitude, genre, formejurid, villenaiss, nationalite,
profession, #codecom)
·
mandat(id_mandat,
datenvoie, typemandat, libelmandat, #codeparexp,
#codepardes, #(id_personne,
numidentif))
· personnel(matricule,
nomperso, postperso, service, grade, fonction,
#codeparquet)
·
acte(num_ordre,
daterecept, num_acte, typeacte, objet, #matricule,
id_dossier,
#(id_personne,
numidentif))
·
fait(num_fait,
datefait, recit, #num_ordre,
#article, #(id_personne,
numidentif), #codecom)
·
dossier(id_dossier,
dateinscript, datearrest, observation, ordonnance, mdprevent,
#codeparquet, #matricule,
#article)
·
annexe(#id_dossier,
#num_ordre, typepiece, element)
V.7.5. Vues
1. Personne_physique
R0= Join(personne, commune, codecom)
personne_physique=Project(R0,id_personne, numidentif, nom, postnom,
prenom, datenaiss, aptitude, genre, villenaiss, nationalite, profession,
nomcom))
2. Personne_morale
personne_morale=Project(R0, id_personne, numidentif, nom,
formejurid, datecreation, nomcom)
3. Personnel_judiciaire
R1=Join(personnel, parquet, codeparquet)
personnel_judiciaire=Project(R1, matricule, nomperso,
postperso, service, grade, fonction, nomparquet)
4. Registre des entrées
(plaintes, dénonciations et courriers) :RENT
R2=Join(acte, personne, id_personne)
R3=Join(R2, annexe, num_ordre)
RENT=Project(R3, num_ordre, typeacte, num_acte, daterecept,
objet, nom, element, codecom)
5. Registre des PV et rapports :
RPV
R4=Join(acte, personnel, matricule)
R5=Join(R4, annexe, num_ordre)
RPV=Restrict(R5, num_ordre, typeacte, num_acte, daterecept,
objet, nomperso, element, codeparquet)
6. Registre du Ministère Public
global : RMPG
R6=Join(dossier, R2, id_dossier)
R7=Join(infraction, R6, article)
RMPG=Project(R7, id_dossier, dateinscript, datearrest, nom,
postnom, profession, nationalite, article, sanction, mdprevent, ordonnance,
observation, codeparquet)
7. Registre des amendes
transactionnelles : RATG
RATG=Restrict(RMPG, (sanction = 4))
8. Registre de détention
préventive : RDPG
RDPG=Restrict(RMPG, (sanction != 0) ? (sanction != 4) ?
(mdprevent = 1))
9. Registre du ministère public
de l'enfance délinquante : RMPEDG
âge de la personne = datefait - datenaiss // N'est
pas conservé dans la base de données, mais calculé par une
méthode
R8=Join(R7, fait, id_personne)
R9=Restrict(R8, datefait - datenaiss < 18)
REIG=Project(R8, id_dossier, dateinscript, datearrest, nom,
postnom, profession, nationalite, article, sanction, mdprevent, ordonnance,
observation, codeparquet)
10. Registre
tutelle : RTG
aptitude 0
R10=Restrict(R9, aptitude = 0)
RTG=Project(R10, id_dossier, dateinscript, datearrest, nom,
postnom, profession, nationalite, article, sanction, mdprevent, ordonnance,
observation, codeparquet)
11. Registre des
faits non infractionnels : RFNIG
article 1.
RFNIG=Restrict(RMPG, article = 1)
12. Registre
d'informations : RIG
RIG=Restrict(RENT, typeacte > 2)
V.7.6. Fragmentation
Les différentes vues sont fragmentées
horizontalement comme-suit :
a) Registre du Ministère public
local : RMP
RMP=Restrict(RMPG, codeparquet = 'code parquet')
b) Registre des faits non
infractionnels : RFNI
RFNI=Restrict(RFNIG, codeparquet = 'code parquet')
c) Registre des autres parquets :
RAP
RAP=Restrict(mandat, codeparqdes = 'code parquet')
d) Registre d'informations : RI
RI=Restrict(RIG, codecom = 'code commune')
e) Registre des amendes
transactionnelles : RAT
RAT=Restrict(RATG, codeparquet = 'code parquet')
f) Registre de contrôle de
détention préventive : RDP
RDP=Restrict(RDPG, codeparquet = 'code parquet')
g) Registre des tutelles : RT
RT=Restrict(RTG, codeparquet = 'code parquet')
h) Registre du ministère public
de l'enfance délinquante : RMPED
REI=Restrict(RMPEDG, codecom = 'code commune')
i) La relation
personne_physique_l :
personne_physique_l=Restrict(personne_physique, codecom =
'code commune')
j) La relation personne_morale_l :
personne_morale_l=Restrict(personne_morale, codecom = 'code
commune')
k) La relation personnel_judiciaire_l
:
personnel_judiciaire_l=Restrict(personnel_judiciaire,
nomparquet = 'nom parquet')
V.7.7. Duplication
Les tables Parquet, infraction, commune et personnel sont
dupliquées dans tous les sites..
V.7.8. Sécurité
des données.
On définit deux catégories
d'utilisateurs :
· Utilisateurs du schéma global : parmi
lesquels on a deux groupes :
Ø administrateur principal, ayant tous les
privilèges sur le schéma global ;
Ø opérateur principal : ayant les droits de
mise à jour sur les relations dupliquées et droit de lecture
seule sur les fragments alloués.
· Utilisateurs du schéma local :
· administrateur local : ayant tous les
privilèges sur le schéma local à la limite des
privilèges définis par l'administrateur principal sur les
relations sources.
· Opérateur local : ayant les droits de mise
à jour sur les fragments alloués et de lecture seule sur les
relations dupliquées.
V.7.9. Sécurité
de communication.
Le schéma global sera implémenté dans le
parquet général de la Gombe et au niveau de chaque parquet de
grande instance sera implémenté le schéma local.
Les communications inter-sites passeront donc par un
réseau public (Internet par fibre optique par exemple) à travers
un réseau privé d'entreprise (VPN).
V.8. Conclusion
La conception de notre base de données répartie
a appliqué les règles utilisées pour les bases de
données normales en ajoutant les notions de répartition à
tous les niveaux des schémas d'une base de données tels que
définis par l'ANSI.
Il a été conçu un schéma global
pour la cour d'appel de la Gombe et des schémas locaux pour les
différents parquets de grande instance de Kinshasa. Le prochain chapitre
présente l'implémentation de notre système sous le SGBD
Oracle et la plate-forme GNU/Debian-Linux.
CHAPITRE VI.
IMPLEMENTATION
VI.1.Introduction
Ce chapitre présente l'implémentation de notre
base de données répartie sous Oracle sur CentOS-Linux. Il
début par présentation des différents outils et logiciels
utilisés dans notre réalisation et la mise en place d'un
réseau privé virtuel des parquets de grande instance pour la
sécurisation des communications. Ensuite l'installation et la
configuration du serveur de bases de données Oracle sur chaque site. Et
puis la création des utilisateurs, des tables et différentes vues
du système. Enfin l'implémentation de la base de données
répartie et la présentation des captures d'écran des
résultats.
La répartition intervient dans tous les niveaux de
conception des bases de données réparties et nous a
poussés à création des vues complexes,
compréhensibles à l'utilisateur, qui ne sont pas directement
modifiables sans faire appel à des déclencheurs.
VI.2. Outils de
développement
L'implémentation de la base de données
répartie a été rendu possible grâce aux outils
suivants :
VI.2.1. CentOS
La toute première version de CentOS (Community
Enterprise Operating System) créé par le groupe CentOS
Development Team est sortie au mois de mai 2004. Etant depuis une distribution
100% Open Source et totalement gratuite, CentOS est basée sur la la
distribution RedHat Entreprise Linux (RHEL). Elle utilise les sources de la
RHEL (téléchargeables librement sur Internet) pour
régénérer la RedHat à l'identique. On peut donc
considérer la CentOS comme une version gratuite de la RedHat.
Techniquement, CentOS est comparable à un clone de RHEL.
VI.2.2. Oracle 11g,
Sqldevelopper et Oracle Aplication Express
Ont été présentés au chapitre 2
(Outils de développement Oracle).
VI.3. Installation d'Oracle
11g sous Centos
La version utilisée dans ce mémoire est Oracle
11g Express Edition (XE) sur CentOS 7.
VI.3.1. Préparation du
serveur
1. Pré-requis
CentOS est installé avec une mémoire vive
minimum de 1024 Mo, l'espace d'échange au-moins deux fois (Swap = 2048
Mo).
Le parquet général seul doit disposer d'une
adresse IP publique et éventuellement d'un nom de domaine, dans le cadre
de notre mémoire nous supposons le nom de domaine est
minister-justice.lan et l'adresse IP 10.0.2.2. Les parquets de grande instance
se connecteront au parquet général à travers un VPN
(réseau à définir 192.168.0.0/24) en passant Internet.
2. Configuration des noms des
serveurs
Sur chaque serveur qui fera partie de la base de
données répartie il est défini, avec un utilisateur
ayant le droit d'administration sous CentOS (root par exemple), ce qui-suit:
3. Le nom de la machine
a) Parquet
Général
[root@cour-gombe ~]# echo
''cour-gombe.minister-justice.lan'' > /etc/hostname
[root@cour-gombe ~]# echo ''10.0.2.2 cour-gombe
cour-gombe.minister-justice.lan'' >> /etc/hosts
[root@cour-gombe ~]# echo ''192.168.0.1 cour-gombe
cour-gombe.minister-justice.lan'' >> /etc/hosts
b) Parquets de grande instance
Pour chaque serveur :
[root@pgi-XXX ~]# echo ''pgi-XXX.minister-justice.lan''
> /etc/hostname
[root@pgi-XXX ~]# echo ''10.0.2.2 cour-gombe
cour-gombe.minister-justice.lan'' >> /etc/hosts
[root@pgi-XXX ~]# echo ''192.168.0.1 cour-gombe
cour-gombe.minister-justice.lan'' >> /etc/hosts
Où XXX représente le du parquet et appartient
à {matete, ndjili, gombe, kalamu}
4. Mise en place du réseau
virtuel privé
OpenVPN est une application VPN open-source permettant la
création des réseaux privés virtuels
sécurisés à travers l'Internet.
a) Installation de openvpn
[root@cour-gombe ~]# yum update&& yum install
epel-release
[root@cour-gombe ~]# yum install openvpn easy-rsa
b) Configuration du serveur
openvpn(Parquet général)
[root@cour-gombe ~]# cp
/usr/share/doc/openvpn-2.3.8/sample/sample-config-files/server.conf
/etc/openvpn
[root@cour-gombe ~]# vi /etc/openvpn/server.conf
Modifier ce fichier de configuration comme suit :
dh dh2048.pem
push "redirect-gateway def1 bypass-dhcp"
push "dhcp-option DNS 208.67.222.222"
push "dhcp-option DNS 208.67.220.220"
user nobody
group nobody
c) Création du répertoire
des clés
[root@cour-gombe ~]# mkdir -p
/etc/openvpn/easy-rsa/keys
[root@cour-gombe ~]# cp -rf /usr/share/easy-rsa/2.0/*
/etc/openvpn/easy-rsa
d) Personnalisation des clés
[root@cour-gombe ~]# vi /etc/openvpn/easy-rsa/vars
export KEY_COUNTRY="CD"
export KEY_PROVINCE="KIN"
export KEY_CITY="Kinshasa"
export KEY_ORG="Minister-justice"
export KEY_EMAIL="ecikho@gmail.com"
export KEY_OU="parquets"
export KEY_NAME="server"
export KEY_CN="minister-justice.lan"
[root@cour-gombe ~]# cp
/etc/openvpn/easy-rsa/openssl-1.0.0.cnf /etc/openvpn/easy-rsa/openssl.cnf
Procéder à la génération des
clés et certificats :
[root@cour-gombe ~]# cd /etc/openvpn/easy-rsa
[root@cour-gombe ~]# source ./vars
[root@cour-gombe ~]# ./clean-all
e) Création du certificat
d'autorité :
[root@cour-gombe ~]# ./build-ca
f) Création des clés pour
le serveur openvpn (parquet général)
[root@cour-gombe ~]# ./build-key-server server
[root@cour-gombe ~]# ./build-dh
[root@cour-gombe ~]# cd /etc/openvpn/easy-rsa/keys
[root@cour-gombe ~]# cp dh2048.pem ca.crt server.crt
server.key /etc/openvpn
g) Création des clés pour
les clients openvpn (parquets de grande instance)
[root@cour-gombe ~]# cd /etc/openvpn/easy-rsa
[root@cour-gombe ~]# ./build-key client
h) Démarrage du serveur
openvpn
[root@cour-gombe ~]# systemctl -f enable
openvpn@server.service
[root@cour-gombe ~]# systemctl start
openvpn@server.service
i) Configuration des clients
openvpn(Parquets de grande instance)
Copier les clés certificats clients
générés à partir du serveur vers le
client :
[root@pgi-XXX ~]# scp
cour-gombe.minister-justice.lan:/etc/openvpn/easy-rsa/keys/{ca.crt,client.crt,client.key}
/etc/openvpn/
Copier le fichier de configuration client.conf et
modifier :
[root@pgi-XXX ~]# cp
/usr/share/doc/openvpn-2.3.8/sample/sample-config-files/client.conf
/etc/openvpn/
[root@pgi-XXX ~]# vi /etc/openvpn/client.conf
Modifier la ligne
remote cour-gombe.minister-justice.lan 1194
VI.3.2. Installation des
dépendances
On installe les dépendances suivantes :
[root@cour-gombe ~]# yum install libaio bc flex
VI.3.3. Installation d'Oracle
11g
On télécharge
oracle-xe-11.2.0-1.0.x86_64.rpm.zip, fdu site OTN.
[root@cour-gombe ~]#
unzip -q oracle-xe-11.2.0-1.0.x86_64.rpm.zip
[root@cour-gombe ~]# cd Disk1
[root@cour-gombe ~]# rpm -ivh oracle-xe-11.2.0-1.0.x86_64.rpm
Preparing...########################################### [100%]
1:oracle-xe ########################################### [100%]
Executing post-install steps...
You must run '/etc/init.d/oracle-xe configure' as the root user to configure the database.
VI.3.4. Configuration de
l'instance d'Oracle
[root@cour-gombe ~]# /etc/init.d/oracle-xe configure
VI.3.5. Définition des
variables d'environnements
Ajouter la ligne suivante dans le fichier .bashrc de
l'utilsateur :
[root@cour-gombe ~]# echo
''/u01/app/oracle/product/11.2.0/xe/bin/oracle_env.sh'' >> ~.basrc
VI.3.5. Configuration du
processus d'écoute (Oracle listener)
[root@hostname ~]#nano
/u01/app/oracle/product/11.2.0/xe/network/admin/listener.ora
# listener.ora Network Configuration File:
SID_LIST_LISTENER =
(SID_LIST =
(SID_DESC =
(SID_NAME = PLSExtProc)
(ORACLE_HOME = /u01/app/oracle/product/11.2.0/xe)
(PROGRAM = extproc)
)
)
LISTENER =
(DESCRIPTION_LIST =
(DESCRIPTION =
(ADDRESS = (PROTOCOL = IPC)(KEY = EXTPROC_FOR_XE))
(ADDRESS = (PROTOCOL = TCP)(HOST =hostname)(PORT =
1521))
)
)
DEFAULT_SERVICE_LISTENER = (XE)
Remplacer hostname par le nom de la machine
VI.4. Implémentation de
la base de données répartie
VI.4.1. Site Cour d'appel de
la Gombe
Démarrer le serveur Oracle et lancer sqlplus et se
connecter au compte system avec le mot de passe qu'on a défini
précédemment :
[root@cour-gombe ~]# systemctl start oracle-xe
ecotrel@cour-gombe:~$ sqlplus /nolog
SQL*Plus: Release 11.2.0.2.0 Production on Dim. Sept. 20
15:08:51 2015
Copyright (c) 1982, 2011, Oracle. All rights reserved.
SQL> connect system
Enter password:
Connected.
SQL>
1) Création de l'utilisateur
PQADMIN
Création du schéma global PQADMIN
SQL>create user pqadmin identified by esmicom;
SQL>grant dba to pqadmin;
SQL> connect pqadmin
Enter password:
Connected.
SQL>
2) Création des tables
a. Parquet
SQL> create table parquet(
codeparquet varchar2(10) primary key,
nomparquet varchar2(32) not null,
typeparquet varchar2(32),
ville varchar2(32));
b. Infraction
SQL>create table infraction(
article number(4,0) primary key,
codepenal varchar2(256),
gravite number(1,0),
sanction number(1,0),
delaiprescript varchar2(6));
c. Commune
SQL> create table commune(
codecom varchar2(10) primary key,
nomcom varchar2(32) not null,
codeparquet varchar2(10),
constraint fk_pq_com foreign key(codeparquet) references
pqadmin.parquet);
d. Personne
SQL>create table personne(
id_personne integer not null,
numidentif varchar2(20) default '000' not null,
nom varchar2(32) default 'x' not null,
postnom varchar2(32),
prenom varchar2(32),
typersonne number(1,0),
datenaiss date,
datecreation date,
aptitude number(1,0),
genre char(1),
formejurid varchar2(32),
villenaiss varchar2(32),
nationalite varchar2(32),
codecom varchar2(10),
constraint fk_pq_perso foreign key(codecom) references
pqadmin.commune,
constraint pk_pq_perso primary
key(id_personne,numidentif));
e. Mandat
SQL> create table mandat(
id_mandat integer primary key,
datenvoie date,
typemandat varchar2(32),
libelmandat varchar2(128),
codeparexp varchar2(10),
codepardes varchar2(10),
id_personne integer,
numidentif varchar2(20),
constraint fk1_pq_mandat foreign key(codeparexp) references
pqadmin.parquet,
constraint fk2_pq_mandat foreign key(codepardes) references
pqadmin.parquet,
constraint fk3_pq_mandat foreign key(id_personne,numidentif)
references pqadmin.personne);
f. Personnel
SQL> create table personnel(
matricule varchar2(16) primary key,
nomperso varchar2(32),
postperso varchar2(32),
service varchar2(3) ,
grade varchar2(32),
fonction varchar2(3),
codeparquet varchar2(10),
constraint fk_pq_personnel foreign key(codeparquet)
references pqadmin.parquet);
g. Dossier
SQL>create table dossier(
id_dossier integer primary key,
dateinscript date default sysdate,
datearrest date,
observation varchar2(128),
ordonnace varchar2(128),
mdprevent number(1,0),
codeparquet varchar2(10),
matricule varchar2(16),
article number(4,0),
constraint fk1_pq_dossier foreign key(codeparquet) references
pqadmin.parquet,
constraint fk2_pq_dossier foreign key(matricule) references
pqadmin.personnel,
constraint fk3_pq_dossier foreign key(article) references
pqadmin.infraction);
h. Acte
SQL> create table acte(
num_ordre integer primary key,
daterecept date default sysdate,
num_acte varchar2(20),
typeacte number(1,0) default 1,
objet varchar2(64),
matricule varchar2(16),
id_dossier integer,
id_personne integer,
numidentif varchar2(20),
constraint fk1_pq_acte foreign key(matricule) references
pqadmin.personnel,
constraint fk2_pq_acte foreign key(id_dossier) references
pqadmin.dossier,
constraint fk3_pq_acte foreign key(id_personne,numidentif)
references personne) ;
Annexe
SQL>create table annexe(
id_dossier integer,
num_ordre integer,
typepiece number(1,0) default 0,
element blob,
constraint fk1_pq_annexe foreign key(id_dossier) references
pqadmin.dossier,
constraint fk2_pq_annexe foreign key(num_ordre) references
pqadmin.acte,
constraint pk_pq_annexe primary
key(id_dossier,num_ordre));
i. Fait
SQL>create table fait(
num_fait integer primary key,
datefait date,recit varchar2(256),
num_ordre integer,article number(4,0),
id_personne integer,numidentif varchar2(20),
codecom varchar2(10),
constraint fk1_pq_fait foreign key(num_ordre) references
pqadmin.acte,
constraint fk2_pq_fait foreign key(article) references
pqadmin.infraction,
constraint fk3_pq_fait foreign key(id_personne,numidentif)
references pqadmin.personne,
constraint fk4_pq_fait foreign key(codecom) references
pqadmin.commune) ;
3) Création des vues
j. Personne_physique
SQL>create view personne_physique as
select
a.id_personne,a.numidentif,a.nom,a.postnom,a.prenom,a.datenaiss,a.aptitude,a.genre,a.villenaiss,a.profession,a.nationalite,b.nomcom
from personne a,commune b
where a.codecom=b.codecom;
k. Personne_morale
SQL> create view personne_morale as
select
a.id_personne,a.numidentif,a.nom,a.formejurid,a.datecreation,b.nomcom
from personne a,commune b
where a.codecom=b.codecom;
l. Personnel_judiciaire
SQL>create view personnel_judiciaire as
select
a.matricule,a.nomperso,a.postperso,a.service,a.grade,a.fonction,b.nomparquet
from personnel a,parquet b
where a.codeparquet=b.codeparquet;
m. Registre des entrées
(plaintes, dénonciations et courriers) : RENT
SQL>create view rent as
select
a.num_ordre,a.typeacte,a.num_acte,a.daterecept,a.objet,b.nom,c.element,b.codecom
from acte a,personne b,annexe c
where a.id_personne=b.id_personne and a.num_ordre=c.num_ordre;
n. Registre des PV et rapports :
RPV
SQL>create view rpv as
select
a.num_ordre,a.typeacte,a.num_acte,a.daterecept,a.objet,b.nomperso,c.element,b.codeparquet
from acte a,personnel b,annexe c
where a.matricule=b.matricule and a.num_ordre=c.num_ordre;
o. Registre du Ministère Public
global : RMPG
SQL> create view rmpg as
select
a.id_dossier,a.dateinscript,a.datearrest,b.nom,b.postnom,b.profession,b.nationalite,b.codecom,a.article,c.sanction,a.mdprevent,a.ordonnance,a.observation,a.codeparquet
from dossier a,personne b,infraction c,acte d
where a.id_dossier=d.id_dossier and b.id_personne=d.id_personne
and a.article=c.article;
p. Registre des amendes
transactionnelles : RATG
SQL> create view ratg as
select * from rmpg
where sanction=4
with check option;
q. Registre de détention
préventive : RDPG
SQL> create view rdpg as
select * from rmpg
where sanction not in '0,4' and mdprevent=1
with check option;
r. Registre du ministère public
de l'enfance délinquante : RMPEDG
SQL>create view rmpedg as
select
a.id_dossier,a.dateinscript,a.datearrest,b.nom,b.postnom,b.profession,b.nationalite,a.article,c.sanction,a.mdprevent,a.ordonnance,a.observation,a.codeparquet
from dossier a,personne b,infraction c,acte d,fait e
where a.id_dossier=d.id_dossier and b.id_personne=d.id_personne
and a.article=c.article and e.datefait-b.datenaiss < 18
with check option;
s. Registre des faits non
infractionnels : RFNIG
SQL> create view rfnig as
select * from rmpg
where article=1
with check option;
t. Registre d'informations : RIG
SQL> create view rig as
select * from rent where typeacte > 2 with check
option;
4) Création des
séquences
Nous créons des séquences pour les tables dont
les clés primaires sont des entiers auto-incrémentés.
SQL> create sequence comptx ;
5) Création des
déclencheurs
Les vues créées ne sont pas directement
modifiables, nous faisons alors recours aux déclencheurs :
a) Déclencheur pour
personne_physique
create or replace trigger ajout_phys
instead of insert on personne_physique
for each row
declare
compteur integer;
cdcom varchar2(10);
begin
select compt1.nextval into compteur from dual;
select codecom into cdcom from commune where
nomcom=:new.nomcom;
insert into
personne(id_personne,numidentif,nom,postnom,prenom,datenaiss,aptitude,genre,villenaiss,profession,nationalite,codecom)
values(compteur,:new.numidentif,:new.nom,:new.postnom,:new.prenom,:new.datenaiss,:new.aptitude,:new.genre,:new.villenaiss,:new.profession,:new.nationalite,cdcom);
end;
/
b) Déclencheur pour
PERSONNE_MORALE
create or replace trigger ajout_mor
instead of insert on personne_morale
for each row
declare
compteur integer;
cdcom varchar2(10);
begin
select compt1.nextval into compteur from dual;
select codecom into cdcom from commune where nomcom=:new.nomcom;
insert into
personne(id_personne,numidentif,nom,formejurid,datecreation,codecom)
values(compteur,:new.numidentif,:new.nom,:new.formejurid,:new.datecreation,cdcom);
end;
/
VI.4.2. Site parquet de grande
instance
1) Création des utilisateurs
Nous créons le schéma local PGIUSER :
SQL>create user pgiuser identified by esmicom;
SQL> grant all privileges to pgiuser;
VI.4.3. Création des
liens des bases de données
a) Lien Parquet général -
PGI
SQL>connect pqadmin
Enter password:
Connected.
SQL> create public database link pgctopgi connect to pgiuser
identified by esmicom using 'pgi-XXX.minister-justice.lan/XE';
b) Lien PGI - Parquet
général
SQL> connect pgiuser
Enter password:
Connected.
SQL>create public database link pgitopg connect to pqadmin
identified by esmicom using 'cour-gombe.minister-justice.lan/XE';
VI.4.4. Création des
synonymes
SQL>create public synonym personne_physique for
personne_physique@pgitopg;
SQL> create public synonym personne_morale for
personne_morale@pgitopg;
SQL> create public synonym personnel_judiciaire for
personnel_judiciaire@pgitopg;
SQL> create public synonym commune for commune@pgitopg;
SQL>create public synonym parquet for parquet@pgitopg;
SQL> create public synonym infraction for
infraction@pgitopg;
SQL> create public synonym rentg for rentg@pgitopg;
SQL> create public synonym rmpg for rmpg@pgitopg;
SQL>create public synonym rpvg for rpv@pgitopg;
SQL> create public synonym mandat for mandat@pgitopg;
SQL>create public synonym annexe for annexe@pgitopg;
VI.4.5. Fragmentation et
duplication
Nous nous servons des vues matérialisées pour
fragmenter et dupliquer les vues globales en vues locales :
Pour un parquet de grande instance dont le code est 'pr01'
a. RMP
SQL> create materialized view rmp
refresh force
start with sysdate
next sysdate+1/3
enable query rewrite
as select * from rmpg
where codeparquet='pr01' ;
b. Personne_physique_l
SQL>create materialized view personne_physique_l
refresh force
start with sysdate
next sysdate+1/3
enable query rewrite
as select * from personne_physique
where nomcom in (select nomcom from commune where
codeparquet='pr01') ;
c. Personne_morale_l
SQL>create materialized view personne_morale_l
refresh force
start with sysdate
next sysdate+1/3
enable query rewrite
as select * from personne_morale
where nomcom in (select nomcom from commune where
codeparquet='pr01') ;
VI.5. Captures
d'écran
VI.5.1. Aperçu du
réseau privé virtuel (192.168.0.0/24) dans un terminalLinux
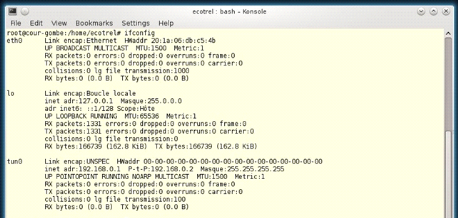
Figure 14.Aperçu du
réseau privé virtuel dans le terminal Linux
VI.5.2. Aperçu des
tables du schéma global dans Oracle SQLDevelopper
Figure 14. Aperçu des tables sous
SQLDevelopper
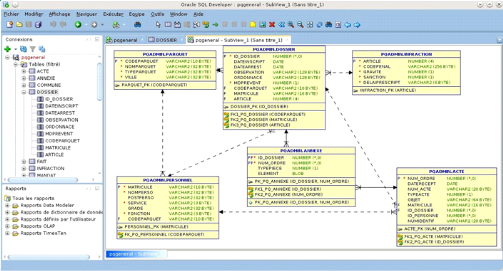
VI.5.3. Aperçu des vues
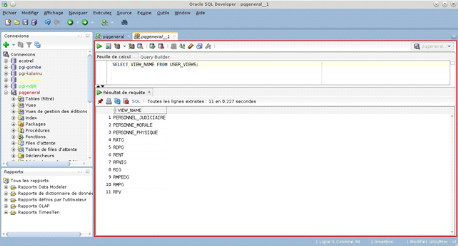
Figure 15.Aperçu des
vues sous SQLDevelopper
Figure 16. Aperçu de la
table Parquet sous Oracle Apex
VI.5.4. Aperçu sous Oracle sous
Apex
Figure 17. Aperçu de la
vue Personne_Physique sous Oracle Apex
VI.6. Conclusion
La base de données répartie vient d'être
implémentée sous Oracle sur Centos à travers un
réseau privé virtuel mis en place avec openvpn. Les exigences
d'une base de données répartie ont été
réalisés par :
· création du schéma global au niveau du
parquet général ;
· création des schémas locaux au niveau des
parquets de grande instance ;
· création des liens entre les bases de
données pour interconnecter différents sites;
· création des synonymes pour rendre transparente
la localisation ;
· création des vues pour cacher à
l'utilisateur certains détails complexes ;
· création des vues matérialisées
pour rendre transparentes la duplication et l'allocation.
En implémentant de la sorte, notre objectif, celui de
mettre en place une base de données répartie sous Oracle, a
été atteint.
CONCLUSION GENERALE
Notre objectif, celui de réaliser une base de
données répartie interconnectant différents parquets de
grande instance de la ville de Kinshasa et permettant ainsi une gestion
optimale des dossiers judiciaires et un accroissement de la
disponibilité des données échangées par les
parquets de grande instance entre eux et avec les parquets
généraux, vient d'être atteint à travers ce
mémoire de fin d'étude.
En ce qui nous concerne, ce mémoire a été
une forte expérience tant scientifique que professionnelle, joignant les
théories reçues durant notre formation à la pratique. Cela
nous a permis d'explorer ce vaste domaine des bases de données
réparties et de les appliquer au SGBD Oracle 11g.
Ce mémoire nous a permis également d'explorer le
domaine du droit pénal et du système judiciaire de l'ordre des
juridictions civiles de notre pays et de constater son grand besoin
d'informatisation.
Comme perspectives, nous envisageons de développer une
application logicielle ergonomique, étant donné que notre
mémoire a été plus orienté application base de
données, présentant au personnel des parquets de grande instance
une vue sécurisée, fiable et fidèle à leur service
respectif et de l'étendre à tous les niveaux de l'ordre
judiciaire.
Nous restons ouverts aux suggestions et corrections
susceptibles d'apporter amélioration à notre mémoire.
Bibliographie
Ouvrages
Blanc, Xavier et Isabelle Mounier. 2004.UML2
pour les développeurs cours avec exercices corrigés.
Paris : Eyrolles, 2004. p. 215.
Briard, Gilles. 2006.Oracle 10g sous
Windows. Paris : Eyrolles, 2006. p. 895.
Diviné, Michel. 2000.Merise : 60
affaires classées. Paris : Les éditions du
phénomène, 2000. p. 291.
Gardarin, Georges. 2003.Bases de
données. Paris : Eyrolles, 2003. p. 826.
Nanci, Dominique et Bernard Esinasse.
2001.Ingéniérie des systèmes d'information :
merise deuxième génération. 4e. Paris : Vuibert,
2001. p. 416.
Ndjike, Mupila. 1996.Des sièges et
ressorts des juridictions civiles de la ville de Kinshasa. Kinshasa :
Pax/Zaïre, 1996. p. 125.
Roques, Pascal et Franck Vallée.
2005.UML2 en action de l'analyse des besoins à la
conception. 4e. Paris : Eyrolles, 2005. p. 394.
Roques, pascal. 2008.UML2 modéliser
une application web. 4e. Paris : Eyrolles, 2008. p. 264.
Roques, Pascal. 2006.UML2 par la pratique
Etudes de cas et exercices corrigés. 5e. Paris : Eyrolles,
2006. p. 364.
Roy, Gilles. 2009.Conception de bases de
données avec UML. Québec : Presses de
l'université du Québec, 2009. p. 530.
Soutou, Christian. 2002.De UML à SQL
Conception de bases de données. Paris : Eyrolles, 2002. p.
385.
Soutou, Christian et Olivier Teste. 2004.SQL
pour Oracle. Paris : Eyrolles, 2004. p. 576.
Soutou, Christian. 2007.UML2 pour les bases
de données. 2e. Paris : Eyrolles, 2007. p. 316.
Wesler, Michael. 2002.Oracle DBA on Unix and
Linux. Indianapolis : SAMS, 2002. p. 599.
Notes de Cours
Prof. NTUMBA, Simon.Cours de base de
données répartie. Kinshasa : ESMICOM, 2013-214.
Moussa, Rim.Systèmes de Gestion de
Bases de Données Réparties & Mécanismes de
Répartition avec Oracle. Carthage : Ecole Supérieure de
Technologie et d'Informatique, 2005-2006.
Internet
Leganet. Loi organique n° 13/011-B du 11
avril 2013. leganet.cd. [En ligne].
http://www.leganet.cd/Legislation/Droit%20Judiciaire/LOI.13.011.11.04.2013.htm.
Oracle. intro Oracle. oracle.com. [En
ligne] [Citation : 14 05 2015.]
http://docs.oracle.com/cd/B28359_01/server.111/b28318/intro.htm.
Articles
Bases de données réparties.
CHRISMENT, Claude, PUJOLLE, Geneviève et ZURFLUH, Gilles
. s.l. : Techniques de l'Ingénieur. H 3 850 - 1.
Bases de Données Réparties. Sabri,
Abdelouahed.2011/2012.
Thèses et
mémoires
SARR, Idrissa.Routage des Transactions dans
les Bases de Données à Large Echelle. Paris :
Université Pierre et Marie Curie, 2010.
Hanane, Bouanani.Suivi et gestion
répartie des clients d'une banque, Cas de la Banque BADR.
s.l. : Université Abou Bakr Belkaid- Tlemcen, 2012-2013.
Table des
matières
Dédicaces
Erreur ! Signet non
défini.
Remerciements
ii
Liste des abréviations et sigles
iii
Liste des figures
iv
Liste des tableaux
iv
INTRODUCTION GENERALE
5
1. Problématique
5
2. Hypothèse
5
3. Choix et intérêt du
sujet
5
4. Délimitation du sujet
6
5. Méthodologie
6
a) Techniques :
6
b) Méthodes :
7
6. Subdivision du travail
7
7. Difficultés rencontrées
7
CHAPITRE I. GENERALITES SUR LES BASES DE
DONNEES REPARTIES
8
I.1. Introduction
8
I.2. Définitions
8
I.2.1. Base de données répartie
8
I.2.2. SGBD réparti
9
I.3. Quelques définitions
complémentaires
9
I.3.1. Base de données
centralisée
9
I.3.2. Multibase
9
I.3.3. Base de données
fédérée
9
I.3.4. Traitement distribué
9
I.3.5. SGBD parallèle
10
I.4. Avantages et inconvénients d'une
base de données repartie
10
I.4.1. Avantages
10
I.4.2. Inconvénients
10
I.5. Les propriétés requises
d'une base de données repartie
11
I.5.1. Transparence
11
I.5.2. Passage à l'échelle
11
I.5.3. Disponibilité
12
I.5.4. Autonomie
12
I.6. Conception d'une base de données
repartie
12
I.6.1. Approche ascendante (BD
Fédérées, Bottom up design)
13
I.6.2. Approche descendante (BD Réparties,
Top down design) :
13
1. Conception du schéma conceptuel
globale
14
2. Processus de fragmentation ou
partitionnement
14
a) Définition
14
b) Les règles de fragmentation
15
c) Techniques de Fragmentation
15
Fragmentation horizontale
15
Fragmentation horizontale primaire
15
Fragmentation horizontale
dérivée
15
Fragmentation verticale
16
Fragmentation mixte
16
Avantages et inconvénients de la
fragmentation
16
Avantages
16
Inconvénients
17
3. Processus d'allocation des fragments (Le
placement)
17
a) Problème d'allocation
17
b) Contraintes
17
c) Allocation de fragments aux sites
17
4. Gestion de transaction
17
5. Processus de réplication
19
a. Définition
19
b. Motivation
19
c. Gestion de la réplication
19
d. Avantages de la réplication
20
e. La haute performance par la
réplication
22
I.7. Conclusion
22
CHAPITRE II. BASES DE DONNEES REPARTIES SOUS
ORACLE
23
II.1. Introduction
23
II.2. Présentation d'Oracle
23
II.3. Architecture d'Oracle
25
II.3.1. Structure de stockage
25
II.3.1.1. Structure physique
25
II.3.1.2. Structure logique
26
II.3.2. Structure de mémoire
26
II.3.3. Structure des processus
27
II.4. Contrôle des données
28
II.4.1. Gestion de l'utilisateur
28
II.4.1.1. Classification
28
II.4.1.2. Création d'un utilisateur
29
II.4.1.3. Suppression d'un utilisateur
29
II.4.2. Profil
29
II.4.3. Privilège
29
II.4.4. Rôle
30
II.4.5. Vue
30
II.5. Oracle et les objectifs d'une base de
données répartie
31
II.5.1. Oracle Net Listener
31
II.5.2. Nom de service
31
II.5.3. Transparence vis-à-vis de la
localisation
31
II.5.3.1. Lien des bases de données
31
II.5.3.2. Synonyme
32
II.5.3.3. Procédure
33
II.5.4. Transparence vis-à-vis de la
fragmentation
33
II.5.4.1. Vue
33
a) Vues monotables
34
b) Vues en lecture seule
34
c) Vues modifiables
34
d) Vues complexes
34
II.5.5. Transparence vis-à-vis à la
réplication
35
II.5.5.1. copy
35
II.5.5.2. Snapshots
35
II.5.5.3. Vues matérialisées
36
II.6. Outils d'Oracle
37
II.6.1. Outils d'administration
37
II.6.1.1. sqlplus
37
II.6.1.2. sqldeveloper
37
II.6.2. Outils de configuration réseau
37
II.6.3. Outils de développement
38
II.6.3.1. SQL Developer
38
II.6.3.2. Oracle Application Express
38
II.6.3.3. Oracle JDeveloper
38
II.6.3.4. Oracle JPublisher
38
II.6.3.5. Oracle Developer pour Visual Studio
.NET
38
II.7. Conclusion
38
CHAPITRE III : PRESENTATION DU PARQUET DE
GRANDE INSTANCE
39
III.1. Introduction
39
III.2. Présentation de l'Ordre judiciaire du
Parquet congolais
39
1) Le Parquet Général de la
République
40
2) Le Parquet Général
40
3) Le Parquet de Grande Instance
40
4) Le Parquet Secondaire
40
III.3. Organisation du Parquet de Grande
Instance
40
A. La Magistrature
41
B. La police Judicaire
41
C. L'Administration
41
III.4. Fonctionnement du Parquet de Grande
Instance
41
a) La section de services
généraux
41
b) La section de l'action publique
42
c) La section de l'instruction
judiciaire
42
d) La section de l'exécution du
jugement
42
III.5. Gestion du dossier judiciaire
42
1. Ouverture du dossier
42
Plainte
43
Dénonciation
43
PV de L'OPJ
43
Saisie d'office
43
2. Instruction du dossier
judiciaire :
43
a) Enregistrement du dossier
43
b) Lancement des pièces de
procédure
43
c) L'audition ou l'interrogation
44
3. Clôture du dossier judiciaire
44
- La transmission du dossier à un
autre office du Parquet :
44
- La conversion du dossier RI en dossier RMP
:
44
- L'envoi du dossier en fixation devant le
Tribunal compétent :
44
- Le classement par amende transactionnelle
:
45
- Le classement sans suite :
45
4. Inventaire des pièces du
dossier
45
III.6. Les parquets de grande instance de la ville
de Kinshasa
46
III.7. Conclusion
46
CHAPITRE IV : GESTION DU PROJET
47
IV.1. Introduction
47
IV.2. Notions théoriques
47
IV.2.1. Identification des actions principales
47
1) Décomposer (ou
découper)
48
2) Evaluer (ou estimer)
48
3) Organiser
48
4) Planifier
48
Méthode PERT
48
a. Origine
48
b. Principes
49
1. Représentation et
symbologie
49
2. Règles
49
3. Algorithme
49
5) Suivre
50
6) Ajuster
50
7) Terminer
50
IV.3. La gestion du projet proprement dite
50
IV.3.1. Découpage du projet
50
IV.3.1.1. Phases du projet
50
IV.3.1.2. Tâches du projet
51
IV.3.2. Organisation
51
IV.3.3. Planification
52
a) Détermination des niveaux de
tâches :
52
b) Mise en ordre du graphe du projet
52
c) Délai de réalisation du
projet
52
1) Calcul des dates au plus tôt
52
2) Calcul des dates au plus tard
53
3) Calcul des marges libres
54
4) Calcul des marges totales
54
5) Détermination du chemin
critique
55
6) Durée globale du projet
55
d) Coût total du projet
55
IV.4. Conclusion
55
V.1. Introduction
56
V.2. Analyse de besoin
56
V.3. Etude des postes de travail
56
V.3.1. Diagramme de flux d'informations
57
V.4. Etude des documents
57
V.5. Spécification de besoin
58
V.6. Solution proposée
58
V.7. Conception
59
V.7.1. UML et les bases de données
60
V.7.2. Modèle d'analyse
60
a) Règles de gestion
60
b) Diagramme de classe d'analyse
61
V.7.3. Modèle conceptuel
62
a. Dictionnaire des données
62
b. Domaines
63
c. Diagramme de classe de conception
64
64
V.7.4. Modèle logique
65
1) Règles de passage schéma
conceptuel - schéma logique
65
a) Transformation des classes
65
b) Transformation des associations
65
1. Associations un-à-plusieurs
65
2. Associations plusieurs-à-plusieurs
et n-aires
65
3. Associations un-à-un
65
2) Schéma relationnel :
66
V.7.5. Vues
66
1. Personne_physique
66
2. Personne_morale
66
4. Registre des entrées (plaintes,
dénonciations et courriers) : RENT
66
5. Registre des PV et rapports :
RPV
67
6. Registre du Ministère Public
global : RMPG
67
7. Registre des amendes
transactionnelles : RATG
67
8. Registre de détention
préventive : RDPG
67
9. Registre du ministère public de
l'enfance délinquante : RMPEDG
67
10. Registre tutelle : RTG
67
11. Registre des faits non
infractionnels : RFNIG
67
12. Registre d'informations : RIG
67
V.7.6. Fragmentation
68
a) Registre du Ministère public
local : RMP
68
b) Registre des faits non
infractionnels : RFNI
68
c) Registre des autres parquets :
RAP
68
d) Registre d'informations : RI
68
e) Registre des amendes
transactionnelles : RAT
68
f) Registre de contrôle de
détention préventive : RDP
68
g) Registre des tutelles : RT
68
h) Registre du ministère public de
l'enfance délinquante : RMPED
68
i) La relation
personne_physique_l :
68
j) La relation personne_morale_l :
68
k) La relation personnel_judiciaire_l :
68
V.7.7. Duplication
69
V.7.8. Sécurité des
données.
69
V.7.9. Sécurité de communication.
69
V.8. Conclusion
69
CHAPITRE VI. IMPLEMENTATION
70
VI.1. Introduction
70
VI.2. Outils de développement
70
VI.2.1. CentOS
70
VI.2.2. Oracle 11g, Sqldevelopper et Oracle
Aplication Express
70
VI.3. Installation d'Oracle 11g sous Centos
70
VI.3.1. Préparation du serveur
70
1. Pré-requis
70
2. Configuration des noms des serveurs
71
3. Le nom de la machine
71
a) Parquet Général
71
b) Parquets de grande instance
71
4. Mise en place du réseau virtuel
privé
71
a) Installation de openvpn
71
b) Configuration du serveur openvpn(Parquet
général)
71
c) Création du répertoire des
clés
72
d) Personnalisation des clés
72
e) Création du certificat
d'autorité :
72
f) Création des clés pour le
serveur openvpn (parquet général)
72
g) Création des clés pour les
clients openvpn (parquets de grande instance)
72
h) Démarrage du serveur openvpn
72
i) Configuration des clients
openvpn(Parquets de grande instance)
73
VI.3.2. Installation des dépendances
73
VI.3.3. Installation d'Oracle 11g
73
VI.3.4. Configuration de l'instance d'Oracle
73
VI.3.5. Définition des variables
d'environnements
73
VI.3.5. Configuration du processus d'écoute
(Oracle listener)
73
VI.4. Implémentation de la base de
données répartie
74
VI.4.1. Site Cour d'appel de la Gombe
74
1) Création de l'utilisateur
PQADMIN
74
2) Création des tables
75
a. Parquet
75
b. Infraction
75
c. Commune
75
d. Personne
75
e. Mandat
76
f. Personnel
76
g. Dossier
76
h. Acte
77
i. Annexe
77
j. Fait
77
3) Création des vues
78
k. Personne_physique
78
l. Personne_morale
78
m. Personnel_judiciaire
78
n. Registre des entrées (plaintes,
dénonciations et courriers) : RENT
78
o. Registre des PV et rapports :
RPV
78
p. Registre du Ministère Public
global : RMPG
78
q. Registre des amendes
transactionnelles : RATG
79
r. Registre de détention
préventive : RDPG
79
s. Registre du ministère public de
l'enfance délinquante : RMPEDG
79
t. Registre des faits non
infractionnels : RFNIG
79
u. Registre d'informations : RIG
79
4) Création des séquences
79
5) Création des
déclencheurs
79
a) Déclencheur pour
personne_physique
80
b) Déclencheur pour
PERSONNE_MORALE
80
VI.4.2. Site parquet de grande instance
80
1) Création des utilisateurs
80
VI.4.3. Création des liens des bases de
données
81
a) Lien Parquet général -
PGI
81
b) Lien PGI - Parquet
général
81
VI.4.4. Création des synonymes
81
VI.4.5. Fragmentation et duplication
81
a. RMP
81
b. Personne_physique_l
82
c. Personne_morale_l
82
VI.5. Captures d'écran
82
VI.5.1. Aperçu du réseau privé
virtuel (192.168.0.0/24) dans un terminal Linux
82
VI.5.2. Aperçu des tables du schéma
global dans Oracle SQLDevelopper
83
VI.5.3. Aperçu des vues
83
83
VI.6. Conclusion
85
CONCLUSION GENERALE
86
Bibliographie
87
Ouvrages
87
Notes de Cours
87
Internet
87
Articles
87
Thèses et mémoires
87
Table des matières
88
| 

