|
|
|
|
Stratégies d'optimisation de requêtes SQL dans un
écosystème Hadoop
|
|
Sébastien FRACKOWIAK
|
15/01/2018
|
SOMMAIRE
SOMMAIRE
1
Remerciements
3
Résumé
4
Liste des figures et des tableaux
5
1
Introduction
7
1.1 Entrepôt et Bases de
Données Relationnelles
7
1.2 Entrepôt et Bases de
Données Big Data
7
1.3 Problématique
7
2
Hadoop
9
2.1 Histoire
9
2.2 Le composant de stockage (HDFS)
9
2.3 Le composant de traitement
(MapReduce)
10
2.3.1 Architecture Hadoop v1
10
2.3.2 Architecture Hadoop v2
11
2.3.3 Le paradigme MapReduce
12
2.4 Discussion
16
2.4.1 Du point de vue HDFS
16
2.4.2 Du point de vue YARN
17
3 SQL
sur Hadoop
19
3.1 Hive
19
3.1.1 Histoire
19
3.1.2 Architecture
19
3.2 La commande
« EXPLAIN »
20
3.2.1 Explication d'une projection
simple
21
3.2.2 Explication d'une projection avec une
restriction
23
3.2.3 Explication d'une projection avec une
restriction et une agrégation
26
3.2.4 Explication d'une jointure entre deux
tables
30
3.3 Discussion
32
3.3.1 Requête avec une restriction
32
3.3.2 Requête avec une
agrégation
32
3.3.3 Requête avec une jointure et une
agrégation
32
4
Optimisation du SQL sur Hadoop
35
4.1 Optimisation par le réglage ou
« tuning »
35
4.1.1 Utiliser Tez
35
4.1.2 Contrôler la taille des fichiers
manipulés
37
4.1.3 Agréger en amont
39
4.1.4 Réaliser un
« benchmark » significatif
39
4.2 Optimisation par la conception ou
« design »
40
4.2.1 Utiliser les tables
partitionnées
41
4.2.2 Optimiser les jointures
42
4.3 Discussion
46
5
Conclusion
47
6
Bibliographie
48
7
Annexes
49
7.1 Hadoop
49
7.1.1 Partition & Sort
détaillé
49
7.1.2 Définition de la distance entre
deux noeuds
49
7.2 SQL sur Hadoop
50
7.2.1 Gérer manuellement le
partitionnement dans une requête
50
7.2.2 Comprendre la sérialisation
sous Hadoop
50
7.3 Optimisation du SQL sur Hadoop
50
7.3.1 Exemple de WordCount avec Tez
50
7.3.2 Grouper les splits avec Tez
50
REMERCIEMENTS
J'aimerais exprimer toute ma gratitude à la Direction
Solution Exploitation de la DSI des Réseaux d'Orange, en particulier
Jean-Claude Marcovici, Nadine Poinson, Jean-Marc Pageot et Serge Schembri pour
m'avoir donné l'opportunité de suivre ce cursus et les moyens de
réaliser ce mémoire.
Je voudrais remercier mon tuteur Stéphane Crozat, pour
ses conseils durant la rédaction de ce mémoire et son
enseignement en Base de Données et en Big Data, ainsi que Dominique
Lenne et Thomas Deshais pour leur soutien et leurs encouragements à
l'égard de notre promotion tout au long de ce Master.
Toute ma reconnaissance va également versmes
collègues développeurs de l'équipe Big Data Technique :
Alioune, Bastien, Christophe, Patrick et particulièrement Régis
et Thomas pour leur disponibilité.
Enfin, je remerciemon épouse pour ses précieux
conseils, ses encouragements et son soutien ainsi que mon fils, mes
beaux-parents et ma mère pour nous avoir grandementfacilités
cette année un peu particulière.
Sébastien Frackowiak
1 RÉSUMÉ
Le Big Data n'est plus un « buzzword », il
est devenu au fil de ces dernières années une
réalité.Ainsi, il n'est plus rare que les grandes entreprises
disposent d'un « puits de données » contenant une
énorme quantité d'informations. C'est le cas d'Orange qui utilise
Hadoop.
Dans ce cadre, le moyen le plus courant de programmer des
traitements Big Data est d'utiliser Hive qui émule le langage SQL. Mais
cette émulation peut être trompeuse car ses mécanismes
sous-jacents sont radicalement différents de ceux que nous connaissons
bien, ils cachent l'utilisation du paradigme MapReduce.Popularisé par
Google, ce paradigme réussit à traiter de gigantesques volumes de
données de manière distribuée. C'est son fonctionnement et
son application au SQL qui seront détaillés dans ce
mémoire afin de pouvoir proposer des stratégies d'optimisation
des requêtes.
Il en ressortira qu'une bonne optimisation ne peut se faire
sans connaissance fine des données manipulées et étude
statistique préalable. Mais surtout, que la multitude d'options et de
techniques d'optimisation proposées au développeur
nécessiteraient de sa part une compétence similaire à
celle d'un administrateur de base de données. C'est l'évolution
de cet aspect qui conditionnera l'avenir de Hadoop et de Hive.
LISTE DES FIGURES ET DES
TABLEAUX
Figure 1 : architecture Hadoop 1.0
Source (reproduction) :
https://fr.hortonworks.com/blog/apache-hadoop-2-is-ga/
Figure 2 : architecture Hadoop 2.0
Source (reproduction) :
https://fr.hortonworks.com/blog/apache-hadoop-2-is-ga/
Figure 3 : répartition de trois
fichiers dans un cluster HDFS
Figure 4 : phases de création des
containers YARN pour l'exécution de l'application
« WordCount »
Figure 5 : phases d'exécution de
l'application « WordCount »
Figure 6 : architecture de Hive
Figure 7 : diagramme de traitement du
parcours d'une table avec projection et restriction
Figure 8 : processus de traitement MapReduce
d'une requête avec projection et restriction
Figure 9 : processus de traitement MapReduce
d'une requête SQL avec agrégation
Figure 10 : graphe des dépendances
d'une requête avec jointure et agrégation
Figure 11 : processus de traitement
MapReduce d'une requête SQL avec jointure
Figure 12 : phase
« Map » d'une jointure sur un Mapper
Figure 13 : phase
« Reduce » d'une jointure sur deux Reducers
Figure 14 : mouvement de données de
type « One-To-One »
Source (reproduction) :
https://fr.hortonworks.com/blog/expressing-data-processing-in-apache-tez/
Figure 15 : mouvement de données de
type « Broadcast »
Source (reproduction) :
https://fr.hortonworks.com/blog/expressing-data-processing-in-apache-tez/
Figure 16 : mouvement de données de
type « Scatter-Gather »
Source (reproduction) :
https://fr.hortonworks.com/blog/expressing-data-processing-in-apache-tez/
Figure 17 : comparaison MapReduce / Tez
Source (reproduction) :
https://fr.hortonworks.com/blog/expressing-data-processing-in-apache-tez/
Figure 18 : du Système d'Information
au Use Case Big Data
Figure 19 : graphe des dépendances
d'une requête SQL avec jointure « Map-Only » (1/2)
Figure 20 : graphe des dépendances
d'une requête SQL avec jointure « Map-Only » (2/2)
Figure 21 : Reducer devant traiter une
donnée « biaisée » ou
« skewed »
Figure 22 : traitement MapReduce
détaillant le « Partition & Sort »
Source :Tom White (2015). Hadoop: The definitive guide, page
197
Tableau 1 : temps d'accès
cumulé sur 1GB de données
Tableau 2 : centiles du nombre de lignes
par date de chargement
Tableau 3 : centiles du nombre de lignes
par date fonctionnelle
2 INTRODUCTION
Créé en 2011, Hadoop s'est imposé depuis
plusieurs années comme la principale plateforme Big Data. Il
représente une réelle rupture dans le traitement des
donnéeset il a modifié en profondeur la manière de
concevoir et d'utiliser les entrepôts de données.
2.1 Entrepôt et
Bases de Données Relationnelles
Un entrepôt de données traditionnel permet de
stocker les données provenant de plusieurs applications d'un
Système d'Information afin d'en tirer des enseignements et ainsi aider
l'entreprise dans ses décisions.
La création d'un tel entrepôt de données
impliquela mise en oeuvre d'une Base de Données Relationnelle dont
lepréalable fondamental est sa modélisation.
Modélisationqui tacitement met en exergue des clés (primaires et
étrangères) et des index, ce qui favoriseune manière de
requêter les données plutôt qu'une autre.En effet, sans
entrer dans les détails du fonctionnement d'un Système de Gestion
de Base de Données Relationnelle (SGBDR), il est important de signaler
que le requêtage SQL de deux tables jointes l'une à l'autre
s'effectue le plus souvent via leurs clés respectives. Ces clés
traduisent des contraintes qui garantissent la cohérence des
résultats et permettent l'utilisation des fonctions d'indexation qui
accélèrent leur obtention.
Lorsque les volumes de données manipulées sont
ceux du Big Data, nous pouvons nous permettre de nous passer de ces contraintes
trop rigides.
2.2 Entrepôt et
Bases de Données Big Data
Les technologies du Big Data permettent dorénavant de
stocker sur des systèmes de fichiers distribués de grandes
quantités de données, issues principalement de flux continus et
de Bases de Données Relationnelles provenant de SI et d'organisations
distinctes.
Des solutions exploitant le paradigme distribué
MapReduce(qui fait notamment l'objet de ce mémoire) permettent
l'interrogation de ces grandes quantités de données, de la
même manière que sur un SGBDR classique, en utilisant le langage
SQL. Dans ce cas de figure, les données sont structurées dans des
tables formant un unique "puits de données", ce qui rend ainsi possible,
au travers de jointures, des croisements de données issues
d'applications et d'organisations différentes (au sein même
d'Orange mais aussi en dehors d'Orange, provenant de l'Open Data par exemple).
Avec un SGBDR classique, ce type de traitement aurait pu prendre des jours
contre seulement quelques minutes aujourd'hui avec le Big Data.
Si dans une Base de Données Relationnelle, les
jointures sont anticipées dès la phase de conception (par
identification des clés et des index), ce n'est pas le cas pour un puits
de données qui ne couvre aucun cas d'usage de prime abord. De ce fait,
les champs utilisés pour joindre deux tables n'expriment aucune
contrainte (il s'agit d'une fonction propre aux clés primaires et
étrangères des SGBDR) et ne sont pas indexés (il serait
hasardeux d'anticiper un plan d'indexation particulier sachant que la
conception du puits de données ne préjuge en rien de la
manière dont il sera requêté). C'est donc une nouvelle
manière d'optimiser les requêtes qui doit être
pensée.
2.3
Problématique
L'implémentation "distribuée" du SQL conduit
à adopter de nouveaux réflexes, très
éloignés de ceux pris durant des années avec les SGBDR. Il
devient alors nécessaire de s'interroger sur les leviers permettant
d'optimiser les temps d'exécution des requêtes SQL dans un
environnement Big Data.
L'objectif de ce mémoire est double : il s'agit
premièrement de se construire une connaissance fine de l'environnement
Big Data le plus répandu, c'est-à-dire Hadoop, qui est aussi
celui sur lequel tout le Big Data d'Orange repose ; deuxièmement,
c'est une technologie en plein essor et en rupture par rapport aux autres
technologies plus conventionnelles, et les pratiques qu'elle implique
nécessitent d'être étudiées spécifiquement
afin d'optimiser son fonctionnement.
Par ailleurs, la documentation existante traduit du
développement rapide de l'écosystème Hadoop. Nous pouvons
ainsi trouver de très nombreux articles témoignant des
différentes phases de son évolution, mais peu s'attardentsur son
fonctionnement réel. Il paraît donc intéressant et non
superflu de faire un état de l'art structuré et à jour de
cet écosystème.
Dans ce mémoire, nous reviendrons tout d'abord sur ce
qu'est Hadoop, ce qui le compose et la manière dont il fonctionne.
Nous détaillerons ensuite comment le langage SQL est
implémenté sous Hadoop par une application nommée Hive. Ce
qui nous permettra de mettre en lumière les principales faiblesses du
paradigme distribué.
Puis, nous proposerons un ensemble de bonnes pratiques, aussi
bien dans la configuration préalable à l'exécution d'une
requête SQL que dans la conception des tables et le développement
des requêtes.
Finalement, nous achèverons ce mémoire en
prenant du recul sur la maturité de Hadoop et son évolution
constante.Nous nous interrogerons aussi sur la pertinence des optimisations que
nous proposons devant la multitude des possibilités offertes. Enfin, se
posera la question de l'avenir de Hadoop dans sa formule actuelle et de son
évolution prévisible dans les années à venir.
3 HADOOP
3.1 Histoire
L'histoire de Hadoop commence avec le projet Nutch,
initié par Doug Cutting en 2002. Son but était de proposer un
moteur de recherche open-source de type « crawler »,
c'est-à-dire capable de parcourir et d'indexer automatiquement
l'ensemble du web, quand les moteurs de recherche de cette époque
pratiquaient un référencement manuel des sites web.
Les quantitéscroissantes voire inattenduesde
données à stocker et à traiter devinrent une
difficulté, l'infrastructure supportant le projet Nutch ne reposaient en
effet que sur quelques machines.
En 2003, Google publia un article de recherche concernant un
système de fichiers, le GoogleFS (Sanjay Ghemawat, Howard Gobioff, and
Shun-Tak Leung, 2003). Ilse compose d'un cluster de noeuds, le rendant scalable
et distribué :
- la taille du FS n'est pas limitée et peut être
étendue par ajout d'un nouveau noeud
- la taille de chacun des fichiers qu'il contient n'est pas
limitée non plus etces fichiers sont répartis, par blocs, sur
plusieurs noeuds
Le GoogleFS est ainsi parfaitement adapté aux traitements
distribués.
En 2004, Google publia un nouvel article de recherche
concernant un framework de traitement distribué : le MapReduce
(Jeffrey Dean and Sanjay Ghemawat, 2004).
Dès 2004, les travaux de Google permirent au projet
Nutchde résoudre ses difficultés de stockage et de traitement en
concevant une implémentation open-source de GoogleFS et
MapReduce :c'est Hadoop. Ce dernier estainsi composéde son propre
composant de stockage (HadoopFS ou HDFS) et de son propre composant de
traitement (MapReduce).
D'abord utilisé par Yahoo en 2006, puis passé sous
licence Apache en 2009, la première version stable de Hadoop fut
proposée en 2011.
3.2 Le composant de
stockage (HDFS)
Tout comme le GoogleFS, le HDFS repose sur un cluster scalable
et distribué (Tom White, 2015). Il est composé d'un noeud
principal exécutant le service « NameNode »
(maître) et de plusieurs noeuds exécutant un service
« DataNode » (esclave).
Les DataNodes contiennent les fichiers découpés
en blocs. Par défaut :
- un bloc a une taille de 128MB (contre 4KB pour un FS
« classique »),
- un même bloc sera copié sur 3 DataNodes
distincts.
Le NameNodemaintient l'arborescence du système de
fichier (répertoires, fichiers et blocs composant chaque fichier) et
connaît l'emplacement (unDataNode) de chaque bloc constituant chaque
fichier.
Il s'ensuit que toute demande de lecture ou d'écriture
d'un fichier passera d'abord par le NameNode, soit pour obtenir la liste des
blocs et leurs emplacements, soit pour allouer/désallouer de nouveaux
blocs.
Ces caractéristiques impliquent que le HDFS est
optimisé pour traiter spécifiquement des fichiers de grande
taille, le plus rapidement possible. En effet, si la taille des blocs est aussi
élevée, c'est pour être en mesure de lire les fichiers
à la vitesse permise par le disque. Si ce dernier à une vitesse
de lecture de 100MB/s et un temps d'accès de 10ms, un fichier de 128MB
sera lu en 1,29s (1,28s+0,01s) et ne sera pas pénalisé pas le
temps d'accès. A contrario, la lecture de 128 fichiers de 1MB
nécessitera 2,56s (1,28s+0,01s×128) et la nécessité
de solliciter autant de DataNodes (si chaque fichier est réparti sur un
DataNode différent).
En outre, le HDFS fonctionne en mode « write-once,
read-many-times », c'est-à-dire qu'une fois
créé, un fichier ne peut être modifié, sauf pour une
opération de concaténation ou de suppression. Cela permet de
garantir la cohérence des données lorsqu'elles sont
sollicitées simultanément. De plus, la modification d'un fichier
de très grande taille serait bloquante et donc incompatible avec
l'objectif de traiter des fichiers le plus rapidement possible.
Enfin, le HDFS est tolérant aux pannes du point de vue
de ses DataNodes, puisque chaque bloc sera recopié 3 fois. En revanche,
le NameNode doit être considéré comme un « single
point of failure », dans la mesure où il stocke en
mémoire l'arborescence du système de fichier et l'emplacement de
chaque bloc. Comme un objet nécessite 150B de mémoire (quelle que
soit sa taille), une quantité élevée d'objets peut
conduire à l'arrêt du NameNode et donc à la panne du HDFS.
A titre indicatif, un milliard de fichiers nécessitent 300GB de
mémoire vive : pour chaque fichier, il faut considérer 150B
pour le fichier et 150B pour le bloc sur lequel il repose.
Le morcellement de HDFS en blocs de données de grande
taille est étudié pour être utilisé par une
application distribuée : MapReduce.
3.3 Le composant de
traitement (MapReduce)
3.3.1 Architecture Hadoop v1
Dansla première version de Hadoop (2011),MapReduce est
le composant de traitement et repose sur un cluster scalable et
distribué. Il est composé d'un noeud principal exécutant
le service « jobtracker » (maître) et de plusieurs
noeuds exécutant un service « tasktracker »
(esclave).Chaque tasktracker contient un nombre fini de
« slots », ressources disponibleset
spécialisées pour exécuter des tâches soit
« map » (lecture et prétraitement des
données) soit « reduce » (agrégation des
résultats du « map »).
Le jobtracker :
- reçoit les demandes de jobs à exécuter,
- localiseles DataNodes où se trouvent les données
à traiter en interrogeant le NameNode,
- localise les tasktrackers avec des slots disponibles et les
plus proches des données (
annexe),
- soumet les tâches« map » ou
« reduce » aux tasktrackers,
- coordonne l'exécution de chaque tâche.
Les tasktrackers :
- exécutent les tâches« map »
ou « reduce » (dans le slot attribué),
- communiquent périodiquement la progression des
tâches qu'ils exécutent au jobtracker. En cas d'erreur, le
jobtracker est ainsi capable de resoumettre une tâche sur un tasktracker
différent.
A ce stade du chapitre, il est à noter que les
composants HDFS et MapReducereposent sur le même cluster de noeuds
physiques. Ainsi, leNameNode et le tasktracker (tous deux gérant leur
cluster logique respectif) s'exécutent généralement sur
des noeuds physiques qui leur sont dédiés (soit un pour deux,
soit un chacun) et unDataNodepartage généralement un noeud
physique avec un tasktracker.
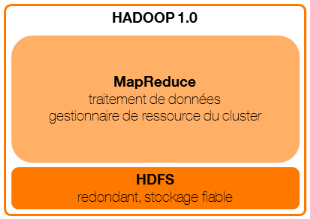
Figure 1 : architecture Hadoop
1.0
Dans cette première version, la spécialisation
des slots « map » ou « reduce » rendait
problématique l'allocation des ressources. Ainsi, si tous les slots
« map » étaient attribués, il était
impossible d'utiliser un slot « reduce » pour effectuer une
tâche « map », et le traitement était donc mis
en attente. C'est notamment ce point que la version 2 a corrigé.
3.3.2 Architecture Hadoop v2
La seconde version de Hadoop (2012)dissocie la fonction de
gestionnaire de ressources de MapReduce et propose un cadre
généraliste au-dessus (API) permettant le développement
d'applications de traitement distribué.
YARN (YetAnother Resource Negotiator) est le gestionnaire de
ressource du cluster et est composé d'un noeud principal
exécutant le service « ResourceManager »
(maître) et de plusieurs noeuds exécutant un service
« NodeManager » (esclave). Chaque NodeManagerpeut
contenirun nombre indéfini de « containers »,
c'est-à-dire, des ressources disponibles pour exécuter tout type
de tâches.
MapReduce devientainsi une application YARN, tout comme
d'autres applications de traitement distribué telles que Tez et Spark.
Ces applications sont des frameworks, ce qui veut dire qu'elles ne
spécifient que la logique de traitement distribué et non le
traitement en lui-même.Dorénavant, lorsque nous parlerons
d'applications MapReduce, Tezou Spark, nous parlerons tacitement d'applications
implémentant ces frameworks et décrivant un traitement
précis.
Quelle que soit l'application YARN, le fonctionnement sera le
même :
Le ResourceManager :
- reçoit les demandes d'applications à
exécuter,
- crée un « ApplicationMaster »sur un
NodeManager par application,
- attribue à l'ApplicationMaster, les NodeManagers
disposant d'assez de ressources disponibles pour créer les containers
demandés,
- priorise les demandes de ressources (file d'attente en mode
FIFO par exemple).
Les ApplicationMasters :
- estiment la quantité de ressources requiseau regard de
laconnaissance de l'application qu'ils exécutent,
- effectuent les demandes de containers au ResourceManager en
précisant leur localisation idéale (par exemple, au plus proche
des données),
- démarrent les containers sur les NodeManagers
attribués par le ResourceManager
Les NodeManagers :
- contiennent les containers démarrés par
l'ApplicationMaster,
- exécutent les tâches(au sens
générique du terme) demandées par leur ApplicationMaster
(dans le container attribué),
- communiquent périodiquement la progression des jobs
qu'ils exécutent à l'ApplicationMaster. En cas d'erreur, ce
dernierpeut ainsi demander d'autres containers au ResourceManager et leur
affecter le job.
L'avantage par rapport à Hadoop v1 est la
capacité à proposer plusieurs frameworks de traitement
distribué (ne répondant pas tous aux mêmes besoins), sur un
même gestionnaire de ressource. En outre, l'introduction de
l'ApplicationMaster permet de décentraliser la coordination de
l'exécution de chaque tâche et ainsi de ne pas surcharger le
ResourceManager. Enfin, la gestion par container permet d'être plus
flexible dans l'attribution des ressources, du fait de leur non
spécificité.
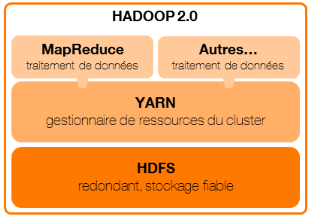
Figure 2 : architecture Hadoop
2.0
3.3.3 Le paradigme MapReduce
Dans ce mémoire, nous considérerons
principalement les frameworks MapReduce et Tez (Hadoop v2). Le premier
implémenteexactement le paradigme MapReduce que Google a décrit
dans ces travaux de 2004 alors que le second se veut plus
généraliste et plus souple (nous y reviendrons). Ainsi,
l'écriture d'une application MapReduce consiste à
décrire :
- une classe « Map » qui
génère un ensemble de couplesclé/valeur
- une classe « Reduce » qui agrège
les valeurs intermédiaires selon leur clé
Pour illustrer le principe du paradigme MapReduce, prenons
l'exemple du « Word Count », qui permet de compter les
occurrences de chaque mot d'un jeu de données.
Considérons un répertoire du HDFScontenant 3
fichiers qui feront l'objet d'un comptage d'occurrences.
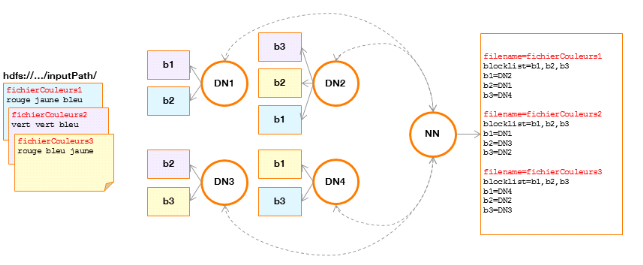
Figure 3 : répartition
de trois fichiers dans un cluster HDFS
Explication :
Chaque fichier « fichierCouleurs » occupe1
bloc de données dupliqué 3 trois fois sur un cluster de 4
DataNodes (DN) gérés par le NameNode (NN).
Leprogramme « WordCount »
suivantimplémenteMapReduce :
public class WordCount {
public static class Map extends Mapper<LongWritable, Text,
Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(LongWritable key, Text value, Context context)
throwsIOException, InterruptedException {
String line = value.toString();
StringTokenizer tokenizer = new StringTokenizer(line);
while (tokenizer.hasMoreTokens()) {
word.set(tokenizer.nextToken());
context.write(word, one);
}
}
}
public static class Reduce extends Reducer<Text, IntWritable,
Text, IntWritable> {
public void reduce(Text key, Iterable<IntWritable> values,
Context context)
throwsIOException, InterruptedException {
int sum = 0;
for (IntWritableval : values) {
sum += val.get();
}
context.write(key, new IntWritable(sum));
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = new Job(conf, "wordcount");
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
job.setMapperClass(Map.class);
job.setReducerClass(Reduce.class);
job.setNumReduceTasks(2);
job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
job.waitForCompletion(true);
}
}
Ce programme s'exécutera dans l'architecture Hadoop et
sollicitera ses différents composants :
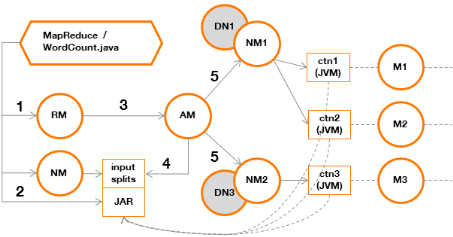
Figure 4 : phases de
création des containers YARN pour l'exécution de l'application
« WordCount »
Explication :
· Etape 1
L'application « WordCount » sollicite le
ResourceManager afin de déclarer une nouvelle application YARN.
· Etape 2
L'application « Wordcount » sollicite le
NameNode afin d'obtenir la liste des blocs composant le ou les fichiers
à traiter puis dépose les références vers ces blocs
(split) dans un répertoire partagé, où sera
également copié le JAR à exécuter.
· Etape 3
Le ResourceManager crée un ApplicationMaster.
· Etape 4
L'ApplicationMaster lit les « input
splits » afin de déterminer l'emplacement des
données.
· Etape 5
L'ApplicationMaster crée des containers qui pourront
exécuter le JAR, sur les NodeManagers les plus proches des DataNodes
contenant les données (voir annexe).
L'exécution du JAR contenant le programme
« WordCount » et qui implémente MapReduce impliquera
les phases suivantes :
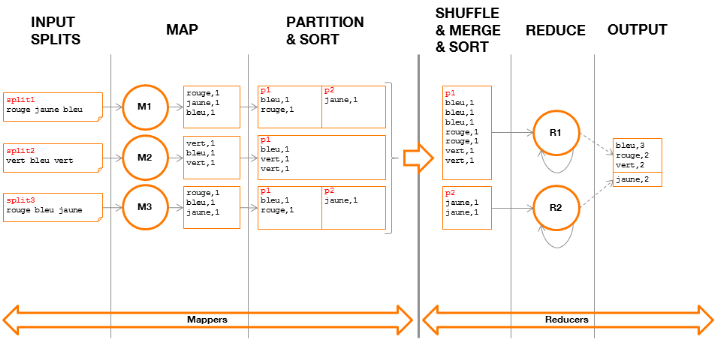
Figure 5 : phases
d'exécution de l'application « WordCount »
Explication :
· Input Splits
L'ApplicationMaster associe un split à un container. Ce
dernier exécutera un et un seul Mapper sur les données
pointées par le split.
· Map
Chaque Mapper exécutesur ses données, la
méthode « Map » qui lira chaque mot
séparément.Pour chaque mot lu, cette méthode
générera un couple clé/valeur où la clé,
correspondant au mot parcouru, sera associée à la valeur 1. Le
fait de rencontrer 2 fois le mot « vert » implique que le
couple {vert, 1} sera généré donc deux fois.
· Partition & Sort
A l'issue de la méthode « Map »,
chaque Mapper déversera les couples
clé/valeurgénérés dans un fichier (sur le disque
local du Mapper,
annexe) où ils seront groupésdans
des partitions suivant leur clé.Une partition contientainsi un ensemble
de couples clé/valeur et, par construction,chaque clé ne peut
figurer que dans une unique partition(par Mapper).
Le nombre de partitions est déterminé dès
le lancement de l'application en précisant le nombre de Reducers
souhaité, par exemple :
job.setNumReduceTasks(2)
Si le nombre de Reducers n'est pas précisé, il
sera fixé par défaut à 1.
Par défaut, le framework MapReduce implémente le
calcul de la partition pour chaque clé comme suit :
(key.hashCode() &Integer.MAX_VALUE) % numReduceTasks
Ce procédé permet de répartir les
clés de manière équilibréelorsque leur nombre est
important.
· Shuffle & Merge &
Sort
Chaque Reducer reçoit les partitions identiques de
chaque Mapper (par transfert HTTP) pour ensuiteles fusionner entre elles et
leur appliquerde nouveau un tri par clé. A l'issue de cette
étape, autant de fichiers que de partitions fusionnées auront
été créés (sur le disque local du Reducer).
Il est important de noter qu'un Reducer est ainsi garanti de
traiter l'intégralité des couples clé/valeur pour une
clé donnée et est donc à même d'effectuer seul le
traitement de cette clé.
· Reduce
Chaque fichier local est traité par son Reducer qui
exécutera la méthode « Reduce » pour chaque
clé. Chaque valeur d'une même clé (d'une même couleur
dans notre exemple),sera ainsi comptée pour obtenir le nombre
d'occurrences.
· Output
Chaque Reducer génère un fichier comportant des
couples clé/valeur et affichera sur la sortie standard son contenu. Le
résultat, vu de l'utilisateur, est la concaténation de l'ensemble
du contenu de ces fichiers.
3.4 Discussion
Cette première partie nous a permis de mieux comprendre le
Paradigme MapReduce et au travers d'un premier exemple, d'entrevoir les
premiers enjeux et problématiques.
3.4.1 Du point de vue HDFS
Le NameNode répond seul aux sollicitations de toutes
les applications, pour leurs besoins de lecture et d'écriture. Nous
avons considéré dans notre exemple
« WordCount », 3 fichiers de quelques octets. La
conséquence immédiate est le besoin de solliciter 3 fois le
NameNode au lieu d'une seulesi les données avaient été
regroupées dans un seul fichier.
Dans ce contexte de « petits
fichiers » :
Ø Le NameNode peut porter atteinte aux performances du
cluster. D'une part, parce que la table d'allocation qu'il stocke en
mémoire peut se saturer rapidement (au regard des 150B
nécessaires pour référencer un fichier, un
répertoire, un bloc). D'autre part, parce qu'il devra gérer seul
un grand nombre d'opérations sur ces métadonnées (plus il
y a de fichiers, plus il y a d'opérations).
Ø Les performances pourront aussi être
affectées par la nécessité d'accéder
simultanément à beaucoup de fichiers stockés sur les
DataNodes. Prenons le cas théorique, d'un ensemble de données
faisant 1GB. Selon la répartition de ces données, pouvant aller
d'un seul fichier jusqu'à 10 000 fichiers, lestemps d'accès
cumulés (à mettre en relation avec la taille totale à
traiter) peuvent provoquer le ralentissement du cluster dans son ensemble.
|
nombre de fichiers
|
taille en bytes
|
nombre de blocs
par fichier
|
temps
d'accès total (sec)
|
|
1
|
1000000000
|
8,0
|
0,08
|
|
1000
|
1000000
|
1,0
|
10
|
|
10000
|
100000
|
1,0
|
100
|
|
100000
|
10000
|
1,0
|
1000
|
Tableau 1 : temps
d'accès cumulés sur 1GB de données suivant le nombre de
fichiers
3.4.2 Du point de vue YARN
Dans ce même contexte de « petits
fichiers » :
Ø L'ApplicationMaster réalise les demandes de
création de containersauprès du ResourceManager, pour
exécuter des tâches Map ou Reduce sur les NodeManagers. Chaquebloc
étant associé à une tâche Map (exécuté
par un container), il faudra donc impliquer un plus grand nombre de containers
lors de traitement sur des petits fichiers.De plus, les ressources sont
négociées au travers d'une file d'attente et elles ne seront pas
systématiquement disponibles en même temps.
Ø L'ApplicationMaster réalise également
la gestion des tâches entre elles (notamment, leur synchronisation), et
ce coût est fixe quel que soit le volume de données
manipulées.Ainsi, les performances de traitement d'un grand nombre de
tâches ne manipulant que peu de données seront fortement
impactées.
A la lumière de ces observations, nous constatons qu'il
faudra être vigilant et bien maîtriser la quantité de petits
fichiers afin d'éviter de ralentir les performances du cluster et donc
du traitement.
4 SQL SUR HADOOP
4.1 Hive
4.1.1 Histoire
Hive est un projet initié en 2007 par
Facebook(AshishThusoo, 2009). Le réseau social disposait alors d'une
infrastructure de traitement de données classique, basée sur un
entrepôt de données construit surun SGBDR du
marché.Année après année, la quantité de
données à traiter devenait de plus en plus importante et
l'architecture en place devint rapidement obsolète. Hadoop s'est ainsi
rapidement imposé comme la solution à ces difficultés de
montée en charge : c'est un projet Open Source et surtout, il
propose une infrastructure scalable déjà
éprouvée.
Si la capacité de traitement de l'infrastructure Hadoop
était aisément extensible et si les traitements
s'exécutaient dorénavant en quelques heures au lieu d'un jour ou
plus, il fallait en revanche les développer en utilisant le paradigme
MapReduce. Les utilisateurs des entrepôts de données, plus
habitués au SQL, n'étaient pas forcément à l'aise
dans l'écriture de programmes de ce type.
L'équipe de Jeff Hammerbacher créa alors Hive, un
entrepôt de données au-dessus de Hadoop, dont le langage
d'interrogation des données, le HQL (Hive Query Langage), est le portage
« distribué »du SQL des SGBDR classiques.
Hive est rapidement passé sous licence Apache, sa
première version stable date d'octobre 2010, et continue d'être
améliorée tout en bénéficiant des évolutions
continues de Hadoop.
4.1.2 Architecture
Hive est composé des éléments suivants
(LeftyLeverenz, 2015) :
· le metastore
Le metastore contient l'ensemble des données
décrivant les tables (schéma de données, localisation des
fichiers, et les statistiques concernant les données telles que le
nombre de lignes, la taille moyenne d'une ligne, etc.).
· un compilateur (compiler) et un optimiseur
(optimizer)
Le compilateur réalise l'analyse syntaxique
(générant un arbre syntaxique abstrait ou AST) puis l'analyse
sémantique (génération d'un arbre d'opérations ou
operatortree) définissant l'ensemble des étapes
nécessaires à l'accomplissement de la requête. Au cours de
cette analyse, le metastoresera sollicité pour validerque l'ensemble des
objets (fichiers et champs) décrits dans la requête sont
valides.
Il est à noter qu'il ne figure aucune dépendance
à MapReduce, ni à d'autres frameworks distribués, à
ce stade de la compilation.
Ensuite, selon le framework distribué utilisé
par Hive, un compilateur de tâche sera exécuté
(MapRedCompiler par exemple) et génèrera une tâche
exécutable (MapRedTask, c'est-à-dire du code Java
implémentant le framework MapReduce dans ce cas de figure) décrit
par un arbre d'opérations qui aura d'abord été
optimisé puis transformé en enchaînement de travaux
(MapRedWork).
Les dernières versions de Hive permettent d'utiliser
d'autres frameworks distribués comme Tez et Spark, sans remettre en
question cette architecture.
· un exécuteur
(executor)
L'exécuteur est en charge de soumettre lestâches
auNodeManager(côté Hadoop). Il supervisera ainsi leur
exécution jusqu'à leur achèvement.
· une interface utilisateur
(UI)
L'interface utilisateur permet à l'utilisateur d'interagir
avec Hive (envoyer des requêtes / obtenir les résultats) au
travers d'un client connecté au serveur Hive via un connecteur ODBC ou
JDBC dans la plupart des cas.
· le pilote (driver)
Le pilote contrôle les échanges entre l'interface
utilisateur, le compilateur et l'exécuteur. Il reçoit ainsi la
demande d'exécution d'une requête par l'utilisateur qu'il
soumettra au compilateur, puis à l'exécuteur après
compilation. Il est également en charge de restituer le résultat
de la requête, reçu par l'exécuteur, à
l'utilisateur.
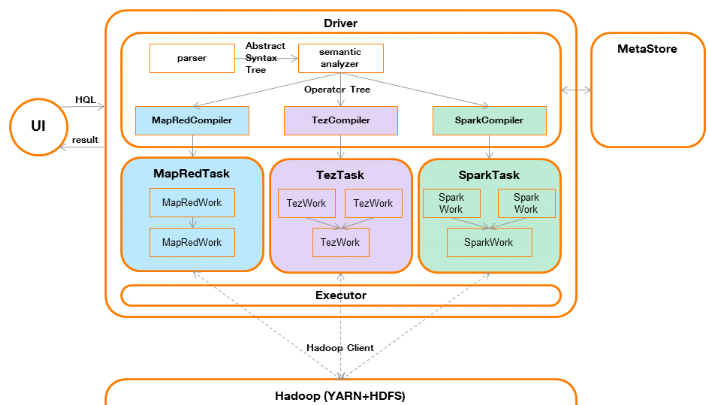
Figure 6 : architecture de
Hive
4.2 La commande
« EXPLAIN »
Tout comme dans les SGBDR classiques, Hive propose la commande
EXPLAIN qui permet d'obtenir le plan d'exécution de la requête
à exécuter. Dans notre environnement distribué, le plan
d'exécution liste l'ensemble des étapesqui seront
exécutées sur le cluster Hadoop.
Nous allons tirer parti de cette commande pour constituer
notre connaissance du fonctionnement de Hive. Ce qui nous permettra plus tard,
d'optimiser nos requêtes. Nous jugeons fondamental de proposer une
méthode d'interprétation des résultats d'un EXPLAIN. En
effet, c'est un outil que tout utilisateur de Hive doit pouvoir s'approprier
afin d'en faire de même. Nous espérons que nos explications
détaillées pourront ainsi servir de modèle. En effet, il
nous a été nécessaire d'analyser le code source de
l'EXPLAIN (
https://github.com/apache/hive)
pour le comprendre pleinement, n'ayant trouvé aucun document
réellement explicatif à son propos.
Commençons donc à construire notre
compréhension du fonctionnement de Hive en utilisant la commande EXPLAIN
EXTENDED sur une requête que nous complexifierons au fur et à
mesure.
Le rajout du mot clé « EXTENDED »
permet d'obtenir notamment l'arbre syntaxique abstraitde la requête ainsi
que des informations issues du metastore, relatives auxtables
manipulées.
En outre, le résultat d'un
« EXPLAIN » étant relativement verbeux, nous le
limiterons dans nos exemples aux informations que nous jugerons pertinentes.
Enfin, pour des raisons de confidentialité
d'entreprise, le nom des bases, des tables et des champs ont été
anonymisés.
4.2.1 Explication d'une projection
simple
La commande suivante permet d'expliquer une requête
simpleeffectuant une projection :
EXPLAIN EXTENDED
SELECT field1FROM z_database1.table1;
Le résultat de l' « EXPLAIN
EXTENDED » est :
ABSTRACT SYNTAX TREE:
TOK_QUERY
TOK_FROM
TOK_TABREF
TOK_TABNAME
z_database1
table1
TOK_INSERT
TOK_DESTINATION
TOK_DIR
TOK_TMP_FILE
TOK_SELECT
TOK_SELEXPR
TOK_TABLE_OR_COL
field1
STAGE DEPENDENCIES:
Stage-0 is a root stage
STAGE PLANS:
Stage: Stage-0
Fetch Operator
limit: -1
Processor Tree:
TableScan
alias: table1
Statistics:
Num rows: 38877279
Data size: 95714574567
Basic stats: COMPLETE
Column stats: NONE
GatherStats: false
Select Operator
expressions: field1 (type: varchar(10))
outputColumnNames: _col0
Statistics:
Num rows: 38877279
Data size: 95714574567
Basic stats: COMPLETE
Column stats: NONE
ListSink
Explications :
Le résultat d'un « EXPLAIN
EXTENDED » contient 3 parties.
· (1) L'arbre syntaxique
abstrait
Il décrit un ensemble de blocs
« TOK_* » symbolisant les tokens (des mots clé)
reconnus par le parser.
Dans notre exemple, nous remarquons notamment les tokens
suivant :
- TOK_QUERY : la racine de l'arbre
o TOK_FROM : la base et la table interrogées
o TOK_INSERT : la destination du résultat dans un
fichier temporaire
o TOK_SELECT : les champs sélectionnés
· (2) Les dépendances entre
étapes
Cette partie décrit le plan de dépendances entre
chaque étape où une étape peut :
- êtreracine (« is a root
stage »)
- dépendre d'une autre étape
(« depends on stage... »)
- consister à déclencher une autre étape
(« consists of stage... »)
Dans notre exemple, il ne figure qu'une seule
étape :
- Stage-0 : l'étape racine
· (3) Le plan
d'étapes
Cette partie décrit la séquence des
étapes qui seront réalisées où chaque étape
peut être de type :
- Map Reduce
- Fetch Operator (lire les données d'une table)
- Move Operator (déplacer un fichier du HDFS)
Une étape peut contenir un ou plusieurs arbres de
traitements, dont chacun peut contenir un ou plusieurs traitements.
Dans notre exemple :
- Stage-0
o est de type « Fetch Operator »
o contient un arbre de traitements « Processor
Tree » décrivantla séquence de traitements
suivants :
§ TableScanSelect OperatorListSink
Où :
- TableScan : « balaye » la table
ligne par ligne
- Select Operator : projette le champ
sélectionné vers un fichier temporaire
- ListSink : transmetles données du fichier
temporaire à l' « executor »
Une simple projection n'implique ni opération
« Map », ni opération « Reduce »
carelle ne requiert aucune manipulation des données. Les informations
fournies par le metastore(l'emplacement des fichiers contenant la table et la
définition de chacun de ses champs) suffiront pour demander directement
au cluster HDFS (NameNode + Datanodes) de transmettre à
l' « executor », les données projetées
de la table, sans solliciter le cluster YARN (ResourceManager +
NodeManagers).
4.2.2 Explication d'une projection avec
une restriction
Complexifions légèrement notre requête en
lui appliquant une restriction puis expliquons-la :
EXPLAIN EXTENDED
SELECT field1 FROM z_database1.table1
WHERE field1="123";
Le résultat de cet « EXPLAIN
EXTENDED » est :
ABSTRACT SYNTAX TREE:
TOK_QUERY
TOK_FROM
TOK_TABREF
TOK_TABNAME
z_database1
table1
TOK_INSERT
TOK_DESTINATION
TOK_DIR
TOK_TMP_FILE
TOK_SELECT
TOK_SELEXPR
TOK_TABLE_OR_COL
field1
TOK_WHERE
=
TOK_TABLE_OR_COL
field1
"123"
STAGE DEPENDENCIES:
Stage-1 is a root stage
Stage-0 depends on stages: Stage-1
STAGE PLANS:
Stage: Stage-1
Map Reduce
Map Operator Tree:
TableScan
alias: table1
filterExpr: (field1 = '123') (type: boolean)
Statistics:
...
GatherStats: false
Filter Operator
isSamplingPred: false
predicate: (field1 = '123') (type: boolean)
Statistics:
...
Select Operator
expressions: field1 (type: varchar(10))
outputColumnNames: _col0
Statistics:
...
File Output Operator
compressed: true
GlobalTableId: 0
directory:
hdfs://NAMENODE/tmp/hive/u_xxxx_yyy/.../-ext-10001
NumFilesPerFileSink: 1
Statistics:
...
Stats Publishing Key Prefix:
hdfs://NAMENODE/tmp/hive/u_xxxx_yyy/.../-ext-10001/
table:
input format:
org.apache.hadoop.mapred.TextInputFormat
output format:
org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat
...
TotalFiles: 1
GatherStats: false
MultiFileSpray: false
Path -> Alias:
hdfs://NAMENODE/.../z_database1.db/table1 [table1]
Path -> Partition:
hdfs://NAMENODE/.../z_database1.db/table1
Partition
base file name: table1
input format:
org.apache.hadoop.hive.ql.io.orc.OrcInputFormat
output format:
org.apache.hadoop.hive.ql.io.orc.OrcOutputFormat
properties:
...
Stage: Stage-0
Fetch Operator
limit: -1
Processor Tree:
ListSink
Explications :
Le résultat de cet « EXPLAIN
EXTENDED » contient les 3 mêmes parties.
· (1) L'arbre syntaxique
abstrait
Nous remarquons qu'il contient un nouveau token
« TOK_WHERE » définissant notre restriction, nous
avons en effet à présent :
- TOK_QUERY : la racine de l'arbre
o TOK_FROM : la base et la table interrogées
o TOK_INSERT : la destination du résultat dans un
fichier temporaire
o TOK_SELECT : les champs sélectionnés
o TOK_WHERE : la restriction opérée sur un
champ
· (2) Les dépendances entre
étapes
Dans notre exemple, le plan de dépendance est devenu
plus complexe puisqu'il figure à présent deux
étapes :
- Stage-1: l'étaperacine
- Stage-0 : une étape dépendant
de l'étape racine
· (3) Le plan
d'étapes
Dans notre exemple :
- Stage-0 :
o est de type « Map Reduce »
o contient un arbre de traitements « Map Operator
Tree » décrivant une séquence de traitements :
§ TableScanFilter OperatorSelect OperatorFile Output
Operator
Où :
Ø TableScan : « balaye » la
table ligne par ligne
Ø Filter Operator : filtre la ligne parcourue
Ø Select Operator : projette le champ
sélectionné
Ø File Output Operator : définit la table
temporaire qui contiendra le résultat et notamment son emplacement
physique sur HDFS, ainsi que ses statistiques
Voici un schéma décrivant cette
étape :
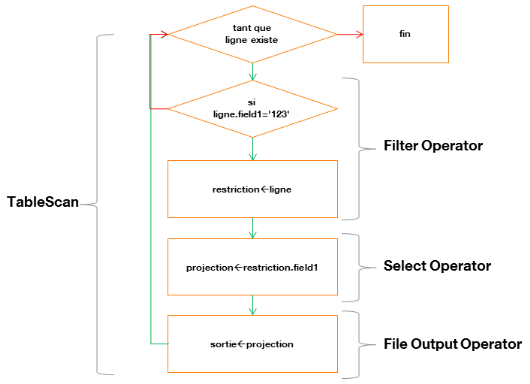
Figure 7 : diagramme de
traitement du parcours d'une table avec projection et restriction
- Stage-1 :
o est de type « Fetch Operator »
o contient un arbre de traitements « Processor
Tree » réalisant un unique traitement :
§ ListSink
Où :
Ø ListSink : transmet les données du
fichier temporaire à l' « executor »
Résumons :
- Le Stage-0 est chargé de construire
une table temporaire, réalisant la projection et la restriction d'une
table (phase Map).
- Le Stage-1 est chargé de
transférer les données de la table temporaire à
l' « executor » de Hive qui se chargera de les
acheminer au client qui aura effectué la requête.Dans cette
étape, l'absence de « TableScan » provient du fait
qu'il n'y plus aucune opération à réaliser (ni projection,
ni restriction), mis à part le transfert.
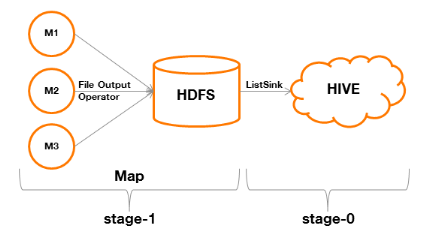
Figure 8 : processus de
traitement MapReduce d'une requête avec projection et restriction
Un tel fonctionnement est appelé « Map-Only
Job ». Sa particularité est de ne faire appel qu'à une
phase Map, épargnant ainsi notamment les étapes
« Partition & Sort » et « Shuffle & Merge
& Sort » préalables à la phase Reduce. C'est un
procédé qui permet dans tous les cas de figure de réaliser
un traitement avec le maximum de distribution sans avoir à
agréger les données sur un ensemble de Reducers.
Notons enfin, les sections « Path Alias » et
« Path Partition » qui s'ajoutent et qui donnent un
ensemble d'informations relatives à la table utilisée dans notre
requête :
· Path Alias : l'emplacement physique de la table dans
HDFS
· Path Partition : l'emplacement physique de la
partition dans HDFS(le rôle d'une partition sera expliqué dans le
prochain chapitre)
o input / output format : le format de la table
o properties
§ columns : la liste des champs de la table
§ columns.types : le type de chaque champ de la
table
o numFiles : la quantité de fichiers utilisés
par la table
o numRows : le nombre de lignes contenues par la table
o rawDataSize : la taille brute de la table (non
compressée)
o totalSize : la taille réelle de la table
(compressée)
4.2.3 Explication d'une projection avec
une restriction et une agrégation
Complexifions à nouveau notre requête en lui
ajoutant une agrégation puis expliquons-la :
EXPLAIN EXTENDED
SELECT field1 FROM z_database1.table1
WHERE field1="123"
GROUP BY field1
Rappelons qu'un « GROUP BY colonne1, ...
colonneN » regroupera sur une même ligne chaque partition d'une
liste de colonnes. Il est donc nécessaire que cette liste de colonnes
apparaisse immédiatement suite au « SELECT ».L'usage
habituel est d'ajouter ensuite des fonctions d'agrégation comme
« COUNT », qui s'appliqueront à chacune des
partitions listées. Notre exemple n'utilise pas de telles fonctions,
pour ne pas ajouter de complexité inutile.
Le résultat de cet « EXPLAIN
EXTENDED » est :
ABSTRACT SYNTAX TREE:
...
STAGE DEPENDENCIES:
Stage-1 is a root stage
Stage-0 depends on stages: Stage-1
STAGE PLANS:
Stage: Stage-1
Map Reduce
Map Operator Tree:
TableScan
alias: table1
filterExpr: (field1 = '123') (type: boolean)
Statistics:
...
GatherStats: false
Filter Operator
isSamplingPred: false
predicate: (field1 = '123') (type: boolean)
Statistics:
...
Reduce Output Operator
key expressions: field1 (type: varchar(10))
sort order: +
Map-reduce partition columns: field1 (type:
varchar(10))
Statistics:
...
tag: -1
auto parallelism: false
Path -> Alias:
hdfs://NAMENODE/.../z_database1/table1 [table1]
Path -> Partition:
hdfs://NAMENODE/.../z_database1/table1
Partition
...
Reduce Operator Tree:
Group By Operator
keys: KEY._col0 (type: varchar(10))
mode: complete
outputColumnNames: _col0
Statistics:
...
File Output Operator
...
Stage: Stage-0
Fetch Operator
limit: -1
Processor Tree:
ListSink
Nous ne reviendrons ni sur l'arbre syntaxique abstrait (qui
ajoute à l'exemple précédent un nouveau token
« TOK_GROUPBY ») ni sur les dépendances entre
étapes (qui sont strictement identiques à l'exemple
précédent : Stage-1Stage-0).
Détaillons en revanche le plan d'étapes :
- Stage-0
o est de type « Map Reduce »
o contient un arbre de traitements
« Map Operator Tree »
décrivant une séquence de traitements :
§ TableScanFilter OperatorReduce Output Operator
o contient un arbre de traitements
« Reduce Operator Tree »
décrivant une séquence de traitements :
§ GroupBy OperatorFile Output Operator
- Stage-1
o est identique à l'exemple précédent, il
consiste à transférer les données issues du
« File Output Operator » (ListSink) à
l' « executor » de Hive
Résumons :
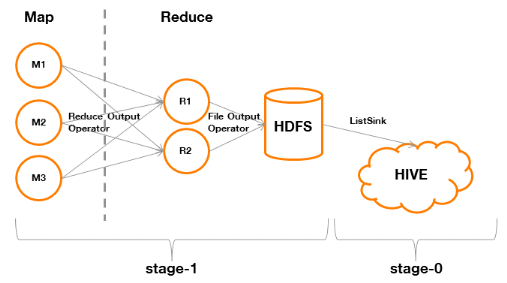
Figure 9 : processus de traitement
MapReduce d'une requête SQL avec agrégation
Nous identifions que le Stage-0implique
l'exécution d'une phase Map (A) puis d'une phase Reduce (B).
A. Phase Map
Dans « Map OperatorTree », le
« File Output Operator » de l'exemple
précédent est remplacé par un « Reduce Output
Operator ». Cela veut dire que la sortie ne s'effectuera pas sur un
fichier du HDFS mais au travers du réseau vers les noeuds
réalisant la phase Reducer. Le « Reduce Output
Operator » définit plusieurs éléments
fondamentaux pour la suite.
· key expressions
Une expression (Ki) peut être une simple colonne ou une
combinaison de plusieurs colonnes dans une formule (concaténation de
deux colonnes par exemple).
Par exemple, nous pourrions avoir :
K1 = field1
ou bien
K1 = concat(field2, field3)
Une « key expressions » est l'ensemble des
expressions composant la clé qui sera utilisée durant toutes les
phases du Map Reduce. Chaque clé peut être ainsi
considérée comme un n-uplet (K1, ..., Kn).
Nous aurions ainsi des couples clé (K) / valeur (V) de
la forme suivante :
((K1, ..., Kn), (V1, ..., Vm))
Notons que le framework MapReduce définit une
clé comme un seul élément (il en va de même pour la
valeur), cela implique donc l'utilisation de mécaniques de
sérialisation par Hive afin d'assurer la compatibilité entre ces
deux environnements (
annexe).
· sort order
Il s'agit du sens du tri (« + » pour
ascendant et « - » pour descendant) qui sera appliqué
à la clé durant les phases de « Partition &
Sort » et « Shuffle & Merge & Sort ».
Il est à noter qu'il y aura autant de
« + » ou de « - » que d'expressions
définissant la clé (le premier ordre s'applique à K1, le
n-ième ordre à Kn).
· map-reduce partition
columns
Il s'agit de l'ensemble des colonnes qui définiront le
partitionnement qui sera utilisé durant les phases « Partition
& Sort & Shuffle » et « Merge &
Sort ».
Le partitionnement permet d'affecter chaque ligne parcourue
à un Reducer. Il garantit que toutes les lignes identiques sur cet
ensemble de colonnes seront traitées au sein d'un même Reducer.
Dans notre exemple, la définition de la clé est
identique au partitionnement. Il s'agit du cas d'application classique du
paradigme MapReduce. Il est cependant possible de distinguer la clé et
le partitionnement en utilisant notamment les instructions suivantes en
fin de requête :
DISTRIBUTE BY <ci, ..., cn> SORT BY <cj, ...,
cm>
ou bien
CLUSTER BY <ci, ..., cn>
« DISTRIBUTE BY » indique l'ensemble de
colonnes qui définira le partitionnement (
annexe).
« SORT BY » indique le sens du tri sur
chaque colonne ou expression définissant la clé.
« CLUSTER BY » consiste en un
« DISTRIBUTE BY » et « SORT BY ».
B. Phase Reduce :
Dans « Reduce Operator Tree », il figure
un bloc « Group By Operator » qui définit les
éléments suivant :
· keys
Il s'agit de l'ensemble des Ki composant la clé
défini durant le « Map Operator Tree » et qui sera
utilisée durant la phase Reduce qui traitera donc
séparément chaque n-uplet.
· mode
Dans le contexte du « GROUP BY », il
indique si le mode est :
- complete
o la phase Reduce a réalisé toute la phase
d'agrégation
- mergepartial
o la phase Reduce n'a réalisé qu'une
agrégation partielle, ce qui indique qu'une agrégation
préliminaire a déjà été
réalisée durant la phase Map
Dans notre exemple, l'agrégation est
« complete ».
· outputColumnNames
Il s'agit des noms des colonnes qui seront retournées dans
la table temporaire.
4.2.4 Explication d'une jointure entre
deux tables
Modifions une dernière fois notre requête, cette
fois-ci en faisant apparaître une jointure et expliquons-la.
EXPLAIN
SELECT t1.field1 FROM z_database1.table1 t1
INNER JOIN z_database1.table2 t2 ON t1.field1=t2.field1
WHERE t1.field1='123'
GROUP BY field1
Le principe de l'EXPLAIN ayant déjà
été expliqué, une représentation en schéma
suffira pour comprendre les différentes étapes.
· Les dépendances entre étapes :
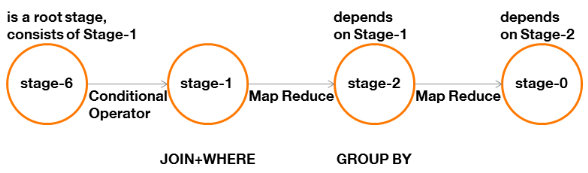
Figure 10 : graphe des
dépendances d'une requête avec jointure et
agrégation
Tout d'abord, nous remarquons la présence d'une
étape « racine » de type « Conditional
Operator » (Stage-6).
Cette étape est générée du fait de
la présence d'une jointure. Elle modifiera la manière dont sera
réalisée cette jointure (Stage-1) si certaines
conditions sont remplies (nous le verrons dans le prochain chapitre
consacré à l'optimisation).
· Le plan d'étapes :
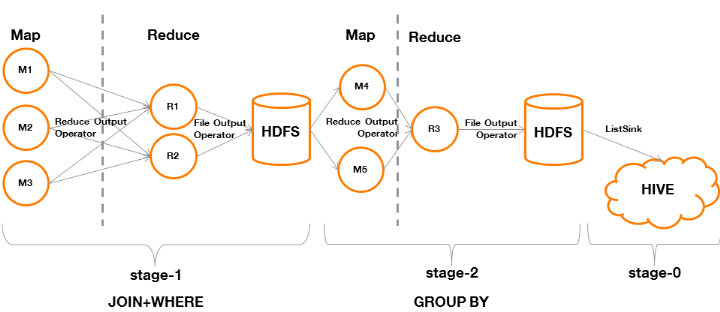
Figure 11 : processus de
traitement MapReduce d'une requête SQL avec jointure
- Stage-1
Par défaut, la jointure s'exécutera de
manière commune(Common-Join), il y aura une phase
« Map » durant laquelle les Mappers seront chargées
de balayer intégralement les deux tables à joindre pour
constituer un ensemble de clé/valeur. La clé choisie sera celle
de la jointure indiquée par l'utilisateur.
Ensuite, dans la phase « Partition &
Sort », chaque Mapper aura à répartir l'ensemble des
couples clé / valeurdes deux tables dans les partitions qui leur auront
été attribuées, puis à appliquer un tri par
clé.
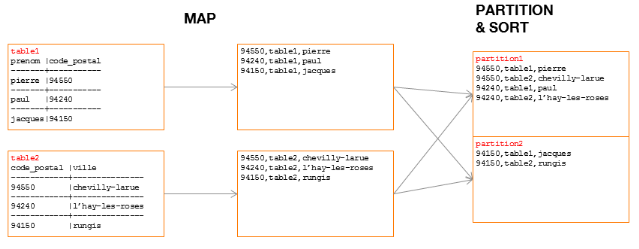
Figure 12 : phase
« Map » d'une jointure sur un Mapper
Dans la phase « Shuffle & Merge &
Sort », les partitions identiques de chaque Mapper seront
fusionnées entre-elles par les Reducers, puis, un nouveau tri par
clé sera appliqué à chaque partition fusionnée.
En fin de traitement, chaque Reducer aura écrit
indépendamment sur HDFS, un des fichiers composant la table temporaire
qui alimentera la prochaine étape.
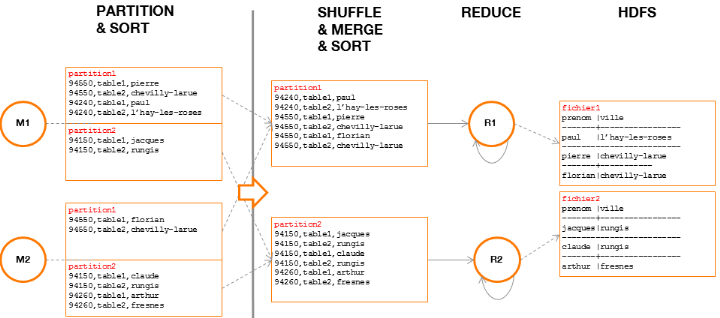
Figure 13 : phase
« Reduce » d'une jointure sur deux Reducers
- Stage-2
Cette étape est identique à l'exemple
précédent, en revanche notons que les données qu'elle
considérera sont celles en sortie du Stage-1.
4.3 Discussion
Notre approche « par l'EXPLAIN », nous a
permis de découvrir comment Hive transforme une requête SQL en
application MapReduce. Elle doit permettre de mieux appréhender toute
requête demandant un travail d'optimisation.
4.3.1 Requête avec une
restriction
Elle montre qu'un« Map-Only Job » permet
de parcourir et traiter très efficacement l'intégralité
d'une tablesans déclencher de phase « Reduce » qui
impliqueraitles phases intermédiaires« Partition &
Sort » et « Shuffle & Merge & Sort ».
ð Il serait donc intéressant d'utiliser ce mode de
traitement le plus souvent possible.
4.3.2 Requête avec une
agrégation
Ellemontre un « Map Reduce » et permet de
mieux appréhender la puissance de ce paradigme. En effet, il ne semble
plus aussi problématique que sur un SGBDR de réaliser un
« full scan » d'une table, puisque plusieurs Mappers se
répartissent le travail.
En revanche, le « Shuffle & Merge &
Sort » est coûteux du fait de la nécessité de
transmettre des données au travers du réseau, de fusionner puis
d'appliquer un tri sur les données, ce qui est particulièrement
vrai lorsque le volume de données à traiter est volumineux.
ð Il serait intéressant de transférer
uniquement les données qui seront utiles pour la suite de la
requête.
4.3.3 Requête avec une jointure et
une agrégation
Elle montre un enchaînement de deux « Map
Reduce » qui implique de lire et d'écrire plusieurs fois sur
HDFS, sollicitant donc le cluster davantage. Ainsi, les données issues
du premier « Map Reduce » seront écrites sur HDFS,
et le second « Map Reduce » commencera par les charger.
Intuitivement, ilaurait été plus immédiat que le premier
« Reduce » (de jointure) enchaîne
immédiatement sur le second « Reduce »
(d'agrégation), puisque les données auraient déjà
toutes été chargées.
ð Il faudrait pouvoir éviter d'une part des
lectures/écritures superflues sur HDFS et d'autre part, une phase
« Map » redondante qui ne ferait que lire une
deuxième fois les mêmes données.
En outre, nous remarquons que la problématique des
« petits fichiers » s'applique également dans le
contexte de Hive. La figure 13 montre que la table temporaire
générée sera composée de plusieurs fichiers et
potentiellement, de petits fichiers. Dans ce cas de figure, la
génération de petits fichiersserait liéeaux faibles
occurrences des clés dans chaque partition.
ð Fusionner en fin de traitement les petits fichiers entre
eux, permettrait d'alléger la pression exercée sur le NameNode et
ses DataNodes. De même, cela optimiserait les traitementsfuturs sur ces
données.
A l'inverse, un déséquilibre pourrait être
provoqué par une partition qui contiendrait beaucoup plus de
données que la moyenne des autres partitions. Cela pourrait provenir
d'une clé représentée bien plus fréquemment par
rapport aux autres. La charge imputée au Reducer responsable de cette
partition serait alors bien supérieure à celle des autres.
ð Il serait intéressant d'être en mesure
d'influencer Hive à l'exécution en lui indiquant comment sont
réparties les données,si elles sont
déséquilibrées.
A la lumière de toutes ces observations, nous disposons
maintenant de nombreuses pistes à explorer afin d'optimiser les
traitements de nos requêtes SQL. C'est ce que nous allons tenter de faire
dans notre prochaine partie.
5 OPTIMISATION DU SQL SUR HADOOP
Les deux premières parties nous ont permis d'expliquer
le fonctionnement de Hadoop, le paradigme « MapReduce » et
comment il s'applique au SQL au travers de Hive.
Les prérequis ayant été exposés,
nous allons pouvoir nous concentrer sur l'objectif de ce mémoire qui est
de proposer des stratégies d'optimisation des requêtes SQL.
Nous aborderons cette partie sous plusieurs angles, d'une part
en proposant des réglages techniques et systématiques pour Hive
(tuning) et d'autre part en proposant des bonnes pratiques de
développement des requêtes qui tirent parti de notre
maîtrise des différentes phases de MapReduce.
5.1 Optimisation
par le réglage ou « tuning »
5.1.1 Utiliser Tez
La première optimisation que nous allons aborder est
l'usage du framework Tez au lieu du framework classique MapReduce.
Comme nous l'avons vu précédemment, MapReduce
est un framework très puissant mais qui montre ses limites dès
qu'il est question d'enchaîner plusieurs traitements impliquant
l'écriture de résultats intermédiaires sur HDFS, ce qui
pénalise les performances.
L'application Tez repose sur YARN (Arun Murthy, 2013), tout
comme l'application MapReduce depuis Hadoop 2.0. Alors que MapReduce
exécute une séquence immuable HDFS Map Reduce HDFS, Tez
exécute un Diagramme Acyclique Orienté(plus communément
appelé DAG pour Directed Acyclic Graph) qui a l'avantage d'être
flexible.
5.1.1.1 Principe d'un Diagramme Acyclique
Orienté
Un DAG est composé de sommets (vertices) et
d'arêtes (edges). Un sommet définit une étape (pouvant
être un Map ou un Reduce par exemple) et une arête définit
le mouvement des données émises (Bikas Saha, 2013).
Les arêtes peuvent être de plusieurs
types :
- One-To-Onela tâche i d'une
étape A productrice transmet toutes ses données à la
tâche i d'une étape B consommatrice
Figure 14 : mouvement de
données de type « One-To-One »
- Broadcastchaque tâche d'une
étape A productrice transmet toutes ses données à toutes
les tâches d'une étape B consommatrice
Figure 15 : mouvement de
données de type « Broadcast »
- Scatter-Gatherchaque tâche d'une
étape A productrice transmet une partie de ses données à
chaque tâche d'une étape B consommatrice
Figure 16 : mouvement de
données de type « Scatter-Gather »
De plus il sera possible de préciser, pour chaque
sommet (correspondant à une étape) :
- le mode de déclenchement des tâches :
o Sequential la tâche consommatrice est
exécutée lorsque ses tâches productrices sont
terminées
o Concurrent la tâche consommatrice est
exécutée en parallèle des tâches productrices
- la durée de vie des données :
o Persistedles données en sortie d'une
tâche sont disponibles quelques temps après sa fin
o Persisted-Reliable les données en
sortie d'une tâche sont garanties d'être disponibles
indéfiniment après sa fin
o Ephemeral les données en sortie d'une
tâche ne sont disponibles que durant son exécution
Ces capacités permettent de transformer le SQL de Hive
en DAG, permettant d'économiser des phases de lecture/écriture
superflues sur HDFS (les données peuvent être conservées en
local du noeud sur lequel la tâche s'exécute) et donc
d'épargner le cluster (NameNode et DataNodes). De plus, elles permettent
également d'être en mesure de paralléliser
l'exécution de certaines tâches (Bikas Saha, 2016).
5.1.1.2 Comparaison MapReduce / Tez
Comparons l'exécution de notre requête la plus
complexe, comportant une jointure et une agrégation, sous MapReduce et
sous Tez :
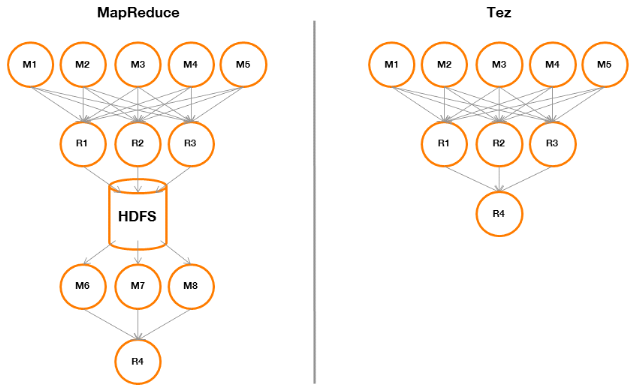
Figure 17 : comparaison
MapReduce / Tez
Dans le cas MapReduce, les Reducers du premier « Map
Reduce » (jointure) devront écrire leur sortie sur HDFS. Les
Mappers du second « Map Reduce » (agrégation)
pourront ainsi lireces données sur HDFS, les traiter et les transmettre
au dernier Reducer pour réaliser l'agrégation.
Dans le cas Tez, les Reducers du premier « Map
Reduce » (jointure) pourront retourner directement leur sortie vers
le Reducer réalisant l'agrégation finale. Cela est rendu possible
grâce à la flexibilité de Tez qui n'implémente pas
« en dur » le paradigme MapReduce mais en fait une
généralisation.
Pour activer Tez, il suffit de placer cette ligne au-dessus de
la requête à exécuter.
set hive.execution.engine=tez
Un exemple d'une implémentation de
« WordCount » pour Tez est fourni en
annexe.
5.1.2 Contrôler la taille des
fichiers manipulés
Comme nous l'avons vu dans le chapitre
précédent, la phase « Reduce » est
génératrice de fichiers et selon la qualité du
partitionnement (homogénéité de la représentation
d'une clé), leur quantité pourra varier. Lorsque ces fichiers
sont de petite taille, toutes les couches composant Hadoop sont
impactées.
Montrons comment il est possible d'optimiser la taille des
fichiers manipulés, soit en phase de lecture (Map), soit en phase
d'écriture (Reduce).
5.1.2.1 durant la phase de lecture (Map)
Une étape « Map » ayant à
traiter de nombreux petits fichiers, engendrera beaucoup de Mappers (et donc de
containers YARN)qui devront solliciter massivement le HDFS au travers du
NameNode et de ses DataNodes pourlire leurs données.
Tez permet de consommer moins de Mappers en créant des
groupes de splits (Bikas Saha, 2016 +
annexe).
Pour rappel, un split est un pointeur sur un blocHDFS et
indique à un Mapper l'emplacement des données à
traiter.
Les options suivantes permettent de définir la taille
d'un groupe :
settez.grouping.min-size=16777216; -- 16 MB min splitset tez.grouping.max-size=1073741824; -- 1 GB max split
Il est également possible de procéder de la
façon suivante, en définissant le nombre de splits que contiendra
un groupe (ce paramétrage est prioritaire par rapport au
précédent) :
set tez.grouping.split-count=50;
Cette approche est très pratique mais n'empêche
pas la sollicitationde HDFS, car il faudra bien que le NameNode soit
interrogé pour indiquer l'emplacement des blocs de données. Il
est donc nécessaire d'agir en amont (c'est-à-dire durant le
processus de création des fichiers) afin d'éviter cela. Or, les
données traitées par les Mappers pourront être issues de
phases Reduce de traitements antérieurs. Il faudra donc agir au niveau
de la phase Reduce.
5.1.2.2 durant la phase d'écriture (Reduce)
Le problème provient des
étapes« Reduce » utilisant de nombreuses partitions
et qui devront également solliciter massivement le HDFS.En effet, elles
devront générer un fichier par partition.
Il est possible d'indiquer à Hive de réaliser
une étape « Map » supplémentaire consistant
à fusionner ces fichiers et ainsi permettre pour un prochain traitement
d'alléger la pression exercée sur le HDFS (Hao Zhu, 2014). Nous
aurons ainsi obtenu un traitement du type Map Reduce HDFS Map.
Pour ce faire, les directives à utiliser sont les
suivantes :
Pour Tez :
set hive.merge.tezfiles=true;set hive.merge.smallfiles.avgsize=16000000;set hive.merge.size.per.task=128000000;
Pour MapReduce :
set hive.merge.mapredfiles=true;set hive.merge.mapfiles=true;set hive.merge.smallfiles.avgsize=16000000;set hive.merge.size.per.task=128000000;
- Les directives en rouge activent le mécanisme de
fusion
- Les deux autres directives définissent respectivement
o la taille moyenne d'un petit fichier (16MB).
o la taille des fichiers générés
(128MB).
Il est important de désactiver la compression des
données, sinon la fusion des petits fichiers ne fonctionnera pas(Hao
Zhu, 2015) une fusion de deux fichiers compressés n'étant pas
réalisable.
set hive.exec.compress.output=false;
Il d'autant plus important de le savoir qu'aucune erreur ne
sera signalée en cas d'échec de la fusion durant la phase de Map
réalisant l'opération.
5.1.3 Agréger en amont
Nous avons vu que la phase de « Shuffle & Merge
& Sort » est coûteuse, au regard de la
nécessité de transmettre les données au travers du
réseau mais aussi,parce que cette phase implique des fusions et des tris
à répétition.
Afin d'alléger considérablement cette charge,
les Mappers peuvent agréger partiellement les données ce qui
réduira la quantité de données à transmettre. Les
Reducers n'auront plus qu'à effectuer un « Group By
Operator » dont le mode sera « mergepartial » au
lieu de « complete », ce qui sera moins coûteux.
La directive suivante devra être utilisée
pour activer l'agrégation au niveau
« Map » :
set hive.map.aggr=true;
5.1.4 Réaliser un
« benchmark » significatif
Terminons cette partie en abordant la problématique de
la réalisation d'un « benchmark » d'une
requête SQL sous Hive.
Il n'y a pas de déterminisme dans le temps qui sera
nécessaire pour obtenir du NameNode et des DataNodes les informations
permettant de lire les données et surtout pour obtenir des containers
YARN.
Ainsi, une même requête pourra avoir des temps
d'exécution drastiquement différents, suivant la
disponibilité du cluster. Il conviendra donc de s'affranchir au maximum
de ce temps préalable à l'exécution réelle de la
requête, afin de mieux évaluer son coût
d'exécution.
Les directives suivantes permettent de réserver
à l'avance une quantité de containers.
set hive.prewarm.enabled=trueset hive.prewarm.numcontainers=10
Suite à ses directives, nous constatons sur l'interface
graphique d'administration YARN la présence de 11 containers (1
ApplicationMaster et 10 containers), chacun reposant sur une JVM de 2GB.

Bien sûr, cette préemption ne dure que le temps
de la session Tez qui est défini par la directive suivante (par
défaut réglé à 30 secondes) :
set tez.client.timeout-ms=30000
Il devient ainsi possible de « jouer »
plusieurs fois une requête et d'estimer son temps d'exécution sans
qu'il soit parasité par la phase de réservation des
ressources.
Enfin, il sera intéressant d'étudier les
techniques du site
http://www.tpc.org/tpcds/ qui
propose plusieurs méthodes de benchmarking. Celles-ci n'ont pu
être étudiées dans le cadre de ce mémoire du fait de
la nécessité de disposer de droits
« administrateur » sur l'infrastructure Hadoop.
Mais c'est un sujet important qui devra faire l'objet d'un
approfondissement durant la réalisation des projets à venir.
5.2 Optimisation
par la conception ou « design »
Si le tuning permet d'améliorer les temps
d'exécutiondes requêtesde manière mécanique,
l'importance de leur conception ne doit pas être occultée, en
particulier lorsqu'il est question de produire un « Use Case Big
Data ».
Un « Use Case Big Data » consiste à
produire de nouvelles données par croisement périodiquede
données sources (issues du SI mais aussi de données externes),
qui pourront être consommées par des tiers, afin de
répondre à un besoin métier spécifique.
Cette production de données consiste ainsi à
réaliser des requêtes sur le puits de données, à
éventuellement créer des tables intermédiaires, puis
à stocker le résultat final pour qu'il puisse être
utilisé.
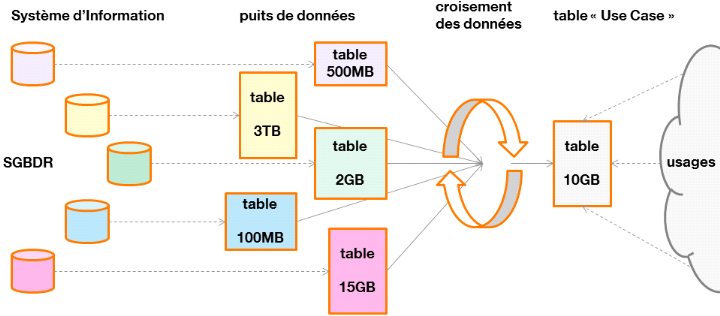
Figure 18 : du Système
d'Information au Use Case Big Data
Nous appellerons « plan de
requêtes », l'ensemble des requêtes permettant d'aboutir
au croisement des données du Use Case.
Un plan de requêtes qui ne tiendrait pas compte de la
spécificité des données à traiter (par exemple,
pour chaque table, le nombre de lignes et la répartition des clés
de jointures) ne pourra pas être optimisé.
En effet, en fonction de la typologie des données
à traiter, il sera possible d'utiliser différentes techniques de
requêtage.
Ainsi, cette partie se propose d'étudier ces
différentes techniques avec le souci d'expliquer les situations qui leur
seront particulièrement adaptées.
5.2.1 Utiliser les tables
partitionnées
Les tables du puits de données atteignent
régulièrement plusieurs TB. Lorsqu'une requête interroge
l'une d'elle, il est rarement utile d'avoir à parcourir
l'intégralité des données qu'elle contient.
Ces tables de grandes tailles sont ainsi partitionnées.
Le partitionnement consiste à disposer les fichiers qui les composent de
manière hiérarchisée dans le HDFS. Cette hiérarchie
est définie à la création de la table dont voici la
syntaxe :
CREATE TABLE z_database1.table1 (field1 string, ...)PARTITIONED BY (year string,month string, daystring);
Les champs définis dans la section « PARTITIONED
BY » définissent la hiérarchie de stockage dans le
HDFS.
Considérons la table « table1 » que
nous venons de définir, dont les fichiers sont sous cette
arborescence :
2.6TB /apps/hive/warehouse/z_database1.db/table1
La requête suivante précise une partition à
considérer :
SELECT * FROM z_database1.table1WHERE year="2018" AND month="01" AND day="01"
Les fichiers réellement considérés seront
donc sous cette arborescence :
5.9GB /apps/hive/warehouse/z_database1.db/table1/year=2018/month=01/day=05
Seuls 5.9GB des données seront ainsi manipulées
au lieu des 2.6TB de départ, ce qui épargnera le cluster HDFS (le
NameNode sera sollicité sur une plus faible quantité de fichiers)
et le cluster YARN (il ne sera pas nécessaire d'allouer une
quantité importante de containers).
Cette méthode n'est pas réservée aux
tables du puits de données, il est également intéressant
d'utiliser le partitionnement pour les tables qui seront produites dans le
cadre d'un « Use Case ». Dans ce cas, le partitionnement
devra être réalisé en considérant des colonnes de
faible cardinalité. En effet, des cardinalités trop importantes
impliqueraient la création de nombreux répertoires et fichiers,
ce qui, nous le savons à présent, est contre-productif.
Les partitions des tables du puits sont couramment
hiérarchisées par la date de chargement des données.
Le tableau suivant montre la répartition du nombre de
lignes insérées par jourde chargement dans la table
« table1 » (sur 6 mois de données).
|
|
0,25
|
0,5
|
0,75
|
0,9
|
0,95
|
0,99
|
|
centile
|
46 114 093
|
47 831 809
|
48 907 836
|
50 198 535
|
51 131 198
|
90 529 083
|
Tableau 2 :centiles du nombre
de lignes chargées par jour
Avec MIN=201 789 et MAX=108 132 735
Le tableau suivant montre la même répartition
mais à l'aide des dates fonctionnelles, par exemple la date à
laquelle a été passée une commande dans le cas d'une table
enregistrant des commandes de clients.
|
|
0,25
|
0,5
|
0,75
|
0,9
|
0,95
|
0,99
|
|
centile
|
16 130 510
|
38 035 331
|
42 779 757
|
45 833 922
|
47 710 421
|
49 173 539
|
Tableau 3 : centiles du nombre
de lignes par date fonctionnelle
Avec MIN=2 609 997 et MAX=49 361 016
Cette répartition est moins intéressante que la
première caril y a de plus grands écarts entre chaque centile. La
répartition des données est donc moins
régulière.
Une étude préalable de la répartition des
données est donc souhaitable avant de déterminer la
manière de partitionner une table.
Cette méthodologie pourra être appliquée
dès lors où il est nécessaire de partitionner une table
volumineuse et que plusieurs colonnes sont en concurrence pour en
établir la hiérarchie.
5.2.2 Optimiser les jointures
Les jointures constituent un challenge pour Hadoop. En effet,
comme nous l'avons vu, dans le contexte d'un Common-Join, la phase
« Shuffle & Merge & Sort » sollicite
énormément le cluster du fait des mouvements et des traitements
de données nécessaires pour réunir les données de
plusieurs tables.
La connaissance des données manipulées et la
compréhension des principaux mécanismes de jointure
implémentés par Hive sont deux atouts pour optimiser leur
fonctionnement.
5.2.2.1 Map-Join
Un Map-Join consiste à réaliser la jointure de
plusieurs tables en une seule étape « Map »(Map-Only
Job) au lieu d'une étape « Map Reduce »
(LeftyLeverenz, 2017). Son intérêt est de traiter avantageusement
le cas de plusieurs tables de tailles très différentes.
Ø Considérons un premier cas de figure avec
le« 2-way join » (jointure entre deux tables) impliquant
une « grande » table (table1) et une
« petite » table (table2).
SELECT *FROM table1INNER JOIN table2 ON table1.field1=table2.field1;
La directive suivante permet d'identifier automatiquement le
rôle de chaque table (grande ou petite) et convertira automatiquement un
Common-Join en Map-Join si la « petite »table est
suffisamment petite.
set hive.auto.convert.join=true
La directive suivante permet de fixer la taille maximum de la
petite table (en MB). Si la « petite » table est
suffisamment petite, celle-ci sera chargée en mémoire de tous les
Mappers assignés au traitement de la « grande »
table.
sethive.mapjoin.smalltable.filesize=25000000
Les dépendances entre étapes fournies par la
commande EXPLAIN deviennent alors :
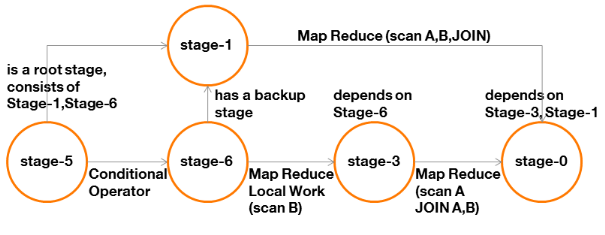
Figure 19 : graphe des
dépendances d'une requête SQL avec jointure
« Map-Only » (1/2)
Explication :
Le Stage-6 réalise un travail local
consistant à parcourir la petite table et à l'envoyer directement
aux Mappers du Stage-3. Ces derniers la chargeront en
mémoire sous forme de table de hachage et pourront alors parcourir la
grande table et réaliser la jointure à la volée.
Notons que le Stage-6 a un « plan
de secours ». En effet la détection de la petite table est
réalisée sur la base de statistiques et dans le cas où sa
taille dépasse effectivement la limite fixée, il sera possible de
basculer sur le Stage-1 qui réalisera un
« Common-Join ».
Ø Considérons à présent un
deuxième cas de figure avec le « n-wayjoin »
(jointures d'une grande table avec plusieurs tables de tailles
inférieures).
SELECT *FROM table1INNER JOIN table2 ON table1.field1=table2.field1;INNER JOIN table3 ON table1.field2=table3.field2;
Les directives suivantes permettent d'activer la conversion
automatique d'un Common-Join en Map-Join en considérant cette fois-ci
les N-1 plus petites tables de la requête.
set hive.auto.convert.join.noconditionaltask=trueset hive.auto.convert.join.nonconditionaltask.size=10000000
Ainsi, dans ce cas de figure, si la taille cumulée des
tables table2 et table3 est inférieure à 10MB, elles seront
chargées en mémoire de tous les Mappers assignés au
traitement de la « grande » table (Hao Zhu, 2016).
Les dépendances entre étapes fournies par la
commande EXPLAIN deviennent alors :
Figure 20 : graphe des
dépendances d'une requête SQL avec jointure
« Map-Only » (2/2)
Notons le retrait de d'étape préliminaire
« Conditional Operator », et donc l'absence de
« plan de secours ». Il faut donc être assuré
de la bonne tenue des statistiques des tables afin d'estimer correctement leur
taille. Dans le cas contraire, la jointure peut échouer et impliquer une
erreur à l'exécution.
5.2.2.2 Skew-Join
Une jointure de deux grandes tables est habituellement
réalisée par un traitement MapReduce qui commence par trier les
tables par la clé de jointure. Chaque Mapper communiquera ensuite les
lignes d'une clé particulière à un même Reducer
(Nadeem Moidu, 2015).
Le Skew-Join permet de différencier le traitement d'une
clé massivement représentée par rapport aux autres. Son
avantage est donc d'éviter que le Reducer en charge de cette clé
devienne un goulot d'étranglement pour le traitement Map Reduce.
Considérons une table table1 que nous souhaitons
joindre à la table table2 par la clé de jointure champ1.
SELECT * FROM table1 INNER JOIN table2 ON table1.champ1=table2.champ1
Une étude sur table1 montre que le nombre d'occurrences
des valeurs possibles de champ1 est relativement constant (entre 2457 et 2470),
à l'exception de la valeur « v1 », qui
apparaît3000 fois plus.
|
champ1
|
nombre d'occurrences
|
|
v1
|
7487662
|
|
v2
|
2470
|
|
v3
|
2469
|
|
...
|
2459
|
|
v5000
|
2457
|
Tableau 4 : exemple de
données « biaisées » ou
« skewed »
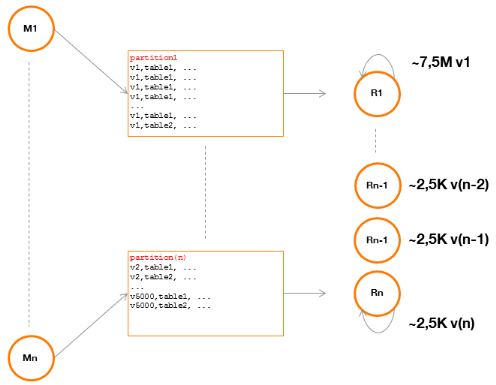
Figure 21 : Reducer devant
traiter une donnée « biaisée » ou
« skewed »
Dans ce schéma, nous remarquons que le Reducer R1 est
surchargé par rapport aux autres.
Ce cas de figure nécessite donc une approche
particulière.
Il serait envisageable, connaissant spécifiquement la
donnée « biaisée », de la
traiterséparément.
Considérons une table « table1 »
dont le champ « champ1 » est biaisé sur la
valeur « v1 » et une table
« table2 », ayant une répartition
homogène.
Nous procéderions ainsi :
SELECT * FROM table1INNER JOIN table2 ON table1.champ1=table2.champ1WHEREtable1.champ1<>"v1"
et dans un deuxième temps :
SELECT * FROM table1INNER JOIN table2 ON table1.champ1=table2.champ1WHEREtable1.champ1="v1"
La première requête génèrera un
Common-Join équilibré (la valeur « v1 » est
évitée), alors que la seconde sera facilement transformable en
« Map-Join ».
Cette approche conduit à réaliser deux
traitements, où il s'agira de lire plusieurs fois les mêmes
données ce qui n'est pas économique.Il est possible de
créer une table biaisée ou « Skewed Table »
très simplement :
CREATE TABLE table1 (champ1 string,champ2 string,...)SKEWED BY (champ1) ON ("v1")
Cette déclaration de table, permet d'indiquer
explicitement quel champ pourrait être biaisé (notions qu'il est
possible d'indiquer plusieurs champs potentiellement biaisés).
La directive suivante active le « Skew-Join »
:
set hive.optimize.skewjoin=true
Et celle-ci définit le seuil d'occurrences
déclencheur :
set hive.skewjoin.key=7500000
Lorsqu'un Skew-Join est effectivement détecté
durant l'exécution, un traitement Map Reduce sera opéré
sur l'ensemble des données, excepté pour la valeur biaisée
qui sera traitée séparément, évitant ainsi l'effet
« goulot d'étranglement ».
5.3 Discussion
Au travers des stratégies d'optimisation que nous
venons de voir, il apparaît que la connaissance fine des données
à traiterest un prérequis indispensable à l'optimisation
du requêtage.Ceci est vrai aussi bien dans le cas d'optimisations par le
réglage que d'optimisations par la conception.
Dans le cadre de la conception d'un Use Case Big Data, la
géométrie des données devra donc impérativement
être prise en compte, dès lors où sont créées
de nouvelles données (intermédiaires ou définitives).
Nous proposons les étapes suivantes comme modèle
méthodologique à respecter avant le développement d'un Use
Case Big Data :
- Analyser statistiquement les données :
déterminer la répartition de chaque donnée
« clé » impliquée dans la requête,
estimer la taille des tables à interroger, ainsi que la taille des
tables à construire.
- Déterminer la meilleure stratégie
d'optimisation en fonction des éléments recueillis : est-ce
que des réglages suffiront ou bien faudra-t-il altérer la
conception des tables et/ou des requêtes ?
- Maintenir une veille technologique : à chaque
changement de version de Hadoop, il faudra prendre le temps de se documenter
sur les nouvelles capacités implémentées. Ce coût
sera vite amorti dans la pratique.
Il ne s'agit là que d'une première
ébauche méthodologique qui demanderait à être
approfondie et complétée. De plus, celle-ci pourrait
évidemment être remise en question selon les évolutions
futures de Hadoop.
6 CONCLUSION
Ce mémoire nous a permis de découvrir en
détail le fonctionnement de l'écosystème de Hadoop. Ce
dernier était relativement rigide à ses débuts,
l'allocation des ressources et le framework de traitement formaient une seule
entité. De plus, MapReduce ne pouvait être utilisé
autrement que par une succession immuable de phases Map puis Reduce.Au fil des
années, de nombreux projets se sont greffés à lui et ont
contribué à lui apporter plus de souplesse (YARN) permettant
l'essor d'autres frameworks de traitement distribué comme Tez (qui
généralise MapReduce).
Nous avons pu dresser un état de l'art à jour de
Hadoop, tout en établissant du sens entre son infrastructure
(NameNode+DataNodes, RessourceManager+NodeManager+ApplicationMaster) et la
réalité d'un traitement (via MapReduce ou Tez).Il en a
été de même vis-à-vis de Hive, application
transformant du SQL en traitement distribué. Nous avons ainsi pu
comprendre la logique MapReduce cachée derrière l'usage de
requêtes SQL classiques.En effet, il est fondamental de bien comprendre
le fonctionnement de Hive, car son usage ne peut se faire en mode
« boîte noire » dès lors où il est
question d'optimiser ses performances.
Notre approche de l'optimisation nous a ensuite permis
d'aborder deux aspects. D'une part, le réglage, dans cette
partie nous avons passé en revue de nombreuses options disponibles pour
régler au mieux la façon dont Hive transformera le SQL en
traitement distribué ; nous avons abordé les plus
fondamentales, apportant de réels gains, tout en sachant qu'il en existe
une myriade.D'autre part, la conceptionqui nous a permis de souligner
l'importance de la connaissance fine des données à traiter, et
ce, durant tout leur cycle de vie ; nous avons établi que les
parades techniques abordées dans cette partien'ont de sens que dans un
contexte d'étude préliminaire et statistique des
données.
Cependant, nous n'avons fait qu'effleurer les quantités
de solutions existantes. Si nous sommes capables de les appréhender plus
facilement à présent, certaines mériteraient de s'y
attarder davantage.Néanmoins, l'écosystème Hadoop est en
mouvement permanent. Ce qui nous semble vrai aujourd'hui ne le sera
peut-être plus demain, aussi sera-t-il plus que nécessaire de
réaliser une veille technologique permanente pour continuer à
maîtriser son usage.
Hadoop, depuis ses débuts, ne cesse de gagner en
maturité. La communauté Open Source qui l'anime est très
active et s'organise professionnellement au côté d'entreprises
qui participent à son développement.A l'heure actuelle, des
travaux sont déjà en cours pour résorber les principaux
goulots d'étranglement comme le NameNode du HDFS ou les latences
liées à l'allocation des ressources par YARN. Mais c'est surtout
la capacité de Hadoopà ne pas se borner au seul paradigme
MapReduce, à continuer de généraliser les concepts qu'il
véhicule, à s'ouvrir aux autres technologiesqui sera
déterminante pour son futur.
Hive se révèlequant à lui, un outil de
haut niveau formidable pour entrer rapidement dans le Big Data de Hadoop.Sa
dernière architecture lui permet d'utiliser indifféremment
plusieurs frameworks de traitement distribués. Et si Tez est un
véritable progrès par rapport à MapReduce, il en existe un
autre, plus récent : Spark. Ce dernier est réputé
pour être encore plus généraliste et entièrement
« in-memory », mais il reste à déterminer
pour quels volumes de données il excelle réellement.
Enfin, Hive nécessiteencore des améliorations,
notamment au regard de l' « art » du
paramétrage qu'il véhicule et qui impose audéveloppeur
d'être à un niveau d'expertise comparable à celui d'un
administrateur de base de données. Ce qui n'est pas acceptable de nos
jours. Un système mature se caractérise notamment par la
confiance que l'utilisateur peut accorder aux choix d'optimisation qu'il
opère sans intervention humaine. Pour que Hive puisse continuer
d'exister, il devra ainsi se charger de ses propres réglages et ne pas
les laisser à la charge du développeur.Une piste envisageable
serait donc d'ajouter davantage d'intelligence artificielle à Hive. Cela
afin de l'aider à la prise de décisions efficaces quant aux
stratégies d'optimisation qu'il devra mettre en oeuvre.
7 BIBLIOGRAPHIE
Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung (2003). The
Google File System
https://research.google.com/archive/gfs.html
Jeffrey Dean and Sanjay Ghemawat (2004).MapReduce: Simplified
Data Processing on Large Clusters
https://research.google.com/archive/mapreduce.html
Tom White (2015). Hadoop: The definitive guide
Ashish Thusoo (2009). Hive - A Petabyte Scale Data Warehouse
using Hadoop
https://fr-fr.facebook.com/notes/facebook-engineering/hive-a-petabyte-scale-data-warehouse-using-hadoop/89508453919/
Lefty Leverenz (2015). Hive Design
https://cwiki.apache.org/confluence/display/Hive/Design#Design-HiveArchitecture
Arun Murthy (2013). Tez: Accelerating processing of data stored
in HDFS
https://fr.hortonworks.com/blog/introducing-tez-faster-hadoop-processing/
BikasSaha (2013). Accelerating Hadoop Query Processing
https://www.slideshare.net/hortonworks/apache-tez-accelerating-hadoop-query-processing
BikasSaha (2016). How initial task parallelism works
https://cwiki.apache.org/confluence/display/TEZ/How+initial+task+parallelism+works
Hao Zhu (2014).How to control the file numbers of hive table
after inserting data on MapR-FS
http://www.openkb.info/2014/12/how-to-control-file-numbers-of-hive.html
Hao Zhu (2015).Hive did not start small file merge if the source
table has .deflate files
https://issues.apache.org/jira/browse/HIVE-9398
Lefty Leverenz (2017).LanguageManualJoinOptimization
https://cwiki.apache.org/confluence/display/Hive/LanguageManual+JoinOptimization
Hao Zhu (2016). Difference between
hive.mapjoin.smalltable.filesize and
hive.auto.convert.join.noconditionaltask.size
http://www.openkb.info/2016/01/difference-between-hivemapjoinsmalltabl.html
Nadeem Moidu (2015).Skewed Join Optimization
https://cwiki.apache.org/confluence/display/Hive/Skewed+Join+Optimization
8 ANNEXES
8.1 Hadoop
8.1.1 Partition & Sort
détaillé
Le fichier local au Mapper qui contient les données
partitionnées et triées par clé, est conçu en
détail par le processus suivant (Tom White, 2015) :
- le Mapper envoie ses données dans un tampon
circulaire, en mémoire (100MB par défaut)
- à chaque fois que ce tampon est chargé
à plus de 80% :
o ses données sont divisées en partitions
o chaque partition est triée par clé
o chaque partition triée par clé est
déversée dans un fichier du disque local du Mapper
o le Mapper continue d'envoyer ses données dans le
tampon circulaire
- à la fin du traitement Map du Mapper, tous les
fichiers générés sont fusionnés par partition puis
retriés par clé
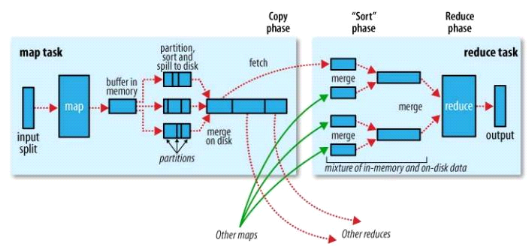
Figure 22 : traitement MapReduce
détaillant le « Partition & Sort »
8.1.2 Définition de la distance entre deux noeuds
Hadoop assimile son infrastructure à un arbre (Tom
White, 2015).
Les niveaux d'un arbre sont définis par le datacenter,
le rack et enfin, le noeud.
La distance entre deux noeuds est la somme de leur distance au
plus proche ancêtre commun.
Ainsi, le noeud le plus proche sera ainsi
prioritairement :
- le même noeud
- un autre noeud sur le même rack
- un autre noeud sur le même datacenter
8.2 SQL sur
Hadoop
8.2.1 Gérer manuellement le partitionnement dans une
requête
Cet exemple est intéressant pour comprendre le rôle
de « DISTRIBUTE BY » et « SORT BY ».
Créons une table contenant deux champs
« x1 » et « y1 » et chargeons quelques
données :
CREATE TABLE z_database1.test AS SELECT 'x1' AS field1,'y1' AS field2;INSERT INTO TABLE z_database1.test VALUES('x2','y2');INSERT INTO TABLE z_database1.test VALUES('x3','y3');INSERT INTO TABLE z_database1.test VALUES('x1','y3');INSERT INTO TABLE z_database1.test VALUES('x0','y3');
Forçons le nombre de Reducer à 3 :
hive> set mapreduce.job.reduces=3;hive> SELECT * FROM z_database1.test DISTRIBUTE BY field2 SORT BY field1;OKx2 y2x0 y3x1 y3x3 y3x1 y1
Nous remarquons bien la distribution par
« field2 » et à l'intérieur, le tri par
« field1 ».
8.2.2 Comprendre la sérialisation sous Hadoop
L'article suivant explique le principe de la sérialisation
sous Hadoop :
http://www.dummies.com/programming/big-data/hadoop/defining-table-record-formats-in-hive/
8.3 Optimisation du
SQL sur Hadoop
8.3.1 Exemple de WordCount avec Tez
Voici le lien vers le code source d'un exemple
« WordCount » pour Tez :
https://github.com/apache/tez/blob/master/tez-examples/src/main/java/org/apache/tez/examples/WordCount.java
8.3.2 Grouper les splits avec Tez
Voici une illustration d'une table contenant beaucoup de petits
fichiers.
hdfsdfs -ls /apps/hive/warehouse/z_database1.db/table1 | grep wc -l13102
L'usage de Tez, permettra de constituer un ensemble de splits
pointant chacun vers un ensemble de bloc.
Dans cet exemple, deux containers ont pu être
créés au lieu des 13102.
--------------------------------------------------------------------------------
VERTICES STATUS TOTAL COMPLETED RUNNING PENDING
FAILED KILLED
--------------------------------------------------------------------------------
Map 1 RUNNING 2 0
2 0 0 0
Reducer 2 INITED 1 0 0 1
0 0
Reducer 3 INITED 1 0 0 1
0 0
--------------------------------------------------------------------------------
VERTICES: 00/03 [>>--------------------------] 0%
ELAPSED TIME: xx.xx s
--------------------------------------------------------------------------------
| 

