Stratégies d'optimisation de requêtes SQL dans un écosystème Hadoop( Télécharger le fichier original )par Sébastien Frackowiak Université de Technologie de COmpiègne - Master 2 2017 |

5 OPTIMISATION DU SQL SUR HADOOPLes deux premières parties nous ont permis d'expliquer le fonctionnement de Hadoop, le paradigme « MapReduce » et comment il s'applique au SQL au travers de Hive. Les prérequis ayant été exposés, nous allons pouvoir nous concentrer sur l'objectif de ce mémoire qui est de proposer des stratégies d'optimisation des requêtes SQL. Nous aborderons cette partie sous plusieurs angles, d'une part en proposant des réglages techniques et systématiques pour Hive (tuning) et d'autre part en proposant des bonnes pratiques de développement des requêtes qui tirent parti de notre maîtrise des différentes phases de MapReduce. 5.1 Optimisation par le réglage ou « tuning »5.1.1 Utiliser TezLa première optimisation que nous allons aborder est l'usage du framework Tez au lieu du framework classique MapReduce. Comme nous l'avons vu précédemment, MapReduce est un framework très puissant mais qui montre ses limites dès qu'il est question d'enchaîner plusieurs traitements impliquant l'écriture de résultats intermédiaires sur HDFS, ce qui pénalise les performances. L'application Tez repose sur YARN (Arun Murthy, 2013), tout comme l'application MapReduce depuis Hadoop 2.0. Alors que MapReduce exécute une séquence immuable HDFS Map Reduce HDFS, Tez exécute un Diagramme Acyclique Orienté(plus communément appelé DAG pour Directed Acyclic Graph) qui a l'avantage d'être flexible.
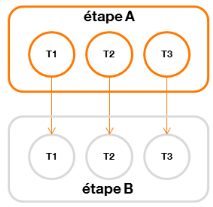
Un DAG est composé de sommets (vertices) et d'arêtes (edges). Un sommet définit une étape (pouvant être un Map ou un Reduce par exemple) et une arête définit le mouvement des données émises (Bikas Saha, 2013). Les arêtes peuvent être de plusieurs types : - One-To-Onela tâche i d'une étape A productrice transmet toutes ses données à la tâche i d'une étape B consommatrice
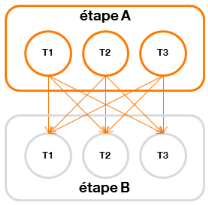
Figure 14 : mouvement de données de type « One-To-One » - Broadcastchaque tâche d'une étape A productrice transmet toutes ses données à toutes les tâches d'une étape B consommatrice
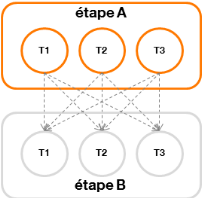
Figure 15 : mouvement de données de type « Broadcast » - Scatter-Gatherchaque tâche d'une étape A productrice transmet une partie de ses données à chaque tâche d'une étape B consommatrice
Figure 16 : mouvement de données de type « Scatter-Gather » De plus il sera possible de préciser, pour chaque sommet (correspondant à une étape) : - le mode de déclenchement des tâches :
- la durée de vie des données :
Ces capacités permettent de transformer le SQL de Hive en DAG, permettant d'économiser des phases de lecture/écriture superflues sur HDFS (les données peuvent être conservées en local du noeud sur lequel la tâche s'exécute) et donc d'épargner le cluster (NameNode et DataNodes). De plus, elles permettent également d'être en mesure de paralléliser l'exécution de certaines tâches (Bikas Saha, 2016).
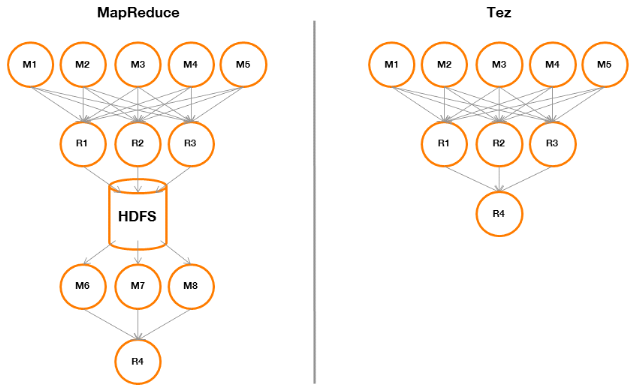
Comparons l'exécution de notre requête la plus complexe, comportant une jointure et une agrégation, sous MapReduce et sous Tez :
Figure 17 : comparaison MapReduce / Tez Dans le cas MapReduce, les Reducers du premier « Map Reduce » (jointure) devront écrire leur sortie sur HDFS. Les Mappers du second « Map Reduce » (agrégation) pourront ainsi lireces données sur HDFS, les traiter et les transmettre au dernier Reducer pour réaliser l'agrégation. Dans le cas Tez, les Reducers du premier « Map Reduce » (jointure) pourront retourner directement leur sortie vers le Reducer réalisant l'agrégation finale. Cela est rendu possible grâce à la flexibilité de Tez qui n'implémente pas « en dur » le paradigme MapReduce mais en fait une généralisation. Pour activer Tez, il suffit de placer cette ligne au-dessus de la requête à exécuter. set hive.execution.engine=tez Un exemple d'une implémentation de « WordCount » pour Tez est fourni en annexe. |
|