Stratégies d'optimisation de requêtes SQL dans un écosystème Hadoop( Télécharger le fichier original )par Sébastien Frackowiak Université de Technologie de COmpiègne - Master 2 2017 |

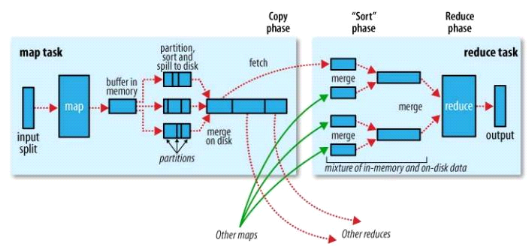
7 BIBLIOGRAPHIESanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung (2003). The Google File System https://research.google.com/archive/gfs.html Jeffrey Dean and Sanjay Ghemawat (2004).MapReduce: Simplified Data Processing on Large Clusters https://research.google.com/archive/mapreduce.html Tom White (2015). Hadoop: The definitive guide Ashish Thusoo (2009). Hive - A Petabyte Scale Data Warehouse using Hadoop Lefty Leverenz (2015). Hive Design https://cwiki.apache.org/confluence/display/Hive/Design#Design-HiveArchitecture Arun Murthy (2013). Tez: Accelerating processing of data stored in HDFS https://fr.hortonworks.com/blog/introducing-tez-faster-hadoop-processing/ BikasSaha (2013). Accelerating Hadoop Query Processing https://www.slideshare.net/hortonworks/apache-tez-accelerating-hadoop-query-processing BikasSaha (2016). How initial task parallelism works https://cwiki.apache.org/confluence/display/TEZ/How+initial+task+parallelism+works Hao Zhu (2014).How to control the file numbers of hive table after inserting data on MapR-FS http://www.openkb.info/2014/12/how-to-control-file-numbers-of-hive.html Hao Zhu (2015).Hive did not start small file merge if the source table has .deflate files https://issues.apache.org/jira/browse/HIVE-9398 Lefty Leverenz (2017).LanguageManualJoinOptimization https://cwiki.apache.org/confluence/display/Hive/LanguageManual+JoinOptimization Hao Zhu (2016). Difference between hive.mapjoin.smalltable.filesize and hive.auto.convert.join.noconditionaltask.size http://www.openkb.info/2016/01/difference-between-hivemapjoinsmalltabl.html Nadeem Moidu (2015).Skewed Join Optimization https://cwiki.apache.org/confluence/display/Hive/Skewed+Join+Optimization 8 ANNEXES8.1 Hadoop8.1.1 Partition & Sort détailléLe fichier local au Mapper qui contient les données partitionnées et triées par clé, est conçu en détail par le processus suivant (Tom White, 2015) : - le Mapper envoie ses données dans un tampon circulaire, en mémoire (100MB par défaut) - à chaque fois que ce tampon est chargé à plus de 80% :
- à la fin du traitement Map du Mapper, tous les fichiers générés sont fusionnés par partition puis retriés par clé
Figure 22 : traitement MapReduce détaillant le « Partition & Sort » 8.1.2 Définition de la distance entre deux noeudsHadoop assimile son infrastructure à un arbre (Tom White, 2015). Les niveaux d'un arbre sont définis par le datacenter, le rack et enfin, le noeud. La distance entre deux noeuds est la somme de leur distance au plus proche ancêtre commun. Ainsi, le noeud le plus proche sera ainsi prioritairement : - le même noeud - un autre noeud sur le même rack - un autre noeud sur le même datacenter |
|