4 SQL SUR HADOOP
4.1 Hive
4.1.1 Histoire
Hive est un projet initié en 2007 par
Facebook(AshishThusoo, 2009). Le réseau social disposait alors d'une
infrastructure de traitement de données classique, basée sur un
entrepôt de données construit surun SGBDR du
marché.Année après année, la quantité de
données à traiter devenait de plus en plus importante et
l'architecture en place devint rapidement obsolète. Hadoop s'est ainsi
rapidement imposé comme la solution à ces difficultés de
montée en charge : c'est un projet Open Source et surtout, il
propose une infrastructure scalable déjà
éprouvée.
Si la capacité de traitement de l'infrastructure Hadoop
était aisément extensible et si les traitements
s'exécutaient dorénavant en quelques heures au lieu d'un jour ou
plus, il fallait en revanche les développer en utilisant le paradigme
MapReduce. Les utilisateurs des entrepôts de données, plus
habitués au SQL, n'étaient pas forcément à l'aise
dans l'écriture de programmes de ce type.
L'équipe de Jeff Hammerbacher créa alors Hive, un
entrepôt de données au-dessus de Hadoop, dont le langage
d'interrogation des données, le HQL (Hive Query Langage), est le portage
« distribué »du SQL des SGBDR classiques.
Hive est rapidement passé sous licence Apache, sa
première version stable date d'octobre 2010, et continue d'être
améliorée tout en bénéficiant des évolutions
continues de Hadoop.
4.1.2 Architecture
Hive est composé des éléments suivants
(LeftyLeverenz, 2015) :
· le metastore
Le metastore contient l'ensemble des données
décrivant les tables (schéma de données, localisation des
fichiers, et les statistiques concernant les données telles que le
nombre de lignes, la taille moyenne d'une ligne, etc.).
· un compilateur (compiler) et un optimiseur
(optimizer)
Le compilateur réalise l'analyse syntaxique
(générant un arbre syntaxique abstrait ou AST) puis l'analyse
sémantique (génération d'un arbre d'opérations ou
operatortree) définissant l'ensemble des étapes
nécessaires à l'accomplissement de la requête. Au cours de
cette analyse, le metastoresera sollicité pour validerque l'ensemble des
objets (fichiers et champs) décrits dans la requête sont
valides.
Il est à noter qu'il ne figure aucune dépendance
à MapReduce, ni à d'autres frameworks distribués, à
ce stade de la compilation.
Ensuite, selon le framework distribué utilisé
par Hive, un compilateur de tâche sera exécuté
(MapRedCompiler par exemple) et génèrera une tâche
exécutable (MapRedTask, c'est-à-dire du code Java
implémentant le framework MapReduce dans ce cas de figure) décrit
par un arbre d'opérations qui aura d'abord été
optimisé puis transformé en enchaînement de travaux
(MapRedWork).
Les dernières versions de Hive permettent d'utiliser
d'autres frameworks distribués comme Tez et Spark, sans remettre en
question cette architecture.
· un exécuteur
(executor)
L'exécuteur est en charge de soumettre lestâches
auNodeManager(côté Hadoop). Il supervisera ainsi leur
exécution jusqu'à leur achèvement.
· une interface utilisateur
(UI)
L'interface utilisateur permet à l'utilisateur d'interagir
avec Hive (envoyer des requêtes / obtenir les résultats) au
travers d'un client connecté au serveur Hive via un connecteur ODBC ou
JDBC dans la plupart des cas.
· le pilote (driver)
Le pilote contrôle les échanges entre l'interface
utilisateur, le compilateur et l'exécuteur. Il reçoit ainsi la
demande d'exécution d'une requête par l'utilisateur qu'il
soumettra au compilateur, puis à l'exécuteur après
compilation. Il est également en charge de restituer le résultat
de la requête, reçu par l'exécuteur, à
l'utilisateur.
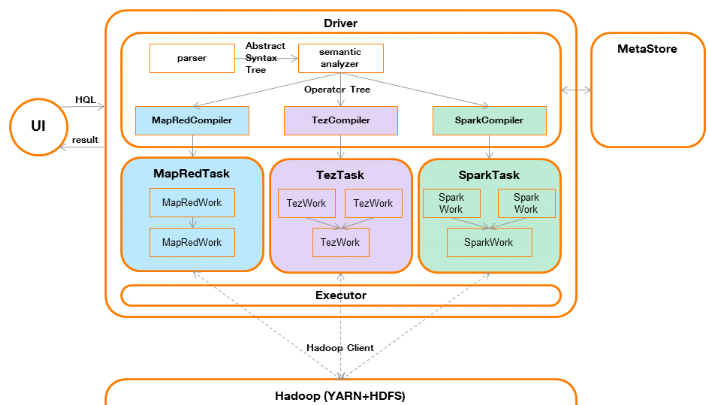
Figure 6 : architecture de
Hive
| 

