|

Institut Africain d'Informatique
Myrabilys Technologies Sarl
Etablissement Inter - Etats d'Enseignement
Supérieur
BP 2263 Libreville (Gabon)
Tél. (241) 07 70 55 00
/ 07 70 56 00
Site web:
www.iai-siege.com
E-mail:
contact@iaisiege.com
Carrefour Ancienne Sobraga
BP 13.984 Libreville
(Gabon)
Tél. (241) 01 73 00 24
Site web:
www.myrabilys.com
MÉMOIRE DE FIN DE CYCLE
En vue de l'obtention du diplôme
D'INGENIEUR EN INFORMATIQUE
THÈME
ÉTUDE, CONCEPTION ET
IMPLÉMENTATION D'UN CLUSTER LOW-
COST HAUTE DISPONIBILITÉ DE
RASPBERRY PI 3
Réalisé par :
TCHUENCHÉ Rodrigue
Élève en fin
de cycle ingénieur
Superviseur
Maître de stage
Dr. NOUSSI Roger
Enseignant Permanent à
IAI
M. NJIOMO Luc Prosper
Ingénieur Informaticien
& MBA
C.E.O de
Myrabilys
Année Académique 2015 - 2016


ÉTUDE, CONCEPTION ET IMPLÉMENTATION
D'UN CLUSTER LOW-COST HAUTE
DISPONIBILITÉ DE RASPBERRY PI 3
Tchuenché Rodrigue
Septembre 2016
Table des matières
Liste des Acronymes vii
DÉDICACE xi
ÉPIGRAPHE xii
REMERCIEMENTS xiii
AVANT-PROPOS xiv
RÉSUMÉ xv
ABSTRACT xvi
INTRODUCTION GÉNÉRALE 1
I PARTIE 1 : Présentation
générale de l'étude 2
INTRODUCTION 3
1 CHAPITRE 1 : Présentation de la
structure d'accueil, du contexte et du su-
jet d'étude 4
1.1 Structure d'accueil 4
1.1.1 Historique 4
1.1.2 Missions et Activités 4
1.1.3 Organigramme 5
1.2 Contexte et Problématique 7
1.3 Sujet d'étude 7
ii
2 CHAPITRE 2 : Concepts
généraux liés au sujet 9
iii
iii
2.1 Quelques Définitions 9
2.2 Etude de quelques concepts liés au sujet
d'étude 10
2.2.1 Raspberry Pi 10
2.2.1.1 Modèle A 11
2.2.1.2 Modèle A+ 11
2.2.1.3 Modèle B 12
2.2.1.4 Modele B+ 12
2.2.1.5 Modèle 2B 13
2.2.1.6 Modèle 3B 14
2.2.1.7 Modèle Zéro 14
2.2.2 Cluster 16
2.2.2.1 Catégories de clusters 16
2.2.2.2 Architecture des Clusters 19
2.2.3 Les Dockers 21
2.2.3.1 C'est quoi un Docker? 22
2.2.3.2 Difference entre Docker et Machine Virtuelle (VM) 22
2.2.3.3 Environnement et notions de base Docker 22
2.2.4 ERP Odoo 23
2.2.4.1 Historique 23
2.2.4.2 Principaux Modules Applicatifs du logiciel Odoo 24
2.2.4.3 Architecture Logiciel d'Odoo 25
CONCLUSION 25
II PARTIE 2 : Conception, Implémentation et
étude de la solution
à proposer 26
INTRODUCTION 27
3 CHAPITRE 3 : Analyse et conception 28
3.1 Solution logicielle de Cluster 28
iv
|
3.1.1
3.1.2
|
Microsoft Cluster / Cluster pour système Windows
3.1.1.1 Microsoft Cluster Server (MSCS)
3.1.1.2 Evidian Safekit
Cluster GNU/Linux
|
28
29
29
30
|
|
|
3.1.2.1 Linux Virtuel Server (LVS)
|
30
|
|
|
3.1.2.2 Beowulf
|
30
|
|
|
3.1.2.3 Linux HA-Project
|
31
|
|
|
3.1.2.4 Multicomputer Operating System for Unix (MOSIX)
|
31
|
|
|
3.1.2.5 Apache Mesos
|
31
|
|
|
3.1.2.6 Cluster Docker Swarm
|
31
|
|
3.2
|
Analyse Des Solutions
|
32
|
|
3.3
|
Concepts de répartition de charge réseau (Load
Balancing)
|
32
|
|
3.3.1
|
Présentation
|
32
|
|
3.3.2
|
Logiciels de distribution de charge réseau et haute
Disponibilité du cluster 33
|
|
|
3.3.2.1 HAProxy
|
33
|
|
|
3.3.2.2 Heartbeat
|
34
|
|
3.4
|
Conception du cluster
|
35
|
|
|
3.4.1 Nombre de Noeuds du Cluster
|
35
|
|
|
3.4.2 Adressage IP du Cluster
|
36
|
|
|
3.4.3 Constituant de chaque noeud
|
36
|
|
|
3.4.4 Architecture de notre cluster
|
37
|
|
CONCLUSION
|
37
|
|
4
|
CHAPITRE 4 : Mise en oeuvre du
cluster
|
39
|
|
4.1
|
Matériel utilisés pour monter notre Cluster
|
39
|
|
4.2
|
Mise en OEuvre du cluster
|
42
|
|
|
4.2.1 Installation du système d'exploitation sur les 10
noeuds du cluster . . . .
|
42
|
|
|
4.2.1.1 Configuration adresse IP des noeuds Raspberry Pi
|
42
|
|
|
|
iv
|
v
v
4.2.1.2 Configuration nom d'hôte des noeuds Raspberry Pi
43
4.2.2 Installation du moteur Docker sur chaque noeud 43
4.2.3 Création d'un container Docker, le cas du container
Odoo 43
4.2.3.1 Création d'un Docker Image à partir d'un
Dockerfile 44
4.2.3.2 Création des Docker Containers 44
4.2.4 Mise en oeuvre du Cluster Docker Swarm 44
4.2.5 Mise en OEuvre du Cluster de Répartition de charges
et Haute Disponi-
bilité 45
4.2.5.1 Mise en oeuvre de la répartition de charge 45
4.2.5.2 Mise en oeuvre Haute Disponibilité du cluster
46
CONCLUSION 47
5 CHAPITRE 5 :Évaluation du cluster et conduite du
projet 48
5.1 Protocole d'évaluation 48
5.2 Évaluation du cluster 49
5.2.1 Évaluation de l'énergie 49
5.2.2 Évaluation coût du cluster 50
5.2.3 Évaluation Performance Cluster 50
5.3 Conduite du projet 50
5.3.1 Les intervenants dans le projet 51
5.3.2 Découpage du projet 51
5.3.3 Diagramme de GANTT 52
5.4 Bilan et perspectives 53
5.4.1 Bilan 53
5.4.2 Perspectives 54
CONCLUSION GÉNÉRALE 55
Les Annexes 56
.1 Annexe 1 56
vi
vi
.2 Annexe 2 58
.3 Annexe 3 59
.4 Annexe 4 60
.5 Annexe 5 61
.6 Annexe 6 68
.7 Annexe 7 68
.8 Annexe 8 70
.9 Annexe 9 75
.10 Annexe 10 80
Référence bibliographique 83
vii
vii
Liste des Acronymes
|
Abréviations
|
Significations
|
|
VM
|
Virtual Machine
|
|
ERP
|
Enterprise Resource Planning
|
|
Sarl
|
Societé à Responsabilité Limité
|
|
IAAS
|
Infrastructure As A Service
|
|
SAAS
|
Software as a service
|
|
CRM
|
Customer Relationship Management
|
|
ARM
|
Advanced RISC Machines
|
|
HDMI
|
Interface Multimédia Haute Définition
|
|
GPIO
|
General Purpose Input/Ouput
|
|
MOSIX
|
Multicomputer Operating System for Unix
|
|
FTP
|
File Transfert Protocol
|
|
DMA
|
Direct Memory Access
|
|
API
|
Application Program Interface
|
|
PVM
|
Parallele Virtual Machine
|
|
MPI
|
Message Passing Interface
|
|
RMA
|
Remote Memory Access
|
|
RAM
|
Random Access Memory
|
|
CPU
|
Central Processing Unit
|
|
LXC
|
Linux Container
|
|
OS
|
Operating System
|
|
GPL
|
General Public License
|
|
LGPL
|
Lesser General Public License
|
|
CMS
|
Content Management System
|
|
MVC
|
Modèle Vue Contrôleur
|
|
NLB
|
Network Load Balancing
|
|
MSCS
|
Microsoft Cluster Service
|
|
CLB
|
Component Load Balancing
|
|
LVS
|
Linux Virtual Server
|
TABLE 1 - Liste des abréviations
viii
Liste des tableaux
|
1
|
Liste des abréviations
|
vii
|
|
2.1
|
Tableau récapitulatif version Odoo
|
24
|
|
4.1
|
Carte MicroSD 8 & 32 Go
|
40
|
|
5.1
|
Comparaison consommation d'énergie
|
50
|
|
5.2
|
Table dépenses
|
50
|
|
5.3
|
Comparaison coût
|
50
|
|
5.4
|
Découpage des tâches
|
52
|
|
5
|
Liste outils nécessaires pour flasher la carte microSD
|
56
|
ix
Table des figures
2.1 Schéma Architecture D'un Cluster 10
2.2 Une carte nue du Raspberry Pi modèle A 12
2.3 Une carte nue du Raspberry Pi modèle A+ 12
2.4 Une carte nue du Raspberry Pi modèle B 13
2.5 Une carte nue du Raspberry Pi modèle B+ 13
2.6 Une carte nue du Raspberry Pi 2 modèle B 14
2.7 Une carte nue du Raspberry Pi 3 modèle B 14
2.8 Une carte nue du Raspberry Pi Zéro 15
2.9 Une carte annotée du Raspberry Pi 3 Modèle B
15
2.10 Cluster haute disponibilité 17
2.11 Cluster répartition de charges 18
2.12 Cluster calcul haute performance 18
2.13 Cluster de stockage 19
2.14 Machine Virtuelle Vs Docker 23
3.1 Architecture Haproxy 34
3.2 Architecture Haproxy/heartbeat 35
3.3 Architecture cluster à implémenter 38
3.4 Architecture cluster Docker Swarm à
implémenter 38
4.1 Switch Gigabit Ethernet 40
x
|
4.2
|
Câble RJ45
|
40
|
|
4.3
|
Batterie d'alimentation
|
40
|
|
4.4
|
Convertisseur 12V - 5V
|
41
|
|
4.5
|
Notre Raspberry Pi 3 Assemblé
|
41
|
|
4.6
|
Notre Cluster Physique monté
|
42
|
|
4.7
|
ifconfig partie eth0 :0 qui indique que le noeud fonction sur
l'adresse virtuelle
|
|
|
172.16.0.50
|
46
|
|
4.8
|
Interface Connexion Odoo sur le cluster à l'adresse
172.16.0.50 :8070
|
47
|
|
5.1
|
Diagramme de GANTT
|
53
|
|
5.2
|
Diagramme de GANTT next
|
53
|
|
3
|
Fenêtre WinDiskImager
|
57
|
|
4
|
Fenêtre Zenmap
|
57
|
|
5
|
Fenêtre Putty.exe
|
58
|
|
6
|
Fenêtre connexion Hypriot OS
|
58
|
|
7
|
Fenêtre acceuil Hypriot OS
|
59
|
|
8
|
Fenêtre docker build
|
65
|
|
9
|
Fenêtre docker images
|
69
|
|
10
|
Fenêtre résultat docker stats
|
75
|
|
11
|
Fenêtre résultat docker ps sur cluster
|
76
|
|
12
|
Fenêtre statistique Haproxy
|
78
|
|
13
|
Fenêtre status Haproxy
|
80
|
|
|
x
|
xi
DÉDICACE
Je dédie ce mémoire à ma feue
grand-mère
Maman KUISSU Pauline
Paix à son âme, que la terre de nos ancêtres
lui soit légère.
xi
xii
xii
ÉPIGRAPHE
« Nous ne pouvons pas prédire où nous
conduira la Révolution
Informatique. Tout ce que nous savons avec
certitude, c'est que,
quand on y sera enfin, on n'aura pas assez de RAM
»
Dave Barry
xiii
xiii
REMERCIEMENTS
Je remercie l'État camerounais pour
m'avoir donné l'opportunité de poursuivre mes
études
d'ingénieur à IAI-GABON en les finançant.
Je voudrais par la même occasion remercier
l'État Gabonais pour
l'accueil, l'assistance et les facilités à nous accordés
pour permettre le
bon déroulement de nos études sur son
territoire.
Je tiens particulièrement à remercier ma feue
grand-mère Maman KUISSU Pauline pour
l'amour, la
patience, le courage, le soutien et les conseils qu'elle a toujours
porté à mon
endroit. Paix à son âme.
Je remercie papa KOUAM Moïse et son
épouse Maman Béatrice pour leur soutiens et
conseils.
Je remercie mes parents pour leurs amours,
soutiens et conseils.
À Mr NJIOMO Luc Prosper , mon
maître de stage, je dis un merci spécial pour
ses
précieux conseils, sa disponibilité, son soutien, son
hospitalité, sa rigueur durant ses trois
années de formation
et pour son encadrement durant ses cinq mois de stage.
À Mr NOUSSI Roger enseignant permanent
à l'IAI, mon superviseur, je dis merci pour
ses conseils et
orientations durant ce stage.
Aux corps administratif et enseignants de
l'Institut Africain d'Informatique(IAI) pour la formation et l'encadrement
reçus, je dis merci.
À mes camarades de promotion plus particulièrement
Apollinaire, Hervé, Mbonwouo, Etienne Willy, Franck
César, Sergeo, Francine, je les remercie pour leurs soutiens,
les échanges fructueux et l'ambiance qui a régné durant le
stage et ses trois années de formation.
À mon grand ami TANON Hervé, je
dis un grand merci pour son soutien et ses conseils.
J'exprime ma gratitude à mes frères,
soeurs, amis et toute la famille pour leur soutiens
inconditionnels.
À la grande famille ASSECI (Association
des étudiants Camerounais de l'IAI), je leur
témoigne mes
sincères remerciements pour leurs soutiens et conseils.
À Mme NJIOMO Marcelle, pour son accueil
aussi chaleureux à chaque visite, son
hospitalité, ses
conseils, son soutien, je lui témoigne mes sincères
remerciements.
Enfin, à tous ceux qui, de près ou de loin, ont
participé à l'élaboration de ce mémoire, je vous
dis sincèrement merci
xiv
xiv
AVANT-PROPOS
L'institut Africain d'Informatique (IAI) est un
établissement Inter-états d'enseigne-ment supérieur
créé en 1971. Il regroupe onze (11) Etats africains : le Burkina
Faso, le Benin, le Cameroun, la République Centrafricaine, le Congo
Brazzaville, la Côte d'Ivoire, le Gabon, le Niger, le
Sénégal, le Tchad et le Togo. L'IAI intègre dans son
cursus de formation plusieurs cycles parmi lesquels celui des Ingénieurs
de conception en Informatique. Arrivés en fin de cycle, les
élèves du cycle Ingénieur sont soumis à un stage
pratique d'une durée de cinq (5) mois. Ce stage a pour finalité
de placer l'étudiant en fin de cycle face aux réalités
diverses et variées du monde professionnel sous l'encadrement d'un
expert métier. Celui-ci a pour mission d'apprendre à
l'étudiant stagiaire les fondamentaux requis pour construire des
solutions informatiques adaptées aux problèmes soumis à
son attention par l'entreprise (qu'elle soit privée, publique ou mixte)
ou par une structure de recherche.
Le présent document représente l'aboutissement
de trois (3) années de formation donc cinq (5) mois de stage pratique
effectué à MYRABILYS TECHNOLOGIES Sarl qui est une entreprise
informatique basée à Libreville au Gabon et tient lieu à
cet effet de notre mémoire de fin de formation d'ingénieur en
Informatique à l'Institut Africain d'Informatique de Libreville.
xv
xv
RÉSUMÉ
Le thème de notre étude porte sur la conception,
l'implémentation et l'étude d'un cluster low cost haute
disponibilité de raspberry pi 3. Ce travail permet de proposer une
solution serveur à faible coût et à faible consommation
d'énergie tout en garantissant les performances d'un serveur normal
à MYRABILYS et à ses clients composés de petites et
moyennes structures et des grandes entreprises. Parfaitement adapté aux
zones reculées, non couvertes par le réseau électrique,
cette solution vise aussi à faciliter l'utilisation et le
déploiement des applications comme l'ERP Odoo par l'utilisation des
Docker et du cluster Docker Swarm.
Après une étude approfondie en vue d'analyser
les solutions déjà existantes et de choisir les outils (logiciels
et matériels) nécessaires à la réalisation, nous
avons procédé à une phase de conception pour créer
l'architecture la mieux adaptée à nos besoins. Par la suite, nous
l'avons implémentée et procédé à une
évaluation de la solution en vue de vérifier si les objectifs en
énergie, coût et performance ont été atteints.
Mots clés : Cluster, Haute
disponibilité, Raspberry Pi, Docker, Docker Swarm
xvi
xvi
ABSTRACT
The focus of our study is on the design, implementation and
study of a low-cost, high-availability cluster of raspberry pi 3. This work
provides a low-cost, low-power server solution while Guaranteeing the
performance of a normal server to MYRABILYS and its customers composed of small
and medium structures and large companies. Perfectly adapted to remote areas,
not covered by the electrical network, this solution also aims at facilitating
the use and deployment of applications such as Odoo ERP through the use of the
Docker and the Docker Swarm cluster.
After a thorough study to analyze the existing solutions and
to choose the tools (software and hardware) necessary for the realization, we
proceeded with a design phase to create the architecture best suited to our
needs. We then implemented it and carried out an evaluation of the solution to
verify whether the energy, cost and performance objectives were met.
Keywords : Cluster, High Availability, Raspberry
Pi, Docker, Docker Swarm
1 IAI Gabon
c~Tchuenché Rodrigue Élève Ingénieur
En Informatique 1
INTRODUCTION GÉNÉRALE
De nos jours, l'informatisation des Systèmes
d'informations des entreprises est un phénomène qui prend de
l'ampleur en Afrique. La plupart des structures veulent ou doivent se doter des
infrastructures serveurs pouvant servir à héberger leurs services
informatiques ou ceux de leurs clients. Dans la démarche d'obtention de
ces serveurs, ces structures se heurtent au problème de prix et
d'énergie.
Fort de ce constat, et confrontée elle aussi à
ces problèmes, MYRABILYS Sarl s'est proposée
d'apporter une solution à cette situation. C'est donc dans cette optique
que le thème « étude, conception, et
implémentation d'un cluster low-cost haute disponibilité de
raspberry pi 3 » nous a été confié.
Le présent mémoire sera composé de deux
parties. La première sera consacrée à la
présentation générale. Elle présentera la structure
d'accueil, décrira le contexte général de l'étude,
l'objectif et la problématique, puis les concepts généraux
liés au sujet. Dans la seconde partie, il s'agira l'analyse, conception
et de la mise en oeuvre de la solution, nous évaluerons le
système implémenté, et nous terminerons par la conduite du
projet.
2
Première partie
PRÉSENTATION GÉNÉRALE DE
L'ÉTUDE
3 IAI Gabon
INTRODUCTION
c~Tchuenché Rodrigue Élève Ingénieur
En Informatique 3
Cette partie est divisée en deux chapitres. Le chapitre
1 présente la structure d'accueil, le contexte d'étude, la
problématique et le sujet d'étude. Dans le chapitre 2, nous
posons la fondation de notre travail en définissant quelques concepts
liés à notre étude. Ce même chapitre traite du
domaine dans lequel se situe notre travail. Au terme de cette première
partie, nous aurons une compréhension claire de la théorie des
concepts utilisés dans la réalisation de notre système.
4
Chapitre1
PRÉSENTATION DE LA STRUCTURE D'ACCUEIL, DU CONTEXTE ET
DU SUJET D'ÉTUDE
1.1 Structure d'accueil
Pour mieux présenter la structure qui nous a
accueillis, nous allons commencer par présenter son historique, puis ses
missions, ses activités et enfin son organigramme. Nous explorerons
enfin le département dans lequel nous avons effectué le stage.
1.1.1 Historique
La société MYRABILYS Sarl a été
créé en 2014 par Mr NJIOMO Luc Prosper le Chief Executive Officer
Actuel. Elle est basée à Libreville (Ancienne SOBRAGA) et une
succursale sera bientôt installée à Douala au Cameroun.
1.1.2 Missions et Activités
MYRABILYS TECHNOLOGIES Sarl est une
entreprise informatique basée à Libreville au Gabon et dont le
coeur de métier couvre trois activités complémentaires
suivantes :
* Le Cloud Computing (que l'on
traduit par nuage informatique) qui consiste à fournir des services ou
des applications informatiques en ligne, accessibles partout, à tout
moment, et de n'importe quel terminal (smartphone, PC de bureau, ordinateur
portable et tablette). Le Cloud Computing permet chez MYRABILYS Technologies
Sarl, de partager une infrastructure (Infrastructure As A Service - IAAS), une
solution applicative (Software As A Service - SAAS) à toute entreprise
utilisatrice qui en fait la demande via une simple connexion internet en
libre-service. MYRABILYS Technologies Sarl se positionne donc comme un «
opérateur de services informatiques managés
» où elle propose à ses clients d'externaliser
l'hébergement, la configuration, la maintenance de leur application sur
ses serveurs de sorte que les clients qui ne possèdent pas toujours de
services informatiques internes digne de ce nom, n'aient plus à se
préoccuper des problématiques
5 IAI Gabon
techniques informatiques afin de se concentrer sur le coeur de
leur métier.
c~Tchuenché Rodrigue Élève Ingénieur
En Informatique 5
* L'intégration et outsourcing,
concernant principalement l'ERP ODOO (ancien Open
ERP). En effet, L'éditeur est un industriel du
logiciel. Il conçoit et développe des produits logiciels pour le
plus grand nombre. L'intégrateur accompagne un tiers
utilisateur dans le déploiement et personnalise le produit logiciel
conçu par l'éditeur.
* Le conseil et l'audit. Cette
activité a pour objectif d'identifier et d'évaluer les risques
(opérationnels, financiers, organisationnels) associés aux
activités informatiques d'une entreprise ou d'une administration. Ceci
permet d'identifier les endroits où agir pour améliorer le
fonctionnement et la performance d'une organisation avec une éventuelle
implication dans la mise en oeuvre de cette amélioration.
1.1.3 Organigramme
Dans le cadre de notre stage, bien que attaché au
département SOFTWARE, notre travail « conception et
implémentation d'une infrastructure serveur basé sur raspberry pi
» s'intègre au département
INFRASTRUCTURE.
Pool Conseillers et Consultants
|
Juridique, Stratégique,
Management
|
DIRECTEUR GENERAL
MYRABILYS TECHNOLOGY
|
Plans, Table Plan
Recru
|
|
|
|
INFRASTRUCTURE
|
SOFTWARE
|
MARKETING
|
AD
|
Matériel, Télécom,
Réseaux
Installation et administration du Datacenter.
Animation de la cellule de veille et
d'éveille.
Cellule de test de robustesse des solutions
proposées aux clients
Installation des environnements matériels et OS
chez les clients
Règle les dysfonctionnement technique en cas
de réclamation incident client
Installe et maintient l'infrastructure interne
de l'entreprise.
Base de données, ERP
Responsable des contenus du
Datacenter.
Cellule de développement des
applications à installer chez les clients ou dans le
Datacenter.
Prépare et effectue les démonstrations chez
les clients ou dans notre salle de formation.
Déploiement fonctionnelle de l'ERP chez
les clients
Formation fonctionnelle sur les applications et
les modules de l'ERP.
Rédaction des documentations techniques.
Comp
gest
Fac
Co
anal
Fisc
l'ad
Ges
Paie
Réd
céd
Stat
bor
Ges tière
riels
Con de r
6
Prospection, Vente, CRM
Rédaction propositions commerciales, et appels
d'offre, ainsi que conditions générales de
vente.
Définition des Produits, ser vices,
Segments, Tarifications, Couple Produit/ Marché, 5 roues de
Porter
Retour d'information des clients sur les
améliorations attendues, des nouveaux besoins,
Définition des nouvelles offres,
ajustement de tarifs
Régler les soucis commerciaux en cas de
réclamation client.
Formation fonctionnelle et technique des
clients utilisant nos solutions hébergées.
Rédaction des documentations fonctionnelles des
modules de l'ERP et des applications hébergées.
7 IAI Gabon
c~Tchuenché Rodrigue Élève Ingénieur
En Informatique 7
1.2 Contexte et Problématique
L'activité coeur de métier de MYRABILYS
Technologies Sarl c'est celle du cloud computing. Elle nécessite
d'acquérir, de posséder, de sécuriser et d'administrer au
quotidien un Datacenter (centre de traitement des données en
français). Le datacenter est un site physique sur lequel se trouvent
regroupés des équipements constituants du système
d'information de l'entreprise (ordinateurs centraux, serveurs, switch,
routeurs, baies de stockage, équipements réseaux et de
télécommunications, etc.) et dans lequel les entreprises clientes
peuvent notamment louer un espace de stockage et ainsi éviter la
présence de serveurs dans leurs locaux. Posséder un datacenter
présente les difficultés suivantes :
* le coût d'acquisition de ces
solutions serveur : En effet le coût d'achat de ces solutions de
serveurs physique (HP, SuperMicro, Dell, etc.) est en général
assez élevé (des dizaines de millions et plus).
* la consommation d'énergie :
Les solutions traditionnelles de serveurs physiques sont assez
énergivores. Dans un contexte africain où la couverture et la
fourniture d'énergie électrique bon marché sont loin
d'être un acquis, l'aspect énergie est également source de
dépenses énormes pour les entreprises. Elle constitue aussi un
frein sérieux dans la généralisation des outils des NTIC
dans tous les secteurs de la vie économique.
* Le système de refroidissement
* La sécurisation
Ainsi, garantir une maintenance technique, un accès
sécurisé permanent, un fonctionnement 24h/24 de ses
infrastructures et de celui de ses clients qui sont pour la plupart des PME,
des mairies, des établissements scolaires souvent situés dans des
zones très reculées sans couverture de réseau
électrique est un grand challenge pour MYRABILYS Technologies.
Le Raspberry Pi est un nano-ordinateur monocarte à
processeur ARM. Cet ordinateur, qui a la taille d'une carte de crédit,
permet l'exécution de plusieurs variantes du système
d'exploitation libre GNU/Linux et des logiciels compatibles. Il est fourni nu
(carte mère seule, sans boîtier, alimentation, clavier, souris ni
écran) dans l'objectif de diminuer les coûts et de permettre
l'utilisation de matériel de récupération. Le raspberry Pi
nécessite très peu d'énergie électrique pour son
fonctionnement (5v et 800 mA). Il consomme 2W.
1.3 Sujet d'étude
Notre travail consiste donc à étudier, concevoir
et implémenter une solution de clustering haute disponibilité
à moindre coût et peu énergivore basée sur les
nano-ordinateurs Raspberry Pi 3 pouvant compléter l'offre serveur de
MYRABILYS Technologies. Malheureusement, les nano-ordinateurs de nos jours
n'ont pas de puissance de calcul pouvant égaler celle des gros serveurs.
Un raspberry pi pris individuellement est faible. Il faudra alors inventer un
modèle de coopération entre ces machines dans une
stratégie du type « l'union fait la force » ou encore «
l'union des petits peut égaler un grand ».
8 IAI Gabon
c~Tchuenché Rodrigue Élève Ingénieur
En Informatique 8
Par ailleurs, étant intégrateur de l'ERP Odoo,
MYRABILYS doit soit en local dans son datacenter, soit chez le client
déployer l'ERP Odoo et par la suite procéder à des
formations à l'utilisation des nouveaux utilisateurs. Une des
difficultés est le déploiement complexe d'Odoo quand il s'agit
d'un système d'exploitation Linux.
Ainsi, après avoir monté notre solution cluster,
nous devons par la suite trouver un moyen de faciliter le déploiement et
la gestion de l'ERP Odoo et d'autres applications similaires dans notre
solution cluster ou dans un système Linux pour serveur.
Chapitre2
CONCEPTS GÉNÉRAUX LIÉS AU SUJET
9
Introduction
Ce chapitre se consacre à une étude des concepts
généraux et spécifiques en rapport avec notre sujet. Dans
la première section de ce chapitre, nous présenterons quelques
définitions des termes techniques liés au domaine
étudié. Dans la deuxième section, nous présenterons
les différents éléments (matériels et logiciels) de
notre sujet d'étude.
2.1 Quelques Définitions
Raspberry Pi : Nano-ordinateur monocarte
ayant la taille d'une carte de crédit, à processeur ARM
conçu par le créateur de jeux vidéo David Braben, dans le
cadre de sa fondation Raspberry Pi
Cluster : Se définit en informatique
comme étant une grappe d'ordinateurs inter-connectés dans le but
de mutualiser leurs ressources.(voir figure 2.1)
Cluster haute disponibilité : C'est un
cluster dont le taux de disponibilité est proche de 99%
1.
Docker : Un Docker est une technologie
permettant de créer des environnements virtuels appelés «
containers » de manière à isoler les
applications. Il permet d'automatiser le déploiement des applications en
embarquant dans un container toutes les dépendances et outils
nécessaires à l'exécution de l'application.
1. Taux proche des 99%, signifie que ce n'est qu'en cas de
trouble majeur que le système sera indisponible
10 IAI Gabon



c~Tchuenché Rodrigue Élève Ingénieur
En Informatique 10
FIGURE 2.1 - Schéma Architecture D'un Cluster
Docker Swarm : C'est un cluster sur les
Docker.
Progiciel : Logiciel applicatif
généraliste aux multiples fonctions, composé d'un ensemble
de programmes paramétrables et destinés à être
utilisés simultanément par plusieurs personnes.
ERP : ( Entreprise Ressource Planning) est un progiciel de
gestion intégré servant à planifier les ressources en
entreprise. 2
Odoo : C'est un progiciel de gestion intégré
open-source comprenant de très nombreux modules permettant de simplifier
la gestion d'entreprise dans son ensemble. 3
2.2 Etude de quelques concepts liés au sujet
d'étude
2.2.1 Raspberry Pi
Comme nous l'avons défini plus haut, un Raspberry Pi
est un nano-ordinateur de la taille d'une carte de crédit à
processeur ARM 4. Son disque dur est une carte
microSD d'au moins 8 Go et de la classe 6 au moins. Le Raspberry Pi a
été crée au départ pour encourager la programmation
en informatique. Il est vendu de nos jours à plus de 10 millions
d'exemplaires.
2. Source :
https://fr.wikipedia.org/wiki/Progiciel_de_gestion_intégré
3. Source :
https://fr.wikipedia.org/wiki/Odoo
4. Les architectures ARM sont des architectures RISC 32 bits
(ARMv1 à ARMv7) et 64 bits (ARMv8) développées par ARM Ltd
depuis 1990 et introduites à partir de 1983 par Acorn Computers.
11 IAI Gabon
c~Tchuenché Rodrigue Élève Ingénieur
En Informatique 11
Il est utilisé par des particuliers et des entreprises
à des fins diverses au quotidien (Apprentissage, bureautiques,
déploiement, etc...) . Il permet l'exécution de plusieurs
variantes système d'exploitation GNU/Linux et Windows tel que:
· RASPBIAN OS
· UBUNTU MATE
· SNAPPY UBUNTU CORE
· PINET
· RISC OS
· WINDOWS 10 IOT CORE
· HYPRIOT OS
· ALPINE LINUX
· ARCH LINUX
· etc ...
La plupart de ces systèmes sont des systèmes
dérivés des systèmes GNU/Linux comme Debian par exemple.
Le Raspberry Pi est fourni nu, c'est-à-dire carte mère seule,
sans boîtier, alimentation, clavier, souris ni écran, dans
l'objectif de diminuer les coûts et de permettre l'utilisation de
matériel de récupération. Son prix est estimé entre
5$ US (soit environ 5000 FCFA) à sa sortie en 2012 et 35$ US (soit
17.500 FCFA) de nos jours, selon les modèles. A l'heure actuelle il
existe sept (07) modèles de Raspberry Pi à savoir les
modèles A, A+, B, B+, 2B, 3B, Modèle Zéro. 5
2.2.1.1 Modèle A
Premier modèle du Raspberry pi, le modèle A a
été mis sur le marché le 29 février 2012 avec un
prix d'environ 25$ US (soit environ 12.500 FCFA). Il pèse 45g avec une
taille de 85,6 mm de long, 53,98 mm de large et 17 mm d'épaisseur. Il a
un processeur ARM11 (ARMv6) à 700 MHz; une mémoire RAM de 256 Mo;
deux sorties vidéos, composite et HDMI; une sortie audio
stéréo Jack 3,5 mm (sortie son 5.1 sur la prise HDMI); une
unité de lecture - écriture de carte mémoire SD : SDHC /
MMC / SDIO; un port USB 2.0; une prise d'alimentation Micro-USB avec une
consommation de 400mA (1,5W); et des entrées/sorties directement
accessibles sur la carte mère (voir figure 2.2).
2.2.1.2 Modèle A+
Ce modèle a presque les mêmes
caractéristiques que le modèle A. Cependant, il a un prix qui est
réduit jusqu'environ 20$ US (soit environ 10.000 FCFA) avec une taille
de 65 mm de long et pèse 23g. Il a une sortie HDMI; une unité de
lecture-écriture mémoire mircoSD au lieu de SD; GPIO 40 broches
et une consommation en électricité de 200 mA (1W) (voir figure
2.3).
5. Source :
https://fr.wikipedia.org/wiki/Raspberry_Pi

12 IAI Gabon
c~Tchuenché Rodrigue Élève Ingénieur
En Informatique 12
FIGURE 2.2 - Une carte nue du Raspberry Pi modèle A

FIGURE 2.3 - Une carte nue du Raspberry Pi modèle A+
2.2.1.3 Modèle B
A la différence du modèle A, le modèle B
contient deux ports USB 2.0, un port réseau Fast Ethernet
(10/100Mbits/s) et une mémoire RAM de 512Mo. Il coûte environs 35$
US (soit environ 17.500 FCFA) avec un poids de 45g et une consommation de 700
mA (3,5W) (voir figure 2.4).
2.2.1.4 Modele B+
Ce modèle est apparu en juillet 2014 et a les
mêmes caractéristiques que le modèle initial,
c'est-à-dire le modèle B, à la différence qu'il
contient quatre ports USB 2.0 et une réduction de la consommation de
3.5W à 3W (600mA); GPIO 40 broches. Il coûte environs 35$ US
(soit

13 IAI Gabon
c~Tchuenché Rodrigue Élève Ingénieur
En Informatique 13
FIGURE 2.4 - Une carte nue du Raspberry Pi modèle B
environ 17.500 FCFA) (voir figure 2.5).

FIGURE 2.5 - Une carte nue du Raspberry Pi modèle B+
2.2.1.5 Modèle 2B
Ce modèle sort le 2 février 2015, plus puissant,
il est équipé d'un processeur Broadcom BCM2836, quatre coeurs
ARMv7 à 900MHz, accompagné de 1 Go de RAM. Il possède les
mêmes dimensions et connectiques que le modèle B.Il coûte
environs 35$ US (soit environ 17.500 FCFA). (voir figure 2.6)

14 IAI Gabon
c~Tchuenché Rodrigue Élève Ingénieur
En Informatique 14
FIGURE 2.6 - Une carte nue du Raspberry Pi 2 modèle B
2.2.1.6 Modèle 3B
Ce modèle apparait le 29 février 2016. Il
coûte environs 35$ US (soit environ 17.500 FCFA). Il dispose d'un
processeur Broadcom BCM2837 64 bit à quatre coeurs ARM Cortex-A53
à 1,2 GHz accompagné de 1 Go de RAM et d'une puce Wifi 802.11n et
Bluetooth 4.1 intégrée. Il possède les mêmes
dimensions et connectiques que les modèles 2B et B+. La vitesse
d'horloge est 33% plus rapide que le Pi 2, ce qui permet d'avoir un gain
d'environ 50-60% de performance en mode 32 bits. Il est recommandé
d'utiliser un adaptateur de 2,5 A. Tous les travaux et tutoriels du Pi 2 sont
parfaitement compatibles avec le Pi 3 (voir figure 2.7).

FIGURE 2.7 - Une carte nue du Raspberry Pi 3 modèle B
2.2.1.7 Modèle Zéro
Le 26 novembre 2015, la fondation Raspberry Pi annonce la
sortie du Raspberry Pi Zero. Il reprend les spécifications du
modèle A et B avec un processeur cadencé à 1 GHz au lieu
de 700 MHz, il est par contre plus petit, disposant d'une connectique minimale.
Son prix de 5$
15 IAI Gabon
c~Tchuenché Rodrigue Élève Ingénieur
En Informatique 15
US (soit environ 2500 FCFA) est largement revu à la
baisse par rapport aux autres Raspberry Pi (voir figure 2.8)

FIGURE 2.8 - Une carte nue du Raspberry Pi Zéro
Pour notre travail, nous avons utilisé le modèle
3B qui est actuellement le modèle le plus récent. Ce
modèle nécessite une carte microSD d'au moins 8Go et d'une classe
entre 6 et 10 d'une bonne marque pour préserver les performances en
accès disque. Une image annoté de ce modèle est la
suivante (voir figure 2.9) :
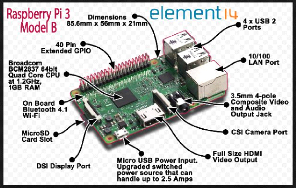
FIGURE 2.9 - Une carte annotée du Raspberry Pi 3
Modèle B
16 IAI Gabon
c~Tchuenché Rodrigue Élève Ingénieur
En Informatique 16
2.2.2 Cluster
Le terme « cluster » (mot anglais signifiant groupe,
grappe...), au sens employé ici est un ensemble de machines
connectées d'une façon ou d'une autre pour distribuer une
tâche très lourde entre ces différentes
machines6.
En fonction de l'objectif à atteindre, un cluster peut
être soit un ensemble d'ordinateurs mis en réseau dans le but de
traiter une même tâche (par exemple le cumul de puissances des
machines d'un cluster pour effectuer une tâche), soit un ensemble
d'ordinateurs mis en réseau dans le but de repartir les tâches sur
chaque noeud du cluster (par exemple un cluster de tâches systèmes
allouera à chaque machine du cluster un ensemble de processus à
traiter suivant sa charge et sa puissance de calcul).
Dans un cluster, les machines peuvent être de simples
stations de travail ou des machines multiprocesseurs et sont appelées
des noeuds. Lorsqu'il y'a besoin, la machine d'entrée sur le
réseau sera appelée noeud serveur et se chargera de diviser la ou
les tâches à travers tous les noeuds du cluster en prenant garde
à ne pas surcharger la machine réceptrice.
Les clusters sont apparus au moment de la montée en
puissance du prix des supercalculateurs alors que les microprocesseurs
devenaient de plus en plus rapides et de moins en moins chers. À partir
de la fin des années 1980, les ingénieurs ont commencé
à développer ce qu'ils appelaient alors un «
multi-ordinateur7 ». Toutefois, c'est le
projet Beowulf mis au point par Goddard Space Flight Center de la NASA en 1994
dont le principe est de construire des clusters en parallèle sous
GNU/LINUX avec du matériel commun (simples PCs), donc peu cher qui a
véritablement lancé l'intérêt sur les clusters
La mise en cluster assure une disponibilité,
c'est-à-dire lorsqu'un serveur tombe en panne alors qu'il est en train
de traiter des requêtes, d'autres serveurs du cluster doivent pouvoir les
traiter d'une manière aussi transparente que possible. Il assure aussi
l'évolutivité c'est-à-dire la capacité d'une
application à supporter un nombre important d'utilisateurs et la
possibilité d'ajouter de nouveaux serveurs sans procéder à
un arrêt du système.
Dans ce chapitre les différentes catégories de
cluster et les architectures logicielles et matérielles des clusters
seront présentées et aussi des solutions logicielles de
clustering seront présentées
2.2.2.1 Catégories de clusters
Nous catégorisons les clusters en quatre groupes :
a) Cluster haute disponibilité
Ces types de clusters ont pour objectif de prévenir les
situations où la défaillance d'un composant du cluster entraine
l'indisponibilité du service. Dans le cas où un noeud a une
défaillance quelconque, matérielle ou logicielle, les autres
prennent en charge les groupes de ressource du noeud défaillant. Ainsi
en une poignée de secondes les services de ce dernier sont pris en
charge par les autres noeuds sans pour autant que l'utilisateur ne soit
perturbé. Dans ce type de cluster le noeud chargé de
l'exécution des requêtes, le noeud
6. Source :
https://www.april.org/historique-et-fonctionnement-des-clusters-beowulf
7. relatif à un système en réseau
basé sur plusieurs ordinateurs
17 IAI Gabon
c~Tchuenché Rodrigue Élève Ingénieur
En Informatique 17
primaire, envoie périodiquement un signal qu'on appelle
heartbeat8 aux noeuds chargés de la prise en charge des
ressources du noeud défaillant, les noeuds secondaires, afin de les
notifier sa présence. Dès que les noeuds secondaires ne
reçoivent plus de heartbeat, ils déclarent le noeud primaire
comme ne faisant plus partie du cluster et un des noeuds secondaires prend son
identité complète.
En effet, le stockage des données étant
redondant, le fonctionnement du cluster, l'assurance contre la perte de
données et la disponibilité des ressources sont garantis à
99.9% pour ne pas dire 100% du temps. La figure ci-dessous représente un
cluster haute disponibilité à 2 serveurs maitres et 3 serveurs
esclaves. (voir figure 2.10)
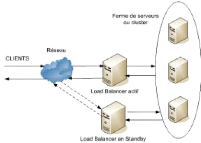
FIGURE 2.10 - Cluster haute
disponibilité
b) Clusters de répartition de charge
Ce type de cluster dispose d'un noeud spécial que l'on
appelle noeud serveur qui a pour tâche de réceptionner les
requêtes et de les répartir sur le noeud adéquat. Ce
dernier est choisi en fonction de sa charge afin de traiter les requêtes
de façon instantanée. Il peut aussi être choisi en fonction
de sa spécialisation, c'est-à-dire que lui seul peut traiter la
demande sur l'ensemble des noeuds du cluster. Toutefois, même si les
noeuds du cluster n'utilisent pas les mêmes systèmes
d'exploitation et les mêmes entrées sorties, il existe tout de
même une relation commune entre eux, matérialisée sous la
forme d'une communication directe entre les machines ou à travers un
noeud serveur contrôlant la charge de chaque noeud. Pour pouvoir
répondre à ce besoin de communication, ce type de cluster utilise
des algorithmes spécifiques permettant de distribuer la charge. Ces
types de clusters requièrent des applications qui ont pour but de
déterminer lequel des noeuds du cluster pourra résoudre de
nouvelles requêtes en examinant la charge courante de chaque noeud du
cluster afin d'éviter la surcharge que peut subir les noeuds. Ce type de
cluster est surtout utilisé dans le domaine du réseau et plus
particulièrement sur les services comme les serveurs Web et FTP. (voir
figure 2.11)
c) Clusters de calculs haute performance
C'est un système considéré de
l'extérieur comme étant une machine multiprocesseur dont les
noeuds cumulent leurs puissances de calcul pour arriver à des
performances égales à celles qu'atteignent les supers
calculateurs. Ce cluster utilise des applications spécialisées
dans la parallélisation de calcul à travers une couche de
communication commune. A la place, un administrateur pourra utiliser le Direct
Memory Acces (DMA, similaire à celui utilisé par certains
périphériques d'un PC) à travers ses noeuds, qui
fonctionne comme une forme de mémoire partagée accessible par
l'ensemble des processeurs du système. Il
8. Battement de coeur.
18 IAI Gabon
c~Tchuenché Rodrigue Élève Ingénieur
En Informatique 18
FIGURE 2.11 - Cluster répartition de charges
pourra aussi utiliser un système de communication dit
de low-overhead comme Message Passing Interface (MPI), qui est une API
(Application Program Interface) pour dévelop-peurs d'applications de
calculs parallèles . (voir figure 2.12)
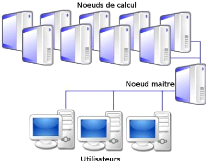
FIGURE 2.12 - Cluster calcul haute performance
d) Clusters de stockage
Ce type de système est comparable au cluster
scientifique, mais ici ce n'est pas la puissance de calcul qui est
recherchée mais plutôt la puissance de stockage. Sa mise en place
est partie d'un constat que les entreprises utilisaient de plus en plus
d'applications performantes utilisant des flux de données
conséquents et donc nécessitant une capacité de stockage
supérieure à celle d'un seul disque dur. Ce problème a pu
être contourné grâce à une vaste capacité de
stockage qu'offre ce système. Les fichiers sont découpés
en bloc de
9.
http://www-igm.univ-mlv.fr/~dr/XPOSE2006/BACHIMONT_BRUNET_PIASZCZYNKSI/index.htm
19 IAI Gabon
c~Tchuenché Rodrigue Élève Ingénieur
En Informatique 19
taille raisonnable et stockés par morceau sur plusieurs
disques, ainsi on a l'impression que l'espace de stockage ne fait qu'un et que
nos fichiers sont stockés en un seul morceau sur un "disque".
Il s'agit pour ce type de cluster d'utiliser le potentiel des
systèmes dits de "stockage combiné", c'est
à dire qu'il distribue les données par l'entremise de plusieurs
disques répartis sur les noeuds du cluster. Ainsi, tout utilisateur aura
le loisir de travailler avec des fichiers de très grandes tailles, tout
en minimisant les transferts. (voir figure 2.13)
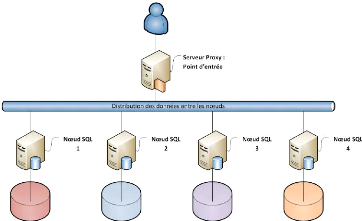
FIGURE 2.13 - Cluster de stockage
NB : Pour notre travail, nous allons utiliser un cluster de
haute disponibilité couplé à un cluster de
répartition de charge.
2.2.2.2 Architecture des Clusters
a) Architecture Matériel
Il n'existe pas de modèle de référence
pour l'architecture matérielle des clusters, mais la plupart des
constructeurs comme IBM, SUN, Hewlet Packard, Compaq et bien d'autres
possèdent leur propre solution issue de leurs recherches.
Néanmoins pour répondre à la problématique que
posent les clusters concernant l'architecture, c'est à-dire que la
répartition des calculs entre les machines doit être la moins
couteuse possible, deux architectures sont possibles.
* Maitre - Esclave
: cette architecture est composée d'un noeud serveur
appelé noeud maitre et des noeuds esclaves. Le noeud maitre peut
être considéré comme l'organisateur du cluster. Il
maintient le système de fichiers et garde une trace de toutes
modifications de leurs propriétés, contrôle
l'exécution des opérations d'entrées/sor-ties des noeuds
clients, gère la configuration du cluster, enregistre les
métadonnées de tous les fichiers enregistrés dans le
cluster, comme par exemple l'emplacement, la taille, les permissions... Il
reçoit également des messages des autres noeuds du cluster afin
d'assurer qu'ils fonctionnent correctement, en cas de défaillance, il
choisit un nouveau noeud client pour exécuter les requêtes du
noeud défaillant. A chaque fois qu'un client externe doit lire ou
écrire des données il communique avec le noeud
20 IAI Gabon
c~Tchuenché Rodrigue Élève Ingénieur
En Informatique 20
serveur lequel répond à sa demande. Les noeuds
clients exécutent les opérations demandées par le noeud
serveur.
* Mono niveau (pair à pair) :
ce type d'architecture permet de mettre en commun un groupe d'ordinateurs pour
fournir un service même en cas défaillance d'un des composants
système. Quand une machine tombe, les autres prennent la relève
et les nouvelles tâches parviennent à la machine qui a pris la
relève. Dans cette architecture seul un noeud, le maître, peut
gérer les ressources à un instant t et les autres noeuds,
esclaves, disposent d'un système de contrôle qu'on appelle
«heartbeat» 10. Quand le maître
n'envoie pas de «heartbeat» pendant une période de temps, les
esclaves détectent cela et assument une défaillance et on
procède à une réélection du maître. Un des
esclaves devient maître, les services sont de nouveau alloués sur
ce noeud. Cette procédure s'appelle le «failover»
11. Le «failover» est donc la capacité
d'un équipement à basculer automatiquement vers un chemin
réseau redondant ou en veille.
Le choix d'une architecture est fortement lié à
l'application du cluster utilisé même si le modèle le plus
répandu est le Maitre-Esclave. Le stockage de toutes les ressources
publiables, fichiers de données, files d'impression, applications,
ressources, et services se font sur les disques partagés. Il est
nécessaire de partager les disques sur un bus, il y a deux
méthodes d'implémentation pour le partage des disques sur un bus,
la technologie SCSI et la technologie Fibre Channel sur un système SAN
(Storage Area Network).
b) Architecture Logiciel
Tout comme l'architecture matérielle, il n'existe pas
de modèle de référence pour l'architecture logicielle,
mais toutefois, il nous faut disposer de deux choses essentielles : un
système d'exploitation et une API (Application Program Interface) de
parallélisations. Ensuite, les choix s'orienteront vers les
préférences de la personne qui installe le système.
Il existe des systèmes d'exploitation
dédiés au clustering. Ces systèmes gèrent eux
mêmes les échanges réseaux et peuvent dans certains cas
découper les applications afin de les répartir sur le cluster.
Ils permettent de lancer des applications qui ne sont pas
développées à la base pour du clustering, mais pour une
utilisation optimale, l'utilisation de librairies dédiées au
clustering est recommandée.
Ainsi il existe des systèmes ou des extensions
systèmes pour tous les environnements comme Linux-Unix, BSD
12, Mac OS et Windows. Néanmoins, pour monter un cluster
performant, il est tout de même préférable d'utiliser des
systèmes d'exploitation ayant une couche TCP/IP bien
développée et sans faille.
Parmi ces systèmes d'exploitation nous pouvons d'abord
citer Beowulf11 qui est un système conçu par la NASA permettant
à partir de librairie de créer et d'utiliser des applications de
calculs répartis, Mosix qui est un système
développé par l'université de Jérusalem permettant
de découper une application pour la lancer sur un cluster et OpenMosix
est une version open-source de Mosix. Ces systèmes sont pour
l'environnement Linux-Unix. Ensuite pour l'environnement Mac OS nous pouvons
citer Xgrid qui est une surcouche à MacOS développé par la
Apple's Advanced Computation Group qui propose une API permettant à un
groupe d'ordinateurs en réseau d'effectuer des calculs répartis.
Xgrid est
10. Battement de coeur: envoi de signal entre les noeuds.
11. groupe de serveurs qui travaillent ensemble pour maintenir
une haute disponibilité des applications et des services
12. Berkeley Software Distribution (BSD, parfois
appelée Berkeley Unix) : une famille de systèmes d'exploitation
dérivée d'Unix.
21 IAI Gabon
c~Tchuenché Rodrigue Élève Ingénieur
En Informatique 21
livré par défaut depuis Tiger
13.
Enfin pour l'environnement Windows nous pouvons citer Windows
2003 cluster server R2 qui est une extension pour Windows 2003 server. Son gros
défaut est que cette solution repose sur un OS peu adapté au
clustering. En effet, la présence d'une interface graphique lourde
ralentit considérablement les performances. Puis pour BSD, nous pouvons
citer Mosix qui est le portage de Mosix sous BSD.
Pour ce qui est des API il existe de nombreuses librairies
permettant de créer des applications réparties. Certaines sont
dédiées aux communications réseaux comme MPI (Message
Passing Interface) et d'autres permettent de transformer un ensemble de
machines en une seule comme PVM (Parallele Virtual Machine). PVM possède
un environnement de contrôle permettant de rendre le lancement d'une
application de manière identique sur tous les noeuds du système.
Il est plutôt orienté vers les réseaux
hétérogènes, c'est à dire que les noeuds du cluster
peuvent être de type différent (PC Linux, PC Windows...).
MPI emploie des fonctionnalités intéressantes
(comme le RMA, Remote Memory Access, ou le système d'entrée
sortie parallèle), mais nécessite un apprentissage de MPI
identique à celui d'un nouveau langage de programmation. Même si
PVM semble mieux répondre aux contraintes d'un cluster et de son
matériel, il faut tout de même savoir que certains
inconvénients viennent s'incruster dans les rouages de PVM. En effet,
les applications l'utilisant doivent obligatoirement être
compilées avec les bibliothèques PVM. Ceci implique donc une
recompilation quasi obligatoire des logiciels déjà existants. De
plus, MPI a été développé après PVM et s'en
est inspiré. Ainsi, MPI répond mieux aux contraintes liées
à la gestion des buffers, des structures de données... En fait
cela sera à vous de choisir l'API répondant encore une fois au
mieux à vos attentes et vos besoins.
En plus du système d'exploitation et de l'API on peut
citer le BIOS (Basic Input/Output System) qui gère l'entrée et la
sortie des données et les échanges avec les
périphériques. A l'heure actuelle aucun cluster ne travaille
à ce niveau pour la gestion des calculs. Néanmoins le BIOS est
utilisé pour accélérer les échanges réseaux
entre les noeuds.
2.2.3 Les Dockers
Docker, l'une des technologies les plus importantes du moment
est un produit développé par la société du
même nom Docker inc basé au USA. Initialement
développé par un ingénieur français,
Solomon Hykes 14, le produit a été
dévoilé en mars 2013. Depuis cette date, Docker est devenu le
soft à la mode. Son potentiel révolutionne notre façon de
construire, de déployer et

13. Cinquième version majeure de Mac OS X, le
système d'exploitation d'Apple pour les ordinateurs Macintosh
14. Solomon Hykes, né à New York en 1983, est un
créateur d'entreprises franco-américain, vivant dans la Silicon
Valley, et le créateur d'un concept à l'origine d'un ensemble de
logiciels, Docker
22 IAI Gabon
c~Tchuenché Rodrigue Élève Ingénieur
En Informatique 22
de distribuer les applications. Les environnements de
développement sont souvent compliqués, difficile de garder la
cohérence entre les différents membres de l'équipe. Une
solution possible est de construire des machines virtuelles
pré-configurées disponibles pour toute l'équipe. Docker
peut sur ce point apporter des solutions en terme de rapidité et de
légèreté par rapport aux VM.
2.2.3.1 C'est quoi un Docker?
Docker permet de créer des environnements virtuels
appelés « containers » de manière
à isoler les applications. Docker n'est pas une machine virtuelle (VM)
à proprement parler, il repose sur le noyau Linux et sur une
fonctionnalité : les containers, que nous connaissons sur le nom de
LXC 15. En plus du LXC linux, un troisième composant est
requis, cgroups16 qui va avoir pour objectif de
gérer les ressources (utilisation de la RAM, CPU entre autres).
Bien que utilisant LXC et le cgroup qui sont natifs à
linux, l'équipe de Docker inc a récemment mis en oeuvre une
version Docker pour les systèmes Windows plus précisément
à partir de Windows Server 2016. Docker est donc disponible pour la plus
part des OS : Linux, Windows, Mac OS X pour les processeurs Intel et AMD x86,
x64 et les processeurs ARM (comme le cas du Raspberry Pi que nous utilisons
dans notre étude).
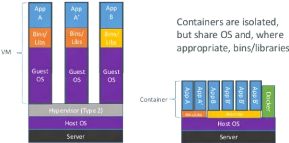
2.2.3.2 Difference entre Docker et Machine Virtuelle
(VM)
Docker ne se comporte pas de la même manière
qu'une machine virtuelle, Une Machine Virtuelle isole tout un système
(son OS), et dispose de ses propres ressources. Dans le cas du Docker, le noyau
va partager les ressources du système hôte et interagir avec le(s)
container(s). Le Docker partage le noyau Linux de la machine hôte et
«isole» les processus qui sont exécutés à
l'intérieur du container. On n'a donc pas besoin de la couche Operating
System complète comme dans une VM ce qui rend un Docker très
léger, très maniable et facilement voyageable dans un
environnement de cloud computing.(voir figure 2.14)
2.2.3.3 Environnement et notions de base
Docker
Trois éléments essentiels forment les bases de la
philosophie d'un Docker :
* Docker Image : c'est un template
qui va servir directement ou indirectement à produire d'autres Docker
Image ou des Docker containers.
* Docker Containers : c'est
«l'exécutable» obtenu à partir d'une Docker Image. On
peut le démarrer, l'arrêter ou le détruire.
* Docker Registry ou Docker
Hub : c'est le repository des Docker Images. On peut y
télécharger des Docker Images créé par d'autres
mais également y stocker les siennes.
15. LXC, Linux containers est un système de
virtualisation, utilisant l'isolation comme méthode de cloisonnement au
niveau du système d'exploitation.
16. cgroups (control groups) est une fonctionnalité du
noyau Linux pour limiter, compter et isoler l'utilisa-tion des ressources
(processeur, mémoire, utilisation disque, etc.).
23 IAI Gabon
c~Tchuenché Rodrigue Élève Ingénieur
En Informatique 23
FIGURE 2.14 - Machine Virtuelle Vs Docker
2.2.4 ERP Odoo
Fondé en 2005 en Belgique par Fabien
Pinckaers 17, Odoo (OpenERP) est l'ERP
open source le plus téléchargé au monde avec 2 millions
d'utilisateurs. Depuis mai 2014, la suite d'applications de gestion
d'entreprise est rebaptisée Odoo. Cette suite d'application permet aux
entreprises de disposer d'une solution intégrée pour gérer
les principales fonctions de l'entreprise. Son interface 100% Web et
adaptative, ses fonctions adaptées à l'entreprise en
réseau en font l'un des ERP les plus moderne et performant du
marché18
Odoo existe en version Communautaire sous
licence LGPLv3 et en version Enterprise sous licence
propriétaire Odoo Enterprise Edition Licence v1.0
19.
2.2.4.1 Historique
Odoo depuis son lancement en 2005 est
passé par plusieurs versions et a changé de nom plusieurs fois.
Le 20 janvier 2011, OpenERP SA annonçait le lancement de la version 6.0
du logiciel, qui comprend une version à la demande (SaaS). Son approche
modulaire permet aux utilisateurs de commencer avec une application, puis
d'ajouter d'autres modules selon leurs besoins.
En décembre 2012, la version 7.0 d'OpenERP est
lancée et peut être testée en ligne,
télé-chargée ou vue en version de démonstration.
En Mai 2014 : OpenERP change de nom et devient Odoo.
Été 2014, Odoo lance la version 8. Cette version
enrichit principalement le logiciel de nou-
17. Fabien Pinckaers, CEO Fondateur et chef visionnaire d'Odoo,
Fabien est la force tranquille derrière Odoo. Il touche à tout :
aux développements du logiciel, au marketing jusqu'aux stratégies
liées à l'expérience client.
18. Source :
http://www.audaxis.com/Odoo-OpenERP
19. Source :
https://fr.wikipedia.org/wiki/Odoo
24 IAI Gabon
c~Tchuenché Rodrigue Élève Ingénieur
En Informatique 24
velles applications qui font de Odoo un logiciel allant au
delà d'un ERP. Ces applications sont: marketing (gestion
d'événements, d'enquêtes de satisfactions, campagnes de
mails auprès de la CRM,...), CMS (construction d'un site internet -
front-end lié au back-end - grâce au déplacement rapide et
simple de 'blocs" d'éditions), e-commerce (application pour vente en
ligne). ci-dessous un tableau récapitulatif:
|
Nom du Logiciel
|
Version
|
Date Lancement
|
Changements significatifs
|
|
Tiny ERP
|
1.0
|
Février 2005
|
Première publication
|
|
2.0
|
Mars 2005
|
|
|
3.0
|
Septembre 2005
|
|
|
4.0
|
Décembre 2006
|
|
|
OpenERP
|
5.0
|
|
|
|
6.0
|
Octobre 2009
|
Première Publication sous AGPL
|
|
6.1
|
|
|
|
7.0
|
Décembre 2012
|
Fin de support prévu Octobre 2016
|
|
Odoo
|
8.0
|
Septembre 2014
|
Support pour le CMS : Construction de site internet,
e-commerce, point de vente, vente et business intelligence
|
|
9.0
|
Novembre 2015
|
Première publication des éditions Community sous
licence LGPLV3 et Enterprise sous licence propriétaire.
|
|
10.0
|
|
|
TABLE 2.1 - Tableau récapitulatif
version Odoo
2.2.4.2 Principaux Modules Applicatifs du logiciel
Odoo
Depuis sa verson v8, Odoo permet les applications logiciels
suivantes :
Principales applications logicielles front
office
* Créateur de site web et système de
gestion de son contenu, CMS
* Vente en ligne, e-commerce
* Interface de point de vente (PDV)
Principales applications logicielles
back-office
* Gestion de relation clients (CRM et SRM (en))
* Gestion des ventes
* Gestion de production
* Gestion de projets
* Gestion des stocks
* Gestion des ressources humaines
* Gestion des achats
* Gestion logistique
* Gestion de manufactures
25 IAI Gabon
c~Tchuenché Rodrigue Élève Ingénieur
En Informatique 25
* Gestion comptable
* Gestion des dépenses
* Gestion des documents
* Générateur de factures
* Gestion et outils marketing
Modules d'Odoo
L'aspect libre du logiciel a permis le développement de
nombreux modules tiers créés par sa communauté de
développeurs. Ces applications sont pour certaines officiellement
validées par l'éditeur tandis que d'autres ne sont
destinées qu'à des versions spécifiques. Le logiciel
compte près de 260 modules officiels et environ 4000 modules
communautaires.
2.2.4.3 Architecture Logiciel d'Odoo
Odoo est concu selon une architecture MVC (Modèle - Vue
- Contrôleur), des flux de travail flexibles, une interface-utilisateur
graphique dynamique, une interface de communication interne XML-RPC, et un
système personnalisable de comptes-rendus.
D'un point de vue de l'architecture technique, Odoo est
construit autour de trois composants principaux qui communiquent entre eux par
les protocoles XML-RPC et NET-RPC:
1. le serveur odoo-server qui stocke ses données dans une
base PostgreSQL.
2. le client odoo mobile (anciennement odoo-client
abandonné depuis la v7) qui s'installe sur le terminal de
l'utilisateur.
3. le serveur web odoo-web qui permet une utilisation depuis
un navigateur.
CONCLUSION
Tout au long de cette première partie, nous avons
essayé de mettre au point le cadre général de notre
travail. Nous avons tout d'abord présenté l'organisme d'accueil
qui s'avère être un élément fondamental dans
l'environnement du projet et ensuite, une étude des concepts liés
au projet a été abordée. Bien plus, nous avons
examiné attentivement le domaine spécifique et technique autour
duquel tourne notre projet. À ce stade, nous avons fourni tout le cadre
théorique sur lequel, va s'appuyer la partie destinée à la
conception et à l'implémentation de notre solution. La
deuxième partie sera donc consacrée à l'aspect pratique de
la réalisation du travail demandé.
26
Deuxième partie
CONCEPTION, IMPLÉMENTATION
ET ÉTUDE DE LA SOLUTION À
PROPOSER
27 IAI Gabon
c~Tchuenché Rodrigue Élève Ingénieur
En Informatique 27
INTRODUCTION
Après avoir circonscrit le sujet dans son contexte
ainsi que le champ d'étude du projet dans la première partie, La
deuxième partie présente l'aspect technique de la solution
proposée. À l'entame de cette partie, le chapitre 3
présente l'analyse et la conception de notre solution. Nous poursuivons
dans le chapitre 4, avec l'implémentation de notre solution et dans le
chapitre 5 avec l'étude de notre solution en vue de vérifier si
les objectifs ont été atteint. À l'issue de cette partie,
nous pourrons déjà faire tourner notre solution.
Chapitre3
ANALYSE ET CONCEPTION
28
Introduction
Notre travail d'Analyse et de Conception se fera en trois
phases. Dans la première phase nous ferons un état de l'art des
solutions logicielles de clustering existantes et ceux fonctionnant sur
Raspberry pi vu que c'est avec ces nano-ordinateurs que nous
implémenterons notre solution et nous finirons par une analyse. Dans la
seconde phase nous étudierons des différentes techniques de
clustering et la troisième phase sera consacrée à la
conception de notre architecture de cluster.
3.1 Solution logicielle de Cluster
Il existe plusieurs solutions sur le marché pour mettre
en place un cluster pour différents systèmes d'exploitation
populaires. La plupart de ces solutions sont commerciales, elles ont un
coût non négligeable dû aux prix des licences logiciels et
au prix du support technique. Ces solutions sont proposées par des
sociétés de prestations en informatique comme Microsoft, IBM,
SUN, Google, Compaq... Il existe aussi des solutions gratuites, à base
de logiciels "libres". Le choix se fera donc en fonction du support technique
voulu et du budget disponible.
3.1.1 Microsoft Cluster / Cluster pour système Windows
Microsoft propose une solution pour mettre en place un cluster
constitué de serveurs Microsoft. Pour cela deux types de clustering sont
proposés, il s'agit de clustering de service ou cluster de Haute
Disponibilité qui consiste à réaliser des clusters
d'application et de rendu de
29 IAI Gabon
c~Tchuenché Rodrigue Élève Ingénieur
En Informatique 29
service et le clustering à répartition de charge
qui garantit une répartition de charge réseau sur des flux IP
à travers un cluster constitué de 32 noeuds au maximum. A travers
ses solutions, Microsoft a implémenté des technologies de
clustering permettant d'améliorer et d'accélérer le
travail quotidien des employés des entreprises désireuses
d'améliorer leur production mais aussi permettant de réaliser du
commerce avec un plus grand nombre de clients.
3.1.1.1 Microsoft Cluster Server (MSCS)
Microsoft Cluster Server est un programme informatique qui
permet aux ordinateurs serveurs de travailler ensemble comme une grappe
d'ordinateurs, afin de fournir le basculement et la disponibilité accrue
des applications, ou une puissance de calcul parallèle en cas de grappes
de calcul haute performance (HPC) (comme dans le calcul intensif). Microsoft a
trois technologies pour le clustering :
1. Microsoft Cluster Service MSCS
Le service MSCS fournit une haute disponibilité pour les
applications critiques, telles que
les bases de données, les serveurs de messagerie, serveur
de fichier et d'impression.
2. Network Load Balancing (NLB)
NLB permet d'équilibrer le trafic IP entrant. Il joue
un rôle de répartition des connexions IP et requêtes
distantes, de répartition de la charge et bande passante sur les noeuds
et de connexion au site web. Les connexions entrantes sont reparties entre les
noeuds à travers différentes règles établies. Ces
noeuds peuvent aller jusqu'au nombre de 32 pour la charge IP en mode NLB. Ce
service augmente la disponibilité et la montée en charge des
applications serveur basées sur l'accès Internet, tels que des
serveurs WEB, des serveurs médias streaming, serveurs Windows Terminal
Server ou autres.
3. Component Load Balancing (CLB)
Équilibrage de Composants, ce type de clustering permet
d'équilibrer les Composants, le service CLB est intégré
à l'Application Center 2000(ou versions
antérieures), il permet aussi de répartir la charge sur plusieurs
noeuds du cluster, pour les applications basées sur la technologie des
objets COM et COM+, une mise à jour pour les objets WMI et la gestion du
Framework.NET est désormais
disponible. On parle de clustering d'application dit clustering de
puissance.
3.1.1.2 Evidian Safekit
Evidian Safekit est un logiciel de haute disponibilité
avec Réplication temps réel, partage de charge et reprise sur
panne pour le clustering. Il est développé par la
société Evidian 1. Le logiciel
SafeKit permet de construire un cluster actif-passif avec failover applicatif
et réplication de données temps réel et continue des
données. Le cluster actif-passif de SafeKit apporte une solution simple
à la haute disponibilité d'applications base de données
critiques sur Windows, Linux ou AIX (même Windows 7 et 8). SafeKit
implémente une réplication continue synchrone
1. Evidian IAM est le leader européen des logiciels de
gestion des identités et des accès, avec une présence en
pleine croissance en dehors du continent européen et notamment aux
Etats-Unis et au Japon
30 IAI Gabon
c~Tchuenché Rodrigue Élève Ingénieur
En Informatique 30
comme les SAN miroirs répliqués mais sans le
coût et la complexité des clusters de failover matériel.

Le cluster actif-passif est une architecture de haute
disponibilité de type miroir. L'application est exécutée
sur un serveur primaire et redémarrée automatiquement sur un
serveur secondaire si le serveur primaire est défaillant.
La réplication des données est configurée
avec les répertoires de fichiers à répliquer. Les
répertoires peuvent contenir des bases de données ou des fichiers
plats. Avec sa fonction de réplication de données temps
réel synchrone, cette architecture est particulièrement
adaptée aux applications transactionnelles avec des données
critiques à protéger contre les pannes.
2
3.1.2 Cluster GNU/Linux
Linux est l'alternative de tous ces clusters chers grâce
à sa gratuité. Grace à lui, vous êtes capables de
mettre en place un cluster répondant à toutes les attentes que
vous pouvez vous formuler. Pour cela, il suffit de posséder quelques
machines, une distribution linux et quelques logiciels permettant de
réaliser la parallélisation des noeuds du cluster. Beaucoup de
projets de clustering sont mis en oeuvre sous Linux à savoir ces
quelques exemples que nous allons citer ci-après :
3.1.2.1 Linux Virtuel Server (LVS)
Ce projet consiste à mettre en place un cluster
à répartition de charge. Son principe est de mettre en grappe des
serveurs et à orchestrer les répartitions de charges par un noeud
serveur qu'on appelle load-balanceur (répartiteur de charge). Il est
implémenté sous forme de patchs applicables au noyau Linux, et
permet alors à des applications réseaux comme les serveurs WEB de
fonctionner sur des clusters acceptant plus de connections.
3.1.2.2 Beowulf
Il s'agit de l'un des projets les plus connus du monde Linux
et le plus utilisé. Il met en place un clustering scientifique par le
biais du système d'exploitation Linux. Le principe est de mettre en
place un système où l'ensemble des noeuds cumulent leur puissance
pour fonctionner comme une seule machine. Ainsi les requêtes
envoyées par les clients externes seront traitées en fonction de
la charge et de la disponibilité de chaque noeud. Beowulf n'est rien
d'autre qu'un
2. Source :
http://www.evidian.com/fr/
31 IAI Gabon
c~Tchuenché Rodrigue Élève Ingénieur
En Informatique 31
package d'outils qui fonctionne sur le noyau linux.
3.1.2.3 Linux HA-Project
Il s'agit d'un projet de clustering qui permet de mettre en
place un système à haute disponibilité. Ce système
est constitué d'applications permettant de maintenir l'envoi de signaux
qu'on appelle heartbeat entre les différents noeuds. Dans le cas
où un noeud n'émet plus de signal, l'application donne les taches
de ce dernier à un autre noeud. Le principal inconvénient vient
du fait qu'il faut bien dimensionner son signal de heartbeat, ceci afin
d'éviter de trop longs moments d'inactivité d'un service en cas
de panne du serveur, ou bien d'éviter de polluer le réseau par
des signaux intempestifs apparaissant trop souvent. 3
3.1.2.4 Multicomputer Operating System for Unix
(MOSIX)
MOSIX est un système de gestion de clusters Linux et de
grilles organisationnelles qui fournit une Single-system image (SSI),
c'est-à-dire l'équivalent d'un système d'exploitation pour
un cluster dans son ensemble. Il s'agit d'un cluster à
répartition de charge développé pour le monde Unix et les
ordinateurs spécialisés. Le but de ce projet est de fournir un
système de clustering, à travers Linux, agissant comme une simple
machine, vu de l'extérieur, c'est à dire vu des utilisateurs et
des processus. Il existe une version "fork" de MOSIX, openMOSIX
qui est une version free open source de
MOSIX. il a été
initié après l'arrêt du développement de MOSIX en
source libre.4
3.1.2.5 Apache Mesos
Apache Mesos est un gestionnaire de cluster open-source qui a
été développé à l'Université de
Californie, Berkeley. Il fournit une isolation efficace des ressources et le
partage entre les applications distribuées, ou des frameworks.Le
logiciel permet le partage des ressources d'une manière fine et
améliore l'utilisation du cluster. Apache Mesos tourne bien sur les
systèmes Linux, Mac OS et
Windows. il existe aussi une version
pouvant tourner sur un nano-ordinateur Raspberry Pi.5
3.1.2.6 Cluster Docker Swarm
Swarm permet la gestion d'un cluster de serveurs Docker. Il
exporte les API standards de Docker mises à l'échelle du cluster
et permet de gérer l'ordonnancement des tâches et l'allocation de
ressources par container au sein du pool de ressources machines. Là
où cela devient très intéressant, c'est que Swarm permet
de gérer le cluster comme une seule et unique machine Docker. Swarm
existe en version Linux, Mac OS et
Windows. il existe aussi une version
pouvant
3. Source :
http://www.linux-ha.org/wiki/Main_Page
4. Source :
https://fr.wikipedia.org/wiki/MOSIX
5. Source :
http://mesos.apache.org/documentation/latest/index.html
32 IAI Gabon
c~Tchuenché Rodrigue Élève Ingénieur
En Informatique 32
tourner sur un nano-ordinateur Raspberry Pi à travers
certains système d'exploitation conçu à cet effet.
3.2 Analyse Des Solutions
De toutes ces panoplies de solutions citées plus haut,
nous devons combiner une solution en tenant compte des différentes
contraintes liées au cluster que nous voulons implémenter et des
applications à déployer sur ce cluster.
En effet, nous devons monter un cluster low-cost consommant
moins d'énergie haute disponibilité basé sur Raspberry Pi
3 et ensuite trouver un moyen de faciliter le déploiement et la gestion
des applications sur ce cluster. Le principal inconvénient d'un
Raspberry Pi est son processeur qui est ARM. Ce qui le rend
généralement moins puissant comparé au processeur Intel ou
AMD des serveurs standards. Sur le Raspberry Pi, peut tourner les
systèmes d'exploitation dérivés de Linux conçu pour
processeur ARM.
Un Raspberry à lui seul n'est pas assez puissant pour
supporter la charge des requêtes serveurs. Nous allons ainsi
implémenter un cluster haute disponibilité couplé à
cela un cluster de répartition de charge. Sur chaque noeud (Raspberry
Pi) du cluster nous allons installer et configurer Docker pour
faciliter le déploiement des applications et par la suite couplé
au cluster deja existant un cluster pour la gestion des Docker "Cluster Docker
Swarm".
Le processeur ARM des Raspberry ne nous permet pas d'utiliser
les cluster Microsoft qui tournent sur processeur Intel ou AMD.
Implémentant une solution low-cost, nous privilégions les
solutions cluster gratuites et pouvant tourner sur un système Linux
conçu pour processeur ARM.
3.3 Concepts de répartition de charge réseau
(Load Balancing)
3.3.1 Présentation
Après avoir fait l'analyse et adopté les types
de cluster à implémenter,avant de passer à la phase de
conception il est important pour nous de maitriser le fonctionnement de
certains concepts comme le Load Balancing entre les noeuds du
cluster.
Une fois le cluster monté, une montée en charge
équivalente au nombre grandissant d'utilisateur se fera ressentir. Pour
assurer cette montée en charge plusieurs méthodes peuvent
être envisageables :
* Augmenter la puissance de traitement des
noeuds : cette méthode n'est pas faisable dans notre cas, car
un raspberry pi tel qu'il est fourni après fabrication ne peut pas
excéder sa puissance nominale. A part sa capacité de stockage que
l'on peut augmenter à souhait.
* Équilibrer les charges à
travers différents noeuds du cluster : cette méthode
consiste à augmenter le nombre de noeuds exécutant les services
en utilisant un processus
33 IAI Gabon
c~Tchuenché Rodrigue Élève Ingénieur
En Informatique 33
permettant l'équilibrage de la charge de travail. c'est
cette méthode que nous allons prévoir pour notre cluster.
Pour repartir les charges dans un cluster ou un réseau
d'ordinateurs, plusieurs technologies existent :
· Le tourniquet DNS (Round robin) :
Permet d'inscrire dans le DNS plusieurs adresses IP pour un même nom
d'hôte. Une fois cette fonction activée, le serveur DNS va
séquen-tiellement renvoyer aux clients faisant une demande de
résolution de nom sur cet hôte une adresse réseau
différente.
· La répartition de charge
matérielle : Fonctionnant sur une base de NAT inversée,
le principe est d'envoyer tous les flux réseaux vers une IP virtuelle
qui va se charger via une translation d'adresse de rediriger les données
vers un membre du cluster.
· Logiciel de distribution de charge
réseau : Ce logiciel prend en charge la répartition du
flux entrant vers les différentes machines du cluster.
· Répartition de charge réseau
: La répartition de charge (NLB) est un système logiciel
distribué et redondant permettant de répartir la charge sur une
ferme de serveur 6. Il ne nécessite pas de
répartiteur car l'ensemble des membres de la ferme du cluster
reçoit les données.
Ci dessous une petite comparaison croisée des quatre
technologies de répartition de charge :
|
Round Robin
|
Hardware
|
Dispatch
|
NLB
|
Facilité D'installation
|
oui
|
|
|
oui
|
Matériel Nécessaire
|
|
oui
|
|
|
Point De Cassure Unique
|
|
oui
|
oui
|
|
Montage En Charge Facilité
|
oui
|
limitée
|
limitée
|
oui
|
Haute Performance
|
oui
|
limitée
|
limitée
|
oui
|
Tolérance aux pannes
|
non
|
limitée
|
limitée
|
oui
|
|
3.3.2 Logiciels de distribution de charge
réseau et haute Disponibilité du cluster
Pour gérer le Load Balancing de notre cluster, nous
allons utiliser un logiciel de distribution de charge réseau. Nous nous
servirons du logiciel Haproxy pour le Load Balancing et nous
allons coupler à ce logiciel le logiciel Heartbeat pour
garantir la haute disponibilité du cluster.
3.3.2.1 HAProxy
HAProxy est une application gratuite permettant de faire du
load-balancing, de la haute disponibilité ainsi que du proxying TCP
& HTTP.
HAProxy est réputé pour être stable,
très fiable, avec de bonnes performances grâce à sa
maturité (douze ans d'existence). L'intérêt d'utiliser
HAProxy, plutôt qu'un des nombreux
6. Une ferme de serveur désigne l'ensemble des noeuds
composant un cluster
34 IAI Gabon
c~Tchuenché Rodrigue Élève Ingénieur
En Informatique 34
35 IAI Gabon
autres reverse proxy ( Nginx, Squid, LYS .. )
est qu'il apporte des fonctionnalités très avancées, comme
le filtrage niveau 7 ( OSI ). HAProxy est disponible pour les systèmes
Linux et Solaris. Il est à sa version 1.7 de nos jours.
Un serveur HAProxy a pour fonction première le
Load-Balancing (répartition des charges) entre plusieurs serveurs web.
Ainsi, en ne joignant qu'une seule IP (celle du serveur HAProxy) nous tomberont
sur des serveurs web différents mais à contenu identique. Le but
est donc de répartir les charges d'un seul serveur web sur deux ou
plusieurs autres de façon transparente pour l'utilisateur. Ce serveur
particulier, appelé " l'équilibreur de charge"
(le load-balancer aussi appelé le
"director") est placé entre les clients et les noeuds
du cluster. Son rôle consiste à aiguiller les requêtes du
client vers un noeud particulier.
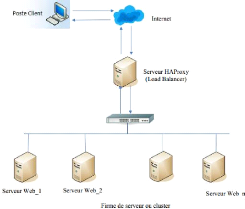
FIGURE 3.1 - Architecture Haproxy
3.3.2.2 Heartbeat
Pour gérer la haute disponibilité du cluster,
nous allons coupler à HAProxy le logiciel heartbeat. Heartbeat est un
logiciel de surveillance de la disponibilité des programmes, pour les
systèmes d'exploitation Linux, FreeBSD, OpenBSD, Solaris et MacOS X. Il
est distribué sous licence GPL.
Heartbeat écoute les battements de coeur - des signaux
émis par les services d'une grappe de serveurs lorsqu'ils sont
opérationnels. Il exécute des scripts d'initialisations
lorsqu'une machine tombe (plus d'entente du battement de coeur) ou est à
nouveau disponible. Il permet aussi de changer d'adresse IP entre les deux
machines à l'aide de mécanismes ARP avancés. Heartbeat
fonctionne à partir de deux machines et peut être mis en place
pour des architectures réseaux plus complexes. ' Les «
battements de coeurs » peuvent être prévus
de différentes façons :
-- Connexion par port série
-- Connexion ethernet UDP/IP broadcast -- Unicast
7. Source :
https://fr.wikipedia.org/wiki/Heartbeat_(logiciel)
c~Tchuenché Rodrigue Élève
Ingénieur En Informatique 35
-- ping (pour des routeurs, commutateur réseau, etc.)
Dans le schéma HAProxy standard, si le serveur HAProxy
(Load Balancer) tombe en panne, le cluster devient indisponible. Le principe
consiste donc à prévoir au moins deux serveurs HAProxy (Load
balancer) redondants tel que à un moment donné, un seul soit
actif et les autres passifs. Heartbeat permet ainsi de vérifier et de
synchroniser les Load Balancer de façon à ce que dès que
le serveur actif tombe en panne (n'est plus disponible) un des Load Balancer
passif prend le relais de façon rapide et transparente. L'administrateur
du système remet le serveur qui vient de tomber en marche et peut le
remettre soit en mode actif, le laisser en mode passif ou laisser Heartbeat
gérer automatiquement.
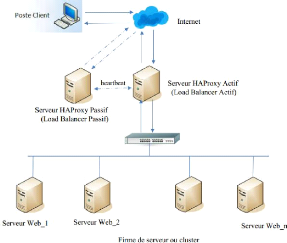
FIGURE 3.2 - Architecture
Haproxy/heartbeat
3.4 Conception du cluster
Après avoir fait un état de l'art sur les
clusters existants et fait une analyse par rapport à notre travail, nous
allons dans cette partie présenter les différentes architectures
à implémenter pour notre cluster. Nous avons opté
implémenter un cluster de répartition de charge (Load Balancing)
auquel nous allons coupler un cluster haute disponibilité et
implémenter par la suite un cluster Docker Swarm.
3.4.1 Nombre de Noeuds du Cluster
Notre cluster sera formé de dix (10) noeuds Raspberry
Pi. Nous avons choisi la dernière version de Raspberry Pi à
l'heure actuelle c'est à dire le Raspberry Pi 3 Modele B (voir section
2.2.1.6). Les dix noeuds seront repartis ainsi :
36 IAI Gabon
* deux (02) noeuds serveurs maitres HAProxy
(Load Balancer)
Sur ces deux noeuds maitres nous allons virtualiser
l'addresse IP d'accès au cluster pour garantir la haute
disponibilité. Un des deux maitres sera actif à un moment
donné tandis que l'autre sera passif et prêt à prendre le
relais dès que le maitre principal tombe.
NB : Ces deux noeuds seront aussi maitre pour le cluster
Docker Swarm. * huit (08) noeuds serveurs esclaves
Sur ces huit noeuds, nous allons déployer les
différentes applications
containerisées8 de l'entreprise comme Odoo
par exemple et planifier la répartition de charge dessus (Load
Balancing).
NB : Les noeuds maitres peuvent aussi jouer le
rôle des noeuds esclaves, c'est à dire contenir des applications
containerisées.
3.4.2 Adressage IP du Cluster
En fonction de certaines contraintes du réseau local
de l'entreprise, nous avons choisi la plage d'adresse suivante pour adresser
les noeuds du cluster.
Adresse du cluster :
-- adresse réseau : 172.16.0.0 -- masque réseau :
255.255.0.0 -- passerelle : 172.16.0.1
Nous avons utilisé la plage allant de 172.16.0.50
à 172.16.0.60 pour adresser les noeuds
du cluster. L'adresse 172.16.0.50 étant la seule adresse
d'accès du cluster les autres étant les
adresses internes au cluster.
Noeud Consul: 172.16.0.51
Noeud Master1 (actif) 172.16.0.52
Noeud Master2 (passif) 172.16.0.56
Noeud exclave Simple: 172.16.0.53; 172.16.0.54; 172.16.0.55;
172.16.0.57; 172.16.0.58; 172.16.0.59;
172.16.0.60
Les noms des hôtes vont de "black-pearl1 à
black-pearl10".
3.4.3 Constituant de chaque noeud
Comme nous l'avions dejà insinué plus haut, les
noeuds du cluster seront des Raspberry Pi. Les Raspberry Pi sont à
processeur ARM et supportent certains versions derivées du
système d'exploitation Linux telles que RASPBIAN, ARCHLINUX,
ALPINELINUX, HYPRIOT OS et bien d'autres (voir section 2.2.1). Pour notre
travail, nous avons utilisé le système HYPRIOT OS
et ce pour des raisons suivantes :
-- ce système a été nativement conçu
pour Raspberry
8. Installer dans un Docker
c~Tchuenché Rodrigue Élève Ingénieur
En Informatique 36
37 IAI Gabon
-- Ce système intègre déjà le moteur
Docker pour gérer les Docker et le Docker Swarm
-- Ce système est facile à installer
-- Ce système permet l'utilisation de HAProxy et
Heartbeat
-- Ce système permet le fonctionnement de beaucoup
d'applications y compris l'application
phare de notre travail.
Au dessus du système HYPRIOT OS de chaque Raspberry
(Noeud) nous allons:
· Pour les noeuds maitre
-- configurer les Docker maitres -- configurer les Docker
esclaves -- installer et configurer HAProxy -- installer et configurer
Heartbeat
· Pour les noeuds esclaves
-- configurer les Docker esclaves
-- installer les applications containerisées
3.4.4 Architecture de notre cluster
Vu que nous avons superposé plusieurs types de clusters
à savoir :
-- cluster de répartition de charge
-- cluster de haute disponibilité
-- cluster Docker Swarm
Nous allons dans la suite présenter deux architectures de
cluster que nous allons implémenter :
CONCLUSION
Arrivé au terme de ce chapitre, nous avons fait une
analyse et nous avons mis sur pied l'architecture de notre cluster. dans la
suite du travail, nous allons procéder à une phase de mise en
oeuvre du cluster.
c~Tchuenché Rodrigue Élève Ingénieur
En Informatique 37
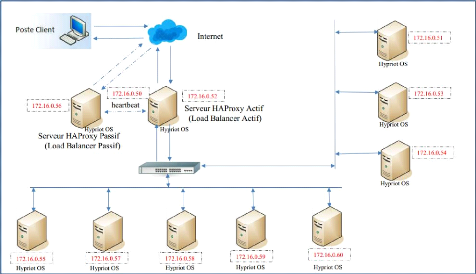
38 IAI Gabon
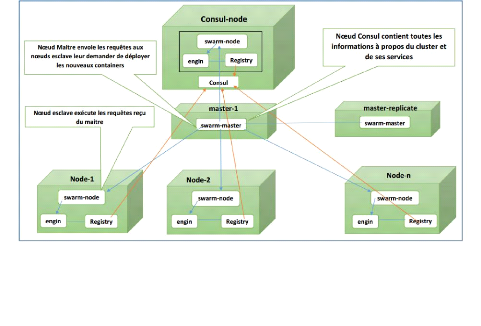
FIGURE 3.4 - Architecture cluster Docker Swarm à
implémenter
c~Tchuenché Rodrigue Élève Ingénieur
En Informatique
38
FIGURE 3.3 - Architecture cluster à
implémenter
Chapitre4
MISE EN OEUVRE DU CLUSTER
39
Introduction
Dans ce chapitre consacré à la mise en oeuvre,
nous allons dans une première phase présenter les
matériels utilisés, et dans la suite nous présenterons les
différentes étapes de la mise en oeuvre du cluster.
4.1 Matériel utilisés pour monter notre Cluster
Pour monter notre cluster, nous avons utilisé les outils
suivantes :
1. Dix (10) Raspberry Pi 3 Modèle B
(voir section 2.2.1.6)
2. Un switch : Pour réaliser notre
cluster, nous devons utiliser un switch 16 ports Gigabit Ethernet
3. Des câbles RJ45
4. Un poste Client : Un poste Client pouvant
établir des connexions SSH pour nous connecter et
configurer les différents noeuds.
5. Une batterie d'alimentation pour faire
fonctionner les Raspberry. Cette batterie peut être par exemple celle
d'une voiture. Nous conseillons une batterie pouvant se charger à l'aide
d'une plaque solaire.
6. Des convertisseurs 12V -
5V
7. Des Carte MicroSD : Des cartes (au moins 10)
MicroSD classe 6 à 10 et d'au moins 8 Go. Ces cartes vont servir comme
disque dur pour les raspberry Pi.

40 IAI Gabon
c~Tchuenché Rodrigue Élève Ingénieur
En Informatique 40
FIGURE 4.1 - Switch Gigabit Ethernet

FIGURE 4.2 - Câble RJ45

FIGURE 4.3 - Batterie d'alimentation

TABLE 4.1 - Carte MicroSD 8 & 32 Go
8. Une bonne connexion internet : pour les
installations des outils logiciels nécessaires et des mises à
jour.
9. Des boites en LEGO : Les raspberry Pi
sont livrés à nus, pour les assembler nous avons

41 IAI Gabon
c~Tchuenché Rodrigue Élève Ingénieur
En Informatique 41
FIGURE 4.4 - Convertisseur 12V - 5V
utilisé des boites en LEGO. Une fois un raspberry Pi bien
assemblé à base des lego, on a ceci :

FIGURE 4.5 - Notre Raspberry Pi 3 Assemblé
Une fois tout agencé, voici à quoi ressemble notre
architecture de cluster physique monté :

42 IAI Gabon
c~Tchuenché Rodrigue Élève Ingénieur
En Informatique 42
FIGURE 4.6 - Notre Cluster Physique
monté
4.2 Mise en OEuvre du cluster
Après avoir mis à disposition les
différents matériels nécessaires et monté
l'architecture physique du cluster, nous allons étape par étape
faire fonctionner chaque noeud et l'associer au cluster.
4.2.1 Installation du système d'exploitation sur les 10
noeuds du cluster
Nous avons choisi le système d'exploitation
HYPRIOT OS 1 comme système à utiliser
sur chaque noeud du cluster. Ce système existe en plusieurs versions.
Pour notre travail nous avons utilisé la version Version 0.7.0
Berry (hypriot-rpi-20160306-192317.img) publié le 06/03/2016.
car cette version est très stable et possède deja les outils
nécessaires pour gérer les Docker.
Installation : (Voir annexe 1)
4.2.1.1 Configuration adresse IP des noeuds Raspberry
Pi
Après avoir scanné le réseau et
trouvé l'adresse IP obtenu dynamiquement par le noeud, Il faudra se
connecter et fixer une adresse statique et un nom d'hôte pour une
meilleure utilisation du noeud. Pour ce faire, se connecter et éditer
les fichiers suivantes : (Voir annexe 2)
1. Source : http://blog.hypriot.com/
43 IAI Gabon
c~Tchuenché Rodrigue Élève Ingénieur
En Informatique 43
4.2.1.2 Configuration nom d'hôte des noeuds
Raspberry Pi
Pour changer le nom d'hôte de la machine, éditer
les fichiers /boot/device-init.yaml ou
/boot/occidentalis.txt selon la version du système
HYPRIOT OS installé en changeant le nom d'hôte (ligne
hostname=nom_hote) préalablement définir. (Voir annexe 3)
4.2.2 Installation du moteur Docker sur chaque
noeud
Une des raisons pour laquelle nous utilisons le système
HypriotOS est qu'il intègre ce moteur par défaut. Mais un
système comme RASPBIAN par exemple n'intègre pas ce moteur. Pour
l'installer suivre les étapes suivantes : (Voir annexe 4)
4.2.3 Création d'un container Docker, le cas du
container Odoo
Après avoir installé le moteur docker, la suite
consiste à créer un container Docker (Docke-riser une
application). Nous rappelons ceci, Trois éléments essentiels
forment les bases de la philosophie d'un Docker :
* Docker Image : c'est un template
qui va servir directement ou indirectement à produire d'autres Docker
Image ou des Docker containers.
* Docker Containers : c'est
«l'exécutable» obtenu à partir d'une Docker Image. On
peut le démarrer, l'arrêter ou le détruire
* Docker Registry ou Docker
Hub : c'est le repository des Docker Images. On peut y
télécharger des Docker Images créés par d'autres
mais également y stocker les siennes.
Ainsi, la création de "l'exécutable" Docker
Container se fait grâce à un Docker Image. Pour créer un
Docker Image, nous avons deux options :
~ Soit nous créons un fichier Dockerfile
en local dans la machine à partir duquel nous créons le
Docker Image.
~ Soit nous nous servons d'une image déjà existante
soit en local soit sur le site Docker Hub2 pour créer notre
image.
Tous d'abord quelques commandes utiles pour Docker :
~ docker info, docker version permet d'avoir
l'information et la version du moteur docker installé.
~ docker build permet de construire
(créer) un Docker Container.
~ docker image permet de lister les images
existantes en local.
~ docker ps permet de lister les Containers en
cours d'exécution à un moment donné.
~ docker run start stop rm permet de lancer,
démarrer, arrêter et supprimer un Docker Container.
NB : Taper docker help pour
avoir une liste plus exhaustive des commandes docker et taper docker
--help nomCommande pour avoir une aide plus détaillée
avec différents attributs sur la commande "nomCommande".
2. Docker Hub est un site qui contient tous les images officiels
Docker accessible au grand public et open source
44 IAI Gabon
c~Tchuenché Rodrigue Élève Ingénieur
En Informatique 44
4.2.3.1 Création d'un Docker Image à partir
d'un Dockerfile
Pour créer une image à partir d'un Dockerfile,
nous devons d'abord créer un fichier de même nom «
Dockerfile » dans un dossier relatif à l'image que nous
voulons créer. Nous rappelons que ce nom est le même quelque soit
l'image à créer.
Exemple d'image
L'ERP Odoo utilise Postgresql comme Serveur de base
données, ci-dessous le contenu d'un Dockerfile pour la création
de l'image Postgresql compatible avec raspberry. (Voir annexe 5)
Ce qui rend les docker intéressants c'est le fait
qu'une image une fois créée peut être exportée,
portative et fonctionnelle sur toute autre plateforme intégrant un
moteur docker. Une image docker une fois exportée ne pèse que
quelques centaines de Mo maximum ce qui rend son transport facile. On exporte
généralement une image sous format d'archive .tar
sous Linux, elle peut être ensuite zipper et sera plus facile
à transporter car plus léger. Les commandes pour exporter et
importer une image sous forme d'archive sont les suivantes : (Voir annexe 6)
4.2.3.2 Création des Docker Containers
Après avoir créé l'image docker, la
création d'un Container Docker se base sur une image Docker. Soit
à créer un container basé sur l'image « postgresql
» au nom de « postgresdemo », voici la commande (Voir annexe
7)
4.2.4 Mise en oeuvre du Cluster Docker Swarm
Après avoir installé le moteur Docker et
créé des containers Docker, nous pouvont implémenter le
cluster Docker Swarm. Nous rappelons que le Docker Swarm
permet d'avoir une visibilité globale et permet de centraliser
la gestion des Docker à travers le ou les noeuds maitres (master). Le
principe consiste à faire communiquer les deamons (moteur) Docker
préalablement installés sur chaque noeud.
La première étape pour créer un cluster
Docker Swarm est d'installer sur chaque noeud l'image rpi-swarm
servant à implémenter le swarm sur les raspberry pi.
$docker build hypriot /rpi-swarm ou
$docker pull hypriot /rpi-swarm
Par défaut cette image existe sur certaines versions du
système Hypriot OS. Après avoir installé ou
vérifié l'existence de cette image, faire ceci :
45 IAI Gabon
c~Tchuenché Rodrigue Élève Ingénieur
En Informatique 45
-- Ouvrir un port TCP sur chaque noeud pour la communication
avec le gestionnaire de Swarm
-- Créer et gérer des certificats TLS pour
sécuriser votre cluster.
Pour la découverte réseau par les
différents noeuds de façon à communiquer en cluster,
Docker a prévu deux methodes :
· Utilisation des jetons cluster (Swarm Token)
: Pour la découverte réseau, Les noeuds se servent d'un
ID unique pour communiquer. Ce ID (Swarm Token) est généralement
créé sur le noeud master et distribué sur les autres
noeuds. On utilise généralement cette méthode pour les
cluster en laboratoire car pas très efficace et pas très
sécurisée.
· Utilisation d'un noeud Consul: Pour
la découverte réseau, les noeuds se servent d'un noeud consul qui
contient les informations sur chaque noeud du réseau. c'est avec ce
noeud consul que le noeud master communique le plus souvent. cette
méthode nécessite l'installation de l'image rpi-consul
(image consul pour les Raspberry Pi). Il est
généralement utilisé pour les clusters en production car
plus stable et sécurisée.
NB : Nous rappelons que c'est cette méthode que nous
avons utilisé dans notre cluster (voir schéma architecture fig.
3.4 ).
Nous rappelons que d'après notre architecture, notre
noeud Consul a pour adresse 172.16.0.51; le noeud maitre (master) actif
172.16.0.52; le noeud maitre (master replicate) passif 172.16.0.56. Une fois
ces pré-requis établis et les dix (10) noeuds étant en
réseau et se communiquant parfaitement, suivre les étapes
suivantes : (Voir annexe 8)
4.2.5 Mise en OEuvre du Cluster de Répartition de
charges et Haute Disponibilité
Après avoir mis sur pied le cluster Docker Swarm, nous
allons implémenter dessus un cluster de répartition de charge
couplé à un cluster haute disponibilité. Les principaux
noeuds à configurer sont des noeuds maitres. Par la suite, nous allons
juste nous assurer que l'inter-communication est parfaite entre les dix (10)
noeuds.
4.2.5.1 Mise en oeuvre de la répartition de
charge
Pour implémenter la répartition de charge, nous
allons utiliser le logiciel HAProxy. Ha-proxy est ce qu'on appelle un
load-balancer, c'est à dire un service permettant de dispatcher les
requêtes TCP/HTTP vers plusieurs serveurs, appelés les
backends. Mais haproxy peut aussi servir comme premier rempart
contre les attaques sur les sites et applications Web.
Il est principalement utilisé en tant que
load-balancer http vers des backends Apache, NginX et bien d'autres mais peut
aussi être utilisé pour faire du load-balancing vers d'autres
services (mysql,redis,node.js ...). Dans notre cluster, nous allons installer
et configurer haproxy sur les deux serveurs maitres de façon identique.
Pour le faire, nous allons suivre les étapes suivantes : (Voir annexe
9)
46 IAI Gabon
c~Tchuenché Rodrigue Élève Ingénieur
En Informatique 46
4.2.5.2 Mise en oeuvre Haute Disponibilité du
cluster
Pour implémenter la haute disponibilité du
cluster, nous allons utiliser le logiciel Heartbeat. C'est un service qui
permet de gérer la haute disponibilité dans un cluster. Elle
permet de mettre en place le balancement entre les deux serveurs.
Son principe consiste à placer une adresse IP sur une
interface virtuelle du serveur actif et ensuite de démarrer le service
haproxy. Quand le serveur actif tombe, le service heartbeat du serveur passif
le détecte et refait la même procédure sur le serveur
passif qui passe en mode actif. Nous rappelons que la configuration de haproxy
et heartbeat est le même sur les deux serveurs. Dans notre cluster, nous
allons installer et configurer heartbeat sur les deux serveurs maitres de
façon identique. Pour le faire, nous allons suivre les étapes
suivantes : (Voir annexe 10)
À ce stade de notre travail, notre cluster haute
disponibilité est fonctionnel et tous les services (applications) du
cluster seront accessibles à l'adresse 172.16.0.50.
Sur le serveur actif, une capture d'écran sur les
interfaces réseaux
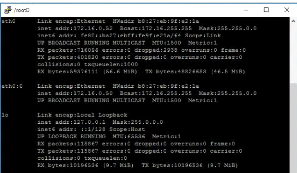
FIGURE 4.7 - ifconfig partie eth0 :0 qui
indique que le noeud fonction sur l'adresse virtuelle 172.16.0.50
C'est l'exemple de l'ERP odoo qui est accessible à
l'adresse 172.16.0.50 :8070 et qui en arrière plan tourne en load
balancing sur 4 serveurs.
47 IAI Gabon
c~Tchuenché Rodrigue Élève Ingénieur
En Informatique 47
FIGURE 4.8 - Interface Connexion Odoo sur le
cluster à l'adresse 172.16.0.50 :8070
CONCLUSION
Arrivé au terme de ce chapitre, nous avons mis en
oeuvre notre cluster haute disponibilité. Dans la suite du travail, nous
allons procéder à une phase d'évaluation du cluster dans
le but de vérifier si les objectifs ont été atteints.
Chapitre5
ÉVALUATION DU CLUSTER ET
CONDUITE DU PROJET
48
Introduction
Dans ce chapitre consacré à l'évaluation
du cluster et conduite du projet, nous allons dans une première phase
évaluer le cluster, et dans la suite nous présenterons la
conduite du projet.
5.1 Protocole d'évaluation
Nous allons dans cette section définir comment
évaluer et valider notre cluster serveur par rapport aux serveurs
standard. L'évaluation de notre cluster se fera sur trois aspects :
-- Évaluation par rapport au cout :
Ici nous allons évaluer le cout de réalisation
de notre cluster et le comparer au cout d'un serveur standard.
-- Évaluation par rapport à l'énergie:
Ici nous allons évaluer la consommation en
énergie de notre cluster et la comparer à celle d'un serveur
standard.
-- Évaluation par rapport à la performance :
Ici nous allons évaluer la performance sur la répartition de
charge réseau et sur la haute disponibilité du cluster.
La vérification de la répartition de charge
consistera à lancer plusieurs requêtes de connexions sur le
serveur maitre actif (dans notre cas 172.16.0.50) et vérifier la
répartition sur les serveurs esclaves hébergeant les
applications.
La vérification de la haute disponibilité
consistera à faire tomber le noeud maitre actif et vérifier que
la connectivité reste effective et en temps réel. C'est à
dire vérifier que le noeud maitre passif est devenu actif et a pris le
relai de façon automatique.
49 IAI Gabon
c~Tchuenché Rodrigue Élève Ingénieur
En Informatique 49
5.2 Évaluation du cluster
5.2.1 Évaluation de l'énergie
Le Raspberry Pi répond aux deux critères :
minuscule et très peu énergivore, pour l'alimenter il faut un
chargeur de smartphone du genre mini usb, il est recommandé du 700 mA
sur 5v, ce qui nous donne comme puissance :
NB : Dans nos calculs, nous ne tenons pas compte des
résistances effets joules ce qui rend nos réponses à des
valeurs approximatives.
P=U*I
P=5v*0.7A = 3.5 Watts = 0.0035 KW
Évaluons sa consommation électrique
journalière d'un Raspberry Pi (24h) :
E=P*t
E=0.0035kw*24h = 0.084 KWh
Pour les dix (10) Raspberry Pi, l'energie donne (soit Et) :
Et = 0.084 KWh * 10 = 0.84 KWh
Évaluons la consommation énergétique
journalière d'un switch :
Un switch TP link 16 ports a les caractéristiques en
puissance : environ 9.26W
Sa consommation électrique journalière :
E=P*t
E=0.00926kw*24h = 0.2222 KWh
Au total, notre cluster à globalement une consommation
électrique journalière d'environ :
Etotal = 0.84 + 0.2222 = 1.06224 KWh
Contrairement à un serveur standard comme
Super Micro qui consomme dans les 1200 Watts soit environ
E=P*t
E=1.2kw*24h = 28.8 KWh par jour
50 IAI Gabon
|
Cluster Réalisé
|
Serveur Standard (Cas du Super Micro)
|
Consommation journalière
|
1.06224 KWh
|
28.8 KWh
|
|
TABLE 5.1 - Comparaison consommation d'énergie
5.2.2 Évaluation coût du cluster
Pour monter notre cluster, nous avons fait les dépenses
suivantes :
Matériel
|
Prix unitaire
|
Nombre
|
Prix Global
|
Raspberry Pi 3
|
25.300 Fcfa
|
10
|
253.000 Fcfa
|
Carte MicroSD 8 Go
|
10.000 FCA
|
6
|
60.000 Fcfa
|
Carte MicroSD 32 Go
|
20.000 Fcfa
|
4
|
80.000 Fcfa
|
convertisseur 12V - 5V
|
7500 Fcfa
|
5
|
37.500 Fcfa
|
Batterie Véhicule 40Ah
|
50.000Fcfa
|
1
|
50.000 Fcfa
|
Switch
|
65.000 Fcfa
|
1
|
65.000 fcfa
|
Câble RJ45
|
500 Fcfa /m
|
20 m
|
10.000 Fcfa
|
Connecteur RJ54
|
6500 Fcfa
|
1 paquet
|
6.500 Fcfa
|
Logistique
|
100.000Fcfa
|
|
200.000Fcfa
|
Prix Total
|
762.000 Fcfa
|
|
|
|
TABLE 5.2 - Table dépenses
|
Cluster Réalisé
|
Serveur Standard (Cas du Super Micro)
|
Coût
|
environ 762.000 Fcfa
|
environ 7.000.000 FCFA
|
|
TABLE 5.3 - Comparaison coût
5.2.3 Évaluation Performance Cluster
En suivant le protocole défini plus haut, la
répartition de charge et la haute disponibilité sont effectives.
En effet, nous avons lancer plusieurs connexion Odoo et avons brusquement mis
le serveur maitre haut réseau. L'ensemble a continué de
fonctionner sans problème. Et nous avons par la suite vérifier la
répartition de charge qui était bien effective.
5.3 Conduite du projet
Cette partie porte sur l'organisation de notre projet et
s'articule en quatre points :
-- les intervenants dans le projet
-- le découpage du projet
-- la planification et le diagramme de GANTT
-- l'estimation des charges et des coûts du projet.
c~Tchuenché Rodrigue Élève Ingénieur
En Informatique 50
51 IAI Gabon
5.3.1 Les intervenants dans le projet
Un projet informatique est certes une aventure technologique,
mais aussi une aventure humaine dans laquelle s'effectuent plusieurs rencontres
de personnes d'horizons divers. La réussite d'un tel projet passe donc
par une organisation efficace de l'équipe de projet. Le maître
d'ouvrage (MOA), est l'entité porteuse du besoin, définissant
l'objectif du projet, son calendrier et le budget consacré à ce
projet. Dans notre cas, ce rôle a été joué par :
· Mr NJIOMO Luc Prosper Chief Executive
Officer of MYRABILYS Sarl; maitre de stage, il a contrôlé
l'avancement de ce projet de bout en bout et nous a permis de cerner les
problématiques liées à l'analyse et la conception de ce
projet et les méthodes statistiques utilisées dans ce domaine.
· Dr NOUSSI Roger Enseignant permanent
à l'IAI, notre superviseur. Nous lui avons présenté le
travail que nous avons effectué et nous nous sommes soumis à ses
orientations, propositions et corrections pour le bon déroulement du
projet
· Nous même Le maître
d'oeuvre (MOE) est le garant de la réalisation technique de la solution
à mettre en place. Dans notre projet, cette tâche a
été réalisée par nous-même
en tant que stagiaire ingénieur.
5.3.2 Découpage du projet
Découper un projet en phases permet de pouvoir mieux le
conduire à terme en respectant les impératifs de qualité,
de coûts et de délais. Chaque phase est découpée en
tâches et accompagnée d'un bilan de fin d'étape
destinée à la validation de la phase écoulée avant
de passer à la phase suivante. Le découpage de notre projet en
phases et en tâches est présenté dans le tableau ci-dessous
:
c~Tchuenché Rodrigue Élève Ingénieur
En Informatique 51
52 IAI Gabon
|
No
|
Phases
|
Tâches
|
1.
|
Étude préliminaire
|
Prise de contact et interviews
|
|
2.
|
Étude de quelques concepts liés au sujet
|
Notion de Raspberry
|
|
|
|
3.
|
Analyse et Conception
|
État de l'art Solutions cluster existante
|
|
|
|
|
|
4.
|
. Mise en oeuvre du clustrer
|
Recherche Matériels utilisés
|
|
|
|
|
|
|
|
5.
|
Étude évaluatrice et conduite du projet
|
Évaluation coût
|
|
|
|
6.
|
|
Documentation
|
Rédaction Mémoire
|
|
TABLE 5.4 - Découpage des
tâches
5.3.3 Diagramme de GANTT
c~Tchuenché Rodrigue Élève Ingénieur
En Informatique 52
53 IAI Gabon
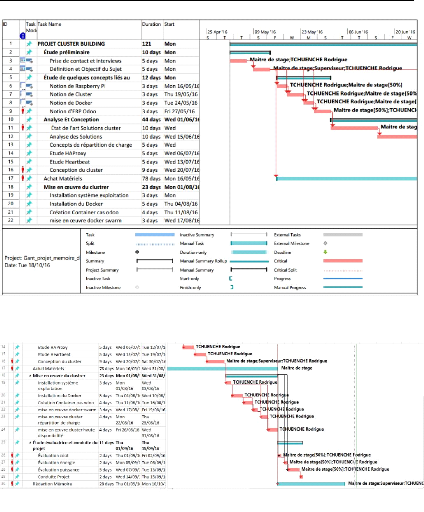
FIGURE 5.1 - Diagramme de GANTT
FIGURE 5.2 - Diagramme de GANTT next
5.4 Bilan et perspectives 5.4.1 Bilan
Ce stage nous a permis de revisiter et de mettre en pratique
les connaissances acquises durant notre formation notamment en réseaux,
en système d'exploitation et en programmation. Cependant, il nous a fait
côtoyer le monde de la recherche.
c~Tchuenché Rodrigue Élève Ingénieur
En Informatique 53
54 IAI Gabon
c~Tchuenché Rodrigue Élève Ingénieur
En Informatique 54
Toutefois, l'expérience, la disponibilité de
l'encadreur ont été pour nous une source d'inspiration, de
formation et de clairvoyance pour le début d'une carrière
fascinante. Nous avons en effet eu quelques difficultés durant le
déroulement de notre travail à savoir :
-- L'acquisition de certains outils servant au montage du
cluster. -- La bonne maitrise de certains concepts liés au sujet.
-- l'implémentation et l'évaluation des
performances de la solution.
5.4.2 Perspectives
Notre sujet portait sur la conception, implémentation
et étude d'un cluster haute disponibilité de raspberry pi et
exécution des dockers swarm. Pour le faire, nous avons utilisé
dix (10) Raspberry Pi 3 modèle B, ainsi en terme de perspectives, nous
comptons l'implémenter avec 32 ou 64 Raspberry Pi pour espérer
avoir un cluster plus puissant et plus stabilité.
Cependant, Raspberry Pi n'est pas le seul nano-ordinateur
low-cost pouvant servir pour ce travail, il existe un autre « Udoo »
qui est un nano-ordinateur de même taille que le Raspberry Pi mais plus
puissant et légèrement plus cher que le Raspberry. Nous comptons
dans la même lancé réaliser ce même type de cluster
mais basé plutot sur ces Udoo. Udoo est une famille de nano-ordinateur,
compatible avec Android et Linux, que l'on peut exploiter à la fois
comme les systèmes embarqués pour les projets de
bricolage-électronique et de faible consommation d'énergie, des
nano-ordinateurs très adaptés pour un usage
quotidien. 1
1. Source : http://www.udoo.org/
55 IAI Gabon
CONCLUSION GÉNÉRALE
Arrivé au terme de notre travail sur la conception et
l'implémentation d'un cluster low-cost haute disponibilité
basé sur Raspberry Pi, nous sortons très bénéfiques
et satisfait des travaux réalisés. les résultats sont
très encourageants. le travail que nous avons mené durant ces
cinq (05) mois de stage a abouti à la réalisation de notre
première version de cluster. Cette réalisation a mis en avant
l'utilisation des technologies comme Docker et Docker Swarm qui font partir des
nouvelles technologies à la mode du moment.
Après évaluation de notre cluster, nous pouvons
affirmer que le challenge en coût et en énergie a
été atteint. Notre solution se trouve ainsi bien adaptée
à tout genre d'entreprises désirant s'offrir un serveur. Elle se
trouve aussi adaptée à fonctionner dans les conditions plus ou
moins dégradées en énergie vue qu'avec une petite batterie
de véhicule, nous pouvont faire tourner notre cluster. Ce qui convient
bien aux zones reculées sans couverture d'énergie
électrique.
Nous comptons poursuivre le travail étant donné
que c'est un projet initié par la structure qui nous a accueillis et
dans laquelle nous comptons être employés. Dans la suite du
projet, il sera réalisé avec plus de Raspberry Pi ou avec des
nano-ordinateurs Udoo qui sont plus puissants que les Raspberry Pi. Nous
comptons aussi nous servir des Docker pas seulement pour Odoo, mais
également pour beaucoup d'autres applications du même type
client-serveur.
En dépit de quelques difficultés
rencontrées que nous pensons mineures et normales dans le
déroulement de toute oeuvre humaine, nous avons atteint nos objectifs.
Ce stage a été plus qu'une expérience enrichissante
à tout point de vue. Il nous a permis à mieux organiser et
manager notre temps. Ce stage nous a été bénéfique
du point de vue connaissance car nous avons pu découvrir certains outils
en pleine évolution : les Raspberry Pi et les Docker. Nous nous sommes
familiarisés avec ces outils. Pour finir, nous pouvons conclure que ce
stage a contribué à accroitre nos connaissances en administration
système Linux.
c~Tchuenché Rodrigue Élève Ingénieur
En Informatique 55
56
Les Annexes
.1 Annexe 1
Installation Système: <>
1. Télécharger le système hypriot
os
Si on ne dispose pas déjà du fichier image du
système, aller sur le site
http://blog.
hypriot.com/downloads/ et télécharger le fichier
hypriot-rpi-20160306-192317.img.zip.
2. Préparer la carte microSD en flashant l'image
téléchargée sur la carte Il existe plusieurs
manières de flasher l'image sur la carte. La méthode
diffère que l'on soit sur un système Windows, Linux ou Mac OS X.
Nous allons décrire la procédure étant sur Windows. Pour
plus d'informations, aller sur le site2 Tout d'abord, nous aurons
besoin des outils suivants :
Applications
|
Description
|
7-Zip
|
Pour extraire l'image compressée à flasher sur la
carte microSD. S'assurer que l'on a choisi le fichier de
téléchargement qui correspond à l'architecture de votre
poste de travail (x86 vs x64)!
|
Win32 Disk Imager"Start
|
Pour flasher l'image sur la carte microSD
Pendant l'installation, vous trouverez une case à cocher
appelée Pcap-Service at startup". Nous vous recommandons de le
désactiver
|
Putty
|
Pour établir une connexion SSH sur les
différents noeuds Il suffit de le télécharger. Aucune
installation nécessaire.
|
Zenmap
|
Pour scanner et identifier l'adresse IP d'un nouveau noeud que
l'on vient de mettre en marche
|
SD Formatter
|
Pour formater la carte microSD au cas ou on aimerai le
réutiliser
|
|
TABLE 5 - Liste outils nécessaires
pour flasher la carte microSD
Après avoir télécharger et installer ses
outils, extraire le fichier hypriot-rpi-20160306-192317.img.zip
et lancer l'application Win32 Disk Imager. (voir figure)
Après avoir finir l'écriture de l'image sur la carte,
éjecter la carte et l'insérer dans le Raspberry.
3. Première connexion et première
configuration du Raspbery sur Hypriot OS Connecter votre raspberry
à un réseau local où il obtiendra une adresse dynamique et
le démarrer. Patienter quelques minutes (2 ou 3) et lancer Zenmap
à partir de votre poste client situer dans le même réseau
local. dans la zone cible, taper l'adresse reseau. dans notre cas
172.16.0.0/16
2. Source :
http://blog.hypriot.com/getting-started-with-docker-on-your-arm-device/
57 IAI Gabon
FIGURE 3 - Fenêtre WinDiskImager
FIGURE 4 - Fenêtre Zenmap
c~Tchuenché Rodrigue Élève Ingénieur
En Informatique 57
dans la zone commande, taper la commande nmap -sn
172.16.0.0/16
NB : Les adresses utilisées ici sont les
adresses de notre structure et celle dont nous utilisons pour notre cluster.
Après avoir identifié l'adresse du noeud en
question, lancer Putty.exe (Voir figure) et se connecter (clic
sur open) en ssh sur le noeud pour des éventuelles modifications
comme:
-- changer l'adresse IP dynamique en static -- changer le nom du
noeud
-- vérifier que le nouveau noeud est dans le réseau
du cluster sinon, le connecter au réseau du cluster.
Une fois cliquer sur open, si le noeud est bien en réseau,
on aura cette fenêtre : (Voir
figure) Pour se connecter à HYPRIOT OS (noeud), taper les
paramètres suivants : login : root
mot de pass : hypriot
Une fois ces paramètres bien saisis et validés, on
obtient cette fenêtre :(Voir figure)
58 IAI Gabon
FIGURE 5 - Fenêtre Putty.exe
FIGURE 6 - Fenêtre connexion Hypriot OS
c~Tchuenché Rodrigue Élève Ingénieur
En Informatique 58
.2 Annexe 2
Configuration Adresse IP : <> Pour changer l'adresse IP,
éditer le fichier /etc/network/in-terfaces en ajoutant
le contenu suivant en supposant que nous voulons fixer les paramètres
suivants en mode administrateur (sudo) :
-- adresse IP : 172.16.0.51 -- masque : 255.255.0.0 -- passerelle
: 172.16.0.1
Éditer le fichier /etc/network/interfaces en mode
administrateur (sudo)
$sudo nano /etc/network/interfaces
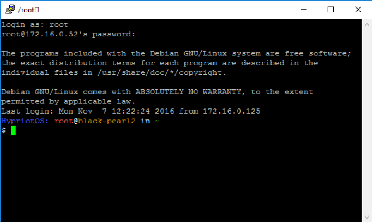
59 IAI Gabon
c~Tchuenché Rodrigue Élève Ingénieur
En Informatique 59
FIGURE 7 - Fenêtre acceuil Hypriot OS
.3 Annexe 3
Configuration Nom des noeuds <>
$sudo nano /boot/occidentalis.txt
# hostname for your Hypriot Raspberry Pi: hostname=hypriot-pi
# basic wireless networking options: wifi_ssid=SSID
wifi_password="secret_password"
ou
$sudo nano /boot/device-init.yaml
hostname: black-pearl
wifi:
interfaces:
wlan0:
ssid: "MyNetwork"
password: "secret_password"
NB : Après avoir changé ces paramètres,
redemarrer la machine et se reconnecter. Répéter cette
étape pour tous les 10 noeuds du cluster.
À ce stade, le noeud est fonctionnel et prêt
à être configurer pour faire partie du cluster.
60 IAI Gabon
c~Tchuenché Rodrigue Élève Ingénieur
En Informatique 60
.4 Annexe 4
Installation du Docker: <> Connecter le noeud (ou la
machine) à internet, lancer l'invite de
commande et taper les commandes suivantes :
1. curl -sSL
http://downloads.hypriot.com/docker-hypriot_1.10.1-
1_armhf.deb > /tmp/docker-hypriot_1.10.1-1_armhf.deb
2. sudo dpkg -i /tmp/docker-hypriot_1.10.1-1_armhf.deb
3. rm -f /tmp/docker-hypriot_1.10.1-1_armhf.deb
4. sudo sh -c 'usermod -aG docker $SUDO_USER'
5. sudo systemctl enable docker.service
Une fois installé, taper la commande docker info
et verifier qu'on obtient un resultat semblable à ceci :
$ docker info
Containers: 3
Running: 3
Paused: 0
Stopped: 0
Images: 2
Server Version: 1.10.2
Storage Driver: overlay
Backing Filesystem: extfs
Execution Driver: native-0.2
Logging Driver: json-file
Plugins:
Volume: local
Network: bridge null host
Kernel Version: 4.1.17-hypriotos-v7+
Operating System: Raspbian GNU/Linux 8 (jessie)
OSType: linux
Architecture: armv7l
CPUs: 4
Total Memory: 925.5 MiB
Name: black-pearl2
ID:
FNWT:25U4:JGOW:SJPB:52UX:U7H6:FWPT:GVIY:54B5:PTD2:LESJ:7F2Z
Debug mode (server): true
File Descriptors: 40
Goroutines: 74
System Time: 2016-10-06T13:45:39.411942274+02:00
EventsListeners: 1
Init SHA1: dfeb8c17f8c3a118753fea8353b715a7a75f5491
Init Path: /usr/lib/docker/dockerinit
Docker Root Dir: /var/lib/docker
Cluster store: consul://172.16.0.51:8500
Cluster advertise: 172.16.0.52:2375
ou taper la commande docker version
$ docker version Client:
61 IAI Gabon
c~Tchuenché Rodrigue Élève Ingénieur
En Informatique 61
Version: 1.10.2
API version: 1.22
Go version: go1.4.3
Git commit: c3959b1
Built: Wed Feb 24 09:51:38 2016
OS/Arch: linux/arm
Server:
Version: 1.10.2
API version: 1.22
Go version: go1.4.3
Git commit: c3959b1
Built: Wed Feb 24 09:51:38 2016
OS/Arch: linux/arm
NB : Faire ceci sur tous les noeuds où l'on veut installer
le moteur docker.
A ce niveau où nous avons installé le moteur
Docker, Nous pouvons déjà créer un Container Docker
.5 Annexe 5
Création d'image Docker <>
# vim:set ft=dockerfile:
FROM resin/rpi-raspbian:jessie
MAINTAINER Rodrigue Dester <
rodridest@gmail.com>
# explicitly set user/group IDs
RUN groupadd -r postgres --gid=999 && useradd -r -g
postgres --uid=999 postgres
# grab gosu for easy step-down from root
RUN gpg --keyserver
pool.sks-keyservers.net
--recv-keys B42F6819007F00F88E364FD4036A95BF357DD4
RUN apt-get update && apt-get install -y
--no-install-recommends ca-
certificates wget && rm -rf /var/lib/apt
lists/* \
&& wget -O /usr/local/bin/gosu "
https://github.com/tianon/gosu/releases
/download/1.2/gosu-$(dpkg --print
architecture)" \
&& wget -O /usr/local/bin/gosu.asc "
https://github.com/tianon/gosu/
releases/download/1.2/gosu-$(dpkg --print
architecture).asc" \
&& gpg --verify /usr/local/bin/gosu.asc \
&& rm /usr/local/bin/gosu.asc \
&& chmod +x /usr/local/bin/gosu \
&& apt-get purge -y --auto-remove ca-certificates wget
62 IAI Gabon
ENV LANG en_US.utf8
RUN mkdir /docker-entrypoint-initdb.d ENV PG MAJOR 9.4
_
#ENV PG_VERSION 9.4.8-0+deb8u1 ENV PG_VERSION 9.4.9-0+deb8u1
RUN apt-get update \
&& apt-get install -y postgresql-common \
&& sed -ri 's/#(create_main_cluster) .*$/\1 = false/'
/etc/postgresql-
common/createcluster.conf \
&& apt-get install -y \
postgresql-$PG_MAJOR=$PG_VERSION \
postgresql-contrib-$PG_MAJOR=$PG_VERSION \
&& rm -rf /var/lib/apt/lists/*
RUN mkdir -p /var/run/postgresql && chown -R postgres
/var/run/postgresql
ENV PATH /usr/lib/postgresql/$PG_MAJOR/bin:$PATH
ENV PGDATA /var/lib/postgresql/data
VOLUME /var/lib/postgresql/data
COPY
docker-entrypoint.sh /
RUN chmod +x /
docker-entrypoint.sh
ENTRYPOINT ["/
docker-entrypoint.sh"]
EXPOSE 5432
CMD ["postgres"]
La syntaxe du Dockerfile : 3
FROM <image> ou FROM <image> :<tag> ou
FROM <image>@<digest>
FROM : indique sur quelle distribution ou image de
référence va se baser cette nouvelle Image
Docker.
MAINTAINER <name>
MAINTAINER: indique qui est responsable de cette image.
RUN <command> ou RUN ["executable", "param1",
"param2"]
RUN : ensemble de commande qui vont successivement être
exécutées pour créer cette Image
Docker.
ENV <key> <value> ou ENV
<key>=<value>
ENV : permet de définir des variables d'environnements qui
pourront ensuite être modifiées
grâce au paramètre de la commande run --env
<key>=<value>.
COPY <src>... <dest> ou COPY
["<src>",... "<dest>"] ou ADD <src>...
<dest>
ou ADD ["<src>",... "<dest>"]
COPY ou ADD : permet de copier un fichier depuis la machine
hôte ou depuis une URL
VOLUME ["/data"]
VOLUMES : permet de créer un point de montage qui
permettra de persister les données.
On pourra alors choisir de monter ce volume dans un dossier
spécifique en utilisant la com-
mande run -v :
EXPOSE <port> [<port>...]
EXPOSE : permet d'ouvrir des ports de communication TCP / UDP
pour communiquer
avec le reste du monde
3. Source :
https://www.grafikart.fr/tutoriels/docker/dockerfile-636,
Source:
https://docs.docker.com/engine/reference/builder/
c~Tchuenché Rodrigue Élève Ingénieur
En Informatique 62
63 IAI Gabon
ENTRYPOINT ["executable", "param1", "param2"] ou
ENTRYPOINT command param1 param2
ENTRYPOINT : permet d'ajouter une commande qui sera
exécutée par défaut, et ce, même si on choisit
d'exécuter une commande différente de la commande standard.
CMD ["executable","param1","param2"] ou CMD
["param1","param2"] ou CMD command param1 param2
CMD : détermine la commande qui sera
exécutée lorsque le container démarrera. elle
détermine les paramètres que vont prendre en compte le fichier
bash de la commande ENTRY-POINT
NB : Pour plus d'information ici
Contenu
docker-entrypoint.sh
#!/bin/bash set -e
set_listen_addresses() {
sedEscapedValue="$(echo "$1" | sed 's/[\/&]/\\&/g')"
sed -ri "s/^#?(listen_addresses\s*=\s*)\S+/\1'$sedEscapedValue'/"
" $PGDATA/postgresql.conf"
}
if [ "$1" = 'postgres' ]; then mkdir -p "$PGDATA"
chown -R postgres "$PGDATA"
chmod g+s /run/postgresql
chown -R postgres /run/postgresql
# look specifically for PG_VERSION, as it is expected in the DB
dir if [ ! -s "$PGDATA/PG_VERSION" ]; then
gosu postgres initdb
# check password first so we can output the warning before
postgres
# messes it up
if [ "$POSTGRES_PASSWORD" ]; then
pass="PASSWORD '$POSTGRES_PASSWORD'"
authMethod=md5
else
# The - option suppresses leading tabs but *not* spaces.
:)
cat >&2 <<-'EOWARN'
****************************************************
WARNING: No password has been set for the
database.
This will allow anyone with access to the Postgres port to
access your database. In Docker's default configuration, this is
c~Tchuenché Rodrigue Élève Ingénieur
En Informatique 63
64 IAI Gabon
effectively any other container on the
same
system.
Use "-e POSTGRES_PASSWORD=password" to
set
it in "docker run".
****************************************************
EOWARN
pass=
authMethod=trust
fi
{ echo; echo "host all all 0.0.0.0/0 $authMethod"; } >>
"
$PGDATA/pg_hba.conf"
# internal start of server in order to allow set-up using
psql-
client
# does not listen on TCP/IP and waits until start finishes
gosu postgres pg_ctl -D "$PGDATA" \
-o "-c listen_addresses=''" \
-w start
: ${POSTGRES_USER:=postgres}
: ${POSTGRES_DB:=$POSTGRES_USER} export POSTGRES_USER
POSTGRES_DB
if [ "$POSTGRES_DB" != 'postgres' 1; then psql --username
postgres <<-EOSQL CREATE DATABASE "$POSTGRES_DB" ;
EOSQL
echo
fi
if [ "$POSTGRES_USER" = 'postgres' 1; then op='ALTER'
else
op='CREATE'
fi
psql --username postgres <<-EOSQL
$op USER "$POSTGRES_USER" WITH SUPERUSER $pass ;
EOSQL echo
echo
for f in /docker-entrypoint-initdb.d/*; do
case "$f" in
*.sh) echo "$0: running $f"; . "$f" ;;
*.sql) echo "$0: running $f"; psql --username "
c~Tchuenché Rodrigue Élève Ingénieur
En Informatique 64
65 IAI Gabon
c~Tchuenché Rodrigue Élève Ingénieur
En Informatique 65
$POSTGRES_USER" --dbname "$POSTGRES_DB" < "$f" && echo
;;
*) echo "$0: ignoring $f" ;;
esac echo
done
gosu postgres pg_ctl -D "$PGDATA" -m fast -w stop
set_listen_addresses '*'
echo
echo 'PostgreSQL init process complete; ready for start up.'
echo
fi
exec gosu postgres "$@"
fi
exec "$@"
Après avoir créé le Dockerfile, on
crée l'image avec la commande suivante : En supposant que notre
Dockerfile et
docker-entrypoint.sh sont dans
un dossier dester/postgres, on a :
$docker build -t postgresql dester/postgres
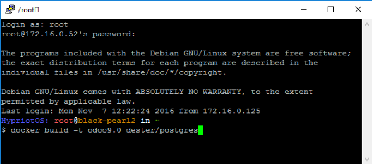
FIGURE 8 - Fenêtre docker build
L'option -t ici permet de donner un nom à l'image.
Lorsque cette commande est validée, docker va d'abord chercher en local
dans le dossier « dester/postgres » s'il trouve un Dockerfile. Si
c'est le cas, il l'exécute sinon il cherche sur internet dans le site
dépôt officiel Docker Hub. S'il ne trouve pas sur internet, alors
une erreur sera généré.
À la fin de création, voir l'image crée
à l'aide de la commande docker image.
Contenu Dockerfile Odoo
FROM resin/rpi-raspbian:jessie
MAINTAINER Rodrigue Dester <
rodridest@gmail.com>
66 IAI Gabon
c~Tchuenché Rodrigue Élève Ingénieur
En Informatique 66
# Install some deps, lessc and less-plugin-clean-css, and
wkhtmltopdf
RUN set -x; \
apt-get update \
&& apt-get install -y --no-install-recommends \
ca-certificates \
curl \
node-less \
python-gevent \
python-pip \
python-pyinotify \
python-renderpm \
python-support \
&& apt-get install wkhtmltopdf -y
# Install Odoo
ENV ODOO_VERSION 9.0
ENV ODOO_RELEASE 20161103
RUN set -x; \
curl -o odoo.deb -SL
http://nightly.odoo.com/${ODOO_VERSION}/nightly/
deb/odoo_${ODOO_VERSION}c.${ODOO_RELEASE}_all.deb \
&& echo 'b5f88c06d8ba3475fa5ef15d93e504891c648f8e
odoo.deb' | sha1sum -
c - \
&& dpkg --force-depends -i odoo.deb \
&& apt-get update \
&& apt-get -y install -f --no-install-recommends \
&& rm -rf /var/lib/apt/lists/* odoo.deb
# Copy entrypoint script and Odoo configuration file
COPY ./
docker-entrypoint.sh /
RUN chmod +x /
docker-entrypoint.sh
COPY ./openerp-server.conf /etc/odoo/
RUN chown odoo /etc/odoo/openerp-server.conf
# Mount /var/lib/odoo to allow restoring filestore and
/mnt/extra-addons for
users addons
RUN mkdir -p /mnt/extra-addons \
&& chown -R odoo /mnt/extra-addons
VOLUME ["/var/lib/odoo", "/mnt/extra-addons"]
# Expose Odoo services EXPOSE 8069 8071
# Set the default config file
ENV OPENERP_SERVER /etc/odoo/openerp-server.conf
# Set default user when running the container #USER odoo
ENTRYPOINT ["/
docker-entrypoint.sh"] CMD
["openerp-server"]
67 IAI Gabon
Contenu openerp-server.conf A modifier selon
les configuration du système :
[options]
addons_path =
/mnt/extra-addons,/usr/lib/python2.7/dist-packages/openerp/
addons
data_dir = /var/lib/odoo
auto_reload = True
; admin_passwd = admin
; csv_internal_sep = ,
; db_maxconn = 64
; db_name = False
; db_template = template1
; dbfilter = .*
; debug_mode = False
; email_from = False
; limit_memory_hard = 2684354560
; limit_memory_soft = 2147483648
; limit_request = 8192
; limit_time_cpu = 60
; limit_time_real = 120
; list_db = True
; log_db = False
; log_handler = [':INFO']
; log_level = info
; logfile = None
; longpolling_port = 8072
; max_cron_threads = 2
; osv_memory_age_limit = 1.0
; osv_memory_count_limit = False
; smtp_password = False
; smtp_port = 25
; smtp_server = localhost
; smtp_ssl = False
; smtp_user = False
; workers = 0
; xmlrpc = True
; xmlrpc_interface =
; xmlrpc_port = 8069
; xmlrpcs = True
; xmlrpcs_interface =
; xmlrpcs_port = 8071
Contenu du fichier
docker-entrypoint.sh.sh:
#!/bin/bash
set -e
# set the postgres database host, port, user and password :
${HOST:=${DB_PORT_5432_TCP_ADDR:='db'}} :
${PORT:=${DB_PORT_5432_TCP_PORT:=5432}}
c~Tchuenché Rodrigue Élève Ingénieur
En Informatique 67
68 IAI Gabon
c~Tchuenché Rodrigue Élève Ingénieur
En Informatique 68
: ${USER:=${DB_ENV_POSTGRES_USER:=${POSTGRES_USER:='odoo'}}}
:
${PASSWORD:=${DB_ENV_POSTGRES_PASSWORD:=${POSTGRES_PASSWORD:='odoo'}}}
# pass them as arguments to the odoo process
DB_ARGS=("--db_user" $USER "--db_password" $PASSWORD "--db_host"
$HOST "--
db_port" $PORT)
case "$1" in
-- | openerp-server)
shift
exec openerp-server "${DB_ARGS[@]}" "$@"
-*)
*)
;;
exec openerp-server "${DB_ARGS[@]}" "$@" ;;
exec "$@"
esac exit 1
Après avoir créé le Dockerfile, on
crée l'image avec la commande suivante : En supposant que notre
Dockerfile et
docker-entrypoint.sh sont dans
un dossier dester/odoo, on a :
$docker build -t odoo9.0 dester/odoo
.6 Annexe 6
Exporter une image : <>
(soit l'image odoo_c9)
$docker save odoo_c9 > dester/odoo/odoo_c9.tar $docker load -i
dester/odoo/odoo_c9.tar
Pour voir les images créées, taper la commande
suivante :
$docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
odoo9c latest 411ffb00ac5b 6 weeks ago 1.061 GB
hypriot/rpi-swarm latest c298de062190 7 months ago 13.27 MB
hypriot/rpi-busybox-httpd latest fbd9685c5ffc 16 months ago 2.156
MB
.7 Annexe 7
Création Container Docker : Le container postgres au
nom de db et le container odoo au nom de odoo-c-9.0 <>
# container postgresql "db"

69 IAI Gabon
FIGURE 9 - Fenêtre docker images
docker run --name db -d --restart=always -v
/var/lib/postgresql/data:/var/lib/ postgresql/data -e POSTGRES_USER=odoo -e
POSTGRES_PASSWORD=odoo -p 5432:5432 postgresql
#container Odoo avec lien "link" sur postgresql "db"
docker run --name odoo_c_9.0 --restart=always -v
/root/dester/:/etc/odoo -v / mnt/extra-addons:/mnt/extra-addons -v
/var/lib/odoo:/var/lib/odoo -p 8069:8069 --link db:db -t odoo9.0
Explication de quelques attributs et paramètres de cette
commande :
-- --name permet de definir le nom du container
Docker. Ici 'db' pour postgrqsql et 'odoo-c-9.0' pour Odoo
-- --restart=always permet un
démarrage automatique du docker à chaque redémarrage de la
machine (noeud)
-- -e POSTGRES_PASSWORD=odoo : permet
d'initialiser la variable POSTGRES_PASSWO à postgres qui
représente ici le mot de passe de connexion à la base de
données à l'inté-
rieur du docker.
-- -d permet au docker de tourner en libérant la
console.
-- -p permet de faire correspondre le port de connexion à
l'application dans le container au port de la machine physique (-p
port-machinehote :port-dans-le-docker). remarquer que le port-dans-le-docker
correspond au port EXPOSE dans le Dockerfile.
-- postgresql ici correspond à l'image
crée précédemment.
-- -v : permet d'indiquer un dossier sur la machine physique
pour persister les données du container. (-v dossier_machine_physique
:dossier_dans_docker)
Si la création (le docker run) se passe
bien, la commande docker ps permet de voir les docker
crée uniquement encours d'exécution dans la machine hôte.
La commande docker ps -a permet de voir tous les containers
(encours, suspendus,etc.) dans la machine hôte.
$docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
2009b2442c49 hypriot/rpi-dockerui "/dockerui -e http://" 6 weeks
ago Up 6 hours 0.0.0.0:9000->9000/tcp tiny_saha
a9f57b9e9ebf hypriot/rpi-swarm "/swarm manage -H :60" 6 weeks
ago Up 6 hours 2375/tcp, 0.0.0.0:6000->6000/tcp naughty_hugle
86ee357572d3 hypriot/rpi-swarm "/swarm join -adverti" 6 weeks
ago Up 6 hours 2375/tcp swarm-agent-2
c~Tchuenché Rodrigue Élève Ingénieur
En Informatique 69
70 IAI Gabon
c~Tchuenché Rodrigue Élève Ingénieur
En Informatique 70
$docker ps -a
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
c7b8e84ffb4e hypriot/rpi-busybox-httpd "/bin/busybox httpd -" 6
weeks ago Exited (137) 6 weeks ago 0.0.0.0:80->80/tcp busybox1
f58d0a4e0439 hypriot/rpi-consul "/consul agent -dev -" 6 weeks
ago Up 6 hours consul
1550aec5185f hypriot/rpi-swarm "/swarm join -adverti" 7 weeks ago
Up 6 hours 2375/tcp swarm-agent-1
On constate que pour un container Docker donné, on a :
~ CONTAINER ID : c'est un id permettant d'identifier un container
de façon unique. ~ IMAGE : c'est l'image à partir de laquelle on
a crée le container.
~ COMMAND : c'est la commande qui s'exécute au lancement
du docker container. ~ CREATED : c'est la date de création du container
Docker.
~ STATUS : c'est l'état du container à un moment
donné.
~ NAME : c'est le nom du container. Ce nom est soit
généré automatiquement par le moteur docker à la
création du container soit donner par l'utilisateur.
NB : Une fois le container docker
créé et encours, on peut soit l'arrêter, le supprimer ou le
relancer. Soit le Container odoo_9 :
docker stop odoo_9; docker rm
odoo_9; docker start odoo_9.
La connexion au serveur postgresql ou à l'application odoo
se fait normalement comme dans une machine ou un serveur standard à
partir de l'adresse du noeud.
Nous pouvons ainsi lancer autant de container à partie de
la même image. Dans le cas d'Odoo, nous pouvons lancer autant d'instances
odoo souhaitées selon la puissance du noeud. Il suffit dans notre cas de
changer la correspondance de port sur la machine (noeud) physique en laissant
le port du docker fixe puisqu'il correspond au port dans l'image et de changer
aussi le nom du container docker.
Exemple
$docker run --name odoo_91 --restart=always -v
/var/lib/postgresql/data:/var/ lib/postgresql/data -e
POSTGRES_PASSWORD=postgres -d -p 8070:8069 -p 5433:5432 odoo_c9
$docker run --name odoo_92 --restart=always -v
/var/lib/postgresql/data:/var/ lib/postgresql/data -e
POSTGRES_PASSWORD=postgres -d -p 8071:8069 -p 5434:5432 odoo_c9
$docker run --name odoo_93 --restart=always -v
/var/lib/postgresql/data:/var/ lib/postgresql/data -e
POSTGRES_PASSWORD=postgres -d -p 8072:8069 -p 5435:5432 odoo_c9
.8 Annexe 8
Mise en oeuvre Docker swarm: <>
71 IAI Gabon
c~Tchuenché Rodrigue Élève Ingénieur
En Informatique 71
a) Sur chaque noeud du cluster, faire ceci
1. Update HYPRIOT OS et des moteurs Docker si la version a
changé
$sudo apt-get update && apt-get install --only-upgrade
docker-hypriot docker-compose
2. éditer le fichier /etc/default/docker en ajoutant ceci
àla variables DOCKER OPTS
_
$DOCKER_OPTS="--storage-driver=overlay -D -H tcp://0.0.0.0:2375
--cluster -store consul://172.16.0.51:8500 --cluster-advertise=eth0:2375"
3. Redémarrer le service docker
$systemctl restart docker
b) Sur le noeud Consul, s'assurer que l'image rpi-consul
existe et faire ceci
1. Configuration du noeud consul (choisir le noeud consul qui va
gérer le relai et le configurer ) cmd:
$docker run -d --net=host --restart=always --name=consul
hypriot/rpi-consul agent -dev -ui -ui-dir=/ui -advertise=172.16.0.51 -bind
=172.16.0.51 -client=172.16.0.51
2. Configuration du noeud esclave
$docker run -d --restart=always --name=swarm-agent-1
hypriot/rpi-swarm join -advertise 172.16.0.51:2375 consul://172.16.0.51:8500
c) Sur le noeud master actif, faire ceci:
1. Configuration des noeuds master
$docker run -d -p 6000:6000 --restart=always hypriot/rpi-swarm
manage -H :6000 --replication --advertise 172.16.0.52:6000 consul
://172.16.0.51:8500
# NB: Ici nous avons choisi écouter le réseau
cluster sur le port 6000 qui est un choix très arbitraire
2. Configuration des noeuds esclaves
$docker run -d --restart=always --name=swarm-agent-2
hypriot/rpi-swarm join -advertise 172.16.0.52:2375 consul://172.16.0.51:8500
3. exporter la variable host_opts $export
DOCKER_HOST=tcp://172.16.0.52:6000
4. Créer un nouveau réseau de recouvrement,
exécuter la commande suivante sur le maitre principal (un des
maitres)
72 IAI Gabon
c~Tchuenché Rodrigue Élève Ingénieur
En Informatique 72
$docker network create --driver=overlay --subnet=172.16.0.0/16
cluster_network
5. container pour visualiser les informations du cluster en
interface graphique sur le port 9000 (choix du port arbitraire)
$docker run -d -p 9000:9000 --restart=always --privileged --env="
constraint:node==black-pearl2" hypriot/rpi-dockerui -e http
://172.16.0.52:6000
d) Sur le noeud master passif, faire ceci:
1. Configuration du noeud master
$docker run -d -p 6000:6000 --restart=always hypriot/rpi-swarm
manage -H :6000 --replication --advertise 172.16.0.56:6000 consul
://172.16.0.51:8500
2. Configuration du noeud esclave
$docker run -d --restart=always --name=swarm-agent-6
hypriot/rpi-swarm join -advertise 172.16.0.56:2375 consul://172.16.0.51:8500
3. container pour visualiser les informations du cluster en
interface graphique sur le port 9000 (choix du port arbitraire)
$docker run -d -p 9000:9000 --restart=always --privileged --env="
constraint:node==black-pearl6" hypriot/rpi-dockerui -e http
://172.16.0.56:6000
e) Sur le reste des noeuds esclaves, faire
ceci:
#l'adresse IP 172.16.0.53 est appliqué au noeud 3, la
changer pour les autres noeuds esclaves.
1. Configuration du noeud esclave
$docker run -d --restart=always --name=swarm-agent-3
hypriot/rpi-swarm join -advertise 172.16.0.53:2375 consul://172.16.0.51:8500
Après avoir fini, vérifier que le cluster est bien
fonctionnel en vérifiant les résultats de ces commandes :
1. Information générale sur le
cluster
$ docker -H :6000 info
Containers: 20
Running: 15
Paused: 0
Stopped: 5
Images: 20
Server Version: swarm/1.1.3
Role: replica
Primary: 172.16.0.56:6000
73 IAI Gabon
c~Tchuenché Rodrigue Élève Ingénieur
En Informatique 73
Strategy: spread
Filters: health, port, dependency, affinity, constraint
Nodes: 9
black-pearl1: 172.16.0.51:2375
âStatus: Healthy
âContainers: 3
âReserved CPUs: 0 / 4
âReserved Memory: 0 B / 971.8 MiB
âLabels: executiondriver=native-0.2,
kernelversion=4.1.17-hypriotos-v7
+, operatingsystem=Raspbian GNU/Linux 8 (jessie),
storagedriver=
overlay
âError: (none)
âUpdatedAt: 2016-10-24T10:29:52Z
black-pearl2: 172.16.0.52:2375
âStatus: Healthy
âContainers: 3
âReserved CPUs: 0 / 4
âReserved Memory: 0 B / 971.8 MiB
âLabels: executiondriver=native-0.2,
kernelversion=4.1.17-hypriotos-v7
+, operatingsystem=Raspbian GNU/Linux 8 (jessie),
storagedriver=
overlay
âError: (none)
âUpdatedAt: 2016-10-24T10:29:57Z
black-pearl3: 172.16.0.53:2375
âStatus: Healthy
âContainers: 1
âReserved CPUs: 0 / 4
âReserved Memory: 0 B / 971.8 MiB
âLabels: executiondriver=native-0.2,
kernelversion=4.1.17-hypriotos-v7
+, operatingsystem=Raspbian GNU/Linux 8 (jessie),
storagedriver=
overlay
âError: (none)
âUpdatedAt: 2016-10-24T10:30:39Z
black-pearl4: 172.16.0.54:2375
âStatus: Healthy
âContainers: 3
âReserved CPUs: 0 / 4
âReserved Memory: 0 B / 971.8 MiB
âLabels: executiondriver=native-0.2,
kernelversion=4.1.17-hypriotos-v7
+, operatingsystem=Raspbian GNU/Linux 8 (jessie),
storagedriver=
overlay
âError: (none)
âUpdatedAt: 2016-10-24T10:30:19Z
black-pearl5: 172.16.0.55:2375
âStatus: Healthy
âContainers: 3
âReserved CPUs: 0 / 4
âReserved Memory: 0 B / 971.8 MiB
âLabels: executiondriver=native-0.2,
kernelversion=4.1.17-hypriotos-v7
+, operatingsystem=Raspbian GNU/Linux 8 (jessie),
storagedriver=
74 IAI Gabon
c~Tchuenché Rodrigue Élève Ingénieur
En Informatique 74
overlay
âError: (none)
âUpdatedAt: 2016-10-24T10:30:44Z
black-pearl6: 172.16.0.56:2375
âStatus: Healthy
âContainers: 2
âReserved CPUs: 0 / 4
âReserved Memory: 0 B / 971.8 MiB
âLabels: executiondriver=native-0.2,
kernelversion=4.1.17-hypriotos-v7
+, operatingsystem=Raspbian GNU/Linux 8 (jessie),
storagedriver=
overlay
âError: (none)
âUpdatedAt: 2016-10-24T10:30:01Z
black-pearl7: 172.16.0.57:2375
âStatus: Healthy
âContainers: 1
âReserved CPUs: 0 / 4
âReserved Memory: 0 B / 971.8 MiB
âLabels: executiondriver=native-0.2,
kernelversion=4.1.17-hypriotos-v7
+, operatingsystem=Raspbian GNU/Linux 8 (jessie),
storagedriver=
overlay
âError: (none)
âUpdatedAt: 2016-10-24T10:30:32Z
black-pearl8: 172.16.0.58:2375
âStatus: Healthy
âContainers: 1
âReserved CPUs: 0 / 4
âReserved Memory: 0 B / 971.8 MiB
âLabels: executiondriver=native-0.2,
kernelversion=4.1.17-hypriotos-v7
+, operatingsystem=Raspbian GNU/Linux 8 (jessie),
storagedriver=
overlay
âError: (none)
âUpdatedAt: 2016-10-24T10:30:29Z
black-pearl9: 172.16.0.59:2375
âStatus: Healthy
âContainers: 3
âReserved CPUs: 0 / 4
âReserved Memory: 0 B / 971.8 MiB
âLabels: executiondriver=native-0.2,
kernelversion=4.1.17-hypriotos-v7
+, operatingsystem=Raspbian GNU/Linux 8 (jessie),
storagedriver=
overlay
âError: (none)
âUpdatedAt: 2016-10-24T10:30:40Z
Plugins:
Volume:
Network:
Kernel Version: 4.1.17-hypriotos-v7+
Operating System: linux
Architecture: arm
CPUs: 36
75 IAI Gabon
Total Memory: 8.541 GiB Name: a9f57b9e9ebf
Dans ce résultat info, nous avons :
· Nombre et détails sur les noeuds
· Nombre de containers du cluster
· Capacité globale du cluster (CPU, RAM)
· Nombre d'images du cluster
· etc.
2. Liste des noeuds du cluster
$ docker run --rm hypriot/rpi-swarm list
consul://172.16.0.51:8500
time="2016-10-24T10:33:16Z" level=info msg="Initializing
discovery
without TLS"
172.16.0.51:2375
172.16.0.52:2375
172.16.0.53:2375
172.16.0.54:2375
172.16.0.55:2375
172.16.0.56:2375
172.16.0.57:2375
172.16.0.58:2375
172.16.0.59:2375
3. Statistique occupation CPU des noeuds $docker -H :6000
stats
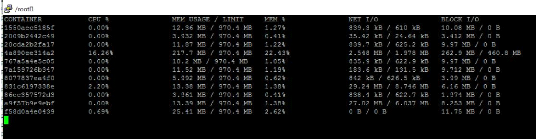
FIGURE 10 - Fenêtre résultat docker stats
4. Liste des Containers du cluster $docker -H :6000 ps
.9 Annexe 9
Répartition de charge : <>
c~Tchuenché Rodrigue Élève Ingénieur
En Informatique 75
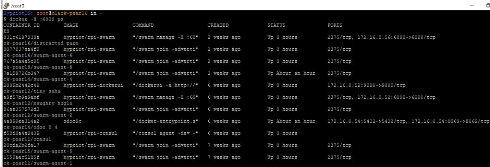
76 IAI Gabon
c~Tchuenché Rodrigue Élève Ingénieur
En Informatique 76
FIGURE 11 - Fenêtre résultat docker ps sur
cluster
1. Installation de Haproxy Taper les commandes
suivantes:
$sudo apt-get update
$sudo apt-get install haproxy
2. Configuration de Haproxy
Le fichier de configuration est le suivant
/etc/haproxy/haproxy.cfg. Faites un backup du fichier de base au cas ou.
Contenu du fichier dans notre cas. (en respectant l'indentation)
global
log /dev/log local0
log /dev/log local1 notice
chroot /var/lib/haproxy
stats socket /run/haproxy/admin.sock mode 660 level admin
stats timeout 30s
user haproxy
group haproxy
daemon
# Default SSL material locations ca-base /etc/ssl/certs
crt-base /etc/ssl/private
# Default ciphers to use on SSL-enabled listening sockets.
# For more information, see ciphers(1SSL). This list is from:
#
https://hynek.me/articles/hardening-your-web-servers-ssl-ciphers
/
ssl-default-bind-ciphers ECDH+AESGCM:DH+AESGCM:ECDH+AES256:DH+
AES256:ECDH+AES128:DH+AES:ECDH+3DES:DH+3DES:RSA+AESGCM:RSA+AES:
RSA+3DES:!aNULL:!MD5:!DSS
ssl-default-bind-options no-sslv3
defaults
77 IAI Gabon
log global
mode http
option httplog
option dontlognull
timeout connect 5000
timeout client 50000
timeout server 50000
errorfile 400 /etc/haproxy/errors/400.http errorfile 403
/etc/haproxy/errors/403.http errorfile 408 /etc/haproxy/errors/408.http
errorfile 500 /etc/haproxy/errors/500.http errorfile 502
/etc/haproxy/errors/502.http errorfile 503 /etc/haproxy/errors/503.http
errorfile 504 /etc/haproxy/errors/504.http
listen stats :70
stats enable
stats hide-version
stats scope webfront
stats scope webbackend
stats uri /
stats realm Haproxy\ Statistics
stats auth haproxy:secret
stats refresh 1s
frontend webfront
bind 172.16.0.50:8070
mode http
option httplog
default_backend webbackend
backend webbackend mode http
option forwardfor option httpchk
balance roundrobin
|
server web01
|
172.16.0.53:8069 weight
|
1
|
cookie web01 check inter
|
1s
|
|
server web02
|
172.16.0.54:8069 weight
|
1
|
cookie web02 check inter
|
1s
|
|
server web03
|
172.16.0.56:8069 weight
|
1
|
cookie web03 check inter
|
1s
|
option httpchk GET /
http-check expect status 200
Explication de quelques terminologie:
global : Dans cette section, on défini
les paramètres globaux de haproxy, les logs (dans syslog), l'utilisateur
et le groupe de fonctionnement du service. Il est possible aussi si le serveur
héberge plusieurs services de chrooter haproxy.
defaults: Dans cette section, on défini
certains paramètres par défaut. Nous avons : -- mode
: mode de fonctionnement par défaut du load-balancer : http
donc load-balancing sur le niveau 7 du modèle OSI;
-- maxconn : nombre de connexion maximum
accepté sur le frontal, cette option
permet de limiter les connexions vers les backend et donc les
attaques de type
c~Tchuenché Rodrigue Élève Ingénieur
En Informatique 77
78 IAI Gabon
c~Tchuenché Rodrigue Élève Ingénieur
En Informatique 78
(D)DOS, si le nombre de connexion dépasse cette limite les
nouvelles connexions seront refusées;
-- timeout : différents timeout
permettant de couper les connexions trop longues, ce qui permet par exemple de
limiter les attaques de type slowloris;
-- errorfile : il est possible de définir
des pages d'erreur générique
listen stats : Dans cette section, on
défini les paramètres liés aux statistiques de charges.
haproxy met à disposition une page de stats accessible, ici par exemple
cette page sera accessible sur l'ip virtuelle 172.16.0.50 et le port 70 avec
une authentification assez complexe!!!
(voir figure)
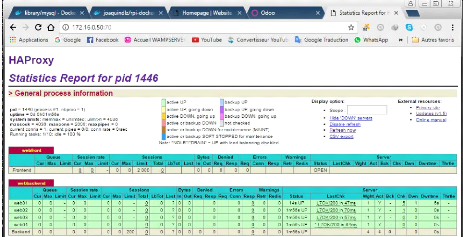
FIGURE 12 - Fenêtre statistique
Haproxy
Backend / Frontend : Le
frontend est un bloc de configuration qui permet de définir toutes les
règles qui s'appliqueront (domaines écoutés, limitations,
etc). Un frontend peut s'appliquer à un ou plusieurs bind. Le backend
est un autre bloc de configuration, que l'on place derrière un frontend.
Si le frontend gère ce qui est public (à "l"avant" du serveur),
le backend gère "l'arrière". C'est là que vous
définirez les serveurs web vers lesquels envoyer les requêtes.
Côté frontend, on écoute sur l'IP et sur un port et on fait
référence au backend « webservers » : Dans ces deux
sections, nous avons :
-- bind : permet de dire sur quelle IP et quel
port HAProxy doit écouter le réseau. Par exemple, 172.16.0.50 sur
le port 8070.
-- acl une "access control list" permet de définir des
conditions dans un bloc, par exemple "si le domaine contient site1, alors faire
cela, si la requête est en https, alors faire ceci".
-- mode http : on définit que ce
frontend va traiter uniquement le protocole HTTP (et donc aussi HTTPS). Cela
permet déjà à haproxy d'analyser les requêtes, et de
rejeter tout ce qui n'est pas formaté correctement vis à vis des
RFC.
-- option httplog : permet de logguer le
détail des requêtes http. Cela permet d'avoir plus d'informations
dans les logs haproxy (headers, session http, ...).
79 IAI Gabon
-- option httpchk : le httpchk permet de faire
en sorte que haproxy vérifie à tout moment l'état des
serveurs web derrière lui. Il peut ainsi savoir si le serveur est
prêt à recevoir des requêtes, basculer vers un serveur de
secours, afficher une page d'erreur en cas de panne, etc. De base, c'est un
simple check HTTP sur le / qui est effectué, mais il est possible par
exemple de spécifier un script ou un chemin précis.
-- forwardfor except 127.0.0.1 : cette option va
permettre d'ajouter un en tête xfor-wardfor dans les requêtes qui
passent par le backend, en tête contenant la véritable adresse IP
du visiteur. En effet, les requêtes passant par le proxy, c'est son IP
qui sera vu niveau réseau par le serveur web ce qui peut être
gênant pour faire des statistiques de visites par exemple, car vous
auriez l'impression que toutes les visites viennent du serveur proxy... Le
except 127.0.0.1 permet d'éviter d'ajouter cet en tête si c'est
127.0.0.1 qui a généré la requête.
-- server web01,web02,web03 : cette
définition va permettre d'indiquer le serveur vers lequel transmettre
les requêtes. 172.16.0.53, 172.16.0.54,172.16.0.56 sont bien sûr
les adresses IP des serveurs web web01, web02,web03. :8069 permet d'indiquer le
port ou transmettre. Il est possible d'indiquer plusieurs lignes pour
définir plusieurs serveur web et faire de la répartition de
charge.
-- maxconn 32 : permet de limiter le nombre
maximum de connexions gérées par ce serveur, ici 32. Cela permet
d'éviter de surcharger le serveur web au dessus de sa
capacité par exemple, et de mitiger directement et
à peu de coût une attaque.
-- balance roundrobin permet de choisir
l'algorithme de répartition à utiliser. Il existe plusieurs
façon de répartir les requêtes :
a) roundrobin : les requêtes sont
réparties les unes après les autres sur chaque serveur de
façon uniforme (modulo le paramètre weight);
b) leastconn : les requêtes sont
envoyées vers le serveur le moins chargé;
c) source : les requêtes seront toujours
envoyées vers le même serveur backend pour la même source.
Ce qui permet par exemple d'être sur de renvoyer vers le bon serveur web
si les sessions sont stockées en dur
Quelques Paramètres ligne server dans backend:
a) nom IP :port : le nom du serveur, son IP et
son port;
b) weight : on est en mode roundrobin mais on
peut affecter un poids aux serveurs, par exemple si un est plus puissant que
l'autre il aura un poids supérieur, la somme des poids doit faire
100;
c) cookie nom : nom du cookie, ce
paramètre est en relation avec la ligne cookie. Cela permet de faire
plus ou moins la même chose que pour le mode source. Le proxy va
positionner un cookie ici nommé LBN avec pour contenu le nom du serveur
backend;
d) check inter 1s : vérifie toutes les
secondes que le serveur est disponible Après avoir fini les
configurations, redémarrer le service haproxy.
$service haproxy restart
#voir etat service
$service haproxy status
c~Tchuenché Rodrigue Élève Ingénieur
En Informatique 79
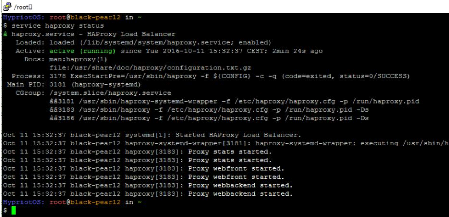
80 IAI Gabon
c~Tchuenché Rodrigue Élève Ingénieur
En Informatique 80
FIGURE 13 - Fenêtre status Haproxy
.10 Annexe 10
Haute disponibilité : <>
1. Installation de Heartbeat sur les deux serveurs
maitres Taper les commandes suivantes:
$sudo apt-get install heartbeat
Il arrive souvent que l'installation ne se termine pas
correctement, dans ce cas, éditer le fichier
/etc/openhpi/openhpi.conf en commentant la ligne :
#OPENHPI_UNCONFIGURED = "YES"
Une fois ceci fait, désinstaller heartbeat avec cette
commande : sudo apt-get remove --purge heartbeat
Et ré-installer heartbeat :
$sudo apt-get install heartbeat
Une fois heartbeat bien installé, pour le démarrer
il faudra d'abord le configurer.
2. Configuration de heartbeat sur les deux serveurs
maitres Les trois fichiers à créer et à
configurer obligatoirement sont les suivants : 4
-- Le fichier /etc/ha.d/
ha.cf
-- le fichier /etc/ha.d/haresources -- le
fichier /etc/ha.d/authkeys
(a) Le fichier /etc/ha.d/
ha.cf
Ce fichier sert de configuration générale. Quand ce
fichier n'existe pas il faut le créer et l'éditer. Dans notre
cas, son contenu est le suivant :
4. Source : Site1 Site2
81 IAI Gabon
$sudo nano /etc/ha.d/
ha.cf
# Contenu
******************************************************** mcast eth0 239.0.0.10
694 1 0
baud 19200
serial /dev/ttyS0
debugfile /var/log/ha.debug
logfile /var/log/ha.log
logfacility local0
# temps avant d.avertir dans le log warntime 4
# temps nécessaire avant de déclarer un noeud comme
mort deadtime 5
# valeur utilise pour le démarrage (au moins 2 fois le
deadtime) initdead 15
# temps entre 2 battements (2 signifie 2s, sinon 2000ms)
keepalive 2
#Re-balance les services sur le maitre primaire quand il revient
en ligne
auto_failback off
#Serveurs du cluster node black-pearl2 node black-pearl6
NB : Attention! Pour que tout fonctionne bien il faut s'assurer
que vous puissiez faire un ping vers black-pearl2 depuis black-pearl6 et
vice-versa.
(b) Le fichier /etc/ha.d/haresources
Ce fichier sert de configuration des ressources.Il indique quels
sont les services à rendre hautement disponibles. Quand ce fichier
n'existe pas il faut le créer et l'éditer. Dans notre cas, son
contenu est le suivant :
$sudo nano /etc/ha.d/haresources
# Contenu
********************************************************
# On doit commencer la ligne par le nom du serveur maitre. Suivi
par la description des services rendus par le cluster.
black-pearl2 IPaddr::172.16.0.50/16/eth0:virt haproxy
(c) Le fichier /etc/ha.d/authkeys
Ce fichier contient la méthode d'encryptage
utilisée pour la communication des serveurs. Cela peut être un mot
de passe, ou un simple mot. Quand ce fichier n'existe
c~Tchuenché Rodrigue Élève Ingénieur
En Informatique 81
82 IAI Gabon
pas il faut le créer et l'éditer. Dans notre cas,
son contenu est le suivant : $sudo nano /etc/ha.d/authkeys
# Contenu
********************************************************
auth 1
1 md5 hypriot
2 crc
3 sha1 hypriot
# ici nous avons defini 3 méthodes d'encryptage et nous
avons utilisé la méthode 1 (au choix)
Après avoir configuré ce fichier, toujours lui
donner le droit rwx 600. $sudo chmod 600 /etc/ha.d/authkeys
Après ces trois fichiers, dans le fichier
/etc/hosts de chaque serveur , renseigner les valeurs
suivantes si c'est pas déjà fait :
$sudo nano /etc/hosts
#adresse_ip_serveur1 nom_serveur1
172.16.0.52 black-pearl2 172.16.0.56 black-pearl6
Ensuite nous allons désactiver le démarrage
automatique de HaProxy sur les serveurs : $insserv -r haproxy
Enfin sur les deux serveur arrêtez haproxy : $sudo
/etc/init.d/haproxy stop
et démarrer le service heartbeat sur les deux serveurs en
commençant par le serveurs maitres primaire
$systemctl restart heartbeat.service
c~Tchuenché Rodrigue Élève Ingénieur
En Informatique 82
83 IAI Gabon
RÉFÉRENCES BIBLIOGRAPHIQUES
Articles et Livres
[1 ] Tidiane Massouba,2013-2014, Etude et implémentation
d'un cluster low-cost basé sur Raspberry pi,UNIVERSITE GASTON BERGER DE
SAINT-LOUIS DU SÉNÉGAL, U.F.R DE SCIENCES APPLIQUÉES ET DE
TECHNOLOGIE SECTION D'INFORMATIQUE, Mémoire de Maîtrise
Informatique
[2 ] Run Hypriot Docker BirthdayParty#3 app,
http://textlab.io/doc/2310814/run-hypriot-do
233-app
Documents web
[1 ] Raspberry Pi,
https://fr.wikipedia.org/wiki/Raspberry_Pi
[2 ] Bien choisir vos accessoires pour les Raspberry Pi 3 et
2,
http://raspbian-france.
fr/acheter-raspberry-pi-3-accessoires/
[3 ] Dockerisez votre Raspberry Pi!,
http://raspbian-france.fr/docker-raspberry-pi/
[4 ] Docker, https://docs.docker.com/
[5 ] Présentation de Docker,
https://www.grafikart.fr/tutoriels/docker/docker-intro-634
[6 ] Comprendre Docker ,
https://www.wanadev.fr/23-tuto-docker-comprendre-docker-partie1
[7 ] How to get Docker running on your Raspberry Pi using
Windows,
http://blog.
hypriot.com/getting-started-with-docker-and-windows-on-the-raspberry-pi/
[8 ] Docker swarm,
https://docs.docker.com/swarm/
[9 ] Installer PostgreSQL 9.3 sur Raspberry Pi Raspbian,
http://domoenergytics.com/ domo.energy/Installer-PostgreSQL-9-3-sur
[10 ]Installer sur Raspberry,
http://blog.hypriot.com/post/how-to-setup-rpi-docker-swarm/
[11 ] Docker en production : la bataille sanglante des
orchestrateurs de conteneurs, http://
blog.octo.com/docker-en-production-la-bataille-sanglante-des-orchestrateurs-de-con
[12 ] Configurer un reverse proxy avec haproxy,
https://blog.victor-hery.com/index.
php?article21/configurer-un-reverse-proxy-sous-haproxy
[13 ] Load Balancing with HAProxy,
https://serversforhackers.com/load-balancing-with-hapr
[14 ] Mise en place haproxy Debian 8,
http://www.hisyl.fr/mise-en-place-haproxy-debian-8/
[15 ] [Tuto]HA : Mettre en place deux serveurs HaProxy actif /
passif avec Heartbeat, http: //
denisrosenkranz.com/tutoha-mettre-en-place-deux-serveurs-haproxy-actif-passif-av
#comment-409445
[16 ] CLUSTER HAUTE-DISPONIBILITÉ AVEC ÉQUILIBRAGE
DE CHARGE, http: //
connect.ed-diamond.com/GNU-Linux-Magazine/GLMF-097/Cluster-haute-disponibilite-a
[17 ] A Raspberry Pi Docker Cluster,
http://www.informaticslab.co.uk/infrastructure/
2015/12/09/raspberry-pi-docker-cluster.html
c~Tchuenché Rodrigue Élève Ingénieur
En Informatique 83
| 

