Etude, conception et implémentation d'un cluster low-cost haut disponibilité de Raspberry Pi 3( Télécharger le fichier original )par Rodrigue Tchuenche Institut Africain d'Informatique (IAI) - Ingénieur 2016 |

2.2.1.6 Modèle 3BCe modèle apparait le 29 février 2016. Il coûte environs 35$ US (soit environ 17.500 FCFA). Il dispose d'un processeur Broadcom BCM2837 64 bit à quatre coeurs ARM Cortex-A53 à 1,2 GHz accompagné de 1 Go de RAM et d'une puce Wifi 802.11n et Bluetooth 4.1 intégrée. Il possède les mêmes dimensions et connectiques que les modèles 2B et B+. La vitesse d'horloge est 33% plus rapide que le Pi 2, ce qui permet d'avoir un gain d'environ 50-60% de performance en mode 32 bits. Il est recommandé d'utiliser un adaptateur de 2,5 A. Tous les travaux et tutoriels du Pi 2 sont parfaitement compatibles avec le Pi 3 (voir figure 2.7).
FIGURE 2.7 - Une carte nue du Raspberry Pi 3 modèle B 2.2.1.7 Modèle ZéroLe 26 novembre 2015, la fondation Raspberry Pi annonce la sortie du Raspberry Pi Zero. Il reprend les spécifications du modèle A et B avec un processeur cadencé à 1 GHz au lieu de 700 MHz, il est par contre plus petit, disposant d'une connectique minimale. Son prix de 5$ 15 IAI Gabon c~Tchuenché Rodrigue Élève Ingénieur En Informatique 15 US (soit environ 2500 FCFA) est largement revu à la baisse par rapport aux autres Raspberry Pi (voir figure 2.8)
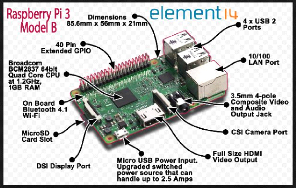
FIGURE 2.8 - Une carte nue du Raspberry Pi Zéro Pour notre travail, nous avons utilisé le modèle 3B qui est actuellement le modèle le plus récent. Ce modèle nécessite une carte microSD d'au moins 8Go et d'une classe entre 6 et 10 d'une bonne marque pour préserver les performances en accès disque. Une image annoté de ce modèle est la suivante (voir figure 2.9) :
FIGURE 2.9 - Une carte annotée du Raspberry Pi 3 Modèle B 16 IAI Gabon c~Tchuenché Rodrigue Élève Ingénieur En Informatique 16 2.2.2 ClusterLe terme « cluster » (mot anglais signifiant groupe, grappe...), au sens employé ici est un ensemble de machines connectées d'une façon ou d'une autre pour distribuer une tâche très lourde entre ces différentes machines6. En fonction de l'objectif à atteindre, un cluster peut être soit un ensemble d'ordinateurs mis en réseau dans le but de traiter une même tâche (par exemple le cumul de puissances des machines d'un cluster pour effectuer une tâche), soit un ensemble d'ordinateurs mis en réseau dans le but de repartir les tâches sur chaque noeud du cluster (par exemple un cluster de tâches systèmes allouera à chaque machine du cluster un ensemble de processus à traiter suivant sa charge et sa puissance de calcul). Dans un cluster, les machines peuvent être de simples stations de travail ou des machines multiprocesseurs et sont appelées des noeuds. Lorsqu'il y'a besoin, la machine d'entrée sur le réseau sera appelée noeud serveur et se chargera de diviser la ou les tâches à travers tous les noeuds du cluster en prenant garde à ne pas surcharger la machine réceptrice. Les clusters sont apparus au moment de la montée en puissance du prix des supercalculateurs alors que les microprocesseurs devenaient de plus en plus rapides et de moins en moins chers. À partir de la fin des années 1980, les ingénieurs ont commencé à développer ce qu'ils appelaient alors un « multi-ordinateur7 ». Toutefois, c'est le projet Beowulf mis au point par Goddard Space Flight Center de la NASA en 1994 dont le principe est de construire des clusters en parallèle sous GNU/LINUX avec du matériel commun (simples PCs), donc peu cher qui a véritablement lancé l'intérêt sur les clusters La mise en cluster assure une disponibilité, c'est-à-dire lorsqu'un serveur tombe en panne alors qu'il est en train de traiter des requêtes, d'autres serveurs du cluster doivent pouvoir les traiter d'une manière aussi transparente que possible. Il assure aussi l'évolutivité c'est-à-dire la capacité d'une application à supporter un nombre important d'utilisateurs et la possibilité d'ajouter de nouveaux serveurs sans procéder à un arrêt du système. Dans ce chapitre les différentes catégories de cluster et les architectures logicielles et matérielles des clusters seront présentées et aussi des solutions logicielles de clustering seront présentées 2.2.2.1 Catégories de clusters Nous catégorisons les clusters en quatre groupes : a) Cluster haute disponibilité Ces types de clusters ont pour objectif de prévenir les situations où la défaillance d'un composant du cluster entraine l'indisponibilité du service. Dans le cas où un noeud a une défaillance quelconque, matérielle ou logicielle, les autres prennent en charge les groupes de ressource du noeud défaillant. Ainsi en une poignée de secondes les services de ce dernier sont pris en charge par les autres noeuds sans pour autant que l'utilisateur ne soit perturbé. Dans ce type de cluster le noeud chargé de l'exécution des requêtes, le noeud
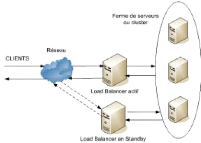
17 IAI Gabon c~Tchuenché Rodrigue Élève Ingénieur En Informatique 17 primaire, envoie périodiquement un signal qu'on appelle heartbeat8 aux noeuds chargés de la prise en charge des ressources du noeud défaillant, les noeuds secondaires, afin de les notifier sa présence. Dès que les noeuds secondaires ne reçoivent plus de heartbeat, ils déclarent le noeud primaire comme ne faisant plus partie du cluster et un des noeuds secondaires prend son identité complète. En effet, le stockage des données étant redondant, le fonctionnement du cluster, l'assurance contre la perte de données et la disponibilité des ressources sont garantis à 99.9% pour ne pas dire 100% du temps. La figure ci-dessous représente un cluster haute disponibilité à 2 serveurs maitres et 3 serveurs esclaves. (voir figure 2.10)
FIGURE 2.10 - Cluster haute disponibilité
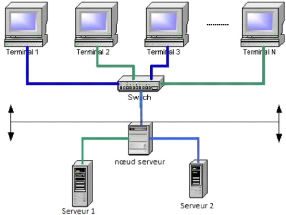
C'est un système considéré de l'extérieur comme étant une machine multiprocesseur dont les noeuds cumulent leurs puissances de calcul pour arriver à des performances égales à celles qu'atteignent les supers calculateurs. Ce cluster utilise des applications spécialisées dans la parallélisation de calcul à travers une couche de communication commune. A la place, un administrateur pourra utiliser le Direct Memory Acces (DMA, similaire à celui utilisé par certains périphériques d'un PC) à travers ses noeuds, qui fonctionne comme une forme de mémoire partagée accessible par l'ensemble des processeurs du système. Il 8. Battement de coeur.
18 IAI Gabon c~Tchuenché Rodrigue Élève Ingénieur En Informatique 18 FIGURE 2.11 - Cluster répartition de charges pourra aussi utiliser un système de communication dit de low-overhead comme Message Passing Interface (MPI), qui est une API (Application Program Interface) pour dévelop-peurs d'applications de calculs parallèles . (voir figure 2.12)
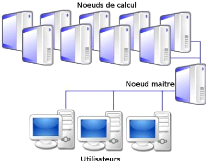
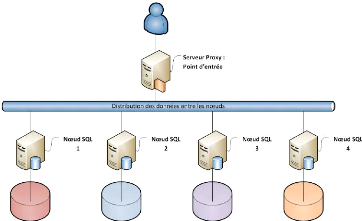
FIGURE 2.12 - Cluster calcul haute performance d) Clusters de stockage Ce type de système est comparable au cluster scientifique, mais ici ce n'est pas la puissance de calcul qui est recherchée mais plutôt la puissance de stockage. Sa mise en place est partie d'un constat que les entreprises utilisaient de plus en plus d'applications performantes utilisant des flux de données conséquents et donc nécessitant une capacité de stockage supérieure à celle d'un seul disque dur. Ce problème a pu être contourné grâce à une vaste capacité de stockage qu'offre ce système. Les fichiers sont découpés en bloc de 9. http://www-igm.univ-mlv.fr/~dr/XPOSE2006/BACHIMONT_BRUNET_PIASZCZYNKSI/index.htm 19 IAI Gabon c~Tchuenché Rodrigue Élève Ingénieur En Informatique 19 taille raisonnable et stockés par morceau sur plusieurs disques, ainsi on a l'impression que l'espace de stockage ne fait qu'un et que nos fichiers sont stockés en un seul morceau sur un "disque". Il s'agit pour ce type de cluster d'utiliser le potentiel des systèmes dits de "stockage combiné", c'est à dire qu'il distribue les données par l'entremise de plusieurs disques répartis sur les noeuds du cluster. Ainsi, tout utilisateur aura le loisir de travailler avec des fichiers de très grandes tailles, tout en minimisant les transferts. (voir figure 2.13)
FIGURE 2.13 - Cluster de stockage NB : Pour notre travail, nous allons utiliser un cluster de haute disponibilité couplé à un cluster de répartition de charge. 2.2.2.2 Architecture des Clusters a) Architecture Matériel Il n'existe pas de modèle de référence pour l'architecture matérielle des clusters, mais la plupart des constructeurs comme IBM, SUN, Hewlet Packard, Compaq et bien d'autres possèdent leur propre solution issue de leurs recherches. Néanmoins pour répondre à la problématique que posent les clusters concernant l'architecture, c'est à-dire que la répartition des calculs entre les machines doit être la moins couteuse possible, deux architectures sont possibles. * Maitre - Esclave : cette architecture est composée d'un noeud serveur appelé noeud maitre et des noeuds esclaves. Le noeud maitre peut être considéré comme l'organisateur du cluster. Il maintient le système de fichiers et garde une trace de toutes modifications de leurs propriétés, contrôle l'exécution des opérations d'entrées/sor-ties des noeuds clients, gère la configuration du cluster, enregistre les métadonnées de tous les fichiers enregistrés dans le cluster, comme par exemple l'emplacement, la taille, les permissions... Il reçoit également des messages des autres noeuds du cluster afin d'assurer qu'ils fonctionnent correctement, en cas de défaillance, il choisit un nouveau noeud client pour exécuter les requêtes du noeud défaillant. A chaque fois qu'un client externe doit lire ou écrire des données il communique avec le noeud 20 IAI Gabon c~Tchuenché Rodrigue Élève Ingénieur En Informatique 20 serveur lequel répond à sa demande. Les noeuds clients exécutent les opérations demandées par le noeud serveur. * Mono niveau (pair à pair) : ce type d'architecture permet de mettre en commun un groupe d'ordinateurs pour fournir un service même en cas défaillance d'un des composants système. Quand une machine tombe, les autres prennent la relève et les nouvelles tâches parviennent à la machine qui a pris la relève. Dans cette architecture seul un noeud, le maître, peut gérer les ressources à un instant t et les autres noeuds, esclaves, disposent d'un système de contrôle qu'on appelle «heartbeat» 10. Quand le maître n'envoie pas de «heartbeat» pendant une période de temps, les esclaves détectent cela et assument une défaillance et on procède à une réélection du maître. Un des esclaves devient maître, les services sont de nouveau alloués sur ce noeud. Cette procédure s'appelle le «failover» 11. Le «failover» est donc la capacité d'un équipement à basculer automatiquement vers un chemin réseau redondant ou en veille. Le choix d'une architecture est fortement lié à l'application du cluster utilisé même si le modèle le plus répandu est le Maitre-Esclave. Le stockage de toutes les ressources publiables, fichiers de données, files d'impression, applications, ressources, et services se font sur les disques partagés. Il est nécessaire de partager les disques sur un bus, il y a deux méthodes d'implémentation pour le partage des disques sur un bus, la technologie SCSI et la technologie Fibre Channel sur un système SAN (Storage Area Network). b) Architecture Logiciel Tout comme l'architecture matérielle, il n'existe pas de modèle de référence pour l'architecture logicielle, mais toutefois, il nous faut disposer de deux choses essentielles : un système d'exploitation et une API (Application Program Interface) de parallélisations. Ensuite, les choix s'orienteront vers les préférences de la personne qui installe le système. Il existe des systèmes d'exploitation dédiés au clustering. Ces systèmes gèrent eux mêmes les échanges réseaux et peuvent dans certains cas découper les applications afin de les répartir sur le cluster. Ils permettent de lancer des applications qui ne sont pas développées à la base pour du clustering, mais pour une utilisation optimale, l'utilisation de librairies dédiées au clustering est recommandée. Ainsi il existe des systèmes ou des extensions systèmes pour tous les environnements comme Linux-Unix, BSD 12, Mac OS et Windows. Néanmoins, pour monter un cluster performant, il est tout de même préférable d'utiliser des systèmes d'exploitation ayant une couche TCP/IP bien développée et sans faille. Parmi ces systèmes d'exploitation nous pouvons d'abord citer Beowulf11 qui est un système conçu par la NASA permettant à partir de librairie de créer et d'utiliser des applications de calculs répartis, Mosix qui est un système développé par l'université de Jérusalem permettant de découper une application pour la lancer sur un cluster et OpenMosix est une version open-source de Mosix. Ces systèmes sont pour l'environnement Linux-Unix. Ensuite pour l'environnement Mac OS nous pouvons citer Xgrid qui est une surcouche à MacOS développé par la Apple's Advanced Computation Group qui propose une API permettant à un groupe d'ordinateurs en réseau d'effectuer des calculs répartis. Xgrid est
21 IAI Gabon c~Tchuenché Rodrigue Élève Ingénieur En Informatique 21 livré par défaut depuis Tiger 13. Enfin pour l'environnement Windows nous pouvons citer Windows 2003 cluster server R2 qui est une extension pour Windows 2003 server. Son gros défaut est que cette solution repose sur un OS peu adapté au clustering. En effet, la présence d'une interface graphique lourde ralentit considérablement les performances. Puis pour BSD, nous pouvons citer Mosix qui est le portage de Mosix sous BSD. Pour ce qui est des API il existe de nombreuses librairies permettant de créer des applications réparties. Certaines sont dédiées aux communications réseaux comme MPI (Message Passing Interface) et d'autres permettent de transformer un ensemble de machines en une seule comme PVM (Parallele Virtual Machine). PVM possède un environnement de contrôle permettant de rendre le lancement d'une application de manière identique sur tous les noeuds du système. Il est plutôt orienté vers les réseaux hétérogènes, c'est à dire que les noeuds du cluster peuvent être de type différent (PC Linux, PC Windows...). MPI emploie des fonctionnalités intéressantes (comme le RMA, Remote Memory Access, ou le système d'entrée sortie parallèle), mais nécessite un apprentissage de MPI identique à celui d'un nouveau langage de programmation. Même si PVM semble mieux répondre aux contraintes d'un cluster et de son matériel, il faut tout de même savoir que certains inconvénients viennent s'incruster dans les rouages de PVM. En effet, les applications l'utilisant doivent obligatoirement être compilées avec les bibliothèques PVM. Ceci implique donc une recompilation quasi obligatoire des logiciels déjà existants. De plus, MPI a été développé après PVM et s'en est inspiré. Ainsi, MPI répond mieux aux contraintes liées à la gestion des buffers, des structures de données... En fait cela sera à vous de choisir l'API répondant encore une fois au mieux à vos attentes et vos besoins. En plus du système d'exploitation et de l'API on peut citer le BIOS (Basic Input/Output System) qui gère l'entrée et la sortie des données et les échanges avec les périphériques. A l'heure actuelle aucun cluster ne travaille à ce niveau pour la gestion des calculs. Néanmoins le BIOS est utilisé pour accélérer les échanges réseaux entre les noeuds. |
|