Les déterminants de l'épargne des ménages au Cameroun( Télécharger le fichier original )par Pierre Alain YOUMBI Université de Douala - DESS en Gestion Financière et Bancaire 2003 |

CHAPITRE IV : L'analyse empirique dela fonction d'épargne des ménagesAprès un survol des aspects théoriques de l'analyse des déterminants de l'épargne des ménages, il reste à tester empiriquement, dans le contexte Camerounais, un modèle qui permet d'identifier les variables explicatives, les facteurs incitatifs ou limitatifs de l'épargne des ménages. En nous inspirant de certains modèles de référence dont celui de HADJIMICHAEL, MICHAÊL et GURA115(*)(1995), NDANSHAU116(*) (1998), FRY117(*)(1995), ARRIERA118(*) (1988) de revenu absolu (KEYNES) et du revenu relatif (DUESENBERRY, 1949), notre analyse de la fonction d'épargne prend la forme générale suivante : St = âo + â1 Yt + â2 TIRt + â3 INFt + â4 IRt + åt (4.1) âi (i = 0,1,2,3,4,) et åt représentent respectivement les coefficients respectifs des différentes variables et le terme de l'erreur, t est le temps. S = L'épargne des ménages. Y = Le revenu disponible brut des ménages. TIR = Le taux d'intérêt réel. INF = L'inflation. IR = L'impôt sur le revenu des ménage. Nous allons présenter les caractéristiques des variables retenues, les tests et estimations utilisés à la section 1, les résultats, interprétations et recommandations à la section 2.
I - Présentation des variables, des tests et estimations.
Nous allons d'abord distinguer les deux types de variables retenues :
Notre étude a retenu une variable dépendante (l'épargne des ménages) et quatre variables indépendantes (le revenu disponible brut des ménages, le taux de l'intérêt, le taux d'inflation et l'impôt sur le revenu).
Nous allons ensuite procéder à la présentation formelle ou théorique des tests et estimations qui seront utilisés pour vérifier les résultats escomptés 1 - PRÉSENTATION ET ÉVOLUTION DES VARIABLES Notre fonction d'épargne est construite de la manière suivante : S = F ( Y, TIR, INF, IR, ) (4.2) (+) (+) (-) (-)
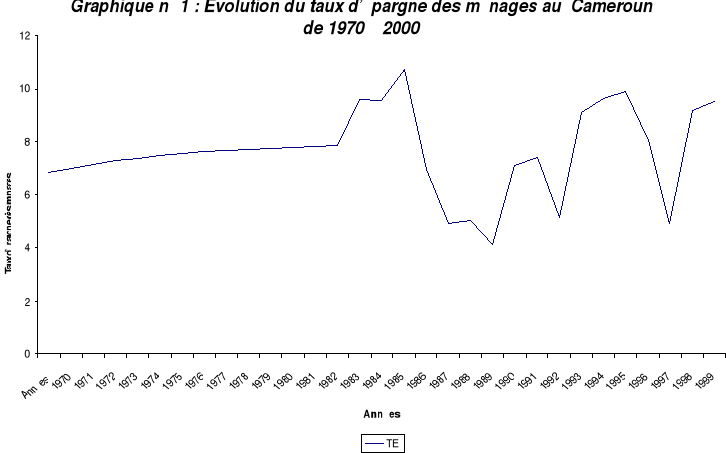
Le signe (+) ou (-) sous chaque variable explicative indique à priori l'impact attendu de la variable considérée sur l'épargne des ménages. L'étude de l'évolution des variables montre qu'elles sont fortement influencées par les évènements économiques et sociaux tant au niveau local qu'à l'international au cours de la période d'étude qui va de 1970 à 2000. On peut par exemple citer : - Les chocs pétroliers de 1973 et 1979. - Les cours des produits de base et des ressources minières. - La crise économique qui sévit au Cameroun à partir de 1987. - La mise en route des politiques d'ajustement structurel (1989) et des stratégies de réduction de la pauvreté (1996). - Les revendications démocratiques et sociales des années 90. - La dévaluation du Franc CFA intervenue le 14 janvier 1994. - Les baisses successifs de salaires dans la fonction publique en 1994. - L'arrimage du Franc CFA à l'Euro en 1999. - Les changements de politique fiscale. De 1987 à 2000, le PIB alterne des phases de baisse continue (1987-1997) et des phases de hausse continue (1995-2000) sans que le niveau de 1986 ne soit jamais atteint. Par ailleurs, l'économie enregistre une croissance négative entre 1987 et 1994. Les gains de compétitivité des lendemains de la dévaluation vont positionner l'économie sur les sentiers de la croissance à partir de 1995. L'épargne des ménages est globalement faible. Elle s'appréhende mieux par le rapport de l'épargne au revenu disponible brut des ménages i.e. par le taux de l'épargne. Nous pouvons observer son évolution à partir du graphique suivant :
Nos calculs à partir des données de L'INS. Le taux de l'épargne (série complète en annexe n°III) croit de façon constante et régulière jusqu'en 1986, année pendant laquelle il culmine à 10,7%. Il commence à décroître en 1987, atteint son plus bas niveau en 1990 (4.16%) et amorce une tendance à la hausse à partir de 1991 (7,11%) malgré les fluctuations cycliques observées en 1993 (5,15%), et 1998 (4,92%). Cette évolution s'explique par le fait que les ménages sont affectés par la crise qui démarre en 1987, par les soubresauts politiques des années 90 et par les effets de la dévaluation du Franc CFA et de la baisse des salaires de la fonction publique en 1994. Bien qu'on observe un fléchissement de l'épargne en 1999, la tendance à partir de 1994, est à la hausse. C'est en quelque sorte le résultat des reformes structurelles amorcées en 1990.
Le revenu disponible brut des ménages est le revenu dont un ménage peut disposer librement au cours d'une année pour la consommation et pour l'épargne. Sous l'angle arithmétique, son évaluation se fait à travers la formule suivante : Revenu disponible = Revenu primaire (Revenu du travail, de la propriété ou d'entreprise individuelle) + Transferts (Prestations familiales, pensions...) - Prélèvements (IRPP, cotisations sociales, impôts divers...). Dans la littérature, le revenu disponible (les données sont disponibles en Annexe n° III) est le facteur majeur et le moyen par excellence de production de l'épargne. Il aurait été souhaitable de tester les différentes approches (revenu absolu, revenu relatif, revenu permanent, approches par le patrimoine et par le cycle de vie). Mais, compte tenu de l'absence de données affinées et continues sur une longue période pour estimer les paramètres desdits modèles, nous avons privilégié le revenu absolu au sens Keynésien. L'évolution de ce revenu est perceptible dans le graphique ci-après :
Source : Institut National de la Statistique
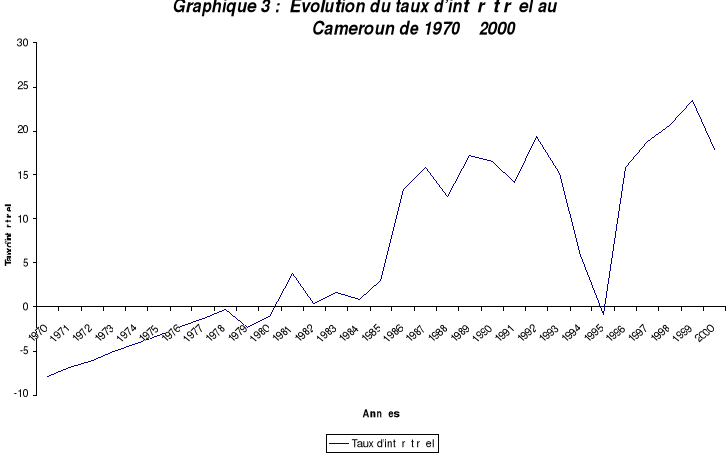
La croissance du revenu des ménages est affectée entre 1986 et 1994 par les effets pervers de la crise économique et politique, de la dévaluation et de la baisse des salaires dans la fonction publique. Globalement considéré, le revenu épouse une tendance haussière. Le revenu disponible le plus élevé jamais atteint est celui de l'année 2000. Le taux d'intérêt retenu est le taux d'intérêt réel (série complète en annexe n°III) La négativité des taux entre 1970 et 1980 s'explique par le contexte économique international. Les capitaux extérieurs en quête de placement sont relativement abondants et bon marché. A cette période, il est plus facile de contracter des emprunts sans intérêts ou à taux bonifiés et de recevoir des aides sans contrepartie.
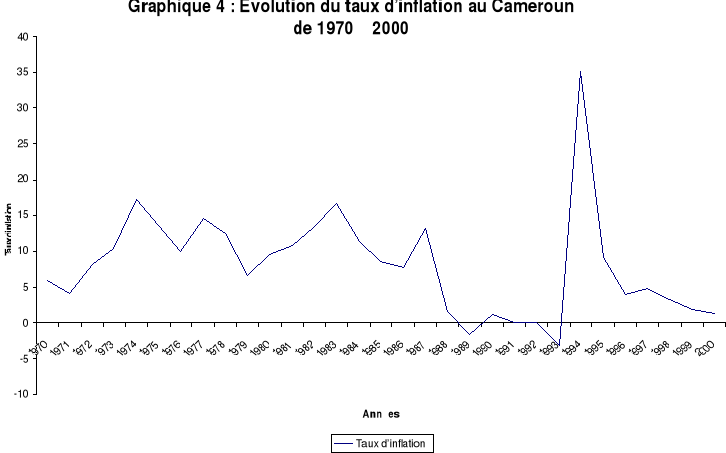
Source : Banque mondiale A partir de 1980, les flux financiers extérieurs se rétrécissent et deviennent rares. Ils sont dorénavant soumis à de rigoureuses conditionnalités. De 1981 à 1992, le taux d'intérêt connaît des fluctuations cycliques avec des pointes en 1981 (3.8%), 1987 (15,7%), 1989 (17,3%) et 1992 (19,2%). Le taux négatif de 1995 résulte de l'impact du taux d'inflation record de 1994 (35%). Cette évolution s'identifie clairement dans le graphique suivant : L'inflation (série complète en annexe n°III) a été appréhendée par l'indice des prix à la consommation. Elle agit directement sur le pouvoir d'achat et par voie de conséquence, sur la capacité d'épargne des ménages.
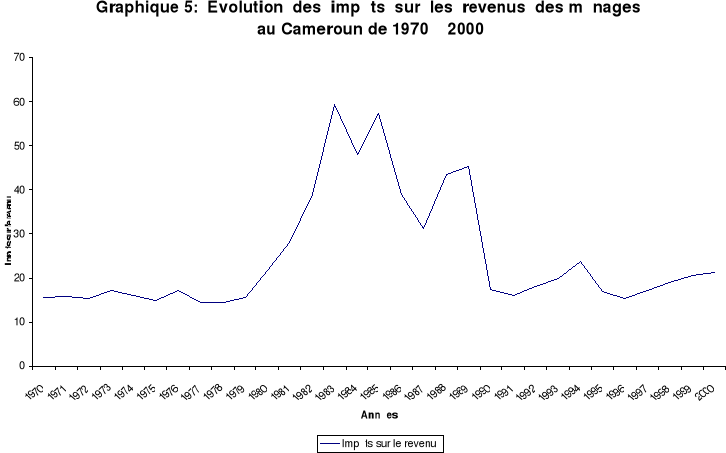
Source : Banque mondiale De 1970 à 1988, l'inflation connaît des sommets comme en 1974 (17,2%), 1977 (14,6%), 1983 (16,63%) et 1987 (13,1%). L'environnement national (fiscalité expansive, politique monétaire un peu lâche...) et international (chocs pétroliers de 1973 et 1979, afflux massif de capitaux extérieurs, déficit chronique des comptes extérieurs...) peuvent expliquer l'existence des taux assez élevés. Les taux minimum de cette période sont à rechercher autour des années 1970 ( 5,8% en 1970, 4,01% en 1971). De 1989 à 1993, l'inflation inaugure un cycle à taux quasi nul ou négatif. Il correspond à l'époque des restructurations et de la libéralisation du système financier. Après le pic atteint en 1994, on va assister à un relâchement des tensions inflationnistes consécutif aux résultats des politiques d'austérité budgétaire et de stabilisation (assainissement, maîtrise et réduction des dépenses publiques, amélioration du solde commercial). L'évolution de l'impôt sur le revenu des ménages (série complète en annexe n°III) peut être décomposée en trois grandes périodes :
Source : Banque mondiale - La première qui va de 1970 à 1979 correspond à une période de relative stabilité de l'impôt sur les revenus. Les taux sont dans l'intervalle allant de 14,35% à 17,16%. - La deuxième qui va de 1980 à 1989 correspond à une période où l'on observe les taux les plus élevés. C'est le cas en 1983 (59,9%), 1985 (57,1%) et 1989 (45,2%). Même le taux minimum de cette période observé 1987 (31,2%) est plus élevé que le taux maximum des autres périodes. Elle correspond à la période de création de nouveaux impôts (redevance CRTV, Fonds National de l'Emploi...). - La troisième qui va de 1990 à 2000, renoue avec une relative stabilité de l'impôt sur les revenus. Les taux oscillent entre 15,45 en 1996 (minimum) et 23,86% en 1994 (maximum). Une pause fiscale est observée par l'Etat pendant cette période. 2- TESTS ET ESTIMATIONS La démarche méthodologique en ce qui concerne les tests et estimations s'articule autour des points suivants : - L'analyse de la stationnarité des variables (identification de l'ordre d'intégration). - Les tests de co-intégration des variables. - L'estimation de la relation de long terme du modèle par la méthode des MCO. - L'estimation du modèle à correction d'erreur ou la relation à court terme par les MCO. - Les tests de causalité au sens de GRANGER. Les séries économiques ne sont ni stationnaires ni co-intégrées par nature. Les valeurs obtenues à chaque date ne sont pas toujours issues d'une même loi de probabilité. Il faut toujours au préalable stationnariser les séries non stationnaires afin d'éviter le risque de «régression fallacieuse». Lorsque les variables ne sont pas stationnaires, l'estimation des coefficients par les MCO ne converge pas vers les vrais coefficients et les tests usuels des t de Student et f de Fisher ne sont plus valides. Pour procéder à l'estimation des relations, il faudrait que la stationnarité soit de forme faible. Une variable At est faiblement stationnaire si son espérance mathématique et sa variance sont constantes et finies et si la covariance de At et At+i (avec i>o) dépend uniquement de i At est stationnaire si elle est intégrée d'ordre zéro At I(0). Pour étudier la stationnarité, on recourt à trois types de tests : - Le test de DICKEY-FULLER (1979). - Le test de DICKEY-FULLER Augmenté (1978,1981). - Le test de PHILLIPS-PERRON (1986,1987). Le test de DF permet de mettre en évidence le caractère stationnaire ou non d'une chronique par la détermination d'une tendance déterministe ou stochastique. Ils sont construits sur la base de trois modèles : [1] Xt = ñXt - 1 + åt Modèle auto régressif d'ordre 1 ou AR (1) [2] Xt = ñXt -1 + b + åt Modèle auto régressif avec constance [3] Xt = ñXt -1 + bt + C+ åt Modèle autorégressif avec tendance. La procédure du test est séquentielle. On part du modèle [3] au modèle [1]. Sur le modèle [3], on teste la significativité du coefficient b à partir des statistiques classiques de Student. - Si b est significativement différent de zéro, alors on teste pour ce même modèle le coefficient ñ i.e. Ho : ñ =1 H1 : ñ <1. Si l'hypothèse Ho est acceptée (tp t tabulé), la série est non stationnaire avec tendance sinon, H1 est acceptée et la série est stationnaire. - Si par contre b est significativement nul, on passe directement au test sur le modèle [2] avec le même cheminement que précédemment, jusqu'au test sur le modèle [1]. Si Xt n'est pas stationnaire, on peut appliquer le test de DF sur les variables différenciées en suivant la même procédure que précédemment. Dans les trois modèles précédents, le processus åt est par hypothèse un bruit blanc. Or il n'y a aucune raison pour qu'à priori, l'erreur soit non corrélée. Le test de ADF prend en compte cette hypothèse. Ils sont fondées sur l'hypothèse alternative | Ø | < 1 issue de l'estimation par les MCO dans les trois modèles ci-dessous. [4] ÄXt = ñ Xt-1
+ [5] ÄXt = ñ Xt-1
+ [6] ÄXt = ñ Xt-1
+ Le test de ADF se déroule de manière similaire aux tests de DF. Seules les tables statistiques diffèrent. La valeur p, nombre de retards à prendre en compte, est déterminée grâce aux tests de AIKAIKE (1974) et SCHWARZ. Ces tests déterminent pour une variable, le nombre de données antérieures à prendre en compte. Ils donnent une information optimale sur le processus de formation de la valeur en t. Ces tests sont nécessaires avant l'estimation des paramètres. Ils permettent d'éviter de mettre en relation les variables qui divergent. Après ces tests, chaque variable aura un trend, soit après le test en niveau, soit après le test en différence première ou seconde. Le test de PP présente l'avantage d'introduire une correction non paramétrique des statistiques de DF en tenant compte des erreurs hétéroscédastiques. Il se déroule en deux étapes : - Estimation par les MCO des trois modèles de base du test de DF et calcul des statistiques associées. - Estimation d'un facteur correctif établi, à partir de la structure des covariances des erreurs des modèles précédemment estimés, de telle sorte que les transformations réalisées conduisent à des distributions identiques à celles de DF standard. Après les tests de stationnarité ou de racine unitaire, on passe aux tests de co-intégration, utilisés dans l'estimation de la relation de long terme entre les variables. Ils se font soit par l'approche de ENGLE et GRANGER (1987), soit par l'approche de JOHANSEN (1988). Ø L'approche de ENGLE et GRANGER porte sur le test de racine unitaire des résidus. La co-intégration traduit le fait que la combinaison linéaire ne s'éloigne jamais très longtemps de sa moyenne même si les séries présentent des évolutions divergentes. Il existe alors une évolution stable à long terme entre les séries. Deux séries Xt et Yt sont dites co-intégrées d'ordre d et b si les deux conditions suivantes sont vérifiées : - Elles sont affectées d'une tendance stochastique ou déterministe de même ordre d'intégration. - Une combinaison linéaire de ces séries est stationnaire i.e. qu'elle permet de se ramener à une série d'ordre inférieur d'intégration telle que :
Zt = Xt + âYt I (d - b) avec d = b = 0 (4.3) On note Xt , Yt C I (d,b) (4.4) [ , â ] est le vecteur de co-intégration Si les séries sont co-intégrées de même ordre (condition nécessaire de co-intégration), on estime par les MCO la relation de long terme entre les variables. L'estimation par les MCO permet de calculer le résidu. Si ce résidu est stationnaire, l'hypothèse d'une co-intégration entre les variables est acceptée. Les tests de stationnarité sur le résidu de DF doivent s'effectuer à partir des valeurs critiques tabulées par MacKINNON (1991) en fonction du nombre total des variables du modèle. Si le résidu est stationnaire, nous pouvons aussi effectuer les tests de normalité et de ARCH. Le test de normalité dont le plus classique est celui de JARQUE et BERA (JB), est fondé sur la notion d'asymétrie (Skewness) et d'aplatissement (Kurtosis). Pour calculer des intervalles de confiance prévisionnels et pour effectuer les tests de Student sur les paramètres, il faut que le bruit blanc at suive une distribution normale. Si les hypothèses Ho : v1 =0 (symétrie) et v2 =0 (aplatissement normal) sont vérifiées, alors v1 1,96 et v2 1,96. Dans le cas contraire, l'hypothèse de normalité est rejetée. Le test de ARCH (AutoRegressive Conditional Heteroscedasticity) permet de détecter l'hétéroscédasticité et de modéliser les chroniques qui ont une variabilité instantanée dépendant du passé. Il suppose que les résidus prévisionnels sont non corrélés. Il est fondé sur le test de Fisher classique. Il y a hétéroscédasticité lorsque la variance du terme de l'erreur n'est pas constante sur l'ensemble des observations (au cours du temps et sur un échantillon). Elle croit et décroît avec les variables explicatives. La principale conséquence de l'hétéroscédasticité est que l'estimateur de MCO n'est plus à variance minimale. Ø L'approche de JOHANSEN permet par la méthode de maximum de vraisemblance de tester l'existence d'une relation de long terme dans les séries temporelles stationnaires et d'obtenir tous les vecteurs de co-intégration dans un cadre multivarié. Contrairement à l'approche de ENGLER et GRANGER qui ne tient compte que d'une seule relation de co-intégration, celle de JOHANSEN apparaît plus attrayante lorsqu'on veut tester la co-intégration dans un système de plusieurs variables. Cette approche est basée sur deux tests : Le premier, appelé statistique de la trace teste l'existence d'au moins n vecteurs de co-intégration dans un système comportant N - n variables. Le second dénommé statistique de la valeur propre maximale, teste s'il existe exactement n vecteurs de co-intégration contre l'alternative de n+1 vecteurs. Le principe du test de JOHANSEN est basé sur la comparaison du ratio de vraisemblance LR à la valeur critique notée CV. - Si LR < CV , on accepte Ho i.e. que les variables ne sont pas co-intégrées. - Si LR = CV, on accepte H1 et on considère les variables co-intégrées . Les valeurs critiques ont été tabulées notamment par JOHANSEN (1988) et JOHANSEN et JUSELIUS (1990). Lorsque la relation de long terme existe, l'estimation par les MCO permet d'analyser les valeurs prises par le coefficient de détermination R2, le coefficient de détermination R2 ajusté, le DURBIN-WATSON (DW), le T de Student et le F de Fisher. Le coefficient de détermination R² permet de tester la significativité globale des variables explicatives. Il montre le rôle joué par l'ensemble des variables exogènes sur l'évolution de la variable endogène. Il est d'autant meilleur qu'il est voisin de 1. Son principal inconvénient est de ne pas tenir compte du nombre d'observations et du nombre de variables explicatives du modèle. Le coefficient de détermination R² ajusté ou corrigé comble principalement cette lacune. La statistique de DW permet de déceler la liaison des erreurs dans les procédures d'estimation. Un DW proche de 2 indique une auto corrélation négative. Le T de Student permet de tester la significativité des paramètres. Il est souhaitable que tcalculé en valeur absolue soit strictement supérieur à 2 pour une bonne intervention de la variable explicative Xi dans l'évolution de la variable endogène Yi. Le F de Fisher permet de juger de la validité globale d'un modèle. Si Fcalculé > Ftabulé, on conclut que : - Le modèle ainsi estimé est globalement significatif i.e. qu'il est bon et que sa spécification est acceptable. - Les variables explicatives véritables ont globalement une influence sur la variable endogène. Après l'estimation des coefficients du modèle par la méthode des MCO, Il convient de s'intéresser à la stabilité de ces coefficients. La stabilité des coefficients est importante quand on cherche à comprendre les mécanismes économiques et à faire des prévisions. La non stabilité des coefficients peut refléter des phénomènes ponctuels dans le temps (crise, dévaluation, changement de politique...). Les tests utilisés pour vérifier la stabilité sont au nombre de deux : - Le CUSUM (Cumulative SUM) fondé sur la somme cumulée des résidus récursifs. Il permet d'étudier la stabilité des équations de régression au cours du temps. Si les coefficients sont stables, alors les résidus récursifs doivent rester dans l'intervalle défini pour des seuils de confiance de 5%. Dans le cas contraire, le modèle est réputé instable. - Le CUSUM SQ (Cumulative SUM Square) fondée sur la somme cumulée du carré des résidus récursifs permet de détecter des modifications aléatoires (ponctuelles) dans le comportement du modèle. Si les coefficients sont stables au cours du temps, alors, les résidus récursifs carrés doivent rester dans l'intervalle de confiance. Ces tests sont fondés sur la dynamique de l'erreur de prévision. Ils permettent de déterminer les instabilités structurelles des équations de régression et d'étudier l'erreur de prévision normalisée au cours du temps. Si les tests de co-intégration permettent de détecter la présence d'une relation de long terme entre les variables, il est aussi important de connaître l'évolution à court terme et à moyen terme de cette relation. L'outil nécessaire pour parvenir à une telle fin est le modèle à correction d'erreur (EMC) Développé pour la première fois par HENDRY (1970), l'EMC permet de réaliser des ajustements qui conduisent à une situation d'équilibre de long terme. Il intègre à la fois des évolutions ou fluctuations de court terme autour de l'équilibre ou relation de long terme. La procédure commence avec l'estimation d'une relation de long terme avec la méthode des MCO. L'information fournit par le terme de l'erreur dans la relation de long terme est ensuite utilisée pour créer un mécanisme de correction dynamique (court terme). Quand le coefficient du terme à correction d'erreur est significatif et négatif, la convergence est assurée. ENGLE et GRANGER (1987) ont démontré que toutes les séries co-intégrées peuvent être représentées par un EMC (théorème de la représentation de GRANGER). L'objectif du EMC est d'une part, d'éliminer l'effet des vecteurs de co-intégration et d'autre part de rechercher la liaison réelle entre les variables. La forme du MCE de la fonction d'épargne des ménages s'écrit comme suit : ?(St ) = o + 1 ?(Yt ) + 2 ?(TIRt ) + 3 ?(INFt ) + 4 ?(IRt ) + o êt-1 + åt (4.5)
?, i (i = 0,1,2,3,4) , et åt représentent respectivement l'opérateur en différence première, les coefficients de court terme de la fonction d'épargne des ménages, le coefficient de correction d'erreur ou force de rappel vers l'équilibre et l'erreur d'estimation. Après l'étude de la relation de long et de court terme entre les variables, nous nous sommes préoccupés à ressortir parmi ces variables (expliquée et explicative), celles dont les variations sont susceptibles de causer des variations d'autres variables une fois les effets déterminés. Le moyen le plus approprié pour cela est le test de causalité. D'après Xt et Yt, deux variables d'un modèle, si la série Yt contient à travers ses valeurs passées une information qui améliore la prédictibilité de Xt et si cette information n'est contenue dans aucune autre série utilisée pour calculer le prédicteur, alors on dira Yt cause Xt. La variable est causale si sa prise en compte améliore la prédiction d'une autre variable. La causalité (ou non) au sens de GRANGER dépend du fait que les valeurs passées de Y améliorent (ou non) l'explication de X plutôt que de l'obtenir à partir des valeurs passées de X lui-même. On peut alors effectuer un simple test en faisant la régression de X sur ses propres valeurs passées ainsi que sur les valeurs passées de Y. Si ces dernières sont significatives, alors on dit que Y cause X au sens de GRANGER. Toutefois, ce test est souvent sensible au nombre de décalages pris en compte dans la modélisation. * 115 HADJIMICHAEL, MICHAÊL et GURA, Growing, Savings ant Investments Subsaharan Africa. IMF occasional papers, 1995, 118 * 116 NDANSHAU O, MICHAEL A, Dependency rate, poverty and saving rate in the LDCS : Evidence from sectional household data in Tanzania, African Review of money, finance and Banking, Saving and Development , 1998, pp. 85 - 96. * 117 FRY M. J. Money, interest and banking in Economic Development, Baltimore : John Hopkins UP, 1995 * 118 ARRIERA GONZALEZ. Interest rate, saving and growth. In LDC. An assessment of recent empirical research, World Development, vol 16, n°5, 1988. |
|



 Øj ÄXt-j +
åt
Øj ÄXt-j +
åt  Øj ÄXt-j + b +
åt
Øj ÄXt-j + b +
åt 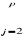 Øj ÄXt-j + bt + C +
åt
Øj ÄXt-j + bt + C +
åt