3.3 Les politiques de sécurité
3.3.1 Définition
"La politique de sécurité d'un système
est l'ensemble des lois, règles et pratiques qui régissent la
façon dont l'information sensible et les autres ressources sont
gérées, protégées et distribuées à
l'intérieur d'un système spécifique" [Com91].
La politique de sécurité décrit les
objectifs de la sécurité du système et identifie les
menaces auxquelles le système devra faire face.
Il est d'abord utile de faire la distinction entre politique et
mécanisme de sécurité. Les politiques de
sécurité définissent les autorités et les
ressources, spécifient les droits et les règles
d'usage. Les mécanismes de sécurité sont
des moyens pour la mise en oeuvre d'une politique de sécurité.
Donc, le terme "politique de sécurité" est
associé à l'ensemble des propriétés de
sécurité que l'on désire appliquer et déployer dans
un système ainsi que les dispositifs pour les assurer. Les approches de
sécurisation des agents mobiles sont multiples. Ces dernières
peuvent être classées, suivant le moyen de sécurisation, en
sécurité basée sur le matériel et
sécurité basée sur le logiciel.
3.3.2 Les approches de sécurisation des agents
mobiles
Sécurité basée sur le matériel
:
Lorsqu'il s'agit d'une sécurité basée sur
le matériel, il est nécessaire d'avoir un outil matériel.
Ce dernier doit être testé par le système avant et pendant
l'exécution. Certaines applications réseaux, en particulier
Internet, implémentent cette approche pour la sécurisation de
leurs logiciels contre le piratage.
a- Sécurisation à base d'un environnement
d'exécution de confiance: Cette méthode de sécurisation
consiste à utiliser un périphérique (coprocesseur)
assurant l'exécution de l'agent, ce dernier s'exécute
exclusivement à l'intérieur de ce périphérique et
ne dialogue avec le site visité qu'à travers une interface
sécurisée [Wil98]. Cette approche a été
proposée par Wilhelm [Wil98] et elle est basée sur ce qu'il
appelle « environnement d'exécution de confiance TPE »
(Trusted Processing Envirenment). Le périphérique TPE est
fabriqué sous le contrôle d'une autorité de confiance et
dispose d'un certificat et d'une politique de sécurité. Dans
cette approche les agents sont cryptés par la machine de leur
propriétaire et ne seront plus exécutés par le site
visité mais par le périphérique TPE. Ainsi les agents
resteront cryptés tout au long de leurs chemins de migration et sur
chaque site visité. Quand ils arrivent à leurs sites de
destinations ils sont encore cryptés et accèderont au
périphérique TPE où ils seront décryptés
puis exécutés [Wil98].
Une telle approche présente une solution très
puissante pour sécuriser les agents sur site d'exécution ainsi
qu'à travers le réseau. Toutefois, le périphérique
TPE n'est pas facile à fabriquer ce qui explique son coût
élevé. De plus l'environnement d'exécution de confiance
TPE ne présente pas les performances d'un ordinateur, ce qui
réduit l'efficacité d'exécution de l'agent. De plus le
problème d'exécution de plusieurs agents en parallèle
reste posé.
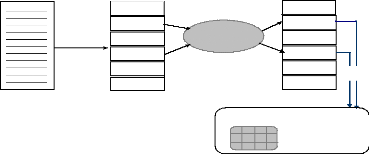
b- Sécurisation à base de cartes à puces :
Cette solution est proposée pour la première fois par Mana
[Man02]
L'idée de Mana consiste à subdiviser le code de
l'agent en sections dont certaines seront cryptées par la clé
publique d'une carte à puces. Ces dernières seront
remplacées par des appels
procéduraux vers la carte. Sur site d'exécution,
on transmet à la carte comme arguments les sections cryptées qui
seront décryptées puis exécutées à
l'intérieur de cette dernière (Figure2. 1). La paire de
clés est générée à l'intérieur de la
carte à puce, la clé publique sera publiée tandis que la
clé secrète résidera exclusivement à
l'intérieur de la carte et ne sera jamais révélée
[ManO2].
Code de l'agent
S1
S2 Crypté
S3
S4 Crypté
S5
S6
Clé publique, clé
secrète
Appel
Subdivision du code
Cryptage
S1
S2
S3
S4
S5
S6
Carte à puces
Figure 2.1 Sécurisation à base de cartes à
puces
De cette façon, on assure la confidentialité du
code et on évite l'exécution de la totalité de l'agent sur
le périphérique de sécurisation.
Sécurisation basée sur le logiciel
Dans ce type d'approches, on cherche à sécuriser
les agents de façon purement logicielle ce qui réduit le
coût de la sécurité et facilite sa maintenance.
Parmi les solutions de sécurisation on cite :
a- Obscurcissement : Cette approche qui est proposée
par Fritz Hohl [Hoh97], consiste à produire à partir d'un agent
A, un autre agent B analogue au premier dans ses fonctionnalités mais
ayant un code difficile à analyser, ce code peut être
assuré par le fait d'introduire un désordre au niveau du code de
l'agent.
Pour cela on peut dire que cette approche présente une
solution de sécurisation de l'agent par son propre code.
Hohl propose la violation totale des règles
nécessaires pour avoir un code non lisible. On peut citer par exemple
les règles suivantes :
- Ecrire un code modulaire.
- Attribuer des noms significatifs aux variables.
- Utiliser des structures de contrôle qui simplifient le
programme.
Ces règles seront respectées au niveau de
l'agent source A et pour passer à l'agent sécurisé B, tout
d'abord on crée à partir des variables originelles de nouvelles
variables ayant des noms non significatifs et un nombre différent. Comme
indiqué dans la figure2.2, chaque nouvelle variable est composée
de fragments de quelques variables originelles.
Variables originelles
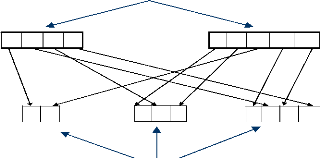
Nouvelles variables ayant des noms non significatifs
Figure 2.2 Génération de variables à noms
non significatifs.
Après l'étape de génération des
variables, on procède à la déstructuration du code. Pour
cela on élimine les variables locales et on les remplace par des
variables globales, on remplace l'appel procédural par le corps des
procédures et on utilise la structure de contrôle "GOTO" pour
remplacer les autres structures [Hoh97]. Enfin, on pourra insérer des
fragments de code mort pour améliorer la protection. Seulement il faut
se méfier des mécanismes de détection de codes morts. Ces
mécanismes assurent la protection de la confidentialité des
agents. Pour assurer l'intégrité de ces derniers, Hohl propose
l'utilisation de la signature électronique de l'agent en totalité
et en association avec sa date de validité après laquelle l'agent
ne sera plus accepté par aucun site et ses actions ne seront plus
valides [Hoh97].
Comme il s'agit d'une sécurisation basée sur le
logiciel, ceci nous a permis de réduire le coût
élevé des solutions matérielles d'où on a pu
retrouver une approche efficace pour sécuriser les agents, mais aussi on
peut lui reprocher le manque de fondement théorique. De plus, la
sécurité de l'agent est temporaire et n'est valide que pour les
agents qui transportent des données à courte durée de
validité. Autrement, l'agent sera enregistré et analysé
lentement afin de déduire les données qu'il transporte.
b- Calcul par fonction cryptographique: Cette idée est
développée par Sander et Tschudin [ST 98], l'objectif de cette
approche est analogue à celui de l'approche d'Obscurcissement. Mais, le
principe est plus développé et dispose d'un fondement
mathématique robuste et la sécurité n'est pas liée
à une durée de vie. Sander et Tschudin proposent l'idée
comme suit :
Soit une fonction f matérialisée par un agent
A, cette fonction sera cryptée en E(f) qui cache les
fonctionnalités et les détails de f. Un programme P(E(f)) sera
écrit pour implémenter E(f), ce qui produit un nouvel agent B.
L'agent B migre sur un site distant où il sera exécuté sur
une donnée x et retourne à son site d'origine qui exécute
l'algorithme de décryptage E1 (P(E(f)))(x)=f(x). Au niveau du site
distant, on exécute P(E(f))(x) qui cache les détails ce qui
assure la sécurité de l'agent. Cette approche définit un
homomorphisme entre l'espace des données claire et celui des
données cryptées tout en se basant sur la fonction PLUS et la
fonction MIXED-MULT. Ces deux fonctions sont valides uniquement sur les
polynômes, ce qui représente la défaillance de l'approche
de Sander sur les données ordinaires. En plus, le travail de l'agent se
limite au calcul d'un résultat sur un site distant puis l'agent retourne
vers son site d'origine, ce qui ne permet ni la négociation sur site ni
la possibilité de signature ou de prise de décision.
c- Traces cryptographiques: Cette approche permet de
vérifier l'intégrité d'exécution des agents
après leur retour; chaque site visité par l'agent
génère une trace d'exécution de l'agent. Cette trace
contient toutes les lignes de code exécutées et toutes les
valeurs externes lues par l'agent. Avant la migration de l'agent vers une
nouvelle destination, en utilisant une fonction de hachage permettant de
caractériser une donnée en faisant subir une suite de traitements
reproductibles à une donnée fournie en entrée et
génère une empreinte servant à identifier la donnée
initiale, le site calcule une représentation condensée de la
trace, la signe et l'accompagne à l'agent mobile lors de sa transmission
vers le site suivant. Afin de réduire la taille de la trace, l'auteur
divise le code de l'agent en segments blancs et segments noirs. Les segments
noirs sont ceux qui résultent des interactions avec la plate-forme
visitée. Et au lieu de la trace d'exécution du code entier, on
génère uniquement la trace d'exécution des segments
noirs.
Après retour de l'agent, son propriétaire aura
une trace de l'exécution de l'agent sur le dernier site et l'adresse du
premier site visité (vers lequel il a envoyé l'agent). Puis si le
propriétaire a un doute envers un site donné, il pourra suivre le
chemin de l'agent et avoir la trace d'exécution sur ce site. Le
propriétaire de l'agent pourra simuler son exécution sur le site
duquel il doute et comparer la simulation avec la trace reçue.
Cette approche permet d'assurer la non répudiation et
la détection de toute manipulation de l'exécution de l'agent
après son retour. Toutefois l'approche reste détective et
n'évite en aucun cas l'utilisation frauduleuse de l'agent.
De plus il faut avoir un doute envers un site particulier pour
lancer le mécanisme de trace, sinon l'utilisation systématique de
ce mécanisme devient assez coûteuse.
d- Agents coopérants : Cette approche de
sécurisation a été proposée par Roth, Schneider et
al. [Sch & al 97].
La protection est assurée en faisant partager
l'information par plusieurs agents analogues dits clones. La tâche
demandée par l'utilisateur est réalisée par plusieurs
agents qui coopèrent plutôt que par un seul agent. L'objectif
principal est que l'information partagée reste protégée
même si plusieurs sites d'exécution collaborent. Dans un exemple
explicatif, Roth [Rot 99] définit deux sous-groupes indépendants
de sites que l'agent visitera, ensuite, deux agents seront créés
et envoyés chacun à l'un de ces sous groupes. Si un agent
retrouve une information pertinente il l'envoie vers son clone qui la
vérifie. Pour avoir plus d'efficacité, l'un des deux agents
s'exécute obligatoirement sur un site de confiance.
L'inconvénient majeur de cette approche, est l'abus
d'utilisation des ressources réseau pour assurer la communication entre
clones. De plus l'approche se base sur l'hypothèse de non- collaboration
entre les différents sites marchands ce qui n'est pas évident.
Enfin, l'approche protège uniquement les données
transportées et non l'agent en totalité.
e- Appréciation d'état : Cette approche permet
de remédier à l'inconvénient majeur de l'approche des
agents coopérants et elle est développée par Farmer et al.
[FGS96a] qui définissent un mécanisme qui permet à un
agent d'évaluer les privilèges dont il dispose sur un site
particulier. Ce qui permet au propriétaire de l'agent de limiter les
actions que l'agent peut effectuer. L'approche repose sur une fonction
protégée qui permet l'évaluation de l'état de
l'agent sur chaque site visité. La fonction sera exécutée
une fois l'agent arrive sur un site donné et permettra de
vérifier la stabilité de son état. L'existence de telle
fonction protège l'agent en détectant les manipulations de son
état. La fonction repose sur un calcul complexe à partir d'un
ensemble de variables d'état.
Une amélioration a été proposée
par Jansen [JanO1] qui consiste à séparer la structure de
données définissant le comportement de l'agent de son propre
code. Cette structure sera définie dans un certificat conforme à
la norme X509 [ISO9594-8]. Dans le certificat, on définit les droits et
les responsabilités d'un agent sur un site donné. On distingue
les certificats d'attributs dans lesquels on définit le comportement de
l'agent et les certificats de politique servant à définir le
comportement du site envers tous les agents qu'il accueille. L'approche
protège l'agent contre une utilisation illicite en fournissant une
preuve des intentions réelles de son propriétaire mais n'offre
aucune protection des données que l'agent transporte.
Une autre approche proposée par Magdy Sayeb [MagO2]
consiste à utiliser un arbre de
diagnostic permettant la détection d'une attaque possible.
Dans cette approche les auteurs associent un symptôme à chaque
attaque et la combinaison de ces symptômes définit un arbre. Parmi
ces symptômes nous citerons :
- La longue durée d'exécution qui informe sur une
analyse du code ou des données au
cours de l'exécution,
- L'enregistrement temporaire de l'agent informe sur une analyse
possible tandis qu'un
comportement anormal de l'agent informe sur la manipulation du
code de l'agent.
L'approche se limite aux attaques dont l'origine ne prend pas
en compte un éventuel mécanisme de détection, sinon il
cherchera à masquer les symptômes et simuler un comportement
normal.
f- Fonction de validation: Les approches à base de
fonctions de validation ont été proposées par Blum [Blu88]
afin de vérifier la fiabilité d'un code. Ces dernières
peuvent être appliquées dans le but de vérifier
l'intégrité d'exécution d'un agent mobile sur un site
distant. L'approche se base sur la propriété de
réductibilité de la fonction qu'implémente l'agent. Une
approche plus récente proposée par Laurero [Lau 01]
définit une fonction de vérification V comme suit :
Soient un programme P qui implémente une fonction f, Y
l'ensemble des résultats possibles de f(xi ), avec xi appartient
à {0,1}n et D(y') le résultat reçu après
exécution à distance. La fonction V satisfait la condition
suivante si (y=D(y')) n'appartient pas à Y alors P(V(y')= accept) < ,
où P représente la probabilité et la probabilité
d'erreur.
Pour conclure, toutes les approches précédemment
vues, qu'elles soient basées sur le matériel ou sur le logiciel,
possèdent des avantages pour la sécurité des agents
mobiles mais aussi elles pressentent certaines limites, comme par exemple : le
coût élevé des solutions matérielles (carte à
puces.) d'une part et la complexité des solutions logicielles et leurs
limites dans des domaines d'applications précis d'une autre part.
| 

