|
UNIVERSITE MOHAMMED V AGDAL
ECOLE MOHAMMADIA D'INGENIEURS

CONTRIBUTION A LA DISCRIMINATION DES
SIGNAUX SISMIQUES
MOHAMMED BENBRAHIM
DEPARTEMENT DE GENIE ELECTRIQUE
THESE PRESENTEE EN VUE DE L'OBTENTION
DU DIPLÔME DE
DOCTORAT EN SCIENCES APPLIQUEES
(AUTOMATIQUE ET INFORMATIQUE
INDUSTRIELLE)
2007
UNIVERSITE MOHAMMED V AGDAL
ECOLE MOHAMMADIA
D'INGENIEURS

Cette thèse intitulée:
CONTRIBUTION A LA DISCRIMINATION DES
SIGNAUX SISMIQUES
présentée par: BENBRAHIM Mohammed
en vue de l'obtention du diplôme de: Doctorat en Sciences
Appliquées Soutenue le 08 Juin 2007 devant le jury composé de:
Prof. TOUZANI Abderrahmane, EMI, Président
Prof. BENJELLOUN Khalid, EMI, Directeur de thèse
Prof. IBENBRAHIM Aomar, ING, Co-encadrant de thèse
et Rapporteur Prof. SBITI Nawal, EMI, Rapporteur
Prof. TOTO El Arbi, FSK, Rapporteur
Dr. BOUZOUBAA Taoufik, TreeDAlgo, Examinateur
Prof. TAALABI Mohamed, EMI, InvitéProf.
KASMI Mohamed, ING, Invité
v
REMERCIEMENTS
Ce travail a été réalisé dans le
cadre du projet PROTARS DIII-48 mettant en collaboration le Laboratoire
d'Automatique et d'Informatique Industrielle (LAII) de l'Ecole Mohammadia
d'Ingénieurs (EMI) et l'Institut National de Géophysique (ING) du
Centre National pour la Recherche Scientifique et Technique (CNRST).
Je tiens à remercier spécialement mon directeur
de thèse, le professeur Khalid BENJELLOUN, pour m'avoir guidé au
cours de mon cursus à l'EMI. Je lui suis très reconnaissant pour
sa patience et je le remercie pour son support académique tout au long
de ce travail. J'ai beaucoup apprécié les années que j 'ai
passées sous sa supervision et je lui souhaite tout le succès
dans ce qu'il entreprend.
Je tiens à remercier également, le professeur
Aomar IBENBRAHIM responsable de l'ING et mon co-encadrant de thèse pour
m'avoir accueilli dans son équipe de recherche où j'ai acquis mes
connaissances dans de le domaine de la sismologie. Je voudrais aussi remercier
les membres de son équipe de recherche, les professeurs Mohamed Kasmi et
Abdelouahed BIROUK responsables du Réseau National de Surveillance et
d'Alerte Sismique Marocain (RESAS) et le professeur Azelarab EL MOURAOUAH
responsable du Service de Prévention Sismique et Coopération.
Je voudrais aussi remercier les honorables membres du jury, le
professeur Abderrahmane TOUZANI directeur du Centre Régional Africain de
Sciences et de Technologie de l'Espace en Langue Française (CRASTE-LF )
à l'EMI, les professeurs Nawal SBITI et Mohamed TAALABI du
département de génie électrique section automatique
à l'EMI, le professeur El Arbi TOTO de la faculté des sciences de
Kénitra (FSK) et Monsieur Taoufik BOUZOUBAA directeur scientifique et
technique de la société TreeDAlgo spécialisée dans
les systèmes d'aide à la décision.
Mes remerciements vont également envers le corps
enseignant du département de génie électrique (plus
particulièrement la section automatique) de l'Ecole Mohammadia
d'Ingénieurs qui, par leur valeur scientifique et leur qualité
pédagogique, ont largement contribué à ma formation
académique.
Enfin, je voudrais exprimer toute ma reconnaissance à mes
proches et à mes amis qui m'ont toujours soutenu et encouragé
pendant ce long travail.
vi
RESUME
Chaque année, les réseaux de surveillance et
d'alertes sismiques enregistrent des milliers d'événements
sismiques. Or, l'examen manuel de ces enregistrements numériques pour la
discrimination entre événements naturels,
événements artificiels et bruits est une tâche difficile
qui demande des coûts et des efforts considérables.
Plusieurs études ont déjà
été menées pour concevoir des méthodes
paramétriques de discrimination sismique. Or, ces méthodes ne
sont, généralement, ni transportables ni robustes. Pour
résoudre ces problèmes, les recherches ont tourné vers le
développement de
méthodes non paramétriques. Cependant, la
majorité de ces méthodes proposées,
jusqu'àprésent, ne traitent que des cas particuliers
tout en faisant des traitements manuels aux
signaux avant de les utiliser. Ce qui limite leur utilité
dans la pratique.
L'objectif de cette thèse est de concevoir un
système modulaire non paramétrique
transportable de discrimination automatique des signaux
sismiques en faisant appel àcertaines techniques du
traitement des signaux et de l'intelligence artificielle. Ce système
modulaire est composé de quatre parties: acquisition,
représentation, réduction de la dimensionnalité et
classification.
Une étude des représentations temporelle,
fréquentielle, temps-fréquence et temps- échelle, pour le
cas des signaux non stationnaires en général et le cas des
signaux sismiques en particulier, a permis de mettre en évidence les
limites de leurs résolutions temporelles et fréquentielles
formulées sous formes de nouvelles inégalités
d'Heisenberg-Gabor. D'autre part, une nouvelle ondelette complexe dite
ondelette de Ben est présentée en démontrant son
admissibilité.
La réduction de la dimensionnalité des images
sismiques issues des représentations bidimensionnelles constitue une
partie principale de notre système de discrimination automatique des
signaux sismiques. En effet, la durée de tels signaux est variable en
dépendance avec l'événement d'origine et sa
proximité des sismomètres. Dans ce cadre, une approche
basée sur la combinaison de la projection aléatoire et l'analyse
en composantes principales est proposée.
Pour la classification, une étude de l'influence des
différents paramètres d'un classificateur de type perceptron
multicouches est réalisée. Ce qui a permis de conclure qu'une
combinaison de plusieurs classificateurs est le seul moyen d'améliorer
les performances. Ainsi, trois approches de discrimination sont
proposées: discrimination locale, régionale et globale. D'autre
part, afin de faire un rejet des signaux bruits, un système de
reconnaissance utilisant les réseaux de neurones auto-associatifs est
présenté.
La mise en oeuvre du système de discrimination
automatique proposé est assurée par le logiciel Marocain
d'analyse des signaux sismiques (MSSSA: Moroccan Software for Seismic Signals
Analysis) qui est conçu et réalisé dans le cadre de cette
thèse tout en utilisant les signaux acquis par le réseau
sismologique Marocain.
Les tests expérimentaux ont permis de montrer les
performances du systèmes proposés. Ainsi, nous avons pu atteindre
via une modèle de la discrimination sismique locale et pour une moyenne
de 100 tests un taux d'erreur de classification de 0.05 % pour le cas d'une
discrimination à deux classes et 0.033 % pour le cas d'une
discrimination à trois classes.
ix
ABSTRACT
The automatic discrimination of seismic signals is an
important goal for earth-science observatories due to the large amount of
information that they receive continuously. An essential discrimination task is
to allocate the incoming signal to a group associated with the kind of physical
phenomena producing it.
In ordre to resolve this task, several researches were
dedicated to design parametric methods which are neither transportable, nor
robust. For this reasons, the development of non parametric methods became an
important issue of research. Nevertheless, the majority of the proposed methods
treat only particular cases and do some manual processing to the signals before
to be used. For this reasons, these methods aren't adequate in practice.
The objective of this thesis is to design a transportable
nonparametric modular system for the automatic discrimination of seismic
signals by means of signals processing techniques and artificial intelligence.
The modular system is composed of four parts: acquisition, representation,
dimensionality reduction and classification.
The study of temporal, frequential, time-frequency and
time-scale representations, for the general case of the nonstationary signals
and the particulary case of the seismic signals, allowed to highlight the
limits of their temporal and frequential resolutions formulated in the forms of
new Heisenberg-Gabor inequalities. In addition, a new complex wavelet known as
Ben wavelet is presented and its admissibility is demonstrated.
The dimensionality reduction of the seismic images resulting
from the bidimensional representations constitutes a principal part of our
system of automatic discrimination of seismic signals. Indeed, the duration of
such signals is variable in dependence with both the event and its proximity of
the seismometers. Within this framework, an approach based on the combination
of random projection and the principal components analysis is proposed.
For the classification, an investigation of the influence of
various parameters of multilayer perceptron classifier was carried out.
Consequent to this, only a combination of several classifiers would enable the
improvement of the classification performances. Thus, three approaches of
discrimination are proposed: local, regional and global discrimination.
Furthermore, for the noise rejection, a system of recognition using the
autoassociative neural networks is presented.
The implementation of the suggested system is ensured by the
Moroccan Software for Seismic Signals Analysis (MSSSA). This system was
designed and realized within the framework of this thesis while using the
signals acquired by the Moroccan seismological network.

xi
TABLE DES MATIERES
REMERCIEMENTS.................................v
RESUME......................................vii
ABSTRACT.....................................ix
TABLE DES MATIERES..............................xi
LISTE DES FIGURES................................xvii LISTE DES
TABLEAUX..............................xxi LISTE DES
ALGORITHMES............................xxiii LISTE DES
ANNEXES...............................xxv LISTE DES
NOTATIONS..............................xxvii LISTE DES
ABREVIATIONS............................xxix CHAPITRE 1
INTRODUCTION........................1
1.1 Evénements sismiques et réseaux sismologiques
1
1.1.1 Evénements sismiques 1
1.1.2 Réseaux sismologiques 3
1.2 Analyse des données sismologiques 5
1.2.1 Détection 5
1.2.2 Timinig et Dépouillement 5
1.2.3 Localisation 6
1.2.4 Quantification 6
1.2.5 Identification 6
1.3 Revue bibliographique 7
1.4 Réseau sismologique Marocain 11
1.5 Contribution de la thèse 11
xii
CHAPITRE 2 REPRESENTATION DES SIGNAUX NON-STATIONNAIRES. 15
2.1 Représentations temporelle et fréquentielle
16
2.1.1 Représentation temporelle 16
2.1.2 Représentation fréquentielle 16
2.2 Signal analytique 21
2.3 Représentations temps-fréquence 23
2.3.1 Transformée de Fourier à court terme 24
2.3.2 Spectrogramme 30
2.3.3 Représentation de Wigner-Ville 37
2.3.4 Représentations à interférences
réduites 42
2.4 Représentations temps-échelle 45
2.4.1 Transformée en ondelettes continues 46
2.4.2 L'ondelette de Ben 49
2.4.3 Scalogramme 56
2.5 Conclusion 58
CHAPITRE 3 REDUCTION DE LA DIMENSIONNALITE 59
3.1 Espaces de grandes dimensions 60
3.1.1 La malédiction de la dimensionnalité 60
3.1.2 Normes des vecteurs aléatoires 61
3.2 Techniques de réduction de la dimensionnalité
63
3.2.1 L'analyse en composantes principales 63
3.2.1.1 PCA unidimensionnelle 64
3.2.1.2 PCA bidimensionnelle 66
3.2.2 La projection aléatoire 68
3.3 Algorithmes pour les images sismiques 71
3.3.1 Algorithme 1 71
3.3.2 Algorithme 2 73
3.3.3 Algorithme 3 74
3.4 Conclusion 75
|
CHAPITRE 4
|
METHODES DE CLASSIFICATION
|
xiii
77
|
|
4.1
|
Notion de classificateur
|
78
|
|
4.2
|
Les classificateurs paramétriques
|
81
|
|
4.2.1
|
Les classificateurs linéaires
|
81
|
|
4.2.2
|
Les classificateurs quadratiques
|
82
|
|
4.2.3
|
Le classificateur Gaussien
|
82
|
|
4.3
|
Les classificateurs non paramétriques
|
83
|
|
4.3.1
|
L'estimation des probabilités à posteriori
|
83
|
|
4.3.2
|
La méthode du plus proche voisin
|
84
|
|
4.3.3
|
La méthode des K plus proches voisins
|
86
|
|
4.4
|
Les classificateurs neuronaux
|
87
|
|
4.4.1
|
Introduction
|
87
|
|
4.4.2
|
Du neurone biologique au neurone artificiel
|
87
|
|
4.4.3
|
Le perceptron
|
90
|
|
4.4.4
|
Le perceptron Multicouches
|
91
|
|
4.4.5
|
Apprentissage du perceptron Multicouches
|
93
|
|
|
4.4.5.1 La rétro-propagation du gradient
|
93
|
|
|
4.4.5.2 Les algorithmes dérivés d'apprentissage
|
95
|
|
|
4.4.5.3 Les modes d'apprentissage
|
99
|
|
4.4.6
|
Généralisation
|
100
|
|
4.5
|
Combinaison de classificateurs
|
103
|
|
4.5.1
|
Stratégies de combinaison
|
104
|
|
4.5.2
|
Combinaison non paramétrique
|
106
|
|
|
4.5.2.1 Type classe
|
107
|
|
|
4.5.2.2 Type rang
|
108
|
|
|
4.5.2.3 Type mesure
|
109
|
|
4.5.3
|
Combinaison paramétrique
|
110
|
|
|
4.5.3.1 Type classe
|
110
|
|
|
4.5.3.2 Type rang
|
112
|
|
|
4.5.3.3 Type mesure
|
112
|
|
4.5.4
|
Comparaison des méthodes de combinaison
|
112
|
4.5.5 Création des systèmes de classification
113
4.6 Conclusion 114
CHAPITRE 5 DISCRIMINATION DES SIGNAUX SISMIQUES 115
5.1 Discrimination sismique locale 115
5.1.1 Méthode proposée 116
5.1.2 Application au réseau sismique Marocain 119
5.1.2.1 Choix de la base de données 119
5.1.2.2 Choix des paramètres de classification 120
5.1.2.3 Application de la méthode proposée 132
5.2 Discrimination sismique régionale 137
5.2.1 Méthode proposée 137
5.2.1.1 Discrimination sismique régionale statique
137
5.2.1.2 Discrimination sismique régionale dynamique
141
5.3 Discrimination sismique globale 141
5.4 Conclusion 144
CHAPITRE 6 RECONNAISSANCE DES SIGNAUX SISMIQUES 147
6.1 Détection de nouveauté 148
6.1.1 Introduction 148
6.1.2 Approche statistique 149
6.1.3 Approche neuronale 150
6.1.4 Quelle approche pour le cas sismique? 151
6.2 Réseau auto-associatif 152
6.3 Reconnaissance des signaux sismiques 153
6.3.1 Méthode proposée 153
6.3.2 Tests expérimentaux 156
6.3.2.1 Test expérimental 1 156
6.3.2.2 Test expérimental 2 159
6.4 Conclusion 160
ANNEXES 195
LISTE DES FIGURES
Figure 1.1 Schéma d'un réseau sismique physique
4
Figure 1.2 Schéma d'un réseau sismique virtuel
4
Figure 1.3 Réseau Marocain de surveillance et d'alerte
sismique (RESAS) . . 12
Figure 1.4 Schéma du système modulaire
proposé 14
Figure 2.1 Représentation temporelle d'une explosion
chimique (a), d'un séisme
local (b) et d'un séisme lointain (c) 17
Figure 2.2 Représentation temporelle d'un séisme
local avec une partie tron-
quée (a) et avec un fort bruit de fond (b) 17
Figure 2.3 Représentation temporelle des signaux S1 (a) et
S2 (b) 19
Figure 2.4 Représentation fréquentielle des signaux
S1 (a) et S2 (b) 19
Figure 2.5 Représentation temporelle d'une explosion
chimique (a) et sa représen-
tation fréquentielle (b) 20
Figure 2.6 Représentation fréquentielle d'une
explosion chimique (a), d'un séisme
local (b) et d'un séisme lointain (c) 21
Figure 2.7 Fréquence instantanée (a) et Retard du
groupe (b) du signal sis-
mique représenté par la figure (2.1.a)
23
Figure 2.8 Le module de la STFT pour deux signaux
différents S1 (a) et S2 (b)
mais ayant le même contenu fréquentiel 27
Figure 2.9 Le module de la STFT pour un séisme local avec
un fort bruit de
fond (a) et avec une partie tronquée (b) 28
Figure 2.10 Le module de la STFT pour une explosion chimique (a),
un séisme
local (b) et un séisme lointain (c) 29
Figure 2.11 Le SPEC d'un signal à 2 composantes non
superposables 34
Figure 2.12 Le SPEC d'un signal à 2 composantes
superposables et non proches 34
Figure 2.13 Le SPEC d'un signal à 2 composantes
superposables et proches . . 35
Figure 2.14 Le SPEC d'une explosion chimique (a), d'un
séisme local (b) et d'un
séisme lointain (c) 36
Figure 2.15 Le WV d'un signal à 2 composantes non
superposables 40
Figure 2.16 Le module de la WV d'une explosion chimique (a), d'un
séisme local
(b) et d'un séisme lointain (c) 41
Figure 2.17 Les représentations de WV du signal (a) et du
signal analytique
correspondant (b) 42
Figure 2.18 La SPWV d'une explosion chimique (a), d'un
séisme local (b) et
d'un séisme lointain (c) 44
Figure 2.20 Le module de la CWT d'un signal à 2
composantes non superposables 53
Figure 2.19 La partie réelle et imaginaire de l'ondelette
chapeau Mexicain (a),
l'ondelette de Morlet avec ù0 = 5 (b) et l'ondelette de
Ben avec ù0=7(c) 54
Figure 2.21 Le module de la CWT pour une explosion chimique (a),
un séisme
local (b) et un séisme lointain (c) 55
Figure 2.22 Les scalogrammes relatifs à une explosion
chimique (a), un séisme
local (b) et un séisme lointain (c) 57
Figure 4.1 Schéma d'une classification à deux
classes 79
Figure 4.2 Schéma d'un neurone biologique [138] 88
Figure 4.3 Schéma d'un neurone artficiel 89
Figure 4.4 Schéma d'un perceptron à C neurones
91
Figure 4.5 Schéma d'un réseau MLP à une
couche cachée 92
Figure 4.6 Schéma de la partition de la base
d'apprentissage au cours du pro-
cessus de la validation croisée 101
Figure 4.7 Combinaison séquentielle de classificateurs
105
Figure 4.8 Combinaison parallèle de classificateurs
105
Figure 4.9 Combinaison hybride de classificateurs 106
Figure 5.1 Schéma global de la discrimination sismique
locale 116
Figure 5.2 Schéma de la discrimination sismique locale
multi-(représentationnelle,
stratégies, experts) 118
Figure 5.3 Signaux sismiques d'une qualité bonne (a),
moyenne (b) et mauvaise
(c) 119
Figure 5.4 Influence de la base d'apprentissage 121
Figure 5.5 Influence de la représentation et de la
réduction de la dimensionnalité 123
Figure 5.6 Evolution de l'erreur pour l'algorithme Rprop (a) et
SCG (b) . . . 129
Figure 5.7 Evolution de l'erreur en fonction de la valeur
objective pour le SPEC
pour la base de test 1 (a) et la base de test 2 (b) 129
Figure 5.8 Evolution de l'erreur en fonction de la valeur
objective pour le SCAL
de Ben pour la base de test 1 (a) et la base de test 2 (b)
129
Figure 5.9 Erreur de classification en fonction du nombre
d'éléments de la couche cachée et du nombre de composantes
pour la dimension 2 de l'algorithme (3.2) 132
Figure 5.10 Influence de la méthode combinaison pour une
discrimination à deux
classes pour la base de test 1 (a) et la base de test 2 (b)
134
Figure 5.11 Influence de la méthode combinaison pour une
discrimination à trois
classes pour la base de test 1 (a) et la base de test 2 (b)
136
Figure 5.12 Schéma de la discrimination sismique
régionale 138
Figure 5.13 Schéma de la discrimination sismique globale
143
Figure 6.1 Les deux approches du concept d'apprentissage:
Discrimination (a)
versus Reconnaissance (b) 149
Figure 6.2 Signaux relatifs à un Bruit (a) et un
événement sismique(b) . . . 151
Figure 6.3 Schéma d'un réseau de neurones
auto-associatif 152
Figure 6.4 Schéma de l'objectif de la reconnaissance des
signaux sismiques . 154
Figure 6.5 Le SPEC d'un signal bruit (a) et d'un signal sismique
(b) 154
Figure 6.6 Schéma du système de reconnaissance des
signaux sismiques . . . 155
Figure 6.7 L'erreur de reconstruction de trois réseaux
AANN entraînés par des signaux relatifs à des explosion
chimique (a), des séismes locaux (b) et des séismes lointains (c)
158
Figure 6.8 L'erreur de reconstruction d'un réseau AANN
entraîné par des signaux relatifs à des explosions
chimiques, des séismes locaux et des séismes lointains 160
Figure I.1 Interface d'entrée (a) et interface principale
(b) de MSSSA-Daq . 196
Figure I.2 Interface d'entrée (a) et interface principale
(b) de MSSSA-Reader
pour le format daq 196
Figure I.3 Interface d'entrée (a) et interface principale
(b) de MSSSA-Reader
pour le format Kinemetrics 196
Figure I.4 Interface d'entrée (a) et interface principale
(b) de MSSSA-Conveter 197
Figure I.5 Interface d'entrée (a) et interface principale
(b) de MSSSA-Recognition 197
Figure I.6 Interface d'entrée (a) et interface principale
(b) de MSSSA-Discrimination 197
LISTE DES TABLEAUX
Tableau 5.1 Influence de la base d'apprentissage 120
Tableau 5.2 Influence de la représentation et de la
réduction de la dimensionnalité123
Tableau 5.3 Influence des fonctions d'activation(Eléments
en gras correspond àla base de test 1 et les autres à
la base de test 2) 126
Tableau 5.4 Influence du choix de l'algorithme d'apprentissage en
mode hors
ligne 127
Tableau 5.5 Influence du choix de l'algorithme d'apprentissage en
mode en ligne 128
Tableau 5.6 Pourcentage de l'énergie
représentée pour l'algorithme (3.2) selon
la dimension 2 avec 6 composantes 130
Tableau 5.7 Influence du nombre de composantes principales de la
dimension 2
(B 1 et B2 désignent respectivement la base de test 1 et 2
131
Tableau 5.8 Influence de la méthode combinaison pour une
discrimination à deux
classes 134
Tableau 5.9 Influence de la méthode combinaison pour une
discrimination à trois
classes 136
Tableau 5.10 Exemple de la discrimination sismique
régionale statique 140
Tableau 5.11 Exemple de la discrimination sismique globale
145
|
3.1
|
xxiii
LISTE DES ALGORITHMES
Réduction de la dimensionnalité des images
sismiques via la RP et la PCA1D 72
|
|
3.2
|
Réduction de la dimensionnalité des images
sismiques via la RP et la
|
|
|
PCA2D2D
|
73
|
|
3.3
|
Réduction de la dimensionnalité via la RP et la
PCA1D appliquées à des
|
|
|
subdivisions des images sismiques
|
74
|
|
4.1
|
Rétro-propagation du gradient
|
95
|
|
5.1
|
Discrimination sismique locale
|
117
|
|
5.2
|
Discrimination sismique régionale statique
|
138
|
|
5.3
|
Discrimination sismique régionale dynamique
|
141
|
|
5.4
|
Discrimination sismique globale
|
142
|
|
6.1
|
Reconnaissance des signaux sismiques via les réseaux AANN
|
156
|
LISTE DES ANNEXES
ANNEXE I LE LOGICIEL MSSSA 195
ANNEXE II L'ALGORITHME DE RETRO-PROPAGATION 198
LISTE DES NOTATIONS
Symboles Descriptions
x(t) signal
L2 ensemble des fonctions de carré sommable
L1 ensemble des fonctions absolument intégrables
ii fréquence
w fréquence angulaire (ou pulsation)
t temps
FT x transformée de Fourier de x
IFT y transformée de Fourier inverse de y
xa(t) signal analytique de x
| x | module de x
H transformée d'Hilbert
iii fréquence instantanée
ôg retard du groupe
STFTX transformée de Fourier à court
terme de x
(*)
(')
signe du conjugué
signe du transposéSPECX
spectrogramme de x
WV x représentation de Wigner-Ville de x
CWT x CWT de x par l'ondelette ø
SCAL x SCAL de x par l'ondelette ø
ø ondelette mère
a échelle
C facteur d'admissibilitéømh ondelette chapeau
mexicain
ømc ondelette de morlet complète
øms ondelette de morlet standard
øben ondelette de Ben
øbenc ondelette de Ben complète
Xpca1d la PCA unidimensionnelle de X
Xpca2d la PCA bidimensionnelle de X
Xpca2d2d la PCA bidimensionnelle et bidirectionnelle de X
Xrp laRPdeX
u = E moyenne
ó2 = Var variance
P probabilité x norme euclidienne de x
tr trace d'une matrice
À valeur propre
LISTE DES ABREVIATIONS
Abréviations Descriptions
AANN Réseau de Neurones Auto-Associatif
BFGS Broyden-Fletcher-Goldfarb-Shanno Quasi-Newton
CGB Gradient Conjugué de Polak-Ribiére
CGF Gradient Conjugué de Fletcher-Powell
CGP Gradient Conjugué de Powell-Beale
CNRST Centre National pour la Recherche Scientifique et
Technique
CTBT Traité d'Interdiction Complète des Essais
Nucléaires
CUSUM Somme Cumulée
CW Représentation de Choï-Williams
CWT Transformée en Ondelette Continue
EMI Ecole Mohammadia d'Ingénieurs
FT Transformée de Fourier
GDA Descente du Gradient avec Moment et Taux d'Apprentissage
Variable
GDM Descente du Gradient avec Moment
Gau Fonction Gaussienne
IFT Transformée de Fourier Inverse
IMS Système International de Surveillance Sismique
ING Institut National de Géophysique
LAII Laboratoire d'Automatique et d'Informatique Industrielle
MDAC Magnitude and Distance Amplitude Corrections
MLP Perceptron Multicouches
MSSSA Moroccan Software for Seismic Signals Analysis
PCA Analyse en Composantes Principales
PCA1D Analyse en Composantes Principales Unidimensionnelle
PCA2D Analyse en Composantes Principales Bidimensionnelle
PCA2D2D Analyse en Composantes Principales Bidimensionnelle et
Bidirectionnelle
PCA2DCO Analyse en Composantes Principales Bidimensionnelle
Orien-
tée en Colonnes
PCA2DRO Analyse en Composantes Principales Bidimensionnelle
Orien-
tée en Lignes
RBF Réseau de Fonctions à Base Radiale
RP Projection Aléatoire
Rprop Rank Propagation
SA Recuit SimuléSCAL Scalogramme
SCAL Ben Scalogramme de l'Ondelette de Ben
SCAL Mexh Scalogramme de l'Ondelette Chapeau Mexicain
SCAL Morl Scalogramme de l'Ondelette de Morlet
SCG Gradient Conjugué RégulariséSPAC Source
and Path Corrections
SPEC Spectrogramme
SPWV Représentation de Pseudo Wigner-Ville
LisséSTFT Transformée de Fourier à Court
Terme
Sig Fonction Sigmoide
TFR Représentation Temps-Fréquence
TSR Représentation Temps-Echelle
Tanh Fonction Tangente Hyperbolique
WV Représentation de Wigner-Ville
CHAPITRE 1
INTRODUCTION
La discrimination des signaux sismiques est l'un des sujets
les plus étudiés de la sismologie. Ceci est dû à son
importance dans plusieurs domaines, particulièrement dans le
contrôle de l'applicabilité du traité d'interdiction
complète des essais nucléaires (CTBT: Comprehensive Nuclear
Test-Ban Treaty). Ce dernier, par le biais du système de surveillance
international (IMS: International Monitoring System) et des techniques de la
discrimination des signaux sismiques, vise la détection, la localisation
et l'identification des différents événements sismiques
à travers le monde.
Afin d'aboutir la tâche de la discrimination des signaux
sismiques, pour un réseau sismologique donné, deux points
cruciaux doivent être accomplis: le premier consiste
àchercher les discriminants les plus adéquats et le
deuxième point concerne l'automatisation
de la procédure de discrimination afin, d'une part,
d'analyser en temps réel les enregistrements sismiques et, d'autre part,
de réduire les efforts nécessaires à leur examen.
1.1 Evénements sismiques et réseaux
sismologiques
1.1.1 Evénements sismiques
Notre planète est constamment secouée par des
tremblements de terre. Parmi lesquels, il y a certains qui font peser de graves
menaces sur les populations vivant dans les régions affectées.
Ils peuvent semer la mort en détruisant des habitations, des
édifices publics, des ponts, des barrages ou en déclenchant de
glissements catastrophiques de terrains. Cependant, il y a des milliers ne
causant aucun dommage. Entre ces deux genres de tremblements de terre
(désastreux ou non), des questions relatives à la nature des
séismes ont préoccupé les sismologues. Ceci a permis de
tirer des principes de base qui ont servi de point de départ à
l'application des méthodes sismiques en géophysique
appliquée. Et avec le développement théorique et
technologique au niveau des ondes sismiques, la sismologie
a devenu, d'une manière vitale, une part contributive
à la compréhension de la tectonique des plaques, à
l'étude de la structure interne de la terre, à la
prévision des tremblements de terre, à l'exploration des
gisements et même un moyen de contrôle de certains traités
internationaux tel que le CTBT.
Les ondes sismiques sont des ondes élastiques pouvant
traverser un milieu sans le modifier durablement. Aujourd'hui, on distingue
trois catégories de sources des signaux sismiques en fonction de leur
origine : tectonique, volcanique et artificielle.
1. Les Sources tectoniques: constituent la source principale
des signaux sismiques. Leurs effets au niveau terrestre apparaissent sous forme
de tremblements de terre (séismes tectoniques). Ces derniers sont les
plus fréquents, les plus dangereux et posent des problèmes
complexes aux scientifiques chargés de découvrir les moyens de
les prévoir. Leur principale cause est liée à la
tectonique des plaques et aux contraintes engendrées par les mouvements
d'une douzaine de plaques majeures et mineures constituant la croûte
terrestre. La plupart de ces séismes se produisent aux limites des
plaques, dans les zones où une plaque glisse le long d'une autre. Les
séismes associés aux zones de subduction représentent
presque la moitié des séismes destructeurs de la terre et
dissipent 75 % de l'énergie sismique de la planète. En dehors de
ces zones, les séismes tectoniques se produisent dans des contextes
géologiques différents. Ainsi, Les dorsales
médio-océaniques sont le siège de nombreux séismes,
d'intensité modérée, dont le foyer est relativement
superficiel (moins de 100 km de profondeur). Ces tremblements de terre sont
rarement ressentis par l'être humain et ne représentent que 5 %
environ de l'énergie sismique de la planète. Autres points
à travers le monde connaissent certaine sismicité liée
principalement à un domaine complexe de chaînes montagneuses
jeunes et élevées.
2. Les Sources volcaniques: constituent une autre source des
tremblements de terre naturels dits séismes volcaniques. Ces derniers se
manifestent lorsque le magma s'accumule dans la chambre magmatique d'un volcan.
Tandis que le sommet du volcan se soulève et que les flancs s'inclinent,
des ruptures dans les roches comprimées sont
révélées par une multitude de micro-séismes.
L'étude de tels événement a con-
duit à la création d'une autre branche de la
sismologie dite sismologie volcanique.
3. Les Sources artificielles: sont dues aux activités
humaines telles que la constitution d'énormes réserves d'eau
derrière des barrages, le pompage de fluides profonds, les centrales
hydro-électriques, l'extraction minière ou les explosions
nucléaires souterraines. On note que de faibles séismes se
produisent de temps en temps lors de l'effondrement de galeries de mines
abandonnées.
Les explosions chimiques, d'une part, avec ses deux types
à savoir, les explosions de tirs simples (single shot explosions) et les
explosions en cascade ou avec micro-retard (ripple-fired explosions), et les
explosions nucléaires, d'autre part,
restent les plus grandes sources (en terme d'énergie) des
signaux sismiques dus àl'activité humaine. Ces
explosions sont, généralement, définies par une
libération
instantanée d'une énergie concentrée. La
réponse du terrain entourant la source entraîne la
génération des ondes sismiques propageant dans le sol en
créant trois sortes d'énergie sismique: l'énergie de
l'explosion, l'énergie d'ordre tectonique induite par l'explosion et
finalement le spall Doglas [87].
1.1.2 Réseaux sismologiques
Un réseau sismologique est un ensemble de
sismomètres pour lesquels les données sont captées dans un
récepteur central. Et selon le type de transmission de données,
unidirectionnel ou bidirectionnel, on pourra définir deux types de
réseaux:
1. Les réseaux sismiques physiques: consistent à
transmettre en temps réel les données, relatives à un
événement sismique, vers une station centrale pour
l'enregistrement et l'analyse (figure (1.1)). La transmission de données
pourra se faire à travers le réseau téléphonique,
les liaisons radios ou un réseau informatique spécifique. Les
dernières conceptions de ce type de réseaux font la transmission
de données via l'internet et peuvent travailler dans le cadre d'une
architecture client/serveur.
Connection Station centrale
Sismomètrepermanente
Sismomètre
Sismomètre
Sismomètre
Sismomètre
Figure 1.1: Schéma d'un réseau sismique
physique
Station sismique considérée comme station
centrale
Station sismique
Station sismique
Station sismique
Station sismique
Réseau de communication
Figure 1.2: Schéma d'un réseau sismique
virtuel
une station donnée (figure (1.2)). Ainsi, pour
n'importe quelle station du réseau, on pourra collecter, enregistrer et
analyser les données parvenues des autres stations sismiques du
réseau. Ceci permet de surpasser les différences existantes entre
le réseau local, régional et global.
On note qu'une station d'un réseau sismique virtuel
pourra être considérée comme une station centrale de
traitement et dans ce cas, on trouve le cas du réseau sismique
physique.
Malgré les différences citées ci-dessus,
la localisation avec une certaine précision des événements
sismiques, l'alerte sismique et le contrôle de la sismicité
restent les principales finalités recherchées pour n'importe quel
type de réseaux sismiques.
1.2 Analyse des données sismologiques
Analyser physiquement les phénomènes sismiques
est une tâche très complexe. Pour vaincre cette complexité,
on fait appel à l'analyse statistique. Ainsi, on représente la
trace de chaque phénomène sismique par des signaux temporels. Ces
derniers sont la combinaison des effets liés à la source, aux
milieux traversés et aux instruments de mesure. Or, la complexité
du mécanisme de la source,
l'hétérogénéité de la structure terrestre et
les bruits engendrés aux divers niveaux demandent plusieurs tâches
pour analyser ces signaux.
1.2.1 Détection
La détection se fait automatiquement pour chaque
station quand le sismomètre ressent une vibration. Ainsi, quand
l'amplitude du signal dépasse l'amplitude moyenne, le sismomètre
détecte cet accroissement significatif de l'énergie du signal. Et
dans ce cas, le sismomètre est dit déclenché et le
système de détection fait un examen de coincidence afin de
s'assurer que le déclenchement n'est pas un phénomène
local causé par des interférences électriques ou par un
appareil proche du sismomètre. Ainsi, le système recueillit les
informations des autres sismomètres, et seulement s'il y a une
coincidence des déclenchements que l'evénement est
déclaré. Par la suite le système d'acquisition passe aux
autres traitements (archivage, reconnaissance, localisation, etc).
1.2.2 Timinig et Dépouillement
Afin d'analyser l'événement
détecté, il est nécessairement, d'abord, de
déterminer son temps d'arrivée. Ce dernier dénote le temps
d'arrivé de l'onde P (P-onset). Ensuite, pour distinguer les
différentes phases et déterminer leurs temps d'arrivée, on
procède au dépouillement des phases (phase-picking) qui pourra se
faire d'une façon numérique ou manuelle.
1.2.3 Localisation
La localisation est la première étape dans
l'analyse détaillée d'un événement sismique. Il
consiste à déterminer l'hypocentre le plus probable via une
ellipse dans laquelle se trouve le vrai emplacement avec un certain
degré de confiance. Ceci est généralement calculé
par des algorithmes d'optimization non-linéaires qui calculent
itérativement le temps de parcours des différentes phases de
l'événement. Et à partir d'une solution initiale,
l'algorithme estime inversement les coordonnées de l'hypocentre, en
utilisant les temps d'arrivée des différentes phases et en
supposant un modèle de vitesses de ces phases.
Nous notons que le degré de précision de la
localisation d'un événement est influencé par plusieurs
facteurs, citons: la qualité du réseau sismique, la
synchronisation et l'étalonnage.
1.2.4 Quantification
La quantification d'un événement sismique consiste
à déterminer sa magnitude. Cette dernière est une mesure
de la quantité d'énergie libérée lors de
l'événement. Pour la
déterminer, ils existent plusieurs méthodes dont
chacune vise un but donné. Ceci a incitéplusieurs
travaux de recherche pour unifier ou homogénéiser les
différentes méthodes [61].
Or, d'autres travaux ont
montré que ces différentes notions de la magnitude pourront
servir à bien comprendre certaines sources sismiques [47].
1.2.5 Identification
L'identification consiste à déterminer la source
de l'événement sismique. Sur une base globale (mondiale), plus de
90 % de tous les événements sismiques peuvent être
identifiés comme des tremblements de terre simplement parce qu'ils sont
trop profonds ou ne sont pas dans un emplacement plausible pour une explosion
chimique ou nucléaire. Pour les événements sismiques qui
ne peuvent pas être distingués par la profondeur et l'emplacement,
d'autres méthodes de discrimination sont utilisées. Ces
méthodes sont basées sur les différences physiques entre
des tremblements de terre et les explosions et
font appel à des techniques de traitements de signaux
très poussées.
1.3 Revue bibliographique
La discrimination des événements sismiques est
l'un des volets les plus étudiés de la sismologie. Et avec le
CTBT, les travaux de recherches sont multipliés afin de trouver les
outils performants qui permettent de caractériser la source des signaux
sismiques captés par les sismomètres.
Pour les recherches statistiques une discrimination par le
temps local peut être suffisante [5]. En effet, les explosions
minières sont interdites durant la nuit. Une autre possibilité
est de tester la distribution de l'événement par rapport à
la distribution poissonienne [267]. Or, cet approche est inapplicable pour les
événements singuliers tel que les explosions nucléaires
souterraines. Ainsi, pour mieux caractériser les
événements sismiques, on fait recours à la discrimination
basée sur les ondes sismiques.
Le principal discriminant basé sur les ondes est la
localisation avec une importance spéciale à la
détermination de la profondeur dont les meilleurs indicateurs sont les
phases pP et sP [226]. Et malgré, la difficulté de
détection de ces signaux, à cause des effets de la trajectoire,
plusieurs méthodes utilisent le mécanisme focal et la
complexité de la coda pour déterminer la profondeur. Ces
méthodes sont généralement basées sur la
modélisation des ondes de corps [127], beamforming [324] et les
techniques cepstrales [8]. Ces derniers sont basées sur l'analyse
cepstrale dont l'objectif est de déterminer les échos dans le
signal en utilisant des méthodes simples du traitement du signal, et en
principe, cette analyse est capable de détecter les retards temporels
des phases sismiques pP et sP qui pourraient être utilisés dans
l'amélioration de l'estimation de la profondeur focale de
l'événement [106]. Une autre méthode cepstrale, dite
F-statistique cepstrale (cepstral Fstatistic), a été
développée par Reiter et Shumway [253] et Bonner et al. [46] en
se basant sur les résultats de Shumway et al. [277]. L'analyse cepstrale
a été utilisée avec succès dans plusieurs travaux
[8, 38, 178], alors que la F-statistique cepstrale a été
testée avec grand succès pour les distances
télésismiques et avec un degré moins pour les distances
régionales [45]. Une autre méthode pour améliorer la
détermination de la profondeur a
été proposée par Murphy et al. [224, 223] en
utilisant un algorithm de Israelsson [159].
Tenant compte de l'importance de la détermination des
premières arrivées (onset) dans la localisation des
événements sismiques, Der et Shumway [85] ont
présenté un papier concernant leur estimation automatique. Ce
travail utilise les deux aspects : CUSUM (Cumulative Sum) qui a fait l'objet de
plusieurs travaux [230, 231, 24], et SA (Simulated Annealing) pour estimer les
arrivées des phases sismiques régionales. Le premier fait la
détection de l'arrivée comme un changement de la tendance de la
CUSUM par un test statistique convenable et le deuxième fait une
recherche aléatoire avec le SA pour la localiser. Une application de la
méthode, pour les signaux sismiques courtes-périodes
régionaux et télésismiques, est donnée dans
[84].
La large incertitude liée à la
détermination de la profondeur rend ce discriminant inefficace dans
plusieurs situation. Donc, on fait appel à d'autres discriminants parmi
lesquels, le ratio mb:Ms reste sans conteste le discriminant le plus efficace
pour les signaux télésismiques [47, 74, 283]. Il repose sur le
fait qu'une explosion favorise la production des ondes P très
énergétiques par rapport aux autres types d'ondes. Alors que les
tremblements de terre engendrent les ondes de cisaillement et de surface qui
dominent le sismogramme à des distances télésismiques.
Cependant, pour les distances régionales et pour le cas des tremblements
de terre profonds, les ondes de surface ont de faibles amplitudes qui sont
très difficile à mesurer, et donc le discriminant mb:Ms ne peut
pas être formulé. Pour résoudre ce problème,
Anderson et al. [13] ont montré que si Ms est très difficile
à mesurer et si on connaît seulement qu'elle est inférieure
à un seuil suffisamment petit par rapport à mb alors
l'événement est fort probable une explosion. Et partant du fait
que les filtres phase-matched peuvent améliorer les faibles ondes de
surface en compressant les signaux dispersés [142], et que les signaux
compressés peuvent être filtrés pour éliminer les
sources de bruit tel que les bruits microsismiques et la coda. Alors par cette
méthodologie, on peut, d'une part, extraire les signaux d'onde de
surface à partir des mesures bruitées et, d'autre part, calculer
Ms aux distances régionales et fixer le seuil de mesure des ondes de
surface [241, 284].
proposés. Ces derniers sont calculés pour
différentes bandes de fréquence et pour différentes phases
régionales (Pn, Pg, Sn, Sg et Lg) [246]. Dans ce contexte, Pomeroy et
al. [249] a étudié plus de 12 paramètres pour la
discrimination régionale et qui peuvent être tirés des
sismogrammes; et il a pu mettre en evidence les ressemblances entre le
discriminant télésismique mb:Ms et le discriminant
régional Pg:Lg. De plus, en étendant,la méthode QNED
(Quadratic Negative Evidence Discrimination) [98] vers le cas régional,
Anderson et al. [13] ont pu prouver que si le seuil de Lg est suffisamment
petit par rapport à Pg alors l'événement est fort probable
une explosion. Un autre discriminant Pn:Lg du même type a montré
de grandes performances pour la discrimination entre les explosions
nucléaires et les tremblements de terre [313, 137]. D'autres
discriminants existent mais sont moins utilisés tel que le ratio P/S
[166] , la coda [136, 215, 216] et la combinaison de plusieurs ratios [296].
Afin d'améliorer les performances des discriminants
ci-dessus, le développement des méthodes transportables
permettant la correction des effets de la trajectoire sur la propagation des
ondes sismiques s'avère nécessaire. Ainsi, de bonnes corrections
de la trajectoire avec certain degré de confiance ont été
définies dans des régions bien calibrées [245]. Mais, le
problème reste posé pour les régions où on a peu de
données. Pour résoudre ce problème, les chercheurs ont
fait des corrections basées sur l'identification des structures
similaires de la croûte, c'est à dire, qui ont des effets
similaires sur la propagation régionale. Les types de la croûte
sont caractérisés par des paramètres géophysique
statistiques variant avec la lithologie. Cette dernière peut inclure la
topographie, la gravité, l'épaisseur de la croûte,
l'épaisseur des sédiments, la magnétisation, l'âge
et le flux de la chaleur [128]. Cette approche a été
initié par Zhang et al. [337] qui ont démontré l'existence
d'une cor- relation entre les statistiques topographiques et les ratios des
amplitudes des ondes P et S pour les distances régionales.
Des travaux récents [194, 195] ont montré que le
problème de la caractérisation et de la correction des phases
régionales au niveau des effets de propagation pourra être vaincu
en utilisant trois approches: les méthodes empiriques basées sur
la dépendance paramétrique des propriétés de la
trajectoire [244], les méthodes d'interpolation tel que cap-averaging et
kriging [270, 261] et les méthodes de modélisation de la forme
d'onde qui
sont basées sur la synthèse complète des
formes d'onde pour les modèles de la croûte en un, deux ou trois
dimensions. Dans ce cadre et partant du fait que la correction des amplitudes
offre plusieurs avantages que la correction des ratios, Taylor et al. [299] et
Walter et al. [315] ont développé une méthodologie dite
MDAC (Magnitude and Distance Amplitude Corrections) permettant
d'éliminer les effets de la magnitude mb et de la distance sur les
amplitudes des phases sismiques régionaux . Cette méthode est une
version améliorée du SPAC (Source and Path Corrections) [297,
298] utilisant le modèle de Brune [51] et des corrections de la
trajectoire à une seule dimension. Cependant, l'application du MDAC a
montré que certaines variations des amplitudes dues à
l'hétérogénéité structurelle persistent.
Afin de palier ce problème, Rodgers et al. [261] ont
développé une correction utilisant un modèle à deux
dimensions et la méthode kriging (nonstationary bayesian
kriging) [270]. Une deuxième version MDAC2 avec un
modèle de Brune généralisé a
étéproposée par Walter et Taylor [316] et
améliorée par Walter et al. [314]. D'autres travaux
de correction ont été faits pour des
discriminants particuliers tel que ceux de Baker [19] pour le discriminant
Pg:Lg, de Patton [242] pour mb :Ms, et de Baumgardt et al. [26] pour les
discriminants P(Pn,Pg)/S(Sn,Lg). Mais, il apparaît que la
transportabilité de ces corrections est très difficile à
assurer ou à évaluer. Dans ce sens, Rodgers et al. [261] ont
montré que les corrections faites dans une région pourraient
être non applicables même dans les régions adjacentes.
L'utilisation des réseaux de neurones de type MLP pour
la classifications des signaux sismiques a été initiée par
les travaux de Dowla et al. [91] et Dysart et Pulli [96] pour discriminer,
respectivement, entre les séismes régionales d'une part, et les
explosions nucléaires et chimiques d'autre part. Ceci en utilisant
certains paramètres spectraux relatifs aux phases régionales
comme paramètres d'entrée pour le réseau MLP. Dans le
même sens, d'autres travaux ont été réalisés
utilisant la même démarche [262, 90, 225, 101]. Cependant, les
performances de ces méthodes sont principalement liées d'une
façon qualitative et quantitative aux paramètres d'entrée
du réseau de neurones. Pour vaincre ce problème, DelPezzo et al.
[81] et Scarpetta et al. [269] ont utilisé le spectrogramme pour
représenter les signaux sismiques et le codage linéaire
prédictif (LPC: Linear Predictive Coding) pour l'extraction des
caractéristiques. Benbrahim et al. [31] ont utilisé le
scalogramme
de l'ondelette de Ben pour améliorer la
représentation, la projection aléatoire pour la réduction
de la dimensionnalité sans faire un découpage au signal acquis et
le réseau MLP pour la classification. On trouve aussi dans la
littérature d'autre méthodes basées sur le réseau
MLP quadratique [9], MLP associatif [97] et les ensembles des réseaux
MLP [275].
1.4 Réseau sismologique Marocain
Le réseau sismologique Marocain (figure (1.3)) est un
réseau géré et exploité par le Centre National pour
la Recherche Scientifique et Technique (CNRST) via l'Institut National de
Géophysique (IN G). Ce réseau est formé actuellement des
éléments suivants:
· une centrale d'acquisition numérique, de detection
automatique des événements et de stockage de type Kinemetrics;
· un support d'enregistrement analogique continu;
· une ensemble de stations
télémétrées «courte période» dont
une à trois composantes;
· une station «longue période» trois
composantes installée à la centrale de Rabat;
· un observatoire large bande (VBB) à Mibladen
(Midelet);
· un réseau d'accélérographes;
· un ensemble de stations analogiques et numériques,
maintenu prêt pour intervention en cas de crise sismique.
La partie télémétrée du
réseau comprend 40 stations «courte période»
réparties en sept sous réseaux. Elle utilise des liaisons radio
UHF/VHF et 7 lignes téléphoniques spécialisées
reliant les stations régionales des 7 sous-réseaux à la
centrale de Rabat.
1.5 Contribution de la thèse
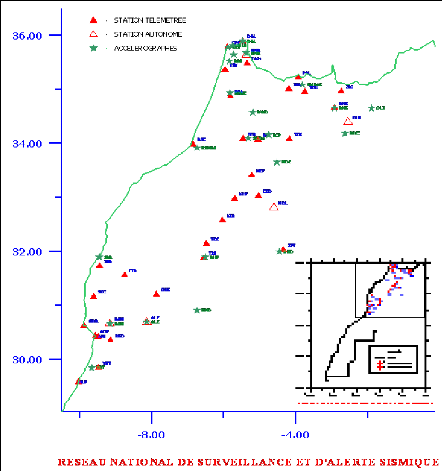
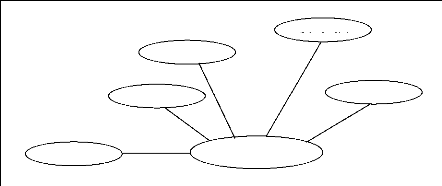
Figure 1.3: Réseau Marocain de surveillance et d'alerte
sismique (RESAS)
se font à la fois de façons analogique et
numérique dont l'examen pour la discrimination entre séismes
naturels, explosions artificielles et bruits est une tâche difficile qui
nécessite des heures et des heures de travail des analystes. Afin
d'optimiser ce travail, l'automatisation de la discrimination des signaux
sismiques devient une nécessité.
Ainsi, ce travail, qui s'inscrit dans le cadre de la
collaboration entre l'ING et le Laboratoire d'Automatique et d'Informatique
Industrielle (LAII) de l'Ecole Mohammadia d'Ingénieurs (EMI), a pour
objectif de développer un système modulaire (figure (1.4)) de
discrimination non paramétrique transportable permettant de vaincre les
problèmes posés par les méthodes paramétriques
décrits dans la revue bibliographique. Pour atteindre cet objectif, nous
suivrons les étapes suivantes:
1. Une étude des différentes méthodes de
représentation des signaux non stationnaires afin de trouver les
représentations les plus discriminantes pour les signaux sismiques;
2. Afin d'extraire certaines caractéristiques des
signaux sismiques servant à la classification automatique sans passer
par aucune méthode paramétrique, le développement d'une
technique de réduction de la dimensionnalité est
nécessaire;
3. Pour une discrimination automatique non
paramétrique des signaux sismiques, l'utilisation des réseaux de
neurones et particulièrement les perceptrons multi-couches comme
classificateurs apparaît adéquate. Dans ce sens, une recherche de
nouvelles méthodes pour augmenter la fiabilité du système
de classification s'avère très utile;
4. Le problème du rejet des bruits ou des signaux qui
peuvent affecter la procédure de la discrimination pourrait être
résolu dans le cadre de la détection de nouveauté en
utilisant les réseaux de neurones auto-associatifs;
5. Finalement, la mise en oeuvre des méthodes
ci-dessus nécessite l'élaboration d'un logiciel,
dénommé par la suite MSSSA (Moroccan Software for Seismic Signals
Analysis), permettant l'acquisition, la représentation, la
reconnaissance, la discrimination et l'archivage des signaux sismiques.

Figure 1.4: Schéma du système modulaire
proposé
Outre cette introduction, cette thèse couvre cinq
autres chapitres. Le chapitre 2 présente les différentes
représentations des signaux non stationnaires avec de nouvelles versions
de l'inégalité d'Heisenberg-Gabor. Au chapitre 3, nous
présentons une nouvelle technique de la réduction de la
dimensionnalité des images sismiques. Le chapitre 4 est consacré
à présentation des différentes méthodes de
classification. Le chapitre 5 consiste en l'étude de la discrimination
des signaux sismiques. Finalement, le chapitre 6 donne une nouvelle technique
pour la reconnaissance des tels signaux. Tous les résultats que nous
présentons dans ce mémoire sont illustrés par des tests
expérimentaux en utilisant des signaux synthétiques et sismiques
par le bias du logiciel MSSSA. Nous terminons ce travail par une conclusion
générale qui résume notre étude et présente
un ensemble de propositions relatives aux perspectives de cette recherche.
CHAPITRE 2
REPRESENTATION DES SIGNAUX NON-STATIONNAIRES
Le choix de la représentation est un paramètre
crucial qu'il faut savoir le choisir de manière adéquate pour
augmenter les performances de tout système de discrimination des signaux
non stationnaires. Ce choix consiste à définir un espace de
représentation discriminant permettant d'extraire l'information
significative portée par le signal, donc qui mette en avant les
différences entre les classes et gomme les ressemblances.
Pour les signaux non stationnaires, devant la
complexité et la variété des situations rencontrées
et compte tenu qu'il n'existe pas de solution universelle valable pour tous
signaux, il s'avère nécessaire de faire une étude
spécifique pour chaque cas afin de sélectionner les
représentations les plus appropriées. Dans ce sens, Marr [211]
note que «Chaque représentation particulière fournit
explicitement certaines informations au dépend d'autres mises en
arrière et qui peuvent être difficiles à retrouver. Ce
point est important car la manière dont l'information est
représentée peut fortement modifier la facilité avec
laquelle on en percevrait les différents
éléments».
Le but de ce chapitre est, d'une part, de mettre en
évidence les différents outils de représentation des
signaux non stationnaires et, d'autre part, de concevoir une nouvelle ondelette
plus adéquate aux signaux sismiques. Nous commençons par les
représentations temporelle et fréquentielle pour lesquelles nous
illustrons le fait qu'en présence de la non stationnarité, ces
deux représentations à une dimension ne sont plus
adaptées. Nous proposons alors d'utiliser des représentations
conjointes en temps et en fréquence (ou échelle). La
démonstration de nouvelles versions du principe d'Heisenberg-Gabor, pour
le spectrogramme, la représentation de Wigner-Ville et la
transformée en ondelette continue font aussi l'objet de ce chapitre.
2.1 Représentations temporelle et fréquentielle
2.1.1 Représentation temporelle
La représentation temporelle (ou spatiale dans certains
cas) constitue la forme la plus simple et naturelle pour représenter les
signaux dérivant d'un phénomène donné. Elle ne
nécessite aucun outil mathématique pour la générer
et son observation révèle plusieurs informations temporelles ou
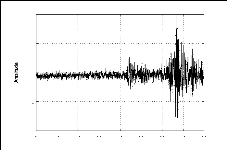
atemporelles. Par exemple, pour le cas des signaux sismiques où la
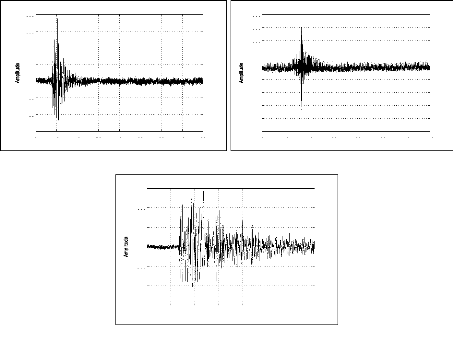
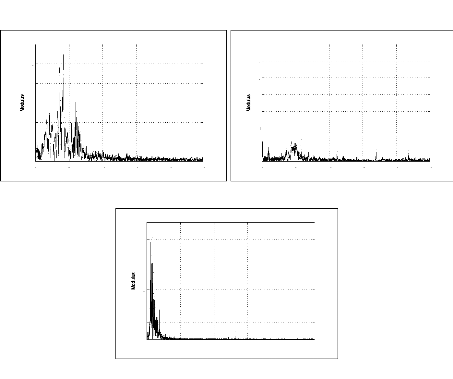
figure (2.1) donne des signaux relatifs à une explosion chimique, un
séisme local et un séisme lointain; la représentation
temporelle pourrait nous indiquer la durée de l'événement
sismique, le temps d'arrivée des phases, la magnitude, etc. Cependant,
ces paramètres ne sont pas toujours facile à avoir, et donc
généralement inadaptés pour la discrimination de ces
signaux. En effet, pour le cas d'un signal sismique à faible ratio
signal/bruit ou tronqué, il est très difficile d'avoir tous ces
paramètres même par un expert du domaine. La figure (2.2) permet
d'expliciter ce problème pour deux signaux sismiques relatifs au
même événement et enregistrés par les stations MIF
et TGT.
Remarque:
Malgré les problèmes posés par les bruits de
fond pour l'analyse des signaux sismiques, ils sont très utiles dans
d'autres domaines tels que le génie civil [95].
2.1.2 Représentation fréquentielle
Une alternative à la représentation temporelle du
signal consiste à représenter son contenu fréquentiel.
Celui-ci est obtenu en calculant sa transformée de Fourier (FT:
Fourier Transform) définie, pour un signal x(t)
d'énergie finie (c'est à dire appartenant
àl'ensemble des fonctions de carré sommable
L2), par:
FTx : L2(R) ? L2(R)
x(t) ? FTx(í) = R8 -8x(t)e-i2ðítdt
(2.1)
ou x(t) ? FTx(ù) = R8 -8x(t)e-iùtdt
17
(a)
(b)
Es0429-JBB -2005-05-06 02:47:39
2000
1500
1000
500
0
-500
-1000
-1500
-2000
Time [sec]
-2500
0 20 40 60 80 100 120 140
(c)
Es0319-CZDV-2005-09-16 00:50:27
1500
1000
500
0
-500
-1000
Time [sec]
-1500
0 20 40 60 80 100 120 140
Es0001-TIS -2003-01-22 13:11:23
800
600
400
200
0
-200
-400
Time [sec]
-600
0 10 20 30 40 50 60 70 80
Figure 2.1: Représentation temporelle d'une explosion
chimique (a), d'un séisme local (b) et d'un séisme lointain
(c)
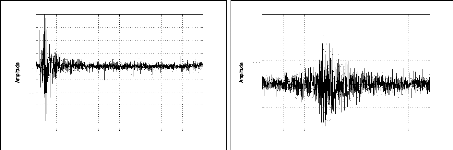
-1000
0 10 20 30 40 50 60 70 80
-500
1500
1000
500
0
Es0103-TGT -2003-01-23 12:32:42
Time [sec]
-100
-150
-200
-250
0 10 20 30 40 50 60 70 80
200
-50
150
100
50
0
Es0103-MIF -2003-01-23 12:32:42
Time [sec]
(a) (b)
qui pourra s'écrire, en notant respectivement
|FTx(u)| et ?(u) le module et la phase de FTx, sous la
forme:
FTx(u) = |FTx(u)|ei?(í)
(2.2)
Cette transformée étant inversible:
Z 8
x(t) = IFTFTx(u) =F
Tx(u)ei2ðítdu (2.3)
-8
La FT mesure donc un indice de similarité entre le
signal et une collection d'ondes (exponentielles complexes) de longueur
infinie, où FT x(u) représente la contribution de
l'onde de fréquence u au signal x(t). La FT est en faite une
transformée en ondes du signal, dans laquelle toute information
temporelle disparaît.
Dans l'étude des signaux, FT x(u), qui est
appelé représentation fréquentielle, fournit une
représentation plus simple à interpréter par rapport
à la représentation temporelle. Dans le cadre de la propagation
des ondes sismiques, on peut considérer le milieu de propagation comme
étant une fonction de transfert entre la source et les
sismomètres qui agit séparément sur chaque
fréquence. La vitesse et l'atténuation du signal sismique
dépendent de la fréquence considérée. Une
modélisation en fréquence de la dispersion d'onde est donc
possible.
Le signal sous sa forme fréquentielle FT
x(u) est le plus souvent étudié par l'analyse de la
courbe |FTx(u)| définissant l'amplitude du signal à
chaque fréquence. Cette description est riche mais elle ne suffit pas
à caractériser complètement le signal. En effet, il est
possible d'avoir des signaux dont les représentations temporelles sont
différentes mais ayant le même contenu fréquentiel comme le
montre l'exemple ci-dessous.
Exemple 2.1: La FT de deux signaux différents en temps
ayant le même con-
tenu fréquentiel.
19
Nous considérons les deux signaux S1 et S2 définis
par:
S1 = sin(2ð.25.t) + sin(2ð.50.t), t ? [0, T]
|
S2=
|
|
sin(2ð.25.t), t ? [0, T1]
sin(2ð.50.t), t ?]T1,T]
|
Bien que leurs représentations temporelles sont
différentes (figure (2.3)), les contenus fréquentiels des signaux
S1 et S2 représentés sur la figure (2.4) sont les mêmes.
(a) (b)
-0.2
-0.4
-0.6
-0.8
0.8
0.6
0.4
0.2
-1
0
1
0 005 01 015 02 025
Time[sec]
Signal S2
-0.5
-1.5
0.5
1.5
-1
-2
2
0
1
0 005 01 015 02 025
Time[sec]
Signal S1
Figure 2.3: Représentation temporelle des signaux S1 (a)
et S2 (b)
(a) (b)
40
60
50
30
20
10
0
0 100 200 300 400 500
Modulus of Fourier transform: S2
Frequency [Hz]
120
100
60
40
20
80
0
0 100 200 300 400 500
Modulus of Fourier transform: S1
Frequency [Hz]
Figure 2.4: Représentation fréquentielle des
signaux S1 (a) et S2 (b)
x 10 4 Es0259-CZDN-2003-03-24 14:49:20
-2.85
-2.95
-3.05
0 10 20 30 40 50 60 70 80
-2.9
-3
(a)
Time [sec]
(b)
4
7
6
5
3
2
0
0 5 10 15 20 25
1
x 10 4 Es0259-CZDN-2003-03-24 14:49:20
Frequency [Hz]
20
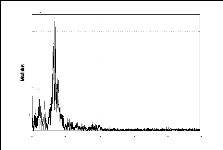
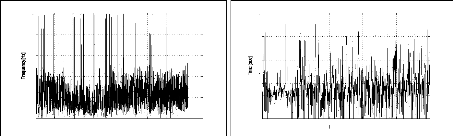
on peut caractériser un signal par son contenu
fréquentiel (figure (2.5)), dans d'autres cas, la perte de la
localisation temporelle dans la FT peut s'avérer handicapante pour
l'analyse de ces signaux. En effet, pour le cas des événements
à faibles amplitudes (ratio signal/bruit faible), la classification
basée sur la FT pourra donner de mauvais résultats à cause
du bruit. La figure (2.6) montre la différence entre la
transformée de Fourier
des signaux représentés dans les figures (2.1.
(a-b-c)) qui correspondent respectivement àune explosion
chimique, un séisme local et un séisme lointain. De plus, la
représentation
fréquentielle limite la généralisation du
système de classification automatique au niveau des classes. Par
exemple, si on veut discriminer des sous-classes du même type, il se peut
qu'elles ont le même contenu fréquentiel mais des
représentations temporelles différentes. Ceci est dû au
fait que l'information temporelle x(t) n'est pas portée par son module
en fréquence |FTx(í)| mais par sa phase en
fréquence ?(í).
(a)
(b)
21
(c)
3
2.5
2
1.5
1
0.5
Frequency [Hz]
x 10 5 Es0429-JBB -2005-05-06 02:47:39
3.5
0
0 5 10 15 20 25
3
2.5
2
1.5
1
0.5
Frequency [Hz]
0
0 5 10 15 20 25
x 10 4 Es0001-TIS -2003-01-22 13:11:23
3
2.5
2
1.5
1
0.5
Frequency [Hz]
x 10 5 Es0319-CZDV-2005-09-16 00:50:27
3.5
0
0 5 10 15 20 25
|
FTxa(u) =
|
? ????
????
|
2FTx(u) si u > 0,
FTx(u) si u = 0,
0 sinon.
|
Figure 2.6: Représentation fréquentielle d'une
explosion chimique (a), d'un séisme local (b) et d'un séisme
lointain (c)
2.2 Signal analytique
Les problèmes posés par la perte de la
localisation temporelle dans la représentation fréquentielle
peuvent être résolus par l'utilisation de grandeurs combinant des
informations de nature temporelle et fréquentielle, à savoir la
fréquence instantanée et le retard de groupe. Avant de
présenter ces deux concepts, il convient de définir au
préalable la notion du signal analytique xa (t).
Le signal analytique xa (t) est défini
simplement en fréquence par [68]:
Ce signal contient la même information que x (t) : la
partie des fréquences négatives (redondante de la partie positive
du fait de la symétrie hermitienne du spectre d'un signal réel,
ce qui n'altère en rien le contenu informationnel) est remplacée
par 0 et le module des fréquences positives est doublé. La
relation qui lie x(t) et xa(t) en temps est:
xa(t) = x(t) + iH[x(t)] (2.4)
où H est la transformée de Hilbert :
[Z +8 ]
1 x(t - r)
H[x(t)] = v.p. r dr (2.5)
ð -8
avec v.p signifiant la valeur principale de Cauchy
donnée par la limite, si elle existe (àcause de la
singularité en r = 0),
[Z ] [Z -å Z +8 ]
x(t - r) x(t - r) x(t - r)
v.p. r dr = lim r dr + r dr (2.6)
å?0
R -8 å
Le signal analytique xa(t) peut se mettre sous la
forme polaire:
xa(t) = |xa(t)|ei÷(t)
(2.7)
où|xa (t)|, et ÷(t) représentent
respectivement l'amplitude (aussi appelée enveloppe) et la phase
instantanée de xa (t). Une telle représentation permet
la séparation de l'information temporelle contenue dans
|xa(t) | et l'information de phase contenue dans ÷(t). De plus,
à partir cette forme polaire, on définit la fréquence
instantanée:
1 d÷(t)
íi(t) = (2.8)
2ð dt
décrivant le contenu spectral instantané du
signal. D'une façon duale, on peut souhaiter décrire le
comportement temporel local d'un signal en fonction de la fréquence.
Ainsi, en considérant la FT du signal analytique sous sa forme
polaire:
23
On peut obtenir une information sur l'instant d'arrivée
d'une fréquence grâce au retard du groupe:
1 dø(í)
ôg(í) = - (2.10)
2ð dí
Le signal analytique permet alors de définir deux
grandeurs conjointes en temps et en fréquence: la fréquence
instantanée et le retard de groupe. Cependant, ces grandeurs ne
conduisent à des représentations aisément
interprétables que dans le cas des signaux mono- composantes [66] pour
lesquels, à un instant donné (respectivement fréquence
donnée), le signal n'existe qu'au voisinage d'une fréquence
donnée (respectivement instant donné). Dans le cas des signaux
sismiques, (multicomposantes, non stationnaires), ces fonctions
unidimensionnelles locales s'avèrent inadéquates, comme le montre
la figure (2.7). Il peut alors être intéressant de
représenter les signaux sismiques conjointement dans les domaines
temporel et fréquentiel afin de caractériser leur
évolution spectrale au cours du temps.
(a) (b)
45
40
35
30
25
20
15
10
5
0
0 5 10 15 20 25
Es0001-TIS -2003-01-22 13:11:23
Frequency[Hz]
25
20
15
10
5
0
0 5 10 15 20 25 30 35 40 45
Es0001-TIS -2003-01-22 13:11:23
Time[sec]
Figure 2.7: Fréquence instantanée (a) et Retard du
groupe (b) du signal sismique représenté par la figure (2.1.a)
2.3 Représentations temps-fréquence
Les limites posées par les représentations
temporelle et fréquentielle ont fait orienter les travaux de recherche
vers l'utilisation des représentations temps-fréquence (TFRs:
Time-Frequency Representations) procurant une information localisée
simultanément dans les domaines du temps et des fréquences. Ce
type de représentations donne une description
naturelle des signaux non stationnaires dont les signaux
sismiques font partie et permet en outre de définir un espace de
représentation discriminant.
Plusieurs formulations de telles représentations ont
été proposées et selon la manière avec laquelle le
signal dépend de sa TFR, on peut répartir les TFRs en trois types
[145]: linéaires, quadratiques et non linéaires non quadratiques.
Pour les représentations quadratiques, une classification basée
sur la propriété de la covariance [148] est très
utilisée et permettant ainsi la définition de quatre classes
très connues [239], à savoir: la classe de Cohen [68], la classe
affine [258], la classe hyperbolique [237, 147] et la classe de puissance [146,
238].
Le problème reste, compte tenu qu'il n'existe pas de
solution universelle valable pour tous signaux, de savoir comment faire le bon
choix de la TFR la plus appropriée pour une application donnée
parmi une infinité de TFRs. Le choix est en fait beaucoup plus vaste,
Meyer [218] note à ce sujet «En exagérant à peine,
nous introduisons presqu'autant d'algorithmes d'analyses qu'il y a de
signaux». Donc, il s'avère nécessaire de faire le choix
selon des critères définis au préalable en
dépendance avec l'application et le signal étudié. Dans ce
sens, des TFRs dépendantes du signal ont été
conçues [22, 141, 80, 124]. Mais la mise en oeuvre de ces
représentations n'est pas possible dans le cas des systèmes de
classifications modulaires. En effet, le noyau d'une représentation
dépendante est toujours liés à un problème
d'optimisation où la connaissance de plusieurs paramètres de
classification au préalable est nécessaire. Par
conséquent, il est justifiable d'utiliser des TFRs indépendamment
du signal étudié. Le compromis consiste à choisir entre
une bonne concentration des motifs et une suppression des termes croisés
d'interférences tout en tenant compte d'autres propriétés
mathématiques telles que la régularité, la
positivité, la marginalité, l'inversibilité, etc.
2.3.1 Transformée de Fourier à court terme
de Fourier à court terme (STFT: Short-Time Fourier
Transform), est définie ainsi:
STFTx : L2(R) ? L2(R)
f 8 (2.11)
x(t) ? ST F Tx(t, í) = x(u)h*(u -
t)e-i2ð"udu
De nombreux choix de h sont possibles. En général,
cette fonction est choisie àsupport compact, suffisamment
régulière et bien localisée en temps et en
fréquence.
Le Signal x(t) peut être reconstruit à l'aide d'une
fenêtre de synthèse g différente de la fenêtre
d'analyse h grâce à la relation:
x(t) = Z8 Z8 STFTx(u,
í)g(t - u)ei2ð"tdudí (2.12)
-8 -8
à condition que g et h vérifient: f8
g(t)h*(t)dt = 1.
La STFT est donc une représentation linéaire
à deux dimensions dépendant du temps et de la fréquence et
permettant la mesure de la contribution de la fréquence í au
signal x à l'instant t. Cependant, cette description n'est pas stricte,
dans la mesure où pour évaluer le contenu spectral pour un
instant choisi, il faut nécessairement observer le signal sur un horizon
non nul autour de cet instant [229]. La fenêtre d'analyse h, dont
plusieurs cas ont été étudiés dans [135, 232], est
ainsi caractérisée par ses extensions temporelles Lt et
fréquentielle Lí. Elle mélange donc l'information contenu
dans le signal entre les instants t #177; Ät
2 dans la bande de fréquence í #177;
Ä" 2 . Ainsi, une localisation arbitrairement précise d'un
événement dans les domaines temporel et fréquentiel n'est
pas possible. En effet, l'augmentation de la résolution temporelle
(respectivement fréquentielle) de cette représentation
nécessite une fenêtre d'analyse plus localisée en temps
(respectivement en fréquence), ce qui a pour effet de dégrader sa
résolution fréquentielle (respectivement temporelle). Par
conséquent, le choix de cette fenêtre repose sur la recherche d'un
compromis entre l'hypothèse de la quasi-stationnarité du signal
sur l'intervalle d'analyse et les résolutions temporelle et
fréquentielle de la représentation. Ceci est dû, au
principe d'incertitude d'Heisenberg-Gabor exprimant le fait qu'un signal ne
puisse être parfaitement localisé à
1/2 ? 1/2
R8 |x(t)|2dt
4ð (2.13)
la fois en temps et en fréquence [273, 252]:
? ? ?
Z8 Z8
-8 -8
?t2|x(t)|2dt ? ? í2|F
Tx(í)|2dí ? =
|
S2=
|
? ?
?
|
sin(2ð.100.t), t ? [0, T1]
sin(2ð.300.t), t
?]T1,T]
|
Cet inégalité a été l'objet de
plusieurs travaux. Ainsi, Rassias [252, 251] a pu la démontrer pour des
ordres supérieurs, Loughlin et Cohen [205] ont abouti à formuler
une version locale, Shinde et Gadre [276] ont pu la reformuler pour le cas de
la transformée de Fourier fractionnaire. Cependant, plusieurs critiques
ont été évoqués tant sur la manière avec
laquelle cet inégalité est interprétée [322, 235]
que sur la limite minimale du terme droite [67]. L'inégalité
(2.13) est un principe général qui tient compte seulement du
signal et de sa FT. Donc, elle ne nous permet pas d'avoir aucune mesure sur
l'influence de la STFT et de la fenêtre d'analyse. Afin d'atteindre cet
objectif, on démontre, dans le paragraphe concernant le spectrogramme,
une nouvelle inégalité en se basant sur le principe
général d' Heisenberg-Gabor.
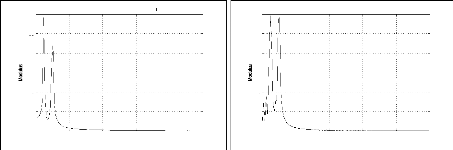
La visualisation de l'image du module de STFT permet une
interprétation sur le nombre de composantes et sur le contenu
temps-fréquence à la limitation de la résolution
près. Ce qui est explicité par l'exemple ci-dessous.
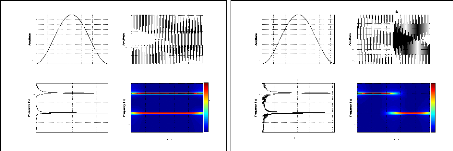
Exemple 2.2: Le module de la STFT de deux signaux
différents en temps
ayant le même contenu fréquentiel.
Nous considérons les deux signaux S1 et S2 suivants:
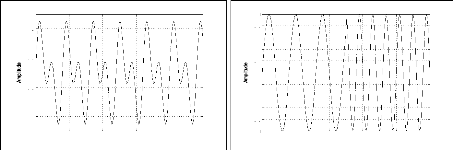
S1 = sin(2ð.100.t) + sin(2ð.300.t), t ? [0, T]
27
représentation bidimensionnelle de ces deux signaux via
le module de la STFT permet de montrer leurs contenus fréquentiels
à tout instant contrairement au module de la FT qui nous donne juste le
contenu fréquentiel sans aucune information temporelle. Ainsi, pour le
signal S1 le module de la STFT nous montre que les deux fréquences 100Hz
et 300 Hz existent sur tout l'intervalle [0, T] alors que pour le signal S2 les
deux fréquences existent mais sur deux intervalles indépendants
[0, T1] et ]T1, T].
(a) (b)
200
400
100
300
0.9
0.8
0.7
0.6
0.5
0.4
0.3
0.2
0.1
0
0 20 40 60 80 100 120
20 40 60 80 100
Hanning window (128 pts)
Modulus
FT
-1.5
200
300
400
100
1.5
0.5
0.5
-1
0
0
1
0 0.05 0.1 0.15 0.2 0.25
0 0.05 0.1 0.15 0.2 0.25
Modulus of STFT
Time [sec]
Signal S1
4.5
4
3.5
3
2.5
2
1
0.5
1.5
200
300
400
100
0.9
0.8
0.7
0.6
0.5
0.4
0.3
0.2
0.1
0
0 20 40 60 80 100 120
10 20 30 40 50 60
Hanning window (128 pts)
Modulus
FT
-0.2
-0.6
200
300
400
100
0.8 0.6 0.4 0.2
0.4
0.8
0
0
0 0.05 0.1 0.15 0.2 0.25
0 0.05 0.1 0.15 0.2 0.25
Modulus of STFT
Time [sec]
Signal
4.5
4
3.5
3
2.5
2
1
0.5
1.5
Figure 2.8: Le module de la STFT pour deux signaux
différents S1 (a) et S2 (b) mais ayant le même contenu
fréquentiel
En comparison avec le module du spectre, l'information du
module des coefficients de la STFT est plus complète. En fait, cette
image d'amplitude suffit à caractériser le signal à un
déphasage près [68]. Cependant, les coefficients de la STFT,
malgré leur
nécessité pour la synthèse du signal, sont
peu utilisés directement à cause de la difficultéde les
interpréter [303]. Quant à l'information de la phase de la STFT,
elle peut être
utilisée pour définir la fréquence
instantanée locale et le retard du groupe local dans le plan
temps-fréquence [131].
Pour le cas de signaux sismiques, la visualisation du module
de la STFT nous permet de différencier entre les différents types
de signaux. Il est clair sur la figure (2.10) que le contenu
temps-fréquence d'une explosion chimique (a), d'un séisme local
(b) et d'un séisme lointain (c) sont différents. En effet, les
fréquences où il y a une grande concentration de l'énergie
sismique (dômes énergétiques en rouge) et même
l'ordre de
28
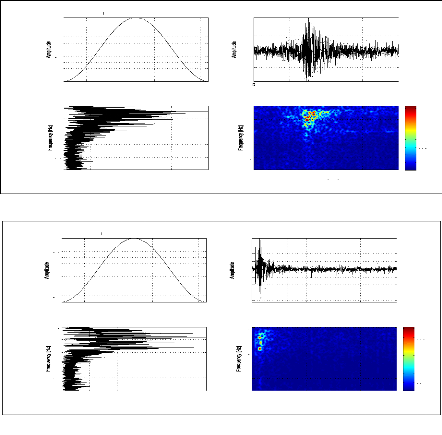
Hanning window (128 pts)
Es0103-TGT -2003-01-23 12:32:42
1000
0.9
0.8
500
0.7
0.6
0.5
0
0.4
0.3
-500
0.2
0.1
0 20 40 60 80 100 120
10 20 30 40 50 60 70
Modulus of STFT
FT
0
0
1600
1400
5
5
1200
10
1000
10
800
15
15
600
400
20
20
200
0 10 20 30 40 50 60 70
Time [sec]
1 2 3 4 5
Modulus x 104
(a)
(c)
0.9
0.8
0.7
0.6
0.5
0.4
0.3
0.2
0.1
20
10
15
0
5
0 20 40 60 80 100 120
1000 2000 3000 4000 5000
Hanning window (128 pts)
Modulus
FT
-100
-150
-200
-50
150
100
50
20
10
15
0
0
5
0 10 20 30 40 50 60 70
0 10 20 30 40 50 60 70
Es01 03-MIF -2003-01-23 12:32:42
Modulus of STFT
Time [sec]
250
200
350
300
50
150
100
grandeur de cette dernière (voir l'échelle
énergétique) sont différents entre les trois types
représentés. Et même dans le cas d'un signal trop
bruité ou tronqué, les composantes fréquentielles
principales sont faciles à distinguer et par conséquent une
discrimination visuelle est possible (figure (2.9)).
29
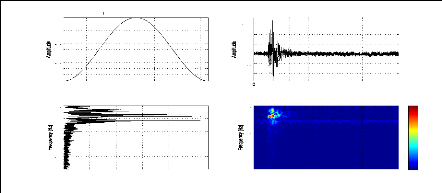
0.9
0.8
0.7
0.6
0.5
0.4
0.3
0.2
0.1
20
10
15
0
5
0 20 40 60 80 100 120
0.5 1 1.5 2 2.5
Modulus x 104
Hanning window (128 pts)
FT
-200
-400
400
600
200
20
10
15
0
0
5
0 10 20 30 40 50 60 70
10 20 30 40 50 60 70
Es0001-TIS -2003-01-22 13:11:23
Modulus of STFT
Time [sec]
800
600
400
200
1200
1000
(a)
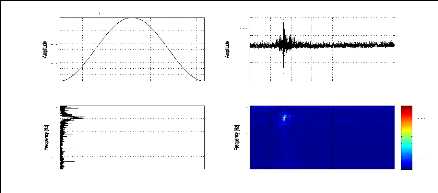
0.9
0.8
0.7
0.6
0.5
0.4
0.3
0.2
0.1
20
10
15
0
5
0 20 40 60 80 100 120
0.5 1 1.5 2 2.5 3
Modulus x 105
Hanning window (128 pts)
FT
-1000
-1500
-2000
-500
1500
1000
500
20
10
15
0
0
5
0 20 40 60 80 100 120
0 20 40 60 80 100 120
Es0429-JBB -2005-05-06 02:47:39
Modulus of STFT
Time [sec]
4500
4000
2500
2000
3500
3000
500
1500
1000
(b)
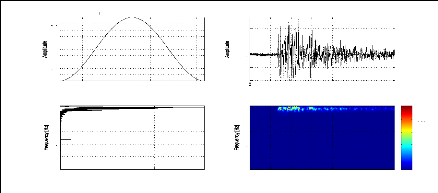
0.9
0.8
0.7
0.6
0.5
0.4
0.3
0.2
0.1
20
10
15
0
5
0 20 40 60 80 100 120
0.5 1 1.5 2 2.5 3
Modulus x 105
Hanning window (128 pts)
FT
-1000
-500
1000
500
20
10
15
0
0
5
0 20 40 60 80 100 120
20 40 60 80 100 120
Es031 9-CZDV-2005-09-16 00:50:27
Modulus of STFT
Time [sec]
4000
2000
5000
3000
1000
(c)
Figure 2.10: Le module de la STFT pour une explosion chimique
(a), un séisme local (b) et un séisme lointain (c)
2.3.2 Spectrogramme
Le module carré de la STFT (2.11) conduit à une
représentation quadratique communément appelée
spectrogramme (SPEC: Spectrogram). Cette représentation, qui dis-
tribue l'énergie du signal dans le plan
temps-fréquence, est la plus ancienne qui ait
étéproposée, mais aussi l'une des plus
utilisées. Elle est précisément définie par
[145]:
SPECx : L2(R) ? L2(R)
x(t) ? SPECx(t, í) = | i8
x(u)h*(u - t)e-i2ðíudu|2 (2.14)
= |STFT |2
où h désigne une fenêtre d'analyse. Comme
pour la STFT, le choix de la fenêtre repose sur la recherche d'un
compromis entre l'hypothèse de la quasi-stationnarité du signal
sur l'intervalle d'analyse et les résolutions temporelle et
fréquentielle de la représentation. Afin de mettre en evidence
l'influence du fenêtre d'analyse et du SPEC sur la localisation
temporelle et fréquentielle, nous démontrons le
théorème ci-dessous.
Théorème 2.1 (Version spectrogramme de
l'inégalité d'Heisenberg-Gabor en í). Soit x ?
L2(R) et h ? L2(R) \ {0} une fenêtre d'analyse,
alors on a l'inégalité:
1/2 ? 1/ 2
8
? ?
fZ8
8 Z
?
-8 -8 -8
t2|x(t)|2dt ? ?
?
(R)
4ð (2.15)
khkL2(R)IIxII2 L2
í2SP ECx(u, í)dudí ?
=
~ i8 ) 1/2 ( i8 )1/2
avec hML2(R) = |h(t)|2dt et
xML2(R) = |x(t)|2dt .
-8 -8
Démonstration. Supposons que les deux
intégrales dans l'inégalité (2.15) sont finies.
Par la
propriété de l'invariance par translation de l'intégrale
au sens de Lebesgue et par
utilisation du fait que la STFT d'un signal x par
une fenêtre d'analyse h n'est que la FT
|
> 1 -- 4/r
|
8
f
|
8
f
|
|ST FTx(u, í))|2 dí du
= 14/r11h112L2
(R)11x112L2 (R)
|
de x multiplié au préalable par le conjugué
de la fenêtre d'analyse h translatée, on a:
8 8 8
11h112L2(R) f t2| x (t) | 2 dt = f | h (u)
| 2 du f t2| x (t)| 2 dt
|
=
=
=
|
8
f
8
f
8
f
|
8
f
8
f
8
f
|
t2 | h (t -- u) |2 | x (t) |2 dtdu
t2|I FT* (ST FTx(u,
í))(t)|2dtdu
t2| I FT (ST FTx(u,
í))(t)|2dtdu
En appliquant l'inégalité d'Heisenberg-Gabor (2.13)
et l'égalité de Plancherel-Parseval (conservation de
l'énergie):
ci | x (t)| 2 dt = ci |
FTx ( í) | 2 dí
on a:
1/2 8 1/2
( f88 í2|STFTx (u,
í))|2dí) x ( f t2|IFT(STFTx(u,
í))(t)|2dt) -8
8
f
> 1 -- 4/r
|ST FTx(u, í))|2 dí
par intégration par rapport à u et par application
de l'inégalité de Cauchy-Schwarz, on obtient:
(
f8 í2|STFTx(u,í))|2dídu) 1/2 (f
|h(t)12dt)1/2 (f t2|x(t)|2dt)1/2
-8 -8 -8-8
7 7
1/2 ,21STFTx(u, 0)12 ch idu)
( 7 7 1/2
t2lIFT(STFTx(u, v))(t)12
dtdu)
= (
-8 -8 -8 -8
f88 ( f88 í2|STFTx(u, í)) |2dí) (
f: t2 | IFT(STFTx(u, í))(t)|2 dt) du
1/21/2
De la même façon, nous pourrons prouver le
théorème ci-dessous.
Théorème 2.2 (Version spectrogramme de
l'inégalité d'Heisenberg-Gabor en t). Soit x E
L2(118) et h E L2(118) \ {0} une
fenêtre d'analyse, alors on a l'inégalité:
(f8 í2 |FTx(í)|2dí ( I f
t2SPECx(t, í)dtdhí
)1/2 8 8 -8
(2.16)
11h11L2(R)11x112L2(R)
>
4ð
) 1/2
1/2 1/2
avec 11h11L2(R) = ( 78 f h(t)|2dt) et
11x11L2(R) = (78 |x(t)|2dt) .
Démonstration. La même démarche que le
théorème (2.1).
A partir des deux théorèmes ci-dessus, nous avons
le résultat suivant:
Corollaire 2.1. Soit x E L2(118) et h E
L2(118) \ 101 une fenêtre d'analyse, alors on a
l'inégalité:
1/2 8 8 1/2
( 0f0 8
t2SPECx(t, í)dtdí) (
f f í2SPECx(u,
í)dudhí)
-8 -8 -8 -8
8 1/2 ( 8 1/2
11h112 11x114 (2.17)
X ( f t2|x(t)|2dt) f
í2|FT(í)|2dí) > L2
(R) L2 (R)
-8 -8 16ð2
1/2 1/2
avec 11h11L2(R) = ( 78 f h(t)|2dt) et
11x11L2(R) = (78 |x(t)|2dt) .
Démonstration. Il suffit de multiplier les termes
des inégalités (2.15) et (2.16) pour
obtenir
l'inégalité (2.17).
Remarques:
· A partir de l'inégalité (2.17), nous
constatons qu'il y a un dilemme entre la résolution de la
transformée de Fourier à court terme et celle de la
transformée de Fourier. Ce qui met en cause certaines
interprétations de la résolution des représentations
temps-fréquence basées sur l'inégalité
d'Heisenberg-Gabor standard (2.13).
· Pour le cas d'une fenêtre d'analyse de norme
unité, nous trouvons dans les inégalités (2.15) et (2.16)
la même borne minimale que celle de l'inégalité (2.13).
Le spectrogramme est une représentation
bilinéaire et covariante aux translations en temps et en
fréquence, donc est un élément de la classe de Cohen.
Cependant, le principal problème posé est les
interférences. En effet, le spectrogramme est une représentation
quadratique qui respecte par conséquent le principe de la superposition
quadratique qui s'écrit pour une TFR quadratique T appliquée
à un signal à deux composantes x(t) = P2 ckxk(t):
k=1
Tx(t, u) = |c1|2Tx1(t, u) +
|c2|2Tx2(t, u) + c1c* 2Tx1,x2(t, u)
+ c2c* 1Tx2,x1(t, u) (2.18)
Ainsi, pour un signal N composantes x(t) = PN ckxk(t),
on a [144]:
k=1
· pour chaque composante du signal ckxk, il
correspond une auto-composante |ck|2Txk(t, u);
· pour chaque pair de composantes ckxk
et clxl avec k =6 l, il correspond un terme inter-composantes
(ou terme d'interférences) ckc* kTxk,xl (t, u) + clc*
kTxl,xk (t, u).
Par conséquent, pour N composantes, on a N auto-composante
et N(N-1)
2 termes
d'interférences. Ceci influence la visualisation de la
TFR quadratique d'un signal multicomposantes et la rend difficile. Mais pour le
spectrogramme, les interférences sont de nature oscillatoire et existent
seulement dans les régions du plan temps-fréquence
oùles composantes se superposent et sont proches [167]. Les
exemples (2.3), (2.4) et (2.5) permettent d'expliciter ce
phénomène.
Exemple 2.3: Le SPEC d'un signal à deux composantes non
superposables.
Nous considérons le signal S2 de l'exemple (2.2)
constitué de deux composantes de fréquences 100Hz et 300hz non
superposables. Le SPEC de ce signal, en utilisant une fenêtre de Hanning
de 128 points, est donné par la figure (2.11) où il est clair
qu'il n'y a pas d'interférences entre les deux composantes.
34
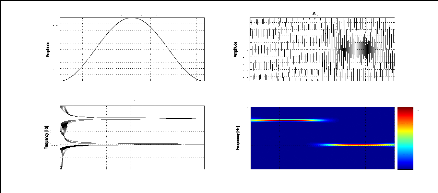
400
200
300
100
0.9
0.8
0.7
0.6
0.5
0.4
0.3
0.2
0.1
0
0 20 40 60 80 100 120
10 20 30 40 50 60
Hanning window (128 pts)
Modulus
FT
-0.2
-0.4
-0.6
-0.8
200
400
300
0.8
0.6
0.4
0.2
100
0
0
0 0.05 0.1 0.15 0.2 0.25
0 0.05 0.1 0.15 0.2 0.25
Time [sec]
ignal S2
SPEC
20
5
15
10
Figure 2.11: Le SPEC d'un signal à 2 composantes non
superposables
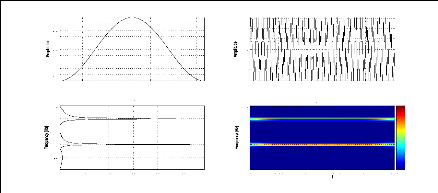
400
200
300
100
0.9
0.8
0.7
0.6
0.5
0.4
0.3
0.2
0.1
0
0 20 40 60 80 100 120
20 40 60 80 100
Hanning window (128 pts)
Modulus
FT
-0.5
-1.5
400
200
300
100
0.5
1.5
-1
0
0
1
0 0.05 0.1 0.15 0.2 0.25
0 0.05 0.1 0.15 0.2 0.25
Time [sec]
Signal S1
SPEC
20
5
0
15
10
Figure 2.12: Le SPEC d'un signal à 2 composantes
superposables et non proches
Exemple 2.4: Le SPEC d'un signal à deux
composantes superposables et non
proches.
Nous considérons le signal S de l'exemple (2.2)
constitué de deux composantes de fréquences 100Hz et 300hz
superposables mais non proches. Le SPEC de ce signal, en utilisant une
fenêtre de Hanning de 128 points, est donné par la figure (2.12)
où il apparaît clairement que malgré la superposition des
deux composantes il n'y a pas d'interferences.
35
Exemple 2.5: Le SPEC d'un signal à deux composantes
superposables et proches.
Nous considérons le signal S de l'exemple (2.2) mais
cette fois-ci constitué de deux composantes de fréquences 100Hz
et 110hz superposables et proches. Le SPEC de ce signal, en utilisant une
fenêtre de Hanning de 128 points, est donné par la figure (2.13)
où on ne peut plus différencier entre les différentes
composantes à cause des interférences dues à la
superposition et la proximité fréquentielle.
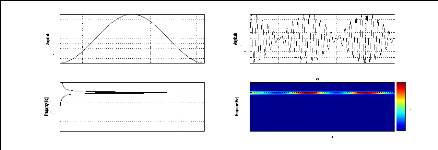
400
200
300
100
0.9
0.8
0.7
0.6
0.5
0.4
0.3
0.2
0.1
0
0 20 40 60 80 100 120
20 40 60 80 100 120
Hanning window (128 pts)
Modulus
FT
-1.5
400
200
300
100
0.5
0.5
1.5
0
0
1
1
0 0.05 0.1 0.15 0.2
0 0.05 0.1 0.15 0.2
Time [sec]
Signal S1
PEC
0.25
0.25
40
35
30
25
20
15 10 5
Figure 2.13: Le SPEC d'un signal à 2 composantes
superposables et proches
Pour le cas des signaux sismiques, signaux multicomposantes
non stationnaires, le SPEC est caractérisé par des
interférences très difficiles à étudier à
cause, d'une part, du nombre indéfini des composantes et, d'autre part,
de la non connaissance de leurs contenus spectraux à tout instant d'une
façon précise. Mais comme les signaux sismiques sont
constitués de composantes principales (phases) alors, dans le SPEC,
elles seront caractérisées par des dômes d'énergie
plus fort que les autres composantes. Ce qui nous permet de caractériser
la catégorie du signal étudié. La figure (2.14) donne le
SPEC d'une explosion chimique (a), d'un séisme local (b) et d'un
séisme lointain (c).
Si le SPEC présente, d'une part, l'avantage d'avoir des
interférences atténuées et d'être positif partout,
d'autre part, il présente l'inconvénient d'être une
transformation singulière [143, 125], en plus de la difficulté du
choix de la fenêtre d'analyse malgré les propositions de combiner
plusieurs types [204, 114].
36
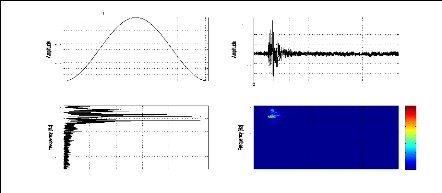
0.9
0.8
0.7
0.6
0.5
0.4
0.3
0.2
0.1
20
10
15
0
5
0 50 100 150 200 250
0.5 1 1.5 2 2.5
Modulus x 104
Hanning window (256 pts)
FT
-200
-400
400
600
200
20
10
15
0
0
5
0 10 20 30 40 50 60 70
10 20 30 40 50 60 70
Es0001-TIS -2003-01-22 13:11:23
Time [sec]
SPEC
x 105
4
2
8
6
14
12
10
(a)
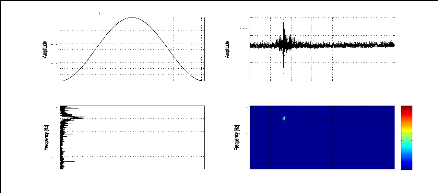
0.9
0.8
0.7
0.6
0.5
0.4
0.3
0.2
0.1
20
10
15
0
5
0 50 100 150 200 250
0.5 1 1.5 2 2.5 3
Modulus x 105
Hanning window (256 pts)
FT
-1000
-1500
-2000
-500
1500
1000
500
20
10
15
0
0
5
0 20 40 60 80 100 120
0 20 40 60 80 100 120
Es0429-JBB -2005-05-06 02:47:39
Time [sec]
SPEC
x 106
4
2
8
6
16
14
12
10
(b)
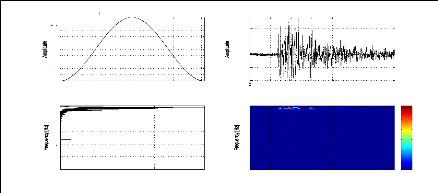
0.9
0.8
0.7
0.6
0.5
0.4
0.3
0.2
0.1
20
10
15
0
5
0 50 100 150 200 250
0.5 1 1.5 2 2.5 3
Modulus x 105
Hanning window (256 pts)
FT
-1000
-500
1000
500
20
10
15
0
0
5
0 20 40 60 80 100 120
20 40 60 80 100 120
Es031 9-CZDV-2005-09-16 00:50:27
Time [sec]
SPEC
x 107
2.5
2
3
0.5
1.5
1
(c)
Figure 2.14: Le SPEC d'une explosion chimique (a), d'un
séisme local (b) et d'un séisme lointain (c)
2.3.3 Représentation de Wigner-Ville
La représentation de Wigner-Ville (WV: Wigner-Ville)
peut être considérée comme la plus importante TFR. Elle a
été définie au début, dans un contexte de la
mécanique quantique, par Wigner en 1932 et ensuite, introduite dans le
domaine d'analyse des signaux par Ville en 1948. Cependant, elle n'est devenu
très utilisée qu'après la publication des articles de
Claasen et Mecklenbrauker [63, 64, 65]. L'importance de cette
représentation provient de ses caractéristiques
intrinsèques par rapport à d'autres TFRs et son application aux
différentes situations [214]. La distribution de WV est définie
à partir de la représentation temporelle du signal par [63,
109]:
WVx : L2(R) ?
L2(R2)
f 8 (2.19)
x(t) ? W Vx(t, í) = x(t -u 2)x*(t
+u 2)e-i2ðíudu
En comparaison avec la STFT, la WV a un avantage pratique:
l'utilisateur n'a pas à se soucier du choix de la fenêtre
d'analyse ni de sa longueur. En fait, l'equation (2.19) montre que la
fenêtre d'analyse du signal x(t) est le signal lui-même
renversé. Ce fenêtrage adaptatif permet une concentration
excellente des motifs et permet à la WV de présenter la meilleur
précision temps-fréquence des TFRs actuelles [172]. Cependant,
comme pour le spectrogramme, cette TFR souffre aussi de la limitation de la
résolution temps-fréquence pour lesquelles nous démontrons
les inégalités ci-dessous.
Théorème 2.3 (Version Wigner-Ville de
l'inégalité d'Heisenberg-Gabor en í). Soit x ?
L2(R), alors on a l'inégalité:
? ? 1/2 ? ? 1/2
f 8 f 8 f 8 kxk3 L2(R)
?
t2|x(t)|2dt ? ? í2|W
Vx(u, í)|2dudí ? = 2ð (2.20)
-8 -8
-8
( f8 )1/2
avec xML2(R) = |x(t)|2dt .
-8
Démonstration. Supposons que les intégrales
de l'inégalité (2.20) sont finis. Nous avons, pour un signal x
réel à énergie finie,
|
WVx(t,í) =
|
Z8
-8
|
u u
x(t - 2)x(t +
2)e-i2ðíudu
|
En faisant le changement de variable y = t +u
2, nous obtenons:
WVx(t,í) = Z8 x(y) [2x(2t - y)e-2
iðí(v-2t)] e-2iðívdy
-8
donc la représentation de WV d'un signal réel,
n'est que la STFT de ce signal par une fenêtre d'analyse h où:
h*(t - y) = 2x(2t - y)e-2iðí(v-2t)
Par conséquent, pour obtenir l'inégalité
(2.20), il suffit de changer la norme de h dans l'inégalité
(2.15) par 2 x L2 (R). ~
De la même façon, nous pouvons prouver le
théorème ci-dessous, en utilisant cette fois-ci
l'inégalité (2.16).
Théorème 2.4 (Version Wigner-Ville de
l'inégalité d'Heisenberg-Gabor en t). Soit x ? L2(R),
alors on a l'inégalité:
|
( f 8 ) 1/2 ( f8 )1/2
f 8
í2|F
Tx(í)|2dí t2|W Vx(t,
í)|2dtdí
-8 -8 -8
( f8 )1/2
avec xML2(R) = |x(t)|2dt .
-8
|
(2.21)
IIxII3 ,2(R)
= 2ð
|
A partir de ces deux théorèmes, nous avons le
résultat suivant:
|
Corollaire 2.2. Soit x ? L2(R), alors on a
l'inégalité:
((f 8 ) 1/2 ( f 8 )1/2
f 8 f 8
t2|W
Vx(t, í)|2dtdí í2|W
Vx(u, í)|2dudí
-8 -8 -8 -8
f 8 )
1/2 ( f 8 )1/2 = iixii6 L2(R)
t2|x(t)|2dt í2|F
Tx(í)|2dí4ð2
-8 -8
|
(2.22)
|
1/2
( f8 )
avec xML2(R) = |x(t)|2dt .
-8
Démonstration. Il suffit de multiplier les termes
des inégalités (2.20) et (2.21) pour
obtenir
l'inégalité (2.22). ~
Remarque:
De l'inégalité (2.22), nous constatons qu'il y a
un dilemme entre la résolution temps- fréquence de la
représentation de Wigner-Ville et celle de la transformée de
Fourier. En effet, en augmentant la résolution de l'une, l'autre diminue
et vice-versa.
La WV est une transformation régulière, ce qui
la permet d'avoir des performances supérieures en comparaison avec les
transformations singulières dans certains problèmes de
classification des signaux [143, 139, 125]. En plus de sa vérification
de plusieurs propriétés
mathématiques désirables dans une TFR [143] et
particulièrement la covariance
(propriétéfortement souhaitable pour discriminer les
signaux [79]), toutes les représentations de la classe de Cohen [68]
s'obtienent par la double convolution temps-fréquence de la WV:
Cöx: L2(R) ?
L2(R2)
x(t) ? Cö x(t, õ) = f8
f8 ç(u - t, f - õ)WVx(u, f)dudf (2.23)
où ç est le noyau de la TFR. Par conséquent,
le SPEC peut être obtenu par un noyau ç(t, í) = WVh(t,
í).
Comme toutes les représentations quadratiques, la
représentation de WV entraîne des termes d'interférences
à cause du principe de la superposition quadratique. Ces termes
d'interférences, dont la géométrie a été
l'objet de plusieurs études [16, 144], se car-
40
actérisent par l'apparition d'un point d'interference
pour chaque deux points du plan temps-fréquence provenant de deux
composantes différentes. Ce qui apparaît sous formes
d'oscillations dont la direction est perpendiculaire à la droite liant
les deux points du signal.
Exemple 2.6: La WV d'un signal à deux composantes non
superposables.
Nous considérons le signal 82 de l'exemple (2.2)
constitué de deux composantes de fréquences 100Hz et 300hz non
superposables. La WV du signal est donné par la figure (2.15).
En comparaison avec le SPEC, nous constatons l'apparition des
termes d'interférences dans la représentation de WV même si
les deux composantes sont non superposables. Ceci est justifiable par le fait
que dans ces régions, la WV ne présente que des
interférences fluctuant rapidement entre valeurs positives et
négatives et se compensent si nous faisons une moyenne locale. Ce qui
amène le SPEC à avoir des valeurs proches de zéro dans ces
régions.
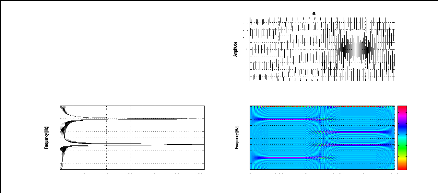
0 50 100 150 200 250 300 350 400 450
10 20 30 40 50 60
Modulus
FT
-0.2
-0.4
-0.6
-0.8
0 50 100 150 200 250 300 350 400 450
0.8
0.6
0.4
0.2
0
0 0.05 0.1 0.15 0.2
0 0.05 0.1 0.15 0.2 0.25
Time [sec]
ignal S2
WV
0.25
20
0
-10
-20
-30
10
Figure 2.15: Le WV d'un signal à 2 composantes non
superposables
La représentation des signaux sismiques par le module
de la WV est illustrée par la figure (2.16) où l'influence des
interférences rend très difficile la caractérisation du
type de l'événement par la voie visuelle.
41
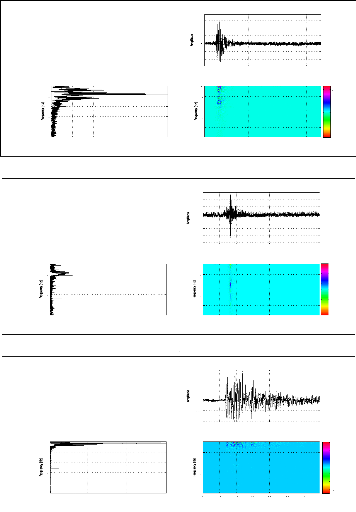
Es0001-TIS -2003-01-22 13:11:23
600
400
200
0
-200
-400
0 10 20 30 40 50 60 70
WV
FT
x 106
0
0
5
5
5
10
10
0
15
15
20
20
-5
0 10 20 30 40 50 60 70
Time [sec]
0.5 1 1.5 2 2.5
Modulus x 104
(a)
(c)
Es0429-JBB -2005-05-06 02:47:39
1500
1000
500
0
-500
-1000
-1500
-2000
0 20 40 60 80 100 120
x 107
FT
WV
0
0
4
3
5
5
2
1
10
10
0
-1
15
15
-2
20
-3
20
-4
0 20 40 60 80
100 120
Time [sec]
0.5 1 1.5 2 2.5 3
Modulus x 105
Es0319-CZDV-2005-09-16 00:50:27
1000
500
0
-500
-1000
0 20 40 60 80 100 120
WV
FT
x 107
0
0
6
4
5
5
2
10
10
0
15
15
-2
-4
20
20
-6
0 20 40 60 80 100 120
Time [sec]
0.5 1 1.5 2 2.5 3
Modulus x 105
(c)
Figure 2.16: Le module de la WV d'une explosion chimique (a),
d'un séisme local (b) et d'un séisme lointain (c)
42
2.3.4 Représentations à interférences
réduites
La lisibilité des représentations
temps-fréquences étant un facteur essentiel pour l'analyse des
signaux non stationnaires. Ainsi, il est souhaitable de diminuer le nombre et
l'amplitude des interférences. Une première étape, dans ce
cadre, consiste à ne représenter que des signaux analytiques afin
d'éliminer les termes interférentiels provenant des interactions
entre les composantes portées par les fréquences positives et
celles portées par les fréquences négatives (figure
(2.17)). Une seconde étape consiste alors à exploiter la
structure oscillante des interférences, ce qui suggère
d'introduire une opération de lissage
dans le plan temps-fréquence. Appliqué à
la représentation de WV, ce lissage conduit
àl'évaluation du produit de convolution
suivant:
öTF(t, u) * WVx(t, u)
Ce qui conduit explicitement aux éléments de la
classe de Cohen. Donc, le SPEC peut être vu comme une version
lissée de la WV du signal par un noyau égal à la WV de la
fenêtre d'analyse h, ce qui atténue les interférences.
Cependant, ce lissage provoque l'étalement de la distribution
d'énergie dans les régions associées au signal, conduisant
le SPEC à une perte de concentration [167, 174, 144].
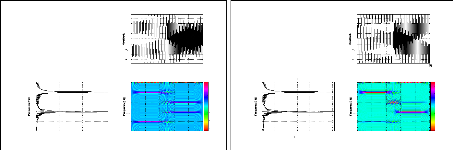
200
400
100
300
0
10 20 30 40 50 60
Modulus
FT
-0.2
-0.6
200
300
400
100
0.8 0.6 0.4 0.2
0.4
0.8
0
0
0 0.05 0.1 0.15 0.2 0.25
0 0.05 0.1 0.15 0.2 0.25
Time [sec]
Signal
WV
20
10
0
20
30
10
200
300
400
100
0
10 20 30 40 50 60
Modulus
FT
-0.2
-0.6
200
300
400
100
0.8 0.6 0.4 0.2
0.4
0.8
0
0
0 0.05 0.1 0.15 0.2 0.
0 0.05 0.1 0.15 0.2 0.25
Time [sec]
Signal
WV
60
40
20
0
-20
-40
-60
(a) (b)
Pour le choix de öTF, plusieurs alternatives
sont envisageables. En effet, nous pouvons choisir un noyau de lissage fixe ou
adapté. Pour le premier cas, la solution la plus naturelle consiste
à utiliser un filtre passe-bas bidimensionnel indépendant du
signal analysé. Un certain nombre de représentations repose sur
ce principe, parmi lesquelles on compte celle de Choï-Williams (CW) et la
pseudo Wigner-Ville lissé (SPWV: Smoothed Pseudo Wigner-Ville) [109].
Pour le deuxième cas, la solution consiste à paramétrer un
noyau de lissage et à l'optimiser au sens d'un critère
donné dépendant du signal à analyser. La figure (2.18)
donne la représentation de trois signaux sismiques via la SPWV où
les fenêtres de lissage sont de type Gauss de largeur 128 points. Il est
clair, après la réduction des interférences, qu'il est
possible de caractériser le type d'événement de la
même façon qu'on a fait pour le SPEC.
44
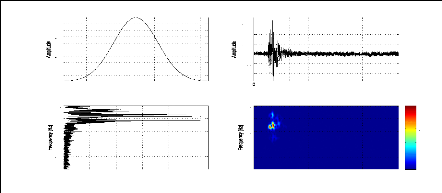
0.9
0.8
0.7
0.6
0.5
0.4
0.3
0.2
0.1
20
10
15
0
5
0 20 40 60 80 100 120
0.5 1 1.5 2 2.5
Modulus x 104
Gauss window (128 pts)
FT
-200
-400
400
600
200
20
10
15
0
0
5
0 10 20 30 40 50 60 70
10 20 30 40 50 60 70
Es0001-TIS -2003-01-22 13:11:23
Time [sec]
SPWV
x 105
4
2
8
6
0
(a)
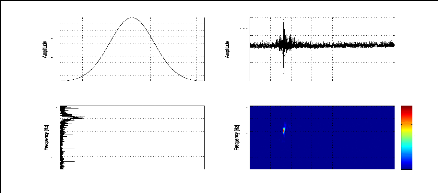
0.9
0.8
0.7
0.6
0.5
0.4
0.3
0.2
0.1
20
10
15
0
5
0 20 40 60 80 100 120
0.5 1 1.5 2 2.5 3
Modulus x 105
Gauss window (128 pts)
FT
-1000
-1500
-2000
-500
1500
1000
500
20
10
15
0
0
5
0 20 40 60 80 100 120
0 20 40 60 80 100 120
Es0429-JBB -2005-05-06 02:47:39
Time [sec]
SPWV
x 106
4
2
8
6
0
10
(b)
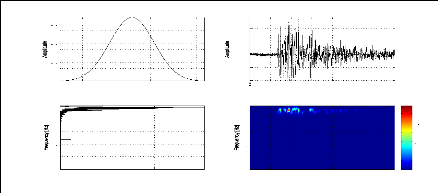
0.9
0.8
0.7
0.6
0.5
0.4
0.3
0.2
0.1
20
10
15
0
5
0 20 40 60 80 100 120
0.5 1 1.5 2 2.5 3
Modulus x 105
Gauss window (128 pts)
FT
-1000
-500
1000
500
20
10
15
0
0
5
0 20 40 60 80 100 120
20 40 60 80 100 120
Es031 9-CZDV-2005-09-16 00:50:27
Time [sec]
SPWV
x 10
4
2
8
6
0
12
10
6
(c)
Figure 2.18: La SPWV d'une explosion chimique (a), d'un
séisme local (b) et d'un séisme lointain (c)
2.4 Représentations temps-échelle
Les méthodes basées sur la STFT ont des
résolutions temporelles et fréquentielles fixes. Il est par
conséquent difficile de faire une mesure précise des composantes
d'un signal à la fois dans les hautes et les basses fréquences.
Pour vaincre ce problème, les représentations
temps-échelle (TSRs: Time-Scale Representations) présentent une
alternative intéressante dans la mesure de pouvoir analyser les
composantes de hautes et de basses fréquences du signal en adoptant
automatiquement une résolution temps-fréquence adéquate.
Dans ce sens, ces représentations sont considérées aussi
comme des TFRs [145]. Mais nous utilisons, dans ce mémoire, la
nomination originale temps-échelle pour les caractériser des TFRs
à résolution fixe.
Comme les TFRs, les TSRs peuvent être réparties
en des représentations linéaires et quadratiques. Pour le cas
linéaire, on trouve les ondelettes et pour le cas quadratique, la classe
affine constitue la classe la plus intéressante des TSR covariantes
[258, 145, 109, 239]. En effet, cette classe, comme la classe de Cohen, est
unitairement équivalente aux classes de puissance et hyperbolique [79]
et admet une formulation similaire à l'equation (2.23) à partir
de la WV par le biais d'une transformation affine [110, 258, 145]. Parmi les
éléments de cette classe, en plus de la WV, on trouve le
scalogramme, la distribution de Bertrand [39] et la distribution de Flandrin
[109] (le lecteur pourra se référer à [239] pour d'autres
représentations).
Dans ce paragraphe, nous restreignons à la
présentation de la transformée en ondelettes continues (CWT:
Continuous Wavelet Transform) et au scalogramme (SCAL: Scalogram). Ces deux
représentations ont montré une grande efficacité dans le
domaine de la géophysique [117] et plus particulièrement dans le
traitement des signaux sismiques utilisés dans la caractérisation
des sous-sols [48, 263].
2.4.1 Transformée en ondelettes continues
La définition de la CWT est proche de celle de la STFT,
où la fenêtre modulée h(t)ei2ðõt a
été remplacée dans l'équation (2.11) par une
ondelette [222, 130, 109]:
|
CWT x ø : L2(R) ?
L2(R2)
x(t) ? CWT x ø (a, t) =
|
|
x(u) * a,t(u)du
|
(2.24)
|
où a > 0 est le paramètre d'échelle (ou
de dilatation), t est le paramètre de position (ou de translation) et
a,t : u?1 va (u-t
a ) représente une famille de fonctions appelées
ondelettes analysantes (ou ondelettes filles) dérivant toutes de la
même ondelette mère .
L'équation (2.24) donne les coefficients d'ondelette
(nombre à valeur généralement complexe) contenant toutes
les informations dont on a besoin pour conduire une analyse
multi-échelle. En effet, changer la valeur de a permet de dilater (a>
1) ou de contracter (a < 1) la fonction a,t
(propriété d'analyse multi-échelle); changer t autorise
l'analyse de la fonction x(t) au voisinage de différents points t
(propriété d'analyse locale). Lorsque le paramètre
d'échelle a croît, l'ondelette couvre une plus grande fraction du
signal permettant d'extraire le comportement à long terme de x(t). Au
contraire, lorsque a diminue,
la fraction du signal analysée diminue et rend possible
l'étude des variations locales àhautes
fréquences. Pour une étude comparative entre l'analyse de Fourier
et l'analyse par ondelettes le lecteur pourra se référer à
[312].
Ainsi par ses propriétés de
dilatation-contraction et de translation, la CWT est caractérisée
dans le plan espace-échelle par une fenêtre dont la largeur
diminue lorsque on se focalise sur les structures de petite échelle
(haute fréquence) ou s'élargit lorsque'on s'intéresse au
comportement à grande échelle (basse fréquence). Cette
capacité d'adaptation en fonction de l'échelle d'analyse lui a
valu la dénomination de «microscope mathématique» dont
le grossissement est donné par1 a et dont l'optique est
donné par le choix de la fonction mère [219].
le domaine fréquentiel par la condition
d'admissibilité suivante:
|
Cø =
|
Z8
-8
|
|F Tø(!)|2
|!| d! <+8 (2.25)
|
et on dit que est admissible. Cette condition étant
relativement souple, un assez grand nombre de fonctions peuvent convenir. Aussi
impose-t-on souvent des contraintes supplémentaires de
régularité, de décroissance rapide ou de compacité
suivant les besoins. Il convient de bien cerner le problème à
étudier et d'être guidé par diverses considérations
incluant, en particulier, une base physique [175] ou à défaut la
ressemblance entre le signal analysé et la famille d'ondelette choisie
[119].
Outre ses propriétés de localisation, une
ondelette possède la propriété de s'annuler en zéro
dans le domaine de Fourier, ce qui simplifie énormément la
condition d'admissibilitédans certains cas comme le montre le
théorème ci-dessous.
Théorème 2.5. Soit ? L2(R) fl
L1(R). Alors les deux assertions suivantes sont équivale
ntes:
1. est admissible,
2. 78 (t)dt = 0 soit FTø(0) = 0.
Démonstration. La démonstration de ce
théorème se trouve dans [278]. ~
La condition d'admissibilité assure la possibilité
de reconstruire un signal à partir de ses coefficients d'ondelettes.
Cette transformée inverse est donnée par [278]:
|
1
x(t) = Cø
|
Z8 Z8
-8 8
|
a-2CWT x ø (a, u) a,u(t)dadu (2.26)
|
Remarque:
Dans les cas où il n'est pas nécessaire de
reconstruire le signal, la fonction ? L2 (R)
Comme toutes les TFRs, la CWT soufre de la limitation de ses
résolutions temporelle et fréquentielle à cause du
principe d'incertitude d'Heisenberg-Gabor (2.13). Le théorème
ci-dessous donne une version de ce principe en t pour la CWT.
Théorème 2.6 (Version ondelette de
l'inégalité d'Heisenberg-Gabor). Soit x E
L2(118) et e une ondelette, alors on a
l'inégalité:
00
8-8
avec 11x11L2(R) = ( i: 1/2
lx(t)12dt) .
8 1/28 81/2
(I y2|FTx (y)|2dy) (
iit2 a- 12 |CWTxe (a,
t)|2dadt > ,V4re
lx112L2(R) (2.27)
Démonstration. Supposons que les deux
intégrales dans l'inégalité (2.27) sont finies. A partir
de la condition d'admissibilité (2.25), nous avons:
Ce f8
y2|FTx(y)|2dy = f8
|'i3(|â|)|2
dâ f8
y2|FTx(y)|2dy
|
=
|
f8
|
f8
|
y2|FTe(ay)|2|FTx(y)|2|a|-1dady
|
(2.28)
|
et en utilisant l'expression de la CWT par le biais de l'IFT:
CWT (a, t) = I FT (FTx (y) ,V|a|
FT*e (ay))(t)
on obtient:
|
i88-i88
|
y2|FT ø (y)| 2 a2 dady = C
nWTx (a,t) -- e
|
I
|
y2|FTx(y)|2dy (2.29)
|
En appliquant l'inégalité d'Heisenberg-Gabor
(2.13), nous avons:
8
1/2 8
(
O'8 t2| CWTxe (a, t)
| 2 dt) (f y2|FTn/uxø (a,t) (y)|2dy) 1/2
-8
7 |nWTxø(a,t)|2dt
8
>
4ð
d'où
1/2 1/2
f [( f8 t2|CWTxø(a, t)|2dt) ( f
í2|FTCWTxø(a,t)(í)|2dí) 1 a2
-8 -8 -8
>
I, I, |CWTxø(a,t)|2 ada dt
4ð
et par la propriété de la conservation
d'énergie,l'inégalité de Cauchy-Schwarz et en utilisant
l'égalité (2.29), nous obtenons:

1/2 ( 8 8 ) 1/2
( f f t2| CWTxø (a, t)|2dtdj
WT
,t
(a,t)(í)|2dídaaffí2|FTC
) 1/2 ) 1/288
o
= ( f f |CWTxø(a,
t)|2dtd; ,VCø ( f í2|FTCWTx
ø (a,t) (í)|2 dí
-8 -8 -8
1/2 8 1/2
> f [( cf°
t2|CWTxø(a, t)|2dt) ( f
í2|FTCWTxø(a,t)(í)|2dí) 1 da2
-8 -8 -8
> C4/r111x112L2(R)
Finalement, en divisant par ,VCø , nous obtenons
l'inégalité (2.27).
2.4.2 L'ondelette de Ben
Dans la littérature, on trouve plusieurs ondelettes qui
ont été utilisées, particulièrement pour
l'exploration du sol par analyse des signaux sismiques. Nous citons:
l'ondelette de Morlet [78], l'ondelette de Berlage [7], l'ondelette de Ricker
[254, 62] et l'ondelette chapeau Mexicain [78]). Dans ce paragraphe, nous
essayons de présenter une nouvelle ondelette complexe dite ondelette de
Ben qui a été utilisée avec succès par l'auteur
dans plusieurs travaux de classifications des signaux non stationnaires dont
les signaux sismiques en font partie [36, 75, 31].
Deux ondelettes particulièrement populaires pour la CWT
sont l'ondelette chapeau mexicain (dérivée seconde d'une
gaussienne) et l'ondelette de Morlet [78]. La première est une ondelette
réelle et symétrique donnée par [190]:
)
-8 -8
2
3
ømh(t) = ð-1/4(1 --
t2)e-t2/2
(2.30)
.V
Ce qui permet de ne pas introduire de déphasage dans la
transformée en ondelettes contrairement à des ondelettes non
symétriques (comme le sont les ondelettes orthonormales à support
compact d'Ingrid Daubechies [78]. De plus, comme étant issue de la
dérivée d'une ondelette (Gaussienne), elle est
particulièrement adaptée à la détection des
discontinuités. Quant à l'ondelette de Morlet complexe, sa forme
complète est donnée par [4]:
ømc(t) = -1/4(eiù0t -
e-ù2 0/2)e-t2/2 (2.31)
où w0 est sa fréquence centrale. Le terme
e-ù2 0/2 est un terme de correction utilisé
pour remplir la condition de moyenne nulle nécessaire pour
l'admissibilité. En pratique, ce terme devient négligeable pour
des valeurs w0 = 5 (la valeur proposée par Morlet est 5.33). Ce qui a
poussé la majorité des chercheurs à utiliser une forme
dite standard de l'ondelette Morlet [102, 190, 4, 3]:
øms(t) = -1/4eiù0te-t2/2 (2.32)
Cette ondelette est à valeurs complexes et à
oscillations faibles [4], permettant ainsi à extraire des informations
sur l'amplitude et la phase du processus analysé [302].
Numériquement, on peut la considérer à support compact.
Enfin, le meilleur avantage de cette ondelette est qu'avec une fenêtre
gaussienne, les composantes sont caractérisées par des ensembles
de points connexes contenant un maximum local sur l'image du module. Une
composante apparaît alors comme un dôme d'énergie [57] ce
qui facilite la compréhension de l'image temps-fréquence.
Pour les signaux sismiques (non stationnaires,
multicomposantes), afin de profiter des propriétés
intrinsèques de l'ondelette de Morlet et l'ondelette chapeau Mexicain,
nous considérons, la fonction ci-dessous (2.33) que nous l'appellerons
par la suite « ondelette de Ben» [30, 36, 75, 31, 35, 32]:
2
øben(t) = v3 -1/4(1 - t2)eiù0te-t2/2
(2.33)
avec w0 = 7. En vérifiant la condition
d'admissibilité cette fonction peut être
considérée
comme ondelette admissible (voir les théorèmes
(2.5) et (2.7)).
Théorème 2.7. La fonction donnée par
l'équation (2.33) est une ondelette asymptotique- ment admissible.
Démonstration. Afin de montrer que la fonction
'l/)ben(t) = 2 v3ð-1/4(1 -
t2)eiù0te-t2/2 est une ondelette asymptotiquement admissible, nous
montrons que 'l/)ben ? L2 fl L1 et qu'elle a une moyenne nulle quand
w0 ? 8 (voir théorème (2.5)).
· 'l/)ben ? L2:
R8 | 'l/)ben(t) |2 dt = R8 |
'l/)mh(t).eiù0t |2 dt
= R8 | 'l/)mh(t) |2 . |
eiù0t |2 dt
= R8 | 'l/)mh(t) |2 dt
et puisque 'l/)mh est une ondelette normalisée
[190], c'est-à-dire, R8 | 'l/)mh(t) |2 dt = 1,
alors R8 | 'l/)ben(t) |2 dt = 1.
· 'l/)ben ? L1:
R8 | 'l/)ben(t) | dt = R8 |
'l/)mh(t).eiù0t | dt
= R8 | 'l/)mh(t) | . | eiù0t |
dt
= R8 | 'l/)mh(t) | dt
et puisque 'l/)mh est une fonction absolument
integrable, c'est à dire, R8 | 'l/)mh(t) | dt <
8, alors R8 | 'l/)ben(t) | dt < 8.
· R8 'l/)ben(t)dt = 0:
-8
R8 'l/)ben(t)dt =
v3ð-1/4(1 -
t2)eiù0te-t2/2dt
2
R8
4 0
v6ð1/4w2 0e-
ù2 2
= -

= FT * ømh(w0)
0
Il est clair que le terme - 4 v6ð1/4w20e- ù2 2
n'est pas nul. Mais numériquement ce terme est négligeable pour
des valeurs de w0 grandes. Ainsi, pour w0 = 7 sa valeur absolue est
inférieur à 2.5 × 10-9. Et on a
lim
ù0?8
|
(
|
4 0
v6ð1/4 w2 0e- ù2 2) = 0.
|
|
Par conséquent, la fonction 'l/)ben est
asymptotiquement admissible. ~
Afin que la condition de la moyenne nulle soit remplie
exactement, nous pouvons ajouter à 'l/)ben un terme de
correction et la fonction résultante devient une ondelette admissible.
Ce qui est explicité par le théorème ci-dessous.
Théorème 2.8. La fonction
2
'l/)benc(t) =
0)eiù0te-t2/2 (2.34)
v3ð-1/4(1 -
t2 + w2
est une ondelette admissible.
Démonstration. Il est clair que 'l/)benc ? L2 fl
L1. Et on a R8 'l/)benc(t)dt = 0. En effet,
R8 'l/)benc(t)dt =
v3ð
2-1/4(1 - t2 +
w20)eiù0te-t2/2dt
R8
= FT* ømh(w0) + 2ù2
v3 0 F T * øms(0)
= -
4 0
v6ð1/4w2 0e-
ù2 2 + 2
0
2
v3w2 v2ð1/4e - ù2
0
=0
Donc d'après le théorème (2.5),
'l/)benc est une ondelette admissible. ~
Remarques:
· 'l/)ms et 'l/)ben sont,
respectivement, la modulation d'une Gaussienne et de 'l/)mh.
· 'l/)ben est plus oscillatoire que 'l/)mh. Ce
qui est explicité par la figure (2.19).
53
· Comme pour la STFT, le module de la CWT permet une
interprétation facile des composantes du signal (exemple (2.7)).
Exemple 2.7: Le module de la CWT d'un signal à deux
composantes non
superposables.
Nous considérons le signal 82 de l'exemple (2.2)
constitué de deux composantes 100Hz et 300Hz. Le module de la CWT du
signal en utilisant les ondelettes 'l/)ms, 'l/)mh et
'l/)ben présentées sur la figure (2.19), est donné par la
figure (2.20) pour le cas d'une échelle entre 0.1 et 30 avec un pas de
0.5. Nous constatons que les trois ondelettes permettent de détecter le
changement de fréquence et le nombre de composantes.
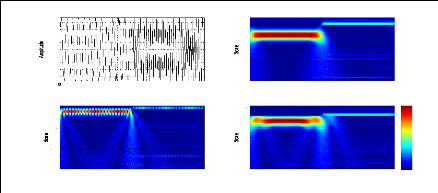
-0.2
-0.4
-0.6
-0.8
0.8
0.6
0.4
0.2
20
25
10
15
0
0
5
0 0.05 0.1 0.15 0.2 0.25
0.05 0.1 0.15 0.2 0.25
Modulus- Mexican hat wavelet
Time [sec]
Signal S2 Modulus- Morlet wavelet
20
25
20
25
30
10
15
10
15
0
5
0
5
0 0.05 0.1 0.15 0.2 0.25
0 0.05 0.1 0.15 0.2 0.25
Modulus- Ben wavelet
Time [sec]
Time [sec]
2.5
2
0.5
1.5
1
Figure 2.20: Le module de la CWT d'un signal à 2
composantes non superposables
Pour le cas des signaux sismiques come étant des
signaux non stationnaires multicomposantes, la visualisation du module de la
CWT nous permet de différencier entre les différents types de
signaux. Ce qui est explicité dans la figure (2.2 1) pour le cas d'une
explosion chimique, d'un séisme local et d'un séisme lointain.
Cependant
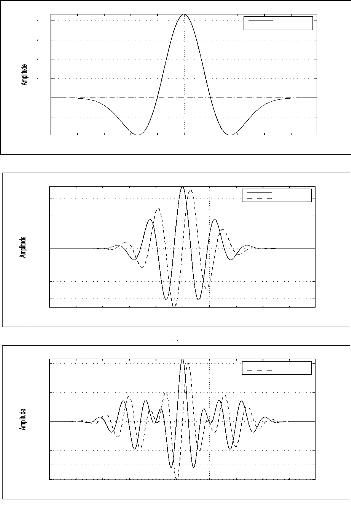
Mexican hat wavelet
Real part Imag part
0.8
0.6
0.4
0.2
0
-0.2
t
-5 -4 -3 -2 -1 0 1 2 3 4
(a)
(c)
Morlet wavelet
Real part Imag part
0.6
0.4
0.2
0
-0.2
-0.4
-0.6
t
-5 -4 -3 -2 -1 0 1 2 3 4
(c)
Ben wavelet
0.8
Real part Imag part
0.6
0.4
0.2
0
-0.2
-0.4
-0.6
-0.8
t
-5 -4 -3 -2 -1 0 1 2 3 4
55
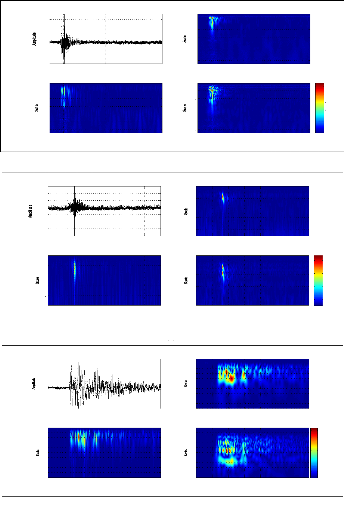
-200
-400
400
200
600
20 40 60 80 100
120
0
0
0 10 20 30 40 50 60 70
0 10 20 30 40 50 60 70
Es0001 -TIS -2003-01-22 13:11:23
Modulus- Mexican hat wavelet
Time [sec]
Time [sec]
60 80 100 120
60 80 100 120
40
40
20
20
0 10 20 30 40 50 60 70
0 10 20 30 40 50 60 70
Modulus- Morlet wavelet
Modulus- Ben wavelet
Time [sec]
Time [sec]
400
200
800
600
1200
1000
(a)
Es0429-JBB -2005-05-06 02:47:39
Modulus- Morlet wavelet
1500
1000
500
0
-500
-1000
-1500
-2000
0 20 40 60 80 100 120
Time [sec]
Time [sec]
Modulus- Mexican hat wavelet
Modulus- Ben wavelet
3500
2
3000
2500
4
2000
6
1500
1000
8
500
10
0 20 40 60 80 100 120
Time [sec]
Time [sec]
5 10 15 20 25 30 35
40
0 20 40 60 80 100 120
5 10 15 20 25 30 35
40
0 20 40 60 80 100 120
(b)
(d)
Es0319-CZDV-2005-09-16 00:50:27
Modulus- Morlet wavelet
1000
500
0
-500
-1000
0 20 40 60 80 100 120
100 120
Time [sec]
Time [sec]
Modulus- Mexican hat wavelet
Modulus- Ben wavelet
7000
10 20 30 40 50 60 70 80 90 100
20 40 60 80 100 120 140 160 180 200
6000
5000
4000
3000
2000
1000
0 20 40 60 80 100 120
0 20 40 60 80 100 120
Time [sec]
Time [sec]
20 40 60 80 100 120 140 160 180
200
0 20 40 60 80
Figure 2.21: Le module de la CWT pour une explosion chimique (a),
un séisme local (b) et un séisme lointain (c)
2.4.3 Scalogramme
Le scalogramme (SCAL: Scalogram) est l'équivalent dans la
classe affine du SPEC dans la classe de Cohen (sa version Q-constant [145]). Il
est donné par [107, 108]:
SCALø x : L2(R) ?
L2(R2)
(2.35)
x(t) ? SCALø x(a,t) = | CWT x ø (a,t)
|2
Il s'obtient aussi par un lissage de la WV du signal avec un
noyau qui est lui même la WV du signal de référence qui
utilise la transformée linéaire qui lui est associée
à savoir l'ondelette ø:
SCALø x : L2(R) ?
L2(R2)
x(t) ? SCALø x(a, t) = (2.36)
WVx(s, î)WVø(s-t
a , aî)dsdî
2ð
Le SCAL présente les mêmes
propriétés que celles du SPEC. Cependant, le SCAL est
préférable pour les signaux sismiques que le SPEC grâce
à la propriété Q-constant qui est adaptée à
la nature physique de ces signaux et même la raison de la
définition des ondelettes par Morlet et al. [222]. Ce point de vue est
repris par les articles de synthèse [56] et [190] en
géophysique.
La figure (2.22) présente, respectivement, les
scalogrammes de trois événements sismiques: explosion chimique,
séisme local et séisme lointain pour l'ondelettes de Morlet,
l'ondelette chapeau mexicain et l'ondelette de Ben. Nous constatons qu'à
l'aide du SCAL, nous pouvons différentier entre les trois
événements sismiques de la même façon que le SPEC.
Cependant, le choix des échelles d'analyse pour chaque ondelette reste
un facteur essentiel pour avoir une meilleur représentation.
Généralement, ce choix est empirique mais cela n'exclut pas
l'existence de certaines suggestions comme celles présentées dans
[302]. De plus, nous notons que les SCALs relatifs au séisme local ne
sont pas tellement clairs pour pouvoir visualiser les composantes à
cause de la faiblesse du signal.
57
-200
-400
600
400
200
2
3
4
5
6
7
8
9
10
0
1
0 10 20 30 40 50 60 70
0 10 20 30 40 50 60 70
Es0001-TIS -2003-01-22 13:11:23
SCAL- Mexican hat wavelet
Time [sec]
Time [sec]
5 10 15 20 25 30 35
40
0 10 20 30 40 50 60 70
20
25
30
35
40 0
0 10 20 30 40 50 60 70
5 10 15
SCAL- Morlet
SCAL- Ben wavelet
Time [sec]
Time [sec]
wavelet
x 105
8
6
4
2
16
14
12
10
(a)
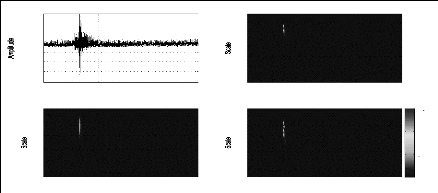
-1000
-1500
-2000
-500
1500
1000
500
10
2
4
0
6
8
0 50 100
0 50 100
Es0429-JBB -2005-05-06 02:47:39
SCAL- Mexican hat wavelet
Time [sec]
Time [sec]
5 10 15 20 25 30 35 40
5 10 15 20 25 30 35
40 0
0 50 100
0 50 100
SCAL- Morlet wavelet
SCAL- Ben wavelet
Time [sec]
Time [sec]
x 106
5
15
10
(b)
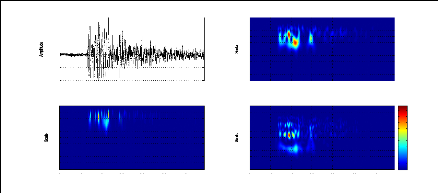
-1000
-500
1000
500
10 20 30 40 50 60 70 80 90 100
0
0 20 40 60 80 100 120
0 20 40 60 80 100 120
Es0319-CZDV-2005-09-16 00:50:27
SCAL- Mexican hat wavelet
Time [sec]
Time [sec]
20 40 60 80 100 120 140 160 180
200
0 20 40 60 80
20 40 60 80 100 120 140 160 180 200
0 20 40 60 80 100 120
SCAL- Morlet
SCAL- Ben wavelet
Time [sec]
Time [sec]
wavelet
100 120
x 107
5
4.5
4
3.5
3
2.5
2
1.5 1 0.5
(c)
Figure 2.22: Les scalogrammes relatifs à une explosion
chimique (a), un séisme local (b) et un séisme lointain (c)
2.5 Conclusion
Nous avons présenté dans ce chapitre les
différentes représentations possibles pour les signaux non
stationnaires en générales et les signaux sismiques en
particulier. Dans ce sens, des versions du principe d'Heisenberg-Gabor ont
été démontrées pour le cas du spectrogramme, la
représentation de Wigner-Ville et la transformée en ondelette
continue. Pour cette dernière, nous avons conçu une nouvelle
ondelette complexe dite ondelette de Ben permettant de mieux représenter
les signaux sismiques. En ce qui concerne l'analyse des performances de ces
représentations dans le cadre de la discrimination des signaux sismiques
via un système modulaire, le lecteur pourra se référer au
chapitre 5.
Nous notons que ce chapitre présente avec certains
détails les éléments de bases de ce qui est appelé
discrimination visuelle dans le logiciel MSSSA (Moroccan Software for Seismic
Signals Analysis) présenté dans l'annexe I.
La représentation des signaux non stationnaires dans un
espace bidimensionnel temps-fréquence ou temps-échelle conduit
généralement à des images de grandes dimensions en
fonction de la durée du signal, de la fréquence
d'échantillonnage et du nombre de points de la fenêtre d'analyse.
Ainsi, il est très difficile à les utiliser directement pour la
discrimination à cause du problème de la malédiction de la
dimensionnalité. Pour vaincre ce dernier et augmenter la
séparabilité des classes, une réduction de la
dimensionnalité de ces images s'avère nécessaire. Ce volet
fera l'objet du prochain chapitre.
CHAPITRE 3
REDUCTION DE LA DIMENSIONNALITE
Les représentations bidimensionnelles des signaux
sismiques dans les espaces temps- fréquence et temps-échelle
fournissent généralement des images de grandes dimensions. Or,
Les espaces vectoriels de grandes dimensions possèdent des
propriétés qui réduisent sensiblement les performances des
méthodes automatiques de classification à cause du
problème de la malédiction de la dimensionnalité (Curse of
dimensionality). Par conséquent, la réduction de la
dimensionnalité doit être une partie intégrante du
processus global de classification automatique des signaux sismiques.
Pour les signaux sismiques, à la différences des
autres signaux non stationnaires, les images fournies par les TFRs et les TSRs
sont de dimensions variables sur l'axe temporel. En effet, la durée des
événements sismiques diffère de l'un à l'autre
même pour des événements de même nature. Ceci est
dû au fait que la longueur du signal sismique enregistré est
lié aux instants d'activation et de désactivation de l'algorithme
de détection qui dépendent aussi de la magnitude et de la
distance hypocentrale de l'événement. Ainsi, pour avoir des
images sismiques ayant la même taille, tous les travaux
précédents font un découpage du signal en conservant des
durées bien déterminées avant et après le temps
d'arrivée. Or, avec cette méthode, on pourra enlever
l'information pertinente et, par conséquent, les performances de
classification se dégradent.
Le but de ce chapitre est, d'une part, de mettre en
évidence l'objectif de la réduction de la dimensionnalité
des données de grandes dimensions et, d'autre part, de présenter
deux méthodes, à savoir, l'analyse en composantes principales et
la projection aléatoire. Enfin, pour les signaux sismiques, nous
proposons trois algorithmes de réduction de la dimensionnalité
invariantes aux translations temporelles.
3.1 Espaces de grandes dimensions
Les espaces de grandes dimensions possèdent des
propriétés mathématiques particulières qui
affectent le comportement des méthodes d'analyse et de traitement des
données dans ces espaces. Ce problème est connu sous le nom de la
malédiction de la dimensionnalité qui fait
référence aux difficultés du traitement des données
qui apparaissent dans les espaces de grandes dimensions.
3.1.1 La malédiction de la dimensionnalité
Selon Donoho [89], l'expression « malédiction de la
dimensionnalité » a été utilisépour
la première fois par Bellman [28] qui l'a utilisé ce terme en
référence à la difficultéde faire l'optimisation
par des méthodes exhaustives dans les espaces de grandes dimen-
sions. Optimiser une fonction à plusieurs variables par
une méthode exhaustive consiste à partitionner le domaine de
chacune des variables à intervalles réguliers, ce qui permet
d'instaurer une grille cartésienne dans l'espace de recherche. Chaque
point d'intersection de cette grille est un optimum possible. Il s'agit alors
d'évaluer la fonction de coût en chacun de ces points et de
choisir l'optimum global. Seulement, le nombre d'optimums possibles, et donc
d'évaluations nécessaires, croît exponentiellement avec la
dimension de l'espace de recherche (le nombre de variables). Ainsi, si l'on
souhaite optimiser une fonction à d variables par une méthode
exhaustive et si cette fonction est lipschitzienne alors
(1/å)d évaluations sont nécessaires pour obtenir
une approximation minimale avec une erreur å sur les variables.
L'expression «malédiction de la
dimensionnalité» est aussi utilisée en statistique. Elle
fait référence à la relation entre la taille de
l'échantillon de données et la précision de l'estimation.
Dans [89], il a été démontré que le nombre
d'échantillons doit augmenter exponentiellement avec la dimension pour
garder le même niveau de précision de l'estimation.
61 Plusieurs travaux se sont intéressés à
ce problème et ont montré que les performances des techniques
d'apprentissages se dégradent lorsque la dimension des données
augmente [308, 309]. Ainsi, pour le cas de données de grandes
dimensions, le phénomène de la «concentration de la
mesure» [287] implique que plus la dimension des données augmente,
plus les vecteurs ont tendance à se concentrer autour de leur moyenne.
Par conséquent, les arguments utilisés par les réseaux de
neurones sont constants [310] et aucune adaptation ne peut être faite.
3.1.2 Normes des vecteurs aléatoires
Les propriétés des espaces de grandes dimensions
sont très différentes de ce que l'on peut imaginer dans les
espaces à une, deux ou trois dimensions. Dans ce sens, il a
étéprouvé par Demartines [82] que
l'écart type de la norme de vecteurs aléatoires converge vers une
constante quand la dimension augmente. Plus précisément, nous
avons le résultat ci-dessous.
Théorème 3.1. Soit X un vecteur en n dimensions
[X1, X2,
·
·
· , Xn] dont les composantes
sont aléatoires, indépendantes, de loi identique et
possédant un moment d'ordre 8 fini. On a:
/1kxk = E(kXk) = van - b + O(1/n)
(3.1)
u2 kxk =Var(MXM) =b+O(1/n)
où a et b sont des paramètres dépendant
uniquement des moments centrés d'ordre 1,2,3 et 4 des Xi:
a = /12 + u2
4/12u2 - u4 + 4/1/13 +
/14
b = 4(/12+u2)
où /1r est le moment centré d'ordre r:
/1r = E[(Xk - /1)r], /1 est la moyenne E(Xk) et u2 la
variance Var(Xk)
La signification de ce résultat est que, à
partir d'un certain nombre de composantes, les vecteurs x semblent
normalisés. En effet, quel que soit le type de distribution des
composantes xk,l'~ecart-type ó11x11de la norme tend vers une
constante lorsqu'on augmente la dimension n, tandis que la moyenne
,u11x11 croît en /n. Plus précisément, à
cause de
l'inégalité de Chebychev:
11x11
P( MxM - ,u11x11 ~ å) = ó2
å2
la probabilité que la norme MxM tombe en dehors d'un
intervalle de taille fixé autour de ,u11x11 devient approximativement
constante quand n augmente. Comme ,u11x11 lui-même continue
à augmenter, l'erreur relative commise en prenant ,u11x11au
lieu de MxM devient négligeable. Ainsi en grandes dimensions, des
vecteurs aléatoires (dont les composantes suivent une loi donnée)
semblent tous répartis à la surface d'une sphère de rayon
,u11x11. Ce qui engendre le phénomène de la
concentration de la mesure.
Les implications de ce phénomène sont multiples.
Pour un n fixé, outre la norme elle-même des vecteurs qui semble
invariable d'un tirage à l'autre, la distance Euclidienne entre deux
vecteurs semble aussi invariable (quel que soit le couple de vecteurs choisi).
En effet, la distance Euclidienne est la norme de la différence entre
les deux vecteurs aléatoires, différence qui est aussi un vecteur
aléatoire; donc cette distance suit les règles (3.1). Ce qui
rejoigne les conclusions du théorème ci-dessous.
Théorème 3.2. Soient q un vecteur requête
choisi indépendamment d'un ensemble de
vecteurs aléatoires xi,
où 1 i m de dimension n constituant l'ensemble de données
et
soit dist(q, x) une variable aléatoire qui suit la distribution de la
distance entre le
vecteur requête q Fq et le vecteur de
données x Fdata leurs densités de
probabilitérespectivement. Si
|
lim
n?+8
|
Var(dist(q, x))
|
= 0 (3.2)
|
|
alors, quel que soit å> 0,
|
E(dist(q, x))2
|
|
lim
n?+8
|
P [|(DMAXn/DMINn) - 1 > å] = 0
(3.3)
|
dist(q, x) : fonction qui donne la distance entre les vecteurs q
et x; DMAXn = max {dist(q, xi), 1 = i = m};
DMIN n = min {dist(q, xi), 1 = i = m}.
Démonstration. La démonstration de ce
théorème se trouve dans [40]. ~
A partir de ces résultats, il est ainsi très
important de s'assurer de l'existence d'une réelle similarité
entre les vecteurs de données avant d'envisager leur classification.
Donc, le recours aux techniques de réduction de la
dimensionnalité, pour les données de grandes dimensions, est
nécessaire.
3.2 Techniques de réduction de la
dimensionnalité
Plusieurs méthodes pour la réduction de la
dimensionnalité ont été développées dans
divers travaux. Ces méthodes permettent de transformer les
données dans un nouvel espace de dimension réduite n gardant le
maximum d'information portée par les données dans leur espace
original. Mathématiquement, le problème que visent à
résoudre ces méthodes peut se formuler de la manière
suivante: étant donnée une variable aléatoire dimension d,
il s'agit de trouver une autre représentation de dimension
réduite p < d, qui exprime la même information que les
données originales selon un certain critère.
Les méthodes de réduction de la
dimensionnalité sont classées généralement en deux
grandes catégories: les méthodes linéaires et les
méthodes non linéaires. Dans cette section, on présente
deux méthodes linéaires, à savoir, l'analyse en
composantes principales (PCA: Principal Component Analysis) et la projection
aléatoire (RP: Random Projection).
3.2.1 L'analyse en composantes principales
La PCA est sans doute la méthode de réduction de
la dimensionnalité la plus connue et la plus utilisée. Selon la
littérature, elle trouve ses origines dans les travaux de Hotelling dans
les années 30, de Karhunen et Loève dans les années 40.
C'est une méthode de second
ordre car elle se base uniquement sur l'étude de la
matrice de covariance des variables (les moments d'ordre 2). Il existe
plusieurs variantes de la PCA, en fonction du domaine d'application, elle est
connue sous le nom de décomposition en valeurs singulières (SVD),
transformée de Karhunen-Loève (KLT), transformée de
Hotelling ou bien encore méthode de fonction orthogonale empirique
[111]. Dans [121], une analyse approfondie des relations entre PCA, KLT et SVD
est donnée.
La PCA consiste à chercher un nouvel espace de
représentation dont les axes sont orthogonales et assurent une
dispersion maximale des données selon chacun d'eux. Ces axes sont
appelés axes principaux. La quantité d'information portée
par chacun des axes est relative à la variance des données: plus
la variance des données selon un axe est
grande, plus l'information portée par celui-ci est
importante. En fait, la PCA consiste àeffectuer une
translation suivie d'une rotation du repère de l'espace. La
réduction de la dimensionnalité s'effectue en éliminant
les axes qui portent peu d'information.
Plusieurs méthodes ont été
développées pour accomplir la PCA [53]. On se limite dans ce
paragraphe à la présentation d'une méthode matricielle
basée sur la matrice de la covariance pour les deux cas unidimensionnel
(PCA1D: One-Dimensional PCA) et bidimensionnel (PCA2D: Two-Dimensional PCA).
3.2.1.1 PCA unidimensionnelle
Soit A1, A2,
·
·
· , AN l'ensemble des
données dont on dispose, sous la forme de vecteurs de n.
Supposons que ces données sont centrées et notons W la matrice
constituant une base orthonormée du sous-espace de dimension d où
on veut représenter les données. Ainsi, la projection orthogonale
des vecteurs A avec i = 1,
·
·
· , N sur W E
n×d est donnée par:
Apca1d = W'A (3.4)
et par conséquent la matrice de covariance des
données projetées peut s'écrire:
où la matrice Sdata est la matrice de
covariance des données initiales:
|
1
Sdata = N
|
XN
=1
|
A A' (3.6)
|
Le critère à maximiser, basé sur la
dispersion des données projetées, est donc:
J(W) = tr(W'SdataW) (3.7)
On peut montrer que les colonnes de W sont constituées
des d vecteurs propres orthonormés de la matrice Sdata
associées aux plus grandes valeurs propres [171]. La valeur propre
associée à chaque vecteur propre est une mesure du pourcentage de
variance expliqué par ce vecteur propre. Ainsi, pour déterminer
la valeur de la dimension d, on peut se baser sur l'étude du spectre des
valeurs propres À de Sdata en fixant la valeur de la
fraction:
qui exprime la quantité d'information qu'on désire
conserver.
Le sous-espace principal vérifie donc deux
propriétés majeures. La première est que, pour une
dimension d fixée, il minimise l'erreur Euclidienne moyenne de
reconstruction å, calculée selon:
|
å =
|
1
N
|
XN
=1
|
kA -
|
Xd
j=1
|
(WjW ' jA )M (3.9)
|
La seconde est que la PCA1D permet de décorréler
les variables, dans un sens que les matrices de covariance des données W
' jA projetées sur chacun des axes discriminants Wj sont
diagonales, pour tout j allant de 1 à d. Cette propriété
assure la non-redondance des variables projetées, et donc le
caractère optimal du sous-espace principal choisi, pour une dimension d
fixée.
3.2.1.2 PCA bidimensionnelle
L'application de la PCA unidimensionnelle pour les images
consiste à les transformer en vecteurs par simple concaténation
des lignes ou des colonnes. Or, cette modélisation unidimensionnelle
engendre dans une certaine mesure la perte d'une partie de la structure
bidimensionnelle des images initiales. De plus la dimension des vecteurs-images
ainsi obtenus est généralement très grande, ce qui pose un
certain nombre de problèmes.
Afin de pallier ces inconvénients, Yang et autres
auteurs [328, 329] ont introduit une technique qu'ils ont baptisée
PCA2D, qui consiste en l'application de la PCA directement sur les matrices
images, utilisant pour cela une matrice de covariance
généralisée calculée directement depuis les lignes
des images.
Soit A1, A2,
·
·
· ,AN l'ensemble des
données dont on dispose, sous la forme de matrices de
n×g . Supposons que ces données sont centrées et
notons W la matrice de projection de taille g x d dans le sous-espace de
dimension d où on veut représenter les données. Ainsi, la
projection des matrices A avec i = 1,
·
·
· , N est
donnée par:
Apca2d = A W (3.10)
où Apca2d est la matrice de taille n x d correspondant
à la projection de la matrice-image A sur W. On cherche à
déterminer la matrice W qui, pour une taille g x d donnée,
maximise le critère J(W):
J(W) = tr(W'SdataW) (3.11)
|
avec
|
1
Sdata = N
|
XN
=1
|
A' A (3.12)
|
Ce critère est appelé critère de
dispersion totale généralisé. On peut montrer que les
colonnes de la matrice W maximisant le critère (3.11) sont les vecteurs
propres de la matrice Sdata, associés aux d plus grandes
valeurs propres [329].
les performances de la PCA2D par rapport à la PCA1D.
Cependant, la modélisation des données n'est pas totalement
bidimensionnelle (comme pourrait le laisser penser le nom de la technique),
mais bidimensionnelle orientée en lignes (PCA2DRO: PCA2D Raw Oriented).
Ce résultat est exprimé par le théorème suivant
[318]:
Théorème 3.3. La PCA2D est équivalente
à la PCA1D appliquée sur l'ensemble des lignes des images.
Démonstration. La démonstration de ce
théorème se trouve dans [319, 183]. ~
A partir de ce théorème, il est clair que la
PCA2D est unidirectionnelle. Ce qui implique une perte de l'information
incorporée dans les colonnes des images. Afin d'avoir une
modélisation bidirectionnelle, plusieurs solutions ont été
proposées [334, 335, 183, 158], mais il est difficile de les mettre en
oeuvre dans le cas général. Dans ce sens, nous proposons une
méthode, dite par la suite PCA2D orientée en colonnes (PCA2DCO:
PCA2D Column Oriented), basée sur la transposée des matrices
images et qui est équivalente à la méthode dite
»Aternative 2DPCA» dans [335] mais dont la mise en oeuvre suit la
même démarche que la PCA2DRO.
Théorème 3.4. La PCA2D appliquée sur la
transposée des images est équivalente à la PCA1D
appliquée sur l'ensemble des colonnes des images.
Démonstration. Soit A1, A2,... ,AN l'ensemble
des données dont on dispose, sous la forme de matrices de
n×g . Et soit B1, B2,... , BN leurs transposées.
Appliquer la PCA2D sur les matrices Bi avec i = 1,... , N, n'est que la PCA1D
appliquée sur les lignes des Bi d'après le théorème
3.3. Or les lignes des Bi ne sont rien d'autre que les colonnes des Ai. ~
Afin d'avoir une analyse en composantes principales
bidimensionnelle en lignes et en colonnes, on pourra utiliser la forme
bidirectionnelle de la PCA2D (PCA2D2D: PCA2D bidirectional), qui consiste
à effectuer la PCA2DRO et PCA2DCO et de faire la projection dans les
deux sens:
68
Remarques:
· La PCA2DCO est équivalente à l'alternative
2DPCA montré par Zhang et Zhou
[335]. En effet, la matrice (3.12) des
matrices Bi avec i = 1,··· , N se calcule par:
Sdata = 1 N PN B' iBi
i=1
=
|
1
N
|
PN
i=1
|
Pg
j=1
|
Bi(j, .)Bi(j, .)'
|
(3.14)
|
|
Ai(., j)Ai(., j)'
1
N
=
PN
i=1
Pg
j=1
d'où la formule donnée par Zhang et Zhou [335].
· Pour la PCA2D2D, une méthode a
été proposée par Kong et al. [183] qui consiste à
trouver simultanément les deux matrices Wpca2dro
et Wpca2dco en applicant un algorithme d'optimisation.
3.2.2 La projection aléatoire
La RP est considérée, ces dernières
années, parmi les méthodes les plus performantes de
réduction de la dimensionnalité pour les données de
très grandes dimensions. Elle a été appliquée avec
succès dans divers domaines: [21, 201, 126, 268, 289, 20, 105, 112, 207,
52, 41, 76, 191, 236, 176, 157, 181].
L'intérêt de cette méthode provient d'un
lemme dite de «Johnson-Lindenstrauss» [170] présenté
ci-dessous:
Lemme 3.1. Soit > 0 etsoientn etk deux entiers positifs
tel que k = k0 = O( -2log(n)). Alors, pour tout ensemble P de n
points dans Rd, il existe f : Rd ? Rk tel que
pour tout u, v ? P
(1- )Mu - vM2 = Mf(u) - f(v)M2 = (1+ )Mu
- vM2
69
Depuis, ce lemme a connu plusieurs versions au niveau de
sa formulation et au
niveau des méthodes de démonstration
[113, 157, 77] et même des extensions ont
étéprouvées [217, 6]. Cependant, la forme de
l'application f dite «application de Johnson-
Lindenstrauss» reste un champ ouvert pour les
chercheurs. Ainsi, il existe plusieurs démonstrations du lemme (3.1) qui
considèrent f comme une application linéaire
représentée par une matrice aléatoire. Une breve
description de son évolution est donnée par Achlioptas [1].
Une première solution consiste à faire une
projection par le biais d'une matrice aléatoire orthonormale. Ainsi, la
projection aléatoire d'une matrice A de taille n × g est
donnée par [113]:
Arp = AR (3.15)
où R est une matrice aléatoire orthonormale de
taille g × d.
Afin de surmonter les difficultés posées par
l'othogonalisation de la matrice R, dont l'objectif est de preserver les
similarités entre les vecteurs d'origine dans les espaces de petites
dimensions, on pourra profiter d'un résultat de Hecht-Nielsen [140]:
«Dans les espaces de grandes dimensions, il existe un grand nombre de
directions presque orthogonales que orthogonales». Ainsi, la matrice R
pourra être prise comme matrice aléatoire normalisée [41,
126].
Dans un but de simplifier les calculs, plusieurs travaux ont
été effectués pour trouver d'autres formes de la matrice
de projection R. Dans ce sens, Arriaga et Vempala [15, 14] ont montré le
théorème suivant:
Théorème 3.5. Soient > 0,u, v ?Rn
et u1 et v1 leurs projections dans Rk par une matrice
aléatoire R ? Rn×k dont les éléments sont
choisis indépendamment à partir de N(0, 1) ou U(-1, 1). Alors,
Prob[(1 - )Mu - vM2 = Mu1 - v1M2 = (1+
)Mu - vM2] = 1 - 2e-(å2-å3) k 4
probabilitée déefinie par:
Rij =
|
? ?
?
|
+1 avec une probabilitée 1/2
--1 avec une
probabilitée 1/2
|
|
Démonstration. La démonstration de ce
théorème se trouve dans [15]. ~
Remarque:
Ce théorème a été
présenté la première fois dans [14], mais nous avons
préféré citer la version existant dans l'article [15].
Une autre forme de la matrice de projection, appelée par
Li et al. [199] «projection aléatoire creuse», a
été présenté par Achlioptas [1] en montrant le
théorème ci-dessous. Théorème 3.6. Soit P un
ensemble arbitraire de n points dans Rd, repréesentées
par la
matrice A de taille n x d. Soient , â ~ 0 et
4+ 2â
k0 = 2/2 -- 3/3log(n)
pour tout entier k ~ k0, soit R une matrice aléeatoire de
taille d x k, où les éeléements Rij sont déefinis
indéependamment selon l'une des distributions de probabilitée
suivantes:
Rij =
|
? ?
?
|
+1 avec une probabilitée 1/2
--1 avec une
probabilitée 1/2
|
,
|
|
Soit
|
V'
Rij = 3
|
? ????
????
|
+1 avec une probabilitée 1/6
0 avec une
probabilitée 2/3
--1 avec une probabilitée 1/6
|
.
|
|
1
E= V' AR
k
et soit f : Rd , Rk qui lie la
ime ligne de A avec la ime ligne de E. Avec une
probabilitée
71
au moins 1 - n-â, pour tout u, v ? P, on a:
(1- )Mu - vM2 = Mf(u) - f(v)M2 = (1+ )Mu
- vM2
Démonstration. La démonstration de ce
théorème se trouve dans [1]. ~
Ce théorème a été étendu
par Li et al. [199] pour d'autres types de distributions de probabilité
en définissant ce qu'ils ont appelé «la projection
aléatoire générale» et «la projection
aléatoire très creuse». Un résultat très
récent de Baraniuk et al. [21] permet de définir la matrice de
projection à partir des distributions de probabilité
vérifiant une inégalité dite «inégalité
de concentration» relative au phénomène de la concentration
de la mesure (section: La malédiction de la dimensionnalité).
3.3 Algorithmes pour les images sismiques
Les signaux sismiques, à la différence de la
plupart des autres signaux non stationnaires, ont des dimensions variables sur
l'axe temporel. En effet, la durée des événements
sismiques diffère de l'un à l'autre même pour des
événements de même nature. Ceci est dû au fait que la
longueur du signal sismique enregistré est liée aux instants
d'activation et de désactivation de l'algorithme de détection.
Ainsi, pour avoir des images sismiques ayant la même taille, tous les
travaux précédents font un découpage du signal en
conservant des durées bien déterminées avant et
après le temps d'arrivée. Or, avec cette méthode, on
pourra enlever l'information pertinente et, par conséquent, les
performances de la discrimination se dégradent.
Dans ce sens, nous proposons trois algorithmes permettant la
réduction de la dimensionnalité des images sismiques en se basant
sur les méthodes présentées ci-dessus.
3.3.1 Algorithme 1
d'une machine de classification. Et soit A la matrice
correspondante au signal sismique que l'on veut classifier. Afin de
réduire la dimensionnalité de cette représentation, nous
proposons l'algorithme suivant qui a été utilisé avec
succès dans plusieurs travaux [30, 31, 35, 36, 75]:
Etape 0: Fixer les paramètres du descripteur atemporel,
de la RP et de la PCA1D;
Etape 1: Calculer la RP de l'ensemble des matrices
Ai pour parvenir à des matrices
Arp
i ayant même taille;
Etape 2: Calculer les valeurs du descripteur atemporel selon
lignes de chaque ma-
trice Arp
i ;
Etape 3: Faire la PCA1D à la matrice
générée par les vecteurs colonnes tirés de
l'étape 2, pour trouver les composantes principales;
Etape 4: Calculer la RP à la matrice A pour parvenir
à une matrice Arp ayant la même taille que les matrices
Arp
i ;
Etape 5: Appliquer le descripteur atemporel selon les lignes de
la matrice Arp;
Etape 6: Faire multiplier le vecteur issue de l'étape 5
par la matrice des composantes principales issue de l'étape 3.
|
|
Algorithme 3.1: Réduction de la dimensionnalité
des images sismiques via la RP et la PCA1D
Cet algorithme, grâce à la projection
aléatoire, permet de surmonter le problème de la détection
de l'origine temporel des signaux non stationnaires avec une longueur variable
dont les signaux font partie. Le calcul du descripteur atemporel (par exemple
la moyenne) au niveau de chaque canal fréquentiel est une façon
de caractériser une classe de signaux. Cependant, cette technique est
généralement très sensible aux bruits et seul le choix du
descripteur adéquat au cas étudié permet
d'améliorer sa robustesse. Quant
au calcul des composantes principales, il peut être
considéré, en plus de la réduction de la
dimensionnalité, comme une classification préliminaire des
signaux étudiés.
3.3.2 Algorithme 2
Soient A1, A2,
·
·
· , AN les
matrices correspondantes à la représentation bidimensionnelle,
par une TFR ou une TSR, des signaux sismiques constituants la base
d'apprentissage d'une machine de classification. Et soit A la matrice
correspondante à un signal sismique que l'on veut classifier. Afin de
réduire la dimensionnalité de cette représentation, nous
proposons l'algorithme suivant [34, 37]:
Etape 0: Fixer les paramètres de la RP et de la
PCA2D2D;
Etape 1: Calculer la RP de l'ensemble des matrices Ai pour
parvenir à des matrices
Arp
i de même taille;
Etape 2: Faire la PCA2DOR aux matricesArp
i pour générer la matrice de com-
posantes principales selon les lignes;
Etape 3: Faire la PCA2DOC aux matricesArp
i pour générer la matrice de com-
posantes principales selon les colonnes;
Etape 4: Calculer la RP de la matrice A pour parvenir à
une matrice Arp de même taille que les matrices Arp
i ;
Etape 5: Faire la PCA2D2D à la matrice Arp en
utilisant les composantes principales issues des étapes 2 et 3.
|
|
Algorithme 3.2: Réduction de la dimensionnalité
des images sismiques via la RP et la PCA2D2D
des composantes principales se fait selon les deux dimensions
sans avoir besoin d'une étape intermédiaire comme pour la PCA1D
et sans perdre la structure bidimensionnel des images initiales. Ce qui la rend
plus robuste que le premier algorithme envers les bruits.
3.3.3 Algorithme 3
Soient A1, A2,
·
·
· , AN les
matrices correspondantes à la représentation bidimensionnelle,
par une TFR ou une TSR, des signaux sismiques constituants la base
d'apprentissage d'une machine de classification. Et soit A la matrice
correspondante à un signal sismique que l'on veut classifier. Afin de
réduire la dimensionnalité de cette représentation, nous
proposons l'algorithme ci-dessous.
Etape 0: Fixer les paramètres de la subdivision
(Géométrie et taille), du descripteur (temporel ou atemporel), de
la RP et de la PCA1D;
Etape 1: Calculer la RP de l'ensemble des matrices Ai pour
parvenir à des matrices
Arp
i de même taille;
Etape 2: Subdiviser les images correspondantes aux
matricesArp
i en zones;
Etape 3: Calculer pour chaque image subdivisée la valeur
du descripteur pour toutes les zones;
Etape 4: Faire la PCA1D à la matrice
générée par l'étape 3, pour trouver les composantes
principales;
Etape 5: Appliquer les étapes 1, 2 et 3 à la
matrice A;
Etape 6: Faire la PCA1D à la matrice résultante de
l'étape 5 en utilisant les composantes principales issues de
l'étapes 4.
Dans cet algorithme, nous avons essayé de proposer une
solution intermédiaire entre l'algorithme (3.1), où il y a une
perte de toute information locale à cause de l'utilisation d'un
descripteur atemporel pour toute l'image avant le calcul des composantes
principales, et l'algorithme (3.2) où cette dernière
opération se fait sur l'image sans aucune étape
intermédiaire. En effet, dans l'algorithme (3.3), la subdivision des
images en zones (par exemples rectangulaires) et le calcul des valeurs du
descripteur pour chacune d'elle permet de conserver dans certaine mesure
l'information locale. Cependant, le bon choix de la géométrie des
zones et du descripteur restent des facteurs déterminants pour avoir de
bonnes performances.
3.4 Conclusion
Nous avons présenté dans ce chapitre, d'une
part, certaines propriétés des espaces de grandes dimensions, et
d'autre part, certaines techniques de réduction de la
dimensionnalité. Parmi ces techniques, nous avons explicité
l'analyse en composantes principales (en une et deux dimension) et la
projection aléatoire.
Pour les signaux sismiques et signaux similaires (signaux
physiologiques par exemple), tenant comptes de leur particularités, nous
avons conçue trois algorithmes basés sur
la projection aléatoire et l'analyse en composantes
principales. Ces algorithmes ont ététestés sur
des signaux acquis par l'Institut National de Géophysique via le
logiciel MSSSA
(Moroccan Software for Seismic Signals Analysis)
présenté dans l'annexe I. Le lecteur pourra se
référer au chapitre 6 pour une comparaison des trois algorithmes
en utilisant la moyenne comme descripteur et une géométrie
rectangulaire pour les zones.
Ce chapitre avec le précédent constituent deux
étapes essentiels dans notre système modulaire de discrimination
des signaux sismiques. L'étape suivante est la classification de ces
signaux mais avant de l'aborder, nous consacrons le prochain chapitre à
la présentation des différentes méthodes de
classification.
CHAPITRE 4
METHODES DE CLASSIFICATION
Les méthodes de classification ont pour but
d'identifier les classes auxquelles appartiennent des objets à partir de
certains traits descriptifs. Elles s'appliquent à un grand nombre
d'activités humaines et conviennent en particulier aux problèmes
de la prise de décision automatisée. Il s'agira, par exemple,
d'identifier un événement sismique ou de déclencher un
processus d'alerte à partir des signaux reçus par le
sismomètre. Une première approche possible pour résoudre
ce type de problème est l'approche «systèmes experts».
Dans ce cadre, la connaissance d'un expert (ou d'un groupe d'experts) est
décrite sous forme de règles. Cet ensemble de règles forme
un système expert qui est utilisé pour classifier de nouveaux
cas. Cette approche, largement utilisée dans les années 80,
dépend fortement de la capacité à extraire et à
formaliser les connaissances de l'expert. Nous considérons ici une autre
approche pour laquelle la procédure de classification sera extraite
automatiquement à partir d'un ensemble d'exemples. Un exemple consiste
en la description d'un cas avec la classification correspondante. Par exemple,
on dispose d'un ensemble de signaux sismiques pré-classifiés par
des sismologues. Un système d'apprentissage doit alors, à partir
de cet ensemble d'exemples, extraire une procédure de classification
qui, au vu des caractéristiques du signal, devra décider du type
de l'événement. Il s'agit donc d'induire une procédure de
classification générale à partir d'exemples. Le
problème est donc un problème inductif, il s'agit en effet
d'extraire une règle générale à partir de
données observées. La procédure
générée devra classifier correctement les exemples de
l'échantillon mais surtout avoir un bon pouvoir prédictif pour
classifier correctement de nouvelles descriptions.
Les méthodes utilisées par les systèmes
d'apprentissage sont très nombreuses et sont issues de domaines
scientifiques variés. Les méthodes statistiques supposent que les
descriptions des objets d'une même classe se répartissent en
respectant une structure spécifique à la classe. On fait des
hypothèses sur les distributions des descriptions à
l'intérieur
des classes et les procédures de classification seront
construites à l'aide d'hypothèses probabilistes. La
variété des méthodes viendra de la diversité des
hypothèses possibles. Ces méthodes sont appelées
paramétriques. Des méthodes non paramétriques (sans
hypothèse a priori sur les distributions) ont été
également proposées en statistiques. Les méthodes issues
de l'intelligence artificielle sont des méthodes non
paramétriques. On distingue les méthodes symboliques (la
procédure de classification produite peut être écrite sous
forme de règles), et les méthodes non symboliques (la
procédure de classification produite est de type «boîte
noire»). Parmi les méthodes non symboliques, les plus
utilisées sont basées sur les réseaux de neurones.
Le but de ce chapitre est, d'une part, de présenter
avec certains détails les différentes méthodes de
classification citées ci-dessus et, d'autre part, de donner les
différents paramètres influençant les performances du
réseau perceptron multicouches et les méthodes permettant de les
améliorer. Enfin, tenant compte du fait qu'une approche
multi-décisionnelle est plus performante qu'un seul classificateur, nous
allons présenter différentes façons de combiner les
classificateurs.
4.1 Notion de classificateur
Soit la représentation d'un objet quelconque au moyen
d'un vecteur de caractéristiques X = [x1x2
·
·
· xd]'. Tous les vecteurs qui représentent
l'ensemble des objets peuvent être positionnés dans l'espace
Euclidien Rd, où ils correspondent chacun à un point.
Ceux- ci peuvent alors être regroupés en amas, chacun de ces amas
étant associé à une classe particulière.
Le rôle d'un classificateur est de déterminer,
parmi un ensemble fini de classes, àlaquelle appartient un
objet donné. Donc, il doit être capable de modéliser au
mieux
les frontières qui séparent les classes les
unes des autres (figure (4.1)). Cette modélisation fait appel à
la notion de fonction discriminante, qui permet d'exprimer le critère de
classification de la manière suivante:
79
+
+
-
-
-
-
-
-
+
+
+
+
+
+
-
+
-
-
-
-
-
-
+
-
Figure 4.1: Schéma d'une classification à deux
classes
valeur de la fonction discriminante de la classe w est
supérieure à celle de la fonction discriminante de n'importe
quelle autre classe w3».
Ou encore, sous forme mathématique:
X ?w ? Ö (X) = Ö3(X)?j = 1,2,... ,C;j=6i (4.1)
oùÖ (X) est appelé fonction discriminante de
la classe w , et C est le nombre total de classes.
Soit une fonction cout(i|j), qui désigne le coût
encouru lorsque la classe w est assignée à un objet appartenant
à la classe w3. Le classificateur optimal est celui qui minimise le
coût total obtenu, étant donné une fonction coût
particulière. Une telle fonction peut être définie par la
fonction «zero-one loss» [93]:
ë(i | j) =
|
|
0, i=j
1, i =6 j
|
|
Cette définition signifie que les classifications
correctes n'introduisent aucune perte, et que les classifications incorrectes
introduisent chacune un coût égal, de valeur unitaire. Dans ce
cas, le coût global obtenu sur un ensemble fini d'objets vaut simplement
le nombre d'erreurs de classification. Le classificateur optimal,
également appelé « Bayesien », est alors celui qui
minimise la probabilité d'erreur, c'est-à-dire la
probabilité qu'une classe
incorrecte soit assignée à un objet. Le
critère de classification devient ainsi [93]:
X ?wi ?p(wi|X) =p(wj|X), ?j = 1,2,··· ,C;j =6 i
(4.2)
où p(wi|X) est la probabilité à
posteriori de la classe wi. La classe attribuée à l'objet
représentée par le vecteur X est alors celle dont la
probabilité étant donné X est supérieure à
la probabilité de n'importe quelle autre classe, étant
donné X.
Le calcul exact des probabilités à posteriori
est cependant rarement possible, et des modèles de classificateurs ont
été développés sur base d'autres fonctions
discriminantes que la probabilité à posteriori. Ces
classificateurs peuvent être séparés en trois
catégories distinctes:
· les classificateurs paramétriques, qui sont
entièrement définis par un ensemble fini de paramètres
qu'il suffit de calculer,
· les classificateurs non paramétriques, qui ne
dépendent d'aucun paramètre en particulier,
· les classificateurs dits
«neuronaux», qui intègrent
des fonctions discriminantes à la suite d'un apprentissage par des
exemples.
Pour chaque catégorie ci-dessus, on peut associer trois
types de classificateurs:
· Type classe: dans ce cas, l'avis du classificateur est
binaire. On peut alors représenter la réponse du classificateur
par un vecteur binaire dans lequel '1'indique la classe proposée par le
classificateur. Un classificateur peut aussi produire un ensemble de classes.
Il considère alors qu'un objet appartient à une des classes de
cet ensemble sans donner d'autres informations permettant de discriminer les
classes,
· Type rang: il s'agit d'un classement sur les classes.
Le classificateur indique ce classement en fournissant en sortie un vecteur de
rangs. La classes placée au premier rang de la liste proposée par
le classificateur est considérée comme la plus probable pour un
objet et la classe du dernier rang est la moins probable,
· Type mesure: dans ce cas, le classificateur indique
le niveau de confiance dans sa proposition. La sortie du classificateur est
donc un vecteur de mesures. Cette mesure, normalisée ou non, peut
être une distance, une probabilité à posteriori, une valeur
de confiance, un score, une fonction de croyance, une possibilité, une
crédibilité, une mesure floue, etc.
Chaque type de sortie (classe, rang ou mesure) correspond
à un niveau d'information différent par le classificateur. La
sortie de type classe est la plus simple mais la moins riche en informations.
La sortie de type rang reflète l'ordre de préférence des
propositions fournies par le classificateur. La sortie de type mesure est la
plus riche en informations puisqu'elle reflète le niveau de confiance du
classificateur dans ses propositions.
On note que lorsque les sorties sont de type rang ou de type
mesure, on peut évidemment les transformer en type classe avec perte
d'informations. Ceci consiste à tenir compte uniquement de la
première solution de la liste proposée par chaque classificateur.
pour le type rang, il suffit de choisir la classe qui est placée au
premier rang et les autres classes ne seront pas prises en compte. Pour le type
mesure, il suffit de choisir la classe ayant la meilleur mesure (valeur
minimale ou maximale, selon que la mesure est croissante ou
décroissante).
4.2 Les classificateurs paramétriques
4.2.1 Les classificateurs linéaires
Il s'agit de l'un des plus simples classificateurs qui
puissent être conçus et qui dépendent des techniques
très connues telles que les correlations et les distances Euclidiennes.
Cependant, au sens Bayesien, les classificateurs linéaires ne sont
optimaux que pour les distributions normales avec des matrices de covariance
égales, chose qui n'est pas toujours valable [116].
distributions non normales. Dans ce sens, les fonctions
discriminantes sont de la forme suivante [93]:
Ö (X) = V '
X + v (4.3)
où les valeurs optimales des V et v sont à
déterminer.
Il faut noter que les frontières de décision de
ce classificateur sont convexes, chose qui limite sa flexibilité et sa
précision, et qu'aucun des classificateurs linéaires ne peut
donner des résultats souhaitables pour les distributions qui sont
séparées par la différence de covariance
(covariance-difference) et non par la différence de moyenne
(mean-difference). Dans ce cas, il n'y a aucun choix que d'adopter un
classificateur plus complexe tel que le classificateur quadratique.
4.2.2 Les classificateurs quadratiques
Comme leur nom l'indique, les frontières de
décision fournies par ce modèle de classificateur sont
quadratiques. L'expression générale des fonctions discriminantes
s'expriment:
Ö (X) = X'Q X + V '
X + v (4.4)
où les valeurs optimales des Q , V et v sont à
déterminer.
Parmi les formes utilisées pour ces classificateurs:
Ö (X) = -2(X - M
)'Ó-1
1 (X - M ) (4.5)
où M est le vecteur de caractéristiques moyen des
éléments de la classe w etÓ est la matrice de covariance
des vecteurs de caractéristiques de la classe w .
4.2.3 Le classificateur Gaussien
Les fonctions discriminantes utilisées ici sont
basées sur une estimation paramétrique des fonctions de
répartition des vecteurs de caractéristiques. Ce classificateur
suppose que les éléments de chaque classe possèdent une
distribution Gaussienne multi-variable. Dans
83 la mesure où cette hypothèse s'avère
exacte, le classificateur Gaussien permet d'obtenir les frontières
optimales de décision de Bayes. En effet, le théorème de
Bayes permet de calculer les probabilités à posteriori p(wi |X)
à partir des probabilités à priori p(wi) et des fonctions
de répartition (ou vraisemblances) p(X|wi) selon:
p(wi|X) = p(wi)p(X|wi) (4.6)
p(X)
et la règle de décision optimale (4.2) peut
dès lors être reformulée comme suit:
X ? wi ? p(wi)p(X|wi) = p(wj)p(X|wj)?j =
1,2,
·
·
· ,C;j =6 i (4.7) Lorsque les vecteurs de
caractéristiques suivent une distribution Gaussienne, les vraisemblances
sont estimées par [93]:
1 1
p(X|wi) = exp(-2(X -
Mi)'Ó-1
i (X - Mi)) (4.8)
(2ð)d 2 |Ói|1 2
Le terme (2ð)d 2, constant, peut être omis
pour la classification. En prenant le logarithme, les fonctions discriminantes
du classificateur Gaussien s'écrivent:
Öi(X) = - 2(X -
Mi)'Ó-1
1 i (X - Mi) - 1 2 ln(|Ói|) + ln(p(wi)) (4.9)
Les fonctions discriminantes du classificateur Gaussien ne
diffèrent de celles du classificateur quadratique (4.5) que par un biais
spécifique à chaque classe. Les frontières de
décision entre les classes sont de formes quadratiques. En pratique, les
probabilités a priori p(wi), les vecteurs de caractéristiques
moyens Mi, et les matrices de covariances Ói, sont remplacés par
leurs estimations expérimentales.
4.3 Les classificateurs non paramétriques
4.3.1 L'estimation des probabilités à posteriori
qu'ils sont capable de modéliser à la suite d'un
apprentissage. En outre, l'estimation des fonctions de densités de
probabilité p(X|w ) est le plus souvent contournée, et ce sont
directement les probabilités à posteriori p(w |X) qui sont
estimées. Le principe de cette estimation est le suivant :
Soit N le nombre total de prototypes de vecteurs de
caractéristiques disponibles, de classe connue. Supposons que l'on
place, autour d'un vecteur de caractéristiques X de classe inconnue, une
hypersphère de volume V qui contient k prototypes de classe connue, dont
k sont de classe w . Dans ce cas, une estimation de la probabilité
conjointe p(X, w ), est simplement donnée par :
k /N
pN(X, w ) = (4.10)
V
Une estimation de p(w |X) est alors obtenue selon :
pN(w |X) = pN(X, w )
C
P pN(X,wj)
j=1
k
= (4.11)
k
Cela signifie qu'une estimation de la probabilité
à posteriori que la classe w soit celle de l'objet
représenté par X est simplement fournie par la fraction des
prototypes de classe w contenus dans l'hypersphère. Afin de minimiser le
taux d'erreur de classification, la classe à assigner au vecteur X devra
donc être choisie comme étant celle la plus fréquemment
représentée dans cette hypersphère. Lorsque le nombre de
prototypes disponibles tend vers l'infini, et que l'hypersphère devient
infiniment petite, cette procedure permet d'atteindre asymptotiquement des
performances optimales de classification. En outre, des performances
comparables peuvent également être obtenues en se basant
uniquement sur la classe du seul plus proche voisin de X, comme le montre la
section suivante.
4.3.2 La méthode du plus proche voisin
Le méthode du plus proche voisin (Nearest Neighbor)
consiste à calculer la distance euclidienne entre l'objet à
classifier et tous les vecteurs de caractéristiques disponibles, et la
classe assignée à l'objet est celle du prototype le plus proche
de celui-ci. Les fonctions
discriminantes sont donc de la forme:
1 (X - Xk)'(X - Xk) (4.12)
~i(X) = -min
Xk Eùi
2
Les frontières de décision entre classes sont
linéaires et constituées de nombreux petits polygones convexes,
chacun contenant un seul prototype d'une seule classe. Chaque classe est alors
délimitée par un polygone très complexe, qui n'est pas
nécessairement convexe, ni même d'une seule pièce. Ce
classificateur permet ainsi d'établir des frontières de
décision relativement complexes lorsque suffisamment d'exemplaires de
chaque classe sont disponibles. Ces performances sont toutefois atteintes au
détriment du volume de calcul à effectuer et de la
quantité de mémoire nécessaire, lesquels deviennent alors
prohibitifs.
Cover et Hart [70] ont montré qu'il existe une relation
entre le taux d'erreur minimal de Bayes et le taux d'erreur obtenu à
l'aide de la règle de décision du Plus Proche Voisin. Cette
relation n'est cependant valable qu'asymptotiquement, en considérant que
le nombre de prototypes disponibles pour chaque classe tend vers l'infini. Pour
un problème à C classes, elle se définit comme suit:
C
R* = R = R*(2 - C - 1R*)
(4.13)
où R* est le taux d'erreur de classification
de Bayes, et R le taux d'erreur obtenu asymptotiquement par la règle du
Plus Proche Voisin. En pratique, cette grandeur ne peut qu'être
estimée pour un nombre de prototypes fini N, qui doit être
suffisamment grand pour que l'estimation soit valable.
L'expression (4.13) permet d'obtenir une estimation de la
borne inférieure de la probabilité d'erreur de Bayes:
C - 1 1 - C
R* = C (1 - C - 1R) (4.14)
Ce résultat est très important, car il permet de
comparer les performances d'un classificateur à une valeur
mathématique théorique qui est une borne inférieure du
taux d'erreur de Bayes.
4.3.3 La méthode des K plus proches voisins
Un des inconvénients majeurs de la méthode du
Plus Proche Voisin est que celle-ci présente une sensibilité
élevée aux abords des frontières entre classes. Le plus
proche voisin d'un objet peut être d'une classe incorrecte, alors que la
majorité de ses voisins ne le sont pas. Afin de contrer cet effet, la
classe assignée à un objet peut être celle qui est la plus
représentée parmi les k plus proches prototypes trouvés.
La méthode porte dans ce cas le nom de «k Plus Proches
Voisins» (K-Nearest Neighbor ou K-NN). La fonction discriminante d'une
classe est alors simplement le nombre de prototypes de cette classe qui se
situent parmi les k plus proches voisins de l'objet à classifier:
Öi(X) = > |Xj ? Øk(X)| (4.15)
Xj ?ùi
où Øk (X) désigne les k plus proches voisins
de X.
Un inconvénient majeur de K-NN reste le temps qu'il met
pour classer un nouveau objet: il faut calculer la similarité entre k
prototypes et le nouveau objet, puis décider quelle classe choisir.
Le volume de calcul, ainsi que la quantité de
mémoire, exigés par les classificateurs du type K-NN, sont
cependant souvent prohibitifs, au vu du grand nombre de prototypes à
prendre en considération et de distances à calculer: pour classer
un nouveau objet, il faut calculer la similarité entre k prototypes et
le nouveau objet, puis décider quelle classe choisir. Bien qu'une
recherche exhaustive puisse être évitée en tenant compte
des propriétés triangulaires de la distance Euclidienne, ou du
fait que seuls les prototypes particuliers qui déterminent effectivement
les frontières entre classes soient réellement
déterminants, la mise en application pratique de tels classificateurs
requiert souvent des ressources de calcul très élevées.
4.4 Les classificateurs neuronaux
4.4.1 Introduction
La reconnaissance du fait que le cerveau fonctionne de
manière entièrement différente de celle d'un ordinateur
conventionnel a joué un rôle très important dans le
développement des réseaux de neurones artificiels. Les travaux
effectués pour essayer de comprendre le comportement du cerveau humain
ont menés à représenter celui-ci par un ensemble de
composants structurels appelés neurones, massivement
interconnectés entre eux. Le cerveau humain en contiendrait plusieurs
centaines de milliards, et chacun de ceux- ci serait, en moyenne,
connecté à dix mille autres. Le cerveau est capable d'organiser
ces neurones, selon un assemblage complexe, non-linéaire et
extrêmement parallèle, de manière à pouvoir
accomplir des tâches très élaborées. Par exemple,
n'importe qui est capable de reconnaître des visages, alors que c'est
là une tâche quasiment impossible pour un ordinateur classique.
C'est la tentative de donner à l'ordinateur les qualités de
perception du cerveau humain qui a conduit à une modélisation
électrique de celui-ci. C'est cette modélisation que tentent de
réaliser les réseaux de neurones artificiels.
Haykin [138] en propose la définition suivante:
« Un réseau de neurones est un processus
distribué de manière massivement parallèle, qui a une
propension naturelle à mémoriser des connaissances de
façon expérimentale et de les rendre disponibles pour
l'utilisation. Il ressemble au cerveau en deux points:
1. la connaissance est acquise au travers d'un processus
d'apprentissage;
2. les poids des connections entre les neurones sont
utilisés pour mémoriser la connaissance».
C'est sur la base de cette définition que repose
l'élaboration des réseaux de neurones artificiels.
4.4.2 Du neurone biologique au neurone artificiel
Le neurone biologique est composé de quatre parties
distinctes (figure (4.2)):
le corps cellulaire (cell body) , qui contient le noyau de la
cellule nerveuse; c'est en cet endroit que prend naissance l'influx nerveux,
qui représente l'état d'activité du neurone;
les dendrites (dendrites) , ramifications tubulaires courtes
formant une espèce d'arborescence autour du corps cellulaire; ce sont
les entrées principales du neurone, qui captent l'information venant
d'autres neurones;
l'axone (axon) , longue fibre nerveuse qui se ramifie à
son extrémité; c'est la sortie du neurone et le support de
l'information vers les autres neurones;
la synapse (synapse) , qui communique l'information, en la
pondérant par un poids synaptique, à un autre neurone; elle est
essentielle dans le fonctionnement du système nerveux.
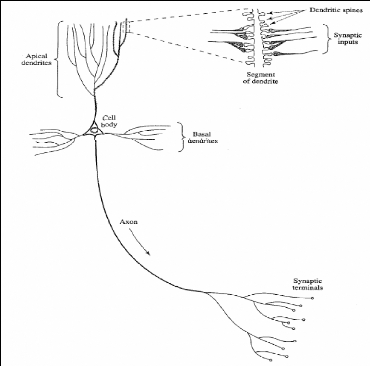
Figure 4.2: Schéma d'un neurone biologique [138]
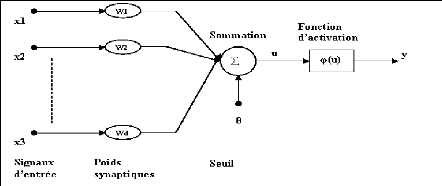
Figure 4.3: Schéma d'un neurone artficiel
Chaque neurone réalise une opération très
simple, qui est en fait une somme pondérée de ses entrées.
Le résultat est comparé à un seuil et le neurone devient
excité si ce seuil est dépassé. L'information contenue
dans le cerveau est représentée par les poids donnés aux
entrées de chaque neurone. Du fait du grand nombre de neurones et de
leurs interconnections, ce système possède une
propriété de tolérance aux fautes. Ainsi, la
défectuosité d'un élément mémoire (neurone)
n'entraînera aucune perte réelle d'information, mais seulement une
faible dégradation en qualité de toute l'information contenue
dans le système. C'est pourquoi nous pouvons reconnaître le visage
d'une personne, même si celle-ci a vieilli, par exemple.
Selon Lippmann [200], la première étude
systématique du neurone artificiel est due au neuropsychiatre McCulloch
et au logicien Pitts qui, s'inspirant de leurs travaux sur les neurones
biologiques, proposèrent en 1943 le modèle de la figure (4.3).
Ce neurone formel est un processeur élémentaire
qui réalise une somme pondérée des signaux qui lui
parviennent. La valeur de cette sommation est comparée à un seuil
et la sortie du neurone est une fonction non linéaire du
résultat:
w x - è (4.16)
Dans le modèle original de McCulloch et Pitts, la non
linéarité était assurée par la fonction seuil de
Heaviside.
4.4.3 Le perceptron
Le perceptron est un réseau présenté
originalement par Rosenblatt en 1959 [187] et constitue la forme la plus simple
de réseaux de neurones. Il permet de classifier des objets appartenant
à deux classes linéairement séparables. Il consiste en un
seul neurone qui possède un seuil ainsi qu'un vecteur de poids
synaptiques ajustables et une fonction d'activation de type Heaviside ou signe,
tout comme le modèle de neurone de McCulloch et Pitts (figure 4.3).
Le perceptron associe à chaque classe une fonction
discriminante linéaire qui s'exprime par: ~i(X) = W ' iX
(4.18) avec:
· Wi = [è w1 w2
· · ·
wd]' est un vecteur de coefficients de pondérations;
· X = [-1 x1 x2 · · · xd]' est le
vecteur des caractéristiques d'un objet à classifier
augmenté par le -1 à l'indice 1.
Dans le cas d'un problème à deux classes, la
règle de classification s'écrit:
X E ù1? 1(X) ~ 2(X), X E ù1 sinon. (4.19)
Le perceptron décrit ci-dessus ne contient qu'un
neurone. Celui-ci ne permet, dès lors, que d'effectuer la classification
dans un problème à deux classes seulement. La reconnaissance de
plusieurs classes est cependant rendue possible par la mise en parallèle
de plusieurs perceptrons (figure (4.4)). Le perceptron ainsi obtenu comporte un
neurone
par classe, chacun de ceux-ci réalisant une fonction
discriminante linéaire de la classe àlaquelle il est
associé.
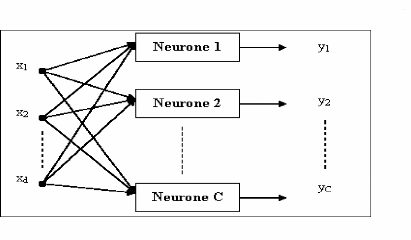
91
Figure 4.4: Schéma d'un perceptron à C neurones
pré-classifiées. Ceci conduit le perceptron
à partitionner l'espace des variables d'entrée en régions
correspondant chacune à une classe, selon des frontières de
décision linéaires, constituées de segments d'hyperplans,
définis par ~i(X) - ~j(X) = 0. Le seuil des neurones permet de
définir des hyperplans qui ne contiennent pas nécessairement
l'origine de l'espace des paramètres.
La règle d'apprentissage du perceptron,
développée originalement par Rosenblatt, converger converge
seulement si les données sont linéairement séparables.
Afin de vaincre cette limitation, une méthode basée sur le
critère des moindre carrés a été
développée par Widrow et Hoif [138].
4.4.4 Le perceptron Multicouches
Les limitations posées par le perceptron, avec le
fameux problème XOR (ou exclusive) de Minsky et Papert [187, 138], ont
mis la question sur l'utilité des perceptrons dans des applications
complexes. Mais c'est eux même qui ont prouvé q'un réseau
de neurones en cascade à deux couches peut surmonter les limitations du
perceptron d'où l'idée de la conception générale du
réseau perceptron multicouches (MLP: Multilayer Perceptron).
aux neurones de la couche suivante [93, 138]. La
première couche s'appelle couche d'entrée, la dernière est
nommée couche de sortie et les couches intermédiaires sont
désignées par le terme couches cachées. Il a
été montré qu'un MLP à deux couches avec des
fonctions d'activation intégrables au sens de Riemann non polynomiales
sur la première couche et une fonction d'activation linéaire sur
la seconde est un approximateur universel [73, 152]. Ceci veut dire que le
réseau est capable d'approximer n'importe quelle fonction lisse avec une
précision donnée, pourvu que l'on fournisse un nombre suffisant
de neurones dans la couche cachée. Cependant, en pratique, il n'est pas
forcément possible d'approximer toute fonction, car dans certains cas le
nombre de neurones nécessaire peut être gigantesque, et il n'est
pas garanti que l'algorithme d'apprentissage pourra converger vers le
résultat souhaité.
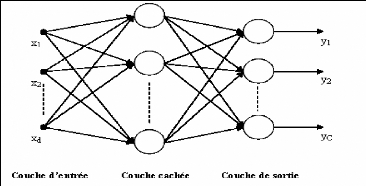
Figure 4.5: Schéma d'un réseau MLP à une
couche cachée
Dans le cas d'un réseau MLP à une seule couche
cachée, les fonctions discriminantes réalisées par un tel
réseau sont de la forme:
(~i(X) = ?2,i -è2,i +
|
Xh1
j=1
|
(w2,ij?1,j -è1,j +
|
Xd
q=1
|
))w1,jqxq (4.20)
|
|
où:
· ?l,i représente la fonction d'activation du
neurone i de la couche l;
· èl,i est le seuil du neurone i de la couche l;
· wl,ij représente le poids entre le neurone i
de la couche l avec le neurone j de la couche l - 1;
· hl est le nombre de neurones de la couche l;
· X = [x1 x2 · · · xd]' est le
vecteur d'entrée.
Les fonctions d'activation des neurones doivent absolument
être non linéaires, sinon le perceptron multicouches ne ferait
qu'implanter une série de transformations linéaires
consécutives, qui pourraient dès lors se réduire à
une seule. Et c'est grâce à l'utilisation de fonctions
d'activations non linéaires que le perceptron multicouches peut
générer des fonctions discriminantes non linéaires.
Le choix de l'architecture optimale d'un réseau
perceptron multicouche reste toujours un problème ouvert et souvent ce
choix se fait par essaie-erreur sur un nombre limité de topologies. En
effet, une recherche exhaustive sur toutes les topologies possibles pour un
réseau MLP est, pratiquement, impossible [221]. Mais parfois certains
résultats tenant compte de l'objectif fixé pourront nous guider
dans le choix de certains paramètres.
4.4.5 Apprentissage du perceptron Multicouches
L'apprentissage des réseaux MLP constitue un point
essentiel dans leur mise en oeuvre. En effet, les performances d'un
réseau sont en étroite relation avec la méthode
d'apprentissage.
4.4.5.1 La rétro-propagation du gradient
La méthode de la rétro-propagation du gradient
(Back propagation) est une méthode d'optimisation utilisée en
particulier dans l'apprentissage des réseaux de neurones, et
conditionnée par la notion de la boucle fermée.
C'est une méthode due à Rumelhart et al. [264],
et consiste à corriger les erreurs selon l'importance des
éléments qui ont justement participé à la
réalisation de ces erreurs. Dans le cas des réseaux de neurones,
les poids synaptiques qui contribuent à engendrer
une erreur importante se verront modifi~es de manière
plus significative que les poids qui ont engendr~e une erreur marginale, de
manière à ce que le r~eseau soit capable de r~ealiser une
transformation donn~ee, repr~esent~ee par un ensemble d'exemples constitu~e
d'une suite de N vecteurs d'entr~ees Xk = [xk1 xk2 · · ·
xkd]' associ~ee à une autre suite de vecteurs de sorties
d- esir- ees T k = [t(k)
1 t(k)
2 · · · t(k)
hL ] ' . Cet objectif est r- ealis-e par
la minimisation d'une fonction coût qui est non-lin~eaire au regard des
poids synaptiques et disposant d'une borne inf~erieure. Parmi ces fonctions,
l'erreur de Minkowski-R [134] dont le critère des moindres carr~es de
l'erreur (MSE: Mean Square Error) n'est qu'un cas particulier obtenu pour R = 2
et s'exprime par:
~
y(k)
L,i - t(k)
i
2
(4.21)
2
1
E=
XhL
i=1
XN
k=1
où:
. N est le nombre d'exemples d'apprentissage;
. L est le nombre de couches du r~eseau;
. hl est le nombre de neurons de la couche l;
. yl, i d-esigne la sortie du neurone i de la couche l
lorsque le vecteur Xk est pr~esent~e
(k)
à l'entr~ee du r~eseau;
. t(k)
irepr~esente la valeur d~esir~ee de la sortie pour le
neurone i de la dernière couche lorsque le vecteur Xk est pr~esent~e
à l'entr~ee du r~eseau.
La minimisation de la fonction coût se fait de
manière it~erative, en utilisant l'algorithme de r~etro-propagation
(Annexe II) selon les ~etapes donn~ees par l'algorithme (4.1)[138].
Etape 1- Initialisation:
- mettre les poids et les seuils d'activation du réseau
à des valeurs aléatoires uniformément
distribuées;
- mettre la valeur du taux d'apprentissage à une petite
valeur positive;
Etape 2- Activation: consiste à présenter les
éléments de la base d'apprentissage en calculant la fonction
coût;
Etape 3- Entraînement des poids: consiste à
mettre à jour les poids du réseau en propageant les erreurs dans
le sense inverse, c'est à dire de la couche de sortie à la
première couche cachée. Cette adaptation se fait selon le mode
d'apprentissage en ligne ou hors ligne;
Etape 4- Itération: consiste à faire itérer
le processus en reprenant de l'étape 2 jusqu'à ce ce que le
critère d'arrêt soit atteint.
Algorithme 4.1: Rétro-propagation du gradient
4.4.5.2 Les algorithmes dérivés d'apprentissage
L'apprentissage des réseaux de neurones est devenu, depuis
la conception de l'algorithme de rétro-propagation du gradient par
Rumelhart et al. [264], un grand champ de recherche qui a suscité
plusieurs questions sur l'efficacité de cette méthode et les
différentes manières pour l'améliorer. La version
originale de la rétro-propagation du gradient (Annexe II) a
été basée sur la minimisation de la fonction coût
((11.1)) tout en adaptant les poids synap-
tiques selon:
?E(k)
wl,ij(ô + 1) =wl,ij(ô) - ç (4.22)
?wl,ij
De ce «problème d'optimisation», il
apparaît plusieurs paramètres sur lesquels nous pourrons apporter
des améliorations. Le premier de ces paramètres est le
critère d'arrêt
de l'algorithme. En effet, généralement la
convergence de l'algorithme n'est pas assurée et il n'y a aucun
critère bien défini pour le stopper sauf bien sure le nombre
d'itérations. Cependant, il y a certains critères empiriques:
Critère 1 [184]: la rétro-propagation est
considérée comme s'elle a convergé quand la
norme
Euclidienne des vecteurs gradient atteint un seuil suffisamment faible;
Critère 2 [138]: la rétro-propagation est
considérée comme s'elle a convergé quand le taux absolu du
changement de l'erreur quadratique par itération est suffisamment
faible.
Le second paramètre est l'utilisation d'autres
distances non Euclidienne au niveau de la fonction coût ((II.1)) tel que
la distance de Minkowski de paramètre différent de 2. Ainsi,
partant du fait que si les vecteurs caractéristiques ne sont pas
Gaussiens, alors le critère ((II.1)) ne pourra être un estimateur
du maximum de vraisemblance des poids, Hanson et Burr [134] ont proposé
d'utiliser l'erreur de Minkowski-r avec r > 2 ou r < 2 pour aboutir
à certains objectifs tel que la réduction de l'effet du bruit
pour les r < 2.
Le troisième paramètre qui a été
l'objet de plusieurs travaux est la fonction coût. Ceci est du à
plusieurs raisons. Il se peut, par exemple, que le critère (II.1) ne
soit pas
la fonction objective optimale pour une tâche donnée
[197]. Le deuxième problème poséest celui des
minimums locaux provenant des faibles valeurs des gradients locaux (voir Annexe
II, equation II.13):
|
8(k)
l,i = _?(u(k)
l ,i )
|
hl+1X
q=1
|
wl+1,qi8(k) (4.23)
l+1,q
|
En effet, lorsque le gradient local relatif à un
neurone est très faible, les corrections appliquées aux poids
synaptiques de ce neurone deviennent alors insignifiantes, conduisant ainsi
à une stagnation de l'apprentissage du perceptron multicouches. Ainsi,
pour le cas d'une fonction d'activation sigmoide:
|
?: x -?
le gradient local pour un neurone i vaut:
|
1(4.24) 1 + exp(-x)
|
1. si est un neurones de la couche de sortie:
8(k)
L,i = y(k)
L,i(1 - y(k)
L,i)(y(k)
L,i - t(k)
i ) (4.25)
2. si est un neurones de la couche cachée l:
|
8(k)
l,i = y(k)
l,i (1 - y(k)
l,i )
|
hl+1>2
q=1
|
wl+1,qi8(k)
l+1,q (4.26)
|
Le produit y(k)
l,i (1 - y(k)
l,i ) , connu sous «sigmoid-prime function» [100]),
tend vers zéro lorsque la sortie est proche de zéro ou de un ce
qui conduit à une stagnation de l'apprentissage. Ce
phénomène se produit quelque soit la valeur de saturation
obtenue, et donc également lorsque celle-ci est à l'opposé
de celle que l'on désire atteindre. Ainsi par exemple, si pour un
neurone de la couche de sortie la valeur de sortie est 0.01 et la valeur
désirée est 1 alors la valeur du gradient local est -0.0098.
Cette valeur est obtenue même pour une valeur de sortie de 0.895376. A la
limite, si une saturation absolue est atteinte, alors aucune adaptation des
poids synaptiques de ce neurone n'est possible, et par conséquent
l'apprentissage reste bloqué dans un minimum local.
Afin de vaincre ce problème, plusieurs solutions ont
été proposées.Ainsi, Fahlman [100] a essayé
d'apporter certaines modifications à la «sigmoid-prime
function» alors que Caruana et al. [54] ont fait une mise à
l'échelle des sorties pour s'éloigner des valeurs zéro et
un. D'autres chercheurs ont proposé d'utiliser des fonctions coût
basées sur l'entropie relative et l'entropie croisée afin de
l'éliminer [213, 306, 234, 233, 173]. On trouve aussi d'autres
méthodes tel que CFM (classification figure-of-merit) [132] et CB
(classificationbased objective functions) [257, 256].
Le quatrième point qui a attiré l'attention des
chercheurs est la réponse à la question: comment
accélérer la convergence de l'algorithme de
rétro-propagation? Avant de répondre à cette question, il
faut savoir pourquoi elle est lente. En fait, c'est pour deux raisons
principales:
poids synaptiques;
2. la direction du vecteur gradient pourrait être loin du
point optimal.
Pour remédier à ces causes, une des solutions
consiste à modifier la formule d'adaptation des poids synaptiques par
l'ajout d'un terme de moment. Dans ce cas, la valeur d'un poids synaptique
n'est plus seulement adaptée proportionnellement à la
dérivée de la fonction coût par rapport à ce poids,
mais est également modifiée en fonction de la correction
appliquée à l'instant précédent. Sous forme
mathématique, la formule d'adaptation des
poids synaptiques s'écrit alors [247]:
?E(k)
wl,ij(ô + 1) - wl,ij(ô) = -ç +
á(wl,ij(ô) - wl,ij(ô - 1)) (4.27)
?wl,i j
où 0 = á = 1 est appelé moment.
Cette expression peut être réécrite sous la
forme:
|
wl,ij(ô + 1) - wl,ij(ô) = -ç
|
Xô
q=0
|
áq ?E(k-q)
(4.28)
?wl,ij
|
Grâce à l'utilisation de ce terme moment, la
direction de recherche du minimum à un instant donné, est une
somme pondérée des gradients actuel et précédents.
La pondération qui intervient, est telle que l'importance relative d'un
gradient décroît exponentiellement au fur et à mesure que
ce dernier est éloigné dans le temps. Le fait de prendre en
compte plusieurs gradients consécutifs aide les poids synaptiques
à traverser les sections plates de la surface de la fonction coût,
après qu'ils en aient descendu des sections abruptes. Ceci permet en
outre de modifier les poids synaptiques, non plus à l'aide d'un
même taux d'adaptation pour l'ensemble de ceux-ci, mais selon un taux qui
est propre à chaque poids, et qui est dépendant de son histoire
particulière.
Les valeurs des paramètres ç et á doivent
être déterminées empiriquement, de manière à
limiter la fréquence d'apparition de deux phénomènes qui
sont opposés, mais qui conduisent tous deux à un net
ralentissement de l'évolution de l'apprentissage.
l'ensemble du système n'évolue alors que
lentement.
· D'autre part, lorsque les valeurs de ces
paramètres sont élevées, des corrections d'amplitude
importante sont appliquées aux poids synaptiques dans les régions
de forte pente de la fonction coût, ce qui peut entraîner une
augmentation de la valeur de cette dernière. Il en résulte ainsi
également un ralentissement de l'évolution de l'apprentissage.
D'autres solutions ont été basées sur
l'adaptation au cours du temps du taux d'apprentissage ç. Parmi les
méthodes proposées, on trouve: Delta-Bar-Delta [160], Quickprop
[100], SuperSAB [301], Auto-détermination [321], Rprop [255].
Les méthodes ci-dessus sont considérées
de premier ordre. Afin d'accélérer l'algorithme de
rétro-propagation, des méthodes, basées
généralement sur la matrice Hessienne [42] de la fonction
coût, dites de second ordre ont été
développées. Parmi ces méthodes: le gradient
conjugué [169], le gradient conjugué régularisé
[220] et les méthodes de Newton [25].
4.4.5.3 Les modes d'apprentissage
Il existe deux modes principaux d'apprentissage, selon la
façon dont les vecteurs de poids synaptiques sont adaptés:
L'apprentissage en ligne consiste à modifier les valeurs
de ces poids synaptiques immédiatement après la
présentation d'un objet. Dans ce cas, seul le gradient
instantanéde la fonction coût est utilisé pour l'adaptation
des paramètres du système. Sous la
condition que les objets soient présentés au
réseau de neurones de manière aléatoire, l'apprentissage
en ligne rend la recherche du minimum de la fonction coût stochastique en
nature, ce qui rend moins probable, pour l'algorithme de
rétro-propagation, de tomber dans un minimum local.
L'apprentissage hors ligne consiste à accumuler les
gradients instantanés consécutifs, et à n'effectuer
l'adaptation des poids synaptiques que lorsque l'ensemble des objets
d'apprentissage ont été présentés au perceptron
multicouches. On parle alors
d'apprentissage hors-ligne. Cette dernière
méthode permet de mieux estimer le gradient réel de la fonction
coût, puisqu'elle est à présent calculée à
partir d'un ensemble d'objets, plutôt qu'à partir d'un seul.
Il existe aussi un autre mode entre les deux, dit
apprentissage mini-batch, qui consiste à présenter successivement
au réseau de neurones un seul exemplaire de chaque classe, d'accumuler
les gradients instantanés, et d'effectuer l'adaptation des poids
synaptiques lorsque, pour chaque classe, un exemplaire aura été
présenté.
L'efficacité relative des modes d'apprentissage en
ligne et hors ligne dépend essentiellement du problème
considéré. L'apprentissage en ligne présente cependant
l'avantage que, pour une seule présentation de l'ensemble de la base de
données, il implique de multiples phases d'adaptations des poids
synaptiques lorsque des données similaires se présentent, ce qui
se produit fréquemment pour des bases de données très
étendues.
4.4.6 Généralisation
Le but général de l'apprentissage
supervisé est, qu'à partir d'une base d'apprentissage, de pouvoir
décider pour d'autres éléments n'appartenant pas à
cette base. Or, le réseau pourrait nous donner de mauvais
résultats quand on lui présentera des données un peu
différentes. Pour avoir de bonnes performances à ce niveau, il
faut améliorer la généralisation du réseau ou en
langage statistique avoir un bon compromis biais-variance [120, 115]. La
formulation de ce compromis pour le cas de classification est plus complexe que
celle pour la régression, et consiste à décomposer
l'erreur de prédiction en deux termes: le premier appelé biais,
mesure l'efficacité de la prédiction; le second, appelé
variance, reflète l'influence du choix de la base d'apprentissage sur la
prédiction [300, 88, 196].
Pour avoir une meilleur généralisation, il faut,
d'une part, choisir l'architecture adéquate et , d'autre part,
»optimiser» la phase d'apprentissage afin que le
phénomène de sur ou sous apprentissage disparaisse. Cependant, il
faut noter que le choix d'une base d'apprentissage, qui reflète le plus
que possible le phénomène étudié, reste le facteur
principal pour avoir de bons résultats. Trois méthodes sont les
plus utilisées pour avoir une bonne généralisation:
La validation croisée: cette méthode,connu aussi
sous le nom K-fold, repose sur une estimation des performances à partir
d'exemples n'ayant pas servi à la conception du modèle. Pour ce
faire, on scinde la base d'apprentissage en K blocs de taille (ap-
proximativement) égale. On réalise alors K
apprentissages du modèle, en laissant àchaque fois une
des parties de côté pour le valider (figure (4.6)) où la
partie grisée
est utilisée pour la validation et les autres pour
l'apprentissage). La performance du modèle s'obtient à partir des
erreurs de validation constatées après les K apprentissages. Le
résultat de l'algorithme de la validation croisée pour un
modèle M, un ensemble de données D, un nombre de blocs K avec ED
j est la valeur de la fonction coût calculé pour le
bloc 1 = j = K de l'ensemble D, s'exprime par:
|
XK
1
CV (M) = K j=1
|
ED j (4.29)
|
Pour faire la selection du meilleur modèle Mopt
sur un ensemble de modèles Mod, on cherche:
Mopt = argmin (CV(M)) (4.30)
M?Mod

Figure 4.6: Schéma de la partition de la base
d'apprentissage au cours du processus de la validation croisée
Dans le contexte de réseaux de neurones, la recherche
de l'architecture optimale, par exemple, s'effectue souvent en partant d'un
modèle linéaire et en augmentant progressivement le nombre de
neurones cachés. Le modèle optimal est alors défini comme
étant celui qui présente le meilleur score de validation
croisée.
La limite naturelle de la validation croisée correspond
au cas où D est égal au nombre
d'exemples dans la base
d'apprentissage. Cette méthode est connue sous le nom
de
«leave-one-out» [248] car chaque apprentissage n'est
validé que sur un seul exemple.
Les difficultés de cette méthode sont de deux
ordres:
· Le temps de calcul nécessaire pour une même
base d'apprentissage est d'autant plus grand que K est élevé (il
est donc maximum dans le cas du leave-one-out),
· Des performances contrastées en termes de taille
de l'architecture sélectionnée et d'estimation des performances
à cause de la taille de la base d'apprentissage.
La régularisation: ses méthodes associées
ne cherchent pas à limiter la complexité du réseau, mais
elles contrôlent la valeur des poids pendant l'apprentissage. Il devient
possible d'utiliser des modèles avec un nombre élevé de
poids et donc un modèle complexe, même si le nombre d'exemples
d'apprentissage est faible. Bartlett [23] a montré que la valeur des
poids était plus importante que leur nombre, de telle façon que
si un grand réseau est utilisé et que l'algorithme
d'apprentissage trouve une erreur quadratique moyenne faible avec des poids de
valeurs absolues faibles, alors les performances en
généralisation dépendent de la taille des poids
plutôt que de leur nombre.
Plusieurs méthodes de régularisation existent dans
la littérature, on cite:
1. «Early stopping» ou arrêt
prématuré est une méthode qui consiste à
arrêter les itérations avant la convergence de l'algorithme
d'apprentissage. Si la convergence n'est pas menée à son terme,
le modèle ne s'ajuste pas trop finement aux données
d'apprentissage: le surajustement est limité. Pour mettre en oeuvre
cette méthode, il faut déterminer le nombre d'itérations
à utiliser pendant l'apprentissage. La méthode la plus classique
consiste à suivre l'évolution de la fonction coût sur une
base de validation, et à arrêter les itérations lorsque le
coût calculé sur cette base commence à croître.
Cependant, cette méthode peut être inapplicable, car il est
difficile de déterminer avec précision le moment exact où
il faut arrêter l'apprentissage puisque les performances sur la base de
validation ne se dégradent pas nettement.
Cette méthode, comme Sloberg et Ljung [281] ont
montré, revient à utiliser un terme de pénalisation dans
la fonction coût, ce qui justifie sa classification parmi les
méthodes de régularisation.
2. Pénalisation de la fonction coût est la
deuxième façon d'influer sur la régularitédu
modèle. Elle consiste à introduire des contraintes dans la
fonction coût à
minimiser.
Etotal = E + ÀEreg (4.31)
où E est la fonction coût ÀEreg
est le terme à introduire. L'apprentissage est réalisé en
minimisant la nouvelle fonction Etotal.
Toute la difficulté de cette méthode
réside dans le dosage optimal entre la fonction coût initiale et
le terme de régularisation. Si l'on choisit À trop grand, le
modèle risque d'avoir un biais élevé. Inversement, si
À est trop petit, l'effet du terme de régularisation est trop
faible, ce qui se traduit par une variance élevée. La grandeur
À devient donc en fait un paramètre, à estimer au
même titre que les poids du reseau: elle est souvent
désignée sous le nom d'hyperparamètre [206].
Parmi les différentes formes possibles pour la fonction
Ereg, la méthode du weight decay [186] qui est simple
à mettre en oeuvre, et plusieurs études ont montré qu'elle
conduisait à de bons résultats [118]. Elle consiste simplement
à ajouter à la fonction coût un terme proportionnel
à la norme du vecteur des poids synaptiques.
Le bruitage: est une technique empirique qui permet
d'augmenter la qualité de la généralisation. Elle consiste
à ajouter un léger bruit à chaque vecteur d'entrée
pendant l'apprentissage, alors que la sortie désirée demeurant
inchangée. De cette façon, on
associe une petite zone de l'espace d'entrée
centrée autour d'un vecteur d'entrée àune
même sortie désirée. Cela permet d'assurer un ajustement du
modèle appris
par le réseau autour des points d'apprentissage.
Plusieurs travaux ont été menés
dans ce sens, nous
citons: Lee et Oh [198], Grandvalet [129], Seghouane et al. [272].
4.5 Combinaison de classificateurs
Les méthodes de classification, basées sur
différentes théories et méthodologies, sont
généralement considérées comme autant de solutions
possibles à un même problème, leur développement n'a
pas permis de mettre en évidence la supériorité
incontestable d'une méthode sur une autre pour répondre aux
contraintes des applications pratiques. En effet,
l'étude de ces techniques a fait apparaître des
différences de comportement et donc une complémentarité
potentielle qu'il semblait intéressant d'exploiter pour obtenir des
performances supérieures à celles d'un seul classificateur. En
fait, de la même manière qu'une caractéristique
supplémentaire apportant une information complémentaire permet
à un
classificateur de mieux décider, une réponse
provenant d'un autre classificateur permet àun système
de classificateurs de mieux décider à condition que cette
réponse soit complé-
mentaire aux décisions des classificateurs existants. Par
conséquent, l'idée d'en utiliser plusieurs simultanément
s'est peu à peu imposée.
4.5.1 Stratégies de combinaison
La multiplication des travaux sur la combinaison a
entraîné au point de nombreux schémas traitant les
données de manières différentes. Trois approches pour la
combinaison
de classificateurs peuvent être envisagées:
séquentielle, parallèle et hybride. Mais, malgréla
diversité des schémas de combinaison, la détermination de
la meilleur organisation reste un problème ouvert.
- La combinaison séquentielle, appelée
également combinaison en série ou en cascade, est
organisée en niveaux successifs de décision permettant de
réduire progressivement le nombre de classe possibles. dans chaque,
niveau, il existe un seul classificateur qui prend en compte la réponse
fournie par le classificateur placé en amont afin de traiter les rejets
ou confirmer la décision obtenue sur la forme qui lui est
présentée (figure (4.7)). Une telle approche peut être vue
comme un filtrage progressif des décisions dans la mesure où elle
permet de diminuer au fur et à mesure l'ambiguïté sur la
classe proposée. Cela permet généralement de diminuer le
taux d'erreur globale de la chaîne de reconnaissance. Néanmoins,
une combinaison de ce type demeure particulièrement sensible à
l'ordre dans lequel sont placés les classificateurs. En effet,
même s'ils ne nécessitent pas d'être les performants, les
premiers classificateurs invoqués doivent être robustes, c'est
à dire que la solution réelle de la forme à identifier
doit apparaître dans les listes successives quelle que soit leur taille.
En cas de mauvaise décision du premier classificateur, placé en
amont de la série des classificateurs utilisés, l'erreur va se
propager de façon irrévocable. Il faudra donc choisir
judicieusement le premier classificateur afin d'éviter -autant que
possible-

Figure 4.7: Combinaison séquentielle de
classificateurs
l'apparition d'une telle situation. La combinaison
séquentielle suppose donc une certaine connaissance à priori du
comportement de chacun des classificateurs. Notons que dans cette approche,
chaque classificateur est réglé en fonction du classificateur
placé en amont de la chaîne. Une simple modification du premier
classificateur peut provoquer un nouveau paramétrage ou apprentissage
des classificateurs suivants.
- La combinaison parallèle, à la
différence de la combinaison séquentielle, elle laisse dans un
premier temps les différents classificateurs opérer
indépendamment les uns des autres puis fusionne leurs réponses
respectives. Cette fusion est faite soit de manière démocratique,
dans le sens où elle ne favorise aucun classificateur par rapport
à un autre, soit au contraire dirigée et, dans ce cas, on
attribue à la réponse de chaque classificateur un poids en
fonction de ses performances. L'ordre d'exécution des classificateurs
n'intervient pas dans cette approche. La figure (4.8) fournit une
représentation de la combinaison parallèle des
classificateurs.
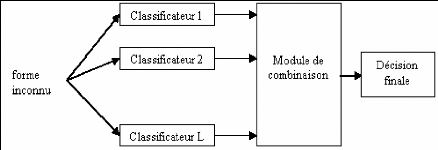
Figure 4.8: Combinaison parallèle de classificateurs
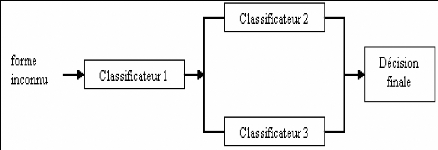
dépendante. Par contre, la décision finale est
prise avec le maximum de connaissances
mises à disposition par chaque
classificateur. Dès lors se posent les problèmes de
précision
des informations fournies par les classificateurs et de la
confiance qu'on peut accorder àchacun d'eux.
- La combinaison hybride consiste à combiner à
la fois des architectures séquentielles et parallèles afin de
tirer pleinement avantage de chacun des classificateurs utilisés. La
figure (4.9) présente un exemple de combinaison hybride dans laquelle on
combine un classificateur en série avec deux classificateurs en
parallèle.
Figure 4.9: Combinaison hybride de classificateurs
Ce type d'approche permet de générer de nombreux
schémas de coopération qui peuvent rapidement devenir complexes
à optimiser. Il illustre les deux aspects de la combinaison qui sont
d'une part la réduction de l'ensemble des classes possibles et d'autres
part la recherche d'un consensus entre les classificateurs afin d'aboutir
à une décision unique.
4.5.2 Combinaison non paramétrique
Ces méthodes n'utilisent que des informations du
premier ordre (sorties de classificateurs). Elles sont faciles à mettre
en oeuvre et ne nécessitent pas de phase d'apprentissage. Cependant, le
point faible de ces méthodes est qu'elles traitent les classificateurs
de manière égale ce qui ne permet pas de tenir compte de leur
capacité individuelle. Elles peuvent être divisées en type
classe, rang et mesure.
4.5.2.1 Type classe
L'avantage de la combinaison de type classe est qu'elle peut
être utilisée pour tout type de classificateur (classe, rang ou
mesure), quelle que soit sa structure. Dans cette combinaison, chaque
classificateur fournit en sortie une réponse sur l'appartenance de la
forme inconnue à une classe ou un ensemble de classes (ayant le
même degré de préférence). Toutefois, il s'agit de
la seule information qu'on pourra utiliser.
La combinaison d'un ensemble de classificateurs de type classe
est souvent basée sur le principe du vote pour lequel on trouve, dans la
littérature, plusieurs méthodes qui ont été
proposées. Ces méthodes consistent à interpréter
chaque sortie d'un classificateur comme un vote pour l'une des classes
possibles. La classe ayant un nombre de votes supérieur à un
seuil préfixé est retenue comme décision finale. Ces
méthodes sont les plus simples à mettre en oeuvre: les votes des
classificateurs ne sont pas pondérés et chaque classe
reçoit autant de votes qu'il y a de classificateurs à combiner.
La plupart de ces méthodes ne nécessite qu'un seul niveau de
décision. On peut classer ces méthodes en trois
catégories: vote avec seuil, majorité sans conflit et
majorité notoire.
· Vote avec seuil: dans ce cas, pour qu'une classe
soit retenue comme résultat de la combinaison, une proportion À
de classificateurs devront répondre à cette classe. Ainsi, pour
À = 0, il s'agit du vote à la pluralité où la
classe qui reçoit le plus de votes est choisie comme classe finale.
Connue aussi sous le nom First past the post [71], cette méthode est la
forme de vote la plus simple et la plus facile à appliquer.
Néanmoins, il y a rejet si toutes les classes ont le même nombre
de votes. Dans ce cas, les risques de conflit sont particulièrement
importants.
Pour À = 0.5, il s'agit du vote à la
majorité. La classe finale est décidée si plus de la
moitié des classificateurs l'ont proposé. Ce vote est aussi
très simple à appliquer mais il peut produire une décision
finale erronée (quand la majorité des classificateurs ne
proposent pas la vraie classe). La production de ce cas est faible surtout
lorsqu'on a un grand nombre de classificateurs. L'utilisation du vote à
la majorité est justifiée dans les situations où il est
difficile d'obtenir d'autres types de sorties à partir
des classificateurs et surtout dans les problèmes
où on l'en combine un très grand
nombre de classificateurs et
pour lesquels il est difficile d'appliquer d'autres méthodes
de combinaison plus complexes [168]. Les performances de cette
méthode ont étél'objet de plusieurs travaux,
nous citons: Ruta et Gabrys [265], Narasimhamurthy [228].
Pour ë = 1, la classe finale est choisie si tous les
classificateurs proposent cette réponse sinon la réponse finale
est le rejet. Cette méthode restrictive qui accepte le moins de risque
possible est appelée majorité unanime. S'il s'agit d'une
méthode fiable, elle présente toutefois l'inconvénient
majeur de produire un taux de reconnaissance assez faible, surtout lorsque le
nombre de classificateurs augmente.
· Majorité sans conflit: Le principe est
identique à celui de la majorité unanime, à ceci
prés qu'on autorise les classificateurs à rejeter. Un
classificateur proposant de rejeter l'élément n'a donc aucun
poids dans ce système: lorsque tous les classificateurs rejettent sauf
un, alors c'est la sortie de ce classificateur qui sera conservée comme
résultat de la combinaison. Il n'y a rejet que lorsque tous les
classificateurs ont proposé de rejeter l'élément ou en cas
de confit.
· Majorité notoire: Dans ce cas, pour être
désignée comme réponse finale, la classe majoritaire doit
de plus se distinguer de la deuxième classe d'une différence
supérieure à un certain seuil. Les résultats de tests
faits par Xu et al. [326] montrent que cette méthode est meilleure que
la majorité avec seuil surtout quand un minimum de fiabilité est
exigée.
Les méthodes que nous avons présentées se
composent d'une seule étape. Il existe d'autres méthodes de vote
qui nécessitent plusieurs étapes [305].
4.5.2.2 Type rang
Les méthodes de type rang ont été
développées essentiellement pour résoudre les
problèmes des méthodes de vote lorsqu'il n'y a pas de vainqueur
majoritaire. Plusieurs méthodes on été proposées
dans ce sens, les plus reconnues sont le Borda count [123, 304, 240, 305] et le
meilleur rang [149].
4.5.2.3 Type mesure
Les méthodes de type mesure combinent des mesures qui
reflètent le degré de confiance des classificateurs sur
l'appartenance de l'objet à reconnaître en chacune des classes.
Toutefois, comme les sorties des classificateurs ne sont pas toujours
comparables, une normalisation est souvent nécessaire [94, 332]. Les
méthodes de combinaison non paramétrique les plus
utilisées sont les méthodes fixes et la moyenne de Bayes.
· Méthodes fixes: Le principe de base
derrière les méthodes fixes est le suivant: les classificateurs
sont indépendants et estiment des probabilités à
posteriori des classes.
Ainsi, pour reconnaître une forme, on utilise une
règle de décision qui revient àchoisir la
classe pour laquelle la probabilité à posteriori est la plus
élevée. Cette
probabilité peut être calculée par l'une des
règles: maximum, minimum, médiane, produit ou linéaire.
Les trois premières règles sont connues sous le
nom d'opérateurs d'ordre statique. La règle maximum consiste
à choisir la classe pour laquelle la probabilité est la plus
élevée. Si le classificateur qui propose cette confiance a une
mauvaise performance alors la règle maximum n'est pas fiable. La
règle minimum consiste à choisir le classificateur qui propose la
probabilité la plus faible. Comme la règle maximum, il est
difficile de prédire les situations dans lesquelles cette règle
est la plus efficace. Pour la règle médiane, elle est plus
robuste que les précédentes mais ne prend pas en compte toutes
les informations de l'ensemble de classificateurs.
La règle de produit donne de bonnes performances si
les classificateurs sont indépendants. Cependant, cette règle est
sensible aux erreurs estimées par les classificateurs(dues à la
présence de bruit dans les données ou à l'utilisation de
base d'apprentissage de petite taille).
La règle linéaire n'est que la règle
somme multipliée par un facteur ë. Ainsi, pour ë = 1, on
obtient la règle somme et pour ë égale à l'inverse du
nombre des classificateurs, on obtient la moyenne simple. La somme fonctionne
bien dans le cas d'utilisation de caractéristiques différentes
par des classificateurs de même structure [150] ou de structures
différentes [180].
· La moyenne de Bayes: Les méthodes
bayésiennes sont utilisées pour fusionner des sorties de
classificateurs exprimées en probabilités à posteriori.
Parmi les méthodes de fusion les plus simples à appliquer, on
trouve la règle moyenne de Bayes. Si chaque classificateur propose une
probabilité à posteriori attribuée à une classe
donnée pour une forme à reconnaître, il est alors possible
de calculer la probabilité à posteriori moyenne de tous les
classificateurs et la décision finale est obtenue selon le
critère de Bayes.
La qualité de cette règle dépend de la
façon dont les probabilités à posteriori sont
estimées et donc du type des sorties des classificateurs à
combiner (distance, confiance,...).
4.5.3 Combinaison paramétrique
Par rapport aux méthodes précédentes, les
méthodes de combinaison paramétrique sont plus complexes à
mettre en oeuvre. Elles utilisent des paramètres supplémentaires
calculés pendant une phase d'apprentissage. La performance de ces
méthodes dépend alors de la bonne estimation des
paramètres donc de la base d'apprentissage. Dans la combinaison
paramétrique, deux cas d'utilisation de la base d'apprentissage sont
possibles:
1) Utiliser la même base pour entraîner les
classificateurs et la méthode de combinaison.
2) Utiliser deux parties, l'une pour les classificateurs,
l'autre pour la combinaison. La réutilisation de la même base
d'apprentissage au niveau de la combinaison (le premier cas) est à
éviter. Il est toujours préférable d'utiliser une
deuxième base de données.
4.5.3.1 Type classe
Les méthodes paramétriques de type classe ne
sont pas très nombreuses. Les méthodes les plus utilisées
sont principalement le vote pondéré, la théorie de Bayes,
la méthode de Dempster-Shafer et la méthode d'espace de
connaissance du comportement (Behaviour Knowledge Space ou BKS).
· Vote avec pondération: dans cette méthode,
la réponse de chaque classificateur est pondérée par un
coefficient indiquent son importance dans la combinaison. Pour
déterminer ces coefficients de pondération, ils
excitent plusieurs façons, citons: Optimisés par algorithme
génétique [192], calculés à partir de la
fiabilité estimée de chacun des classificateurs [2]. Pour plus
d'informations le lecteur pourra se référer à [12] pour le
cas des réseaux de neurones.
· Théorie de Bayes: elle consiste à
déterminer la classe pour laquelle la probabilitéà
posteriori est maximale. Cette dernière est déterminée en
supposant que les clas-
sificateurs sont indépendants et en se basant sur la
matrice de confusion obtenue pour les classificateur sur une base
d'apprentissage. Pour plus de détails le lecteur pourra se
référer à [93].
· Dempster-Shafer: Dans le cas où les
classificateurs accordent un certain crédit à plusieurs classes,
l'utilisation de la règle de Bayes peut être inadaptée
à la combinaison de ces classificateurs. En effet, la règle de
Bayes nécessite l'utilisation de probabilités dont la somme est
toujours égale à 1 ce qui n'est pas nécessaire dans la
théorie de Dempster et Shafer, appelée aussi théorie de
l'évidence et des croyances [327]. Par rapport aux approches
statistiques, cette méthode présente l'avantage d'inclure une
modélisation à la fois de l'incertitude et de
l'imprécision dans les systèmes à plusieurs
classificateurs. Par exemple, lorsque la décision d'un classificateur
est ambigue, la théorie prend en compte cela en affectant des masses
à la réunion de plusieurs classes. La théorie de Bayes se
retrouve comme un cas particulier de la théorie de l'évidence.
Cependant, elle se base sur l'hypothèse d'indépendance des
sources à combiner. Pour plus de détails sur cette méthode
utilisée avec les réseaux de neurones, on pourra se
référer à [203, 83, 18, 104].
· Espace de connaissance du comportement: la
méthode d'espace de connaissance du comportement (BKS) utilise un espace
de connaissance contenant les décisions de tous les classificateurs. Cet
espace permet de connaître le comportement des classificateurs
d'où son nom espace de connaissance du comportement. La méthode
BKS permet alors de tenir compte des informations de cet espace en les
intégrant directement dans la règle de décision afin
d'obtenir la solution finale. L'hypothèse d'indépendance de
classificateurs n'est pas nécessaire. Pour plus de détails, le
lecteur pourra se référer à [153].
4.5.3.2 Type rang
Dans le cas non paramétrique, les méthodes de type
rang ne tiennent pas compte de la différence dans la performance des
classificateurs (tous les classificateurs participent
de manière égale dans la prise de décision).
Or, il est important d'intégrer le degréde
crédibilité des classificateurs dans la combinaison surtout quand
on sait qu'un des
classificateurs est plus performant que les autres. Les
méthodes de type rang les plus
citées dans ce cas sont la
somme pondérée , la régression logistique, l'intersection
et
l'union. Pour plus de détails, le lecteur pourra se
référer à [149, 311].
4.5.3.3 Type mesure
D'autres méthodes paramétriques qui ont
bénéficié de l'essor des travaux sur la classification
dans plusieurs domaines sont utilisées pour combiner les classificateurs
de type mesure tels que les règles pondérées qui
consistent tout simplement à appliquer des pondérations aux
sorties des classificateurs [179], les méthodes floues qui consiste
à retenir la classe ayant la mesure floue la plus élevée
[317] et les réseaux de neurones [122].
4.5.4 Comparaison des méthodes de combinaison
Les diverses méthodes de combinaison que nous avons
passées en revue montrent la diversité des approches offertes au
concepteur de systèmes de reconnaissance à plusieurs
classificateurs. Ces méthodes se distinguent essentiellement par le
niveau d'information en sortie qu'apporte chacun des classificateurs. Au niveau
classe, la sortie de chaque classificateur est une étiquette. Au niveau
rang, chaque classificateur fournit en sortie une liste ordonnée de
solutions. Au niveau mesure, les classificateurs proposent en plus des mesures
reflétant la confiance qu'ils ont dans les classes. La combinaison est
alors différente si on dispose d'un classificateur produisant des
mesures (riche en information), ou seulement des classificateurs donnant des
classes (pauvre en information). La combinaison des sorties de type classe a
reçu de la part des chercheurs une attention plus grande que la
combinaison des sorties de type mesure car elles sont très simples
à appliquer et à analyser expérimentalement et même
théoriquement. Même si les méthodes de type mesure sem-
blent à priori plus séduisantes (quand on peut
les utiliser) puisqu'elles exploitent toute l'information fournie par les
classificateurs, cela ne veut pas dire qu'elles sont toujours plus
intéressantes que les méthodes de type rang. Cette idée a
été clarifier par Parker [240] qui a montré que les
méthodes de type rang peuvent être plus performantes que les
méthodes de type classe et mesure.
Il faut noter également que le problème du choix
entre les méthodes paramétriques et non paramétriques est
toujours posé. La combinaison paramétrique est plus
intéressante que la combinaison non paramétrique surtout lorsque
la base d'apprentissage est à la fois informative et
représentative ce qui n'est pas toujours le cas. Pourtant, ce sont les
méthodes de combinaison non paramétriques qui sont les plus
utilisées par les chercheurs. Cela est du au fait que ces
méthodes sont simples à mettre en oeuvre et n'utilisent pas de
traitements supplémentaires (apprentissage).
4.5.5 Création des systèmes de classification
Pour avoir plusieurs systèmes de classification qu'on peut
combiner pour un problème donné, il y a plusieurs façons
de faire:
1. Cas mult i-sources: Si le problème a plusieurs
sources de données (utilisation de plusieurs capteurs par exemple), on
peut spécifier chaque source au même classificateur;
2. Cas multi-représentations: Selon le cas
étudiée, les données pourraient avoir des
représentations différentes où chacune permet d'extraire
des informations plus spécifiques que l'autre (représentation
dans des espaces différents), alors on peut spécifier chaque
représentation au même classificateur;
3. Cas mono-stratégie: Pour la même méthode
de classification, on peut changer certains paramètres pour
générer plusieurs occurrences du même classificateur. Par
exemple, pour un réseau MLP, on peut changer l'algorithme
d'apprentissage, l'architecture, la fonction coût, les fonctions
d'activations, etc;
4. Cas multi-stratégies: On peut associer plusieurs
occurrences de plusieurs classificateurs de natures différentes. Par
exemple, des classificateurs statistiques et neuronaux.
4.6 Conclusion
Dans ce chapitre, nous avons présenté avec
certaines limitations l'état de l'art des méthodes de
classification. Dans ce sens, nous avons défini ce qu'est un
classificateur et les paramètres qui le caractérisent. Nous avons
ensuite présenté-avec quelques détails- les
classificateurs paramétriques, non paramétriques et neuronaux.
Pour ces derniers, après un bref historique, nous avons
présenté le perceptron multicouches avec la fameuse
méthode d'apprentissage rétro-propagation du gradient et les
algorithmes dérivées. Et tenant compte de l'importance de la
généralisation pour les réseaux de neurones, nous avons
cité trois méthodes, à savoir: la validation
croisée, la régularisation et le bruitage. Enfin, tenant compte
de l'amélioration des performances de classification en combinant
plusieurs méthodes, nous avons présenté les trois
approches de combinaison: séquentielle, parallèle et hybride.
Le prochain chapitre sera consacré à la
discrimination des signaux sismiques en se basant sur certains
éléments présentés dans ce chapitre et les
résultats des chapitres précédents.
CHAPITRE 5
DISCRIMINATION DES SIGNAUX SISMIQUES
Le nombre de travaux concernant la discrimination des signaux
sismiques par les réseaux de neurones est très limité en
comparison avec ceux utilisant les méthodes classiques basées sur
les ratios et l'analyse des phases. De plus, ils ne traitent ce sujet que d'une
façon très restrictive sans prendre en considération les
caractéristiques propres des signaux sismiques et sans profiter de la
redondance fournie par les stations du réseau sismique. En effet, d'une
part, toutes ces études traitent des signaux qui ont la même
longueur en faisant un découpage du signal acquis et, d'autre part, la
classification est fait au niveau de la station sans prendre en compte ni les
autres éléments du réseau ni les autres paramètres
liés à l'événement (par exemple l'épicentre
et le foyer).
L'objet de ce chapitre est de présenter un
système intégré de discrimination des signaux sismiques.
Dans ce sens, trois méthodes de discrimination des signaux ont
étéproposés: discrimination locale,
régionale et globale en se basant sur le classificateur
perceptron multicouches (MLP: Multilayer Perceptron) dont les
paramètres font l'objet d'une étude très
détaillée.
Nous notons que les méthodes proposées dans ce
chapitre reposent seulement sur les signaux fournis par les composantes
verticales des sismomètres. Pour le cas où ces derniers ont trois
composantes, les deux autres ne sont pas prises en compte.
5.1 Discrimination sismique locale
La discrimination sismique locale consiste à faire une
classification d'un signal sismique au niveau de chaque station
indépendamment des autres stations du réseau sismique.
5.1.1 Méthode proposée
Les réseaux sismiques de la troisième
génération reposent généralement sur le traitement
des données au niveau de chaque station avant d'être
traitées au niveau de la station centrale. Dans ce sens, avec les
progrès réalisés au niveau de la rapidité des
traitements informatiques, on peut concevoir des réseaux sismiques de la
troisième génération d'une façon virtuelle en
utilisant le même matériel informatique pour toutes les stations.
Le traitement de l'information pour chaque station se fera
séquentiellement. Le schéma global de la discrimination sismique
locale est donnée par la figure (5.1).
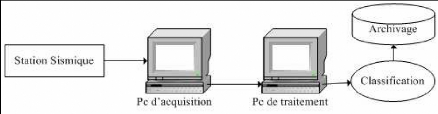
Figure 5.1: Schéma global de la discrimination sismique
locale
La discrimination sismique locale est étroitement
liée aux paramètres de la station. C'est-à-dire que pour
chaque station, les paramètres du classificateur doivent être
choisis en correspondance avec la forme des données acquises. Ainsi,
pour un classificateur de type MLP, la majorité des données
d'apprentissages correspondant aux événements locaux doivent
être sélectionner de l'archive de la station afin d'avoir de
bonnes similarités entre les signaux de la même classe. Pour les
autres types d'événements, on peut les sélectionner
à partir des archives des autres stations du réseau sinon d'une
base de données internationale tout en tenant compte des
caractéristiques du sismomètre de la station.
Dans ce mode de discrimination, pour prendre la
décision, le classificateur ne tient compte que des
caractéristiques propres du signal acquis. Donc, afin d'avoir de bonnes
performances du classificateur, deux points cruciaux doivent être
remplis: le premier est le choix de la base de donnée d'apprentissage
qui doit décrire au maximum les différentes classes. Le
deuxième point est le choix des caractéristiques du signal
sismique qui vont
servir à la classification. Ceci est lié
à la représentation du signal et à la méthode de
réduction de la dimensionnalité et d'extraction de ces
caractéristiques. Tenant compte, d'une part, qu'on dispose aujourd'hui
d'une multitude de méthodes de représentation, de
réduction de la dimensionnalité, d'extraction de
caractéristiques et de classification et, d'autre part, il n'existe pas
un seul modèle pour tous les problèmes de classification non plus
une seule technique applicable pour tous les problèmes, nous proposons
alors un système de classification modulaire mono-source
multi-(représentationnelle, stratégies, experts) décrit
par la figure (5.2).
Pour le choix et le réglage des différents
paramètres de la classification, le logiciel MSSSA [33] fournit une
certaine flexibilité et une simplicité pour aboutir cette
tâche pour toute station sismique selon l'algorithme (5.1).
Etape 0: Choix des bases d'apprentissage et de test, des
représentations bidimensionnelles, des algorithmes de réduction
de la dimensionnalité, des classificateurs, des ensembles et des
experts;
Etape 1: Faire correspondre à chaque classificateur un
ensemble de représentations, de données et d'experts;
Etape 2: Faire l'apprentissage du système;
Etape 3: Faire les tests;
Etape 4: Refaire les étapes 1, 2 et 3 jusqu'à
l'obtention des performances désirées; Etape 5: Combiner les
résultats par un expert pour avoir la décision finale.
Figure 5.2: Schéma de la discrimination sismique locale
multi- (représentationnelle, stratégies, experts)
119
(a) (b)
(c)
-1000
-1500
-2000
-2500
-500
2000
1500
1000
500
0
20 40 60 80 100 120
ES0786-DAL -2005-05-12 09:14:17
Time [sec]
-1000
-1500
-2000
-500
1500
1000
500
0
0 20 40 60 80 100 120
ES0429-JBB -2005-05-06 02:47:39
Time [sec]
-100
-150
-200
200
-50
150
100
50
0
0 20 40 60 80 100 120
ES0928-CZDV-2005-05-31 16:11:38
Time [sec]
Figure 5.3: Signaux sismiques d'une qualité bonne (a),
moyenne (b) et mauvaise (c)
5.1.2 Application au réseau sismique Marocain
5.1.2.1 Choix de la base de données
Le choix de la base de données constitue un
paramètre crucial pour avoir une bonne généralisation des
classificateurs neuronaux. Dans ce sens, nous avons choisi un nombre suffisant
de signaux correspondant à des explosions chimiques, des séismes
locaux et des des séisme lointains . La fréquence
d'échantillonnage est de 50 Hz et les magnitudes sont entre 2 et 5 sur
l'échelle de Richter pour les séismes locaux. Ces signaux sont
sélectionnés à partir de la base de données de
l'Institut National de Géophysique et sont acquis par le système
DataSeis II de Kinemetrics dont une description est donnée dans [33].
Pour les visualiser, les convertir et les enregistrer au format adopté
par MSSSA , nous avons utilisé Kinemetrics Data Reader conçu dans
le cadre du MSSSA [33]. Les signaux sont classés par voie visuelle selon
le bruit de fond en trois catégories: Bon, Moyen et Mauvais (figure
(5.3)).
5.1.2.2 Choix des paramètres de classification
Dans cette section nous essayons de montrer, d'une part,
l'influence de paramètres d'un réseau MLP sur les
résultats de classification des signaux sismiques issus d'une station
donnée et, d'autre part, de donner les différentes façons
de régler ces paramètres pour avoir de bonnes performances.
A. Influence de la base d'apprentissage:
Comme il est déjà noté auparavant, le
choix de la base d'apprentissage constitue un paramètre crucial dans
l'amélioration ou la détérioration des performances d'un
classificateur. Dans ce sens, nous considérons un classificateur MLP
d'architecture 36-30-2 avec un algorithme d'apprentissage de type Rprop (Rank
propagation), un taux d'apprentissage 0.001, la sigmoide pour les fonctions
d'activation, la représentation de données par le spectrogramme
et pour la reduction de la dimensionnalité, l'algorithme (3.2) a
été utilisé avec 6 composantes pour chaque dimension (Voir
chapitre réduction de la dimensionnalité). Nous obtenons en
moyenne pour 100 tests le tableau (5.1) et le graphique (5.4).
Tableau 5.1: Influence de la base d'apprentissage
|
Cas
|
Explosions chimiques
|
|
Séismes locaux
|
Erreur
|
|
Apprentissage
|
|
Test
|
Apprentissage
|
|
Test
|
|
1
|
|
0
|
|
0
|
30
|
(100%)
|
20
|
(100%)
|
0 %
|
|
2
|
|
0
|
20
|
(100%)
|
30
|
(100%)
|
|
0
|
100 %
|
|
3
|
10
|
(25%)
|
20
|
(100%)
|
30
|
(75%)
|
|
0
|
23.1 %
|
|
4
|
30
|
(50%)
|
20
|
(100%)
|
30
|
(50%)
|
|
0
|
10.30 %
|
Les résultats du premier et du deuxième cas
reflètent le fait que le réseau MLP ne peut reconnaître que
les classes pour lesquelles il est entraîné. En effet, la classe
non apprise est considérée comme un nouveauté pour le
réseau MLP. Dans ce cas, généralement, la procédure
de discrimination n'est plus adéquate et il faut adopter une
procédure de reconnaissance [164, 161].
121
100
80
60
40
20
0
1
2
3
Cas
4
Explosions: Apprentissage Explosions: Test
Séismes: Aprentissage Séismes: Test
Erreur
Figure 5.4: Influence de la base d'apprentissage
La comparaison entre les résultats du troisième
cas et du quatrième cas montre l'influence de l'imbalance de classes qui
cause une perte d'exactitude des résultats de la classification. En
effet, le nombre d'exemples pour les séismes locaux dans le
troisième cas couvre bien cette classe, alors que ce n'est pas le cas
pour les explosions chimiques. Ce problème connu par certains auteurs
sous «malédiction des imbalances de classes» [189] a
été l'objet de plusieurs conférences [58, 59] et travaux
[165, 99, 202, 339]. Pour le cas sismique, il a été
étudié par Eavis et Japkowicz [97] pour les signaux de types
explosions nucléaires et séismes. Cependant, les performances de
la méthode proposée restent limitées (Erreur par
validation croisée = 16.1 %) malgré le choix et le
dépouillement manuel des signaux.
Le choix de la base d'apprentissage doit se faire
minutieusement par un sismologue, seul ayant l'aptitude de savoir quels signaux
sont capables de bien couvrir les différentes types
d'événements pour une station donnée.
B. Influence de la représentation et de la
réduction de la dimensionnalité:
La représentation des données est le
deuxième point principal dans notre système modulaire de
classification. Cette étape permet de passer d'un espace moins
discriminant à un espace plus discriminant. Dans le chapitre
représentation des signaux sismiques, nous
avons discuté les différentes
représentations possibles, tout en montrant que les
représentations bidimensionnelles quadratiques sont plus
adéquates aux signaux sismiques. La question qui se pose, est dans
quelle mesure la représentation influence-t-elle la classification?
La réduction de la dimensionnalité est aussi une
étape nécessaire pour vaincre la malédiction de la
dimensionnalité. Dans le chapitre 3, nous avons présenté
trois algorithmes basés sur la projection aléatoire et l'analyse
en composantes principales. Mais malgré les bases théoriques de
ces algorithmes, ils ne sont pas nécessairement adéquats pour
toutes les représentations à cause de la différence de la
répartition de l'énergie pour chacune d'elles. La question qui se
pose à ce niveau quel algorithme pour quelle représentation?
Pour répondre à ces deux questions, nous
considérons une base d'apprentissage formée de 80 signaux
sismiques dont 50% des explosions chimiques et 50% des séismes locaux.
Pour chaque type, les éléments d'apprentissage sont
constitués de 3/4 de signaux de bonne qualité et le 1/4 restant
est formé de signaux de moyenne qualité. Quant aux tests, nous
les avons effectué sur deux bases: la première est formée
de 20 signaux (moitié-moitié) dont 1/2 de signaux de bonne
qualité et 1/2 de signaux de mauvaise qualité et la
deuxième suit la même répartition mais avec des signaux de
bonnes qualité. Pour la représentation, nous avons
considéré six représentations quadratiques : SPEC, WV,
SPWV, SCAL de Ben, SCAL du chapeau Mexicain et le SCAL de Morlet. Pour la
réduction de la dimensionnalité, nous considérons les
trois algorithmes présentés au chapitre 3 où la projection
aléatoire permet de passer à des matrices de tailles 128 ×
512, puis on sélectionne 36 composantes principales pour l'algorithme
(3.1) en utilisant la moyenne comme descripteur atemporel, 6 composantes pour
chaque dimension pour l'algorithme (3.2) et pour le troisième algorithme
(3.3) 36 composantes choisies à partir de 1024 blocs de 4 × 16
pixels. Ainsi, pour un classificateur MLP d'architecture 36-30-2 avec un
algorithme d'apprentissage de type Rprop, un taux d'apprentissage 0.001, terme
de moment 0.95, la sigmoide pour les fonctions d'activation, une erreur
quadratique, un objectif de l'erreur d'apprentissage de 10-3 et une
valeur minimale du gradient pour l'arrêt de l'apprentissage
10-12, nous obtenons pour une moyenne de 100 tests les
résultats
123
figurant au tableau (5.2) et représentés par le
graphique (5.5) qui montrent la variation de l'erreur de classification des
signaux sismiques relatifs à la base de test 1 (B. test1) el la base de
test 2 (B.test 2) .
Tableau 5.2: Influence de la représentation et de la
réduction de la dimensionnalité
|
Représentation
|
Algorithme 3.1
|
Algorithme 3.2
|
Algorithme 3.3
|
|
B. test 1
|
B. test 2
|
B. test 1
|
B. test 2
|
B. test 1
|
B. test 2
|
|
SPEC
|
12.75 %
|
10.55 %
|
11.05 %
|
6.9 %
|
37 %
|
10.5 %
|
|
WV
|
15.75 %
|
15.65 %
|
13.95 %
|
5.15 %
|
21.5 %
|
5 %
|
|
SPWV
|
18.6 %
|
9.4 %
|
12.6 %
|
7.3 %
|
22.95 %
|
8 %
|
|
SCAL Ben
|
26.5 %
|
25.05 %
|
16.9 %
|
13.2 %
|
20.05 %
|
17 %
|
|
SCAL Morl
|
26.2 %
|
19.25 %
|
25.7 %
|
14.4 %
|
21.5 %
|
9.5 %
|
|
SCAL Mexh
|
27.25 %
|
16.6 %
|
25.5 %
|
10.09 %
|
28.5 %
|
11 %
|
40
35
30
25
20
15
10
5
0
SPEC WV SPWV SCAL
Ben
SCAL Morl
Algorithme 3.1 : Base de test 1 Algorithme 3.1 : Base de test
2 Algorithme 3.2 : Base de test 1 Algorithme 3.2 : Base de test 2 Algorithme
3.3 : Base de test 1 Algorithme 3.3 : Base de test 2
SCAL
Mexh
Figure 5.5: Influence de la représentation et de la
réduction de la dimensionnalité
Nous avons aussi testé le classificateur sur les
données d'apprentissage et nous avons obtenu 0 % d'erreur pour 10 tests,
où le but de la fonction objective a été atteint au cours
de l'apprentissage.
A la première vue, ces résultats nous montrent
que les résultats concernant la base de test 2 sont meilleurs que ceux
de la base de test 1, à l'exception du cas des représentations WV
et SCAL de Ben avec l'algorithme (3.1) qui est minime. Ceci est logique,
puisque la base de test 1 contient des signaux de mauvaise qualité
où il y a trop de bruit de fond alors que la base de test 2 ne contient
que de signaux de bonne qualité. L'algorithme (3.2) présente des
résultats remarquables pour toutes représentations sauf pour le
SCAL de morlet où l'algorithme (3.3) se comporte bien. L'algorithme
(3.3) présente des meilleurs résultats, pour la base de test 2,
qui sont proches de ceux obtenus par l'algorithme (3.2), sauf pour le cas du
SCAL de Ben. Les résultats fournis en utilisant l'algorithme (3.1)
restent généralement modestes en comparaison avec les deux autres
à cause de sa grande sensibilité aux bruits de fond. En
conclusion, l'algorithme (3.2) reste le meilleur grâce au calcul
bidimensionnel des composantes principales sans aucun altération des
caractéristiques du signal fournies par la projection aléatoire
de la représentation quadratique du signal.
En ce qui concerne les représentations, nous constatons
que les représentations temps-fréquence donnent de meilleurs
résultats que les représentations temps-échelle au niveau
classification bien sure. Ceci est dû principalement au fait que les
représentations temps-échelle fournissent une image très
fidèle de toutes les changements qui se passent au cours du temps pour
un signal sismique donné. Ce qui implique l'apparition de certains
points énergétiques qui font des différences, mêmes
pour des signaux du même type, s'ils atteignent certains seuils. Pour les
représentations temps-échelle avec l'algorithme (3.2), le SCAL de
l'ondelette de Ben donne les meilleurs résultats, si nous
considérons la moyenne des résultats des deux bases de test, en
comparaison avec l'ondelette de Morlet et le chapeau Mexicain. Ce qui confirme
les remarques faites au chapitre 2. Pour les représentations
temps-fréquence avec l'algorithme (3.2), c'est le SPEC qui fournit le
bon résultat en moyenne 8.975%. Le résultat de la WV se trouve au
milieu avec une erreur moyenne de 9.55%. Ceci est dû au fait que la WV
présente des interférences qui diminuent l'influence des faibles
bruits mais permet aussi une concentration excellente des motifs qui
reflète avec précision les forts bruits, chose qui se voit
clairement en faisant la comparaison avec le SPEC et le SPWV qui ne sont qu'une
version lissée de la WV.
Ces résultats expérimentaux confirment qu'il n'y
a ni de représentation, ni une méthode de réduction de la
dimensionnalité, pour lesquelles nous pouvons confirmer ses performances
pour un problème donné avant de faire les tests. Toutefois, ce
choix reste lier aux signaux traités et aux autres paramètres de
classification.
C. Influence des fonctions d'activation:
Les fonctions d'activation restent des possibilités
cachées pour l'amélioration d'un classificateur MLP comme le dit
Duch et Jankowski [92]. En effet la forme de ces fonctions influence, d'une
part l'apprentissage, comme le montre l'equation (II.14) de l'annexe II et,
d'autre part, elle influence les valeurs de sorties. Par exemple, en
considérant des fonctions linéaires dans un réseau ne
permet de modéliser que des problèmes linéaires. Et
même, certaines propriétés des réseaux MLP ne sont
remplies que lors de l'utilisation de formes spécifiques des fonctions
d'activation (approximation universelle et réseaux RBF par exemple).
Pour la discrimination sismique, certes c'est un
problème non linéaire nécessitant un réseau MLP non
linéaire permettant de délimiter les classes. Dans ce sens, nous
faisons un ensemble de tests en prenant des combinaisons formées de la
fonction sigmoide (Sig), la tangente hyperbolique (Tanh) et la Gaussienne
(Gau). Nous considérons les conditions des tests du paragraphe
précèdent, sauf que nous utilisons l'algorithme (3.2) et la
moyenne de l'erreur pour 10 tests. Les résultats obtenus sont
données par le tableau (5.3).
Ces résultats nous montrent que pour chaque
représentation, certaines combinaisons se comportent bien que les
autres. Ainsi par exemple pour le SPEC, toutes les combinaisons donnent une
moyenne d'erreur pour les deux bases de test entre 9% et 11% sauf pour la
combinaison Tanh-Sig. La même chose pour la WV sauf pour Tanh-Tanh et
Tanh-Gau. Pour d'autres représentation, nous constatons qu'il y a des
combinaison qui améliorent largement les résultats telles que
Tanh-Gau et Tanh-Tanh pour le SCAL , Sig- Sig pour le SPWV et Sig-Gau pour le
SCAL de Mexh. Pour d'autres représentations, la variation de l'erreur
moyenne n'est pas significative pour toutes les combinaisons, c'est le cas du
SCAL de Morlet.
Tableau 5.3: Influence des fonctions d'activation(Eléments
en gras correspond à la base de test 1 et les autres à la base de
test 2)
|
SPEC
|
WV
|
SPWV
|
SCAL Ben
|
SCAL Morl
|
SCAL Mexh
|
|
Sig-Sig
|
12 %
|
14.5%
|
12.5%
|
16.5%
|
26.5%
|
27%
|
|
Sig-Sig
|
6.5%
|
4%
|
6.5%
|
12%
|
14.5%
|
11.5%
|
|
Tanh-Tanh
|
12.5%
|
16.5%
|
21%
|
13%
|
24%
|
26.5%
|
|
Tanh-Tanh
|
6%
|
9.5%
|
6.5%
|
6.5%
|
12%
|
17.5%
|
|
Tanh-Sig
|
19%
|
17%
|
19%
|
29%
|
27%
|
26%
|
|
Tanh-Sig
|
9.5%
|
5.5%
|
6%
|
10.5%
|
10%
|
20%
|
|
Gau-Gau
|
15.5%
|
14%
|
17%
|
16%
|
25%
|
25.5%
|
|
Gau-Gau
|
5.5%
|
9%
|
6.5%
|
6%
|
13%
|
17%
|
|
Gau-Sig
|
11.5%
|
14.5%
|
17%
|
17%
|
22%
|
26%
|
|
Gau-Sig
|
6.5%
|
6.5%
|
5.5%
|
9.5%
|
15 %
|
13.5%
|
|
Gau-Tanh
|
14.5%
|
13.5%
|
20%
|
14%
|
26.5%
|
23.5%
|
|
Gau-Tanh
|
4%
|
10%
|
6%
|
7%
|
12%
|
17.5%
|
|
Sig-Gau
|
12.5%
|
11.5%
|
16.5%
|
14.5%
|
24.5%
|
23%
|
|
Sig-Gau
|
8%
|
5.5%
|
8%
|
7%
|
12.5%
|
12.5%
|
|
Tanh-Gau
|
14%
|
17.5%
|
19.5%
|
12%
|
25.5%
|
22%
|
|
Tanh-Gau
|
8%
|
8%
|
7.5%
|
7%
|
11%
|
19%
|
En conclusion, le bon choix des fonctions d'activation pour un
réseau MLP, doit être basé sur des tests
expérimentaux liés aux données traitées et non sur
les suggestions faites dans d'autres études. En effet, même si
certaines fonctions sont du même type (Tanh et Sig par exemple), elles ne
fournissent pas nécessairement les mêmes résultats.
D. Influence de la phase d'apprentissage:
La phase d'apprentissage a une grande influence sur les
résultats de la classification. En effet, ces résultats sont en
étroite relation avec le choix des paramètres d'apprentissage et
de son déroulement. Les exemples ci-dessous essayent de donner certains
de ces aspects.
· Choix de l'algorithme d'apprentissage: Dans le
chapitre précédent, nous avons discuté les
différentes façons permettant d'améliorer l'algorithme de
la rétro-propagation du gradient. Mais, est ce que toutes ces
améliorations sont adéquates pour notre problème de
classification des signaux sismiques? Pour répondre à cette
question, nous avons testé les algorithmes suivants: descente du
gradient avec moment (GDM : Gradient Descent with Moment), descente du gradient
avec taux
Tableau 5.4: Influence du choix de l'algorithme d'apprentissage
en mode hors ligne
|
Algorithme
|
Perf. atteinte
|
N. itérations
|
Temps [sec]
|
Cause d'arrêt
|
|
GDM
|
0.2497
|
50000
|
1023
|
N maxi d'itérations
|
|
GDA
|
0.0997
|
50000
|
630
|
N maxi d'itérations
|
|
SCG
|
0.0750
|
50000
|
840
|
N maxi d'itérations
|
|
CGF
|
0.1389
|
1378
|
34.37
|
V mini du gradient
|
|
CGP
|
0.1038
|
1293
|
32.74
|
V mini du gradient
|
|
CGB
|
0.1363
|
287
|
10.85
|
V mini du gradient
|
|
Rprop
|
0.0250
|
141
|
4.672
|
V objectve
|
d'apprentissage variable et terme moment (GDA: Gradient
Descent with Variable Learning Rate and Moment), le gradient conjugué
régularisé (SCG : Scaled Conjugate Gradient), gradient
conjugué de Fletcher-Powell (CGF: Conjugate Gradient of
Fletcher-Powell), gradient conjugué de Polak-Ribiére (CGP:
Conjugate Gradient of Polak-Ribiére), gradient conjugué de
Powell-Beale (CGB: Conjugate Gradient of Powell-Beale) et Rprop (Rank
propagation). Les tests pour le même réseau défini
auparavant avec une valeur objective de 0.025 et un nombre maximum
d'itérations de 50000 permet de donner les résultats du tableau
(5.4) pour une moyenne de 10 tests avec la représentation SPEC et
l'algorithme (3.2).
Ces résultats, nous montrent que les trois premiers
algorithmes consomment beaucoup de temps avant d'atteindre la valeur objective.
Pour les trois autres versions du gradient conjugué, nous remarquons qu'
un arrêt d'appren-tissage se produit alors qu'on est trop loin de la
valeur objective. L'algorithme Rprop apparaît comme le meilleur
algorithme pour notre cas où l'on a utilisé des
représentations temps- fréquence et l'algorithme (3.2). Nous
avons aussi testé l'algorithme BFGS mais on atteint, au cours de
l'apprentissage, des valeurs dépassant la précision
computationnelle permise.
Le changement du mode d'apprentissage du mode hors ligne au
mode en ligne n'a pas apporté de changements significatifs comme il est
montré au tableau (5.5). Cependant, il confirme l'utilité de
l'algorithme Rprop pour notre cas.
Tableau 5.5: Influence du choix de l'algorithme d'apprentissage
en mode en ligne
|
Algorithme
|
Perf. atteinte
|
N. itérations
|
Temps [sec]
|
Cause d'arrêt
|
|
GDM
|
0.2495
|
50000
|
967
|
N maxi d'itérations
|
|
GDA
|
0.0994
|
50000
|
1019
|
N maxi d'itérations
|
|
SCG
|
0.0750
|
10398
|
840
|
V mini du gradient
|
|
CGF
|
0.1175
|
1573
|
27.8
|
V mini du gradient
|
|
CGP
|
0.1040
|
1227
|
33.42
|
V mini du gradient
|
|
CGB
|
0.0831
|
369
|
17.18
|
V mini du gradient
|
|
Rprop
|
0.0250
|
133
|
5.75
|
V objectve
|
résultats pour les données d'apprentissage, tout
en espérant que la même chose se passera pour des données
différentes. Cependant, parfois un arrêt de l'apprentissage se
produira non parce que la valeur objective a été atteinte mais
parce que le nombre d'itérations maximales ou la valeur minimale du
gradient a été atteint.
Nous prenons le même cas étudié pour
l'influence des représentations. Ainsi, pour le cas d'une
représentation par le SPEC avec une valeur de la fonction objective de
0.025 et un nombre d'itérations maximale de 1000, nous faisons
l'apprentissage par deux algorithmes: Rprop et le gradient conjugué
régularisé pour lesquels, nous obtenons les courbes
d'évolution des performances de la figure (5.6), et pour lesquels nous
constatons que Rprop permet d'atteindre la valeur objective avec une erreur
de
classification de 5% alors que ce n'est pas le cas pour le
gradient conjugué régulariséqui donne 10%. Même
lorsque l'algorithme converge ou s'approche de la valeur
objective, on ne sait pas si cette valeur objective est
adéquate pour les données traitées en tenant compte des
bruits de fonds dont la forme est chaotique pour le cas sismique. Dans ce sens,
afin de montrer l'influence de la valeur objective sur les résultats de
la classification et sa dépendance avec la base de test, nous avons
effectué deux experimentations en considérant la
représentation par SPEC et la représentation par le SCAL de Ben
avec une réduction de la dimensionnalité via
l'algorithme (3.2). Ainsi, en faisant changer la valeur
objective de 0.0005 (0.05%) à0.15 (15%) avec un pas de 0.0005
et en calculant l'erreur moyenne du réseau pour
10 test, nous avons obtenu les courbes des figures (5.7) et (5.8)
pour les deux bases de test 1 et 2 respectivement.
129
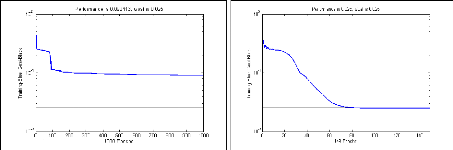
(a) (b)
Figure 5.6: Evolution de l'erreur pour l'algorithme Rprop (a)
et SCG (b)
(a) (b)
0.12
0.11
0.09
0.08
0.07
0.06
0.05
0.04
0.03
0.02
0 0.02 0.04 0.06 0.08 0.1 0.12 0.14 0.16
0.1
Test base 2 - SPEC
Goal Value
0.28
0.26
0.24
0.22
0.18
0.16
0.14
0.12
0.08
0 0.02 0.04 0.06 0.08 0.1 0.12 0.14 0.16
0.2
0.1
Test base 1 - SPEC
Goal Value
Figure 5.7: Evolution de l'erreur en fonction de la valeur
objective pour le SPEC pour la base de test 1 (a) et la base de test 2 (b)
0.16
0.14
0.12
0.08
0.06
004
0.02
0.1
0
0 002 004 006 008 01 012 014 016
Test base 2 - SCAL Ben
Goal Value
Test base 1 - SCAL Ben
0 002 004 006 008 01 012 014 016
Goal Value
0.5
045
0.4
0.35
03
0.25
0.2
(a) (b)
Tableau 5.6: Pourcentage de l'énergie
représentée pour l'algorithme (3.2) selon la dimension 2 avec 6
composantes
|
SPEC
|
WV
|
SPWV
|
SCAL Ben
|
SCAL Morl
|
SCAL Mexh
|
|
79.3%
|
59.32%
|
83.62%
|
92.25%
|
93.58%
|
97.972%
|
lure pour les deux bases de test. Pour la base de test 1,
l'erreur de classification augmente avec la valeur objective, alors que pour la
base de test 2 l'erreur de classification atteint des valeurs minimales pours
des valeur de la fonction objective vers le voisinage de 0.1 pour le SPEC et
0.12 pour le SCAL de Ben. Donc, choisir une valeur objective minimale ne donne
pas toujours de bons résultats.
E. Influence de l'architecture du réseau:
Le choix de l'architecture du réseau MLP est un facteur
déterminant dans l'obtention de meilleurs résultats. Or, la non
existence d'une règle déterministe permettant de
déterminer cet architecture implique le recours à des
méthodes heuristiques. Ce paragraphe est consacré à la
détermination de l'architecture adéquate d'un réseau MLP
à deux couches destiné à la classification des signaux
sismiques.
Pour l'algorithme (3.2), nous constatons que le choix de six
composantes pour la dimension 1 permet de représenter plus que 99%
d'énergie de l'image d'origine pour toutes
les représentations. Alors que pour la dimension 2, ce
taux varie d'une représentation àune autre pour le
même nombre de composantes comme il est illustré dans le tableau
(5.6).
Afin de bien choisir le nombre de composantes principales de
la dimension 2 dans l'algorithme (3.2), nous avons procédé
à une analyse de la sensibilité pour mesurer l'influence de
chaque entrée sur les performances du réseau. Pour cela, nous
avons utilisé le même réseau du paragraphe (influence de la
représentation) avec l'algorithme (3.2) pour la réduction de la
dimensionnalité sauf que nous avons fait varier le nombre de composantes
de la dimension 2. Ainsi, nous avons obtenu les résultats du tableau
(5.7).
Tableau 5.7: Influence du nombre de composantes principales de la
dimension 2 (B 1 et B2 désignent respectivement la base de test 1 et
2
|
NComp
|
4
|
5
|
6
|
7
|
8
|
|
Repr
|
B1
|
B2
|
B1
|
B2
|
B1
|
B2
|
B1
|
B2
|
B1
|
B2
|
|
SPEC
|
14.95
|
5.05
|
8.55
|
7.55
|
11.05
|
6.9
|
7.6
|
9.25
|
16.65
|
22.725
|
|
WV
|
14.40
|
3.6
|
11.95
|
4.55
|
13.95
|
5.15
|
15.3
|
7.95
|
16.2
|
6
|
|
SPWV
|
13.6
|
7.35
|
10.6
|
5.8
|
12.6
|
7.3
|
14.2
|
10.82
|
19.35
|
17.9
|
|
Ben
|
16.4
|
8.45
|
22.55
|
9.85
|
16.9
|
13.2
|
21.05
|
13.75
|
24.85
|
18.8
|
|
Morl
|
23.55
|
5.3
|
25.45
|
17.3
|
25.7
|
14.55
|
23.8
|
16.25
|
25.5
|
22.05
|
|
Mexh
|
24.05
|
11.55
|
24.4
|
11.45
|
25.5
|
10.09
|
26.4
|
17.75
|
23.7
|
18.1
|
pour la dimension 2 dans l'algorithme (3.2) pour les trois
représentations temps-fréquence permet d'améliorer les
performances de la classification pour la base de test 1 et en moyenne pour les
deux classes et même pour la base de test 2 sauf pour le spectrogramme.
Pour le cas des représentations temps-échelle, en choisissant un
nombre de composantes égale à 4, nous constatons une
amélioration des performances pour les deux bases de test sauf pour la
base de test 2 avec la représentation du SCAL Mexh où il y a une
légère dégradation.
Les résultats ci-dessus, nous ont montré
l'influence du nombre d'entrées sur les performances de la
classification. Cependant, ces résultats restent aussi
dépendantes du nombre de couches cachées et de ses
éléments. La déterminations du nombre optimal est de
l'impossible dans le cas général sinon très difficile pour
le cas d'un MLP à 2 couches. Pour ce dernier cas, la figure (5.9) nous
montre la variation de l'erreur moyenne du classificateur pour 10 tests
utilisant le SPEC et la base de test 1 en fonction du nombre de composantes de
la dimension 2 et de nombre d'éléments de la couche
cachée. De cette figure, nous ne pouvons pas opter pour une combinaison
ou une autre mais elle peut nous indiquer la meilleur région à
faire ce choix.
En conclusion, si l'analyse de la sensibilité nous
permet de faire le choix du nombre d'entrées, il n'est pas le cas pour
le nombre de couches cachées et ses éléments. Il existe
certaines méthodes sous-optimales tels que «network growing»
et «network pruning» mais difficile à appliquer
généralement. Ce qui fait de la méthode essaie-erreur la
bonne solution pour le moment.
132
Classification error
0.4
0.35
50
0.3
0.25
100
0.2
150
0.15
0.1
200
0.05
0
N. Component . Dim2
2 4 6 8 10 12 14
Figure 5.9: Erreur de classification en fonction du nombre
d'éléments de la couche cachée et du nombre de composantes
pour la dimension 2 de l'algorithme (3.2)
F. Influence du dilemme erreur-rejet:
Dans les paragraphes précédents, nous avons
utilisé un classificateur MLP à deux classes sans tenir compte
des confusions qui pourraient survenir au cour de la classification. Pour
traiter ces confusions, nous avons analysé le comportement des valeurs
de sorties du réseau MLP générées lors d'une
classification, en les comparant avec des seuils de la forme (u + á
ó) tirés des signaux bien classifiés en 100 tests. Cette
analyse, nous a permis de conclure que pour la majorité des erreurs, les
valeurs des sorties sont dans le mêmes intervalles des valeurs de sorties
des signaux bien classifiés. ce qui rend l'ajout d'une classe rejet ou
de faire une analyse ROC (Receiver Operating Curve) [340] sans grande
importance. En revanche, le problème pourra être résolu par
une combinaison de classificateurs.
5.1.2.3 Application de la méthode proposée
Dans le paragraphe précédent, nous avons
discuté les différents paramètres influençant les
performances de la classification par un réseau MLP et pour lesquels
nous ne pouvons que faire un compromis pour améliorer les performances.
Afin de vaincre les faiblesses d'un seul classificateur MLP, nous pouvons
combiner plusieurs classificateurs
selon le schéma donné par la figure (5.2) dont un
modèle basé sur les réseaux MLP est l'objet de ce
paragraphe.
· Cas d'une discrimination à deux classes: Dans
ce cas, nous considérons les représentations: SPEC, WV, SPWV,
SCAL de BEN et SCAL de MORL. Pour les représentations
temps-fréquence, nous associons un réseau MLP d'une architecture
30-30-2 et pour les représentations temps-échelle, un
réseau MLP 24-30-2. Les deux réseaux sont entraînés
par la base d'apprentissage décrite ci-dessus avec l'algorithme
d'apprentissage Rprop, un taux d'apprentissage de 0.001, une valeur objective
de 0.001, un minimum de gradient de 10-12, 0.95 pour le moment, 1000
comme nombre maximum d'itérations et fonctions d'activation sigmoidales.
Les bases de tests utilisées sont celles décrites ci-dessus. Les
résultats fournis par les deux réseaux sont combinés par
un expert selon une règle de combinaison fixée au
préalable. Pour les pondérations, nous avons utilisé les
pourcentages des performances des classificateurs donnés par le tableau
(5.7). Le tableau (5.8), représenté par la figure (5.10), donne
les résultats moyens de 100 tests pour certaines combinaisons
décrites au chapitre précédent.
Les résultats du tableau (5.8), nous permettent de
conclure que la combinaison des classificateurs a amélioré d'une
façon générale les performances de la discrimination.
Cependant, pour le cas du vote à l'unanimité et avec seuil, il y
a un pourcentage de signaux rejetés et qui doivent être
classés manuellement ou par une autre combinaison. Nous notons aussi que
l'augmentation de la fiabilité du système de classification
implique automatiquement une augmentation du taux de rejet (cas du vote
à l'unanimité comparé avec le vote à seuil), c'est
le dilemme erreur/rejet [133]. La pondération des classificateurs n'a
pas apporté d'amélioration significatives puisque leur
performances sont proches.
· Cas d'une discrimination à trois classes: Dans
ce cas, nous considérons les représentations SPEC, WV, SPWV, SCAL
de BEN et SCAL de MORL. Pour les représentations temps-fréquence,
nous associons un réseau MLP d'une architecture 30-30-2 et pour les
représentations temps-échelle un réseau MLP 24-30-2. Les
deux
134
Tableau 5.8: Influence de la méthode combinaison pour une
discrimination à deux classes
45
Erreur Rejet
40
35
30
25
20
15
10
5
0
Majorité avec pondération
Produit avec pondération
Majorité Unanimité Seuil
à
80%
Somme Produit Somme
avec pondération
(a)
(c)
18
Erreur Rejet
16
14
12
10
8
6
4
2
0
Majorité avec pondération
Produit avec pondération
Majorité Unanimité Seuil
à
80%
Somme Produit Somme
avec pondération
Méthode de combinaison
|
Base de test 1
|
Base de test 2
|
|
Erreur
|
Rejet
|
Erreur
|
Rejet
|
|
Majorité
|
6.85 %
|
0 %
|
4.75 %
|
0%
|
|
Unanimité
|
0.05 %
|
40.7 %
|
0.1 %
|
17.65 %
|
|
Seuil à 80 %
|
0.85 %
|
24.85 %
|
2.95 %
|
3.9 %
|
|
Majorité avec pondération
|
6.85 %
|
0 %
|
4.75 %
|
0%
|
|
Somme
|
7.05 %
|
0 %
|
4.8 %
|
0%
|
|
Produit
|
7.4 %
|
0 %
|
4.75 %
|
0%
|
|
Somme avec pondération
|
6.8 %
|
0 %
|
4.8 %
|
0%
|
|
Produit avec pondération
|
7.4 %
|
0 %
|
4.75 %
|
0%
|
réseaux sont entraînés par la base
d'apprentissage décrite ci-dessus augmentée de 20 signaux
relatifs à des séismes lointains dont les 2/3 de bonne
qualité et le 1/3 d'une qualité moyenne. L'algorithme
d'apprentissage utilisé est le Rprop avec les mêmes
paramètres considérés dans le cas de la discrimination
à deux classes. Les bases
de tests utilisées sont celles décrites ci-dessus
augmentées de 10 signaux relatifs àdes séismes
lointains dont le 1/2 de bonne qualité et le 1/2 de mauvaise
qualité.
Les résultats fournis par les deux réseaux sont
combinés par un expert selon une règle de combinaison
fixée au préalable. Le tableau (5.9), représenté
par la figure (5.11), donne les résultats moyens de 100 tests pour
certaines combinaisons décrites au chapitre précédent.
Les résultats du tableau (5.9), confirment les
mêmes remarques du cas précédent. Sauf pour le cas du
produit pour la base de test 1 où il y a une dégradation
remarquable des performances à cause de l'effet du veto causé par
l'existence d'une faible mesure (proche de zéro) produite par au moins
l'un des classificateurs à combiner
pour un signal où il y a une confusion totale. Les
résultats fournis par le vote àpluralité sont
les mêmes que ceux du vote à la majorité puisqu'on a une
combinaison de cinq classificateurs dans notre cas.
En conclusion, la discrimination sismique locale des signaux
sismiques, utilisant un système de classification modulaire mono-source
multi- (représentationnelle, stratégies, experts) décrit
par la figure (5.2), a permis d'atteindre des résultats meilleur qu'une
classification mono-(source, représentation, stratégie). De plus,
selon la stratégie adoptée, nous pourrons obtenir
différents niveaux de fiabilité. Ces résultats pourront
aussi être améliorer en tenant compte des résultats des
autres stations du réseau, ce qui fera l'objet du prochain
paragraphe.
136
Tableau 5.9: Influence de la méthode combinaison pour une
discrimination à trois classes
|
Méthode de combinaison
|
Base de test 1
|
Base de test 2
|
|
Erreur
|
Rejet
|
Erreur
|
Rejet
|
|
Pluralité
|
8.70 %
|
0.93 %
|
3.66 %
|
1.80 %
|
|
Majorité
|
8.70 %
|
0.93 %
|
3.66 %
|
1.80 %
|
|
Unanimité
|
0.36 %
|
47.70 %
|
0.033 %
|
28.20 %
|
|
Seuil à 80 %
|
2.63 %
|
21.46 %
|
0.93 %
|
12.53 %
|
|
Notoire
|
2.766 %
|
18.7 %
|
1.366 %
|
11 %
|
|
Somme
|
7.36 %
|
0 %
|
5.46 %
|
0%
|
|
Produit
|
12.93 %
|
0 %
|
5.96 %
|
0%
|
50
45
40
35
30
25
20
15
10
5
0
Pluralité Majorité Unanimité Seuil à
80% Notoire Somme Produit
Erreur Rejet
(a)
30
25
20
15
10
5
0
Pluralité Majorité Unanimité Seuil à
80% Notoire Somme Produit
Erreur Rejet
(b)
5.2 Discrimination sismique régionale
La discrimination sismique régionale consiste à
profiter des résultats de la discrimination sismique locale d'un
ensemble de stations sismiques selon un schéma statique ou dynamique.
5.2.1 Méthode proposée
5.2.1.1 Discrimination sismique régionale statique
L'administrateur d'un réseau sismique partitionne le
territoire contrôlé par le dit réseau en régions
où il attribue à chacune d'elle un ensemble de stations
sismiques. Lors de l'arrivée d'un événement sismique, un
nombre de stations d'une région, appelées par
la suite stations actives, détectent
l'événement. Les autres stations qui n'ont pas
détectéle signal, pour une raison ou une autre, seront
appelées par la suite stations inactives.
La discrimination sismique régionale statique consiste
à faire une discrimination sismique locale du signal relatif à
l'événement sismique pour chaque station active de la
région et de combiner par la suite les différentes
décisions des discriminations locales par un expert pour avoir la
décision finale (figure(5.12)). Donc, c'est une discrimination
multi(sources, représentationnelle, stratégies, experts) et
lorsqu'on se trouve avec une région ne comportant qu'une seule station
active, la discrimination sismique régionale devient identique à
la discrimination locale. Les différentes étapes de mise en
oeuvre de cette méthode sont données par l'algorithme (5.2).
L'utilisation du multi-sources permet d'améliorer la
décision lorsque la discrimination sismique locale donne une fausse
décision ou un rejet d'un signal relatif à un
événement sismique. Ceci est clarifié par l'exemple
ci-dessous.
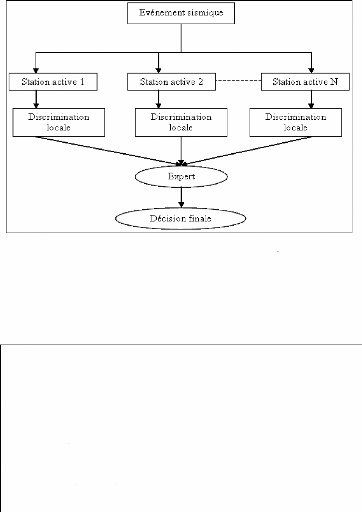
Figure 5.12: Schéma de la discrimination sismique
régionale
Etape 0: Fixer les stations attribuées à la
région;
Etape 1: Acquisition des signaux sismiques par les stations
actives de la région; Etape 2: Faire la discrimination sismique locale
au niveau de chaque station active
de la région;
Etape 3: Combiner les résultats des discriminations
sismiques locales via un expert choisi au préalable pour avoir la
décision finale.
Algorithme 5.2: Discrimination sismique régionale
statique
Exemple 5.1: Discrimination sismique régionale.
Nous considérons trois signaux, relatifs à un
séisme lointain (ES0206-2005-05- 0119:05:38), enregistrés par
trois stations, à savoir CZD, MIF et ZFT appartenant à la region
5 qui comporte aussi la station TGT. Lors de l'arrivée de
l'événement, la station TGT a été inactive. Nous
essayons d'appliquer la discrimination sismique régionale décrite
ci-dessus en analysant la décision de la discrimination sismique locale
pour différents experts et pour les trois stations CZD, MIF et ZFT. Pour
cela, nous considérons les paramètres des classificateurs qui
sont donnés dans le paragraphe discrimination locale. L'expert
considéré pour la discrimination sismique régionale est le
vote majoritaire. Les résultats pour 10 tests sont donnés par le
tableau (5.10) où C, F, R et T indiquent respectivement, classification
correcte, classification fausse, rejet et test numéro i.
Nous constatons que la discrimination sismique locale au
niveau de la station MIF donne dans certains tests de fausses décisions
même pour le cas d'unanimité. Ces fausses décisions sont
corrigées au niveau de la discrimination sismique régionale par
vote majoritaire puisque les deux autres décisions de la discrimination
sismique locale au niveau CZDV et ZFT sont correctes.
Tableau 5.10: Exemple de la discrimination sismique
régionale statique
|
Méthode de discrimination
|
T1
|
T2
|
T3
|
T4
|
T5
|
T6
|
T7
|
T8
|
T9
|
T10
|
|
Unanimité- CZDV Unanimité- MIF Unanimité-
ZFT Régionale
|
C C C C
|
C C C C
|
C F C C
|
C C C C
|
C F C C
|
C F C C
|
C F C C
|
C C C C
|
C F C C
|
C C C C
|
|
Majorité- CZDV Majorité- MIF Majorité-ZFT
Régionale
|
C C C C
|
C C C C
|
C F C C
|
C C C C
|
C F C C
|
C F C C
|
C F C C
|
C C C C
|
C F C C
|
C C C C
|
|
Pluralité- CZDV Pluralité- MIF Pluralité-ZFT
Régionale
|
C C C C
|
C C C C
|
C F C C
|
C C C C
|
C F C C
|
C F C C
|
C F C C
|
C C C C
|
C F C C
|
C C C C
|
|
Seuil à 80% - CZDV Seuil à 80% - MIF
Seuilà80%-ZFT Régionale
|
C C C C
|
C C C C
|
C F C C
|
C C C C
|
C F C C
|
C F C C
|
C F C C
|
C C C C
|
C F C C
|
C C C C
|
|
Notoire - CZDV Notoire - MIF Notoire-ZFT Régionale
|
C C C C
|
C C C C
|
C F C C
|
C C C C
|
C F C C
|
C F C C
|
C F C C
|
C C C C
|
C F C C
|
C C C C
|
|
Somme-CZDV Somme-MIF Somme-ZFT Régionale
|
C C C C
|
C F C C
|
C F C C
|
C C C C
|
C F C C
|
C C C C
|
C C C C
|
C C C C
|
C C C C
|
C C C C
|
|
Produit - CZDV Produit-MIF Produit-ZFT Régionale
|
C F C C
|
C F C C
|
C F C C
|
C F C C
|
C C C C
|
C C C C
|
C C C C
|
C F C C
|
C F C C
|
C C C C
|
5.2.1.2 Discrimination sismique régionale dynamique
Le schéma global de la discrimination sismique
régionale dynamique reste le même que celui de la discrimination
sismique régionale statique, sauf que les régions sont
formées dynamiquement en dépendance avec l'épicentre de
l'événement sismique et de l'indice d'activation des stations
selon des règles fixées par l'administrateur du réseau
sismique. Ainsi, cette approche ne traite que des événements
locaux.
Cette conception permet de mieux profiter des stations proches
de l'épicentre de l'événement sismique pour le cas des
événements locaux afin d'alléger l'effet de la distance.
En effet, la durée d'un signal sismique enregistré par une
station sismique dépend de la distance hypocentrale. De plus, elle
permet de diminuer le taux de rejet et de fausses décisions comme la
discrimination sismique régionale statique. Les différentes
étapes de mise en oeuvre de cette méthode sont données par
l'algorithme (5.3).
Etape 0: Fixer les règles de création d'une
région dynamique;
Etape 1: Acquisition des signaux sismiques par les stations
actives de la région dynamique;
Etape 2: Faire la discrimination sismique locale au niveau de
chaque station active de la région;
Etape 3: Combiner les résultats des discriminations
sismiques locales via un expert choisi au préalable pour avoir la
décision finale.
Algorithme 5.3: Discrimination sismique régionale
dynamique
5.3 Discrimination sismique globale
pour générer un système
intégré de discrimination des signaux sismiques selon le
schéma donné par la figure (5.13). Les différentes
étapes de mise en oeuvre de cette méthode sont données par
l'algorithme (5.4).
La discrimination sismique globale permet d'améliorer
les performances de la discrimination sismique régionale
particulièrement lorsqu'il y a une seule station active par
région lors de l'arrivée d'un événement sismique
(Voir exemple ci-dessous).
Etape 0: Acquisition des signaux sismiques par les stations
actives du réseau; Etape 1: Faire la discrimination sismique locale au
niveau de chaque station active;
Etape 2: Si (Localisation: Automatique) Alors Si
(Evénement: Locale) Alors
Faire la discrimination sismique régionale dynamique
Sinon
Faire la discrimination sismique régionale statique Fin
Si
Sinon
Faire la discrimination sismique régionale statique
Fin Si
Etape 3: Combiner les résultats de l'étape 2 via un
expert pour avoir la décision finale.
Algorithme 5.4: Discrimination sismique globale
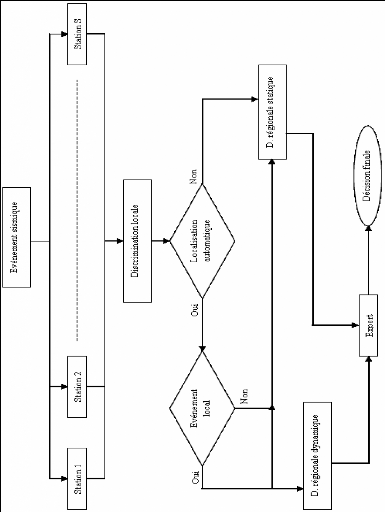
Figure 5.13: Schéma de la discrimination sismique
globale
Exemple 5.2: Discrimination sismique globale.
Nous considérons trois signaux, relatifs à un
séisme lointain (ES0221-2005- 08-14 02:52:02), enregistrés par
trois stations, à savoir TZC, MIF et CIA appartenant à trois
regions 4, 5 et 6 respectivement. Nous essayons d'appliquer la discrimination
sismique globale décrite ci-dessus en analysant la décision de la
discrimination sismique régionale (même chose que la
discrimination sismique locale dans ce cas). Pour cela, nous considérons
les paramètres des classificateurs qui sont donnés dans le
paragraphe discrimination locale. L'expert considéré pour la
discrimination sismique globale est le vote majoritaire. Les résultats
pour 10 tests sont donnés par le tableau (5.11) où C, F, R et T
indiquent respectivement, classification correcte, classification fausse, rejet
et test numéro i.
Nous constatons que la discrimination sismique locale au
niveau de la région 5 représentée par la station MIF donne
dans certains tests de fausses décisions même pour le cas
d'unanimité. Ces fausses décisions sont corrigées au
niveau de la discrimination sismique globale par vote majoritaire puisque les
deux autres décisions des discriminations régionales 4 et 6 sont
correctes.
5.4 Conclusion
Dans ce chapitre, nous avons essayé de présenter
certaines méthodes de classification des signaux sismiques basées
sur les réseaux de neurones. Dans ce sens, nous avons discuté les
différents paramètres influençant les performances d'une
classification mono-
source et mono-classificateur. Ainsi, pour diminuer le taux
d'erreur, nous avons proposétrois schémas de
classification: discrimination sismique locale (mono-source), discrimi-
nations sismiques régionale et globale (multi-source).
L'utilisation de l'approche multi(représentationnelle,
stratégies, experts) donne plusieurs alternatives à l'utilisateur
selon ces objectifs.
Tableau 5.11: Exemple de la discrimination sismique globale
|
Méthode de discrimination
|
T1
|
T2
|
T3
|
T4
|
T5
|
T6
|
T7
|
T8
|
T9
|
T10
|
|
Régionale 4 - unanimité Régionale 5 -
unanimité Régionale 6 - unanimité Globale
|
C C C C
|
C F C C
|
C C C C
|
C C C C
|
C C C C
|
C C C C
|
C C C C
|
C C C C
|
C C C C
|
C C C C
|
|
Régionale 4 - majorité Régionale 5 -
majorité Régionale 6 - majorité Globale
|
C C C C
|
C F C C
|
C C C C
|
C C C C
|
C C C C
|
C C C C
|
C C C C
|
C C C C
|
C C C C
|
C C C C
|
|
Régionale 4 - pluralité Régionale 5 -
pluralité Régionale 6 - pluralité Globale
|
C C C C
|
C F C C
|
C C C C
|
C C C C
|
C C C C
|
C C C C
|
C C C C
|
C C C C
|
C C C C
|
C C C C
|
|
Régionale 4 - seuil à 80% Régionale 5 -
seuil à 80% Régionale 6 - seuil à 80% Globale
|
C C C C
|
C F C C
|
C C C C
|
C C C C
|
C C C C
|
C C C C
|
C C C C
|
C C C C
|
C C C C
|
C C C C
|
|
Régionale 4 - notoire Régionale 5 - notoire
Régionale 6 - notoire Globale
|
C C C C
|
C F C C
|
C C C C
|
C C C C
|
C C C C
|
C C C C
|
C C C C
|
C C C C
|
C C C C
|
C C C C
|
|
Régionale 4- somme Régionale 5- somme
Régionale 6- somme Globale
|
C C C C
|
C C C C
|
C C C C
|
C C C C
|
C C C C
|
C C C C
|
C C C C
|
C C C C
|
C C C C
|
C C C C
|
|
Régionale 4 - produit Régionale 5 - produit
Régionale 6 - produit Globale
|
C C C C
|
C F C C
|
C C C C
|
C F C C
|
C C C C
|
C F C C
|
C C C C
|
C C C C
|
C C C C
|
C C C C
|
faire par le logiciel MSSSA (Moroccan Software for Seismic
Signals Analysis) pour lequel, ce chapitre donne les méthodes
utilisées pour sa conception.
Si d'un côté, la discrimination des signaux
sismiques permet d'attribuer un événement à une classe
avec de bonnes performances, de l'autre côté, elle ne permet ni de
rejeter les bruits qui pourraient être enregistrés pour une raison
ou une autre, ni de détecter de nouvelles classes. Donc, avant de passer
à la phase de classification, il faut prévoir une phase de
reconnaissance des signaux sismiques, ce qui fera l'objet du prochain
chapitre.
CHAPITRE 6
RECONNAISSANCE DES SIGNAUX SISMIQUES
Comme les tremblements de terre, une explosion chimique ou
nucléaire souterraine crée des signaux sismiques qui se propagent
à l'intérieur de la terre. Pour satisfaire la tâche de
contrôle, un réseau d'enregistrement de signaux sismiques doit
être capable d'identifier la source des signaux enregistrés. Mais
tenant compte que les sismomètres sont très sensibles, de faibles
signaux dus à des processus comme le vent, les ondes océaniques
et même le trafic routier sont aussi détectés. De plus,
même les bruits radiophoniques pourraient être enregistrés
lors du déclenchement du processus de détection (Cas qu'on le
trouve souvent dans les enregistrements du système DataSeisII
utilisé par l'institut national de la géophysique du Maroc).
Donc, avant de faire la discrimination des signaux sismiques bruts, il
s'avère nécessaire de faire un rejet des signaux bruits afin de
ne garder que les vrais enregistrements sismiques. Ce qui nous amène
à faire une procédure de reconnaissance d'une seule classe de
signaux, à savoir la classe des signaux sismiques, parmi une
infinité de classes, à savoir les classes des signaux bruits.
Ce problème, connu dans la littérature sous le
nom détection de nouveauté (Novelty detection), a
été traité dans plusieurs travaux de recherche pour des
applications spécifiques. En effet, pour l'instant, il n'existe aucune
solution universelle permettant de le résoudre dans le cadre
général. Pour le cas des signaux sismiques, à notre
connaissance, tous les travaux réalisés traitent la
discrimination entre les différentes classes de ces signaux et non leur
reconnaissance parmi les différentes classes de bruit.
Le but de ce chapitre est, d'une part, de présenter la
notion détection de nouveautéet, d'autre part, de
présenter avec certains détails l'approche neuronale pour deux
types
de réseaux de neurones, à savoir le perceptron
multicouche et le réseau auto-associatif.
Enfin, pour le cas des
signaux sismiques en particulier, et les signaux non
stationnaires
similaires en général, nous proposons une
méthode basée sur les réseaux auto-associatifs.
Les performances de cette dernière sont
évaluées en utilisant des données de l'Institut National
de Géophysique.
6.1 Détection de nouveauté
6.1.1 Introduction
La détection de nouveauté (Novelty detection)
[295], la détection des données aberrantes (Outliers detection)
[151] et la classification à une classe (One-class classification) [293]
sont des termes qui ont été utilisés dans la
littérature, selon le domaine de recherche, pour désigner la
détection des données anormales appartenant à des classes
différentes de la classe des données normales. Par exemple, pour
le cas sismiques, tous les signaux sismiques sont des données normales
et tous les autres signaux sont des données anormales. Dans ce sens, il
est généralement impossible d'utiliser une procédure de
discrimination par apprentissage pour différencier entre les
données anormales et normales. En effet, si ces dernières peuvent
être facilement et parfaitement caractérisées à
partir d'un modèle ou d'un nombre d'exemples;
généralement, ce n'est pas le cas pour les autres données
[260]. Donc, le recours à des procédures de reconnaissance
s'avère très utile.
La différence entre les deux stratégies
discrimination et reconnaissance est illustrée dans la figure (6.1).
Pour la discrimination, les limites sont tracées entre les
données normales et anormales, c'est à dire qu'il y a un
découpage de l'espace des classes par des frontières de
décision en plusieurs zones, chacune correspond à une classe.
Alors que pour la reconnaissance les limites sont tracées, seulement,
autour des données normales.
La détection de nouveauté a été
appliquée avec succès dans plusieurs domaines d'ingénierie
[291, 151]. Ainsi, On la trouve à titre d'exemple dans: la maintenance
industrielle [227, 325], la robotique [212, 320], le domaine médical
[292, 259], l'informatique [282, 330, 333], les
télécommunications [103], l'environnement [188] et l'astronomie
[338].
Pour la conception d'une méthode de détection de
nouveauté, deux approches sont possibles: l'approche statistique et
l'approche neuronale. Ceci fait l'objet des deux paragraphes suivants,
où nous essayons de présenter certaines méthodes et de
donner certaines
149
(a) (b)
-
+
+
+
-
-
+
-
-
+
+
+
-
+
+
-
+
+
+
+
+
+
+
-
+
+
+
-
-
-
-
+
-
-
Figure 6.1: Les deux approches du concept d'apprentissage:
Discrimination (a) versus Reconnaissance (b)
références. Toutefois, le lecteur pourra se
référer à [209, 210] et [151] pour plus de
détails.
6.1.2 Approche statistique
Les méthodes statistiques sont les premières
méthodes qui ont été utilisées dans la conception
des détecteurs de nouveauté. Ces méthodes consistent
à modéliser les données à partir de leurs
propriétés statistiques et de faire la comparaison avec un seuil
fixé au préalable. La plus simple de ces méthodes est de
construire la fonction de densité de probabilité pour des
données où la distribution est connue, ce qui n'est pas toujours
le cas. En effet, il est rare d'avoir des informations sur la distribution des
données traitées dans les cas pratiques surtout dans les cas de
distributions complexes ou multimodales. Pour surpasser ce problème,
deux possibilités existent: la première consiste à estimer
la fonction de densité de probabilité et la deuxième
consiste à utiliser des méthodes où cette fonction n'est
pas nécessaire.
Pour le deuxième cas, la plus simple des
méthodes consiste à mesurer la dispersion de la nouvelle
donnée par rapport à la moyenne d'une classe de données et
faire la
comparaison avec un seuil [208]. Une autre méthode
simple basée sur les box-plots a
étéutilisée par Laurikkala et al. [193]. Pour
combler certaines lacunes d'autres techniques
dites techniques de proximité, basées sur la
méthode du K-plus proche voisin (K-Nearest
Neighbor ou K-NN), ont
été proposées [182, 50, 250]. Ces derniers ont
été unifiés dans
un modèle de Tang et al. [290] en se basant sur un
schéma de connectivité des données aberrantes.
Différemment de ces méthodes d'autres approches ont
été développées, tel que K-moyenne (K-means) [10,
227], K-medoids (Partition Around Medoids-PAM) [49, 44] et connectivité
des graphes [274].
Pour l'estimation d'une fonction de densité de
probabilité à partir des échantillons, l'idée est
simple. Cependant, les démonstrations de convergence sont souvent
difficiles [93]. Dans le domaine de la detection de nouveauté, plusieurs
méthodes ont été utilisées. Nous citons les
fenêtres de Parzen (Parzen Windows) [43, 294, 331] et le modèle de
mélange gaussien (Gaussian Mixture Models-GMM) [43, 294, 259, 156].
6.1.3 Approche neuronale
Les réseaux de neurones ont été largement
utilisés dans le champ de la détection de nouveauté. Ces
réseaux ont l'avantage qu'ils nécessitent peu de
paramètres à optimiser lors de l'apprentissage et aucunes
hypothèses sur les propriétés des données ne sont
faites. La plus simple de ces méthodes consiste à faire un
seuillage de la sortie du réseau de neurones [288, 266, 17]. Ce principe
a été utilisé intensivement et différemment dans
plusieurs travaux. La différence réside dans le type du
réseau et la façon de faire le seuillage.
Pour les réseaux MLP plusieurs travaux ont
été réalisés. Ainsi, Vasconcelos et al. [307] ont
démontré comment un réseau de ce type construit ses
régions de décision pour les différentes fonctions
d'activation et règles de propagation afin de détecter des
données aberrantes, Wilson et al. [323] ont montré que certains
changements sur le réseau MLP peuvent aboutir à des meilleurs
performances dans la détection de nouveauté en comparaison avec
les réseaux de neurones probabilistes, Cordella et al. [69] et DeStefano
et al. [86] ont défini une fonction de performance permettant de donner
le seuil optimal pour plusieurs types de réseaux, d'autres aspects ont
été aussi traités.
151
(a) (b)
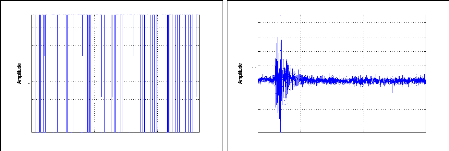
-1
-2
-3
-4
-5
0
0 10 20 30 40 50 60 70
x 10 4 ES0001-RTC -2003-01-22 13:11:23
Time [sec]
-100
-200
-300
400
200
300
100
0
0 10 20 30 40 50 60 70
ES0001-MIF -2003-01-22 13:11:23
Time [sec]
Figure 6.2: Signaux relatifs à un Bruit (a) et un
événement sismique(b)
l'entrée par la sortie du réseau et de comparer
l'erreur avec un seuil. Leur performances
ont été
révélées dans plusieurs publications: [243, 164, 285, 286,
154, 282, 279, 336, 27, 280]
D'autres réseaux ont été aussi
appliqués à la détection de nouveauté, nous citons:
réseau de Kohonen [60], réseau Hopfield [72], Théorie de
la résonance adaptative (Adaptive Resonance Theory-ART) [55, 155].
6.1.4 Quelle approche pour le cas sismique?
La détection des données aberrantes traite
généralement trois situations, à savoir le cas où
on n'a aucune connaissance à priori sur les données, le cas
où on a des connaissances sur les données normales et anormales,
et la troisième situation, seulement les données normales sont
connues. Le cas sismique est inclus dans cette dernière situation. En
effet, on a seulement des connaissances sur les signaux sismiques provenant des
événements naturels ou artificiels, alors que pour les bruits,
ils pourraient parvenir d'une infinité de classes. La figure (6.2)
montre deux signaux relatifs au même événement
enregistrés par deux stations du réseau Marocain, où un
correspond au bruit et l'autre à l'événement. Ceci peut
être dû à plusieurs raisons: panne au niveau de la station,
panne au niveau de la transmission, événement faible et/ou loin
pour être enregistré par la station, etc.
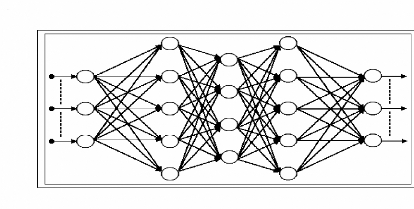
152
Figure 6.3: Schéma d'un réseau de neurones
auto-associatif
des données aberrantes dans les bases de données
sismiques, il serait judicieux d'utiliser des méthodes d'apprentissage
(statistiques ou neuronales). Et tenant comptes des performances des
réseaux de neurones démontrées dans plusieurs domaines,
nous adoptons dans ce mémoire l'approche neuronale en utilisant les
réseaux auto-associatifs.
6.2 Réseau auto-associatif
Le réseau de neurones auto-associatif (AANN:
Autoassociative Artificial Neural Network), connu aussi sous les appellation
réseau diabolo et auto-encodeur [271], est un réseau MLP (figure
(6.3)) dont la sortie, après apprentissage, doit être proche de
l'entrée, entraînant en particulier que la couche de sortie a la
même dimension que la couche d'entrée. Les poids entre la couche
d'entrée et la couche cachée au milieu du réseau
effectuent un codage de la donnée présentée de sorte qu'
ils sont appelés les poids encodeurs. Les poids entre la couche
cachée au milieu du réseau et la couche de sortie sont
appelés poids générateurs puisqu'ils reproduisent
l'entrée.
Ce type de réseau est connu depuis longtemps. Les
premières références remontent même aux
années 80 [264]. L'apprentissage se fait généralement par
rétro-propagation du gradient, mais il est non supervisé
puisqu'on utilise une sortie désirée qui est identique à
l'entrée. La majorité des travaux concernant ce réseau a
traité la couche cachée existant au milieu puisqu'elle
représente un codage compact du vecteur d'entrée [185]. Le
réseau effectue donc une réduction de la dimensionnalité
au sens de la PCA non linéaire
(uniquement pour le même type d'exemples que ceux
appris) mais sans équivalence entre les deux méthodes [163]. On
note que les résultats fournis par ce type de réseaux sont
influencés par les mêmes paramètres cités pour le
réseau MLP dans le chapitre précédent. Sauf qu'ils ne
nécessitent pas un grand nombre d'élément dans la base
d'apprentissage comme les MLP.
6.3 Reconnaissance des signaux sismiques
Un système de reconnaissance s'avère
nécessaire pour un réseau sismique à grande
échelle. En effet, quelque soit les performances de l'algorithme de
détection des événements sismiques, il y aura toujours de
fausses détections à cause de plusieurs facteurs qui sont dus
à la conception de l'algorithme lui-même ou à
l'environnement du réseau (emplacement des stations, réseau de
transmission, etc). Pour le premier cas, lors de la conception de la
procédure de détection, souvent le réseau sismique est
subdivisé en sous réseaux au niveau matériel et en
régions au niveau géographique. Ces régions englobent un
nombre de stations pour lesquelles la procédure d'enregistrement se
déclenche une fois certaines conditions sont remplies pour un certain
nombre d'entre elles. Donc, il y a de l'enregistrement même pour les
stations qui n'ont pas détecté l'événement. Cette
situation s'applique parfaitement au système DataSeis II
d'enregistrement numérique des signaux sismiques installé
à l'Institut National de Géophysique où l'enregistrement
se fait même pour les régions dont aucune station n'a
détecté l'événement. Le lecteur pourra se
référer à [177] pour les enregistrements sismiques
provenant des sautages de l'office chérfien des phosphates (OCP).
6.3.1 Méthode proposée
Notre objectif dans ce paragraphe est de présenter une
méthodologie globale pour concevoir un système de reconnaissance
de signaux sismiques. C'est à dire un système permettant de
filtrer une base de données sismiques en faisant un regroupement des
signaux (figure (6.4)). Et comme le nombre de signaux acquis par un
réseau est énorme, alors le traitement au sein du système
de reconnaissance doit être le plus rapide possible.
154
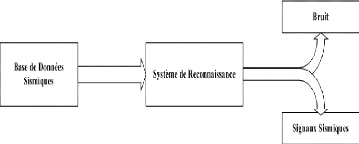
Figure 6.4: Schéma de l'objectif de la reconnaissance des
signaux sismiques
Pour atteindre l'objectif présenté ci-dessus et
afin de profiter des conclusions faites au chapitre 2 concernant les
représentations discriminantes temps-fréquence et
temps-échelle, on propose d'abord d'utiliser la moyenne comme
descripteur atemporel au niveau de chaque canal fréquentiel pour
générer les caractéristiques qui serviront comme des
entrées pour le système de reconnaissance. Ce choix repose sur le
fait que les représentations bidimensionnelles permettent de bien
différencier entre un signal bruit et un vrai signal sismique comme le
montre la figure (6.5) pour le cas d'une représentation avec le SPEC.
(a) (b)
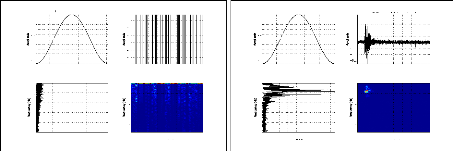
0.9
0.8
0.7
0.6
0.5
0.4
0.3
0.2
0.1
10
15
20
0
5
0 50 100 150 200
0.5 1 1.5 2
Modulus x 107
Hanning window (256 pts)
FT
250 0 10 20 30 40 50 60 70
-3
20
10
15
4
x 104 Es0001RTC 20030122 13:11:23
0
2
5
0
5
1
0 10 20 30 40 50 60 70
Time [sec]
SPEC
0.9
0.8
0.7
0.6
0.5
0.4
0.3
0.2
0.1
20
10
15
0
5
0 50 100 150 200 250
2000 4000 6000 8000 10000 12000 14000 16000
Hanning window (256 pts)
Modulus
FT
-100
400 300 200 100
200
00
20
10
15
0
0
5
0 10 20 30 40 50 60 70
0 10 20 30 40 50 60 70
Es0001MIF 20030122 13:11:23
Time [sec]
SPEC
Figure 6.5: Le SPEC d'un signal bruit (a) et d'un signal
sismique (b)
Pour le système de reconnaissance, nous proposons
d'utiliser un réseau AANN par classe comme le montre la figure (6.6). Le
nombre de réseaux AANN à utiliser est déterminé par
le nombre de classes spécifié dans le système de
classification automatique si le
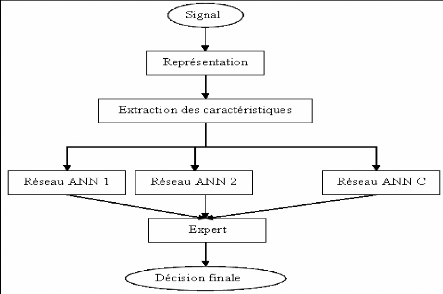
Figure 6.6: Schéma du système de reconnaissance
des signaux sismiques
système de reconnaissance est lié au
système de classification sinon le nombre de classes est
déterminé par les classes dont on veut reconnaître les
signaux correspondants. Le choix de ce modèle modulaire a pour
objectifs, d'une part, d'être très rapide et, d'autre part, de
bien modéliser chaque classe en diminuant ainsi l'effet de recouvrement
des classes qui pourra être généré si on
considère un seul réseau AANN et qui pourra engendrer à
son rôle des confusions avec les bruits, les sous classes ou avec de
nouvelles classes.
La mise en oeuvre du système ci-dessus passe par les
mêmes étapes que celles du réseau MLP sauf qu'il y a une
étape de détermination du seuil de rejet en plus. Ces
étapes sont : 1) le choix des bases d'apprentissage et de test, 2) le
choix des paramètres du réseau, 3) l'apprentissage et 4) la
détermination du seuil de rejet. Ce dernier est déterminé
après l'apprentissage via l'erreur de reconstruction, c'est-à-
dire la distance entre l'entrée et la sortie du réseau. Par
exemple, on peut utiliser sa valeur absolue pour formuler un critère de
rejet de distance, et les différences relatives pour un rejet
d'ambiguïté. En résumé, la reconnaissance des signaux
sismiques s'effectue selon l'algorithme (6.1).
Etape 0: Choix des classes, des bases d'apprentissage et de
test, des méthodes de représentation et d'extraction des
caractéristiques, des réseaux AANN et de l'expert;
Etape 1: Faire correspondre à chaque classe un
réseau AANN;
Etape 2: Faire l'apprentissage du système;
Etape 3: Faire les tests en calculant les erreurs de
reconstruction;
Etape 4: Refaire les étapes 2 et 3 jusqu'à
l'obtention des performances désirées; Etape 5: Determiner le
seuil de rejet pour chaque réseau AANN;
Etape 6: combiner les résultats par un expert pour avoir
la décision finale.
Algorithme 6.1: Reconnaissance des signaux sismiques via les
réseaux AANN
Nous notons que les méthodes de combinaison
présentées pour les réseaux MLP dans le chapitre
précédent restent valables pour les réseaux AANN. Le MSSSA
Recognition [33] donne à l'administrateur du réseau sismique une
multitude d'alternatives pour réaliser la méthode de
reconnaissance convenable en se basant sur le schéma (6.6) et
l'algorithme (6.1).
6.3.2 Tests expérimentaux
6.3.2.1 Test expérimental 1
Dans ce test nous essayons, d'argumenter notre choix de
considérer un réseau auto- associatif pour chaque classe. Pour
cela nous considérons une base d'apprentissage et de test
constituée de 160 signaux dont le 1/4 pour chaque classe (explosions
chimiques, séismes locaux, séismes lointains et bruits). Pour la
représentation, nous considérons le spectrogramme où nous
choisissons la moyenne de 32 canaux spectraux c'est à dire les
fréquences inférieures à 12.5Hz. La
reconnaissance est assurée par un réseau AANN
entraîné par l'algorithme gradient conjugué
régularisé (SCG) avec des fonction d'activations sigmoide, un
taux d'apprentissage 0.001, une valeur objective de l'erreur 0.005, un moment
de 0.95, une valeur minimale du gradient de 10-12, et un nombre
maximale d'itération 10000. Pour voir quelles sont les
possibilités d'avoir un seuil de rejet à partir des erreurs de
reconstruction des signaux d'apprentissage, nous traçons, d'une part,
ces erreurs et d'autre par celles des signaux tests ordonnées d'une
façon croissante.
Afin de tester notre approche, nous considérons une
base de 40 signaux d'une classe à reconnaître dont 20 pour
l'apprentissage et 20 pour le test. Pour les autres classes, nous
considérons 20 signaux pour le test. Ainsi, nous obtenons pour chaque
classe la figure (6.7(a)) pour les explosions chimiques, la figure (6.7(b))
pour les séismes locaux et la figure (6.7(c)) pour les séismes
lointains.
Nous constatons que pour les trois cas, nous pouvons fixer un
seuil de rejet selon la fiabilité désirée. Ainsi, pour les
explosions chimiques, un seuil de 0.2 permet de rejeter tous les
éléments des autres classes. Cependant, pour ce seuil il y a
aussi un rejet de certains éléments de la classe objective soit
qui appartiennent à la base d'apprentissage ou de test. Ceci pourra
être dû à certains bruits de fonds influençant les
caractéristiques fréquentielles des signaux et par
conséquent l'erreur de reconstruction, ou même à cause
d'une confusion dans notre choix de la base de test des bruits en
considérant un signal comme étant un bruit alors qu'il est
sismique mais dominé par un grand bruit de fond.
Pour le cas où la classe objective est formée de
séismes locaux, on constate d'abord qu'il y a une séparation
totale avec les explosions et les séismes lointains. Et pour les bruits,
un seuil de 0.25 de l'erreur de reconstruction permet de les rejeter totalement
mais en contrepartie il y a aussi un rejet des élément de la
classe objective déjà soit de la base d'apprentissage ou de test.
Ceci pourrait être expliqué comme précédemment.
Pour le cas où la classe objective constituée de
séismes lointains, un changement du nombre de canaux fréquentiels
à prendre en compte s'avère nécessaire pour s'adapter au
contenu fréquentiel de tels événements. Ainsi, pour une
architecture 15-5-15, nous
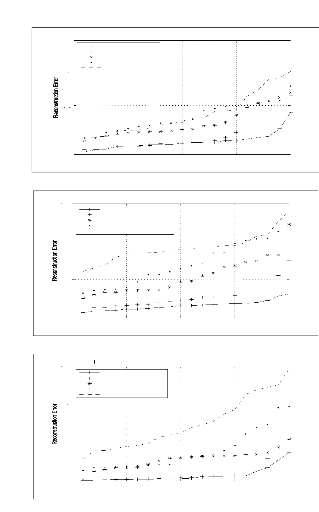
158
1 .4
1.2
1
0.8
0.6
0.4
0.2
0
Sam ple
0 5 10 15 20
Recognition by SPEC and ANN with architecture 32-15-7-15-32
Explosions Train Explosions Test Noise
Local earthquakes Far earthquakes
(a)
(c)
1.5
1
0.5
0
Sam ple
0 5 10 15 20
Recognition by SPEC and ANN with architecture 32-15-7-15-32
Local earthquakes Train Local earthquakes Test Noise
Explosions
Far earthquakes
(c)
1.5
1
0.5
0
Sam ple
0 5 10 15 20
Recognition by SPEC and ANN with architecture 15-5-15
Far earthquakes Train Far earthquakes Test Noise
Explosions
Local earthquakes
Figure 6.7: L'erreur de reconstruction de trois réseaux
AANN entraînés par des signaux relatifs à des explosion
chimique (a), des séismes locaux (b) et des séismes lointains
(c)
avons obtenu une séparation totale avec les
séismes locaux et une bonne séparation avec les explosions et les
bruits. Ceci est dû aux propriétés fréquentielles
des séismes lointains (entre 0.1Hz et 1 Hz).
Le seuil de rejet reste un choix de l'administrateur du
réseau sismique selon les objectives désirées. Toutefois,
les performances de la reconnaissance peuvent être
améliorées en considérant des combinaisons de plusieurs
systèmes de reconnaissance (en changeant la représentation par
exemple) comme pour le cas de la discrimination. Aussi, il faut noter que le
choix des paramètres du réseau AANN doit être basé
sur une multitude de tests en correspondance avec le cas étudié
en plus de certains résultats de la littérature (Par exemple le
choix de fonctions d'activation non linéaires n'est pas arbitraire. En
effet, il a été démontré par Japkowicz [162] que
l'utilisation de telles fonctions permet de créer une certaines
spécialisation pour les réseaux AANN en l'absence de contre
exemples).
6.3.2.2 Test expérimental 2
Dans ce test, nous essayons d'expliciter pourquoi nous avons
choisi un réseau par classe et non un seul réseau pour toutes les
classes objectives. Pour cela nous considérons une base d'apprentissage
formée de 60 signaux dont chaque classe objective est
représentée par 20 signaux. La base de test est formée de
80 signaux dont 60 sont relatifs aux classes objectives (1/3 pour chacune
d'elle) et 20 sont relatifs aux bruits. Nous considérons les mêmes
paramètres que le test précédent et nous traçons
les erreurs de reconstruction ordonnées d'une façon croissante.
Nous obtenons ainsi la figure (6.8).
Il est clair sur la figure (6.8) qu'il est impossible d'avoir
un seuil de rejet pour les bruits. Et même si on fait changer le nombre
de couches cachées, on obtient des résultats similaires. Ceci est
dû à la grande différence des caractéristiques
fréquentielles des classes objectives. Ce qui entraîne des
confusions pour le réseau AANN.
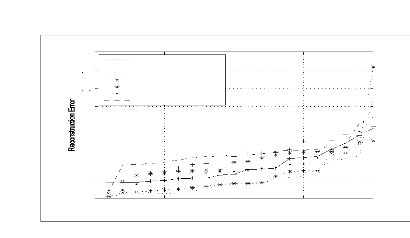
(a)
0.8
0.7
0.6
0.5
0.4
0.3
0.2
0.1
0
Sam ple
0 5 10 15 20
Recognition by SPEC and ANN with architecture 32-15-7-15-32
Local earthquakes Train Local earthquakes Test Far earthquakes
Train Far earthquakes Test Explosions Train Explosions Test
Noise
Figure 6.8: L'erreur de reconstruction d'un réseau AANN
entraîné par des signaux relatifs à des explosions
chimiques, des séismes locaux et des séismes lointains
6.4 Conclusion
Dans ce chapitre, nous avons présenté une
technique basée sur les réseaux AANNs et les
représentations bidimensionnelles pour la reconnaissance des signaux
sismiques. Notre approche trouve ses fondements dans le domaine de la detection
de nouveautésans contre-exemples. De plus, c'est une approche
générale qui pourra être utilisée dans d'autres
domaines comme la détection des défauts dans les systèmes
multimodes [29].
La validation de l'approche proposée a
été assurée par des tests expérimentaux par le
biais du MSSSA (Moroccan Software for Seismic Signals Analysis) qui permet
àl'administrateur une grande facilité et
flexibilité dans le choix des paramètres de reconnaissance.
REFERENCES
[1] D. Achlioptas. «Database friendly random
projections». Dans 20th ACM SIGMODSIGACT-SIGART symposium on Principles of
database systems, pp. 274281, 2001.
[2] B. Ackermann et H. Bunke. «Combination of
classifiers on the decision level for face recognition». Technical Report
IAM-96-002, Institut fur Informatik und Angewandte Mathematik, University of
Bern, 1996.
[3] P. S. Addison. «Wavelet transforms and the ECG: a
review». Physiological Measurement, 26:R155R199, 2005.
[4] P. S. Addison, J. N. Watson et T. Feng.
«Low-oscillation complex wavelets». The Journal of Sound and
Vibration, 254(4):733762, 2002.
[5] D. C. Agnew. «The use of time of day seismicity maps
for earthquake/explosion discrimination by local networks, with an application
to the seismicity of San Diego». Bulletin of the Seismological Society of
America, 80:747750, 1990.
[6] N. Ailon et B. Chazelle. «Approximate nearest
neighbors and the fast JohnsonLindenstrauss transform». Dans 32th Annual
ACM Symposium on Theory of Computing, pp. 557563, 2006.
[7] D. F. Aldridge. «The Berlage wavelet».
Geophysics, 55(11):15081511, 1990.
[8] S. S. Alexander. «A new method for determining source
depth from a single regional station». Seismic Research Letters, pp. 63,
1996.
[9] M. Allameh-Zadeh et P. Nassery. «Application of
quadratic neural networks to seismic signal classification». Physics of
the Earth and Planetary Interiors, 113 (1-4):103110, 1999.
[10] J. Allan, J. Carbonell, G. Doddington, J. Yamron et Y.
Yang. «Topic detection and tracking pilot study: Final report». Dans
the DARPA Broadcast News Transcription and Understanding Workshop, 1998.
[11] L. B. Almeida. «Handbook of Neural Computation»,
Chaptitre: Multilayer perceptrons. Oxford University Press, 1997.
[12] E. Alpaydin. «Multiple neural networks and weighted
voting». Dans 11th International Conference on Pattern Recognition (ICPR),
volume 2, pp. 2932, 1992.
[13] D. N. Anderson, S. R. Taylor et K. K. Anderson.
«Discrimination information in phase amplitude thresholds». Dans the
21th Annual Seismic Research Symposium: Technologies for Monitoring
the CTBT, pp. 344345, 1999.
[14] R. I. Arriaga et S. Vempala. «An algorithmic theory
of learning: Robust concepts and random projection». Dans 40th Annual
Symposium on Foundations of Computer Science, pp. 616623, 1999.
[15] R. I. Arriaga et S. Vempala. «An algorithmic theory of
learning: Robust concepts and random projection». Machine Learning, 63(2):
161182, 2006.
[16] F. Auger. «Représentation
temps-fréquence des signaux non-stationnaires: synthèse et
contribution». Thèse de doctorat, Ecole centrale de Nantes,
1991.
[17] M. F. Augusteijn et B. A. Folkert. «Neural network
classification and novelty detection». International Journal of Remote
Sensing, 23(14):28912902, 2002.
[18] D. Authors. «Special Issue on Dempster-Shafer Theory,
Methodology, and Applications». International Journal of Approximate
Reasoning, 31(1-2), 2002.
[19] G. E. Baker. «Predicting crustal phase propagation
efficiency from topography, gravity and crustal thickness». Dans the 20th
Annual Seismic Research Symposium on Monitoring a Comprhensive Test Ban Treaty,
pp. 153162, 1998.
[20] M-F. Balcan, A. Blum et S. Vempala. «On kernels,
margins, and low-dimensional mappings». Dans Conference on Algorithms
Learning Theory (ALT'04), pp. 194 205, 2004.
[21] R. Baraniuk, M. Davenport, R. DeVore et M. Wakin.
«A simple proof of the restricted isometry property for random
matrices». To appear, Revision of 18 January 2007.
[22] R. G. Baraniuk et D. L. Jones. «A signal dependant
time-frequency representation: Optimal kernel design». IEEE Trans on
Signal Processing, 41:15891601, 1993.
[23] P. L. Bartlett. «The sample complexity of pattern
classification with neural networks: the size of the weights is more important
than the size of thenetwork». IEEE Trans on Information Theory,
44(2):525536, 1998.
[24] M. Basseville et I. V. Nikiforov. «Detection of
abrupt changes: theory and application». Prentice Hall Information and
System Science series. Prentice Hall,Englewood cliifs, NJ, 1993.
[25] R. Battiti. « First- and second- order methods for
learning: between steepest descent and Newton's method». Neural
Computation, 4:141166, 1992.
[26] D. R. Baumgardt, Z. Der et A. Freeman.
«Investigation of the partioning of source and receiver site factors on
the variance of regional P/S amplitude ratio discriminants». Dans the
23th Annual Seismic Research Symposium: Technologies for Monitoring
the Comprhensive Test Ban Treaty, pp. 156165, 2001.
[27] J. Beh, R. Baran et H. KO. «Dual channel based
speech enhancement using novelty filter for robust speech recognition in
automobile environment ». IEEE Trans on Consumer Electronics,
52(2):583589, 2006.
[28] R. Bellman. «Adaptive control processes: a guided
tour». Princeton University Press, 1961.
[29] M. Benbrahim et K. Benjelloun. «A novel approach for
fault detection in multimode systems». Dans Conference on Systems and
Control (CSC'2007), 2007.
[30] M. Benbrahim, K. Benjelloun et A. Ibenbrahim.
«Discrimination des signaux sismiques par réseaux de neurones
artificiels». Dans 3 èmes Journées Nationales sur les
Systèmes Intelligents (SITA '04), Rabat, Maroc, pp. 6266, 2004.
[31] M. Benbrahim, K. Benjelloun, A. Ibenbrahim et A. Daoudi.
«Classification of non stationary signals using Ben wavelet and artificial
neural networks». International Journal of Signal Processing, 2(1):3438,
2005.
[32] M. Benbrahim, K. Benjelloun, A. Ibenbrahim, M. Kasmi, et
E. Ardil. «Ben wavelet: a new function for signals analysis».
Accepté, International Journal of Signal Proceesing, 2007.
[33] M. Benbrahim, K. Benjelloun, A. Ibenbrahim et M. Kasmi.
«The Moroccan Software for Seismic Signals Analysis». Rapport
technique, Intitut National de Géophysique, CNRST, Maroc, 2007.
[34] M. Benbrahim, K. Benjelloun, A. Ibenbrahim, M. Kasmi, A.
El Mouraouah et A. Birouk. «Une nouvelle méthode pour la
réduction de la dimensionnalité des images sismiques». Dans
4 èmes Journées Nationales sur les Systèmes Intelligents
(SITA'06), Rabat, Maroc, pp. 104110, 2006.
[35] M. Benbrahim, K. Benjelloun, A. Ibenbrahim, A. El
Mouraouah, M. Kasmi et A. Birouk. «An integrated system to classify
seismic signals». Dans International Conference on Modelling and
Simulation (ICMS'05), 2005.
[36] M. Benbrahim, A. Daoudi, K. Benjelloun et A. Ibenbrahim.
«Discrimination of seismic signals using artificial neural networks».
Dans 2th World Enformatika Congress (WEC'05), pp. 47, 2005.
[37] M. Benbrahim, k. Benjelloun, A. Ibenbrahim, M. Kasmi et
E. Ardil. «A new approaches for seismic signals discrimination».
Trans on Engineering, Computing and Technology, 19:183186, 2007.
[38] T. J. Bennet, B. W. Baker, K. L. McLaughlin et J. R.
Murphy. «Regional discrimination of quarry blasts, earthquakes and
underground nuclear explosions». Final Report GL-TR-89-0114, Geophysics
Laboratory, Hanscom Air Force Base, MA, 1989.
[39] J. Bertrand et P. Bertrand. « Time-frequency signal
analysis: Methods and applications», Chaptitre: Affine time-frequency
distributions, pp. 118140. LongmanCheshire, Melbourne, 1992.
[40] K. Beyer, J. Goldstein, R. Ramakrishnan et U. Shaft.
«When is nearest neighbor
meaningful?». Dans 7th International Conference on
Database Theory, volume 1540, pp. 217235, 1999.
[41] E. Bingham et H. Mannila. «Random projection in
dimensionality reduction: Applications to image and text data». Dans 7th
ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, pp.
245250, 2001.
[42] C. M. Bishop. «Exact calculation of the Hessian matrix
for the multi-layer perceptron». Neural Computation, 4:494501, 1992.
[43] C. M. Bishop. «Novelty detection and neural network
validation». Dans IEE Proceedings on Vision, Image and Signal Processing,
volume 141, pp. 217222, 1994.
[44] R. J. Bolton et D. J. Hand. «Unsupervised profiling
methods for fraud detection». Dans Credit Scoring and Credit Control VII,
2001.
[45] J. Bonner, D. Reiter et R. H. Shumway. «Application
of a cepstral F-statistic for improved depth estimation». Dans the
22th Annual Seismic Research Symposium: Planning for verification of
and compliance with the Comprhensive Test Ban Treaty, pp. 5362, 2000.
[46] J. L. Bonner, D. T. Reiter, A. M. Rosca et R. H.
Shumway. «Cepstral F-statistic performance at regional distances».
Dans the 23th Annual Seismic Research Symposium: World Wide
Monitoring of Nuclear Explosions, pp. 177185, 2001.
[47] P. Bormann. «Identification of teleseismic events in
the records of Moxa station». Gerlands Beitr. Geophysik, 81:105116,
1972.
[48] E. Bournay-Bouchereau. «Analyse d'images par
transformée en ondelettes-
application aux images sismiques».
Thèse de doctorat, Université de Joseph Fourier, 1997.
[49] P. S. Bradley, U. M. Fayyad et O. L. Mangasarian.
«Mathematical programming for data mining: formulations and
challenges». INFORMS Journal on Computing, 11(3):217238, 1999.
[50] M. Breuning, H. P. Kriegel, R. Ng et J. Sander.
«LOF: Identifying densitybased Local Outliers». Dans ACM SIGMOD
International Conference on Management of Data, pp. 93104, 2000.
[51] J. N. Brune. « Tectonic stress and spectra of seismic
shear waves from earthquakes». J. Geophys. Res, 75:49975009, 1970.
[52] J. Buhler et M. Tompa. «Finding motifs using random
projections». Journal of Computational Biology, 9(2):225242, 2002.
[53] R. A. Calvo, M. Partridge et M. A. Jabri. «A
comparative study of principal component analysis». Dans 9th Australian
Conference in Neural Networks, 1998.
[54] R. Caruana, S. Baluja et M. Tom. «Using the Future
to 'Sort Out' the Present: Rankprop and Multitask Learning for Medical Risk
Evaluation». Dans Advances in Neural Information Processing Systems
(NIPS), volume 8, pp. 959965, 1996.
[55] T. Caudell et D. Newman. «An adaptive resonance
architecture to define normality and detect novelties in time series and
databases». Dans IEEE World Con gress on Neural Networks, pp. 166176,
1993.
[56] A. Chakraborty et D. Okaya. «Frequency-time
decomposition of seismic data using wavelet-based methods». Geophysics,
60(6): 19061916, 1995.
[57] E. Chassande-Mottin. «Méthodes de
réallocation dans le plan temps-fréquence pour l'analyse et le
traitement de signaux non stationnaires». Thèse de doctorat,
Université de Cergy-Pontoise, 1998.
[58] N. Chawla, N. Japkowicz et A. Kolcz, éditeurs.
«Proceedings of the ICML'2003 Workshop on Learning from Imbalanced Data
Sets», 2003.
[59] N. Chawla, N. Japkowicz et A. Kolcz, éditeurs.
«Special issue on learning from imbalanced datasets, ACM SIGKDD
Explorations Newsletter», volume 6, 2004.
[60] B. H. Chowdhury et K. Wang. «Fault classification
using Kohonen feature mapping». Dans International Conference on
Intelligent Systems Applications to Power Systems, pp. 194198, 1996.
[61] L. Christoskov, N. V. Kondorskaya et J. Vanek.
«Magnitude calibration functions for a multidimensional homogeneous system
of reference stations». Tectonophysics, 118:213226., 1985.
[62] H-M Chung et D. C. Lawton. «Frequency characteristics
of seismic reflections from the beds». Canadian Journal of Exploration
Geophysics, 31(1-2):3237, 1995.
[63] T. A. C.M. Claasen et W. F. G. Mecklenbrauker. «The
Wigner distribution-a tool for time-frequency signal analysis; Part I:
continuous-time signals». Philips J. Res, 35(3):217250, 1980.
[64] T. A. C.M. Claasen et W. F. G. Mecklenbrauker. «The
Wigner distribution-a tool for time-frequency signal analysis; Part II:
discrete-time signals». Philips J. Res, 35 (4/5):276300, 1980.
[65] T. A. C.M. Claasen et W. F. G. Mecklenbrauker. «The
Wigner distribution-a tool for time-frequency signal analysis; Part III:
relations with other time-frequency signal transformations». Philips J.
Res, 35(6) :372389, 1980.
[66] L. Cohen. «What is a multicomponent signal?».
Dans IEEE International Confrernce on Acoustics, Speech and Signal Processing,
pp. 113116, 1992.
[67] L. Cohen. «The uncertainty principle in signal
analysis». Dans Proc. IEEE TimeFreq/Time-Scale Anal, pp. 182185, 1994.
[68] L. Cohen. « Time-frequency anal ysis». Prentice
Hall, 1995.
[69] L.P. Cordella, C. Sansone, F. Tortorella, M. Vento et C.
DeStefano. «Neural network classification reliability: problems and
applications». Image Processing and Pattern Recognition, 5:161200,
1998.
[70] T. M. Cover et P. E. Hart. «Nearest neighbor pattern
classification». IEEE Trans on Informations Theory, 13(1), 1967.
[71] L. Cranor. « Declared-strategy voting: an instrument
for group decison-making». Thèse de doctorat, Washington
University, 1996.
[72] P. Crook et G. Hayes. «A robot implementation of a
biologically inspired method for novelty detection». Dans Towards
Intelligent Mobile Robots Conference, Manchester, 2001.
[73] G. Cybenko. «Approximation by superposition of a
sigmoidal function». Mathematics of Control, Signals, and Systems,
2:303314, 1989.
[74] O. Dahlman et H. Israelson. «Monitoring underground
nuclear explosions». Elsevier, Amsterdam, 1977.
[75] A. Daoudi, M. Benbrahim et K. Benjelloun. «An
intelligent system to classify leaks in water distribution pipes». Dans
2th World Enformatika Congress (WEC'05), pp. 13, 2005.
[76] S. Dasgupta. «Experiments with random
projection». Dans the 16th Conference on Uncertainty in Artificial
Intelligence, pp. 14315 1, 2000.
[77] S. Dasgupta et A. Gupta. «An elemnetary proof of the
johnson-Lindenstrauss lemma». Rapport technique 99-006, UC Berkeley,
1999.
[78] I. Daubechies. « Ten lectures on wavelets». SIAM,
Philadelphia, Pa, 1992.
[79] M. Davy. «Noyaux optimises pour la classification
dans le plan temps-frequence - Proposition d'un algorithme constructif et d'une
reference bayesienne basee sur les methodes MCMC - Application au diagnostic
d'enceintes acoustiques». Thèse de doctorat, Universite de Nantes,
2000.
[80] M. Davy et C. Doncarli. «Optimal kernels of
time-frequency representations for signal classification». Dans IEEE
International Symposium on TFTS, pp. 581584, 1998.
[81] E. DelPezzo, A. Esposito, F. Giudicepietro, M. Marinaro,
M. Martini et S. Scarpetta. «Discrimination of earthquakes and underwater
explosions using neural networks». Bulletin of the Seismological Society
of America, 93(1):215223, 2003.
[82] P. Demartines. «Analyse de données par
réseaux de neurones auto-organisés». Thèse de
doctorat, Institut National Polytechnique de Grenoble, 1994.
[83] T. Denoeux. «A neural network classifier based on
Dempster-Shafer theory». IEEE Trans on Systems, Man, and Cybernetics, Part
A: Systems and humans, 30(2): 131150, 2000.
[84] Z. A. Der, M. W. McGarvey et R. H. Shumway.
«Automatic interpretation of regional short period seismic signals using
the CUSUM-SA algorithms». Dans the 22th Annual Seismic Research
Symposium: Planning for Verification of and Compliance with the CTBT, 2000.
[85] Z. A. Der et R. H. Shumway. «Phase onset time
estimation at regional distances using the CUSUM-SA algorithm». Phy, Earth
and Planet, 113:227246, 1999.
[86] C. DeStefano, C. Sansone et M. Vento. «To reject or
not to reject: that is the question-an answer in caseof neural
classifiers». IEEE Trans on Systems, Man and Cybernetics-Part C:
applications and reviews, 30(1):8494, 2000.
[87] A. Doglas. «Seismic source identification: a review of
past and present research effort». eds. E.S. Husebye and S. Mykkeltveit,
1981.
[88] P. Domingos. «Unified bias-variance decomposition for
zero-one and squared loss». Dans 17th National Conference on Artificial
Intelligence, pp. 564569, 2000.
[89] D. L. Donoho. «High-dimensional data analysis: the
curses and blessings of dimensionality». Dans The American Mathematical
Society Conference »Math Challenges ofthe 21st Centry», 2000.
[90] F. U. Dowla. «Neural networks in seismic
discrimination». Dans Monitoring a Comprehensive Test Ban Treaty, volume
NATO ASI, Series E, 303, pp. 777789, 1995.
[91] F. U. Dowla, S. R. Taylor et R. W. Anderson.
«Seismic discrimination with artificial neural networks: preliminary
results with regional spectral data». Bulletin of the Seismological
Society of America, 80(5): 13461373, 1990.
[92] W. Duch et N. Jankowski. «Transfer functions:
hidden possibilities for better neural networks». Dans 9th European
Symposium on Artificial Neural Networks, pp. 8194, 2001.
[93] R. O. Duda, P. E. Hart et D. G. Stork. «Pattern
Classification». Wiley Interscience, second édition, 2000.
[94] R. Duin. «The combining classifier: to train or not
to train?». Dans The 16th International Conference on Pattern recognition
(ICPR), volume 2, pp. 765770, 2002.
[95] F. Dunand. «Pertinence du bruit de fond sismique
pour la caractérisation dynamique et l'aide du diagnostic sismique des
structures de génie civil». Thèse de doctorat,
Université Joseph Fourier, 2005.
[96] P. S. Dysart et J. J. Pulli. «Regional seismic
event classification at the NORESS array: seismological measurements and the
use of trained neural networks». Bulletin of the Seismological Society of
America, 80(6B):19101933, 1990.
[97] T. Eavis et N. Japkowicz. «A Recognition-Based
Alternative to DiscriminationBased Multi-Layer Perceptrons». Dans Advances
in Artificial Intelligence: 13th Biennial Conference of the Canadian Society
for Computational Studies of Intelligence, volume 1822 de Lecture Notes in
Computer Science, pp. 280292. Springer Berlin, 2000.
[98] E. Elvers. «Seismic identification by negative
evidence». Bulletin of the Seismological Society of America,
64(6):16711683, 1983.
[99] A. Estabrooks, T. Jo et N. Japkowicz. «A Multiple
Resampling Method for Learning from Imbalances Data Sets». Computational
Intelligence, 20(1):1836, 2004.
[100] S. E. Fahlman. «An empirical study of learning speed
in back-propagation networks ». Technical Report CMU-CS-88- 162,
Carnegie-Mellon University, 1988.
[101] S. Falsaperla, S. Graziani, G. Nunnari et S.
Spampinato. «Automatic classification of volcanic earthquakes by using
multi-layered neural networks». Natural Hazards, 13(3):205228, 1996.
[102] M. Fargé. «Wavelet transforms and their
applications to turbulence». Annu. Rev. Fluid Mech, 24:395457, 1992.
[103] T. E. Fawcett et F. Provost. «Adaptive fraud
detection». Data Mining and Knowledge Discovery, 1(3):291316, 1997.
[104] R. Fay, F. Schwenker C. Thiel et G. Palm.
«Hierarchical neural networks utilising Dempster-Shafer evidence
theory». Dans Artificial Neural Networks in Pattern Recognition, volume
4087, pp. 198209, 2006.
[105] X. Z. Fern et C. E. Brodley. «Random projection
for high dimensional data clustering: a cluster ensemble approach». Dans
20th International Conference on Machine Learning (ICML'03), pp. 186193,
2003.
[106] M. D. Fisk, C. COnrad et D. Jepsen. «Developement
of improved capabilities for depth determination». Dans the 23th Annual
Seismic Research Symposium: World Wide Monitoring of Nuclear Explosions, pp.
215224, 2001.
[107] P. Flandrin. «Time-frequency and time-scale».
Dans Proceedigns of the 4th Acoustic, Speech and Signal Processing Workshop on
Spectrum Estimation Modeling, pp. 77 80, 1988.
[108] P. Flandrin. «Wavelet analysis and synthesis of
fractional Brownian motion». IEEE Trans on Information Theory,
38(2):910916, 1992.
[109] P. Flandrin. «Temps-fréquence». Academic
Press, 1998.
[110] P. Flandrin et O. Rioul. «Affine Smoothing of the
Wigner-Ville distribution». Dans IEEE Int. conference on Acoustics,
Speech, and Signal Processing, Albuquerque, pp. 24552458, 1990.
[111] I. K. Fodor. «A survey of dimension reduction
techniques». Technical report UCRLID-148494, Lawrence Livermore National
Laboratory, 2002.
[112] D. Fradkin et D. Madigan. «Experiments with random
projections for machine learning». Dans 7th ACM SIGKDD International
Conference on Knowledge Discovery and Data Mining, pp. 517522, 2003.
[113] P. Frankl et H. Maehara. «The Johnson-Lindenstrauss
lemma and the sphericity of some graphs». J. Comb. Theory Ser. A,
44(3):355362, 1987.
[114] G. Frazer et B. Boashash. «Multiple window
spectrogram and time-frequency distributions». Dans Proceedings of the
IEEE Int. Conf. Acoust. Speech Signal Process., volume 4, pp. 293296, 1994.
[115] J. H. Friedman. «On bias, variance, 0/1-loss, and the
curse-of-dimensionality». Data Mining and Knowledge Discovery, 1(1):5577,
1997.
[116] K. Fukunaga. «Introduction to statistical pattern
recognition». Academic Press, second édition, 1990.
[117] P. Gaillot. « Ondelettes continues en sciences de la
terre». Thèse de doctorat, Université de toulouse III,
2000.
[118] P. Gallinari et T. Cibas. « Practical complexity
control in multilayerperceptrons». Signal Processing, 74:2946, 1999.
[119] J. H. Gao, R. S. Wu et B. J. Wang. «A new type of
analyzing wavelet and its applications for extraction of instantaneous spectrum
bandwidth». Dans SEG Int'l Exposition and Annual Meeting,San Antonio,
Texas, 2001.
[120] S. Geman, E. Bienenstock et R. Doursat. «Neural
networks and the bias/variance dilemma». Neural Computation, 4:158,
1992.
[121] J. Gerbrands. «On the relationships between SVD, KLT,
and PCA». Pattern Recognition, 14(1-6), 1981.
[122] G. Giacinto. «Design of multiple classifier
systems». Thèse de doctorat, universitéde Salerno, 1998.
[123] W. Gilbert, J. Bassett et J. Persky. «Robust
voting». Public Choice, 99:299310, 1999.
[124] B. W. Gillespie et L. E. Atlas. «Optimizing
time-frequency kernels for classification». IEEE Trans on Signal
Processing, 49(3):485496, 2001.
[125] B. W. Gillespie et L. E. Atlas. « Optimizing
time-frequency kernels for classification». IEEE Trans on Signal
Processing, 49(3):485496, 2001.
[126] N. Goel, G. Bebis et A. Nefian. «Face recognition
experiments with random projection». Dans SPIE, Biometric Technology for
Human Identification II, volume 5779, pp. 426437, 2005.
[127] P. Goldstein et D. Dodge. «Depth mechnism
estimation using waveform modeling». Dans the 20th Annual
Seismic Research Symposium on Monitoring a Comprhensive Test Ban Treaty, pp.
238247, 1998.
[128] P. Goldstein, C. Schultz et S. Larsen. «The
influence of deep sedimentary basins, crustal thinning, attenuation and
topography on regional phases; selected examples from Eastern Mediterraneen and
Caspian sea regions». Dans the 19th Annual Seismic Research
Symposium on Monitoring a Comprhensive Test Ban Treaty, 1997.
[129] Y. Grandvalet. «Injection de bruit dans les
perceptrons multicouches». Thèse de doctorat, l'Université
de Technologie de Compiègne, 1995.
[130] A. Grossman et J. Morlet. «Decomposition of hardy
functions into square integrable wavelets of constant shape». SIAM J.
Math. Anal, 15(4):723736, 1984.
[131] P. Guillemain et R. Kronland-Martinet.
«Characterization of acoustic signals through continuous linear
time-frequency representations». IEEE Trans on Signal Processing,
48(4):561585, 1996.
[132] J. Hampshire et A. Waibel. «A novel objective
function for improved phoneme recognition using time delay neural
networks». IEEE Trans on Neural Networks, 1 (2):216228, 1990.
[133] L. K. Hansen, C. Liisberg et P. Salamon. «The
error-reject tradeoif». Open Systems & Information Dynamics,
4(2):159184, 1997.
[134] S. Hanson et D. Burr. «Minkowski-r
backpropagation: Learning in connectionist models with non-Euclidian error
signals». Dans Advances in Neural Information Processing Systems (NIPS),
pp. 348357., 1988.
[135] F. J. Harris. «On the use of windows for harmonic
analysis with discrete Fourier transform». Dans Proc. IEEE, volume 66, pp.
5183, January 1978.
[136] H. E. Hartse, W. S. Phillips, M. C. Fehler et L. S.
House. «Single-station discrimination using coda waves». Bulletin of
the Seismological Society of America, 85: 14641474, 1995.
[137] H. E. Hartse, S. R. Taylor, W. S. Phillips et G. E.
Randall. «An evaluation of generalized likelihood ratio outlier detection
to identification of seismic events in western china». Bulletin of the
Seismological Society of America, 87:551568, 1997.
[138] S. Haykin. «Neural networks - a comprehensive
foundation». Pearson Education, 9th indian reprint of the second
édition, 2005.
[139] S. Haykin et T. K. Bhattacharya. «Modular learning
strategy for signla detection in a nonstationary environment». IEEE Trans
on signal Processing, 45:16191637, 1997.
[140] R. Hecht-Nielsen. «Context vectors: general
purpose approximate meaning representations self-organized from raw data».
Dans Computation Intelligence: Im ating Life, pp. 4356, 1994.
[141] C. Heitz. «Optimum time-frequency representations for
the classification and detection of signals». Appl. Signal Process,
2(3):124143, 1995.
[142] E. Herrin et T. Goforth. «Phase matched-filters:
applications to the study of Rayleigh waves». Bulletin of the
Seismological Society of America, 67:12591275, 1977.
[143] F. Hlawasch. «Regulariry and unitarity of bilinear
time-frequency signal representations». IEEE Trans on Inform Theory,
38:8294, 1992.
[144] F. Hlawasch et P. Flandrin. « The wigner
distribution-theory and applications in signal processing», Chaptitre: The
interference structure of the wigner distribution and related time-frequency
signal representationsle, pp. 59133. Amsterdam (The Netherlands): Elsevier,
1997.
[145] F. Hlawatsch et G.F. Boudreaux-Bartels. «Linear and
quadratic time-frequency signal representations». IEEE Signal Processing
Magazine, 9:2167, 1992.
[146] F. Hlawatsch, A. Papandreou-Suppappola et G. F.
Boudreaux-Bartels. «The power classes of quadratic time-frequency
representations: A generalization of the hyperbolic and affine classes».
Dans 27th Asilomar Conf. on Signals, Systems and Computers, Pacific Grove, CA,
pp. 12651270, 1993.
[147] F. Hlawatsch, A. Papandreou-Suppappola et G. F.
Boudreaux-Bartels. «The hyperbolic class of quadratic time-frequency
representations. Part II. Subclasses, intersection with the affine and power
classes, regularity and unitarity». IEEE Trans on Signal Processing,
45:303315, 1997.
[148] F. Hlawatsch et G. Taubock. « Time-frequency
signal analysis and processing: a comprehensive reference», Chaptitre:
4.3:The covariance theory of time-frequency analysis, pp. 102113. Oxford (UK):
Elsevier, 2003.
[149] T. Ho. «A theory of multiple classifier systems and
its application to visual recognition». Thèse de doctorat, State
University of New York at Buffalo, 1992.
[150] T. K. Ho, J. J. Hull et S. N. Srihari. «Decision
Combination in Multiple Classifier Systems». IEEE Trans on Pattern Anal
ysis and Machine Intelligence, 16(1):6675, 1994.
[151] V. J. Hodge et J. Austin. «A Survey of outlier
detection methodologies». Artificial Intelligence Review, 22(2) :85126,
2004.
[152] K. Hornik. «Some new results on neural network
approximation». Neural Networks, 6(8):10691072, 1993.
[153] Y. S. Huang et C. Y. Suen. «A method of combining
multiple experts for the recognition of unconstrained handwritten
numerals». IEEE Trans on Pattern Analysis and Machine Intelligence,
17(1):9094, 1995.
[154] H. Byungho Hwang et C. Sungzoon. «Characteristics
of auto-associative MLP as a novelty detector». Dans IEEE International
Joint Conference on Neural Networks (IJCNN), volume 5, pp. 30863091, 1999.
[155] H. B. Hwarng et C. W. Chong. «A fast-learning
identification system for SPC: an adaptive resonance theory approach».
Dans Intelligent Engineering Systems Through Artificial Neural Networks, volume
4, pp. 10971102, 1994.
[156] J. Ilonen, P. Paalanen, J. K. Kamarainen et H.
Kalviainen. «Gaussian mixture pdf in one-class classification: computing
and utilizing confidence values». Dans 18th International Conference on
Pattern Recognition, volume 2, pp. 577580, 2006.
[157] P. Indyk et R. Motwani. «Approximate nearest
neighbors: towrds removing the curse of dimensionality». Dans 30th ACM
Symp. on Theory of Computing, pp. 604613, 1998.
[158] K. Inoue, K. Hara et K. Urahama. «Matrix principal
compoent analysis for image compression and recognition». Dans 1st Joint
Workshop on Machine Perception and Robotics, MPR, pp. 115120, 2005.
[159] H. Israelsson. «Stacking of waveforms for depth
estimation». Final report, Center for Seismic Studies, 1994.
[160] R. J. Jacobs. «Increased rates of convergence throght
learning rate adaptation». Neural Networks, 1:295307, 1988.
[161] N. Japkowicz. «Are we better off without counter
examples?». Dans the 1st International ICSC Con gress on Computational
Intelligence Methods and Applications (CIMA), pp. 242248, 1999.
[162] N. Japkowicz. « Concept-learning in the abscence of
counter-examples: an
autoassociation-based approach to classification».
Thèse de doctorat, State University of New Jersey, 1999.
[163] N. Japkowicz, S. J. Hanson et M. A. Gluck. «Nonlinear
autoassociation is not equivalent to PCA». Neural Computation,
12(3):531545, 2000.
[164] N. Japkowicz, C. Myers et M. Gluck. «A novelty
detection approach to classification». Dans the 14th International Joint
Conference on Artificial Intelligence (IJCAI), pp. 518523, 1995.
[165] N. Japkowicz et S. Stephen. «The Class Imbalance
Problem: A Systematic Study». Intelligent Data Anal ysis, 6(5):429450,
2002.
[166] R. D. Jenkins et T. J. Sereno. «Calibration of
regional S/P amplitude-ratio discriminants». Pure Appl Geophys,
158(7):12791300, 2001.
[167] J. Jeong et W. J. Williams. «On the cross-terms in
spectrograms». IEEE Int. Symp. Circuits Syst, pp. 15651568, 1990.
[168] C. Ji et S. Ma. «Combinations of weak
classifiers». IEEE Trans on Neural Networks, 8(8):3242, 1997.
[169] E. M. Johansson, F. U. Dowla et D. M. Goodman.
«Backpropagation learning for multilayer feed-forward neural networks
using the conjugate gradient method». International Journal of Neural
Systems, 2(4):291301, 1991.
[170] W. Johnson et L. Lindenstrauss. «Extensions of
Lipschitz maps into a Hilbert space». Contemporary Mathematics, 26:189206,
1984.
[171] I. T. Joliffe. «Principal component analysis».
Springer-Verlag, New York, 1986.
[172] D. L. Jones et T. W. Parks. «A resolution comparaison
of several time-frequency representations». IEEE Trans on Signal
Processing, 40(2):413420, 1992.
[173] M. Joost et W. Schiffmann. «Speeding up
backpropagation algorithms by using cross-entropy combined with pattern
normalization». International Journal of Uncertainty, Fuzziness and
Knowledge- based Systems (IJUFKS), 6(2): 117126, 1998.
[174] S. Kadambe et G. F. Boudreaux-Bartels. «A
comparaison of the existence of crossterms in the Wigner distribution and
squared magnitude of the wavelet transform and the short-time Fourier
transforma». IEEE Trans on Signal Processing, 40(10): 24982517, 1992.
[175] G. Kaiser. «Physical wavelets and radar: a variation
approach to remote sensing». IEEE Antennas and Propagation Magazine,
38:1524, 1996.
[176] S. Kaski. «Dimensionality reduction by random
mapping». Dans Int. Joint Conf. on Neural Networks, volume 1, pp. 413418,
1998.
[177] M-A. Kasmi. «Etude des enregistrements sismiques
provenant des sautages de l'office chérifien des phosphates».
Mémoire de maîtrise, Faculté des Sciences de
Kénitra, 2001.
[178] R. C. Kemerait et A. F. Sutton. «A multidimensional
approach to seismic event depth estimation». Geoexploration, 20:113130,
1982.
[179] J. Kim, K. Kim, C. Nadal et C. Suen. «A
methodology of combining hmm and mlp classifiers for cursive word
recognition». Dans International Conference Document Analysis and
Recognition (ICDAR), volume 2, 2000.
[180] J. Kittler, M. Hatef, R. Duin et J. Matas. «On
combining classifiers». IEEE Trans on Pattern Anal ysis and Machine
Intelligence, 20(3):226239, 1998.
[181] J. M. Kleinberg. «Two algorithms for nearest-neighbor
search in high dimensions». Dans 29th ACM Symp. on Theory of Computing,
pp. 599608, 1997.
[182] E. M. Knorr, R. T. Ng et V. Tucakov. «Distance-based
outliers: algorithms and applications». VLDB Journal: Very Large Data
Bases, 8(3-4):237253, 2000.
[183] H. Kong, L. Wang, E. K. Teoh, X. Li, J-G. Wang et R.
Venkateswarlu. «Generalized 2D principal component analysis for face image
representation and recognition». Neural Networks, 18(5-6):585594, 2005.
[184] A. Kramer et A. Sangiovanni-Vincentelli.
«Efficient parallel learning algorithms for neural networks». Dans
Advances in Neural Information Processing Systems (NIPS), volume 1, pp. 4048,
1989.
[185] M. A. Kramer. «Non linear principal component
analysis using autoassociative neural networks». AIChE Journal,
37(2):233243, 1991.
[186] A. Krogh et J. A. Hertz. «A simple weight decay
can improve generalization». Dans Advances in Neural Information
Processing Systems (NIPS), volume 4, pp. 950957, 1992.
[187] B. Kroose et P. Van der Smagt. «An introduction to
neural networks». The University of Amsterdam, 5th édition,
1993.
[188] M. Kubat, R. Hote et S. Matwin. «Machine learning for
detection of oil spills in satellite radar image». Machine Learning,
30:195215, 1998.
[189] M. Kubat et S. Matwin. «Addressing the curse of
imbalanced training sets: onesided selection». Dans 14th International
Conference on Machine Learning (ICML), pp. 179186, 1997.
[190] P. Kumar et E. Foufoula-Georgiou. «Wavelet analysis
for geophysical applications». Reviews of Geophysics, 35(4): 385412,
1997.
[191] M. Kurimo. «Indexing audio documents by using latent
semantic analysis and SOM». Dans E. Oja et S. Kaski, éditeurs,
Kohonen Maps, pp. 363374, 1999.
[192] L. Lam et C. Y. Suen. «A theoretical analysis of
the application of majority voting topattern recognition». Dans 12th
International Conference on Pattern Recognition (ICPR), volume 2, pp. 418420,
1994.
[193] J. Laurikkala, M. Juhola et E. Kentala. «Informal
identification of outliers in medical data». Dans Intelligent Data Anal
ysis in Medicine and Pharmacology (IDAMAP), pp. 2024, 2000.
[194] T. Lay, G. Fan, R-S. Wu et X-B. Xie. «Path
correction for regional phase discriminant». Dans the 21 Annual Seismic
Research Symposium: Technologies for Monitoring the CTBT, pp. 510519, 1999.
[195] T. Lay, G. Fan et J. Zhang. «Path corrections for
regional phase discriminant». Dans the 21th Annual Seismic Research
Symposium: Planning for verification of and compliance with the Comprhensive
Test Ban Treaty, pp. 510519, 1999.
[196] Y. LeBorgne. «Bias-variance trade-off
characterization in a classification problem. what differences with
regression?». Technical report 534, Université Libre de Bruxelles,
2005.
[197] Y. LeCun, J. Denker et S. Solla. «Optimal brain
damage». Dans Advances in Neural Information Processing Systems (NIPS),
volume 2, pp. 598605, 1990.
[198] Y. Lee et S. H. Oh. «Input noise immunity of
multilayer perceptrons». ETRI Journal, 16(1):3543, 1994.
[199] P. Li, T. J. Hastie et K. W. Church. «Improving
Random Projections Using Marginal Information». Dans 19th Annual
Conference on Learning Theory (COLT), pp. 635 649, 2006.
[200] R. Lippmann. «An introduction to computing with
neural nets». IEEE ASSP Magazine, 4(2):422, 1987.
[201] K. Liu, H. Kargupta et J. Ryan. «Random
projection-based multiplicative data perturbation for privacy preserving
distributed data mining». IEEE Trans on Knowledge and Data Engineering,
18(1):92106, 2006.
[202] Y. Liu, N.V. Chawla, M.P. Harper, E. Shriberg et A.
Stolcke. «A study in machine learning from imbalanced data for sentence
boundary detection in speech». Computer Speech and Language, 20(4):468494,
2006.
[203] P. Loonis, E. H. Zahzah et J. P. Bonnefoy.
«Multi-classifiers neural network fusion versus Dempster-Shafer's
orthogonal rule». Dans IEEE International Conference on Neural Networks,
volume 4, pp. 21622165, 1995.
[204] P. Loughlin, J. Pitton et B. Hannaford.
«Approximating time-frequency density via optimal combinations of
spectrograms». IEEE Signal processing Letters, 1(12): 199202, 1994.
[205] P. J. Loughlin et L. Cohen. «The uncertainty
principle: global, local, or both?». IEEE Trans on Signal Processing,
52(5):12181227, 2004.
[206] D. MacKay. «A practical Bayesian framework for
backpropagation networks». Neural Computation, 4(3):448472, 1992.
[207] A. Magen. «Dimensionality reductions that preserve
volumes and distance to affine spaces, and their algorithmic
applications». Dans 6th International Workshop on Randomization and
Approximation Techniques, pp. 239253, 2002.
[208] G. Manson, G. S. Pierce, K. Worden, T. Monnier, P. Guy
et K. Atherton. «Longterm stability of normal condition data for novelty
detection». Dans SPIE's 7th Annual International Symposium on Smart
Structurs and Materials, volume 3985, pp. 323334, 2000.
[209] M. Markou et S. Singh. «Novelty detection: a
review-part 1: statistical approaches». Signal Processing, 83(12)
:24812497, 2003.
[210] M. Markou et S. Singh. «Novelty detection: a
review-part 2: neural network based approaches». Signal Processing,
83(12): 24992521, 2003.
[211] D. Marr. «Vision». W. H. Freeman, New York,
1982.
[212] S. Marsland, U. Nehmzow et J. Shapiro. «A real-time
novelty detector for a mobile robot». Dans European Advanced Robotics
Systems Conference, 2000.
[213] K. Matsuoka et J. Yi. «Backpropagation based on
the logarithmic error function and elimination of local minima». IEEE
International Joint Conference on Neural Networks (IJCNN), 2:11171121, 1991.
[214] G. Matz et F. Hlawatsch. «Wigner distributions
(nearly) everywhere: timefrequency analysis of signals, systems, random
processes, signal spaces, and frames». Signal Processing, 83:13551378,
2003.
[215] K. Mayeda. «mb(Lg Coda): a stable single station
estimator of magnitude». Bulletin of the Seismological Society of America,
83:851861, 1993.
[216] K. Mayeda et W. R. Walter. «Moment, energy, sress
drop and source spectra of western united states earthquakes from regional coda
envelopes». J Geophys Res, 101:1119511208, 1996.
[217] M. Mendel et A. Naor. «Some applications of Ball's
extension theorem». Dans Proc of the American Mathematical Society, volume
134, pp. 25772584, 2006.
[218] Y. Meyer. «Les ondelettes, algorithmes et
applications». Armand Colin, 1992.
[219] Y. Meyer, S. Jaffard et O. Rioul. «L'analyse par
ondelettes». Pour la Science ( French edition of Scientific American),
11:2837, 1987.
[220] M. F. Moller. «A scaled conjugate gradient algorithm
for fast supervised learning». Neural Networks, 6(4):525533, 1993.
[221] J. Moody. «Prediction risk and architecture
selection for neural networks». Dans From statistics to neural networks,
volume NATO ASI, series F, 136, pp. 147165, 1994.
[222] J. Morlet, G. Arens, E. Fourgeau et D. Giard.
«Wave propagation and sampling theory,Part 1: Complex signal and
scattering in multilayered media». Geophysics, 47(2):203221, 1982.
[223] J. R. Murphy, B. W. Barker et W. L. Rodi.
«Improved focal determination for use in nuclear explosion
monitoring». Dans the 24th Annual Seismic Research Symposium:
Nuclear Explosion Monitoring: Innovation and Integration, pp. 522529, 2002.
[224] J. R. Murphy, R. W. Cook et W. L. Rodi. «Improved
focal determination for use in CTBT Monitoring». Dans the 21th
Annual Seismic Research Symposium: Technologies for Monitoring the CTBT, pp.
5053, 1999.
[225] M. Musil et A. Plesinger. «Discrimination between
local microearthquakes and quarry blasts by multi-layer perceptrons and Kohonen
maps». Bulletin of the Seismological Society of America, 86(4):10771090,
1996.
[226] S. C. Myers et W. R. Walter. «Using epicentre
location to differentiate events from natural background seismicity». Dans
the 21th Annual Seismic Research Symposium: Technologies for
Monitoring the CTBT, pp. 731740, 1999.
[227] A. Nairac, N. Townsend, R. Carr, S. King, P. Cowley et
L. Tarassenko. «A system for the analysis of jet engine vibration
data». Integrated Computer-A ided Engineering, 6(1):5356, 1999.
[228] A. Narasimhamurthy. «A Framework for the Analysis
of Majority Voting». Dans 13th Scandinavian Conference Image Analysis
(SCIA), volume 2749, pp. 268274, 2003.
[229] S. H. Nawab et T. F. Quatieri. «Short-time Fourier
transform». Dans Advanced topics in Signal Processing, pp. 289337,
1988.
[230] L. V. Nikoforov et I. N Tikhonov. «Application of
change detection theory to seismic signal processing». Dans
»Detection of abrupt changes in signals et dynamicals systems»,
éditeurs, M. Basseville and A. Benviste. Springer, NewYork, 1986.
[231] L. V. Nikoforov, I. N Tikhonov et T. G. Mikhailova.
«Automatic on-line oricessing of seismic data: theory and
application». Far Eastern Dept of USSR Academy of Science, vladivostok,
USRR, 1989.
[232] A. H. Nuttall. «some windows with very good sidelobe
behavior». IEEE Trans on Acoustics, Speech and Signal Processing,
ASSP-29:8491, Feb 1981.
[233] S. H. Oh. «Improving the error backpropagation
algorithm with a modified error function». IEEE Trans on Neural Networks,
8(3):799803, 1997.
[234] S. H. Oh et Y. Lee. «A modified error function to
improve the error back-propagation algorithm for multi-layer perceptrons».
ETRI Journal, 17(1):1122, 1995.
[235] P. M. Oliveira et V. Barroso. «Uncertainty in the
time frequency plane». Dans Proc. IEEE SSAP, pp. 607611, 2000.
[236] C. H. Papadimitriou, P. Raghavan, H. Tamaki et S.
Vempala. «Latent semantic indexing: a probabilistic analysis». Dans 1
7th ACM Symp on the Principles of Database Systems, pp. 159168, 1998.
[237] A. Papandreou-Suppappola, F. Hlawatsch et G. F.
Boudreaux-Bartels. «The hyperbolic class of quadratic time-frequency
representations. Part I. Constant-Q wraping, the hyperbolic paradigm,
properties and members». IEEE Trans on Signal Processing, 41:34253444,
1993.
[238] A. Papandreou-Suppappola, F. Hlawatsch et G. F.
Boudreaux-Bartels. «Power class time-frequency representations:
interference geometry, smoothing and implementation». Dans IEEE Symposium
on Time-Frequency and Time-Scale Analysis, pp. 193196, Paris, France, 1996.
[239] A. Papandreou-Suppappola, F. Hlawatsch et G. F.
Boudreaux-Bartels. «Quadratic time-frequency representations with scale
covariance and generalized time-shift covariance: a unified framework for the
affine, hyperbolic, and power classes». Digital Signal Processing, 8:348,
1998.
[240] J. R. Parker. «Rank and response combination from
confusion matrix data». Information Fusion, 2(2):113120, 2001.
[241] M. E. Pasyanos, W. R. Walter, S. R. Ford et S. E.
Hazler. «Improving mb:Ms discrimination using phase matched filters
derived from regional group velocity tomgraphy». Dans the 21th
Annual Seismic Research Symposium: Technologies for Monitoring the CTBT, pp.
565571, 1999.
[242] H. J. Patton. «Investigations into regional
magnitude scaling: transportability and mb:Ms relationships based on Nuttli's
mb(Lg)». Dans the 21th Annual Seismic Research Symposium:
Technologies for Monitoring the CTBT, pp. 572578, 1999.
[243] T. Petsche, A. Marcantonio, C. Darken, S. Hanson, G.
Kuhn, et I. Santoso. «A neural network autoassociator for induction motor
failure prediction». Dans Neural Information Processing Systems (NIPS),
volume 8, pp. 924930, 1995.
[244] W. S. Phillips. «Empirical path corrections for
regional phase amplitudes». Bulletin of the Seismological Society of
America, 89:384393, 1999.
[245] W. S. Phillips, G. E. Randall et S. R. Taylor.
«Reginal phase path effects in central china». Geophys. Res. Lett,
25:27292732, 1998.
[246] D. Plafcan, E. Sandvol, D. Seber, M. Barazangi, A.
Ibenbrahim et T. Cherkaoui. «Regional discrimination of chemical
explosions and earthquakes: A case studt in Morocco». Bulletin ofthe
Seismological Society of America, 87(5):11261139, 1997.
[247] D. C. Plaut, S. J. Nowlan et G. E. Hinton.
«Experiments on learning by back propagation». Technical Report
CMU-CS-86-126, Carnegie-Mellon University, 1986.
[248] M. Plutowski, S. Sakata et H. White.
«Cross-Validation Estimates IMSE». Dans Advances in Neural
Information Processing Systems (NIPS), volume 6, pp. 391398, 1994.
[249] P. W. Pomeroy, W. J. Best et T. V. McEvilly. «Test
ban treaty verification with regional data-a review». Bulletin of the
Seismological Society of America, 72(6): 89129, 1983.
[250] S. Ramaswamy, R. Rastogi et K. Shim. «Efficient
algorithms for mining outliers from large data sets». Dans ACM SIGMOD
International Conference on Management of Data, pp. 427438, 2000.
[251] J. M. Rassias. «On the Heisenberg-Pauli-Weyl
inequality». Journal of Inequalities in Pure and Applied Mathematics,
5(1), 2004.
[252] J. M. Rassias. «On the Heisenberg-Weyl
inequality». Journal of Inequalities in Pure and Applied Mathematics,
6(1), 2005.
[253] D. T. Reiter et R. H. Shumway. «Improved seismic
event depth estimation using cepstral analysis». Dans the 21th Annual
Seismic Research Symposium: Technologies for Monitoring the CTBT, pp. 599606,
1999.
[254] N. Ricker. «The form and nature of seismic waves and
the structure of seismograms». Geophysics, 5:348366, 1940.
[255] M. Riedmiller et H. Braun. «A direct adaptive
method for faster backpropagation learning: the RPROP algorithm». Dans
IEEE International Conference on Neural Networks, volume 1, pp. 586591,
1993.
[256] M. Rimer et T. Martinez. «CB3: an adaptive error
function for backpropagation training». Neural Processing Letters, 24(1)
:8192, 2006.
[257] M. Rimer et T. Martinez. «Classification-based
objective functions». Machine Learning, 63(2):183205, 2006.
[258] O. Rioul et P. Flandrin. «Time-scale energy
distributions: A general class extending wavelet transforms». IEEE Trans
on Signal Processing, 40:17461757, 1992.
[259] S. Roberts. «Extreme value statistics for novelty
detection in biomedical signal processing». IEE Proceedings Science,
Technology and Measurement, 147(6):363 367, 2000.
[260] S. Roberts et L. Tarassenko. «A probabilistic
resource allocating network for novelty detection». Neural Computation,
6(2):270284, 1994.
[261] A. J. Rodgers, W. R. Walter, C. A. Schultz, S. C. Myers
et T. Lay. «Acomparison of methodologies for representing path effects on
regional P/S discriminant». Bulletin of the Seismological Society of
America, 89:394408, 1999.
[262] G. Romeo. «Seismic signal detection and classfication
using artificial neural networks ». Annali di geophysica, XXXVII (3)
:343353, 1994.
[263] A. Roueff. «Traitement des signaux sismiques
multicapteurs et multicomposantes, utilisant les représentations
temps-fréquence». Thèse de doctorat, INPG, Grenoble,
2003.
[264] D. E. Rumelhart, G. E. Hinton et R. J. Williams.
«Learning internal representations by error propagation». Dans
Parallel Distributed Processing, volume 1: Foundations, Chaptitre: 8, pp.
318362. MIT Press, 1986.
[265] D. Ruta et B. Gabrys. «A theoretical analysis of
the limits of majority voting errors for multiple classifier systems».
Pattern Analysis and Applications, 5(4):333350, 2002.
[266] J. Ryan, M. J Lin et R. Miikkulainen. «Intrusion
detection with neural networks». Dans Conference on Advances in Neural
Information Processing Systems, volume 10, pp. 943949, 1998.
[267] P. A. Rydelek et L. Hass. «On estimating the
amount of blasts in seismic catalogs with Schuster's method». Bulletin of
the Seismological Society of America, 84: 12561259, 1994.
[268] O. D. Sahin, A. Gulbeden, F. Emekci, D. Agrawal et A.
El Abbadi. «PRISM: indexing multi-dimensional data in P2P networks using
reference vectors». Dans 13th Annual ACM International Conference on
Multimedia, pp. 946955, 2005.
[269] S. Scarpetta, F. Giudicepietro, C. Ezin, S. Petrosino,
E. DelPezzo, M. Martini et M. Marinaro. «Automatic classification of
seismic signals at Mt. Vesuvius volcano,
Italy using neural networks». Bulletin of the Seismological
Society of America, 95 (1):185196, 2005.
[270] C. A. Schultz, S. C. Myers, J. Hipp et C. J. Young.
«Non stationary bayesian kriging: a predictive technique ton generate
spatial corrections for seismic detection, location and identification».
Bulletin of the Seismological Society of America, 88:12751288, 1998.
[271] H. Schwenk. «The diabolo classifier». Neural
Computation, 10:21752200, 1998.
[272] A. Seghouane, Y. Moudden et G. Fleury.
«Regularizing the effect of input noise injection in feedforward neural
networks training». Neural Computing and Applications, 13(3):248254,
2004.
[273] K. K. Selig. «Uncertainty principles revisited».
Technical report, Technische Univeristat Munchen, 2001.
[274] S. Shekhar, C. T. Lu et P. Zhang. «Detecting
graph-based spatial outliers». Intelligent Data Anal ysis, 6(5):451468,
2002.
[275] Y. Shimshoni et N. Intrator. «Classification of
seismic signals by integrating ensembles of neural networks.». IEEE Trans
on Signal Processing, 46(1-4):11491201, 1998.
[276] S. Shinde et V. M. Gadre. «An uncertainty
principle for real signals in the fractional Fourier transform domain».
IEEE Trans on Signal Processing, 49(11):25452548, 2001.
[277] R. H. Shumway, D. R. Baumgardt et Z. A. Der. «A
cepstral F-statistic for detecting delay-fired seismic signals ».
Technometrics, 40:100110, 1998.
[278] A-H. Siddiqi. «Applied functional analysis».
Marcel Dekker, New York, 2004.
[279] S. Singh et M. Markou. «An approach to novelty
detection applied to the classification of image regions». IEEE on
Knowledge and Data Engineering, 16(4):396407, 2004.
[280] S. Singh et M. Markou. «A neural network-based
novelty detector for image sequence analysis». IEEE Trans on Pattern Anal
ysis and Machine Intelligence, 28(10):1664 1677, 2006.
[281] J. Sloberg et L. Ljung. «Overtraining, regularization
and searching for minimum in neural networks». Int. J. Control,
62(6):13911407, 1995.
[282] H. Sohn, K. Worden et C. R. Farrar. «Novelty
detection under changing environ- mental conditions». Dans SPIE's 8th
Annual International Symposium on Smart Structurs and Materials, volume 4330,
pp. 108118, 2001.
[283] J. L. Stevens et S. Day. «the physical basis of
mb:Ms and variable frequency magnitude methods for earthquake/explosion
discrimination». J. Geophys. Res, 90: 30093020, 1985.
[284] J. L. Stevens et K. L. McLaughlin. «Improved
methods for regionalized surface wave analysis». Rapport technique
PL-TR-972175, Maxwell Technologies Technical Report to Phillips Laboratory,
1997.
[285] R. J. Streifel, R. J. Maks et M. A. El-Sharkawi.
«Detection of shorted-turns in the field of turbine- generator rotors
using novelty detectors- development and field tests». IEEE Trans on
Energy Conversion, 11(2):312317, 1996.
[286] C. Surace et K. Worden. «A novelty detection
method to diagnose damage in structures: an application to an offshore
platform». Dans The 8th International Conference of Offshore and Polar
Engineering, volume 4, pp. 6470, 1998.
[287] M. Talagrand. «Concentration of measure and
isoperimetric inequalities in product spaces». Publications
Mathématiques de l'IHES, 81:73205, 1995.
[288] K. Tan. «The application of neural networks to
UNIX computer security». Dans IEEE International Conference on Neural
Networks (ICNN), volume 1, pp. 476481, 1995.
[289] C. Tang, S. Dwarkadas et Z. Xu. «On scaling latent
semantic indexing for large peer-to-peer systems». Dans 27th Annual
International ACM SIGIR Conference on Research and Development in Information
Retrieval, pp. 112121, 2004.
[290] J. Tang, Z. Chen, A. W. Fu et D. Cheung. «A robust
outlier detection scheme in large data sets». Dans 6th Pacific-Asia
Conference on Knowledge Discovery and Data Mining, 2002.
[291] L. Tarassenko. «Novelty detection: from patient to
jet engines». Dans International Conference on Artificial Neural Networks
(ICANN),Invited Talk, 1999.
[292] L. Tarassenko, P. Hayton, N. Cerneaz et M. Brady.
«Novelty detection for the identification of masses in mammograms».
Dans IEE International Conference on Artificial Neural Networks, volume 4, pp.
442447, 1995.
[293] D. M. J. Tax. « One-class classification».
Thèse de doctorat, Delft University of Technology, 2001.
[294] D. M. J Tax et R. P. W. Duin. «Outlier detection
using classifier instability». Dans the Joint IAPR International Workshops
on Advances in Pattern Recognition, volume 1451, pp. 593601, 1998.
[295] O. Taylor et D. Addison. «Novelty detection using
neural network technology». Dans Condition Monitoring and Diagnostic Eng.
Management Congress (COMA DEN), 2000.
[296] S. R. Taylor et H. E. Hartse. «An evaluation of
generalized likelihood ratio out- lier detection to identification of seismic
events in western china». Bulletin of the Seismological Society of
America, 87:82483 1, 1997.
[297] S. R. Taylor et H. E. Hartse. «A procedure for
estimation of source and propagation amplitude corrections for regional seismic
discriminants». J. Geophys. Res, 103: 27812789, 1998.
[298] S. R. Taylor et A. A. Velasco. « User's manual for
SPAC 1.0: A matlab program for computing source and pth amplitude
corrections». Los Alamos National Laboratory, NM, LA-UR-98-4363, 1998.
[299] S. R. Taylor, A. A. Velasco, H. E. Hartse, W. Phillips,
W. R. Walter et A. J. Rodgers. «Amplitude corrections for regional seismic
discriminant». Dans the 21 th
Annual Seismic Research Symposium: Technologies for Monitoring
the CTBT, pp. 646655, 1999.
[300] R. Tibshirani. «Bias, variance and prediction error
for classification rules». Technical report, University of Toronto,
1996.
[301] T. Tollenaere. «SuperSAB: fast adaptive back
propagation with good scaling properties». Neural Networks, 3:561573,
1990.
[302] C. Torrence et G. P. Compo. «A practical guide to
wavelet analysis». Bull. Amer. Meteor. Soc, 79:6178, 1998.
[303] B. Torrésani. «Analyse continue par
ondelettes». Savoirs Actuels InterEditionsCNRS Editions, 1995.
[304] M. Van-Erp et L. Schomaker. «Variants of Borda
count method for combining ranked classifier hypotheses». Dans 7th
International Workshop on Frontiers in Handwriting Recognition, pp. 443452,
2000.
[305] M. Van-Erp, L. Vuurpijl et L. Schomaker. «An
overview and comparison of voting methods for pattern recognition». Dans
8th International Workshop on Frontiers in Handwriting Recognition, pp. 195200,
2002.
[306] A. Van-Ooyen et B. Nienhuis. «Improving the
convergence of the backpropagation algorithm». Neural Networks, 5:465471,
1992.
[307] G. C. Vasconcelos, M. C. Fairhurst et D. L. Bisset.
« Investigating feedforward neural networks with respect to the rejection
of spurious patterns». Pattern Recognition Letters, 16(2):207212, 1995.
[308] M. Verleysen. «Machine learning of
high-dimensional data: local artificial neural networks and the curse of
dimensionality». Thèse d'agrégation,
Universitécatholique de Louvain, 2001.
[309] M. Verleysen. «Limitations and future trends in
neural computation», Chaptitre: Learning high-dimensional data, pp.
141162. IOS Press, 2003.
[310] M. Verleysen, D. François, G. Simon et V. Wertz.
«On the effects of dimensionality on data analysis with neural
networks». Dans 7th International Work-Conference on Artificial and
Natural Neural Networks3, volume 2, pp. 105112, 2003.
[311] B. K. Verma, P. Gader et W. Chen. «Fusion of multiple
handwritten word recognition techniques». Pattern Recognition Letters,
22(9):991998, 2001.
[312] J. S. Walker. «Fourier analysis and wavelet
analysis». Notices of the AMS, 44(6): 658670, 1997.
[313] W. R. Walter, K. Mayed et H. J. Patton. «Phase and
spectral ratio discriminant between NTS earthquakes and explosion Part I:
empirical observations». Bulletin of the Seismological Society of America,
85:10501067, 1995.
[314] W. R. Walter, A. J. Rodgers, , M. E. Pasyanos, K.
Mayeda et A. Sicherman. «Identification in western Eurasia: regional
body-wave corrections and surface-wave tomography models to improve
discrimination». Dans the 24th Annual Seismic Research Symposium: Nuclear
Explosion Monitoring: Innovation and Integration, pp. 592600, 2002.
[315] W. R. Walter, A. J. Rodgers, K. Mayeda et S. R. Taylor.
«Regional body-wave discrimination research». Dans the 22th Annual
Seismic Research Symposium: Planning for verification of and compliance with
the Comprhensive Test Ban Treaty, 2000.
[316] W. R. Walter et S. R. Taylor. «A revised magnitude
and distance correction (MDAC2) procedure for regional seismic
discriminants». Lawrence Livermore National Laboratory, UCRL-ID- 146882,
2001.
[317] D. Wang, J. Keller, C. Carson, K. McAdoo-Edwards et C.
Bailey. «Use of fuzzylogic-inspired features to improve bacterial
recognition through classifier fusion». IEEE Trans on Systems, Man, and
Cybernetics, Part B: Cybernetics, 28(4):583 591, 1998.
[318] L. Wang, X. Wang et J. Feng. «On image matrix
based feature extraction algorithms». IEEE Trans on Systems, Man, and
Cybernetics, Part B, 36(1):194197, 2006.
[319] L. Wang, X. Wang, X. Zhang et J. Feng. «The
equivalence of two-dimensional PCA to line-based PCA». Pattern Recogn.
Lett., 26(1):5760, 2005.
[320] Q. Wang et L. S Lopes. «One-class learning for
human-robot interaction». Dans BASYS, pp. 489498, 2004.
[321] M. K. Weir. «A method for self-determination of
adaptive learning rates in backpropagation». Neural Networks, 4:371379,
1991.
[322] W. J. Williams, M. L. Brown et A. O. Hero.
«Uncertainty, information, and timefrequency distributions». Dans
Proc. SPIE, volume 1566, pp. 144156, 1991.
[323] C. Wilson, J. Blue et O. Omidvar. «Improving
neural network performance for character and fingerprint classification by
altering network dynamics». Dans The World Congress on Neural Networks,
1995.
[324] C. R. D. Woodgold. «Wide-aperture beamforming of
depth phases by timescale contraction». Bulletin of the Seismological
Society of America, 89:165177, 1991.
[325] K. Worden, G. Manson et D. J. Allman.
«Experimental validation of structural health monitoring methodology I:
novelty detection on a laboratory structure». Journal of Sound and
Vibration, 259:323343, 2003.
[326] L. Xu, A. Krzyzak et C. Y. Suen. «Methods of
combining multiple classifiers and their applications tohandwriting
recognition». IEEE Trans on Systems, Man and Cybernetics, 22(3):418435,
1992.
[327] R. R. Yager, M. Fedrizzi et J. Kacprzyk. «Advances in
the Dempster-Shafer theory of evidence». Wiley, 1994.
[328] J. Yang et J-Y. Yang. «From image vector to matrix: a
straightforward image projection technique-IMPCA vs. PCA». Pattern
Recognition, 35(9):19971999, 2002.
[329] J. Yang, D. Zhang, A. F. Frangi et J-Y. Yang.
«Two-dimensional PCA: a new approach to appearance-based face
representtation and recognition». IEEE Trans on Pattern Anal ysis and
Machine Intelligence, 26(1):131137, 2004.
[330] Y. Yang, J. Zhang, J. Carbonell et C. Jin.
«Topic-conditioned novelty detection». Dans 8th ACM SIGKDD
International Conference on Knowledge Discovery and Data Mining, pp. 688693,
2002.
[331] D. Y. Yeung et C. Chow. «Parzen window network
intrusion detectors». Dans 16th International Conference on Pattern
recognition, volume 4, pp. 385388, 2002.
[332] Y.Huang, K. Liu et C. Suen. «The combination of
multiple classifiersby neural network approach». International Journal of
Pattern Recognition and Artificcial Intelligence, 9(3):579597, 1995.
[333] B. L. Zhang et G. Gupta. «Anomaly detection in
internet intrusion detection by hybrid of self-organization and kernel
auto-associators». Dans International Conference on Intelligent Systems
and Knowledge Engineering (ISKE2006), 2006.
[334] D. Zhang, S. Chen et Z-H Zhou. «Learning the kernel
parameters in kernel minimum distance classifier». Pattern Recognition,
39(1): 133135, 2006.
[335] D. Zhang et Z-H. Zhou. « (2D)2PCA:
Two-directional two-dimensional PCA for efficient face representation and
recognition». Neurocomputing, 69(1-3):24231, 2005.
[336] H. Zhang, W. Huang, Z. Huang et B. Zhang. «A
kernel autoassociator approach to pattern classification». IEEE Trans on
Systems, Man and Cybernetics,Part B, 35 (3):593606, 2005.
[337] T-R. Zhang, S. Y. Schwartz et T. Lay.
«Multivariate analysis of waveguide effects on short-period regional wave
propagation in Eurasia and its application in seismic discrimination». J.
Geophys. Res, 99(B11):714725, 1994.
[338] Y. Zhang, , A. Luo et Y. Zhao. «Outlier detection
in astronomical data». Dans Proceedings of the SPIE, Optimizing Scientific
Return for Astronomy through Information Technologies, volume 5493, pp. 521529,
2004.
[339] Z-H. Zhou et X-Y. Liu. «Training cost-sensitive
neural networks with methods addressing the class imbalance problem». IEEE
Trans on Knowledge and Data Engineering, 18(1):6377, 2006.
[340] M. H. Zweig et G. Campbell. «Receiver-operating
characteristic (ROC) plots: a fundamental evaluation tool in clincal
medcine». Clincal Chemistry, 39(4):561577, 1993.
ANNEXE I
LE LOGICIEL MSSSA
Le logiciel Marocain d'Analyse des Signaux Sismiques (MSSSA:
Moroccan Software for Seismic Signals Analysis) est un logiciel conçu et
réalisé au cours de ce mémoire avec une collaboration du
LAIT de l'EMI et l'ING du CNRST. Ce logiciel est composé dans sa
première version de cinq parties:
1. MSSSA-Daq permet l'acquisition et l'archivage des
données sismiques (figure (1.1));
2. MSSSA-Reader permet de lire les données acquis
MSSSA-daq et les données du système DataSeis II de Kinemetrics
(figures (1.2) et (1.3));
3. MSSSA-Converter permet de convertir les données en
certains formats sismiques internationaux (figure (1.4));
4. MSSSA-Recognition permet la reconnaissance des signaux
sismiques en rejetant les bruits et certains signaux acquis qui pourraient
perturber l'étape de discrimination (figure (1.5));
5. MSSSA-Discrimination permet la discrimination automatique et
manuelle des signaux sismiques (figure (1.6)).
Pour plus de détails sur l'utilisation de ce logiciel,
le matériel nécessaire et les compétences requises, le
lecteur pourra se référer à [33]. Pour les fondements
théoriques et les algorithmes utilisés, ce mémoire permet,
d'une part de les clarifier et, d'autre part, de montrer l'influence des
différents paramètres sur les performances du système.
Nous notons que ce
(a) (b)
Figure I.1: Interface d'entrée (a) et interface
principale (b) de MSSSA-Daq
(a) (b)
Figure I.2: Interface d'entrée (a) et interface principale
(b) de MSSSA-Reader pour le format daq
(a) (b)
(a) (b)
Figure I.4: Interface d'entrée (a) et interface
principale (b) de MSSSA-Conveter
(a) (b)
Figure I.5: Interface d'entrée (a) et interface
principale (b) de MSSSA-Recognition
(a) (b)
ANNEXE II
L'ALGORITHME DE RETRO-PROPAGATION
L'apprentissage du perceptron multicouches consiste à
adapter les poids synaptiques des neurones, de manière à ce que
le réseau soit capable de réaliser une transformation
donnée, représentée par un ensemble d'exemples
constitué d'une suite de N vecteurs
d'entrées Xk = [xk1 xk2 · · ·
xkd]' associée à une autre suite de vecteurs de
sorties désirées Tk = [t(k)
1 t(k)
2 · · · t(k)
hL ]'.
Lorsque le critère des Moindres Carrés de l'Erreur
est utilisé pour définir la fonction de coût à
minimiser, celle-ci s'exprime:

XhL
i=1
XN
k=1
1
E=
2
~
y(k)
L,i - t(k)
i
2
(II.1)
où:
· N est le nombre d'exemples d'apprentissage;
· L est le nombre de couches du réseau;
· hl est le nombre de neurons de la couche l;
· yl,i désigne la sortie du neurone i de
la couche l lorsque le vecteur Xk est présenté(k)
à l'entrée du réseau;
· t(k) ireprésente la valeur
désirée de la sortie pour le neurone i de la dernière
couche
lorsque le vecteur Xk est présenté à
l'entrée du réseau.
La minimisation de cette fonction de coût se fait d'une
manière itérative, en utilisant une méthode du gradient.
Pour le cas d'un apprentissage en ligne dit aussi rétro- propagation
stochastique [11], la démarche standard suit les points ci-dessous.
A chaque itération, et pour tous les
éléments de la base d'apprentissage, un vecteur d'entrée
Xk = [xk1 xk2 · · · xkd]' ainsi que sa sortie
désirée Tk = [t(k)
1t(k)
2 · · · t(k)
hL ]'sont
présentés au système. L'erreur localement
effectuée est alors calculée selon:
E(k) = 1
2
|
XhL
i=1
|
~
y(k)
L,i - t(k)
i
|
|
2
(11.2)
|
|
Les poids synaptiques qui relient les neurones entre eux peuvent
ensuite être adaptés en fonction de la relation:
?E(k)
wl,ij(ô + 1) = wl,ij(ô) - ç (11.3)
?wl,ij
où çest le taux d'apprentissage et ?E(k)
?wl,ij la descente du gradient (gradient descent) ou gradient
instantanée de l'erreur. Avant de continuer, nous adoptons les notation
suivantes:
· ?l,i: la fonction d'activation du neurone i de la couche
l;
· W l,i = [èl,i wl,i1 wl,i2 · · ·
wl,ihl_1]': le vecteur de poids du neurone i de la couche l
augmenté de son seuil;
· Xk = [-1 xk1 xk2 · · ·
xkd]': est le vecteur des caractéristiques de
l'élément présentéà l'entrée
augmenté par le -1 à l'indice 1;
· Y (k)
l = [-1 y(k)
l,1 y(k)
l,2 · · · y(k)
l,hl]': est le vecteur des sorties augmenté par le -1
à l'indice 1 lorsque Xk est présenté à
l'entrée.
Les valeurs de yki sont déterminées
à partir des sorties des neurones de la couche précédente
par:
yl,i = ?l,i(W'
(k)l,iY (k)
l-1) (11.4)
en posant:
ul, i = W '
(k)l,iY (k) (11.5)
l-1
cette équation s'écrit:
Le gradient instantané de l'erreur peut s'exprimer:
(11.7)
Ôu(k) Ôwl,ij
l,i
ÔE(k)
ÔE(k) Ôu(k)
l,i
Ôwl,ij
En posant:
8(k)
l,i , ÔE(k) (11.8)
Ôu(k)
l,i
où 8(k)
l,i est appelé gradient local de l'erreur, et en tenant
compte que de 11.5 on a:
|
Il vient ainsi:
|
Ôu(k)
l,i
Ôwl,ij
|
= y(k) (11.9)
l-1,j
|
|
ÔE(k)
|
= 8(k)
l,i y(k) (11.10)
l-1,j
|
|
Ôwl,ij
|
Le gradient local 11.8 peut se développer selon:
|
ÔE(k)
|
|
hl+1X
q=1
|
ÔE(k)
|
Ôu(k)
l+1,q
|
(11.11)
|
|
=
|
|
|
|
Ôu(k)
l,i
|
Ôu(k)
l+1,q
|
Ôu(k)
l,i
|
ou encore:
Ôy(k)
l,i (11.12)
Ôy(k) Ôu(k)
l,i l,i
Ôu(k)
l+1,q
ÔE(k)
ÔE(k)
=
hl+1X
q=1
Ôu(k)
l+1,q
Ôu(k)
l,i
et comme on a de (11.8) ?E(k) l,i = wl+1,qi et de (11.6)
?y(k)
?u(k)
l+1,q = 8(k)
l+1,q, de (II.5) ?u(k)
l+1,q l,i l, i ),
l,i =
· ?(u(k)
?y(k)
?u(k)
il vient:
|
8(k)
l,i =
· ?(u(k)
l ,i )
|
hl+1X
q=1
|
wl+1,qi8(k) (11.13)
l+1,q
|
C'est l'expression (11.13) qui a donné son nom à
l'algorithme d'apprentissage du perceptron multicouches:
rétro-propagation du gradient de l'erreur. En effet, le gradient
local8(k)
l,i , d'un neurone est calculé à partir des
gradients locaux 8(k)
l+1,q, des neurones de la couche ultérieure. Le calcul
des gradients commence donc par la dernière couche, et est ensuite
propagé de celle-ci vers la première couche du réseau.
sortie. De l'expression (11.8), il vient:
= ?E(k) ?y(k)
ä(k) L,i
L,i = ?E(k) (11.14)
?u(k) ?y(k) ?u(k)
L,i L,iL,i
Dans le cas de l'utilisation du critère (11.2) est
utilisé, alors on:
|
?E(k)
|
= yL,i - t (k)
(k) (11.15)
i
|
|
?y(k)
L,i
|
et l'expression du gradient local pour la couche de sortie est
donné par:
ä(k)
L,i = (y(k)
L,i - t(k)
i ) _?(u(k)
l,i ) (11.16)
Les formules (11.10), (11.13) et (11.16) permettent de calculer
facilement la valeur de la modification qui doit être apportée
à chaque poids du réseau.
| 

