|

REPUBLIQUE ALGERIENNE DEMOCRATIQUE ET
POPULAIRE
MINISTERE DE L'ENSEIGNEMENT SUPERIEUR
ET DE LA RECHERCHE
SCIENTIFIQUE
UNIVERSITE MOHAMED KHEIDER DE BISKRA
FACULTE DES
SCIENCES ET SCIENCES DE L'INGENIEUR
DEPARTEMENT D'AUTOMATIQUE
Mémoire de fin d'études
En Vue de
l'Obtention du Diplôme
d'Ingénieur d'état en
Automatique
Authentification de visages par la
méthode d'analyse
discriminante
linéaire de Fischer
Présenté par : Proposé et
dirigé par :
Dr.Djamel Saigaa
Guettal Lamia Bedoui Loubna
Promotion juin 2008
Sommaire
Sommaire I
Liste des figures III
Liste des tableaux IV
Introduction générale 1
Chapitre 1 : La vérification
biométrique d?identité
1-1.Introduction 4
1-2.La biométrie 5
1-3.Technologie de la biométrie 5
1-4.Identification et authentification 6
1-5.Méthodes de reconnaissance d?individus 8
1-5-1.Méthode intrusives 9
1-5-2.Méthode non intrusives 9
1-6.Comparaison entre quelque techniques biométriques
10
1-7.Biométrie et processus d?identification 11
1-7-1.Acquisition 11
1-7-2.Extraction 11
1-7-3.Classification 11
1-7-4.Decision 12
1-8.La reconnaissance de visages 13
1-9.Système de reconnaissance de visages 14
1-9-1.Acquisition de l?image 15
1-9-2.Prétraitements 15
1-9-3.Détection puis localisations 15
1-9-4.Extraction des paramétres et classification 16
1-9-5.Apprentissage 16
1-9-6.Décision 16
1-10.Les méthodes de reconnaissance du visage 16
1-10-1.Méthode globale 17
1-10-2.Méthode locales 17
1-10-3.Méthode hybrides 18
1-11.Conclusion 18
Chapitre 2 : Méthode d?extraction de
l?information
2-1.Introduction 19
2-2.Réduction des images 19
2-2-1.Le prétraitement 19
2-2-2.L?Analyse en composantes principales (ACP) 22
2-2-2-1.Visages propres (Eigen Faces) 23
2-2-2-2.Comment choisir la dimension de l?espace 27
2-2-3.Analyse discriminante linéaire de Fischer (LDA)
27
2-2-3-1.Méthode originale de Fischer 28
2-2-3-2.Méthode de Fischer basée sur une base ortho
normale 30
2-3.Mesure de similarité. 32
2-3-1.La norme L1 33
2-3-2.La norme L2 33
2-3-3.Covariance(Angle) 33
2-3-4.Corrélation 34
1-11.Conclusion 34
Chapitre 3 : Base de données
3-1.Introduction 35
3-2.La base de données XM2VTS 35
3-3.Le protocole de XM2VTS ou ?protocole de
Lausanne??. 36
3-4.Mesure de qualité 40
3-5.Traitement préliminaires 42
3-6.Language de programmation 42
3-7.Conclusion 43
Chapitre 4 : Résultats exprimantaux
4-1.Introduction 44
4-2.Architecteur structurelle de système 44
4-3.Réduction des données 46
4-3-1.Découpage et décimation 47
4-3-2.Enchainement des lignes ou colonnes 48
4-3-3.Photonormalisation 48
4-3-4.Création de la matrice d?apprentissage 49
4-3-5.Normalisation des données 49
4-4.Les critéres de performance 49
4-5.La classification 50
4-6.Authentification de visages basée sur Eigen Face (ACP)
51
4-7.Authentification de visages basée sur Fischer Face
(LDA) 55
4-8.Conclusion 60
Conclusion générale 61
Bibliographies 63
Liste des figures
Figure 1.1 :Shéma explicatif de l?identification 6
Figure 1.2 :Schéma explicatif de l?authentification 7
Figure 1.3 :Les principales techniques de reconnaissance de
l?individu 8
Figure 1.4 :Graphique qui montre le point milieu entre FR et FA
12
Figure 1.5 :Système de reconnaissance 14
Figure 2.1 :L?image de visage A avant et B après
découpage 20
Figure 2.2 :Image de visage A avant et B après
décimation 21
Figure 2.3 :Exemple de projection les points sur deux axes 28
Figure 4.1: Le schéma bloc de système 45
Figure 4.2 : Quelque exemple des images de la base de
données XM2VTS 46
Figure 4.3 : Présentation des mêmes images
précédentes après le découpage 47
Figure 4.4 : Présentation des mêmes images
précédentes après la décimation 47
Figure 4.5 : Le TEE dans l'ensemble d'évaluation en
fonction de la dimension du sous-
espace ACP en utilisant différentes distances de mesure de
similarité 54
Figure 4.6 : TEE pour différents distance de mesure de
similarité ?LDA?? 58
Figure 4.7: Comparaison des performances de méthode
d?Eigen-Faces, la méthode Fisher-Faces pour l?authentification de visage
en utilisent la covariance (angle) pour la mesure de similarité dans
l?ensemble d?évaluation 59
Liste des tableaux
Tableau 1.1 :Comparaison entre quelque technique 10
Tableau 3.1 :Répartition des images de la base de
données selon la configuration I 37
Tableau 3.2 :Répartition des images de la base de
données selon la configuration II 38
Tableau 3.3 :Répartition des photos dans les
différents ensembles 39
Tableau 3.4 :Nombre de comparaisons possibles 39
Tableau 4.1 :Influence du type de la distance de mesure de
similarité sur les taux d?erreur
d?authentification en utilisant différentes
métriques dans le sous espace ACP 52
Tableau 4.2 :Les résultats de la méthode de l?ACP
avec photonormalisation 53
Tableau 4.3 :Les résultats des taux erreurs dans les sous
espace LDA sans photonormalisation 56
Tableau 4.4: Les résultats des
taux erreurs dans le sous espace LDA avec
photonormalisation 57
Remerciement
Nous tenons à remercier avant tout Dieu tout
puissant qui nous a donné la
volonté, la force, la
santé et la patience pour élaborer notre travail.
Nous remercions en particulier notre encadreur Dr. Djamel
Saigaa qui nous a
aidé et conseillé durant cette
année.
Nos vifs remerciements vont à l'encontre du
Professeur Abdel-Malik Taleb et
le Dr. Mechraoui Salah Eddine pour le
soutien moral.
Ainsi nous tenons également à exprimer nos
remerciements à tous les
enseignants du département d
'AWTOMATIQWE qui ont contribué à notre
formation.
Nos remerciements vont aussi à tous les membres de
jury qui ont accepté de
jury notre travail.
Nous adressons nos vifs remerciements à notre amie
Fedias Meriem pour leurs
conseils.
En fin, nous tenons à remercier nos familles et nos
amis, qui ont toujours été
près de nous dans les
moments difficiles.
Résumé
Malgré la pléthore d'approches et de
méthodes qui ont été proposées pour résoudre
le problème de vérification automatique de visage humains, il
demeure un problème extrêmement difficile, ceci est du au fait que
le visage de personnes différentes ont globalement la même forme
alors que les images d'un même visage peuvent fortement varier du fait
des conditions d'éclairage, de la variation de posture, des expressions
faciales. De nos jours ces systèmes de vérification
d'identité sont de plus en plus nécessaires, vu la multitude des
applications qui leurs font appel (contrôle d'accès aux sites dits
sensibles, interface homme -machine ...).
Dans ce travail, nous présentons le modèle
de vérification (authentification) de visage basé sur la
technique d'analyse discriminante linéaire (LDA) ou (Fisher-Face) pour
l'extraction du vecteur caractéristique de l'image de visage .pour
validé ce travail nous avons testé cette technique sur des images
frontales de la base de données XM2VTS selon son protocole
associé (protocole de Lausanne).
Introduction
générale
Introduction générale
Les moyens classiques de vérification
d'identité pour les contrôles d'accès : comme passeport, la
carte d'identité, les mots de passe ou les codes secrets peuvent ~tre
facilement falsifiés .La solution apparaît pour remédier
à ce problème est d'utiliser la biométrie. Cette
dernière joue un rôle de plus ou plus important dans les
systèmes d'authentification et identification. Les processus de
reconnaissance biométrique permettent la reconnaissance d'individus en
se basant sur les caractéristiques physique et comportementale de
l'individu. Différentes technologies ont été
développées telle que: les empreintes digitale, l'iris, la voix
la main et le visage .Ce dernier constitue l'objectif principale de notre
mémoire.
La reconnaissance des visages est l'une des techniques de la
biométrie la plus utilisée, ceci est dû à ses
caractéristiques avantageuses dont on peut citer:
- Disponibilité des équipements d'acquisition
et leur simplicité
- Passiveté du système : un système
de reconnaissance de visages ne nécessite aucune coopération de
l'individu, du genre : mettre le doigt ou la main sur un dispositif
spécifique ou parler dans un microphone .En effet, la personne n'a
qu'à rester ou marcher devant une caméra pour qu'elle puisse
être identifiée par le système.
En plus, cette technique est très efficace pour la
situation non standard. C'est le cas oft on ne peut avoir la coopération
de l'individu à identifier, par exemple lors d'une arrestation des
criminels.
Certes la reconnaissance des visages n'est pas la
technique la plus fiable comparée aux autres techniques de
biométrie, mais elle peut être ainsi si on peut trouver les bons
attributs d'identification représentant le visage à
analyser.
Dans un système de reconnaissance de visage, ce
dernier est soumis à un éclairage très varié en
contraste et luminosité, un arrière plan. Cette forme à
trois dimensions, lorsqu'elle s'inscrit sur une surface à deux
dimensions, comme c'est le cas d'une image, peut donner lieu à des
variations importantes .Le visage n'est pas rigide, il peut subir une grande
variété de changements dus à l'expression (joie,
peine...), à l'tge, aux cheveux, à l'usage de produits
cosmétiques...etc
Le but de notre travail est l'authentification
d'identité par l'analyse du visage, un système d'authentification
a pour but de vérifier l'identité d'un individu après que
celui-ci se soit identifié. Il ne s'agit donc pas d'un système
d'identification qui lui se charge de découvrir l'identité a
priori inconnue d'un individu.
L'idée principale de ce travail est d'utiliser la
méthode discriminante linéaire (LDA) pour l'extraction des
caractéristiques de l'image de visage. Nos expériences ont
été exécutées sur la base de données XM2VTS
(Extended Multi Modal Verification for Teleservices and Security application)
selon le protocole de Lausanne. La performance du système
d'authentification est évaluée en termes du taux de faux rejet
(TFR); la proportion d'accès clients rejetés par le
système, et du taux de fausse acceptation (TFA) ; la proportion
d'imposteurs réussissant à y pénétrés. Le
Taux de réussite (TR) d'un système d'authentification est
défini comme étant :
TR = 1 -- (TFA + TFR).
Le présent mémoire est répartir comme
suit :
Le premier chapitre présente un bref aperçu
des technologies biométriques et la distinction entre l'authentification
et l'identification, et les différentes méthodes de
reconnaissance de visage.
Le chapitre 2 donne les étapes de réduction de
la dimension d'image, ainsi qu'une explication détaillée sur la
vérification de visage à l'aide d'une méthode globale dite
"l'analyse en composantes principales (ACP)" et la méthode d'analyse
discriminante A linéaire.
Le chapitre 3 présente la base de données de
visages sur laquelle nos expériences ont été
exécutées. Le protocole de test est décrit en
détail et la motivation pour le choix de cette base est
expliquée.
Le chapitre 4 donne les résultats
expérimentaux obtenus en utilisant l'analyse en composantes principales
et l'analyse discriminante linéaire. Nous insistons sur l'influence des
paramètres de l'algorithme réalisé (comme : la taille du
vecteur caractéristique de l'image du visage et le type de distance
utilisée pour la mesure de similarité).
Nous terminons enfin par une conclusion
générale.
Chapitre 01
La vérification biométrique
d'identité
1-1.Introduction
Savoir déterminer de manière à la fois
efficace et exacte l?identité d?un individu est devenu un
problème critique car de nos jours l?accès sécurisé
et la surveillance constituent un sujet de très grande importance. En
effet bien que nous ne nous en rendions pas toujours compte, notre
identité est vérifiée quotidiennement par de multiples
organisations : lorsque nous accédons à notre lieu de travail,
lorsque nous utilisons notre carte bancaire, lorsque nous nous connectons
à un réseau informatique, etc.
Il existe traditionnellement deux manières d?identifier un
individu :
· La première à partir d?une connaissance qui
correspond par exemple à un mot de passe ou un code qui permet d?activer
un appareil numérique.
· La deuxième à partir d?une possession, il
peut s?agir d?une pièce d?identité, d?une clef, d?un badge.
La biométrie est une alternative à ces deux
modes, et consiste à identifier un individu à partir de ses
caractéristiques physiques et comportementales. Elle connaît un
renouveau spectaculaire depuis quelques années.
Les principales propriétés souhaitables d?une
biométrie sont les suivantes : universelle, mesurable, uniques,
permanente, performante, difficilement falsifiable ou reproductible, et bien
acceptée des utilisateurs.
On distingue deux types de caractéristique : physique
et comportementales. Les caractéristiques physiques : le visage, les
empreintes digitales, l?iris, la voix et la forme de la main, etc. Les
caractéristiques comportementales : la démarche,
l?écriture, etc.
1-2.La biométrie
La biométrie est la science qu?on utilise pour
différencier des personnes entre elles grâce à leur
biologie (physiologique ou comportementale), automatiquement reconnaissable et
vérifiable.
Le traditionnel système de contrôle
d?accès ou de sécurité exige d?avoir soit une carte
d?identité ou un mot de passe mémorisé. Avec la
biométrie, cela n?est plus exigé, la personne n?a pas
s?inquiété de laisser sa carte à la maison ou d?oublier
son mot de passe. De plus, les cartes d?identités peuvent être
perdues ou volées et les mots de passe peuvent être
utilisés par n?importe le qui. Cependant, la biométrie constitue
un identificateur d?une personne qui ne peut pas être copié,
volé ni oublié. [1]
1-3.Technologie de la biométrie : Il
existe deux catégories de technologies biométriques [1]
- Les techniques d'analyse du comportement :
Dans cette catégorie on peut faire l?analyse de : La dynamique
de signature (la vitesse de déplacement de stylo, les
accélérations, la pression exercée et l?inclinaison).La
façon d?utiliser un clavier d?ordinateur (la pression exercée et
la vitesse de frappe).
- Les techniques d'analyse de la morphologie humaine
: Dans cette catégorie on peut faire l?analyse des (empreintes
digitales, forme de la main, trait de visage, dessin du réseau veineux
de l?oeil et la voix). L?avantage de ces éléments est qu?ils ne
changent pas dans la vie d?un individu et ne subissent pas autant les effets du
stress que les éléments comportementaux.
1-4.Identification et authentification [2]
L'identification : consiste à
déterminer l?identité de la personne qui se présente en
recherchant l?échantillon biométrique fourni par cette personne
avec une liste d?échantillon. Il s?agit de la réponse à la
question « Qui suis-je ? ».La figure (1.1) représente un
schéma explicatif de l?identification.
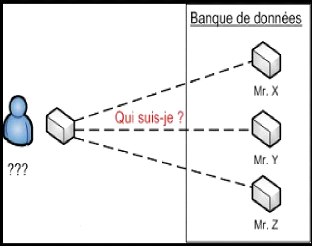
Figure 1.1 : schéma explicatif de
l?identification.
L'action est la même que lorsque l'on renseigne son
login dans un système login/password. Le système va rechercher
les informations concernant ce login dans sa base de
références.
L'authentification : consiste à
vérifier que la personne qui se présente est bien la personne
qu?elle prétend être. Pour cela, la personne donne son
identité et fournit un échantillon biométrique. Get
échantillon est comparé avec un échantillon
biométrique propre à cette personne fourni antérieurement.
Si les deux échantillons coïncident, avec une marge d?erreur
prédéfinie, la personne est authentifiée. Il s?agit de la
réponse à la question « Suis-je bien Mr. X ? ».La
figure (1.2) représente un schéma explicatif de
l?authentification.
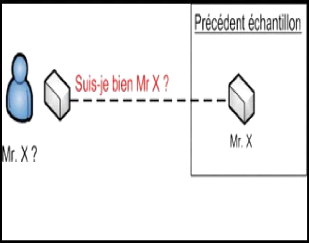
Figure 1.2 : un schéma explicatif de
l?authentification.
L'action correspond à la vérification du mot de
passe dans un système login/ password. Après s'être
identifié, on s'authentifie par un mot de passe que le système
compare à celui qu'il possède dans sa base de
références.
1-5.Méthodes de reconnaissance d'Individus
[3]
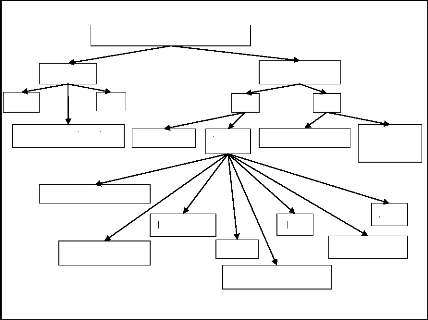
Technologie de reconnaissance
Intrusive
Coleurs (yeux, peau)
Iris
ADN
2D
3D
Démarche
Mesure et ratios
Visage
SVM
EigenFaces
DCT
Eigen-Objects
HMM
Mesure et ratios
Empreintes digitales
Réseaux neuronaux
Modèles surfacique
Non intrusives
Les techniques de reconnaissance d?individus peuvent
essentiellement se diviser en deux grandes catégories : les
méthodes intrusives qui requièrent la coopération de
l?individu pour l?identifier par exemple (empreintes digitales) et les
méthodes non intrusives qui ne requièrent pas la
coopération de l?individu en question, ce sont celles qui peuvent
êtres appliqués à distance en observant les individus avec
des capteurs. Le schéma de la figure (1.3) illustre en détail les
méthodes ou techniques de reconnaissances d?individus :
1-5-1.Méthodes Intrusives
Parmi les techniques de reconnaissances d?individus qui
existent à ce jour, les plus performantes appartiennent sans contre dit
à la catégorie des méthodes intrusives. On peut citer
comme faisant partie de ces méthodes : la comparaison d?ADN (DNA
matching), ainsi que l?identification à partir d?informations
biométriques provenant d?empreinte digitales, de rétine, d?iris,
de la géométrie de la main [4].
1-5-2.Méthodes Non Intrusives
Contrairement aux méthodes intrusives les
méthodes non intrusives ne requièrent pas un contact direct avec
les individus. On peut tirer plein d?information sur un individu de par son
corps, ces informations peuvent servir soit à identifier la personne,
soit à raffiner le processus d?identification, en effet, lorsque
plusieurs techniques d?identification sont simultanément possibles, bon
nombre d?individus peuvent être éliminés uniquement
à la vue du corps. Par exemple si la taille d?un individu et de 1m80, il
est inutile de tenter une reconnaissance sur des individus qui ne
vérifie pas cette condition dans la base de donnée parmi les
méthodes envisageables on citera : les mesures morphologiques (3D) ainsi
que l?analyse de la démarche, et bien sur le visage. [3]
1-6. Comparaison entre quelques techniques
biométriques [6]
La colonne « physique/ logique » précise
l?usage le plus courant de chaque technique.
Techniques
|
Avantage
|
Inconvénients
|
Physique / Logique
|
*Empreintes digitale
|
*Coût moyen. *Ergonomie moyenne * Facilité de mise
en place.
*Taille de la capture
|
*Qualité optimale des
appareils de mesure (fiabilité) *Acceptabilité
moyenne. *Possibilité d?attaque. (rémanence de l?empreinte.)
|
P/L
|
*Forme de la main
|
*Très ergonomique *Bonne acceptabilité
|
*Système encombrant.
*Coût élevé
*Perturbation possible par des blessures et l?authentification
des membres d?une même famille.
|
P
|
*Visage
|
*Coût moyen
*Peu encombrant
*Bonne acceptabilité
|
*Jumeaux.
*Psychologie religion. *Déguisement.
*Vulnérable aux attaques.
|
P
|
*Rétine
|
*Fiabilité *Pérennité
|
*Coût élevé
*Acceptabilité faible
*Installation difficile
|
P
|
*Iris
|
*Fiabilité
|
*Acceptabilité très faible *Contrainte
d?éclairage
|
P
|
*Voix
|
*Facile
|
*Vulnérable aux attaques
|
P/L
|
*Signature
|
*Ergonomie
|
*Dépendance de l?état émotionnel de la
personne
|
L
|
*Frappe au
clavier
|
*Ergonomie
|
*Dépendance de l?état de la personne
|
L
|
|
Tableau 1.1 : Comparaison entre quelque
technique biométrique
1-7.Biométrie et processus d'authentification
Le processus d'identification consiste à comparer la
caractéristique en question, souvent appelée modèle de
l'utilisateur avec les modèles équivalents de tous les
utilisateurs, déjà stockés dans une base de
données. L'utilisateur inconnu est identifié comme l'utilisateur
ayant la caractéristique biométriques ou le modèle qui
ressemble le plus, selon un critère donné, au modèle
d'entrée. Notons que le système est capable de fournir uniquement
l'identité d'un utilisateur ayant déjà un modèle
stocké dans la base de données. Contrairement à
l'identification, l'authentification consiste à comparer le
modèle d'entrée avec seulement celui de l'identité
proclamée. Ici, il s'agit de classer l'utilisateur comme un vrai
utilisateur ou un imposteur. Les différentes étapes du processus
d'authentification sont:[11]
1-7-1.Acquisition
Un système d'acquisition équipé d'un
capteur est utilisé pour acquérir une caractéristique
spécifique de l'utilisateur, par exemple: une caméra ou un
microphone dans le cas de la voix.
1-7-2.Extraction
Ayant une image ou une voix en entrée,
une étape de segmentation permet d'extraire la
caractéristique dont le processus d'authentification a besoin. Par
exemple: extraire le visage du fond d'une image dans le cas d'authentification
de visage.
1-7-3.Classification
En examinant les modèles stockés dans la base
de données, le système collecte un certain nombre de
modèles qui ressemblent le plus à celui de la personne à
identifier, et constitue une liste limitée de candidats. Cette
classification intervient uniquement dans le cas d'identification car
l'authentification ne retient qu'un seul modèle (celui de la personne
proclamée).
1-7-4.Décision [8] [11]
Dans le cas de l'identification, il s'agit d'examiner les
modèles retenus par un agent humain et donc décider. En ce qui
concerne l'authentification, la stratégie de décision nous permet
de choisir entre les deux alternatives suivantes: l'identité de
l'utilisateur correspond à l'identité proclamée ou
recherchée ou elle ne correspond pas. Elle est basée sur un seuil
prédéfini. L'estimation du seuil de la décision constitue
la plus grande difficulté de ces techniques, et elle peut engendrer deux
types d'erreurs, souvent prises comme mesures de performances pour ces
techniques d'authentification: faux rejet (FR) qui correspond à rejeter
un vrai utilisateur ou une identité valable, et fausse acceptation (FA)
qui donne accès à un imposteur. Bien sûr, un système
d'authentification idéal est celui qui donne FA=FR=0. Malheureusement,
dans les conditions réelles, ceci est impossible. Quand FR augmente, FA
diminue et vice versa. Par exemple, si l'accès est donné à
tout le monde, FR=0 signifiant que FA=1. Par contre, un accès
refusé à tout le monde correspond à FR=1, mais
entraîne un FA=0. Par conséquent, un compromis doit être
fait dans le choix du seuil, et ce dernier est très dépend de
l'application: FA doit avoir une valeur très faible dans les
applications bancaires afin de garantir plus de sécurité.
Généralement, un système d'authentification opère
entre les deux extrêmes pour la majorité des applications: on
ajuste le seuil de décision pour atteindre une valeur
désirée et prédéfinie de FR ou de FA (voir
figure.1.4). Il est donc difficile de comparer les performances des
systèmes d'authentification en se basant uniquement sur les valeurs de
FA.
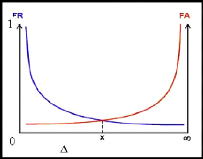
Figure 1.4 : Graphique qui montre le point
milieu entre FR et FA
1-8.La reconnaissance de visage
La reconnaissance de visages fait partie de la
biométrie, elle est la plus répondue, c?est une science de
programmation qui rend la machine capable d?identifier les visages humains.
Quand une personne est enrôlée dans un
système de reconnaissance des visages, une caméra vidéo
prend une série d?images de son visage qui seront ensuite
transformées en un code holistique unique, dans la phase de
vérification le système décidé si la personne est
autorisée ou non. [1]
Les systèmes de reconnaissance de visages, par rapport
aux autres systèmes biométriques, présentent les avantages
suivants :
· Non invasif c'est-à-dire : aucun dispositif
à toucher.
· Moins sources d?erreur comparant avec d?autres
systèmes (par exemple le système de reconnaissance des empreintes
digitales est sensible s?il y a présence de poussière sur le
dispositif d?acquisition).
· Offre un meilleur outil de révision, en gardant
trace des images acquises, on aura un historique qui peut être utile pour
le but d?inspection.
· La camera vidéo peut déjà être
utilisée pour d?autres buts cependant, aucun dispositif spécial
n?est exigé.
En affichant l?image candidate et l?image reconnue, le
système de reconnaissance des visages peut servir d?un outil d?aide
à la décision (en cas de fausse identification, l?être
humain peut se rendre compte de l?erreur). [7]
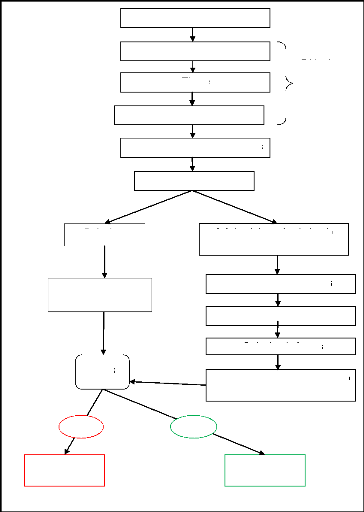
1-9.Systèmes de reconnaissance de visages
[5]
Un système de reconnaissance de visages est un
système d?identification et de vérification d?individus, qui
permet de vérifier si une personne appartient à la base de
données du système, et de l?identifier si c?est le cas.
Extraction des
paramètres et
Classification
Monde
Extérieurs
Acquisition
d?image
Teste
et Décision
Apprentissage
Les
Prétraitements
Détection
et Localisation
Un système de reconnaissance est donné par le
diagramme de la figure (1.5) :
Comme l?indique la figure (1.5), un système de
reconnaissance de visages passe par plusieurs étapes sont : [5]
1-9-1.Acquisition de l'image
C?est l?opération qui permet d?extraire du monde
réel une représentation bidimensionnelle pour des objets en 3D,
cette opération peut être statique (Appareil photo, Scanner, etc.)
ou dynamique (Caméra, Web Cam), dans ce cas on aura une séquence
vidéo .A ce niveau on aura une image brute.
1-9-2.Prétraitements
Les données brutes issues des capteurs sont les
représentations initiales des données, à partir des
quelles des traitements permettent de construire celles qui seront
utilisé pour la reconnaissance. L?image brute peut être
affectée par différents facteurs causant ainsi sa
détérioration, elle peut être bruitée, c?est
à dire contenir des informations parasites à cause des
dispositifs optiques ou électroniques. Pour pallier à ces
problèmes, il existe plusieurs méthodes de traitement et
d?amélioration des images, telle que: la normalisation,
l?égalisation de l?histogramme, etc.
1-9-3.Détection puis localisation
Les systèmes de reconnaissance de visages sont
complexes. La difficulté réside notamment dans la partie
détection automatique du visage, bien que nous développions
surtout la partie reconnaissance, il est intéressant de parler de
l?étape de détection automatique du visage qui est très
importante dans un système de reconnaissance. Ce qui rend la
détection de visages dans une image très difficile, c?est surtout
la complexité du décor, les variations de poses, les conditions
de lumières généralement inconnues, etc. Il existe
plusieurs méthodes qui peuvent être appliquées à la
détection automatique des visages. Il faut détecter la
présence d?un visage dans l?image, ensuite le localiser en vue
d?extraire les traits pour le caractériser et le différentier des
autres. Le résultat de cette étape est l?obtention de la partie
d?image à traiter.
1-9-4.Extraction des paramètres et
Classification
Dans cette étape on extrait de l'image les informations
qui seront sauvegardées en mémoire pour être
utilisées plus tard dans la phase de Décision. Le choix de ces
informations utiles revient à établir un modèle pour le
visage, elles doivent être discriminantes et non redondantes. Ces
informations seront ensuite classées, en d?autres termes,
affectés à la classe la plus proche, les individus ayant des
similarités sont regroupés dans la même classe. Ces classes
varient selon le type de décision.
1-9-5.Apprentissage
L'apprentissage consiste à mémoriser les
modèles calculées dans la phase analyse pour les individus
connus. Un modèle est une représentation compacte des images qui
permet de faciliter la phase de reconnaissance mais aussi de diminuer la
quantité de données à stocker en quelque sorte
l?apprentissage est la mémoire du système.
1-9-6.Décision
La décision est la partie du système ou on
tranche sur l?appartenance d?un individu à l?ensemble des visages ou
pas, et si oui quelle est son identité. Donc la décision c?est
l?aboutissement du processus. On peut le valorisé par taux de
reconnaissance (fiabilité) qui est déterminé par le taux
de justesse de la décision.
1-10.Les méthodes de reconnaissances du visage
L?authentification par le visage est la technique la plus
commune et la plus populaire puisqu?elle correspond à ce que nous
utilisons naturellement pour reconnaître une personne. Les
caractéristiques qui servent à la reconnaissance du visage sont
bien sur les yeux, la bouche, la forme du visage (contour), etc. On peut
diviser les méthodes de reconnaissances du visage en trois
catégories : les méthodes globales, les méthodes locales,
et les méthodes hybrides [3].
1-10-1.Méthodes globales
Le principe des méthodes globales est d?utiliser le
visage au complet comme source d?information, et ce sans segmentation de ses
parties. En effet une image en niveau de gris de taille 112 x 92 est
représentée par un vecteur de taille 10304, les couleurs ne sont
généralement pas utiliser dans ses méthodes ce qui
simplifie un grand nombre d?opérations.
Parmi ses méthodes on cite les Visages propres (Eigen
Faces), la DCT (transformation en cosinus discrète), Réseaux de
neurones, LDA. [5]
1-10-2.Méthodes locales [3]
Le principal inconvénient des méthodes globales
réside au niveau du détail utilisé, car en s?attardant sur
les variations de l?image entière, c?est méthodes tenteront de
limiter les changements locaux en concentrons le maximum d?énergie pour
représenter adéquatement l?ensemble de l?image, (exemple : Eigen
Faces), cependant le cas de personnes ayant une physionomie faciale très
semblable peut se présenter avec des petits détailles qui
différent grandement. C?est le cas par exemple d?une personne ayant un
nez imposant.
En utilisant une méthode locale, d?avantage
d?énergie sera accorder aux petits détailles locaux
évitant ainsi le bruit engendré par les cheveux, les lunettes,
les chapeaux, la barbe, etc. De plus certaines parties du visage sont
relativement invariantes pour une même personne malgré ses
expressions faciales ; c?est le cas notamment des yeux et du nez. Ceci demeure
vrai tant que ces caractéristiques du visage ne sont pas en occultation.
Parmi ses méthodes on cite les Eigen Object (EO), les HMM (Hidden Markov
Models). [5]
1-10-3. Méthodes Hybrides
La robustesse d?un système de reconnaissance peut
être augmentée par la fusion de plusieurs méthodes. Cette
technique de reconnaissance consiste à combiner plusieurs
méthodes pour résoudre le problème d?identification. Le
choix d?un outil de reconnaissance robuste n?est pas une tache triviale,
cependant l?utilisation d?une approche multi- classifier pour l?identification
des visages est une solution adéquate à ce problème
[3].Parmi ses méthodes on cite la DCT- PCA, PCA-LDA, etc.
1-11.Conclusion
Dans ce chapitre, nous avons essayé de donner un bref
aperçu des technologies biométriques les plus connue et les
différentes étapes de processus d'authentification ainsi les
performances d?un système de vérification biométrique (les
taux d?erreurs TFA, TFR). Nous avons conclut à partir de comparaison
entre quelque technique biométrique que le visage est un moyen
chère avec un cout moyenne, peu encombrant, bonne acceptabilité
et le plus facile utilisé donc il est une modalité
biométrique spécifique la plus répondue. Pour cela on
s?intéressera dans notre travail à l?authentification de
visages.
Chapitre 02
Méthode d'extraction de
l'information
2-1.Introduction
Dans ce chapitre nous décrivons la technique d'Analyse
Discriminante Linéaire (LDA). L'analyse discriminante linéaire
part de la connaissance de la partition en classes des individus d'une
population et cherche les combinaisons linéaires des variables
décrivant les individus qui conduisent à la meilleure
discrimination entre les classes.
Dans ce chapitre nous indiquons que l'utilisation des
composantes principales ne donne pas nécessairement les meilleures
solutions pour la discrimination, car les directions de variabilité
principale ne correspondent pas nécessairement aux directions de
meilleure discrimination.
2-2.Réduction des images 2-2-1.Le
prétraitement
La reconnaissance de visage est un problème difficile en
vision par ordinateur. Pour simplifier la reconnaissance nous allons normaliser
l?image par quelques prétraitements.
Le prétraitement atténue les effets d?une
différence des conditions lors des prises de vues. C?est une phase
importante dans le domaine globale d?identification. Elle augmente en
général les performances du système.
Pour cela une réduction d?image est nécessaire
dont l?opération est d?extraire seulement les paramètres
essentiels pour l?identification et qui changent très peu avec temps.
La méthode de réduction de dimension permet de
faire l?économie de phase d?extraction de caractéristiques. Les
étapes de la réduction des images sont :
· Découpage
Le découpage de l?image consiste à conserver les
maximums des variations intrinsèques du visage, et de supprimer les
autres informations comme l?arrière plan, les cheveux, les cols de
chemise, les oreilles et toutes les informations qui sont changeantes avec le
temps. La figure 2.1 montre la procédure de découpage.

A B
Figure 2.1: L?image de visage A
avant et B après découpage.
· Filtrage
Pour améliorer la qualité visuelle de l?image, on
doit éliminer les effets des bruits (parasites) en lui faisant subir un
traitement appelé filtrage.
Le filtrage consiste à modifier la distribution
fréquentielle des composantes d?un signal selon des
spécifications données. [12]
Ce filtre n?affecte pas les composantes de basse fréquence
dans les données d?une image, mais doit atténuer les composantes
de haute fréquence.
L?opération de lissage est souvent utilisée pour
atténuer le bruit et les irrégularités de l?image. Elle
peut être répétée plusieurs fois, ce qui crée
un effet de flou.
En pratique, il faut choisir un compromis entre
l?atténuation du bruit et la conservation des détails et contours
significatifs. [12]
? Décimations
La décimation consiste à ne prendre qu?un pixel
sur deux par exemple .Cela réduit bien entendu la résolution des
images. Cette opération est précédée d?un filtrage
passe bas, détruisant les hautes fréquences, de manière
à respecter les conditions d?échantillonnage.
L?image de visage passera ainsi d?une dimension 256 x
256=65536 pixels vers une dimension de 66 x 60=3960 pixels « après
le découpage et la décimation, comme il est illustré sur
la figure (2.2) ».

A B
Figure 2.2 : Image de visage A
avant B après décimation
· Normalisation
La normalisation permet d?assurer
l?homogénéité des données. La photo-normalisation
s?applique à une seule image. Alors que la normalisation s?applique
à un groupe d?images, pour chaque composante, nous retirons la moyenne
de cette composante pour toutes les images et nous divisons par
dérivation standard.
Donc le prétraitement est une étape qui
mène à une première réduction de la donnée
avant d?utiliser une deuxième étape de réduction comme par
exemple l?analyse en composantes principales « ACP ».
2-2-2.L'Analyse en composantes principales
(ACP)
L'analyse en composantes principales (ACP) consiste à
exprimer un ensemble de variables en un ensemble de combinaisons
linéaires de facteurs non corrélés entre eux, ces facteurs
rendent compte d'une fraction de plus en plus faible de la variabilité
des données. Cette méthode permet de représenter les
données originelles (individus et variables) dans un espace de dimension
inférieure à l'espace original, tout en limitant au maximum la
perte d?information.
Utilisez l'analyse en composantes principales pour
résumer la structure de données décrites par plusieurs
variables quantitatives, tout en obtenant des facteurs non
corrélés entre eux. Ces facteurs peuvent être
utilisés comme de nouvelles variables, ces dernières sont deux
à deux dé corrélées. [5]
L?ACP peut donc être vu comme une technique de
réduction de dimensionnalité.
2-2-2-1.Visages propres (Eigen faces)
En 1991, TURK et PENTLAND introduisent le concept d?Eigen
Faces à des fins de reconnaissances. Basée sur une analyse en
composantes principales (ACP), la méthode des Eigen Faces repose sur une
utilisation des premiers vecteurs propres comme visages propres, d?où le
terme Eigen Faces. La base formée par ces vecteurs génère
alors un espace utilisé pour représenter les images des visages.
Les personnes se voient donc attribuer un vecteur d?appartenance pour chacune
de leur image. [5]
Cela étant dit, la reconnaissance est
réalisée en comparant les coefficients de projection d?un visage
test avec ceux appartenant aux visages d?entraînement. La méthode
Eigen faces se déroule comme suit :
> Etape 1
Cette étape consiste à définir les images
des personnes, soit ?? le nombre d?image
allant de ??1 , ??2 ,??3 , ???? .
Ces images doivent être centré et de même
taille. > Etape 2
Après le prétraitement (décimation) on
transforme l'image vers un vecteur d?image, c'est-à-dire l'image
à deux dimensions d'un visage est transformée en un vecteur de
taille ?? obtenu en enchaînement les lignes (ou colonnes) de l'image
correspondante.
Ici ?? représente le nombre de pixels dans l'image du
visage. Après décimation.
??i = ??1??2 .....????]
Comme dans l?exemple qui suit, ??~ est une image de taille ?? = 3
× 3
??. = Par transformation on obtiendra le vecteur ?? =
> Etape 3
Cette étape consiste à calculer la moyenne des
visages et de la représenter sous forme de vecteur ??. (Où ?? est
un nombre d'image)
|
> Etape 4
|
1
?? =
M
|
i=1 (2 .1)
M xi
|
Cette étape consiste à enlever la moyenne du
vecteur d?image ??1 , en d?autres termes : enlever tous ce qui est commun aux
individus.
Le vecteur résultant ??~~ est obtenu comme suit :
?? ~ = ??~ - ?? (2 .2)
Les vecteurs ??~~ i : 1,2, ... ??) sont combinés,
côte à côte, pour créer une matrice de données
d'apprentissage de taille ?? × ?? (Où ?? est le nombre d'images de
l?ensemble d?apprentissage et ?? est le nombre de pixels d'image).
> Etape 5
La matrice de donnés est multipliée par sa
transposé pour obtenir une matrice de covariance 12 comme montrée
dans l'équation (2.3).
,O. = x x t (2 .3)
Cette matrice de covariance a jusqu'aux M vecteurs propres
liés aux valeurs propres non nulles. En supposant que M < N.
> Etape 6
Dans cette étape on calcule les valeurs propres et les
vecteurs propres correspondants à la matrice de covariance par
l'équation suivante:
12V = AV Et det [12 -- Ai] = 0 ( ??i E A) (2 .4)
Où V est une matrice orthogonale de vecteurs propres et A
est une matrice diagonale de valeurs propres.
On classe les vecteurs propres vi E V , selon les valeurs
propres décroissantes Ai E A.
La matrice des vecteurs propres V représente l?espace
propre de projection.
V = [v1v2
· . . vM ] (2 .5)
> Etape 7
Cette étape est assez simple à réaliser,
elle consiste à ne prendre que K vecteurs propres correspondant aux K
plus grandes valeurs propres pour constituer la base (espace propre) de
projection.
> Etape 8
Dans cette étape on projete les vecteurs images
centrés dans l?espace propre. Pour cela on doit calculer le produit
scalaire de ces vecteurs images ??~~ avec la transposé de la matrice des
vecteurs propres ?? comme suit :
??~ = ??????~~ (2 .6)
Pour simplifier le calcul des vecteurs propres ?? , la matrice de
covariance est crée par l?équation (2.7).
??' = ?? ???? (2 .7)
On calcule les vecteurs de la matrice ?? par l?équation (2
.8) :
??'??' = ?~??~ (2.8)
Le calcul de la matrice des vecteurs propres ?? correspondants
à la matrice ?? se fait par (2.9).
?? =?? ??'?? (2.9)
~
On divise les vecteurs propres ??~ par leurs normes comme suit
:
2-2-2-2.Choix de la dimension de l'espace de projection
Le problème qui reste à résoudre est le
choix de K, la dimension de l?espace de projection des vecteurs d?images. Pour
cela on aura besoin d?un seuil (pourcentage) dit de quantité
d?information. Le but est de pouvoir représenter une certaine
quantité d?information en utilisant un minimum de vecteurs base. Si par
exemple on veut représenter 80% (0.80) de l?information alors on trouve
K tel que : [5]
K
At
N
t=1
At
t=1
> 0.8 (seutl = 0.8) (2.12)
Enfin l?ACP ne prend pas en compte la discrimination des
classes. Pour augmenter la séparabilité des classes dans le sous
espace de composantes principales on utilise l?analyse discriminante
linéaire de Fischer bien connue en anglais (Fischer Linear Discriminant
Analysis : FLD ou LDA) [7] décrire en détail ci-dessous.
2-2-3.Analyse discriminante linéaire de Fischer
L13]
L?analyse discriminante linéaire de Fischer groupe les
images de mêmes catégories et sépare les images de
différentes classes. Les images sont projetées de l'espace de
dimension N (où N est le nombre de pixels de l'image) dans un espace de
dimension C-1(où C est le nombre de classes
d?images).Considérons, par exemple, deux ensembles de points dans
l'espace en deux dimensions qui sont projetées sur une seule ligne
(Figure 2.3.A). Selon la direction de la ligne, les points peuvent être
mélangés (Figure 2.3.B) ou séparés (figure 2.3.C).
L?analyse discriminante linéaire de Fischer trouve la ligne qui
sépare les meilleurs points. Pour identifier une image test, les
projections de l'image test sont comparées à chaque image
projetée en matière de formation, et l'image test est
identifiée comme la plus proche de formation image.
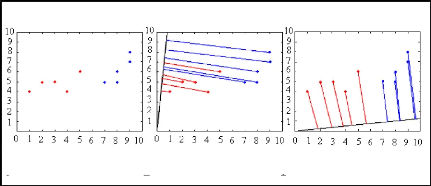
A B C
Figure 2.3 : Exemple de projection des points
sur deux axes
2-2-3-1.Méthode originale de Fischer
[13]
La méthode originale d?analyse linéaire
discriminante de Fisher se déroule selon les étapes suivantes
:
? Calcule de la matrice de dispersion
intra-classes
La matrice de dispersion intra-classes mesure la
quantité de la dispersion entre les images dans la même classe.
Pour la i?ème classes, la matrice ??~ est calculée comme la somme
de matrices de covariance des images centrées dans cette
catégorie.
?? = (?? - ??~)(?? - ??i)?? (2.12)
?????~
Où ?? est la moyenne des images dans la classe i et ?? est
vecteur d?image. La matrice de la dispersion intra-classes ???? est la somme de
toutes les matrices de dispersion.
?? ?? = ??~
?? ~=1 (2.13)
Où C est le nombre de classes.
? Calcule de la matrice de dispersion
inter-classes
La matrice de dispersion inter-classes ???? mesure la
quantité de dispersion entre les classes. Elle calcule la somme des
différences entre la moyenne total et la moyenne de chaque classe.
???? = ?? (?? - ??)
?? (?? - ??)?? (2.14)
~=1
Où ??~ est le nombre d'images dans la classe i, ??1 est la
moyenne des images dans la classe i et ?? est la moyenne de toutes les
images.
? Résoudre le problème
généralisé des valeurs propres
Calcul des valeurs propres et des vecteurs propres correspondants
aux deux matrices de dispersion intra-classes et inter-classes par
l'équation suivante :
??????= ?????? (2.15)
Où ?? représente une matrice des vecteurs
propres et ?? est une matrice des valeurs propres. Les vecteurs sont
ordonnés selon l?ordre décroissant de leurs valeurs propres.
Finalement on ne garde que les premiers C-1 vecteurs propres. Ces C-1 vecteurs
propres forment la base de projection de Fischer.
2-2-3-2.Méthode de Fischer basée sur une
Base-Ortho normale
Cette méthode consiste à projeter les
données de la matrice d?apprentissage des images dans une base
orthogonale. Cette projection produit une matrice de données de rang
plus petit, ce qui diminue le temps de calcul. La projection préserve
également les informations de manière définitive les
étapes à suivre pour trouver une base de Fisher d'une
série d'images en utilisant une projection en une base orthogonale. Se
fait selon les étapes suivantes :
· Calcule des moyennes
Calcule des moyennes ??i des images dans chaque classe i et la
moyenne total ?? de toutes les images .
· Centrer les images dans chaque classe
Soustraire la moyenne de chaque classe des images en cette
classe.
??? ? ??i , ??i ? ?? ,?? = ?? - ??i (2.16)
· Centrer la moyenne de chaque classe:
Soustraire la moyenne totale de la moyenne de chaque classe.
??~ = ??l - ?? (2.17)
· Créer une matrice de
données
Combiner tous les images, côte à côte, dans
une matrice de données.
· Trouver une base orthogonale ??
pour la matrice de données
Cela peut être effectué par calcul de l'ensemble
des vecteurs propres de la matrice de covariance des données
d?apprentissage.
· Projection de toutes les images
centrées dans la base orthogonale
Créer des vecteurs qui sont le produit des vecteurs
d?image et les vecteurs de la base orthogonale.
?? = ?????? (2.18)
· Projection de la moyenne centrée dans la
base orthogonale
?? = ??????~ (2.19)
· Calcule de la matrice de dispersion
intra-classes
La matrice de dispersion intra-classes mesure la
quantité de la dispersion entre les éléments dans la
méme classe. Pour l?i éme classes la matrice de dispersion ??,
est calculé comme la somme des matrices de covariance des projections
centrées des images de cette catégorie.
??i = ?? ?? ??? 1 ?? ?? (2.20)
La matrice de dispersion intra-classes ???? est la somme de
toutes les matrices de dispersion ??i .
???? = ??i
?? ~=1 (2.21)
Où C est le nombre de classes.
· Calcule de matrice de dispersion
inter-classes
La matrice de dispersion inter-classes ???? mesure la
quantité de dispersion entre les classes. Elle est calculée comme
la somme des matrices de covariance des projections centrées des
moyennes des classes, pondérées par les nombres d'images dans
chaque classe.
???? = ??~
?? ~=1 ~??~ ??~~?? (2.22)
Où ??~ est le nombre d?image dans la classe i.
? Résoudre le problème
généralisé des valeurs propres
Calcule des valeurs propres et des vecteurs propres
correspondants aux deux matrices de dispersion intra-classes et inter-classes
par l'équation suivante :
SBV=ASW V (2.23)
Où V représente une matrice des vecteurs propres
et A est une matrice des valeurs propres.
? Gardez les premières C-l vecteurs
propres
On classe les vecteurs propres par ordre décroissant
leurs valeurs propres et on ne garde que les premiers C -1 vecteurs propres.
Ces vecteurs propres forment la base de projection de Fisher.
2-3.Mesure de similarité
Une fois que les images sont projetées dans un
sous-espace, il reste à déterminer quelles sont les images
semblables. Il y a deux manières en général pour
déterminer à quel point deux images sont semblables.
La première manière et qu?on doit mesurer la
distance entre les images. Deux images semblables produisent entre eux une
distance faible (petite).
La deuxième manière se fait en mesurant la
similitude ; on souhaite maximiser la similitude de sorte que deux images
semblables produisent une valeur élevée de similitude.
Il y a beaucoup de mesures possibles de distance et de
similitude, parmi les quelles on cite :
2-3-1.La norme L1
La norme L1 entre deux vecteurs ?? et ?? c?est la somme des
valeurs absolue de la différence entre les composantes des deux vecteurs
?? et ?? [14] [15]. Elle est donnée par la relation suivante :
??1= ??~ -??i
?? (2.24)
~=1
2-3-2.La norme L2
Connue aussi sous le nom norme euclidienne, c?est la somme de
la différence carré entre les composantes des deux vecteurs ?? et
?? [14] [15] [16].Elle est donnée par l?équation suivant :
??2= i??=1 (??i - ??1)2 (2.25)
2-3-3.Covariance (Angle)
La covariance est une mesure d?angle. Elle calcule l?angle entre
deux vecteurs normaux [15] [16]. Elle est donnée par :
?? ??
?????? ??, ??) = ?? ?? (2.26)
2-3-4. Correlation
Elle mesure le taux de changement entre les composantes de deux
vecteurs ?? et ?? [16]. Elle est donnée par la relation :
???????? ??,??) = ??~- u??~(??~-u??)
??
=1 ????*????
|
(2.27)
|
|
Où
???? = l?écart type de ?? , u?? = la moyenne de ??
???? = l?écart type de ?? , u??= la moyenne de ??
2-4.Conclusion
Dans ce chapitre nous avons étudié le
prétraitement sur les images et nous avons présenté les
méthodes de vérification de visage en particulier les techniques
d?ACP et LDA utilisées pour la réduction de dimension d?image et
d?extraction de caractéristiques.
Les résultats expérimentaux de ces méthodes
sont présentés dans le chapitre 4.
Le chapitre suivant est consacré à la base de
données ainsi qu?à son protocole de test ou nos
expériences sont exécutées.
Chapitre 03
Base de données
3-1.Introduction
Il existe beaucoup de bases de données de visages ; l?un
des facteurs principaux de choie d?une base de données est
l?adéquation avec les conditions d?application.
Et dans notre objectif on essaie de développer une
application de reconnaissance de visage grâce à un outil
particulier, et de tester ensuite sur une base de données de visages,
selon un protocole bien précis, de manière à faciliter la
comparaison des résultats.
Ces résultats sont en effet soumis à des
mesures de qualité. La base de données que nous avons
travaillée sur laquelle est la base de données prolongée
de M2VTS, celle qui a été enregistrée pendant le projet
européen M2VTS (Multi Modal Vérification for Teleservices and
Security applications).Ce projet traite le contrôle d?accès par
l?utilisation de l?identification.
3-2.La base de données XM2VTS
Cette base de données XM2VTS a été
prolongée de M2VTS (Multi Modal Vérification for Teleservices and
Security applications), par le centre CVSSP (Centre for Vision, Speech and
Signal Processing), de l?université de Surrey, en grande Bretagne, dans
le cadre du projet européen qui traite le contrôle d?accès
par une vérification multimodale d?identité , afin de comparer
les différentes méthodes de vérification d'identité
[17].
La base de données multimodale XM2VTS offre des
enregistrements synchronisés des Photos de visages prises de face et de
profil et des paroles de 295 personnes des deux sexes Hommes et femmes de
différents âges. Pour chaque personne huit prises ont
été effectuées en quatre sessions distribuées
pendant cinq mois afin de prendre en compte les changements d?apparence des
personnes selon plusieurs facteurs (lunettes, barbe, coupe de cheveux, pose..),
et chaque session est composée de deux enregistrement, une pour les
séquences de parole et l'autre pour les séquences vidéo de
la tête.
Les vidéos et photos sont en couleur de haute
résolution (format ppm), la taille est de 256 x 256 pixels pour les
images et de très bonne qualité codé sur 24 bits dans
l'espace RGB. Cela permet de travailler en niveaux de gris ou en couleur.
Le choix principal de XM2VTS est sa taille grande, avec 295
personnes et 2360 images en total et sa popularité puisqu'elle est
devenue une norme dans la communauté biométrique audio et
visuelle de vérification multimodale d?identité.
Nous ne nous intéresserons évidemment, dans le
cadre de ce mémoire, qu?aux photographies prises de face pour le
processus de l'authentification de visage [8].
3-3.Le protocole de XM2VTS ou "protocole de Lausanne
L'existence d'une base de données pour la
vérification d'identité nécessite un protocole rigoureux
qui permet la comparaison entre les algorithmes de vérification. Donc,
ce protocole de Lausanne est lié directement à la
vérification d?identité. Sont principe est de diviser la base de
données en deux classes, 200 personnes pour les clients, et 95 pour les
imposteurs. Il partage la base de données en trois ensembles :
l?ensemble d?apprentissage, l?ensemble d?évaluation (ou validation), et
l?ensemble de test [8] [18].
· L'ensemble d'apprentissage est
l'ensemble de référence. Il contient l?information concernant les
personnes connues du système (seulement les clients).
· L'ensemble d'évaluation permet de
fixer les paramètres du système de reconnaissance de visage.
· L'ensemble de test permet de tester le
système en lui présentant des images de personnes lui
étant totalement inconnues.
Les imposteurs de l?ensemble de test ne doivent pas
être connus du système, ce qui signifie qu?ils ne seront
utilisés que pendant la toute dernière phase de test, lorsque le
système est supposé fonctionnel et correctement
paramétré.
En effet, il existe deux configurations différentes,
la configuration I et la configuration II. Nous n?utiliserons la configuration
I dans ce mémoire. Dans la configuration I, pour la formation de
l?ensemble d?apprentissage trois images par client sont employées afin
de créer les caractéristiques ou modèles clients.
L?ensemble d?évaluation est constitué de trois autres images par
clients, ils sont utilisés essentiellement pour fixer les
paramètres de l?algorithme de reconnaissance ou de vérification
des visages. L?ensemble de test est formé par les deux autres images
restantes.
Pour la classe des imposteurs, les 95 imposteurs sont
répartis dans deux ensembles : 25 pour l'ensemble d'évaluation et
70 pour l'ensemble de test.
La répartition des images selon la configuration I est
représentée par le tableau 3.1 :
Session
|
Pose
|
Clients
|
Imposteurs
|
1
|
1
|
Apprentissage
|
Evaluation
|
Test
|
|
Evaluation
|
|
1
|
Apprentissage
|
|
Evaluation
|
|
1
|
Apprentissage
|
|
Evaluation
|
|
1
|
Test
|
|
|
Dans la configuration II, quatre images par clients des deux
premières sessions sont employées pour former l?ensemble
d?apprentissage et les deux images de la troisième session constituent
l?ensemble d?évaluation, alors que les deux images restantes de la
quatrième session constituent l?ensemble de test. Pour la
catégorie imposteurs la répartition est identique à la
répartition de la configuration I.
La répartition des images selon la configuration II est
représentée par le tableau 3.2.
Session
|
Pause
|
Clients
|
Imposteurs
|
|
1
|
|
|
|
1
|
|
|
|
|
|
2
|
|
|
|
|
|
Apprentissage
|
Evaluation
|
Test
|
|
1
|
|
|
|
2
|
|
|
|
|
|
2
|
|
|
|
|
1
|
|
|
|
|
|
Evaluation
|
|
|
3
|
|
|
|
|
|
2
|
|
|
|
|
1
|
|
|
|
|
|
Test
|
|
|
4
|
|
|
|
|
|
2
|
|
|
|
|
Les tailles des différents ensembles de la base de
données selon les deux configurations cités
précédemment sont reprises dans le tableau 3.3.
Ensemble
|
Clients
|
Imposteurs
|
Apprentissage
|
600(3 par personne)
|
0
|
Evaluation
|
600(3 par personne)
|
200(8 par personne)
|
Test
|
400(2 par personne)
|
560(8 par personne)
|
|
Tableau 3.3 : Répartition des photos
dans les différents ensembles.
Puisque notre application va se baser sur la comparaison
d?images, donc il est important de savoir les nombres maximaux de comparaisons
qu?ont peut atteindre. Selon la configuration I, et pour fixer les
paramètres dans l?ensemble d?évaluation, on peut compter, 9
comparaisons par clients (1800 en tout) et 200 comparaisons par imposteur
(40000 en tout).
Ensemble
|
Clients
|
Imposteurs
|
Evaluation
|
9 par personne (1800 en tout)
|
200 par personne (40000 en tout)
|
Test
|
6 par personne (1200 en tout)
|
560 par personne (112000 en tout)
|
|
Tableau 3.4 : Nombre de comparaisons
possibles.
3-4.Mesure de qualité [7]
Quel que soit le problème qu?ils résolvent,
tous les algorithmes ont leur mesure de qualité. Pour les algorithmes
déterministes donnant la solution exacte et optimale au problème,
on mesurera généralement les complexités en temps ou en
espace. Pour les algorithmes approximant une fonction, on parlera plutôt
d?erreur des moindre carrés.
Pour un algorithme de classification c?est le nombre de mauvaise
classification qui est important.
Supposant un problème à n
classes .Pour chaque élément ou d?entrée
l?algorithme doit déterminer à quelle classe ce dernier
appartient. Pour en estimer les performances, il suffit donc de tester
l?algorithme sur des données connues, c?est-à-dire dont les
éléments sont à priori classés. On peut alors
compter et répertorier les erreurs commises par le système, et
les regrouper dans ce qu?on appelle une matrice de confusion. Une telle matrice
est constituée de la manière suivante.
M1,1 = nombre d?éléments de la classe
i attribués à la classe
j.
Les valeurs diagonales de la matrice représentent donc
le nombre de bonnes classifications. On normalise souvent cette matrice en
divisant chaque élément d?une méme colonne par le nombre
total de tests effectués dans la classe indicée par le
numéro de cette ligne, on obtient ainsi des pourcentages d?erreur.
Considérons à présent le problème
qui nous occupe, il contient deux classes, à savoir d?une part les
clients et d?autre part les imposteurs. La matrice de confusion M est donc
carrée de dimension deux. Si chaque client doit être
accepté et chaque imposteur rejeté on peut écrire :
M= TBA TFA TFR TBR~
Les TFR et
TFA sont respectivement les taux de faux rejet et
taux de fausse acceptation. Ils doivent être bien sur le plus faible
possible. Les TBA et TBR
sont on l?aura compris le Taux de Bonne Acceptation et le Taux de Bon Rejet.
Ces chiffres caractérisent ce que l?on appelle en reconnaissance de
visage le pouvoir d?identification.
La matrice de confusion possède certaines
caractéristiques intéressantes. Tout d?abord, on remarque
aisément que la somme des éléments d?une colonne vaut
l?unité, puisque ce sont des pourcentages de bon et fausse rejet ou
acceptation. La corrélation entre les colonnes est par contre plus
subtile, mais il est important de la comprendre et de la garder à
l?esprit lorsque l?on veut comparer entre eux des pouvoirs d?identification.
Supposons qu?un système de vérification
d?identité contrôlant l?accès à un bâtiment
soit renforcé pour limiter au maximum les possibilités
d?imposture. Il sera alors impitoyable, et extrêmement strict. Le taux de
fausse acceptation sera bien sur faible, il sera donc difficile à un
imposteur de pénétrer dans l?enceinte. Mais il sera
également difficile aux clients légitimes de ce faire
reconnaître ; ils devront souvent s?y reprendre plusieurs fois avant
d?être acceptés. La tendance générale sera au rejet
; le taux de faux rejet sera en conséquence fort élevé.
Au contraire, un système laxiste sera
caractérisé par un taux de fausse acceptante élevé
et un taux de faux rejet plutôt bas. Les clients seront facilement
acceptés, mais les imposteurs auront moins de mal à se faire
passer pour quelqu?un d?autre.
Le juste milieu se situe quelque part entre les deux, et si
les coûts des erreurs sont égaux, il se trouvera au taux
d?égale erreur ou TEE, c?est à dire
quand TFR=TFA. Dans un système de
contrôle d?accès critique, on préférera souvent un
TFA plus faible que le TFR.
Lorsque le TEE ne peut être atteint, on utilise
une mesure similaire qui est le demi taux d?erreur total, on
DTER c?est en fait la moyenne de
TFA et du TFR.
Tous ces taux d?erreurs sont calculés dans deux des
trois ensembles : d?abord dans l?ensemble d?évaluation, ce qui va
permettre de fixer plus ou moins le TEE en faisant
varier les paramètres d?acceptation et de rejet du système.
Ensuite dans l?ensemble de test, en utilisant les paramètres
fixés précédemment .Il est possible de vérifier la
robustesse du système. Si les chiffres dans les deux ensembles sont
proches, le système est stable .Si par contre les chiffres divergent, on
peut soupçonner l?algorithme de sur apprentissage ; il est trop
spécifique aux exemples fournis pour l?entraînement .En d?autre
mots, il généralise mal : les photos des clients n?ayant pas
servi à l?apprentissage ne sont pas reconnues.
3-5.Traitements préliminaires
Comme nous voulons comparer les images, il est
nécessaire de normaliser les photos que nous utilisons, d?en extraire
une représentation canonique. Cela doit se faire d?une part au niveau
support, c'est-à-dire que les images doivent être toutes de la
même dimension et codées de la méme manière, et
d?autre part, au niveau du contenu. Cela veut dire que les photos doivent
êtres toutes centrées et calibrées .Si pourquoi sur nos
images, les positions des yeux sont les mêmes pour toutes .Il faut
également que le font soit uniforme, et d?une couleur forte
différente de celle de la peau ou des cheveux de la personne
représentée .Elle doit en outre être la même pour
toutes les photographies. [1] [7]
La base de données que nous avons reçue
présente toutes ces caractéristiques.
3-6.Langage de programmation
Puisque nous nous intéressons au traitement des
images, qui sont en fait des matrices de pixels .Nous avons choisi
l?environnement de travail Matlab, parce que c'est un environnement
basé sur les matrices et qui possède de bons algorithmes pour la
manipulation de celle -- ci (multiplication, factorisation ....).
Il possède en outre des bibliothèques de
manipulation d?images proposant des fonctionnalités
intéressantes.
Enfin, c?est un logiciel bénéficiant d?un large
support dans la communautéscientifique.
3-7.Conclusion
Dans ce chapitre nous avons donnés en détail la
base de données XM2VTS et son protocole de Lausanne, et comment la
performance des systèmes de reconnaissances peut être
mesurée par deux mesures principales le TFR et
le TFA, ainsi les traitements préliminaires et
la motivation du choix de l?environnement Matlab.
Dans le chapitre suivant nous présenterons les
résultats expérimentaux des méthodes d?authentifications
présentées dans le chapitre 2.
Chapitre 04
Résultats
expérimentaux
4.1. Introduction
Jusqu?ici nous avons approché l?authentification
automatique des visages d?un point de vue théorique, et dans ce chapitre
nous présentons notre étude expérimentale des divers
algorithmes d?authentification de visages présenter en chapitre 2. Les
expériences ont été exécutées sur les
visages de la base de données XM2VTS décrit en chapitre 3.
Le chapitre est organisé comme suit : nous
présentons les étapes de prétraitement utilisées,
en suite les résultats expérimentaux exécutés sur
la base de données XM2VTS des algorithmes ACP (Eigen Face) et de LDA
sont donnés et discutés.
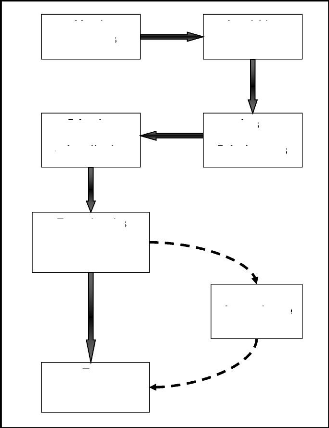
4-2.Architecture structurelle du système
d'authentification proposé
Notre objectif est de réalisé un système
automatique d?authentification basé sur l?approche LDA ayant pour but de
vérification (authentification) des personnes.
L?architecture structurelle du système d?authentification
proposé est présentée par la figure (4.1).
- Acquisition d'image : Il faut
d?acquérir les images de visage par un capteur (caméra).
- Réduction d'image : Sont les
étapes de prétraitement (découpage, décimation,
filtrage, normalisation), ont pour but l?amélioration de l?aspect visuel
de l?image en éliminant tous les bruits éventuels.
- Création des matrices de données :
On crée les matrices et enchaîner ces vecteurs. -
Calcul LDA : Les étapes de LDA sont rédigées en
chapitre 2.
- Projection des images : On projete les images
dans un sous espace LDA.
- Calcul les distances intra et extra et le seuil :
On a calculé les distances entre les mêmes individus et
les différents individus et le seuil de comparaison.
Individu inconnu
Rejet'
Non Oui
Calcul de la
distance « D »
Projection
D < S
Enchainement des lignes ou colonnes
Décimation d?image
Photo-normalisation
Acquisition d?image
Découpage d?image
Filtrage
Calcul des distances (intra/extra) et le
seuil
« S »
Création de la matrice de
donnée
d?apprentissage
Calcul LDA (Vp de LDA)
Normalisation des données
Individu connu
'Accepté'
Projection des images
Réduction
d?image
- Test : L?individu est accepté si la
distance est inférieure au seuil, l?individu est rejeté si la
distance est supérieure au seuil.
4-3. Réduction des données
L?étape de prétraitement joue le rôle
d?une réduction des données ainsi d?une atténuation des
effets d?une différence de conditions lors des prises de vues. Dans
notre travail nous supposons que les images sont prises dans les conditions
favorables suivantes :
· Une vue frontale de toutes les images.
· L?éclairage des visages ne change pas.
· Une distance fixe entre le visage et la caméra
(plus /moins quelque cm).
La figure 4.2 présente quelques exemples des images de la
base de données XM2VTS prises dans des conditions favorables.

Figure 4.2 : Exemple d?images de la base de
données XM2VTS.
4-3-1.Découpage et décimation
Les images de la base de données utilisée dans
notre travail sont constituées de plusieurs informations tels que
(l?arrière plan, les cheveux. .etc.), elles gonflent inutilement
la taille des données, et augmente le temps de calcul du
processus d?authentification, d?oüune diminution de la
performance du système.
Travailler avec des vecteurs de grandes dimensions n?est pas
toujours facile. Nous allons dans cette étape réduire de
manière grossière et radicale la dimension des images par des
opérations de découpage et décimation (sous
échantillonnage). Voir les figures (4.3) et (4.4).
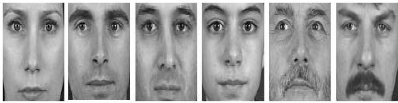
Figure 4.3 : Les images de l?exemple
précédent après le découpage.

4-3-2.Enchainement des lignes / ou colonnes
C?est la conversion de la matrice image vers un vecteur.
Extrayons de l?image les trois matrices des composantes couleurs : Rouge, Vert
et Bleu. Puis nous faisons la conversion de l?image couleur vers une image en
niveau de gris selon la formule suivante :
Y = 0.3 × R + 0.59 × V + 0.11 × B (4.1)
Où :
R : La composante couleur rouge.
V : La composante couleur vert.
B : La composante couleur bleu.
Après l?opération de découpage et
décimation en transforme l?image matrice à un vecteur par
l?enchainement des lignes (ou colonnes).
4-3-3.Photo-normalisation
La photo-normalisation a un double effet : d?une part elle
supprime pour tout vecteur un éventuel décalage par rapport
à l?origine, et ensuite elle supprime tout effet d?amplification
(multiplication par un scalaire).
Pour chaque vecteur d?image x on
effectue l'opération suivante :
x --mean (x)
photonormalisation (x) = (4.2)
std (x)
Où :
mean (x) : La moyenne de x. std (x) : La variance de x.
4-3-4.Création de la matrice d'apprentissage
L?ordonnancement des vecteurs images des clients cote à
cote va crée cette matrice d?apprentissage.
4-3-5. Normalisation des données
Pour que les étapes de comparaison qui suivent dans le
processus d?authentification soient efficaces et pertinentes, il est
nécessaire que les données soient normalisées .Il s?agit
là d?une étape classique d?un processus de classification .La
normalisation permet d?assurer l?homogénéité des
données.
4-4. Les critères de performance [7]
Les critères retenue pour caractériser les
performances des méthodes utilisées dans nos expériences
se basent sur deux mesures fondamentales déjà introduites
précédemment, soient le taux fausse acceptation(TFA), c'est la
proportion d'imposteurs ayant réussi à usurper l'identité
d'un client et le taux de faux rejet (TFR), la proportion de clients
rejetés par le système.
Ces mesures sont intimement liées à la valeur
de seuil d'acceptation u .pour rendre cette dépendance plus explicite,
la fausse acceptation et le faux rejet peuvent être écrite sous
forme de fonction TFA(u) et TFR(u).de par leur définition, il
apparaît que TFA(u) ne peut être qu'une fonction monotone
croissante et TFR(u) une fonction monotone décroissante.
Les critères de performances utilisées sont alors
les suivant :
· La courbe caractéristique, qui donne pour
chaque valeur de TFA, la valeur TFR qui lui est associée. Elle est
obtenue en faisant varier continûment le seuil u et en traçant
l'ensemble des couples (TFA(u) ,TFR(u)).Cette courbe fournit de façon
graphique un aperçu de tous les compromis TFA/TFR possibles et permet de
sélectionner un seuil u adéquat selon l'application
envisagée. Une méthode sera d'autant meilleure que sa courbe
caractéristique sera proche des axes de coordonnées.
. Le taux d'égale erreur (TEE), qui correspond au seuil
u tel que TFA(u) =
TFR(u) = TEE dans l'ensemble d'évaluation. Ce taux,
à lui seul, résume assez bien les performances que l'on peut
attendre du système.
4-5. La classification [7]
Dans le problème de vérification
d'identité, nous cherchons à définir un seuil. Ce seuil va
déterminer le minimum de ressemblance entre deux images pour admettre
qu'il s'agit de la même personne .Ce minimum de ressemblance va
s'exprimer, on s'en doute, comme une distance maximale entre les
caractéristique des deux images.
Pour fixer ce seuil, nous allons utiliser l'ensemble
d'évaluation. Nous avons à ce stade déjà construit
toutes les caractéristiques de chaque image de l'ensemble
d'apprentissage et de l'ensemble d'évaluation .Nous avons
également calculé les distances entre les caractéristiques
de l'ensemble d'apprentissage et l?ensemble d'évaluation. Rappelons-nous
que ces derniers sont au nombre de deux, le premier contenant des individus
jouant le rôle des clients, le second contenant des imposteurs. Aucun de
ces derniers ne se trouve dans l'ensemble d'apprentissage. Les distances
calculées dans le premier groupe sont appelées distances
intra-classes, ou plus simplement intra, les autres, sont appelées
distances extra.
Dans l'ensemble d'apprentissage, il y a trois images par
client. On va donc comparer chaque image de l'ensemble d'évaluation avec
au moins trois images correspondant à la même personne. Pour fixer
une seule valeur, qui sera retenue pour la suite du procédé, on
va généralement choisir une des deux solutions suivantes:
. En calculer la moyenne. . En calculer le minimum.
Théoriquement, le maximum des distances intra est plus
petit que le minimum distances extra, il est possible de déterminer un
seuil u qui détermine une classification parfaite (sans erreur : (TEE =
0) dans l'ensemble d'évaluation.
Donc si :
max?(dintra ) > min(dextra ) => 3
,u/TFA = TFR = 0 (4.3)
Il suffit de prendre :
du-- u=
|
max
max (dintra )+(d extra )
2 (4.4)
|
|
Malheureusement cette situation (TEE = 0) ne se rencontre que
très rarement en pratique.
Donc nous devons choisir un critère à minimiser
pour fixer le seuil .Il peut s'agir du TFA, du TFR, ou de la différence
des deux, de manière à atteindre le TEE.
4-6. Authentification de visages basée sur
Eigen-Face ou ACP
Afin de mieux pouvoir étudier l?apport de la
méthode d?Eigen Faces ou ACP, nous allons présenter les
résultats obtenus avec une méthode très basique .Ces
résultats de base serviront par la suite de comparaison. Les
paramètres de la méthode de base sont : [15]
· Prétraitement : sans la photo-normalisation.
· Composante couleur : luminance (niveau de gris).
· Coefficients : les coefficients de projection des
vecteurs propres (triés suivant les valeurs propres
décroissantes).
· Mesure de score : Distances L1, L2 (euclidienne), la
covariance (angle), et la corrélation.
· Seuillage : global
Remarque
Dans toutes les expériences qui vont suivre, nous
allons fixer le seuil de telle manière à obtenir un taux d?erreur
égal (TEE) dans l?ensemble d?évaluation, ensuite dans l?ensemble
de test on utilisant le seuil fixé précédemment.
Les résultats obtenus avec ces paramètres sont
repris dans le tableau (4.1)
Mesure de
score
|
Ensemble
d?Evaluation
|
Ensemble de test
|
Dimension de
L?ACP
|
|
TFA
|
TFR
|
|
0.07705
|
0.0757
|
0.0950
|
50
|
|
0.0733
|
0.0900
|
100
|
|
0.0729
|
0.0875
|
199
|
L1
|
0.1098
|
0.10
|
0.1450
|
50
|
|
0.1092
|
0.140
|
100
|
|
0.1328
|
0.1550
|
199
|
L2
Euclidienne
|
0.1385
|
0.1313
|
0.1325
|
50
|
|
0.1353
|
0.1375
|
100
|
|
0.1385
|
0.1375
|
199
|
Angle
|
0.0747
|
0.0779
|
0.0975
|
50
|
|
0.0740
|
0.090
|
100
|
|
0.0735
|
0.085
|
199
|
|
Tableau 4.1. Influence du type de la distance
de mesure de similarité sur les taux d'erreur
d'authentification en
utilisant différentes métriques dans le sous-espace ACP
Nous remarquons que les différents taux sont très
stables dans les différents ensembles (évaluations et test) pour
toutes les mesures de score.
Nous remarquons aussi que les taux erreurs en utilisant la
mesure de similitude par corrélation et covariance (angle) sont
très proches.
Dans le but d'améliorer les résultats du
système d'authentification obtenus par la méthode de l'ACP nous
avons appliqué une photo-normalisation aux images.
Les résultats de la méthode ACP avec
photo-normalisation sont repris dans le tableau (4.2) :
Mesure de
score
|
Ensemble
d?Evaluation
|
Ensemble de test
|
Dimension de
L?ACP
|
|
TFA
|
TFR
|
|
0.0549
|
0.0663
|
0.0500
|
50
|
|
0.0585
|
0.0500
|
100
|
|
0.0577
|
0.0825
|
199
|
L1
|
0.0695
|
0.0710
|
0.0825
|
50
|
|
0.0776
|
0.0900
|
100
|
|
0.0809
|
0.0875
|
199
|
L2
Euclidienne
|
0.0715
|
0.0750
|
0.0875
|
50
|
|
0.0948
|
0.1025
|
100
|
|
0.1233
|
0.0525
|
199
|
Angle
|
0.05365
|
0.0659
|
0.0525
|
50
|
|
0.0582
|
0.0525
|
100
|
|
0.0576
|
0.0525
|
199
|
|
Tableau 4.2: Les résultats de la
méthode l'ACP avec photo-normalisation
Nous voyons donc, que la photo-normalisation, est en accord avec
nous espérances. Elle améliore sensiblement les
résultats.
Pour choisir la dimension k du sous-espace ACP, nous choisissons
la valeur de k qui minimise le TEE sur l'ensemble d?évaluation.
La variation du TEE en fonction de la dimension de l'ACP est
montrée sur la figure (4.5) pour divers arrangements de mesure de
similarité.
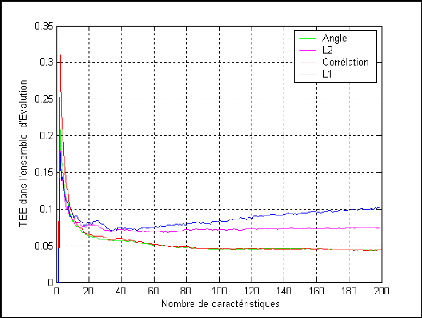
Figure 4.5 : Le TEE dans l'ensemble
d'évaluation en fonction de la dimension du sous-
espace ACP en
utilisant différentes distances de mesure de similarité.
Le TEE diminue très rapidement avec les 50 premiers
vecteurs propres et il stabilise au-dessus de 50 ou augmente.
Nous observons que la covariance (angle) et la
corrélation exigent un nombre sensiblement plus grand de vecteurs
propres pour une performance optimale.
À partir du tableau (4.2) et la figure (4.5), nous
remarquons que la mesure de similarité en utilisant la covariance
(angle) améliore sensiblement les résultats. Elle est mieux
adaptée que les autres distances à des données
présentées en grande dimension.
L?ACP donne d?assez bons résultats. Elle est d?autant
plus performante avec la distance de covariance (angle). La mesure en
covariance apporte un gain en performance non négligeable.
4-7. Authentification de visage basée sur Fisher
Face (LDA)
Les performances du système de vérification ou
authentification de visage peut être encore améliorée en
projetant les vecteur de visage d?ACP sur un sous espace ou la discrimination
est améliorée ceci est fait par l?analyse discriminante
linéaire (LDA), décrite en chapitre 2.
L?ensemble d?apprentissage est employé pour estimer la
matrice de dispersion intra-classe ???? .Et la matrice de dispersion inter
classe ???? . Comme cet ensemble contient seulement 200 sujet (ou personne), il
y a donc 200 classes.
Nous calculons les valeurs propres et les vecteurs propres
correspondant aux deux matrices ???? et ???? et on ordre les vecteurs propres
selon leurs valeurs propres décroissante et on ne garde que les
premières C-1 vecteurs, où C est le nombre de classes. Donc la
dimension maximale du sous espace LDA est 199.
Les paramètres de la méthode de base sont :
[19]
· Prétraitement : sans la photo-normalisation.
· Composante couleur : luminance (niveau de gris).
· Coefficients : les coefficients de projection des
vecteurs propres de l?espace LDA (triés suivant les valeurs propres
décroissantes).
· Mesure de score : Distances L1, L2 (euclidienne), la
covariance (angle), et la corrélation.
· Seuillage : global.
Le tableau (4.3) montre les résultats des taux
d?égale erreur obtenus par la méthode
LDA.
Mesure de
score
|
Ensemble
d?Evaluation
|
Ensemble de test
|
Dimension de
LDA
|
|
TFA
|
TFR
|
|
0.0347
|
0.0327
|
0.0475
|
50
|
|
0.0329
|
0.0525
|
72
|
|
0.0301
|
0.0450
|
100
|
|
0.0276
|
0.0525
|
199
|
L1
|
0.037
|
0.5132
|
0.0450
|
50
|
|
0.5921
|
0.0450
|
72
|
|
0.6932
|
0.0375
|
100
|
|
0.7847
|
0.0475
|
199
|
L2
Euclidienne
|
0.03155
|
0.4864
|
0.0400
|
50
|
|
0.5616
|
0.0525
|
72
|
|
0.6370
|
0.0400
|
100
|
|
0.7236
|
0.0475
|
199
|
Angle
|
0.0332
|
0.0319
|
0.0425
|
50
|
|
0.0320
|
0.0550
|
72
|
|
0.0316
|
0.0425
|
100
|
|
0.0276
|
0.0525
|
199
|
|
Tableau 4.3 : Les résultats des taux
erreurs dans les sous-espaces LDA sans photo-
normalisation
Ce tableau présente aussi le taux de fausse
acceptation et le taux de faux rejet obtenus dans l?ensemble de test pour
différentes valeurs de la dimension du vecteur de
caractéristiques du sous-espace LDA, et en utilisant différentes
mesures de similarité sans photo-normalisation des images.
Nous remarquons que les différents taux sont presque
égaux dans les deux ensembles (test et évaluation) pour les
mesures de similarité par la corrélation et la covariance. Par
contre lorsqu? on utilise pour la mesure de similarité les distances L1
et L2, on remarque que les différents taux ont des valeurs
éloignés ce qui signifie que le système d?authentification
est instable. Et pour une meilleure amélioration de ces
résultats, nous appliquons la photo-normalisation aux images.
Le tableau (4.4) montre les résultats obtenus en
utilisant la méthode de base avec photo-normalisation.
Mesure de
score
|
Ensemble
d?Evaluation
|
Ensemble de test
|
Dimension de
LDA
|
|
TFA
|
TFR
|
|
0.038
|
0.0337
|
0.0325
|
50
|
|
0.0303
|
0.0325
|
72
|
|
0.0302
|
0.0325
|
100
|
|
0.0313
|
0.0375
|
199
|
L1
|
0.06855
|
0.2216
|
0.0750
|
50
|
|
0.2361
|
0.0725
|
72
|
|
0.2354
|
0.0850
|
100
|
|
0.2876
|
0.0975
|
199
|
Euclidienne
L2
|
0.06175
|
0.2026
|
0.0625
|
50
|
|
0.2123
|
0.0675
|
72
|
|
0.2154
|
0.0775
|
100
|
|
0.2517
|
0.0825
|
199
|
Angle
|
0.03535
|
0.0319
|
0.0350
|
50
|
|
0.0282
|
0.0325
|
72
|
|
0.0295
|
0.0325
|
100
|
|
0.0306
|
0.0375
|
199
|
|
Tableau 4 .4: Les résultats des taux
erreurs dans le sous-espace LDA avec photo-
normalisation
Nous remarquons que la photo-normalisation améliore
sensiblement les résultats.
La photo-normalisation est très utilisée en
authentification à l?aide des images de visages.
Les taux d?égale erreur TEE obtenus sur l?ensemble
d?évaluation de la méthode LDA pour l?authentification de visages
en appliquant les quatre distances suivants norme L1 et L2, covariance (angle)
et corrélation pour la mesure de similarité sont
représentés sur la figure (4.6).
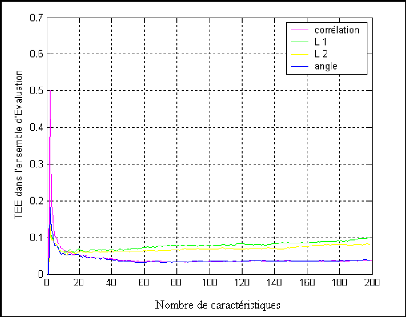
Figure 4.6 : TEE pour différents
distance de mesure de similarité en utilisant la
méthode
?LDA??
Nous observons dans cette figure que les taux d?égale
erreur diminue tout à fait très rapidement avec l?utilisation des
premiers vecteurs propres (presque jusqu?au 40 vecteurs propres), et ils se
stabilisent au dessus de cette valeur (40) ou augmente.
À partir du tableau (4.4) et la figure (4.6), nous
remarquons que la mesure de similitude en utilisant la covariance (angle)
améliore sensiblement les résultats. Elle est mieux
adaptée que les autres distances à des données
présentées en grande dimension.
La distance de covariance « angle » avec
photo-normalisation des données présente les taux d?erreur les
plus faible.
Les taux d?erreur TEE obtenus sur l?ensemble
d?évaluation des deux méthodes ACP et LDA en authentification de
visages sont représentés par la figure (4.7).
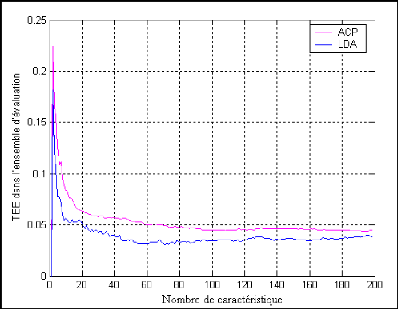
Figure 4.7 : Comparaison des performances de
la méthode d?Eigen-Faces et la méthode
Fisher-Faces pour
l?authentification de visage en utilisent la covariance (angle) pour
la
mesure de similarité dans l?ensemble d?évaluation.
On peut voir de cette figure que la méthode de
Fisher-Face (LDA) est mieux performante que la méthode d?Eigen-Face
(ACP) en employant un nombre restreint de caractéristiques.
4-8.Conclusion
Dans ce chapitre nous avons présenté les
résultats obtenus en effectuant une étude comparative entre
l?approche d?Eigen face (ACP) et la méthode de Fisher face (LDA) pour
l?authentification de visages sur la base de données XM2VTS.
Nous concluons que l?ACP ne fait pas la discrimination des
classes, donc nous utilisons l?analyse discriminante linéaire de Fischer
pour augmenter la séparabilité des classes dans le sous espace de
composantes principales. Les résultats obtenus montrent clairement
l?efficacité de l?approche LDA. Elle est d?autant plus performante avec
la covariance (angle) comme fonction de mesure du score.
Nous avons essayé plusieurs moyens pour augmenter les
performances du système d?authentifications (photo-normalisation, choix
de la distance de mesures de similarité.....).
Nous concluons que théoriquement un système de
reconnaissance idéal donne un taux de réussite TR=100%. Mais ceci
n?est pas réalisable par un système réel à cause
des différentes variations (l?éclairage, le changement de la
coiffure, le porte de lunette.).Le taux de réussite de notre
système d?authentification est de l?ordre de 93,93%.
Conclusion
générale
Conclusion générale
Notre but été de concevoir un
système d'authentification d'identité qui soit facile et peu
coûteux dans l'implémentation et qui utilise une modalité
biométrique particulière (le visage humain). Le visage est l'une
des formes les plus domestiques et qui est très bien acceptée par
les utilisateurs. Car elle est non invasive. La tache est simple ; l'image du
visage est captée par une caméra. Le sujet peut se
présenter devant celle-ci et selon la technique utilisée, le
système extrait les caractéristiques du visage pour faire la
comparaison avec les caractéristiques de la personne
réclamée qui est conservées dans une base de
données.
Le problème qui nous occupe contient deux classes.
A savoir d'une part les clients et d'autres parts les imposteurs. Un
système d'authentification impitoyable et extrêmement strict
indique un TFA (Taux de Fausse acceptation) faible et un TFR (Taux de Faux
rejet) élevé. Par contre un système laxiste sera
caractérisé par un TFA élevé et un TFR plutôt
bas. Le juste milieu se situe quelque part entre les deux, et si les taux
d'erreurs sont égaux, il se trouvera au taux d'égale erreur ou
TEE.
Tous ces taux d'erreurs ont été
calculés dans deux ensembles d'abord dans un ensemble
d'évaluation. Qui va permettre de fixer plus ou moins le TEE en faisant
varier les paramètres d'acceptation et de rejet du système.
Ensuite dans un ensemble de test en utilisant les paramètres
fixés précédemment. Ainsi, on peut vérifier la
robustesse du système d'authentification.
Notre système d'authentification de visage utilise
la représentation de l'image en niveau de gris comme
caractéristique d'entrée. Pour l'extraction du vecteur de
caractéristiques de visage nous avons utilisé la méthode
d'analyse en composantes principales. Mais cette dernière ne prend pas
en compte la discrimination des classes. Pour augmenter la
séparabilité des classes nous avons utilisé l'analyse
discriminante linéaire.
Nous avons testé les performances des deux
méthodes précédentes sur la base de données XM2VTS
selon son protocole associé "protocole de Lausanne". Le choix principal
de cette base de données est sa grande taille, et sa popularité
puisqu'elle est devenue une norme dans la communauté biométrique
audio et visuelle de vérification multimodale d'identité.
Les résultats trouvés montrent que
l'utilisation de la méthode l'analyse discriminante linéaire
améliore les performances du système d'authentification de
visage.
Dans ce travail le taux de réussite le plus
élevé a été obtenue en utilisant la covariance
« angle » comme fonction de mesure de similarité Ce taux est
de l'ordre de 93.93%.
En perspective et dans le but d'augmenter le taux de
réussite on propose d'utiliser l'information couleur de
différents espaces colorimétriques avec la méthode
l'analyse discriminante linéaire (LDA), ou d'autre méthode comme
l'analyse en composantes indépendantes (ICA)......etc Ou de faire la
fusion des différentes techniques
d'authentificatio
Bibiographie
Bibliographies
· [1]. Nebbar Hanane et Bensizerara
Saliha, vérification d?identité à l?aide d?image de
visage, thèse d?ingénieur d?état en automatique,
Université Mohamed Khieder Biskra Algérie.2005.
· [2].Adrien scotte,
élève --ingénieur supinfo, paris promotion supinfo ,2006
.
· [3].A Lemieux <<système
d?identification de personnes par vision numérique>>,
université Laval, Québec décembre 2003.
· [4].Florent Perronnin et Jean-, Luc
Dugelay <<introduction à la biométrie authentification des
individus par traitement audio vidéo>>, Revue traitement du
signal, volume 19, numéro 4,2002.
· [5].Hazim Mohamed Amir et Nabi Rachid,
thème reconnaissance de visages, Universités d?Avignon et du pays
du Vaucluse IUPGMT 2006 /2007.
· [6].Club de la sécurité
des systèmes d?information français --techniques de control
d?accès par biométrie, juin 2003.
· [7].Djamel Saigaa, Contribution
à l?authentification d?individus par la reconnaissance de visages,
thèse de Doctorat d?état en automatique, Université
Mohamed Khieder Biskra Algérie. Novembre 2006.
· [8].Fedias Meriem, L?apport de la
couleur à la vérification d?identité à l?aide
d?images de visage, thèse de Magister d?état en
électronique, Université Mohamed Khieder Biskra
Algérie.2006/2007.
· [9].H.L.Van Trees. Detection, Estimation
and Modulation theory, volume 1.John Wiley & Sons, New York, 1968.
· [10].F. Bimot and G. Chollet.
» Assessment of speaker verification systems «.In Handbook of
Standards and Resources for Spoken Language Systems .Mouton de Gruyter ,
1997.
· [11]. Djamila. Mahmoudi ,
Biométrie et Authentification, département Corporate Information
and Technology de Swisscom AG.
http://ditwww.epfl.ch/SIC/SA/publications/FI00/fi-sp-00/sp-00-page
25.html
· [12]. B. Michel, Cours d?infographie
(chapitre 1 Généralités), I.S.I.Gramme, 2007.
· [13]. Wendy S. Yambor. Analysis of
PCA-based and Fisher discriminate-based image recognition algorithms. Computer
Science Technical Report in Partial Fulfillment of the requirements for the
degree of Master of Science Colorado State University Fort Collins, Colorado
July 2000.
· [14].Horn R. and Johnson C, Matrix
Analysis New York: Cambridge University Press, 1985.
· [15].Moon H. and Phillips J, Analysis
of PCA-based faced recognition Algorithms. In Boyer K and Phillips J. editors.
Empirical Evolution Techniques in computer vision, IEEE computer society press,
Los Alamitos, CA, 1998.
· [16].Stevens M. (1999).Reasoning about
object Appearance in terms of a scene context Ph.D. thesis.
· [17]. K.Messer, J.Matas, J.Kittler et
K.Jonson :Xm2vtsdb : The extended m2vts database. Audios-and Video-based
Biometric Person Authentication (AVBPA), pages 72-77, Mars 1999.
· [18].J.Luettin and G Maitre.
»Evaluation protocol for the extende M2VTS database» .IDIAP,available
at
http://www.ee.surrey.ac.uk/Research/VSSP/xm2vtsdb/faceavbpa2001/protocol.ps,1998.
· [19].D. Saigaa , N. Benoudjit,
K.Bemahammed et S. Lelandais «Authentification d?individus par
reconnaissance de visages», Courier du savoir, journal de
l?université de Biskra ,ISSN 1112-3338 no.6,juin 2005,pp.61-66.
| 

