4-3-1.Découpage et décimation
Les images de la base de données utilisée dans
notre travail sont constituées de plusieurs informations tels que
(l?arrière plan, les cheveux. .etc.), elles gonflent inutilement
la taille des données, et augmente le temps de calcul du
processus d?authentification, d?oüune diminution de la
performance du système.
Travailler avec des vecteurs de grandes dimensions n?est pas
toujours facile. Nous allons dans cette étape réduire de
manière grossière et radicale la dimension des images par des
opérations de découpage et décimation (sous
échantillonnage). Voir les figures (4.3) et (4.4).
Figure 4.3 : Les images de l?exemple
précédent après le découpage.

4-3-2.Enchainement des lignes / ou colonnes
C?est la conversion de la matrice image vers un vecteur.
Extrayons de l?image les trois matrices des composantes couleurs : Rouge, Vert
et Bleu. Puis nous faisons la conversion de l?image couleur vers une image en
niveau de gris selon la formule suivante :
Y = 0.3 × R + 0.59 × V + 0.11 × B (4.1)
Où :
R : La composante couleur rouge.
V : La composante couleur vert.
B : La composante couleur bleu.
Après l?opération de découpage et
décimation en transforme l?image matrice à un vecteur par
l?enchainement des lignes (ou colonnes).
4-3-3.Photo-normalisation
La photo-normalisation a un double effet : d?une part elle
supprime pour tout vecteur un éventuel décalage par rapport
à l?origine, et ensuite elle supprime tout effet d?amplification
(multiplication par un scalaire).
Pour chaque vecteur d?image x on
effectue l'opération suivante :
x --mean (x)
photonormalisation (x) = (4.2)
std (x)
Où :
mean (x) : La moyenne de x. std (x) : La variance de x.
4-3-4.Création de la matrice d'apprentissage
L?ordonnancement des vecteurs images des clients cote à
cote va crée cette matrice d?apprentissage.
4-3-5. Normalisation des données
Pour que les étapes de comparaison qui suivent dans le
processus d?authentification soient efficaces et pertinentes, il est
nécessaire que les données soient normalisées .Il s?agit
là d?une étape classique d?un processus de classification .La
normalisation permet d?assurer l?homogénéité des
données.
4-4. Les critères de performance [7]
Les critères retenue pour caractériser les
performances des méthodes utilisées dans nos expériences
se basent sur deux mesures fondamentales déjà introduites
précédemment, soient le taux fausse acceptation(TFA), c'est la
proportion d'imposteurs ayant réussi à usurper l'identité
d'un client et le taux de faux rejet (TFR), la proportion de clients
rejetés par le système.
Ces mesures sont intimement liées à la valeur
de seuil d'acceptation u .pour rendre cette dépendance plus explicite,
la fausse acceptation et le faux rejet peuvent être écrite sous
forme de fonction TFA(u) et TFR(u).de par leur définition, il
apparaît que TFA(u) ne peut être qu'une fonction monotone
croissante et TFR(u) une fonction monotone décroissante.
Les critères de performances utilisées sont alors
les suivant :
· La courbe caractéristique, qui donne pour
chaque valeur de TFA, la valeur TFR qui lui est associée. Elle est
obtenue en faisant varier continûment le seuil u et en traçant
l'ensemble des couples (TFA(u) ,TFR(u)).Cette courbe fournit de façon
graphique un aperçu de tous les compromis TFA/TFR possibles et permet de
sélectionner un seuil u adéquat selon l'application
envisagée. Une méthode sera d'autant meilleure que sa courbe
caractéristique sera proche des axes de coordonnées.
. Le taux d'égale erreur (TEE), qui correspond au seuil
u tel que TFA(u) =
TFR(u) = TEE dans l'ensemble d'évaluation. Ce taux,
à lui seul, résume assez bien les performances que l'on peut
attendre du système.
4-5. La classification [7]
Dans le problème de vérification
d'identité, nous cherchons à définir un seuil. Ce seuil va
déterminer le minimum de ressemblance entre deux images pour admettre
qu'il s'agit de la même personne .Ce minimum de ressemblance va
s'exprimer, on s'en doute, comme une distance maximale entre les
caractéristique des deux images.
Pour fixer ce seuil, nous allons utiliser l'ensemble
d'évaluation. Nous avons à ce stade déjà construit
toutes les caractéristiques de chaque image de l'ensemble
d'apprentissage et de l'ensemble d'évaluation .Nous avons
également calculé les distances entre les caractéristiques
de l'ensemble d'apprentissage et l?ensemble d'évaluation. Rappelons-nous
que ces derniers sont au nombre de deux, le premier contenant des individus
jouant le rôle des clients, le second contenant des imposteurs. Aucun de
ces derniers ne se trouve dans l'ensemble d'apprentissage. Les distances
calculées dans le premier groupe sont appelées distances
intra-classes, ou plus simplement intra, les autres, sont appelées
distances extra.
Dans l'ensemble d'apprentissage, il y a trois images par
client. On va donc comparer chaque image de l'ensemble d'évaluation avec
au moins trois images correspondant à la même personne. Pour fixer
une seule valeur, qui sera retenue pour la suite du procédé, on
va généralement choisir une des deux solutions suivantes:
. En calculer la moyenne. . En calculer le minimum.
Théoriquement, le maximum des distances intra est plus
petit que le minimum distances extra, il est possible de déterminer un
seuil u qui détermine une classification parfaite (sans erreur : (TEE =
0) dans l'ensemble d'évaluation.
Donc si :
max?(dintra ) > min(dextra ) => 3
,u/TFA = TFR = 0 (4.3)
Il suffit de prendre :
du-- u=
|
max
max (dintra )+(d extra )
2 (4.4)
|
|
Malheureusement cette situation (TEE = 0) ne se rencontre que
très rarement en pratique.
Donc nous devons choisir un critère à minimiser
pour fixer le seuil .Il peut s'agir du TFA, du TFR, ou de la différence
des deux, de manière à atteindre le TEE.
4-6. Authentification de visages basée sur
Eigen-Face ou ACP
Afin de mieux pouvoir étudier l?apport de la
méthode d?Eigen Faces ou ACP, nous allons présenter les
résultats obtenus avec une méthode très basique .Ces
résultats de base serviront par la suite de comparaison. Les
paramètres de la méthode de base sont : [15]
· Prétraitement : sans la photo-normalisation.
· Composante couleur : luminance (niveau de gris).
· Coefficients : les coefficients de projection des
vecteurs propres (triés suivant les valeurs propres
décroissantes).
· Mesure de score : Distances L1, L2 (euclidienne), la
covariance (angle), et la corrélation.
· Seuillage : global
Remarque
Dans toutes les expériences qui vont suivre, nous
allons fixer le seuil de telle manière à obtenir un taux d?erreur
égal (TEE) dans l?ensemble d?évaluation, ensuite dans l?ensemble
de test on utilisant le seuil fixé précédemment.
Les résultats obtenus avec ces paramètres sont
repris dans le tableau (4.1)
Mesure de
score
|
Ensemble
d?Evaluation
|
Ensemble de test
|
Dimension de
L?ACP
|
|
TFA
|
TFR
|
|
0.07705
|
0.0757
|
0.0950
|
50
|
|
0.0733
|
0.0900
|
100
|
|
0.0729
|
0.0875
|
199
|
L1
|
0.1098
|
0.10
|
0.1450
|
50
|
|
0.1092
|
0.140
|
100
|
|
0.1328
|
0.1550
|
199
|
L2
Euclidienne
|
0.1385
|
0.1313
|
0.1325
|
50
|
|
0.1353
|
0.1375
|
100
|
|
0.1385
|
0.1375
|
199
|
Angle
|
0.0747
|
0.0779
|
0.0975
|
50
|
|
0.0740
|
0.090
|
100
|
|
0.0735
|
0.085
|
199
|
|
Tableau 4.1. Influence du type de la distance
de mesure de similarité sur les taux d'erreur
d'authentification en
utilisant différentes métriques dans le sous-espace ACP
Nous remarquons que les différents taux sont très
stables dans les différents ensembles (évaluations et test) pour
toutes les mesures de score.
Nous remarquons aussi que les taux erreurs en utilisant la
mesure de similitude par corrélation et covariance (angle) sont
très proches.
Dans le but d'améliorer les résultats du
système d'authentification obtenus par la méthode de l'ACP nous
avons appliqué une photo-normalisation aux images.
Les résultats de la méthode ACP avec
photo-normalisation sont repris dans le tableau (4.2) :
Mesure de
score
|
Ensemble
d?Evaluation
|
Ensemble de test
|
Dimension de
L?ACP
|
|
TFA
|
TFR
|
|
0.0549
|
0.0663
|
0.0500
|
50
|
|
0.0585
|
0.0500
|
100
|
|
0.0577
|
0.0825
|
199
|
L1
|
0.0695
|
0.0710
|
0.0825
|
50
|
|
0.0776
|
0.0900
|
100
|
|
0.0809
|
0.0875
|
199
|
L2
Euclidienne
|
0.0715
|
0.0750
|
0.0875
|
50
|
|
0.0948
|
0.1025
|
100
|
|
0.1233
|
0.0525
|
199
|
Angle
|
0.05365
|
0.0659
|
0.0525
|
50
|
|
0.0582
|
0.0525
|
100
|
|
0.0576
|
0.0525
|
199
|
|
Tableau 4.2: Les résultats de la
méthode l'ACP avec photo-normalisation
Nous voyons donc, que la photo-normalisation, est en accord avec
nous espérances. Elle améliore sensiblement les
résultats.
Pour choisir la dimension k du sous-espace ACP, nous choisissons
la valeur de k qui minimise le TEE sur l'ensemble d?évaluation.
La variation du TEE en fonction de la dimension de l'ACP est
montrée sur la figure (4.5) pour divers arrangements de mesure de
similarité.
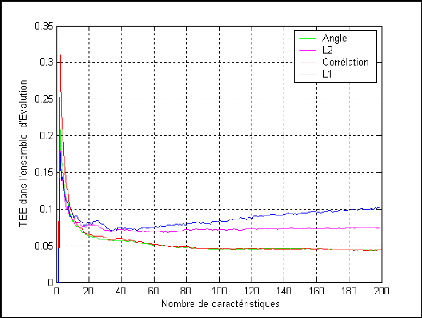
Figure 4.5 : Le TEE dans l'ensemble
d'évaluation en fonction de la dimension du sous-
espace ACP en
utilisant différentes distances de mesure de similarité.
Le TEE diminue très rapidement avec les 50 premiers
vecteurs propres et il stabilise au-dessus de 50 ou augmente.
Nous observons que la covariance (angle) et la
corrélation exigent un nombre sensiblement plus grand de vecteurs
propres pour une performance optimale.
À partir du tableau (4.2) et la figure (4.5), nous
remarquons que la mesure de similarité en utilisant la covariance
(angle) améliore sensiblement les résultats. Elle est mieux
adaptée que les autres distances à des données
présentées en grande dimension.
L?ACP donne d?assez bons résultats. Elle est d?autant
plus performante avec la distance de covariance (angle). La mesure en
covariance apporte un gain en performance non négligeable.
4-7. Authentification de visage basée sur Fisher
Face (LDA)
Les performances du système de vérification ou
authentification de visage peut être encore améliorée en
projetant les vecteur de visage d?ACP sur un sous espace ou la discrimination
est améliorée ceci est fait par l?analyse discriminante
linéaire (LDA), décrite en chapitre 2.
L?ensemble d?apprentissage est employé pour estimer la
matrice de dispersion intra-classe ???? .Et la matrice de dispersion inter
classe ???? . Comme cet ensemble contient seulement 200 sujet (ou personne), il
y a donc 200 classes.
Nous calculons les valeurs propres et les vecteurs propres
correspondant aux deux matrices ???? et ???? et on ordre les vecteurs propres
selon leurs valeurs propres décroissante et on ne garde que les
premières C-1 vecteurs, où C est le nombre de classes. Donc la
dimension maximale du sous espace LDA est 199.
Les paramètres de la méthode de base sont :
[19]
· Prétraitement : sans la photo-normalisation.
· Composante couleur : luminance (niveau de gris).
· Coefficients : les coefficients de projection des
vecteurs propres de l?espace LDA (triés suivant les valeurs propres
décroissantes).
· Mesure de score : Distances L1, L2 (euclidienne), la
covariance (angle), et la corrélation.
· Seuillage : global.
Le tableau (4.3) montre les résultats des taux
d?égale erreur obtenus par la méthode
LDA.
Mesure de
score
|
Ensemble
d?Evaluation
|
Ensemble de test
|
Dimension de
LDA
|
|
TFA
|
TFR
|
|
0.0347
|
0.0327
|
0.0475
|
50
|
|
0.0329
|
0.0525
|
72
|
|
0.0301
|
0.0450
|
100
|
|
0.0276
|
0.0525
|
199
|
L1
|
0.037
|
0.5132
|
0.0450
|
50
|
|
0.5921
|
0.0450
|
72
|
|
0.6932
|
0.0375
|
100
|
|
0.7847
|
0.0475
|
199
|
L2
Euclidienne
|
0.03155
|
0.4864
|
0.0400
|
50
|
|
0.5616
|
0.0525
|
72
|
|
0.6370
|
0.0400
|
100
|
|
0.7236
|
0.0475
|
199
|
Angle
|
0.0332
|
0.0319
|
0.0425
|
50
|
|
0.0320
|
0.0550
|
72
|
|
0.0316
|
0.0425
|
100
|
|
0.0276
|
0.0525
|
199
|
|
Tableau 4.3 : Les résultats des taux
erreurs dans les sous-espaces LDA sans photo-
normalisation
Ce tableau présente aussi le taux de fausse
acceptation et le taux de faux rejet obtenus dans l?ensemble de test pour
différentes valeurs de la dimension du vecteur de
caractéristiques du sous-espace LDA, et en utilisant différentes
mesures de similarité sans photo-normalisation des images.
Nous remarquons que les différents taux sont presque
égaux dans les deux ensembles (test et évaluation) pour les
mesures de similarité par la corrélation et la covariance. Par
contre lorsqu? on utilise pour la mesure de similarité les distances L1
et L2, on remarque que les différents taux ont des valeurs
éloignés ce qui signifie que le système d?authentification
est instable. Et pour une meilleure amélioration de ces
résultats, nous appliquons la photo-normalisation aux images.
Le tableau (4.4) montre les résultats obtenus en
utilisant la méthode de base avec photo-normalisation.
Mesure de
score
|
Ensemble
d?Evaluation
|
Ensemble de test
|
Dimension de
LDA
|
|
TFA
|
TFR
|
|
0.038
|
0.0337
|
0.0325
|
50
|
|
0.0303
|
0.0325
|
72
|
|
0.0302
|
0.0325
|
100
|
|
0.0313
|
0.0375
|
199
|
L1
|
0.06855
|
0.2216
|
0.0750
|
50
|
|
0.2361
|
0.0725
|
72
|
|
0.2354
|
0.0850
|
100
|
|
0.2876
|
0.0975
|
199
|
Euclidienne
L2
|
0.06175
|
0.2026
|
0.0625
|
50
|
|
0.2123
|
0.0675
|
72
|
|
0.2154
|
0.0775
|
100
|
|
0.2517
|
0.0825
|
199
|
Angle
|
0.03535
|
0.0319
|
0.0350
|
50
|
|
0.0282
|
0.0325
|
72
|
|
0.0295
|
0.0325
|
100
|
|
0.0306
|
0.0375
|
199
|
|
Tableau 4 .4: Les résultats des taux
erreurs dans le sous-espace LDA avec photo-
normalisation
Nous remarquons que la photo-normalisation améliore
sensiblement les résultats.
La photo-normalisation est très utilisée en
authentification à l?aide des images de visages.
Les taux d?égale erreur TEE obtenus sur l?ensemble
d?évaluation de la méthode LDA pour l?authentification de visages
en appliquant les quatre distances suivants norme L1 et L2, covariance (angle)
et corrélation pour la mesure de similarité sont
représentés sur la figure (4.6).
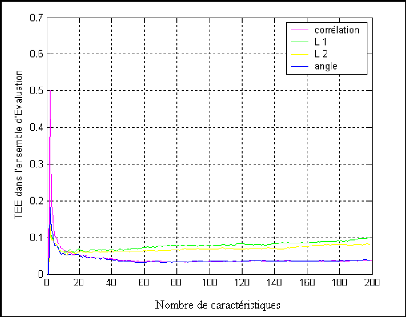
Figure 4.6 : TEE pour différents
distance de mesure de similarité en utilisant la
méthode
?LDA??
Nous observons dans cette figure que les taux d?égale
erreur diminue tout à fait très rapidement avec l?utilisation des
premiers vecteurs propres (presque jusqu?au 40 vecteurs propres), et ils se
stabilisent au dessus de cette valeur (40) ou augmente.
À partir du tableau (4.4) et la figure (4.6), nous
remarquons que la mesure de similitude en utilisant la covariance (angle)
améliore sensiblement les résultats. Elle est mieux
adaptée que les autres distances à des données
présentées en grande dimension.
La distance de covariance « angle » avec
photo-normalisation des données présente les taux d?erreur les
plus faible.
Les taux d?erreur TEE obtenus sur l?ensemble
d?évaluation des deux méthodes ACP et LDA en authentification de
visages sont représentés par la figure (4.7).
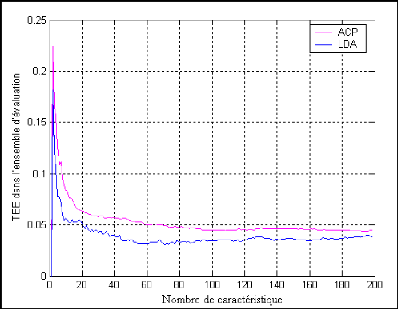
Figure 4.7 : Comparaison des performances de
la méthode d?Eigen-Faces et la méthode
Fisher-Faces pour
l?authentification de visage en utilisent la covariance (angle) pour
la
mesure de similarité dans l?ensemble d?évaluation.
On peut voir de cette figure que la méthode de
Fisher-Face (LDA) est mieux performante que la méthode d?Eigen-Face
(ACP) en employant un nombre restreint de caractéristiques.
| 

